Distance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics
 Yutaro Iiyama1*
Yutaro Iiyama1*  Gianluca Cerminara2 Abhijay Gupta2
Gianluca Cerminara2 Abhijay Gupta2  Jan Kieseler2 Vladimir Loncar2,3
Jan Kieseler2 Vladimir Loncar2,3  Maurizio Pierini2
Maurizio Pierini2  Shah Rukh Qasim2,4 Marcel Rieger2 Sioni Summers2 Gerrit Van Onsem2
Shah Rukh Qasim2,4 Marcel Rieger2 Sioni Summers2 Gerrit Van Onsem2  Kinga Anna Wozniak2,5
Kinga Anna Wozniak2,5  Jennifer Ngadiuba6
Jennifer Ngadiuba6  Giuseppe Di Guglielmo7
Giuseppe Di Guglielmo7  Javier Duarte8 Philip Harris9 Dylan Rankin9 Sergo Jindariani10
Javier Duarte8 Philip Harris9 Dylan Rankin9 Sergo Jindariani10  Mia Liu10
Mia Liu10  Kevin Pedro10
Kevin Pedro10  Nhan Tran10,11 Edward Kreinar12
Nhan Tran10,11 Edward Kreinar12  Zhenbin Wu13
Zhenbin Wu13- 1International Center for Elementary Particle Physics, University of Tokyo, Tokyo, Japan
- 2Experimental Physics Department, European Organization for Nuclear Research (CERN), Geneva, Switzerland
- 3Institute of Physics Belgrade, Belgrade, Serbia
- 4Manchester Metropolitan University, Manchester, United Kingdom
- 5University of Vienna, Vienna, Austria
- 6Department of Physics, Math and Astronomy, California Institute of Technology, Pasadena, CA, United States
- 7Department of Computer Science, Columbia University, New York, NY, United States
- 8Department of Physics, University of California, San Diego, San Diego, CA, United States
- 9Laboratory for Nuclear Science, Massachusetts Institute of Technology, Cambridge, MA, United States
- 10Department of Physics and Astronomy, Purdue university, West Lafayette, IL, United States
- 11Department of Electrical and Computer Engineering, Northwestern University, Evanston, IL, United States
- 12HawkEye360, Herndon, VA, United States
- 13Department of Physics, University of Illinois at Chicago, Chicago, IL, United States
Graph neural networks have been shown to achieve excellent performance for several crucial tasks in particle physics, such as charged particle tracking, jet tagging, and clustering. An important domain for the application of these networks is the FGPA-based first layer of real-time data filtering at the CERN Large Hadron Collider, which has strict latency and resource constraints. We discuss how to design distance-weighted graph networks that can be executed with a latency of less than one μs on an FPGA. To do so, we consider a representative task associated to particle reconstruction and identification in a next-generation calorimeter operating at a particle collider. We use a graph network architecture developed for such purposes, and apply additional simplifications to match the computing constraints of Level-1 trigger systems, including weight quantization. Using the hls4ml library, we convert the compressed models into firmware to be implemented on an FPGA. Performance of the synthesized models is presented both in terms of inference accuracy and resource usage.
1. Introduction
At the CERN Large Hadron Collider (LHC), high-energy physics (HEP) experiments collect signals generated by the particles produced in high-energy proton collisions that occur every 25 ns, when two proton beams cross. The readout from the detectors that capture the particles emerging from the collision is filtered by a real-time processing system, known as the trigger, that discards uninteresting collision events, based on a set of predefined algorithms. The trigger system is structured in two stages: a Level-1 trigger (L1T), implemented with custom electronics on-detector and field-programmable gate arrays (FPGAs); and a high-level trigger (HLT), consisting of a computer farm, possibly including co-processor accelerators like graphics processing units (GPUs) and FPGAs. Because of asynchronous event processing at the HLT, the accept/reject decision has to be reached with a typical latency of
While HLT algorithms have a complexity comparable to those used offline to produce the final physics results, a typical L1T algorithm consists of simpler rules based on coarser objects to satisfy the latency constraint. Consequently, the resolution of quantities computed at the L1T is typically poor compared to offline quantities. Recently, the successful deployment of the first machine learning (ML) L1T algorithm, based on a boosted decision tree (BDT), at the LHC (Acosta et al., 2018) has changed this tendency, raising interest in using ML inference as fast-to-execute approximations of complex algorithms with good accuracy. This first example consisted of a large, pre-computed table of input and output values implementing a BDT, which raises the question of how to deploy more complex architectures. This question motivated the creation of hls4ml (Duarte et al., 2018; Loncar et al., 2020), a library designed to facilitate the deployment of ML algorithms on FPGAs.
A typical hls4ml workflow begins with a neural network model that is implemented and trained using Keras (Keras, 2015), PyTorch (Paszke et al., 2019), or TensorFlow (Abadi et al., 2015). The trained model is passed to hls4ml, directly or through the ONNX (Bai et al., 2019) interface, and converted to C++ code that can be processed by a high-level synthesis (HLS) compiler to produce an FPGA firmware. By design, hls4ml targets low-latency applications. To this end, its design prioritizes all-on-chip implementations of the most common network components. Its functionality has been demonstrated with dense neural networks (DNNs) (Duarte et al., 2018), extended to also support BDTs (Summers et al., 2020). Extensions to convolutional and recurrent neural networks are in development. The library comes with handles to compress the model by quantization, up to binary and ternary precision (Di Guglielmo et al., 2020). Recently, support for QKeras (Qkeras, 2020) models has been added, in order to allow for quantization-aware training of models (Coelho et al., 2020). While the hls4ml applications go beyond HEP, its development has been driven by the LHC L1T use case.
Graph neural networks (GNNs) are among the complex architectures whose L1T implementations are in high demand, given the growing list of examples showing how well GNNs can deal with tasks related to HEP (Henrion et al., 2017; Choma et al., 2018; Abdughani et al., 2019; Arjona Martínez et al., 2019; Jin et al., 2019; Ju et al., 2019; Qasim et al., 2019b; Bernreuther et al., 2020; Moreno et al., 2020a; Moreno et al., 2020b; Qu and Gouskos, 2020; Shlomi et al., 2020). In fact, while the irregular geometry of a typical HEP detector complicates the use of computing vision techniques such as convolutional neural networks, GNNs can naturally deal with the sparse and irregular nature of HEP data.
In this work, we show how a graph model can be efficiently deployed on FPGAs to perform inference within
We present a case study of a neural network algorithm based on GarNet, applied to a task of identifying the nature of an incoming particle and simultaneously estimating its energy from the energy deposition patterns in a simulated imaging calorimeter. The inference accuracy of the firmware implementation of the algorithm is compared against its offline counterpart running on processors (CPUs and GPUs). Latency and resource utilization of the translated FPGA firmware are reported, along with a discussion on their implications for real-world usage of similar algorithms.
This paper is structured as follows. In Section 2, we briefly recount related work. Section 3 defines the main problem by outlining the challenges in designing a graph network compatible with L1T latency and resource constraints. Section 4 describes how GarNet addresses these challenges, and introduces a simplified form of the algorithm with a better affinity to a firmware implementation. The case study using a calorimeter simulation is presented in Section 5, with detailed descriptions of the task setup, model architecture, training results, and the summary of FPGA firmware synthesis. Finally, conclusions are given in Section 6.
2. Related Work
Graph neural networks are gaining interest in HEP applications, mainly due to their intrinsic advantage in dealing with sparse input datasets, which are very common in HEP. A recent review of applications of GNNs to HEP problems may be found in Shlomi et al., (2020). In particular, dynamic GNNs (Qasim et al., 2019b; Wang et al., 2019; Gray et al., 2020; Kieseler, 2020) are relevant for particle reconstruction tasks, such as tracking (Ju et al., 2019) and calorimetry (Qasim et al., 2019b).
Development of ML models deployable to FPGA-based L1T systems is helped by tools for automatic network-to-circuit conversion such as hls4ml. Using hls4ml, several solutions for HEP-specific tasks (e.g., jet tagging) have been provided (Duarte et al., 2018; Coelho et al., 2020; Di Guglielmo et al., 2020; Summers et al., 2020), exploiting models with simpler architectures than what is shown here. This tool has been applied extensively for tasks in the HL-LHC upgrade of the CMS L1T system, including an autoencoder for anomaly detection, and DNNs for muon energy regression and identification, tau lepton identification, and vector boson fusion event classification (CMS Collaboration, 2020). However, prior to this work, GNN models had not yet been supported by hls4ml. To the best of our knowledge, the present work is the first demonstration of GNN inference on FPGAs for a HEP application.
Outside of HEP, hardware and firmware acceleration of GNN inference, and graph processing in general, has been an active area of study in recent years, motivated by the intrinsic inefficiencies of CPUs and GPUs when dealing with graph data (Besta et al., 2019; Gui et al., 2019). Nurvitadhi et al., 2014; Ozdal et al., 2016; Auten et al., 2020; Geng et al., 2020; Kiningham et al., 2020; Yan et al., 2020; Zeng and Prasanna, 2020 describe examples of GNN acceleration architectures. Auten et al., 2020; Geng et al., 2020; Yan et al., 2020; Zeng and Prasanna, 2020. are specific to the graph convolutional network (GCN) (Kipf and Welling, 2017), while the graph inference processor (GRIP) architecture in Kiningham et al., (2020) is efficient across a wide range of GNN models. All five architectures are designed for processing graphs with millions of vertices under a latency constraint (10–1,000
3. General Requirements and Challenges
In the framework of Battaglia et al., (2018), a graph is a triplet
To be usable as a part of an LHC L1T system, an algorithm must execute within
• Model depth: Within each GN block, vertices exchange information with other directly connected vertices or with global attributes. Therefore, to expand the receptive field of each vertex beyond the nearest neighbors, multiple GN blocks must be repeated in the network. Given that various transformations within each GN block are often themselves multilayer perceptrons (MLPs), GNN models tend to be quite deep. Deep networks go against the latency requirement, as each perceptron layer uses at least one clock cycle on an FPGA under a straightforward implementation, and also against the resource usage requirement, because MLPs utilize multiplications heavily.
• Input size: Typically, for problems where the application of GNNs is interesting, the cardinality of
• Memory usage: Related to the problem of the input size, if the algorithm requires temporary retention of features for all vertices or edges, memory usage may be prohibitive for an FPGA firmware implementation.
• Memory access pattern: Except for certain cases, algorithms that have both
The case of
In the next section, we study a GNN architecture with these exact properties, then discuss the modifications to the architecture to make it suitable for an FPGA firmware implementation.
4. A Simplified GARNET Layer in the HLS4ML Framework
In this work, we consider GarNet (Qasim et al., 2019b) as a specific example of GNN. A GarNet layer is a GN block that takes as input a set of V vertices, each possessing
The original GarNet algorithm, while already using less compute and memory resource than other similar GNN architectures in Qasim et al., (2019b) and Wang et al., (2019), is still challenging to implement as fast and high-throughput FPGA firmware. The biggest problem arises from the use of the input feature vector as a part of the input to the decoder, which requires retention of the input data until the last steps of the algorithm. An immediate consequence of this requirement is a longer II, because processing of new samples cannot start while the input data for the current sample is still in use. Furthermore, the input feature vector is already used to compute the distance parameter as well as the internal representation of each vertex, and therefore a reuse of the input in the decoder creates a complex data flow, restricting the options for pipelining the algorithm.
We therefore designed a modified GarNet algorithm with a simplified processing flow:
• Input transformation (Figures 1A,B): An encoder network converts the features
where
• Aggregation (Figure 1C): The learned representation vectors
The factor
• Output transformation (Figures 1D,E): The aggregated features are sent back to the vertices using the same weights as
and then transformed by a single-layer decoder network with linear activation function into the final output representation
This simplified algorithm differs from the original design in the following ways. First, only the mean over vertices is computed at the aggregators, whereas the maximum is also used in the original design. In other words, the aggregators in the original design have
as an additional set of features. Secondly, as already noted, the input feature vector is not used as a part of the input to the decoder network. In the original GarNet design, the decoder is expressed as
with additional sets of kernel weights
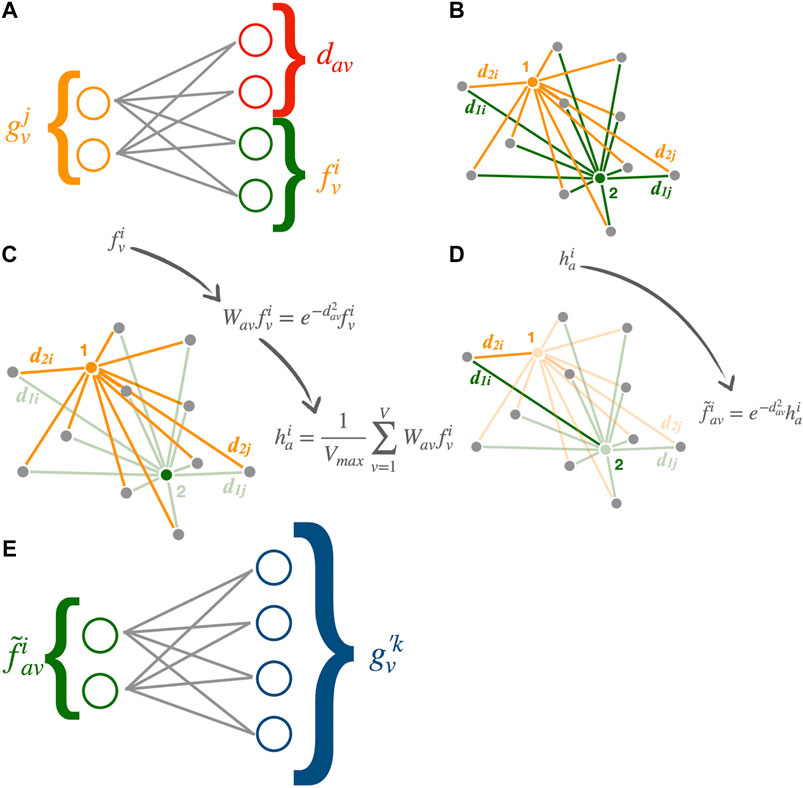
FIGURE 1. Processing flow of the modified GarNet algorithm: (A) The input features
It is worth pointing out that while the GarNet layer uses only linear activation functions for all of the internal neural networks, it can still learn nonlinear functions through the nonlinearity of the potential function
An FPGA firmware implementation of the GarNet layer using Vivado (O’Loughlin et al., 2014) HLS is integrated into the hls4ml library. The HLS source code is written in C++ and is provided as a template, from which an HLS function for a GarNet layer can be instantiated, specifying the configurable parameters such as S,
In the HLS source code of GarNet, all quantities appearing in the computation are expressed as either integers or fixed-point numbers with fractional precision of at least eight bits. In particular, the distance parameter
The processing flow in Eqs 1–5 is compactified in the hls4ml implementation by exploiting the linearity of the encoder, average aggregation, and the decoder. Equations 1, 3, and 5 can be combined into
where
In particular, the kernel and bias tensors of the encoder and decoder are contracted into
With this simplification, the input data from each sample are encoded into
The computation of
where
Finally, the kernel and bias of the encoder and the kernel of the decoder can be quantized, such that each element takes only values
5. Case Study: Particle Identification and Energy Regression in an Imaging Calorimeter
As a case study, the hls4ml implementation of GarNet is applied to a representative task for the LHC L1T, namely reconstructing electrons and pions in a simulated 3D imaging calorimeter. In the following, we first describe the dataset used for the study, then define the task and the architectures of the ML models, and present the inference performance of the models and the resource usage of the synthesized firmware.
5.1. Dataset
The calorimeter is a multi-layered full-absorption detector with a geometry similar to the one described in Qasim et al., (2019b). The detector is made entirely of tungsten, which is considered as both an absorber and a sensitive material, and no noise or threshold effects in the readout electronics are simulated. While this homogeneous calorimeter design is not a faithful representation of a modern sampling calorimeter, this simplification allows us to evaluate the performance of the ML models decoupled from detector effects.
The calorimeter extends 36 cm in x and y and has a total depth in z of 2 m, corresponding to approximately 20 nuclear interaction lengths and 170 radiation lengths. The coordinate origin is placed at the center of the front face of the calorimeter. The calorimeter is segmented into 50 layers along z, with each layer divided into small square cells in the x-y plane, forming a three-dimensional imaging detector. Cells are oriented so their sides are parallel to the x and y axes. Tiling of the cells in each layer is uniform except for in one quadrant, where the cell sides are half as long as those in the other area. The aim of the tiling is to incorporate the irregularity of the geometry of a real-life particle physics calorimeter. The quadrant with smaller cells and the remainder of the layer are respectively called the high granularity (HG) and low granularity (LG) regions. The first 25 layers in z correspond to the electromagnetic calorimeter, with a layer thickness of 1 cm and cell dimensions of 2.25 cm
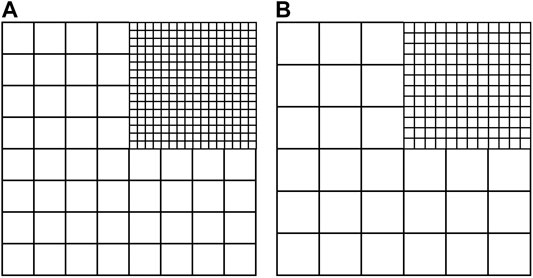
FIGURE 2. Schematics of the high-granularity and low-granularity regions of the (A) electromagnetic and (B) hadron layers.
Each event used in this study contains a high-energy primary particle and low-energy pileup particles, which represent backgrounds from simultaneous additional proton-proton interactions. The primary particle is either an electron (
The output of the simulation for each event is the array of total energy deposition values by the particles at individual detector cells (hits). Energy depositions by the particles in the homogeneous calorimeter are recorded exactly, i.e., the detector output does not require calibration and is not affected by stochastic noise.
In an L1T system, hits containing energy depositions from a potentially interesting particle would be identified through a low-latency clustering algorithm. The clustering algorithm used in this study mimics the one planned for the L1T system of the HGCAL detector in CMS (CMS Collaboration, 2017a). In this approach, the hit with the largest energy deposition in the event is elected to be the seed, and the cluster consists of all hits contained in a cylinder whose axis passes through the center of the seed cell and extends along the z direction. The radius of the cylinder is set at 6.4 cm so that the resulting cluster contains 95% of the energy of the primary particle for 50% of the pion events. Because electromagnetic showers have a narrower energy spread than hadronic showers in general, all of the electron events have at least 95% of the energy contained in the same cylinder. Typical events with momenta of the primary particles around 50 GeV and the total pileup energy close to the median of the distribution are shown in Figures 3A and 3B. The hits in the figure are colored by the fraction of the hit energy due to the primary particle (primary fraction,
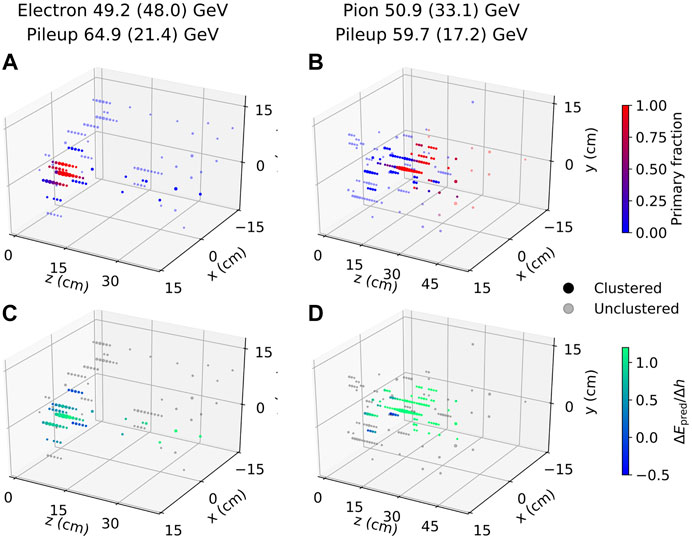
FIGURE 3. Examples of electron (A), (C) and pion (B), (D) events. Values in parentheses in the graph titles are the respective energy depositions contained in the cluster around the seed hit. Points represent hits in the detector, with their coordinates at the center of the corresponding detector cells and the size of the markers proportional to the square root of the hit energy. Opaque points are within the cluster, while the translucent ones are not. In (A) and (B), the point color scale from blue to red corresponds to the primary fraction (see Section 5.1 for definition). In (C) and (D), the color scale from blue to green corresponds to
The actual dataset used in this study thus contains one cluster per sample, given as an array of hits in the cluster, and one integer indicating the number of hits in the sample. Only the hits with energy greater than 120 MeV are considered. Each cluster contains at most 128 hits, sorted by hit energy in decreasing order. Note that sorting of the hit has no effect on the neural network, and is only relevant when truncating the list of hits to consider smaller clusters, as explored later. In fact, 0.2% of the events resulted in clusters with more than 128 hits, for which the lowest energy hits were discarded from the dataset. Each hit is represented by four numbers, corresponding to the hit coordinates, given in x, y, and z, and energy. The x and y coordinates are relative to the seed cell. The dataset consists of 500,000 samples, split evenly and randomly into
5.2. Task and Model Architecture
The task in this study is to identify the nature of the primary particle and to simultaneously predict its energy, given the hits in the cluster. The ability to reliably identify the particle type and estimate its energy at the cluster level in a local calorimeter trigger system greatly enhances the efficacy of high-level algorithms, such as particle-flow reconstruction (ALEPH Collaboration, 1995; ATLAS Collaboration, 2017; CMS Collaboration, 2017b), downstream in the L1T system. However, because of the distortion of the energy deposition pattern in the cluster due to pileup, particle identification based on collective properties of the hits, such as the depth of the energy center of mass, can achieve only modest accuracy. Furthermore, only half of the pion events have 95% of the energy deposition from the pion contained in the cluster, requiring substantial extrapolation in the energy prediction. This task is thus both practically relevant and sufficiently nontrivial as a test bench of a GarNet-based ML model.
The architecture of the model is as follows. First, the input data represented by a two-dimensional array of
This model is built in Keras (Keras, 2015), using the corresponding implementation of GarNet available in Qasim et al., (2019a). In total, the model has 3,402 trainable parameters (2,976 in the three GarNet layers), whose values are optimized through a supervised training process using the Adam optimizer (Kingma and Ba, 2014). Input is processed in batches of 64 samples during training. The overall objective function that is minimized in the training is a weighted sum of objective functions for the classification and regression tasks:
with
where
Additionally, we prepare a model in which the encoders and decoders of the GarNet layers are quantized as ternary networks using QKeras (Coelho et al., 2020; Qkeras, 2020), which performs quantization-aware training with the straight-through estimator by quantizing the layers during a forward pass but not a backward pass (Courbariaux et al., 2015; Zhou et al., 2016; Moons et al., 2017; Coelho et al., 2020). In the following, this model is referred to as the quantized model, and the original model as the continuous model. The quantized model is trained with the same objective function and training hyperparameters as the continuous model.
To evaluate the inference performance of the trained models, reference algorithms are defined separately for the classification and regression subtasks. The reference algorithm for classification (cut-based classification) computes the energy-weighted mean
where i is the index of hits in the cluster and
where
5.3. Training Result
Performance of the trained continuous and quantized models, evaluated using the validation sample, are shown in Figure 4. For each ML model, the inference results based on the original Keras model and the HLS model, converted using hls4ml, are shown. The HLS model provides a realistic emulation of the synthesized FPGA firmware.
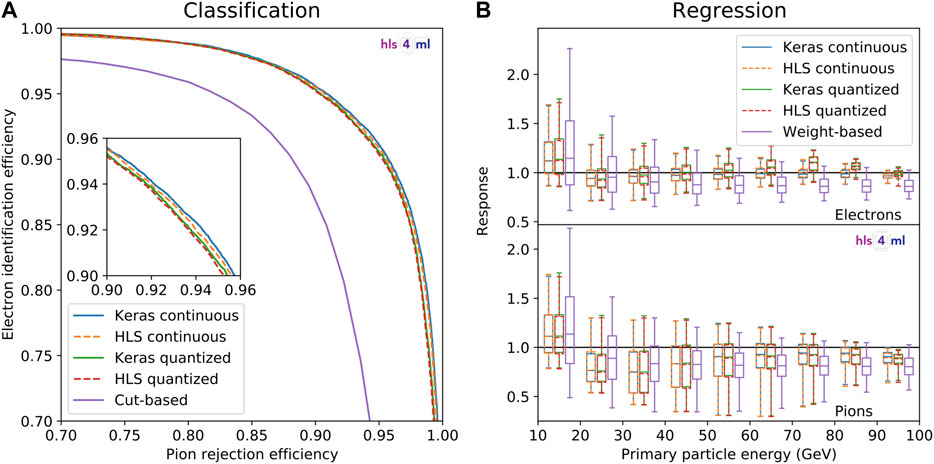
FIGURE 4. Classification (A) and regression (B) inference performance of the continuous and quantized GarNet-based models and the reference algorithms. Results from the Keras and HLS implementations are shown for the GarNet-based models. The classification performance is quantified with a ROC curve of electron identification efficiency vs. pion rejection efficiency. The inset in (A) shows a close-up view of the efficiency range 0.90–0.96 for both axes. The regression performance is quantified as the response
The classification performance is given in terms of receiver operating characteristic (ROC) curves that trace the electron identification efficiency (true positive fraction) and pion rejection efficiency (true negative fraction) for different thresholds of the classifiers. The two GarNet-based models perform similarly and better than the cut-based reference in terms of the electron identification efficiency for a given pion rejection efficiency. A detailed comparison of the four sets of results from the GarNet-based models in the inset reveals that the continuous model performs slightly better than the quantized model, and that the difference between the Keras and HLS implementations is smaller for the quantized model.
The regression performance is given in terms of the response
The differences between the Keras and HLS implementations are due to the numerical precision in the computation. While the former represents all fractional numbers in 32-bit floating-point numbers, the latter employs fixed-point numbers with bit widths of at most 18. Consequently, for the quantized model, where the encoder and decoder of the GarNet layers employ integer weights for inference, the difference between the two implementations are smaller.
For both subtasks, the GarNet-based models generally outperform the reference algorithms. The reference algorithm has narrower spread of the response in some energy bins for the regression subtask. However, it is important to note that the weights and biases appearing in Eq. 14 are optimized for a specific pileup profile, while in a real particle collider environment, pileup flux changes dynamically even on the timescale of a few hours. In contrast, algorithms based on inference of properties of individual hits, such as the GarNet-based models presented in this study, are expected to be able to identify hits due to pileup even under different pileup environments and thus to have a stable inference performance with respect to change in pileup flux. Since a detailed evaluation of application-specific performance of GarNet is not within the scope of this work, we leave this and other possible improvements to the model architecture and training to future studies.
To verify that GarNet can infer relations between individual vertices without edges
5.4. Model Synthesis and Performance
The latency, II, and resource usage of the FPGA firmware synthesized from the HLS implementations are summarized in Table 1. Vitis Core Development Kit 2019.2 (Kathail, 2020) is used for synthesis, with a Xilinx Kintex UltraScale FPGA (part number xcku115-flvb2104-2-i) as the target device and a clock frequency of 200 MHz. The reported resource usage numbers reflect the synthesis estimates from Vivado HLS. The latency and II reported here are the maximum values for samples with full

TABLE 1. Summary of the latency, II, FPGA resource usage metrics, and inference accuracy metrics of the synthesized firmware. The reported resource usage numbers reflect the synthesis estimates from Vivado HLS. The target FPGA is a Xilinx Kintex UltraScale FPGA (part number xcku115-flvb2104-2-i), which has 5,520 DSPs, 663,360 LUTs, 1,326,720 FFs, and 77.8 Mb of BRAM (Xilinx, 2020). The utilized percentage of the targeted FPGA resources are denoted in the square brackets.
Comparing the continuous and quantized models with
The latency of the synthesized quantized model at 148 clock periods, corresponding to 740
The simplest down-scoping measure is to reduce the size of the input. This is effective because the most prominent factor driving both the latency and the II of the firmware is
The results of synthesis of the additional models are given in the last three rows of Table 1. The values of FPGA resource usage metrics are similar in all quantized models because the ratio
6. Conclusion
In this paper, we presented an implementation of a graph neural network algorithm as FPGA firmware with
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://doi.org/10.5281/zenodo.3992780, doi:10.5281/zenodo.3992780. Simulation data set and the KERAS source code used for the case study are available on the Zenodo platform (Iiyama, 2020).
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
MP, AG, KW, SS, VL and JN are supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (Grant Agreement No. 772369). SJ, ML, KP, and NT are supported by Fermi Research Alliance, LLC under Contract No. DE-AC02-07CH11359 with the U.S. Department of Energy (DOE), Office of Science, Office of High Energy Physics. PH is supported by a Massachusetts Institute of Technology University grant. ZW is supported by the National Science Foundation under Grants Nos. 1606321 and 115164. JD is supported by DOE Office of Science, Office of High Energy Physics Early Career Research program under Award No. DE-SC0021187. CERN has provided the open access publication fee for this paper.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We acknowledge the Fast Machine Learning collective as an open community of multi-domain experts and collaborators. This community was important for the development of this project.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., et al. (2015). TensorFlow: large-scale machine learning on heterogeneous distributed systems. Available at: http://download.tensorflow.org/paper/whitepaper2015.pdf.
Abdughani, M., Ren, J., Wu, L., and Yang, J. M. (2019). Probing stop pair production at the LHC with graph neural networks. J. High Energy Phys. 8, 55. doi:10.1007/JHEP08(2019)055
Acosta, D., Brinkerhoff, A., Busch, E., Carnes, A., Furic, I., Gleyzer, S., et al. (2018). “Boosted decision trees in the Level-1 muon endcap trigger at CMS,” in Proceedings, 18th international workshop on advanced computing and analysis techniques in physics research (ACAT 2017), Seattle, WA, August 21–25, 2017 (Seattle, WA: ACAT), 042042. doi:10.1088/1742-6596/1085/4/042042
Agarap, A. F. (2018). Deep learning using rectified linear units (ReLU). [Preprint]. Available at: https://arxiv.org/abs/1803.08375.
Agostinelli, S., Allison, J., Amako, K., Apostolakis, J., Araujo, H., Arce, P., et al. (2003). Geant4—a simulation toolkit. Nucl. Instrum. Methods Phys. Res. 506, 250. doi:10.1016/S0168-9002(03)01368-8
ALEPH Collaboration (1995). Performance of the ALEPH detector at LEP. Nucl. Instrum. Methods Phys. Res. 360, 481. doi:10.1016/0168-9002(95)00138-7
Apollinari, G., Béjar Alonso, I., Brüning, O., Fessia, P., Lamont, M., Rossi, L., et al. (2017). High-luminosity large hadron collider (HL-LHC): technical design report V. 0.1, CERN Yellow Reports: Monographs (Geneva, Switzerland: CERN). doi:10.23731/CYRM-2017-004
Arjona Martínez, J., Cerri, O., Pierini, M., Spiropulu, M., and Vlimant, J. R. (2019). Pileup mitigation at the Large Hadron Collider with graph neural networks. Eur. Phys. J. Plus 134, 333. doi:10.1140/epjp/i2019-12710-3
ATLAS Collaboration (2017). Jet reconstruction and performance using particle flow with the ATLAS detector. Eur. Phys. J. C 77, 466. doi:10.1140/epjc/s10052-017-5031-2
Auten, A., Tomei, M., and Kumar, R. (2020). “Hardware acceleration of graph neural networks,” in 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, July 20–24, 2020 (San Francisco, CA: IEEE), 1–6. doi:10.1109/DAC18072.2020.9218751
Bai, J., Lu, F., and Zhang, K. (2019). ONNX: open neural network exchange. Available at: https://github.com/onnx/onnx (Accessed August 20, 2020).
Battaglia, P. W., Hamrick, J. B., Bapst, V., Sanchez-Gonzalez, A., Zambaldi, V., Malinowski, M., et al. (2018). Relational inductive biases, deep learning, and graph networks. [Preprint]. Available at: https://arxiv.org/abs/1806.01261.
Bernreuther, E., Finke, T., Kahlhoefer, F., Krämer, M., and Mück, A. (2020). Casting a graph net to catch dark showers. [Preprint]. Available at: https://arxiv.org/abs/2006.08639.
Besta, M., Stanojevic, D., De Fine Licht, J., Ben-Nun, T., and Hoefler, T. (2019). Graph processing on FPGAs: taxonomy, survey, challenges. [Preprint]. Available at: https://arxiv.org/abs/1903.06697.
Choma, N., Monti, F., Gerhardt, L., Palczewski, T., Ronaghi, Z., Prabhat, , et al. (2018). Graph neural networks for IceCube signal classification. [Preprint]. Available at: https://arxiv.org/abs/2006.10159.
CMS Collaboration (2017a). The phase-2 upgrade of the CMS endcap calorimeter. CMS Technical Design Report CERN-LHCC-2017-023. CMS-TDR-019 (Geneva, Switzerland: CERN).
CMS Collaboration (2017b). Particle-flow reconstruction and global event description with the CMS detector. J. Instrum. 12, P10003. doi:10.1088/1748-0221/12/10/P10003
CMS Collaboration (2020). The phase-2 upgrade of the CMS level-1 trigger. CMS Technical Design Report CERN-LHCC-2020-004. CMS-TDR-021 (Geneva, Switzerland: CERN).
Coelho, C. N., Kuusela, A., Zhuang, H., Aarrestad, T., Loncar, V., Ngadiuba, J., et al. (2020). Automatic deep heterogeneous quantization of Deep Neural Networks for ultra low-area, low-latency inference on the edge at particle colliders. [Preprint]. Available at: https://arxiv.org/abs/2006.10159.
Courbariaux, M., Bengio, Y., and David, J. P. (2015). “BinaryConnect: training deep neural networks with binary weights during propagations,” in Advances in neural information processing systems 28. Editors C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett (Red Hook, NY: Curran Associates, Inc.), 3123.
Di Guglielmo, G., Duarte, J., Harris, P., Hoang, D., Jindariani, S., Kreinar, E., et al. (2020). Compressing deep neural networks on FPGAs to binary and ternary precision with hls4ml. Mach. Learn. Sci. Technol. 2, 015001. doi:10.1088/2632-2153/aba042
Duarte, J., Han, S., Harris, P., Jindariani, S., Kreinar, E., Kreis, B., et al. (2018). Fast inference of deep neural networks in FPGAs for particle physics. J. Instrum. 13, 07027. doi:10.1088/1748-0221/13/07/P07027
Geng, T., Li, A., Shi, R., Wu, C., Wang, T., Li, Y., et al. (2020). AWB-GCN: a graph convolutional network accelerator with runtime workload rebalancing. [Preprint]. Available at: https://arxiv.org/abs/1908.10834.
Gray, L., Klijnsma, T., and Ghosh, S. (2020). A dynamic reduction network for point clouds. [Preprint]. Available at: https://arxiv.org/abs/2003.08013.
Gui, C. Y., Zheng, L., He, B., Liu, C., Chen, X. Y., Liao, X. F., et al. (2019). A survey on graph processing accelerators: challenges and opportunities. J. Comput. Sci. Technol. 34, 339. doi:10.1007/s11390-019-1914-z
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., et al. (2020). Array programming with NumPy. Nature 585, 357. doi:10.1038/s41586-020-2649-2
Henrion, I., Cranmer, K., Bruna, J., Cho, K., Brehmer, J., Louppe, G., et al. (2017). “Neural message passing for jet physics,” in Deep learning for physical sciences workshop at the 31st conference on neural information processing systems, Long Beach, CA, April 2017 (Long Beach, CA: NIPS), 1–6.
Iiyama, Y. (2020). Keras model and weights for GARNET-on-FPGA. Available at: https://zenodo.org/record/3992780.
Iiyama, Y., and Kieseler, J. (2020). Simulation of an imaging calorimeter to demonstrate GARNET on FPGA. Available at: https://zenodo.org/record/3888910.
Jin, C., Chen, Sz., and He, H. H. (2019). Classifying the cosmic-ray proton and light groups on the LHAASO-KM2A experiment with the graph neural network. [Preprint]. Available at: https://arxiv.org/abs/1910.07160.
Ju, X., Farrell, S., Calafiura, P., Murnane, D., Prabhat, , Gray, L., et al. (2019). Graph neural networks for particle reconstruction in high energy physics detectors. Available at: https://ml4physicalsciences.github.io/files/NeurIPS_ML4PS_2019_83.pdf.
Kathail, V. (2020). “Xilinx vitis unified software platform,” in 2020 ACM/SIGDA international symposium on field-programmable gate arrays, New York, NY, March 2020 (New York, NY: Association for Computing Machinery), 173. doi:10.1145/3373087.3375887
Keras Special Interest Group (2015). Keras. Available at: https://keras.io (Accessed August 20, 2020).
Kieseler, J. (2020). Object condensation: one-stage grid-free multi-object reconstruction in physics detectors, graph and image data. [Preprint]. Available at: https://arxiv.org/abs/2002.03605.
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. 3rd international conference for learning representations. [Preprint]. Available at: https://arxiv.org/abs/1412.6980.
Kiningham, K., Re, C., and Levis, P. (2020). GRIP: a graph neural network accelerator architecture. [Preprint]. Available at: https://arxiv.org/abs/2007.13828.
Kipf, T. N., and Welling, M. (2017). Semi-supervised classification with graph convolutional networks. Available at: https://openreview.net/forum?id=SJU4ayYgl.
Loncar, V., Tran, N., Kreis, B., Ngadiuba, J., Duarte, J., Summers, S., et al. (2020). hls-fpga-machine-learning/hls4ml: v0.3.0. Available at: https://github.com/hls-fpga-machine-learning/hls4ml.
Moons, B., Goetschalckx, K., Van Berckelaer, N., and Verhelst, M. (2017). “Minimum energy quantized neural networks,” in 51st Asilomar conference on signals, systems, and computers, Pacific Grove, CA, October 29–November 1, 2008 (Pacific Grove, CA: IEEE), 1921.
Moreno, E. A., Cerri, O., Duarte, J. M., Newman, H. B., Nguyen, T. Q., Periwal, A., et al. (2020a). JEDI-net: a jet identification algorithm based on interaction networks. Eur. Phys. J. C 80, 58. doi:10.1140/epjc/s10052-020-7608-4
Moreno, E. A., Nguyen, T. Q., Vlimant, J. R., Cerri, O., Newman, H. B., Periwal, A., et al. (2020b). Interaction networks for the identification of boosted decays. Phys. Rev. D 102, 012010. doi:10.1103/PhysRevD.102.012010
Nurvitadhi, E., Weisz, G., Wang, Y., Hurkat, S., Nguyen, M., Hoe, J. C., et al. (2014). “GraphGen: an FPGA framework for vertex-centric graph computation,” in 2014 IEEE 22nd annual international symposium on field-programmable custom computing machines, Boston, MA, May 11–13, 2014 (Boston, MA: IEEE), 25–28. doi:10.1109/FCCM.2014.15
Ozdal, M. M., Yesil, S., Kim, T., Ayupov, A., Greth, J., Burns, S., et al. (2016). Energy efficient architecture for graph analytics accelerators. Comput. Archit. News 44, 166. doi:10.1145/3007787.3001155
O’Loughlin, D., Coffey, A., Callaly, F., Lyons, D., and Morgan, F. (2014). “Xilinx Vivado high level synthesis: case studies,” in 25th IET Irish signals and systems conference 2014 and 2014 China-Ireland international conference on information and communications technologies (ISSC 2014/CIICT 2014), Limerick, Ireland, June 26–27, 2014 (Limerick, Ireland: IET), 352–356. doi:10.1049/cp.2014.0713
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). “PyTorch: an imperative style, high-performance deep learning library,” in Advances in neural information processing systems. Editors H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché Buc, E. Fox, and R. Garnett (Red Hook, NY: Curran Associates, Inc.), 8026.
Qasim, S. R., Kieseler, J., Iiyama, Y., and Pierini, M. (2019a). caloGraphNN. Available at: https://github.com/jkiesele/caloGraphNN (Accessed August 20, 2020).
Qasim, S. R., Kieseler, J., Iiyama, Y., and Pierini, M. (2019b). Learning representations of irregular particle-detector geometry with distance-weighted graph networks. Eur. Phys. J. C 79, 608. doi:10.1140/epjc/s10052-019-7113-9
Qkeras (2020). Google. Available at: https://github.com/google/qkeras (Accessed August 20, 2020 ).
Qu, H., and Gouskos, L. (2020). ParticleNet: jet tagging via particle clouds. Phys. Rev. D 101, 056019. doi:10.1103/PhysRevD.101.056019
Shlomi, J., Battaglia, P., and Vlimant, J. R. (2020). Graph neural networks in particle physics. Machine Learn. Sci. Tech. doi:10.1088/2632-2153/abbf9a
Summers, S., Di Guglielmo, G., Duarte, J., Harris, P., Hoang, D., Jindariani, S., et al. (2020). Fast inference of boosted decision trees in FPGAs for particle physics. J. Instrum. 15, 05026. doi:10.1088/1748-0221/15/05/P05026
The HDF Group (2020). Hierarchical data format, version 5 (1997–2020). Available at: https://www.hdfgroup.org/HDF5/ (Accessed August 20, 2020).
van der Walt, S., Colbert, S. C., and Varoquaux, G. (2011). The NumPy array: a structure for efficient numerical computation. Comput. Sci. Eng. 13, 22. doi:10.1109/MCSE.2011.37
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., and Bengio, Y. (2018). Graph attention networks. Available at: https://openreview.net/forum?id=rJXMpikCZ.
Wang, Y., Sun, Y., Liu, Z., Sarma, S. E., Bronstein, M. M., and Solomon, J. M. (2019). Dynamic graph CNN for learning on point clouds. ACM Trans. Graph. 38. doi:10.1145/3326362
Xilinx, Inc. (2020). UltraScale FPGA product tables and product selection guide. Available at: https://www.xilinx.com/support/documentation/selection-guides/ultrascale-fpga-product-selection-guide.pdf (Accessed August 20, 2020).
Yan, M., Deng, L., Hu, X., Liang, L., Feng, Y., Ye, X., et al. (2020). “HyGCN: a GCN accelerator with hybrid architecture,” in 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, February 2020 (New York, NY: IEEE), 15–29. doi:10.1109/HPCA47549.2020.00012
Zeng, H., and Prasanna, V. (2020). “GraphACT: accelerating GCN training on CPU-FPGA heterogeneous platforms,” in 2020 ACM/SIGDA international symposium on field-programmable gate arrays, New York, NY, April 2020 (New York, NY: Association for Computing Machinery), 255. doi:10.1145/3373087.3375312
Zhou, S., Wu, Y., Ni, Z., Zhou, X., Wen, H., and Zou, Y. (2016). DoReFa-Net: training low bitwidth convolutional neural networks with low bitwidth gradients. [Preprint]. Available at: https://arxiv.org/abs/1606.06160.
Zhu, C., Han, S., Mao, H., and Dally, W. J. (2017). Trained ternary quantization. Available at: https://openreview.net/pdf?id=S1_pAu9xl.
Keywords: deep learning, field-programmable gate arrays, fast inference, graph network, imaging calorimeter
Citation: Iiyama Y, Cerminara G, Gupta A, Kieseler J, Loncar V, Pierini M, Qasim SR, Rieger M, Summers S, Van Onsem G, Wozniak KA, Ngadiuba J, Di Guglielmo G, Duarte J, Harris P, Rankin D, Jindariani S, Liu M, Pedro K, Tran N, Kreinar E and Wu Z (2021) Distance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics. Front. Big Data 3:598927. doi: 10.3389/fdata.2020.598927
Received: 25 August 2020; Accepted: 26 October 2020;
Published: 12 January 2021.
Edited by:
Daniele D’Agostino, National Research Council (CNR), ItalyCopyright © 2021 Iiyama, Cerminara, Gupta, Kieseler, Loncar, Pierini, Qasim, Rieger, Summers, Van Onsem, Wozniak, Ngadiuba, Di Guglielmo, Duarte, Harris, Rankin, Jindariani, Liu, Pedro, Tran, Kreinar and Wu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yutaro Iiyama, yutaro.iiyama@cern.ch