Serial Spike Time Correlations Affect Probability Distribution of Joint Spike Events
 Mina Shahi
Mina Shahi Carl van Vreeswijk
Carl van Vreeswijk Gordon Pipa
Gordon Pipa- 1Department of Neuroinformatics, Institute of Cognitive Science, University of Osnabrück, Osnabrück, Germany
- 2Centre de Neurophysique, Physiologie et Pathologie, Université René Descartes, Paris, France
Detecting the existence of temporally coordinated spiking activity, and its role in information processing in the cortex, has remained a major challenge for neuroscience research. Different methods and approaches have been suggested to test whether the observed synchronized events are significantly different from those expected by chance. To analyze the simultaneous spike trains for precise spike correlation, these methods typically model the spike trains as a Poisson process implying that the generation of each spike is independent of all the other spikes. However, studies have shown that neural spike trains exhibit dependence among spike sequences, such as the absolute and relative refractory periods which govern the spike probability of the oncoming action potential based on the time of the last spike, or the bursting behavior, which is characterized by short epochs of rapid action potentials, followed by longer episodes of silence. Here we investigate non-renewal processes with the inter-spike interval distribution model that incorporates spike-history dependence of individual neurons. For that, we use the Monte Carlo method to estimate the full shape of the coincidence count distribution and to generate false positives for coincidence detection. The results show that compared to the distributions based on homogeneous Poisson processes, and also non-Poisson processes, the width of the distribution of joint spike events changes. Non-renewal processes can lead to both heavy tailed or narrow coincidence distribution. We conclude that small differences in the exact autostructure of the point process can cause large differences in the width of a coincidence distribution. Therefore, manipulations of the autostructure for the estimation of significance of joint spike events seem to be inadequate.
1. Introduction
The mammalian brain is comprised of billions of neurons, each connected to thousands of other neurons by synapses. Every millisecond, thousands of neurons get excited and transmit brief, identical and stereotyped electrical pulses, called action potentials or spikes, to other neurons. The question of what kind of information is embedded in the spike trains, or how sensory and other information is represented in the spike trains and transmitted to other neurons, refers to a well-known puzzle namely, the neural coding problem. This problem has been a longstanding challenge within the neuroscience community and up to the present, there has not been a defined answer to this issue.
To decipher the neural codes, two candidates have largely been examined : 1- rate coding (e.g., Shadlen and Movshon, 1999), 2- temporal coding (e.g., Uhlhaas et al., 2009). Rate coding refers to the scheme which assumes that most, if not all, of the relevant information is transferred via mean firing rate of the neuron that neglects all the information which may exist in the exact timing of spikes. In recent years, the contrary idea of temporal coding has gained increasing attention. The temporal coding hypothesis claims that the temporal patterns of the neural activity may play a role in information coding, i.e., the precise temporal structures of neuronal discharges participate in coding information. Different coding strategies based on spike timing have been proposed, including, the time-to-first-spike (time of the first spike relative to onset of single event), phase-of-firing (phase of the spike with respect to the background oscillation in the brain) and correlations in spike timing of a group of neurons. The first two strategies are mostly concerned with how a single neuron encodes information, and the third strategy, which is known as the correlation coding model, claims that correlations between the spike timing of groups of neurons or cell assemblies convey information.
One extreme case of the correlation is synchrony, by which the spike patterns come in precise millisecond coordination across group of neurons. Coding by synchrony has been studied extensively both experimentally and theoretically (e.g., von der Malsburg, 1981; Gray and Singer, 1989; Gray et al., 1989; Riehle et al., 1997; Vicente et al., 2008; Pipa and Munk, 2011; Haslinger et al., 2013; Toutounji and Pipa, 2014; Torre et al., 2016b). Mounting evidence indicates the importance of neural synchrony in cognitive and executive processes and disruption of synchronization in cognitive dysfunctions (e.g., Niebur et al., 2002; Uhlhaas and Singer, 2006; Haenschel et al., 2007; Palva et al., 2010). Hence, theoretical tools for analyzing synchronized events is a necessity in the field of theoretical neuroscience.
To address the problem of coding by synchrony, one crucial step to take is to determine whether the synchronized events occur above chance. In other words, whether they occur more often than is expected if the individual neurons fire independently. To investigate this issue, different approaches and methods have been taken (e.g., Aertsen et al., 1989; König, 1994; Grün et al., 1999; Grün et al., 2002a,b; Pipa and Grün, 2003; Pipa et al., 2007, 2008; Staude et al., 2010; Torre et al., 2013, 2016a). To analyze ensembles of spike trains from simultaneously recorded neurons for precise spike correlations, many of these approaches model the spike train as a Poisson process with the same rate profile as the neuron under investigation (e.g., Grün et al., 2002a,b). Poisson process is a memoryless process, i.e., the occurrence of a spike at time t does not depend on the time occurrence of the previous spikes. In other words, the generation of each spike is independent of all other spikes. Another characteristic of the spike trains modeled as a Poisson process is that the inter-spike interval (ISI) follows an exponential distribution. However, the experimental spike trains show substantial deviation from these characteristics of Poisson process, i.e., independence of spike times and an exponential ISI distribution (e.g., Burns and Webb, 1976; Levine, 1991; Iyengar and Liao, 1997; Teich et al., 1997; Krahe and Gabbiani, 2004; Nawrot et al., 2007, 2008; Farkhooi et al., 2009). For example, neural spike trains exhibit absolute and relative refractory periods during which the probability of oncoming action potential, based on the time of the last spike, is zero or very low, respectively, or the bursting behavior, which is characterized by short epochs of rapid action potentials, followed by longer episodes of silence.
To model such characteristics of the neural firing, i.e., refractoriness, burstiness, and the regularity of the spike trains, Pipa et al. (2013) used two types of renewal processes, namely, a gamma process and a log-normal process, to study the effects of the autostructure of the spike trains on the shape of the probability distribution of coincidence count distribution of pairs of mutually independent spike trains. It is shown that the width of the coincidence count distribution depends on detailed properties of the ISI distribution, such as the coefficient of variation CV.
Assuming mutually independent ISIs, Pipa et al. (2013) used a renewal process to model the autostructure of the spike trains. However, this assumption may not be always in agreement with the characteristics of the biological spike trains. Neural firing might be described by non-renewal processes which can model higher order dependence of spike times that lie further back in the past (Nawrot et al., 2007). We will show that the higher order dependence can be modeled by a non-renewal process. We will further investigate the impact of the higher order dependence of the spike times on the probability distribution of coincidence events.
2. Materials and Methods
2.1. Renewal Process
Renewal process is a simple class of point process model with a very rich mathematical structure that can be an appropriate candidate to model events that occur randomly in time or space.
Definition 1. Renewal process is a stochastic process to models the random events in time (space) that are independent and identically distributed. It is called renewal because the process starts over after each event occurs, and the only factor that affects the likelihood of occurrence of an event is the elapsed time (space) since the last event.
Renewal process is frequently used to model the spike train, which implies that the inter-spike interval is i.i.d and the probability of occurrence of a spike depends on the elapsed time since the last spike. However, the occurrences of other spikes in the past do not affect the generation of the oncoming spike, in other words, if λ is an instantaneous firing rate at time t and H(t) is the history of the spikes and tN(t) is the time of the last spike then:
2.1.1. Poisson Process
Poisson process is a simple renewal process where the time between the successive arrivals is distributed exponentially, i.e.,
where x, λ ≥ 0. Since Poisson process is a memoryless process, the probability of occurrence of a new spike does not depend on the elapsed time since the last spike. For a homogenous Poisson process, the instantaneous firing rate is given by:
and for an inhomogenous Poisson process, the instantaneous firing rate is as follows:
Two other renewal processes widely used in modeling the spike trains are gamma and log-normal processes with the inter-spike intervals distributed from gamma and log-normal probability distribution, respectively.
2.1.2. Gamma Process
The gamma probability distribution is a two parameter probability distribution defined as follows:
θ and β are two parameters that describe the shape and the rate of the gamma process, respectively.
Given a constant firing rate λ = R and an average inter-spike interval , two properties of the gamma process with the parameters θ and β are as follows:
since and . CV is the coefficient of variation of the inter-spike interval distribution and it is one of the factors that is widely used to characterize the autostructure of the spike trains. Thus, gamma spike trains can be either described by the shape parameter θ and the rate β or with the coefficient of variation of the inter-spike interval CV and the firing rate R.
Poisson process is a special case of the gamma process for which θ = 1 and ISI distribution is exponential. The distribution of ISI becomes hyperexponential for a shape parameter θ < 1, which makes the short intervals more likely to happen than for a Poisson process with the same firing rate. Gamma process with θ < 1 can be used to model the bursty spike trains which is characterized by short epochs of rapid action potentials, followed by longer episodes of silence. On the contrary, when θ > 1, the gamma distribution approaches a narrow normal distribution which can be used to model regular spike trains (Pipa et al., 2013).
2.1.3. Log-Normal Process
If {X} is a random variable which is log-normally distributed with two parameters a and k then:
Given a constant firing rate R and a coefficient of variation of inter-spike interval CV two parameters a and k can be expressed as follows:
The log-normal distribution of the inter-spike intervals is more heavy-tailed than the inter-spike intervals distributed according to the gamma distribution. Also, very short intervals are unlikely to happen, which makes this distribution a good candidate to model the refractory period when short inter-spike intervals on the order of several milliseconds are unlikely to happen.
2.2. Non-renewal Process
One further step to generalize a stochastic process model to generate the spike trains is to remove the property of independence of the inter-spike intervals, as abundant experimental observations have shown that the spiking activity of many neurons cannot be modeled as a renewal process, since the occurrence of an action potential depends on other action potentials that occurred in the past (Burns and Webb, 1976; Levine, 1991; Iyengar and Liao, 1997; Teich et al., 1997; Krahe and Gabbiani, 2004; Nawrot et al., 2007, 2008; Farkhooi et al., 2009). In other words, they display history dependence in their spiking activity that persists over multiple action potential firings (Perkel et al., 2011). To model such spiking activities, a non-renewal process (denoted as C-log-normal process) is introduced in this paper. To this end, a new ISI probability distribution, called the C-log-normal probability distribution, which is a generalized form of the log-normal probability distribution, is presented. In the following section, a formal definition of the C-log-normal probability distribution and its properties are given.
2.2.1. C-Log-Normal Process
Definition 2. C-log-normal probability distribution is a doubly-stochastic Gaussian process with log-normal intensity, and it is obtained as follows:
1. Let Xn ~ N(0, 1), Xn−1 ~ N(0, 1) and
2. Define Xn = γXn−1 + ζn
3. Define
4. Define
The marginal distribution of C-log-normal probability distribution is defined as follows:
where a, k, α, and γ are the parameters of the distribution. The difference between the log-normal process and the C-log-normal process is given in the following example.
Example: Let Xn be an independent random variable with a normal distribution, i.e., . Then Tn = exp(Xn) follows a log-normal distribution. However, Xns from the C-log-normal probability distribution are not independent variables. If we define Xn and Zn according to definition 2 (2) and 2 (3) respectively, then Tn = exp(Zn) has a C-log-normal distribution. Bare in mind that here, (See Supplement 2.1 and 2.2). However, they are not independent.
To illustrate the effect of dependent ISIs on the spike train's autostructure, we compare the spike trains generated from the Poisson, log-normal and C-log-normal processes. Figures 1A–C shows the raster plots for 50 trials of mutually independent spike trains from the aforementioned processes, respectively. The spike rate for all three processes is 50Hz, however, the autostructure of the spike trains is different in the C-log-normal process. That is, the burst firings with longer periods happen more often in the C-log-normal process than in the other two processes. The next section provides a more in-depth look at the properties of C-log-normal processes.
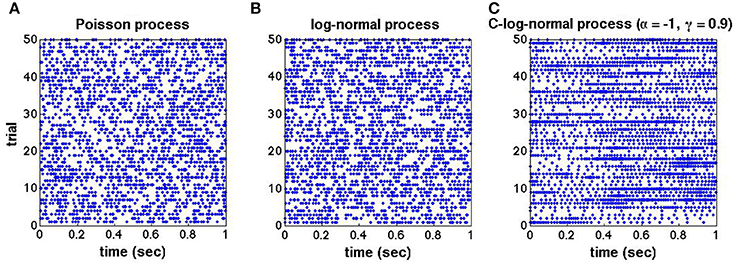
Figure 1. (A–C) Raster plots for 50 trials of mutually independent spike trains generated from the Poisson, log-normal, and C-log-normal processes, respectively. Spike rate for all spike trains are chosen to be R = 50Hz and CV = 1.
2.2.2. Properties of the C-Log-Normal Process
(i) If , then the successive Xis obtained by definition 2 (2) are also normally distributed, i.e., (See Supplement 2.1 for the proof).
(ii) Zn given by definition 2 (3) has a normal distribution, i.e., (See Supplement 2.2 for the proof).
(iii) If Zn and Zn−k are defined by definition 2 (3), then
(See Supplement 2.3 for the proof).
(iv) The log normal process is a special case of the C-log-normal process, when α = γ, which in this case:
That is, there is no dependence between Zns, which results in mutually independent ISIs of a spike train, and that is the property of the log-normal process.
(v) C-log-normal and log-normal processes have the same ISI distribution. However, the ISIs of the C-log-normal process are correlated but the ISIs of the log-normal process are independent. Figure 2 illustrates the ISI distribution of the C-log-normal process for different pairs of α and γ (parameters of C-log-normal process). The solid distribution is the ISI distribution of the C-log-normal process, while the red curve indicates the ISI distribution of the log-normal process. Both ISI distributions have the same profile.
(vi) Since the ISI distribution of C-log-normal and log-normal process are the same, the first order statistics of their ISIs, such as the mean and variance of their ISIs, are also equal. Thus, the parameters a and k of C-log-normal process can be substituted by the spike rate R and the coefficient of variance CV according to Equation (2.4.2.4) and (2.4.2.5), respectively.
(vii) The values of α and γ affect the autostructure of the spike train. Figure 3 shows 8 spike rasters, each has 50 mutually independent spike trains generated from the C-log-normal process for different pairs of γ and α. For the same pairs of γ and α, Figure 4 illustrates E[ZnZn−k] defined in Equation (26). For a negative γ, E[ZnZn−k] oscillates between negative and positive values. If α1 < α < α21 then oscillation starts from a positive value (first lag) (Figure 4A2). If α < α1 or α > α2 then oscillation is in the opposite order, it starts from a negative and then to a positive (Figures 4A1,A4). For a positive γ, E[ZnZn−k] does not oscillate and it is either positive or negative depending on the value of α. If α1 < α < α2, then E[ZnZn−k] is negative (Figure 4B3), and if α < α1 or α > α2 it is positive for all lags (Figures 4B1,B4). Table 1 summarizes the results. Refer to the Figure S1 for the autocorrelation of the spike times.
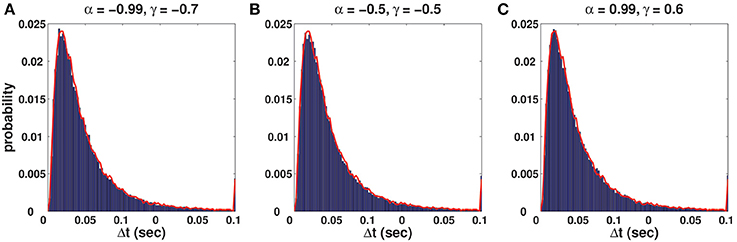
Figure 2. (A–C) Solid distribution shows the ISI distribution of the C-log-normal process for different pairs of α and γ. The red curve illustrates the ISI distribution of the log-normal process. For all distributions CV = 1, R = 50Hz.
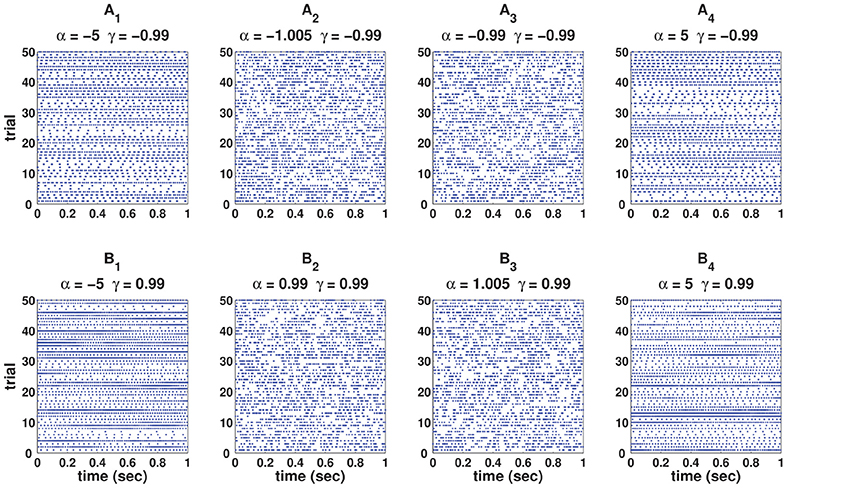
Figure 3. Eight spike rasters, each has 50 mutually independent spike trains generated from C-log-normal process for different pairs of γ and α. For all distributions CV = 1, R = 50Hz. (A1–A4) correspond to γ < 0 and (B1–B4) correspond to γ > 0.
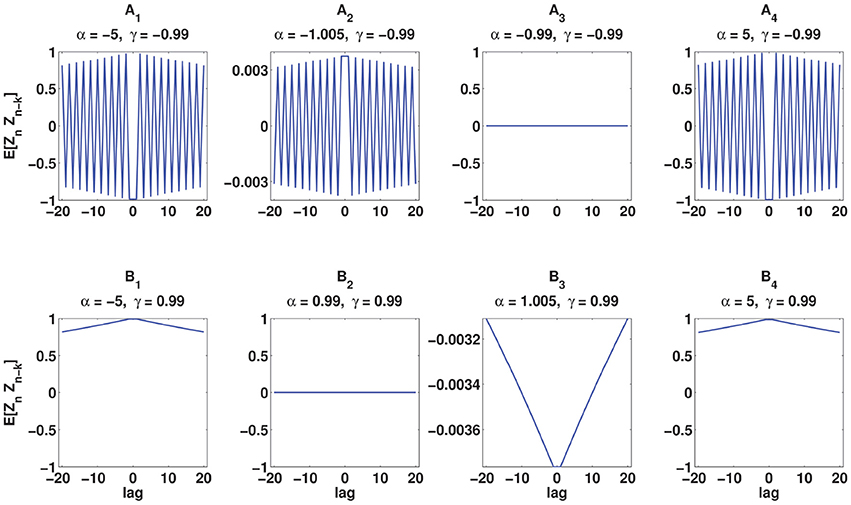
Figure 4. Analytical E[ZnZn−k] (Equation 26) for the same pairs of γ and α used in Figure 3. (A1–A4) correspond to γ < 0 and (B1–B4) correspond to γ > 0.

Table 1. Effects of parameters α and γ on the sign of E[ZnZn−k].
2.3. Simulation Methods
2.3.1. Coincidence Count Distribution
To estimate the coincidence count distribution, the following procedure is applied:
1. Generate N = 600 mutually independent spike trains of length T = 5 s from the C-log-normal distribution.
2. Divide the length of the first spike train into Nbin exclusive bins with the length of Δt = 4 ms, thus the total number of bins, Nbin, is
3. For each spike train, count the number of spikes that fall into each bin. , is the number of the spikes that are assigned to the bin i from the jth spike train.
4. Count the number of coincidences for each independent pair of spike trains a and b, that is, multiply the number of the spikes in the bin i of the spike train a, i.e., , by the number of the spikes in the bin i of te spike train b, i.e., . Repeat this step for all the bins. The number of coincidences of these two spike trains is the sum of the number of coincidences of all the bins, i.e.,
5. Generate a histogram of Ncs as an estimate of the coincidence count distribution.
2.3.2. Estimation of False Positive Rate
To estimate the false positive rate of the coincidence count distribution of C-log-normal process, we take the following steps:
1. Generate N1 = 200 mutually independent spike trains of length T = 5 s and firing rate of R = 50 Hz from the Poisson process.
2. Compute the coincidence count distribution, fp, according to the Section Coincidence Count Distribution.
3. Estimate the expected number the coincidence counts, λ, by taking the mean fp.
4. Find the empirical estimation of fp, Fp.
5. Generate N2 = 1000 random numbers from the Poisson probability distribution with rate λ.
6. Estimate the empirical cumulative distribution function, Fp, of fp.
7. Use Fp and find the critical number, NcriticalPoisson, for which 1 − F(NcriticalPoisson) < 1%. This critical number corresponds to 1% significance level.
8. Set i = 1.
9. Generate N = 200 mutually independent spike trains of length T = 5 s and firing rate of R = 50 Hz from C-log-normal process.
10. Compute the coincidence count distribution, fp, according to the Section Coincidence Count Distribution.
11. Find the empirical estimation of fC−logN, FC−logN.
12. Use FC−logN and NcriticalPoisson to compute:
13. FP is the false positive rate of coincidence count distribution of C-log-normal process corresponds to 1% significance level under the assumption that the underlying spike trains are generated from Poisson process.
14. Iterate steps 9–12 for i = 2, …, 10 trials.
15. Iterate steps 1–14 and substitute the Poisson process with the Log-Normal process.
3. Results
This section presents the effects of parameters of the C-log-normal process, namely, α and γ, on the autostructure of the spike trains. The questions addressed in this section are: 1-how do parameters α and γ influence the autocorrelation of C-log-normal process 2- what is the role of parameters α and γ on the order of serial correlation of ISIs? 3- how so parameters α and γ affect the shape of the coincidence count distribution? and finally, how do values of α and γ influence the false positive rate for a particular test level?
3.1. Effect of α and γ on the ISI Correlation
Figure 5 illustrates in the form of a colormap of a comparison E[ZnZn−k] for different values of parameters α and γ. Figures 5A1– A3 show E[ZnZn−k] for k = 1, k = 2, and k = 3, respectively. Two examples, namely γ = −0.7 and γ = 0.7 which are indicated by two black lines, are considered to be explained in more detail in this part. Two solutions of E[ZnZn−k] = 0 when γ = −0.7 and γ = 0.7 are [α1 = −1.42, α2 = −0.7] and [α1 = 0.7, α2 = 1.42], respectively. α1s and α2s are shown by red crosses in Figures 5A1–A3. First consider the value of E[ZnZn−k] for γ = −0.7. As it is summarized in Table 1, for γ < 0 and α1 < α < α2, E[ZnZn−k] oscillates from a positive to a negative value. The same results are shown in Figures 5A1–A3. For α1 < α < α2, E[ZnZn−k] is positive for k = 1, negative for k = 2, and it is positive for k = 3. For α < α1 or α > α2 the oscillation is in the opposite order, i.e., E[ZnZn−k] is negative for k = 1, positive for k = 2, and for k = 3 is negative.
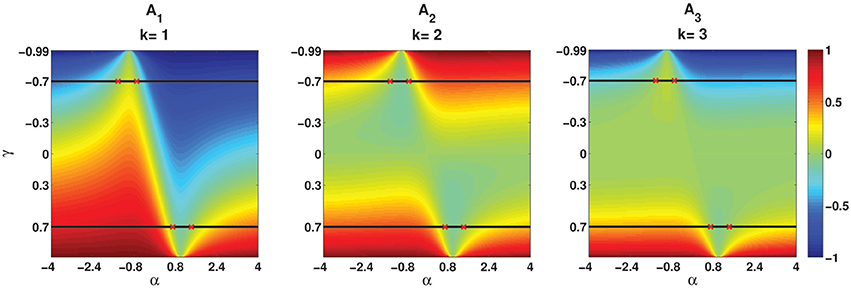
Figure 5. Analytical E[ZnZn−k] (Equation 26) for different values of parameters (α, γ). (A1–A3) Correspond to k = 1, k = 2, and k = 3, respectively. Red crosses indicate the values of α which are the solutions of E[ZnZn−k] = 0 for γ = −0.7 and γ = −0.7.
In the second case when γ = 0.7, E[ZnZn−k] does not oscillate and it is either positive or negative based on the value of α. As given in Table 1, for γ > 0 and α1 < α < α2, E[ZnZn−k] is negative and for α < α1 or α > α2 it is positive, irrespective of the value of k. As indicated in Figures 5A1–A3 for γ = 0.7, E[ZnZn−k] is negative where α1 < α < α2 and it is positive where α < α1 or α > α2.
Moreover, the effects of the values of α and magnitude of γ are illustrated in Figure 5. The more α is away from one side of the interval, the higher the absolute value of E[ZnZn−k], and the bigger the magnitude of γ is, the more Zns are correlated to the previous Zn−is and the correlation goes further into the past.
Another characteristic that can be observed by comparison of the magnitude of E[ZnZn−k] in Figures 5A1–A3 is that the magnitude of E[ZnZn−k] is higher for k = 1 for different parameters of αs and γs. Whereas, E[ZnZn−k] in Figures 5A2,A3 is mostly indicated by green, which, has the range of [−0.1–0.2]. That is, the bigger k is, the smaller the magnitude of E[ZnZn−k].
The previous section presented the relation between parameters α and γ and E[ZnZn−k]. However, the roles of α and γ in ISI serial correlation has not yet been and will be covered in this section.
The correlation between ISIi and ISIi+j is quantified by the ISI serial correlation coefficient, ρj, where j is the lag. ρj is given as follows:
where Ii is the length of ith inter-spike interval. Figures 6, 7 illustrate the effects of α and γ on the ISI serial correlation. Each box plot corresponds to N = 15 spike trains of length T = 5 s. The green line indicates ρj = 0 as the base line.
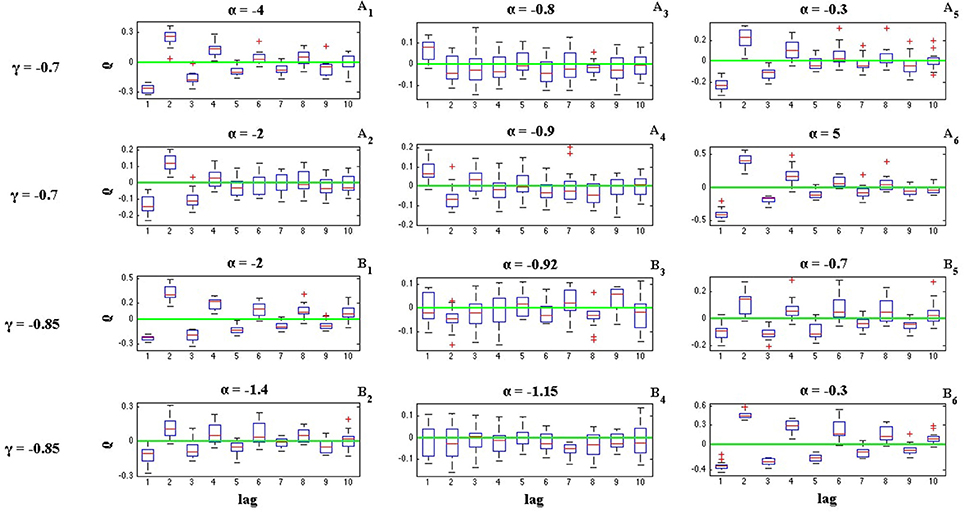
Figure 6. Effects of parameters α and γ on the ISI serial correlation of the C-log-normal process. The first column corresponds to α < α1, the second column corresponds to α1 < α < α2, and the third column corresponds to α > α2, where α1 and α2 are the solutions for E[ZnZn−k] = 0 for a given parameter γ (CV = 1, R = 50Hz). (A1–A6) correspond to γ = −0.7 and different α. (B1–B6) correspond to γ = −0.85 and different α.
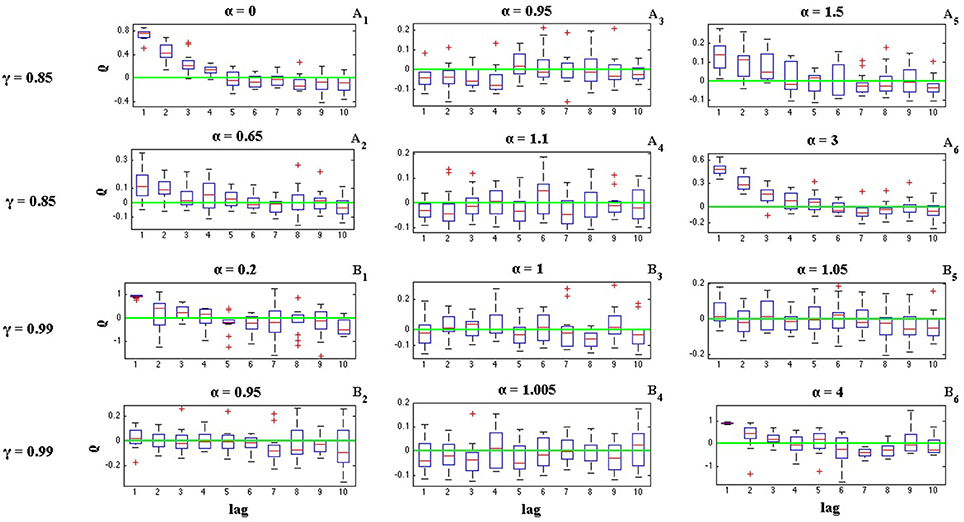
Figure 7. Effects of parameters α and γ on the ISI serial correlation of the C-log-normal process. The first column corresponds to α < α1, the second column corresponds to α1 < α < α2, and the third column corresponds to α > α2, where α1 and α2 are the solutions for E[ZnZn−k] = 0 for a given parameter γ (CV = 1, R = 50Hz). (A1–A6) correspond to γ = 0.85 and different α. (B1–B6) correspond to γ = 0.99 and different α.
The effects of α and γ on the ISI correlation coefficient, are in the same way as they are on E[ZnZn−k]. For negative γs, ρj oscillates between positive and negative values and if α < α1 or α > α2, then the ISI correlation coefficient for j = 1 is negative and for j = 2 is positive and so on. However, if α1 < α < α2 then the sequence of ρj oscillates in the opposite order, it is first positive and then negative and so on. For positive γ, ρj does not show any oscillatory behavior and it is either positive or negative depends on the value of α (Figure 7). It is positive if α < α1 or α > α2 and it is negative if α1 < α < α2.
Figures 6, 7 also show the effect of the value of α on the ISI serial correlation. The more α is away from one side of the interval [α1, α2] the higher the value of ρj. For example, Figures 7A1,A2 compare the values of ρj for parameters γ = 0.85, α = 0 and γ = 0.85, α = 0.65, respectively. Since for γ = 0.85 two solutions of E[ZnZn−k] = 0 are α1 = 0.85 and α2 = 1.176, and |0−0.85| > |0.65−0.85|, ρj shows higher value for α = 0. For each value of γ shown in Figures 6, 7, first column corresponds to α < α1, second column corresponds to α1 < α < α2, and the third column corresponds to α > α2, where α1 and α2 are the solutions for E[ZnZn−k] = 0 for a given parameter γ.
3.2. Influence of α and γ on the Coincidence Count Distribution
Figures 8, 9 show the coincidence count distribution for the spike trains generated from the C-log-normal process with parameters γ = 0.99 and α = [0.95, 0.99, 1, 1.05]. The red profile in Figure 8 indicates the coincidence count distribution of the Poisson process and in Figure 9 indicates the coincidence count distribution of the log-normal process with the same firing rate as is chosen for the C-log-normal process, i.e., R = 50Hz. The green vertical line in both figures shows the critical number of coincidences that corresponds to 1% significance level under the assumption that the underlying spike trains are generated from the C-log-normal process and the red vertical line in Figures 8, 9 indicates the critical number of coincidences that corresponds to 1% significance level under the assumption that the underlying spike trains are generated from the Poisson process and the log-normal process, respectively. In Figures 8, 9A,D) (with α = 0.95 and α = 1.05 which are out of the interval [0.99, 1.01], two solutions of E[ZnZn−k] = 0) the coincidence count distributions have long tail which results in a higher false positive rate. On the contrary, in Figure 9C (with α = 1 which is in the interval [0.99, 1.01]) the coincidence count distribution has a shorter tail and the false positive value is smaller. Figure 8B (with α = γ) also shows a shorter tail and a smaller false positive value, but in Figure 9B the red and green lines show the same critical number since the condition of α = γ implies that the C-log-normal process can be considered as the log-normal process.
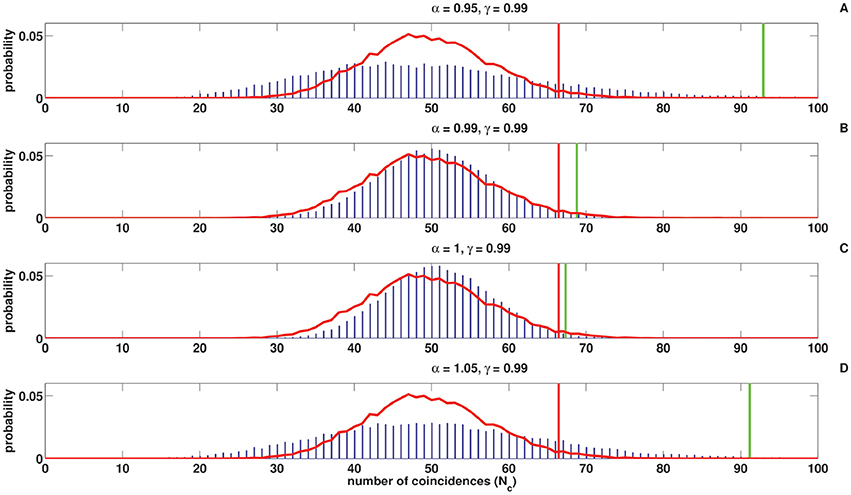
Figure 8. Coincidence count distribution for the spike trains generated from the C-log-normal process with the parameters γ = 0.99 and α = [0.95, 0.99, 1, 1.05], indicated by the blue histogram. The red profile indicates coincidence count distribution of the Poisson process. The red and green vertical lines show the critical numbers of coincidences that correspond to 1% significance level under the assumption that the underlying spike trains are generated from the Poisson and C-log-normal processes, respectively (CV = 1, R = 50Hz). (A–D) correspond to γ = 0.99 and different α.
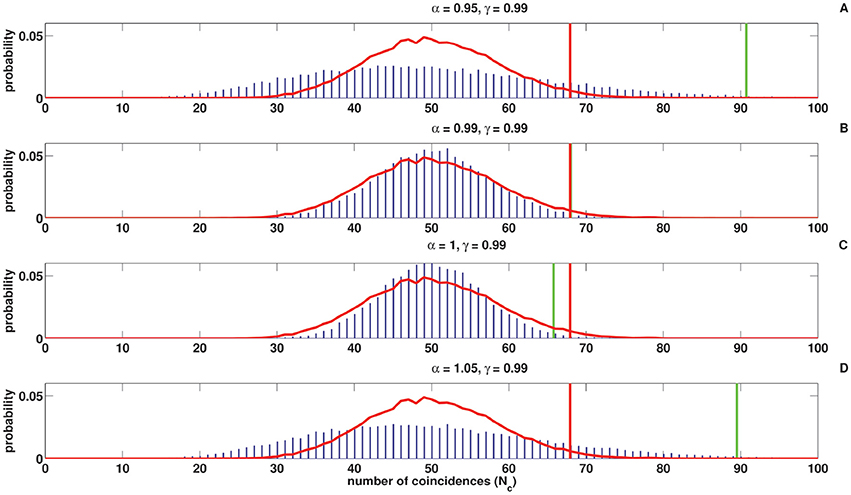
Figure 9. Coincidence count distribution for the spike trains generated from the C-log-normal process with the parameters γ = 0.99 and α = [0.95, 0.99, 1, 1.05], indicated by the blue histogram. The red profile indicates the coincidence count distribution of the log-normal process. The red and green vertical lines show the critical numbers of coincidences that correspond to1% significance level under the assumption that the underlying spike trains are generated from the the log-normal and C-log-normal processes, respectively (CV = 1, R = 50Hz). (A–D) correspond to γ = 0.99 and different α.
3.3. Impact of α and γ on the False Positive Rate
As it is shown in Figures 8, 9 the coincidence count distribution for αs out of the interval [α1, α2] are more heavily tailed and for αs in the interval [α1, α2] the tail of coincidence count distribution of C-log-normal is shorter than the tail of coincidence count distribution of the Poisson and the log-normal processes. The heavy tailed coincidence count distribution results in strong consequences for hypothesis testing. Figures 10, 11 quantitatively compare the false positive rate of the coincidence count distribution of the C-log-normal with the Poisson process and the log-normal process, respectively. In Figure 10, the critical number of coincidences that corresponds to 1% significance level under the assumption that the underlying spike trains are Poissonian, is first estimated and based on this number, the false positive rate of the coincidence count distribution of the C-log-normal process is computed. In Figure 11, instead of the Poisson process, the false positive rates of the coincidence count distribution of the C-log-normal process are computed, based on the critical number of coincidences that corresponds to 1% significance level under the assumption that the underlying spike trains are from the log-normal process. In both Figures 10, 11, when α is out of the interval [α1, α2], then the false positive rates are more than 1% (for both γ > 0 and γ < 0), except in Figure 11B1 when γ = −0.7. When α is in the interval [α1, α2] and γ > 0, then the false positive is decreasing. However, if γ < 0 the false positive rate is again increasing. Moreover, in Figure 11, when α = γ, the false positive rate is close to 1%, i.e., it equals the false positive of the coincidence count distribution under the assumption that the spike trains are generated from the log-normal process.
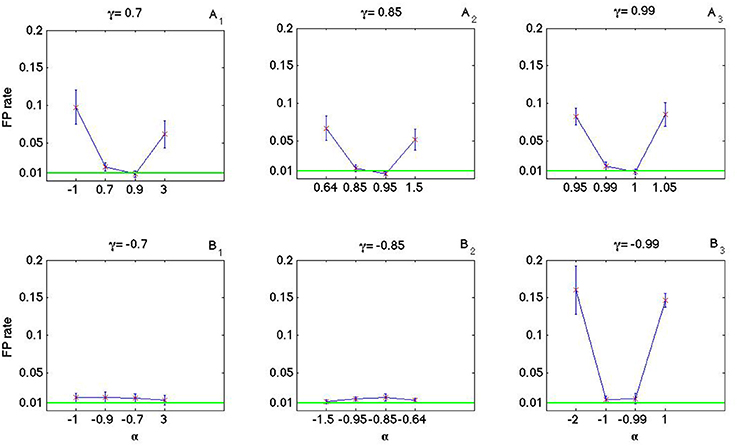
Figure 10. False positive rate of the coincidence count distribution of the C-log-normal process based on the critical number of coincidences that corresponds to 1% significance level under the assumption that the underlying spike trains are from the Poisson process. (A1–A3) correspond to positive γs and (B1–B3) correspond to negative γs (CV = 1, R = 50Hz).
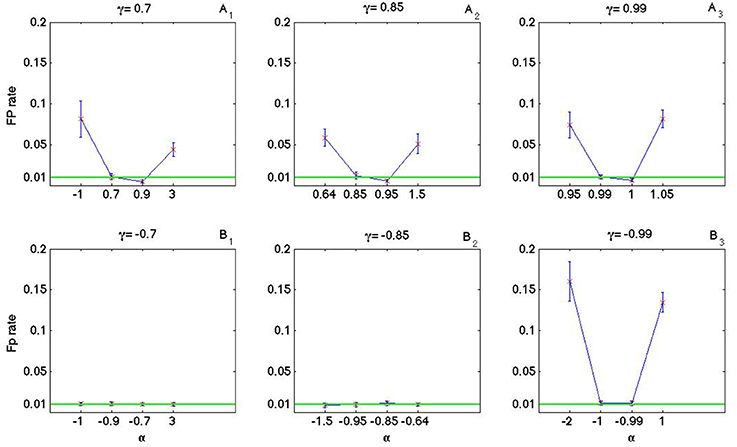
Figure 11. False positive rate of the coincidence count distribution of the C-log-normal process based on the critical number of coincidences that corresponds to 1% significance level under the assumption that the underlying spike trains are from the log-normal process. (A1–A3) correspond to positive γs and (B1–B3) correspond to negative γs (CV = 1, R = 50Hz).
3.4. Comparison of the Full Coincidence Count Distribution
To compare the full distribution of the coincidence count of the C-log-normal process with the coincidence count distribution of the Poisson process and the log-normal process, quantile-quantile (QQ) plots are shown in Figures 12, 13, respectively. The qualitative behavior of plots in both Figures 12, 13 are the same. The higher the magnitude of γ, the more the curve diverges from the diagonal. Also, in each panel where the magnitude of γ is constant, the value of α affects how much the curve diverges from the diagonal. The further α is away from one side of the interval [α1, α2], the more the curve diverges from the diagonal. For example, in Figures 12A3, 13A3, α = 0.95, 1.05 are both out of the interval [α1 = 0.99, α2 = 1.01] and the divergence of their corresponding curves is strongly pronounced. For α = 1, which is in the interval [0.99, 1.01], the divergence is not very pronounced since its distance from α1 or α2 is not high. The curve corresponding to α = 0.99 lies on the diagonal because when α = γ the C-log-normal process can be considered as the log-normal process, thus both have the same coincidence count distribution. In both figures, on the bottom left of the panels, any curve above the diagonal indicates an increased false-positive level, and below the diagonal indicates a reduced number of false positives if the test statistics is based on the assumption that spike trains follow Poissonian firing or log-normal ISIs. In contrast, on the top right of the panels, any curve below the diagonal indicates an increased false-positive level and above the curve indicates a decreased false positive rate.
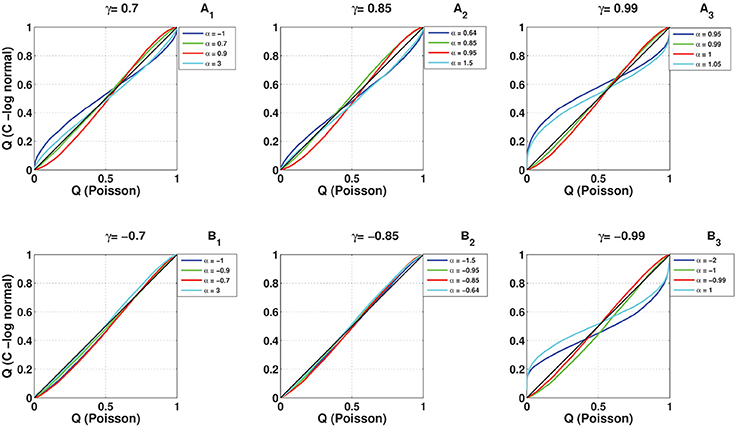
Figure 12. Quantile-Quantile (QQ) plots of the coincidence count distribution of the Poisson and C-log-normal processes (CV = 1, R = 50Hz). (A1–A3) correspond to γ > 0 and different α. (B1–B3) correspond to γ < 0 and different α.
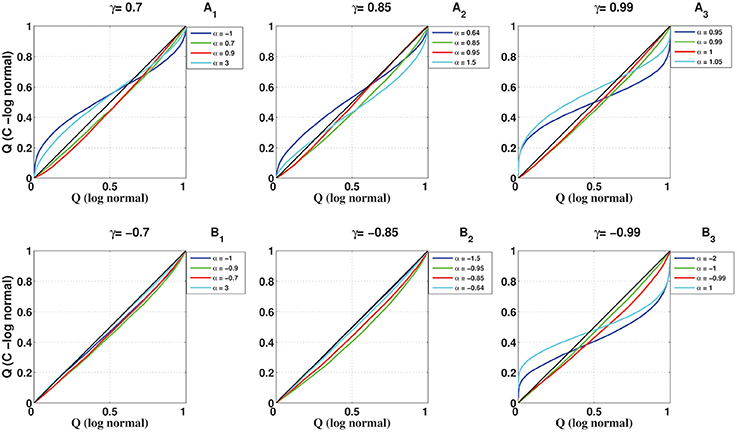
Figure 13. Quantile-Quantile (QQ) plots of the coincidence count distribution of the log-normal and C-log-normal processes (CV = 1, R = 50Hz). (A1–A3) correspond to γ > 0 and different α. (B1–B3) correspond to γ < 0 and different α.
4. Discussion
The discussion of whether the coordinated neural activities really exist and occur more often than expected by chance, in other words, whether they occur more often than is expected if the neurons fire independently has long tantalized neuroscientists.
To examine this issue, different approaches have been taken, which, most of them intentionally destroying or involuntarily neglecting the autostructure of the spiking activity of individual neurons. To analyze the simultaneous spike trains for precise spike correlation and test whether the observed coincidence events occur significantly above chance, many of these approaches model the spike train as a Poisson Process, implying that the generation of each spike is independent of all the other spikes, and the inter-spike intervals (ISIs) has an exponential distribution (Grün et al., 2002a,b). However, the experimental ISIs show substantial deviation from these assumptions. For example, they exhibit dependence among spike sequences, such as absolute and relative refractory periods, or bursting, periodic, or regular behaviors. Additionally, spike times might show higher order dependence of spike times lying further in the past, and thus cannot be modeled by the Poisson process.
In this paper, we have studied the influence of higher order dependence of spike times which lie further in the past and exist in the autostructure of the spike times, on the shape of the coincidence count distribution of pairs of mutually independent spike trains. To this end, we proposed a non-renewal process (denoted C-log-normal process) which is a generalized model of a renewal log-normal process. We derived the properties of C-log-normal process analytically. In addition, we used the Monte Carlo estimation to examine the effects of the model's parameters, α and γ, on the shape of the coincidence count distribution of pairs of mutually independent spike trains generated from the C-log-normal process. The results were also compared with the shape of the coincidence count distribution of pairs of mutually independent spike trains generated from the log-normal process and the Poisson process.
The first finding is that the sign of γ causes E[ZnZn−k] to be either positive or negative (if γ > 0), or oscillates between positive and negative values (if γ < 0). If γ > 0 and α1 < α < α2, then E[ZnZn−k] is negative, which results in the long inter-spike intervals to be followed by the short inter-spike intervals and vice versa. If α < α1 or α2 < α, then E[ZnZn−k] is positive, that is, long inter-spike intervals are intended to be followed by long inter-spike intervals and vice versa. However, if γ < 0, then E[ZnZn−k] shows oscillatory behavior, that is, if α1 < α < α2, then E[ZnZn−k] oscillates from a positive to a negative value and if α < α1 or α2 < α, then E[ZnZn−k] oscillates from a negative to a positive value.
The second finding is that, compared to the coincidence distributions of homogeneous Poisson processes and also non-Poisson processes, the width of the distribution of joint spike events of the C-log-normal process changes. The non-renewal C-log-normal process can lead to both heavy tailed or narrow coincidence distribution, which results in higher or lower false positive rates, respectively, in relation to 1% significance level under the assumption that the underlying spike trains from the Poisson or the log-normal process. If γ > 0 and α1 < α < α2 the false positive rate is decreased and if α < α1 or α2 < α the false positive rate is increased. The impact of γ < 0 is more complex and does not exactly follow the same behavior for different values of γ. However, for a higher magnitude of γ (e.g., γ = −0.99), the false positive rate when α1 < α < α2 is decreased and if α < α1 or α2 < α the false positive rate is increased.
In this study, the other parameters that can affect the autostructure of spike trains, namely the coefficient of variation of the inter-spike interval distributions CV and the Fano factor FF were kept constant. These two parameters also have an impact on the probability distribution of joint spikes events (Pipa et al., 2013). In future work, the effects of these two factors along with the parameters of the C-log-normal process on the autostructure of spike trains, coincidence count distribution and false positive rate can be studied.
Additionally, the complexity of interactions between neurons can be extended. So far, we have discussed the effects of the autostructure of spike trains on the coincidence count distribution across pairs of neurons. In future work, this can be extended to higher complexities, such as triplet, quintuplet, or in general ζ-tuplet coincidences.
Another future direction worth pursuing is to use the C-log-normal process for modeling the experimental data. To this end, a method to fit the parameters of C-log-normal process, namely α and γ, needs to be developed.
In conclusion, the simulations done in this paper highlight the possible issues when spike trains deviate from Poisson but Poisson is assumed. In respect to the neural code, the lesson to learn is: do not make such a strong assumption about the data since it can make the analysis fragile. That is, the higher order dependence of spike times which lie further in the past can affect the autostructure of spike times, which can falsify the statistical inference of the existence of coordinated neuronal activity. This effect results in over or underestimation of statistical significancies.
Author Contributions
MS performed the calculus, simulations and wrote the original draft. CV provided the initial spike train model. GP was involved in the simulation, calculus and writing.
Funding
We acknowledge support by Deutsche Forschungsgemeinschaft (DFG) and Open Access Publishing Fund of Osnabrück University.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/article/10.3389/fncom.2016.00139/full#supplementary-material
Footnotes
1. ^α1 and α2 are two solutions for equation E[ZnZn−k] = 0
References
Aertsen, A. M., Gerstein, G. L., Habib, M. K., and Palm, G. (1989). Dynamics of neuronal firing correlation: modulation of “effective connectivity.” J. Neurophysiol. 61, 900–917.
Burns, B. D., and Webb, A. (1976). The spontaneous activity of neurones in the cat's cerebral cortex. Proc. R. Soc. Lond. B Biol. Sci. 194, 211–223.
Farkhooi, F., Strube-Bloss, M. F., and Nawrot, M. P. (2009). Serial correlation in neural spike trains: experimental evidence, stochastic modeling, and single neuron variability. Phys. Rev. E 79:021905. doi: 10.1103/PhysRevE.79.021905
Gray, C. M., König, P., Engel, A. K., and Singer, W. (1989). Oscillatory responses in cat visual cortex exhibit inter-columnar synchronization which reflects global stimulus properties. Nature 338, 334–337.
Gray, C. M., and Singer, W. (1989). Stimulus-specific neuronal oscillations in orientation columns of cat visual cortex. Proc. Natl. Acad. Sci. U.S.A. 86, 1698–1702.
Grün, S., Diesmann, M., and Aertsen, A. (2002a). Unitary events in multiple single-neuron spiking activity: I detection and significance. Neural Comput. 14, 43–80. doi: 10.1162/089976602753284455
Grün, S., Diesmann, M., and Aertsen, A. (2002b). Unitary events in multiple single-neuron spiking activity: II. nonstationary data. Neural Comput. 14, 81–119. doi: 10.1162/089976602753284464
Grün, S., Diesmann, M., Grammont, F., Riehle, A., and Aertsen, A. (1999). Detecting unitary events without discretization of time. J. Neurosci. Methods 94, 67–79.
Haenschel, C., Uhlhaas, P. J., and Singer, W. (2007). Synchronous oscillatory activity and working memory in schizophrenia. Pharmacopsychiatry 40, S54–S61. doi: 10.1055/s-2007-990302
Haslinger, R., Pipa, G., Lewis, L. D., Nikolić, D., Williams, Z., and Brown, E. (2013). Encoding through patterns: regression tree–based neuronal population models. Neural Comput. 25, 1953–1993. doi: 10.1162/NECO_a_00464
Iyengar, S., and Liao, Q. (1997). Modeling neural activity using the generalized inverse gaussian distribution. Biol. Cybern. 77, 289–295.
König, P. (1994). A method for the quantification of synchrony and oscillatory properties of neuronal activity. J. Neurosci. Methods 54, 31–37.
Krahe, R., and Gabbiani, F. (2004). Burst firing in sensory systems. Nat. Rev. Neurosci. 5, 13–23. doi: 10.1038/nrn1296
Levine, M. W. (1991). The distribution of the intervals between neural impulses in the maintained discharges of retinal ganglion cells. Biol. Cybern. 65, 459–467.
Nawrot, M., Boucsein, C., Rodriguezmolina, V., Aertsen, A., Grün, S., and Rotter, S. (2007). Serial interval statistics of spontaneous activity in cortical neurons in vivo and in vitro. Neurocomputing 70, 1717–1722. doi: 10.1016/j.neucom.2006.10.101
Nawrot, M. P., Boucsein, C., Rodriguez Molina, V., Riehle, A., Aertsen, A., and Rotter, S. (2008). Measurement of variability dynamics in cortical spike trains. J. Neurosci. Methods 169, 374–390. doi: 10.1016/j.jneumeth.2007.10.013
Niebur, E., Hsiao, S. S., and Johnson, K. O. (2002). Synchrony: a neuronal mechanism for attentional selection? Curr. Opin. Neurobiol. 12, 190–194. doi: 10.1016/S0959-4388(02)00310-0
Palva, J. M., Monto, S., Kulashekhar, S., and Palva, S. (2010). Neuronal synchrony reveals working memory networks and predicts individual memory capacity. Proc. Natl. Acad. Sci. U.S.A. 107, 7580–7585. doi: 10.1073/pnas.0913113107
Perkel, D. H., Gerstein, G. L., and Moore, G. P. (2011). In vivo conditions influence the coding of stimulus features by bursts of action potentials. J. Comput. Neurosci. 31, 369–483. doi: 10.1007/s10827-011-0313-4
Pipa, G., and Grün, S. (2003). Non-parametric significance estimation of joint-spike events by shuffling and resampling. Neurocomputing 52-54, 31–37. doi: 10.1016/S0925-2312(02)00823-8
Pipa, G., Grün, S., and Van Vreeswijk, C. (2013). Impact of spike train autostructure on probability distribution of joint spike events. Neural comput. 25, 1123–1163. doi: 10.1162/NECO_a_00432
Pipa, G., and Munk, M. (2011). Higher order spike synchrony in prefrontal cortex during visual memory. Front. Comput. Neurosci. 5:23. doi: 10.3389/fncom.2011.00023
Pipa, G., Riehle, A., and Grün, S. (2007). Validation of task-related excess of spike coincidences based on neuroxidence. Neurocomputing 70, 2064–2068. doi: 10.1016/j.neucom.2006.10.142
1 Pipa, G., Wheeler, D. W., Singer, W., and Nikolic, D. (2008). Neuroxidence: reliable and efficient analysis of an excess or deficiency of joint-spike events. J. Comput. Neurosci. 25, 64–88. doi: 10.1007/s10827-007-0065-3
Riehle, A., Grün, S., Diesmann, M., and Aertsen, A. (1997). Spike synchronization and rate modulation differentially involved in motor cortical function. Science 278, 1950–1953.
Shadlen, M. N., and Movshon, J. A. (1999). Synchrony unbound: a critical evaluation of the temporal binding hypothesis. Neuron 24, 67–77.
Staude, B., Rotter, S., and Grün, S. (2010). Cubic: cumulant based inference of higher-order correlations in massively parallel spike trains. J. Comput. Neurosci. 29, 327–350. doi: 10.1007/s10827-009-0195-x
Teich, M. C., Heneghan, C., Lowen, S. B., Ozaki, T., and Kaplan, E. (1997). Fractal character of the neural spike train in the visual system of the cat. J. Opt. Soc. Am. A Opt. Image Sci Vis. 14, 529–546.
Torre, E., Canova, C., Denker, M., Gerstein, G., Helias, M., and Grün, S. (2016a). Asset: analysis of sequences of synchronous events in massively parallel spike trains. PLoS Comput. Biol. 12:e1004939. doi: 10.1371/journal.pcbi.1004939
Torre, E., Picado-Muiño, D., Denker, M., Borgelt, C., and Grün, S. (2013). Statistical evaluation of synchronous spike patterns extracted by frequent item set mining. Front. Comput. Neurosci. 7:132. doi: 10.3389/fncom.2013.00132
Torre, E., Quaglio, P., Denker, M., Brochier, T., Riehle, A., and Grün, S. (2016b). Synchronous spike patterns in macaque motor cortex during an instructed-delay reach-to-grasp task. J. Neurosci. 36, 8329–8340. doi: 10.1523/JNEUROSCI.4375-15.2016
Toutounji, H., and Pipa, G. (2014). Spatiotemporal computations of an excitable and plastic brain: neuronal plasticity leads to noise-robust and noise-constructive computations. PLoS Comput. Biol. 10:e1003512. doi: 10.1371/journal.pcbi.1003512
Uhlhaas, P. J., Pipa, G., Lima, B., Melloni, L., Neuenschwander, S., Nikolić, D., and Singer, W. (2009). Neural synchrony in cortical networks: history, concept and current status. Front. Integr. Neurosci. 3:17. doi: 10.3389/neuro.07.017.2009
Uhlhaas, P. J., and Singer, W. (2006). Neural synchrony in Brain disorders: relevance for Cognitive Dysfunctions and Pathophysiology neural synchrony in brain disorders. Neuron 52, 155–168. doi: 10.1016/j.neuron.2006.09.020
Keywords: renewal process, Poisson process, synchrony, ISI, joint spike events, coincidence distribution
Citation: Shahi M, van Vreeswijk C and Pipa G (2016) Serial Spike Time Correlations Affect Probability Distribution of Joint Spike Events. Front. Comput. Neurosci. 10:139. doi: 10.3389/fncom.2016.00139
Received: 07 September 2016; Accepted: 02 December 2016;
Published: 23 December 2016.
Edited by:
Yoram Burak, Hebrew University of Jerusalem, IsraelReviewed by:
Maoz Shamir, Ben-Gurion University of the Negev, IsraelSonja Grün, Forschungszentrum Jülich, Germany
Copyright © 2016 Shahi, van Vreeswijk and Pipa. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gordon Pipa, gpipa@uos.de