A dual contrastive learning-based graph convolutional network with syntax label enhancement for aspect-based sentiment classification
 Yuyan Huang
Yuyan Huang Anan Dai3
Anan Dai3 - 1Department of Electronics and Information Engineering, South China Normal University, Foshan, China
- 2Datastory, Guangzhou, China
- 3China Merchants Bank Foshan Branch, Foshan, China
- 4Department of Financial Mathematics, University of Chicago, Chicago, IL, United States
- 5Guangzhou Qizhi Information Technology Co., Ltd., Guangzhou, China
- 6Industrial Centre School of Undergraduate Education, Shenzhen Polytechnic University, Shenzhen, China
Introduction: Aspect-based sentiment classification is a fine-grained sentiment classification task. State-of-the-art approaches in this field leverage graph neural networks to integrate sentence syntax dependency. However, current methods fail to exploit the data augmentation in encoding and ignore the syntactic relation in sentiment delivery.
Methods: In this work, we propose a novel graph neural network-based architecture with dual contrastive learning and syntax label enhancement. Specifically, a contrastive learning-based contextual encoder is designed, integrating sentiment information for semantics learning. Moreover, a weighted label-enhanced syntactic graph neural network is established to use both the syntactic relation and syntax dependency, which optimizes the syntactic weight between words. A syntactic triplet between words is generated. A syntax label-based contrastive learning scheme is developed to map the triplets into a unified feature space for syntactic information learning.
Results: Experiments on five publicly available datasets show that our model substantially outperforms the baseline methods.
Discussion: As such, the proposed method shows its effectiveness in aspect-based sentiment classification tasks.
1 Introduction
Aspect-based sentiment classification (ABSC) is a fundamental task in sentiment analysis [1]; [2], which aims to infer the sentiment of a specific aspect in sentences [3]. Generally, the sentiment of each aspect is classified according to a predefined set of sentiment polarities, i.e., positive, neutral, or negative. For example, in the comment “the price is reasonable, although the service is poor,” the sentiment toward aspects “price” and “service” is positive and negative, respectively.
In general, an ABSC process involves two steps: the identification of sentiment information toward the aspect from the context and the classification of the expressed sentiment from predefined sentiment polarities [4]. Comprehensively, the first step contains key contextual information learning and aspect–context word relation establishment. To capture important contextual words and prevent redundant information, recent publications reveal that encoders and attention networks are taken to encode the sequential information and determine the attentive weights of contexts, respectively [5]. Typically, these deep learning methods are trained via a large amount of textual data to improve their working performance. Notwithstanding, the existing manually annotated data resources are still limited, which causes issues such as model overfitting. As a result, the precise capturing of key contextual words remains challenging. More recently, contrastive learning shows its superiority under the condition of limited training samples. Based on data augmentation, both positive and negative samples are generated. By setting contrastive loss of training models, the representations of positive samples are brought closer, while those of negative samples are pushed apart. In line with the contrastive learning, the model training can be improved, which paves a way for key contextual information learning in ABSC tasks.
On the basis of key contextual information, the aspect–opinion word relation mainly lies in syntax dependency of the sentence [6]. With the parsing of syntax dependency, the relation between the aspect and context words is built. Ongoing studies substantially focus solely on the distance of words while neglecting the syntax label of specific context words toward the aspect. That is, all syntactic relations are interpreted as the same. Figure 1 shows the syntax structure of a given sentence. The establishment of the subject–predicate syntactic relation (nsubj) and adjective modifier syntactic relation (attr) plays a dominate role in sentiment classification, especially compared with other syntactic information. Moreover, the syntax label is also the foundation of textual logical reasoning due to its effects in distinguishing the importance among syntactic relations. So much is the significance of the syntax label that it can be further applied to the aspect–opinion word relation establishment in ABSC.
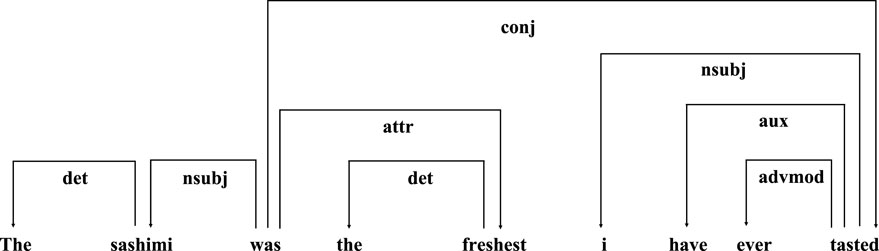
Figure 1. Example of syntax dependency parsing.
To address the above issues in ABSC, we propose a graph convolutional network (GCN) based on dual contrastive learning and syntax label enhancement (i.e., DCL-GCN). First, a contrastive learning-based encoder is devised, which brings the context representations of the same sentiment closer and pushes those of different sentiments apart. Furthermore, a weighted label-enhanced syntactic GCN is put forward, dealing with not only the syntactic relation but also the syntax dependencies among words. Lastly, a contrastive learning scheme that focuses on the sentence syntax label is developed. A syntactic triplet between words is constructed. The same syntax label-based triplets are given similar semantic representations, while different syntax label-based triplets are distinguished. Thereby, the syntax and semantics are integrated, which contributes to the sentiment classification.
The contribution of our work is three-fold and given as follows:
• A GCN-based ABSC method is proposed with the integration of dual contrastive learning and syntax label enhancement. Specifically, the sentence is encoded using contrastive learning to bring the context representations of the same sentiment closer and push those of different sentiments apart.
• A weighted label-enhanced syntactic GCN and a contrastive learning scheme are established to tackle the sentence syntax. A syntactic triplet between words can be generated. The same syntax label-based triplets are given similar semantic representations to facilitate the ABSC.
• Experiments conducted on five benchmark datasets demonstrate that our model achieves state-of-the-art results. The proposed method significantly improves the working performance compared to competitive baselines in the ABSC field.
2 Related work
Owing to the advancement of deep learning networks, current methods with various structures are widely developed, aiming to identify their superiority in ABSC tasks [7]. ABSC models are devised to deal with either semantics [8], syntax [9], or both [10] from the given text. In this section, these two major issues in the field of ABSC are presented. In order to achieve better working performance, previous work and their findings about these two focuses are dedicatedly investigated and depicted.
2.1 Contextual information learning
One bottleneck in ABSC comes from capturing key contextual words, which considerably affects the aspect–opinion word relation modeling. Much recent work uses neural networks, attention networks, or both to concentrate on useful contextual information [11]; [12]. Tang et al. focused on different contextual parts based on LSTM, targeting at obtaining valuable information [13]. In addition, attention-based neural networks are proposed to discriminate more relevant features toward the aspect [14]; [15]. Sun et al. used a BERT-based model to capture semantic features from contexts via fine-tuning, which significantly improves the working performance [16]. Text encoders are widely applied to various tasks [17,18]. Encouragingly, advances in contrastive learning hold great potential in natural language processing (NLP) tasks. Suresh et al. integrated contrastive learning strategy into the pre-training of Bidirectional Encoder Representations from Transformers (BERT) to improve the model efficacy [19]. A contrastive loss among different input categories is introduced, while a weight network refines the differences between each sample pair. In our work, contrastive learning can be taken to distinguish the contextual representations during sentence encoding.
2.2 Syntax dependency parsing
The parsing of syntax dependency plays a pivotal role in the field of ABSC due to its relation establishment between the aspect and contextual words. Previous work primarily tackles the syntactic relation of either single or multiple word pairs. In recent years, the application of a GCN in NLP gave rise to new opportunities in a number of fields [20]; [21]. Regarding sentence syntax parsing, Sun et al. transformed the syntax dependency into an adjacency matrix and propagated the syntactic information using the GCN [22]. Furthermore, Zhang et al. incorporated the aspect-oriented attention mechanism to benefit the contextual information extraction toward a specific aspect [23]. To extract both aspect-focused and inter-aspect sentiment information, an interactive graph convolutional network (InterGCN) is built to leverage the sentiment dependencies of the context [24]. Wang et al. reconstructed the syntax dependency tree rooted at an aspect. A relational graph attention network (R-GAT) is then proposed to encode the aspect-oriented dependency tree and to establish the syntactic relation between the aspect and its opinion words [25].
3 Methodology
A dual contrastive learning GCN (DCL-GCN) is devised on the task of ABSC. Figure 2 shows the framework of the proposed model. A pretrained BERT model is used as the sentence encoder. A contrastive learning scheme is incorporated into contextual encoding during model training, which enhances the semantic information via sentiment labels to obtain differentiated contextual representations. Then, both the semantic and syntactic features are integrated within a weighted label GCN, aiming at addressing the syntactic relation of context words with the aspect. In line with contrastive learning, the syntax labels of words are used for learning the sentence syntax at a higher level. The sentiment polarity is predicted by sending the final sentence representation into a sentiment classifier. More details of the proposed model are given as follows:
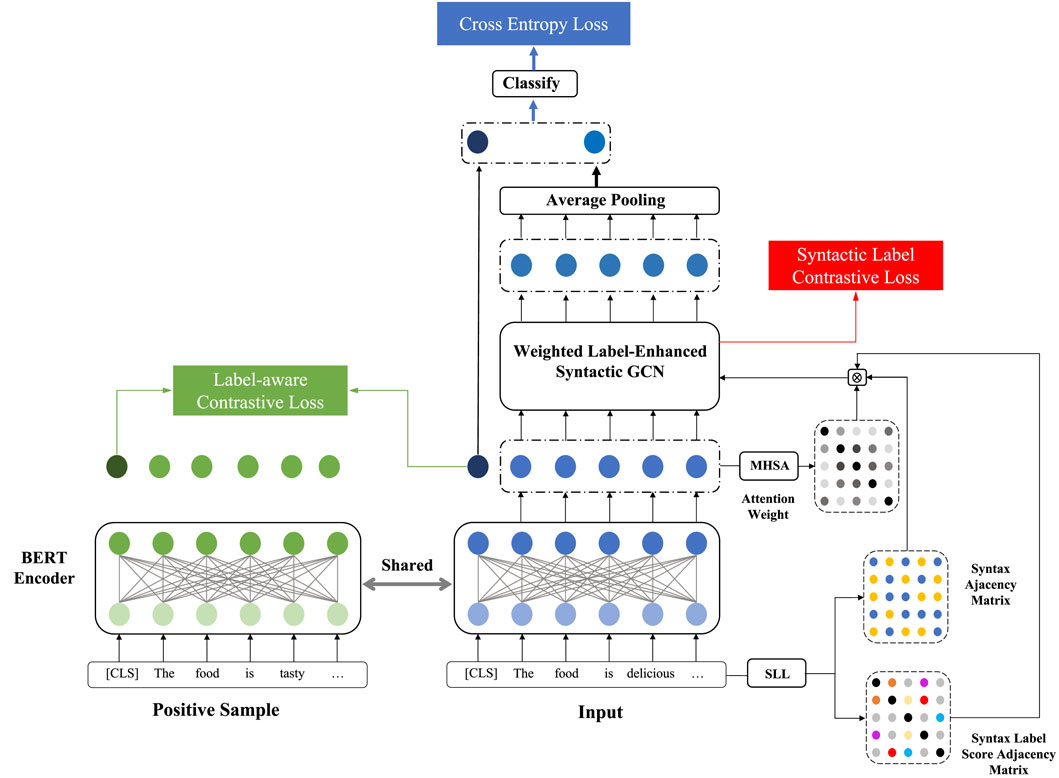
Figure 2. Model architecture.
3.1 Contextual encoder with contrastive learning
The architecture of the contrastive learning-based contextual encoder is shown in Figure 3. Let X = [w1, …, wa, …, wa+m−1, …, wn] be a sentence of n words and A = [wa, …, wa+m−1] be the aspect of m words within S. The contrastive learning scheme during sentence encoding is implemented via data augmentation, feature extraction, and contrastive loss construction. Inspired by the data augmentation in image recognition [26]; [27], positive samples of the same polarities are generated using synonym substitution and random noise injection. Specifically, synonym substitution refers to randomly replacing words within the sentence with their synonyms from WordNet, while noise injection indicates introducing more aspect words and neutral sentiment words to the sentence. The sentiment is enhanced in (1):
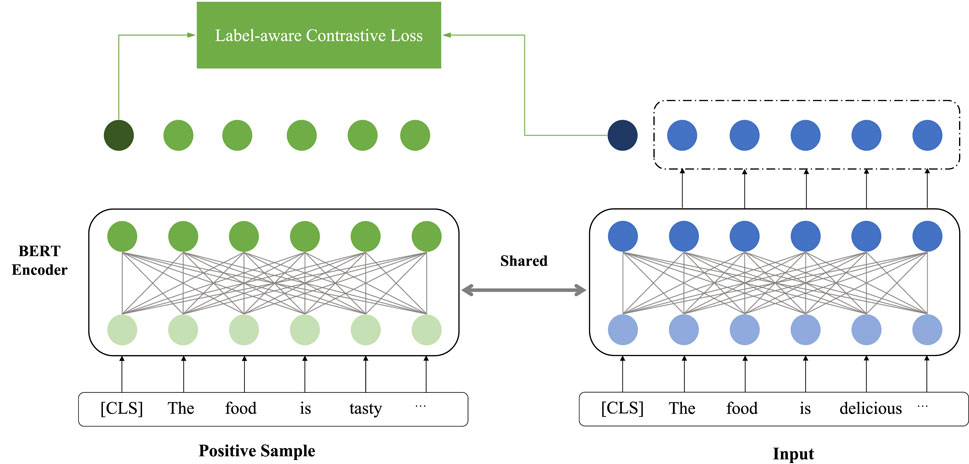
Figure 3. Contrastive learning-based contextual encoder.
The original sentence X and the data-enhanced sentence XE are mapped to word vectors within the same feature space. We use the BERT model obtained through large-scale corpus training by Kenton et al to enhance the semantics of word representations. We then train the BERT model in a fine-tuned manner by freezing part of its parameters, which is written in (2):
where CLS and SEP are BERT tokens representing the overall representation and the separation of the sentence, respectively. We thus obtain the sentence-level feature representation hCLS, the word-level feature representation HX, and the aspect feature representation HA. Assuming that a batch consisting of k sentences is the model input for training, the sentence set composed of the original and the enhanced sentences is
where τ is a hyperparameter, indicating the temperature coefficient of contrastive learning. The higher the temperature coefficient is, the smaller the sum of the loss reaches. The parameter
3.2 Weighted label-enhanced syntactic GCN
The framework of the syntactic GCN via weighted label enhancement is presented in Figure 4. The syntax dependency of the input sentence is derived using the spaCy toolkit. Specifically, the sentence syntax dependency is characterized by a triplet, i.e., (wi, wj, ri,j), where words wi and wj are of the relation ri,j. In line with the sentence syntax, we construct a syntax adjacency matrix
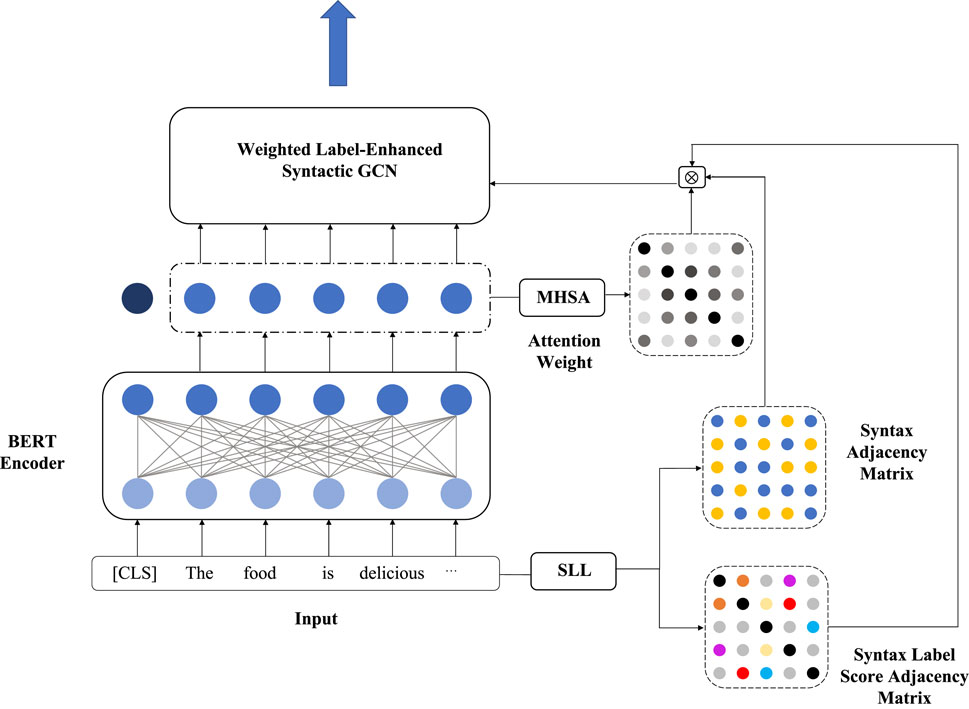
Figure 4. Framework of the weighted label-enhanced syntactic graph convolutional network (GCN).
To address the effects of various syntactic labels in the sentiment classification, a syntax label learning (SLL) unit is built. The main purpose of the SLL unit is to transform the syntax label matrix to a learnable syntax label score matrix.
A lexicon R = {relation1: 1, relation2: 2, …, relationt: t} that consists of all syntactic relations from the corpus is constructed, from which each syntactic label is mapped to an index number. For each input sentence, all index numbers denote the syntactic relations consisting of a syntax label matrix. Then, the syntax label adjacency matrix
where Emb (⋅) represents transforming the syntax label matrix into a learnable matrix for syntax label characterization,
Likewise, the same syntactic relation type can have different degrees of importance within different semantic contexts. For this reason, the semantics among words are also integrated into the computation of the syntax label score. We take the multi-head self-attention (MHSA) mechanism to learn the semantic features and to revise the syntax label scores based on attentive weights. Notably, the elements in ALS represent all the syntactic relation scores, which are not zero. To preserve the original syntax dependencies and remove irrelevant syntactic information, the basic syntax adjacency matrix is also used. The weighted syntax label adjacency matrix can be computed in (5):
where
The working principle of the weighted label-enhanced syntactic GCN is shown in Figure 5. The input of the GCN is the weighted syntax label adjacency matrix AWL and the feature representation HX from BERT. The learning of syntactic information is derived in (9):
where
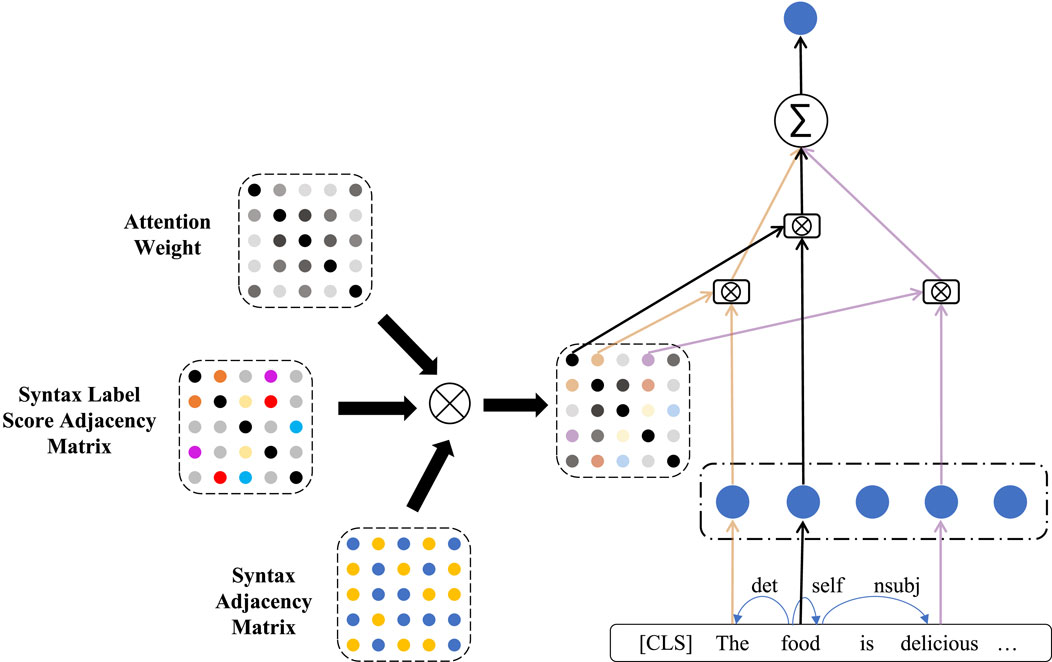
Figure 5. Working principle of the weighted label GCN.
3.3 Syntax label-based contrastive learning scheme
Considering the effect of syntactic information in ABSC, the node pairs with the same syntax label indicate similar syntactic features, and those with different syntax labels have differentiated features. As such, a contrastive learning scheme using syntax labels is proposed, aiming to enhance the learning of syntactic features at a higher level.
Assuming that K′ triplets are of syntax dependencies within all the K sentences, the node-pair set of these triplets is
together with (11)
where τ′ is the temperature coefficient for contrastive learning and gm’ represents the semantic feature representation by mapping the node-pair representations from the syntax dependency triplet and is normalized before the contrastive learning loss computation. We define
3.4 Feature fusion
Average pooling is performed on Hout to obtain the syntactic information-enhanced feature representation Hout in (12), which is further concatenated with hCLS derived from the BERT encoder. The final sentence representation
where ⊕ denotes the concatenation operation. The final sentence representation
The pseudocode of the proposed model is given as follows:
Algorithm 1.Dual contrastive learning-based GCN forward propagationalgorithm.
1: Input: data D, batch_size N.
2: Output: Sentiment polarity y
3: for i = 0 to n by N do
4: batch ← D [i: i + N]
5: for j in [i, i + batch_size) do
6:
7: AS, AW ← SLL (Xj)
8:
9: AWL = AS*AW*ALS
10:
11:
12:
13: end for
14:
15: Update network by combined loss
16: end for
3.5 Model training
Model training is implemented using cross-entropy and regularization as the loss function in (15):
where (x, a) represents the vector of a sentence–aspect pair; C refers to the set of sentiment classes;
On account of the training of contrastive learning in our model, the total loss function
where α is a learnable coefficient to adjust the weights of contrastive learning losses in loss function.
4 Experiment
4.1 Experimental setup
The working performance of the DCL-GCN is evaluated on five benchmark datasets, which are Restaurant 14, Restaurant 15, Restaurant 16, and Laptop 14 from SemEval [28]; [29,30], and Twitter [31]. The sentiment of each aspect from the datasets is labeled as positive, neutral, or negative.
Following the idea of [15], the sentences labeled as conflicting sentiment or without explicit aspects from Restaurant 15 and Restaurant 16 are removed. Details of each dataset are given in Table 1.
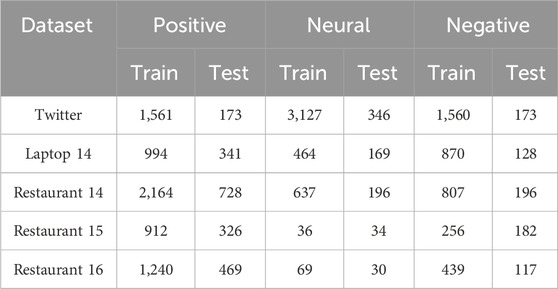
Table 1. Statistics of datasets.
In this experiment, the lexicon size of the BERT model is set to 30,522, the word embedding dimension is 768, and the layer number of the transformer is 12. The head number of the MHSA is 8, and the learning rate is 0.00001. The layer number of the weighted label-enhanced syntactic GCN is 2. Both τ and τ′ in contrastive learning schemes are set to 0.02. The
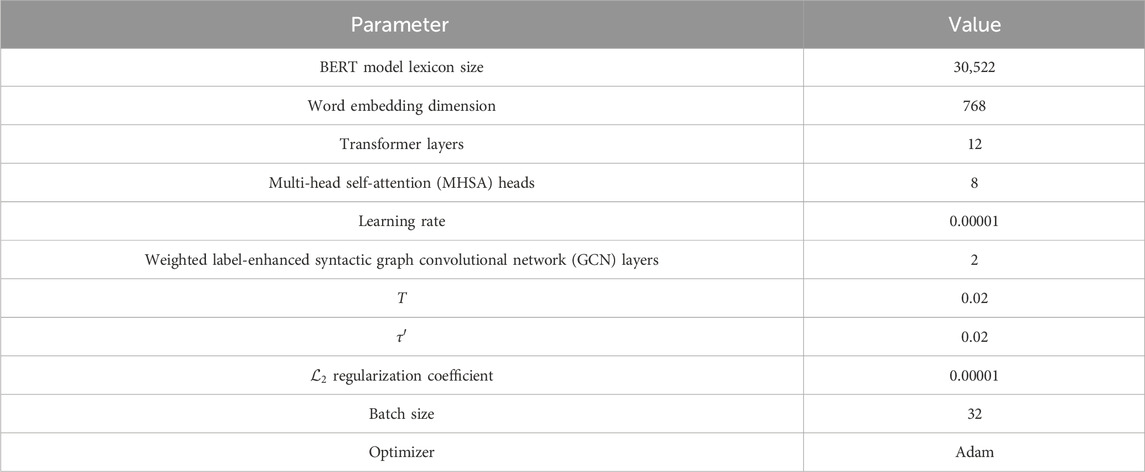
Table 2. Parameter settings.
4.2 Baseline
In order to verify the effectiveness of the DCL-GCN in ABSC, five state-of-the-art methods are taken for comparison:
• BERT [32]: The basic BERT model is established based on the bidirectional transformer. With the concatenation of sentences and the corresponding aspect, BERT can be applied to ABSC.
• BERT4GCN [33]: The BERT model and GCN are integrated, which exploits sequential features and positional information to augment the model learning.
• R-GAT + BERT [25]: The pre-trained BERT is integrated with the R-GAT, where BERT is used for sentence encoding.
• DGEDT + BERT [34]: The pre-trained BERT is integrated with DGEDT, where BERT is used for sentence encoding.
• TGCN + BERT [35]: The dependency type is identified with type-aware graph convolutional networks, while the relation is distinguished with an attention mechanism. The pre-trained BERT is used for sentence encoding.
All results are expressed in percentage values. “-” denotes that the results are not reported in the published research article. The best performance achieved is marked in bold.
4.3 Result analysis
We take two metrics, i.e., accuracy and Macro-F1, to evaluate the working performance of the proposed model. Table 3 shows the results of six different methods on the task of ABSC. One can observe that our model achieves the best and most consistent result among all the evaluation settings. It is clear that the DCL-GCN result is more remarkable than a range of competitive baselines on all five benchmark datasets. In line with these results, the following observations are made.
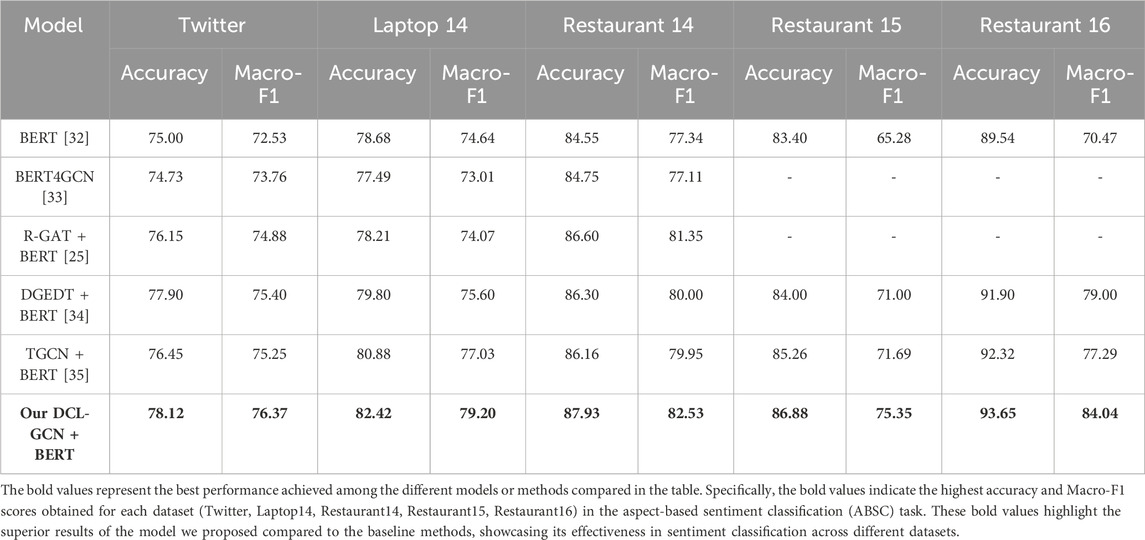
Table 3. Experimental results on five public datasets.
First, our model achieves the best and most consistent result among all the evaluation settings. The minimum performance gaps between the DCL-GCN and the baselines are 1.33% (against the R-GAT) on Restaurant 14, 1.62% (against the T-GCN) on Restaurant 15, 1.33% (against the T-GCN) on Restaurant 16, 1.54% (against DGEDT) on Laptop 14, and 0.22 (against DGEDT) on Twitter. In addition, the F1 values on Restaurant 15 and Restaurant 16 are 3.64% (against the T-GCN) and 5.04% (against DGEDT), respectively, higher than the best-performing baseline method, which are significant.
Second, the syntax-dependent-method (BERT4GCN) performs worse than models integrated with both syntax dependency and syntactic relations (R-GCT and T-GCN). The main reason is that the deeper-level syntactic information can be neglected by solely exploiting the dependencies among words. By contrast, the syntactic relation encoded in our model benefits the sentiment comprehending to a large extent. The highest accuracy of our model reaches 93.65 on Restaurant 16, indicating the importance of syntax dependency and syntactic relations in ABSC.
Third, compared with other baselines, the basic BERT model has its own distinctiveness in tackling sentence semantic information. By incorporating BERT into state-of-the-art methods, the working performance is substantially improved, which is the outcome of our model. Notably, the proposed model significantly outperforms the baselines, demonstrating that the contextual semantics take full advantage in line with the BERT-based contrastive learning scheme.
It is worth noting that the DCL-GCN gives rise to the enhancement in both syntax and semantics learning. With the application of the dual contrastive learning scheme, it is reasonable to expect better working performance in ABSC, as it is the case.
4.4 Ablation study
The impact of different components in our model is investigated by conducting an ablation study (Table 4). w/o LECL specifies that the contrastive learning scheme of the contextual encoder is removed; w/o LLCL specifies that the syntax label-based contrastive learning scheme is removed; and w/o WL-GCN indicates that the weighted label-enhanced syntactic GCN is ablated.
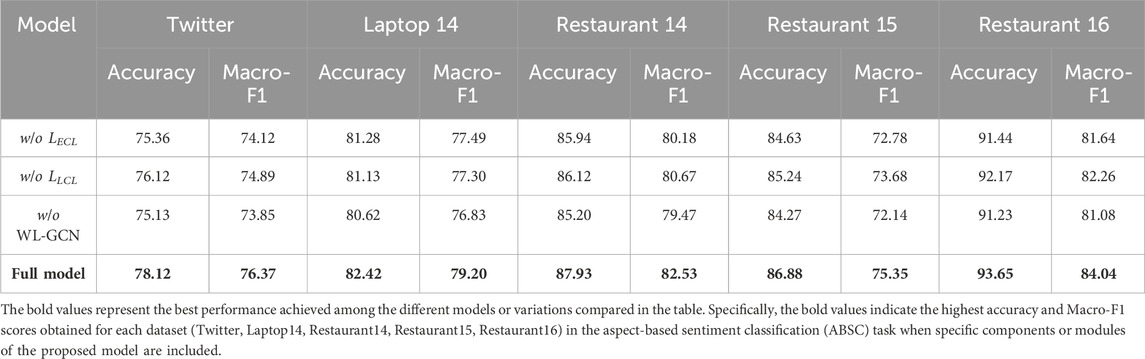
Table 4. Results of the ablation study.
As presented in Table 4, the most significant module in our model is the weighted label-enhanced syntactic GCN. The exploiting of syntactic information shows its effectiveness in word sentiment learning. With the sole utilization of semantics, even with a contrastive learning strategy, the working performance is inferior to the syntactic-based methods in all evaluation settings. Clearly, the integration of semantics and syntax has superiority in ABSC tasks. Moreover, the removal of the contrastive learning scheme from the contextual encoder leads to a substantial decrease on all five datasets. The performance decreases of the accuracy and F1 score on Twitter are 2.76% and 2.25%, respectively. As a result, the contrastive learning scheme in the BERT encoder effectively promotes semantic information learning. By contrast, the syntax label-based contrastive learning scheme makes a relatively small contribution to the model. We can infer that the application of syntax labels also enhances the use of syntactic information and, thus, contributes to the sentiment classification.
4.5 Impact of hyperparameters
An experiment is carried out to analyze the effect of the self-attention head number on model working performance. The head number of the self-attention network is set to [1, 2, 3, …, 8]. The model accuracy with different head numbers is presented in Figure 6.
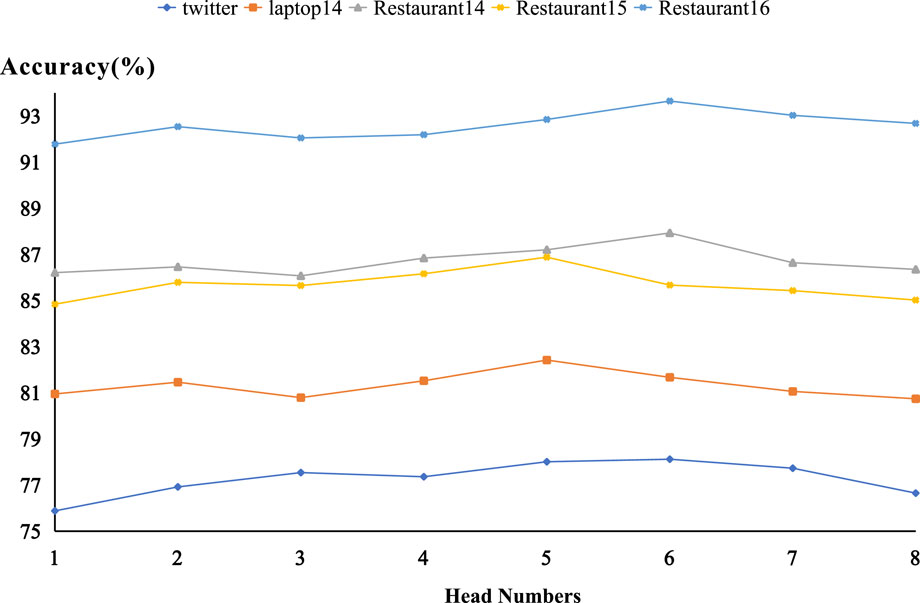
Figure 6. Accuracy of different head numbers.
Apparently, the DCL-GCN achieves the highest accuracy with a head number of 5 on Laptopt 14 and Restaurant 15 and a head number of 6 on Twitter, Restaurant 14, and Restaurant 16. In line with the multi-head self-attention mechanism, the attention head stands for the vector representation in feature spaces via different mapping methods. When the number of attention heads is reduced, the self-attention mechanism operates within a smaller space with correspondingly fewer semantic features. Accordingly, the proposed model fails to capture sufficient semantic information. On the other hand, when the head number exceeds 6, the model parameter size significantly increases, resulting in overfitting issues during training. In this way, a test accuracy decrease is inevitable.
4.6 Case study
Two samples are selected to visualize the working performance, in order to further validate the distinctiveness of DCL-GCN. Specifically, the representations of the sentence and the words are maintained. We shall define a parameter φ as the contribution of each word for sentiment delivery in the sentence, which is defined in Eq. 17:
The sentiment contribution of each word is shown in Figure 7. For the sample given in Figure 7A, the contextual words “professional,” “courteous,” and “attentive” make the largest contribution toward the aspect “waiters.” Our model is capable of extracting the most informative words for sentiment expressing. The sentence in Figure 7B contains two aspects, i.e., “food” and “waiting.” For the aspect word “food,” the proposed model accurately identifies the top two highest sentiment contribution words as “good” and “so.” Regarding “waiting,” not only is the the sentiment word “nightmare” captured but also the syntactic relation words “so…that…” for resultative adverbial clause establishment. Both semantics and syntax are used for sentiment classification.
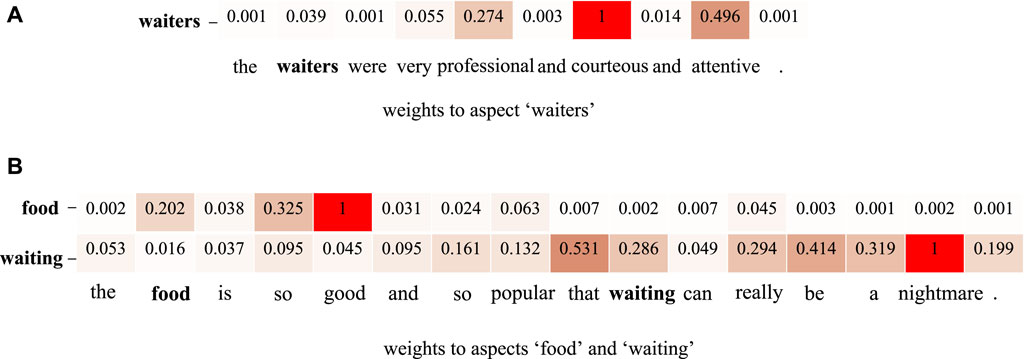
Figure 7. Word sentiment contribution. (A) Weights to aspect “waiters” (B) and weights to aspects “food” and “waiting.”
In our model, the use of contrastive learning enhances the learning of sentence semantics, and the build of the weighted label-enhanced syntactic GCN fully exploits the syntactic information. The integration of semantic information and syntactic information leads to a competitive manner in ABSC.
5 Conclusion
In this work, we propose a GCN based on dual contrastive learning and syntax label enhancement for ABSC tasks. To obtain sentiment information, a contrastive learning scheme is integrated to a BERT encoder to enhance the learning of semantic-related contextual information. Then, our model exploits both the syntax dependency and syntactic relation, based on which a weighted label-enhanced syntactic GCN is established. In addition, the learning of the syntax label is enhanced using contrastive learning. A syntactic triplet between words is mapped into a unified feature space for syntax and semantic integration. The rxperimental results reveal that the proposed model achieves state-of-the-art performance on five benchmark datasets. The ablation study, the hyperparameter analysis experiment, and the case study also obtain superior working performance.
Future work will focus on introducing more information for further improving the accuracy of ABSC and other sentiment analysis tasks, such as background knowledge and part-of-speech information. In addition, the integration of different categories of information into the model is also considered.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
YH: conceptualization, methodology, and writing–original draft. AD: conceptualization, methodology, and writing–original draft. SC: formal analysis, methodology, and writing–original draft. QK: conceptualization, formal analysis, and writing–original draft. HZ: funding acquisition, supervision, and writing–review and editing. QC: supervision and writing–review and editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported in part by the Guangdong Basic and Applied Basic Research Foundation (no. 2023A1515011370), the National Natural Science Foundation of China (no. 32371114), and the Characteristic Innovation Projects of Guangdong Colleges and Universities (no. 2018KTSCX049).
Conflict of interest
Author YH was employed by Datastory, author AD was employed by China Merchants Bank, and author QK was employed by Guangzhou Qizhi Information Technology Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Pang B, Lee L. Opinion mining and sentiment analysis. Foundations Trends® in information retrieval. Now Publishers Inc. (2008) 2 (1–2):1–135. doi:10.1561/1500000011
2. Bing L. Sentiment analysis and opinion mining (synthesis lectures on human language technologies). Chicago, IL, USA: University of Illinois (2012).
3. Zheng Y, Zhang R, Mensah S, Mao Y. Replicate, walk, and stop on syntax: an effective neural network model for aspect-level sentiment classification. Proc AAAI Conf Artif intelligence (2020) 34:9685–92. doi:10.1609/aaai.v34i05.6517
4. Tsytsarau M, Palpanas T. Survey on mining subjective data on the web. Data Mining Knowledge Discov (2012) 24:478–514. doi:10.1007/s10618-011-0238-6
5. Lin T, Joe I. An adaptive masked attention mechanism to act on the local text in a global context for aspect-based sentiment analysis. IEEE Access (2023) 11:43055–66. doi:10.1109/access.2023.3270927
6. Žunić A, Corcoran P, Spasić I. Aspect-based sentiment analysis with graph convolution over syntactic dependencies. Artif Intelligence Med (2021) 119:102138. doi:10.1016/j.artmed.2021.102138
7. Yusuf KK, Ogbuju E, Abiodun T, Oladipo F. A technical review of the state-of-the-art methods in aspect-based sentiment analysis. J Comput Theories Appl (2024) 2:67–78. doi:10.62411/jcta.9999
8. He Y, Huang X, Zou S, Zhang C. Psan: prompt semantic augmented network for aspect-based sentiment analysis. Expert Syst Appl (2024) 238:121632. doi:10.1016/j.eswa.2023.121632
9. Huang X, Li J, Wu J, Chang J, Liu D, Zhu K. Flexibly utilizing syntactic knowledge in aspect-based sentiment analysis. Inf Process Manag (2024) 61:103630. doi:10.1016/j.ipm.2023.103630
10. Wang P, Tao L, Tang M, Wang L, Xu Y, Zhao M. Incorporating syntax and semantics with dual graph neural networks for aspect-level sentiment analysis. Eng Appl Artif Intelligence (2024) 133:108101. doi:10.1016/j.engappai.2024.108101
11. Nazir A, Rao Y, Wu L, Sun L. Iaf-lg: an interactive attention fusion network with local and global perspective for aspect-based sentiment analysis. IEEE Trans Affective Comput (2022) 13:1730–42. doi:10.1109/taffc.2022.3208216
12. Gou J, Sun L, Yu B, Wan S, Ou W, Yi Z. Multilevel attention-based sample correlations for knowledge distillation. IEEE Trans Ind Inform (2022) 19:7099–109. doi:10.1109/tii.2022.3209672
13. Tang D, Qin B, Feng X, Liu T. Effective lstms for target-dependent sentiment classification (2015). Available at: https://arxiv.org/abs/1512.01100 (Accessed December 3, 2015).
14. Wang Y, Huang M, Zhu X, Zhao L. Attention-based lstm for aspect-level sentiment classification. In: Proceedings of the 2016 conference on empirical methods in natural language processing; November, 2016; Austin, Texas (2016). p. 606–15.
15. Chen P, Sun Z, Bing L, Yang W. Recurrent attention network on memory for aspect sentiment analysis. In: Proceedings of the 2017 conference on empirical methods in natural language processing; September, 2017; Copenhagen, Denmark (2017). p. 452–61.
16. Sun C, Huang L, Qiu X. Utilizing bert for aspect-based sentiment analysis via constructing auxiliary sentence (2019). Available at: https://arxiv.org/abs/1903.09588 (Accessed March 22, 2019).
17. Gou J, Yuan X, Yu B, Yu J, Yi Z. Intra-and inter-class induced discriminative deep dictionary learning for visual recognition. IEEE Trans Multimedia (2023) 25:1575–83. doi:10.1109/tmm.2023.3258141
18. Gou J, Xie N, Liu J, Yu B, Ou W, Yi Z, et al. Hierarchical graph augmented stacked autoencoders for multi-view representation learning. Inf Fusion (2024) 102:102068. doi:10.1016/j.inffus.2023.102068
19. Suresh V, Ong DC. Not all negatives are equal: label-aware contrastive loss for fine-grained text classification (2021). Available at: https://arxiv.org/abs/2109.05427 (Accessed September 12, 2021).
20. Wang S-H, Govindaraj VV, Górriz JM, Zhang X, Zhang Y-D. Covid-19 classification by fgcnet with deep feature fusion from graph convolutional network and convolutional neural network. Inf Fusion (2021) 67:208–29. doi:10.1016/j.inffus.2020.10.004
21. Zhang Y-D, Satapathy SC, Guttery DS, Górriz JM, Wang S-H. Improved breast cancer classification through combining graph convolutional network and convolutional neural network. Inf Process Manag (2021) 58:102439. doi:10.1016/j.ipm.2020.102439
22. Sun K, Zhang R, Mensah S, Mao Y, Liu X. Aspect-level sentiment analysis via convolution over dependency tree. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP); November, 2019; Hong Kong, China (2019). p. 5679–88.
23. Zhang C, Li Q, Song D. Aspect-based sentiment classification with aspect-specific graph convolutional networks (2019). Available at: https://arxiv.org/abs/1909.03477 (Accessed September 8, 2019).
24. Liang B, Yin R, Gui L, Du J, Xu R. Jointly learning aspect-focused and inter-aspect relations with graph convolutional networks for aspect sentiment analysis. In: Proceedings of the 28th international conference on computational linguistics; December, 2020; Barcelona, Spain (Online) (2020). p. 150–61.
25. Wang K, Shen W, Yang Y, Quan X, Wang R. Relational graph attention network for aspect-based sentiment analysis (2020). Available at: https://arxiv.org/abs/2004.12362 (Accessed April 26, 2020).
26. Chen T, Kornblith S, Norouzi M, Hinton G. A simple framework for contrastive learning of visual representations. In: International conference on machine learning (PMLR); July, 2020; Virtual (2020). p. 1597–607.
27. Khosla P, Teterwak P, Wang C, Sarna A, Tian Y, Isola P, et al. Supervised contrastive learning. Adv Neural Inf Process Syst (2020) 33:18661–73. doi:10.48550/arXiv.2004.11362
28. Kirange D, Deshmukh RR, Kirange M. Aspect based sentiment analysis semeval- 2014 task 4. Asian J Comp Sci Inf Tech (Ajcsit) (2014) 4. doi:10.15520/ajcsit.v4i8.9
29. Pontiki M, Galanis D, Papageorgiou H, Manandhar S, Androutsopoulos I. Semeval-2015 task 12: aspect based sentiment analysis. In: Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015); June, 2015; Denver, Colorado (2015). p. 486–95.
30. Pontiki M, Galanis D, Papageorgiou H, Androutsopoulos I, Manandhar S, Al-Smadi M, et al. Semeval-2016 task 5: aspect based sentiment analysis. In: ProWorkshop on Semantic Evaluation (SemEval-2016) (Association for Computational Linguistics); June, 2016; San Diego, California, USA (2016). p. 19–30.
31. Dong L, Wei F, Tan C, Tang D, Zhou M, Xu K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In: Proceedings of the 52nd annual meeting of the association for computational linguistics; June, 2014; Baltimore, Maryland (2014). p. 49–54.
32. Devlin J, Chang M-W, Lee K, Toutanova K. Bert: pre-training of deep bidirectional transformers for language understanding (2018). Available at: https://arxiv.org/abs/1810.04805 (Accessed October 11, 2018).
33. Xiao Z, Wu J, Chen Q, Deng C. Bert4gcn: using bert intermediate layers to augment gcn for aspect-based sentiment classification (2021). Available at: https://arxiv.org/abs/2110.00171 (Accessed October 1, 2021).
34. Tang H, Ji D, Li C, Zhou Q. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification. In: Proceedings of the 58th annual meeting of the association for computational linguistics; July, 2020; Online (2020). p. 6578–88.
35. Tian Y, Chen G, Song Y. Aspect-based sentiment analysis with type-aware graph convolutional networks and layer ensemble. In: Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies; June, 2021 (2021). p. 2910–22.
Keywords: aspect-based sentiment classification, graph convolutional networks, dual contrastive learning, syntax label enhancement, bidirectional encoder representations from transformers (BERT)
Citation: Huang Y, Dai A, Cao S, Kuang Q, Zhao H and Cai Q (2024) A dual contrastive learning-based graph convolutional network with syntax label enhancement for aspect-based sentiment classification. Front. Phys. 12:1336795. doi: 10.3389/fphy.2024.1336795
Received: 11 November 2023; Accepted: 11 March 2024;
Published: 05 April 2024.
Edited by:
Xin Lu, De Montfort University, United KingdomReviewed by:
E. Zhang, University of Leicester, United KingdomYinong Chen, Arizona State University, United States
Amin Ul Haq, University of Electronic Science and Technology of China, China
Copyright © 2024 Huang, Dai, Cao, Kuang, Zhao and Cai. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qianhua Cai , caiqianhua@m.scnu.edu.cn