 Victor Rodrigo Mercado
Victor Rodrigo Mercado Ferran Argelaguet
Ferran Argelaguet Gery Casiez
Gery Casiez Anatole Lécuyer
Anatole Lécuyer- 1Inria Rennes—Bretagne Atlantique, Rennes, France
- 2Univ. Lille, Inria, CNRS, Centrale Lille, UMR 9189 CRIStAL, Lille, France
Encountered-Type Haptic Displays (ETHDs) enable users to touch virtual surfaces by using robotic actuators capable of co-locating real and virtual surfaces without encumbering users with actuators. One of the main challenges of ETHDs is to ensure that the robotic actuators do not interfere with the VR experience by avoiding unexpected collisions with users. This paper presents a design space for safety techniques using visual feedback to make users aware of the robot’s state and thus reduce unintended potential collisions. The blocks that compose this design space focus on what and when the feedback is displayed and how it protects the user. Using this design space, a set of 18 techniques was developed exploring variations of the three dimensions. An evaluation questionnaire focusing on immersion and perceived safety was designed and evaluated by a group of experts, which was used to provide a first assessment of the proposed techniques.
1 Introduction
Human-robot interaction (HRI) in virtual reality (VR) promises to enhance immersive applications by adding a new level of interaction between users and machines. This paper focuses on Encountered-Type Haptic Displays (ETHDs), which represent a case of HRI in which robots are used as a means to render haptic feedback in VR. ETHDs possess a surface display, which is displaced by actuators through the real environment to render surfaces that can be touched by users in a virtual environment (VE). ETHDs depend on technologies such as head-mounted displays (HMDs) to “hide” their actuators and to show a VE that contextualizes the haptic feedback rendered by their surface displays. The combination of these technologies allows users to touch surfaces in a VE without disclosing the fact that these surfaces are being brought and placed by a robotic actuator in the real environment (Mercado et al., 2021).
Researchers have considered collisions between users and elements of the real environment fundamental when planning the use of a space for interacting in VR (Kanamori et al., 2018). Commercial VR systems such as SteamVR request users to establish a zone where they could be “safe” from any unexpected collision with elements they cannot see when wearing an HMD (Yang et al., 2018; Steam, 2021). Interacting with an ETHD when wearing an HMD adds a degree of complexity: users are interacting with a moving machine they cannot see. Thus, one of the main challenges of ETHDs is to ensure that the robotic actuators do not interfere with the VR experience.
ETHD systems use path planning algorithms for conceiving a trajectory that optimizes the placement of their end-effector and for avoiding collisions with users at the same time (Yokokohji et al., 2001). This premise has been present in ETHD literature ever since its earliest days (Hirata et al., 1996; Yokokohji et al., 1996). ETHDs need to take into account several factors to position their end-effector in an encountered position: 1) the actuators’ configuration, 2) the actuators’ movement speed, 3) users’ position, 4) users’ movement, and 5) users’ speed (Yokokohji et al., 2005). These factors have been considered in previous path planning research for ETHDs and yet researchers still consider that there is work to be done to properly optimize this feature for ETHDs (Yokokohji et al., 2005; Araujo et al., 2016; Vonach et al., 2017; Kim et al., 2018). The displacements and movements of a user are often hard to predict and increase the chance of collisions. Additionally, the complexity of calculating an optimal trajectory escalates when the precision of the tracking systems is taken into account. Therefore, this paper explores the use of visual feedback for representing the robotic actuators which are normally hidden from the user’s view within VR.
Related research works have proposed solutions integrating visual feedback for avoiding collisions with other users and objects that could be located in the same physical room where the interaction in VR occurs (Lacoche et al., 2017; Scavarelli and Teather, 2017; Kang and Han, 2020). Additionally, commercial VR systems such as SteamVR Steam (2021) and Oculus SDK Oculus (2021) use visual feedback that displays the workspace limits. In the case of human-robot collaboration, literature suggests giving users visual feedback about the robotic system’s behavior as a way to increase users’ perceived safety when interacting with a robot in virtual reality (Guhl et al., 2018; Kästner and Lambrecht, 2019; Oyekan et al., 2019). However, in the case of ETHDs, disclosing too much information about the robotic actuator’s behavior might break users’ immersion in a VR application. Recent research works for ETHDs have considered the use of visual feedback integrated into interaction techniques that are designed to optimize the use of an ETHD and also to inform the user about possible collisions (Abtahi et al., 2019; Mercado et al., 2020a). Nevertheless, to the best of our knowledge, related works in the ETHD field have not considered clear design guidelines that address the user’s perceived safety when interacting with an ETHD without compromising their immersion in a VE. Many different visual feedback types can be considered, but some may be more efficient than others to inform the user about possible collisions. Safety techniques that disclose more information about the ETHD hidden in the VE might be more effective than other techniques providing more subtle feedback when a collision may occur. However, if the user’s perceived safety is increased with techniques displaying the robotic actuator all the time, this might degrade immersion. Thus, signaling a potential trade-off between immersion and perceived safety. The challenge is to find visual techniques that provide at the same time a high sense of perceived safety while degrading the immersion as little as possible.
After discussing the related work, we present our first contribution, 1) a design space for safety techniques for ETHDs that intends to serve as a guide for researchers who desire to provide feedback for avoiding collisions between users and ETHDs. Then, we introduce our second contribution: 2) 18 techniques designed to explore the generative power of our design space. Later we present our third contribution which is 3) the definition of criteria for evaluating safety techniques for ETHDs. And finally 4), we present a preliminary evaluation with expert users to investigate the trade-off performance of the safety techniques in terms of immersion and perceived safety.
2 Related Work
Collisions with elements that are hidden from the users’ view when interacting in VR can not only break the immersion provided by the system but also compromise users’ safety (Cirio et al., 2012). Integrating visual feedback that represents objects that are occluded in VEs has been explored by previous research as a means to increase usability in VR scenarios (McGill et al., 2015; Yang et al., 2018). The presented related works can be classified into visual feedback made for avoiding collisions with robots and feedback for avoiding elements present in the real environment such as walls and/or people. We describe these efforts hereby.
2.1 Visual Feedback for Avoiding Collisions With Robots
Avoiding collisions between users and robots within VEs has been explored primarily in the context of user training for robot teleoperation (Kuts et al., 2017; Guhl et al., 2018; Oyekan et al., 2019; Chen et al., 2020). The work of Oyekan et al. (2019) reported that users’ stress concerning the robot’s presence in a shared workspace increased under three conditions: when the robot’s speed increased 1), when the user and robot were close 2), and when the user did not know what the robot was going to do next 3). The importance of knowing about the robot’s actions was also highlighted in the work of Guhl et al. (2018). Their research reported that in order to increase users’ perceived safety when interacting with a robot in a VE, users should be aware of the intentions of the robot, particularly concerning the knowledge of the robot’s trajectory. Thus, these researchers conceived an AR system that displayed the robot’s path planning for avoiding potential risks of collisions with users. Other approaches come from visualizing robot navigation data in mixed reality as in Kästner and Lambrecht (2019) system, and Shepherd et al. (2019) system that displays the co-located robot’s trajectory.
In the field of ETHDs, safety techniques revolve around visual feedback to indicate where users can and cannot touch. Abtahi et al. (2019) interaction technique considers the display of a panel in the VE when users are at risk of collision with their ungrounded drone-based ETHD.
The works of Mercado et al. (2020b,a) and Posselt et al. (2017) displayed the contact area when their grounded ETHDs displace from one position to another as a means to indicate to the user when to enter in contact with the surface.
2.2 Visual Feedback for Avoiding Collisions With Elements in Real Environments
Large environments where users can navigate can often be crowded with elements that could break users’ immersion when a collision occurs. Kanamori et al. (2018) explored methods for displaying elements of a real environment in VR, consisting of superimposing a virtual point cloud to represent objects in the real environment. The results of their user study suggested that VR objects did not reduce immersion as much as compared the point cloud and commercial chaperone methods such as SteamVR’s Steam (2021). In the former method, real objects are represented in the VE as a point cloud presented using the same shapes as the real object. In the latter method, a circle is projected on the floor of the VE indicating the boundaries of the interaction zone.
In addition, the work of Hartmann et al. (2019) proposed an approach for displaying in VR the real environment elements that are close to colliding with users. Their approach was compared to the SteamVR chaperone in a user study where participants played VR games in a room with obstacles. After the experiment, participants were asked to answer a subjective questionnaire to evaluate users’ reflections about the approaches in matters of safety, physical manipulations, communication, their transition between virtual and real environments, and immersion. Results yielded a higher perceived immersion and safety coming from approaches that integrated real-life elements in the VE. Recent research work from Kang and Han (2020) proposed a series of visual feedback to represent real objects that users could encounter when navigating in VR based on point clouds that appeared in the VE. A user study was conducted to evaluate users’ experience with the visual feedback techniques. The user study considered the following conditions for displaying the point cloud: once per trial; gradually as the users got closer to the object; and permanently during the entire trial. Participants were asked to walk in an area with obstacles in the real environment that were not depicted in the VE. After the experimental trials, participants were asked to answer a subjective experience questionnaire that asked them about their experience in terms of awareness of the surrounding environment, task attention, perceived safety, and their preferences for all the techniques. Participants reported that they preferred the feedback display using the gradual approach. This approach also yielded the highest scores in task attention and perceived safety.
Safety techniques in VR also consider the possibility of colliding with walls or boundaries of the workspace where interaction takes place in the real environment. Cirio et al. (2012) proposed several visual metaphors to indicate to users the presence of a screen in an immersive projection system. Researchers conducted a user study where they assessed the performance of the visual metaphors for helping users to avoid collisions with the CAVE walls when walking in VEs. Results from the analysis of the participants’ walking indicated that using a virtual companion was efficient for keeping participants in a “safe zone” relatively far from the CAVE walls.
Lacoche et al. (2017) proposed different visual feedback approaches to help users to acknowledge the presence of collaborators sharing the same physical workspace when interacting in VR. A subjective questionnaire about users’ global satisfaction was used to measure users’ experience quality, aestheticism, and efficiency for each visual feedback condition. Results suggested that users appreciated more sharing a virtual space with a ghost avatar of the user’s when sharing a workspace in VR.
Another example of user collision avoidance methods is considered by the work of Medeiros et al. (2021). In their work, they explored visual feedback for users in VR for disclosing the position of other people present in the real environment. They implemented several techniques based on UI overlays and virtual elements. Researchers conducted a user study where participants played a game in a VE in which recorded motions of people were used as obstacles. After the experimental trials, researchers assessed participants’ perceived presence in the VE, focus on the task, their alert preference, and the alert’s efficiency. Participants stressed that even if visual feedback was useful for indicating the presence of other people in the real environment, receiving alerts of possible collisions compromised their immersion in the system.
2.3 Summary
Related research works suggest the use of visual feedback to indicate the presence of objects in the real environment that could collide with users when executing a task in the VE.
This feedback considers integrating elements of the real environment into the virtual one or displaying a warning to indicate to users that a possible collision could take place.
However, displaying information and/or warnings about the real environment’s configuration could compromise users’ immersion (Medeiros et al., 2021).
To the best of our knowledge, and more especially when it comes to ETHDs, there are no design guidelines that suggest how to balance the trade-off between providing visual feedback to increase users perceived safety without compromising their immersion in the VE.
3 Design Space
The first contribution of this paper is a design space meant to classify the previous work from the literature and help researchers to generate new safety techniques for ETHDs. As such, our design space allows to generate different possibilities of visual feedback meant to represent the ETHD system’s status when rendering haptic feedback. The design space considers several blocks with features that describe the way the safety techniques could be implemented.
3.1 Design Space Organization
The design space is organized in three blocks that describe the feedback given to the user by answering three questions: what?, when?, and how?
• The what? block answers to the question: what information is the user receiving from the feedback delivered by the safety technique?
• The when? block answers to the question: when is the feedback is delivered by the safety technique?
• The how? block answers to the question: how is the feedback is displayed by the safety technique?
These blocks are further described hereby:
3.1.1 Block What
3.1.1.1 Feedback Information
This design space category refers to the information the user is going to receive as feedback. The two features considered are warning and system state. Warning consists of displaying a warning about a possible collision with a real element in the environment. System State consists of providing information about the system state when the user gets close to the ETHD.
Examples of warning are the works of Abtahi et al. (2019) and Cirio et al. (2012) that display an abstract warning for indicating users not to get close to the robot. Some techniques use visual feedback for describing the system state in matters of position, configuration, and trajectory. An example of the state of the art is the robot integration in the VE proposed by Vosniakos et al. (2019) where users can also acknowledge the robot’s actions in the VE (Table 1).
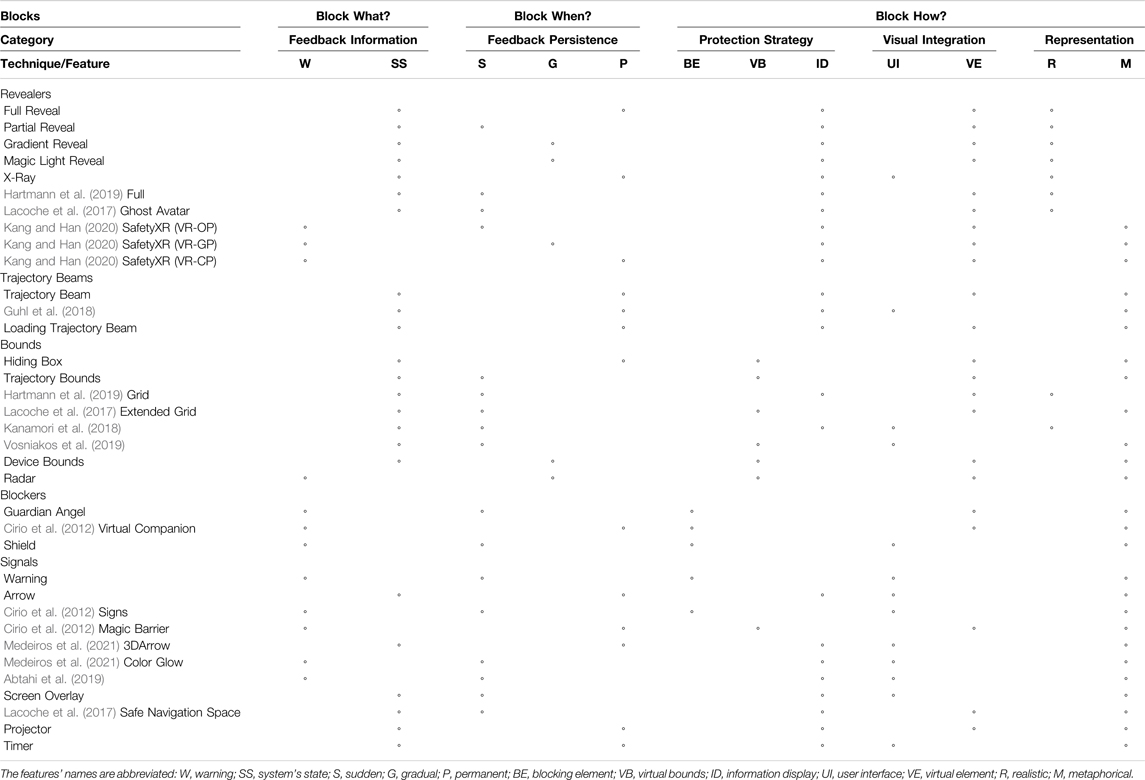
TABLE 1. Design Space with related research works and the 18 techniques we designed. This table represents the three blocks of the design space along with their respective features. The conceived techniques along with related literature research works represent different combinations of the design space’s features.
3.1.2 Block When
This block comprises the feedback persistence category which is described hereby:
3.1.2.1 Feedback Persistence
This category refers to the time and the way feedback appears in the VE. The feedback can be displayed only for a moment (sudden), gradually (gradual), or permanently (permanent). The gradual feature consists of gradually making the feedback appear based on a parameter such as the distance between the user and the element being represented. The work of Kang and Han presented a set of visual feedback techniques using a point cloud representing an object that could come in collision with the users. Their work considers a point cloud that could appear suddenly (once), gradually as the users come closer to the object, or permanently (Kang and Han, 2020).
3.1.3 Block How
This block comprises the protection strategy, visual integration, and representation. The categories comprised in this block aim at describing how the safety technique protects the user (protection strategy) and integrates itself in the VE (visual integration and representation). These categories are described hereby:
3.1.3.1 Protection Strategy
This category refers to how the feedback protects users. Three different features are considered for this category: blocking elements, virtual bounds, and information display. The Blocking Element feature consists in having a virtual element that interposes itself between the user’s hand and the haptic display. This allows having a blocking element that could avoid undesired contact with the haptic device. The Virtual Bounds feature consists in having bounds surrounding elements of the VE for avoiding any possible collisions between the user and a part of the VE that is still to be rendered or that is occluding the haptic display’s virtual position. The information display feature consists in displaying information about the real elements that are occluded in the VE. The displayed information could allow the users to acknowledge the position of real elements for avoiding any undesired collisions with those elements. In the context of ETHD interaction, information display can comprise the robot’s position, trajectory, and actuator configuration.
An example of a blocking element in the literature comes from the work of Cirio et al. (2012). Their work presents a virtual companion that interposes itself between users and an element that could collide with the users in the real environment. In the case of the virtual bounds, the extended grid technique proposed by Lacoche et al. (2017) uses bounding for an object/person that could collide with users when interacting in a VE. In the case of information display the Area technique proposed by Lacoche et al. presents information about the position of the other person who could collide with the user (Table 1).
3.1.3.2 Visual Integration
This category refers to the way the information is going to be displayed to the user concerning the visual elements. The two branches considered are information displayed on the user interface or as a virtual element integrated into the environment. The user interface feature consists in displaying an element as if it was part of the system’s user interface. The virtual element feature consists in using or integrating an element into the VE that could serve as visual support or metaphor for displaying information.
The work of Medeiros et al. (2021) illustrates an example of the user interface feature. This work used visual feedback overlaid on the system’s UI in the case of their Color Glow and 3DArrow techniques. The virtual element feature is represented in the works of Cirio et al. for the magic barrier tape and the virtual companion (Table 1).
3.1.3.3 Representation
This category refers to the way the techniques can be represented in the VE. Two different features are considered: realistic and metaphorical. In the realistic feature category, the safety elements are represented as realistic as they can be in the VE as in the work of Hartmann et al. (2019) where elements of the real environment are inserted as they are captured from images of the real environment. On the other hand, the metaphorical feature category refers to feedback representations based on metaphors and/or analogies. For this feature, safety elements are adapted into metaphors to provide more congruence between the task and/or the VE’s context such as the virtual companion proposed by Cirio et al. (2012).
Table 1 presents all safety techniques identified in the literature according to the different features of our design space. Figure 1 depicts the design space’s features and how they are illustrated through some of the safety techniques.
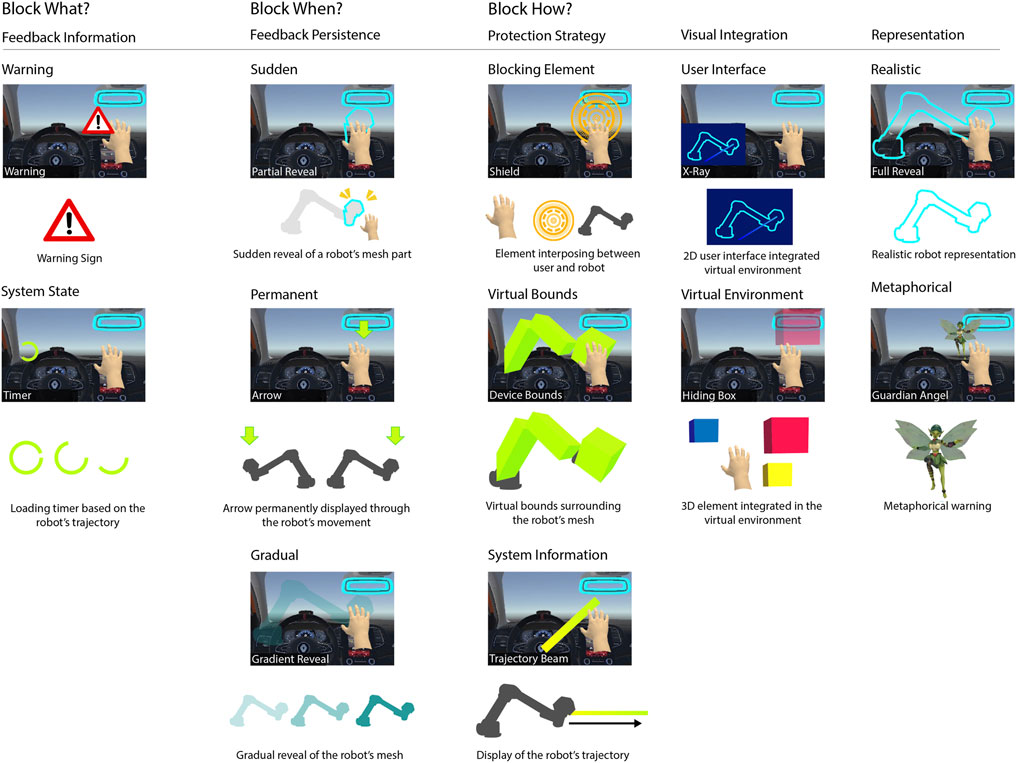
FIGURE 1. Examples of the design space features. This figure illustrates the features of the design space by showcasing the visual feedback used in the implemented in some of the safety techniques.
3.2 Safety Techniques
The second contribution of this paper is the development of a set of 18 safety techniques that illustrate the generative power of the previously presented design space. These techniques were largely inspired by previous techniques proposed in the literature and adapted to the context of interaction with an ETHD. All the conceived techniques were implemented in a simulation made in Unity where a virtual model of a grounded ETHD based on the Universal Robot’s UR5 cobot was used to render different elements of a virtual automobile cockpit. Figures 2–6 depict the implementation of all the techniques in this VE. More details about the techniques are available in the accompanying video. The techniques were grouped into five groups that represent the techniques’ main features. The conceived groups are presented hereby:

FIGURE 2. The revealers group. This group comprises techniques that display the ETHD’s virtual counterpart in the virtual environment.
3.2.1 Revealers
This group comprises several techniques dedicated to displaying and rendering the haptic device in the VE. The revealers group integrates techniques inspired by the works of Lacoche et al. (2017), Kang and Han (2020), and Kanamori et al. (2018) that represent a part of the environment or an element close to colliding with the users. This information display is made for users to acknowledge the presence of near elements and thus helping users to avoid collisions with the elements.
Several visual feedback strategies are comprised in this group such as revealing the haptic display entirely, gradually or partially. In the Full Reveal technique, the haptic display mesh is rendered entirely through the whole simulation. This technique is inspired by the constant point cloud display proposed by Kang and Han (2020) and the contour display presented by Kanamori et al. (2018). The difference from the previous research work relies on the fact that our technique displays the device’s contour rather than a point cloud (Figure 1, top-right). We conceived a technique to gradually display the ETHD (Gradient Reveal) in which the robot’s virtual mesh transparency is modified according to the distance between the robot and the users’ hands. Beyond a certain threshold, the robot’s mesh becomes more opaque as the hand gets closer to it (Figure 1, bottom-left). The implementation of this technique is inspired by the gradient point technique proposed by Kang and Han (2020). We considered the option of only displaying the parts of the robot that were the closest to the user for the Partial Reveal technique. When the user approaches the ETHD, the mesh of the closest part activates and gets displayed in the VE. This indicates the user of the presence and proximity of the robot without disclosing the entire device and compromising the users’ immersion. This technique requires dividing the ETHD’s mesh into several parts (Figure 1, second column from the left, top). In our case, we divided the ETHD’s based on the joints that compose the robot. The implementation of this technique is inspired by the partial rendering of the user virtual representation by Lacoche et al. (2017). Their technique consisted in representing a ghost avatar of another user’s HMD as a means to represent the users’ positions in a collaborative VE. We also considered the opportunity of revealing the robot under other approaches based on real-life methods for revealing hidden objects such as the Magic Light Reveal and X-Ray techniques. This first technique consists of a “black light” that emanates from the user’s virtual hand model that shows the haptic display’s mesh within the light range. When the users come close to the robot, the part of the robot’s mesh that enters the light range is displayed, as if it was revealed the same way that invisible ink is revealed under a black light. The X-Ray technique consists of a viewport screen located in the VE that displays the users’ hand and the haptic display. The metaphor was inspired by the use of x-rays in medicine to see through the skin of patients. This technique is conceived to inform the users about the proximity of their hands to the haptic display without displaying a co-located mesh in the VE (Figure 1, second column from the right, top). Figure 2 showcases the techniques that are part of this group.
3.2.2 Trajectory Beams
This group comprises the safety techniques that visually represent the haptic device trajectory when the movement is discrete and the trajectory is planned with anticipation. This principle is inspired by the technique proposed by Guhl et al. (2018) that consists in displaying the robot’s trajectory when in motion.
The Trajectory Beam technique consists in displaying the predefined trajectory of the haptic device’s end-effector in the VE (Figure 1, bottom-right). This allows users to better acknowledge the space where the haptic interface will travel. The Loading Trajectory Beam technique has a similar behavior compared to the previous one. The main difference is that the rendered trajectory shrinks as the haptic display arrives from the starting position to the final one. Figure 3 displays the two techniques that are part of this group.

FIGURE 3. The trajectory beams group. This group comprises techniques that display the ETHD’s trajectory when moving to one point to another.
3.2.3 Blockers
This group comprises safety techniques that use a blocking virtual element between the user and the haptic device. These techniques use visual feedback that interposes itself between the user and the device to catch the user’s attention and “block” any possible movement that would yield a direct collision with the haptic device (Figure 1, middle column, top).
The Guardian Angel technique uses a virtual guardian that places itself between the user’s hand and the haptic device (Figure 1, right column, middle). When the user’s hand is far from the robot, the guardian enters an “idle” state. In this state the guardian wanders around the users, out of their vision field. Once the user’s hand becomes closer to the device, the guardian “reacts” and appears immediately between the users’ hand and a part of the device where contact could have taken place. We conceived a similar technique using more abstract visual feedback called Shield. This technique, as its name suggests, consists of a virtual shield that appears between the user’s hand and the device. This “shield” permits users to acknowledge they might enter in collision with the haptic device at the moment users enter in proximity with it. Both techniques require detecting the distance from the users’ hand to the closest point of the haptic display virtual representation into the VE. Once a proximity threshold has been detected, the blocker element (in these cases: the guardian angel and the shield) will appear in the midpoint between the users’ hand and the closest point between the hand and the haptic display mesh. The main difference between these techniques is that the guardian angel uses an animated character that can be integrated in the VE, while the shield appears as a 2D UI for blocking any contact between users and robot. These safety techniques were conceived under the inspiration of the work of Cirio et al. (2012) who proposed a virtual companion for helping users to avoid collisions with the walls in a CAVE system. Figure 4 showcases the techniques that comprise this group.

FIGURE 4. The blockers group. This group comprises techniques that interpose a virtual object between user and ETHD to block/avoid a possible unexpected collision.
3.2.4 Signals
This group comprises safety techniques that consist of metaphorical signaling methods. This group considers the use of basic signs such as arrows or the conventional warning signs used in work environments. The Arrow technique consists of an arrow placed at the top of the haptic display’s end-effector. This arrow is always visible throughout the whole simulation and it allows the user to acknowledge the device’s end-effector position (Figure 1, second column from the left, middle). This technique is somehow inspired by the 3D Arrow metaphor presented in the work of Medeiros et al. (2021). The Warning technique consists of a virtual warning signal that appears right next to the user’s hand when the latter is close to the haptic display (Figure 1, top-left). This technique is inspired by the work of Abtahi et al. (2019) which displays a warning panel when users get close to the ungrounded UAV-based ETHD. We also considered retrieving a warning technique used frequently in gaming contexts such as Screen Overlay. This technique consists of a screen overlay that colors the contour of the users’ field of view in red whenever their hand gets close to the haptic display. A similar work in the literature is the Color Glow technique presented by Medeiros et al. (2021).
We considered another approach for “signaling” the robot’s position through a more abstract metaphor. The Projection technique consists in projecting in the VE a floor representing a walking user sharing the interaction workspace in the real environment. Projections are made to display the position and area that an element has in the VE so users can avoid collisions with the aforementioned element. This technique is inspired by the safe navigation space technique presented by Lacoche et al. (2017) that projects on the floor of the VE the position of another user sharing the same physical workspace in a VR application. The techniques proposed in this group can also indicate other properties of the robot’s movement beyond its position. For instance, the Timer technique consists of a timer displayed when the robot is moving in a predefined trajectory. The timer indicates the amount of completion of the predefined trajectory thus indicating when the user can interact with a rendered surface by the haptic display (Figure 1, left column, middle). Figure 5 illustrates the techniques that comprise this group.
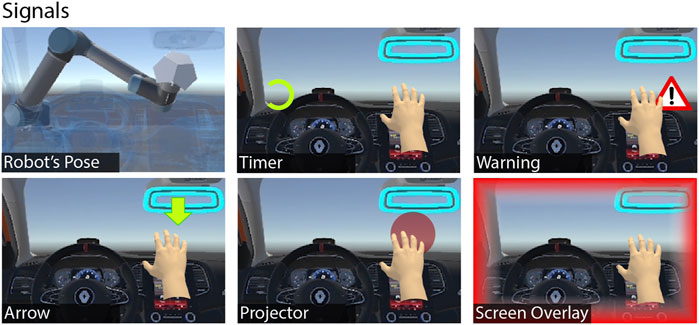
FIGURE 5. The signals group. This group comprises techniques that use basic signaling metaphors for displaying information about the position of the ETHD’s end-effector.
3.2.5 Bounds
This group comprises safety techniques that use barriers and/or bounds that surround the elements that the user could collide with. These bounds can surround the device, the device trajectory path, or the target contact area. The bounds techniques are inspired by the work proposed by Lacoche et al. (2017) and in the SteamVR Chaperone Steam (2021). This group comprises techniques that bound the workspace and/or the haptic device as a means to indicate the user that the interaction space is limited or constrained. Examples of this group are: Hiding Box, Trajectory Bounds, and Device Bounds, and Radar (Figure 6).

FIGURE 6. The bounds group. This group comprises techniques that bound the ETHD device for protecting the user from getting closer to the ETHD.
In order to add bounds around the device’s mesh, we conceived the Device Bounds technique. This technique consists of mesh boxes surrounding the haptic display’s virtual model (Figure 1 middle column, middle row). When the user gets close to these bounds, the mesh will appear to disclose the device configuration as well as its position. We also considered bounding the final position of the ETHD’s trajectory. To do so, we designed the Hiding Box technique which consists of a box mesh placed at a desired end-effector’s final position. As the haptic display arrives at this desired position, the box’s mesh starts to fade and reveals the zone that can be explored and touched once the ETHD has reached its target. The possibility of surrounding the device’s trajectory was also considered with the Trajectory Bounds technique. When users cross a given proximity threshold to any point of the trajectory, the mesh surrounding the entire trajectory will appear to indicate that the haptic rendering process is not finished and that the haptic display is displacing its end-effector from one position to another. We conceived a technique that acts as an “inverse” bound called Radar. This technique consists of a spinning arrow attached to the users’ virtual hand models that acts as a compass and radar, indicating the haptic display’s position and proximity. The arrow changes color from green to red as the users’ hand gets closer to the haptic device. The technique’s behavior as an inverse bound is justified in the sense that the information displayed by this technique is expected to “bound” the users’ hand from any involuntary contact with the ETHD’s hidden mesh. The technique is based on radars for detecting objects mainly in military contexts.
3.3 Example
Our design space can be used as a tool for creating safety techniques for ETHDs. Table 1 depicts how the 18 safety techniques presented in this research address the blocks and features of our design space. Hereby an example is provided on how the “guardian angel” safety technique was created using our design space. The first block that was considered was the block what? In this case, the guardian angel technique delivers warning feedback information. Then the block when? was addressed by selecting a sudden appearance of the guardian angel when the users come close to colliding with the ETHD. The block how? was addressed as follows: a protection strategy consisting of a blocking element was used since it is the guardian angel that interposes itself between the users’ hand and the robot; a visual integration consisting of a virtual element (the guardian angel) integrated in the VE; and a metaphorical representation since the blocking element is represented as a “guardian” that interposes itself between the user and the robot to keep the former safe. The rest of the techniques presented in this paper followed the same approach when they were created, with the only difference being that other branches in the blocks’ categories were explored.
4 Evaluation With Encountered-Type Haptic Displays Experts
An evaluation was conducted with a group of ETHD experts for assessing the performance of the safety techniques mainly in the dimensions of users’ immersion and perceived safety. This led to the third contribution of this paper: the definition of a set of evaluation criteria from the literature and an interview with experts. These criteria were designed to be used for assessing qualitatively safety techniques for ETHDs.
4.1 Evaluation Criteria
The proposed criteria were retrieved from insights of the literature on evaluation methods for assessing the performance of their safety techniques and also discussed with four experts in the ETHD and haptic research fields. Two primary criteria were identified: immersion and perceived safety. In this paper, we consider immersion as the capability that the system (the ETHD and visual display technologies) has for ensuring users’ immersion in the VE by properly rendering sensory feedback without disclosing the presence of real elements behind the scene rendering. Research works such as the works of Kanamori et al. (2018) and Hartmann et al. (2019) considered immersion as a criterion to evaluate their techniques.
In the context of interacting with an ETHD in VR, we considered perceived safety as the users’ sensation of being safe during their interaction with the haptic display in VR. This criterion has been considered in the literature for assessing if the users feel comfortable when interacting with elements that could come in physical contact with them such as robots (Bartneck et al., 2017; Oyekan et al., 2019), walls (Hartmann et al., 2019), and other objects present in the workspace (Kang and Han, 2020).
Our literature review and discussion with the experts identified a set of complementary criteria, which could also be linked with immersion and perceived safety. We first considered other criteria that can be related to properties directly associated with the visual feedback used by safety techniques such as visual clutter and ecological adaptability. For example, Lacoche et al. (2017) assessed the efficiency of the visual feedback proposed by their safety techniques. We considered measuring the visual efficiency of our techniques through cluttering (visual clutter) and aesthetics (ecological adaptability). Visual clutter refers to the degree to which the additional visual feedback occludes the virtual environment, and is linked with the additional virtual elements added to the environment. If the visual feedback used within a safety technique clutters the VE, then users’ immersion could be compromised since there could exist a larger number of distractors when users are performing a task in the VE. Ecological adaptability addresses an aspect of visual feedback more oriented towards aesthetics and pertinence to the context of the VE. We defined ecological adaptability as the visual feedback’s adaptability level for being represented in different tasks and contexts in VE. In this context, a safety technique with high ecological adaptability should be able to be implemented using different visual metaphors for a large diversity of contexts and use-case scenarios. On the other hand, a technique with low ecological adaptability might be inefficient under different scenarios and thus it might break users’ immersion in the task carried out within a VE.
The safety techniques should also be evaluated in matters of their capability of accurately representing information about the presence of the ETHD. We considered the use of co-location as an important factor that might help users to acknowledge the presence of the ETHD when they are using an HMD. In the context of visual feedback for safety techniques for ETHDs, co-location refers to the correspondence of the visual feedback with respect to the ETHD’s position in the real environment. In the literature, co-location has been considered to display visual feedback about the robot’s behavior (Shepherd et al., 2019) in an HMD. We considered that safety techniques should also make users aware that they are interacting with a robot in real-life. Therefore, we included the feature device awareness. This feature refers to how much users are aware of the ETHD’s position and state in the VE. Being aware of the actuator’s presence is useful for users’ perceived safety since they acknowledge the presence of something that can collide with them as signaled in previous research works (Hartmann et al., 2019; Oyekan et al., 2019; Kang and Han, 2020).
We further considered two additional criteria referred as users’ trust and mental workload. In the context of safety techniques, we defined mental workload as the demand imposed on users in the process of understanding the safety techniques. This notion of mental workload is derived from that of Moray (2013). A Low mental workload should be favorable for user safety since users could be easily focused on simple tasks and therefore it could be easier for them to avoid any involuntary collision with the system. Mental workload could also be linked to immersion, as low mental workload could also be linked with less noticeable safety techniques. We considered mental workload based on the study of Kang and Han (2020) and Medeiros et al. (2021) who assessed users’ subjective perception of the attention they invested in doing tasks in VR while avoiding at the same time collisions with elements present in the real environment. Finally, we defined user trust as the level of trust users can have towards the system based on the understanding of the ETHD behavior within the VE. The higher the level of trust in the system, the higher the sense of perceived safety for potential users could be. In the literature, the work of Oyekan et al. (2019) evaluated user trust for their studies.
The eight different criteria were assembled in a unique questionnaire with eight items scored with a 7-Likert scale. For each criterion, the definition was provided to ensure that participants well understood the different concepts. Except for visual clutter and mental workload, higher values mean better. For the sake of clarity, the analysis of the results will consider inverse scores (8 − 1) for visual clutter and mental workload to ensure that for all criteria higher values means better.
The fourth contribution of this paper consists in an preliminary evaluation carried out by a set of experts. Further details about the preliminary evaluation procedure and results are presented hereby.
4.2 Participants
Ten participants (2 female, 24–57, M = 34) took part in the experiment. They were all international experts with an average of 2.8 years spent in the fields of haptics and VR in both academia and industry. The four participants of the preliminary evaluation participated in this experiment. Each member of this set of experts has at least one scientific publication in the field of ETHDs and has been involved in a project with ETHDs for more than two years. We used experts instead of non-experts given the form of the experiment. As an important note, none of the authors participated in the two evaluations carried out in this paper.
4.3 Experimental Procedure
Due to the COVID-19 sanitary situation, the experiment was conducted through an online questionnaire sent to the participants so they could answer it individually. This questionnaire required participants to visualize videos of each safety technique and then provide the score for each evaluation criteria. Although it would have been ideal to let participants test the actual ETHD system, we assumed the experts would be able to imagine the technique in an immersive setting when watching the videos, compared to non-experts. Each technique was presented as a ∼25s video showing the ETHD rendering several interest points of an automobile interior, highlighted in blue as presented in Figure 7. The Supplementary Video S1 displayed two views: 1) a view of the robot moving through the automobile model and 2) the user’s view. This allowed participants to see the users’ view and, at the same time, the actual movement of the ETHD, to better assess the safety issues by comparing the actual robot configuration in the real workspace to the visual feedback provided by the techniques in the VE. Participants could play the video as many times as they wanted before answering the questions. They were instructed to imagine being in a VR setting with the video showing the technique presented in the VR headset. The participants were then prompted to evaluate on a 7-point Likert scale each one of the criteria discussed in the previous section. Descriptions from the criteria were included for each question to remind the participants about the meaning of each criterion.

FIGURE 7. Illustration of the conceived 18 safety techniques designed. The safety techniques are represented in a virtual environment representing an automobile interior. All the technique screenshots represent a status with a robot pose as similar as possible to the robot pose shown on the top left.
4.4 Results
During an initial analysis, we explored the role of the principal criteria, immersion and perceived safety (Figure 8). The visual inspection of the data showed one big cluster, with techniques with mean immersion scores between 3.5 and 5.5 and mean perceived safety scores between 3.5 and 4.5. Full Reveal and Gradient reveal techniques stood out in the perceived safety score. Although the Friedman ANOVA found significant differences for the perceived safety (χ2(17) = 38.8, p < 0.001) and immersion scores (χ2(17) = 54.18, p < 0.001), post-hoc tests (Wilcoxon pairwise with Bonferroni correction) were not significant (all p > 0.05). The non-significance of the results can mainly be attributed to the high number of conditions and the correction for multiple pairwise tests.
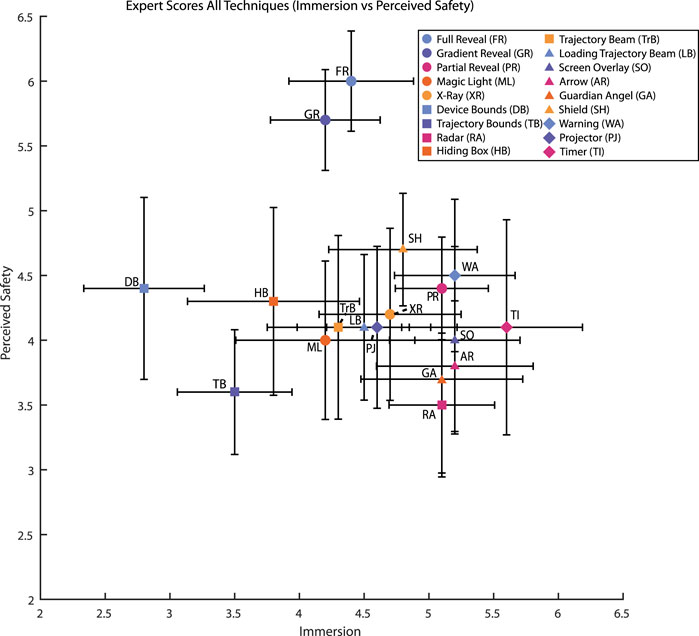
FIGURE 8. Mean scores (95% CI) for the perceived safety and immersion criteria, for each technique (7-Likert Scale). Axes are cropped for clarity. Figure 7 and the accompanying video for watching the illustrations of the techniques.
In a second step, we explored the potential relationships between the primary (immersion and perceived safety) and the secondary criteria (device awareness, co-location, user trust, visual clutter, ecological adaptability, and, mental workload). For this purpose, instead of using cross-correlations, we decided to conduct a principal component analysis (Table 2) to extract meaningful relationships among all criteria.
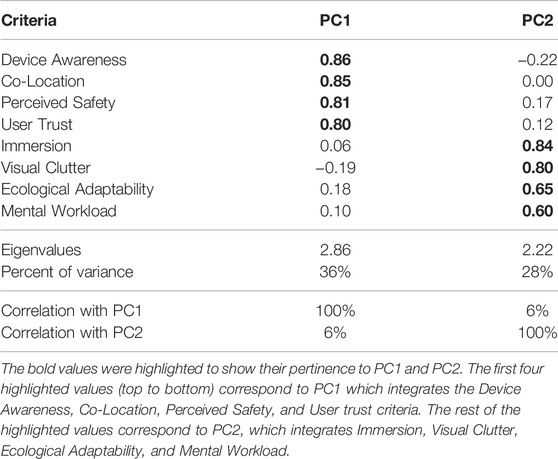
TABLE 2. The principal component analysis from the questionnaire data. The first part details the correlations for each criterion. The second part presents the eigenvalues and the percent of the variance explained by the principal component. Finally, the third part shows the correlation between principal components.
Before conducting the PCA analysis, we checked for the sampling adequacy using the Kaiser-Meyer-Olkin (KMO) measure. The overall KMO was 0.7, which can be considered as moderate sampling adequacy. In addition, we used the Bartlet’s test of sphericity to observe if the correlations between the criteria were enough for running a PCA (χ2(28) = 160.107; p < 0.001). Considering the limited sample size, we considered that this was sufficient for a preliminary assessment.
When considering only two components, the PCA analysis showed that they could explain the 64% of the observed variance and provided a fit of 0.92.
The PCA analysis, see correlation coefficients in Table 2, revealed a clear dichotomy of the criteria enabling to split them into two major clusters. The first one considering device awareness, co-location, perceived safety, and user trust. The second one considering immersion, visual clutter, ecological adaptability, and mental workload. The separation between the two clusters was clear, as the correlation between the unused criteria is weak (smaller or equal than |0.22|). Furthermore, the correlations between principal components were low
We also explored the addition of a third factor, which increased the variance explained to 11% and increased the fit by 0.03. With three factors configuration, the main difference was that the mental workload was strongly correlated with the third component and not the second one. The remaining correlation remained similar. We did not consider the third component for simplicity and the good fit for two first components.
Table 3 presents the average score for each safety technique for each evaluation criterion and the aggregated scores for both subscales. The aggregation was computed by averaging the criteria scores for each cluster.
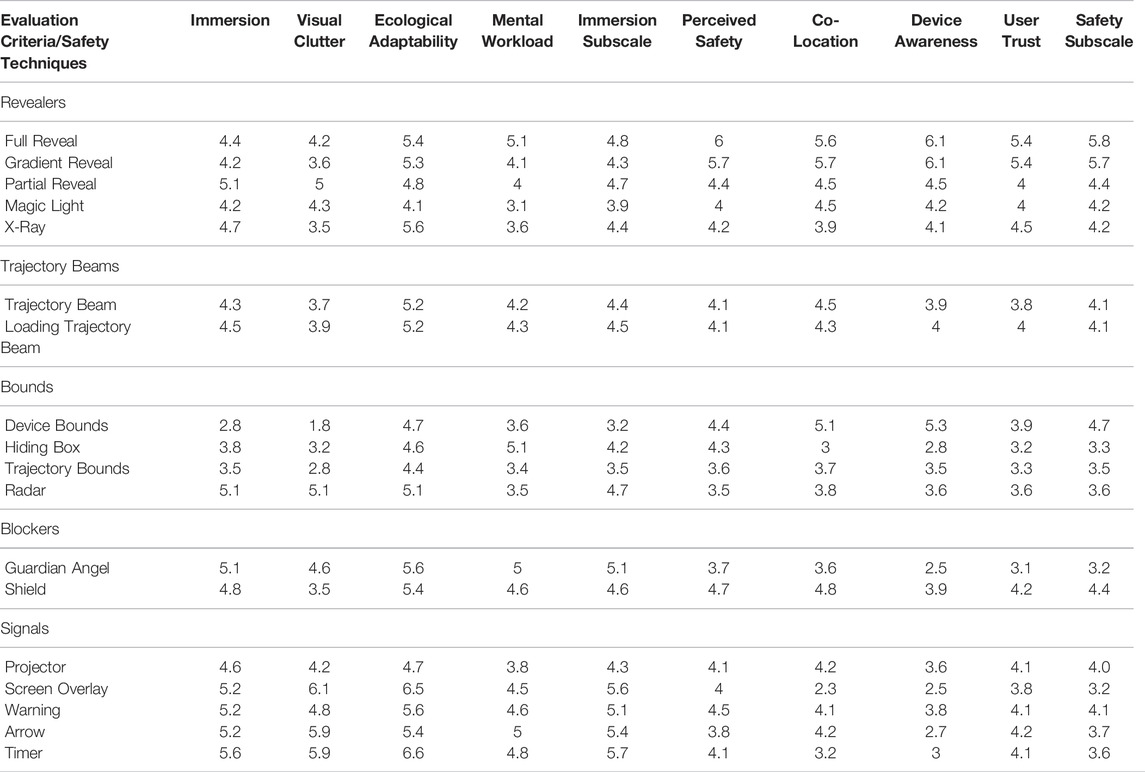
TABLE 3. Average response scores for all the techniques and all the evaluation criteria. The three highest values are highlighted in blue while the three lowest values are highlighted in orange.
Moreover, Figure 8 displays the mean and confidence intervals for each technique concerning the immersion and safety subscales.
The Friedman ANOVA analysis showed a similar result as the one conducted on the immersion and perceived safety criteria, thus we present the results considering the rank among each subscale to provide qualitative results.
Regarding the technique clusters, overall, revealer techniques obtained higher scores in the safety-related subscale while presenting average scores in the immersion-related subscale.
The trajectory beam techniques obtained average scores in both subscales, while bound techniques tended to obtain the lowest scores in both subscales.
For blockers, both techniques obtained average scores, although the guardian angel technique obtained one of the worst scores in the safety subscale.
Finally, signal techniques obtained in overall the highest scores for the immersion-related subscale, while presenting lower scores for the safety-related subscale.
Technique-wise, the Full reveal obtained the highest scores for both subscales, while Partial reveal, Shield and Warning and Gradient reveal techniques presented a good trade-off between subscales.
5 Discussion
This paper presented a design space for safety techniques for ETHDs based on visual feedback. This contribution intends to serve as a tool for researchers to create safety techniques for ETHDs within multiple-use contexts. This design space is based on previous research works from both VR and HRI research fields. This combination allows exploring possible solutions from two disciplines that we consider to be fundamental within the ETHD field. The generative power of our design space is seen in the diversity of techniques presented in this paper. The factor that makes the techniques specialized in ETHDs consists in providing information of an element outside the VE that users should be aware of, that ideally should not be seen, and that has to be touched by users at some point during interaction. The 18 techniques presented in this paper explore factors related to feedback information, permanence, and representation so as to provide as much information as possible to the user without breaking the illusion of touching elements that are in the VE but rendered through an ETHD. Another difference between these techniques and other approaches for avoiding collisions in VR is that these techniques are triggered whenever the users’ hands get close to the ETHD specifically when the robotic device has not yet placed the surface display in a position where users can actually engage contact. We considered primarily hand collisions with the ETHD since the user’s hand is the extremity that is commonly in contact with the robot, mainly for surface exploration and object manipulation Mercado et al. (2021).
In order to evaluate the safety techniques, we proposed a set of criteria to characterize the techniques in their immersion and perceived safety (primary criteria), and six additional criteria corresponding to visual clutter, co-location, ecological adaptability, device awareness, mental workload, and user trust (secondary criteria). While there are indeed questionnaires to assess in depth each one of these factors, we decided to keep the evaluation focused on the factors that the ETHD experts suggested that could be useful for evaluating our techniques.
The use of the design space could help researchers to optimize the performance of a safety technique on the criteria previously mentioned. Since the results of this preliminary evaluation suggest that different technique clusters have different performance on the different evaluation criteria, we decided to provide design guidelines so researchers and designers might find or create the most suitable technique for their needs. In the following, we discuss the scores obtained for each presented technique, design recommendations for safety techniques, the limitations of our study, and future work.
5.1 Results Discussion
The statistical analysis of the preliminary results suggests that there were relationships among the different criteria considered. Two independent clusters of criteria were formed, one aggregating criteria strongly correlated with immersion (Immersion subscale) and another one strongly correlated with perceived safety (Safety subscale).
First, although we hypothesized that there would be a trade-off between Immersion and Perceived Safety, none of the subscales had a significant correlation
From Figure 9, we can observe that the majority of the techniques obtained average scores for both subscales. If we observe the techniques obtaining higher scores in the immersion and safety subscale, we can find techniques with higher safety scores but lower immersion scores (e.g., Device Bounds) and vice versa (e.g., Screen Overlay). Two outliers can also be found, Full Reveal and Gradient Reveal, which resulted in the techniques with the highest safety scores.
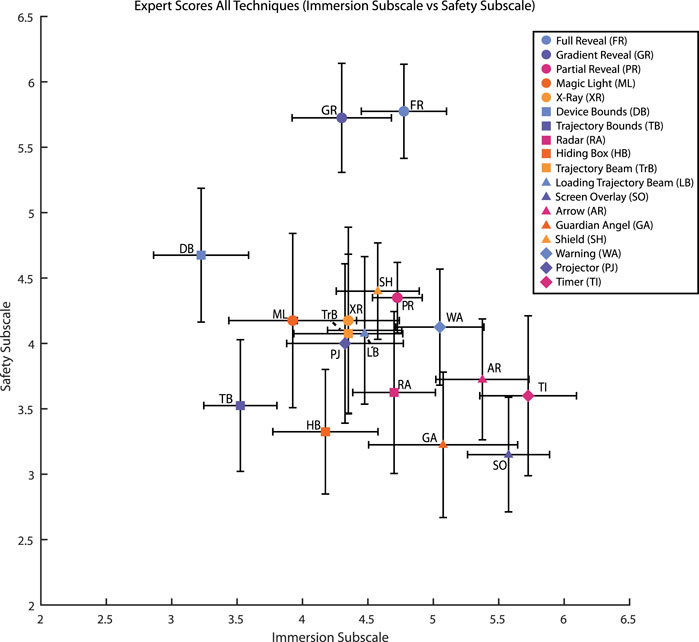
FIGURE 9. Overall average scores for the Safety and (PC1) and Immersion (PC2) subscales, for each technique. Axes are cropped in order to display values and 95% confidence intervals as clearly as possible. Figure 7 and the accompanying video for seeing the illustrations of the techniques.
The balance between immersion and perceived safety for Full Reveal and Gradient Reveal might be because the whole device is being represented and therefore it indicates the device’s configuration and position. However, the fact that the device is being fully shown but in a subtle way had only a moderate impact on immersion according to the experts.
We further discuss the results for each subscale.
5.1.1 Safety Subscale
The safety subscale, in addition to the perceived safety criteria, also included co-location, device awareness, and user trust.
We can hypothesize that co-location and device awareness increased the knowledge about the robot state, which can be linked with perceived safety. User trust was also positively correlated with perceived safety.
The highest scores were obtained with the techniques that displayed the entire robotic actuator, Full Reveal, Gradient reveal.
Both techniques use visual feedback to represent the haptic display as accurately as possible and accordingly to the actuator’s configuration and position in the real environment, thus achieving the highest scores in co-location and device awareness. In addition, these two techniques also reported the highest scores for device awareness and user trust. These results are in agreement with results in HRI stating that it is important to disclose the robot’s position and configuration when it is integrated into a VE (Guhl et al., 2018).
The Device Bounds technique also obtained a high score in the safety subscale, yet, the fact that the representation of the robot was more “clumsy” could have generated a lower perceived safety and user trust.
In contrast, the lowest scores were obtained with the techniques that did not display the robot actuator such as the Screen Overlay, the Guardian Angel or the Hiding Box.
The only technique that achieved a moderate safety score without displaying the robot actuator was the Shield technique, which provided a moderate perceived safety and co-location, but was penalized by a lower device awareness and user trust.
5.1.2 Immersion Subscale
The immersion subscale, in addition to the immersion criterion, also included visual clutter, ecological adaptability, and mental workload.
We can hypothesize that subtle techniques (low visual clutter), and techniques that can be seamlessly integrated with the VE (high ecological adaptability) have a smaller negative impact on user immersion. Finally, we expect that mental workload would be more correlated with safety, yet this was not the case. This suggests that techniques that were easier to interpret had a lower impact on immersion.
The techniques achieving the highest scores were mainly techniques in the Signals cluster, in particular Timer, Arrow, and Screen Overlay. These three techniques subtly displayed information regarding the robot, thus obtaining the highest scores in immersion and visual clutter. In addition, as the feedback was subtle, they also obtained high scores in ecological adaptability.
In contrast, the techniques that were ranked lower on immersion were those that used bounds around the device (Device Bounds), its trajectory (Trajectory Bounds), and its final position (Hiding Box). The evaluation results suggest that these techniques also ranked high on visual clutter as can be seen in Figure 7. These techniques, when active, display large and colorful mesh boxes that highly contrast with the VE used as a use-case scenario.
Concerning mental workload, the Magic Light Reveal technique reported the lowest score. This might be because users needed to place their hand in a position close to the robot but also in an angle that permitted to “reveal” the robot’s mesh. Paying attention to those factors while “avoiding” a collision with something that cannot be directly seen in the VE could be highly demanding for users’ mental workload. At the opposite, the Full Reveal technique yielded one of the highest scores for the aforementioned feature since the information of the haptic display is always shown in the VE and thus it is easier to understand what is going on in the real environment.
5.2 Design Recommendations
From the results on the immersion and safety subscales, several design recommendations could be provided regarding the potential application requirements.
For applications focusing on safety, safety techniques that display the entirety of the ETHD’s, such as Full Reveal and Gradient Reveal seem the best choices. Moreover, both techniques had a moderate impact on the user’s immersion. The use of Device Bounds although having a high perceived safety score is discouraged as its impact in immersion is too high. However, it is important to consider that the bounds’ mesh could be adapted to be less strident and visually cluttering.
In contrast, for applications having its focus on immersion techniques such as Timer, Arrow and Screen Overlay seem the best choices. However, these three techniques obtained relatively low scores on safety. Thus, potentially being only usable in an expected context in which users are well aware of the ETHD behavior. With this same rationale, the Radar technique could also be considered, but it had a strong negative impact on mental workload, which could be overcome with training.
Other methods also presented some good trade-offs between safety and immersion, although they did not excel in any of them. These techniques were the Shield, Partial Reveal and Warning. We believe that these three methods are worth being considered in further analysis.
Furthermore, for particular applications requiring displaying the trajectory of the robot, could also consider both Trajectory Beam and Loading Trajectory Beam. Although not achieving high scores, they obtained average scores.
Finally, the graphical representation can be considered a key factor in designing the visual feedback. In this work, we considered the use of colors that are highly contrasted with the VE since we wanted to design visual elements that could be easily perceived.
However, in a real application, the visual feedback’s aesthetics should be adapted to the context of the VE.
Adapting the visual feedback as much as possible to the context of use could enhance safety and increase immersion. However, designers should be aware that users should perceive the visual feedback, and therefore, visual contrast should be considered for alerting users of possible collisions.
For example, the Guardian Angel low performance in the evaluation might be related to the graphic representation of the blocking element, which contrasted notably with the automobile scenario. A notably similar technique, Shield yielded a better perceived safety score. This could be due to the simpler visual representation and metaphor presented in the technique’s visual feedback.
Balancing the trade-off between immersion and perceived safety is a challenge that could not be ultimately solved by the implementation of a safety technique. The best that researchers and designers could do is to select and/or design the most appropriate technique for a given context. Providing feedback about the real environment behavior is crucial when interacting within an immersive VE. Previous research works in VR and HRI have already signaled the problems that come up when feedback is not provided to the users. Even when having an ideal ETHD capable of dodging and adapting to every user’s movement, the variables of human error and trust will still be present. Thus, we consider that as long as users are informed about a robotic device “hidden” in a VE, then the risk of collision could be lower.
5.3 Limitations and Future Work
One of the main objectives of this paper was to design and evaluate a wide range of safety techniques for ETHDs. In order to increase the number of techniques evaluated, we decided to run an online evaluation based on video examples for all the techniques. We assumed the experts could imagine being in a real VR environment with an ETHD, which remains different from actually experiencing each technique in a real VR setup. Remotely testing a VR setup using an ETHD brings up challenges in matters of having the same setup (PCVR, HMD, and ETHD) for controlling variability in visual and haptic feedback.
However, some of the criteria might have been harder to evaluate than others. For example, being immersed in a virtual environment would have increased the depth perception of the users and they would not have to imagine themselves performing actions in the VE. One of such criteria might have been the mental workload, as users were passive and not active. Furthermore, an increased exposure time would have been beneficial for a better assessment.
Nevertheless, the initial evaluation has provided a wide range of relevant results, first providing a validation of the different criteria proposed and highlighting a set of safety techniques that stood out from the rest. These preliminary results could serve as a base for future research as it is detailed in the following paragraphs.
Another aspect that could be further explored is the creation of additional safety techniques. In this paper, we proposed a set of distinct techniques which explored the proposed design space. However, although finding techniques, which a good balance of immersion and safety, none of the proposed techniques was able to achieve high scores in both subscales. Considering that the principal component analysis showed that there was no correlation between the immersion and the safety subscales, techniques for achieving high scores in both subscales seem still possible.
The relevance of our design space and the findings of this paper rely on highlighting the importance of the aspects that compose a safety technique for ETHDs, and how design decisions could have an impact on user experience. Factors such as the application context, users’ previous experience and background, interactions, and tasks performed in the VE could influence on the performance of the techniques for informing users about the risk of collision with the ETHD. These factors could be explored in future research.
The presented virtual car-cockpit scenario is dedicated entirely to surface exploration. However, the use of ETHDs can also consider object manipulation in a part assessment scenario for the industry, for instance. The technique’s feedback information (Block What?) could be adapted to the industrial scenario and the warnings that are emitted to users in that context. The permanence of the visual feedback (Block When?) should be adapted to the length of the object manipulation task. A safety technique designed for industrial part assessment could consider a protection strategy (Block How?) based on virtual bounds since the user is going to manipulate a volume. The aesthetics of the visual feedback case could be adapted to represent the seriousness of the use context. Future work could dive deeper into the use and integration of the design space and the techniques in different use contexts.
Future works should consider the evaluation of safety techniques in the actual VR system. The techniques, which obtained better scores in the different subscales, should be further evaluated to ensure that the same scores could be replicated.
Future work could dive even further into the techniques aesthetics and the use of other types of feedback for signaling the possibility of collision. One possibility could be the creation of a meta-technique that selects the most suitable safety technique according to the users’ proximity to the ETHD. In the case of multimodal feedback, the visual feedback displayed by the techniques could also be complemented with additional auditory and haptic cues for warning users about a possible collision.
An orthogonal approach could be the combination of several safety techniques, yet, there is a high risk of complexifying their interpretation and adding too many visual elements to the virtual environment.
The evaluation was carried out with a limited number of ETHD experts, who were expected to well apprehend the pros and cons of every safety technique. The statistical analysis displayed interesting tendencies. However, these are still preliminary results. Future work could explore the insights of a larger user population considering both experienced and novice profiles. The favored techniques might vary for different user groups based on their experience with HRI in VR.
The safety techniques for ETHDs proposed in this paper intend to serve as visual feedback for making users aware that they are interacting with a robot. Visual feedback has already been used in VR research as a means to prevent and warn users about the presence of objects that could collide with them in the interaction environment (Cirio et al., 2012; McGill et al., 2015; Yang et al., 2018; Kang and Han, 2020). This measure is complementary to the path planning strategies used in ETHD research to “help” the robotic device for avoiding the user (Araujo et al., 2016; Yokokohji et al., 2005, 2001). Since human behavior is often unpredictable, we consider that the design space we propose in this paper could help ETHD researchers and designers to find strategies to disclose the presence of a robotic actuator without sacrificing immersion nor users’ perceived safety.
6 Conclusion
This paper presented a design space for safety techniques based on visual feedback for avoiding collisions when using an ETHD in a VE. Ensuring user safety when interacting with an ETHD within an immersive VE represents a challenge for designers and researchers, as two key factors need to be balanced to ensure optimal interaction with the system. On one hand, users’ immersion needs to be favored to not disrupt the task and the “realism” the ETHD is providing when rendering haptic feedback. On the other hand, users’ perceived safety needs to be ensured by providing appropriate information about the system’s behavior.
This trade-off between immersion and perceived safety needs to be addressed with the design of safety techniques for avoiding involuntary collisions with an ETHD. For this purpose, inspired by previous works, we designed a total of 18 different safety techniques and a set of eight evaluation criteria. In order to assess the proposed techniques with the proposed evaluation criteria, we recruited a group of experts in ETHDs. Preliminary results from this evaluation pave the way to design guidelines for visual feedback for avoiding collisions that balance immersion and perceived safety. Taken together, the contributions of this paper could help designers and researchers to explore different possibilities to augment users’ perceived safety and immersion by using visual feedback when integrating an ETHD for rendering haptic feedback in a VE.
Data Availability Statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Ethics Statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author Contributions
VRM contributed with the manuscript writing, the literature review, the conduction of the user evaluations, and the design and implementation of the safety techniques. FA contributed with the scientific design of this paper and the statistical analysis. GC contributed with the scientific design and vision of this paper. AL contributed with envisioning and guiding the research conducted in this paper.
Funding
The research carried out within this research article was funded by the French National Research Agency (ANR) for the LobbyBot project.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank the French National Research Agency (ANR) for the funding of the LobbyBot project.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frvir.2022.928517/full#supplementary-material
References
Abtahi, P., Landry, B., Yang, J., Pavone, M., Follmer, S., and Landay, J. A. (2019). Beyond the Force. Proc ACM CHI 1. 589. doi:10.1145/3290605.3300589
Araujo, B., Jota, R., Perumal, V., Yao, J. X., Singh, K., and Wigdor, D. (2016). Snake Charmer. Proc. ACM TEI, 218–226. doi:10.1145/2839462.2839484
Bartneck, C., Kulic, D., and Croft, E. (2017). Measuring the Anthropomorphism, Animacy, Likeability, Perceived Intelligence, and Perceived Safety of Robots. Amsterdam, Netherlands: Artwork Size: 311700 Bytes Publisher: figshare.
Chen, C., Pan, Y., Li, D., Zhang, S., Zhao, Z., and Hong, J. (2020). A Virtual-Physical Collision Detection Interface for AR-based Interactive Teaching of Robot. Robotics Computer-Integrated Manuf. 64, 101948. doi:10.1016/j.rcim.2020.101948
Cirio, G., Vangorp, P., Chapoulie, E., Marchal, M., Lecuyer, A., and Drettakis, G. (2012). Walking in a Cube: Novel Metaphors for Safely Navigating Large Virtual Environments in Restricted Real Workspaces. IEEE Trans. Vis. Comput. Graph. 18, 546–554. doi:10.1109/TVCG.2012.60
Guhl, J., Hügle, J., and Krüger, J. (2018). Enabling Human-Robot-Interaction via Virtual and Augmented Reality in Distributed Control Systems. Procedia CIRP 76, 167–170. doi:10.1016/j.procir.2018.01.029
Hartmann, J., Holz, C., Ofek, E., and Wilson, A. D. (2019). “RealityCheck,” in Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (ACM), 1. doi:10.1145/3290605.3300577
Hirata, R., Hoshino, H., Maeda, T., and Tachi, S. (1996). A Force and Shape Display for Virtual Reality System. Trans. Virtual Real. Soc. Jpn. 1, 32
Kanamori, K., Sakata, N., Tominaga, T., Hijikata, Y., Harada, K., and Kiyokawa, K. (2018). “Obstacle Avoidance Method in Real Space for Virtual Reality Immersion,” in 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, October 16–20, 2018 (IEEE), 80. doi:10.1109/ISMAR.2018.00033
Kang, H., and Han, J. (2020). SafeXR: Alerting Walking Persons to Obstacles in Mobile XR Environments. Vis. Comput. 36, 2065–2077. doi:10.1007/s00371-020-01907-4
Kästner, L., and Lambrecht, J. (2019). Augmented-Reality-Based Visualization of Navigation Data of Mobile Robots on the Microsoft Hololens – Possibilities and Limitations Bangkok, Thailand: IEEE. arXiv:1912.12109 [cs, eess] ArXiv: 1912.12109.
Kim, Y., Kim, H. J., and Kim, Y. J. (2018). Encountered-type Haptic Display for Large VR Environment Using Per-Plane Reachability Maps. Comput. Anim. Virtual Worlds 29, e1814. doi:10.1002/cav.1814
Kuts, V., Modoni, G. E., Terkaj, W., Tähemaa, T., Sacco, M., and Otto, T. (2017). “Exploiting Factory Telemetry to Support Virtual Reality Simulation in Robotics Cell,” in Augmented Reality, Virtual Reality, and Computer Graphics Series Title: Lecture Notes in Computer Science. Editors L. T. De Paolis, P. Bourdot, and A. Mongelli (Ugento, Italy: Springer International Publishing), 10324, 212–221. doi:10.1007/978-3-319-60922-5_16
Lacoche, J., Pallamin, N., Boggini, T., and Royan, J. (2017). “Collaborators Awareness for User Cohabitation in Co-located Collaborative Virtual Environments,” in Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology (ACM), 1. doi:10.1145/3139131.3139142
McGill, M., Boland, D., Murray-Smith, R., and Brewster, S. (2015). A Dose of Reality: Overcoming Usability Challenges in VR Head-Mounted Displays. Proc. ACM CHI (ACM), 2143–2152. doi:10.1145/2702123.2702382
Medeiros, D., Anjos, R. d., Pantidi, N., Huang, K., Sousa, M., Anslow, C., et al. (2021). “Promoting Reality Awareness in Virtual Reality through Proxemics,” in 2021 IEEE Virtual Reality and 3D User Interfaces (VR), Lisboa, Portugal, March 27–April 1, 2021 (IEEE), 21–30. doi:10.1109/VR50410.2021.00022
Mercado, V., Marchal, M., and Lecuyer, A. (2021b). ENTROPiA: Towards Infinite Surface Haptic Displays in Virtual Reality Using Encountered-type Rotating Props. IEEE Trans. Vis. Comput. Graph. 27, 2237–2243. doi:10.1109/TVCG.2019.2963190
Mercado, V. R., Marchal, M., and Lecuyer, A. (2021). "Haptics On-Demand": A Survey on Encountered-type Haptic Displays. IEEE Trans. Haptics 14, 449–464. doi:10.1109/TOH.2021.3061150
Mercado, V. R., Marchal, M., and Lecuyer, A. (2020a). “Design and Evaluation of Interaction Techniques Dedicated to Integrate Encountered-type Haptic Displays in Virtual Environments,” in IEEE VR Atlanta, GA, United States: IEEE. doi:10.1109/vr46266.2020.00042
Moray, N. (2013). Mental Workload: Its Theory and Measurement, 8. Boston, MA, United States: Springer Science & Business Media.
Oyekan, J. O., Hutabarat, W., Tiwari, A., Grech, R., Aung, M. H., Mariani, M. P., et al. (2019). The Effectiveness of Virtual Environments in Developing Collaborative Strategies between Industrial Robots and Humans. Robotics Computer-Integrated Manuf. 55, 41–54. doi:10.1016/j.rcim.2018.07.006
Posselt, J., Dominjon, L., Bouchet, A., and Kemeny, A. (2017). “Toward Virtual Touch: Investigating Encounter -type Haptics for Perceived Quality Assessment in the Automotive Industry,” in Industrial Track. EuroVR: Inustrial Track Laval, France.
Scavarelli, A., and Teather, R. J. (2017). “VR Collide! Comparing Collision-Avoidance Methods between Co-located Virtual Reality Users,” in Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems (ACM), Denver, Colorado, United States, May 6–11, 2017. 2915. doi:10.1145/3027063.3053180
Shepherd, D. C., Kraft, N. A., and Francis, P. (2019). “Visualizing the ”Hidden” Variables in Robot Programs,” in 2019, Visualizing the "Hidden" Variables in Robot Programs IEEE/ACM 2nd International Workshop on Robotics Software Engineering (RoSE) (IEEE), Montreal, QC, Canada, May 27, 2019. 13. doi:10.1109/RoSE.2019.00007
Vonach, E., Gatterer, C., and Kaufmann, H. (2017). “VRRobot: Robot Actuated Props in an Infinite Virtual Environment,” in Proc of IEEE VR Los Angeles, CA, United States, 74–83. doi:10.1109/vr.2017.7892233
Vosniakos, G.-C., Ouillon, L., and Matsas, E. (2019). Exploration of Two Safety Strategies in Human-Robot Collaborative Manufacturing Using Virtual Reality. Procedia Manuf. 38, 524–531. doi:10.1016/j.promfg.2020.01.066
Yang, K.-T., Wang, C.-H., and Chan, L. (2018). “ShareSpace,” in Proc. UIST (ACM) Berlin, Germany, 499. doi:10.1145/3242587.3242630
Yokokohji, Y., Hollis, R. L., and Kanade, T. (1996). “What You Can See Is what You Can Feel-Development of a Visual/haptic Interface to Virtual Environment,” in Proc. IEEE VRAIS Santa Clara, CA, United States, 46–53. doi:10.1109/VRAIS.1996.490509
Yokokohji, Y., Kinoshita, J., and Yoshikawa, T. (2001). “Path Planning for Encountered-type Haptic Devices that Render Multiple Objects in 3d Space,” in Proc of IEEE VR Yokohama, Japan, 271. doi:10.1109/VR.2001.913796
Keywords: virtual reality, encountered-type haptic display, immersion, perceived safety, human robot interaction, visual feedback
Citation: Mercado VR, Argelaguet F, Casiez G and Lécuyer A (2022) Watch out for the Robot! Designing Visual Feedback Safety Techniques When Interacting With Encountered-Type Haptic Displays. Front. Virtual Real. 3:928517. doi: 10.3389/frvir.2022.928517
Received: 25 April 2022; Accepted: 15 June 2022;
Published: 12 July 2022.
Edited by:
Dangxiao Wang, Beihang University, ChinaReviewed by:
Mario Lorenz, Chemnitz University of Technology, GermanyHiroaki Yano, University of Tsukuba, Japan
Copyright © 2022 Mercado, Argelaguet, Casiez and Lécuyer. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Victor Rodrigo Mercado , dnJtZXJjYWRvQG91dGxvb2suY29t