 Xiaoping Chen1†
Xiaoping Chen1† Lihui Zheng1†Shupei Ye2†
Lihui Zheng1†Shupei Ye2† Mengxin Xu3
Mengxin Xu3 YanLing Li3
YanLing Li3 KeXin Lv3Haipeng Zhu4
KeXin Lv3Haipeng Zhu4 Yusheng Jie5*
Yusheng Jie5* Yao-Qing Chen3*
Yao-Qing Chen3*- 1College of Mathematics and Statistics & FJKLMAA, Fujian Normal University, Fuzhou, China
- 2Pulmonary and Critical Care Medicine, The Third People’s Hospital of Dongguan City, Dongguan, China
- 3School of Public Health (Shenzhen), Sun Yat-sen University, Shenzhen, China
- 4Department of Infectious Diseases, The Ninth People’s Hospital of Dongguan City, Dongguan, China
- 5Department of Infectious Diseases, The Third Affiliated Hospital of Sun Yat-sen University, Guangzhou, China
Objective: To analyze the epidemiological history, clinical symptoms, laboratory testing parameters of patients with mild and severe COVID-19 infection, and provide a reference for timely judgment of changes in the patients’ conditions and the formulation of epidemic prevention and control strategies.
Methods: A retrospective study was conducted in this research, a total of 90 patients with COVID-19 infection who received treatment from January 21 to March 31, 2020 in the Ninth People’s Hospital of Dongguan City were selected as study subject. We analyzed the clinical characteristics of laboratory-confirmed patients with COVID-19, used the oversampling method (SMOTE) to solve the imbalance of categories, and established Lasso-logistic regression and random forest models.
Results: Among the 90 confirmed COVID-19 cases, 79 were mild and 11 were severe. The average age of the patients was 36.1 years old, including 49 males and 41 females. The average age of severe patients is significantly older than that of mild patients (53.2 years old vs 33.7 years old). The average time from illness onset to hospital admission was 4.1 days and the average actual hospital stay was 18.7 days, both of these time actors were longer for severe patients than for mild patients. Forty-eight of the 90 patients (53.3%) had family cluster infections, which was similar among mild and severe patients. Comorbidities of underlying diseases were more common in severe patients, including hypertension, diabetes and other diseases. The most common symptom was cough [45 (50%)], followed by fever [43 (47.8%)], headache [7 (7.8%)], vomiting [3 (3.3%)], diarrhea [3 (3.3%)], and dyspnea [1 (1.1%)]. The laboratory findings of patients also included leukopenia [13(14.4%)] and lymphopenia (17.8%). Severe patients had a low level of creatine kinase (median 40.9) and a high level of D-dimer. The median NLR of severe patients was 2.82, which was higher than that of mild patients. Logistic regression showed that age, phosphocreatine kinase, procalcitonin, the lymphocyte count of the patient on admission, cough, fatigue, and pharynx dryness were independent predictors of COVID-19 severity. The classification of random forest was predicted and the importance of each variable was displayed. The variable importance of random forest indicates that age, D-dimer, NLR (neutrophil to lymphocyte ratio) and other top-ranked variables are risk factors.
Conclusion: The clinical symptoms of COVID-19 patients are non-specific and complicated. Age and the time from onset to admission are important factors that determine the severity of the patient’s condition. Patients with mild illness should be closely monitored to identify those who may become severe. Variables such as age and creatine phosphate kinase selected by logistic regression can be used as important indicators to assess the disease severity of COVID-19 patients. The importance of variables in the random forest further complements the variable feature information.
Introduction
Coronavirus disease 2019 (COVID-19) is an ongoing pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) (Zhu et al., 2020). The virus was isolated and the whole genome sequenced in a short time, and was further found to have high homology with SARS coronavirus and bat coronavirus sequences through phylogenetic analysis (Lu et al., 2020; Wu et al., 2020; Zhou et al., 2020). The emergence of SARS-CoV-2 caused a profound change all over the world.
SARS-CoV-2 is an enveloped-RNA coronavirus. Symptoms of COVID-19 are highly variable, from none to severe illness. The symptoms are primarily fever, fatigue and dry cough, while gastrointestinal symptoms are not common. Most severe cases develop dyspnea after one week, and rapidly progress to acute respiratory distress syndrome, septic shock, coagulation dysfunction, and metabolic acidosis that are difficult to correct (Guan et al., 2020; Huang et al., 2020a).
Therefore, learning from the clinical characteristics and influencing factors of patients with mild and severe COVID-19, monitoring the changes in the patient’s condition, and providing strategies for severe patients entering the intensive care unit (ICU) as soon as possible, which may contribute to reduce mortality and deliver proper care.
Research Objects and Methods
Research Objects
This study retrospectively included 90 COVID-19-infected patients admitted to the Ninth People’s Hospital of Dongguan City from January 21 to March 31, 2020.All patients were confirmed in accordance with the protocol of “Diagnosis and Treatment Plan for COVID-19 (Trial Version 7)” issued by the General Office of the National Health Commission and the Office of the State Administration of Traditional Chinese Medicine on February 19, 2020, and were detected by quantitative reverse transcription PCR (RT-QPCR), and both chest radiographs and nasopharyngeal swabs and were performed for all patients upon admission. This study was approved by the Ethics Committee of the Ninth People’s Hospital of Dongguan, China.
Data Set Processing
The severity (mild and serious) of COVID-19 patients is defined according to the diagnosis and description of the disease course in the electronic medical record. The laboratory values of heart rate, the white blood cell count of the patient on admission (white blood cell count 1), the lymphocyte count of the patient on admission (lymphocyte count 1), the platelet count of the patient on admission (platelet count 1), and white blood cell count after admission (white blood cell count 2), lymphocyte count after admission (lymphocyte count 2), platelet count after admission (platelet count 2), NLR(Neutrophil to lymphocyte ratio), prothrombin time, phosphocreatine kinase, phosphocreatine kinase isoenzyme, procalcitonin, D-dimer were all measured. Some indexes lack data, so the random forest method is used for interpolation. The outcome of the patients were discharged from hospital.
The proportion of mild and severe patients is unbalanced (79 mild patients and 11 severe patients). The imbalance of categories will affect the modeling effect, the prediction effect of the classification model will be reduced, and the prediction result tends to favor the majority category. Therefore, the synthetic minority sample oversampling method (SMOTE) was used to balance the data. The SMOTE method is a data preprocessing technique applied to imbalance problems proposed by (Chawla et al., 2002). It uses the K-nearest neighbors and linear interpolation to add artificially synthesized minority class samples to the data, combined with the under-sampling method in the majority class, to balance the class distribution and reduce the possibility of overfitting. The SMOTE method operates in the feature space, so that the minority decision-making regions become more general. The SMOTE method can make the classifier build a larger decision-making area, including nearby minority class points, so it can improve the classification performance (Chawla et al., 2002). At present, SMOTE algorithm has been widely used in many fields, and SMOTE can effectively speed up classification, such as random forest, decision tree, Bayesian network, etc. Some studies have shown that the accuracy of these classification models using SMOTE training models is better than that of models not using SMOTE training (Alahmari, 2020).
The parameter percent.over in the minority sample was set to 1000, and percent.under for the majority sample was set to 100. This parameter setting means that the minority class will eventually generate 1+ percent.over/100 times the original, and the majority class will eventually be generated as (percent.under/100)*(percent.over/100) times the minority class. Finally got 110 mild cases and 121 severe cases in the model. Since the algorithm needs to extract samples from most types of samples, the data of mild and severe cases after balancing has increased.
Research Methods
In this paper, descriptive statistical methods are used to study the clinical characteristics of mild and severe patients. A T-test was used for the data subject to normal distribution, a Wilcox rank sum test was used for the continuous skewed data, and a chi-square test was used to compare the differences between the two groups of data for the classified data. After the data is balanced, based on the Lasso-Logistic regression model to screen the risk factors and symptoms related to severe illness, a P value of less than 0.05 is considered statistically significant. This article use the Shapiro-Wilk (S-W) method to judge the normality of continuous variables.
Lasso regression is a kind of machine learning regression, which is used to select the important factors influencing the results. Leucopenia was defined as a white blood cell count below 4×109/L; lymphocytopenia was defined as a lymphocyte count below 1×109/L. The software used in this article is R 3.6.2, where the balance data is the SMOTE function in the DMwR package in the R language. The Lasso regression model uses the gelnet function in the R language. This paper also uses random forest for classification modeling. The model is a classification tree-based algorithm proposed by Breiman and Cutler, which improves the prediction accuracy of the model by summarizing a large number of classification trees. Compared with general regression, it is not sensitive to multivariable collinearity, and it is more robust to missing data and unbalanced data. At the same time, it can give the importance of variables, evaluate the role of each variable in classification, and make good predictions (Yang et al., 2020b). The model is implemented using the Random Forest function in R language.
Results
Basic Information, Epidemiological History and Clinical Manifestations
Among the 90 confirmed COVID-19 patients (49 males and 41 females), 79 patients were mild and 11 patients were severe. The average age of all patients was 36.1 years, the median was 36.5 years, and 50% of patients were between 21.3-47 years old. The age quartile of mild patients ranged from 19 to 45 years, while the severe patients ranged from 46 to 59.5 years. The mean age of severe patients was 53.1 years, which is significantly higher than the mean age of mild patients (33.7 years). With the increase of age, the proportion of serious patients with increased (P < 0.05). The average time from onset to admission was 4.1 days, with a median of 2.5 days. The average actual hospital stay was 18.7 days, with a median of 18 days. And the above two for severe patients were both longer compared to mild patients. Forty-eight of 90 patients (53.3%) had family cluster infections in severe patients, which was similar among in mild patients. Nearly half of the patients suffered from basic diseases [40 (44.4%)], mainly including hypertension [11 (12.2%)], chronic liver disease [7 (7.8%)] and other basic diseases [25 (27.8%)]. Basic diseases were more common in severe patients than mild ones, while hypertension, diabetes and other diseases were also more obvious. Eleven of the 90 patients were seriously ill, 8 of whom had underlying diseases, accounting for 72.7%. There were 79 patients with mild disease, among which 32 patients had underlying disease, accounting for 40.5%. On admission, most patients had fever [43 (47.8%)] or cough [45 (50%)]. Among them, 36(45.6%) of the mild patients had fever and 7(63.6%) of the mild patients had fever. There were 37 mild patients with cough (46.8%) and 8 severe patients with cough (72.7%). A total of 29 patients (32.2%) presented with both cough and fever. Other symptoms included dyspnea [1 (1.1%)], diarrhea [3 (3.3%)], emesis [3 (3.3%)], headache [7 (7.8%)]. (Table 1; Figure 1). This suggested that elderly patients with delayed diagnosis and admission for treatment were more likely to develop severe illnesses after being infected with COVID-19. (The continuous variables in the table have been tested for normality. Among them, age and actual hospital stay follow a normal distribution. Other variables use the median (quartile).
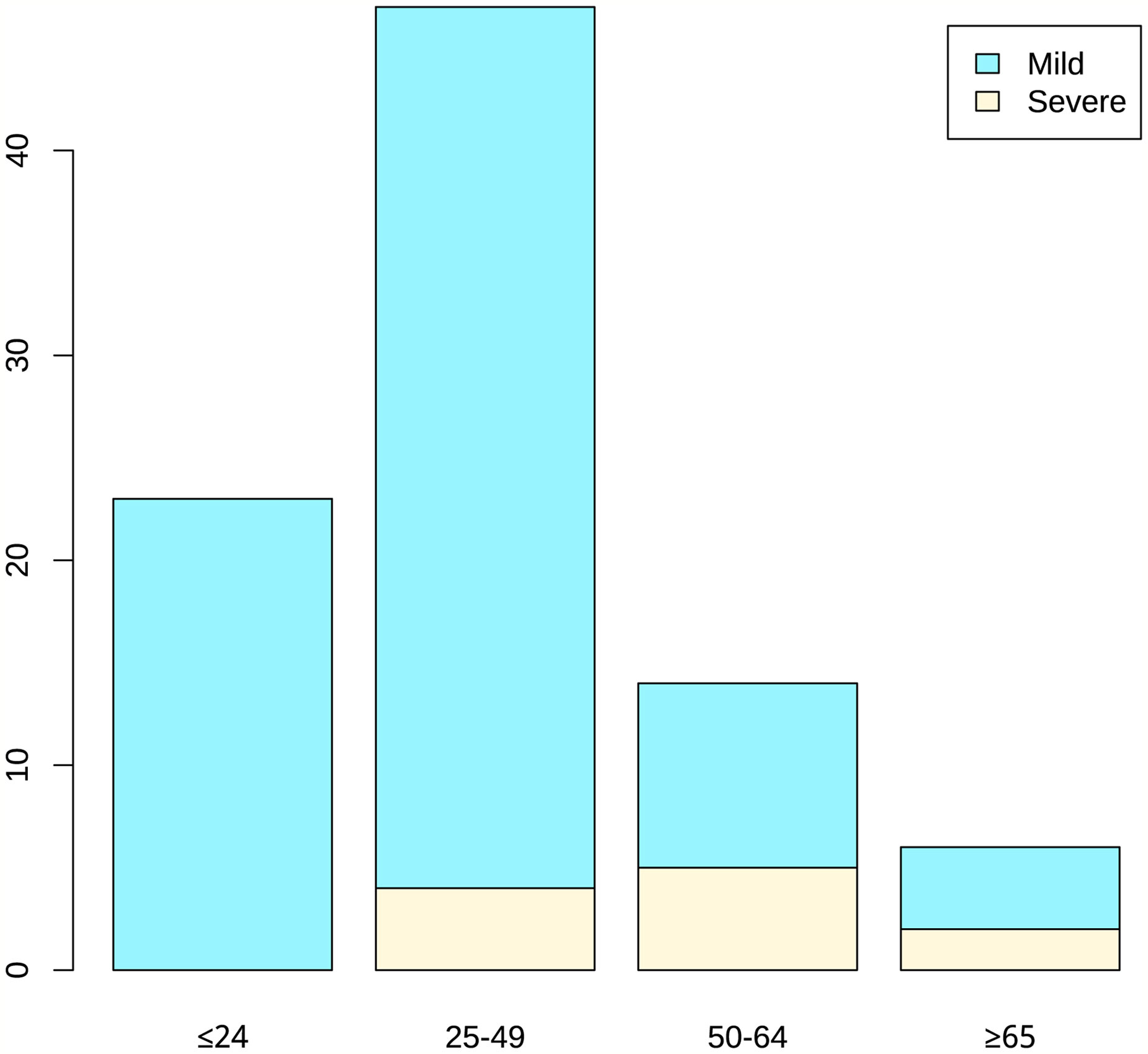
Figure 1 Age distribution of patients.
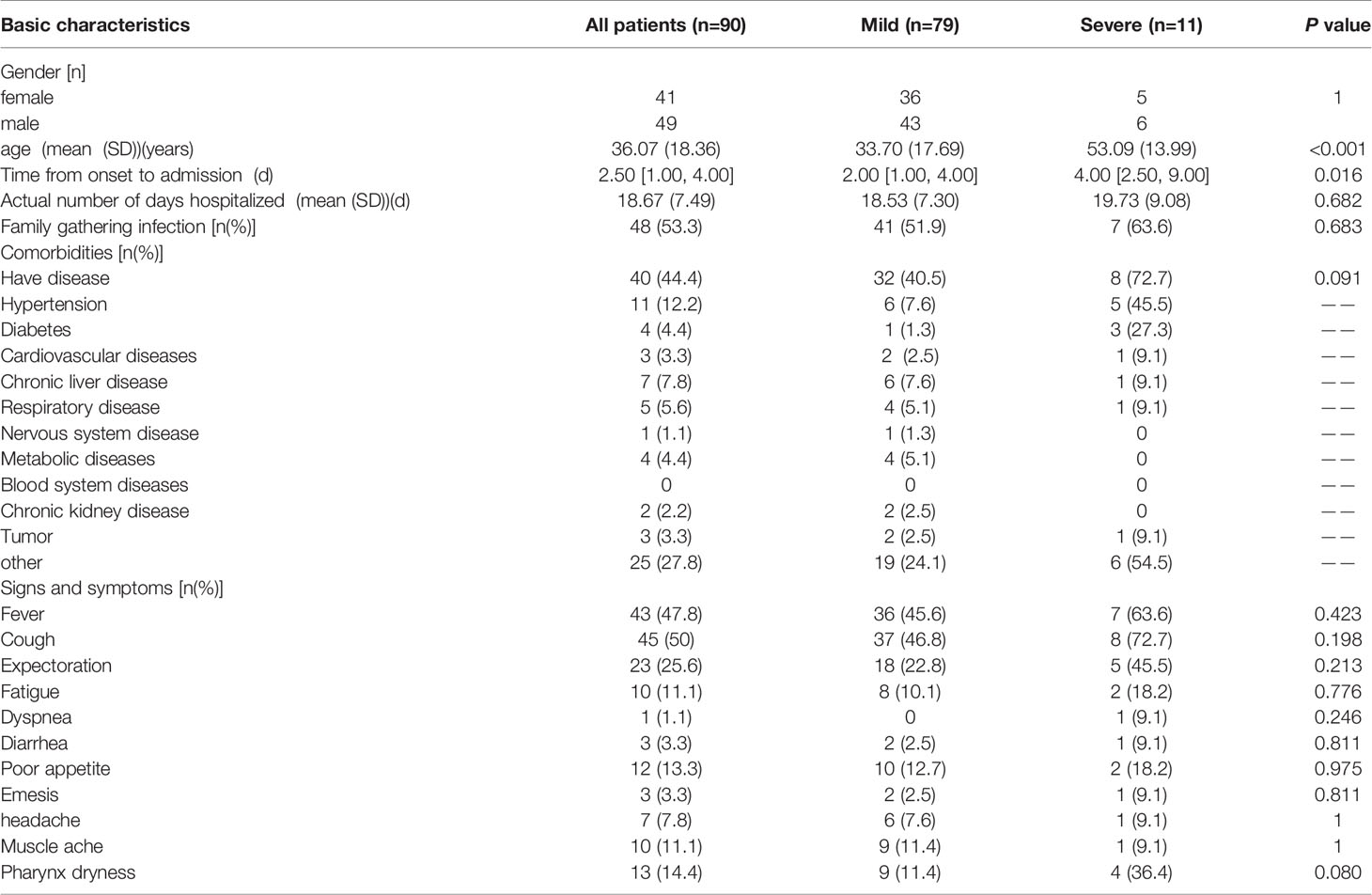
Table 1 Demographic and clinical characteristics of COVID-19 infected patients.
Table 1-2 showed the demographic and clinical characteristics of the patients after the SMOTE balance. In terms of the difference indicators of the patients with mild and severe diseases, the significant variables, except age and the time from onset to admission, were newly added with basic diseases, fever, cough, expectoration, fatigue and pharynx dryness.
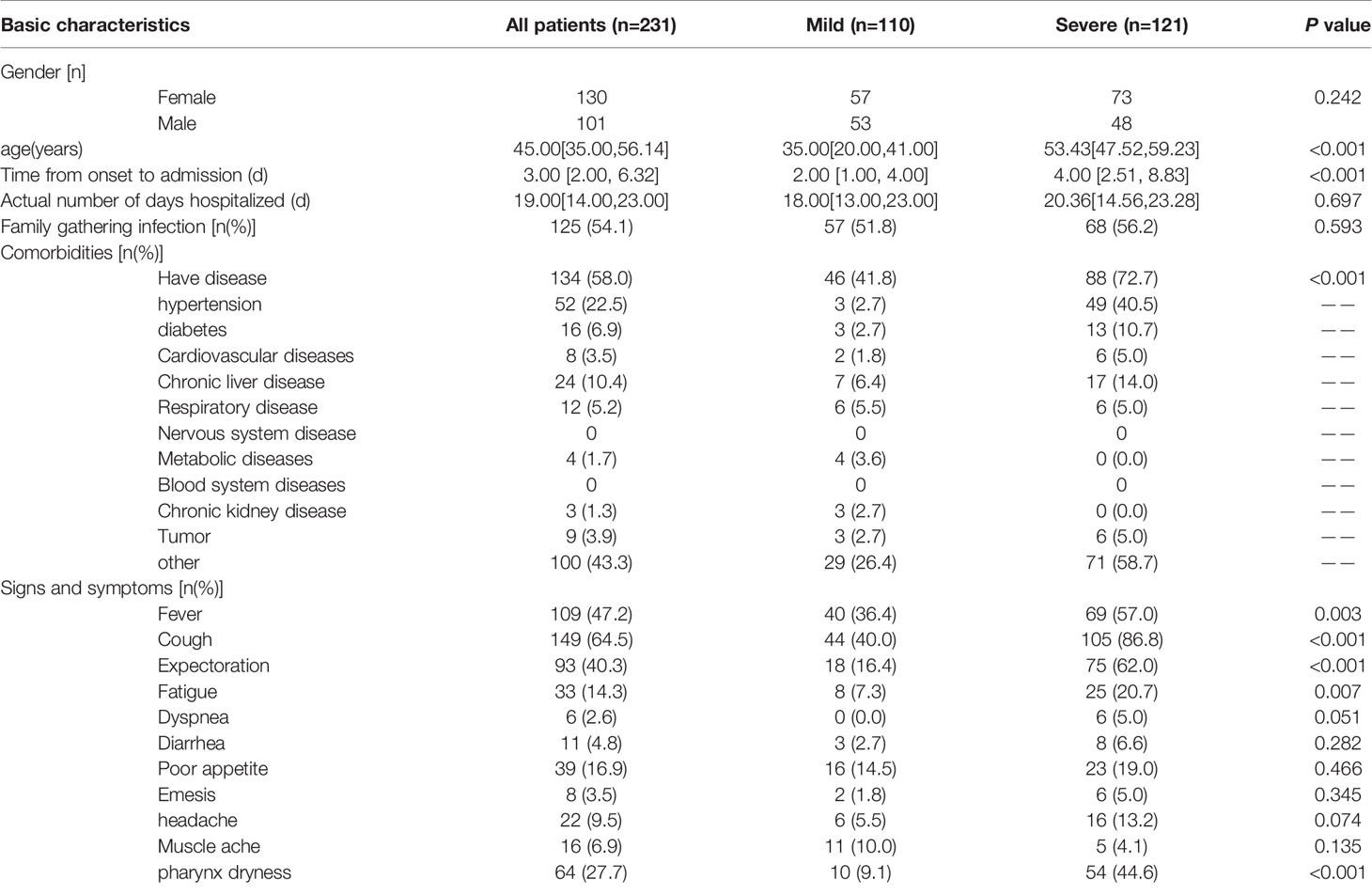
Table 1-2 The demographic and clinical characteristics of patients infected with COVID-19 after SMOTE balance data.
Laboratory Examination Indexes
The statistical results of laboratory examination indexes of 90 patients were shown in Table 2. There was no significant difference in the heart rate among with mild to severe cases upon admission. On admission, the blood count of the patients showed leukopenia in 13 of them (14.4%), lymphocytosis in 16 of them (17.8%), and thrombocytopenia in 0. After a period of treatment, the blood count of the patients measured during the hospitalization showed that there were 6 patients with leukopenia (6.67%), 4 patients with lymphopenia (4.44%), and 2 patients with thrombocytopenia (2.22%). These indicators were not statistically significant between mild and severe patients (P>0.05). The median time of development of prothrombin was 12.5 in both mild and severe cases, and the level of procalcitonin was also similar. Levels of phosphocreatine kinase were low in critically ill patients (The median of creatine phosphokinase was 40.9). The D-dimer level was higher in severe patients than in mild patients, but there was a difference in severe patients (P < 0.05). The NLR level of severe patients is higher than that of mild patients. The median NLR of severe patients was 2.82, which was higher than the median of 2.44 for mild patients. There is no significant difference between the two groups in the original data. After class-balanced data, NLR is significant(P=0.048). The treatment plan was based on antiviral and anti-infective treatment, and severe patients used oxygen therapy more than mild patients. Table 2-2 showed the results of laboratory examinations and treatment plans for patients after the class balance. In terms of different indicators for mild and severe patients, in addition to D-dimer, the newly added (just admitted) lymphocytes count, procalcitonin, NLR, (after admission) platelet count, creatine phosphate kinase.
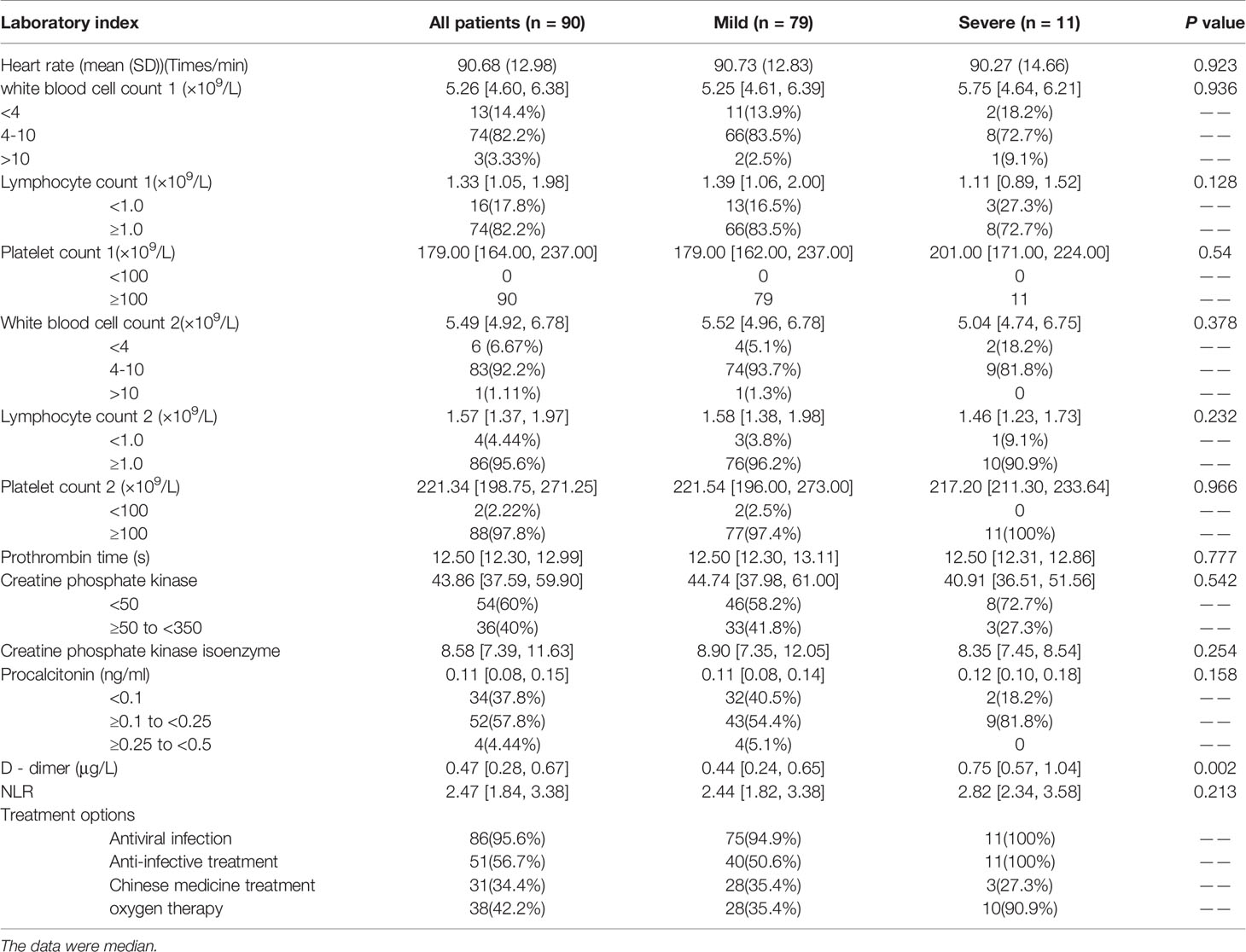
Table 2 Laboratory test results and treatment regimens for COVID-19 patients during hospitalization.
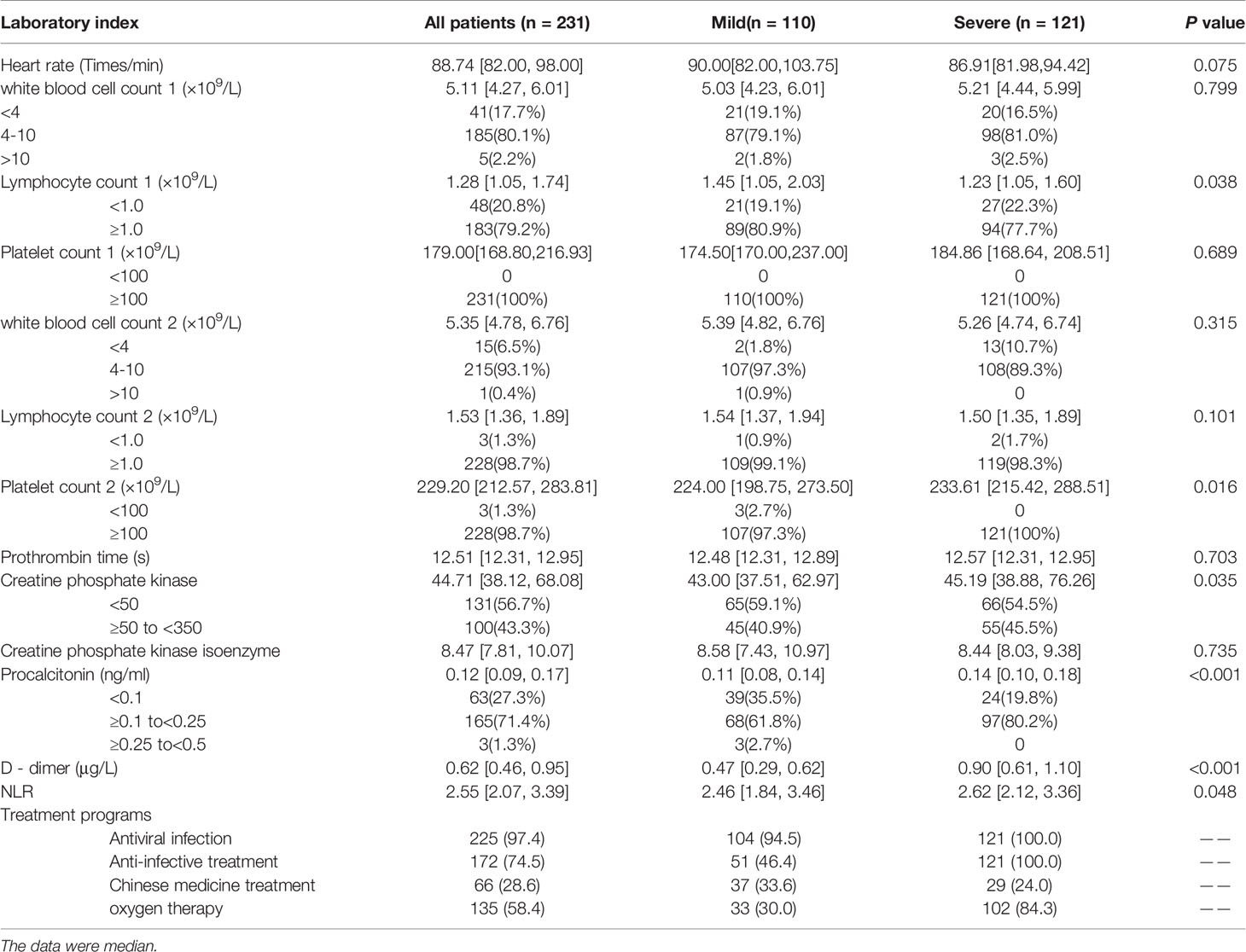
Table 2-2 Laboratory test results and treatment plan of COVID-19 patients during hospitalization after SMOTE algorithm balancing data.
Lasso-Logistics Regression Model
The dependent variable was severity. Severe was 1 and mild was 0. There were a total of 30 independent variables, including population basic information (age, gender), hospital medical detection (heart rate), time from onset to admission, actual number of days hospitalized, blood routine examination on admission (white blood cell count 1, lymphocyte count 1, platelet count 1), hospitalization, blood routine examination (white blood cell count 2, lymphocyte count 2, platelet count 2) and blood coagulation (prothrombin time, D-dimer), NLR(Neutrophil to lymphocyte ratio), myocardial enzymes including creatine phosphate kinase (CK) and creatine phosphate kinase isoenzyme (CK-MB), myocardial markers (calcitonin former), underlying disease, family gathering infection, and symptoms (fever, cough, expectoration, fatigue, dyspnea, diarrhea, poor appetite, emesis, headache, muscle aches, pharynx dryness). Some variable names are abbreviated as follows: Time from onset to admission (onset time), actual number of days hospitalized (Actual days), Family gathering infection (FG infection), Have underlying disease (HU disease), White blood cell count 1 (WBC1), Lymphocyte count 1 (LYMBH1), Platelet count 1 (PLT1), White blood cell count 2 (WBC2), Lymphocyte count 2 (LYMBH2), Platelet count 2 (PLT2), creatine phosphate kinase (CK), creatine phosphate kinase isoenzyme (CK MB).
The significance of the variables under the univariate logistic regression was calculated first. The results were shown in Table 3. The significant variables were age, underlying disease, fever, cough, expectoration, fatigue, pharynx dryness, time from onset to admission, creatine phosphate kinase, procalcitonin, D-dimer, lymphocyte count 2 and lymphocyte count 1.
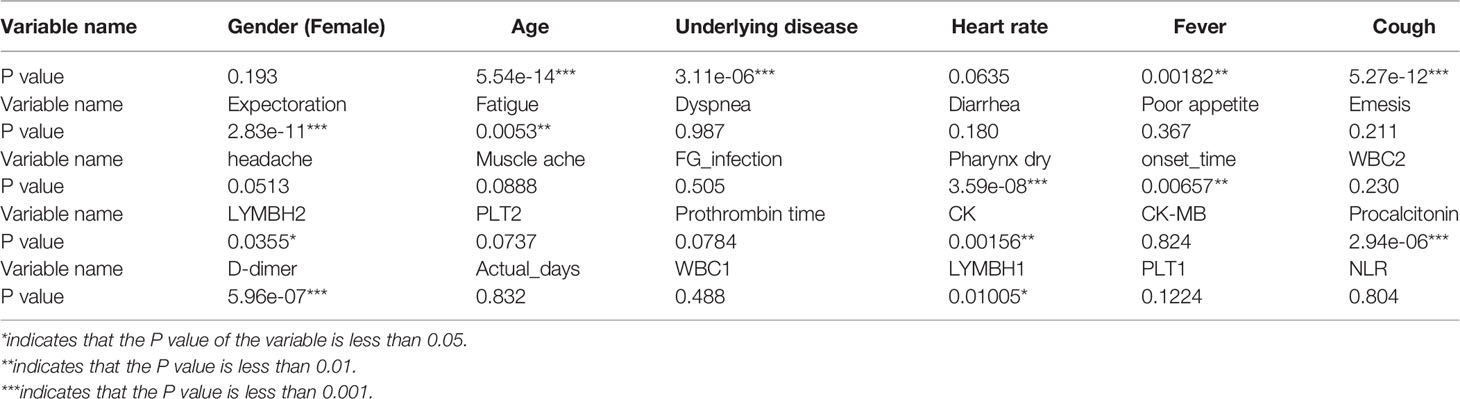
Table 3 Significance of single-factor logistic regression variables.
The above variables were substituted into the Lasso regression. The complexity of Lasso was controlled by lambda, and the model obtained by different lambda was different. Figure 2A showed that the best lambda value can be selected according to the AUC value when compressing different variables. In Figure 2B, each colored line represented one variable, and the horizontal axis represented the L1 norm, which was the sum of the absolute values of the regression coefficients. The vertical axis represented the coefficient. If a vertical dashed line was drawn in the figure, the vertical line represented a penalty value, and the variable that intersects the color line was the selected variable.
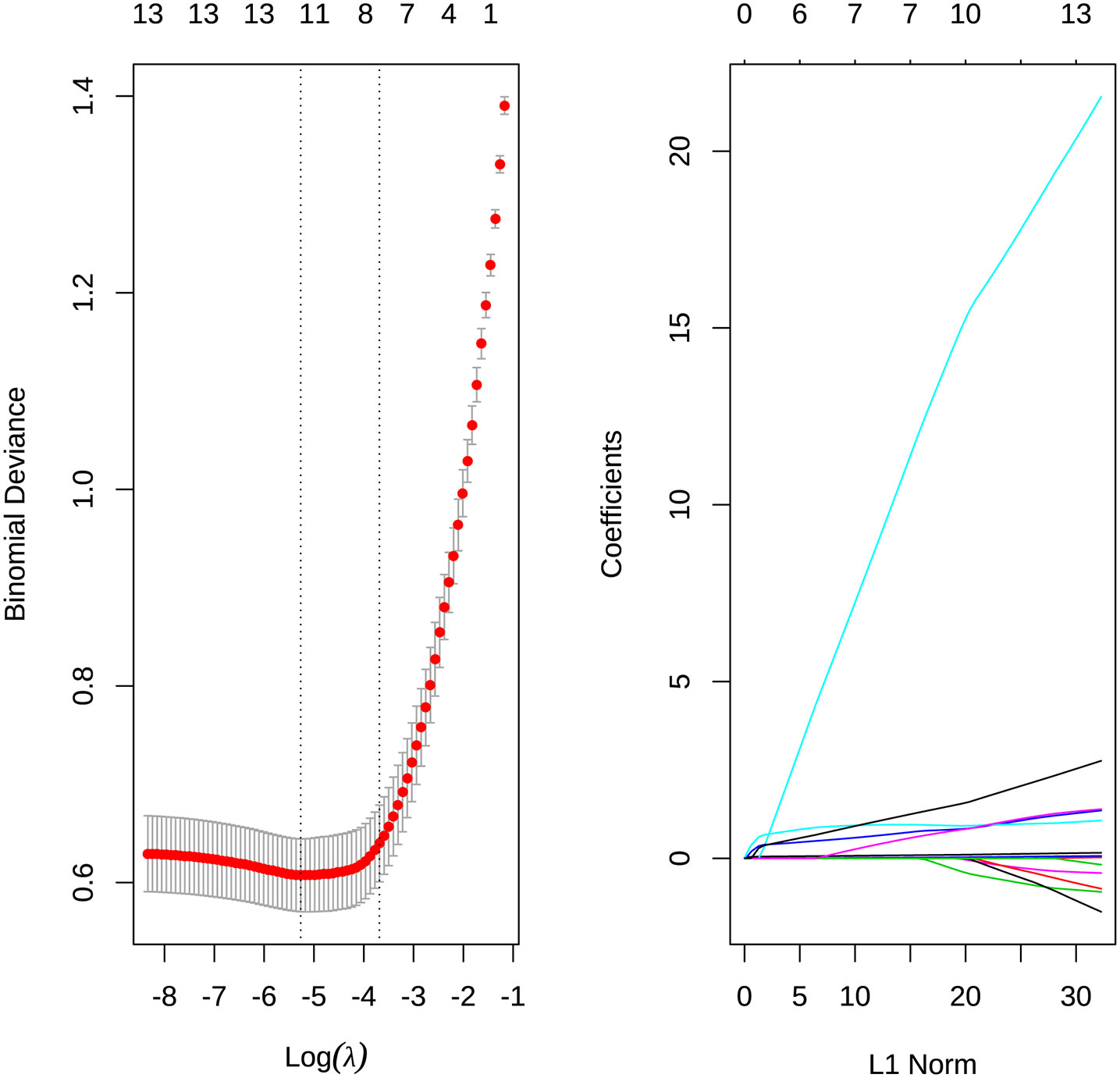
Figure 2 (A) Select the best λ value for the AUC value when compressing different variables. (B) The degree of compression of each variable under different penalty parameters λ.
According to the results of Lasso, the variables including age, CK, procalcitonin, D-dimer, LYMBH1, LYMBH2, underlying disease, fever, cough, expectoration, fatigue, pharynx dryness were selected as important variables. These variables were classified into the logistics model, and variables with insignificant P values were eliminated according to significance. The results were obtained (Table 4). Age, CK, procalcitonin, LYMBH1, cough, fatigue, and pharynx dryness were important variables.

Table 4 Logistics model results.
It can be seen from the results that, except for the constant term and LYMBH1, the coefficients of the other variables were all positive. Among them, age, CK, LYMBH1 and procalcitonin were continuous variables. Cough, fatigue and pharynx dryness were categorical variables. The results were tested for collinearity. VIF values were all less than 5. And there was no collinearity among the variables.
The logistic regression model was obtained according to the balanced data, and prediction accuracy was 81.1% when the original data was substituted into the model. The ordinate of ROC curve (Figure 3) was the true positive rate (sensitivity), and the abscissa was the false positive rate (1-specificity). The ideal point on the ROC curve was (0,1), which means all positive classes were correctly classified and all negative classes were not mistakenly classified as positive classes. Therefore, the closer the ROC point was to the upper left corner, the better the performance. In this article, the abscissa of the ROC graph is specific, and the ideal point is (1,1). The closer the AUC value of the area under the ROC curve to 1, the better the diagnostic effect. The coordinates of the best critical point on the curve in Figure 3 were (0.823, 0.727), and the threshold was 0.5. It has high sensitivity and specificity at this point. The AUC value in the figure was 0.775. It showed that the accuracy of the model is good
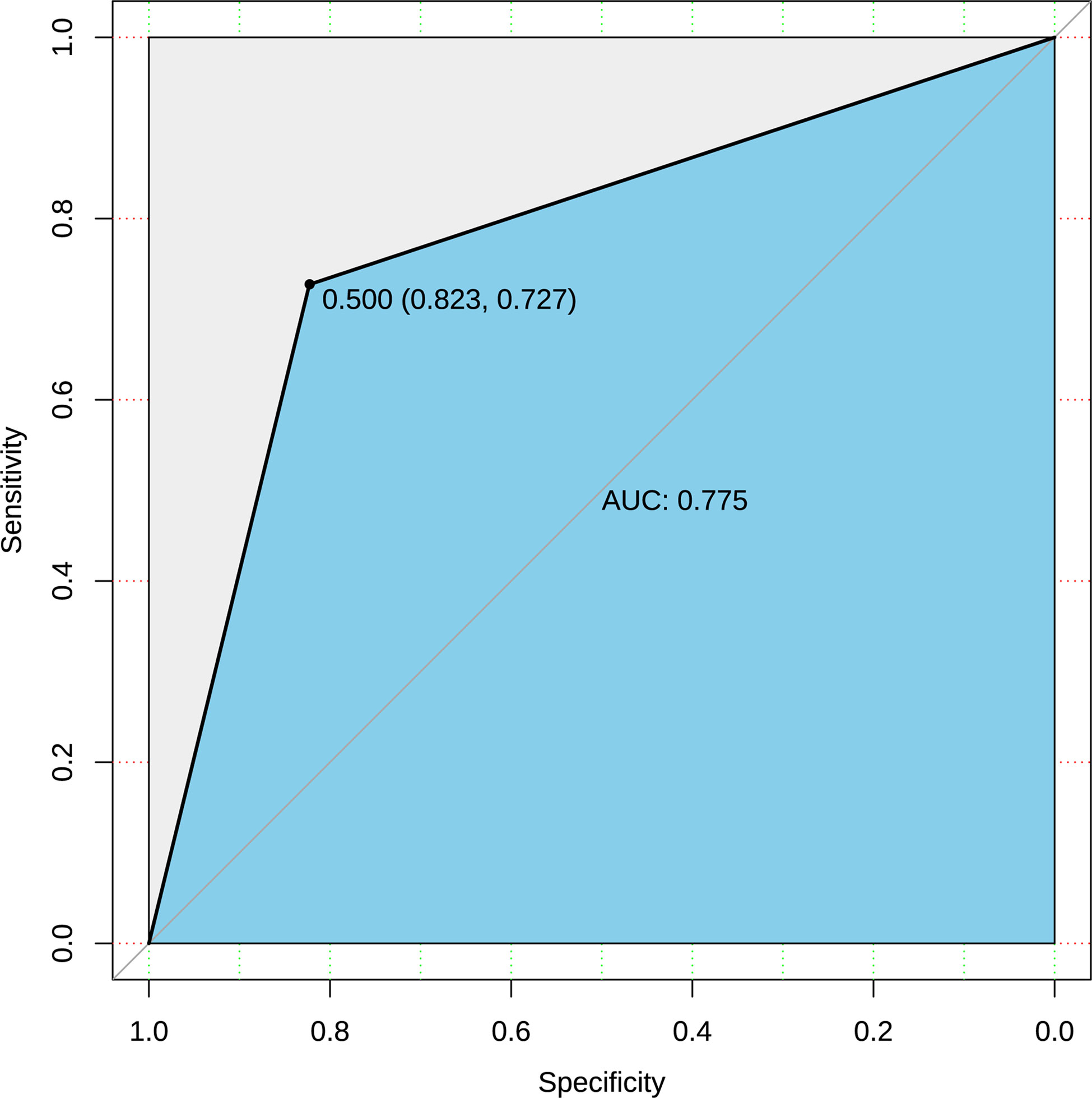
Figure 3 ROC curve of prediction based on raw data.
Random Forest
Random forest was used to extract a certain number of self-service samples from the original data using the bootstrap method with replacement and a decision tree was built for each sample. At each node, among all competing independent variables, several random competitive split variable were selected. Each tree in the random forest was left unpruned and allowed to grow fully. The final prediction result was a simple average of the results of all decision trees (Moghadas et al., 2020). In this paper, the random forest method was used to classify variables, give the importance of variables, and make prediction.
The data was extracted by 7:3 for the training set and the test set. For the node binary tree parameter mtry, the loop statement was used to calculate the mean value of the misjudgment rate of all models, and the optimal mtry was 6. It can be seen from Figure 4 that when the number of decision trees contained in the random forest ntree was about 1300, the three lines tended to be stable, that is, the error within the model was basically stable, so ntree=1300. At this time, the OOB error is 5.45%. It can be seen from Table 5 that 74 patients with mild illness and 82 patients with severe illness were judged correctly, but still with a certain probability of misjudgment, and 6 patients with mild illness were judged as severe. In general, the correct rate of the model, that was, the proportion of samples that were correctly identified by all samples was (74 + 82)/165 = 94.54%; the accuracy mild rate indicates how many of the guessed positive samples are correct, and the mild disease was regarded as the positive sample. The precision rate was 74/(74 + 3)=96.1%; the recall rate indicates how many positive samples were recalled among all the positive samples, so the recall rate was 74/(74 + 6)=92.5%.
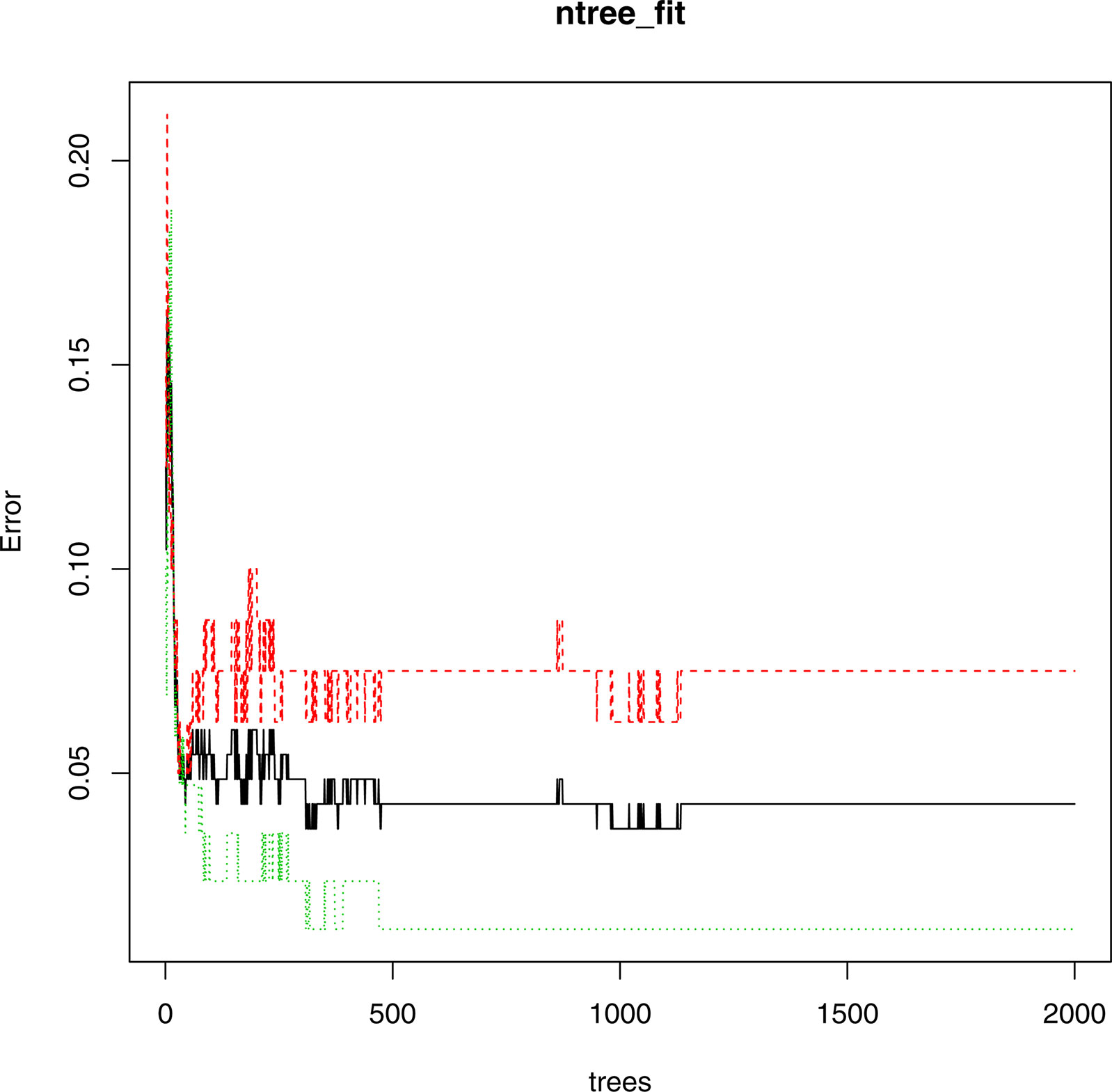
Figure 4 The false positive rate of each tree in the random forest.

Table 5 Confusion matrix.
Table 6 showed the importance of variables, in which Mean Decrease Accuracy represents an average Decrease in Accuracy, and Mean Decrease Gini represents an average Decrease in node unpurity. A larger value indicates a stronger importance of variables. It can be seen from the table that age, D-dimer, time from onset to admission and other large values were important variables.
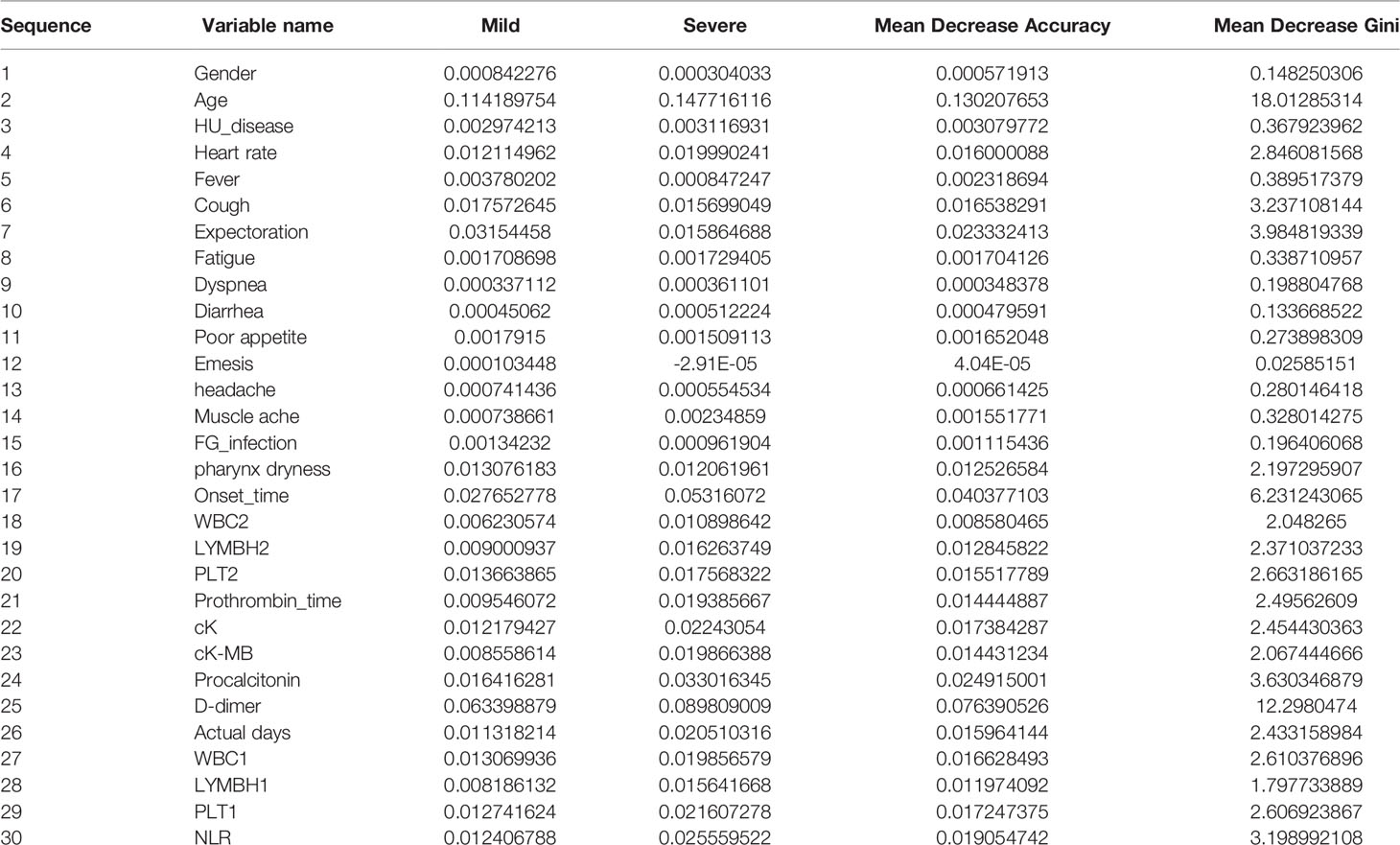
Table 6 Importance of variables.
After sorting the Mean Decrease Accuracy and Mean Decrease Gini of the variables, Figure 5 showed the visualization results of the variable importance ranking. According to the results of MeanAccuracy, we can see that the top 10 important variables were age, D dimer, onset time, Actual days, NLR, WBC1, procalcitonin, expectoration, CK, heart rate. According to the results of MeanDecreaseGini, we can see that the top 10 important variables were age, D dimer, onset time, expectoration, procalcitonin, cough, NLR, heart rate, PLT2, WBC1. Important variables in these two selection criteria include 8 variables: age, D dimer, onset time, procalcitonin, NLR, WBC1, expectoration, heart rate.
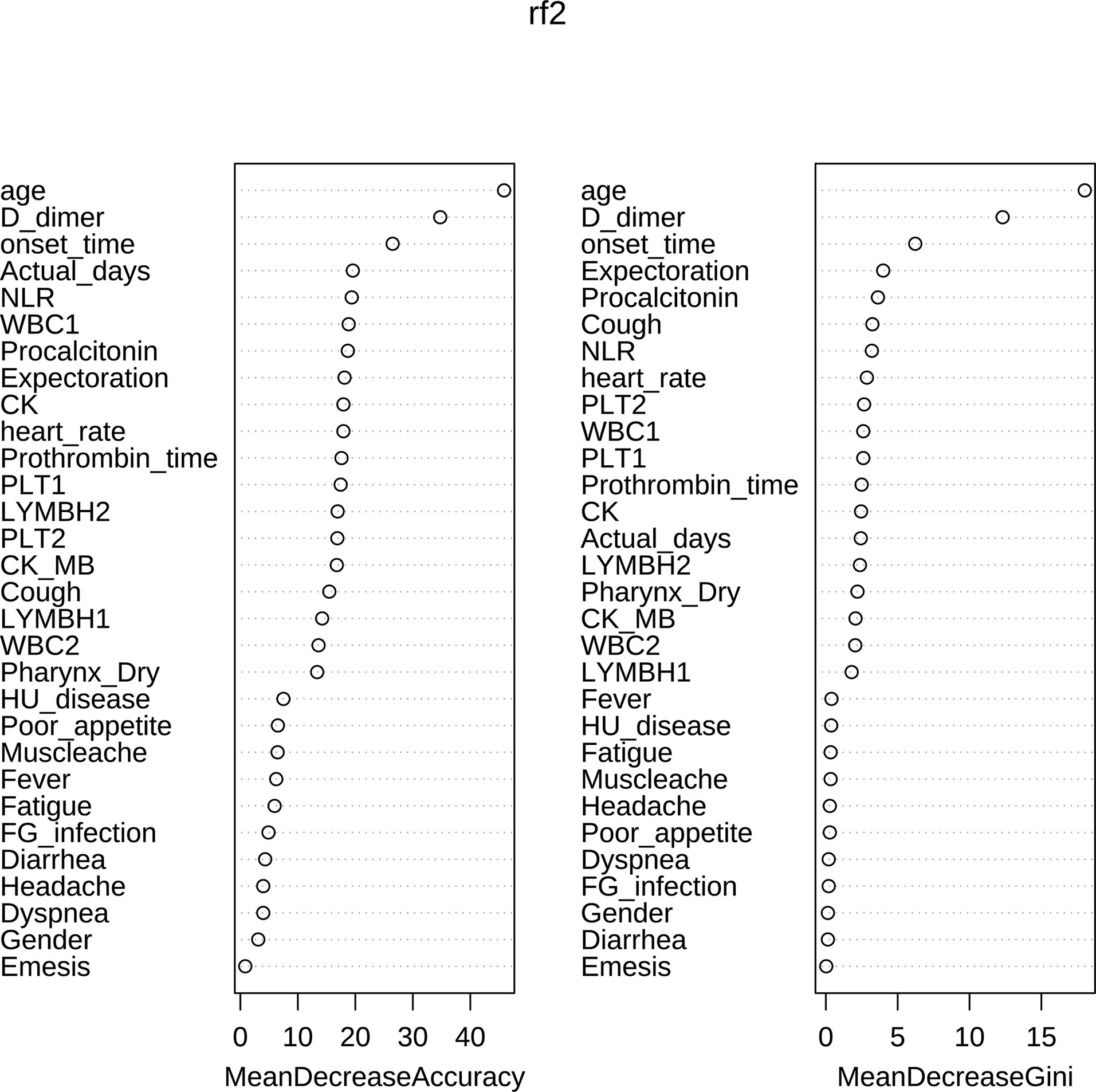
Figure 5 Ranking chart of importance of variables.
The prediction function was further used to verify the test set, and the model accuracy was 96.97%, the Sensitivity rate was 93.33%, and the recall rate was 93.3%. Figure 6 was a random forest ROC curve and AUC evaluation graph. The optimal critical point threshold of the ROC curve was 1.5, and the coordinates are (0.933, 1), very close to the upper left. The AUC score under the ROC curve was 0.967 and the overall area of the curve was close to 1, indicating a strong recognition ability. All these indicate that the random forest method has a good effect.
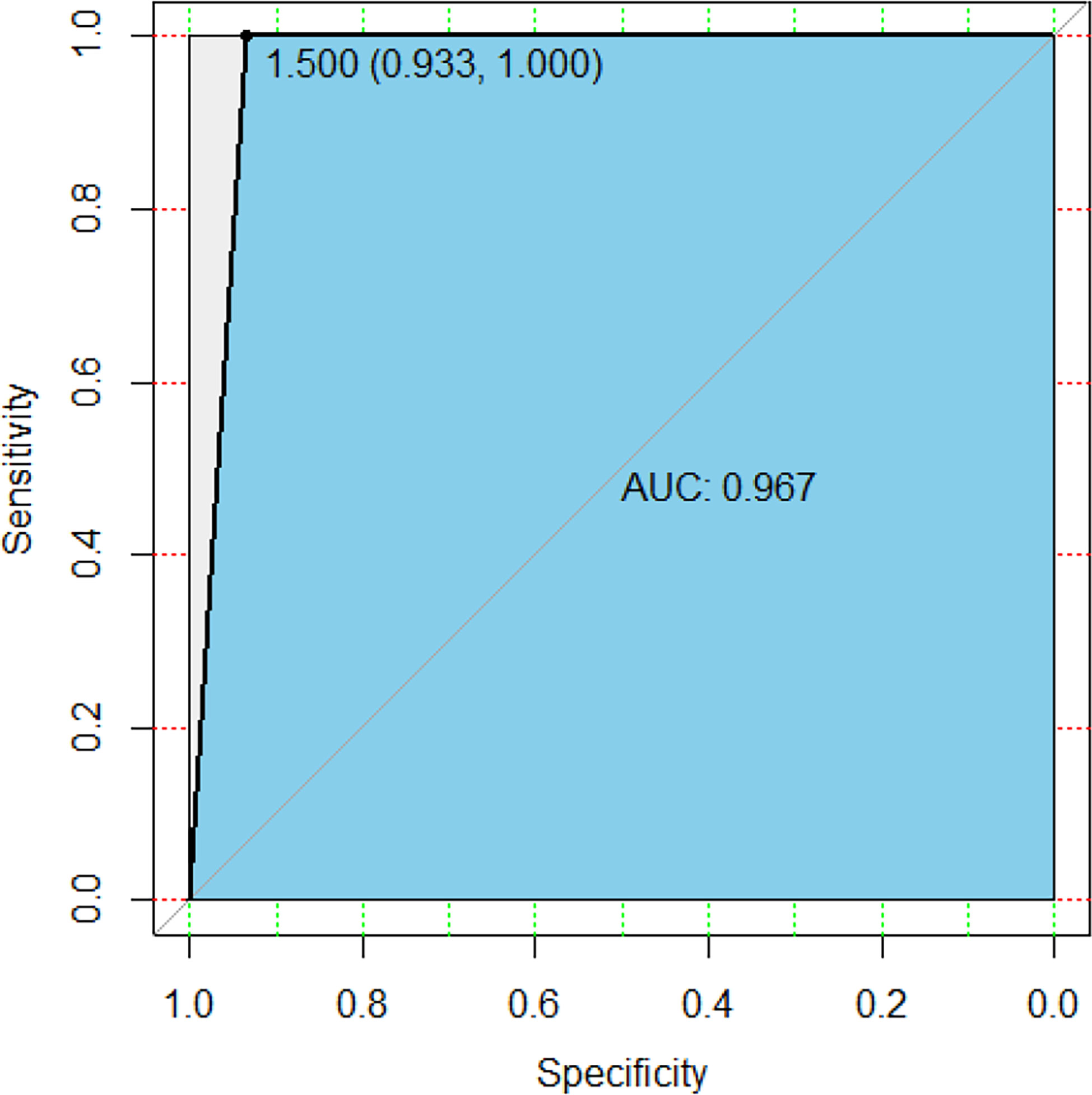
Figure 6 ROC curve and AUC area of random forest.
Discussion
Looking back on the past 20 years, the world has experienced two severe beta coronavirus pandemics, SARS-CoV in 2002-2003 and MERS-CoV in 2012. They had a fatality rate of 10% and 35% respectively (Drosten et al., 2003; Chen B. et al., 2020), which dealt a huge blow to public health. In early 2020, SARS-CoV-2 causing COVID-19 spread rapidly worldwide. At the same time, we need to be wary of the superposition of influenza and COVID-19 in the winter.
In this study, the epidemiological history, clinical characteristics and laboratory test indicators of 90 SARS-COV-2 nucleic acid positive patients with severe and mild illness were analyzed. The clinical manifestations are non-specific, mainly fever and cough. A small number of patients appeared breathing difficulties. Gastrointestinal symptoms are not common, which has also been confirmed by similar studies (Chen N. et al., 2020; Li et al., 2020). The incubation period of SARS-CoV-2 infection is longer than that of SARS and MERS. The viral load of asymptomatic infected patients is similar to that of symptomatic infected patients, which may lead to the underestimation the potential transmissibility of SARS-CoV-2 among people (Zou et al., 2020). More studies have shown that the invisible transmission of the COVID-19 is caused by the incubation period and asymptomatic infection (Moghadas et al., 2020; Wang et al., 2020). This is also one of the reasons why it is difficult to effectively control asymptomatic infection in the COVID-19 epidemic. Our data suggested that clinical monitoring should not just focus on fever symptoms. Otherwise, it will increase the missed diagnosis rate. It is necessary to strictly implement nucleic acid testing and be assisted by comprehensive judgment on clinical chest radiographs (Ai et al., 2020). Tracing and early isolation of asymptomatic infected persons are two of the key points for pandemic control (Grasselli et al., 2020). In addition, there is a serious family cluster infection in this study, which also suggests that we should be on guard against human-to-human transmission of the virus in families and hospitals, even inter-city and overseas transmission. It also reflects the importance of timely isolation of the source of infection and isolation at home in the early stage of the epidemic.
In this study, logistic regression presents seven important factors that influence the risk of severe COVID-19, which may be of great value in screening patients with mild or severe disease. Clinicians can quickly assess what kind of risk a patient is at. The seven variables are age, creatine kinase, procalcitonin, lymphocyte count 1, cough, fatigue and pharynx dryness.
In the COVID-19 epidemic, the high-risk groups affected are mainly the elderly and people with underlying diseases. Taking into account the decline in the rehabilitation ability of the elderly, the older patients are more likely to develop into severe patients (Hendren et al., 2020). The myocardial enzymes of patients with severe COVID-19 increased significantly, and the abnormal rate of myocardial enzymes of severe COVID-19 was higher than other groups (Babapoor-Farrokhran et al., 2020). Creatine phosphokinase is a kind of myocardial enzymes. Myocardial enzymes refer to a class of enzymes that catalyze the metabolism of myocardial cells and regulate the electrophysiological activities of myocardial cells. Once the cardiomyocytes are ruptured and necrotic, these enzymes are released into the blood and their values increase. Therefore, the changes in the myocardial enzyme indicators can measure the degree of damage to the cardiomyocytes. Especially in the early stage of myocardial infarction, when the myocardium has not yet undergone extensive necrosis, creatine kinase can be detected in human blood. Therefore, if this index is elevated, the degree of myocardial damage can be diagnosed in time (Babapoor-Farrokhran et al., 2020). Procalcitonin (PCT) is a biological marker that can be used to assess the possibility of bacterial infection, reflecting the severity of bacterial infection (Dymicka-Piekarska and Wasiluk, 2015). Different diseases have different concentrations of procalcitonin. The higher the concentration of procalcitonin, the higher the possibility of organ failure and the higher the risk of death. Severe disease in patients with COVID-19 is also closely related to lymphocytes. Studies have shown that lymphocytes in patients with COVID-19 show a significant decreasing trend, among which CD4+ and CD8+T lymphocytes are the most obvious. Therefore, CD4+ and CD8+T lymphocytes can be considered as early warning signals and prognostic indicators to judge the severity of COVID-19 patients (Huang et al., 2020b; Zhang et al., 2020). Three clinical symptoms, including cough, fatigue and pharyngeal dryness can be used as important clinical symptoms to judge the degree of disease development. Combined with the patient’s laboratory indicators, they have a certain reference.
The random forest classification method solves the problem of variable collinearity, and has a better prediction effect. At the same time, it also provides important predictors in the method, such as the age, D-dimer, time from onset to admission, procalcitonin, NLR, heart rate, white blood cell count. Among these variables, in addition to the age and procalcitonin variables explained above, D-dimer and NLR also have an important position. In this epidemic, some severe patients died because of an inflammatory storm, which is an overreaction of the human immune system. D-dimer is one of the markers for detecting thrombus, and the rise of D-dimer can also be seen when the human body undergoes inflammation (Shah et al., 2020). NLR is the ratio of neutrophils to lymphocytes. Neutrophils are the main component of the white blood cell population. After microbial pathogens invade the body, they will quickly reach the inflammation site and exert phagocytosis. In addition, the human immune response triggered by viral infections mainly relies on lymphocytes. In the previous logistic regression, it was also analyzed that the lymphocytes decreased, the higher the possibility of the patient being severely ill (Yang et al., 2020a; Kerboua, 2021). Therefore, elevated D-dimer and NLR indicate that the patient’s condition is getting worse. In this article, the D-dimer and NLR of severe patients are higher than those of mild patients. Random forests can still maintain accuracy for data with unbalanced classification and have a strong anti-overfitting ability. Therefore, the importance of variables given by random forests is further added to the variable information in addition to the logistics model. In the future, it can be considered as a direction in which to continue to look for key variables to distinguish the mild and severe diseases.
In this study, the clinical characteristics and modeling significant variables of patients with mild and severe diseases are of great value, and can help to identify whether or not the patients are at risk of critical illness in the early stage. However, there are some limitations in this study. Firstly, the clinical symptoms or signs and laboratory test results of patients extracted from electronic medical records lack some data, and some cases are incomplete. Secondly, because the research subjects are all hospitalized patients, the actual research lacks those with asymptomatic infections and mild patients who are not treated in hospital, causing the research results may be more inclined to serious outcomes. Thirdly, the sample size is limited, so the results may not be robust enough. The SMOTE algorithm performs class balancing and has certain errors. For example, it may repeatedly use outliers or wrong values in the data, or may incorrectly strengthen the local chance, thereby increasing the risk of overfitting. In addition, during the data collection period of this article, the Ninth People’s Hospital of Dongguan City had no moderate cases, so patients were divided into two types.
To sum up, the COVID-19 outbreak in 2020 is a huge public health crisis to the whole world. In the context of the pandemic, early detection, early isolation and early intervention have always been the basic strategies for epidemic prevention and control. The data shows that we need to closely monitor patients with mild COVID-19, reduce the transformation from mild to severe, and rationally allocate medical resources in a scientific and efficient way to improve the cure rate of COVID-19.
Data Availability Statement
The datasets and R language code presented in this study can be found at GitHub (https://github.com/johnsnowgo/covid-90data).
Ethics Statement
The studies involving human participants were reviewed and approved by The Ethics Committee of the Ninth People’s Hospital of Dongguan, China.
Author Contributions
XC: Conceptualization, Methodology, Writing-review & editing, Project administration. LZ: Software, Formal analysis, Writing - original draft, Writing - review & editing. SY and HZ: Resources, Conceptualization, Methodology, Writing - review & editing. YJ: Conceptualization, Methodology, Writing-review & editing, Project administration. Y-QC: Conceptualization, Methodology, Writing-review & editing, Project administration. MX: Writing-original draft, Formal analysis. KL: Writing-original draft, Formal analysis. YL: Writing-original draft, Formal analysis. All authors contributed to the article and approved the submitted version.
Funding
This study was supported by the National Natural Science Foundation of China (11601083), the program for Probability and Statistics: Theory and Application (IRTL1704) and Innovative Research Team in Science and Technology in Fujian Province University (IRTSTFJ). This study was also supported by National Natural Science Foundation of China (31970881) and Shenzhen Science and Technology Program under Grant (SGG20200225152008136) to Y-QC. The special topic of prevention and control technology research and promotion of emergency tackling on Covid-19 in Dongguan city (2020717150119128).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ai, T., Yang, Z., Hou, H., Zhan, C., Chen, C., Lv, W., et al. (2020). Correlation of Chest CT and RT-PCR Testing for Coronavirus Disease 2019 (Covid-19) in China: A Report of 1014 Cases. Radiology 296, E32–E40. doi: 10.1148/radiol.2020200642
Alahmari, F. (2020). A Comparison of Resampling Techniques for Medical Data Using Machine Learning. J. Inf Knowl. Manag. 19, 1–13. doi: 10.1142/S021964922040016X
Babapoor-Farrokhran, S., Gill, D., Walker, J., Rasekhi, R. T., Bozorgnia, B., Amanullah, A. (2020). Myocardial Injury and COVID-19: Possible Mechanisms. Life Sci. 253, 117723. doi: 10.1016/j.lfs.2020.117723
Chawla, N. V., Bowyer, K. W., Hall, L. O., Kegelmeyer, W. P. (2002). SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 16, 321–357. doi: 10.1613/jair.953
Chen, B., Tian, E. K., He, B., Tian, L., Han, R., Wang, S., et al. (2020). Overview of Lethal Human Coronaviruses. Signal Transduct. Target Ther. 5, 89. doi: 10.1038/s41392-020-0190-2
Chen, N., Zhou, M., Dong, X., Qu, J., Gong, F., Han, Y., et al. (2020). Epidemiological and Clinical Characteristics of 99 Cases of 2019 Novel Coronavirus Pneumonia in Wuhan, China: A Descriptive Study. Lancet 395, 507–513. doi: 10.1016/S0140-6736(20)30211-7
Drosten, C., Gunther, S., Preiser, W., van der Werf, S., Brodt, H. R., Becker, S., et al. (2003). Identification of a Novel Coronavirus in Patients With Severe Acute Respiratory Syndrome. N. Engl. J. Med. 348, 1967–1976. doi: 10.1056/NEJMoa030747
Dymicka-Piekarska, V., Wasiluk, A. (2015). Procalcitonin (PCT), Contemporary Indicator of Infection and Inflammation. Postepy Hig. Med. Dosw. 69, 723–728. doi: 10.5604/17322693.1158796
Grasselli, G., Zangrillo, A., Zanella, A., Antonelli, M., Cabrini, L., Castelli, A., et al. (2020). Baseline Characteristics and Outcomes of 1591 Patients Infected With SARS-Cov-2 Admitted to ICUs of the Lombardy Region, Italy. JAMA 323, 1574–1581. doi: 10.1001/jama.2020.5394
Guan, W. J., Ni, Z. Y., Hu, Y., Liang, W. H., Ou, C. Q., He, J. X., et al. (2020). Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 382, 1708–1720. doi: 10.1056/NEJMoa2002032
Hendren, N. S., Drazner, M. H., Bozkurt, B., Cooper, L. T., Jr. (2020). Description and Proposed Management of the Acute Covid-19 Cardiovascular Syndrome. Circulation 141, 1903–1914. doi: 10.1161/CIRCULATIONAHA.120.047349
Huang, C., Wang, Y., Li, X., Ren, L., Zhao, J., Hu, Y., et al. (2020). Clinical Features of Patients Infected With 2019 Novel Coronavirus in Wuhan, China. Lancet 395, 497–506. doi: 10.1016/S0140-6736(20)30183-5
Huang, W., Berube, J., McNamara, M., Saksena, S., Hartman, M., Arshad, T., et al. (2020). Lymphocyte Subset Counts in COVID-19 Patients: A Meta-Analysis. Cytometry A 97, 772–776. doi: 10.1002/cyto.a.24172
Kerboua, K. E. (2021). Nlr: A Cost-Effective Nomogram to Guide Therapeutic Interventions in COVID-19. Immunol. Invest. 50, 92–100. doi: 10.1080/08820139.2020.1773850
Li, Q., Guan, X. H., Wu, P., Wang, X. Y., Zhou, L., Tong, Y. Q., et al. (2020). Early Transmission Dynamics in Wuhan, China, of Novel Coronavirus-Infected Pneumonia. N. Engl. J. Med. 382, 1199–1207. doi: 10.1056/NEJMoa2001316
Lu, R., Zhao, X., Li, J., Niu, P., Yang, B., Wu, H., et al. (2020). Genomic Characterisation and Epidemiology of 2019 Novel Coronavirus: Implications for Virus Origins and Receptor Binding. Lancet 395, 565–574. doi: 10.1016/S0140-6736(20)30251-8
Moghadas, S. M., Fitzpatrick, M. C., Sah, P., Pandey, A., Shoukat, A., Singer, B. H., et al. (2020). The Implications of Silent Transmission for the Control of COVID-19 Outbreaks. Proc. Natl. Acad. Sci. U. S. A. 117, 17513–17515. doi: 10.1073/pnas.2008373117
Shah, S., Shah, K., Patel, S. B., Patel, F. S., Osman, M., Velagapudi, P., et al. (2020). Elevated D-Dimer Levels Are Associated With Increased Risk of Mortality in Coronavirus Disease 2019: A Systematic Review and Meta-Analysis. Cardiol. Rev. 28, 295–302. doi: 10.1097/CRD.0000000000000330
Wang, D., Hu, B., Hu, C., Zhu, F., Liu, X., Zhang, J., et al. (2020). Clinical Characteristics of 138 Hospitalized Patients With 2019 Novel Coronavirus-Infected Pneumonia in Wuhan, China. JAMA 323, 1061–1069. doi: 10.1001/jama.2020.1585
Wu, F., Zhao, S., Yu, B., Chen, Y. M., Wang, W., Song, Z. G., et al. (2020). A New Coronavirus Associated With Human Respiratory Disease in China. Nature 579, 265–269. doi: 10.1038/s41586-020-2008-3
Yang, A. P., Liu, J. P., Tao, W. Q., Li, H. M. (2020a). The Diagnostic and Predictive Role of NLR, d-NLR and PLR in COVID-19 Patients. Int. Immunopharmacol. 84, 106504. doi: 10.1016/j.intimp.2020.106504
Yang, L., Wu, H., Jin, X., Zheng, P., Hu, S., Xu, X., et al. (2020b). Study of Cardiovascular Disease Prediction Model Based on Random Forest in Eastern China. Sci. Rep. 10, 5245. doi: 10.1038/s41598-020-62133-5
Zhang, X., Tan, Y., Ling, Y., Lu, G., Liu, F., Yi, Z., et al. (2020). Viral and Host Factors Related to the Clinical Outcome of COVID-19. Nature 583, 437–440. doi: 10.1038/s41586-020-2355-0
Zhou, P., Yang, X. L., Wang, X. G., Hu, B., Zhang, L., Zhang, W., et al. (2020). A Pneumonia Outbreak Associated With a New Coronavirus of Probable Bat Origin. Nature 579, 270–273. doi: 10.1038/s41586-020-2012-7
Zhu, N., Zhang, D., Wang, W., Li, X., Yang, B., Song, J., et al. (2020). A Novel Coronavirus From Patients With Pneumonia in Chin. N. Engl. J. Med. 382, 727–733. doi: 10.1056/NEJMoa2001017
Keywords: COVID-19, mild and severe, clinical characteristic, Lasso-Logistic regression, random forest
Citation: Chen X, Zheng L, Ye S, Xu M, Li Y, Lv K, Zhu H, Jie Y and Chen Y-Q (2021) Research on Influencing Factors and Classification of Patients With Mild and Severe COVID-19 Symptoms. Front. Cell. Infect. Microbiol. 11:670823. doi: 10.3389/fcimb.2021.670823
Received: 22 February 2021; Accepted: 25 June 2021;
Published: 18 August 2021.
Edited by:
Ian George Barr, VIDRL, AustraliaReviewed by:
Shashank Ganatra, Texas Biomedical Research Institute, United StatesMohamed Gomaa Kamel, Minia University, Egypt
Copyright © 2021 Chen, Zheng, Ye, Xu, Li, Lv, Zhu, Jie and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yao-Qing Chen, Y2hlbnlhb3FpbmdAbWFpbC5zeXN1LmVkdS5jbg==; Yusheng Jie, amlleXVzaEBtYWlsLnN5c3UuZWR1LmNu
†These authors have contributed equally to this work and share first authorship