Control of Jump Markov Uncertain Linear Systems With General Probability Distributions
 Patrick Flüs
Patrick Flüs Olaf Stursberg
Olaf Stursberg- Control and System Theory, Department of Electrical Engineering and Computer Science, University of Kassel, Kassel, Germany
This paper introduces a method to control a class of jump Markov linear systems with uncertain initialization of the continuous state and affected by disturbances. Both types of uncertainties are modeled as stochastic processes with arbitrarily chosen probability distributions, for which however, the expected values and (co-)variances are known. The paper elaborates on the control task of steering the uncertain system into a target set by use of continuous controls, while chance constraints have to be satisfied for all possible state sequences of the Markov chain. The proposed approach uses a stochastic model predictive control approach on moving finite-time horizons with tailored constraints to achieve the control goal with prescribed confidence. Key steps of the procedure are (i) to over-approximate probabilistic reachable sets by use of the Chebyshev inequality, and (ii) to embed a tightened version of the original constraints into the optimization problem, in order to obtain a control strategy satisfying the specifications. Convergence of the probabilistic reachable sets is attained by suitable bounding of the state covariance matrices for arbitrary Markov chain sequences. The paper presents the main steps of the solution approach, discusses its properties, and illustrates the principle for a numeric example.
1 Introduction
For some systems to be controlled, the dynamics can only be represented with inherent uncertainty, stemming not only from disturbance quantities, but also from uncertain operating modes leading to different parameterization or even varying topology. Examples are production lines, in which units may be temporarily unavailable, or cyber-physical systems embedding communication networks, in which link failures lead to reduced transmission rates or varied routing. If the underlying continuous-valued dynamics is linear, jump Markov linear systems (JMLS) are a suitable means for representing the dynamics. In this system class, the transitions between different operating modes with associated linear dynamics are modeled by Markov chains (Costa et al., 2005). If disturbances are present in addition, the dynamics of each mode comprises stochastic variables with appropriate distribution. The control of JMLS has found considerable attention in recent years, e.g. with respect to determining state feedback control laws for infinite and finite quadratic cost functions (Do Val and Basar, 1997; Park et al., 1997).
Many research groups have focused on schemes of model-predictive control (MPC) for JMLS, motivated by the fact that MPC enables one to include constraints (Maciejowski, 2002). Since the states and inputs of almost all real-world systems have to be kept in feasible or safe ranges, this aspect is a crucial one. The first contributions to constrained control of JMLS date back to the work (Costa and Filho, 1996; Costa et al., 1999), in which state feedback control laws have been determined. Additionally, their control designs consider uncertainties in the initial state and in the transition matrix of the Markov chain. An approach for unconstrained JMLS with additive stationary disturbances based on MPC was proposed in (Vargas et al., 2004), embedding a procedure to determine a set of state feedback controllers. In designing such controllers for bounded additive disturbances, formulations using semi-definite program are well-known (Park et al., 2001; Park and Kwon, 2002; Vargas et al., 2005). For constrained JMLS, an MPC scheme was presented in (Cai and Liu, 2007), in which embedded feedback controllers are synthesized based on linear matrix inequalities, too. Subsequent work improved this approach in (Liu, 2009; Lu et al., 2013; Cheng and Liu, 2015) by using dual-mode predictive control policies, periodic control laws, and multi-step state feedback control laws. In (Yin et al., 2013; Yin et al., 2014), MPC approaches have been presented which ensure robust stability in case of uncertain JMLS.
The mentioned MPC approaches for JMLS are all based on the principle of strict satisfaction of the specified constraints. However, in the case of modeling uncertainties in terms of stochastic variables with unbounded supporting domain, the satisfaction of constraints with high confidence only is a reasonable alternative, leading to a form of soft constraints. For such a probabilistic perspective on constraint satisfaction, which is also adopted in this paper, two approaches are used in literature: In the first one, only the expected values of the random variables are constrained in strict form, and then are referred to expectation constraints. In (Vargas et al., 2006), the first and second moments of the state and input have been considered in this form. In (Tonne et al., 2015), only the first moment was strictly constrained, but the computational complexity has been reduced significantly for higher-dimensional JMLS. In the second approach, the constraints are formulated such that the distribution of the stochastic variables has to satisfy the constraints with a high confidence, then termed chance constraints. Some papers following this principle use particle filter control (Blackmore et al., 2007; Blackmore et al., 2010; Farina et al., 2016; Margellos, 2016), in which a finite set of samples is used to approximate the probability distributions of the JMLS. Typically, these approaches are formulated in form of mixed-integer linear programming problems. While these approaches can handle arbitrary distributions, the computational complexity rises exponentially for increasing the dimension of the spaces of the JMLS or for large prediction horizons. Following a different concept, the work in (Chitraganti et al., 2014) transforms the stochastic problem into a deterministic one (Chitraganti et al., 2014), but the method is restricted to Gaussian distributions of the stochastic variables. The same applies to the approach in (Asselborn and Stursberg, 2015; Asselborn and Stursberg, 2016), which uses probabilistic reachable sets to solve optimization problems with chance constraints, and the work does not use a prediction scheme. The authors of (Lu et al., 2019) have proposed a stochastic MPC approach for uncertain JMLS using affine control laws, but this scheme is restricted to bounded distributions.
Apart from the last-mentioned paper, all previous ones are tailored to Gaussian distributions. In contrast, the paper on hand aims at proposing a control approach by which JMLS with general (bounded or unbounded) distributions are transferred into a target set while chance constraints are satisfied and the computational effort is relatively low. The key step is an analytic approximation of the distribution to reformulate the stochastic control problem into a deterministic one. A method for computing bounds for the covariance matrix is proposed, which enables to compute probabilistic reachable sets (PRS) for the underlying dynamics. The determination of PRS for jump Markov systems has already been considered in (LygerosCassandras, 2007; Abate et al., 2008; Kamgarpour et al., 2013), but these approaches cannot handle arbitrary probability distributions. Here, we use a tightened version of these sets in order to achieve the satisfaction of chance constraint for the states. Furthermore, a scheme of stochastic MPC, which builds on over-approximated probabilistic reachable sets (PRS) for the given arbitrary probability distributions, is proposed in order to realize the transfer of the JMLS into a target set for arbitrary sequences of the discrete state. The paper is organized as follows: Section 2 clarifies some notation used throughout the paper, and introduces the considered system class as well as the control problem. Section 3 describes the procedure for designing the control law, the handling of the construction and approximation of the probabilistic constraints, the determination of the prediction equations, and the predictive control. A numerical example for illustration is in Section 4, before Section 5 concludes the paper.
2 Problem Statement
2.1 Notation
Within this paper, weighted 2-norms are written as
The standard Kronecker product is denoted by ⊗, and the Minkowski difference by ⊖. The operator vec(M) returns a vector which stacks all elements of the matrix M column-wise.
A distribution
An ellipsoidal set ɛ(q, Q) is parametrized by a center point
If an ellipsoidal set is transformed by an affine function f(x) = Mx + b with
2.2 The Control Task
Consider the following type of jump Markov linear and time-invariant system (JMLS) with continuous state
In here, the initial continuous state x0 as well as the disturbance wk as stochastic variables are selected from arbitrarily selected distributions
Assumption 1. The system state xk, the Markov state θk, as well as the probability distribution μk are measurable. Furthermore, the distributions of x0 and wk are independent.
The measurability assumption of the Markov state and its probability distribution is quite common for JMLS. If the Markov state is used to model whether a process is in a nominal or a failure state, and if a suitable failure detection mechanism exists for the process, this assumption is certainly justified. Note that only the Markov state in the current time step k is assumed to be measurable, while the next transitions is unknown. For a system of type (1), let a terminal set
Furthermore, let admissible state and input sets be defined by:
as polytopes, which are parameterized by
Then, the control problem investigated in this paper is to find a control strategy ϕu = {u0, u1, …, uN−1},
• ϕu stabilizes the JMLS with confidence δ,
• ϕx and ϕu fulfill the chance constraints:
in any time step k and for any disturbances wk,
• and for which a finite
3 Probabilistic Control of Jump Markov Affine Systems
In order to solve the stated control problem, this paper proposes a new method which combines concepts of stochastic model predictive control (SMPC), the conservative approximation of the distributions
An underlying principle is to separate the evolution of the continuous state into a part referring to the expected state and a part encoding the deviation from the latter, as also followed in some approaches of tube-based MPC (Fleming et al., 2015). This principle allows for a control strategy, in which the expected state is steered towards the target set by a solving a deterministic optimization problem within the MPC part, as was proposed in (Tonne et al., 2015). The fact that repeated optimization on rolling horizons is used rather than the offline solution of one open-loop optimal control problem not only tailors the scheme to online solution, but also reduces the computational effort due to the possibility of employing rather short horizons. For the deviation part of the dynamics, a new scheme based on probabilistic reachable sets is established, which are computed and used for constraint tightening of the MPC formulation to satisfy the chance constraints (Eqs 4, 5). Since these sets depend on the covariances of the continuous system states and thus, on future discrete states of the JMLS, a boundary of the covariances for arbitrary sequences of the Markov state can be established. One of the main contributions of this paper is that a control strategy is derived which stabilizes the uncertain JMLS into the target with a specified and high probability.
3.1 Structure of the Control Strategy
To design a control strategy for the given problem, the probabilistic continuous system state xk as well as the disturbance wk are split into an expected and an error part:
Similar to methods of MPC employing reachability tubes, see e.g., (Fleming et al., 2015), a local affine control law of the form
is defined, in which vk is the expected value of uk. The state feedback matrix Ki is determined off-line, such that Acl,i = Ai − BiKi for i ∈ Θ is stable. Note that stability here refers only to Acl,i, not to that the complete switching dynamics. The stability of the JMLS will be taken care of later in this section. The feedback matrix Ki of the control law ensures that the error part ek is kept in a neighborhood of qk. By applying the control law (8) to the dynamics (1), the following difference equations for the expected value qk and error ek of xk are obtained:
The stochastic term ew,k of the uncertainty is considered in Eq. 10, while Eq. 9 considers only the deterministic part (expected value) qw. Since the error part encodes the covariance of xk around the expected value qk, the following difference equation for the covariance matrix Qk results from using linear transformation of the covariance matrices:
As already mentioned, an approach of SMPC is chosen in the upcoming parts of the paper to determine a sequence of expected inputs vk+j|k, such that the expected value of xk will be transferred and stabilized into the target set. SMPC has the crucial advantage (compared to optimal control), that the sequence of input signals are computed on-line based on the current discrete state which can be measured, see Asm. 1. Thus, the probabilistic reachable sets can be computed with higher accuracy. Since Eq. 9 is only stochastic with respect to the Markov state θk, the SMPC scheme can be formulated as a deterministic predictive control scheme with respect to the expected values of xk. This scheme predicts the future expected continuous states over a finite horizon using the affine dynamics Eq. 9. To ensure that a certain share of all possible xk (according to the underlying distributions) satisfies the constraints, the feasible set of states and inputs is reduced. This step of constraint tightening is described in detail in Section 3.4.
3.2 Construction of PRS Using the Chebyshev Inequality
In order to satisfy the chance constraints (4) and (5), probabilistic reachable sets for the error part of the continuous states are computed and used for tightening the original constraints. This allows one to use the reformulated constraints in a deterministic version of an optimization problem (with the MPC scheme) with respect to the continuous state of the JMLS. Probabilistic reachable sets are first defined as follows:
Def. 1. A stochastic reachable set contains all error parts which are reachable according to Eq. 10 from an initial set
In the general case, the computation of the true PRS may turn out to be difficult and can result in non-convex sets. If so, the true PRS can be be over-approximated by convex sets as described in the following: as a main contribution of this paper, it is proposed to use the Chebychev inequality (Marshall and Olkin, 1960) to conservatively bound the true PRS. The n-dimensional Chebyshev inequality for random variables provides a lower bound on the probability that an ellipsoidal set contains a realization of the stochastic variable. Thus, the inequality can be used to approximate the true reachable sets by ellipsoids in case that the expected value as well as the covariance matrix of the random variable is known.
Theorem 3.1. Let X be a random variable with finite expected value
for all δ > 0.
PROOF. (Ogasawara, 2019). Consider the transformed new random variable Z:
Since Q > 0, the random variable Z can be decomposed as follows:
The random variable Y satisfies
and
Therefore,
Finally, by using the Markov’s inequality,
holds for all δ > 0.
Now, the Chebyshev inequality is used to formulate a bound on the probability that the error part of the continuous state xk of the JMLS at time k is contained in an ellipsoid around the origin:
In here, the matrix
Nevertheless, this leads to time-varying constraints which depend on the discrete state of the JMLS. To reduce the computational complexity, and thus the computation time, a possible alternative is to use a more conservative approximation of the constraints, such that they remain time-invariant and independent of θk, as described in the following.
3.3 Bounding the State Covariance Matrix
For time-invariant constraints being independent of the discrete state of the JMLS, the shape matrices
holds for all states θk ∈ Θ. Note that
Def. 2. For any symmetric matrix
i.e., the elements of S are stacked columnwise, and the off-diagonal elements are multiplied by
Def. 3. The symmetric Kronecker product of two matrices
where
By using the definitions above, the covariance difference Eq. 11 turns into a pseudo-affine system:
where φk is the pseudo state, and again i ∈ Θ. Note that the next state φk+1 = svec(Qk+1) depends also on the Markov state. Furthermore, let
Now a quadratic Lyapunov function
The center point φc of the Lyapunov function is chosen as the mean value of the steady states for the different Markov states. Next, the smallest common invariant set is determined for the pseudo system (14). The common Lyapunov stability condition is given by
By applying the S-procedure to Eq. 15, a corresponding LMI can be obtained for λ > 0:
The minimum positive definite matrix
where
Theorem 3.2. Let the optimization problem (17)-(18) have a feasible solution. The back transformation of the solution is an over-approximation of all covariance matrices, i.e.
PROOF. (Sketch) The transformation of Eqs 11–14 by using Kronecker algebra does not modify the solution for a specific i ∈ Θ (Schäcke, 2004). Consider now arbitrary sequences of i, the set
Note that solving the optimization problem Eqs 17, 18 and thus, the computation of the PRS for the error part ek of the state xk can be computationally demanding for larger-scale Markov systems. But this optimization problem has to be solved only once and is carried out offline before starting the online optimization (to be described in the following). The offline computation is possible, since
3.4 Computation of the Tightening Constraints and MPC Formulation
In this section, a method to compute the tightened constraints in a stochastic manner for arbitrary distributions is presented. Tightening the constraints plays a crucial role if the optimization problem refers to the (conditional) expected values of xk [and thus uk according to the control law (Eq, 8)], as in this paper. Since the true values lie around the expected values (depending on the chosen distribution), the original constraints have to be tightened to ensure satisfaction of the chance constraints Eqs 4, 5. Since the tightening is obtained as the Minkowski difference of
Note that these computations can be carried out offline. Based on the ellipsoidal form of
where rx,i the i-th row of Rx, and bx,i the i-th entry of bx, defining the polytope
The computation of the input constraint (5) follows analogously by determination of an over-approximated matrix for
The following assumption is necessary for ensuring the existence of a feasible solution of the following optimization problem to be carried out online within the MPC scheme.
Assumption 2. After constraint tightening, the resulting sets
Note that if the computations according to Eqs 20, 21 lead to empty sets
with the sequence of expected continuous inputs ϕv = {vk|k, …, vk+H−1|k} and for a quadratic cost function with matrices P, Q, R > 0. Convergence is enforced by a shrinking ellipsoid
Note that throughout the derivation of this problem, no specific assumptions for the distributions of x0 and wk were required. Previous contributions in this field consider bounded distributions or assume that there are normally distributed.
Generally, the constraints Eq. 25 have to be fulfilled for every possible discrete state since the future states are not deterministically known. For JMLS with high-dimensional continuous spaces or many discrete states, as well as instances of the MPC problem with large horizons H, the computational complexity of solving Eq. 23 can be significant. To improve the solution performance, the following section proposes the modification of not only predicting the expected values of xk and uk, but also those of the discrete states.
3.5 Prediction Equations for the Expected Discrete State
The solution of the optimization problem Eqs 23–28 requires to determine the predictions qk+j|k. The recursive procedure proposed in (Tonne et al., 2015) can be used also for Eqs 23–28 in order to determine the predictions with relatively computational effort.
Let the conditional expected value of xk+j|k under the condition of a discrete predecessor state i be defined as:
The predicted conditional expected value of the continuous state over all discrete states can then be expressed as:
Due to the Markov property of
With these matrices, the prediction Eq. 29 is rewritten to:
Using Eq. 30, the conditional expected value
leading to the following form of the optimization problem Eqs 23–28:
Since the Markov state θk is measurable, the prediction
Theorem 3.3. For the optimization problem Eqs 32–36, consider the case that a feasible solution exists in every time step k. In addition, assume that Q, R, P > 0 and that the problem Eqs 17, 18 has a feasible solution as well. The state of the closed-loop system then converges to the origin with at least a probability of δx, i.e.:
and
PROOF. From Theorem 3.1, the resulting over-approximated sets contain the error parts ek of xk with at least a probability of δx, independently of the chosen probability distribution, i.e.,
When using constraint tightening based on
In addition, since the discrete state is measurable (Assumption 1), the constraints of the prediction are always strictly enforced. Finally, by combining (38) and (39), it follows that Pr( limk→∞xk = 0) ≥ δx, implying also
4 Numerical Example
In order to illustrate the principle of the proposed method, numerical examples are provided in this section. First consider the following small system with n = 2 and |Θ| = 4:
The state region (2) is parameterized by:
the input constraints chosen to:
and the chance constraints selected as:
The initial distribution of the Markov state is specified by:
and the transition matrix
The matrices parameterizing the cost function (23) are selected to Q = diag(100, 1), and R = 20 ⋅ I. The feedback matrices Ki are determined as the solution of the Riccati equation, and the prediction horizon is set to H = 20. To get a challenging example regarding the stochastic parts, x0 is sampled from a bimodal distribution, obtained from a weighted superposition of two normal distributions parametrized by q0,1 = [−7,50]T, q0,2 = [−7.5,47]T, weighted by π1 = π2 = 0.5, and with the following covariance matrices:
In addition, the disturbances are chosen uniformly distributed:
In the first step, the (off-line) optimization Eqs 17, 18 is carried out to determine an upper bound of the covariance matrix of the state. Figure 1 shows the ellipse corresponding to the bounded over-approximated covariance matrix
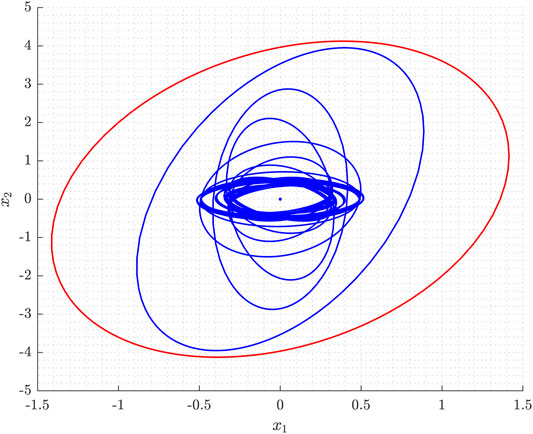
FIGURE 1. Over-approximation of the ellipses corresponding to shape matrices for an arbitrary sequence of discrete states.
Figure 2 illustrates the result of applying the SMPC scheme in the sense of a Markov simulation: The optimization problem Eqs 32–36 is solved repeatedly for sampled realizations of the stochastic variables of the given example. The average computation time for one iteration is about 17.4 ms, i.e. fast enough for online computation. The confidence ellipsoids (blue ellipses) are transferred into the terminal region (green ellipse) over time. For this example, the PRS is guaranteed to contain at least δx = 85% of the realizations, but it can be seen that almost every sample (indicated by black stars) lies inside the corresponding PRS. This behavior confirms the conservativeness of the approximation by using the Chebyshev inequality.
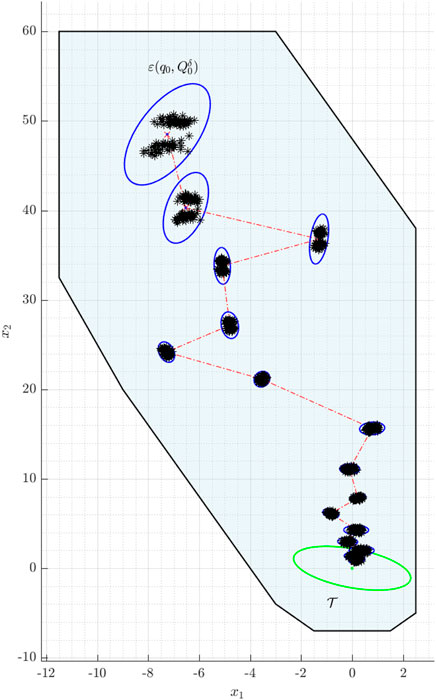
FIGURE 2. Example for n =2: The blue ellipses mark the over-approximated probabilistic reachable sets, the dashed red line indicates the sequence of the expected states, and the green ellipse refers to the target set. The black stars are sampled from a bimodal distribution.
To also demonstrate the applicability of the proposed approach to a JMLS with higher-dimensional continuous state space and more discrete states, next an example with nz = 8, n = 10, nu = 6, and a prediction horizon of H = 15 is considered. The matrices Ai, Bi, and Gi were determined randomly. For the initial condition, μ0 = [1,0,…,0]T is used, and as in the previous example, x0 is sampled from a bimodal distribution, obtained from a weighted superposition of two normal distributions parametrized by
The component-wise input and state chance constraints are selected to Pr(|ui,k| ≤ 5) ≥ 80% and Pr(|xi,k| ≤ 25) ≥ 80%, and all components of the transition matrix are chosen to pi,m = 0.125. The average computational time for the determination of the inputs in each time step k is about 124 ms. The results are shown for the different components of xk over time in Figure 3. The different colors represent these components, for any of which 10 samples are taken. The dashed lines represent the state chance constraints. It is to observe that the presented approach stabilizes any state of this high-dimensional JMLS, while satisfying the chance constraints. The sampled states are far away from the chance constraints, though these are chosen to only δx = 80%. As in the first example, this behavior confirms the conservativeness of the Chebyshev approximation. Furthermore, the computational time is low even for larger JMLS, thus enabling the online execution for many real-world systems.
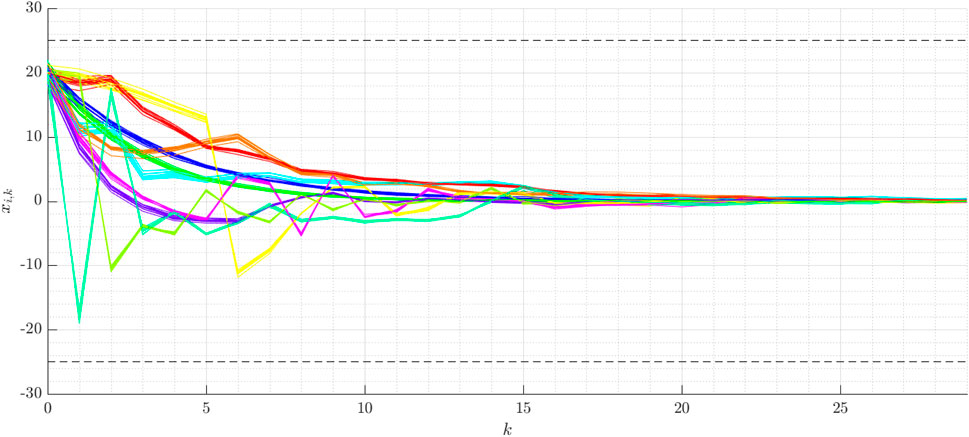
FIGURE 3. Example for the high dimensional JMLS: The different colors represent the components of xk over the time k.
5 Conclusion
The paper has proposed a method to synthesize a stabilizing control strategy for JMLS with uncertainties, which are modeled as random variables with arbitrarily chosen distributions. The approach can cope with chance constraints for the input and the state. The control strategy is obtained by determining stabilizing feedback control matrices as well as a feasible input sequence by using an MPC-like approach for the conditional expected values. The novel contribution of this paper is to combine the principles of optimization-based controller synthesis and probabilistic reachability for JMLS with arbitrary disturbances, modeled as random variables. Additionally, a method to compute the bounded state covariance matrix for the same system class was derived. In computing the PRS, the use of confidence ellipsoidal sets was motivated by Chebychev estimation. The advantage is, that the PRS of the error part can be computed off-line and together with the tailored formulation of the prediction equations for the expected continuous states, the on-line computational effort of the scheme is relatively low, even for high dimensional Markov systems.
Possible extensions of the proposed technique include the formulation of additional constraints to ensure recursive feasibility, as well as further means to reduce the computational complexity. In addition, in order to avoid the measurability assumptions for the Markov state and the continuous states, the extension of the scheme to state observers may constitute a promising investigation.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcteg.2022.806543/full#supplementary-material
References
Abate, A., Prandini, M., Lygeros, J., and Sastry, S. (2008). Probabilistic Reachability and Safety for Controlled Discrete Time Stochastic Hybrid Systems. Automatica 44 (11), 2724–2734. doi:10.1016/j.automatica.2008.03.027
Asselborn, L., and Stursberg, O. (2016). “Probabilistic Control of Switched Linear Systems with Chance Constraints,” in Europ. Contr. Conf. (ECC), 2041–2047. doi:10.1109/ecc.2016.7810592
Asselborn, L., and Stursberg, O. (2015). Probabilistic Control of Uncertain Linear Systems Using Stochastic Reachability. IFAC-PapersOnLine 48, 167–173. doi:10.1016/j.ifacol.2015.09.452
Blackmore, L., Bektassov, A., Ono, M., and Williams, B. C. (2007). Robust, Optimal Predictive Control of Jump Markov Linear Systems Using Particles. 05, 4416, 104–117.
Blackmore, L., Ono, M., Bektassov, A., and Williams, B. C. (2010). A Probabilistic Particle-Control Approximation of Chance-Constrained Stochastic Predictive Control. IEEE Trans. Robot. 26 (3), 502–517. doi:10.1109/tro.2010.2044948
Cai, Y., and Liu, F. (2007). Constrained One-step Predictive Control of Discrete Time Markovian Jump Linear Systems. Syst. Eng. Elect. 06, 950–954.
Cheng, J., and Liu, F. (2015). Feedback Predictive Control Based on Periodic Invariant Set for Markov Jump Systems. Circuits Syst. Signal. Process. 34 (8), 2681–2693. doi:10.1007/s00034-014-9936-9
Chitraganti, S., Aberkane, S., Aubrun, C., Valencia-Palomo, G., and Dragan, V. (2014). On Control of Discrete-Time State-dependent Jump Linear Systems with Probabilistic Constraints: A Receding Horizon Approach. Syst. Control. Lett. 74, 81–89. doi:10.1016/j.sysconle.2014.10.008
Costa, O. L. V., Assumpção Filho, E. O., Boukas, E. K., and Marques, R. P. (1999). Constrained Quadratic State Feedback Control of Discrete-Time Markovian Jump Linear Systems. Automatica 35 (4), 617–626. doi:10.1016/s0005-1098(98)00202-7
Costa, O. L. V., and Filho, E. O. A. (1996). Discrete-Time Constrained Quadratic Control of Markovian Jump Linear Systems. Proc. 35th IEEE Conf. Decis. Control. 22, 1763–1764.
Do Val, J. B. R., and Basar, T. (1997). Receding Horizon Control of Markov Jump Linear Systems. Proc. 1997 Am. Control. Conf 55, 3195–3199. doi:10.1109/acc.1997.612049
Farina, M., Giulioni, L., and Scattolini, R. (2016). Stochastic Linear Model Predictive Control with Chance Constraints - A Review. J. Process Control. 44, 53–67. doi:10.1016/j.jprocont.2016.03.005
Fleming, J., Kouvaritakis, B., and Cannon, M. (2015). Robust Tube MPC for Linear Systems with Multiplicative Uncertainty. IEEE Trans. Automat. Contr. 60 (4), 1087–1092. doi:10.1109/tac.2014.2336358
Kamgarpour, M., Summers, S., and Lygeros, J. (2013). “Control Design for Specifications on Stochastic Hybrid Systems,” in Proc. Int. Conf. on Hybrid Systems: Comp. and Contr (ACM), 303–312. doi:10.1145/2461328.2461374
Kurzhanskii, A. B., and Vàlyi, I. (1997). Ellipsoidal Calculus for Estimation and Control. Systems and Control : Foundations and Applications. Boston, MA: Birkhäuser.
Liu, F. (2009). Constrained Predictive Control of Markov Jump Linear Systems Based on Terminal Invariant Sets. Acta Automatica Sinica 34, 496–499. 04. doi:10.3724/sp.j.1004.2008.00496
Lu, J., Li, D., and Xi, Y. (2013). Constrained Model Predictive Control Synthesis for Uncertain Discrete‐time Markovian Jump Linear Systems. IET Control. Theor. Appl. 7 (5), 707–719. March. doi:10.1049/iet-cta.2012.0884
Lu, J., Xi, Y., and Li, D. (2019). Stochastic Model Predictive Control for Probabilistically Constrained Markovian Jump Linear Systems with Additive Disturbance. Int. J. Robust Nonlinear Control. 29 (15), 5002–5016. doi:10.1002/rnc.3971
LygerosCassandras, J. C. G. (2007). Stochastic Hybrid Systems. Taylor & Francis Group/CRC Press. Jan.
Margellos, K. (2016). “Constrained Optimal Control of Stochastic Switched Affine Systems Using Randomization,” in European Control Conf., 2559–2554. doi:10.1109/ecc.2016.7810675
Marshall, A. W., and Olkin, I. (1960). Multivariate Chebyshev Inequalities. Ann. Math. Statist. 31 (4), 1001–1014. doi:10.1214/aoms/1177705673
Ogasawara, H. (2019). The Multivariate Markov and Multiple Chebyshev Inequalities. Commun. Stat. - Theor. Methods 49, 441–453. doi:10.1080/03610926.2018.1543772
Park, B.-G., Kwon, W. H., and Lee, J.-W. (2001). Robust Receding Horizon Control of Discrete-Time Markovian Jump Uncertain Systems. IEICE Trans. Fundamentals Electronics, Commun. Comp. Sci. 09, 2272–2279.
Park, B.-G., and Kwon, W. H. (2002). Robust One-step Receding Horizon Control of Discrete-Time Markovian Jump Uncertain Systems. Automatica 38 (7), 1229–1235. doi:10.1016/s0005-1098(02)00017-1
Park, B.-G., Lee, J. W., and Kwon, W. H. (1997). Receding Horizon Control for Linear Discrete Systems with Jump Parameters. 36th IEEE Conf. Decis. Control. 44, 3956–3957.
Tonne, J., Jilg, M., and Stursberg, O. (2015). “Constrained Model Predictive Control of High Dimensional Jump Markov Linear Systems,” in 2015 American Control Conference (ACC), 2993–2998. doi:10.1109/acc.2015.7171190
Vargas, A. N., do Val, J. B. R., and Costa, E. F. (2004). Receding Horizon Control of Markov Jump Linear Systems Subject to Noise and Unobserved State Chain. 43rd IEEE Conf. Decis. Control. 44, 4381–4386. doi:10.1109/cdc.2004.1429440
Vargas, A. N., do Val, J., and Costa, E. (2005). Receding Horizon Control of Markov Jump Linear Systems Subject to Noise and Unobserved State Chain. 4, 4381–4386.
Vargas, A. N., Furloni, W., and do Val, J. B. R. (2006). “Constrained Model Predictive Control of Jump Linear Systems with Noise and Non-observed Markov State,” in 2006 American Control Conference, 6. doi:10.1109/acc.2006.1655477
Yin, Y., Liu, Y., and Karimi, H. R. (2014). A Simplified Predictive Control of Constrained Markov Jump System with Mixed Uncertainties. Abstract Appl. Anal. 2014, 1–7. Special Issue:. doi:10.1155/2014/475808
Keywords: jump markov linear systems, stochastic systems, Chebyshev inequality, probabilistic reachable sets, kronecker algebra, invariant sets
Citation: Flüs P and Stursberg O (2022) Control of Jump Markov Uncertain Linear Systems With General Probability Distributions. Front. Control. Eng. 3:806543. doi: 10.3389/fcteg.2022.806543
Received: 31 October 2021; Accepted: 27 January 2022;
Published: 25 February 2022.
Edited by:
Olivier Gehan, Ecole Nationale Superieure d’ingenieurs De Caen, FranceReviewed by:
Yanling Wei, Technical University of Berlin, GermanyFlorin Stoican, Politehnica University of Bucharest, Romania
Copyright © 2022 Flüs and Stursberg. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Patrick Flüs, patrick.flues@uni-kassel.de