 Olivier White
Olivier White Fabien Buisseret
Fabien Buisseret Frédéric Dierick2,4,5
Frédéric Dierick2,4,5 Nicolas Boulanger
Nicolas Boulanger- 1Université Bourgogne Europe, INSERM, CAPS UMR 1093, Dijon, France
- 2Haute Ecole Louvain en Hainaut, Laboratoire Forme et Fonctionnement Humain (FFH), Montignies-sur-Sambre, Belgium
- 3Service de Physique Nucléaire et Subnucléaire, UMONS Research Institute for Complex Systems, Université de Mons, Mons, Belgium
- 4RehaLAB, Centre National de Rééducation Fonctionnelle et de Réadaptation – Rehazenter, Luxembourg, Luxembourg
- 5Faculté des Sciences de la Motricité, UCLouvain, Louvain-la-Neuve, Belgium
- 6Service de Physique de l'Univers, Champs et Gravitation, UMONS Research Institute for Complex Systems, Université de Mons, Mons, Belgium
1 Introduction
Optimal Feedback Control (OFC) provides a theoretical framework for goal-directed movements, where the nervous system adjusts actions based on sensory feedback [1, 2]. In OFC, the central nervous system (CNS) not only reacts to stimuli but proactively predicts and adjusts motor commands, minimizing errors and (often energetic) costs through internal models. OFC theory can be extended beyond motor control to encompass perception and learning [3]. This theory assumes that there exists a cost function that is optimized throughout one's movement. It is natural to assume that mechanical quantities should be involved in cost functions. This does not imply that the mechanical principles that govern human voluntary movements are necessarily Newtonian. Indeed, the undisputed efficiency of Newtonian mechanics to model and predict the motion of non-living systems does not guarantee its relevance to model human behavior. We propose that integrating principles from Lagrangian and Hamiltonian higher-derivative mechanics, i.e., dynamical models that go beyond Newtonian mechanics, provides a more natural framework to study the constraints hidden in human voluntary movement within OFC theory. Such an integration is displayed in Figure 1 and will be extensively discussed hereafter. The outcome of our comment will be a refined framework for OFC that considers recent analyses based on Lagrangian or Hamiltonian mechanics, and that unifies them in a consistent way.
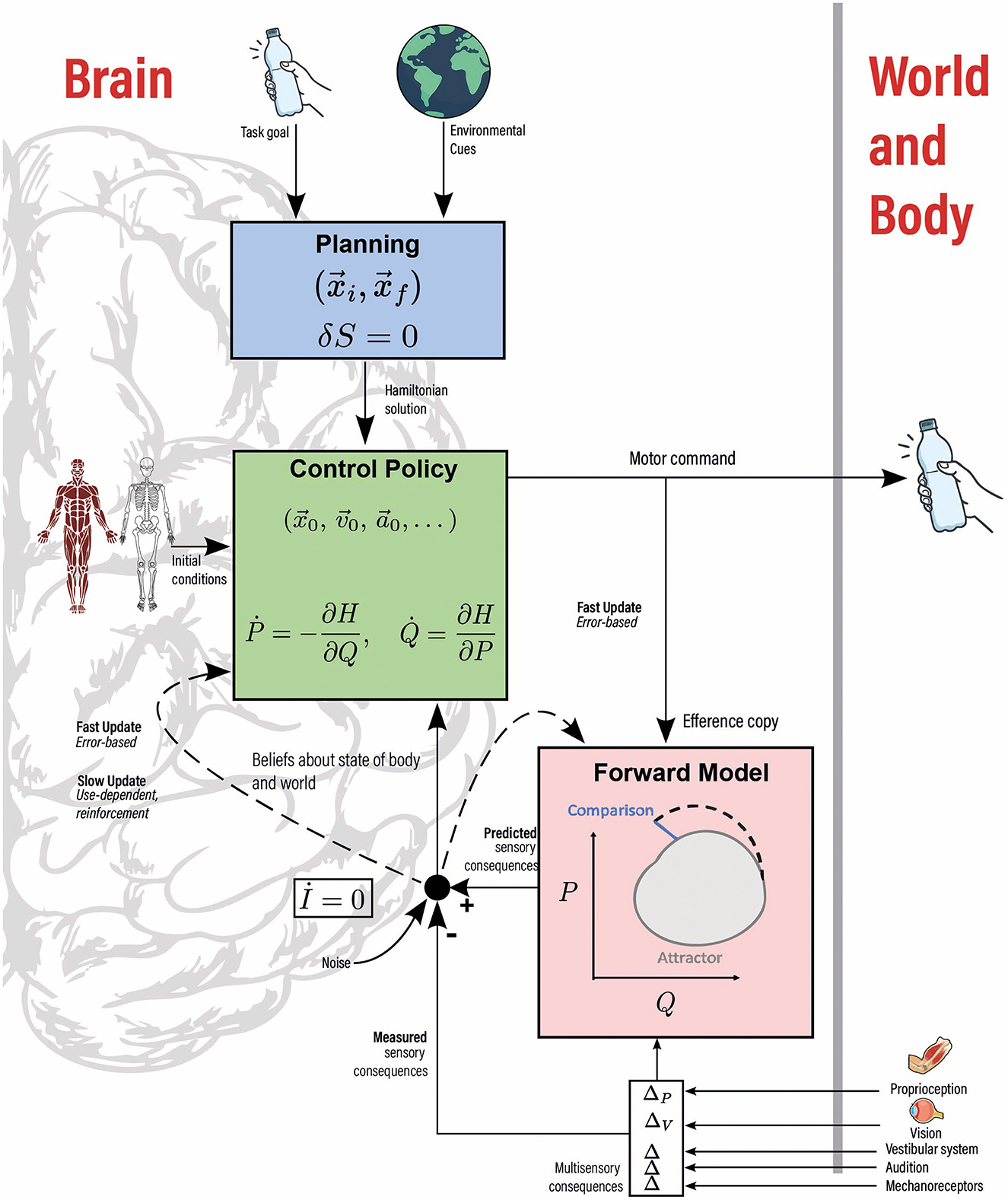
Figure 1. Integration of higher-derivative mechanical concepts within components of an optimal feedback control model. It integrates task goals and environmental cues, such as gravity, into the planning process. A Hamiltonian equation of motion (green box), formulated through a higher-derivative least-action principle (blue box), informs the control policy. S and H represent the action and Hamiltonian respectively. Initial conditions and Hamilton's equations then guide movement execution. The optimal phase-space trajectory, or attractor, serves as a forward model (pink box), continuously compared to the actual trajectory. In rhythmic motion, the invariance of the adiabatic invariant (I) can act as a robust comparator. Movement updates occur rapidly through this comparison (error-based learning), while significant changes in task or environment may lead to longer-term adaptations in the variational principle (use-dependent learning). Illustrator: Robin Raedt.
2 The need for higher-derivative mechanics
Newtonian mechanics obviously helps describe the immediate causal relationships from initial conditions to generation of a trajectory through the action of external forces—recall that according to standard terminology, internal forces are such that their sum always vanishes. However, Newtonian mechanics is not directly suited to address two primary challenges in understanding motor control: modeling the redundancy inherent in the musculoskeletal system and the ability to perform voluntary movements against external loads, such as those induced by gravity.
Redundancy refers to the multiple ways in which the same movement or task can be performed due to the numerous degrees of freedom available in our joints and muscles, and the question of how an individual is able to select a particular movement. Lagrangian mechanics is a priori well suited to model redundancy: It asserts that, out of all possible trajectories between two positions at initial and final times ti and tf, and , the actual path followed by the system under study is the one that minimizes an action functional , where , and denote the first, second and Nth time-derivatives of the dynamical variables , respectively. Velocity and acceleration are denoted and respectively. The function L is called the Lagrangian and the actual motion is given by Hamilton's variational principle, δS = 0, supplemented by a total of 2N conditions , j = 0, 1, …, N−1, at both initial and final times, which leads to the least-action trajectory [4]. The action functional may therefore be a basic principle of movement planning, i.e. it provides a principle by which the CNS can leverage multiple pathways to achieve the same movement goal and eventually chooses the best one, the one for which the action is minimal. In that sense, the action functional may be thought of as a cost function in the OFC jargon. Newtonian mechanics has only N = 1, with L being the difference between kinetic and potential energies. Higher-derivative systems are such that N>1, and Lagrangians that are quadratic in lead to equations of motion of order 2N with a solution requiring 2N initial conditions to be specified [5]. Note that both the non-local, Hamiltonian principle, and the local integration of an order−2N differential equation require the same number 2N of conditions, either N conditions at both ti and tf in Hamilton's principle, or 2N initial (i.e., at ti) conditions at the level of the equation of motion.
The case N = 1 is ruled out by human's ability to perform voluntary movements against given external forces, i.e., to choose accelerations that are not proportional to the total external force applied. The motor command and sensory feedback processed by the CNS constantly control muscle forces, hence the acceleration of a given joint or limb. The ability of the muscles to separately fine-tune initial position, velocity and acceleration has been shown by Ueyama [6], leading to the conclusion that the minimal value of the integer N should be 2. An N = 2 action, , is then higher-derivative and four initial conditions must be specified in the solution of the equations of motion: from to . Interestingly, in the field of motor control, movements exhibiting two-thirds power-law, such as natural tracing or even writing, demand at least N = 2 to be produced [7, 8]. Therefore, we conclude that the action principle governing movement planning has to be higher-derivative.
The seemingly complex nature of selecting a trajectory by minimizing an action raises the question of how the brain manages it. The CNS adapts and optimizes motor control by learning from previous movements. This learning involves continuously updating internal models to improve predictions of motor command outcomes, based on feedback and on initial conditions. Hence, an action can serve as a reliable implementation of an internal model if an individual can “learn” it through repeated trials and observations. A four-layer neural network model with 500 hidden units is already able to learn a Lagrangian from the observation of 600,000 randomly generated trajectories [9]. Furthermore, a small neural network can replicate reaching movements in monkeys, suggesting that the CNS, with its vast complexity, can learn and optimize similar tasks [10]. These network architectures being considerably simpler than the human brain, it is reasonable to assume that several Lagrangians may be learned concurrently by one individual. This implies that motor strategies, such as non-trivial cost functions, may be encoded in neural circuits.
3 Hamiltonian mechanics and optimal feedback control
Once the action is selected, the corresponding Hamiltonian, H, follows. Let us clarify the relevance of Hamiltonian mechanics at this stage. In higher-derivative mechanics, the N positions () and N momenta () degrees of freedom can be computed from L, see e.g., Boulanger et al. [8] for formal developments. The space spanned by the pairs of variables is called phase-space (b denotes the vector component), in which the full system trajectory forms a single curve whose properties can be geometrically studied. To initiate the planned movement after the choice of higher-derivative action is made and the optimal trajectory selected, initial conditions on all the 2N higher-derivative degrees of freedom are designed, that will trigger the movement in compliance with Hamilton's equations in the higher-derivative phase space. This process is illustrated in Figure 1 (Planning and Control Policy boxes). Therefore, Hamilton's equations coupled with appropriate initial conditions determine the attractor to be followed in OFC.
Phase-space provides a detailed map of the energy landscape of trajectories, guiding the CNS in its selection of the most efficient movement patterns. In an OFC framework, the optimal state estimator uses a forward model to convert motor commands into estimates of limb position. We propose that one individual can “store” phase-space trajectories corresponding to a given dynamics and initial conditions, called attractors hereafter, and exploit them as forward models, i.e. predicted attractors. It predicts sensory consequences of motor commands and compares them to actual feedback to calculate the error. This iterative process occurs in real-time, allowing the CNS to refine the trajectory dynamically by comparison between the planned trajectory and the actual one. In our framework, the comparison is made between the predicted and measured attractors, that may reveal potential discrepancies in every degree of freedom. This naturally addresses the responsibility assignment problem, as the approach helps identify which of the many degrees of freedom diverge from the target trajectory [11]. By updating initial conditions without changing the dynamics, i.e. by updating internal models through sensory feedback in an OFC language, the CNS optimizes short-term adaptation. This mechanism may be related to error-based learning.
Long-term adaptation can occur by comparison of parameters relevant at longer time scales. In the case of a rhythmic movement for example, attractors become closed loops in phase-space planes . The areas of these loops, called adiabatic invariants and denoted I, are known to be constant in Hamiltonian mechanics and even remain weakly fluctuating in presence of noise. They also remain roughly constant in the presence of radically new environments, such as rapid transitions between different gravitational fields [12, 13]. In other words, İ≈0. This constraint may allow the CNS to refine its control strategies over longer timescales by minimizing errors related to the fluctuations of I, thereby improving performance over a longer time scale than the process based on the attractor. We think that such long-range adaptations may even result in a change in the action functional and chosen Hamiltonian, through use-dependent learning mechanism. As an illustration, Raffalt et al. [14] have shown that the walk-run transition may be seen as the transition toward two attractors, the attractor for running becoming more stable (as assessed by Lyapunov exponent) at higher speed.
4 Discussion
How may the brain implement higher-derivative mechanical principles? Decades of research have uncovered functional specialization within both cortical and subcortical regions. However, a significant gap persists between our ability to leverage the brain for application and our deeper understanding of how various brain areas contribute to these tasks [15]. Today, most prosthetic control systems, for instance, heavily rely on signals from the primary motor cortex (M1), largely because it is easily accessible. This reliance on M1 oversimplifies the complexity of brain functions. Traditional approaches, such as using brain imaging with region-of-interest analysis, often assume distinct functions for each area. In fact, many brain regions serve diverse and overlapping roles. For example, the insula is involved in a wide range of processes, despite these processes being very different in nature, such as empathy [16] and graviception [17]. In this view, examining a brain area in isolation overlooks the complex, context-dependent interactions that occur across the vast neural network. No single region operates independently; instead, functions are likely implemented by distributed networks, with each area contributing in a dynamically modulated manner. Task goals and environmental cues are integrated within the dorsolateral prefrontal cortex, forming initial movement intentions. The posterior parietal cortex combines multisensory inputs to construct a state estimate of the body (initial conditions) and refine the motor planning component. M1 generates motor commands, while the cerebellum and primary somatosensory cortex process sensory feedback to refine ongoing movements. Going beyond this highly simplified story will open new avenues in motor control research.
An explicit class of higher-derivative Lagrangians has been proposed by Boulanger et al. [8]:
with N ≥ 2, λ > 0, and U an arbitrary real function. These Lagrangians encompass well-known higher-derivative candidates based on minimal jerk [7] while allowing for rhythmic motion and leading to trajectories that exhibit two-thirds power-law, i.e., , with κ the trajectory's curvature. We summarize the study of LN as a worked-out example, and refer the reader to the previous reference for computational details. Following Ostrogradsky [18], the corresponding phase-space is defined as follows: The position-like dynamical variables are defined as with j = 0, …, N−1, and the conjugate momenta are given by
The corresponding Hamiltonian, computed from Equations 1, 2, reads
The Hamilton (canonical) equations read
When the corresponding trajectory is periodic in phase-space, noting and , the adiabatic invariant reads
In the latter equation, the closed curve Γ is a phase-space cycle in the plane starting at ti and ending at tf, so that the period of the motion is T = tf−ti. The peculiar structure of HN leads to unbounded trajectories because of the term . This phenomenon, known as Ostrogradsky instability, is often seen as an intrinsic weakness of higher-derivative models. We believe however that individuals, through the comparison stage of OFC model, are able to avoid this instability by maintaining to zero the N−1 momenta , thereby avoiding the well-known pitfall of generic higher-derivative models. Furthermore, regardless of human motor control, we have shown in a previous work that classes of higher-derivative Lagrangians, of Pais-Uhlenbeck type, can be constructed, that are free from Ostrogradsky instability [19].
To experimentally test our framework, we propose a rhythmic wrist/arm oscillation task with an abrupt context switch on a planar backdrivable robotic manipulandum along the lines of the protocol studied by White et al. [20]. Previous explicit higher-derivative models as proposed in Richardson and Flash [21] rely indeed on actions that do not allow for rhythmic motions, while our model based on LN does. Participants will oscillate the handle at a metronome-paced frequency. The robot renders either a viscous (velocity-dependent drag) force field, or an inertial (mass-like load) force field, , with . At an unpredictable instant, we will introduce a step change in the environment by instantaneously updating B while keeping task instructions and metronome unchanged. We hypothesize that the Lagrangian LN written above, with a simple harmonic potential U(z)~z, should be able to reproduce the observed trajectories before and after the update of B while predicting an invariant IN. Note that, with U(z)~z, one has . This integral corresponds to the action originally proposed by Richardson and Flash [21], and in our framework, it emerges naturally as an adiabatic invariant. Crucially, the concept of maintaining an invariant provides a holistic and principled way to understand motor learning: Rather than simply minimizing immediate errors, the motor system may aim to preserve deeper structural quantities across changing environments.
This perspective aligns with growing empirical evidence that the brain can switch between internal control policies depending on contextual cues. For example, White and Diedrichsen [22] showed that learning opposing force fields is only possible when each is associated with a distinct feedback control strategy. Similarly, White et al. [20] demonstrated that during tool-mediated interaction with elastic force fields, grip force control undergoes a discrete switch as stiffness crosses a threshold − suggesting the brain uses switched feedforward strategies in response to continuous task changes. In this view, classic motor learning mechanisms−such as error-based adaptation, use-dependent learning, and reinforcement learning−can be interpreted as complementary processes working to preserve an underlying invariant. Error-based mechanisms may handle rapid online corrections, reinforcement learning may guide strategic policy selection based on long-term outcomes, and use-dependent processes may refine execution through repetition. All three can be seen as converging toward a common goal: maintaining stability in internal control structure despite environmental variability. The action assumed by Richardson and Flash [21] actually emerges as the adiabatic invariant of our model. We will analyse the data for different N and find the best value, that is the N for which IN is maximally constant (i.e., with the lowest coefficient of variation across the successive cycles) before and after the B switch. This approach, grounded in the principle of adiabatic invariance, offers a unified lens through which both abrupt and gradual motor adaptations can be interpreted.
Our framework brings a new vantage point on motor control, regarding for example (1) Connection to neurological diseases and rehabilitation as e.g., gait in patients suffering from Parkinson's disease, for which fluctuations between consecutive strides have lost predictability [23]. This loss may be related to an inability to ensure the constancy of the action variable (İ = 0), eventually supporting the use of auditory rhythmic stimulations as an effective rehabilitation option, see Figure 1; (2) Identification of new motor invariants from N≥2 action principles, as already done to recover two-thirds law [8]; (3) Use of adiabatic invariant theory as the most powerful way to model the response of a system to external perturbations. This will enhance the predictive power of OFC models for individuals moving in variable environments with factors such as vibrations, luminosity, acoustic environment or even gravity [12]. In the intricate dance of motor control, the brain is not just a reactive machine: it is an anticipatory maestro, fine-tuning every movement through layers of prediction, feedback, and adaptation. By pairing higher-derivative mechanical concepts and components of optimal feedback control models, one is led to a comprehensive framework that can link the intricate neural computations at work in voluntary movement to mathematically elegant physical laws governing them.
Author contributions
OW: Conceptualization, Writing – review & editing, Methodology, Writing – original draft. FB: Writing – original draft, Formal analysis, Writing – review & editing, Conceptualization, Methodology. FD: Writing – original draft, Conceptualization, Methodology, Writing – review & editing. NB: Methodology, Conceptualization, Writing – original draft, Formal analysis, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. Research support (salaries) was provided by all the organizations reported in the affiliations.
Acknowledgments
The authors thank Robin Raedt (UMONS) for his work as illustrator of Figure 1.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Todorov E, Jordan MI. Optimal feedback control as a theory of motor coordination. Nat Neurosci. (2002) 5:1226–35. doi: 10.1038/nn963
2. Wolpert DM, Ghahramani Z. Computational principles of movement neuroscience. Nat Neurosci. (2000) 3:1212–7. doi: 10.1038/81497
3. Friston K. The free-energy principle: a unified brain theory? Nat Rev Neurosci. (2010) 11:127–38. doi: 10.1038/nrn2787
4. José JV, Saletan EJ. Classical Dynamics: A Contemporary Approach. Cambridge UK: Cambridge University Press (1998). doi: 10.1017/CBO9780511803772
5. Pais A, Uhlenbeck GE. On field theories with non-localized action. Phys Rev. (1950) 79:145–65. doi: 10.1103/PhysRev.79.145
6. Ueyama Y. Costs of position, velocity, and force requirements in optimal control induce triphasic muscle activation during reaching movement. Sci Rep. (2021) 11:16815. doi: 10.1038/s41598-021-96084-2
7. Flash T, Handzel AA. Affine differential geometry analysis of human arm movements. Biol Cybern. (2007) 96:577–601. doi: 10.1007/s00422-007-0145-5
8. Boulanger N, Buisseret F, Dierick F, White O. The two-thirds power law derived from a higher-derivative action. Physics. (2024) 6:1251–63. doi: 10.3390/physics6040077
9. Cranmer MD, Greydanus S, Hoyer S, Battaglia PW, Spergel DN, Ho S. Lagrangian neural networks. arXiv preprint arXiv:2003.04630. (2020).
10. Sussillo D, Churchland MM, Kaufman MT, Shenoy KV. A neural network that finds a naturalistic solution for the production of muscle activity. Nat Neurosci. (2015) 18:1025–33. doi: 10.1038/nn.4042
11. White O, Diedrichsen J. Responsibility assignment in redundant systems. Curr Biol. (2010) 20:1290–5. doi: 10.1016/j.cub.2010.05.069
12. Boulanger N, Buisseret F, Dehouck V, Dierick F, White O. Motor strategies and adiabatic invariants: the case of rhythmic motion in parabolic flights. Phys Rev E. (2021) 104:024403. doi: 10.1103/PhysRevE.104.024403
13. Boulanger N, Buisseret F, Dehouck V, Dierick F, White O. Adiabatic invariants drive rhythmic human motion in variable gravity. Phys Rev E. (2020) 102:062403. doi: 10.1103/PhysRevE.102.062403
14. Raffalt PC, Kent JA, Wurdeman SR, Stergiou N. To walk or to run — a question of movement attractor stability. J Exp Biol. (2020) 223(13):jeb224113. doi: 10.1242/jeb.224113
15. Gallego JA, Makin TR, McDougle SD. Going beyond primary motor cortex to improve brain-computer interfaces. Trends Neurosci. (2022) 45:176–83. doi: 10.1016/j.tins.2021.12.006
16. Decety J, Jackson PL. The functional architecture of human empathy. Behav Cogn Neurosci Rev. (2004) 3:71–100. doi: 10.1177/1534582304267187
17. Rousseau C, Barbiero M, Pozzo T, Papaxanthis C, White O. Gravity highlights a dual role of the insula in internal models. bioRxiv.659870. (2019). doi: 10.1101/659870
18. Ostrogradsky M. Mémoires sur les équations différentielles, relatives au problème des isopérimètres. Mem Acad St Petersbourg. (1850) 6:385–517.
19. Boulanger N, Buisseret F, Dierick F, White O. Higher-derivative harmonic oscillators: stability of classical dynamics and adiabatic invariants. Eur Phys J C. (2019) 79:60. doi: 10.1140/epjc/s10052-019-6569-y
20. White O, Karniel A, Papaxanthis C, Barbiero M, Nisky I. Switching in feedforward control of grip force during tool-mediated interaction with elastic force fields. Front Neurorobot. (2018) 12:31. doi: 10.3389/fnbot.2018.00031
21. Richardson MJE, Flash T. Comparing smooth arm movements with the two-thirds power law and the related segmented-control hypothesis. J Neurosci. (2002) 22:8201–11. doi: 10.1523/JNEUROSCI.22-18-08201.2002
22. White O, Diedrichsen J. Flexible switching of feedback control mechanisms allows for learning of different task dynamics. PLoS ONE. (2013) 8:1–8. doi: 10.1371/journal.pone.0054771
23. Lheureux A, Warlop T, Cambier C, Chemin B, Stoquart G, Detrembleur C, et al. Influence of autocorrelated rhythmic auditory stimulations on Parkinson's disease gait variability: comparison with other auditory rhythm variabilities and perspectives. Front Physiol. (2020) 11:601721. doi: 10.3389/fphys.2020.601721
Keywords: motor control, higher derivative classical mechanics, human movement, Hamiltonian mechanics, optimal feedback control
Citation: White O, Buisseret F, Dierick F and Boulanger N (2025) From brain to motion: harnessing higher-derivative mechanics for neural control. Front. Appl. Math. Stat. 11:1692890. doi: 10.3389/fams.2025.1692890
Received: 26 August 2025; Accepted: 10 November 2025;
Published: 25 November 2025.
Edited by:
Appanah Rao Appadu, University of the Western Cape, South AfricaReviewed by:
Zhuowen Zou, University of California, Irvine, United StatesCopyright © 2025 White, Buisseret, Dierick and Boulanger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fabien Buisseret, YnVpc3NlcmV0ZkBoZWxoYS5iZQ==