 Brayan Alexander Fonseca Martinez1
Brayan Alexander Fonseca Martinez1 Vanessa Bielefeldt Leotti2
Vanessa Bielefeldt Leotti2 Gustavo de Sousa e Silva1
Gustavo de Sousa e Silva1 Luciana Neves Nunes2
Luciana Neves Nunes2 Gustavo Machado1†
Gustavo Machado1† Luís Gustavo Corbellini1*
Luís Gustavo Corbellini1*
- 1Laboratory of Veterinary Epidemiology, Faculty of Veterinary, Department of Preventive Veterinary Medicine, Universidade Federal do Rio Grande do Sul (UFRGS), Porto Alegre, Brazil
- 2Faculty of Medicine, Department of Statistics, Institute of Mathematics and Statistics and Post-Graduate Program of Epidemiology, Universidade Federal do Rio Grande do Sul, Porto Alegre, Brazil
One of the most commonly observational study designs employed in veterinary is the cross-sectional study with binary outcomes. To measure an association with exposure, the use of prevalence ratios (PR) or odds ratios (OR) are possible. In human epidemiology, much has been discussed about the use of the OR exclusively for case–control studies and some authors reported that there is no good justification for fitting logistic regression when the prevalence of the disease is high, in which OR overestimate the PR. Nonetheless, interpretation of OR is difficult since confusing between risk and odds can lead to incorrect quantitative interpretation of data such as “the risk is X times greater,” commonly reported in studies that use OR. The aims of this study were (1) to review articles with cross-sectional designs to assess the statistical method used and the appropriateness of the interpretation of the estimated measure of association and (2) to illustrate the use of alternative statistical methods that estimate PR directly. An overview of statistical methods and its interpretation using the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines was conducted and included a diverse set of peer-reviewed journals among the veterinary science field using PubMed as the search engine. From each article, the statistical method used and the appropriateness of the interpretation of the estimated measure of association were registered. Additionally, four alternative models for logistic regression that estimate directly PR were tested using our own dataset from a cross-sectional study on bovine viral diarrhea virus. The initial search strategy found 62 articles, in which 6 articles were excluded and therefore 56 studies were used for the overall analysis. The review showed that independent of the level of prevalence reported, 96% of articles employed logistic regression, thus estimating the OR. Results of the multivariate models indicated that logistic regression was the method that most overestimated the PR. The findings of this study indicate that although there are methods that directly estimate PR, many studies in veterinary science do not use these methods and misinterpret the OR estimated by the logistic regression.
Introduction
Cross-sectional studies are one of the most frequently designed observational studies in veterinary epidemiology (1), likely because they are rapid, inexpensive and of moderate difficulty. This type of design has been widely used in veterinary medicine to address a variety of research inquiries. Establishing a causal relationship between an exposure and outcome is not possible in these studies given that both are measured simultaneously, and therefore, to speak of risk is inadequate, since risk is the probability of an outcome in a population or the probability that a specific outcome or disease will develop during a specific period of time (2, 3). In this design, where binary outcomes (e.g., disease/not disease, positive/negative) are frequent, the odds ratio (OR) or prevalence ratio (PR) can be used as measures of association. However, some authors suggest the use of the PR because its interpretation is easier than the interpretation of the OR (4, 5).
In human epidemiology much has been discussed about the use of the OR exclusively for case–control studies and some authors encourage the use of PR for cross-sectional designs because the precise interpretation of the OR is difficult and often mistakenly interpreted as PR (4). Despite being mathematically identical to relative risk (RR), PR can only be used in cross-sectional studies and not in clinical trials or cohorts since the former measures prevalence instead of risk (6). It is noteworthy that leading journals in human health fields such as New England Journal of Medicine and the American Journal of Epidemiology have officially discouraged the use of the OR for any study in which other measures of association are ascertainable. Spiegelman and Hertzmark stated that “There is no longer any good justification for fitting logistic regression models and estimating odds ratios when the odds ratio is not a good approximation of the risk or prevalence ratio” (7).
The OR can be interpreted as the PR for rare outcomes, as they will be similar (8). Some authors even indicate that the OR is a good approximation of the PR and can be interpreted as such only when the outcome is rare along the two strata of exposure (9). When the binary outcome is common, usually with a prevalence greater than 10%, the PR can be overestimated by the OR when the PR is greater than 1 or underestimated when the PR is less than 1 (8, 10–14). Additionally, it has been reported that interpreting the OR as if it was a PR is inadequate not only in terms of the possible bias but also because confounding may not be appropriately controlled (14). Phrases including words such as “risk,” “more likely,” “likelihood,” or “probability” to interpret the OR are commonly found in the literature. These phrases are a risk-language, not odds-language, and it is important not to use them when the odds is the measure of disease frequency (8, 15, 16). It was stated that language like “X times as likely to” implies comparison of probabilities, not odds (17). Additionally, incorrect quantitative interpretation of data by confusing risk and odds, such as “OR = X, therefore the risk is X times greater” was reported (18).
One reason for the popularity of the OR is that it is directly estimated by the logistic regression, one of the statistical methods widely employed in the epidemiological literature (14, 19). Nevertheless, other alternatives methods to logistic regression that can estimate directly PR have been reported. One option is the log-binomial model, which is a generalized linear model with a binomial distribution and logarithmic link function (12, 14, 20, 21). Other options proposed are Poisson regression and Poisson regression with robust variance (11, 14). Poisson regression can estimate wide confidence intervals, and for that reason, a robust Poisson regression has been proposed (14, 22). Both models can eventually estimate probabilities greater than one, which is unrealistic (11). Problems of convergence have been described with log-binomial regression, especially when there are continuous independent variables. In this case, Poisson regression with robust variance should be used (7, 23, 24). The Bayesian approach for the log-binomial model has been proposed as an alternative when the frequentist log-binomial model presents convergence problems (25). Additionally, the Bayesian approach has been described as an interesting alternative when the outcome is polytomous or the data are correlated (i.e., has an hierarchical structure), which is common in veterinary medicine (9).
Although the issues exposed above have been widely discussed and identified primary in the human epidemiology literature, it is interesting to know if many observational studies in veterinary medicine are still using logistic regression and its OR estimation to interpret the PR even when there are statistical packages models that estimate PR directly. To our knowledge, few authors in veterinary science have explored and exemplified the issue concerning the interpretation of the OR in randomized trials and cohort studies (15, 26, 27).
Consistency is important for epidemiological studies, and thus it is necessary to establish consensus standards for analyzing and reporting results (28, 29) and also for the methods used as extensively discussed in medical literature (14, 21, 30). For this, examining epidemiological studies within the scope of the veterinary literature and discussing statistical methods to analyze data and its interpretation is needed. Therefore, the aims of this study were as follows: (1) to review articles that used cross-sectional studies among a range of peer-reviewed journals in veterinary science to assess both the statistical method employed and the appropriateness of the interpretation of the measure of association; (2) to illustrate the use of statistical methods that directly estimate the PR (log-binomial, Poisson, Poisson regression with robust variance and Bayesian approach for the log-binomial regression) using the results of a cross-sectional study carried out by our research group. Our hypothesis is that most of cross-sectional studies in veterinary would fit logistic regression models to estimate OR despite the prevalence of the disease and that incorrect interpretation of the association using risk-language would be reported. Therefore, this study intends to raise a discussion about alternatives models for estimating PR and the interpretation of the estimates.
Materials and Methods
Review Strategy
Search Strategy, Selection Criteria and Appraisal
An overview of statistical methods and its interpretation using the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (31), of the available literature was conducted using PubMed as the search engine and included articles that used a cross-sectional study design from January 1, 2013, to July 1, 2016. The expression “overview” is based on the definition of review types previously reported (32); here, we made a not exhaustive (i.e., not including all the journals) and comprehensive searching, in which an eligibility criteria was set, and analysis comprised the tabulation of the specifics information searched, as explained later in this section.
This review deemed a diverse set of peer-reviewed journals among the veterinary science field presented on the SCImago Journal Rank (SJR). Ten journals were selected based on whether their scope considers aspects such as methods and approaches in veterinary epidemiology, veterinary public health, prevention and management of infectious animal diseases (Table 1). Our hypothesis was that if we found that many articles in these Journals reported data analysis from cross-sectional studies using logistic regression and misinterpreted odds ratio as “risk,” the frequency of these findings would be equal or even worst compared to other Journals with lower impact factors.
Table 1. Peer-reviewed journals within the veterinary science field presented based on the SCImago Journal Rank (SJR).
Search syntax was designed using Boolean operators (AND, OR, and NOT), the name of the journal, keywords and year of publication for selecting items of specific interest. The search strategy identified only articles published in English language literature and those whose epidemiological design were cross sectional. It was decided a priori to exclude letters to editor, comments, and review articles. When we sought articles by only the abstract and keywords (described in the syntax for “Word Text”), the research was limited because a specific issue could not be written in the abstract and keywords. For that reason, “MeSH terms” were also used as it had the functionality of selecting articles sorted by terms. MeSH is a set of terms naming descriptors in a hierarchical structure that enables the search at various levels of specificity. The syntax used in the search strategy is available in the S1 Syntax in Supplementary Material. The process of screening and inclusion of the studies were made according to the PRISMA flow diagram.
From each article found using the search strategy, information about the prevalence of the disease, measure of association and statistical method employed was recorded. Two authors (Brayan Alexander Fonseca Martinez and Gustavo de Sousa e Silva) independently assessed the appropriateness of the methods according to the following criteria: (1) the interpretation of the measure of association estimated by the statistical method employed and (2) the statistical method used accordingly with the prevalence level.
Reviewers (Brayan Alexander Fonseca Martinez and Gustavo de Sousa e Silva) were advised to classify the interpretation of the OR and PR as inappropriate when it was interpreted using risk-language and was assumed as appropriate when it was interpreted as the ratio between odds for the OR or prevalence for the PR. The cut off for prevalence values was set at 10%. In the situation where the prevalence is greater than 10%, the OR estimated in logistic regression can overestimate the PR, as explained previously (8, 10, 11, 13, 14, 16). Therefore, models other than logistic regression are considered more appropriate. On the other hand, when the prevalence is less than 10%, the OR estimates will be closer to PR estimates. The full-length articles were reviewed in detail if the information needed was not adequate or clear in the abstracts.
Following the review, disagreements between the reviewers about the interpretations were solved by the evaluation of a biostatistician (Vanessa Bielefeldt Leotti) and a veterinarian epidemiologist (Luís Gustavo Corbellini). Inter-observer agreement between the reviewers about the number of articles with inconsistent interpretations of the measure of association estimated was quantified using the kappa statistic (33). This was calculated using an Excel (Microsoft Excel 2010) spreadsheet.
Illustration of Models That Directly Estimate Prevalence Ratio in a Cross-sectional Study
Description of the Dataset Used
The dataset used to exemplify methods that directly estimate the PR comes from a cross-sectional study performed to estimate the herd prevalence of antibodies against bovine viral diarrhea virus (BVDV) in bulk tank milk in southern Brazil (available in the S2 Dataset in Supplementary Material). Samples were randomly selected from a population of 81,307 dairy herds in the state of Rio Grande do Sul, Brazil, wherein 388 herds were collected. More details about the sample design and BTM collection can be found elsewhere (34). A questionnaire was designed to gather information about the potential factors associated with BVDV transmission and/or its maintenance within a herd. It was applied during visits to the 388 selected herds in November 2013.
Multivariable Model
A robust Poisson multivariable model was built with the variables screened in the univariable analysis using data from a previously published study (33). The variables identified as significantly associated with BVDV (p < 0.05) in the main multivariable model were also used in four other models: log-binomial regression, logistic regression, Poisson regression, and Bayesian approach for log-binomial regression.
Denoting Yi as the dichotomous outcome indicating the BVDV serostatus of the i-th farm (1 for positive samples and 0 otherwise), and assuming that this outcome follows a binomial distribution, the model formulation to log-binomial regression is written as follows:
where πi is the probability of the i-th farm being seropositive for BVDV, conditional on the independent variables X1, …, Xk. β0 is the intercept and β1, …, βk are the coefficients for each independent variable. The model using Poisson regression is formulated as follows:
where λi is the mean of the i-th farm (in this case, the mean approximates the probability of being seropositive for BVDV) conditional on the independent variables X1, …, Xk. γ0 is the intercept and γ1, …, γk are the coefficients for each independent variable. Finally, the logistic regression is written as:
where πI is the probability of the i-th farm being seropositive for BVDV, conditional on the independent variables X1, …, Xk. δ0 is the intercept and δ1, …, δk are the coefficients for each independent variable.
All models were fitted to this dataset using SAS version 9.3 (SAS Institute, Cary, NC, USA) with PROC GENMOD, except for the Bayesian approach for the log-binomial regression (available in S3 Codes in Supplementary Material). The link function for logistic regression was logit and was log for Poisson regression and log-binomial regression. To specify the use of the robust variance estimator for the robust Poisson regression, the REPEATED statement was used (7). Both logistic and log-binomial regressions have the same binomial distribution for the outcome, while Poisson regression assumes Poisson distribution for the outcome. Predicted probabilities were obtained for each farm in the dataset using the PRED statement to check probabilities greater than one for the Poisson regression methods. The exponential of each regression coefficient and its confidence intervals were used as point and interval estimates for the OR for logistic regression and PR for the other models.
The Bayesian approach for the log-binomial model, with posterior distributions estimated by employing the Markov Chain Monte Carlo (MCMC) method, was performed using OpenBugs 3.2.2 (35) together with the R statistical environment [R Development Core Team (36)] and BRugs package (35) (available in S3 Codes in Supplementary Material). The CODA package (37) was used for summarizing and plotting the output from MCMC simulations. The prior distributions assigned to the model coefficients were normal with zero mean and variance 106 with the addition of a restriction to prevent simulation of probabilities outside the interval [0,1] (25). To choose the number of interactions, burn-in period and thin for MCMC, graphical analysis and Gelman and Rubin statistic were used (38). The model was run with 50,000 iterations with the first 5,000 discarded as burn-in using three sample chains. The mode and the equal tails credible interval were used as Bayesian point and interval estimators, respectively.
For all methods, point estimates and 95% confidence/credible interval estimates were shown. For comparisons purposes between methods, the ranges of the confidence/credible intervals and the relative changes in point estimates were calculated (Δ%). For the point estimates, log-binomial regression was used as reference and the relative change with the other methods employed was calculated as follows:
The point estimate in log-binomial regression was chosen as reference value to compare the estimates produced by the other methods since some studies using simulated and observed data concluded that its estimates are more precise and accurate, and therefore, it would be the method of choice between the frequentist alternatives (12, 23, 24, 39).
Results
Literature Review
The initial search strategy found 62 articles. Upon review of these abstracts, 6 articles were excluded for reasons outlined in Figure 1, and therefore 56 studies were used for the overall analysis (all articles reviewed are described in detail in the Table S1 in Supplementary Material; PRISMA Flow Diagram used is shown in Figure S1 in Supplementary Material). Once the biostatistician and the veterinarian epidemiologist resolved differences about interpretation and the statistical methods used in the studies, the review showed that 83.9% of the studies (47/56) reported prevalence values greater than 10% in the level of the outcome modeled (i.e., animal or herd level). Irrespective of the prevalence reported in the articles, logistic regression was described as the method for modeling the binary outcome in 96.4% (54/56) of the articles and only two described other methods, specifically robust Poisson regressions (Figure 1).
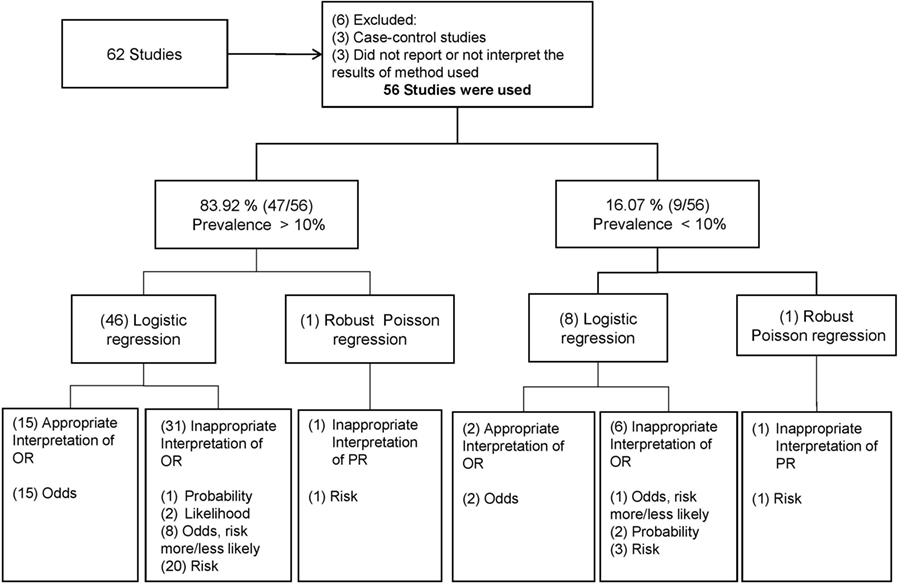
Figure 1. Results of the overview of reported statistical methods and their interpretations. The distribution of the number of articles by statistical methods and specific words used to interpret their estimates are within the brackets. The interpretation of the odds ratio (OR) and prevalence ratio (PR) was assumed as inappropriate when it was interpreted using words as “risk,” “(more/less) likely,” “probability,” or “likelihood” of the event and was assumed as appropriate when it was interpreted as the ratio between odds for the OR or prevalence for the PR.
Regarding the interpretation of the measure of association, from the 47 articles with prevalence values greater than 10%, 15 of them made an appropriate interpretation of the OR as a ratio of odds or simply did not give a direct interpretation of the OR (Figure 1). Thirty-one articles reported the OR inappropriately using expression such as “risk” (n = 20), “likelihood” (n = 2), “probability” (n = 1), and “Odds and more/less likely” (n = 8). One article, despite reporting the PR estimated by a robust Poisson regression, presented an inappropriate interpretation of the PR as “risk.” Among the nine articles with prevalence values smaller than 10%, only two correctly interpreted the OR as a ratio of odds. Inappropriateness was found in six articles, since three interpreted the OR as “risk,” two reported the term “probability,” and one reported “Odds and more/less likely” interchangeable. One article, despite having estimated the PR, was interpreted inappropriately (Figure 1).
The two authors who reviewed the studies agreed on the appropriateness of the interpretation of the OR in 18 studies and agreed that 26 studies inappropriately interpreted the measure estimate based on the method used. The interobserved agreement, as measured by kappa statistics, was 0.6, showing a moderate agreement (33). Most of disagreement occurred in articles that reported terms such as “more/less likely.”
Results from the Data Set Used as Example
The estimated prevalence of BVDV in the dataset used was 24% (CI 95%: 19.8–28.1). The final multiple robust Poisson regression identified three variables significantly associated with BVDV seropositivity (p < 0.05, Table 2). The results of the analyses using logistic, log-binomial, Poisson, and Bayesian log-binomial methods are also shown in Table 2. Regarding the relative changes observed between the methods used against the log-binomial regression, it can be observed that the point estimates in the logistic regression presented the largest differences ranging from 25.7 to 69.9%, whereas Poisson and Poisson regression with robust variance, which yielded the same point estimate as expected, had a difference ranging from 1.4 to 16.2%. The Bayesian approach for log-binomial regression had the lowest difference, ranging from 3.5 to 6.8%. For all the methods, logistic regression had wider intervals ranging from 2.19 to 4.97 (Table 2).
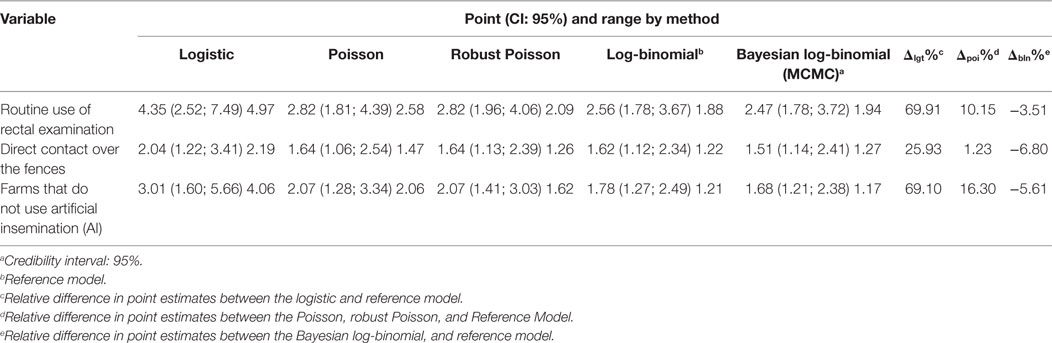
Table 2. Results for the three variables associated with the presence of antibodies against bovine viral diarrhea virus (BVDV) using different statistical methods.
As expected, the range of the intervals of the robust Poisson regression was less than those calculated by the Poisson regression. Except by the variable “farms that do not use artificial insemination,” the log-binomial regression had the narrowest intervals out of all the methods. In terms of statistical decision, no differences were found because the confidence intervals did not include the value 1; all variables were significantly associated with BVDV.
Discussion
This study has several pertinent strengths and limitations. To our knowledge, this is the first study that assessed and reinforced the importance of the interpretation given to the measure of association estimated and the suitability of the statistical method used in cross-sectional studies published within the veterinary medicine. One limitation of this study is that the journals selected represent only a portion of the existing literature for a determined period. Therefore, these findings represent only the selected journals during a specific time-period and should not be extended to the whole universe of journals. The hypothesis was that if in the more recent publications from the selected journals that we assumed to publish articles within the scope of veterinary epidemiology we found mistakes of interpretation and the use of logistic regression in highly prevalent diseases, these results would be similar or even worst for older publications or in others Journals.
From the review performed in this study, only 3.5% (2/56) of the articles used some statistical method to directly estimate the measure of association indicated in cross-sectional studies, i.e., the PR, and all of them misinterpreted this measure of association. Moreover, the remaining 96.5% of the articles reported using a logistic regression to estimate the measure of association between the exposure and the binary outcome. This proportion contrasts with a similar search carried out online in 2003 that included highly reputable international journals of human epidemiology, in which logistic regression was used in 37 (34%) of the 110 cross-sectional studies (14). This vast majority of studies using logistic regression could lead to problems related to the interpretation given to the OR, and the overestimation/underestimation of the measure of association.
It is not inherently incorrect to report the OR in cross-sectional studies and its use does not incur in any problems if the authors interpret the OR as the ratio between odds or for rare diseases (14, 40). However, the majority of the articles (n = 37) reviewed interpreted the OR using sentences such as “Animals located on farm A have two times higher probability or risk of illness than other farm animals.” Sentences such as this are incorrect in cross-sectional studies for two reasons: the odds is not a ratio of probabilities or risks, and the cross-sectional design cannot evaluate risk, as the outcome and exposure are measured simultaneously. Perhaps the concepts of risk or likelihood are easier to understand than odds and for that reason it is common that the terms OR and RR/PR are treated interchangeably. Therefore, there is no guarantee that readers interpret the OR in the right way. This complexity with the interpretation of the OR was also evidenced by the moderate agreement between two authors about the appropriateness of the interpretation given to the OR, since they were instructed to report as inappropriate when they observe “risk-language,” which in fact have many expression such as “risk,” “likely,” “likelihood,” or “probability.” We attribute these differences to the use of confusing phrases such as “more/less likely” and “likely” to describe the OR. In fact, some authors have noted that the OR is difficult to understand and unintuitive (4, 41–43).
For example, a reasonable interpretation of the PR obtained for the variable “Direct contact over the fences” provided by the log-binomial regression in our example would be “Farms in which bovines have contact over fences with bovines from other farms had a prevalence of BVDV that was 0.62 times greater than farms in which bovines have no contact over fences with animals from other farms.” On the other hand, a good interpretation of the OR estimated by logistic regression for the same variable would be “Farms in which bovines have contact over fences with bovines from other farms had 1.04 times greater odds for BVDV than farms in which bovines have no contact over fences with animals from other farms.”
To overcome this problem of misinterpretation, it would be necessary and suitable to establish a pattern to prevent readers from making incorrect interpretations. In human health and veterinary research, Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) and STROBE-Vet guidelines were developed to create homogeneity in the report of observational study results (29, 44). Authors are encouraged to use them to report observational study results. In this context, it would be important to alert researchers about the meaning of OR and PR and their interpretation avoiding to report estimates of cross-sectional studies using risk or probability-language.
The second problem is related to the overestimation or underestimation of the true association between exposure and outcome, as was observed in the example used in this study. In our review, from the 47 articles that reported a prevalence greater than 10%, 31 (66%) estimated OR and miss-interpreted them as risk language, consequently overestimating or underestimating the PR. On the other hand, in six articles wherein the OR was estimated, it could be approximated to the PR since the prevalence was lower than 10% (45).
Regarding this example used as illustration, the intervals produced by log-binomial regression were the narrowest, except for one variable; a simulation study has pointed that its confidence interval may be narrower than is true (12). As expected, the point estimates produced by the Poisson regression with and without robust variance were the same and distinct from the log-binomial regression, although some studies have reported that robust Poisson and log-binomial regression had similar results (22). It was expected that the confidence intervals obtained in Poisson regression would be wider than for log-binomial regression. This situation has been reported when the binary outcome is common (>10%), such as in our example, as a consequence of the fact that the Poisson distribution can have larger variance than the binomial distribution (11, 14). Moreover, the precision observed in the confidence intervals obtained by Poisson regression with robust variance was greater than Poisson regression due to the use of a sandwich estimator for the variances of the regression coefficients (22).
The well-recognized convergence problem using log-binomial regression when explanatory continuous variables are introduced (14, 46) was not observed here. To induce these problems, one continuous variable “total area of the farm dedicated to bovines” was added to the model, and convergence was not achieved (data not shown). The Bayesian approach was used to illustrate an alternative in cases where the convergence is a problem for the log-binomial method. The differences observed between Bayesian and frequentist approach for log-binomial regression were small, with relative change in point estimation ranging from 3.51 to 6.8%. Chu and Cole (25) reported that the inferences obtained by Bayesian and frequentist methods agree when the sample sizes are large and when a weak a priori distribution with respect to the information contained in the probability of observed data is used. Therefore, considering that prior distributions with minimal information were used, the slight differences observed could be attributed to the sample size and the MCMC simulation. Despite some studies using Poisson with variance robust regression reporting probabilities greater than one (47), all the predicted probabilities by this method in the example presented here were bound between 0 and 1.
The point estimate obtained by the logistic regression showed the greatest differences from all the other methods. Schiaffino et al. (45) reported that logistic regression overestimated the true measure of association, especially when the prevalence is greater than 10%, like the one used here (23.9%). This same study also reported that the confidence intervals provided by logistic regression were the widest in relation to other methods, as observed in our example. Therefore, this result reinforces the idea that logistic regression and its measure of association (OR) is only suitable for case–control studies and could approximate the PR only when the prevalence is smaller than 10%. Despite logistic regression estimations (i.e., OR) are distinct than the other models (i.e., PR), we compared the results of the point estimates and their intervals to illustrate how logistic regression estimates can be biased assuming that the PR is the most appropriated measure of association in cross-sectional studies. In other words, in many situation the reported impact of a given factor on the prevalence could be higher (or lower) than the reality if the results were based on the logistic regression models in a situation where the disease is common (i.e., >10%).
Given that the results of the studies and their interpretation are used as “raw material” for other processes such as systematic review, meta-analyses and quantitative risk assessment (28), it is important to provide reliable estimates and correct interpretation to avoid errors in medical decision making and even adverse public policy implications. Hence, excluding cross-sectional studies that reports improper measures of association, i.e., the ones that uses logistic regression in highly prevalent diseases and/or the ones reporting wrong interpretation could be a selection criterion when conducting a meta-analysis, for example.
In conclusion, to avoid possible inappropriate estimates and interpretations, the proper use of statistical techniques when conducting a cross-sectional study must be reinforced. Furthermore, it is important to standardize the interpretations of the measure of association, given the great confusion observed in the interpretations of the OR and PR. The use of prevalence ratio in cross-sectional studies should be encouraged since it is easier to interpret, also implying that logistic regression should not be used when the prevalence is high. Instead, log-binomial regression (frequentist or Bayesian approach) or robust Poisson regression should be used in these scenarios. Therefore, the key points toward improving the methodology applied in cross-sectional studies would be the following: (1) include in the guidelines of Journals the appropriateness of the methods for cross-sectional studies for a given prevalence level; (2) avoid using risk-language terms in cross-sectional studies, which are “risk,” “more/less likely,” “likelihood,” or “probability”; (3) prevalence ratio is the preferred measure of association in cross-sectional studies, which could be easily estimated with the advance of statistical softwares using the aforementioned models.
Author Contributions
Conceptualization: LC and VL. Data curation: BM and GM. Formal analysis: BM, GS, VL, LN, and LC. Supervision: LC, VL, and LN. Writing—original draft preparation: BM.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors wish to thank (in alphabetical order): Dr. Eduardo de Freitas Costa, MSc. Waldemir Santiago Neto for valuable comments on the manuscript.
Supplementary Material
The Supplementary Material for this article can be found online at http://www.frontiersin.org/article/10.3389/fvets.2017.00193/full#supplementary-material.
References
1. Dohoo IR, Martin W, Stryhn H. Introduction to observational studies. In: Dohoo IR, Martin W, Stryhn H. Veterinary Epidemiologic Research. VER Inc. (2009). p. 151–62.
2. Carlson MDA, Morrison RS. Study design, precision, and validity in observational studies. J Palliat Med (2009) 12:77–82. doi:10.1089/jpm.2008.9690
3. Levin KA. Study design III: cross-sectional studies. Evid Based Dent (2006) 7:24–5. doi:10.1038/sj.ebd.6400375
4. Grimes DA, Schulz KF. Making sense of odds and odds ratios. Obstet Gynecol (2008) 111:423–6. doi:10.1097/01.AOG.0000297304.32187.5d
5. Zocchetti C, Consonni D, Bertazzi PA. Relationship between prevalence rate ratios and odds ratios in cross-sectional studies. Int J Epidemiol (1997) 26:220–3. doi:10.1093/ije/26.1.220
6. Holcomb WLJ, Chaiworapongsa T, Luke DA, Burgdorf KD. An odd measure of risk: use and misuse of the odds ratio. Obstet Gynecol (2001) 98:685–8. doi:10.1097/00006250-200110000-00028
7. Spiegelman D, Hertzmark E. Easy SAS calculations for risk or prevalence ratios and differences. Am J Epidemiol (2005) 162:199–200. doi:10.1093/aje/kwi188
8. Thompson ML, Myers JE, Kriebel D. Prevalence odds ratio or prevalence ratio in the analysis of cross sectional data: what is to be done? Occup Environ Med (1998) 55:272–7. doi:10.1136/oem.55.4.272
9. Torman VBL, Camey SA. Bayesian models as a unified approach to estimate relative risk (or prevalence ratio) in binary and polytomous outcomes. Emerg Themes Epidemiol (2015) 12:8. doi:10.1186/s12982-015-0030-y
10. Greenland S. Model-based estimation of relative risks and other epidemiologic measures in studies of common outcomes and in case-control studies. Am J Epidemiol (2004) 160:301–5. doi:10.1093/aje/kwh221
11. Nijem K, Kristensen P, Al-Khatib A, Bjertness E. Application of different statistical methods to estimate relative risk for self-reported health complaints among shoe factory workers exposed to organic solvents and plastic compounds. Nor Epidemiol (2005) 15:111–6. doi:10.5324/nje.v15i1.233
12. McNutt L-A, Wu C, Xue X, Hafner JP. Estimating the relative risk in cohort studies and clinical trials of common outcomes. Am J Epidemiol (2003) 157:940–3. doi:10.1093/aje/kwg074
13. Behrens T, Taeger D, Wellmann J, Keil U. Different methods to calculate effect estimates in cross-sectional studies. A comparison between prevalence odds ratio and prevalence ratio. Methods Inf Med (2004) 43:505–9. doi:10.1267/METH04050505
14. Barros AJD, Hirakata VN. Alternatives for logistic regression in cross-sectional studies: an empirical comparison of models that directly estimate the prevalence ratio. BMC Med Res Methodol (2003) 3:21. doi:10.1186/1471-2288-3-21
15. O’Connor AM. Interpretation of odds and risk ratios. J Vet Intern Med (2013) 27:600–3. doi:10.1111/jvim.12057
16. Prasad K, Jaeschke R, Wyer P, Keitz S, Guyatt G, Wyer PC, et al. Tips for teachers of evidence-based medicine: understanding odds ratios and their relationship to risk ratios. J Gen Intern Med (2008) 23:635–40. doi:10.1007/s11606-007-0453-4
17. Martin J. Odds Ratio. CTSpedia (2012). Available from: https://www.ctspedia.org/do/view/CTSpedia/OddsRatioMeasures
19. Lee J, Tan CS, Chia KS. A practical guide for multivariate analysis of dichotomous outcomes. Ann Acad Med Singapore (2009) 38:714–9.
20. Wacholder S. Binomial regression in GLIM: estimating risk ratios and risk differences. Am J Epidemiol (1986) 123:174–84. doi:10.1093/oxfordjournals.aje.a114212
21. Deddens JA, Petersen MR. Approaches for estimating prevalence ratios. Occup Environ Med (2008) 65(481):501–6. doi:10.1136/oem.2007.034777
22. Zou G. A modified poisson regression approach to prospective studies with binary data. Am J Epidemiol (2004) 159:702–6. doi:10.1093/aje/kwh090
23. Yelland LN, Salter AB, Ryan P. Relative risk estimation in randomized controlled trials: a comparison of methods for independent observations. Int J Biostat (2011) 7:1–31. doi:10.2202/1557-4679.1278
24. Blizzard L, Hosmer DW. Parameter estimation and goodness-of-fit in log binomial regression. Biom J (2006) 48:5–22. doi:10.1002/bimj.200410165
25. Chu H, Cole SR. Estimation of risk ratios in cohort studies with common outcomes: a Bayesian approach. Epidemiology (2010) 21:855–62. doi:10.1097/EDE.0b013e3181f2012b
26. Beaudeau F, Fourichon C. Estimating relative risk of disease from outputs of logistic regression when the disease is not rare. Prev Vet Med (1998) 36:243–56. doi:10.1016/S0167-5877(98)00095-6
27. Ospina PA, Nydam DV, DiCiccio TJ. Technical note: the risk ratio, an alternative to the odds ratio for estimating the association between multiple risk factors and a dichotomous outcome. J Dairy Sci (2012) 95:2576–84. doi:10.3168/jds.2011-4515
28. Sargeant JM, O’Connor AM. Issues of reporting in observational studies in veterinary medicine. Prev Vet Med (2014) 113:323–30. doi:10.1016/j.prevetmed.2013.09.004
29. Sargeant JM, O’Connor AM, Dohoo IR, Erb HN, Cevallos M, Egger M, et al. Methods and processes of developing the strengthening the reporting of observational studies in epidemiology-veterinary (STROBE-Vet) statement. Prev Vet Med (2016) 134:188–96. doi:10.1016/j.prevetmed.2016.09.005
30. Deeks J. When can odds ratios mislead? Odds ratios should be used only in case-control studies and logistic regression analyses. BMJ (1998) 317:1155–7. doi:10.1136/bmj.317.7166.1155a
31. Moher D, Liberati A, Tetzlaff J, Altman DG. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS Med (2009) 6:e1000097. doi:10.1371/journal.pmed.1000097
32. Grant MJ, Booth A. A typology of reviews: an analysis of 14 review types and associated methodologies. Health Info Libr J (2009) 26:91–108. doi:10.1111/j.1471-1842.2009.00848.x
33. Aviva P, Watson P. Statistics for Veterinary and Animal Science. 2nd ed. London: Wiley-Blackwell (2006).
34. Machado G, Mendoza MR, Corbellini LG. What variables are important in predicting bovine viral diarrhea virus? A random forest approach. Vet Res (2015) 46:85. doi:10.1186/s13567-015-0219-7
36. R Development Core Team. R A Lang Environ Stat Comput. (Vol. 55). Vienna: R Foundation for Statistical Computing (2011). p. 275–86.
37. Plummer M, Best N, Cowles K, Vines K. CODA: convergence diagnosis and output analysis for MCMC. R News (2006) 6:7–11. doi:10.1159/000323281
38. Gelman A, Rubin DB. Inference from iterative simulation using multiple sequences. Stat Sci (1992) 7:457–72. doi:10.1214/ss/1177011136
39. Carter RE, Lipsitz SR, Tilley BC. Quasi-likelihood estimation for relative risk regression models. Biostatistics (2005) 6:39–44. doi:10.1093/biostatistics/kxh016
40. Wilber ST, Fu R. Risk ratios and odds ratios for common events in cross-sectional and cohort studies. Acad Emerg Med (2010) 17:649–51. doi:10.1111/j.1553-2712.2010.00773.x
41. Schmidt CO, Kohlmann T. When to use the odds ratio or the relative risk? Int J Public Health (2008) 53:165–7. doi:10.1007/s00038-008-7068-3
43. Lee J. Odds ratio or relative risk for cross-sectional data? Int J Epidemiol (1994) 23:201–3. doi:10.1093/ije/23.1.201
44. Vandenbroucke JP, von Elm E, Altman DG, Gotzsche PC, Mulrow CD, Pocock SJ, et al. Strengthening the reporting of observational studies in epidemiology (STROBE): explanation and elaboration. Epidemiology (2007) 18:805–35. doi:10.1097/EDE.0b013e3181577511
45. Schiaffino A, Rodriguez M, Pasarin MI, Regidor E, Borrell C, Fernandez E. [Odds ratio or prevalence ratio? Their use in cross-sectional studies]. Gac Sanit (2003) 17:70–4. doi:10.1016/S0213-9111(03)71694-X
46. Skov T, Deddens J, Petersen MR, Endahl L. Prevalence proportion ratios: estimation and hypothesis testing. Int J Epidemiol (1998) 27:91–5. doi:10.1093/ije/27.1.91
Keywords: odds ratio, prevalence ratio, veterinary epidemiology, log-binomial model, Bayesian model, cross-sectional study, Poisson model, logistic regression
Citation: Martinez BAF, Leotti VB, Silva GS, Nunes LN, Machado G and Corbellini LG (2017) Odds Ratio or Prevalence Ratio? An Overview of Reported Statistical Methods and Appropriateness of Interpretations in Cross-sectional Studies with Dichotomous Outcomes in Veterinary Medicine. Front. Vet. Sci. 4:193. doi: 10.3389/fvets.2017.00193
Received: 15 August 2017; Accepted: 25 October 2017;
Published: 10 November 2017
Edited by:
Timothée Vergne, Institut de Recherche pour le Développement (IRD), FranceReviewed by:
Fabien Corbiere, Ecole Nationale Vétérinaire de Toulouse, FranceLaura Cristina Falzon, University of Liverpool, United Kingdom
Copyright: © 2017 Martinez, Leotti, Silva, Nunes, Machado and Corbellini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Luís Gustavo Corbellini, bHVpcy5jb3JiZWxsaW5pQHVmcmdzLmJy, bGdjb3JiZWxsaW5pQGhvdG1haWwuY29t
†Present address: Gustavo Machado, Department of Population Health and Pathobiology, College of Veterinary Medicine, North Carolina State University, Raleigh, NC, United States