 Xiaopeng Wu
Xiaopeng Wu Yi Zhang
Yi Zhang Rongxiu Wu4
Rongxiu Wu4 Tianshu Xu
Tianshu Xu- 1Faculty of Education, Northeast Normal University, Changchun, China
- 2School of Mathematics and Statistics, Qiannan Normal University for Nationalities, Duyun, China
- 3School of Mathematical Sciences, East China Normal University, Shanghai, China
- 4Science Education Department, Harvard-Smithsonian Center for Astrophysics, Harvard University, Cambridge, MA, United States
- 5College of Education, Purdue University, West Lafayette, IN, United States
Ability of data analysis, as one of the essential core qualities of modern citizens, has received widespread attention from the international education community. How to evaluate students’ data analysis ability and obtain the detailed diagnosis information is one of the key issues for schools to improve education quality. With an employment of cognitive diagnostic assessment (CDA) as the basic theoretical framework, this study constructed the cognitive model of data analysis ability for 503 Grade 9 students in China. The follow-up analyses including the learning path, learning progression and corresponding personalized assessment were also provided. The result indicated that first, almost all the students had the data awareness. Furthermore, the probability of mastering the attribute Interpretation and inference of data was relatively low with only 60% or so. Also, the probabilities of mastering the rest of attributes were about 70% on average. It was expected that this study would provide a new cognitive diagnostic perspective on the assessment of students’ essential data analysis abilities.
Introduction
Importance of data analysis ability
With the arrival of big data era, substantial changes have taken place in different fields of society, such as the emergence of artificial intelligence, machine learning, precision medicine, and computational education (François and Monteiro, 2018). Data has become an essential asset in various professions for daily use, and data analysis ability correspondingly becomes a necessity for our work and life (Dani and Joan, 2004). In fields such as business, economics, and others, they increasingly rely on data analytics rather than experience or intuition only to make decisions in management (Bryant et al., 2008). Due to the popularity of data in daily life and workplace, data literacy has gradually become an ability that everyone shall have instead of an ability mastered by only few senior personnel in some specific industries (Borges-Rey, 2017; Sharma, 2017). Prado and Marzal (2013) have provided a list of standards for data literacy, which include (1) Determining the context of data production and reuse, as well as the value, category and format of data; (2) Figuring out when you need data and obtain it appropriately; (3) Properly evaluating data and data sources; (4) Using certain plans, measures, system architecture and appropriate evaluation methods to determine the appropriate methods to operate and analyze the data; (5) Visualization of data analysis results; (6) Using the analysis results to learn, make decisions, or solve certain problems. This list covers almost all required in data literacy and has become one of the basic qualities necessary for the future use. Moreover, data literacy also plays a crucial role in mathematics. Generation and solution of some certain mathematical problems are based on data analysis as well. Good data analysis ability can effectively help students find and solve problems. Therefore, it is of far-reaching significance to focus on cultivating students’ data analysis ability.
Definition of data analysis ability
Commonly cultivated by means of statistical disciplines or statistical content, data analysis ability tightly relates with statistics and can be extracted from statistical literacy. However, statistical literacy so far has not been well defined and there is no consensus achieved on its definition among statistics educators, statisticians, and researchers globally (Kaplan and Thorpe, 2010; Schield, 2010; Ridgway et al., 2011; English, 2014). Moore and Cobb (2000) took “change” as the core element of statistical thought and believed that “change” was everywhere in the process. Wallman (1993) stated that statistical literacy was the ability to understand and critically evaluate the statistical results that permeate our daily lives, as well as the ability to understand the contributions of statistical thinking in the public, professional, personal, and private spheres. Through the literature, we can see that there exist common core elements in both the statistical literacy and data analysis ability. Pedagogically, data analysis offers an opportunity for students to explore openly. Conceptually, data analysis examines patterns, hubs, clusters, gaps, dissemination, and variation in data. Philosophically, some advocates of data analysis recommend introducing data in a non-probabilistic environment, while others suggest establishing a link between data analysis and the notion of probability. In the latter view, both data and contingency were considered in the framework of a systematic study of probability (Shaughnessy et al., 1996). In this study, we extracted the data analysis ability from the statistical literacy as the evidence for its definition. Specifically, we defined data analysis ability as the ability to perceive data from daily life, to consciously collect and organize data, to represent data according to different needs, and to rationally analyze and interpret data through operations.
Assessment of data analysis ability
In the assessment of data analysis ability, Graham et al. (2009) built a framework representing children’s statistical thinking based on the Cognitive Diagnostic Model (CDM) and other relevant research. This framework provided the theory for the characterization of children’s statistical thinking and planning guidance for data processing. Reading (2002) established a four-level statistical thinking analysis framework, which were Data Collection, Data Tabulation and Representation, Data Reduction, and Interpretation and Inference. Using the Structure of the Observed Learning Outcome (SOLO, Biggs and Collis, 2014) classification framework, he analyzed the typical responses of students in different levels and drew corresponding conclusions. Mooney (2002) portrayed statistical thinking into four dimensions: Describing data, Organizing and Generalizing data, Representing data, and Analyzing and Interpreting data. Still based on the SOLO classification framework, four levels were described for each aspect: Idiosyncratic, Transitional, Quantitative, and Analytical. What’s more, they also pointed out the necessity of establishing learning trajectories that connect students with different levels of statistical thinking. Due to the high expectation in statistics teaching (Jacobe et al., 2014), effective assessment tools were in a great necessity to evaluate learners’ understanding of statistical concepts more precisely.
As we can see, people have sufficiently realized the significance of data analysis and put the cultivation of students’ data analysis ability in a more centered position. Although there is no clear definition of data analysis ability yet, a lot of research has been conducted on its attribute division, which lays the foundation for future research. Currently, the assessment of students’ data analysis ability has mostly constructed the students’ levels of abilities according to the traditional Classical Testing Theory (CTT). It exhibits great advantages in understanding the overall status of students’ data analysis ability, however, it cannot provide students with more fine-grained diagnostic information, which is the key to promoting students’ development (Huff and Goodman, 2007). The new Cognitive Diagnostic Assessment (CDA), a measurement tool developed in the most recent years combining both cognitive psychology and modern psychometrics, can analyze students’ knowledge or skill attributes involved in the process of answering questions from the perspective of cognitive psychology, and integrate attributes into the measurement model. The individual’s psychological cognitive process is measured to determine students’ mastery of attributes. CDA provides students with more detailed diagnostic information and supports a further in-depth study of students’ cognitive process (Leighton and Gierl, 2007). In this study, CDA was applied to construct a cognitive model of students’ data analysis ability. Through an examination of 503 Grade 9 students in China, the probability of mastering the attributes of students’ data analysis ability can be obtained. On this basis, the students’ learning path, learning progression, and personal assessment were then explored, providing a reference for the further study of students’ data analysis ability.
Construction of cognitive model of data analysis ability
Sorting out the attributes of data analysis ability
In the attribute classification of data analysis ability, data processing includes organization, description, presentation, and analysis of data, which strongly depends on the representation of various graphics and icons (Shaughnessy et al., 1996). Jones et al. (2000) formed a model composed four attributes of data analysis ability, namely, Data organization, Data representation, Data analysis, and Data interpretation. In this model, the continual process of data analysis was systematically presented. What’s more, they also made detailed operational definitions for each attribute and coded them accordingly. Mooney (2002) portrayed statistical thinking as four dimensions: Data description, Data organization and generalization, Data representation, Data analysis, and interpretation. Reading (2002) concluded a few steps in general, which included Data collection, Data tabulation and presentation, Data summarization, interpretation, and inference in the established statistical thinking framework. Arican and Kuzu (2020) divided data analysis literacy into four aspects: (a) Data representation and interpretation, (b) Sample interpretation, (c) Statistical methods selection, (d) Understanding and application. These studies provided the basis for the classification of data analysis ability attributes.
The expert method
The construction of the cognitive model, especially the construction of the relationship between the attributes in the cognitive model, is more complex. Normally, expert method is used to analyze the cognitive process of students in a certain field, to obtain the relationship between different attributes. In this study, five experts were selected, including three middle school math teachers who were awarded the title of Guizhou Provincial or Municipal Famous Teachers, with rich teaching experience and knowledge of students. Another expert was a mathematics education researcher who focuses on the assessment of data analysis ability and can inspect the cognitive model of data analysis ability from the theoretical level. The last expert we invited was a doctoral student majoring in mathematics education, who has been engaging in the teaching of data problem-solving for a long time, and can examine the cognitive model of data analysis ability from the perspective of assessment.
Through open questionnaires, experts were required to enumerate the attributes of data analysis ability and draw the structural relationships between the attributes. Results of the expert method were presented in Table 1.
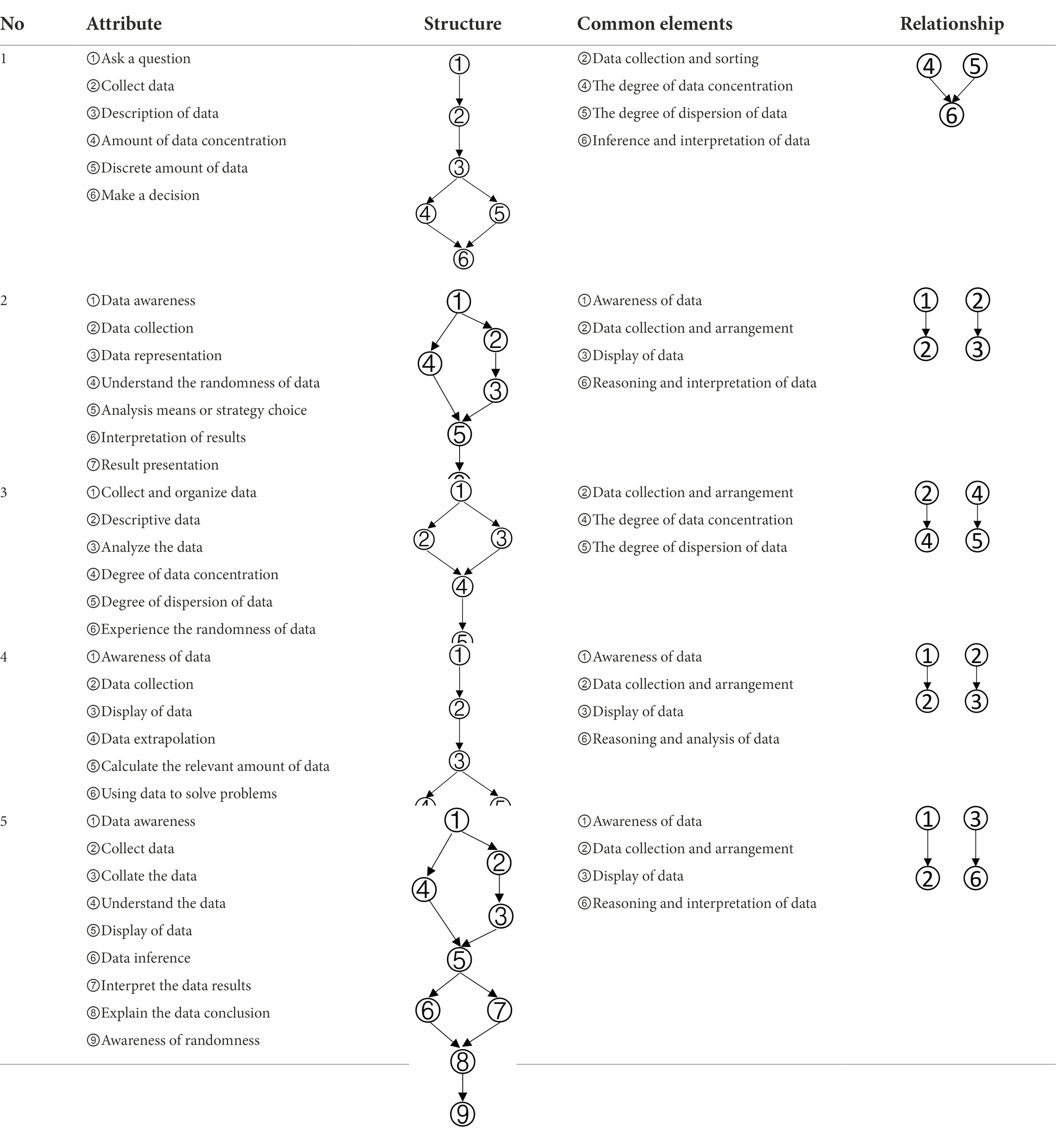
Table 1. Analysis of the expert survey of the cognitive model of data analysis ability.
Based on the common elements in Table 1 and the existing definitions of data analysis ability, the attributes of data analysis ability were extracted, which were: (1) Data awareness; (2) Data collection and sorting; (3) Data representation; (4) Data concentration; (5) Dispersion of Data; (6) Data interpretation and reasoning. According to the relationship between the extracted elements in Table 1, the structure model of data analysis ability was obtained in Figure 1.

Figure 1. Cognitive model of data analysis ability.
Cognitive diagnosis assessment of data analysis ability
Subjects
The subjects of this study were 503 Grade 9 students from 10 classes in two middle schools in Guizhou Province, China. Guizhou is a relatively underdeveloped province in terms of education. Based on the annual proportion of admission to the secondary school entrance examination, the two schools selected belong to the upper middle level in Guizhou Province. The test was 1 h long and all Grade 9 students in both schools took the test. Informed consent was obtained from all the students and teachers before the implementation of test.
Assessment tool
Construction of the Q-matrix
According to the method of constructing the Q-matrix in the Rule Space Model (RSM), the adjacency matrix was obtained according to the cognitive model shown in Figure 1. The preliminary Q-matrix can be further obtained through Boolean algebra (Tatsuoka, 2009), which was presented in Table 2.
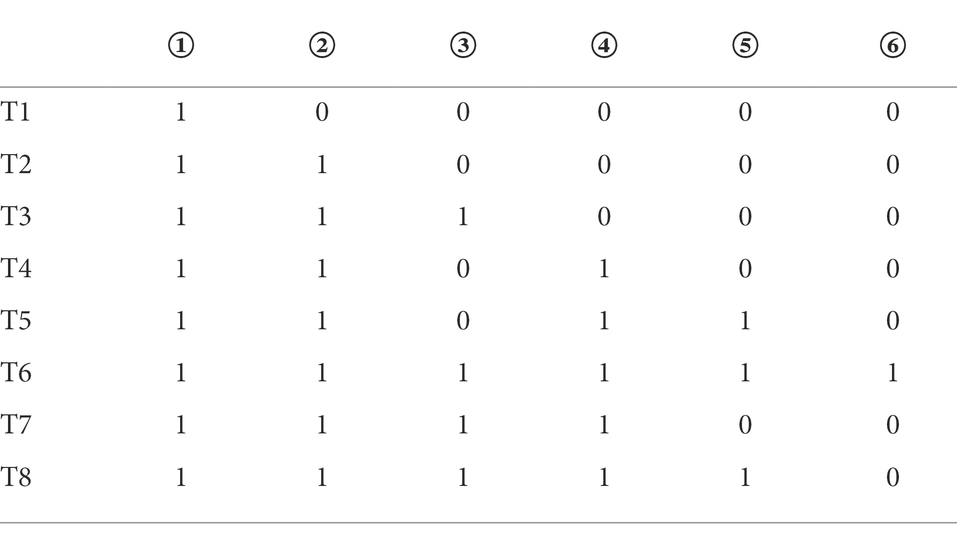
Table 2. Preliminary Q-matrix of data analysis ability.
According to Table 2, the test should be composed of 8 items. However, considering the requirements for the number of tasks completed by the students in the test, the preliminary Q-matrix in Table 2 was expanded, and 2 to 3 items were designed for the same examination mode each. The final Q-matrix including 22 items was formed, as shown in Table 3.
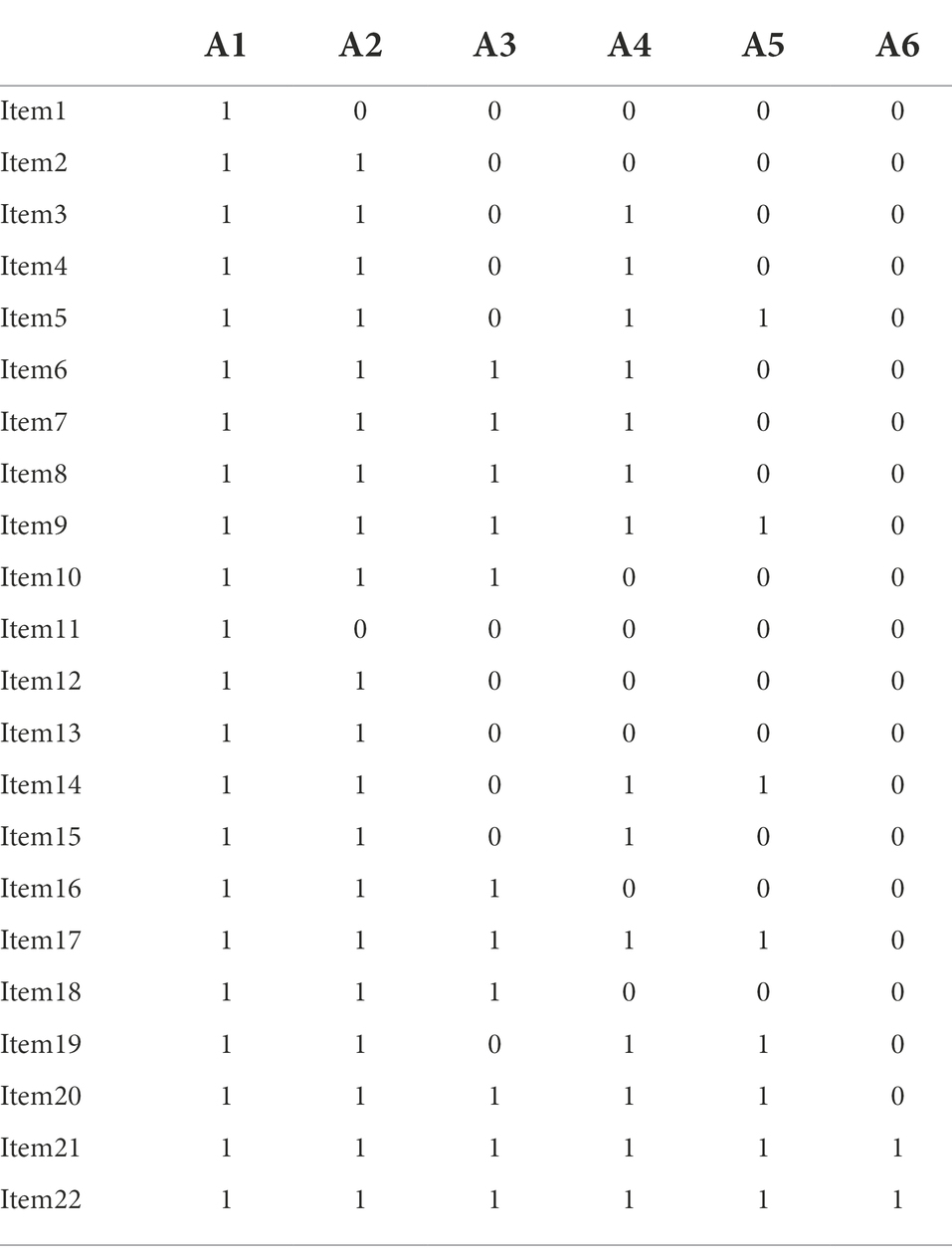
Table 3. Final Q-matrix of data analysis ability.
Formation of assessment tools
CDA can not only reflect the internal relationship between the test items and cognitive attributes, but also demonstrate the relationship between the subject’s knowledge state and attributes (de la Torre and Chiu, 2016). One of the outstanding characteristics of CDA is its assessment structure. Through a more operational and internally consistent Q-matrix, subjects’ unobservable cognitive state can be linked to the observable item responses, which goes beyond the simple two-way list format (Wu et al., 2020). In this study, based on the final Q-matrix in Table 3, we selected 60 items from one of the large-scaled assessment tests Trends in International Mathematics and Science Study (TIMSS) as the first round of items selected. Through coding the attributes of these items by the five experts, 22 items with high label consistency were finally selected as the assessment tools.
Selection of CDM
Comparison and selection of models play a vital role in CDA process. A large number of cognitive diagnostic practices have shown that choosing an appropriate CDM is an important prerequisite for accurate diagnosis and classification of subjects (Templin and Henson, 2010). Since the theory of CDA was put forward, hundreds of measurement models varying in assumptions, parameters, mathematical principles, and actual conditions have been developed. In order to obtain a more suitable model, using the G-DINA package in the R language, this study evaluated the parameters of common models, such as Deterministic Input; Noisy ‘And’ Gate (DINA; Haertel, 1989; Junker and Sijtsma, 2001; de La Torre, 2009), Deterministic Input; Noisy ‘or’ Gate (DINO; Templin and Henson, 2006, 2010), Reduced Reparametrized Unified Model (RRUM; Hartz, 2002), Additive Cognitive Diagnosis Model (ACDM; de La Torre, 2011), Generalized Diagnostic Model (GDM; von Davier, 2014), Log-linear Cognitive Diagnosis Model (LCDM; Henson et al., 2009), Linear Logistic Model (LLM; Maris, 1999), Generalized DINA (G-DINA; de La Torre, 2011), and Mixture Model (von Davier, 2010). Based on the Q-matrix in Table 3 and test data, the relevant parameters of the CDMs were estimated, as shown in Table 4.
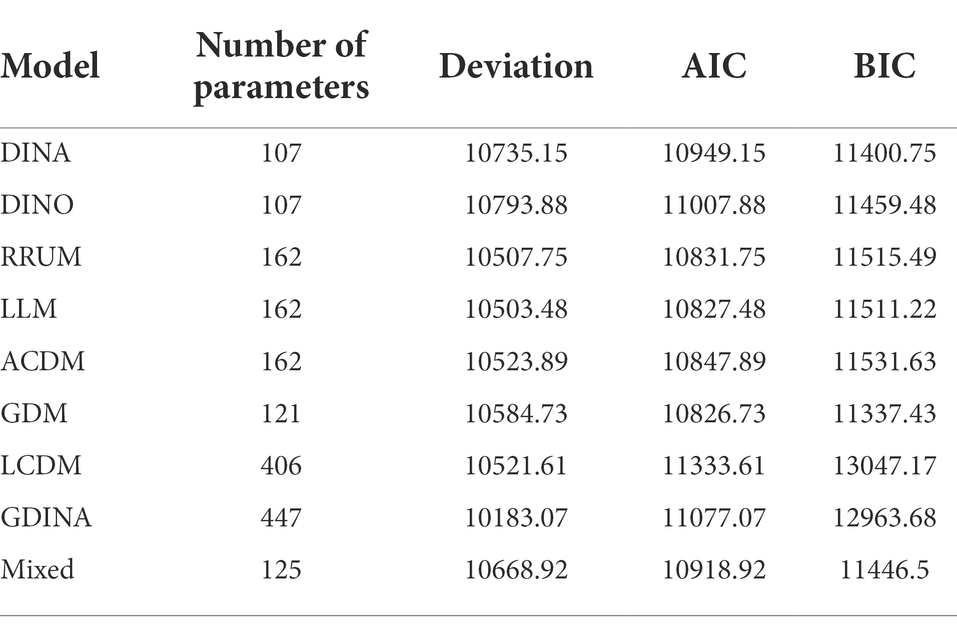
Table 4. Statistical comparison of parameters in different models.
Two criteria are generally considered in the selection of CDMs, which are Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC). The number of parameters represents the load in the model evaluation process. The smaller the value of AIC and BIC, the smaller the load and the better the model fitting (Vrieze, 2012). Through the comparisons of AIC and BIC in Table 3, the three indicators of the GDM were the smallest, which represented the most appropriate model fit to the data.
GDM model
The GDM is a model that adapts to multi-level response variables and has two or more skill levels. It extends the commonly used IRT model to a multivariate, multiskilled classification model (von Davier and Yamamoto, 2004). Like other CDMs, Q-matrix is an effective part of the model. Its general form can be applied to non-integer, multi-dimensional and multi-attribute skills. It provides a more general way to specify the skill mode and the Q-matrix interact. The model (von Davier, 2008) is presented as:
where indicates that the distribution of observation variable x is in a given condition (, difficulty parameter , guessing parameter and Q-matrix . , however, in IRT, therefore, the kth element of b
where is a matrix with true value . This matrix associates I observed variables with K unobserved (skills) variables to determine these variables in a specific model in cognitive diagnosis. GDM is a general diagnostic model suitable for both dichotomous and multichoice data, which can model multi-dimensional mixed binary and sequential skill variables.
Quality of assessment tool
Reliability of the test
Reliability represents the stability and reliability of measurement, which is one of the most important indicators of tool evaluation in the test. As a new generation of assessment, CDA has its own uniqueness that its reliability mainly focuses on the consistency index of attribute retest (Templin and Bradshaw, 2013). Similar to the Subkoviak method of decision consistency in the CTT standard reference test, this indicator is calculated by correlating the probabilities of the attribute’s mastery of the same subjects in two successive measurements, with the assumption that the probabilities of the attributes mastered by the subjects remain the same (Templin and Bradshaw, 2013). The reliabilities for different models were shown in Table 5.

Table 5. Reliability of data analysis ability.
According to the statistics in Table 5, the test–retest reliability was estimated by repeatedly extracting from examinee’s posterior distribution to simulate repeated testing (Templin and Bradshaw, 2013). The test–retest consistency index was acceptable, with the average value reaching 0.8938. The reliability of each attribute was above 0.78, and most of them were above 0.85, indicating that the GDM model was reliable to use for the current dataset.
Item fit
Item fit is also the focal point in the CDM analysis. Studies have shown that whether the test data of a CDM fits the items or not directly determines the accuracy of the model’s diagnostic effect (Song et al., 2016). The conventional method to examine the fitting effect of items is the chi-square test, however, since the characteristics of the CDA do not conform to the hypothesis of the chi-square test, and the preconditions of the chi-square test do not meet, the traditional chi-square test are not appropriate to evaluate the fitting effect of items in CDM (Batanero and Díaz, 2010). In CDA, RMSEA is used to measure the fitting effect of test items by mainly comparing the square root error of observed response and predicted response under the different potential classifications. The calculation formula of RMSEA for item j is:
where represents the classification probability of the potential trait level of type c, and represents the probability estimated by the item response function. represents the expected number of people at the kth dimension of the cth potential trait level in the jth item, and represents the expected number of people at the cth potential trait level. Through the calculation of residual information, the residual information of the test items was shown in Table 6.

Table 6. RMSEA information of the test items.
The closer the RMSEA value is to 0, the smaller the deviation of the fit and the better the fitting effect. The critical value of RMSEA is normally set to 0.1. Values greater than 0.1 for RMSEA is an indication of poor item fit (Oliveri and von Davier, 2011). According to this standard, the GDM model was still the one with the best fit in the test items since the RMSEA values for all the test items were less than 0.1. Only items 3, 7, 9, 13, 17, 18, 19, 20, 21, 22 had the values slightly greater than 0.1. Therefore, the GDM model still had the most appropriate item level fit in this study.
Assessment result
Probability of mastery of attributes of data analysis ability
The probability of each student’s attribute mastery can be obtained through the assessment of the model in CDA. To further analyze the gender differences in students’ mastery of attributes, comparison analyses of the attribute mastery probability were conducted on genders and the mastery probabilities of the six attributes were obtained as shown in Figure 2.
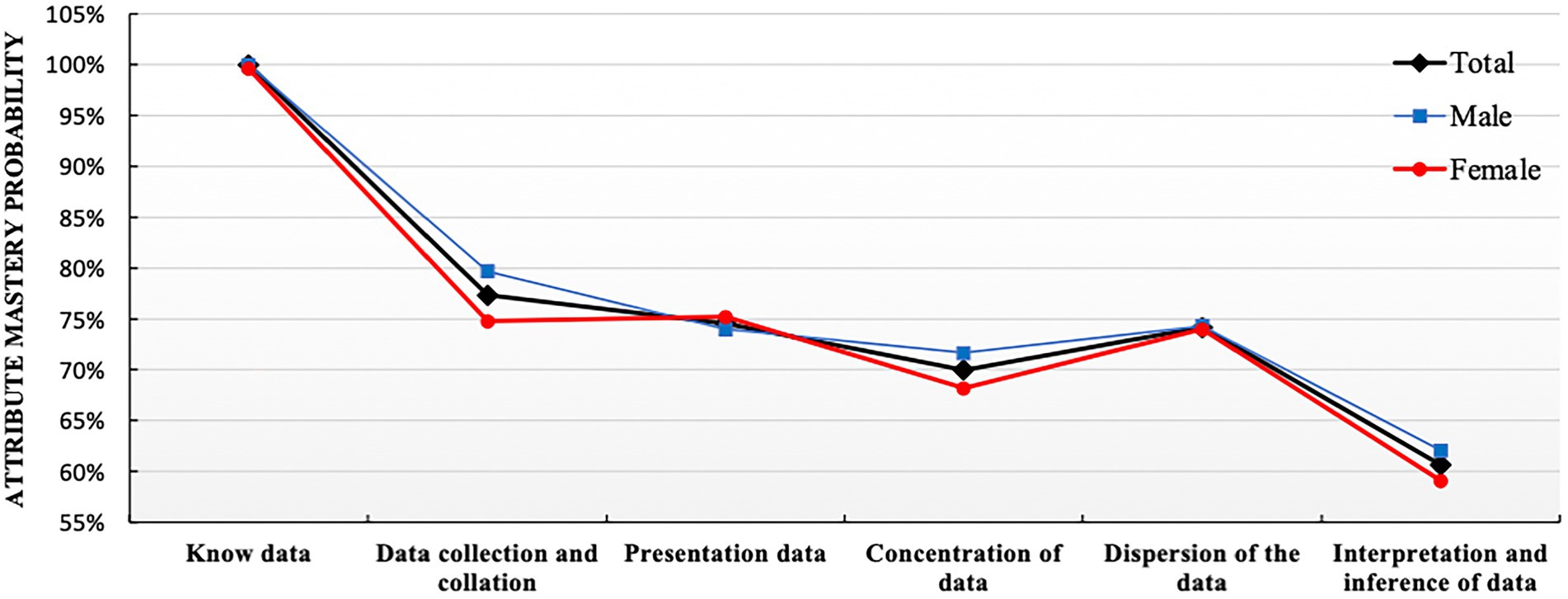
Figure 2. Distribution diagram for attribute mastery probability of data analysis ability.
Figure 2 showed that the mastery probability of the attribute Know data was the highest, reaching 100%, which indicated that almost all students had the basic data awareness. The probability of mastering these four attributes, Data collection and collation, Data presentation, Concentration of data, and Dispersion of the data, were quite similar at about 70%. Among these four, the probabilities of mastering attributes of Data collection and collation and Dispersion of the data were slightly higher. Last, the mastery probability of Interpretation and inference of data was the lowest, about 60%.
Overall, in Figure 2, what we can observe was that there was no obvious gender difference in attribute mastery probability, especially the probability of mastering Know data, Data presentation and Dispersion of data were almost the same for both male and female students. In terms of Data collection and collation, Concentration of data and Interpretation and inference of data, the probabilities of male students mastering attributes were slightly higher than these for female ones, showing certain advantages for male students.
Construction of learning progression for data analysis ability
With a combined method of learning progression construction with Item Response Theory (IRT), students’ abilities were calculated in each type of knowledge state, and students in different knowledge state categories were divided (Wu et al., 2021). The ability value 1.37 was the highest for the knowledge state (111111), and the ability value −2.41 was the lowest for the knowledge state (010000). We have divided the interval (−2.5, 1.5) into 5 levels and the diagram for learning progression was shown in Figure 3.
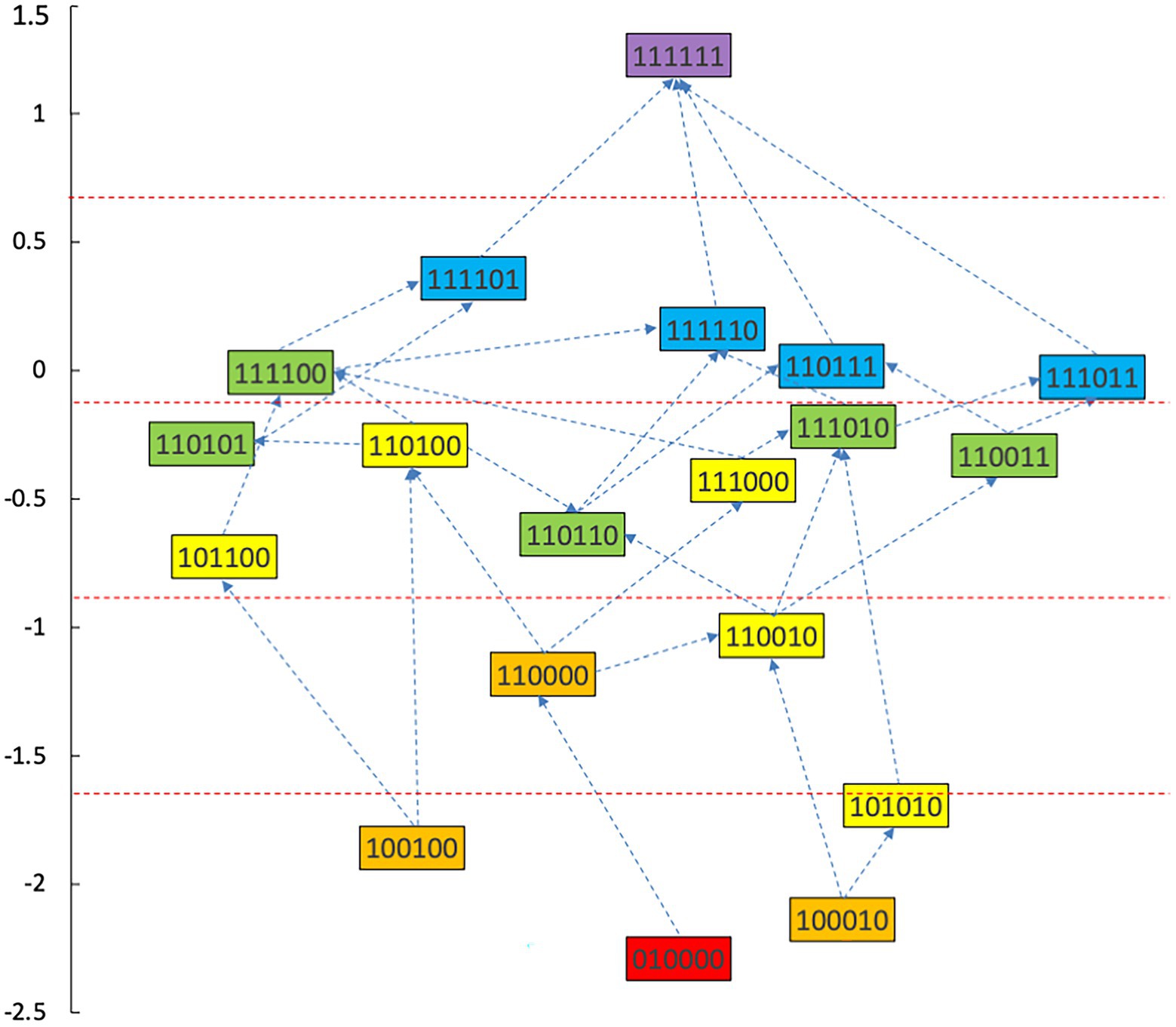
Figure 3. Advanced diagram of data analysis ability progression.
According to the attributes of the knowledge states in the different stages in Figure 3, the learning progression of the ladder were defined, and the divisions of learning progression level were organized in Table 7. It provided a more reliable theoretical basis for student learning, teacher teaching, textbook compilation, and test compilation.

Table 7. Divisions of learning progression levels of data analysis ability.
Personalized analysis of data analysis ability
Accurately depicting the knowledge state of each student is the greatest advantage of CDA. To fully illustrate the fine-grained information that CDA can provide for each student, three students numbered 337, 476 and 424 were selected for the analysis. The radar chart of their attribute mastery was shown in Figure 4.
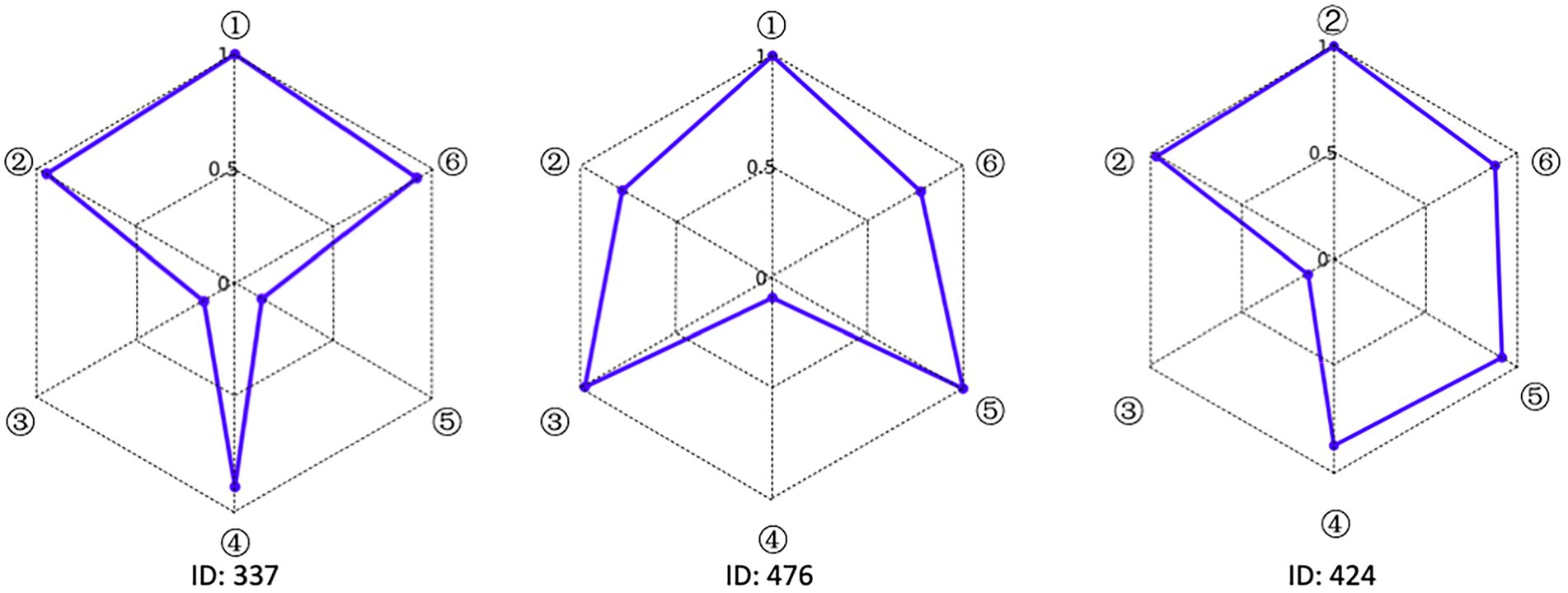
Figure 4. Radar chart of the mastery results of students’ data analysis ability.
The characteristic of the three students shown in Figure 4 was that they correctly answered the same number of questions. If through the traditional evaluation methods, these students were considered to have the same total score, showing that there was no difference among them. However, in CDA, differences were still obvious in Figure 3. Student No. 337 had mastered attributes ①, ②, ④, ⑥; student No. 476 had mastered attributes ①, ②, ③, ⑤, ⑥, but not fully mastered attributes ② or ⑥, whose probability of attribute mastery was approximately 80%; and student No. 424 had mastered the attributes ①, ②, ④, ⑤, ⑥. Therefore, what we can conclude was that these three students not only differed in the type of attribute mastery, but also in the number and degree of attribute mastery. These results offered more fine-grained information for students’ personalized learning.
Discussion
This study constructed a reasonable cognitive model for students’ data analysis ability based on the expert method. Results showed that students had a good attribute mastery of Know data, but students’ mastery of Interpretation and inference of data was relatively poor. Data analysis ability can be clearly divided into five levels of learning progression and students with the same scores differed obviously in the knowledge state.
As one of the essential core qualities of modern citizens, the importance of data analysis ability has been recognized by all walks of life. The accurate assessment of data analysis ability is a topic that is worthy further exploration. As a new generation of assessment theory, CDA is designed to detect students’ specific knowledge structure or operational skills in a certain field, so as to provide students with more fine-grained diagnostic information on cognitive strengths and weaknesses (Leighton and Gierl, 2007). It is essentially a diagnosis of cognitive attributes, and the construction of attributes plays a vital role in the assessment process (Wu et al., 2020). However, most of the extant research have only considered the division of cognitive attributes without taking their prerequisite relationship into account. Starting from expert method, this study constructed a cognitive model while having the prerequisite relationship between attributes into account. The model that was formed has provided a theoretical basis for clarifying the relationship between the attributes of data analysis ability and further guiding the teaching and students’ personal assessment. It provided a more standardized research method for the assessment of students’ data analysis abilities, which was more in line with the research paradigm of CDA.
In this study, we also explored the learning path and learning progression of students’ data analysis ability. The learning path depicted student’s thinking and learning in a specific field of mathematics, reflecting student’s learning process through a series of instructive tasks. These tasks were designed to promote the development of students’ mental process and thinking level (Clements and Sarama, 2012). The learning path reflects the trend of students’ actual learning progress, rather than focusing on subject knowledge, which distinguishes the learner’s logic from the subject logic and plays an intermediary role in the selection of learning goals and methods (Corcoran et al., 2009). The realization of different learning objectives needs to be supported by the corresponding learning paths, and different learning paths will determine the choice of learning methods. In the selection of learning methods, learning path distinguishes the student’s “voice” from the subject’s perspective, emphasizes the development of students’ cognitive order, and further clarifies the importance of learners in guiding future teaching, curriculum and assessment (Confrey, 2006). Students are all in different levels of learning paths, with various learning resources and learning environment around, therefore, a selection of a suitable learning path and learning method according to their individual conditions and backgrounds will be more appropriate. Learning path helps learners choose appropriate teaching activities, tasks, tools, interaction and evaluation methods, and promotes students to gradually master increasingly complex concepts (Confrey et al., 2009). It combines the evaluation results of each student with the corresponding learning mode, extracts the formative evaluation results from the summative evaluation data, and provides a basis for students to formulate their personalized learning plans.
This study provided a more complete and standardized research method, constructed a cognitive model of data analysis ability, and made contributions to the theory as well as methods to a certain degree. However, due to the limited material and financial resources, this study also had some shortcomings inevitably. First, the sample size available was limited. With only approximately 500 students in China, the result of the study lacked generalizability to some extent. In addition, any assessment cannot make without the discipline itself. The evaluation content should be analyzed based on the characteristics of the discipline (Zhang et al., 2019). Last, a longitudinal study with similar method and approach is recommended in the future to verify the result reliability and validity (Zhan et al., 2019; Wu et al., 2020).
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request. Requests to access these datasets should be directed to XW, 18198689070@126.com.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author contributions
XW designed the study and wrote this manuscript. YZ contributed to the manuscript writing and the continued revision provided by the reviewers. XT collected the data and wrote this manuscript. RW and TX have revised the language of the article and provided comments. All authors contributed to the article and approved the submitted version.
Funding
This work was support by 2021 Humanities and Social Science Research project of Ministry of Education of China: Cognitive Diagnosis and Evaluation of Mathematics Core Literacy (21YJC880102). Teacher Education “JIEBANGLINGTI” Project of Northeast Normal University: Learning Progression Construction and Learning Path Analysis Based on Cognitive Diagnosis (JSJY20220305).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Arican, M., and Kuzu, O. (2020). Diagnosing preservice teachers’ understanding of statistics and probability: developing a test for cognitive assessment. Int. J. Sci. Math. Educ. 18, 771–790. doi: 10.1007/s10763-019-09985-0
Batanero, C., and Díaz, C. (2010). Training teachers to teach statistics: what can we learn from research? Statist. et enseignement 11, 83–20. doi: 10.1111/j.1467-9639.1989.tb00069.x
Biggs, J. B., and Collis, K. F. (2014). Evaluating the quality of learning: The SOLO taxonomy (structure of the observed learning outcome) Hobart, Tasmania, Austraila: Academic Press.
Borges-Rey, E. L. (2017). “Data literacy and citizenship: understanding ‘big Data'to boost teaching and learning in science and mathematics,” in Handbook of research on driving STEM learning with educational technologies. eds. M. S. Ramírez-Montoya (IGI Global), 65–79. doi: 10.4018/978-1-5225-2026-9.ch004
Bryant, R., Katz, R. H., and Lazowska, E. D. (2008). Big-data computing: creating revolutionary breakthroughs in commerce, science and society. Available at: https://cra.org/ccc/wp-content/uploads/sites/2/2015/05/Big_Data.pdf (Accessed October 20, 2022).
Clements, D. H., and Sarama, J. (2012). “Learning trajectories in mathematics education,” in Julie Sarama hypothetical learning trajectories eds. H. Douglas, D. H. Clements, and H. Sarama (NewYork: Routledge), 81–90.
Confrey, J. (2006). “The evolution of design studies as methodology. A aparecer en RK Sawyer,” in The Cambridge handbook of the learning sciences. ed. R. K. Sawyer (Thessaloniki, Greece: Cambridge, UK: Cambridge University Press), 135–151.
Confrey, J., Maloney, A., Nguyen, K., Mojica, G., and Myers, M. (2009). “Equipartitioning/splitting as a foundation of rational number reasoning using learning trajectories,” in Paper presented at the 33rd conference of the International Group for the Psychology of mathematics education eds. M. Tzekaki, M. Kaldrimidou, and H. Sakonidis, (Thessaloniki, Greece: PME).
Corcoran, T. B., Mosher, F. A., and Rogat, A. (2009). Learning progressions in science: an evidence-based approach to reform. Available at: http://repository.Upenn.Edu/cpre_researchreports/53 (Accessed October 20, 2022).
Dani, B. Z., and Joan, G. (2004). “Statistical literacy, reasoning, and thinking: goals, definitions, and challenges,” in The challenge of developing statistical literacy, reasoning and thinking. eds. D. Ben-Zvi and J. Garfield (Dordrecht: Springer)
de La Torre, J. (2009). DINA model and parameter estimation: a didactic. J. Educ. Behav. Stat. 34, 115–130. doi: 10.3102/1076998607309474
de La Torre, J. (2011). The generalized DINA model framework. Psychometrika 76, 179–199. doi: 10.1007/s11336-011-9207-7
de la Torre, J., and Chiu, C. Y. (2016). A general method of empirical Q-matrix validation. Psychometrika 81, 253–273. doi: 10.1007/s11336-015-9467-8
English, L. D. (2014). “Promoting statistical literacy through data modelling in the early school years,” in Probabilistic thinking. Advances in mathematics education. eds. E. Chernoff and B. Sriraman (Dordrecht: Springer)
François, K., and Monteiro, C. (2018). Big data literacy. Paper presented at the looking back, looking forward. Proceedings of the 10th international conference on the teaching of statistics, Kyoto, Japan, July.
Graham, A. T., Pfannkuch, M., and Thomas, M. O. J. (2009). Versatile thinking and the learning of statistical concepts. ZDM 41, 681–695. doi: 10.1007/s11858-009-0210-8
Haertel, E. H. (1989). Using restricted latent class models to map the skill structure of achievement items. J. Educ. Meas. 26:301. doi: 10.1111/j.1745-3984.1989.tb00336.x
Hartz, S. M. (2002). A Bayesian framework for the unified model for assessing cognitive abilities: Blending theory with practicality, Illinois, America: University of Illinois at Urbana-Champaign.
Henson, R. A., Templin, J. L., and Willse, J. T. (2009). Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 74, 191–210. doi: 10.1007/s11336-008-9089-5
Huff, K., and Goodman, D. P. (2007). “The demand for cognitive diagnostic assessment,” in Cognitive diagnostic assessment for education: Theory and applications. eds. J. P. Leighton and M. J. Gierl (Cambridge, UK: Cambridge University Press), 19–60.
Jacobe, T., Foti, S., and Whitaker, D. (2014). Middle school (ages 10–13) students. Understanding of stat- istics. In K. Makar, B. de Sousa, and R. Gould (Eds.), Sustainability in statistics education. Proceedings of the ninth international conference on teaching statistics (ICOTS9, July, 2014), Flagstaff, Arizona, USA. Voorburg: International Statistical Institute.
Jones, G. A., Thornton, C. A., Langrall, C. W., Mooney, E. S., Perry, B., and Putt, I. J. (2000). A framework for characterizing children's statistical thinking. Math. Think. Learn. 2, 269–307. doi: 10.1207/S15327833MTL0204_3
Junker, B. W., and Sijtsma, K. (2001). Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 25, 258–272. doi: 10.1177/01466210122032064
Kaplan, J. J., and Thorpe, J. (2010). “Post-secondary and adult statistical literacy: assessing beyond the classroom” in Data and context in statistics education: towards an evidence-based society. Proceedings of the eighth international conference on teaching statistics. Voorburg, The Netherlands: International Statistical Institute.
Leighton, J. P., and Gierl, M. J. (2007). Defining and evaluating models of cognition used in educational measurement to make inferences about examinees’ thinking processes. Educ. Meas. Issues Pract. 26, 3–16. doi: 10.1111/j.1745-3992.2007.00090.x
Maris, E. (1999). Estimating multiple classification latent class models. Psychometrika 64, 187–212. doi: 0033-3123/1999-2/1995-0422-A, doi: 10.1007/BF02294535
Mooney, E. S. (2002). A framework for characterizing middle school students' statistical thinking. Math. Think. Learn. 4, 23–63. doi: 10.1207/S15327833MTL0401_2
Moore, D. S., and Cobb, G. W. (2000). Statistics and mathematics: tension and cooperation. Am. Math. Mon. 107, 615–630. doi: 10.1080/00029890.2000.12005247
Oliveri, M. E., and von Davier, M. (2011). Investigation of model fit and score scale comparability in international assessments. Psychol. Test Assess. Model. 53, 315–333.
Prado, J. C., and Marzal, M. Á. (2013). Incorporating data literacy into information literacy programs: Core competencies and contents. Libri 63, 123–134. doi: 10.1515/libri-2013-0010
Reading, C. (2002). Profile for statistical understanding. Paper presented at the proceedings of the sixth international conference on teaching statistics, Cape Town, South Africa.
Ridgway, J., Nicholson, J., and McCusker, S. (2011). “Developing statistical literacy in students and teachers,” in Teaching statistics in school mathematics-challenges for teaching and teacher education: A joint ICMI/IASE study. eds. C. Batanero, G. Burrill, and C. Reading (Dordrecht: Springer), 311–322.
Schield, M. (2010). “Assessing statistical literacy: take care,” in Assessment methods in statistical education: An international perspective. eds. P. Bidgood, N. Hunt, and F. Jolliffe (Milton: John Wiley & Sons), 133–152.
Sharma, S. (2017). Definitions and models of statistical literacy: a literature review. Open Rev. Edu. Res. 4, 118–133. doi: 10.1080/23265507.2017.1354313
Shaughnessy, J. M., Garfield, J., and Greer, B. (1996). “Data handling,” in International handbook of mathematics education. eds. A. J. Bishop, K. Clements, C. Keitel, J. Kilpatrick, and C. Laborde, vol. 4 (Dordrecht, The Netherlands: Kluwer), 205–238.
Song, L., Wang, W., and Dai, H. (2016). Overall and item fitting indicators under the cognitive diagnostic model. Psychol. Explor. 36, 79–83.
Tatsuoka, K. K. (2009). Cognitive assessment: An introduction to the rule space method, NewYork: Routledge.
Templin, J., and Bradshaw, L. (2013). Measuring the reliability of diagnostic classification model examinee estimates. J. Classif. 30, 251–275. doi: 10.1007/s00357-013-9129-4
Templin, J. L., and Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 11, 287–305. doi: 10.1037/1082-989X.11.3.287
Templin, J., and Henson, R. A. (2010). Diagnostic measurement: Theory, methods, and applications, New York: Guilford Press.
von Davier, M. (2008). A general diagnostic model applied to language testing data. Br. J. Math. Stat. Psychol. 61, 287–307. doi: 10.1348/000711007X193957
von Davier, M. (2010). Hierarchical mixtures of diagnostic models. Psychol. Test Assess. Model. 52, 8–28.
von Davier, M. (2014). The log-linear cognitive diagnostic model (LCDM) as a special case of the general diagnostic model (GDM). ETS Res. Rep. Series 2014, 1–13. doi: 10.1002/ets2.12043
von Davier, M., and Yamamoto, K. (2004). A class of models for cognitive diagnosis. Paper presented at the 4th spearman conference, Philadelphia, PA.
Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychol. Methods 17, 228–243. doi: 10.1037/a0027127
Wallman, K. K. (1993). Enhancing statistical literacy: enriching our society. J. Am. Stat. Assoc. 88, 1–8. doi: 10.1080/01621459.1993.10594283
Wu, X., Wu, R., Chang, H.-H., Kong, Q., and Zhang, Y. (2020). International comparative study on PISA mathematics achievement test based on cognitive diagnostic models. Front. Psychol. 11:2230. doi: 10.3389/fpsyg.2020.02230
Wu, X., Wu, R., Zhang, Y., Arthur, D., and Chang, H. H. (2021). Research on construction method of learning paths and learning progressions based on cognitive diagnosis assessment. Assess. Edu.: Princip. Policy Pract. 28, 657–675. doi: 10.1080/0969594X.2021.1978387
Zhan, P., Jiao, H., Liao, D., and Li, F. (2019). A longitudinal higher-order diagnostic classification model. J. Educ. Behav. Stat. 44, 251–281. doi: 10.3102/1076998619827593
Keywords: data analysis ability, cognitive diagnostic assessment, math education, ability assessment, cognitive model
Citation: Wu X, Zhang Y, Wu R, Tang X and Xu T (2022) Cognitive model construction and assessment of data analysis ability based on CDA. Front. Psychol. 13:1009142. doi: 10.3389/fpsyg.2022.1009142
Edited by:
Yiming Cao, Beijing Normal University, ChinaReviewed by:
Tommy Tanu Wijaya, Beijing Normal University, ChinaZhemin Zhu, Beihua University, China
Copyright © 2022 Wu, Zhang, Wu, Tang and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yi Zhang, 13609399385@126.com