 Bo Gao1,2
Bo Gao1,2 Michael Baudis1,2*
Michael Baudis1,2*- 1Department of Molecular Life Sciences, University of Zurich, Zurich, Switzerland
- 2Swiss Institute of Bioinformatics, Zurich, Switzerland
Copy number aberrations (CNA) are one of the most important classes of genomic mutations related to oncogenetic effects. In the past three decades, a vast amount of CNA data has been generated by molecular-cytogenetic and genome sequencing based methods. While this data has been instrumental in the identification of cancer-related genes and promoted research into the relation between CNA and histo-pathologically defined cancer types, the heterogeneity of source data and derived CNV profiles pose great challenges for data integration and comparative analysis. Furthermore, a majority of existing studies have been focused on the association of CNA to pre-selected “driver” genes with limited application to rare drivers and other genomic elements. In this study, we developed a bioinformatics pipeline to integrate a collection of 44,988 high-quality CNA profiles of high diversity. Using a hybrid model of neural networks and attention algorithm, we generated the CNA signatures of 31 cancer subtypes, depicting the uniqueness of their respective CNA landscapes. Finally, we constructed a multi-label classifier to identify the cancer type and the organ of origin from copy number profiling data. The investigation of the signatures suggested common patterns, not only of physiologically related cancer types but also of clinico-pathologically distant cancer types such as different cancers originating from the neural crest. Further experiments of classification models confirmed the effectiveness of the signatures in distinguishing different cancer types and demonstrated their potential in tumor classification.
Introduction
Copy number variations (CNV) are a class of structural genomic variants, in which the regional ploidy differs from the normal state of the corresponding chromosome. Germline copy number variations constitute a major part of genomic variability within and between populations and are an important contributor to genetic and inherited diseases (Zhang et al., 2009). In most cancer types, an extensive number of somatic CNV, usually referred to as sCNV or CNA (copy number aberrations), accumulate during the progression of the disease (Baudis, 2007; Beroukhim et al., 2010). CNAs have been shown to be directly associated with the expression of driver genes (Upender et al., 2004; Cox et al., 2005) where expression of oncogenes can be increased by copy number amplifications and tumor suppressor genes can be suppressed through heterozygous or homozygous deletions. On a genomic level, recurrent patterns of CNVs are observed in a number of cancer types and have been associated with cancer prognosis and development (Zack et al., 2013).
While traditional karyotyping and various DNA hybridization techniques had provided insights into specific CNV events, the systematic, genome-wide screening for CNV emerged in the 1990s as a reverse in-situ hybridization technology termed “comparative genomic hybridization” (CGH; Kallioniemi et al., 1992; Joos et al., 1993). Chromosomal CGH allowed the semi-quantitative profiling of copy number changes over complete (tumor-)genomes. However, the technology was limited through its chromosomal banding based low resolution (Bentz et al., 1998) and only indirect association of CNV events with putative target genes. The hybridization of tumor (or germline) DNA to genome-spanning matrices was refined through the use of substrates (“arrays”) containing thousands to more than 2 millions of mapped DNA sequence elements (Solinas-Toldo et al., 1997; Pinkel et al., 1998), now allowing the direct association of the experimental read-out to specific genome features. A variation of this principle, SNP (single nucleotide polymorphisms) based arrays (Wang et al., 1998), originally developed for the detection of allelic variations within populations, was rapidly adopted for CNV detection and allelic decomposition analysis in cancer (Zhao et al., 2004). Nowadays, Next-Generation Sequencing (NGS) techniques are increasingly adopted to detect copy number variations, Zare et al. (2017), Li et al. (2018), and Zhang et al. (2019) although technologies with coverage below shallow whole genome sequencing (Macintyre et al., 2016) show reduced utility for the analysis of CNV events when compared to high-density arrays. Regardless of their technical heterogeneity, a large number of CNV data has been generated in the past three decades, which represents an invaluable asset for genomics studies.
Spurred by an increasing interest in genomic heterogeneity as well as mutational patterns shared across tumor types, the exponential growth of available cancer CNV profiling data stimulated the study of patterns in the context of meta-analyses and large consortia studies, across multiple groups of tumors (Beroukhim et al., 2010; Grasso et al., 2012; Stephens et al., 2012; Ciriello et al., 2013; Wang et al., 2013; Zack et al., 2013; Zhao et al., 2013; Juhlin et al., 2015). The majority of the studies focused on finding either associations to cancer driver genes or the impact of focal regions in specific tumor types. As a result, the CNA patterns were often characterized by the coverage of driver genes in contrast to comparative analyses of the whole genome. While this approach can provide direct connections to the established theories, it also bears two drawbacks. First, the distribution of cancer driver genes is extremely skewed: a few hallmark drivers are responsible for a large percentage of tumorigenesis, while a long-tail of rare or putative drivers are reckoned to be the cause of the rest (Hou and Ma, 2014). Second, besides the association with somatic mutations, researches have also discovered different facets of CNA in their relations to cellular regulations and genome dynamics (Conrad et al., 2010; Völker et al., 2010; Chen et al., 2014; Mishra and Whetstine, 2016). Therefore, CNA patterns that solely rely on driver genes often lack the capacity to embrace the full spectrum of the aberrations. To generate CNA patterns, which capture their multitude of uniqueness, it would be more comprehensive to abstract by the aberrations' characteristics, rather than using focal regions that overlap with driver genes.
In translational research, an imminent goal of studying the CNA patterns of different cancers is to gain insight in designing new therapeutic protocols. Recently, the discovery of circulating cell-free DNA (cfDNA), which presents a potential for early-stage and non-invasive cancer detection, attracts the attention of both the academia and the industry (Pathak et al., 2006; Li et al., 2017; Phallen et al., 2017; Panagopoulou et al., 2019). While many cfDNA methods in cancer detection are focusing on somatic mutations, it is believed that the ultimate solution would come from an ensemble of different genomic aberrations (Huang et al., 2019). One of such aberrations is CNA in cancers that bear high burdens of copy number mutation. Large-scale cancer genome studies have illustrated the recurrent CNA patterns across different types of cancer. Several studies have employed CNA of cfDNA as biomarkers and demonstrated their potential in identifying cancer types and tissues of origin (Leary et al., 2012; Dawson et al., 2013; Heitzer et al., 2013). As an emerging field, the accurate identification of genomic abnormalities and classifications of the cfDNA yet remains challenging, and the characterization of CNA patterns across cancer types would provide a valuable piece of the solution to the puzzle.
Due to the technical heterogeneity and underlying biological variability, the meta-analysis of multi-platform cancer CNV data, which is necessary for comprehensive “pan cancer” studies, also poses great challenges in data integration and normalization (Gao and Baudis, 2020). In this study, we have assembled a collection of 56,077 CNA profiles and created the CNA signatures of 31 cancer subtypes, where each signature represented the CNA landscape of a specific cancer group. The signatures were generated from a computational pipeline (Figure 1), which unifies heterogeneous data and is powered by a hybrid model of neural networks and attention algorithm. Using the signatures, we also constructed a multi-label classifier of cancer types and tissues of origin from copy number segmentation data. The result illustrates the genetic uniqueness of CNA in different cancer types and demonstrates the potential of CNA signatures in tumor identification.
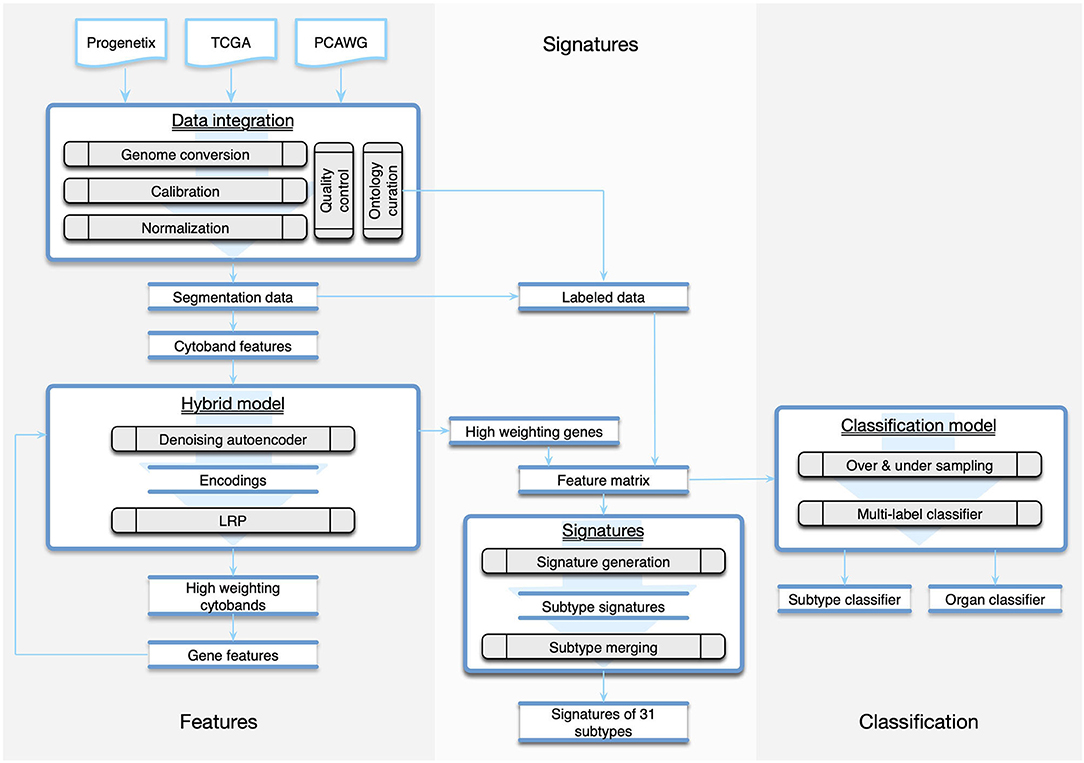
Figure 1. The workflow of the study was composed of three parts. The Features part consisted of methods of data integration and feature generation. The Signature part focused on creating CNA signatures for cancer subtypes and the categorization of subtypes. The Classification part recruited machine learning techniques to predict the organ and the subtype from a given copy number profile.
Method
Data Integration
In this study, we integrated CNA profiles of tumor samples from three prominent resources. Progenetix (Cai et al., 2013) is a curated resource targeting copy number profiling data in human cancer. It features a large collection of data from different tissues and platforms. The Cancer Genome Atlas (TCGA) (Hutter and Zenklusen, 2018) represents a comprehensive cancer genomics initiative that generated standardized molecular profiling data for a wide range of cancer types. The Pan-Cancer Analysis of Whole Genomes (PCAWG) represents an initiative from the International Cancer Genome Consortium (ICGC) for the uniform analysis of a representative set of cancer samples using Whole Genome Sequencing (WGS) (Campbell et al., 2020). All three repositories provide publicly—though with the exception of Progenetix—partially access-controlled genomic data together with clinical information and diagnostic classifications. The initial collection consisted of 56,077 samples, representing an accumulation of CNA data from a wide range of tumor types and technological platforms.
When integrating data of high diversity for analyses, two major technical challenges can be encountered. First, genomics studies performed over the last decade will have applied different reference genome editions in their analysis pipeline, leading to shifted coordinates in results such as CNV segments. It is crucial to convert all data to the same coordinate system when analyzing data from multiple studies through a remapping procedure. However, unlike with SNP or other types of mutations involving short DNA sequences, applying standard remapping tools such as liftover (Kuhn et al., 2013) would result in a considerable information loss when converting copy number data, due to the occurrence of disruptive remapping in a relevant proportion of CNA segments. We previously addressed this problem with the development of a generic tool named segmentLiftover, to convert CNA data with high efficiency and minimized data loss (Gao et al., 2018). Second, regardless of the underlying technology, genomic copy number data is derived from the relative assessment and integration of multiple signals, with the data generation process being prone to contamination from several sources. Estimated copy number values have no absolute or strictly linear correlation to their corresponding DNA levels, and the extent of deviation differs between sample profiles, which poses a great challenge for data integration and comparison in large scale genome analysis. To tackle this problem, we designed a method called Mecan4CNA (Minimum Error Calibration and Normalization for Copy Numbers Analysis) to perform a uniform normalization (Gao and Baudis, 2020).
In the integration pipeline, samples were first converted to GRCh38(Hg38) using segmentLiftover. Then, the values in the sample were aligned to the corresponding true copy number levels of the main tumor clones using Mecan4CNA. For each step, a quality control protocol was set up to filter out samples carrying a low number of alternations, causing ambiguity in interpretation, or such having incomplete diagnostic information. The details of the integration are elaborated in Supplementary Implementations. In the end, a normalized dataset of high-quality samples was generated, which consisted of 44,988 tumor samples covering 271 ICDO-topography terms and 211 ICDO-morphology terms (Table 1).
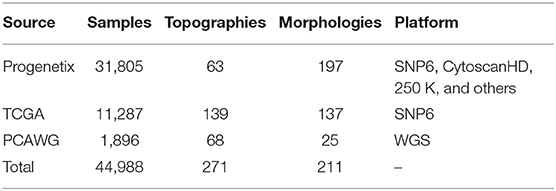
Table 1. The data composition in the final dataset after quality filtering.
Feature Representation
All copy number data can be represented in a platform-independent format of genomic segments, where each segment represents a continuous region on a chromosome. As the segments vary dramatically in platform-dependent resolution, reported size, and biologically supported thresholds (Krijgsman et al., 2014; Hastings et al., 2016), a pragmatic approach for cross-study normalization lies in the creation of equally sized genomic bins and mapping of segment data into those. This method is elastic on the number of generated bins (features); therefore, it cooperates well with follow-up computational models that are sensitive to the feature numbers. However, the binning method disregards the uneven distribution of genes and does not capture any functional or structural information of the genome, thereby limiting biological correlations between features and the final model.
Another straightforward approach is to use the coverage of protein coding genes to represent each segment. This method provides inherent connections to genetic functions; however, direct mapping to protein coding genes overlooks the structural impact of CNA and also results in a large number of features, which are often difficult for machine learning methods to perform in optimal. In this study, we designed a two-phase approach to generate a refined gene panel as the feature representation, so that the noise and redundancy of the feature space could be reduced with consideration to functional significance. In the first phase, CNA segment data was mapped to cytobands, which represent “genomic phenotypes” correlated to gene density and chromosome structure and provided a good balance between feature number and genomic resolution. The cytobands features were then added to a hybrid model of Autoencoder and Layer-wise Relevance Propagation (LRP) to perform a feature extraction, which generated a panel of cytobands with high separation power. In the second phase, the selected cytoband features were denormalized to the protein coding genes from each band. Finally, another iteration of the feature selection process was performed to arrive at a selection of genes that contribute to the distinctiveness of individual sample profiles.
Feature Extraction
Autoencoder
An autoencoder is an unsupervised neural network that can derive abstracted representations from data. It usually consists of two parts, an encoder and a decoder, and both are also neural networks on their own. The input is first transformed to an encoding, then restored to its original by the decoder. The aim of an autoencoder is to reconstruct the input as exact as possible, and in the process, it learns a representation (encoding) of the input. It's typically used for dimensionality reduction and to remove noise from signals (Feng et al., 2014; Gondara, 2016; Pei et al., 2020).
An autoencoder possesses several features that are suitable for our research. Its ability to remove noise is well-suited to limit the amount of “noise” from true passenger mutations, which may represent a considerable part of the copy number variations in tumors but do not have a functional impact. In the process of restoration, the encoding is able to capture the traits and distinguishing details, which is ideal for sample characterization in terms of their individual uniqueness. Finally, as a neural network, it can benefit from the extensive collection of heterogeneous data through its generalization capability. In this study, four different autoencoders (basic, denoising, sparse, and contractive autoencoders) were compared on their abilities of input reconstruction. The denoising and contractive autoencoders showed the best performance in the restoration of CNV data, and the denoising autoencoder was chosen for its efficiency in implementation. The details of the comparison are elaborated in Supplementary Implementations.
Layer-Wise Relevance Propagation
Layer-wise Relevance Propagation (LRP) is a technique to scale the importance and contribution of input features in a deep neural network. It utilizes the network weights and activation functions to propagate the output backward until the input. The basic propagation rule is illustrated as the following:
Here, j and k are two neurons from two adjacent layers. a is the activation of a neuron, and w is the weight between two neurons. The initial R is known from the output, and this formula is iterated to compute R for each neuron in the previous layer until reaching the input layer. LRP provides a solution to the “black-box” problem of deep neural networks, and is especially useful in tracing the network attentions and understanding the network behavior. In our hybrid model, we exploited LRP's ability to quantify the importance of input features in distinguishing different samples. When an autoencoder can reconstruct a large number of inputs with high accuracy, it provides an encoding that carries the information to recognize the differences between samples. If we apply LRP to this encoding, we would be able to measure the importance of each feature in the encoding.
The Hybrid Model
A primary goal of the research was to investigate the similarity and differences of CNA between cancers, through CNA feature dimension reduction toward an optimal representation of the uniqueness of each sample. In our hybrid model, we combined autoencoder's ability to recognize differences and the LRP's ability to scale feature relevance. First, the transformed feature matrix was used as the input data for the training of a denoising autoencoder. Then, the encoding generated by the autoencoder was used as the input of LRP to compute the weightings of each feature in the initial feature matrix. Next, the weightings of each feature were summed and normalized for all samples. Finally, by applying a threshold, we obtained a panel of high weighting features representing the uniqueness of each input sample.
In the two-phased feature extraction, the hybrid model first returned a panel of cytobands with high weighted CNA coverage; then, the hybrid model was utilized on the new feature matrix (CNA coverage on protein coding genes of the high-weighting cytobands), to calculate a panel of high-weighting genes as a representation of each sample's feature space. Table 2 shows the resulting feature numbers for each step. The details of the procedures are provided in Supplementary Implementations.
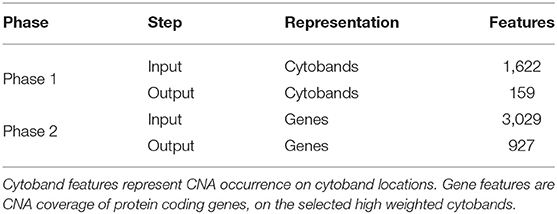
Table 2. The number of features before and after each extraction phase.
Signature Generation
A Dataset of Major Cancer Types
To derive the genomic characteristics of different cancer types, it is important to utilize accurate, systematic mappings between samples and disease classifications. Following the standardized protocol set up for the Progenetix and arrayMap resources (Cai et al., 2013, 2015), all samples were labeled using morphology and topography defined by International Classification of Diseases for Oncology (ICD-O 3) (World, 2013). The complete data collection included 211 unique morphology (ICDOM) and 271 unique topography (ICDOT) terms. While the combination of ICDOM and ICDOT terms in principle can result in detailed disease classifications, the granularity of available sample descriptors varied dramatically between different studies. For example, while some samples were annotated as “epidermoid carcinoma, keratinizing” at “lower lobe, bronchus,” for other pulmonary carcinomas a more general “squamous cell carcinoma” of the “lung” was available in the input data. Also, the number of samples mapped to individual classification terms was extremely imbalanced. For example, while “infiltrating duct carcinoma of breast” was available with more than 5,000 samples, “mucinous adenocarcinoma of lung” only was represented with 14 samples. For the sake of statistical validity and to minimize small-batch effects, we decided to focus on a data subset of 11 major organ systems with abundant samples and reliable copy number mutation content.
Signatures of Cancer Subtypes
After the two-phase feature extraction, we obtained a panel of genes, which drastically reduced the feature space to the signals of 927 genes. For any given sample, a small subset of the genes from this panel reflects its “signature” mutations and is able to represent the uniqueness of the sample against all other samples. When aggregating the samples of a disease type, we should be able to identify a subset of feature genes that are significantly altered in this disease (implementation details in Supplementary Implementations). Thus, we could use this subset of feature genes and their intensities as the CNA signature of the group. However, as mentioned in earlier sections, the samples were not labeled with the same granularity. For the clarity of analyses, samples of similar signatures were grouped together with a consistent label. First, samples were grouped into subtypes by the combination of their topography and morphology. Subtypes with <50 samples were removed. Then, the signature of each subtype was generated and the Pearson's correlation coefficient of signatures was computed for subtypes of the same organ. Next, for each organ, subtypes of the same morphology level were merged into a more general morphology term if their correlation is >0.9. Similarly, a subtype with a more detailed morphology is merged into another subtype of a more general morphology if their correlation is >0.9. Finally, a dataset with refined disease labels was produced, which consisted of 22,671 samples covering 11 topography (organs) and 31 cancer subtypes. Table 3 shows the number of selected samples and subtypes in each organ. The complete table of subtypes and the merging are presented in Supplementary Subtypes.
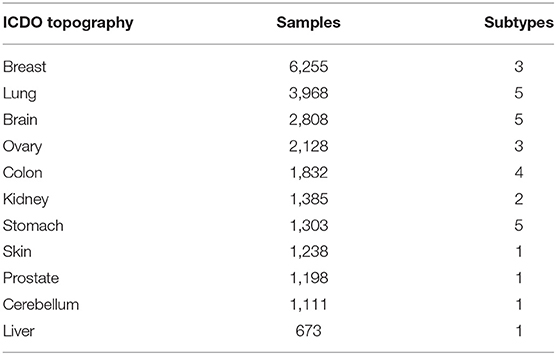
Table 3. The number of samples and cancer subtypes in the studied organs.
Classifiers of Subtypes and Organ Involvement
The compact feature panel and the curated labels provided us an opportunity to apply machine learning methods of classification performance. We constructed a multi-label classifier using the signature genes and their normalized signal intensities as features, and the subtype of each sample as labels. The primary challenge of building a multi-label classifier came from the extremely imbalanced number of samples in different classes, because the classifier would be significantly biased by the classes with a high number of samples. To create a robust classifier, we first applied undersampling on classes with a high number of samples and oversampling on classes with a low number of samples, so that the number of samples in each class became relatively balanced. Then, we recruited a random forest to learn and predict the subtypes. In addition to the prediction of subtypes, we were also able to evaluate the classifier's performance on predicting samples' organ of origin by mapping the subtype labels from predictions to the corresponding organ labels. Comparing with the approach that directly used the organ of each sample as labels in training, the subtype mapping method showed an improved performance. The implementation details of the model and comparisons are presented in Supplementary Implementations.
Results
CNA Signatures
By using the data processing and modeling procedures described in the Method section, we generated a panel of feature genes from the collected CNA samples. Then, with the feature genes, we were able to create an abstract representation for each copy number profile, where only alternations that contributed to the distinctiveness of the sample were preserved. Figure 2 compares the original CNA patterns with the derived signature features where the frequent and extensive regional alterations in the original data have been replaced by a small number of feature genes, which visibly compare to subsets of characteristic changes in the original CNA data and represent the most discriminative alternations. With our methodology, ubiquitous alterations such as deletions on the short arm of chromosome 8 (Figure 2) are considered “non-typical” and therefore are not represented in the abstracted signatures.
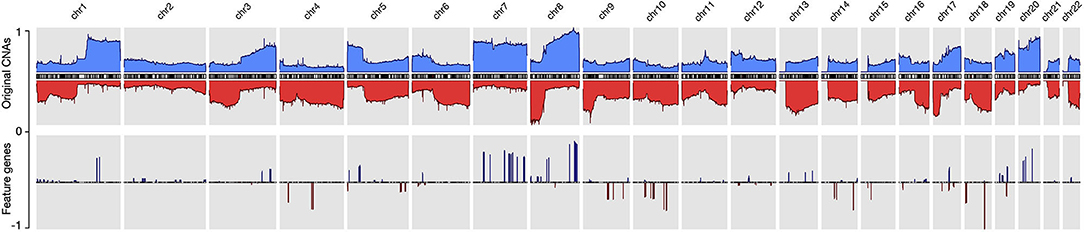
Figure 2. The copy number alternation landscape of all samples using the original CNVs and the feature genes. The feature genes are able to dramatically reduce the complexity of CNA signals while maintaining the mutational characteristics. The blue colors above the chromosome axis represent the average amplifications, and the red colors below the chromosome axis represent the average deletions. The amplitude of amplifications and deletions are normalized to [0,1] separately.
While the complete panel of feature genes provides the feature space for the whole of analyzed samples, in each individual sample only a small subset of these features reflects the sample's own mutations. By aggregating samples from individual cancer subtypes, we were able to deduct the set of subtype related, significantly altered feature genes and could generate the CNA signatures of 31 cancer subtypes. Every signature consists of a subset of the general feature genes and their relative signal intensity comparing to other signatures. Figure 5 illustrates parts of the signature of medulloblastoma, glioma, and melanoma. The complete list of signatures in all subtypes are included in Supplementary Signatures.
In the majority of copy number studies, analyses of tumor samples are focused on identifying the driver genes or the focal regions. However, in this study, the frequent drivers such as TP53 and PTEN, and the common aberrations such as CDKN2A/B and MYC are removed due to their prevalence. The genes in the signatures rather reflect the uniqueness of each sample or each cancer subtype. It is importance to note that the feature genes are not intended as the only nor the optimal representation. The fundamental objective of the study is to explore the potential driver mutations that are infrequent but relevant to specific cancer types. Although the signatures do not imply pathogenic causation, we can instead reveal their potential implications and correlations by investigating the signatures and the feature genes (Figure 6). In general, spatial and annotation analysis suggest that some feature genes reflect structural and functional alternations in samples; the signatures of different subtypes show high preference in several genomic regions that suffer frequent CNAs in many cancer types; and some subtypes, which have distinct disease codes, exhibit high similarity in their signatures.
Focal and Regional Feature Groups
The vast number of CNAs in cancer distribute in a wide spectrum of sizes, ranging from several kilobases to entire chromosomes. Recent research showed they are neither randomly nor uniformly distributed (Beroukhim et al., 2010; Mermel et al., 2011). Regarding their individual extent, CNAs can be categorized into two primary groups: they are either focal, affecting a region with a limited set of potential target genes, or very large and covering an extensive fraction of a chromosome. It has been found that—in general—these two groups of CNAs are caused by different biological mechanisms and can play different roles in tumorigenesis (Pihan et al., 1998; van Gent et al., 2001; Hastings et al., 2009). Focal CNAs usually arise from errors during DNA repairs and can suppress or promote the affected genes. On the other hand, chromosome level CNAs usually arise from errors during mitosis and can lead to dramatic structural aberrations, also involving large numbers of genes. Therefore, it seems important to explore the distinctions of focal and larger CNAs among the signatures' features.
In studies of focal and large CNAs, no strict consensus on exact size the limits exists though general practice is to use an upper limit of 1–3 Mb for “focal” events (Bignell et al., 2010; Krijgsman et al., 2014) while others used a proportional cut-off such as 90% of a chromosome arm for “chromosomal” CNA (Beroukhim et al., 2010; Mermel et al., 2011). Because the signature feature genes are the simplification of the original CNA landscape, all chromosome arm level variations have been reduced to much smaller representations. Instead of studying arm-level CNAs, we merged adjacent feature genes within the distance of 5 MB to construct regional features, which indicates the high frequency and significant discriminative weightings of the covered region and the nearby regions. Feature genes, which are away from others for more than 5 MB on both ends, were considered focal features. After merging, the 927 signature genes were separated into 15 focal features and 43 regional feature groups. Figures 3A,B show the distributions of the different feature groups on the entire genome by their types and sizes. As expected, there are more regional feature groups than focal features in the merged feature space in both amplifications and deletions. This is because high-frequency focal CNAs were removed in the process of feature selection for their weak discriminating abilities. Among the regional groups, there are 50% more small regions (<5 MB) than large regions, especially in the deletions. It suggests that the small regions may represent the difference of the original arm level alternations between different cancer subtypes. Although at a lower frequency, the size of large regional groups can extend up to 200 MB, which strongly suggests that they represent distinctive arm-level events at these loci. Spatially, the large regions often occur exclusively and do not overlap with the same or the other type of CNVs. As illustrated in Figure 3C, the large regional groups are mostly of low amplitude (the average of normalized CNV log-ratios across all samples); and no significant correlations with the amplitude are observed between different groups or types. The analysis of regional and focal features' patterns across a large number of samples and cancer types confirmed and agreed with observations in several previous studies (Baudis, 2007; Beroukhim et al., 2010; Zack et al., 2013; Mishra and Whetstine, 2016). The size distribution of merged feature groups also provided important implications to the underlying representation of different features.
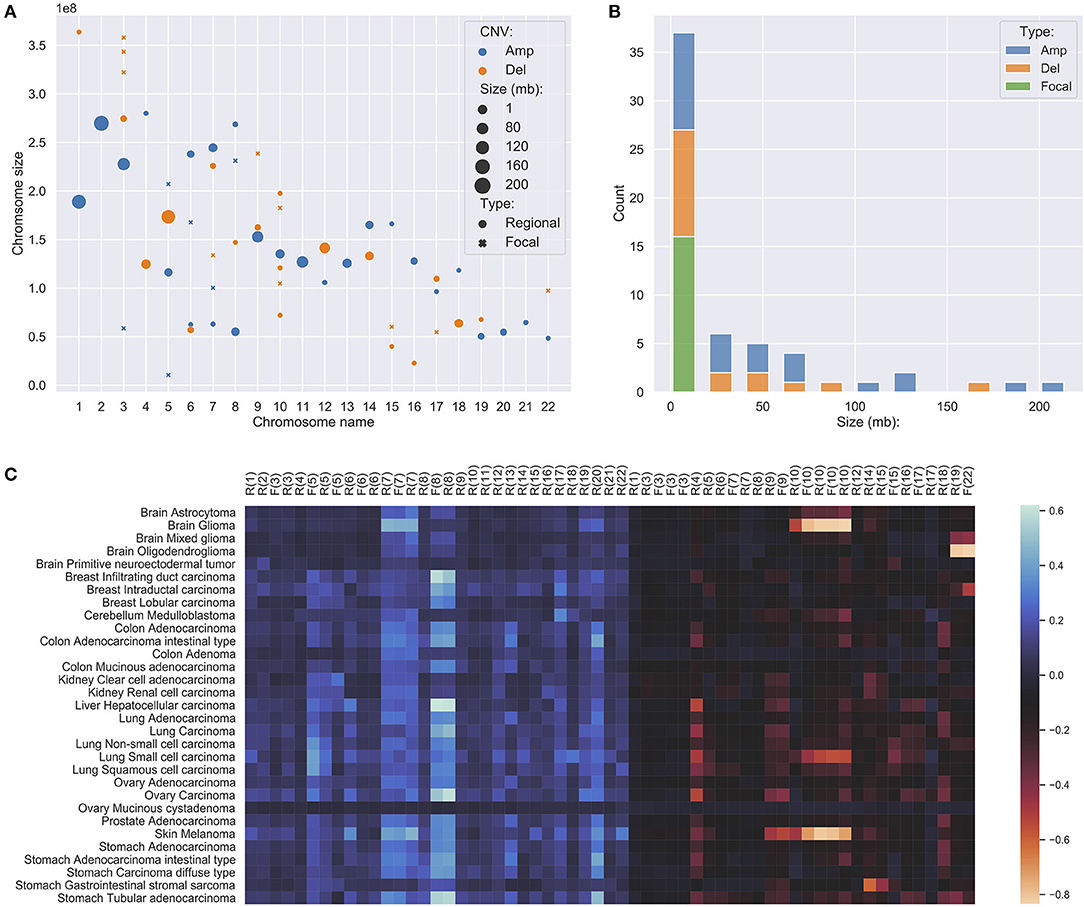
Figure 3. (A) The distribution of focal and regional feature groups on the genome. The groups were generated from the 927 feature genes, where genes within 5 million-bases were merged into a group. The position of the mark was determined using the center of the group or gene. The size of the mark was determined by the length of the group or gene, in the unit of million-bases and a minimum size of 1 MB. (B) The length distribution of feature groups. (C) The amplitude of feature groups in 31 studied cancer subtypes. The values were computed using the average of the normalized CNV log ratios of all samples in each subtype. On the x-axis, F denotes focal, R denotes regional, the number denotes chromosome name.
Functional Implications of the Feature Genes
A cardinal concept in this study was to describe cancer subtypes using CNAs based on their uniqueness and discriminating ability, instead of their frequencies. The selected feature genes usually exhibited different patterns in either their presents or variation amplitude between different subtypes. As a result, the final features mainly included non-focal and less prevalent genes that do not play known central roles in tumorigenesis. However, it is still interesting to investigate the feature genes by their annotations and discuss their potential functional meanings.
The HGNC (HUGO Gene Nomenclature Committee) gene families are defined based on evolutional and functional homologies (Daugherty et al., 2012). Table 4 lists the significantly over and under expressed HGNC families, where the family has <0.05 p-value in Binomial test and includes at least five feature genes: (1) The immunoglobulin heavy chains related genes showed the highest significance. Although the mutations of these genes are known to play causal roles in B-cell related malignancies (Nishida et al., 1997; Othman et al., 2016), surprisingly, accumulating evidence has also shown their frequent overexpression in epithelial cancers (Babbage et al., 2006; Hu et al., 2008). Though their functions and mechanisms in oncogenesis are still not well understood, several studies have demonstrated their tumor-promoting impacts and observed their prognostic implications in breast cancer and ovarian cancer (Lee and Ge, 2009; Hu et al., 2011; Larsson et al., 2020). (2) Olfactory receptors are one of the largest gene families in the human genome. Similar to immunoglobulin genes, their overexpression has also been observed in various cancers and is often neglected in genomic cancer studies because of their specific role (Weber et al., 2018). However, recent studies have begun to reveal their functional roles and prognostic potentials in prostate cancer and breast cancer (Ranzani et al., 2017; Li M. et al., 2019; Masjedi et al., 2019). (3) The tripartite-motif (TRIM) family proteins are involved in a variety of biological processes including transcriptional regulation, cell growth and apoptosis, and their dysregulation has been extensively linked to cancer risk and prognosis (Hatakeyama, 2011; Jaworska et al., 2020; Mandell et al., 2020). (4) The HOXL subclass homeoboxes are overexpressed in amplifications and underexpressed in deletions. The family consists mainly of HOX genes, which are master regulatory transcription factors in embryogenesis, cellular development, and issue homeostasis (Li B. et al., 2019). Recent researches have shown that depending on the type of the tumor, the expression of HOX genes may be increased or decreased and play roles in oncogenesis or tumor suppression (Shah and Sukumar, 2010; Bhatlekar et al., 2014; Brotto et al., 2020). (5) Keratin-associated proteins have no confirmed role in cancer. (6) The combined actions of glycosidases and glycosyltransferases constitute the primary catalytic machinery for the synthesis and breakage of glycosidic bonds. The aberrant glycosylation patterns are often considered a hallmark of cancer, which promotes tumor proliferation, invasion, and metastasis (Bernacki et al., 1985; Sandrine and Juillerat-Jeanneret, 2006; Andergassen et al., 2015; Wu et al., 2019). (7) Intermediate filaments proteins are often used as diagnostic markers in cancer, because changes in their expression patterns are often associated with tumor progression and cancerous cells usually partially retain their original structural signatures (Strouhalova et al., 2020). Several recent studies have reported their active roles in tumor invasion and metastasis (Holle et al., 2017; Sharma et al., 2019). (8) Zinc fingers C2H2-type family is the largest group of transcription factors in humans. A number of studies have revealed that aberrant expression of C2H2 proteins promotes tumorigenesis with various roles in several cancer types (Jen and Wang, 2016; Munro et al., 2018).
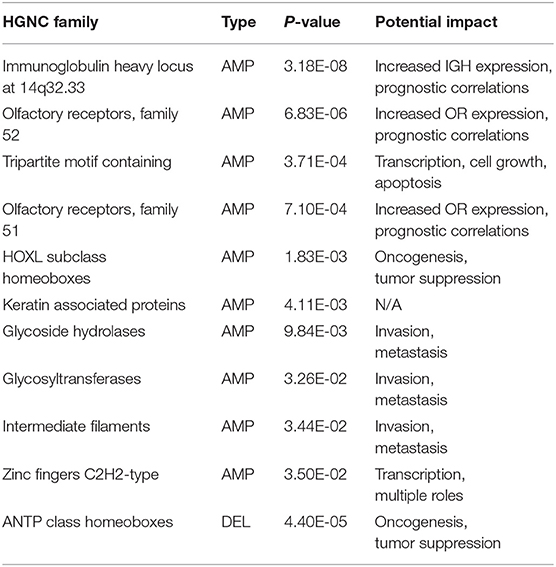
Table 4. The significant HGNC gene families of the 927 feature genes, where the family is covered by at least five genes and with the Binomial test <0.05.
The functional background of the significantly expressed HCNC families reveals several exciting aspects of the feature genes. First, the features consist of biomarker genes, which are frequently and abnormally expressed in many cancer types. Although their exact mechanisms in tumorigenesis are not fully understood, many studies have confirmed their functional roles and prognostic correlations in cancer. Second, the features describe functional aberrations by including several families that are related to transcriptional regulations. Previous studies have shown the high correlation of CNAs and differential gene expression in cancers (Shao et al., 2019; Bhattacharya et al., 2020), and partially elucidated their involvement in tumor development and progression. Finally, the features include hallmark signatures in invasion and metastasis, which are crucial indications of late-stage cancer progression. They are more likely to represent the consequence of other mutational activities rather than the direct impact of CNAs.
In summary, the analysis of feature genes agreed with a variety of previous research in their cancer-promoting or related roles and suggested the potential rationales behind the features. It also confirmed that malignant cell transformation is often an orchestrated process of many interplaying parts. While important driver mutations can signify the milestones in tumor development, the minor mutations during the development can also provide valuable characterization to specifics between different cancer types.
Discriminative Genomic Loci
Since feature genes represented the uniqueness of individual samples, it is expected that they would distribute exclusively among different subtypes in general. Interestingly, while most of the features are sparsely distributed, there are also a few “hot zones,” which are frequent CNV regions in general, that are commonly included in many signatures with high significance. Figures in the Supplementary Distribution Density illustrate the distribution and frequency of duplication and deletion feature genes separately. Figures on the first row are plotted using the full panel of feature genes, and figures on the second row are plotted using feature genes from all signatures (i.e., significantly high frequency). The most prominent feature genes among subtypes are those representing duplications on chromosome 7 and 8. Specifically, the feature genes are distributed in groups in several regions: chr7:28,953,358–34,878,332 and chr7:49,773,638–50,405,101 on the p arm of chromosome 7; chr7:91,692,008–93,361,123, chr7:105,014,190–117,715,971, chr7:129,611,720–130,734,176, and chr7:148,590,766–152,855,378 on the q arm of chromosome 7; chr8:47,260,878–50,796,692, chr8:51,319,577–54,871,720 and chr8:112,222,928–138,497,261 on the q arm of chromosome 8. As shown in Figure 2, chromosome 7 and 8 contain the most frequently duplicated regions among all studied cancer types. Despite their common existence, analysis of individual signatures and samples reveals three patterns that may explain their prominence in features: first, on the two chromosomes, samples often have large duplications. The aggregated signals in individual subtypes usually show high alternation frequency of the whole region and pose a plausible hint of frequent chromosome or arm level events. Second, the spans of duplications differ among subtypes. For example, the signature of melanoma consists of feature genes covering the entire chromosome 7 and 8; the signature of lung adenocarcinoma consists of feature genes only on the p arm of chromosome 7, and the signature of ovary carcinoma consists of feature genes only on the q arm of chromosome 8. Third, the alternation amplitude of the feature genes also shows distinctive patterns among subtypes. The subtle difference in the scale and amplitude of CNV on chromosome 7 and 8 suggest that aberrations of these hot regions may play differentiating roles in different cancers.
Similar to duplications, the most common deletion features distribute on three regions on chromosome 18: chr18:2,916,994–7,117,797 on the p arm; chr18:58,481,247–60,372,775 and chr18:69,400,888–70,330,199 on the q arm. Different from duplications on chromosome 7 and 8, the deletions on chromosome 18 show a similar pattern of high amplitude deletions on the entire chromosome 18, where feature genes on the p arm suggest a one-copy deletion on average, and feature genes on the q arm indicate frequent homozygous deletions. Interestingly, the deletion features on chromosome 18 are usually mutually exclusive to the deletion features on chromosome 10, which are under high pressure of chromosome level deletions in several subtypes. Previous studies have observed strong correlations of deletions on chromosome 18 and chromosome 10 to the progression of several cancer types. Other analyses have investigated their functional impacts and suggested the presence of several tumor suppressor genes (Bax et al., 2010; Xie et al., 2012; Kwong and Chin, 2014; Shao et al., 2019). Another hot zone of deletion features locates on the q arm of chromosome 22 (chr22:48,489,460–48,850,912). High-level deletions are frequently observed and selected as features in many subtypes. Different studies have shown similar observations of frequent deletions on chromosome 22, however, the mechanism of the deletion is still obscure and the functional impact remains putative (Castells et al., 2000; Morikawa et al., 2018).
Besides high prevalence, the feature “hot zones” also exhibit a higher copy number alternation level than average features. As shown in Figure 4, the average copy number alternation levels are far greater in these regions than in aggregated features: 56% higher in amplifications, and 70% higher in deletions. Furthermore, several hot zones and the associated cancer types, including the frequent amplifications near the centromere of chromosome 7, on the q arm of chromosome 8, and deletions closed to the telomere of chromosome 18, are in coherence with the general CNA patterns identified in previous pan-cancer studies (Beroukhim et al., 2010; Zack et al., 2013; McNulty et al., 2019), which suggests these regions are related to high CNA frequency. More specifically, some hot zones show correlations with nearby driver genes, which are frequently observed with high CNAs in cancers having high alternations in these hot zones. First, the high alternations level on chromosome 7 hot zones are in accordance with the overexpression of nearby EGFR, MET, and BRAF genes in glioma, lung cancers, and melanoma. EGFR is a well-studied oncogene in lung cancers and gliomas, MET is also a frequent driver in lung cancers, and BRAF is a signature driver gene in melanoma. A variety of studies have reported the CNA amplifications at or near the hot zones, and investigated their driver roles in these cancers (Taoudi Benchekroun et al., 2010; Janjigian et al., 2011; Trombetta et al., 2011; Kang, 2013; McNulty et al., 2019). Next, the frequent but relatively low-amplitude hot zone on the q arm of chromosome 8 is correlated with MYC, which is frequently amplified in numerous cancers. The extensively amplified hot zones on the p of chromosome 8 may be associated with FGFR1 and IKBKB, which are often deregulated by amplification in lung, colon, and bladder cancers. Studies of copy number patterns in these cancers have shown the significant correlations of increased gene expressions and amplification at the hot zone regions (El Gammal et al., 2010; Moelans et al., 2010; Weiss et al., 2010). Finally, the supporting evidence on deletion hot zones are mostly prognostic instead of functional confirmed, except on chromosome 10, where two frequent and high-alternation hot zones are closed to PTEN. Although it is one of the most common inactivated tumor suppressor genes in cancers, the signal amplitude of these zones is in high consistency with cancer types (gliomas, lung cancers, melanoma, and breast), where the loss of PTEN is especially frequent and crucial (Milella et al., 2015; Fusco et al., 2020).
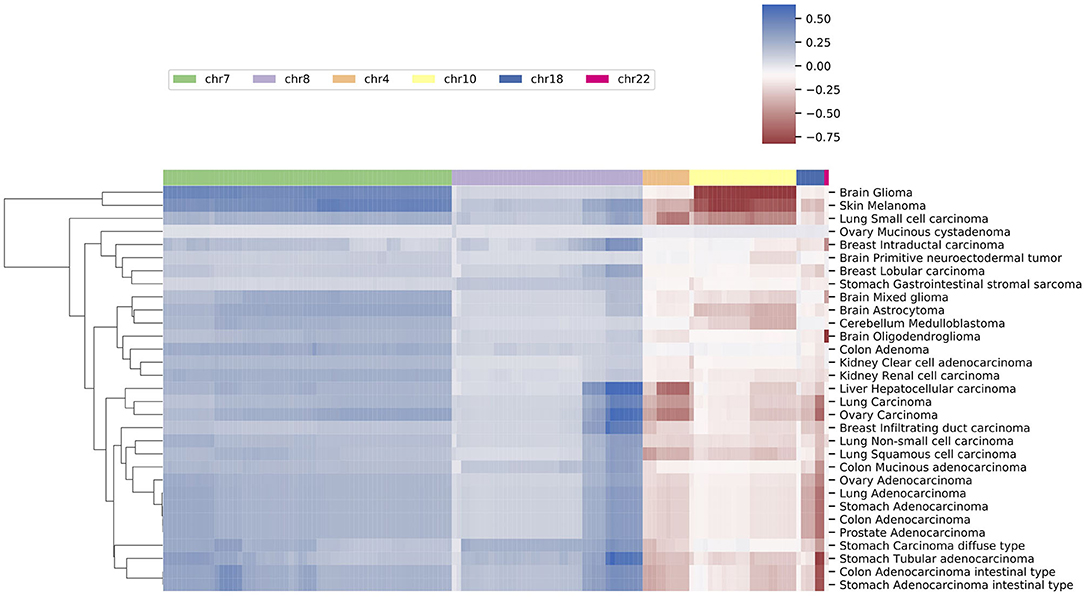
Figure 4. The average copy number alternation level of the hot-zone features among different cancer subtypes. The values were calculated using the mean of the normalized CNV log ratios of all samples in each subtype.
Similarities of Neural Crest Originated Subtypes
The signature based clustering of cancer subtypes (Figure 5) shows that diseases in the same cluster usually also share close ontologies. However, there is an interesting outlier, which consists of medulloblastoma, melanoma, and glioma (astrocytoma is a subtype of glioma). The three clinically and topographically distant cancer types have signatures of high similarity in both the selection of features and their alternation frequencies. Figure 6 shows the comparison of the original CNV data, the features and the known drivers of the three cancers on chromosomes harboring similar signatures. Their signatures exhibit high similarities in the duplication of chromosome 7 and the deletion of chromosome 10. They also share pairwise similarities on the duplication of chromosome 1 and 20, and the deletion of 9 and 14. For the three cancers, the most frequently amplified chromosome 7 harbors several of the key oncogenes. For example, EGFR, CDK6, and MET in glioma; KMT2C and PMS2 in medulloblastoma; BRAF, RAC1 and TRRAP in melanoma. The most frequently deleted chromosome 9 and 10 harbor several important suppressor genes. For example, CDKN2A and PTEN in glioma; XPA, PPP6c, and CDKNA in melanoma; PTCH1 and SUFU in medulloblastoma. Noticeably, the CDKN2A/B deletion is the most frequent copy number aberrations across all cancer types. Although the distribution of driver genes shows a close correlation with the frequency and amplitude of CNV, most drivers do not demonstrate signal peaks nor overlap with the feature genes. Frequent duplications on chromosome 1 and deletions on chromosome 14 do not show direct correlations to common driver genes; however, a number of studies have shown the connection of CNAs on these regions to the progress and prognosis in these cancer types (Cross et al., 2005; Parsons et al., 2011; Mathieu et al., 2012; Boots-Sprenger et al., 2013; Cohen et al., 2015; Park et al., 2019).
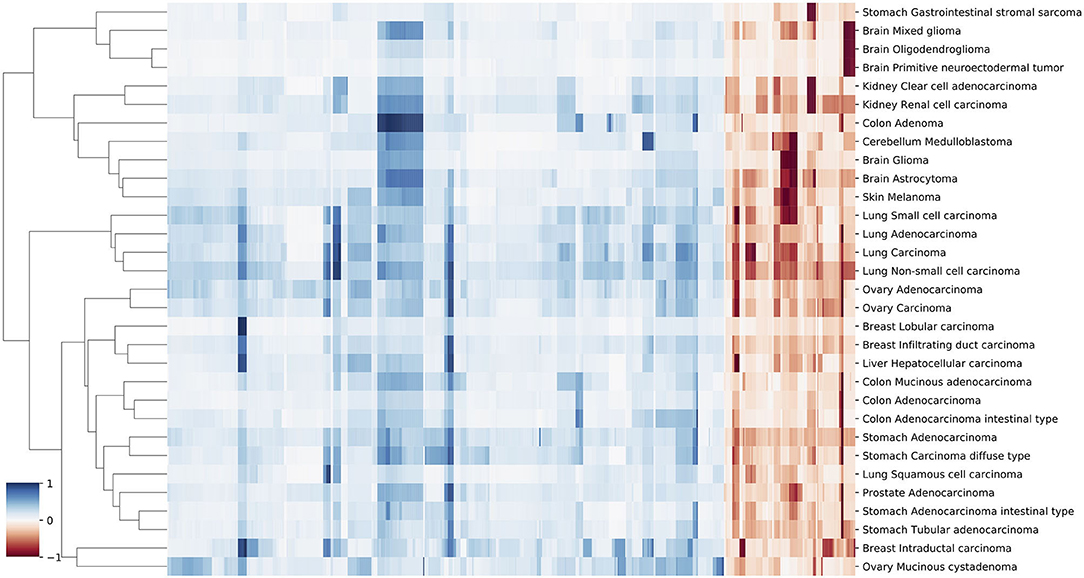
Figure 5. A clustering heatmap of features in 31 signatures. Columns are normalized average CNV intensities of feature genes, where the blue colors are duplication features and red colors are deletion features. Duplication and deletion frequencies are normalized separately.
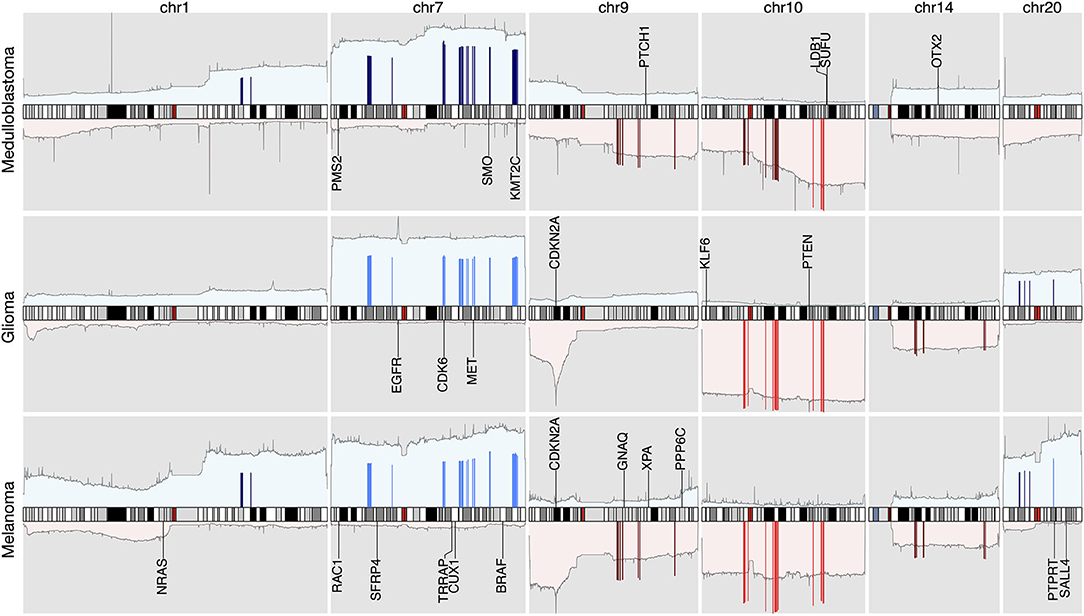
Figure 6. The integrated view of the original data and the selected features, in the neural crest originating entities medulloblastoma, glioma, and melanoma. The shaded background area color illustrates the original data. Color bars illustrate the feature genes, where brighter colors indicate stronger signal intensity. The blue colors above the chromosome axis represent the average amplifications, and the red colors below the chromosome axis represent the average deletions. The amplitude of amplifications and deletions are normalized to [0,1] separately. The adjacent known driver genes are also included for each tumor type.
In the 1990s, epidemic studies (Azizi et al., 1995; Desai and Grossman, 2008; Scarbrough et al., 2014) first revealed the connection between melanoma and tumors of the nervous system: not only a familial association, which was confirmed by germline mutations; but also a significantly increased risk of one disease in people having a history of the other one. Although there was evidence showing their potential common pathophysiologic pathways and responsiveness to the same drugs, the genetic connection of the two disease groups was still largely unclear (Middleton et al., 2000). In spite of their ontological difference, medulloblastoma, melanoma, and glioma are all derived from the lineages of neural crest cells. Recent studies of neural crest cells and the cancers from their lineage cells suggest that malignant cells mimic many of the behavioral, molecular, and morphologic aspects of neural crest development (Jiang et al., 2011; Powell et al., 2014; Maguire et al., 2015). Aberrations in tumor cells may lead to the reactivation of their embryonic developmental programs and promote tumorigenesis and metastasis. For example, the WNT family members, which play import roles during the epithelial-to-mesenchymal transition of neural crest cell, are reactivated during invasive transformation in melanoma (Kovacs et al., 2016; Sinnberg et al., 2018). In glioblastoma, experimental data suggests that the dysregulation of the WNT signaling pathway supports the onset of cancer stem cells, which assure the enlargement of the tumoral mass and eventually the spread of metastases (Zuccarini et al., 2018). In medulloblastoma, the WNT subgroup signifies one of the four molecular subtypes of the disease (Doussouki et al., 2019). In regions represented by the similar signatures, several WNT genes exhibit abnormal amplification frequencies, which are a potential reflection of the overexpression of WNT signaling. Specifically, WNT2B and WNT4 are covered by amplifications of moderate frequencies, and WNT2, WNT3A, WNT9A, and WNT16 are encompassed by amplifications of high frequencies. WNT2 and WNT16 are signature genes in all three subtypes implicating their prevalence among individual samples.
Another interesting result from the similar signatures is the connection between melanoma and medulloblastoma, which has dramatic differences in many biological aspects. For example, medulloblastoma is considered primarily originated from embryonal cells in early development. It mostly occurs in children and usually has good prognosis outcomes. On the other hand, melanoma is primarily caused by ultraviolet light exposure. Its risk has a positive correlation with age and the prognosis is usually very poor once passing the early stage of the disease. However, besides their differences, all three cancer types are notorious for their fast progression, high invasiveness and wide metastasis. It's possible that their common CNA signatures are the imprint of their acquired cancer hallmarks instead of their mutational characteristics. The combined evidence suggests that different types of tumor may achieve their hallmark abilities through different evolution paths (Gallik et al., 2017). The acquired hallmarks exhibit a number of common genotypes such as copy number aberrations, which are potentially the downstream result of primary mutation events that contribute to the functional sustainability of tumor cells.
Classification of Subtypes and Organs
In the previous sections, we explored the implications of the feature genes and cancer signatures. It is also interesting to assess the robustness and usefulness of the feature genes in sample classifications, especially when most of the primary driver genes are excluded from the features. The identification of the origin of a tumor sample is a challenging task that attracted significant attention from both academia and industry. A great number of computational methods have been proposed in recent years to facilitate the early diagnosis of cancers from liquid biopsies (Heitzer et al., 2013; Volik et al., 2016; Phallen et al., 2017; Wood-Bouwens et al., 2017; Chin et al., 2019). Among the various explored genomic aberrations, several studies have illustrated the predictive effectiveness of copy number aberrations (Leary et al., 2012; Dawson et al., 2013; Heitzer et al., 2013). In the meantime, machine learning researchers have also proposed a number of classification methods to predict cancer types using copy number data (Zhang et al., 2016; Karim et al., 2020; Liang et al., 2020). However, these methods usually utilized a uniform dataset such as TCGA to investigate the feasibility of the method and the performance of the model. They often lack the generalization experiments to apply the method on data that is not from the training data pipeline. Also, the goal of machine learning researches usually focused on constructing a classifier of high accuracy, whereas in this study, we focused on exploring the unique and typical mutations in different cancer subtypes. Therefore, we would like to use the classification results of copy number signatures to demonstrate their potential in the predictions of cancer subtypes and organs of origin from liquid biopsies, and performed no direct comparisons with other predictive studies.
In the prediction of subtypes, the model showed a wide range of performance spectrum on different subtypes. Figure 7A shows the confusion matrix of individual subtypes, where the x-axis represents the true labels and the y-axis represents the predicted labels. Specifically, the classifier achieved good performance in predicting: breast intraductal carcinoma, colon adenocarcinoma, brain glioma, cerebellum medulloblastoma, cerebellum medulloblastoma, and kidney clear cell adenocarcinoma, where the F1-score of individual subtypes ranged from 0.72 to 0.67. On the other hand, the prediction performance was deficient in several subtypes, such as brain astrocytoma, stomach carcinoma diffuse type, and colon mucinous adenocarcinoma. The complete metrics of each subtype are included in Supplementary Performance. Investigation on false negatives and false positives showed that most of the false predictions fell into the subtypes that were from the same organ and had significantly more samples. In general, the performance of individual subtypes was positively correlated with the number of samples (Figure 7C). The difficulty in predicting some subtypes suggests that some clinico-pathologically closed cancer subtypes share similar copy number mutation patterns. While the copy number signatures showed promising predictive potential for some cancer subtypes, data from complementary genomic aberrations are needed for a comprehensive model to classify similar subtypes.
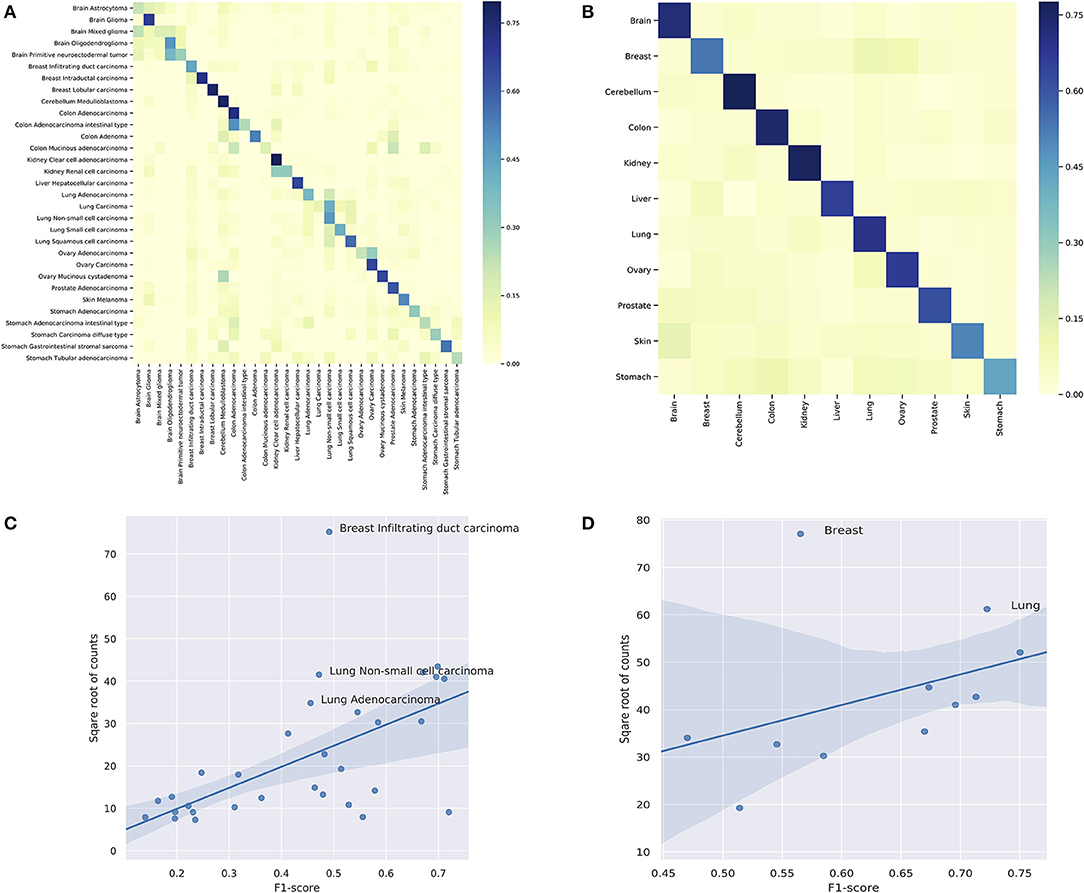
Figure 7. (A) The classification performance of individual subtypes. (B) The classification performance of individual organs. For (A,B), the x-axis are true labels, and the y-axis are predicted labels. (C) The correlation between the performance and the number of samples in the classification of subtypes. (D) The correlation between the performance and the number of samples in the classification of organs.
In the prediction of organs, the model showed a more consistent performance than in subtypes. Figure 7B shows the confusion matrix of individual organs. Specifically, the classifier achieved good results in predicting: brain, lung, colon, cerebellum, ovary, and kidney, where the F1-sore of individual organs ranged from 0.75 to 0.67. Although some organs showed relatively low prediction accuracy, they all had dramatic improvements compared with the prediction results of the divided subtypes. The complete metrics of each subtype are included in Supplementary Performance. In general, the performance was also positively correlated with the total number of samples in each organ (Figure 7D). In contrast, the prediction results of organs showed a significant overall improvement over the subtypes. For example, none of the lung subtypes had a good performance in the subtype classification. However, when combined, the lung achieved the second-best performance (0.72 F1-score) in organ prediction. A similar improvement was also observed for the stomach while the prediction performance of breast had a drastic decline compared with divided subtypes; the latter is further discussed in the subsequent section.
In summary, our classification experiments indicated that the copy number signatures have good potential in predicting several cancer subtypes and organs of origin. However, not all investigated subtypes and organs achieved satisfying performance with solely CNA features, which confirmed the need for ensemble strategies to identify unknown tumor cells' type and origin. Moreover, the improved performance in organ classifications suggested the correlations of CNA and organ's functional influence in tumorigenesis. In future research, it would be interesting to further investigate the difference between organ-specific CNAs and subtype-specific CNAs.
Heterogeneity Within Subtypes
The results of the classifier showed significant differences in performance among different subtypes and organs. While some of the under-performance may be attributed to the insufficient number of samples, the false predictions of several classes suggested the heterogeneity within these subtypes. As shown in Figure 7A, for breast infiltrating duct carcinoma and cerebellum medulloblastoma, the false predictions were widely distributed over several unrelated classes. Figures 7C,D highlighted breast infiltrating duct carcinoma, lung non-small cell carcinoma, and lung adenocarcinoma as outliers of the correlation, where the high number of samples did not improve but deteriorate their performance.
Large-scale cancer genome studies have shown that tumors from the cerebellum, lung, and breast usually carry high burdens of copy number mutations (Beroukhim et al., 2010; Zack et al., 2013). With the extensive number of CNA in these subtypes, it is expected to be more challenging to identify key signals. Genomic studies in the past two decades have revealed mutation characteristics in these diseases, and established classifications of their molecular subtypes. For example, medulloblastomas are now commonly categorized into four subgroups: WNT, SHH, G3, and G4. Similarly, breast carcinomas can be categorized into four subgroups: Luminal A, Luminal B, Her2-enriched, and basal-like. Studies of their mutational patterns showed distinct markers and different mutation landscapes of each subtype, and multi-omics studies further revealed the intrinsic complexity within subtypes and suggested classifications of more subgroups (Banerji et al., 2012; Curtis et al., 2012; Tyanova et al., 2016). However, the majority of the samples in our dataset were labeled by their morphology, with the molecular subtype classification missing in the sample annotations. As a result, large diagnostic groups such as “breast infiltrating duct carcinoma” could not be further separated a priory, resulting in a common label for breast carcinomas with the diagnostic subtype consisting of 5,657 samples, over three times more than the second-largest subtype. While we addressed these skewed overall subtype sizes through the application of undersampling techniques, the implicit mixture of different molecular subgroups provided an inevitable impact on the association of diagnostic labels and CNA based classifiers.
Discussion
For this study, we assembled a large collection of cancer CNA profiles with the aim to identify genomic aberration signatures with specificity for individual cancer types. In order to integrate technically diverse data, we developed innovative tools for genome data conversion and signal normalization. Targeting the identification of unique components in diagnosis mapped CNA profiles, we were able to derive the CNA signatures of 31 cancer subtypes, where each signature was characterized by a minimal representation of genes with high discrimination capacity. The signatures were further evaluated to derive classifiers identifying tumor types and organs of origin. The comparative analyses of signature genes and their represented regions showed that duplications on chromosome 7 and 8, and deletions on chromosome 22 were the most common aberrations among studied cancer types. However, these regions also harbored features of high differentiating power, which may indicate the functional significance of cancer related genes with specificity for cancer-type related pathway involvement.
While our feature genes exhibited certain correlations with known driver genes, this itself does not provide direct evidence of their functional significance. Feature genes could also be the result of the downstream effects of mutational activities or be co-opted as a representation of an aberrant region where the pathogenetic activity is provided by different genomic elements (Szalai and Saez-Rodriguez, 2020). In the analysis, we were prudent to limit propositions of the impact of individual feature genes.
Our analyses showed that three clinico-pathologically distant cancer types—medulloblastoma, melanoma, and glioma—shared CNA signatures of high similarity. Developmentally, the three tumor types can be traced back to common lineages of neural crest cells. Research of neural crest cells and epidemiologic studies of glioma and melanoma have shown sporadic evidence of their connections in cancer development, but the genetic foundation of their association with respect to oncogenetic processes is still elusive. Here, comparative analysis of shared mutations together with improvements of developmental processes in the corresponding normal tissues may provide insights into shared pathologies and potential therapeutic targets.
The studies on genomic classifiers demonstrated the capacity and potential of CNA signatures in tumor identification. However, while the multi-label classification approach showed promising performance in many cancers, in a few subtypes the performance was deteriorated by the intrinsic heterogeneity of their CNA profiles. Here we expect that future follow-up studies with extended input data and employing different ontology-based grouping strategies may lead to improved performance and the potential emergence of better group aggregations.
An essential challenge in the study was the integration of data from varying genomic profiling platforms. During normalization and quality control, we removed samples that were ambiguous in interpretation or had an abnormal distribution of signals. However, as a trade-off, many genomically heterogeneous samples (e.g., aneuploid or containing CTLP) were removed in the process. For future studies, complementary strategies should be developed to include these samples without detrimental effects on data normalization and quality. With respect to sample annotation for histologic and diagnostic classifications, extensive efforts went into the curation of the data with the aim to use a unified set of classifications. Here, future analyses may make use of emerging cancer specific ontologies for a better integration of varying annotation granularities using hierarchical terms and concepts. Currently, our research group is finishing a parallel study on ontology mappings of cancer samples, and we are expecting a considerable improvement in the disease annotation of samples in future studies.
In summary, this study presents a systematic pipeline for integrative and comparative analyses of a large amount of copy number data. The resulting CNA signatures offer new perspectives on the understanding of common foundations in cancers and show promising potential in applications of tumor classification.
Data Availability Statement
Data from Progenetix is available at: https://www.progenetix.org;Data from TCGA is available at: https://portal.gdc.cancer.gov;Data from PCAWG is available at: https://dcc.icgc.org; Segmentation data and metadata of open-access samples used in the study are available at https://progenetix.org/progenetix-cohorts/gao-2021-signatures/.
Author Contributions
BG developed the method and implemented the analysis. MB conceived the original concept and supervised the project. All authors contributed to the writing and revisions of the manuscript.
Funding
BG was a recipient of a grant from the China Scholarship Council. The funder had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Paula Carrio Cordo and Qingyao Huang for support with the data ontologies, and all current and previous members of the Baudis group for contributions to the Progenetix resource.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2021.654887/full#supplementary-material
• Implementation details: Supplementary Implementations.pdf/
• Performance details of individual classifications: Supplementary Performance.pdf/
• Analyses results of subtypes: Supplementary Signatures.zip/
• Labeling and merging of subtypes: Supplementary Subtypes.pdf.
• Distribution and amplitudes of feature genes in different subtypes: Supplementary Distribution Density.pdf.
• Illustration of cross-sample CNV normalization: Supplementary Normalization Examples.pdf.
References
Andergassen, U., Liesche, F., Kölbl, A. C., Ilmer, M., Hutter, S., Friese, K., et al. (2015). Glycosyltransferases as markers for early tumorigenesis. BioMed Res. Int. 2015:792672. doi: 10.1155/2015/792672
Azizi, E., Friedman, J., Pavlotsky, F., Iscovich, J., Bornstein, A., Shafir, R., et al. (1995). Familial cutaneous malignant melanoma and tumors of the nervous system. Cancer 76, 1571–1578. doi: 10.1002/1097-0142(19951101)76:9<1571::AID-CNCR2820760912>3.0.CO;2-6
Babbage, G., Ottensmeier, C. H., Blaydes, J., Stevenson, F. K., and Sahota, S. S. (2006). Immunoglobulin heavy chain locus events and expression of activation-induced cytidine deaminase in epithelial breast cancer cell lines. Cancer Res. 66:3996. doi: 10.1158/0008-5472.CAN-05-3704
Banerji, S., Cibulskis, K., Rangel-Escareno, C., Brown, K. K., Carter, S. L., Frederick, A. M., et al. (2012). Sequence analysis of mutations and translocations across breast cancer subtypes. Nature 486, 405–409. doi: 10.1038/nature11154
Baudis, M. (2007). Genomic imbalances in 5918 malignant epithelial tumors: an explorative meta-analysis of chromosomal CGH data. BMC Cancer 7:226. doi: 10.1186/1471-2407-7-226
Bax, D. A., Mackay, A., Little, S. E., Carvalho, D., Viana-Pereira, M., Tamber, N., et al. (2010). A distinct spectrum of copy number aberrations in pediatric high-grade gliomas. Clin. Cancer Res. 16:3368. doi: 10.1158/1078-0432.CCR-10-0438
Bentz, M., Plesch, A., Stilgenbauer, S., Dohner, H., and Lichter, P. (1998). Minimal sizes of deletions detected by comparative genomic hybridization. Genes Chromos. Cancer 2, 172–175. doi: 10.1002/(SICI)1098-2264(199802)21:2<172::AID-GCC14>3.0.CO;2-T
Bernacki, R. J., Niedbala, M. J., and Korytnyk, W. (1985). Glycosidases in cancer and invasion. Cancer Metast. Rev. 4, 81–101. doi: 10.1007/BF00047738
Beroukhim, R., Mermel, C. H., Porter, D., Wei, G., Raychaudhuri, S., Donovan, J., et al. (2010). The landscape of somatic copy-number alteration across human cancers. Nature 463, 899–905. doi: 10.1038/nature08822
Bhatlekar, S., Fields, J. Z., and Boman, B. M. (2014). Hox genes and their role in the development of human cancers. J. Mol. Med. 92, 811–823. doi: 10.1007/s00109-014-1181-y
Bhattacharya, A., Bense, R. D., Urzúa-Traslavi na, C. G., de Vries, E. G. E., van Vugt, M. A. T. M., and Fehrmann, R. S. N. (2020). Transcriptional effects of copy number alterations in a large set of human cancers. Nat. Commun. 11:715. doi: 10.1038/s41467-020-14605-5
Bignell, G. R., Greenman, C. D., Davies, H., Butler, A. P., Edkins, S., Andrews, J. M., et al. (2010). Signatures of mutation and selection in the cancer genome. Nature 463, 893–898. doi: 10.1038/nature08768
Boots-Sprenger, S. H. E., Sijben, A., Rijntjes, J., Tops, B. B. J., Idema, A. J., Rivera, A. L., et al. (2013). Significance of complete 1p/19q co-deletion, IDH1 mutation and MGMT promoter methylation in gliomas: use with caution. Modern Pathol. 26, 922–929. doi: 10.1038/modpathol.2012.166
Brotto, D. B., Siena, I. I., Carvalho, S. d. C. e. S., Muys, B. R., Goedert, L., Cardoso, C., et al. (2020). Contributions of hox genes to cancer hallmarks: enrichment pathway analysis and review. Tumour Biol. 42:1010428320918050. doi: 10.1177/1010428320918050
Cai, H., Gupta, S., Rath, P., Ai, N., and Baudis, M. (2015). Arraymap 2014: an updated cancer genome resource. Nucleic Acids Res. 43, D825–D830. doi: 10.1093/nar/gku1123
Cai, H., Kumar, N., Ai, N., Gupta, S., Rath, P., and Baudis, M. (2013). Progenetix: 12 years of oncogenomic data curation. Nucleic Acids Res. 42, D1055–D1062. doi: 10.1093/nar/gkt1108
Campbell, P. J., Getz, G., Korbel, J. O., Stuart, J. M., Jennings, J. L., Stein, L. D., et al. (2020). Pan-cancer analysis of whole genomes. Nature 578, 82–93. doi: 10.1038/s41586-020-1969-6
Castells, A., Gusella, J. F., Ramesh, V., and Rustgi, A. K. (2000). A region of deletion on chromosome 22q13 is common to human breast and colorectal cancers. Cancer Res. 60:2836.
Chen, L., Zhou, W., Zhang, C., Lupski, J. R., Jin, L., and Zhang, F. (2014). cnv instability associated with DNA replication dynamics: evidence for replicative mechanisms in CNV mutagenesis. Hum. Mol. Genet. 24, 1574–1583. doi: 10.1093/hmg/ddu572
Chin, R.-I., Chen, K., Usmani, A., Chua, C., Harris, P. K., Binkley, M. S., et al. (2019). Detection of solid tumor molecular residual disease (MRD) using circulating tumor DNA (CTDNA). Mol. Diagn. Ther. 23, 311–331. doi: 10.1007/s40291-019-00390-5
Ciriello, G., Miller, M. L., Aksoy, B. A., Senbabaoglu, Y., Schultz, N., and Sander, C. (2013). Emerging landscape of oncogenic signatures across human cancers. Nat. Genet. 45, 1127–1133. doi: 10.1038/ng.2762
Cohen, A., Sato, M., Aldape, K., Mason, C. C., Alfaro-Munoz, K., Heathcock, L., et al. (2015). DNA copy number analysis of grade II-III and grade IV gliomas reveals differences in molecular ontogeny including chromothripsis associated with IDH mutation status. Acta Neuropathol. Commun. 3:34. doi: 10.1186/s40478-015-0213-3
Conrad, D. F., Pinto, D., Redon, R., Feuk, L., Gokcumen, O., Zhang, Y., et al. (2010). Origins and functional impact of copy number variation in the human genome. Nature 464, 704–712. doi: 10.1038/nature08516
Cox, C., Bignell, G., Greenman, C., Stabenau, A., Warren, W., Stephens, P., et al. (2005). A survey of homozygous deletions in human cancer genomes. Proc. Natl. Acad. Sci. U.S.A. 102, 4542–4547. doi: 10.1073/pnas.0408593102
Cross, N. A., Rennie, I. G., Murray, A. K., and Sisley, K. (2005). The identification of chromosome abnormalities associated with the invasive phenotype of uveal melanoma in vitro. Clin. Exp. Metast. 22, 107–113. doi: 10.1007/s10585-005-5142-2
Curtis, C., Shah, S. P., Chin, S.-F., Turashvili, G., Rueda, O. M., Dunning, M. J., et al. (2012). The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups. Nature 486, 346–352. doi: 10.1038/nature10983
Daugherty, L. C., Seal, R. L., Wright, M. W., and Bruford, E. A. (2012). Gene family matters: expanding the HGNC resource. Hum. Genom. 6:4. doi: 10.1186/1479-7364-6-4
Dawson, S.-J., Tsui, D. W., Murtaza, M., Biggs, H., Rueda, O. M., Chin, S.-F., et al. (2013). Analysis of circulating tumor DNA to monitor metastatic breast cancer. N. Engl. J. Med. 368, 1199–1209. doi: 10.1056/NEJMoa1213261
Desai, A. S., and Grossman, S. A. (2008). Association of melanoma with glioblastoma multiforme. J. Clin. Oncol. 26(15 Suppl.):2082. doi: 10.1200/jco.2008.26.15_suppl.2082
Doussouki, M. E., Gajjar, A., and Chamdine, O. (2019). Molecular genetics of medulloblastoma in children: diagnostic, therapeutic and prognostic implications. Fut. Neurol. 14:FNL8. doi: 10.2217/fnl-2018-0030
El Gammal, A. T., Brüchmann, M., Zustin, J., Isbarn, H., Hellwinkel, O. J., Köllermann, J., et al. (2010). Chromosome deletions and gains are associated with tumor progression and poor prognosis in prostate cancer. Clin. Cancer Res. 16:56. doi: 10.1158/1078-0432.CCR-09-1423
Feng, X., Zhang, Y., and Glass, J. (2014). “Speech feature denoising and dereverberation via deep autoencoders for noisy reverberant speech recognition,” in 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Florence).
Fusco, N., Sajjadi, E., Venetis, K., Gaudioso, G., Lopez, G., Corti, C., et al. (2020). PTEN alterations and their role in cancer management: are we making headway on precision medicine. Genes 11:719. doi: 10.3390/genes11070719
Gallik, K. L., Treffy, R. W., Nacke, L. M., Ahsan, K., Rocha, M., Green-Saxena, A., et al. (2017). Neural crest and cancer: divergent travelers on similar paths. Mech. Dev. 148, 89–99. doi: 10.1016/j.mod.2017.08.002
Gao, B., and Baudis, M. (2020). Minimum error calibration and normalization for genomic copy number analysis. Genomics 112, 3331–3341. doi: 10.1016/j.ygeno.2020.05.008
Gao, B., Huang, Q., and Baudis, M. (2018). segment_liftover : a python tool to convert segments between genome assemblies. F1000Res. 7:319. doi: 10.12688/f1000research.14148.1
Gondara, L. (2016). “Medical image denoising using convolutional denoising autoencoders,” in 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW) (IEEE), 241–246.
Grasso, C. S., Wu, Y.-M., Robinson, D. R., Cao, X., Dhanasekaran, S. M., Khan, A. P., et al. (2012). The mutational landscape of lethal castration-resistant prostate cancer. Nature 487, 239–243. doi: 10.1038/nature11125
Hastings, P. J., Lupski, J. R., Rosenberg, S. M., and Ira, G. (2009). Mechanisms of change in gene copy number. Nat. Rev. Genet. 10, 551–564. doi: 10.1038/nrg2593
Hastings, R. J., Bown, N., Tibiletti, M. G., Debiec-Rychter, M., Vanni, R., Espinet, B., et al. (2016). Guidelines for cytogenetic investigations in tumours. Eur. J. Hum. Genet. 24, 6–13. doi: 10.1038/ejhg.2015.35
Heitzer, E., Ulz, P., Belic, J., Gutschi, S., Quehenberger, F., Fischereder, K., et al. (2013). Tumor-associated copy number changes in the circulation of patients with prostate cancer identified through whole-genome sequencing. Genome Med. 5:30. doi: 10.1186/gm434
Holle, A. W., Kalafat, M., Ramos, A. S., Seufferlein, T., Kemkemer, R., and Spatz, J. P. (2017). Intermediate filament reorganization dynamically influences cancer cell alignment and migration. Sci. Rep. 7:45152. doi: 10.1038/srep45152
Hou, J. P., and Ma, J. (2014). Dawnrank: discovering personalized driver genes in cancer. Genome Med. 6:56. doi: 10.1186/s13073-014-0056-8
Hu, D., Duan, Z., Li, M., Jiang, Y., Liu, H., Zheng, H., et al. (2011). Heterogeneity of aberrant immunoglobulin expression in cancer cells. Cell. Mol. Immunol. 8, 479–485. doi: 10.1038/cmi.2011.25
Hu, D., Zheng, H., Liu, H., Li, M., Ren, W., Liao, W., et al. (2008). Immunoglobulin expression and its biological significance in cancer cells. Cell. Mol. Immunol. 5, 319–324. doi: 10.1038/cmi.2008.39
Huang, C.-C., Du, M., and Wang, L. (2019). Bioinformatics analysis for circulating cell-free DNA in cancer. Cancers 11:805. doi: 10.3390/cancers11060805
Hutter, C., and Zenklusen, J. C. (2018). The cancer genome atlas: creating lasting value beyond its data. Cell 173, 283–285. doi: 10.1016/j.cell.2018.03.042
Janjigian, Y. Y., Tang, L. H., Coit, D. G., Kelsen, D. P., Francone, T. D., Weiser, R. M., et al. (2011). Met expression and amplification in patients with localized gastric cancer. Cancer Epidemiol. Biomark. Prev. 20:1021. doi: 10.1158/1055-9965.EPI-10-1080
Jaworska, A. M., Wlodarczyk, N. A., Mackiewicz, A., and Czerwinska, P. (2020). The role of trim family proteins in the regulation of cancer stem cell self-renewal. Stem Cells 38, 165–173. doi: 10.1002/stem.3109
Jen, J., and Wang, Y.-C. (2016). Zinc finger proteins in cancer progression. J. Biomed. Sci. 23:53. doi: 10.1186/s12929-016-0269-9
Jiang, M., Stanke, J., and Lahti, J. M. (2011). The connections between neural crest development and neuroblastoma. Curr. Top. Dev. Biol. 94, 77–127. doi: 10.1016/B978-0-12-380916-2.00004-8
Joos, S., Scherthan, H., Speicher, M., Schlegel, J., Cremer, T., and Lichter, P. (1993). Detection of amplified DNA sequences by reverse chromosome painting using genomic tumor DNA as probe. Hum. Genet. 90, 584–589. doi: 10.1007/BF00202475
Juhlin, C. C., Goh, G., Healy, J. M., Fonseca, A. L., Scholl, U. I., Stenman, A., et al. (2015). Whole-exome sequencing characterizes the landscape of somatic mutations and copy number alterations in adrenocortical carcinoma. J. Clin. Endocrinol. Metab. 100, E493–E502. doi: 10.1210/jc.2014-3282
Kallioniemi, A., Kallioniemi, O., Sudar, D., Rutovitz, D., Gray, J., Waldman, F., et al. (1992). Comparative genomic hybridization for molecular cytogenetic analysis of solid tumors. Science 5083, 818–821. doi: 10.1126/science.1359641
Kang, J. U. (2013). Characterization of amplification patterns and target genes on the short arm of chromosome 7 in early-stage lung adenocarcinoma. Mol. Med. Rep. 8, 1373–1378. doi: 10.3892/mmr.2013.1686
Karim, M. R., Rahman, A., Jares, J. B., Decker, S., and Beyan, O. (2020). A snapshot neural ensemble method for cancer-type prediction based on copy number variations. Neural Comput. Appl. 32, 15281–15299. doi: 10.1007/s00521-019-04616-9
Kovacs, D., Migliano, E., Muscardin, L., Silipo, V., Catricalá, C., Picardo, M., et al. (2016). The role of WNT/β-catenin signaling pathway in melanoma epithelial-to-mesenchymal-like switching: evidences from patients-derived cell lines. Oncotarget 7, 43295–43314. doi: 10.18632/oncotarget.9232
Krijgsman, O., Carvalho, B., Meijer, G. A., Steenbergen, R. D., and Ylstra, B. (2014). Focal chromosomal copy number aberrations in cancer–needles in a genome haystack. Biochim. Biophys. Acta 1843, 2698–2704. doi: 10.1016/j.bbamcr.2014.08.001
Kuhn, R. M., Haussler, D., and Kent, W. J. (2013). The ucsc genome browser and associated tools. Brief. Bioinform. 14, 144–161. doi: 10.1093/bib/bbs038
Kwong, L. N., and Chin, L. (2014). Chromosome 10, frequently lost in human melanoma, encodes multiple tumor-suppressive functions. Cancer Res. 74, 1814–1821. doi: 10.1158/0008-5472.CAN-13-1446
Larsson, C., Ehinger, A., Winslow, S., Leandersson, K., Klintman, M., Dahl, L., et al. (2020). Prognostic implications of the expression levels of different immunoglobulin heavy chain-encoding RNAs in early breast cancer. NPJ Breast Cancer 6:28. doi: 10.1038/s41523-020-0170-2
Leary, R. J., Sausen, M., Kinde, I., Papadopoulos, N., Carpten, J. D., Craig, D., et al. (2012). Detection of chromosomal alterations in the circulation of cancer patients with whole-genome sequencing. Sci. Transl. Med. 4:162ra154. doi: 10.1126/scitranslmed.3004742
Lee, G., and Ge, B. (2009). Cancer cell expressions of immunoglobulin heavy chains with unique carbohydrate-associated biomarker. Cancer Biomark. 5, 177–188. doi: 10.3233/CBM-2009-0102
Li, B., Huang, Q., and Wei, G.-H. (2019). The role of HOX transcription factors in cancer predisposition and progression. Cancers 11:528. doi: 10.3390/cancers11040528
Li, M., Wang, X., Ma, R.-R., Shi, D.-B., Wang, Y.-W., Li, X.-M., et al. (2019). The olfactory receptor family 2, subfamily T, member 6 (OR2T6) is involved in breast cancer progression via initiating epithelial-mesenchymal transition and MAPK/ERK pathway. Front. Oncol. 9:1210. doi: 10.3389/fonc.2019.01210
Li, S., Dou, X., Gao, R., Ge, X., Qian, M., and Wan, L. (2018). A remark on copy number variation detection methods. PLoS ONE 13:e0196226. doi: 10.1371/journal.pone.0196226
Li, W., Zhang, X., Lu, X., You, L., Song, Y., Luo, Z., et al. (2017). 5-hydroxymethylcytosine signatures in circulating cell-free DNA as diagnostic biomarkers for human cancers. Cell Res. 27, 1243–1257. doi: 10.1038/cr.2017.121
Liang, Y., Wang, H., Yang, J., Li, X., Dai, C., Shao, P., et al. (2020). A deep learning framework to predict tumor tissue-of-origin based on copy number alteration. Front. Bioeng. Biotechnol. 8:701. doi: 10.3389/fbioe.2020.00701
Macintyre, G., Ylstra, B., and Brenton, J. (2016). Sequencing structural variants in cancer for precision therapeutics. Trends Genet. 32, 530–542. doi: 10.1016/j.tig.2016.07.002
Maguire, L. H., Thomas, A. R., and Goldstein, A. M. (2015). Tumors of the neural crest: common themes in development and cancer. Dev. Dyn. 244, 311–322. doi: 10.1002/dvdy.24226
Mandell, M. A., Saha, B., and Thompson, T. A. (2020). The tripartite nexus: autophagy, cancer, and tripartite motif-containing protein family members. Front. Pharmacol. 11:308. doi: 10.3389/fphar.2020.00308
Masjedi, S., Zwiebel, L. J., and Giorgio, T. D. (2019). Olfactory receptor gene abundance in invasive breast carcinoma. Sci. Rep. 9:13736. doi: 10.1038/s41598-019-50085-4
Mathieu, V., Pirker, C., Schmidt, W. M., Spiegl-Kreinecker, S., Lötsch, D., Heffeter, P., et al. (2012). Aggressiveness of human melanoma xenograft models is promoted by aneuploidy-driven gene expression deregulation. Oncotarget 3, 399–413. doi: 10.18632/oncotarget.473
McNulty, S. N., Cottrell, C. E., Vigh-Conrad, K. A., Carter, J. H., Heusel, J. W., Ansstas, G., et al. (2019). Beyond sequence variation: assessment of copy number variation in adult glioblastoma through targeted tumor somatic profiling. Hum. Pathol. 86, 170–181. doi: 10.1016/j.humpath.2018.12.004
Mermel, C. H., Schumacher, S. E., Hill, B., Meyerson, M. L., and Getz, G. (2011). Gistic2.0 facilitates sensitive and confident localization of the targets of focal somatic copy-number alteration in human cancers. Genome Biol. 12:R41. doi: 10.1186/gb-2011-12-4-r41
Middleton, M., Grob, J., Aaronson, N., Fierlbeck, G., Tilgen, W., Seiter, S., et al. (2000). Randomized phase iii study of temozolomide versus dacarbazine in the treatment of patients with advanced metastatic malignant melanoma. J. Clin. Oncol. 18:158. doi: 10.1200/JCO.2000.18.1.158
Milella, M., Falcone, I., Conciatori, F., Cesta Incani, U., Del Curatolo, A., Inzerilli, N., et al. (2015). Pten: Multiple functions in human malignant tumors. Front. Oncol. 5:24. doi: 10.3389/fonc.2015.00024
Mishra, S., and Whetstine, J. R. (2016). Different facets of copy number changes: permanent, transient, and adaptive. Mol. Cell. Biol. 36, 1050–1063. doi: 10.1128/MCB.00652-15
Moelans, C. B., de Weger, R. A., Monsuur, H. N., Vijzelaar, R., and van Diest, P. J. (2010). Molecular profiling of invasive breast cancer by multiplex ligation-dependent probe amplification-based copy number analysis of tumor suppressor and oncogenes. Modern Pathol. 23, 1029–1039. doi: 10.1038/modpathol.2010.84
Morikawa, A., Hayashi, T., Kobayashi, M., Kato, Y., Shirahige, K., Itoh, T., et al. (2018). Somatic copy number alterations have prognostic impact in patients with ovarian clear cell carcinoma. Oncol. Rep. 40, 309–318. doi: 10.3892/or.2018.6419
Munro, D., Ghersi, D., and Singh, M. (2018). Two critical positions in zinc finger domains are heavily mutated in three human cancer types. PLoS Comput. Biol. 14:e1006290. doi: 10.1371/journal.pcbi.1006290
Nishida, K., Tamura, A., Nakazawa, N., Ueda, Y., Abe, T., Matsuda, F., et al. (1997). The IG heavy chain gene is frequently involved in chromosomal translocations in multiple myeloma and plasma cell leukemia as detected by in situ hybridization. Blood 90, 526–534. doi: 10.1182/blood.V90.2.526
Othman, M. A. K., Grygalewicz, B., Pienkowska-Grela, B., Rygier, J., Ejduk, A., Rincic, M., et al. (2016). A novel IGH@ gene rearrangement associated with CDKN2A/B deletion in young adult b-cell acute lymphoblastic leukemia. Oncol. Lett. 11, 2117–2122. doi: 10.3892/ol.2016.4169
Panagopoulou, M., Karaglani, M., Balgkouranidou, I., Biziota, E., Koukaki, T., Karamitrousis, E., et al. (2019). Circulating cell-free DNA in breast cancer: size profiling, levels, and methylation patterns lead to prognostic and predictive classifiers. Oncogene 38, 3387–3401. doi: 10.1038/s41388-018-0660-y
Park, A. K., Lee, J. Y., Cheong, H., Ramaswamy, V., Park, S.-H., Kool, M., et al. (2019). Subgroup-specific prognostic signaling and metabolic pathways in pediatric medulloblastoma. BMC Cancer 19:571. doi: 10.1186/s12885-019-5742-x
Parsons, D. W., Li, M., Zhang, X., Jones, S., Leary, R. J., Lin, J. C.-H., et al. (2011). The genetic landscape of the childhood cancer medulloblastoma. Science 331:435. doi: 10.1126/science.1198056
Pathak, A. K., Bhutani, M., Kumar, S., Mohan, A., and Guleria, R. (2006). Circulating cell-free DNA in plasma/serum of lung cancer patients as a potential screening and prognostic tool. Clin. Chem. 52, 1833–1842. doi: 10.1373/clinchem.2005.062893
Pei, G., Hu, R., Dai, Y., Zhao, Z., and Jia, P. (2020). Decoding whole-genome mutational signatures in 37 human pan-cancers by denoising sparse autoencoder neural network. Oncogene 39, 5031–5041. doi: 10.1038/s41388-020-1343-z
Phallen, J., Sausen, M., Adleff, V., Leal, A., Hruban, C., White, J., et al. (2017). Direct detection of early-stage cancers using circulating tumor DNA. Sci. Transl. Med. 9:eaan2415. doi: 10.1126/scitranslmed.aan2415
Pihan, G. A., Purohit, A., Wallace, J., Knecht, H., Woda, B., Quesenberry, P., et al. (1998). Centrosome defects and genetic instability in malignant tumors. Cancer Res. 58:3974.
Pinkel, D., Segraves, R., Sudar, D., Clark, S., Poole, I., Kowbel, D., et al. (1998). High resolution analysis of DNA copy number variation using comparative genomic hybridization to microarrays. Nat. Genet. 2, 207–211. doi: 10.1038/2524
Powell, D. R., O'Brien, J. H., Ford, H. L., and Artinger, K. B. (2014). “Chapter 16: Neural crest cells and cancer: Insights into tumor progression neural crest cells,” in Neural Crest Cells, ed P. A. Trainor (Boston, MA: Academic Press), 335–357. doi: 10.1016/B978-0-12-401730-6.00017-X
Ranzani, M., Iyer, V., Ibarra-Soria, X., Del Castillo Velasco-Herrera, M., Garnett, M., Logan, D., et al. (2017). Revisiting olfactory receptors as putative drivers of cancer [version 1; peer review: 2 approved]. Wellcome Open Res. 2:9. doi: 10.12688/wellcomeopenres.10646.1
Sandrine, G.-L., and Juillerat-Jeanneret, L. (2006). Glycosylation pathways as drug targets for cancer: glycosidase inhibitors. Mini-Rev. Med. Chem. 6, 1043–1052. doi: 10.2174/138955706778195162
Scarbrough, P. M., Akushevich, I., Wrensch, M., and Il'yasova, D. (2014). Exploring the association between melanoma and glioma risks. Ann. Epidemiol. 24, 469–474. doi: 10.1016/j.annepidem.2014.02.010
Shah, N., and Sukumar, S. (2010). The hox genes and their roles in oncogenesis. Nat. Rev. Cancer 10, 361–371. doi: 10.1038/nrc2826
Shao, X., Lv, N., Liao, J., Long, J., Xue, R., Ai, N., et al. (2019). Copy number variation is highly correlated with differential gene expression: a pan-cancer study. BMC Med. Genet. 20:175. doi: 10.1186/s12881-019-0909-5
Sharma, P., Alsharif, S., Fallatah, A., and Chung, B. M. (2019). Intermediate filaments as effectors of cancer development and metastasis: a focus on keratins, vimentin, and nestin. Cells 8:497. doi: 10.3390/cells8050497
Sinnberg, T., Levesque, M. P., Krochmann, J., Cheng, P. F., Ikenberg, K., Meraz-Torres, F., et al. (2018). WNT-signaling enhances neural crest migration of melanoma cells and induces an invasive phenotype. Mol. Cancer 17:59. doi: 10.1186/s12943-018-0773-5
Solinas-Toldo, S., Lampel, S., Stilgenbauer, S., Nickolenko, J., Benner, A., Dohner, H., et al. (1997). Matrix-based comparative genomic hybridization: biochips to screen for genomic imbalances. Genes Chromos. Cancer 4, 399–407. doi: 10.1002/(SICI)1098-2264(199712)20:4<399::AID-GCC12>3.0.CO;2-I
Stephens, P. J., Tarpey, P. S., Davies, H., Van Loo, P., Greenman, C., Wedge, D. C., et al. (2012). The landscape of cancer genes and mutational processes in breast cancer. Nature 486, 400–404. doi: 10.1038/nature11017
Strouhalova, K., Přechová, M., Gandalovičová, A., Brábek, J., Gregor, M., and Rosel, D. (2020). Vimentin intermediate filaments as potential target for cancer treatment. Cancers 12:184. doi: 10.3390/cancers12010184
Szalai, B., and Saez-Rodriguez, J. (2020). Why do pathway methods work better than they should. bioRxiv. 594, 4189–4200. doi: 10.1101/2020.07.30.228296
Taoudi Benchekroun, M., Saintigny, P., Thomas, S. M., El-Naggar, A. K., Papadimitrakopoulou, V., Ren, H., et al. (2010). Epidermal growth factor receptor expression and gene copy number in the risk of oral cancer. Cancer Prev. Res. 3:800. doi: 10.1158/1940-6207.CAPR-09-0163
Trombetta, D., Magnusson, L., von Steyern, F. V., Hornick, J. L., Fletcher, C. D., and Mertens, F. (2011). Translocation t(7;19)(q22;q13)–a recurrent chromosome aberration in pseudomyogenic hemangioendothelioma. Cancer Genet. 204, 211–215. doi: 10.1016/j.cancergen.2011.01.002
Tyanova, S., Albrechtsen, R., Kronqvist, P., Cox, J., Mann, M., and Geiger, T. (2016). Proteomic maps of breast cancer subtypes. Nat. Commun. 7:10259. doi: 10.1038/ncomms10259
Upender, M., Habermann, J., McShane, L., Korn, E., Barrett, J., Difilippantonio, M., and Ried, T. (2004). Chromosome transfer induced aneuploidy results in complex dysregulation of the cellular transcriptome in immortalized and cancer cells. Cancer Res. 64, 6941–6949. doi: 10.1158/0008-5472.CAN-04-0474
van Gent, D. C., Hoeijmakers, J. H. J., and Kanaar, R. (2001). Chromosomal stability and the DNA double-stranded break connection. Nat. Rev. Genet. 2, 196–206. doi: 10.1038/35056049
Volik, S., Alcaide, M., Morin, R. D., and Collins, C. (2016). Cell-free DNA (CFDNA): clinical significance and utility in cancer shaped by emerging technologies. Mol. Cancer Res. 14:898. doi: 10.1158/1541-7786.MCR-16-0044
Völker, M., Backström, N., Skinner, B. M., Langley, E. J., Bunzey, S. K., Ellegren, H., et al. (2010). Copy number variation, chromosome rearrangement, and their association with recombination during avian evolution. Genome Res. 20, 503–511. doi: 10.1101/gr.103663.109
Wang, D., Fan, J., Siao, C., Berno, A., Young, P., Sapolsky, R., et al. (1998). Large-scale identification, mapping, and genotyping of single-nucleotide polymorphisms in the human genome. Science 280, 1077–1082. doi: 10.1126/science.280.5366.1077
Wang, K., Lim, H. Y., Shi, S., Lee, J., Deng, S., Xie, T., et al. (2013). Genomic landscape of copy number aberrations enables the identification of oncogenic drivers in hepatocellular carcinoma. Hepatology 58, 706–717. doi: 10.1002/hep.26402
Weber, L., Maßberg, D., Becker, C., Altmüller, J., Ubrig, B., Bonatz, G., et al. (2018). Olfactory receptors as biomarkers in human breast carcinoma tissues. Front. Oncol. 8:33. doi: 10.3389/fonc.2018.00033
Weiss, J., Sos, M. L., Seidel, D., Peifer, M., Zander, T., Heuckmann, J. M., et al. (2010). Frequent and focal FGFR amplification associates with therapeutically tractable FGFR1 dependency in squamous cell lung cancer. Sci. Transl. Med. 2:62ra93. doi: 10.1126/scitranslmed.3001451
Wood-Bouwens, C., Lau, B. T., Handy, C. M., Lee, H., and Ji, H. P. (2017). Single-color digital PCR provides high-performance detection of cancer mutations from circulating DNA. J. Mol. Diagn. 19, 697–710. doi: 10.1016/j.jmoldx.2017.05.003
World Health Organization (2013). International Classification of Diseases for Oncology (ICD-O)-3rd Edn, 1st revision. Geneva: World Health Organization.
Wu, Y., Chen, X., Wang, S., and Wang, S. (2019). Advances in the relationship between glycosyltransferases and multidrug resistance in cancer. Clin. Chim. Acta 495, 417–421. doi: 10.1016/j.cca.2019.05.015
Xie, T., d'Ario, G., Lamb, J. R., Martin, E., Wang, K., Tejpar, S., et al. (2012). A comprehensive characterization of genome-wide copy number aberrations in colorectal cancer reveals novel oncogenes and patterns of alterations. PLoS ONE 7:e42001. doi: 10.1371/journal.pone.0042001
Zack, T. I., Schumacher, S. E., Carter, S. L., Cherniack, A. D., Saksena, G., Tabak, B., et al. (2013). Pan-cancer patterns of somatic copy number alteration. Nat. Genet. 45:1134. doi: 10.1038/ng.2760
Zare, F., Dow, M., Monteleone, N., Hosny, A., and Nabavi, S. (2017). An evaluation of copy number variation detection tools for cancer using whole exome sequencing data. BMC Bioinformatics 18:286. doi: 10.1186/s12859-017-1705-x
Zhang, F., Gu, W., Hurles, M. E., and Lupski, J. R. (2009). Copy number variation in human health, disease, and evolution. Annu. Rev. Genom. Hum. Genet. 10, 451–481. doi: 10.1146/annurev.genom.9.081307.164217
Zhang, L., Bai, W., Yuan, N., and Du, Z. (2019). Comprehensively benchmarking applications for detecting copy number variation. PLoS Comput. Biol. 15:e1007069. doi: 10.1371/journal.pcbi.1007367
Zhang, N., Wang, M., Zhang, P., and Huang, T. (2016). Classification of cancers based on copy number variation landscapes. Biochim. Biophys. Acta 1860(11 Pt B), 2750–2755. doi: 10.1016/j.bbagen.2016.06.003
Zhao, S., Choi, M., Overton, J. D., Bellone, S., Roque, D. M., Cocco, E., et al. (2013). Landscape of somatic single-nucleotide and copy-number mutations in uterine serous carcinoma. Proc. Natl. Acad. Sci. U.S.A. 110:2916. doi: 10.1073/pnas.1222577110
Zhao, X., Li, C., Paez, J., Chin, K., Jänne, P., Chen, T., et al. (2004). An integrated view of copy number and allelic alterations in the cancer genome using single nucleotide polymorphism arrays. Cancer Res. 64, 3060–3071. doi: 10.1158/0008-5472.CAN-03-3308
Keywords: cancer subtype classification, copy number variant, cancer, copy number, copy number alteration, cancer signatures
Citation: Gao B and Baudis M (2021) Signatures of Discriminative Copy Number Aberrations in 31 Cancer Subtypes. Front. Genet. 12:654887. doi: 10.3389/fgene.2021.654887
Received: 17 January 2021; Accepted: 15 April 2021;
Published: 13 May 2021.
Edited by:
Mehdi Pirooznia, National Heart, Lung, and Blood Institute (NHLBI), United StatesReviewed by:
Peikai Chen, University of Hong Kong, ChinaStephen R. Piccolo, Brigham Young University, United States
Paul Rejto, Pfizer, United States
Copyright © 2021 Gao and Baudis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Michael Baudis, michael.baudis@mls.uzh.ch