Predicting the Response of Laminated Composite Beams: A Comparison of Machine Learning Algorithms
 George C. Tsiatas
George C. Tsiatas Sotiris Kotsiantis
Sotiris Kotsiantis Aristotelis E. Charalampakis
Aristotelis E. Charalampakis- 1Department of Mathematics, University of Patras, Patras, Greece
- 2Department of Civil Engineering, University of West Attica, Athens, Greece
A comparative study of machine learning regression algorithms for predicting the deflection of laminated composite beams is presented herein. The problem of the scarcity of experimental data is solved by ample numerically prepared data, which are necessary for the training, validation, and testing of the algorithms. To this end, the pertinent geometric and material properties of the beam are discretized appropriately, and a refined higher-order beam theory is employed for the accurate evaluation of the deflection in each case. The results indicate that the Extra-Trees algorithm performs best, demonstrating excellent predictive capabilities.
Introduction
Beams as structural components are crucial in many structural systems. The prediction of their deflection is essential since excessive values can lead to the structural system losing its operational serviceability (Serviceability Limit State—SLS). On the other hand, composite materials are increasingly used in structural engineering due to their enhanced stiffness combined with reduced weight. Several shear deformation theories have been developed so far to evaluate the response of thin, moderately thick, or deep beams. They fall into three main categories: the Euler-Bernoulli beam theory (or Classical Beam Theory—CBT), the Timoshenko beam theory (or First Order Beam Theory—FOBT) and the Higher-Order Beam Theories (HOBTs). CBT is applicable for thin beams with no shear effect. In the FOBT, a constant state of transverse shear strain is assumed that does not satisfy the zero shear stress condition at the top and bottom edges of the beam and thus requires a shear correction factor to compensate for this error (see, e.g., Wang et al., 2000; Eisenberger, 2003; Civalek and Kiracioglu, 2010; Lin and Zhang, 2011; Endo, 2016). In general, the HOBTs adopt a specific function (parabolic, trigonometric, exponential, or hyperbolic) to more accurately represent the shear stress distribution along the beam’s thickness and do not require the shear correction factor (see e.g., Reddy, 1984; Heyliger and Reddy, 1988; Khdeir and Reddy, 1997; Murthy et al., 2005; Vo and Thai, 2012; Pawar et al., 2015; Nguyen et al., 2017; Srinivasan et al., 2019). The literature contains a plethora of publications on the subject, and the interested reader is referred to the excellent review paper of Liew et al. (2019). In this investigation, a refined higher-order beam theory is utilized for the analysis of laminated composite beams based on Reddy-Bickford’s third-order beam theory (Wang et al., 2000) which was derived independently by Bickford (1982) and Reddy (1984).
Utilizing higher-order beam theories for more accurate analyses entails a significant increase in complexity as compared to low-order theories, as the latter are mathematically simpler and more widely used. The main motivation of this work is to bridge this gap and provide a simple computational tool to allow for the fast design of beams while keeping the best of both worlds, i.e., the more accurate results of a refined high-order theory and the ease of application of the low-order theories. In order to achieve that, the geometric and material variables are discretized within fairly wide, yet reasonable ranges. After applying the high-order analyses, the results are collected, tabulated, and used as input for multiple machine learning algorithms, i.e., regression models. These models provide a fast and easy-to-use computational tool that can be used for preliminary design and optimization. Regression analysis also yields important insights regarding the performance of each model, the effect of boundary conditions, and the relative importance of each input variable for the problem at hand.
The rest of the paper is organized as follows. A theoretical formulation of the problem is carried out and explained in detail next, followed by a summary of the regression methods utilized in this work. The numerical results are presented next, along with their discussion. Finally, the conclusions drawn based on the findings of this work are presented.
Theoretical Formulation
Consider an elastic symmetric cross-ply laminated rectangular beam (
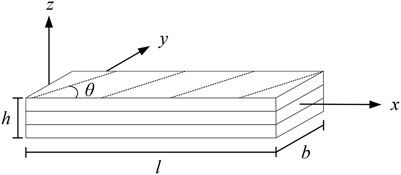
FIGURE 1. Geometry of a cross-ply laminated composite beam.
The beam is subjected to a transverse distributed loading
where
Splitting the transverse displacement
and introducing the transformation
Equations 1–3 can be rewritten in the following form
where
where
Substituting Eqs 9, 10 into the stress-strain relations for the kth lamina in the lamina coordinate we obtain (Khdeir and Reddy, 1997)
with
and
while
Applying the Principle of Virtual Work
and substituting Eqs 9, 10 yields
Introducing now the following stress resultants
Integrating the appropriate terms in the above equation and collecting the coefficients of
together with the following associated boundary conditions of the form: specify
Substituting Eqs 11, 12 into Eq. 19 and using Eqs 9, 10 yields the stress resultants in terms of the displacements as
where
Finally, after the substitution of the stress resultants, Eqs 27, 28 into Eqs 21, 22, we arrive at the equilibrium equations in terms of the displacements
which together with the pertinent boundary conditions (23)–(26) constitute the boundary value problem solved using the Analog Equation Method (AEM), a robust numerical method based on an integral equation technique (Katsikadelis and Tsiatas, 2003; Tsiatas et al., 2018).
Regression Models
In this work, several linear and nonlinear regression models are comparatively examined. Linear regression is a linear model that assumes a linear relationship between the input variables and the output variable, and the predicted value can be calculated from a linear combination of the input variables (Narula and Wellington, 1982). The distance from each data point to the predicted values is calculated and sum all these squared errors together. This quantity is minimized by the ordinary least squares method to estimate the optimal values for the coefficients of each independent variable.
There are extensions of the linear model called regularization methods. These methods seek to both minimize the sum of the squared error of the model on the training set but also to reduce the complexity of the model. Two popular regularization methods for linear regression are the Lasso Regression (Zou et al., 2007) where Ordinary Least Squares is modified to also minimize the absolute sum of the coefficients (L1 regularization), and the Ridge Regression (Hoerl et al., 1985) where Ordinary Least Squares is modified to also minimize the squared absolute sum of the coefficients (L2 regularization). A Bayesian view of ridge regression is obtained by noting that the minimizer can be considered as the posterior mean of a model (Tipping, 2001). The elastic net (Friedman et al., 2010) is a regularized regression method that linearly combines the L1 and L2 penalties of the lasso and ridge methods. Huber’s criterion is a hybrid of squared error for relatively small errors and absolute error for relatively large ones. Lambert-Lacroix and Zwald (2011) proposed Huber regressor to combine Huber’s criterion with concomitant scale and Lasso.
An L1 penalty minimizes the size of all coefficients and allows any coefficient to go to the value of zero, acting as a type of feature selection method since removes input features from the model. Least Angle Regression (Efron et al., 2004) is a forward stepwise version of feature selection for regression that can be adapted for the Lasso not to require a hyperparameter that controls the weighting of the penalty in the loss function since the weighting is discovered automatically by Least Angle Regression method via cross-validation. LassoLars is a lasso model implemented using the Least Angle Regression algorithm, where unlike the implementation based on coordinate descent, this yields the exact solution, which is piecewise linear as a function of the norm of its coefficients.
Orthogonal matching pursuit (Pati et al., 1993) tries to find the solution for the L0-norm minimization problem, while Least Angle Regression solves the L1-norm minimization problem. Although these methods solve different minimization problems, they both depend on a greedy framework. They start from an all-zero solution, and then iteratively construct a sparse solution based on the correlation between features of the training set and the output variable. They converge to the final solution when the norm approaches zero.
K Neighbors Regressor (KNN) algorithm uses feature similarity to predict the values of new instances (Altman, 1992). The distance between the new instance and each training instance is calculated, the closest k instances are selected based on the preferred distance and finally, the prediction for the new instance is the average value of the dependent variable of these k instances.
Unlike linear regression, Classification and Regression Tree (CART) does not create a prediction equation, but data are partitioned into subsets at each node according to homogeneous values of the dependent variable and a decision tree is built to be used for making predictions about new instances (Breiman et al., 1984). We can enlarge the tree until always gives the correct value in the training set. However, this tree would overfit the data and not generalize well to new data. The correct policy is to use some combination of a minimum number of instances in a tree node and maximum depth of tree to avoid overfitting.
The basic idea of Boosting is to combine several weak learners into a stronger one. AdaBoost (Freund and Schapire, 1997) fits a regression tree on the training set and then retrains a new regression tree on the same dataset but the weights of each instance are adjusted according to the error of the previous tree predictions. In this way, subsequent regressors focus more on difficult instances.
Random Forests algorithm (Breiman, 2001) builds several trees with the CART algorithm using for each tree a bootstrap replica of the training set with a modification. At each test node, the optimal split is derived by searching a random subset of size K of candidate features without replacement from the full feature set.
Like Random Forests, Gradient Boosting (Friedman, 2001) is an ensemble of trees, however, there are two main differences. Firstly, the Random forests algorithm builds each tree independently while Gradient Boosting builds one tree at a time since it works in a forward stage-wise manner, introducing a weak learner to improve the shortcomings of existing weak learners. Secondly, Random Forests combine results at the end (by averaging the result of each tree) while Gradient Boosting combines results during the process.
LightGBM (Ke et al., 2017) extends the gradient boosting algorithm by adding automatic feature selection and focusing on instances with larger gradients to speed up training and sometimes even improve predictive performance.
The Extra-Trees algorithm (Geurts et al., 2006) creates an ensemble of unpruned regression trees according to the well-known top-down procedure of the regression trees. The main differences concerning other tree-based ensemble methods are that the Extra-Trees algorithm splits nodes by choosing fully at random cut-points and that uses the whole learning set (instead of a bootstrap replica) to grow the trees.
Passive-Aggressive regressor (Crammer et al., 2006) is generally used for large-scale learning since it is an online learning algorithm. In online learning, the input data come sequentially, and the learning model is updated step-by-step, as opposed to batch learning, where the entire dataset is used at once.
Numerical Results and Discussion
The scope of the current study is to exploit predictive models for the maximum deflection
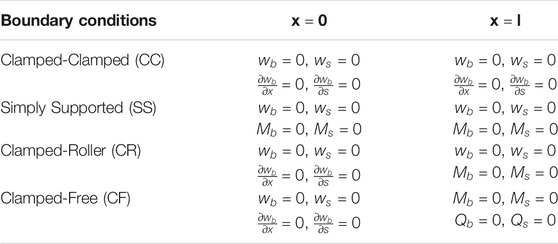
TABLE 1. Boundary conditions examined for the prediction of the maximum deflection
A plethora of regression algorithms, presented in the previous section, were employed for building corresponding predictive models of the
Mean absolute error (MAE)
Mean absolute percentage error (MAPE)
Mean square error (MSE)
Root mean square error (
Root mean squared log error (
Coefficient of determination (
where
Apart from the evaluation metrics of the machine learning algorithms, two other useful tools are presented for the predictive analysis of the
Clamped-Clamped Beam
First, a clamped-clamped beam is analyzed. The evaluation metrics of the employed regression algorithms are tabulated in Table 2. The Extra-Trees Regressor algorithm is the most effective algorithm reaching a
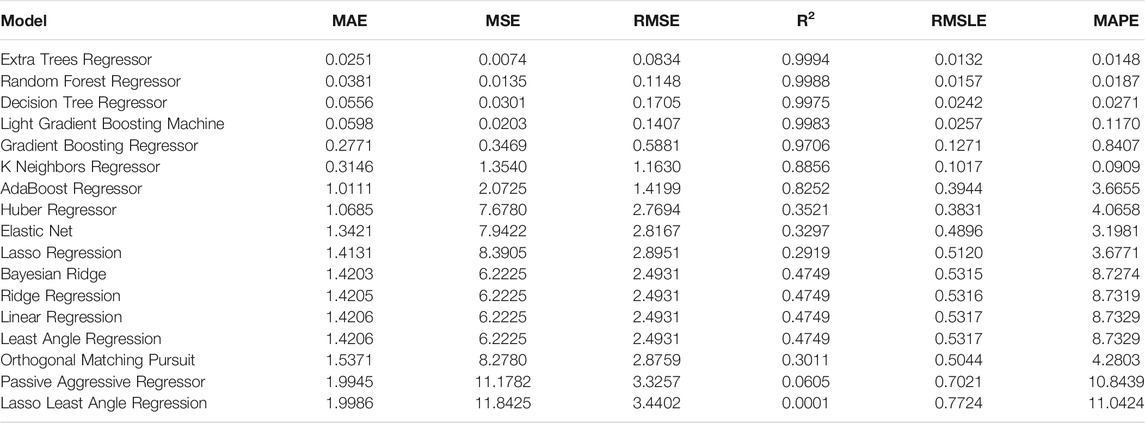
TABLE 2. Evaluation metrics for the clamped-clamped beam.
From the feature importance plot (see Figure 2A), it is observed that the most important parameters for predicting the target attribute
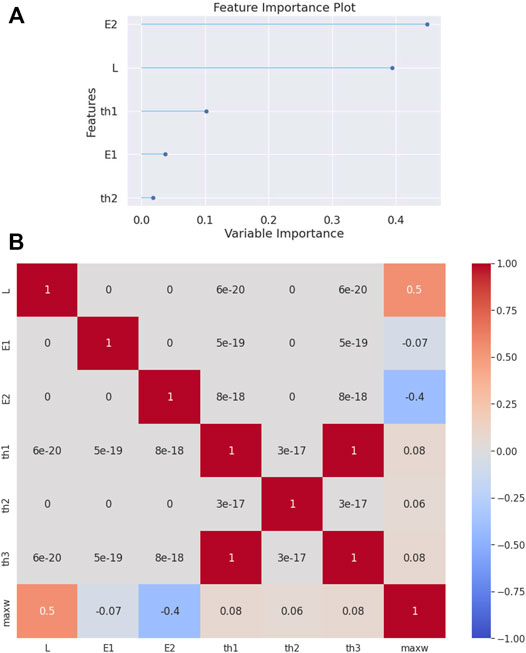
FIGURE 2. (A) Feature importance plot and (B) correlation matrix heatmap for the clamped-clamped beam.
Simply Supported Beam
In this second example, a simply supported beam is analyzed. The Extra-Trees Regressor algorithm outperforms the other regression algorithms once again (see Table 3). The feature importance plot (see Figure 3A) shows an importance sequence different from that of the previous example. That is, the span-to-depth ratio
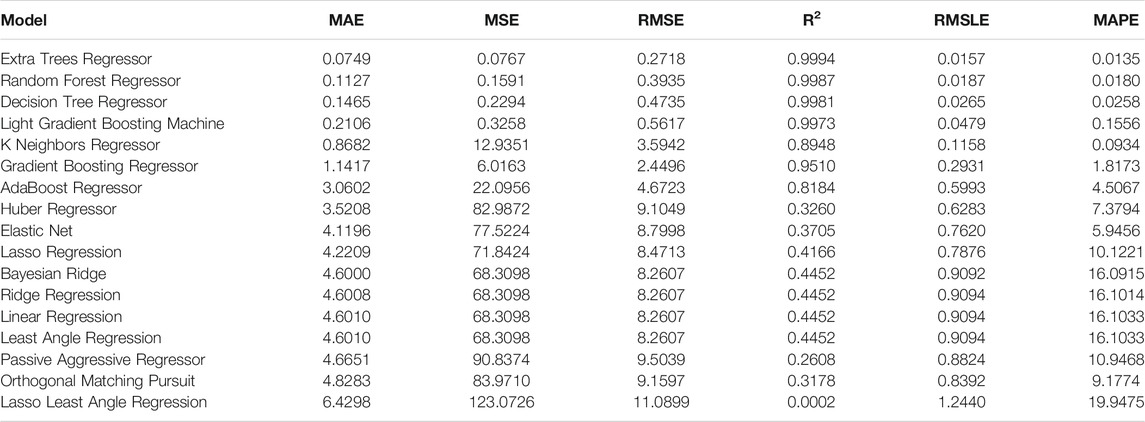
TABLE 3. Evaluation metrics for the simply supported beam.
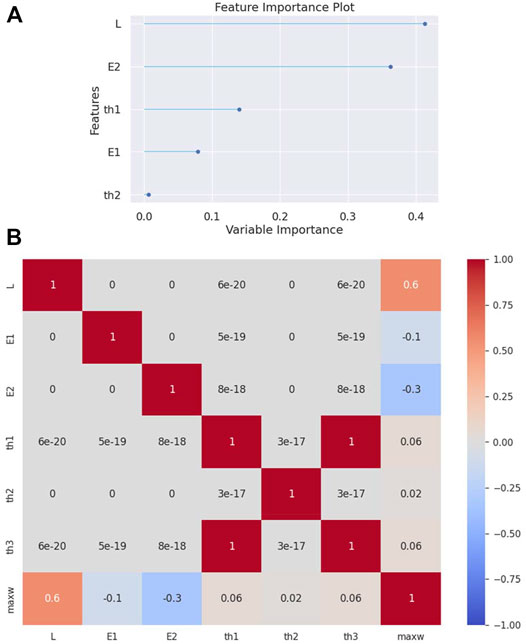
FIGURE 3. (A) Feature importance plot and (B) correlation matrix heatmap for the simply supported beam.
Clamped-Roller Beam
In this example, a clamped-roller beam is analyzed. In Table 4 it is shown that the Extra-Trees Regressor algorithm is again the most effective, as compared to the other regression algorithms. The feature importance plot (see Figure 4A) shows once more a similar to the clamped-clamped beam importance sequence. That is, the most important parameter is the modulus of elasticity
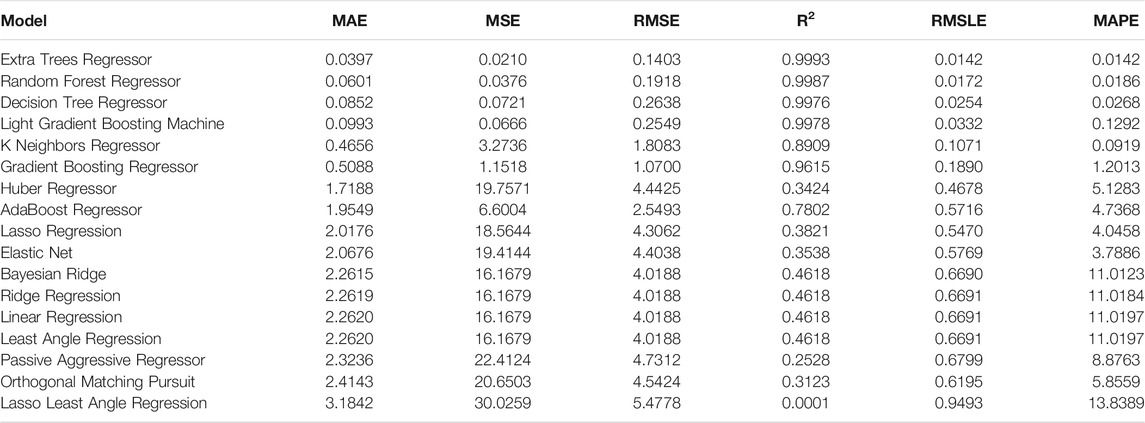
TABLE 4. Evaluation metrics for the clamped-roller beam.
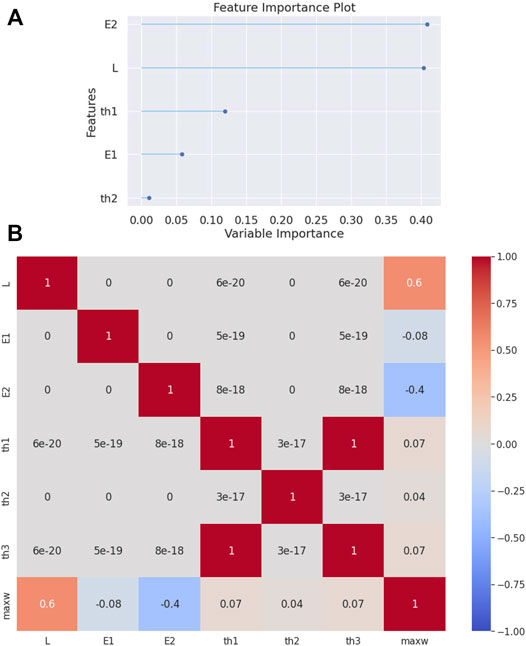
FIGURE 4. (A) Feature importance plot and (B) correlation matrix heatmap for the clamped-roller beam.
Clamped-free Beam
In the case of a clamped-free beam (cantilever), while the evaluation metrics designates once more the Extra-Trees Regressor algorithm superiority (see Table 5), the feature importance plot (see Figure 5A) presents a similar to the simply supported beam importance sequence. That is, the most important parameter is the span-to-depth ratio
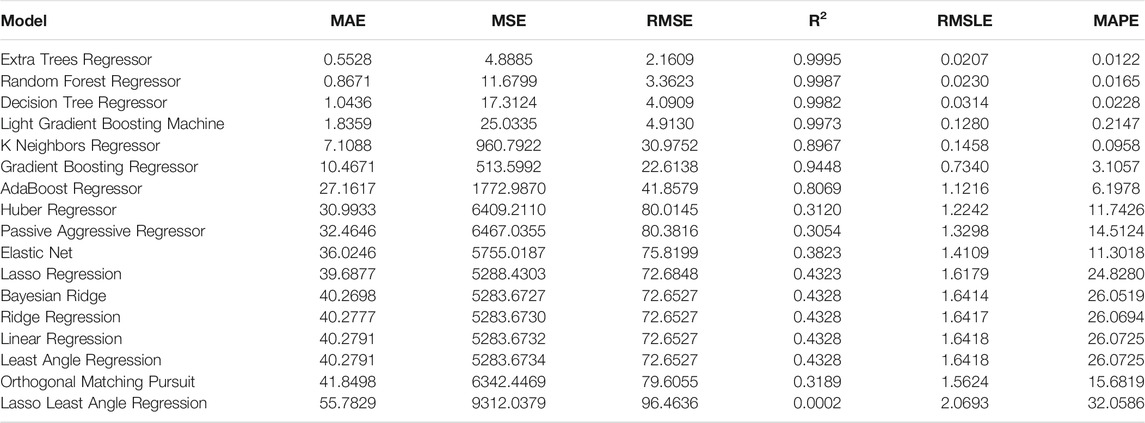
TABLE 5. Evaluation metrics for the clamped-free beam.
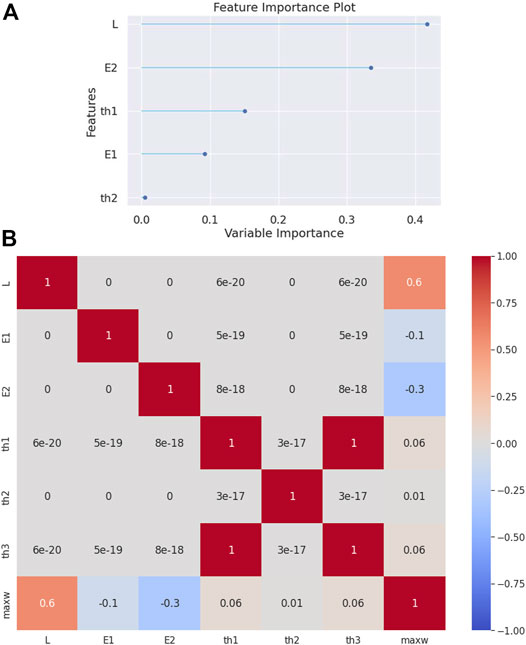
FIGURE 5. (A) Feature importance plot and (B) correlation matrix heatmap for the clamped-free beam.
The correlation matrix heatmap (see Figure 5B) again shows that the
Friedman Ranking
Finally, to better assess the results obtained from each algorithm, the Friedman test methodology proposed by Demšar (2006) was employed for the comparison of several algorithms over multiple datasets (Table 6). As was expected, the Extra-Trees Regressor algorithm is the most accurate in our case. A simple computational tool, written in JAVA programming language using Weka API (Hall et al., 2009) along with the relevant data, is provided to the interested reader as Supplementary Data to this article.
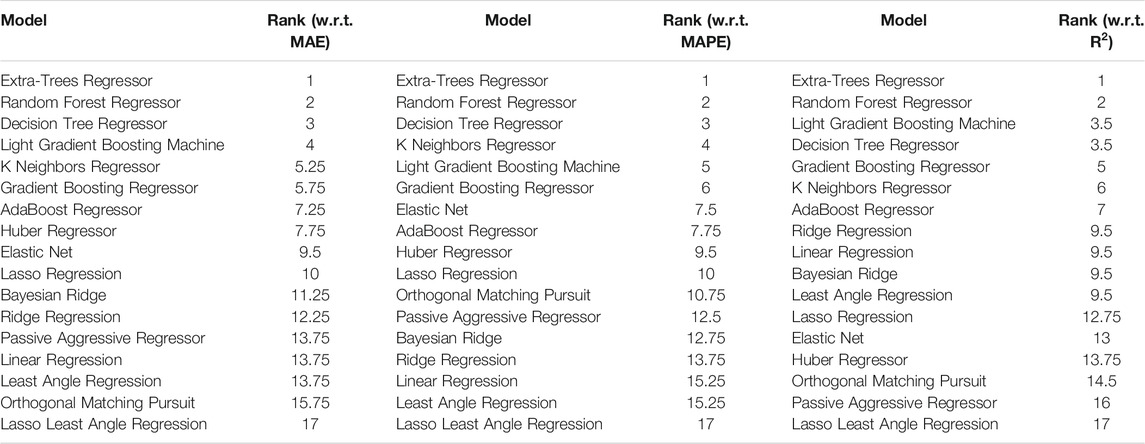
TABLE 6. Friedman ranking.
Conclusion
In this paper, several machine learning regression models were employed for the prediction of the deflection of symmetric laminated composite beams subjected to a uniformly distributed load. Training, validation, and testing of the models require large amounts of data that cannot be provided by the scarce experiments. Instead, ample amounts of data are generated numerically using a refined higher-order beam theory for various span-to-depth ratios and boundary conditions, by appropriate discretization of all pertinent geometric and material properties.
The main conclusion that can be drawn from this investigation are as follows:
• Regarding the regression models, the Extra-Trees algorithm is, without doubt, the best performer for all cases of boundary conditions, followed by the Random Forest Regressor, the Decision Tree Regressor, the Light Gradient Boosting Machine, and the K Neighbors Regressor.
• The prediction errors of the best-performing models are adequately small for engineering purposes. This allows for the rapid design of the composite beams without resolving to a mathematical implementation of higher-order beam theories. Moreover, these models can be integrated into modern metaheuristic optimization algorithms which use only payoff data (i.e., no derivative data) to allow for the fast and reliable optimization of such beams.
• Regarding the relative importance of the design variables for the evaluation of the deflection, the span-to-depth ratio and the modulus of elasticity
• The span-to-depth ratio
• An easy-to-use computational tool has been implemented which is provided as Supplementary Material to the present article.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
GT had the research idea, drafted the article, and contributed to the theoretical formulation of the beam theory. SK and AC contributed to the conception and design of the work, and the theoretical analysis of the regression techniques. The manuscript was written through the contribution of all authors. All authors discussed the results, reviewed, and approved the final version of the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fbuil.2022.855112/full#supplementary-material
References
Ali, M. (2020). PyCaret: An Open-Source, Low-Code Machine Learning Library in Python. Available at: https://www.pycaret.org
Altman, N. S. (1992). An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. The Am. Statistician 46, 175–185. doi:10.1080/00031305.1992.10475879
Breiman, L., Friedman, J. H., Olshen, R. A., and Stone, C. J. (1984). Classification and Regression Trees. New York, NY: Routledge. doi:10.1201/9781315139470
Civalek, Ö., and Kiracioglu, O. (2010). Free Vibration Analysis of Timoshenko Beams by DSC Method. Int. J. Numer. Meth. Biomed. Engng. 26, 1890–1898. doi:10.1002/CNM.1279
Crammer, K., Dekel, O., Keshet, J., Shai, S.-S., and Singer, Y. (2006). Online Passive-Aggressive Algorithms. J. Mach. Learn. Res. 7, 551–585.
Demšar, J. (2006). Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 7, 1–30.
Efron, B., Hastie, T., Johnstone, I., Tibshirani, R., Ishwaran, H., Knight, K., et al. (2004). Least Angle Regression. Ann. Statist. 32, 407–499. doi:10.1214/009053604000000067
Eisenberger, M. (2003). An Exact High Order Beam Element. Comput. Structures 81, 147–152. doi:10.1016/S0045-7949(02)00438-8
Endo, M. (2016). An Alternative First-Order Shear Deformation Concept and its Application to Beam, Plate and Cylindrical Shell Models. Compos. Structures 146, 50–61. doi:10.1016/J.COMPSTRUCT.2016.03.002
Freund, Y., and Schapire, R. E. (1997). A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 55, 119–139. doi:10.1006/JCSS.1997.1504
Friedman, J., Hastie, T., and Tibshirani, R. (2010). Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Soft. 33, 1. doi:10.18637/jss.v033.i01
Friedman, J. H. (2001). Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 29, 1189–1232. doi:10.1214/aos/1013203451
Geurts, P., Ernst, D., and Wehenkel, L. (20062006). Extremely Randomized Trees. Mach. Learn. 63, 3–42. doi:10.1007/S10994-006-6226-1
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., and Witten, I. H. (2009). The WEKA Data Mining Software. SIGKDD Explor. Newsl. 11, 10–18. doi:10.1145/1656274.1656278
Heyliger, P. R., and Reddy, J. N. (1988). A Higher Order Beam Finite Element for Bending and Vibration Problems. J. Sound Vibration 126, 309–326. doi:10.1016/0022-460X(88)90244-1
Hoerl, A. E., Kennard, R. W., and Hoerl, R. W. (1985). Practical Use of Ridge Regression: A Challenge Met. Appl. Stat. 34, 114–120. doi:10.2307/2347363
Katsikadelis, J. T., and Tsiatas, G. C. (20032003). Large Deflection Analysis of Beams with Variable Stiffness. Acta Mechanica 164, 1–13. doi:10.1007/S00707-003-0015-8
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., et al. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 30. Available at: https://github.com/Microsoft/LightGBM (Accessed December 14, 2021).
Khdeir, A. A., and Reddy, J. N. (1997). An Exact Solution for the Bending of Thin and Thick Cross-Ply Laminated Beams. Compos. Structures 37, 195–203. doi:10.1016/S0263-8223(97)80012-8
Lambert-Lacroix, S., and Zwald, L. (2011). Robust Regression through the Huber’s Criterion and Adaptive Lasso Penalty. Electron. J. Statist 5, 1015–1053. doi:10.1214/11-EJS635
Liew, K. M., Pan, Z. Z., and Zhang, L. W. (2019). An Overview of Layerwise Theories for Composite Laminates and Structures: Development, Numerical Implementation and Application. Compos. Structures 216, 240–259. doi:10.1016/J.COMPSTRUCT.2019.02.074
Lin, X., and Zhang, Y. X. (2011). A Novel One-Dimensional Two-Node Shear-Flexible Layered Composite Beam Element. Finite Elem. Anal. Des. 47, 676–682. doi:10.1016/J.FINEL.2011.01.010
Louppe, G., Wehenkel, L., Sutera, A., and Geurts, P. (2013). Understanding Variable Importances in Forests of Randomized Trees. Adv. Neural Inf. Process. Syst. 26, 431–439.
Murthy, M. V. V. S., Roy Mahapatra, D., Badarinarayana, K., and Gopalakrishnan, S. (2005). A Refined Higher Order Finite Element for Asymmetric Composite Beams. Compos. Structures 67, 27–35. doi:10.1016/J.COMPSTRUCT.2004.01.005
Narula, S. C., and Wellington, J. F. (1982). The Minimum Sum of Absolute Errors Regression: A State of the Art Survey. Int. Stat. Rev./Revue Internationale de Statistique 50, 317. doi:10.2307/1402501
Nguyen, T.-K., Nguyen, N.-D., Vo, T. P., and Thai, H.-T. (2017). Trigonometric-Series Solution for Analysis of Laminated Composite Beams. Compos. Structures 160, 142–151. doi:10.1016/J.COMPSTRUCT.2016.10.033
Pati, Y. C., Rezaiifar, R., and Krishnaprasad, P. S. (1993). “Orthogonal Matching Pursuit: Recursive Function Approximation with Applications to Wavelet Decomposition,” in Conf. Rec. Asilomar Conf. Signals, Syst. Comput., Pacific Grove, CA, November 1–3, 1993 1, 40–44. doi:10.1109/ACSSC.1993.342465
Pawar, E. G., Banerjee, S., and Desai, Y. M. (2015). Stress Analysis of Laminated Composite and Sandwich Beams Using a Novel Shear and Normal Deformation Theory. Lat. Am. J. Sol. Struct. 12, 1340–1361. doi:10.1590/1679-78251470
Reddy, J. N. (1984). A Simple Higher-Order Theory for Laminated Composite Plates. J. Appl. Mech. 51, 745–752. doi:10.1115/1.3167719
Srinivasan, R., Dattaguru, B., and Singh, G. (2019). Exact Solutions for Laminated Composite Beams Using a Unified State Space Formulation. Int. J. Comput. Methods Eng. Sci. Mech. 20, 319–334. doi:10.1080/15502287.2019.1644394
Tipping, M. E. (2001). Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 1, 211–244.
Tsiatas, G. C., Siokas, A. G., and Sapountzakis, E. J. (2018). A Layered Boundary Element Nonlinear Analysis of Beams. Front. Built Environ. 4, 52. doi:10.3389/FBUIL.2018.00052/BIBTEX
Vo, T. P., and Thai, H.-T. (2012). Static Behavior of Composite Beams Using Various Refined Shear Deformation Theories. Compos. Structures 94, 2513–2522. doi:10.1016/J.COMPSTRUCT.2012.02.010
Wang, C. M., Reddy, J. N., and Lee, K. H. (2000). Shear Deformable Beams and Plates : Relationships with Classical Solutions. Elsevier.
Keywords: machine learning, regression models, composite beams, orthotropic material model, higher-order beam theories
Citation: Tsiatas GC, Kotsiantis S and Charalampakis AE (2022) Predicting the Response of Laminated Composite Beams: A Comparison of Machine Learning Algorithms. Front. Built Environ. 8:855112. doi: 10.3389/fbuil.2022.855112
Received: 14 January 2022; Accepted: 31 January 2022;
Published: 21 February 2022.
Edited by:
Makoto Ohsaki, Kyoto University, JapanReviewed by:
Ömer Civalek, Akdeniz University, TurkeyAhmad N. Tarawneh, Hashemite University, Jordan
Copyright © 2022 Tsiatas, Kotsiantis and Charalampakis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: George C. Tsiatas, gtsiatas@upatras.gr