 Matteo N. Colombo
Matteo N. Colombo Marco Paganoni
Marco Paganoni Luca Presotto
Luca Presotto- Department of Physics “Giuseppe Occhialini”, University of Milano-Bicocca, Milano, Italy
Introduction: The positron emission tomography (PET) problem with Poisson log-likelihood is notoriously ill-conditioned. This stems from its dependence on the inverse of the measured counts and the square of the attenuation factors, causing the diagonal of the Hessian to span over 5 orders of magnitude. Optimization is, therefore, slow, motivating decades of research into acceleration techniques. In this paper, we propose a novel preconditioner tailored for maximum a posteriori (MAP) PET reconstruction priors that is designed to achieve approximately uniform spatial resolution.
Methods: Our approach decomposes the Hessian into two components: one diagonal and one circulant. The diagonal term is the Hessian expectation computed in an initial solution estimate. As the circulant term, we use an apodized 2D ramp filter. We evaluated our method on the PET Rapid Image reconstruction Challenge dataset that includes a wide range of phantoms, scanner models, and count levels. We also varied the regularization strengths. Our preconditioner was implemented in a conjugate gradient descent algorithm without subsets or stochastic acceleration.
Results: We show that the proposed preconditioner consistently achieves convergence in fewer than 10 full iterations—each consisting of just one forward and one backward projection. We also show that the circulant component, despite its crude 2D approximation, provides very meaningful acceleration beyond the diagonal-only case.
Discussion: These results demonstrate that decomposing the Hessian into diagonal and circulant components is an effective strategy for accelerating MAP PET reconstruction. The proposed preconditioner significantly improves convergence speed in challenging, ill-conditioned Poisson PET inverse problems.
1 Introduction
Positron emission tomography (PET) plays a crucial role in modern medical imaging, offering functional insights into tissue metabolism and receptor activity. However, accurate image reconstruction from PET data remains a mathematically ill-posed and computationally demanding inverse problem (1). Indeed, the favored approach is the Bayesian framework; with the acquisition modeled as a Poisson process and the possibility to include a priori information. However, the curvature of the Poisson log-likelihood makes the optimization especially difficult (2, 3). In this work, we investigate a novel preconditioning approach to accelerate maximum a posteriori (MAP) image reconstruction, which, being generalizable, can be combined with further acceleration techniques.
1.1 The PET reconstruction problem
In emission tomography, individual events are recorded in each detector bin; therefore, the data follow the Poisson statistics. In positron emission tomography, detector bins are represented by lines of response (LORs), each characterized by an attenuation coefficient, , that represents the probability of both photons reaching the detector without being attenuated. In PET, this coefficient is independent of the emission position along the LOR. In this article, we will refer to the log-likelihood of the data as , where is the number of events recorded in LOR , while is the number of expected counts in the same LOR, given an image ; the two are related by , where is the aforementioned attenuation factor, is the probability that a positron emission starting in pixel and not attenuated in the body is detected as a coincidence in LOR , and is the number of expected background counts in that bin (i.e., the sum of the random and scatter corrections). Note that it is possible to include the factor in .
In PET, penalized maximum likelihood image reconstruction algorithms have emerged as a powerful method class (4, 5). Their main advantage lies in the possibility of incorporating accurate statistical models of the acquisition process together with prior information, which makes it possible to simultaneously encourage the preservation of smooth regions while still promoting sharp edges and clear structural boundaries. This balance often translates into images with improved diagnostic quality, reduced noise amplification, and enhanced robustness with respect to measurement variability. In the Bayesian framework, these algorithms are interpreted as MAP estimation, where the goal is to reconstruct by maximizing the posterior distribution . The prior introduces a regularization, typically through a penalty term . In practice, MAP estimation leads to the minimization of a penalized objective function, as shown in the following equation:
The parameter in Equation 1 controls the tradeoff between resolution and noise.
The gradient and Hessian of the tomographic log-likelihood are given by the following equations, respectively:
Equation 2 highlights immediately two issues in the Hessian. As in a field of view containing a human adult abdomen, the presence of this value at the second power already shows how the diagonal of the Hessian typically spans more than 4 orders of magnitude. Furthermore, even the expectation of spans 1 or more orders of magnitude when moving from LORs that intersect the majority of the body to purely background LORs. All of these factors make the convergence of algorithms maximizing the gradient of the Poisson likelihood especially slow.
For MAP PET reconstruction, the state-of-the-art approaches include gradient-based methods, primal-dual algorithms, and surrogate techniques. To accelerate computation, subset strategies, such as ordered subset expectation maximization (OSEM) (6) and block sequential regularized expectation maximization (BSREM) (7), are widely used, though they may suffer from convergence issues. More recently, stochastic variance reduction (SVR) methods, including stochastic variance reduced gradient (SVRG), stochastic average gradient (SAG), and SAGA (8), have been introduced to reduce gradient variance and allow more stable convergence toward the MAP solution (9). These algorithms work by storing and utilizing previously computed subset gradients to improve the accuracy of the update direction. The SVR techniques have been shown to reduce variations in successive image updates and can achieve faster convergence to the penalized maximum likelihood solution under suitable conditions, while still relying on gradient-based updates.
All the previously listed techniques mainly focus on stochastic-based acceleration. Another independent strategy to achieve fast convergence is preconditioning. This modifies the optimization problem so that the effective Hessian becomes better conditioned. The concept is that of scaling the gradient update by an approximation of the inverse Hessian. Common choices include simple diagonal preconditioners. Although diagonal preconditioners can accelerate convergence in many optimization problems, they cannot provide the fastest convergence rate for imaging problems since they ignore the off-diagonal structure of the Hessian of the objective function (in this context, mainly the response of tomographic systems). Given these premises, strategies that improve the conditioning of the optimization problem have wide applications. Preconditioning is broadly generalizable, and therefore, it can be used in conjunction with other acceleration strategies.
In this article, we propose a new preconditioning strategy and apply it to a gradient descent algorithm with conjugate acceleration. We test it against a subset of the PET Rapid Image reconstruction Challenge (PETRIC) dataset that contains different anthropomorphic phantoms, each of which is representative of different setups encountered in clinical settings (e.g., high/low number of counts per bin, Time-of-flight (TOF) vs non-TOF, cold contrast, and high/low hot contrast).
1.2 Non-negatively constrained vs. unconstrained problems
While PET image reconstruction problems are generally discussed as if they are unconstrained, all popular algorithms actually apply a non-negativity constraint to the current estimate . The original ML-EM algorithm by Vardi et al. (10) uses a multiplicative update, which naturally preserves positivity. The popular BSREM algorithm, which is useful for applying a priori regularization strategies, as described by De Pierro and Yamagishi (7), briefly mentions that for elements that “fall below a small threshold, we reset them to the threshold value before proceeding to the next iteration.” This apparently negligible modification modifies the optimization task from an unconstrained to a constrained one, which has different behavior. It is also known that this non-negativity constraint results in bias in the reconstructed image, especially in cold areas [e.g., see Cloquet and Defrise (11)].
Negative numbers in the image could indeed be avoided as PET images represent physical concentration of radioactivity, for which negative values carry no physical meaning. However, they could also be accepted with the understanding that negative numbers are to be interpreted as within the statistical error. The only constraint given by the Poisson log-likelihood is that .
2 Materials and methods
2.1 Reconstruction algorithm
In this article, we decided to allow the solution to be negative. To achieve this, we modified the gradient of the log-likelihood to be
The parameter in Equation 3 is the additive correction term of the forward model. To see the effect of this modification, we will highlight three cases that show how using instead of a generic “small value” allows one to obtain an unbiased solution.
2.1.1 Hot region within the convex hull of the signal
For a pixel located within the convex hull of the signal (e.g., the body or a phantom), it holds that (i.e., all the LORs that intersect pixel ). In , both the gradient and the Hessian for a pixel are identical to those of the Poisson log-likelihood. In a “hot” area (i.e., reconstructed activity much higher than compared to the noise), the constraint is not active; therefore, our modified optimization function has identical solution.
2.1.2 Cold region within the convex hull of the signal
Given the considerations highlighted above about for pixels within the convex hull of an object, in a cold region (i.e., ), the gradient and the Hessian of our modified function will be identical to that of the Poisson log-likelihood. Given the absence of a constraint in the image space, will be different from that of a constrained problem; however, the expectation of the solution will be that of the ideal Poisson problem, which is constrained in sinogram space (i.e., ).
2.1.3 Cold region outside the convex hull of the signal
Outside the convex hull of the signal, we have for all LORs not intersecting it: deviations from the exact Poisson log-likelihood will be found here. Nonetheless, the curvature of the solution remains very close, especially in expectation:
where for all LORs not intersecting the convex hull of the signal . Given the same expected curvature and a gradient that points to the same minimum (e.g., ), we expect the solution, even in this background region, to converge very closely to the values of the exact Poisson likelihood, with the only constraint applied in sinogram space.
It should be noted that if one used , with or even , to push farther away from 0, one would effectively change the expected curvature and bias the solution.
2.2 Relative difference prior
It was originally shown by Fessler and Rogers (12) that spatial resolution in regularized emission tomography image reconstruction problems is highly non-uniform. Specifically, hot areas, which in general are those of highest interest, are the most smoothed, given that they have the highest absolute variance in a Poisson experiment (despite the lowest relative variance).
To overcome this, a relative difference prior (RDP) was proposed by Nuyts et al. (13) and has been successfully adopted, even in clinical tomographs. To allow for negative numbers, we defined a slightly modified version as follows:
In Equation 4, are weighting factors depending on the position in the image and and are two spatially connected pixels.
The gradient of this prior for is
The Hessian of this prior can also be computed explicitly as follows:
2.3 The proposed preconditioner
In this article, we present a preconditioning method inspired by Fessler and Booth (14). The original theory was based on a quadratic problem similar to , with denoting the system matrix and the covariance matrix. In this article, we extend it to Poisson log-likelihood and 3D systems, introducing further approximations. An ideal preconditioner for a quadratic problem is the inverse of the Hessian. If we can invert the Hessian exactly, the problem would be directly solved. However, this is usually not feasible due to the high computational cost or the non-analytic nature of the inversion, and approximations are needed.
This PET reconstruction problem is not quadratic: the local curvature depends on the current estimate . Nonetheless, the terms are constant and , a forward projection, is largely influenced by the lowest frequencies of the image; for this reason, the Hessian is approximately constant over all the iterations when provided a reasonable starting point (e.g., a few iterations of OSEM and a low-res filtered backprojection, etc.).
2.3.1 Mixed diagonal-circulant preconditioner
In Fessler and Booth (14), they applied the intuition that in general
The approximation in Equation 5 is exact along the diagonal; instead is, under general reasonable assumptions for a 2D tomograph, the spatial frequency filter of the Radon transform. This factorization is useful as it is easy to invert, given that it is the product of two diagonal matrices and a circulant matrix, which is therefore diagonalized by the Fourier transform.
2.3.2 Technical implementation and further approximations
In the original article, a complex method was proposed to approximate the inversion of the circulant matrix, considering a regularization prior that had different “effective strengths” in different parts of the image, which is common for quadratic penalties.
To achieve a more practical preconditioner, we needed to address the following issues: (i) how to estimate given the non-quadratic nature of our problem and the curvature change over iterations; (ii) how to identify an effective alternative to approximate the inversion of , also considering the 3D nature of modern PET scanners; and (iii), how to account for the effect of the prior.
Our final preconditioner will still have the structure shown in Equation 6:
where is the search direction, is the gradient of the complete log-likelihood, is a diagonal matrix, is the Fourier transform, and is a filter in the spatial frequencies space.
2.3.2.1 Diagonal component of the preconditioner
The matrix will approximate the inverse of the diagonal of the Hessian. Assuming that the geometrical term is largely Boolean, (i.e., when an LOR intersects a pixel and elsewhere), we state that . We also replace with its expectation , with the aim of making smoother, even in low-count settings; indeed is a back-projection, so is intrinsically a low-frequency image.
With Equation 7 we finally define the diagonal component of the preconditioner as
with being the Kronecker delta.
2.3.2.2 Circulant component of the preconditioner
The other component of the proposed preconditioner is the spatial-frequency filter operation. In the original article, a filter was derived that accounted for the local “effective” strength of the prior and of the tomographic likelihood. Here, under the assumption that the prior used aims for approximately uniform resolution, we assume that the factorization in Equation 5 is identical when including the prior diagonal in . Therefore, we only need to approximate the matrix operation on a generic vector . We assume that, even in a 3D PET system, the effect of this operation is almost entirely an in-plane 2D low-pass filter (i.e., the typical blurring), with negligible blurring in the axial direction. The final filter, , that we propose is defined as follows:
• Build a 1D band-limited Ram-Lak filter impulse response.
• Eventually multiply it by a function to account for the TOF kernel , with denoting the TOF resolution ]note the factor , as used in Conti et al. (15), to approximate the non-analytical ideal TOF kernel].
• Take the resulting impulse response and compute its Fourier transform.
• Multiply it by a Hamming window with cut-off at the Nyquist frequency [i.e., ].
• Interpolate the filter in 2D.
• Apply the same 2D filter to all 3D slices independently.
2.3.3 Implementation within a preconditioned conjugate gradient descent algorithm
The final algorithms implemented were as follows, using a preconditioned gradient descent algorithm, with step size estimation. The algorithm was initialized this way:
• Initialize a reconstruction using few OSEM iterations, (14 sub-iterations using 2 subsets) and use it as .
• Compute the diagonal part of the preconditioner using this initialization and Equation 7.
• Precompute the filter .
• Compute the sinogram of the current image estimate .
Subsequently, in every iteration , we perform the following steps:
• Compute the gradient .
• Compute the preconditioned search direction using Equation 6.
• For Compute the conjugate search direction using the Polak-Ribière method, as follows:
• Compute the forward projection .
• Compute the step size by approximating the problem as quadratic and using the tomographic Hessian expectation, as follows:
.
• Update the current estimate of the image and of the sinogram as follows:
Note that, by keeping negative numbers in the solution, we can complete one iteration using just one forward and one back projection, despite the need to use a forward projection to compute the quadratic step size for Equation 8. Given the fast nature of this algorithm, we do not employ any subset-based acceleration techniques.
2.4 Algorithm testing
Our proposed preconditioner was tested by reconstructing a diverse dataset of PET acquisitions from different PET scanners and different phantoms. All the reconstructions were implemented in SIRF (16), a framework that wraps geometrical routines written in STIR (17).
We used data that were made available during the “PETRIC” challenge (see the official website).
2.4.1 The PETRIC dataset
The PETRIC comprised the following seven datasets:
• mMR-NEMA: NEMA-IQ phantom acquired on a Siemens mMR hybrid PET/MR scanner (Siemens Healthineers, Erlangen, Germany). The phantom was filled with a solution and a contrast ratio between the spheres and the background. Data were acquired over 10 min. The phantom contains six spheres with the following diameters: 10, 13, 17, 22, 28, and 37 mm.
• NEMA-LowCounts: NEMA-IQ phantom acquired on a Siemens mMR, with lower statistics. The same dataset was re-processed to keep only of the total statistics.
• NEMA-Mediso: NEMA-IQ acquired on a Mediso Anyscan PET/CT system (Mediso Medical Imaging Systems, Budapest, Hungary). A phantom with the same geometry was realized using , with a lower lesion to background contrast ratio. Acquisition was performed for 1 h.
• mMR-ACR: ACR phantom acquired on a Siemens mMR scanner. The phantom, filled with , contains multiple hot (spheres) and cold (rods) targets, and it was acquired for 200 s.
• HBP: Hoffman 3D Brain Phantom acquired on the Positrigo NeuroLF PET scanner (Positrigo AG, Zurich, Switzerland). The phantom was filled with 39 MBq of F-FDG and was acquired for 20 min. This scanner has small (3.3 mm) crystals; the phantom represents a human brain glucose distribution, with contrast between gray and white matter.
• Thorax: Thorax Phantom acquired on the Siemens Vision 600 phantom. This anthropomorphic phantom, filled with F-FDG, includes multiple areas of different attenuation and lesions with irregular shapes to mimic realistic lesions. This scanner has a TOF resolution of 214 ps. It was acquired for 1,200 s.
• Vision-HBP: The Hoffman 3D Brain Phantom acquired on the previously described Siemens Vision 600 scanner (Siemens Healthineers, Erlangen, Germany). This was filled with F-FDG and acquired for 300 s.
2.4.2 Compared reconstructions
For every dataset, we performed the following four reconstruction strategies:
• PCG: the complete proposed method as described in Section 2.3.3.
• PG: a preconditioned gradient descent method with the same preconditioner but without using the conjugate search direction strategy.
• DCG: conjugate gradient descent with only the diagonal preconditioner (e.g., compared to Equation 6, only doing ).
• DG: applying the same preconditioner as before, without the conjugate search direction.
• BSREM: the standard BSREM algorithm to be used as a comparison. It was set up using between five and nine subsets, depending on the scanner’s number of views.
The DG algorithm was run for at least 1,100 iterations to generate reference images. The gradient norm of each step was monitored to ensure that numerical convergence was safely reached. To compare the effect of our unconstrained reconstruction, we ran the same algorithm and also applied a negative value truncation after each update.
Images were also reconstructed using the following three values: a “mid” value, tuned to provide light smoothing; a value three times higher that resulted in a “high” prior strength; and a “low” value of the “mid” one, where the influence of the prior is almost negligible. This was done to test the effectiveness of our preconditioner at different levels of relative importance of the prior Hessian vs. the tomographic problem one.
2.4.2.1 Metrics
To analyze the reconstruction speed and compare multiple reconstructions when necessary, we used the following metrics:
• Root mean squared error (RMSE): root mean squared error between the pixels of the two images and . This value was normalized to the mean activity value within the “whole object mask.” .
• Volume of interest (VOI) error: relative error between the mean activity within a VOI in two images In the PETRIC dataset, for each phantom, a different number of pre-established VOIs were provided by the organizers (min: 3; max: 6). Some phantoms (mMR-ACR and HBP) also included cold VOIs.
These metrics were plotted as a function of “epochs,” with one epoch representing a complete pass over the whole dataset, to allow a fair comparison between BSREM and the proposed unaccelerated algorithms.
3 Results
3.1 Impact of negative numbers on the solution
In Table 1, we report the RMSE between a positively constrained reconstruction and our proposed unconstrained reconstruction. The RMSE was computed within the “whole object mask,” as we are interested in the differences between the images within the convex hull of the activity. In general, values smaller than 2% were observed. The highest value was found in the Thorax and HBP phantoms, which included cold areas. We also report, among all the ROIs, the highest and lowest absolute error for each phantom, which showed very high levels of agreement, even for phantoms that included cold VOIs.
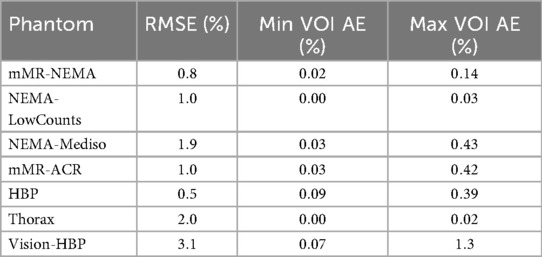
Table 1. Comparison of positively constrained reconstructions vs. unconstrained reconstructions showing the standard deviation between the reconstructions and the highest and lowest absolute error values between regions of interest.
3.2 Convergence speed comparison
In Figure 1, we show the convergence speed with the four tested algorithms for the smallest sphere of the NEMA-IQ phantom in the three different acquisitions where it was used (mMR-NEMA, NEMA-LowCounts, and NEMA-Mediso). With the PCG algorithm, a near convergence value was obtained in less than 10 iterations, while with BSREM, 20 iterations were still clearly insufficient.
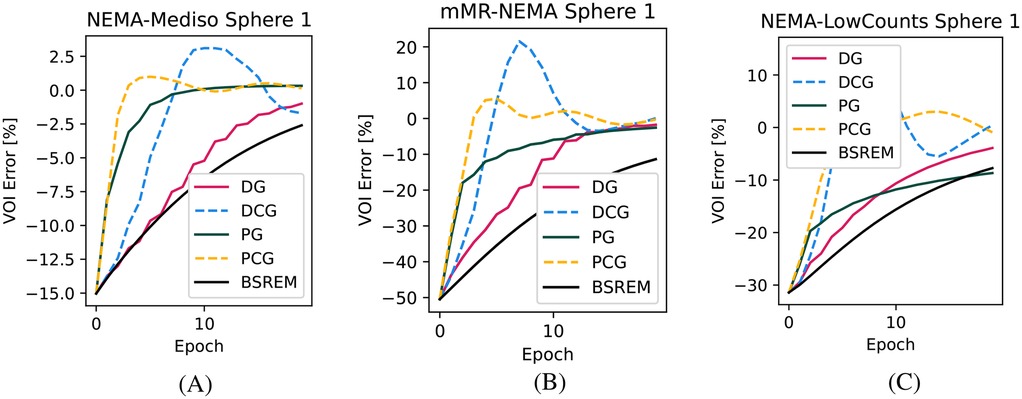
Figure 1. Convergence plots of the smallest (10 mm) sphere for the three NEMA-IQ phantoms from the PETRIC. (A) Mediso scanner, contrast, (B) mMR scanner, contrast, and (C) same but with 1/5th of the counts.
In Figure 2, we show the convergence for the four other VOIs, including two cold VOIs (ventricles in the HBP phantom), with one characterized by many high-frequency details (gray matter in the HBP phantom) and a realistic lesion in the Thorax phantom. Similarly to above, in these cases, we found the fastest convergence with the PCG algorithm. Especially in the cold regions, the superiority of the proposed algorithm compared to BSREM can clearly be appreciated.
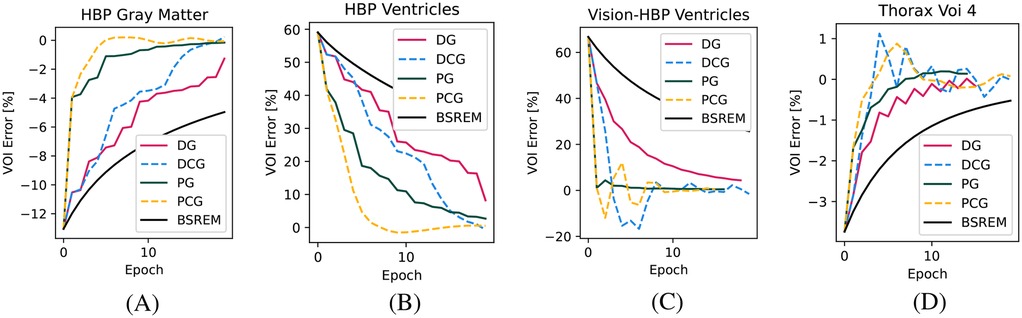
Figure 2. Convergence plots for the other three relevant VOIs. (A) HBP gray matter, (B) HBP ventricles, (C) HBP ventricles acquired on the Vision-600 TOF scanner, and (D) Thorax phantom VOI 4.
In Figure 3, we show the RMSE of the whole image for four acquisitions with different properties, which show the advantage in all contexts of using both the diagonal and circulant preconditioners of varying magnitudes.
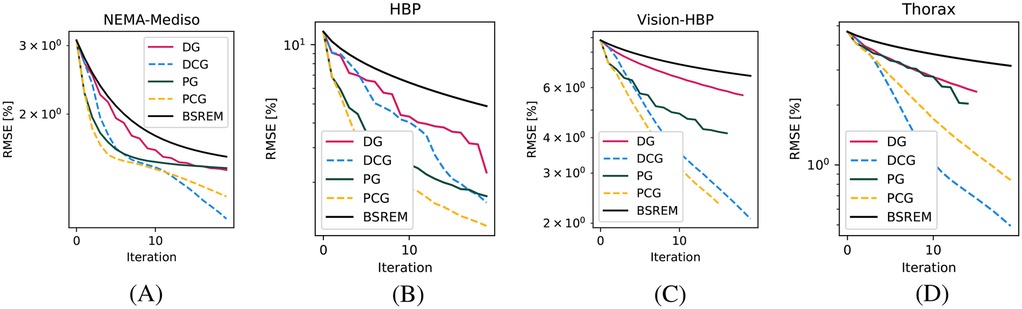
Figure 3. RMSE convergence plots for four phantoms. (A) MEDISO IQ, (B) HBP, (C) HBP acquired on the Vision-600 TOF scanner, and (D) Thorax phantom.
3.3 Impact of the prior’s strength
In Figure 4, we show the qualitative images of the reconstructions obtained using the three values, showing how effective the RDP is in noise suppression. The value impacts the effectiveness of the circulant part of the preconditioner, especially for the RMSE of the whole object. This is shown for the mMR-NEMA phantom in Figures 5, 6. At the low , the inclusion of the spatial filtering operation maximally improves the convergence speed, while at the highest value, its impact was reduced.
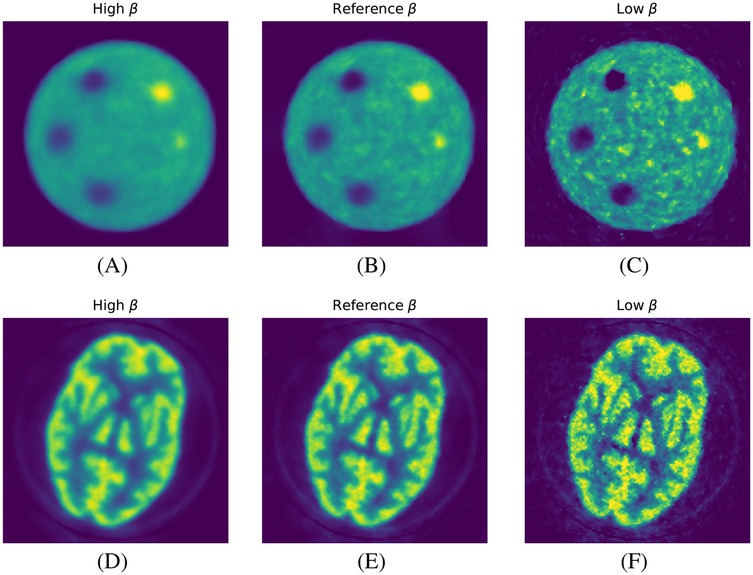
Figure 4. Qualitative images from the reconstruction of two phantoms as a function of strength. (A–C) ACR phantom and (D–F) HBP phantom. Left to right: high, reference, and low .

Figure 5. RMSE plot as a function of for the mMR-NEMA phantom. (A) High , (B) reference high , and (C) low .
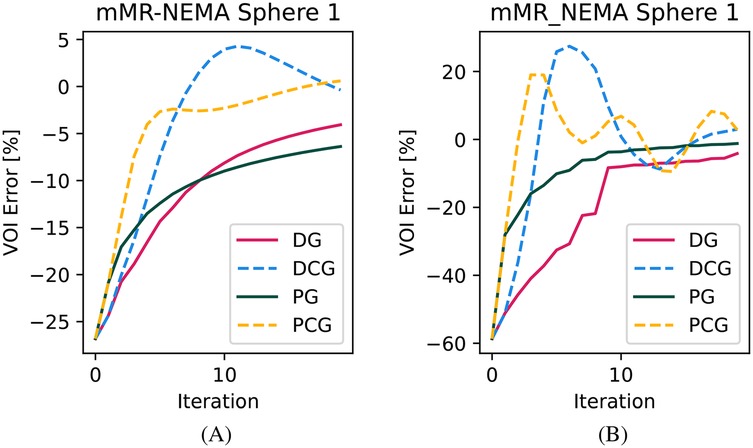
Figure 6. Convergence plot for the NEMA-IQ phantom VOI of the smallest sphere. (A) High and (B) low .
4 Discussion
In this article, we proposed a new preconditioner based on one suggested by Fessler and Booth (14). This preconditioner, combining diagonal and circulant parts and implemented as a filter acting on spatial frequencies, is especially effective in a number of diverse test conditions.
First, it should be appreciated that, in all tested conditions, even the smallest targets reached values extremely close to convergence (e.g., <0.5%) in less than 10 iterations, and 4 iterations were often sufficient to get to <1%. In this case, there is no need for subset-based acceleration, guaranteeing convergence to the unique optimal solution without the need for stochastic acceleration techniques, at least if the prior used has a unique solution. Nonetheless, future work can explore the integration of this preconditioner into stochastic algorithms for even faster convergence. Of particular interest is the fact that, by using gradient descent, this convergence is also similar for cold targets, as can be appreciated in the comparison with BSREM. Such regions are a major problem for multiplicative algorithms [e.g., see Presotto et al. (2)]. In this article, we also used an unconstrained reconstruction approach. Beyond faster optimization of the problem, this should also be welcome as it removes the bias in cold regions, which is known to hinder quantitative PET applications.
An analysis of the behavior of the proposed preconditioner results in some interesting findings. The full preconditioner, including the spatial filter, first improved the convergence of the activity value in the VOIs for all conditions (phantoms and values). The RMSE of the whole object, which also weighs background regions, often plateaus for a couple of iterations, especially at higher values. This can be explained by difficulties in following search directions containing frequencies suppressed by the filter. Combining the preconditioner with conjugate search directions improved this. Improving the filter design and changing its cut-off frequency as a function of could further improve it. It should be remembered that the solution implied by the relative difference prior still does not have uniform spatial resolution: for activity values lower than , the solution is effectively unregularized, and the edges between regions with contrast higher than are —intentionally— preserved and not smoothed. It was noticeable, indeed, that introducing the filter provided the highest acceleration with lower values, where the approximation made in neglecting the effect of the prior was less influential.
In the reconstruction of the Thorax dataset, acquired on a TOF scanner with very high temporal resolution, the application of the filter provided only marginal improvements (which indeed can only be seen in the RMSE plots in the first iteration). This can be expected given that the better the TOF resolution, the lower the filter strength.
This article opens the possibility for further research that can be achieved by further optimizing the relative difference prior and making it better behaved, and also by fine-tuning the filtering part of the preconditioner. While it was studied here using a conjugate gradient descent, the same can be applied to any optimization algorithm or other acceleration strategies (e.g., Primal-dual and Nesterov).
The main innovations presented in this article can be summarized as follows:
• We used an approximate expectation of the tomographic Hessian instead of its observed value, which leads to a smooth image.
• We used an easy-to-compute approximated 2D filter as compared to the one proposed by Fessler and Booth (14), which would have required a 3D extension and a less generalizable approach.
• We allowed the solution to contain negative numbers, to allow for faster convergence.
5 Conclusions
In this article, we proposed a preconditioning strategy that, when implemented in a conjugate gradient descent algorithm with step size estimation, allows for effective convergence to be reached in less than 10 iterations over the whole dataset, even in the usually challenging cold regions.
Data availability statement
The datasets analyzed for this study can be found in the PETRIC challenge repository at https://github.com/SyneRBI/PETRIC. The code developed has been uploaded in this dedicated GitHub repository: https://github.com/SyneRBI/PETRIC-Tomo-Unimib/tree/Frontiers-paper.
Author contributions
MNC: Writing – original draft, Software, Data curation, Investigation, Writing – review & editing. MP: Funding acquisition, Investigation, Supervision, Writing – review & editing. LP: Writing – original draft, Conceptualization, Investigation, Supervision, Software, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was partially funded by the European Union, Next Generation EU, Mission 4 Component 1, CUP H53D23007430001, with the project “Multiple Emission Tomography.” This work was partially funded by the National Plan for NRRP Complementary Investments (PNC, established with the decree-law 6 May 2021, n. 59, converted by law n. 101 of 2021) in the call for the funding of research initiatives for technologies and innovative trajectories in the health and care sectors (Directorial Decree n. 931 of 06-06-2022)—project n. PNC0000003—AdvaNced Technologies for Human-centrEd Medicine (ANTHEM). This work reflects only the authors’ views and opinions, neither the Ministry for University and Research nor the European Commission can be considered responsible for them.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Tong S, Alessio AM, Kinahan PE. Image reconstruction for PET/CT scanners: past achievements and future challenges. Imaging Med. (2010) 2:529. doi: 10.2217/iim.10.49
2. Presotto L, Bettinardi V, De Bernardi E. A simple contrast matching rule for OSEM reconstructed PET images with different time of flight resolution. Appl Sci. (2021) 11:7548. doi: 10.3390/app11167548
3. Qi J, Leahy RM. Iterative reconstruction techniques in emission computed tomography. Phys Med Biol. (2006) 51:R541. doi: 10.1088/0031-9155/51/15/R01
4. Qi J, Leahy RM. Resolution and noise properties of MAP reconstruction for fully 3-D PET. IEEE Trans Med Imaging. (2000) 19:493–506. doi: 10.1109/42.870259
5. Lindström E, Sundin A, Trampal C, Lindsjö L, Ilan E, Danfors T, et al. Evaluation of penalized-likelihood estimation reconstruction on a digital time-of-flight PET/CT scanner for 18F-FDG whole-body examinations. J Nucl Med. (2018) 59:1152–8. doi: 10.2967/jnumed.117.200790
6. Hudson HM, Larkin RS. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans Med Imaging. (1994) 13:601–9. doi: 10.1109/42.363108
7. De Pierro AR, Yamagishi MEB. Fast EM-like methods for maximum “a posteriori” estimates in emission tomography. IEEE Trans Med Imaging. (2001) 20:280–8. doi: 10.1109/42.921477
8. Defazio A, Bach F, Lacoste-Julien S. SAGA: a fast incremental gradient method with support for non-strongly convex composite objectives. In: Cortes C, Welling M, Ghahramani Z, Weinberger KQ, Lawrence ND, editors. Advances in Neural Information Processing Systems. Montreal, QC: Neural Information Processing Systems Foundation (2014). p. 1646–54.
9. Twyman R, Arridge S, Kereta Z, Jin B, Brusaferri L, Ahn S, et al. An investigation of stochastic variance reduction algorithms for relative difference penalized 3D PET image reconstruction. IEEE Trans Med Imaging. (2023) 42:29–41. doi: 10.1109/TMI.2022.3203237
10. Vardi Y, Shepp LA, Kaufman L. A statistical model for positron emission tomography. J Am Stat Assoc. (1985) 80:8–20. doi: 10.1080/01621459.1985.10477119
11. Cloquet C, Defrise M. MLEM and OSEM deviate from the Cramer-Rao bound at low counts. IEEE Trans Nucl Sci. (2012) 60:134–43. doi: 10.1109/TNS.2012.2217988
12. Fessler JA, Rogers WL. Spatial resolution properties of penalized-likelihood image reconstruction: space-invariant tomographs. IEEE Trans Image Process. (1996) 5:1346–58. doi: 10.1109/83.535846
13. Nuyts J, Bequé D, Dupont P, Mortelmans L. A concave prior penalizing relative differences for maximum—a-posteriori reconstruction in emission tomography. IEEE Trans Nucl Sci. (2002) 49:56–60. doi: 10.1109/TNS.2002.998681
14. Fessler JA, Booth SD. Conjugate-gradient preconditioning methods for shift-variant pet image reconstruction. IEEE Trans Image Process. (1999) 8:688–99. doi: 10.1109/83.760336
15. Conti M, Bendriem B, Casey M, Chen M, Kehren F, Michel C, et al. First experimental results of time-of-flight reconstruction on an LSO PET scanner. Phys Med Biol. (2005) 50:4507. doi: 10.1088/0031-9155/50/19/006
16. Ovtchinnikov E, Brown R, Kolbitsch C, Pasca E, da Costa-Luis C, Gillman AG, et al. SIRF: synergistic image reconstruction framework. Comput Phys Commun. (2020) 249:107087. doi: 10.1016/j.cpc.2019.107087
Keywords: image reconstruction, tomography, preconditioning, Poisson likelihood, optimization, positron emission tomography
Citation: Colombo MN, Paganoni M and Presotto L (2025) Generalizable preconditioning strategies for MAP PET reconstruction using Poisson likelihood. Front. Nucl. Med. 5:1661332. doi: 10.3389/fnume.2025.1661332
Received: 7 July 2025; Accepted: 14 October 2025;
Published: 2 December 2025.
Edited by:
Charalampos Tsoumpas, University Medical Center Groningen, NetherlandsReviewed by:
Georg Schramm, KU Leuven, BelgiumXiaotong Hong, Southern Medical University, China
Tianyi Zeng, Yale University, United States
Copyright: © 2025 Colombo, Paganoni and Presotto. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Luca Presotto, bHVjYS5wcmVzb3R0b0B1bmltaWIuaXQ=