 Xuan Chu1
Xuan Chu1 Hongli Liu
Hongli Liu- 1College of Mechanical and Electrical Engineering, Zhongkai University of Agriculture and Engineering, Guangzhou, China
- 2College of Engineering, South China Agricultural University, Guangzhou, China
- 3College of Mechanical and Electronic Engineering, Nanjing Forestry University, Nanjing, China
Introduction: Anthracnose of banana caused by Colletotrichum species is one of the most serious post-harvest diseases, which can cause significant yield losses. Clarifying the infection mechanism of the fungi using non-destructive methods is crucial for timely discriminating infected bananas and taking preventive and control measures.
Methods: This study presented an approach for tracking growth and identifying different infection stages of the C. musae in bananas using Vis/NIR spectroscopy. A total of 330 banana reflectance spectra were collected over ten consecutive days after inoculation, with a sampling rate of 24 h. The four-class and five-class discriminant patterns were designed to examine the capability of NIR spectra in discriminating bananas infected at different levels (control, acceptable, moldy, and highly moldy), and different time at early stage (control and days 1-4). Three traditional feature extraction methods, i.e. PC loading coefficient (PCA), competitive adaptive reweighted sampling (CARS) and successive projections algorithm (SPA), combining with two machine learning methods, i.e. partial least squares discriminant analysis (PLSDA) and support vector machine (SVM), were employed to build discriminant models. One-dimensional convolutional neural network (1D-CNN) without manually extracted feature parameters was also introduced for comparison.
Results: The PCA-SVM and·SPA-SVM models had good performance with identification accuracies of 93.98% and 91.57%, 94.47% and 89.47% in validation sets for the four- and five-class patterns, respectively. While the 1D-CNN models performed the best, achieving an accuracy of 95.18% and 97.37% for identifying infected bananas at different levels and time, respectively.
Discussion: These results indicate the feasibility of identifying banana fruit infected with C. musae using Vis/NIR spectra, and the resolution can be accurate to one day.
1 Introduction
As a nutritious kind of fruit, bananas are vulnerable to pathogenic micro-organism and saprophyte attacks during storage and transport in the post-harvest period (Li et al., 2019; Cho and Koseki, 2021). Banana anthracnose caused by Colletotrichum musae (C. musae) is one of the most aggressive post-harvest fungal diseases. Fruit usually become infected in the field, and the infection develops after harvest (Khaliq et al., 2019). Anthracnose symptoms involve black or sunken brown lesions on the peel, and even finger or crown rot (Thangavelu et al., 2004). Even if only a few fruit are infected, the disease can spread rapidly to other bananas, leading to serious quality losses (Lorente et al., 2015). Previous publications have indicated that the disease can cause 30–40% losses of the marketable fruit, and even up to 80% in some cases (Vilaplana et al., 2018; Maqbool et al., 2021). Therefore, timely, rapid, and accurate recognition of this disease is crucial for guaranteeing fruit quality.
However, identifying the disease in bananas at an early stage is still challenging. Several laboratory methods, such as microbiological and/or physicochemical techniques, are accurate but they are usually slow, labor-intensive, costly and need complicated sample pretreatment (Yao et al., 2008; Alander et al., 2013; Sun et al., 2023). These compelled non-destructive and economic methods for the early detection of fungal infection (Brosnan and Sun, 2004). In recent years, a series of non-destructive methods have been employed, including soft X-ray imaging (Pearson and Wicklow, 2006), dielectric (Li et al., 2013), electronic nose (Liu et al., 2018) and hyperspectral imaging technology (Yeh et al., 2016). Although these methods showed good performance, there are still some limitations in commercial application, such as ionizing radiation, difficulty in data processing and high costs (Haff and Toyofuku, 2008; Gu et al., 2017). Visible and near-infrared (Vis/NIR) spectroscopy is an alternative method, which are faster (approximately a full spectral reading per second), easier-to-use, and lower-cost advantages (Magwaza et al., 2012; De Azevedo et al., 2019). This technique has been widely used for evaluating fruit quality, such as taste parameters (Li et al., 2019a), internal quality attributes (Chandrasekaran et al., 2019), maturity (Shah et al., 2020), and mechanical or insect damage (Moscetti et al., 2014; Nturambirwe et al., 2023). It can record the multi-frequency and co-frequency information of organic molecules (e.g., C–H, N–H, C–O, and O–H) that are related to the internal components. Sample tissue’s physical state (e.g., density, cell structures, or cellular matrices) (Cen et al., 2013; Costabile et al., 2013) also can be represented from the spectral scatter. During fungi infecting, both internal compositions and external attributes will be changed. The hypha pierces the cuticle and cell wall, then secretes large amounts of cell wall-degrading enzymes to destroy the cell structure, thus causing the fruit tissue to become soft (Sun et al., 2020). Meanwhile, fungi exploit fruit as living substrates and consume nutrients, such as chlorophyll, moisture, and saccharides (Mendgen and Hahn, 2002). The consequent changes in microstructure of tissue and chemical composition can affect the infrared radiation. Therefore, NIR spectra has a great potential in detection of the fungi infection.
Many cases of fungal contamination in fruit using NIR spectra have been reported (Huang et al., 2017; Najjar and Abu-Khalaf, 2021), such as the detection of Alternaria alternata and Penicillium digitatum infection in orange fruit (Lorente et al., 2015; Ghooshkhaneh et al., 2023), bitter pit disease in ‘Fuji’ apples (Mogollón et al., 2021), Monilia contamination in plum (Vitalis et al., 2021), moldy core in apple and pears (Zhang et al., 2022; Zhang et al., 2022a). In addition, several researchers have been aimed to identify fruit or plant anthracnose caused by Colletotrichum spp. infection using NIR spectra. For example, Lu et al. (2017) identified anthracnose crown rot in strawberry leaves. The identification was based on models established by 33 spectral vegetation indices that were selected from the VIS and NIR regions (400–2000 nm). Jiang et al. (2021) also achieved the early identification of anthracnose on strawberry leaves through the spectral fingerprint features in the 400–1000 nm range in reflectance mode, and obtained perfect accuracy (100%) and robust performance. Ardila et al. (2020) built models based on 29 significant spectral bands from spectral range of 350–1900 nm for the early detection of anthracnose in Mango, and obtained accuracies of 91–100% when characterizing healthy, asymptomatic, and diseased samples. Wu et al. (2012) explored the spectral characteristics of oil camellia canopies suffering from different severity of anthracnose using the NIR reflectance spectra of 200-1000 nm, and built a prediction model for its chlorophyll content. The above studies indicated excellent performance in detecting fruit and plant anthracnose using NIR spectra. For bananas, NIR spectra are commonly reported for detecting chemical composition attributes, such as moisture content, chlorophyll content, solid soluble content (SSC), and pH during microwave vacuum drying, ripening, or storing processes (Ali et al., 2018; Pu et al., 2018; Sripaurya et al., 2021; Ferreira et al., 2022). In contrast, few studies have focused on non-invasively screening fungi infecting banana fruit.
In the analysis of NIR spectral data, it should be noted that the spectral data usually contain hundreds or thousands of wavelength variables, implying a large amount of hidden information. Thus, particular attention should be paid to data mining and feature optimization (Cen et al., 2007; Li et al., 2013a). In recent years, deep learning algorithms, such as deep convolutional neural networks (DCNNs), have been widely used in fruit classification, as they can automatically learn and extract high-level data features (Liu et al., 2021). For instance, Rong et al. (2020) constructed a 1D-CNN model using Vis-NIR spectra to identify five cultivars of peaches, obtaining an accuracy of 94.4% on the test data set. Tian et al. (2022) analyzed freezing damage in orange using transmission NIRs with a 1D-CNN model. Similarly, Chen et al. (2019) proposed an end-to-end 1D-CNN model based on near-infrared spectral data to detect aristolochic acids and their analogues in Chinese herbs. In other reports, 1D-CNN models based on spectra have also used for detecting maize kernels contaminated with fungi (Mansuri et al., 2022), prediction of specialty coffee flavors (Chang et al., 2021), and geographical origin identification of Chinese chestnuts (Li et al., 2021). Therefore, in the analysis of banana fruit infected with fungi, the use of such a deep learning-based model would be a good attempt.
The aim of this study was to utilize Vis/NIR spectra to track the infection of the C. musae in bananas and determine the identifiable time node. The specific objectives were to: (1) classify fungal infection levels on bananas qualitatively; (2) explore the feasibility of discriminant fungal infection time and determine the earliest identifiable time node; (3) extract the informative spectral features based on traditional machine learning methods and deep learning methods.
2 Materials and methods
2.1 Sample preparation
Considering the uncontrollability and unpredictability of the fungi contamination in natural environment, it is rather difficult to directly apply the NIR spectra on detection of samples contaminated naturally. This study started with the identification of different stages of banana fruits that were artificially inoculated with fungi under laboratory-controlled condition.
The banana fruit were purchased from a local orchard in Guangzhou, China. After picking from the orchard, they were immediately transported to the lab. Banana fingers were selected with uniform maturity, shape, size, and visual absence of surface bruises and disease. The fingers were wiped with 75% of alcohol to sterilize the surface, then rinsed with sterile distilled water. All fruit were divided into control and infected groups.
C. musae, provided by Agricultural Culture Collection of China (Beijing, China), was used for the in vitro inoculation test. Infected samples were obtained by pricking the middle of the finger to a depth of approximately 1.5 cm using a steel needle with mycelium and spores. Samples in the control group were also pricked to 1.5 cm with a sterile inoculation steel needle. All samples were stored in an incubator at 28°C and 75% relative humidity (RH). Thirty samples in the infected group were selected for NIR spectra collection every 24 h. As the bananas had seriously rotted by the 11th day, the inoculated samples were only assessed on the first ten days in this study.
2.2 Spectroradiometer and data collection
The reflectance spectra collecting system was composed of a Vis/NIR spectrophotometer (USB2000, Ocean Optics, Dunedin, Florida), a stabilized halogen light source (HL2000, Ocean Optics, Dunedin, Florida), a Y-shaped fiber-optic reflectance probe, and a custom lifting platform. The visible–NIR spectrometer scanning range and sampling interval were 339–1019 nm and 0.29 nm, respectively. During acquiring spectral data, samples were placed on a custom lifting platform and manually adjusted to approach the probe. The integral time was set to 2.8 ms. One spectrum was obtained with 20 averaged scans, and the smoothing window point was set as 9 to reduce noise in the spectra. As shown above, the spectra were obtained for the control group and every 24 h for the infected groups. Consequently, a total of 30 spectra for the control group and 300 spectra for the infected group were achieved.
2.3 Primary chemometrics methods
In this work, traditional feature extraction methods (e.g., PCA) and distinct effective wavelength extraction algorithms were utilized to mine spectral feature information. SVM- and PLSDA-based models were established using the full-spectra, PCs, and effective spectral variables. Deep learning models (1D-CNN) were also constructed and compared.
2.3.1 Feature selection methods
The PCA, PC loading coefficient, SPA, and CARS methods were adopted for spectral feature extraction. PCA can reduce the dimensions of the data, and get a glimpse of the patterns hidden in the full spectral data (Liu et al., 2010). Variable selection methods, such as PC loading coefficient, SPA, and CARS, can extract characteristic wavelengths in the original spectra, removing irrelevant and redundant information.
The PCA method that original spectral variables were projected into new orthogonal variables, known as principal components (PCs), was allowed for maximization of the sample variance (Yang et al., 2022). PCA can help to explore the spectral characteristics used for class separation (Munera et al., 2018). The wavelengths with larger absolute coefficients are considered necessary in the corresponding PC (Xing et al., 2010). Thus, the PC loading coefficients could help to determine the effective wavelengths.
SPA is a forward-loop variable selection algorithm. It starts with one wavelength and individually incorporates a new one at each iteration, until a specified number of wavelengths with the largest projection vector is reached (Araújo et al., 2001; Galvao et al., 2008). In other words, the number of wavelengths is determined by the minimum root mean square error (RMSE) values from the full internal cross-validation.
CARS combines Monte Carlo sampling with the partial least squares regression (PLSR) model. It selects N subsets of variables from N Monte Carlo (MC) sampling runs iteratively and competitively (Wang and Wang, 2022). The subset with the lowest RMSE of cross-validation (RMSECV) value is chosen as the optimal wavelength combi-nation. In every sampling phase, the spectral variables are selected by the adaptive reweighted sampling (ARS) method and the exponentially decreasing function (EDF), based on the regression coefficients of the PLS model (Zhang et al., 2019).
2.3.2 Establishment of models
Traditional classification algorithms—including SVM and PLSDA methods—and deep learning algorithms—including the 1D-CNN—were employed in this study.
SVM is a supervised machine learning approach based on statistical learning theory. It projects data into a higher dimensional space and creates hyperplanes to separate each class (Pardo and Sberveglieri, 2005; Zhang et al., 2021). The higher-dimensional space is generally implemented using a kernel function, such as a Linear Function, Polynomial Function (Poly), Radial Basis Function (RBF), or Sigmoid Function (Sigmoid) (Kurosaki et al., 2020). SVM exhibits excellent performance in classifying high-dimensional data with limited training data.
PLS-DA is a supervised classification algorithm based on the principle of PLSR (Ivorra et al., 2013), which has also been widely applied in discriminant analysis. It projects the data matrix into a group of linear latent variables (LVs), then uses the PLS model combined with a suitable threshold to give the class number for each sample. During model training, the optimal number of LVs was determined according to the results of cross-validation (He et al., 2022).
A typical 1D-CNN consists of convolutional, pooling, and fully connected layers (Shen and Viscarra Rossel, 2021). It can also be understood as concatenating a feature extractor block with a classification head (Fazari et al., 2021). The convolutions, pooling operations, and non-linear activation functions belong to the feature extractor block. The convolutional layer can be used to realize feature mapping, which consists of a series of convolution kernels. The kernels are used to perform a convolution operation on a local data area, extracting the continuous features of different areas by sliding translation with a specific stride (Chai et al., 2021). In NIR spectral analysis, as the input vectors are one-dimensional spectral data, the feature map was calculated using one-dimensional convolution (Rong et al., 2020). The pooling layer can prevent overfitting by reducing the parameters of the CNN, and can also realize the spatial invariance of features while lowering the feature map. In addition, the activation function is used in a CNN to increase the non-linear capability of the network. The classification head is a fully connected classical neural network that produces a probability vector, which indicates the probability of the input data belonging to each class.
2.4 Model evaluation
The performance of all the models was evaluated in terms of sensitivity, precision, specificity, and accuracy. The sensitivity, specificity, and precision are used to evaluate a model’s classification performance for each group, while the accuracy is used to assess the overall performance of the model. Sensitivity and specificity are used to evaluate the capacity of a model to correctly recognize samples belonging to a specific group or reject samples from other groups (Jiang et al., 2022). Precision represents the ability of a model to correctly quantify the number of positive predictions (Tian et al., 2022). The accuracy denotes the ratio of the number of correctly classified samples to the total number of samples in a group. These parameters were calculated based on the confusion matrix, which comprises counts of true positive (TP), true negative (TN), false negative (FN), and false positive (FP) results. TP and TN represent that the samples are correctly classified as belonging or not belonging to a specific class, respectively. In contrast, FP and FN represent the samples incorrectly classified as belonging or not belonging to a given class, respectively (Kurosaki et al., 2020). The model evaluation parameters were calculated as follows:
3 Results and discussion
3.1 Preliminary level division and overview of the spectra
The RGB images of the control group and inoculated fruit of 1 to 10 days are shown in Figure 1. It can be seen that the symptoms of the fungal infection expanded gradually as the inoculation time increased. In the first four days, the banana was bright green, and the pricked regions were small. The samples in the control and acceptable group looked quite similar. Especially, there is no obvious difference in sample exterior between days 1 and 2 in the acceptable group and control group. From the fifth day, the symptom size sharply increased, and the color of the fruit turned yellow. The appearance of more yellow implies increased ripening. The symptoms further expanded from days 8 to 10, until they were severely rotted. To identify bananas infected with C. musae at different levels, all samples were tentatively divided into four classes—control, acceptable (days 1–4), moldy (days 5–7), and highly moldy (days 8–10)—according to the change of the symptom. A five-class dataset, including the control and day 1–4, was also prepared for identifying the fungi infection time at early stage.
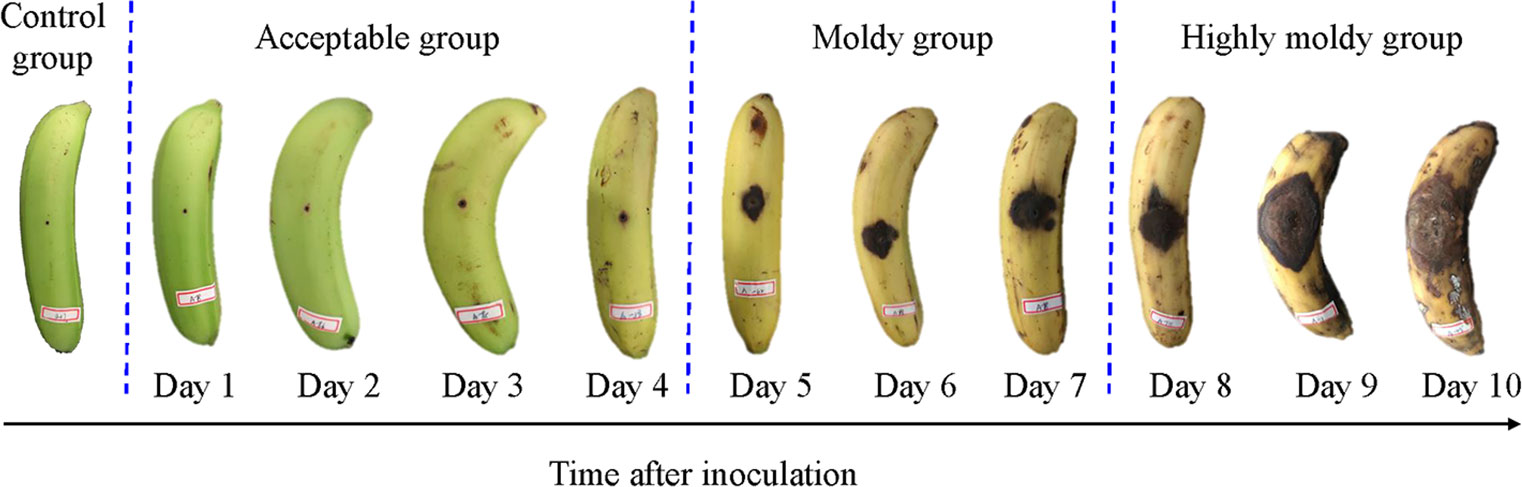
Figure 1 The appearance of infected banana fingers at different incubation time.
The original average reflectance spectra of the four-class samples are shown in Figure 2A. The wavelength ranges of 339–400 nm and 950–1019 nm were removed to reduce noise caused by the lower sensitivity of the spectrometer. The shaded regions with different colors denote the deviation bands of the spectra. The mean spectrum of the control group (pricked with a sterile steel needle) presented a higher reflectance intensity. The overall trend of the acceptable group’s spectral profile was similar to that of the control group, while the reflectance intensities were relatively small. This is because the fungal infection caused a black disease spot and made the tissue more porous, causing more light to diffuse scattering, rather than reflecting (Liu et al., 2020). In addition, the peaks and valleys on the spectra represent some chemical composition or functional groups. The apparent peak at around 550 nm, as mentioned by Min et al. (2006), is related to nitrogen absorption. Furthermore, the regions in the 600–680 nm range represent anthocyanin and other pigments that are responsible for fruit coloration (ElMasry et al., 2007). Among them, the distinct valley around 675 nm can be attributed to chlorophyll. There was a sharp rise in the 680–740 nm band, which can be denoted as the ‘red edge’. The spectral pattern and reflectance values for the moldy and highly moldy groups obviously differed from those of the control and acceptable groups. In these two groups, the wave peaks and valleys became unclear as the reflection intensity further reduced. For example, in the moldy and highly moldy groups, the valley at 675 nm disappeared. With the increase in culture days, the changes in spectra agreed with those previously reported by Liu et al. (Liu et al., 2019). The difference in spectral profiles may be due to the changes of chemical composition and structural destruction of banana tissue caused by the fungal infection.
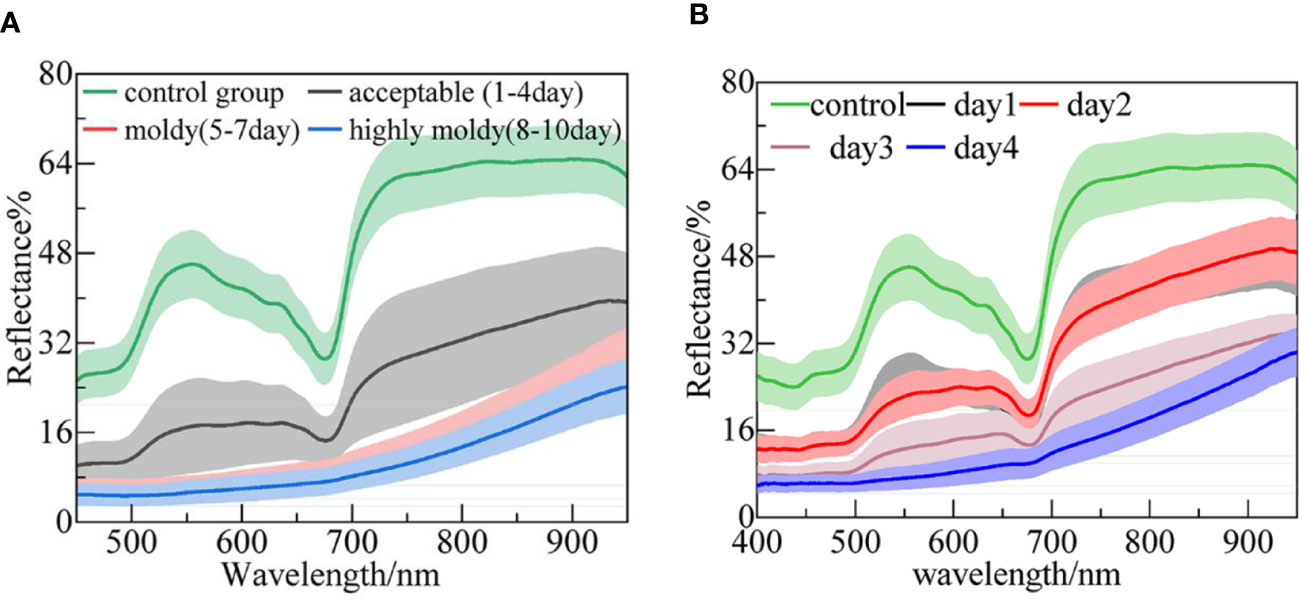
Figure 2 The mean spectra of banana fingers at different: (A) Infection levels; and (B) days post-infection.
The average reflectance spectra of the five-class samples (i.e., control and days 1–4) are shown in Figure 2B. The patterns of the spectra are similar to those presented in Figure 2A. The highest reflectance appeared in the control group. It was difficult to distinguish the spectra between days 1 and 2. This may be because the fungi in the bananas were in a lag phase on these days, and the tissue structure had not been broken out (Sun et al., 2017). With the invasion of the fungi, the reflectance was further reduced, and the peak and valley were no longer obvious.
Principal component analysis (PCA) was carried out further to analyze the differences in spectra among the four-class sample. The scores of the first three PCs (Figure 3A) explained 92.13%, 5.25%, and 1.63% of the variance, respectively. It was found that samples in the four groups were distributed along the direction of PC1, and samples in the control and acceptable groups could be generally separated from those in the moldy and highly moldy groups. Similar results have also been observed for moldy peanuts and fungi-contaminated peaches, based on near-infrared spectroscopy (Liu et al., 2020; Shen et al., 2018). However, visual boundaries between the control and acceptable groups, as well as between the moldy and highly moldy groups, were missing. This motivated the use of chemometric techniques to improve the separation performance. Similar to the analysis of fungi infection levels, PCA was also performed for the five-class samples. The contribution rate of the first three PCs was 89.39%, 7.32% and 2.19%, which were accounted for >98% of the spectral variance. A three-dimensional (3D) score plot of those PCs was constructed and shown in Figure 3B. The samples in the control group and days 1–4 were also distributed along the direction of PC1, while the boundary of each class was not obvious.
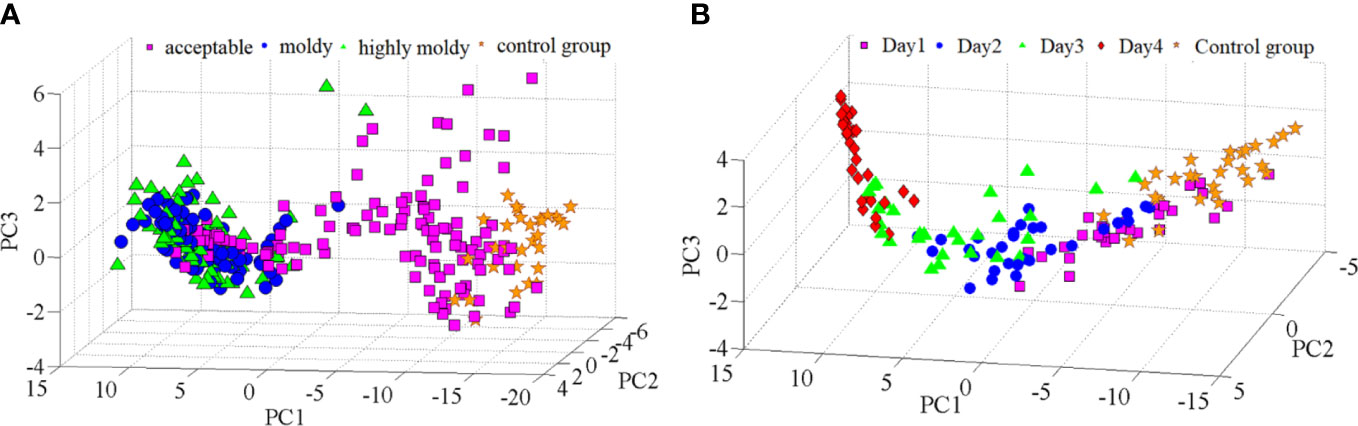
Figure 3 PC score plots: (A) Banana fingers with different fungi infection levels; and (B) banana fingers with different fungi infection time.
3.2 Discriminant models based on traditional methods
3.2.1 Spectral pre-treatment and division
In this study, the SVM and PLSDA methods were selected to establish models to discriminate bananas with different infection levels and time based on the four- and five-class datasets, respectively. As a pre-treatment process, the standard normal variate (SNV) was first applied to correct scatter caused by variations in the appearance of the disease spots (Li et al., 2020). For the SVM models, a polynomial kernel was selected as the kernel function, and the parameters of SVM were optimized by grid search method. A five-fold cross-validation were used during the construction of SVM models. Both the full spectral data and the PCs were taken as inputs of the SVM, and all the SVM inputs were normalized using the min–max method to improve the model performance. For the PLSDA models based on the full spectral data, five-fold cross-validation was also used. During modeling, the four- and five-class data sets were randomly divided into calibration and validation sets with a ratio of 3:1. The model performance was evaluated according to the accuracy in the calibration, cross-validation, and validation sets.
3.2.2 Model construction based on full spectra
The performances of the Full-SVM, PCA-SVM, and Full-PLSDA models on the four- and five-class data sets are detailed in Table 1. During the construction of the PCA-SVM models, the proper input numbers of PCs was determined based on their accumulative contribution rates and the criterion of correct classification of the models (Ropodi et al., 2016). For the four-class model, a high model accuracy was achieved when the first 14 PCs were used. After that, the accuracies fluctuated little with an increasing number of PCs. Thus, the first 14 PCs were selected as input. The first 12 PCs were selected for the five-class PCA-SVM model, based on the same principles. For the PLSDA models, optimum input components (LVs) were selected based on the compromise between less input and lower error rate during model training and cross-validation. A total of 14 and 10 LVs were chosen for the four- and five-class PLSDA models, respectively. Table 1 lists the accuracies of the PLS-DA and SVM models with their optimal parameters for comparison.
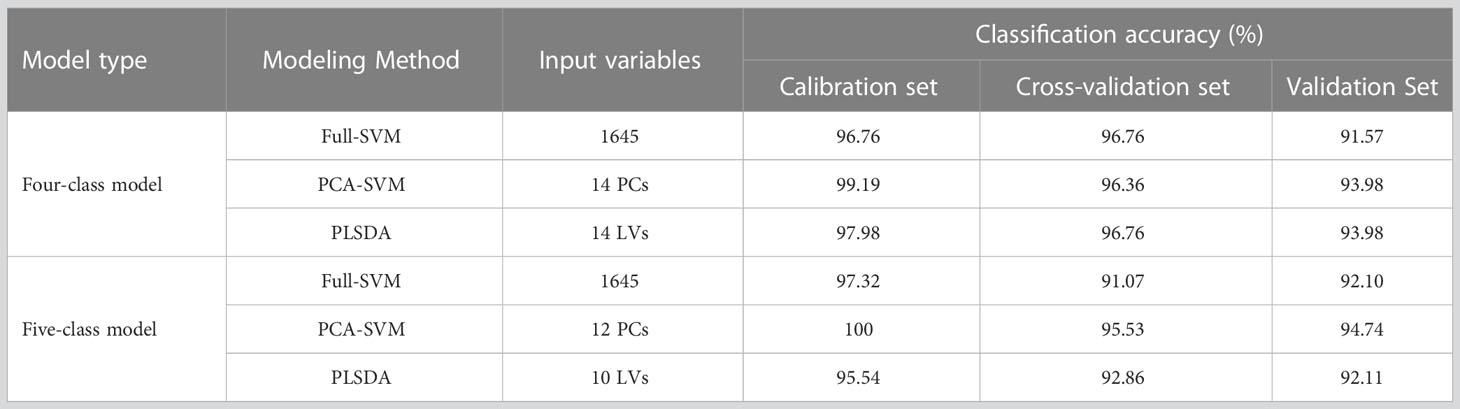
Table 1 Classification results of SVM and PLSDA models built with full spectra.
It can be seen that all four- and five-class discriminant models achieved favorable results, with calibration accuracies over 95.54% and validation accuracies over 91.57%. The results indicated that the use of NIR spectra with proper modeling methods feasibly allows for identifying bananas with different fungi infection levels and time. For the Full-SVM models, the accuracies were 91.57% and 92.10% for the four- and five-class, respectively. However, large number of variables (full wavelengths of 1645 variables) resulted in complex computations during model construction. In the PCA-SVM and PLSDA models, the number of variables was remarkably reduced to a dozen. The PCA and PLSDA methods decompose the data into new, uncorrelated variables, reducing the number of variables in the model. New variables imply new directions in the pattern space, and they can explain as much variance as possible with respect to the raw full spectral data (Ciosek et al., 2005). This may be also the reason why the PCA-SVM and PLSDA models performed better than the full-SVM models, with validation accuracies of 93.98% and 93.98% for four-class models and 94.74% and 92.11% for five-class models, respectively. As the PCA-SVM models obtained the highest accuracies, they were selected for further analysis.
3.2.3 Simplified models based on selected wavelengths
Through spectral data analysis, selecting effective wavelengths can eliminate redundant information, retain critical information in the original data, and reduce the calculation burden. We considered three effective wavelength selection methods: SPA, CARS, and PC loading coefficient. Taking four-class data as an example to introduce the application of these methods. In the process of SPA, the RMSE iteration decline curves are shown in Figure 4A. The RMSE decreased dramatically with increasing number of wavelength variables, then fluctuated slightly when the value reached 11. Therefore, the number of effective wavelengths for the four-class models was determined to be 11 (Figure 4B). In the process of selecting variables by CARS (Figure 4C), the results are shown in Figure 4D. The number of sampled variables decreased rapidly at first with the increase of sampling time, then stabilized. Regarding the RMSECV values in the second sub-plots of Figure 4C, they also gently declined and remained stable when the sampling time was 35. This indicated that the uninformative variables were gradually eliminated, and the subsequent increase in the RMSECV was due to the removal of effective variables. Consequently, the optimal effective wavelength subset of variables was determined in the 35th sampling run. The loading lines for the PC1, PC2, and PC3 are shown in Figure 4E. The peaks and valleys correspond to greater absolute coefficient values, and the corresponding wavelengths were considered crucial (Xing et al., 2010). Thus, the seven wavelengths (442.6, 535.3, 564.1, 648.4, 682.4, 736.5, and 846.4 nm) from the PC loading were identified as the informative wavelengths for classifying the infection level (Figure 4F). Similarly, the effective wavelengths in the five-class spectra were also extracted using these three methods.
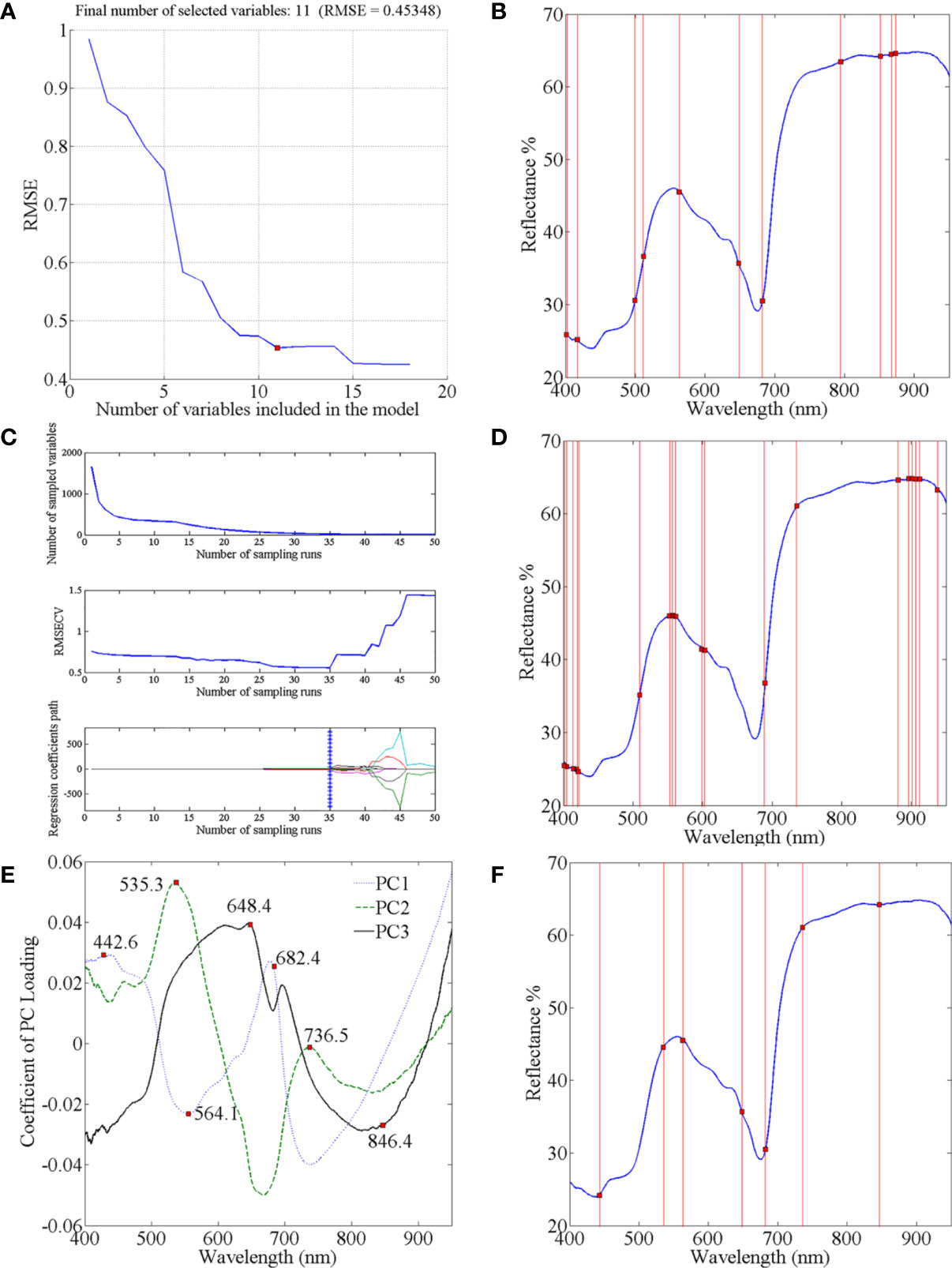
Figure 4 Selection of characteristic wavelengths using SPA CARS and PC Loading coefficient: (A) RMSE iteration decline curves of SPA; (C) process of CARS wavelength selection; (E) characteristic wavelengths selected by PC Loading coefficient; and location of characteristic wavelengths extracted by (B) SPA; (D) CARS; and (F) PC Loading coefficient.
All the selected wavelengths are summarized in Table 2. For the two data sets, the effective wavelengths selected by the three methods were spread over the entire Vis–NIR wavelength range. The wavelengths chosen by CARS and SPA were similar and mainly concentrated in the regions of 400–700 nm and 850–900 nm. CARS select-ed a greater number of wavelengths, but some successive wavelengths were chosen, and bands were clustered around certain wavelengths (e.g., 402 nm, 555 nm, and 897 nm). Compared with CARS and SPA, the PC Loading coefficient method produced sparser distributions of effective variables in the full spectra. The above-mentioned selected wavelengths were subsequently used, instead of the original full spectra, to build new simplified SVM and PLS-DA models. The sample division method, kernel function and parameters optimized method for the simplified models were the same as those used in the modeling based on the full-spectra.
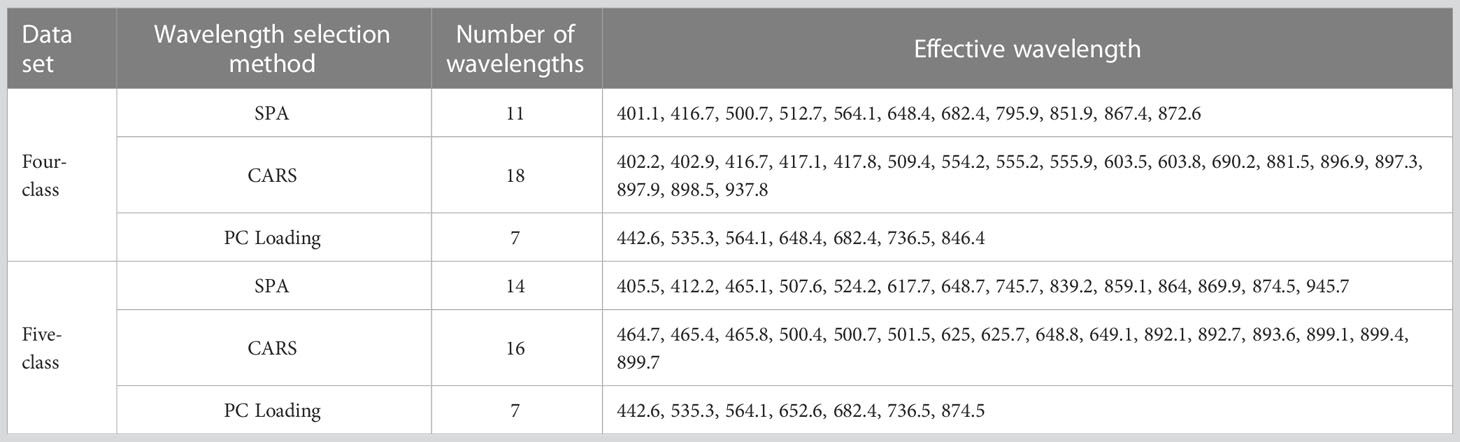
Table 2 Effective wavelengths selected by different methods.
The prediction results are shown in Table 3. In both the four- and five-class data sets, the models based on SPA and CARS achieved acceptable classification accuracy of over 81%. These indicated that the wavelengths extracted by the SPA and CARS algorithms were efficient. The results of PC loading-based models were inferior to those of the SPA and CARS models. Of the wavelengths selected by PC Loading, some were also selected by CARS and SPA, indicating that this method could screen feature spectra information; however, as this method selected few variables, too much information may be lost, resulting in lower classification accuracy.
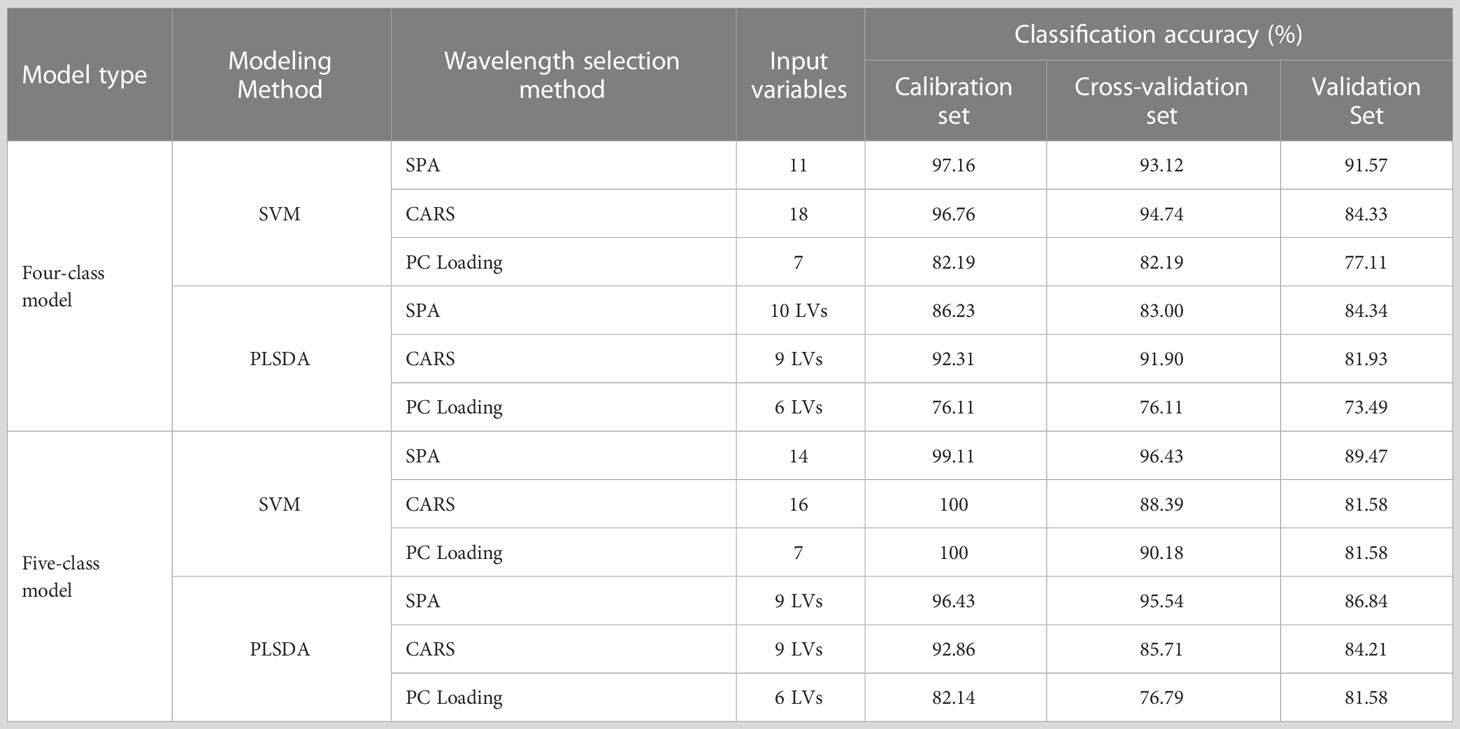
Table 3 Classification results of SVM and PLSDA models built with effective wavelengths.
On the other hand, combining with different wavelength selection methods, all SVM models slightly outperformed the PLSDA models, which were similar to those in the full-spectra models. Compared with all the models, SPA-SVM achieved the best performance, with accuracies of 91.57% and 89.47% in the validation sets of the four- and five-class datasets, respectively. Although they did not perform as satisfactorily as the full-spectra models, the number of wavelengths was significantly reduced (by 99.3% and 99.1%, respectively) in this step. In addition, the feature wavelengths in the spectral band of 600–680 nm may be related to certain colorants, which could be changed due to fungal infection. Wavelengths near 740 nm are assigned to the O–H stretching third overtone, while those near 842 and 899 nm are assigned to the C–H third overtone. Moreover, the wavelength 851.9 was near 850 nm, which is related to anthocyanin (Tian et al., 2019). The above aspects may explain why these wavelengths played an important role in the analysis.
3.3 Discriminant models established using 1D-CNN
Based on the excellent performance in feature extraction and classification problems, 1D-CNN models based on full spectra were also established for comparison. For both four- and five-class discriminant pattern, calibration and validation sets were also divided by 3:1. Taking the four-class 1D-CNN model as an example, it consists of a convolutional layer, a max-pooling layer, a transition layer, and two fully connected layers, as shown in Figure 5. As the input spectral data were one-dimensional, the convolutional layer and pooling layer were also set to be one-dimensional. The convolutional layer used Rectified linear unit (ReLU) as an activation function, in order to increase the non-linear capability of the network. The kernel size, stride, and number of kernels were set as 4×1, 1, and 16, respectively. A fully connected layer was added after the convolutional layer to further extract features of the data. The number of output units was set as 8. A max-pooling layer was used for dimension reduction, configured with a pooling size of 2×1 and a stride of 2. The following transition layer (flatten layer) was used to tile the data in one dimension and realize the transition from the convolutional layer to the fully connected layer. The normalized exponential function (SoftMax) and cross-entropy were used in the last fully connected layer. The training set was divided into batches with a size of 32 to achieve rapid convergence of the model. The structure of the five-class 1D-CNN model was generally similar to that of the four-class model, except that the number of output units in the first fully connected layer was set as 16, and the batch size in the other fully connected layer was set as 64.
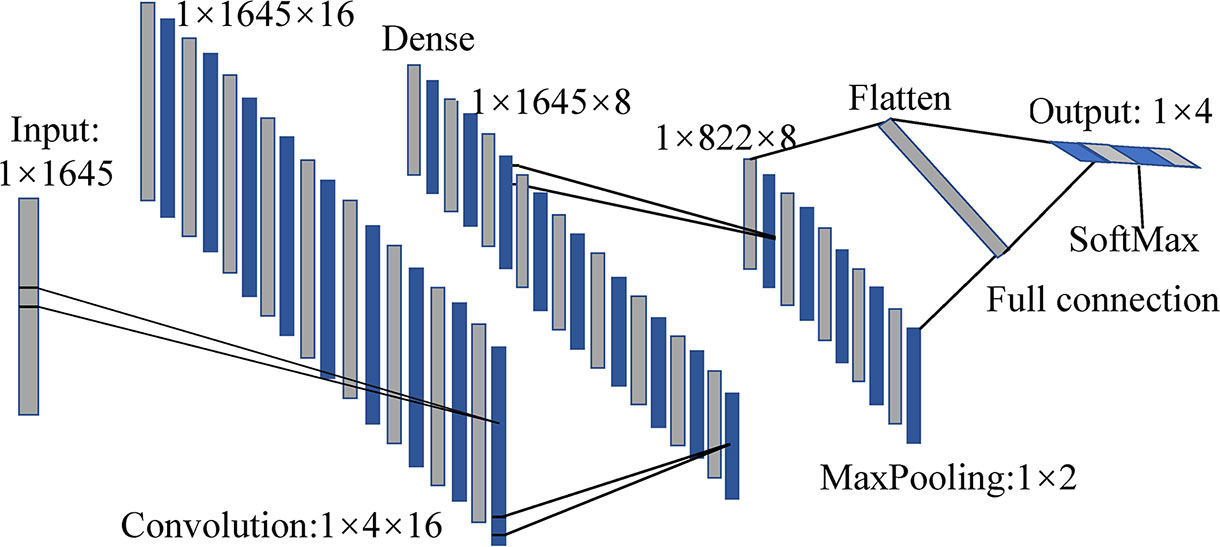
Figure 5 The structure of the 1D-CNN four-class model.
As shown in Figure 6, during the training and validation of the 1D-CNN models, the accuracies on the training and validation sets were increased, while the losses decreased with the increase in number of epochs. At the initial training, both the accuracy and the loss curve oscillate in a range respectively, which may be caused by the noisy in the spectra data and the inappropriate setting of learning rate. The use of backpropagation and gradient descent algorithms could help to calculate and adjust the weights of parameters and obtain the optimal solution of the model during the learning process. With the increase of training times and the optimization of parameters, the loss function gradually converges and the model becomes more stable. The validation accuracies in the last epoch increased to more than 95.18% and 97.73% for the four- and five-class data sets, respectively, while the corresponding losses declined to less than 0.12 and 0.16.
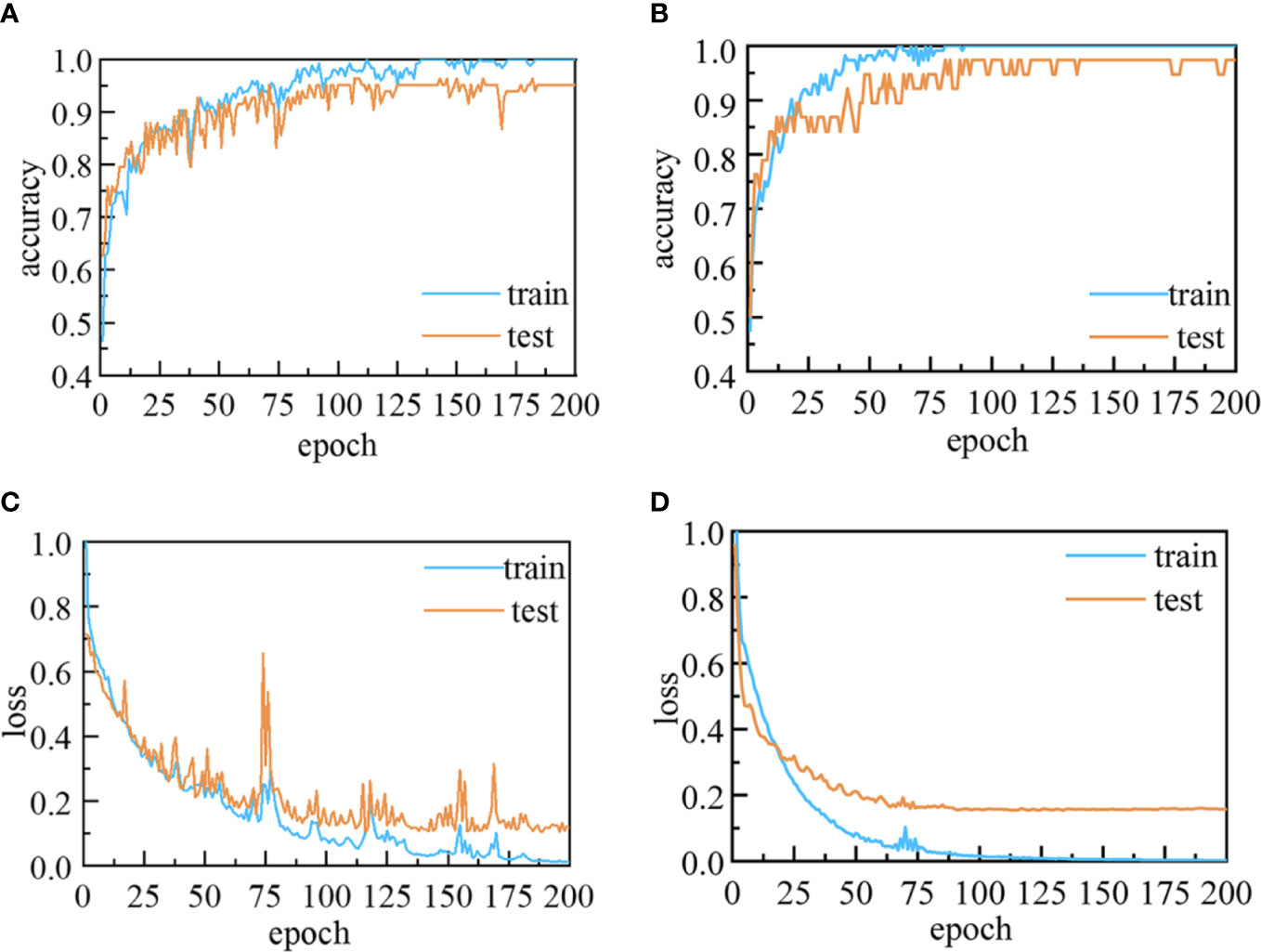
Figure 6 Accuracy and loss curves for the 1D-CNN models: (A) Accuracy and (C) loss curves for four-class 1D-CNN model; and (B) accuracy and (D) loss curves for five-class 1D-CNN model.
3.4 Comparisons of traditional models and 1D-CNN models
For comparison of the traditional and 1D-CNN models, Tables 4, 5 summarize the sensitivity, specificity, precision, and accuracy of the PCA-SVM, SPA-SVM, and 1D-CNN models for four- and five-class data sets, respectively.
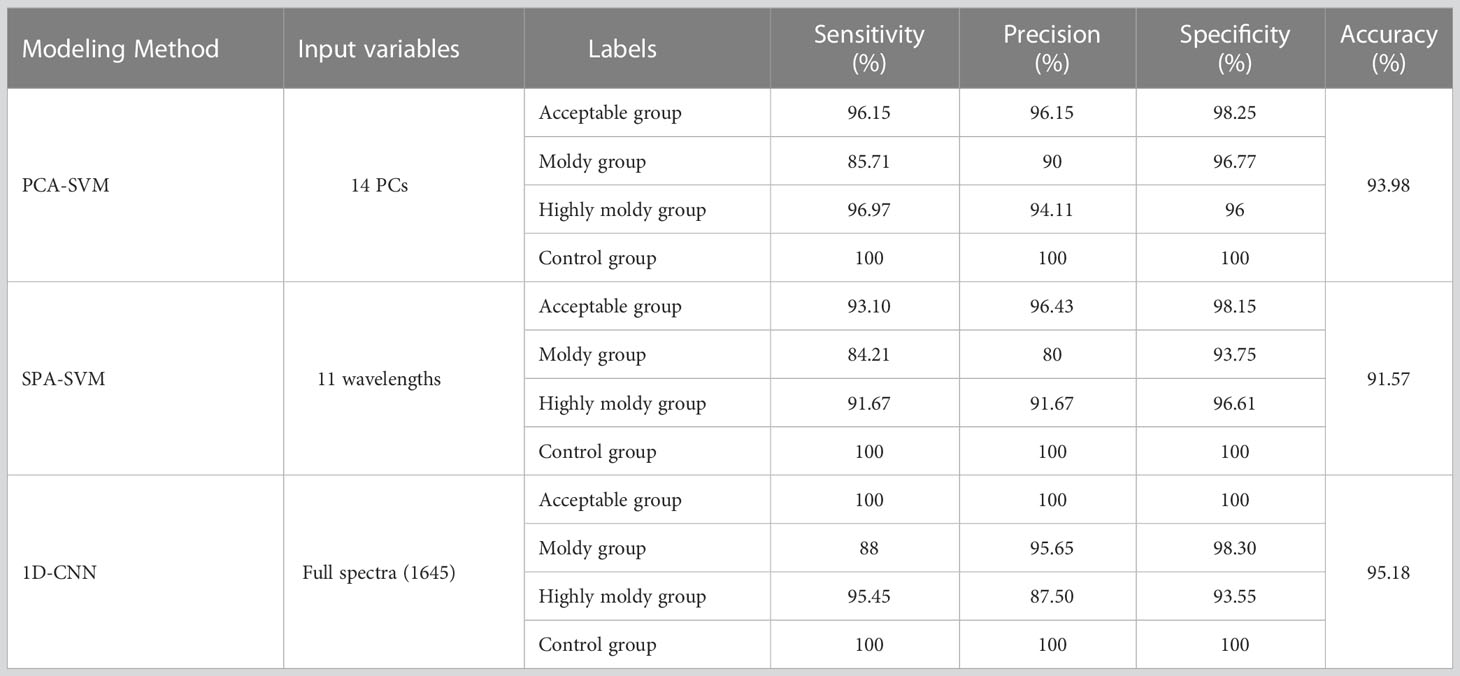
Table 4 Classification results for the four-class data set obtained by traditional and 1D-CNN models.
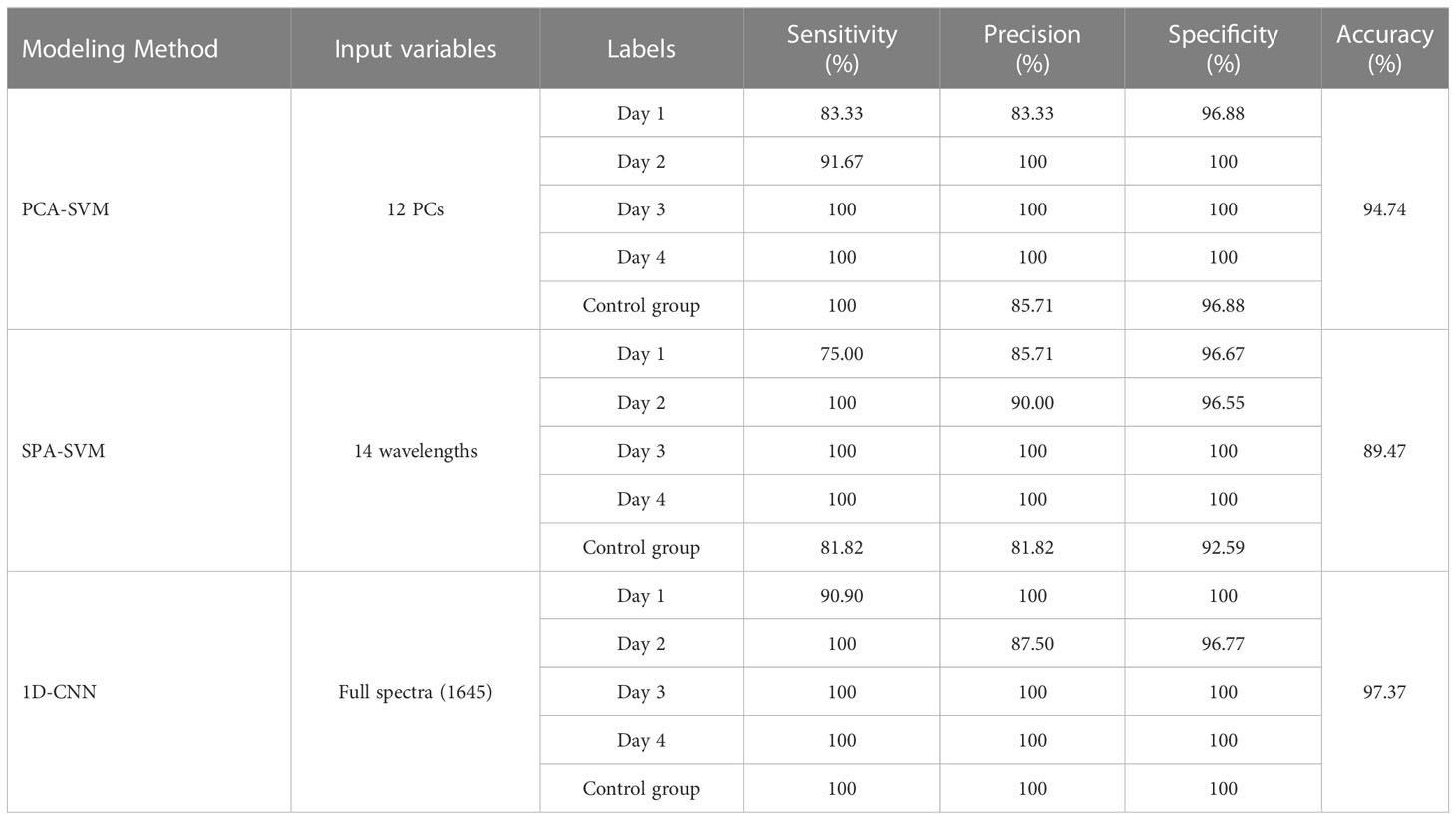
Table 5 Classification results for the five-class data set obtained by traditional and 1D-CNN models.
For the traditional models, the PCA-SVM models presented better performance than the SPA-SVM models, with an accuracy of 93.98% and 94.74% for the four- and five-class data sets, respectively. The PCs are comprehensive indices produced by linearly combining original spectral data (Su et al., 2021), eliminating correlations in the original data while preserving the variance in the raw data. While, SPA selects effective spectral variables directly from the 1645 variables. Eliminating a large number of variables may lead to the loss of some effective information. These may cause the prediction results of the SPA-SVM model to be slightly inferior.
From the results listed in Tables 4, 5, it can be seen that the 1D-CNN models achieved the best results, with the highest accuracies of 95.18% and 97.37% for four- and five-class identification, respectively. The sensitivity, specificity, and precision were also found to be optimal for the 1D-CNN models. These encouraging results suggest that 1D-CNN models combined with NIR spectra have great potential in identifying bananas infected with the fungi at different levels and time. Compared with traditional methods, the models obtained satisfactory classification results without requiring the manual extraction of feature parameters, and could automatically extract more hidden features in the spectra. As mentioned by Tian et al. (2022), the convolutional layers in the 1D-CNN are equivalent to the operations of data pre-processing and feature extraction used in traditional machine learning approaches. As these layers were tuned by back-propagation, the optimization algorithm of deep learning could extract the hidden features in the spectra more accurately and effectively.
Confusion matrixes for each 1D-CNN model were established, in order to further analyze the identification results (Figure 7). For the four-class model, the control and acceptable groups achieved better results, with 100% of individuals being well-classified. Thus, the stage of infection development can be precisely recognized, and separation between infected and uninfected fruit with great accuracy is possible. On the other hand, misidentification mainly occurred between the moldy and highly moldy groups. This may be caused by the slight differences in reflectance from the infected areas between these two groups, as black disease spots on the samples in these two groups were already obvious and the infected zone was rotten. These results are in agreement with the findings of Sun et al. (2018), who discriminated the degree of decay in peaches, based on the spectral range of 400–1000 nm.
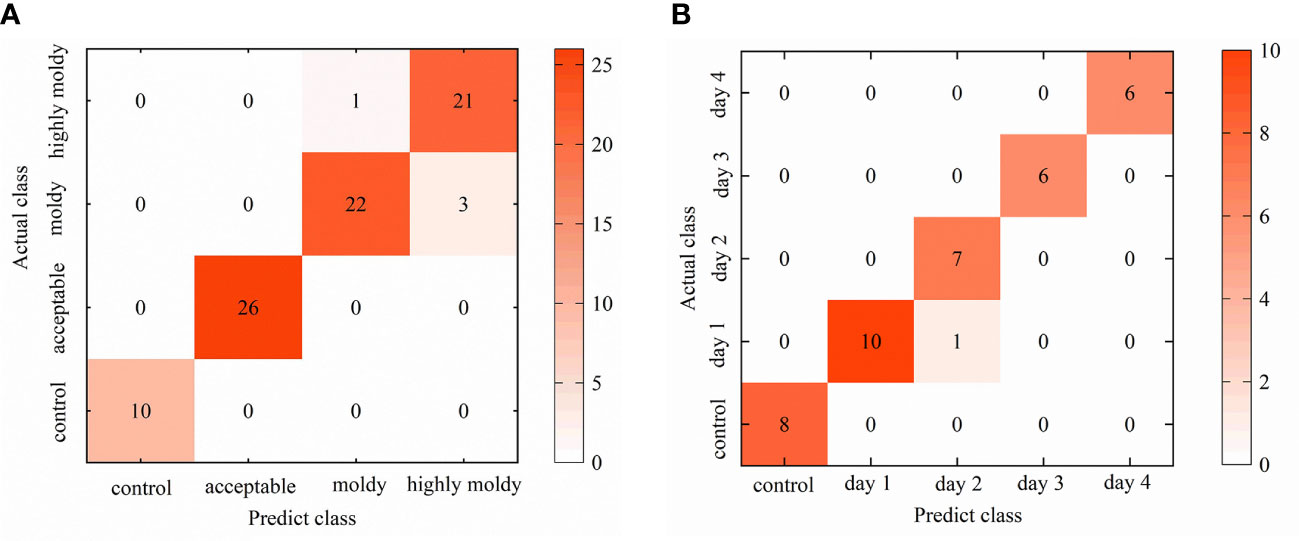
Figure 7 Visualized confusion matrix for: (A) Validation set of four-class 1D-CNN model; and (B) validation set of five-class 1D-CNN model.
The results for the five-class model confirmed that the days after inoculation could be separated with high accuracy using the 1D-CNN method. The 100% accuracy of the control group indicated that infected fruit could be accurately recognized after 24h. Some misclassification occurred when identifying days 1 and 2. To some extent, this is due to the fungi being in the lag phase withing the first few days, and the damage to banana tissue was not serious in this period. Consequently, the similarity of physical and chemical properties between samples in the first few days may lead to misclassification. These results were consistent with the findings of Siedliska et al. (2018), who identified the inoculation days of strawberries with BC fungi, and showed that the misclassification also more commonly occurred in the samples within the first few days. Sun et al. (2017) have discriminated peaches at different incubation time, and they also indicated that the very early diseased peaches (at 1 and 2 days) were in the same category. From the third day, the accuracy reached 100% as, over the first four days, symptoms gradually appeared with the ongoing infection, and the difference in the internal contents and exterior tissue surface gradually became obvious. The obvious spectral characteristics resulted in an accurate classification result.
4 Conclusions
This study tracked the growth and identified different infection stages of the C. musae in bananas using the Vis/NIR spectroscopy. Two types of discriminant models including 4-class and 5-class models were established using traditional methods, i.e combinations of three traditional feature extraction (SPA, CARS, and PC Loading) and two machine learning methods (PLSDA and SVM). A deep learning method of 1D-CNN was also used for comparison. The two models were used to examine the capability of NIR spectra in discriminating bananas infected at different levels (control, acceptable, moldy, and highly moldy), and different time at early stage (control and days 1-4), respectively. The models built by traditional methods had good performance with the detection accuracies in validation sets of 93.98% and 94.47% for 4- and 5-class models, respectively. The proposed 1D-CNN models can automatically extract the feature parameters and improved the detection accuracies, which were 95.18% and 97.37% for the 4- and 5-class discriminant models, respectively. These results demonstrated the feasibility of characterizing the process of C. musae infection in bananas using the Vis/NIR spectra. The resolution using Vis/NIR spectra in identifying bananas infected with C. musae can be accurate to 24 h. In addition, 11 and 14 effective wavelengths for the 4-class and 5-class models were selected using the traditional methods, which may serve as a simplified alternative for future practical implementation.
Additionally, it should be noted that this study preliminary analyzed the spectra change during the fungi infection process. To further characterize the infection mechanism of the fungi using the Vis/NIR, more physical and chemical changes, e.g. microstructure of tissue and chemical composition that are related to the changes of the spectral characteristics, will be analyzed combining with other methods such as physical and chemical examination, electron microscope scanning and fluorescence labeling in the near future.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
ZM, HF, and HL contributed to conception and design of the study. KZ, PM, and XC organized the database. XC, KZ, and HJ performed the statistical analysis. XC and HL wrote the first draft of the manuscript. ZM and HW provide the resources and supervised the experiment. All authors contributed to the article and approved the submitted version.
Funding
This research was funded by the National Natural Science Foundation of China (grant No. 32102087); Natural Science Foundation of Guangdong Province (grant No. 2020A151501795); Guangzhou basic and applied basic research project, (grant No. SL2023A04J0125) and Guangdong Provincial Agricultural Science and Technology Innovation and Extension Project (grant No. 2023A04J1667).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Alander, J. T., Bochko, V., Martinkauppi, B., Saranwong, S., Mantere, T. (2013). A review of optical nondestructive visual and near-infrared methods for food quality and safety. Int. J. Spectrosc 341402, 1–36. doi: 10.1155/2013/341402
Ali, M. M., Janius, R. B., Nawi, N. M., Hashim, N. (2018). Prediction of total soluble solids and pH in banana using near infrared spectroscopy. J. Eng. Sci. Technol. 13, 254.
Almaiah, M. A., Almomani, O., Alsaaidah, A., Al-Otaibi, S., Bani-Hani, N., Hwaitat, A. K. A., et al. (2022). Performance investigation of principal component analysis for intrusion detection system using different support vector machine kernels. Electronics 11 (21), 3571. doi: 10.3390/electronics11213571
Araújo, M. C. U., Saldanha, T. C. B., Galvao, R. K. H., Yoneyama, T., Chame, H. C., Visani, V. (2001). The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 57 (2), 65–73. doi: 10.1016/S0169-7439(01)00119-8
Ardila, C. E. C., Ramirez, L. A., Ortiz, F. A. P. (2020). Spectral analysis for the early detection of anthracnose in fruits of sugar mango (Mangifera indica). Comput. Electron. Agric. 173, 105357. doi: 10.1016/j.compag.2020.105357
Brosnan, T., Sun, D. W. (2004). Improving quality inspection of food products by computer vision–-a review. J. Food Eng. 61 (1), 3–16. doi: 10.1016/S0260-8774(03)00183-3
Cen, H., Bao, Y., He, Y., Sun, D. W. (2007). Visible and near infrared spectroscopy for rapid detection of citric and tartaric acids in orange juice. J. Food Eng. 82 (2), 253–260. doi: 10.1016/j.jfoodeng.2007.02.039
Cen, H., Lu, R., Mendoza, F., Beaudry, R. M. (2013). Relationship of the optical absorption and scattering properties with mechanical and structural properties of apple tissue. Postharvest Biol. Technol. 85, 30–38. doi: 10.1016/j.postharvbio.2013.04.014
Chai, Q., Zeng, J., Lin, D., Li, X., Huang, J., Wang, W. (2021). Improved 1D convolutional neural network adapted to near-infrared spectroscopy for rapid discrimination of anoectochilus roxburghii and its counterfeits. J. Pharm. Biomed. Anal. 199, 114035. doi: 10.1016/j.jpba.2021.114035
Chandrasekaran, I., Panigrahi, S. S., Ravikanth, L., Singh, C. B. (2019). Potential of near-infrared (NIR) spectroscopy and hyperspectral imaging for quality and safety assessment of fruits. Food Anal. Method. 12, 2438–2458. doi: 10.1007/s12161-019-01609
Chang, Y. T., Hsueh, M. C., Hung, S. P., Lu, J. M., Peng, J. H., Chen, S. F. (2021). Prediction of specialty coffee flavors based on near-infrared spectra using machine− and deep-learning methods. J. Sci. Food Agric. 101 (11), 4705–4714. doi: 10.1002/jsfa.11116
Chen, X., Chai, Q., Lin, N., Li, X., Wang, W. (2019). 1D convolutional neural network for the discrimination of aristolochic acids and their analogues based on near-infrared spectroscopy. Anal. Methods 11 (40), 5118–5125. doi: 10.1039/C9AY01531K
Cho, B. H., Koseki, S. (2021). Determination of banana quality indices during the ripening process at different temperatures using smartphone images and an artificial neural network. Sci. Hortic. 288, 110382. doi: 10.1016/j.scienta.2021.110382
Ciosek, P., Brzózka, Z., Wróblewski, W., Martinelli, E., Di Natale, C., D’amico, A. (2005). Direct and two-stage data analysis procedures based on PCA, PLS-DA and ANN for ISE-based electronic tongue–effect of supervised feature extraction. Talanta 67 (3), 590–596. doi: 10.1016/j.talanta.2005.03.006
Costabile, F., Barnaba, F., Angelini, F., Gobbi, G. P. (2013). Identification of key aerosol populations through their size and composition resolved spectral scattering and absorption. Atmos. Chem. Phys. 13 (5), 2455–2470. doi: 10.5194/acp-13-2455-2013
De Azevedo, R. A., de Morais, J. W., Lang, C., de Sales Dambros, C. (2019). Discrimination of termite species using near-infrared spectroscopy (NIRS). Eur. J. @ Soil Biol. 93, 103084. doi: 10.1016/j.ejsobi.2019.04.002
ElMasry, G., Wang, N., ElSayed, A., Ngadi, M. (2007). Hyperspectral imaging for nondestructive determination of some quality at-tributes for strawberry. J. Food Eng. 81 (1), 98–107. doi: 10.1016/j.jfoodeng.2006.10.016
Fazari, A., Pellicer-Valero, O. J., Gómez-Sanchıs, J., Bernardi, B., Cubero, S., Benalia, S., et al. (2021). Application of deep convolutional neural networks for the detection of anthracnose in olives using VIS/NIR hyperspectral images. Comput. Electron. Agric. 187, 106252. doi: 10.1016/j.compag.2021.106252
Ferreira, I. J., Almeida, S. L. D. O., Figueiredo Neto, A., Costa, D. D. S. (2022). Determination of quality and ripening stages of ‘pacovan’ bananas using vis-NIR spectroscopy and machine learning. Eng. Agric. 42 e20210160, v.42. doi: 10.1590/1809-4430-Eng.Agric.v42nepe20210160/2022
Galvao, R. K. H., Araujo, M. C. U., Fragoso, W. D., Silva, E. C., Jose, G. E., Soares, S. F. C., et al. (2008). Variable elimination method to improve the parsimony of MLR models using the successive projections algorithm. chemom. intell. Lab. Syst. 92 (1), 83–91. doi: 10.1016/j.chemolab.2007.12.004
Ghooshkhaneh, N. G., Golzarian, M. R., Mollazade, K. (2023). VIS-NIR spectroscopy for detection of citrus core rot caused by Alternaria alternata. Food Control. 144, 109320. doi: 10.1016/j.foodcont.2022.109320
Gu, X., Sun, Y., Tu, K., Pan, L. (2017). Evaluation of lipid oxidation of Chinese-style sausage during processing and storage based on electronic nose. Meat Sci. 133, 1–9. doi: 10.1016/j.meatsci.2017.05.017
Haff, R. P., Toyofuku, N. (2008). X-Ray detection of defects and contaminants in the food industry. Sens. Instrumen. Food Qual. 2, 262–273. doi: 10.1007/s11694-008-9059-8
He, X., Liu, L., Liu, C., Li, W., Sun, J., Li, H., et al. (2022). Discriminant analysis of maize haploid seeds using near-infrared hyperspectral imaging integrated with multivariate methods. Biosyst. Eng. 222, 142–155. doi: 10.1016/j.biosystemseng.2022.08.003
Huang, L., Meng, L., Zhu, N., Wu, D. (2017). A primary study on forecasting the days before decay of peach fruit using near-infrared spectroscopy and electronic nose techniques. Postharvest Biol. Biotechnol. 133, 104–112. doi: 10.1016/j.postharvbio.2017.07.014
Ivorra, E., Girón, J., Sánchez, A. J., Verdú, S., Barat, J. M., Grau, R. (2013). Detection of expired vacuum-packed smoked salmon based on PLS-DA method using hyperspectral images. J. Food Eng. 117 (3), 342–349. doi: 10.1016/j.jfoodeng.2013.02.022
Jiang, H., Jiang, X., Ru, Y., Chen, Q., Li, X., Xu, L., et al. (2022). Rapid and non-destructive detection of natural mildew degree of postharvest camellia oleifera fruit based on hyperspectral imaging. Infrared Phys. Technol. 123, 104169. doi: 10.1016/j.infrared.2022.104169
Jiang, Q., Wu, G., Tian, C., Li, N., Yang, H., Bai, Y., et al. (2021). Hyperspectral imaging for early identification of strawberry leaves diseases with machine learning and spectral fingerprint features. Infrared Phys. Technol. 118, 103898. doi: 10.1016/j.infrared.2021.103898
Khaliq, G., Abbas, H. T., Ali, I., Waseem, M. (2019). Aloe vera gel enriched with garlic essential oil effectively controls anthracnose disease and maintains postharvest quality of banana fruit during storage. Hortic. Environ. Biotechnol. 60 (5), 659–669. doi: 10.1007/s13580-019-00159-z
Kurosaki, K., Wu, R., Uesawa, Y. (2020). A toxicity prediction tool for potential agonist/antagonist activities in molecular initiating events based on chemical structures. Int. J. Mol. Sci. 21 (21), 7853. doi: 10.3390/ijms21217853
Li, F., Cai, C., Ma, H., Wang, S., Wang, Y. (2013). Nondestructive detection of apple mouldy core based on bioimpedance properties. Food Sci. 34 (18), 197–202. doi: 10.7506/spkx1002-6630-201318040
Li, X. P., Jiang, H. Z., Jiang, X. S., Shi, M. H. (2021). Identification of geographical origin of Chinese chestnuts using hyperspectral imaging with 1D-CNN algorithm. Agriculture 11 (12), 1274. doi: 10.3390/agriculture11121274
Li, X., Luo, L., He, Y., Xu, N. (2013a). Determination of dry matter content of tea by near and middle infrared spectroscopy coupled with wavelet-based data mining algorithms. Comput. Electron. Agric. 98, 46–53. doi: 10.1016/j.compag.2013.07.014
Li, T., Wu, Q., Zhu, H., Zhou, Y., Jiang, Y., Gao, H., et al. (2019). Comparative transcriptomic and metabolic analysis reveals the effect of melatonin on delaying anthracnose incidence upon postharvest banana fruit peel. BMC Plant Biol. 19 (1), 1–15. doi: 10.1186/s12870-019-1855-2
Li, J., Zhang, H., Zhan, B., Wang, Z., Jiang, Y. (2019a). Determination of SSC in pears by establishing the multi-cultivar models based on visible-NIR spectroscopy. Infrared Phys. Technol. 102, 103066. doi: 10.1016/j.infrared.2019.103066
Li, X., Zong, B., Guo, H., Luo, Z., He, P., Gong, S., et al. (2020). Discrimination of white teas produced from fresh leaves with different maturity by near-infrared spectroscopy. Spectrochim. Acta Part A. 227, 117697. doi: 10.1016/j.saa.2019.117697
Liu, Y., Pu, H., Sun, D. W. (2021). Efficient extraction of deep image features using convolutional neural network (CNN) for applications in detecting and analysing complex food matrices. Trends Food Sci. Technol. 113, 193–204. doi: 10.1016/j.tifs.2021.04.042
Liu, Q., Sun, K., Zhao, N., Yang, J., Zhang, Y. R., Ma, C., et al. (2019). Information fusion of hyperspectral imaging and electronic nose for evaluation of fungal contamination in strawberries during decay. Postharvest Biol. Technol. 153, 152–160. doi: 10.1016/j.postharvbio.2019.03.017
Liu, Z. Y., Wu, H. F., Huang, J. F. (2010). Application of neural networks to discriminate fungal infection levels in rice panicles using hyperspectral reflectance and principal components analysis. Comput. Electron. Agric. 72 (2), 99–106. doi: 10.1016/j.compag.2010.03.003
Liu, Q., Zhao, N., Zhou, D., Sun, Y., Sun, K., Pan, L., et al. (2018). Discrimination and growth tracking of fungi contamination in peaches using electronic nose. Food Chem. 262, 226–234. doi: 10.1016/j.foodchem.2018.04.100
Liu, Q., Zhou, D., Tu, S. Y., Xiao, H., Zhang, B., Sun, Y., et al. (2020). Quantitative visualization of fungal contamination in peach fruit using hyperspectral imaging. Food Anal. Methods 13 (6), 1262–1270. doi: 10.1007/s12161-020-01747-x
Lorente, D., Escandell-Montero, P., Cubero, S., Gómez-Sanchís, J., Blasco, J. (2015). Visible–NIR reflectance spectroscopy and manifold learning methods applied to the detection of fungal infections on citrus fruit. J. Food Eng. 163, 17–24. doi: 10.1016/j.jfoodeng.2015.04.010
Lu, J., Ehsani, R., Shi, Y., Abdulridha, J., Castro, A. I., Xu, Y. (2017). Field detection of anthracnose crown rot in strawberry using spectroscopy technology. Comput. Electron. Agric. 135, 289–299. doi: 10.1016/j.compag.2017.01.017
Magwaza, L. S., Opara, U. L., Nieuwoudt, H., Cronje, P. J., Saeys, W., Nicolaï, B. (2012). NIR spectroscopy applications for internal and external quality analysis of citrus fruit–a review. Food Bioprocess Tech. 5, 425–444. doi: 10.1007/s11947-011-0697
Mansuri, S. M., Chakraborty, S. K., Mahanti, N. K., Pandiselvam, R. (2022). Effect of germ orientation during vis-NIR hyperspectral imaging for the detection of fungal contamination in maize kernel using PLS-DA, ANN and 1D-CNN modelling. Food Control. 139, 109077. doi: 10.1016/j.foodcont.2022.109077
Maqbool, M., Ali, A., Ramachandran, S., Smith, D. R., Alderson, P. G. (2021). Control of postharvest anthracnose of banana using a new edible composite coating. Crop Prot. 29 (10), 1136–1141. doi: 10.1016/j.cropro.2010.06.005
Mendgen, K., Hahn, M. (2002). Plant infection and the establishment of fungal biotrophy. Trends Plant Sci. 7 (8), 352–356. doi: 10.1016/S1360-1385(02)02297-5
Min, M., Lee, W., Yong, H. K., Bucklin, R. A. (2006). Nondestructive detection of nitrogen in Chinese cabbage leaves using VIS–NIR spectroscopy. HortScience 41 (1), 5. doi: 10.21273/HORTSCI.41.1.162
Mogollón, M. R., Contreras, C., Freitas, S. T., Zoffoli, J. P. (2021). NIR spectral models for early detection of bitter pit in asymptomat-ic ‘Fuji’apples. Sci. Hortic. 280, 109945. doi: 10.1016/j.scienta.2021.109945
Moscetti, R., Haff, R. P., Saranwong, S., Monarca, D., Cecchini, M., Massantini, R. (2014). Nondestructive detection of insect infested chestnuts based on NIR spectroscopy. Postharvest Biol. Tec. 87, 88–94. doi: 10.1016/j.postharvbio.2013.08.010
Munera, S., Amigo, J. M., Aleixos, N., Talens, P., Cubero, S., Blasco, J. (2018). Potential of VIS-NIR hyperspectral imaging and chemometric methods to identify similar cultivars of nectarine. Food Control. 86, 1–10. doi: 10.1016/j.foodcont.2017.10.037
Najjar, K., Abu-Khalaf, N. (2021). Visible/near-infrared (VIS/NIR) spectroscopy technique to detect gray mold disease in the early stages of tomato fruit: VIS/NIR spectroscopy for detecting gray mold in tomato. J. Microbiol. Biotechnol. Food Sci. 11 (2), e3108. doi: 10.15414/jmbfs.3108
Nturambirwe, J. F. I., Hussein, E. A., Vaccari, M., Thron, C., Perold, W. J., Opara, U. L. (2023). Feature reduction for the classification of bruise damage to apple fruit using a contactless FT-NIR spectroscopy with machine learning. Foods 12 (1), 210. doi: 10.3390/foods12010210
Pardo, M., Sberveglieri, G. (2005). Classification of electronic nose data with support vector machines. Sens. Actuators B. 107 (2), 730–737. doi: 10.1016/j.snb.2004.12.005
Pearson, T. C., Wicklow, D. T. (2006). Detection of corn kernels infected by fungi. Trans. ASABE. 49 (4), 1235–1245. doi: 10.13031/2013.21723
Pu, Y. Y., Zhao, M., O’Donnell, C., Sun, D. W. (2018). Nondestructive quality evaluation of banana slices during microwave vacuum drying using spectral and imaging techniques. Drying Technol. 36 (13), 1542–1553. doi: 10.1080/07373937.2017.1415929
Rong, D., Wang, H., Ying, Y., Zhang, Z., Zhang, Y. (2020). Peach variety detection using VIS-NIR spectroscopy and deep learning. Comput. Electron. Agric. 175, 105553. doi: 10.1016/j.compag.2020.105553
Ropodi, A. I., Panagou, E. Z., Nychas, G. J. (2016). Data mining derived from food analyses using non-invasive/non-destructive ana-lytical techniques; determination of food authenticity, quality & safety in tandem with computer science disciplines. Trends Food Sci. Technol. 50, 11–25. doi: 10.1016/j.tifs.2016.01.011
Shah, S. S. A., Zeb, A., Qureshi, W. S., Arslan, M., Malik, A. U., Alasmary, W., et al. (2020). Towards fruit maturity estimation using NIR spectroscopy. Infrared Phys. Technol. 111, 103479. doi: 10.1016/j.infrared.2020.103479
Shen, Z., Viscarra Rossel, R. V. A. (2021). Automated spectroscopic modelling with optimized convolutional neural networks. Sci. Rep., 11(1), 1–2. doi: 10.1038/s41598-020-80486-9
Shen, F., Wu, Q., Liu, P., Jiang, X., Fang, Y., Cao, C. (2018). Detection of aspergillus spp. contamination levels in peanuts by near infra-red spectroscopy and electronic nose. Food Control 93, 1–8. doi: 10.1016/j.foodcont.2018.05.039
Siedliska, A., Baranowski, P., Zubik, M., Mazurek, W., Sosnowska, B. (2018). Detection of fungal infections in strawberry fruit by VNIR/SWIR hyperspectral imaging. Postharvest Biol. Technol. 139, 115–126. doi: 10.1016/j.postharvbio.2018.01.018
Sripaurya, T., Sengchuai, K., Booranawong, A., Chetpattananondh, K. (2021). Gros Michel banana soluble solids content evaluation and maturity classification using a developed portable 6 channel NIR device measurement. Measurement 173, 108615. doi: 10.1016/j.measurement.2020.108615
Su, N., Pan, F., Wang, L., Weng, S. (2021). Rapid detection of fatty acids in edible oils using vis-NIR reflectance spectroscopy with multivariate methods. Biosensors 11 (8), 261. doi: 10.3390/bios11080261
Sun, Y., Lu, R., Wang, X. (2020). Evaluation of fungal infection in peaches based on optical and microstructural properties. Postharvest Biol. Technol. 165, 111181. doi: 10.1016/j.postharvbio.2020.111181
Sun, Y., Wang, Y. H., Xiao, H., Gu, X. Z., Pan, L. Q., Tu, K. (2017). Hyperspectral imaging detection of decayed honey peaches based on their chlorophyll content. Food Chem. 235, 194–202. doi: 10.1016/j.foodchem.2017.05.064
Sun, Y., Xiao, H., Tu, S., Sun, K., Pan, L., Tu, K. (2018). Detecting decayed peach using a rotating hyperspectral imaging testbed. LWT 87, 326–332. doi: 10.1016/j.lwt.2017.08.086
Sun, Y., Ye, Z., Zhong, M., Wei, K., Shen, F., Li, G., et al. (2023). Rapid and nondestructive method for identification of molds growth time in wheat grains based on hyperspectral imaging technology and chemometrics. Infrared Phys. Technol. 128, 104532. doi: 10.1016/j.infrared.2022.104532
Thangavelu, R., Sundararaju, P., Sathiamoorthy, S. (2004). Management of anthracnose disease of banana caused by Colletotrichum musae using plant extracts. J. Hortic. Sci. Biotechnol. 79 (4), 664–668. doi: 10.1080/14620316.2004.11511823
Tian, X., Fan, S., Li, J., Xia, Y., Huang, W., Zhao, C. (2019). Comparison and optimization of models for SSC on-line determination of intact apple using efficient spectrum optimization and variable selection algorithm. Infrared Phys. Technol. 102, 102979. doi: 10.1016/j.infrared.2019.102979
Tian, S., Wang, S., Xu, R. (2022). Early detection of freezing damage in oranges by online Vis/NIR transmission coupled with diameter correction method and deep 1D-CNN. Comput. Electron. Agric. 193, 106638. doi: 10.1016/j.compag.2021.106638
Vilaplana, R., Pazmiño, L., Valencia-Chamorro, S. (2018). Control of anthracnose, caused by Colletotrichum musae, on postharvest organic banana by thyme oil. Postharvest Biol. Technol. 138, 56–63. doi: 10.1016/j.postharvbio.2017.12.008
Vitalis, F., Tjandra Nugraha, D., Aouadi, B., Aguinaga Bósquez, J. P., Bodor, Z., Zaukuu, J. L. Z., et al. (2021). Detection of monil-ia contamination in plum and plum juice with NIR spectroscopy and electronic tongue. Chemosensors 9 (12), 355. doi: 10.3390/chemosensors9120355
Wang, L., Wang, R. (2022). Determination of soil pH from vis-NIR spectroscopy by extreme learning machine and variable selection: a case study in lime concretion black soil. Spectrochim. Acta Part A. 283, 121707. doi: 10.1016/j.saa.2022.121707
Wu, N., Liu, J. A., Zhou, G. Y., Yan, R. K., Zhang, L. (2012). Prediction of chlorophyll content of leaves of oil camelliae after being infected with anthracnose based on vis/NIR spectroscopy. spectrosc. Spectral Anal. 32 (5), 1221–1224. doi: 10.3964/j.issn.1000-0593(2012)05-1221-04
Xing, J., Symons, S., Shahin, M., Hatcher, D. (2010). Detection of sprout damage in Canada Western red spring wheat with multiple wavebands using visible/near-infrared hyperspectral imaging. Biosyst. Eng. 106 (2), 188–194. doi: 10.1016/j.biosystemseng.2010.03.010
Yang, Q., Tian, S., Xu, H. (2022). Identification of the geographic origin of peaches by VIS-NIR spectroscopy, fluorescence spectroscopy and image processing technology. J. Food Compos. Anal. 114, 104843. doi: 10.1016/j.jfca.2022.104843
Yao, H., Hruska, Z., Kincaid, R., Brown, R. L., Cleveland, T. E. (2008). Differentiation of toxigenic fungi using hyperspectral imagery. Sens. Instrumen. Food Qual. 2, 215–224. doi: 10.1007/s11694-008-9055-z
Yeh, Y. H., Chung, W. C., Liao, J. Y., Chung, C. L., Kuo, Y. F., Lin, T. T. (2016). Strawberry foliar anthracnose assessment by hyperspectral imaging. Comput. Electron Agr. 122, 1–9. doi: 10.1016/j.compag.2016.01.012
Zhang, Q., Huang, W., Wang, Q., Wu, J., Li, J. (2022). Detection of pears with moldy core using online full-transmittance spectroscopy combined with supervised classifier comparison and variable optimization. Comput. Electron. Agric. 200, 107231. doi: 10.1016/j.compag.2022.107231
Zhang, Z., Pu, Y., Wei, Z., Liu, H., Zhang, D., Zhang, B., et al. (2022a). Combination of interactance and transmittance modes of Vis/NIR spectroscopy improved the performance of PLS-DA model for moldy apple core. Infrared Phys. Technol. 126, 104366. doi: 10.1016/j.infrared.2022.104366
Zhang, X., Sun, J. L., Li, P. P., Zeng, F. Y., Wang, H. H. (2021). Hyperspectral detection of salted sea cucumber adulteration using different spectral preprocessing techniques and SVM method. LWT 152, 112295. doi: 10.1016/j.lwt.2021.112295
Keywords: Vis/NIR spectra, banana fruit, Colletotrichum musae infection, fungi contamination detection, traditional classification methods, deep learning algorithms
Citation: Chu X, Zhang K, Wei H, Ma Z, Fu H, Miao P, Jiang H and Liu H (2023) A Vis/NIR spectra-based approach for identifying bananas infected with Colletotrichum musae. Front. Plant Sci. 14:1180203. doi: 10.3389/fpls.2023.1180203
Received: 05 March 2023; Accepted: 09 May 2023;
Published: 02 June 2023.
Edited by:
Edvaldo Da Silva, São Paulo State University, BrazilCopyright © 2023 Chu, Zhang, Wei, Ma, Fu, Miao, Jiang and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hongli Liu, bGl1aG9uZ2xpQHpoa3UuZWR1LmNu