Cluster partition-based two-layer expansion planning of grid–resource–storage for distribution networks
 Song Yang
Song Yang Chenglong Wang
Chenglong Wang - State Grid Shandong Electric Power Research Institute, Jinan, China
In order to realize the optimal planning of grid–resource–storage for distribution networks (DNs) with high penetrated distributed photovoltaics (PVs), a cluster partition-based two-layer expansion planning for DNs is proposed. First, a comprehensive cluster partition index-based cluster partition method is proposed, which involves the indexes such as electrical distance, power balance of the cluster, and cluster size. Second, a cluster partition-based two-layer expansion planning model is proposed. In the upper layer, a line planning model for clusters is established to carry out the planning of cluster connection lines. In the lower layer, a robust source-storage planning model is established with the uncertainty of PVs and loads, and then, the optimal location and capacity of PVs and energy storages (ESs) can be obtained. In addition, the uncertainty regulation parameter is utilized to control the range of uncertainty sets, which can reduce the conservatism of the optimization. Finally, the proposed method is carried out in a real DN in China, which can effectively improve the economy of DN planning.
1 Introduction
With the rapid growth of energy demand, photovoltaics (PVs) are developing rapidly in China. The large amount of distributed PVs has significantly changed the power flow of the distribution network (DN) (Li Z. et al., 2022), which poses new challenges to DN planning and operation (Li et al., 2022b). How to carry out optimal DN planning is the key to realize the economic operation of the DNs with large-scale distributed PVs.
Currently, the main idea for planning the DNs with distributed PVs is to build a centralized planning model (Liu et al., 2021) by strengthening or extending the lines of the DNs (Wu H. et al., 2022), which takes into account the investment of PVs (Koutsoukis et al., 2018) and the operating costs (Shen et al., 2018). The centralized planning model is suitable for the DN planning when the proportion of distributed PVs is low. However, when large-scale distributed PV is connected to the DNs, the dimensionality of the variables in the centralized planning model increases significantly (Wu L. et al., 2022), and the planning model becomes too complex to be solved (Zhang et al., 2021). To solve the challenges of centralized optimization, a cluster partition-based planning method provides a new way for DN planning. The cluster partition-based planning method can not only decompose the centralized optimization problem into simple sub-problems of cluster optimization but also maximize the degree of power matching between PVs and the load within the cluster during the planning process, which can greatly increase the PV consumption (Hu et al., 2023).
Cluster partition-based DN planning mainly includes two aspects of cluster partition and cluster planning. In terms of cluster partition, existing research mainly establishes cluster partition indexes based on the grid structure (Xiao et al., 2017) and the power balance in the clusters (Kong et al., 2022). Cluster partition is optimized by particle swarm algorithms (Li and Yang, 2022), clustering algorithms (Wang et al., 2021), and community detection algorithms (Yang et al., 2017). By improving the community algorithm, the division of reactive and active clusters considering the power balance and node coupling degree is realized by Ge et al. (2024). The gray clustering method based on the improved whitening weight function is used to partition the distribution network by Xu L. et al. (2021), and the index weight is obtained by comprehensively applying the analytic hierarchy process and the entropy weight method. The modular index based on the electrical distance and the active power balance index are used as comprehensive division indexes by Li et al. (2022c), and the distributed photovoltaic generation in the distribution network is divided into clusters by using genetic algorithms. Based on the theory of the modularity function model in complex networks, a voltage coordination control method of partitioning the aggregated domain of reactive voltage sensitivity weights and active network loss-voltage sensitivity weights of power systems is proposed by Wang Z. et al. (2023). The nodes with a strong coupling relationship are merged to determine the initial number of partitioning by Ji et al. (2023), and then, the final partitioning result is determined according to the affiliation between each load node and each reactive power source. Combining the K-means clustering algorithm and optimized PSO algorithm for voltage regulation within the cluster ensures that the voltage crossing problem is solved by Su et al. (2023). A cluster partition index system considering the structural and functional properties is proposed by Pan et al. (2021), and the modular index that takes into account the characteristics of electric and heat networks is used on the structural property to describe the connection strength between different network nodes. However, the existing cluster partition indexes only concern the active power balance in each cluster, ignoring the impact of reactive power. Meanwhile, the existing cluster partition indexes ignore the influence of cluster size on the planning results, which can easily lead to large differences in the cluster size, even leading to isolated nodes (Li et al., 2023). In addition, the existing cluster partition methods have insufficient computational accuracy, and for a complex cluster partitioning index, the optimization results tend to fall into local optimum solutions.
The current active distribution network (ADN) planning strategy usually includes the reinforcement or expansion of distribution networks and DG integration under the active management of DG outputs (Mukherjee and Sossan, 2023). A two-level robust optimal feeder routing model for the planning of radial distribution networks is proposed by Zdraveski et al. (2023), where power demand is uncertain. The robust model is solved by implementing the column and constraint generation strategy. A method based on calculating the probability of electric vehicles (EVs) entering each parking lot is proposed by Haji-Aghajani et al. (2023) for the long-term planning of EV parking lots. An integrated power and gas systems of IPGS considering cascading effects for enhancing resilience is proposed by Wang Y. et al. (2023), and the two-phase framework containing phases of “demand reachability evaluation” and “integrated planning” is proposed. A framework for the optimal planning of battery swapping stations (BSSs) in centralized charging mode is proposed by Shaker et al. (2023), and in this mode, the batteries are charged at a central charging station. Possible equipment measures are classified into several categories by Sasaki et al. (2023), formulating the “low-voltage system configuration determination problem;” in addition, a solution algorithm based on the practical priorities of classified measures is proposed. The resilience-oriented distribution network planning problem utilizing a novel three-stage hybrid framework is proposed by Faramarzi et al. (2023), and the decision-making on the line hardening and DG placement is carried out in the first stage. In the second stage, emergency and normal operation optimization is conducted. A collaborative stochastic expansion planning model of a cyber–physical system with resilience constraints is proposed by Zhang et al. (2023), and the model can reduce the coupling risk and enhance the resilience under extreme scenarios. An appropriate probabilistic wind power capacity expansion planning method for a bundled wind–thermal generation system with retrofitted coal-fired units is reformulated as a mixed-integer second-order cone programming problem by Lei et al. (2023). In terms of cluster planning, the existing research mainly considers deterministic scenarios as the research background (Bi et al., 2019), ignoring the impact of source-load uncertainty (Cai et al., 2022). Aiming at solving the problems of resource waste caused by the large-scale access of distributed generators to distribution networks and improving the economy of energy storage systems, a cluster energy-storage control strategy for prompting the distributed generation accommodation and improving the economy of energy storage systems is proposed by Li et al. (2021). In considering the optimization of load distribution among units and introducing consumption costs, a grid evaluation index system including the coordination index of the power transmission and distribution network is constructed by Xu X. et al. (2021). A novel cluster-based distributed generation planning approach is proposed by Ding et al. (2019), and the distribution network is divided into several partitions considering the system network structure and the load characteristics, thus conducting a hierarchical and partitioned network structure. A planning model of renewable energy access is established by Hu et al. (2020) based on cluster partition considering the investments and power generation interests of power producers and the power match degree within clusters. With the increasing proportion of distributed PVs, the source-load uncertainty increases the difficulty in modeling the uncertainty of DNs (Liu et al., 2022) and increases the dimensionality of variables in the planning model (Jiang et al., 2022). How to establish a cluster planning model based on the source-load uncertainty (Zhu et al., 2018) and simplify the traditional centralized planning model need to be further researched.
Based on the above analysis, this paper proposes a cluster partition-based two-layer expansion planning model of grid–resource–storage for DNs. The main contributions of this paper are summarized as follows:
(1) To deal with poor power balance and unbalanced cluster size in existing cluster partition, a comprehensive cluster partition index is proposed, which includes the modularity index, power balance index, and nodal size index. In addition, based on the comprehensive cluster partition index, an improved genetic algorithm is proposed to partition the DN into some clusters.
(2) To deal with complex models in centralized planning methods, a cluster partition-based two-layer expansion planning model is established for the DNs. In the upper layer, a line planning model is established to carry out the planning of cluster connection lines. In the lower layer, the PV and ES planning model within a cluster is established, which can realize the optimal planning of PVs and ESs in each cluster.
(3) To reduce the conservatism of the traditional robust optimization, a box uncertainty set is utilized to characterize the uncertainty of loads and PVs, and an uncertainty regulation parameter is used to control the range of uncertainty sets, which can reduce the conservatism of the optimization and simplify the calculation process.
The remainder of this paper is organized as follows: a comprehensive cluster partition index-based cluster partition method is proposed in Section 2; a cluster partition-based two-layer expansion planning method is proposed in Section 3; in Section 4, the case study is analyzed; and the conclusion is given in Section 5.
2 Comprehensive cluster partition index-based cluster partition method
2.1 Comprehensive cluster partition index
As the existing cluster partition index is not comprehensive, based on the DN structure and cluster function, a comprehensive cluster partition index is proposed to complete the cluster partition in this paper. The proposed comprehensive cluster partition index includes the modularity index, power balance index, and nodal size index.
2.1.1 Modularity index
The coupling degree between nodes can be measured by a modularity index based on voltage sensitivity, which is expressed as
where ρm is the modularity index.
where
The relationship between the edge weight and electrical distance is that the larger the edge weight, the smaller the electrical distance. Then, the mathematical expression between the edge weight and electrical distance can be obtained as follows:
where max(Lij) is the maximum value of the elements in the electrical distance matrix.
2.1.2 Power balance index
In order to avoid large-scale power transfer between clusters, the PV output and load demand within a cluster should be as equal as possible. In order to evaluate the ability of clusters to hold the distributed PVs, this paper proposes the power balance index. The active power balance index φP is given as follows:
where Nk is the number of clusters.
where Qsup is the maximum value of reactive power supply within the cluster and Qneed is the value of reactive power demand within the cluster.
2.1.3 Nodal size index
A reasonable cluster size will directly impact the complexity of the subsequent cluster planning, as well as avoid the differences in the complexity of optimization among different clusters caused by unbalanced cluster size. In addition, a reasonable cluster size can avoid the isolated nodes in the planning process. In order to balance the size of each cluster, a nodal size index is established as follows:
where
The indexes shown in Eq 1, (7), (8), and (9) are combined into a comprehensive cluster partition index
where ω1, ω2, ω3, and ω4 are the weights of each index. In the process of cluster partition, different weights can be set for each index depending on different needs.
2.2 Improved genetic algorithm-based cluster partition method
To carry out the cluster partition, a hybrid genetic-simulated annealing (HGSA) algorithm is utilized. The HGSA algorithm uses the annealing selection as the individual replacement strategy, while the global information obtained by the genetic algorithm can be completely used, and the premature convergence of the genetic algorithm can be avoided. Then, the global convergence of the algorithm is enhanced. The cluster partition is implemented as follows:
Step 1: Initial optimization parameters are set: population size n, initial temperature T0, termination temperature Tend, temperature cooling factor r, maximum number of genetic generations M, and objective function for the cluster partitioning index
Step 2: The number of temperature updates is set equal to 0. Considering that the cluster partition is carried out based on the original network connectivity, this paper uses the unweighted adjacency matrix
Step 3: The individuals that satisfy the cluster constraints are screened. Considering that the reverse power flow only occurs within the cluster, the net power within each cluster needs to be greater than 0 at each moment among the cluster partition. For the individuals who cannot satisfy the constraint, the population eliminates these individuals.
Step 4: Eq. (12) is chosen as an indicator to calculate the fitness of individuals. Considering that the value of fitness intuitively reflects the superiority or inferiority of cluster partition, the individuals with greater fitness are replicated to the offspring to form the new population
Step 5: The crossover and mutation are carried out for
Step 6:
Step 7: The temperature is updated, i.e., Tl =rT0, k = 0,
3 Cluster partition-based two-layer expansion planning method
In this paper, a cluster partition-based two-layer expansion planning model is proposed, which involves the uncertainty of PVs and loads. In the upper layer, a line planning model is established with the objective of minimizing the line investment and network loss costs. In the lower layer, a source-storage planning model is proposed for PVs and ESs with the objective function of minimizing source-storage investment and operation costs within a cluster. Meanwhile, the box-type uncertainty set is utilized to characterize the uncertainty of PVs and loads in the lower layer, and an uncertainty parameter is used to control the range of uncertainty sets, which can reduce the conservatism of the optimization.
3.1 Upper-layer line planning model
In the upper layer, the objective function of the line planning model is established as follows:
where
(1) Power flow constraint
The power flow containing line variables is constrained by second-order conic relaxation (SOCR) (Shaker et al., 2023) as follows:
where ψj is the upstream node set of node j.
(2) Penetration rate constraint of PVs
Many isolated nodes exist in the DN that need to be connected to the system, and the penetration rate of PVs should be constrained when carrying out line planning to access these isolated nodes, which is defined as follows:
where
3.2 Lower-layer PV and ES planning model
In the lower layer, the PV and ES planning model is established to identify the “worst scenario " of the uncertain variables, and based on the worst scenario, the proposed model minimizes the investment and operation costs of source storage within the cluster. Therefore, the objective function for the PV and ES planning model within the cluster is established as
where F1 is the annual investment and operation costs of PVs in cluster k. F2 is the annual revenue of PVs in cluster k. F3 is the annual investment costs of ESs in cluster k. CPV is the investment cost parameter of PVs. COMPV is the annual fixed maintenance cost parameter of PVs. Пk is the node set of cluster k.
(1) Uncertainty constraints for PVs and loads
The box uncertainty set is utilized to characterize the uncertainty range of active load power, reactive load power, and PV outputs. Meanwhile, an uncertainty parameter is utilized that can be set to adjust the conservativeness of the optimal solution. The larger the uncertainty parameter, the more conservative the solution. The specific formula is as follows:
where U represents the boxed uncertainty set.
(2) PV and ES constraints
where
(3) Power flow constraints
Eqs (14), (15), and (17) are referred to for the power flow constraints.
3.3 Iterative solving process
In this paper, an iterative solution method is utilized to solve the proposed planning models. For the upper layer, the planning model can be expressed by a specific form as follows:
where x is the optimization vectors. c is the coefficient matrices corresponding to the objective functions. P, k, B, C, Rx, S* u, G, and H are the coefficient matrices corresponding to the variables under the constraints. α, D, O, V, and W are the constant column vectors. l is the current number of iterations. k is the maximum iteration. yl is the variable at the lth iteration. u* l is the value of the uncertain variable u in the “worst” scenario after the lth iteration.
The specific form of the lower-layer model is
where y is the optimization vectors.
where[γ,ν,π,μ,μ1 ] are the dual variables in the lower-layer model.
After the above transformation, the proposed model can be solved by the iterative solution method as follows:
Step 1: Given a set of u values as the initial worst-case scenario, a lower bound is set on the operating cost LB =
Step 2: The upper model is solved based on the worst-case scenario ul to obtain the optimal solution x* l and α* l. The value of α* l is used as the new lower bound LB = max(LB, α* l).
Step 3: The lower layer is optimized based on the optimization results of the upper layer, and the optimized results fl (x* l) and the worst-case scenario x* l are obtained. The upper bound is updated as UB = min(UB, fl (x* l)).
Step 4: If UB-LB < ε, where ε is a threshold of convergence, then, the optimal solutions can be obtained, and the iteration is stopped. Otherwise, the variable yl+1 and the following constraints are added:
Let l = l + 1, and step 2 is repeated until the algorithm converges.
4 Case study
4.1 Case study system
In order to verify the effectiveness of the proposed method, an actual 35 kV/10 kV DN in China is utilized for analysis. The total loads in this DN are 7.3 MVA, and the total capacity of PVs in this DN is 4 MW. The installed PV capacity is shown in Table 1. The topology of this system is shown in Figure 1, the lines to be planned are shown in Table 2, and the line parameters of the network are shown in Table 3.

Table 1. Installed capacity of photovoltaics (PVs).
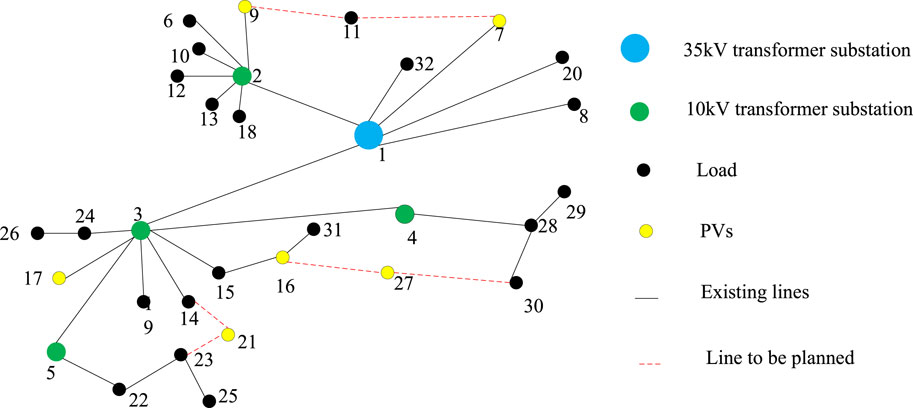
Figure 1. Physical topology of the system.

Table 2. Lines to be planned.
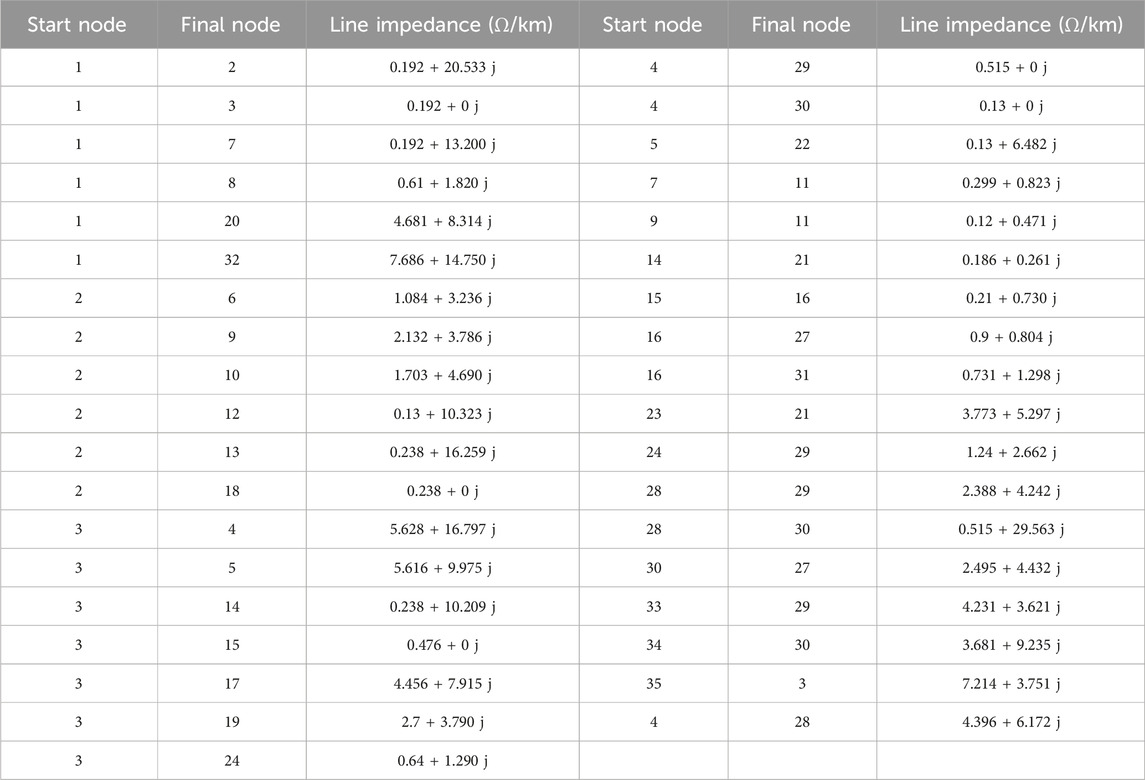
Table 3. Line parameters of the network.
The simulated genetic annealing algorithm used in this paper sets the population size n = 40, the initial temperature T0 = 100°C, the termination temperature Tend = 1°C, the temperature cooling factor r = 0.8, the maximum number of genetic generations N = 500, the crossover probability pc = 0.4, and the variation probability pm = 0.2. This paper uses MATLAB version 2019 to program the algorithm.
4.2 Analysis of cluster partition
In order to illustrate the superiority of the proposed cluster partition index in this paper, the modularity function used by Wang et al. (2021) is selected to compare with the proposed cluster partition index. The weights of the proposed cluster partition index in this paper are taken as ω1 = ω2 = ω3 = ω4 = 0.25. The cluster partition results under the proposed cluster partition index are shown in Figure 2, and the cluster partitioning results under the modularity function are shown in Figure 3.
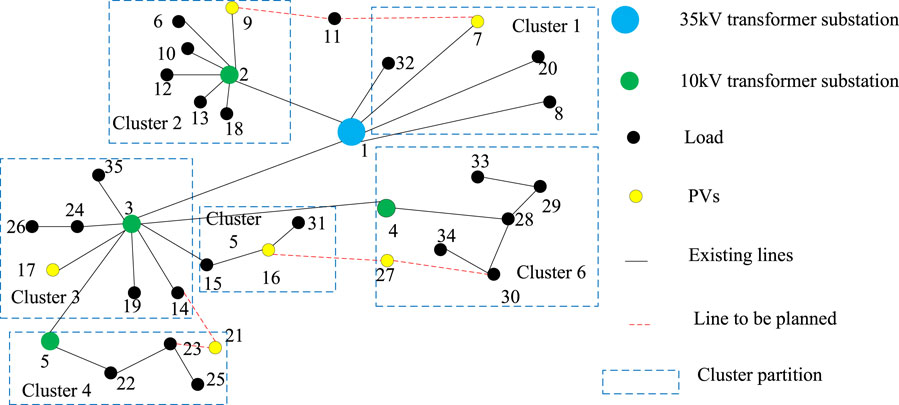
Figure 2. Partition results under the proposed cluster partition index.
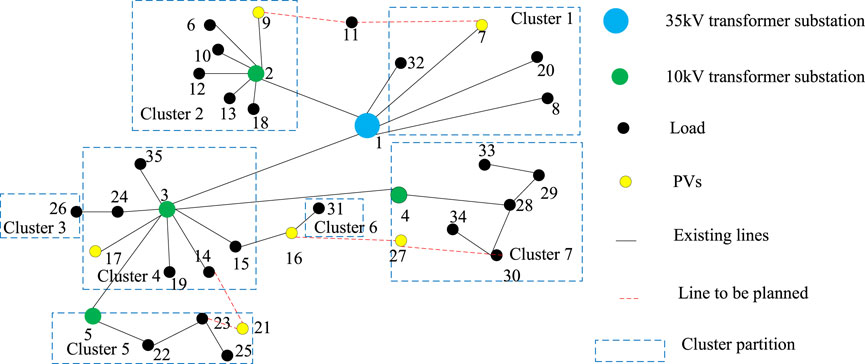
Figure 3. Partition results under the modularity function.
Figure 2 and Figure 3 show that the size difference among sub-networks attained by the proposed cluster partition index is smaller than that attained by the modularity function, and isolated nodes forming separate clusters (cluster 3 and cluster 6) occur in modularity function. In addition, there are PVs in each cluster attained by the proposed method, while no PVs exist in cluster 1 attained by the modularity function. The differences between the two methods prove that the cluster partition index can result in a more reasonable cluster partition for the subsequent cluster control and operation.
In order to illustrate the superiority of the proposed cluster partitioning algorithm, the traditional genetic algorithm is selected to be compared. The comparison of cluster partition results obtained by the two algorithms is shown in Table 4. Table 4 shows that the optimization results of each cluster partitioning index of the proposed algorithm are greater than those of the traditional genetic algorithm, which indicates that the proposed cluster partitioning algorithm has better optimization performance.
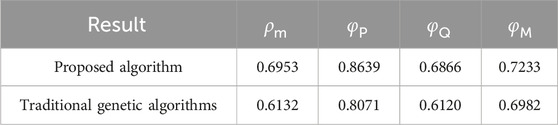
Table 4. Comparison of cluster partition results obtained by different algorithms.
Different combinations of partition index weights are given in Table 5. As shown in Table 5, when increasing the weight of the modularity index, the nodes within the cluster are better connected, but the cluster power complementarity decreases. When increasing the weight of the active and reactive power balance index, the cluster power complementarity characteristics improve, but the nodes within the cluster are significantly less connected. When increasing the weight of the nodal size index, the number of clusters changes. When increasing the weight of the nodal size index, the number of clusters changes, and the cluster partition is more focused on the change in cluster size.

Table 5. Influence of different weights on cluster partition.
4.3 Analysis of the proposed planning strategy
In order to verify the flexibility of the proposed two-layer expansion planning model, three sets of uncertain regulation parameters are selected and compared in terms of network connection, planned capacity of PVs and ESs, and total planning costs. Three sets of uncertain regulation parameters are set as follows:
Case 1:. ГPL = ГQL = ГPV = 0 is set, and in this case, the active load power, reactive load power, and PV output are all equal to the predicted values.
Case 2:. ГPL = ГQL = 16 and ГPV = 4 are set, and in this case, the active and reactive load power of 16 nodes is taken to the minimum value of the prediction interval, while the PV outputs of 4 nodes are taken to the maximum value of the prediction interval.
Case 3:. ГPL = ГQL = 27 and ГPV = 6 are set. In this case, the active and reactive load power of 27 nodes is taken to the minimum value of the prediction interval, while the PV outputs of 4 nodes are taken to the maximum value of the prediction interval, which is the worst scenario.
The comparisons of the three cases in planned PV capacity and ES capacity are shown in Figure 4 and Figure 4, and the planning results and total planning costs are shown in Table 6 and Table 7, respectively.
Figure 4 shows that with the increase in uncertainty regulation parameters, the planned PV capacity decreases. The reason is that the scenario becomes increasingly severe, and to maintain the safe operation of the cluster, the corresponding PVs are reduced.
As shown in Table 6, with the increase in uncertainty regulation parameters, the connection of nodes 21 and 27 is different under the three cases. The reason is that as the operating scenario becomes more severe, and the load power increases, the planning results tend to favor a reduction in the power supply range.
As shown in Figure 5, as the conservatism of the planning increases, the ES installed capacity also increases. The reason is that the active power and reactive power of the load in cases 2 and 3 are smaller than those of case 1, and the PV outputs are larger; hence, more ESs are needed to mitigate the uncertainty of PVs and loads.
In addition, Table 7 shows that as the uncertainty regulation parameter increases, although the annual investment and operation costs of PVs correspondingly decrease, the annual income of PVs decreases, and the annual investment costs of networks, network losses, and the annual investment costs of ESs correspondingly increase. The reason is that the more uncertainty of DNs considered in the planning process, the more conservative the resulting solution becomes, and the corresponding total cost increases.
In order to further illustrate the superiority of the proposed planning method, the centralized planning method is selected to compare with the proposed planning method. The uncertain regulation parameters in this comparison are set as ГPL = ГQL = 12 and ГPV = 3, and in this case, the active and reactive load power of 12 nodes is taken to the minimum value of the prediction interval, while the PV outputs of 3 nodes are taken to the maximum value of the prediction interval. The network connection of the two methods is shown in Figure 6 and Figure 7. The comparison of the calculation time and total planning cost of the two methods is shown in Table 6.
Figure 6 and Figure 7 show that the connection of node 11 and node 27 under the proposed method is different from the centralized planning scheme. The length of the power supply lines for node 11 and node 27 under the proposed method has been reduced by 6.73 km and 6.02 km, respectively; the power supply range is greatly shortened, which can effectively reduce the line investment costs and network loss costs, as well as improve the economic efficiency of the planning scheme.
The calculation method for the difference rate given in Table 8 is to subtract the results of the proposed method from those of the centralized planning method and divide them by the results of the centralized planning method. As shown in Table 8, in the proposed method, the annual PV investment costs and PV operation costs, as well as the annual income of PVs, increased by 5.3% and 14.1%, respectively, compared to the centralized planning method, and the annual investment costs of lines, network losses, and annual investment costs of ESs decreased by 13.5%, 25.7%, and 15.5%, respectively. These different rates indicate that the proposed method can improve the overall economic efficiency of the planning, as well as reduce the costs of planning. In addition, the calculation time of the proposed method is 20.41 s, but that of the centralized planning method is 43.62 s. Owing to the fact that the centralized planning method requires a whole optimization process, the huge variables complex the optimization. However, the proposed method can partition the complex network into smaller sub-networks, and the complex problem is divided into several relatively simple sub-problems that can be solved rapidly and easily by a parallel computing way. Therefore, the computing time can be greatly shortened. The optimization speed of the proposed method is improved by 53.2% compared to centralized planning methods, which indicates that proposed method is more suitable for DN planning with large-scale PVs.
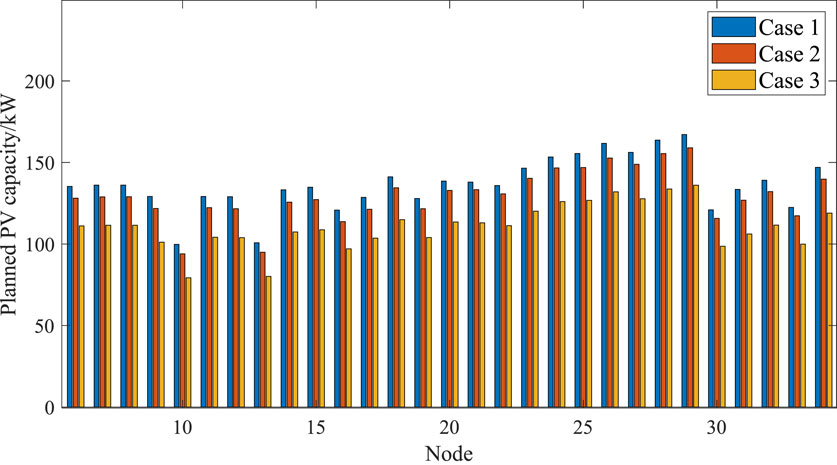
Figure 4. Planned photovoltaic (PV) capacity under different cases.
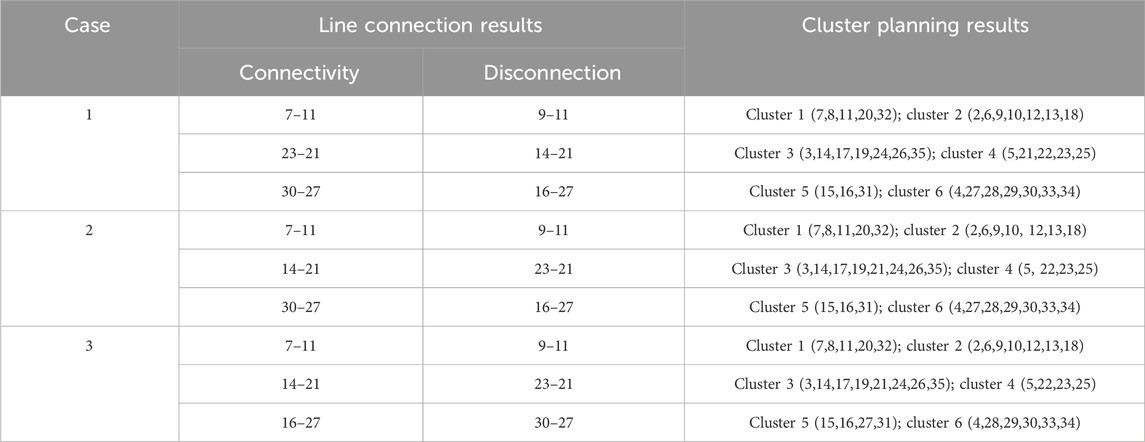
Table 6. Planning results of different schemes.
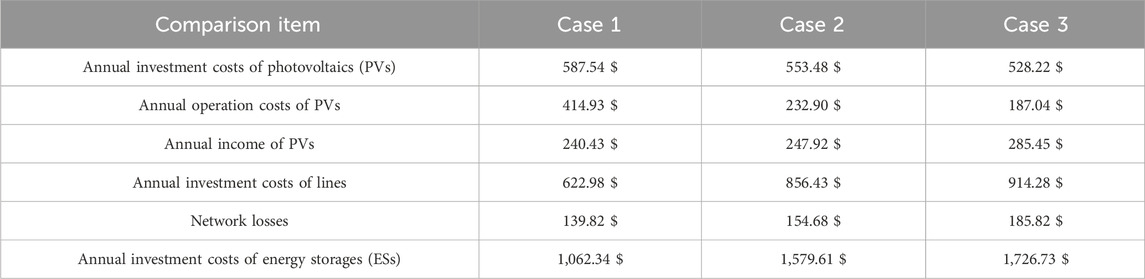
Table 7. Planning costs in different cases.
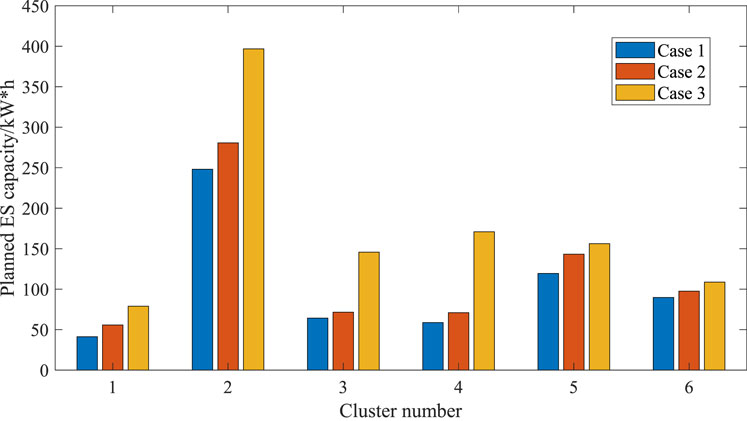
Figure 5. Planned energy storage (ES) capacity under different cases.
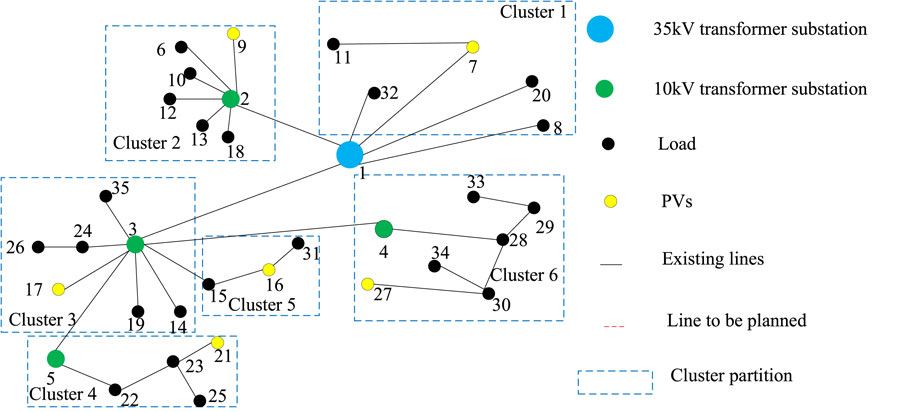
Figure 6. Planning results based on the proposed method.
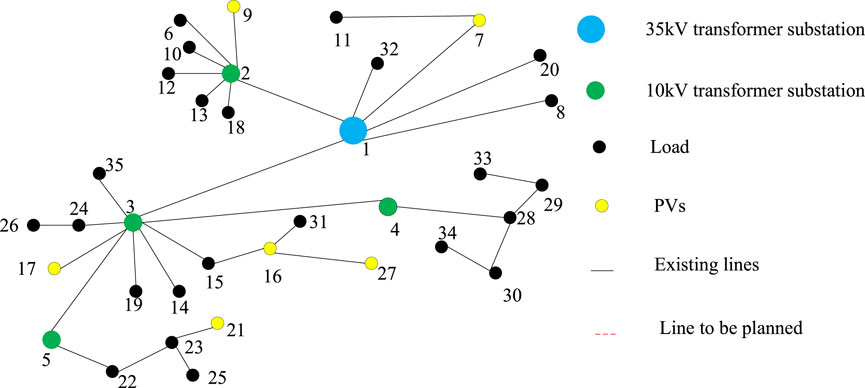
Figure 7. Planning results based on the centralized planning method.
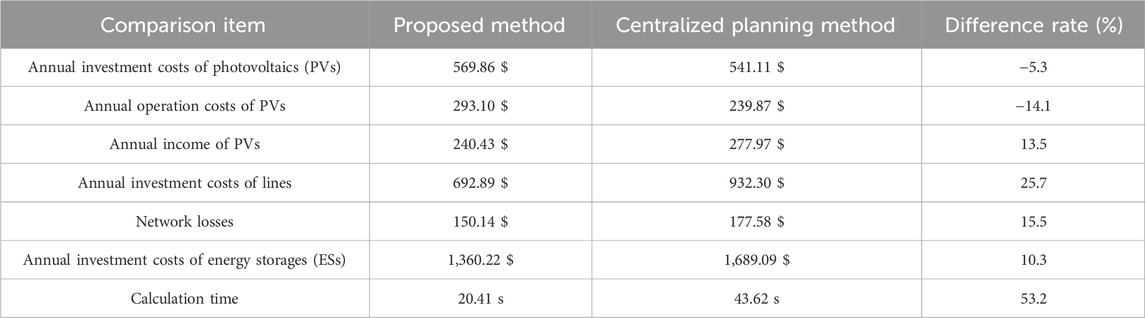
Table 8. Comparison between the proposed method and centralized planning method.
5 Conclusion
In this paper, a cluster partition-based two-layer expansion planning for DNs is proposed, and an actual 35 kV/10 kV DN in China is utilized for analysis. The results show that
1) To deal with poor power balance and unbalanced cluster size in existing cluster partition, a comprehensive cluster partition index is proposed in this paper, which includes the modularity index, power balance index, and nodal size index, and in order to avoid the cluster partition falling into local optimum, an improved genetic algorithm is utilized to carry out the network partition. The differences in cluster size among the clusters attained by the proposed cluster partition are smaller, and every cluster has PVs.
2) To deal with complex models in centralized planning methods, a cluster partition-based two-layer expansion planning model is established for the DNs, which decomposes the complex centralized planning model into cluster planning. The proposed method can improve the overall economic efficiency of the planning, as well as reduce the costs of planning. Meanwhile, the optimization speed is also improved.
3) To reduce the conservatism of traditional robust optimization, a box uncertainty set is utilized to characterize the uncertainty of loads and PVs, and an uncertainty regulation parameter is used to control the range of uncertainty sets, which can reduce the conservatism of the optimization, as well as simplify the calculation process.
In the actual operation, the PV outputs are uncontrollable and may exceed the worst scenario set in the planning stage. Then, the PV outputs within the cluster may not be fully absorbed. In future research, a cluster partition-based scheduling method for DNs should be further researched to enhance the source-load complementarity of the DNs.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
SY: writing–original draft and writing–review and editing. SS: writing–original draft. YC: writing–review and editing. PY: writing–review and editing. CW: writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This study was supported by the project supported by the Science and Technology Project of State Grid Shandong Electric Power Company “Research and application of access and control technology targeting the distributed photovoltaics developed by the entire county (city, district)” (520626220014).
Conflict of interest
The authors declare that this study received funding from State Grid Shandong Electric Power Company. The funder had the following involvement in the study: The funder was involved in the study design.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bi, R., Liu, X., Ding, M., et al. (2019). A method of renewable energy power generation cluster classification with the goal of improving the consumption capacity. Chin. J. Electr. Eng. 39 (22), 6583–6592. doi:10.13334/j.0258-8013.pcsee.182512
Cai, Z., Shuang, H., and Shan, J. (2022). Optimal scheduling strategy for electric bus cluster power exchange considering operation cost. Power Syst. Autom. 46 (17), 205–217. doi:10.7500/AEPS20210916007
Ding, M., Fang, H., Bi, R., et al. (2019). Distributed photovoltaic and energy storage siting and capacity planning for distribution networks based on cluster delineation. Chin. J. Electr. Eng. 39 (8), 2187–2201. doi:10.13334/j.0258-8013.pcsee.180757
Faramarzi, D., Rastegar, H., Riahy, G. H., and Doagou-Mojarrad, H. (2023). A three-stage hybrid stochastic/IGDT framework for resilience-oriented distribution network planning. Int. J. Electr. Power Energy Syst. 146 (5), 108738–108738.15. doi:10.1016/j.ijepes.2022.108738
Ge, J., Liy, Y., Pang, D., et al. (2024). Cluster division voltage control strategy of photovoltaic distribution network with high permeability. High. Volt. Eng. 50 (1), 74–82. doi:10.13336/j.1003-6520.hve.20230816
Haji-Aghajani, E., Hasanzadeh, S., and Heydarian-Forushani, E. (2023). A novel framework for planning of EV parking lots in distribution networks with high PV penetration. Electr. Power Syst. Res. 217 (4), 109156–109156.12. doi:10.1016/j.epsr.2023.109156
Hu, D., Ding, M., Bi, R., et al. (2020). Analysis of the impact of photovoltaic and wind power complementarity on the planning of high penetration renewable energy cluster access. Chin. J. Electr. Eng. 40 (3), 821–836. doi:10.13334/j.0258-8013.pcsee.182308
Hu, D., Sun, L., and Ding, M. (2023). Integrated planning of an active distribution network and DG integration in clusters considering a novel formulation for reliability assessment. CSEE J. Power Energy Syst. 9 (2), 561–576. doi:10.17775/CSEEJPES.2020.00150
Ji, Y., Chen, X., He, P., Liu, X., Wu, X., and Zhao, C. (2023). A novel voltage/var sensitivity calculation method to partition the distribution network containing renewable energy. Recent Adv. Electr. Electron. Eng. 16 (4), 380–394. doi:10.2174/2352096516666221130150549
Jiang, Y., Ren, Z., Li, Q., et al. (2022). New energy consumption strategy in distribution networks considering coordinated scheduling of multi-flexibility resources. J. Electr. Eng. Technol. 37 (7), 1820–1835. doi:10.19595/j.cnki.1000-6753.tces.211464
Kong, X., Liu, C., Chen, S., et al. (2022). A multi-time-node response potential assessment method for adjustable resource clusters considering dynamic processes. Power Syst. Autom. 46 (18), 55–64. doi:10.7500/AEPS20220501001
Koutsoukis, N., Georgilakis, P., and Hatziargyriou, N. (2018). Multistage coordinated planning of active distribution networks. IEEE Trans. Power Syst. 33 (1), 32–44. doi:10.1109/tpwrs.2017.2699696
Lei, C., Wang, Q., Zhou, G., Bu, S., Lin, T., et al. (2023). Probabilistic wind power expansion planning of bundled wind-thermal generation system with retrofitted coal-fired plants using load transfer optimization. Int. J. Electr. Power Energy Syst. 151 (9), 109145–109145.18. doi:10.1016/j.ijepes.2023.109145
Li, C., Dong, Z., Li, J., et al. (2021). Optimal control strategy for distributed energy storage clusters to enhance new energy consumption capacity of distribution networks. Power Syst. Autom. 45 (23), 76–83. doi:10.7500/AEPS20210224004
Li, P., Shen, J., Wu, Z., Yin, M., Dong, Y., and Han, J. (2023). Optimal real-time Voltage/Var control for distribution network: droop-control based multi-agent deep reinforcement learning. Int. J. Electr. Power Energy Syst. 153 (11), 109370–109370.11. doi:10.1016/j.ijepes.2023.109370
Li, S., and Yang, X. (2022). Siting and capacity determination of photovoltaic energy storage based on bi-directional dynamic reconfiguration and cluster delineation. Power Syst. Prot. Control 50 (3), 51–58. doi:10.19783/j.cnki.pspc.210385
Li, Y., Lu, N., Liu, X., et al. (2022c). Output evaluation method of distributed photovoltaic cluster considering renewable energy accommodation and power loss of network. Electr. Power Constr. 43 (10), 136–146. doi:10.12204/j.issn.1000-7229.2022.10.013
Li, Y., Yao, T., Qiao, X., et al. (2022b). Optimal allocation of distributed PV and energy storage based on joint timing scenarios and source-grid-load synergy. J. Electr. Eng. Technol. 37 (13), 3289–3303. doi:10.19595/j.cnki.1000-6753.tces.210712
Li, Z., Wang, W., Han, S., et al. (2022a). Study on voltage adaptation of distributed photovoltaic access to distribution network considering reactive power support. Power Syst. Prot. Control 50 (11), 32–41. doi:10.19783/j.cnki.pspc.211781
Liu, R., Sheng, W., Ma, X., et al. (2021). Research on the planning of distributed photovoltaic access to distribution networks based on multiple swarm genetic algorithms. J. Sol. Energy 42 (6), 146–155. doi:10.19912/j.0254-0096.tynxb.2019-0370
Liu, Z., Zhang, T., and Wang, Y. (2022). Model-based predictive control for multi-scenario variable time-scale optimal scheduling of active distribution network. Power Autom. Equip. 42 (4), 121–128. doi:10.16081/j.epae.202201001
Mukherjee, B., and Sossan, F. (2023). Optimal Planning of single-port and multi-port charging stations for electric vehicles in medium voltage distribution networks. IEEE Trans. Smart Grid 14 (2), 1135–1147. doi:10.1109/tsg.2022.3204150
Pan, M., Liu, N., and Lei, J. (2021). A dynamic classification method for distributed energy clusters containing cogeneration units. Power Syst. Autom. 45 (1), 168–176. doi:10.7500/AEPS20200217013
Sasaki, Y., Fukuba, S., Yokota, H., Yorino, N., Fukuba, S., et al. (2023). Comprehensive solution method considering load distribution for determining low-voltage network configurations. IEEE Trans. Electr. Electron. Eng. 18 (6), 1023–1032. doi:10.1002/tee.23808
Shaker, M., Farzin, H., and Mashhour, E. (2023). Joint planning of electric vehicle battery swapping stations and distribution grid with centralized charging. J. Energy Storage 58 (2), 106455–106455.11. doi:10.1016/j.est.2022.106455
Shen, X., Shahidehpour, M., Zhu, S., Han, Y., and Zheng, J. (2018). Multi-stage planning of active distribution networks considering the co-optimization of operation strategies. IEEE Trans. Smart Grid 9 (2), 1425–1433. doi:10.1109/tsg.2016.2591586
Su, S., Lei, J., Yan, Y., Pan, S., Yang, Y., et al. (2023). Voltage regulation strategy of distribution network with decentralized wind power based on cluster partition. Recent Adv. Electr. Electron. Eng. 16 (1), 30–44. doi:10.2174/2352096515666220902125455
Wang, L., Zhang, F., Kou, L., et al. (2021). Scaled distributed PV power cluster classification based on Fast Unfolding clustering algorithm. J. Sol. Energy 42 (10), 29–34. doi:10.19912/j.0254-0096.tynxb.2018-0896
Wang, Y., Yang, Y., and Xu, Q. (2023b). Integrated planning of natural gas and electricity distribution systems for enhancing resilience. Int. J. Electr. Power Energy Syst. 151 (9), 109103–109103.11. doi:10.1016/j.ijepes.2023.109103
Wang, Z., Tan, W., Li, H., Ge, J., and Wang, W. (2023a). A voltage coordination control strategy based on the reactive power-active network loss partitioned aggregation domain. Int. J. Electr. Power Energy Syst. 144 (1), 108585–108585.10. doi:10.1016/j.ijepes.2022.108585
Wu, H., Sun, L., Xiang, S., et al. (2022a). Active distribution network expansion planning with high-dimensional time-series correlation of renewable energy and load. Power Syst. Autom. 46 (16), 40–51. doi:10.7500/AEPS20220104004
Wu, L., Xin, J., and Wang, C. (2022b). Installed capacity forecasting of distributed photovoltaic taking into account user herding psychology. Power Syst. Autom. 46 (14), 83–92. doi:10.7500/AEPS20210902006
Xiao, C., Zhao, B., Zhou, J., et al. (2017). Voltage control of high proportional distributed PV clusters in distribution networks based on network partitioning. Power Syst. Autom. 41 (21), 147–155. doi:10.7500/AEPS20170101002
Xu, L., Yang, J., and Xiong, Z. (2021a). A method of power distribution network classification based on improved grey cluster. Electr. Eng. (13), 81–84. doi:10.19768/j.cnki.dgjs.2021.13.021
Xu, X., Zheng, X., Wang, S., et al. (2021b). Coordinated planning method for transmission and distribution networks based on improved genetic annealing algorithm. Power Syst. Prot. Control 49 (15), 1 24–131. doi:10.19783/j.cnki.pspc.201236
Yang, J., Hao, J., and Bo, Z. (2017). Hierarchical control strategy for reactive voltage of wind farm clusters based on adjacency empirical particle swarm algorithm. Power Grid Technol. 41 (6), 1823–1829. doi:10.13335/j.1000-3673.pst.2016.2237
Zdraveski, V., Vuletic, J., Angelov, J., and Todorovski, M. (2023). Radial distribution network planning under uncertainty by implementing robust optimization. Int. J. Electr. Power Energy Syst. 149 (7), 109043–109043.12. doi:10.1016/j.ijepes.2023.109043
Zhang, T., Xie, M., Wang, P., et al. (2021). System dynamics simulation of the shared value of distributed photovoltaic and its impact on the distribution network. Power Syst. Autom. 45 (18), 35–44. doi:10.7500/AEPS20200901004
Zhang, Y., Li, C., Wan, H., Shi, Q., Liu, W., and Xu, Y. (2023). Collaborative stochastic expansion planning of cyber-physical system considering extreme scenarios. IET Generation, Transm. Distribution 17 (10), 2419–2434. doi:10.1049/gtd2.12819
Keywords: cluster partition, distribution network, expansion planning, distributed photovoltaics, energy storages
Citation: Yang S, Wang C, Sun S, Cheng Y and Yu P (2024) Cluster partition-based two-layer expansion planning of grid–resource–storage for distribution networks. Front. Energy Res. 12:1390073. doi: 10.3389/fenrg.2024.1390073
Received: 22 February 2024; Accepted: 08 April 2024;
Published: 07 May 2024.
Edited by:
Minglei Bao, Zhejiang University, ChinaCopyright © 2024 Yang, Wang, Sun, Cheng and Yu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Song Yang, yangsong19971@163.com