 Jesús A. Garrido
Jesús A. Garrido Niceto R. Luque
Niceto R. Luque Egidio D'Angelo
Egidio D'Angelo Eduardo Ros
Eduardo Ros- 1Neurophysiology Unit, Department of Brain and Behavioral Sciences, University of Pavia, Pavia, Italy
- 2A. Volta Physics Department, Consorzio Interuniversitario per le Scienze Fisiche della Materia, University of Pavia Research Unit, Pavia, Italy
- 3Department of Computer Architecture and Technology, University of Granada, Granada, Spain
- 4Brain Connectivity Center, C. Mondino National Neurological Institute, Pavia, Italy
Adaptable gain regulation is at the core of the forward controller operation performed by the cerebro-cerebellar loops and it allows the intensity of motor acts to be finely tuned in a predictive manner. In order to learn and store information about body-object dynamics and to generate an internal model of movement, the cerebellum is thought to employ long-term synaptic plasticity. LTD at the PF-PC synapse has classically been assumed to subserve this function (Marr, 1969). However, this plasticity alone cannot account for the broad dynamic ranges and time scales of cerebellar adaptation. We therefore tested the role of plasticity distributed over multiple synaptic sites (Hansel et al., 2001; Gao et al., 2012) by generating an analog cerebellar model embedded into a control loop connected to a robotic simulator. The robot used a three-joint arm and performed repetitive fast manipulations with different masses along an 8-shape trajectory. In accordance with biological evidence, the cerebellum model was endowed with both LTD and LTP at the PF-PC, MF-DCN and PC-DCN synapses. This resulted in a network scheme whose effectiveness was extended considerably compared to one including just PF-PC synaptic plasticity. Indeed, the system including distributed plasticity reliably self-adapted to manipulate different masses and to learn the arm-object dynamics over a time course that included fast learning and consolidation, along the lines of what has been observed in behavioral tests. In particular, PF-PC plasticity operated as a time correlator between the actual input state and the system error, while MF-DCN and PC-DCN plasticity played a key role in generating the gain controller. This model suggests that distributed synaptic plasticity allows generation of the complex learning properties of the cerebellum. The incorporation of further plasticity mechanisms and of spiking signal processing will allow this concept to be extended in a more realistic computational scenario.
Introduction
The cerebellum plays a critical role in the precise control of movements, as is evident when studying patients with cerebellar malfunctioning and diseases (Thach, 1996). The cerebellum receives proprioceptive signals (Sawtell, 2010) and copies of motor commands (Schweighofer et al., 1998a) together with haptic information (Ebner and Pasalar, 2008; Shadmehr and Krakauer, 2008; Weiss and Flanders, 2011) through MFs. By means of these signals and its own internal circuitry, the cerebellum is able to learn and process sensorimotor information, and thereby regulate the initiation, intensity and duration of motor acts in an anticipatory manner (Spencer et al., 2005; Manto et al., 2012). This gain control operation is a fundamental aspect of motor control in animals, as it allows not only the rapid regulation of motor acts according to contextual cues, but also, through learning, adaptation of these acts to bodily and environmental changes. This adaptable gain control requires closed-loop interactions between command centers and effectors and is thought to involve the cerebellum embedded in the so-called forward controller loop (Schweighofer et al., 1998a; Wolpert et al., 1998; Wolpert and Ghahramani, 2000). In fact, the abstraction of models (kinematics and dynamics) of objects under manipulation (Shadmehr and Mussa-Ivaldi, 2012) is efficiently achieved thanks to close interaction between the cerebral and the cerebellar cortex (Middleton and Strick, 2000; Wang et al., 2008). However, two main issues remained unresolved. First, the adaptable gain controller localized in the cerebellum is thought to require suitable learning and memory mechanisms, whose nature is still debated. Secondly, it remains to be explained how a gain control system involving the cerebellum is able to optimize its performance in the face of broad and varying operative ranges.
Several attempts have been made to understand how the cerebellum implements adaptable gain control. The original theories, based on analysis of network connectivity (Marr, 1969; Albus, 1971; Fujita, 1982), defined the cerebellum as a timing and learning machine. The granular layer was hypothesized to perform expansion recoding of input signals and the PF-PC synapse to learn and store relevant patterns under the control of the teaching signal provided by CFs. On the basis of electrophysiological determinations, it has been suggested that the inferior olive (IO), by comparing proprioceptive and predicted signals, is indeed able to provide quantitative error estimation (Bazzigaluppi et al., 2012; De Gruijl et al., 2012). Moreover, some authors, on the basis of eye-movement analysis, have advanced the hypothesis of a two-state learning mechanism (Shadmehr and Brashers-Krug, 1997; Shadmehr and Holcomb, 1997), wherein a fast learning process takes place in the cerebellar cortex (granular and molecular layer, possibly involving PF-PC plasticity) and a slow consolidation process takes place in deeper structures (possibly the DCN) (Shadmehr and Brashers-Krug, 1997; Shadmehr and Holcomb, 1997; Medina and Mauk, 2000). Clearly, in the development of an adequate model of adaptable cerebellar gain control, it has to be known where and how learning actually occurs. Long-term synaptic plasticity is thought to provide the biological basis for learning and memory in neuronal circuits (Bliss and Collingridge, 1993) and appears in various forms of potentiation (LTP) and depression (LTD). In the cerebellum, long-term synaptic plasticity was initially thought to occur only as LTD or LTP (Marr, 1969; Albus, 1971) at the PF-PC synapse, but now synaptic plasticity is known to be distributed and to occur also in the granular layer, molecular layer and DCN (Hansel et al., 2001; Gao et al., 2012). In particular:
(1) Synaptic plasticity in the granular layer is unsupervised and may serve to improve spatiotemporal recoding of MF input patterns into new GC discharges [expansion recoding (D'Angelo and De Zeeuw, 2009)].
(2) Synaptic plasticity in the molecular layer is supervised and may serve to store correlated granular layer patterns under the teaching signal generated by CFs. This plasticity is in fact composed of multiple mechanisms: PF-PC LTD may occur together with PF-MLI LTP, globally reducing PC responses, while PF-PC LTP may occur together with PF-MLI LTD and MLI-PC LTD, globally increasing PC responses (Gao et al., 2012).
(3) Synaptic plasticity in the DCN is supervised and may serve to store correlated granular layer patterns under the teaching signal generated by PCs (Hansel et al., 2001; Boyden et al., 2004; Gao et al., 2012). This plasticity is, in turn, composed of several mechanisms generating MF-DCN (Bagnall and du Lac, 2006; Pugh and Raman, 2006) and PC-DCN (Morishita and Sastry, 1996; Aizenman et al., 1998; Ouardouz and Sastry, 2000) LTP and LTD. On the one hand, it has been suggested that MF-DCN and PF-DCN plasticity are important in controlling cerebellar learning in the context of EBCC (Medina and Mauk, 1999, 2000) and that equivalent forms of plasticity in the VN are important in controlling cerebellar learning in the VOR (Masuda and Amari, 2008). On the other hand, it has been proposed that the nature of cerebellar cortical and nuclear plasticity and the involvement of extra-cerebellar plasticity sites are highly dependent on the task to be performed, e.g., EBCC or VOR (De Zeeuw and Yeo, 2005; Porrill and Dean, 2007; Lepora et al., 2010). In the present context, with the aim of developing a general computational scheme, we have not considered the potential task-dependence of the learning process.
We explored the impact of distributed cerebellar synaptic plasticity on gain adaptation using a robotic control task in a closed loop, starting from the assumption that there are three learning sites, one in the cerebellar cortex (PF-PC) and two in the DCN (MF-DCN and PC-DCN), all generating LTP and LTD. We found that simultaneous recalibration of weights at these multiple synaptic sites was required to implement self-adaptable gain control over a broad dynamic range involving manipulation of objects with different masses. Moreover, the model implied, due to the definition of the learning rules and the configuration of the learning parameters, that learning was faster in the molecular layer than in DCN, supporting adaptation mechanisms on different time scales. This result suggests that distributed synaptic plasticity is needed to generate the complex computational and learning properties of the cerebellum and to improve motor learning and control.
Methods
A cerebellar model was constructed taking into account the major functional hypotheses concerning the granular layer, the PC layer and the DCN. The main synaptic connections between these structures (PF-PC, PC-DCN, and MF-DCN) were endowed with long-term synaptic plasticity mechanisms. The cerebellar model was embedded into a control loop designed to operate a simulated robotic arm manipulating different masses. The simulator of the robotic arm and the control loop were implemented in Simulink (Matlab R2011a), in accordance with previous models (Luque et al., 2011a,b,c; Tolu et al., 2013) (see Appendix B). The cerebellar model was implemented in C++ and was embedded in Simulink as an S-function block. The source code is available at: https://senselab.med.yale.edu/modeldb/ShowModel.asp?model=150067.
Cerebellar Model
The model provides a simplified representation of signal processing, while accounting for the main computational and learning properties of the cerebellar circuit. Each layer of the cerebellum was implemented as a set of parameter values corresponding to the firing rate of the neural population. Consequently, and since the interaction between neuronal layers in the model is linear, “synaptic strength” and “synaptic weight” correspond to gain factors describing the influence that firing frequency in the presynaptic cell group has on the postsynaptic cell group. Thus, like gain, “synaptic weights” are adimensional. An overview of the cerebellar circuit is shown in Figure 1 and of computational features of the model is shown in Figure 2.
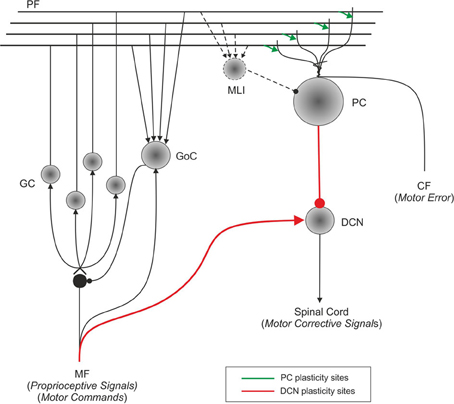
Figure 1. Schematic representation of the main cell types in the cerebellum and of their connections. Suggestions about the nature of inputs signals are indicated [according to Schweighofer et al. (1998b)]. The pathways involved in long-term synaptic plasticity are drawn in green (for DCN afferents) and blue (for PC afferents). PF, parallel fiber; MF, mossy fiber; CF, climbing fiber; GC, granule cell; GoC, Golgi cell; PC, Purkinje cell; DCN, deep cerebellar nuclei; IO, inferior olive; MLI, molecular layer interneuron.
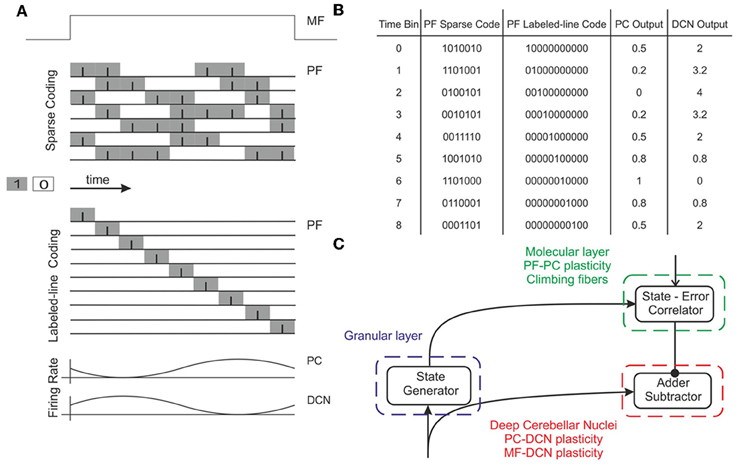
Figure 2. Working hypothesis of cerebellar learning in a manipulation task. In our model, the system is further simplified by computing states without explicit spike representation. (A) During each manipulation trial, the onset of the movement initiates a non-recurrent sequence of firing states in the PFs (Yamazaki and Tanaka, 2007) due to the incoming activity in MFs. Each state is correlated with the error signal, representing the difference between the desired and actual positions of the robotic joint, and reaches the PCs through the CFs. This correlation is thought to occur through plasticity at the PF-PC synapses (Marr, 1969). After repeated pairing of PF states and CF error signals, an association is formed between the two; a learned corrective torque occurs and precedes the wrong movement. This association involves either reduction or increase of PC firing rate at different times. Finally, the temporally correlated signals from PCs are inverted (due to the inhibitory nature of the PC-DCN connection) and rescaled before reaching the motor neurons. The figure presents two alternative coding strategies: in our model, there are no spikes and the states correspond directly to the offset from movement onset indicated by the time bin. Formally, this corresponds to passing from a sparse coding to a labeled-line coding. (B) Binary representation of activity in a PF subset (1: active synapses, 0: inactive synapses) and firing rates in the corresponding PC and DCN neuron (in PCs the values are normalized in the range 0–1). A low PC firing rate corresponds to a high DCN firing rate. (C) Block diagram of the elements involved in the model. A state generator (which is reinitialized with the onset of a new trial) mimics the functionality of the cerebellar granular layer. A state-error correlator emulates the PC function: PF-PC long-term plasticity under supervision of CFs. Finally, an adder/subtractor receives the inputs coming from the MFs (multiplied by the MF-DCN synaptic weights) and subtracts the signal coming from the PCs (multiplied by the PC-DCN synaptic weights).
Signal coding in the cerebellar model
Previous models of cerebellar control of eyelid conditioning assumed that MFs convey spike sequences with a constant firing rate during presentation of the conditioned stimulus (Medina and Mauk, 1999; Yamazaki and Tanaka, 2007, 2009). Accordingly, in the present model, MF activity was represented by a constant firing rate. The MFs received constant signals (1) during the execution of each learning trial, and their input was set to 0 after the trial. It was assumed that, owing to internal dynamics, the granular layer circuit is capable of generating time-evolving states even in the presence of a constant MF input (Fujita, 1982). The CFs were assumed to transmit an error signal (0–1) representing the normalized difference between the desired and actual positions and velocities of each arm joint.
The onset of MF activity started the generation of the granular layer state sequence (see below) and also provided the excitatory drive to DCN cells (Figure 2). The DCN generated the cerebellar output by emitting positive (or zero) corrective torques that were added (with a positive or negative sign depending on whether it corresponded to agonist or antagonist muscles) to the crude inverse dynamic signal coming from the motor cortex.
The granular layer
The granular layer was implemented as a state generator (Yamazaki and Tanaka, 2005). When MF activity reaches the granular layer, it produces non-recurrent time patterns that are repeated exactly in each learning trial (Figure 2A). Thus, the relative time offset along the arm plant trajectory is represented by the correlative activation of 500 different states, mimicking the behavior of 500 PFs sequentially activated during movement execution. It should be noted that the procedure adopted here formally corresponds to a labeled-line coding scheme (Figures 2A,B).
The purkinje layer
The PC layer has been suggested to correlate the PF input activity with the CF error-based teaching signal (Marr, 1969; Albus, 1971). Taking advantage of the state representation occurring in PFs, the PC layer was implemented by means of a look-up table, which associates each actual state with an output firing rate progressively learned along the trial (Figure 2B; see also below the synaptic plasticity section for a comprehensive description of mechanisms). The activity of the PC layer is defined as follows:
where Puri(t) represents the firing rate of the PCs associated with the i-th muscle and fi associates each granular layer state (i.e., one active PF) with a particular output firing rate at the i-th PC (Figure 2B). In the present 3-joint arm, there are six PCs accounting for the three pairs of agonist-antagonist muscles (one pair per joint).
DCN cells
The DCN cells integrate the excitatory activity coming from MFs and the inhibitory activity coming from PCs (Figure 2C). By linearly approximating the influence of excitatory and inhibitory synapses on DCN firing rate, the output of the DCN cell population was described as follows:
where DCNi(t) represents the average firing rate of the DCN cell associated with the ith muscle, WMF − DCNi is the synaptic strength of the MF-DCN connection at the ith muscle, and WPCi − DCNi is the synaptic strength of the PC-DCN connections at the ith muscle. Thus, the DCN layer was implemented as an adder/subtractor and the afferent activity coming from the MFs and PCs was scaled by synaptic strengths (MF-DCN and PC-DCN synapses, respectively). These synaptic weights were progressively adapted during the learning process, following the synaptic plasticity mechanisms explained below. It is important to note the absence of an MF activity term. As previously explained, we assume a constant input rate from MFs during the learning process. Thus, the excitatory component of the DCN firing rate is dependent only on the MF-DCN synaptic weight.
Synaptic Plasticity
The cerebellar model included plasticity mechanisms at three different sites: the PF-PC, PC-DCN, and MF-DCN synapses. As a whole, this set of learning rules led the cerebellum toward a relatively fast adaptation using PF-PC plasticity and a subsequent slow adaptation using MF-DCN and PC-DCN plasticity. This allowed the PF-PC synaptic weights to be kept within their optimum functional range through feedback coming from the actual movement. Importantly, the inclusion of the proposed learning rules allowed the cerebellar model to learn, independently, the timing (in the PF-PC synapses) and gain (in the MF-DCN and PC-DCN synapses) of the task.
PF-PC synaptic plasticity
This is the most widely investigated cerebellar plasticity mechanism and different studies have supported the existence of multiple forms of LTD (Ito and Kano, 1982; Boyden et al., 2004; Coesmans et al., 2004) and LTP (Hansel et al., 2001; Ito, 2001; Boyden et al., 2004; Coesmans et al., 2004). PF-PC plasticity was recently observed in alert animals (Márquez-Ruiz and Cheron, 2012). The main form of LTD is heterosynaptically driven by CF activity, and is therefore related to the complex spikes generated by CFs, while the main form of LTP is related to the simple spikes generated by PFs. The present model implements PF-PC synaptic plasticity as follows:
where ΔWPFj − PCi(t) is the weight change between the jth PF and the target PC associated with the ith muscle, εi is the current activity coming from the associated CF (which represents the normalized error along the executed arm plant movement), LTPMax and LTDMax are the maximum LTP/LTD values, and α is the LTP decaying factor. It should be noted that in previous cases when a synaptic weight had to be modified according to a teaching signal, a linear function was used (Masuda and Amari, 2008). However, this implied that while LTD was generated proportionally to the incoming error signal through CFs, LTP was constantly generated when spikes reached the target PC. In this way, plasticity was not able to fully remove the manipulation task error since LTD was always counterbalanced by “unsupervised” LTP. In order to avoid this problem, LTPMax and LTDMax were set to 0.01 and 0.02 and α was set at 1000. This led to a marked decrease of LTP (evolving with the change in ε) and prevented plasticity saturation (e.g., see Figure 3).
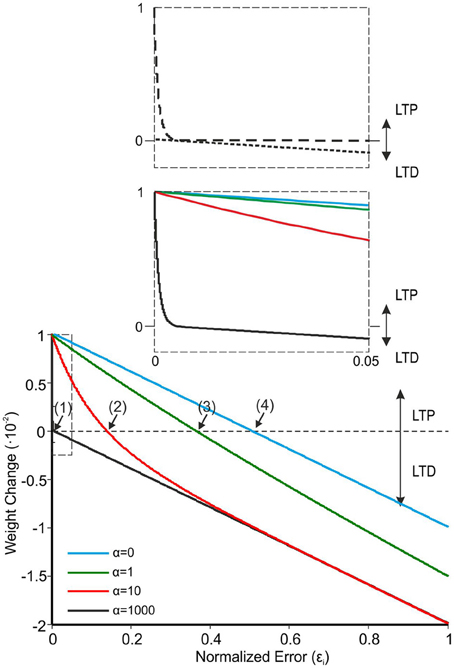
Figure 3. The learning rule for PF-PC plasticity. Comparison of four different α values in Equation 3 (LTPMax and LTDMax were set at 0.01 and 0.02). Equation 3, which represents the synaptic weight change as a function of normalized error reaching the cerebellum through the CFs, shows better learning performances at high α values (black solid line). With α = 1000, Equation 3 crosses the X-axis at a very low value (curve 1: εi ≈ 4.7·10−3). When α is lowered, the curves cross the X-axis at progressively higher εi values (curve 2: α = 100, εi ≈ 137.7·10−3; curve 3: α = 1, εi ≈ 366·10−3; curve 4: α = 0, εi ≈ 500·10−3). The inset shows that with α = 1000 there is a rapid decrease of LTP toward zero, while the LTD evolves linearly with the error.
In accordance with the assumption that the granular layer operates as a state generator (Yamazaki and Tanaka, 2007), this synaptic plasticity rule modified the strength only of the active PFs. The synaptic weight variation was positive (LTP) when CF activity approached 0 (low error levels in the movement). Otherwise the weight variation was negative (LTD) and was linearly proportional to CF activity.
MF-DCN synaptic plasticity
MF-DCN synaptic plasticity, which has been reported to depend on the intensity of DCN cell excitation (Racine et al., 1986; Medina and Mauk, 1999; Pugh and Raman, 2006; Zhang and Linden, 2006), was implemented as:
where ΔWMF − DCNi(t) represents the weight change between the active MF and the target DCN associated with the ith muscle, Pur(t) is the current activity coming from the associated PCs, LTPMax, and LTDMax are the maximum LTP/LTD values, and α is the LTP decaying factor. In order to maintain the stability of the learning process, the LTPMax and LTDMax values had to be lower than those defined at the PF-PC synapse and were set at 10−3 and 10−4, respectively. As in Equation 3, α was set at 1000, thus allowing a fast decrease of LTP and preventing early plasticity saturation (e.g., see Figure 3).
The MF-DCN learning rule, although formally similar to the PF-PC learning rule, bore two relevant differences. The first is due to the reduced ability of MFs, compared with PFs, to generate sequences of non-recurrent states (Yamazaki and Tanaka, 2007, 2009; Yamazaki and Nagao, 2012). The learning rule in Equation 4 would lead synaptic weights to their local maximum values (one activity value per different state) allowing plasticity to store temporally correlated information. In order to simplify the interpretation of the results, we used a single MF activity state, which was then associated by plasticity mechanisms with different gain values at MF-DCN synapses. The second difference concerns the connection driving LTD and LTP. While PF-PC plasticity was driven by CF activity, MF-DCN plasticity was driven by PC activity. This mechanism can optimize the activity range in the whole inhibitory pathway comprising MF-PF-PC-DCN connections: high PC activity causes MF-DCN LTD, while low PC activity causes MF-DCN LTP. This mechanism implements an effective cerebellar gain controller, which adapts its output activity to minimize the amount of inhibition generated in the MF-PF-PC-DCN inhibitory loop.
PC-DCN synaptic plasticity
PC-DCN synaptic plasticity was reported to depend on the intensity of DCN cell and PC excitation (Morishita and Sastry, 1996; Aizenman et al., 1998; Ouardouz and Sastry, 2000; Masuda and Amari, 2008) and was implemented as:
where ΔWPCi−DCNi(t) is the synaptic weight adjustment at the PC-DCN connection reaching the DCN cell associated with the ith muscle. LTPMax and LTDMax are the maximum LTP/LTD values that this learning rule can apply at any time (as with the MF-DCN learning rule, these values were set at 10−3 and 10−4 respectively), Puri(t) is the current activity coming from the associated PC (in the range [0,1]), DCNi(t) is the current DCN output of the target DCN cell, and α represents the decaying factor of the LTP (again, it was set at 1000 as in MF-DCN and PF-PC learning rules). This learning rule led the PC-DCN synapses into a synaptic weight range appropriate to match the synaptic weight range at PFs. Equation 5 caused LTP only when both the PCs and their target DCN cell were simultaneously active.
Control Loop and Input-Output Organization
The brain can plan and learn the optimal trajectory of a movement in intrinsic coordinates (Houk et al., 1996; Nakano et al., 1999; Todorov, 2004; Hwang and Shadmehr, 2005). This operation consists of three major tasks: computation of the desired trajectory in external coordinates, translation of the task space into body coordinates, and generation of the motor command (Uno et al., 1989). In order to deal with dynamic variations, the system needs to incorporate a feedback error learning scheme (Kawato et al., 1987) in conjunction with a crude inverse dynamic model of the arm plant.
It was recently reported that multiple closed loops characterize the input-output organization of cerebro-cerebellar networks (Bostan et al., 2013). It has been proposed that the association cortices provide the motor cortex with the desired trajectory in body coordinates (Figure 4A). In the motor cortex, the motor command is calculated using an inverse dynamic arm model (for a review see Siciliano and Khatib, 2008). The spinocerebellum-magnocellular red nucleus system provides an accurate model of musculoskeletal dynamics, which are learned with practice by sensing motor command consequences in terms of executed movements (proprioception). The cerebrocerebellum-parvocellular red nucleus system, which projects back to the motor cortex, provides a crude inverse-dynamic model of the musculoskeletal system, which is acquired while monitoring the desired trajectory (Kawato et al., 1987). The crude inverse-dynamic model works together with the dynamic model, thus updating motor commands according to predictable errors occurring when executing a movement. In our control system, only the dynamic model involving cerebellar feedback to actual movement was implemented.
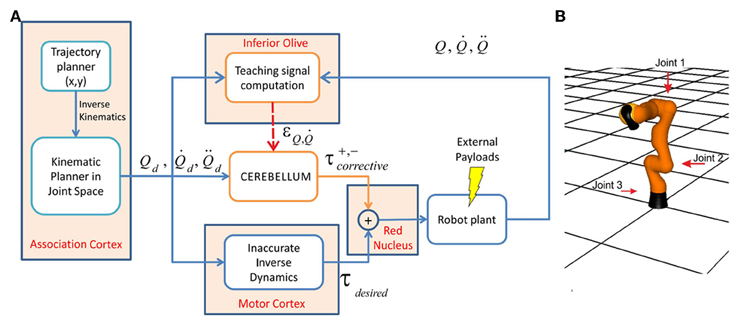
Figure 4. Control scheme and robotic arm. (A) Essential control loop used for simulated manipulation tasks. The association cortex generates the desired trajectory (in terms of position, velocity, and acceleration) in body coordinates and the corresponding command signal is transmitted to both the motor cortex and to the cerebellum through the MFs. In the motor cortex command torques are calculated using an inverse dynamic arm model. The cerebellum generates corrective torques compensating for deviations from target trajectory (error) caused by the dynamic interaction of the arm with the object during manipulation. The signals from the motor cortex and cerebellum are added together in the red nucleus and then the output is delivered to the robot arm. The cerebellar corrective torques can be adapted in order to minimize the motor error. This requires a teaching signal generated by the IO. In the IO, the actual state is compared with the desired state in order to obtain the teaching error-dependent signal which reaches the cerebellum through the CFs. (B) The LWR arm. The three joints used in our experiments are indicated (red arrows); all the other joints were fixed (made rigid).
On the basis of these theories, we implemented a control loop using a forward architecture (see Figure 4A), in which only information about sensorial consequences of non-accurate commands was available (i.e., the difference between actual and desired arm plant joint positions). The natural error signal for learning was obtained as the difference between the actual movement and the motor command. This implies that if M muscles control a motor system endowed with N sensors, the N sensory errors must be converted into M motor errors (MxN complexity). How to use this sensory information to drive motor learning is the so-called distal error problem or motor error problem (Porrill et al., 2004; Haith and Vijayakumar, 2007). In order to circumvent this problem, the present cerebellar model used the adaptation mechanisms described above, which correlated the actual and desired states toward the generation of an accurate corrective motor command.
The system controller comprised different modules in accordance with studies indicating that the brain first plans the optimal trajectory in task-space coordinates, translates these into intrinsic-body coordinates, and finally generates the appropriate motor commands to achieve these transitions (Houk et al., 1996; Nakano et al., 1999; Todorov, 2004; Hwang and Shadmehr, 2005; Izawa et al., 2012). The system controller was composed of some pre-defined non-adaptive modules and a cerebellar model adapting over the learning trials (Figure 4A). The pre-defined modules, which maintained fixed parameters throughout the trials, independently of the load under manipulation, were the following:
- Association cortex. This module operated as a trajectory planner delivering desired positions and velocities of the target trajectory and it included an inverse kinematic model translating this trajectory from Cartesian into arm-joint coordinates.
- Motor cortex. This module, based on a recursive Newton-Euler algorithm (RNEA), generated crude step-by-step motor commands implementing the desired trajectory through an inverse dynamic model. The corresponding torque values could drive the robot arm along the desired trajectory in the absence of any external load, but failed to do so when loads were added during manipulation.
- Red nucleus. This module added the motor commands provided by motor cortex module to the corrective torques coming from the adaptive cerebellar module.
The cerebellar model is the only adaptive module in the system controller. This module learnt to correct the inverse dynamic model, pre-calculated for the desired trajectory in the absence of external load, in order to manipulate the actual load. The inclusion of three different learning rules allowed the cerebellar model to store the temporal properties of corrective torques in the PF-PC synapses and the gain of corrective torques in the MF-DCN and PC-DCN synapses.
The system integrated a lightweight robot (LWR) simulator within a feedforward control loop (Albu-Schäffer et al., 2011). The physical characteristics of the simulated robot plant were dynamically modified to match different contexts (e.g., the payload to be handled, which translated into a variation of the arm+object dynamics model). The LWR is a 7-degrees of freedom (7-DOF) arm composed of revolute joints. In our experiments, for simplicity, we only used the first, second and fifth joints, while the other joints were kept fixed (Figure 4B). The robot's dynamics were taken into account as indicated in appendix B.
Manipulation Task and Experimental Protocol: Training Trajectory
Several reports in the literature have provided evidence of the role played by the cerebellum in complex manipulation-like tasks: (i) animal studies have shown that rapid target-reaching movements (Kitazawa et al., 1998) and circular manual tracking (Roitman et al., 2009) induced error encoding by PCs, (ii) imaging techniques have shown increased cerebellar activation in response to errors occurring during the execution of various tasks including tracking (Imamizu et al., 2000; Diedrichsen et al., 2005), and (iii) more specifically, prediction error has been shown to drive motor learning in saccades (Wallman and Fuchs, 1998) and reaching (Tseng et al., 2007). Thus, PCs are able to produce corrective signals in response to error signals (assumed to reach PCs through the CFs). The proposed model offers an explanation, based on evidence from complex learning tasks but also on theories proposed in relation to EBCC and VOR experiments, of how gain control (required for VOR and manipulation tasks) and timing control (also required for EBCC tasks) might occur in a plausible cerebellar model.
The model was tested in a smooth pursuit task (Luque et al., 2011a,b,c), in which the LWR targeted a repeated trajectory using its three revolute joints (Figure 4B). The benchmark 8-shape trajectory (Figure 5A) was composed of vertical and horizontal sinusoidal components, whose equations in angular coordinates are given for each joint by:
where Ai and Ci are the amplitude and phase of the trajectories followed by each robot joint. The movement for the whole trajectory took just one second with masses requiring considerable corrective torques. This task was chosen to be sufficiently challenging to allow proper assessment of the learning capability of the cerebellar model. The corrective action driven by the cerebellum is especially relevant with respect to inertial components, Coriolis force and friction generated by movement (Schweighofer et al., 1998a). Changing the payload made it possible to assess the dynamics model abstraction capability of the cerebellum. As an example, Figure 5B shows the corrective torque values that the cerebellum should infer when manipulating a 10-kg payload. This corrective torque is calculated for each mass by means of the RNEA, which is able to solve the inverse dynamics problem.
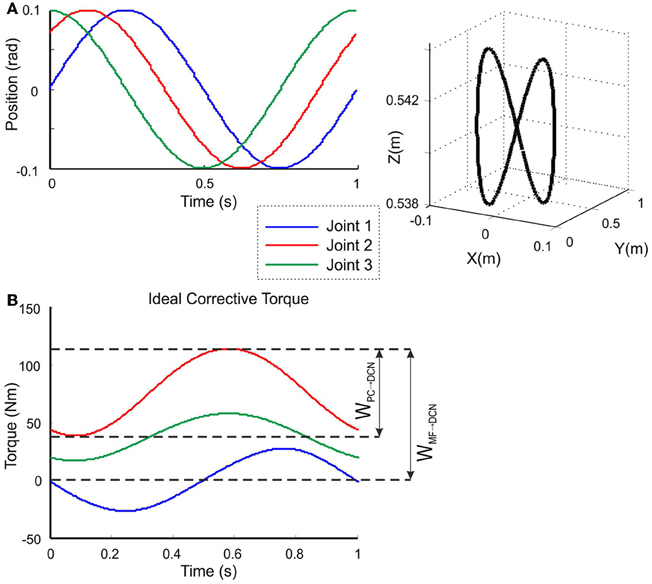
Figure 5. Calculation of the target trajectory. Three-joint periodic trajectory defining an 8-shape movement [redrawn with permission from Luque et al. (2011c)] (A) Angular coordinates of each joint of the LWR (left), and 3D view of the robot end-effector trajectory in Cartesian coordinates (right). This 8-shape trajectory demands a movement difficult enough to allow robot arm dynamics to be revealed in fast movements (Hoffmann et al., 2007). (B) Ideal corrective signals that the cerebellar model had to infer for each of the three joints in order to correct the produced error when manipulating a 10-kg payload. According to the proposed hypothesis, the MF-DCN synaptic weights (WMF − DCN) had to adapt to the gain of the maximum torque value at every joint, while the PC-DCN weight (WPC − DCN) had to set the maximum inhibition (or torque value subtraction) needed.
In order to quantitatively evaluate movement performance, the mean absolute error (MAE) of each robot joint was calculated. This performance estimator was monitored in each trial and allowed evaluation of movement accuracy and of its improvement during the learning process.
Results
As a first step in simulating the 8-shape task, the corrective torques needed for smooth manipulation of different masses (0.5, 1.5, 2.5, 6, and 10 kg) were calculated (Figure 5B). The maximum and minimum torque values for each joint and mass (see Table A1 in Appendix A) were used to estimate the ideal weight values at DCN afferents. It was assumed that, as a consequence of learning, the maximum torque values corresponded to the MF-DCN synaptic weights, while the difference between the maximum and minimum torque values corresponded to PC-DCN synaptic weights. It should be noted that the PC-DCN synapse, by forming the only inhibitory pathway to the cerebellar nuclei, provides the only mechanism capable of reducing the output torques in the model.
Network Activity and Motor Performance with Fixed Weights at DCN Synapses
In order to evaluate the impact, on the cerebellar circuit, of weights at synapses afferent to DCN, the PC firing rate was monitored after setting the MF-DCN and PC-DCN weights at their ideal values pre-calculated to handle different masses. The PF-PC weights were then allowed to change along a learning process composed of 1-s trial trajectories repeated 150 times. Figure 6A shows the normalized firing rate of one PC during a 1-s trial. The PC firing range changed clearly depending on the payload. It should be noted that in this configuration learning occurred only at the PF-PC synapse. As explained in the Methods, the change in PF-PC synaptic weights corresponds linearly to the change in PC firing rate.
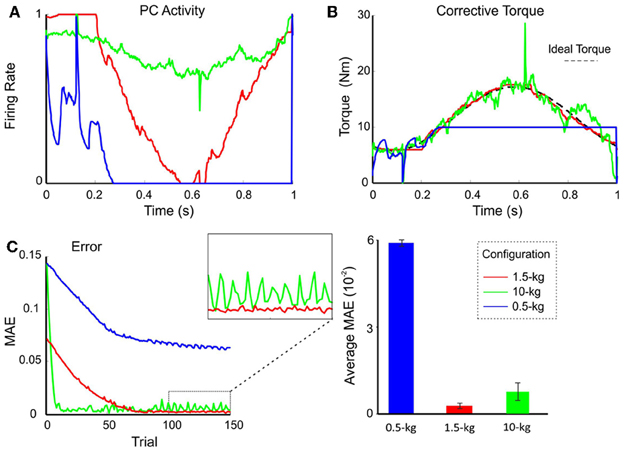
Figure 6. Performance and learning with different weight configurations. Plasticity occurred only at PF-PC synapses, and was disabled at the MF-DCN and PC-DCN synapses. The synaptic weights were set at values appropriate for the manipulation of 0.5-kg (blue lines), 1.5-kg (red lines), and 10-kg (green lines) masses. In all three cases, 1.5-kg masses were actually manipulated. (A) Normalized activity of the PCs associated with the 2nd joint after 149 learning trials. For clarity, only the behavior of the second joint is shown, but similar results were found along the learning process also in joints 1 and 3. Note that by using the proper weight configuration (red line), PC activity effectively ranged from 0 to 1. It should be noted that the time course of the PC firing rate corresponds to the synaptic weights at the PF-PC synapses (see Methods for explanation). (B) Corrective torque values provided by the DCN associated with the 2nd joint after 149 learning trials. (C) Evolution of the MAE during the learning process (left). The box highlights the different stability of motor control during the last 50 trials. The histogram (right) shows the average MAE calculated over the last 50 trials for different payloads, revealing that smallest MAE values and variability occurred with the proper setting.
Using the pre-calculated synaptic weight setting for a 1.5-kg payload allowed the PCs to operate over the whole range of firing rates producing, as a consequence, a fine adjustment of the DCN firing rate. This allowed the circuit to approach the ideal theoretical values of PC and DCN activity (Figure 6B) thus optimizing the learning corrective action in terms of stability and accuracy (Figure 6C). However, when DCN afferents were set at values pre-calculated for the manipulation of a heavier mass (10 kg), the PC activity was limited to a small frequency range in order to counteract the gain overscaling at DCN afferent synapses. Likewise, when DCN afferents were set at values pre-calculated for the manipulation of a lighter mass (0.5 kg), the learning process constrained PC activity to saturate to its minimum (no inhibition at DCN cells) along the trial (Figure 6A). These effects reduced the cerebellar output precision (Figure 6B) and made the corrective action unstable, decreasing the learning performance (Figure 6C). These experiments showed that synaptic weights at MF-DCN and PC-DCN connections were crucial to allow the cerebellar model to generate accurate and stable corrective motor outputs when manipulating different masses.
Network Activity and Motor Performance with Adaptable Weights at DCN Synapses
In order to investigate the effectiveness of learning rules regulating DCN synaptic weights, a simulation involving manipulation of a 10-kg payload was performed (Figure 7). The synaptic weights of MF-DCN and PC-DCN connections were allowed to self-adjust along a learning process composed of 1-s-trial trajectories repeated 1500 times.
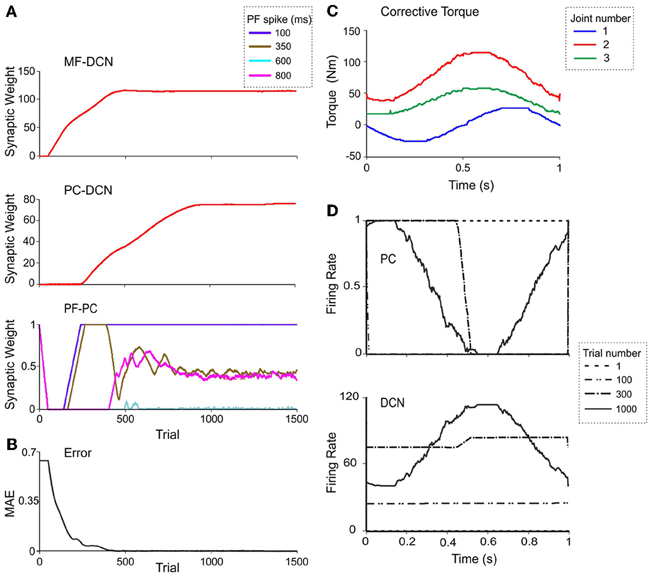
Figure 7. Weight evolution in the cerebellar model with multiple plasticity mechanisms. Simulations were carried out using all the plasticity mechanisms (PF-PC, MF-DCN, and PC-DCN) for manipulation of a 10-kg external payload during 1500 trials. Initial synaptic weights allowed accurate movement of the arm without manipulation of any object (0-kg external payload). (A) Evolution of synaptic weights at MF-DCN (top), PC-DCN (middle) and PF-PC (bottom) connections related to joint 2 agonist muscle. In PF-PC synapses, four different PFs that become active 100 ms (purple), 350 ms (brown), 600 ms (cyan), and 800 ms (pink) after movement initiation are shown. (B) Corrective torques along a 1-s movement, provided by the cerebellar model at the 1500th trial in the learning process. Note the similarity of these values with the ideal ones calculated in Figure 5C. (C) Evolution of the average MAE of the three joints during the learning process. (D) Normalized PC firing rate (top) and DCN firing rate (bottom) during trials taken at different stages of the learning process: trial 1 (red), trial 100 (yellow), trial 300 (gray), and trial 1000 (green).
Remarkably, the MF-DCN and PC-DCN synaptic weights tended to stabilize more slowly than those of the PF-PC synapse (Figure 7A) for two main reasons. First, the LTDMax and LTPMax parameters were higher in the PF-PC (10−2 and 2·10−2 in Equation 3) than in MF-DCN and PC-DCN plasticity mechanisms (10−3 and 10−4 in Equations 4, 5). These LTDMax and LTPMax values were needed in order to stabilize the learning rules. Second, learning at the MF-DCN and PC-DCN synapses depended on PC normalized activity. Thus, the MF-DCN and PC-DCN synaptic weights changed only when some PF-PC weights tended to saturate (toward 0 and 1, respectively; see above) (Figure 7A). Indeed, the evolution of weights was significantly slower at the PC-DCN than at the MF-DCN synapses. As exemplified for the agonist of joint 2, the MF-DCN weights stabilized in about 800 trials while the PC-DCN weights stabilized in more than 10,000 trials (for a comprehensive list of evolution of weights at the MF-DCN and PC-DCN synapses with different masses, see Table A2 in Appendix A). This slow evolution was caused by the dependence of PC-DCN learning on DCN activity, which in turn depended on MF-DCN and PC-DCN adaptation (detailed information about the PC-DCN synaptic weights after the learning process is shown in Table A3 in Appendix A). In parallel to the evolution of MF-DCN and PC-DCN synaptic weights, PF-PC weights evolved to stable values that were reached after 800 trials (Figure 7A).
After the DCN synaptic weight adaptation process, the cerebellum was able to provide corrective torques pretty similar to those theoretically calculated to solve the manipulation problem (Figure 7B; cf. Figure 5C). These torque values rapidly brought the MAE of the movement toward 0 (Figure 7C). When the synaptic weights were stabilized, the PC and DCN exploited their whole firing frequency range (Figure 7D). Thus, MF-DCN and PC-DCN plasticity allowed the system to efficiently self-rescale for optimal performance. Movies of learning simulations during manipulation of a 10-kg load are shown in the Supplemental Material.
DCN Synaptic Plasticity Improves Predictive Mass Manipulation
To further evaluate the effectiveness of the DCN learning rules, we considered how the difference between the predicted and actual manipulated mass influenced the accuracy of movement. To this end, learning trials with different payloads (0.5, 1.5, 2.5, 6, or 10 kg) were performed testing four different cerebellar model configurations. This made it possible to test the impact of adaptation occurring at multiple synaptic sites: (i) plasticity only at PF-PC synapses, (ii) plasticity at PF-PC and MF-DCN synapses, (iii) plasticity at PF-PC and PC-DCN synapses, and (iv) plasticity at PF-PC, MF-DCN, and PC-DCN synapses.
The synaptic weights that were not allowed to change were set at their theoretical values pre-calculated for the accurate manipulation of 10-kg masses. In this way both MFs and PCs were able to provide enough excitation and inhibition, respectively, in order to avoid saturation at DCN. These experiments allowed us to evaluate the complementary and cooperative role of the different plasticities.
For each combination of plasticities and masses, the learning process was simulated during 1500 trials, and the MAE at each joint was calculated at the end of the adaptation process. Figure 8A shows the average MAE during the last 100 trials. Plasticity at either MF-DCN or PC-DCN synapses reduced the average MAE, especially during the manipulation of lighter masses. Remarkably, enabling adaptation at just one of the two DCN afferent synapses was enough to improve manipulation precision. In line with this, plasticity at both MF-DCN and PC-DCN synapses simultaneously further increased the precision of manipulation. In order to obtain an objective evaluation of task performance independently of the manipulated mass, the “MAE reduction index” (MAERI) was defined:
where MAEC+ is the MAE of the manipulation task when using the cerebellar model corrective action and MAEC− is the MAE in the absence of cerebellar adaptation (1 is the perfect error correction by the cerebellar action and 0 represents lack of correction). Using MAERI it is possible to compare the adjustment capacity of the cerebellar model independently of the payload.
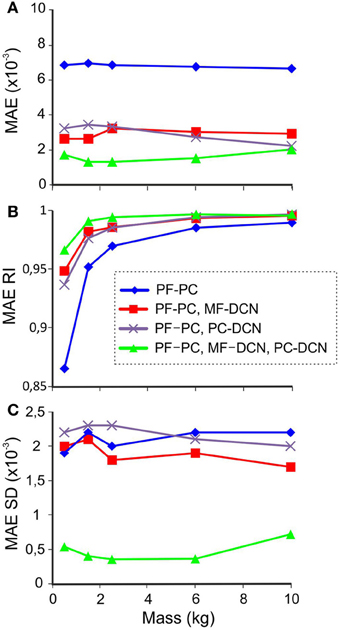
Figure 8. Performance with different masses. In synaptic connections with fixed weights, the values correspond to the 10-kg set up to avoid saturation during manipulation of heavier masses. The last 100 of 1500 trials during learning processes were used for MAE estimation with different combinations of active learning rules at different masses. (A) MAE (B) MAERI (1 is perfect error correction by the cerebellar action and 0 is no correction), (C) MAE standard deviation (SD).
The effect of the different cerebellar models during the manipulation of different masses is shown in Figure 8B. In all the cerebellar models, the trajectory error decreased when manipulating heavier masses. However, only the models incorporating both MF-DCN and PC-DCN plasticity were able to improve lighter mass manipulation. These results could be explained by evaluating the variability of MAE (Figure 8C). On incorporating plasticity at all the synapses (PF-PC, MF-DCN, PC-DCN), the variability of MAE after learning was markedly reduced, thus enhancing the stability of movements.
Thus, the model, by adjusting the MF-DCN and PC-DCN synaptic weights, thereby causing the indirect adjustment of PC activity to its widest possible firing range, improved the smoothness of the robot arm trajectory during the manipulation of objects with different masses. This made it possible to produce an accurate and stable learning process irrespective of the manipulated payload, thus providing the cerebellar system with the capability to self-adapt in order to manipulate different objects.
Implicit Representation of a Double Learning Time Scale
In order to verify whether the model supported the emergence of cerebellar learning consolidation, as indicated in recent behavioral and computational studies (Medina and Mauk, 1999; Ohyama et al., 2006; Xu-Wilson et al., 2009), the evolution of weight changes at DCN synapses was analyzed. During a 10-kg manipulation task (Figure 9A) the learning process was remarkably faster when DCN synaptic weights were pre-calculated. In this case, only the PF-PC synaptic weights, which stored the temporally correlated information, underwent adaptation, and learning was completed in around 50 trials. Otherwise, when weight changes at DCN synapses were enabled, learning required 200 trials (PC-DCN), 400 trials (MF-DCN), or 450 trials (PC-DCN and MF-DCN). In parallel, the MAE was remarkably reduced (Figure 9B).
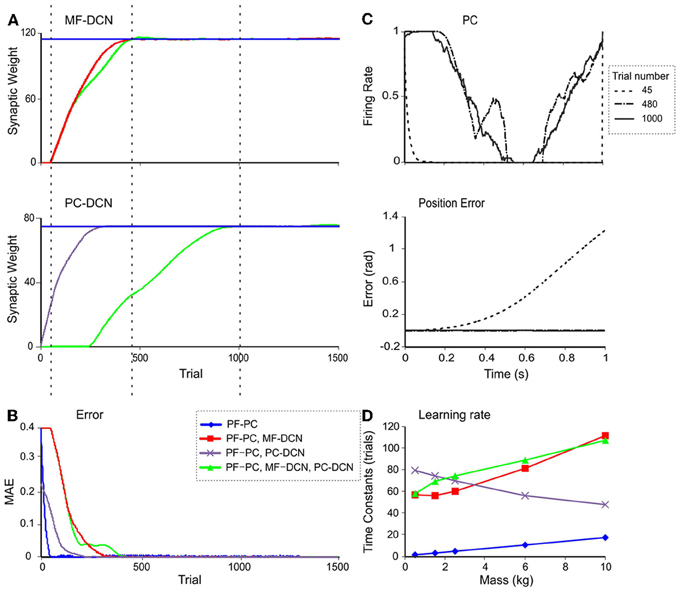
Figure 9. Double time-scale learning. (A) Evolution of MF-DCN synaptic weight (top), and PC-DCN synaptic weight (bottom) during the learning process when a 10-kg payload is being manipulated. (B) Evolution of MAE in the same trials as in A. (C) PC firing rate (top) and actual position error (bottom) in joint 2 at three different times: after 45 trials (gray line), 480 trials (yellow line), and 1000 trials (green line). (D) Time constants of the fitted exponential functions of the MAE with different learning rule settings and masses. The MAE evolution during the learning process has been fitted to exponential decaying functions. The time constants are shown when enabling the use of plasticity only at the PF-PC synapses (blue line), at the PF-PC and MF-DCN synapses (red line), at the PF-PC and PC-DCN synapses (purple line), and at the PF-PC, MF-DCN, and PC-DCN synapses (green line).
Inspection of learning curves clearly showed that the learning process consisted of three different stages (Figure 9):
(i) The cerebellar model tried first to correct the initial error by using only PF-PC plasticity. This process took about 50 trials. When the MF-DCN or PC-DCN synaptic weights were not properly preconfigured, the PC activity saturated (Figure 9C).
(ii) When PC activity did not completely remove the error, the MF-DCN synaptic weights were slowly adjusted after the PF-PC synaptic weights became saturated. This process started after 50 trials and took about 480 trials to complete. After stabilization of MF-DCN synaptic weights, the error was highly reduced; nonetheless, object manipulation remained imprecise.
(iii) After about 300 trials, where the PC activity reached its maximum and in parallel with the MF-DCN weight evolution, the PC-DCN weights started increasing until the 1000th trial. Between 300 and 1000 trials the PC activity profile maintained a smooth shape and its trajectory remained close to the desired one.
Therefore, the model supported the existence of two different learning time scales consisting of: (i) a fast learning process, in which temporal information was inferred and stored at PF-PC synapses, and (ii) a slow learning process, in which the cerebellar excitatory and inhibitory gain values were adapted in the DCN and the manipulation precision increased. This second process was necessary only when the tool had never been manipulated before. During this process the MF-DCN and PC-DCN weights were simultaneously adapted at the same time as the PF-PC weights.
The fast and slow learning curves were fit to exponential decaying functions with time constants of 1–20 trials and 40–120 trials, depending on the object under manipulation (Figure 9D). The slow learning process could be further split into two components related to the MF-DCN and PF-PC connection with time-constants of 55–120 trials and 50–80 trials, respectively.
Discussion
In this work, a theoretical model of the cerebellum is presented in the framework of a manipulation task, in which objects with different masses are moved along a desired trajectory. The main observation is that plastic mechanisms at DCN synapses effectively complement the learning capabilities of PF-PC synapses and contribute to the acquisition of the dynamics model of the arm/object plant. A proper synaptic weight adjustment at DCN synapses acts as a gain adaptation mechanism allowing the PFs to work within their most effective operative range, thus making the plasticity mechanisms between PFs and PCs more precise. This model, by incorporating distributed synaptic plasticity and by generating closed-loop simulations, allowed progressive error reduction based on feedback from the actual movement and accounted for three main theoretical aspects of cerebellar functioning.
First, the results support the principle that the cerebellum operates as a corrective inverse dynamic model (Schweighofer et al., 1996a,b, 1998b; Spoelstra et al., 2000). In the present model, the cerebellar granular layer was effectively implemented as a non-recurrent state generator (Yamazaki and Tanaka, 2007), in which the states correspond to the offset from stimulus onset implementing a labeled-line coding scheme. The granular layer states are then correlated with the error-based teaching signal received through the CFs. Thus, the model can be considered a particular case of an adaptive filter (Dean et al., 2009), in which the base functions in the granular layer are Dirac-deltas (impulse functions) with different delays for each granular cell or, in other words, a set of granular cells responding to different input stimuli along an arm trajectory trial (cf. D'Angelo and De Zeeuw, 2009).
Secondly, in the model, PF-PC plasticity temporally correlates the input state (or its representation in PFs) and the error estimation obtained during execution of the manipulation task. Instead, MF-DCN and PC-DCN plasticities store the excitatory and inhibitory gain of the neural network required to generate accurate correction of movement. Thus, the DCN afferent synapses infer the main properties of the object under manipulation, while the PF-PC synapses store the temporal characteristics of the task. As a consequence of this, plasticity at DCN synapses provides a homeostatic mechanism capable of keeping PC activity at its optimal range during learning. This effect can be observed in closed-loop simulations allowing progressive error reduction based on feedback from the actual movement.
Thirdly, the model supports the existence of a learning consolidation process, which has been demonstrated in behavioral experiments in human saccades (Brashers-Krug et al., 1996; Shadmehr and Brashers-Krug, 1997; Shadmehr and Holcomb, 1997; Xu-Wilson et al., 2009). While the cerebellar cortex plays a fundamental role at initial learning stages, the consolidation process seems to occur elsewhere. Our model provides a possible explanation of the learning consolidation process, locating it in the cerebellar nuclei. In our model, PF-PC plasticity evolves rapidly, while DCN plasticity evolves more slowly, because it depends on the previous evolution of plasticity at the PF-PC synapse itself. Therefore, our model naturally implements a double time-constant plasticity mechanism.
The Impact of Plasticity at DCN Synapses on Adaptable Gain Control
Several experimental studies have reported LTD and LTP in DCN neurons (Morishita and Sastry, 1996; Aizenman et al., 1998; Ouardouz and Sastry, 2000; Bagnall and du Lac, 2006; Pugh and Raman, 2006) and a few hypotheses have been advanced about the role they play in the whole network. In previous studies, (Medina and Mauk, 1999, 2000) it was suggested that MF-DCN plasticity provides a mechanism for consolidating time-correlated information in the cerebellum and proposed that PC activity could drive the DCN learning process. Our model extends this hypothesis to the process of gain consolidation. Moreover, our model includes the possibility, by using a PC-driven learning rule, of storing gain information at PC-DCN connections. A model proposed for the VOR suggested that combined plasticity at the MF-DCN and PC-DCN synapses plays an important role in learning consolidation (Masuda and Amari, 2008). Our model further suggests that simultaneous MF-DCN and PC-DCN plasticity enhances movement precision in a manipulation task using a simulated robotic arm.
On the mechanistic level, our experimental approach allows different roles to be attributed to the different plasticity sites: PF-PC plasticity could act as a time correlator between the actual input state and the system error, while MF-DCN and PC-DCN plasticity together generated the gain controller. It is also possible that MF-DCN plasticity operates, at least in part, as a state correlator, as suggested previously (Masuda and Amari, 2008). Therefore, for improved performance, different aspects of computation have to be distributed over multiple adaptable network nodes.
Biological Realism and Model Limits
Before considering the further implications of this cerebellar model, its plausibility needs to be examined, analyzing the system design, learning rules, and coding strategies.
(1) In this model we implemented the PC as a table correlating granular layer states with output torques evolving through the learning process. This, in conjunction with the PF-PC learning rule, allows the PC to behave as a state-error correlator. However, PC recordings in awake animals (Lisberger and Fuchs, 1978; Van Kan et al., 1993; Escudero et al., 1996; Cheron et al., 1997; Medina and Lisberger, 2009) suggest that PCs are more complex than state-error correlators. In the present model, given the high level of abstraction, it is impossible to evaluate PC features in terms of spike patterns. Inferences about signal coding in PCs would probably require the incorporation of realistic cerebellar network models into the system controller.
(2) Since the learning rules used here at the MF-DCN and PC-DCN synapses depend only on PC and DCN activity, our model of gain control is compatible with different approaches to the distal error problem. Following the detailed descriptions provided on potential error detection mechanisms in the IO (Ito, 2013), the IO was assumed to receive both desired state information (encoding desired joint positions and velocities) conveyed by the motor cortex (Saint-Cyr, 1983) and actual state information (encoding actual joint positions and velocities) conveyed by the afferent sensory pathways, e.g., by the external cuneate nucleus concerning tactile and proprioceptive signals (Berkley and Hand, 1978; Molinari et al., 1996). This choice was supported by a computational model of the IO, which showed that the IO can indeed compare incoming signals (De Gruijl et al., 2012). It should be noted that alternative solutions to the distal error problem can be envisaged (Jordan and Rumelhart, 1992; Kawato, 1999), provided that PC activity saturates when the MF-DCN and PC-DCN weights are not properly tuned.
(3) We used cerebellar feedback to correct the actual movement and we assumed that the teaching signal comes only through the CFs. However, there are indications that cerebellar feedback is also reverberated to the motor cortex (Kawato et al., 1987; Siciliano and Khatib, 2008), and some investigations suggest that the teaching signal is also received and correlated at the granular layer level (Krichmar et al., 1997; Kistler and Leo van Hemmen, 1999; Anastasio, 2001; Rothganger and Anastasio, 2009). The introduction of these elements is expected to increase the level of flexibility in motor control and learning.
(4) We did not include the basal ganglia in our system controller. Recent evidence has suggested the existence of di-synaptic pathways connecting the cerebellum with the basal ganglia (Bostan et al., 2013). Both cerebellum (Swain et al., 2011) and basal ganglia (Bellebaum et al., 2008) have been suggested to contribute to reward-related learning tasks, but how these subsystems interact and reciprocally improve their operations remains an open issue.
(5) We assumed that PF-PC plasticity tends to saturate toward LTP and that salient codes are stored when the CFs drive plasticity toward LTD at specific synapses. This mechanism could correspond to classical postsynaptic LTD (Márquez-Ruiz and Cheron, 2012) coupled with presynaptic LTP (Gao et al., 2012). The effectiveness of this core plasticity mechanism could be extended through multiple forms of LTP and LTD occurring at the PF-PC synapses and could be integrated with the inhibitory role played by MLIs (Wulff et al., 2009). MF-DCN and PC-DCN plasticity is implemented according to principles set out elsewhere (Medina and Mauk, 2000; Masuda and Amari, 2008). In our model, MF-DCN LTD followed increased PC activity. The full mechanism would comprise a secondary DCN spike increase through a rebound mechanism (Pugh and Raman, 2006), but this was irrelevant at our spike-less modeling level. Similarly, other details about the mechanisms of plasticity have not been applied. It remains to be established whether a biologically precise representation of plasticity mechanisms (e.g., Solinas et al., 2010) might modify the core conclusion of this model.
(6) LTP and LTD between MFs and GCs have been shown to occur in slice experiments (D'Angelo et al., 1999; Armano et al., 2000; Maffei et al., 2002; Rossi et al., 2002; Sola et al., 2004; Gall et al., 2005; Mapelli and D'Angelo, 2007) and in vivo (Roggeri et al., 2008). However, the inclusion of granular layer LTP and LTD (Hansel et al., 2001) in a biologically realistic scenario would require (i) definition of the learning rules and teaching signals through the MFs (e.g., see D'Errico et al., 2009), (ii) definition of the spatiotemporal organization of the granular layer activity (D'Angelo, 2011; D'Angelo and Casali, 2012; D'Angelo et al., 2013; Garrido et al., 2013), and (iii) introduction of an explicit representation of spike timing (Nieus et al., 2006; D'Angelo and De Zeeuw, 2009). It has been suggested that MF-GC LTP and LTD, in conjunction with GC intrinsic plasticity and regulation of GoC–GC synaptic weights, could improve the learning capabilities of the system in target-reaching tasks (Schweighofer et al., 2001). In general, this hypothesis on the granular layer is compatible with the present model. Indeed, the labeled-line coding scheme that our model implements in the granular layer (Figure 2) can be seen as a particular case of sparse coding (although it is not very efficient in terms of the number of cells required to represent multiple states). Recent discoveries have revealed that sparse coding in the granular layer is related to the amount of GCs available for a particular task (Galliano et al., 2013). Our model, in fact, represents an extreme case of this hypothesis in which the population of GCs is so extensive that each PF encoded a unique non-recurrent condition. Moreover, it has been shown that the same GC can receive convergent inputs from proprioceptive sensory pathways coming from the external cuneate nucleus and efferent motor copies coming from the cerebral cortex via the pontine nucleus (Huang et al., 2013). In previous studies we already predicted that multi-modal information in the GCs could improve state representation capabilities (and, as a consequence, manipulation performance) in a non-adaptive model of the granular layer (Luque et al., 2011a). The development of a cerebellar model accounting for all these discoveries in the granular layer would require the use of realistic models implementing synaptic plasticity mechanisms and managing spike information (Solinas et al., 2010; Luque et al., 2011b,c). The integration of the present model into a spike-timing computational scheme including MF-GC plasticity rule remains a future challenge.
Theoretical Implications
This model has been conceived in order to be simple enough to become mathematically tractable while, at the same time, including salient properties of the system so as to retain its links with biology. In this sense it lies halfway between a classical black-box model and a realistic biological model. A non-trivial consequence of the way the model is constructed is that of providing a theoretical explanation for DCN plasticity, which increases cerebellar adaptable solutions. Moreover, this model could be compared to prototypical cases elaborated for dynamic neural networks (Spitzer, 2000; Hoellinger et al., 2013). In these networks, learning of complex tasks is better accomplished when the number of hidden neurons increases, as they form complex categories that are needed to interpret the multi-parametric input space. In the cerebellar network, the hidden units could intervene at different levels, including that of GCs lying between extracerebellar neurons and PCs, PCs lying between GCs and DCN, and also GoCs or MLIs in their respective subcircuits. In fact, extrapolation from theoretical works is limited by several biological constraints. For example, category formation is probably much more efficient in PCs than in GCs given the 105 higher number of inputs in the PCs than in GCs, however there are many more GCs than PCs, and this results in a delicate balance between these cell types (the issue dates back to the seminal work of Marr, 1969). Conversely, GoCs and MLIs could implement exclusive-or (XOR) hidden layers, as suggested by experimental network analysis (Mapelli et al., 2010; Solinas et al., 2010). Moreover, PCs make synaptic connections with adjacent PCs through axonal collaterals suggesting that self-organizing properties might emerge in the molecular layer.
It should be noted that theoretical networks are oversimplified compared to the cerebellar model presented herein. For example, in Hoellinger's network plasticity can change the synapse from excitatory to inhibitory, connections are all-to-all, and gain and timing are stored in the same synapse (Hoellinger et al., 2013). A complementary step will be the inclusion of spiking dynamics, through the use of realistic network models (D'Angelo et al., 2009; Garrido et al., 2013). In this way, the implications of physiology (i.e., the role of the inhibitory PC collaterals, the complex structure of the PC dendritic tree and the operation of DCN cells with their characteristic postsynaptic rebounds) will be fully addressed.
Conclusions
This model proposes a plausible explanation on how multiple plasticity sites, including the PF-PC and the MF-DCN and PC-DCN synapses, may effectively implement cerebellar gain control. According to the proposed model, distributed synaptic plasticity implements a gain controller, which (i) is self-adaptable, i.e., automatically rescales as a function of the manipulated masses over a large dynamic range, (ii) operates over multiple time scales, i.e., accounts for fast learning of time correlations and for subsequent gain consolidation, and (iii) improves learning accuracy and precision. These functions can be partly separated: the PF-PC synapse is suggested to operate mostly as a time correlator, while gain is more effectively regulated in DCN afferent synapses under PC control. In this way, time correlation and gain can be partially processed and stored independently. This organization of learning could explain the impact of genetic mutations impairing plasticity at cerebellar synapses. Indeed, irrespective of the specific synaptic plasticity mechanism involved (be it in the granular layer, molecular layer or DCN), transgenic mice bearing LTP or LTD alterations show deficits in cerebellar-related behavior and learning. However, the learning of timing and gain appear to be differentially affected, revealing that processing of these two components of learning are at least partially segregated (for a review see Boyden et al., 2004; Gao et al., 2012). Finally, it should be noted that the coexistence of fast and slow learning mechanisms can be reconciled with the double time-scale phenomenological model of learning proposed by Shadmehr and Mussa-Ivaldi (2012), which has been proposed to depend on localization of a fast learning process in the PF-PC synapse and a slower one in the DCN afferent synapses (Medina and Mauk, 1999; Medina et al., 2000).
A controller with distributed plasticity is convenient from a system designer's point of view, since it allows efficient adjustment of the corrective signal regardless of the dynamic features of the manipulated object and of the way it affects the dynamics of the arm plant involved. It should be noted that the adaptation mechanism adopted herein is not constrained to any specific plant or testing framework, and could therefore be extrapolated to other common testing paradigms like EBCC and the VOR. In order to do so, further details may be added to the model accounting for specific synaptic plasticity mechanisms and circuits involved in the different learning processes.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by grants of European Union to Egidio D'Angelo (CEREBNET FP7-ITN238686, REALNET FP7-ICT270434) and by a grant of the Italian Ministry of Health to Egidio D'Angelo (RF-2009-1475845). We thank G. Ferrari and M. Rossin for technical support.
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fncir.2013.00159/abstract
Movie S1 | Learning simulation, joint-1-related activity and weight evolution during manipulation of a 10-kg load. Simulations were carried out using all the plasticity mechanisms (PF-PC, MF-DCN, and PC-DCN) along 1000 trials. Only 1 every 10 trials is shown. The movement has been recorded in real-time (each trial lasts 1 s) evidencing the difficulty of the task. (top left) 3D view of the actual (black) and desired (red) robot end-effector trajectory in Cartesian coordinates. (medium left) Ideal (dotted lines) and actual (solid lines) corrective torques during the current trial for joint 1 (blue), 2 (red), and 3 (green). (bottom left) Evolution of the MAE. (top right) Evolution of four randomly chosen PF-PC synaptic weights. (second to fifth rows right) Evolution of PC activity, DCN activity, MF-DCN, and PC-DCN synaptic weights related to joint 1 agonist (solid line) and antagonist (dotted line) muscles. Note that, at the end of learning, joint-1 DCN neurons provided higher corrective torques to the antagonist muscle during the first half of the trial and to the agonist muscle during the second half of the trial.
Movie S2 | Learning simulation, joint-2-related activity and weight evolution during manipulation of a 10-kg load. Simulations were carried out using all the plasticity mechanisms (PF-PC, MF-DCN, and PC-DCN) along 1000 trials. Only 1 every 10 trials is shown. The movement has been recorded in real-time (each trial lasts 1 s) evidencing the difficulty of the task. (top left) 3D view of the actual (black) and desired (red) robot end-effector trajectory in Cartesian coordinates. (medium left) Ideal (dotted lines) and actual (solid lines) corrective torques during the current trial for joint 1 (blue), 2 (red), and 3 (green). (bottom left) Evolution of the MAE. (top right) Evolution of four randomly chosen PF-PC synaptic weights. (second to fifth rows right) Evolution of PC activity, DCN activity, MF-DCN, and PC-DCN synaptic weights related to joint 2 agonist (solid line) and antagonist (dotted line) muscles. Differently from what observed for joint 1, at the end of learning, joint-2 DCN neurons provided higher corrective torques to the agonist muscle during the whole trial.
Movie S3 | Learning simulation, joint-3-related activity and weight evolution during manipulation of a 10-kg load. Simulations were carried out using all the plasticity mechanisms (PF-PC, MF-DCN, and PC-DCN) along 1000 trials. Only 1 every 10 trials is shown. The movement has been recorded in real-time (each trial lasts 1 s) evidencing the difficulty of the task. (top left) 3D view of the actual (black) and desired (red) robot end-effector trajectory in Cartesian coordinates. (medium left) Ideal (dotted lines) and actual (solid lines) corrective torques during the current trial for joint 1 (blue), 2 (red), and 3 (green). (bottom left) Evolution of the MAE. (top right) Evolution of four randomly chosen PF-PC synaptic weights. (second to fifth rows right) Evolution of PC activity, DCN activity, MF-DCN and PC-DCN synaptic weights related to joint 3 agonist (solid line) and antagonist (dotted line) muscles. Similarly to what observed for joint 2, joint 3 corrective torques provided by DCN neurons were dominated by agonist muscle activity, but different gain values were provided with respect to joint 2.
Abbreviations
PF, parallel fiber; MF, mossy fiber; CF, climbing fiber; GC, granule cell; GoC, Golgi cell; PC, Purkinje cell; DCN, deep cerebellar nuclei; VN, vestibular nuclei; IO, inferior olive; MLI, molecular layer interneuron; EBCC, eye-blink classical conditioning; VOR, vestibule-occular reflex; MAE, mean average error.
References
Aizenman, C. D., Manis, P. B., and Linden, D. J. (1998). Polarity of long-term synaptic gain change is related to postsynaptic spike firing at a cerebellar inhibitory synapse. Neuron 21, 827–835. doi: 10.1016/S0896-6273(00)80598-X
Albus, J. S. (1971). A theory of cerebellar function. Math. Biosci. 10, 25–61. doi: 10.1016/0025-5564(71)90051-4
Albu-Schäffer, A., Eiberger, O., Fuchs, M., Grebenstein, M., Haddadin, S., Ott, C., et al. (2011). Anthropomorphic soft robotics–from torque control to variable intrinsic compliance. Rob. Res. 70, 185–207. doi: 10.1007/978-3-642-19457-3_12
Albu-Schäffer, A., Haddadin, S., Ott, C., Stemmer, A., Wimböck, T., and Hirzinger, G. (2007). The DLR lightweight robot: design and control concepts for robots in human environments. Ind. Rob. Int. J. 34, 376–385. doi: 10.1108/01439910710774386
Anastasio, T. J. (2001). Input minimization: a model of cerebellar learning without climbing fiber error signals. Neuroreport 12, 3825. doi: 10.1097/00001756-200112040-00045
Armano, S., Rossi, P., Taglietti, V., and D'Angelo, E. (2000). Long-term potentiation of intrinsic excitability at the mossy fiber-granule cell synapse of rat cerebellum. J. Neurosci. 20, 5208.
Bagnall, M. W., and du Lac, S. (2006). A new locus for synaptic plasticity in cerebellar circuits. Neuron 51, 5–7. doi: 10.1016/j.neuron.2006.06.014
Bazzigaluppi, P., De Gruijl, J. R., van der Giessen, R. S., Khosrovani, S., De Zeeuw, C. I., and de Jeu, M. T. (2012). Olivary subthreshold oscillations and burst activity revisited. Front. Neural Circuits 6:91. doi: 10.3389/fncir.2012.00091
Bellebaum, C., Koch, B., Schwarz, M., and Daum, I. (2008). Focal basal ganglia lesions are associated with impairments in reward-based reversal learning. Brain 131, 829–841. doi: 10.1093/brain/awn011
Berkley, K., and Hand, P. (1978). Projections to the inferior olive of the cat II. Comparisons of input from the gracile, cuneate and the spinal trigeminal nuclel. J. Comp. Neurol. 180, 253–264. doi: 10.1002/cne.901800205
Bliss, T. V., and Collingridge, G. L. (1993). A synaptic model of memory: long-term potentiation in the hippocampus. Nature 361, 31–39. doi: 10.1038/361031a0
Bona, B., and Curatella, A. (2005). “Identification of industrial robot parameters for advanced model-based controllers design,” in Robotics and Automation, 2005. ICRA 2005. Proceedings of the 2005 IEEE International Conference on (IEEE), (Barcelona), 1681–1686.
Bostan, A. C., Dum, R. P., and Strick, P. L. (2013). Cerebellar networks with the cerebral cortex and basal ganglia. Trends Cogn. Sci. 17, 241–254. doi: 10.1016/j.tics.2013.03.003
Boyden, E. S., Katoh, A., and Raymond, J. L. (2004). Cerebellum-dependent learning: the role of multiple plasticity mechanisms. Neuroscience 27, 581–609. doi: 10.1146/annurev.neuro.27.070203.144238
Brashers-Krug, T., Shadmehr, R., and Bizzi, E. (1996). Consolidation in human motor memory. Nature 382, 252–255. doi: 10.1038/382252a0
Cheron, G., Dufief, M. P., Gerrits, N. M., Draye, J. P., and Godaux, E. (1997). Behavioural analysis of Purkinje cell output from the horizontal zone of the cat flocculus. Prog. Brain Res. 114, 347–356. doi: 10.1016/S0079-6123(08)63374-9
Coesmans, M., Weber, J. T., De Zeeuw, C. I., and Hansel, C. (2004). Bidirectional parallel fiber plasticity in the cerebellum under climbing fiber control. Neuron 44, 691–700. doi: 10.1016/j.neuron.2004.10.031
D'Angelo, E. (2011). Neural circuits of the cerebellum: Hypothesis for function. J. Integr. Neurosci. 10, 317–352. doi: 10.1142/S0219635211002762
D'Angelo, E., and Casali, S. (2012). Seeking a unified framework for cerebellar function and dysfunction: from circuit operations to cognition. Front. Neural Circuits 6:116. doi: 10.3389/fncir.2012.00116
D'Angelo, E., and De Zeeuw, C. I. (2009). Timing and plasticity in the cerebellum: focus on the granular layer. Trends Neurosci. 32, 30–40. doi: 10.1016/j.tins.2008.09.007
D'Angelo, E., Koekkoek, S. K. E., Lombardo, P., Solinas, S., Ros, E., Garrido, J., et al. (2009). Timing in the cerebellum: oscillations and resonance in the granular layer. Neuroscience 162, 805–815. doi: 10.1016/j.neuroscience.2009.01.048
D'Angelo, E., Rossi, P., Armano, S., and Taglietti, V. (1999). Evidence for NMDA and mGlu receptor-dependent long-term potentiation of mossy fiber-granule cell transmission in rat cerebellum. J. Neurophysiol. 81, 277.
D'Angelo, E., Solinas, S., Mapelli, J., Gandolfi, D., Mapelli, L., and Prestori, F. (2013). The cerebellar Golgi cell and spatiotemporal organization of granular layer activity. Front. Neural Circuits 7:93. doi: 10.3389/fncir.2013.00093
D'Errico, A., Prestori, F., and D'Angelo, E. (2009). Differential induction of bidirectional long-term changes in neurotransmitter release by frequency-coded patterns at the cerebellar input. J. Physiol. 587, 5843–5857. doi: 10.1113/jphysiol.2009.177162
De Gruijl, J. R., Bazzigaluppi, P., de Jeu, M. T., and De Zeeuw, C. I. (2012). Climbing fiber burst size and olivary sub-threshold oscillations in a network setting. PLoS Comput. Biol. 8:e1002814. doi: 10.1371/journal.pcbi.1002814
De Zeeuw, C. I., and Yeo, C. H. (2005). Time and tide in cerebellar memory formation. Curr. Opin. Neurobiol. 15, 667–674. doi: 10.1016/j.conb.2005.10.008
Dean, P., Porrill, J., Ekerot, C. F., and Jörntell, H. (2009). The cerebellar microcircuit as an adaptive filter: experimental and computational evidence. Nat. Rev. Neurosci. 11, 30–43. doi: 10.1038/nrn2756
Diedrichsen, J., Hashambhoy, Y., Rane, T., and Shadmehr, R. (2005). Neural correlates of reach errors. J. Neurosci. 25, 9919–9931. doi: 10.1523/JNEUROSCI.1874-05.2005
Ebner, T., and Pasalar, S. (2008). Cerebellum predicts the future motor state. Cerebellum 7, 583–588. doi: 10.1007/s12311-008-0059-3
Escudero, M., Cheron, G., and Godaux, E. (1996). Discharge properties of brain stem neurons projecting to the flocculus in the alert cat. II. Prepositus hypoglossal nucleus. J. Neurophysiol. 76, 1775–1785.
Fujita, M. (1982). Adaptive filter model of the cerebellum. Biol. Cybern. 45, 195–206. doi: 10.1007/BF00336192
Gall, D., Prestori, F., Sola, E., D'Errico, A., Roussel, C., Forti, L., et al. (2005). Intracellular calcium regulation by burst discharge determines bidirectional long-term synaptic plasticity at the cerebellum input stage. J. Neurosci. 25, 4813. doi: 10.1523/JNEUROSCI.0410-05.2005
Galliano, E., Gao, Z., Schonewille, M., Todorov, B., Simons, E., Pop, A. S., et al. (2013). Silencing the majority of cerebellar granule cells uncovers their essential role in motor learning and consolidation. Cell Rep. 3, 1239–1251. doi: 10.1016/j.celrep.2013.03.023
Gao, Z., van Beugen, B. J., and De Zeeuw, C. I. (2012). Distributed synergistic plasticity and cerebellar learning. Nat. Rev. Neurosci. 13, 619–635. doi: 10.1038/nrn3312
Garrido, J. A., Ros, E., and D'Angelo, E. (2013). Spike timing regulation on the millisecond scale by distributed synaptic plasticity at the cerebellum input stage: a simulation study. Front. Comput. Neurosci. 7:64. doi: 10.3389/fncom.2013.00064
Haith, A., and Vijayakumar, S. (2007). “Robustness of VOR and OKR adaptation under kinematics and dynamics transformations,” in Development and Learning, 2007. ICDL 2007. IEEE 6th International Conference on, (London), 37–42.
Hansel, C., Linden, D. J., and Angelo, E. D. (2001). Beyond parallel fiber LTD: the diversity of synaptic and non-synaptic plasticity in the cerebellum. Nat. Neurosci. 4, 467–476.
Hoellinger, T., Petieau, M., Duvinage, M., Castermans, T., Seetharaman, K., Cebolla, A. M., et al. (2013). Biological oscillations for learning walking coordination: dynamic recurrent neural network functionally models physiological central pattern generator. Front. Comput. Neurosci. 7:70. doi: 10.3389/fncom.2013.00070
Hoffmann, H., Petkos, G., Bitzer, S., and Vijayakumar, S. (2007). “Sensor-assisted adaptive motor control under continuously varying context. Icinco 2007,” in Proceedings of the Fourth International Conference on Informatics in Control, Automation and Robotics, Vol Icso, (Angers), 262–269.
Houk, J. C., Buckingham, J. T., and Barto, A. G. (1996). Models of the cerebellum and motor learning. Behav. Brain Sci. 19, 368–383. doi: 10.1017/S0140525X00081474
Huang, C. C., Sugino, K., Shima, Y., Guo, C., Bai, S., Mensh, B. D., et al. (2013). Convergence of pontine and proprioceptive streams onto multimodal cerebellar granule cells. Elife 2, e00400. doi: 10.7554/eLife.00400
Hwang, E. J., and Shadmehr, R. (2005). Internal models of limb dynamics and the encoding of limb state. J. Neural Eng. 2, S266. doi: 10.1088/1741-2560/2/3/S09
Imamizu, H., Miyauchi, S., Tamada, T., Sasaki, Y., Takino, R., Pütz, B., et al. (2000). Human cerebellar activity reflecting an acquired internal model of a new tool. Nature 403, 192–195. doi: 10.1038/35003194
Ito, M. (2001). Cerebellar long-term depression: characterization, signal transduction, and functional roles. Physiol. Rev. 81, 1143–1195.
Ito, M. (2013). Error detection and representation in the olivo-cerebellar system. Front. Neural Circuits 7:1. doi: 10.3389/fncir.2013.00001
Ito, M., and Kano, M. (1982). Long-lasting depression of parallel fiber-Purkinje cell transmission induced by conjunctive stimulation of parallel fibers and climbing fibers in the cerebellar cortex. Neurosci. Lett. 33, 253–258. doi: 10.1016/0304-3940(82)90380-9
Izawa, J., Pekny, S. E., Marko, M. K., Haswell, C. C., Shadmehr, R., and Mostofsky, S. H. (2012). Motor learning relies on integrated sensory inputs in ADHD, but over−selectively on proprioception in autism spectrum conditions. Autism Res. 5, 124–136. doi: 10.1002/aur.1222
Jordan, M. I., and Rumelhart, D. E. (1992). Forward models: supervised learning with a distal teacher. Cogn. Sci. 16, 307–354. doi: 10.1207/s15516709cog1603_1
Kawato, M. (1999). Internal models for motor control and trajectory planning. Curr. Opin. Neurobiol. 9, 718–727. doi: 10.1016/S0959-4388(99)00028-8
Kawato, M., Furukawa, K., and Suzuki, R. (1987). A hierarchical neural-network model for control and learning of voluntary movement. Biol. Cybern. 57, 169–185. doi: 10.1007/BF00364149
Khalil, W., and Dombre, E. (2004). Modeling, Identification and Control of Robots. Oxford: Butterworth-Heinemann.
Kistler, W. M., and Leo van Hemmen, J. (1999). Delayed reverberation through time windows as a key to cerebellar function. Biol. Cybern. 81, 373–380. doi: 10.1007/s004220050569
Kitazawa, S., Kimura, T., and Yin, P. B. (1998). Cerebellar complex spikes encode both destinations and errors in arm movements. Nature 392, 494–497. doi: 10.1038/33141
Krichmar, J., Ascoli, G., Hunter, L., and Olds, J. (1997). A model of cerebellar saccadic motor learning using qualitative reasoning. Biol. Artif. Comput. Neurosci. Tech. 1240, 133–145. doi: 10.1007/BFb0032471
Lepora, N. F., Porrill, J., Yeo, C. H., and Dean, P. (2010). Sensory prediction or motor control. Application of marr-albus type models of cerebellar function to classical conditioning. Front. Comput. Neurosci. 4:140. doi: 10.3389/fncom.2010.00140
Lisberger, S. G., and Fuchs, A. F. (1978). Role of primate flocculus during rapid behavioral modification of vestibuloocular reflex. I. Purkinje cell activity during visually guided horizontal smooth-pursuit eye movements and passive head rotation. J. Neurophysiol. 41, 733–763.
Luque, N. R., Garrido, J. A., Carrillo, R. R., Coenen, O. J., and Ros, E. (2011a). Cerebellar input configuration toward object model abstraction in manipulation tasks. IEEE Trans. Neural Netw. 22, 1321–1328. doi: 10.1109/TNN.2011.2156809
Luque, N. R., Garrido, J. A., Carrillo, R. R., Coenen, O. J., and Ros, E. (2011b). Cerebellarlike corrective model inference engine for manipulation tasks. IEEE Trans. Syst. Man Cybern. B Cybern. 41, 1–14. doi: 10.1109/TSMCB.2011.2138693
Luque, N. R., Garrido, J. A., Carrillo, R. R., Tolu, S., and Ros, E. (2011c). Adaptive cerebellar spiking model embedded in the control loop: context switching and robustness against noise. Int. J. Neural Syst. 21, 385–401. doi: 10.1142/S0129065711002900
Maffei, A., Prestori, F., Rossi, P., Taglietti, V., and D'Angelo, E. (2002). Presynaptic current changes at the mossy fiber–granule cell synapse of cerebellum during LTP. J. Neurophysiol. 88, 627.
Manto, M., Bower, J. M., Conforto, A. B., Delgado-García, J. M., da Guarda, S. N., Gerwig, M., et al. (2012). Consensus paper: roles of the cerebellum in motor control–the diversity of ideas on cerebellar involvement in movement. Cerebellum 11, 457–487. doi: 10.1007/s12311-011-0331-9
Mapelli, J., and D'Angelo, E. (2007). The spatial organization of long-term synaptic plasticity at the input stage of cerebellum. J. Neurosci. 27, 1285. doi: 10.1523/JNEUROSCI.4873-06.2007
Mapelli, J., Gandolfi, D., and D'Angelo, E. (2010). Combinatorial responses controlled by synaptic inhibition in the cerebellum granular layer. J. Neurophysiol. 103, 250. doi: 10.1152/jn.00642.2009
Márquez-Ruiz, J., and Cheron, G. (2012). Sensory stimulation-dependent plasticity in the cerebellar cortex of alert mice. PLoS ONE 7:e36184. doi: 10.1371/journal.pone.0036184
Masuda, N., and Amari, S. (2008). A computational study of synaptic mechanisms of partial memory transfer in cerebellar vestibulo-ocular-reflex learning. J. Comput. Neurosci. 24, 137–156. doi: 10.1007/s10827-007-0045-7
Medina, J. F., Garcia, K. S., Nores, W. L., Taylor, N. M., and Mauk, M. D. (2000). Timing mechanisms in the cerebellum: testing predictions of a large-scale computer simulation. J. Neurosci. 20, 5516–5525.
Medina, J. F., and Lisberger, S. G. (2009). Encoding and decoding of learned smooth-pursuit eye movements in the floccular complex of the monkey cerebellum. J. Neurophysiol. 102, 2039–2054. doi: 10.1152/jn.00075.2009
Medina, J. F., and Mauk, M. D. (1999). Simulations of cerebellar motor learning: computational analysis of plasticity at the mossy fiber to deep nucleus synapse. J. Neurosci. 19, 7140–7151.
Medina, J. F., and Mauk, M. D. (2000). Computer simulation of cerebellar information processing. Nat. Neurosci. 3, 1205–1211. doi: 10.1038/81486
Middleton, F. A., and Strick, P. L. (2000). Basal ganglia and cerebellar loops: motor and cognitive circuits. Brain Res. Brain Res. Rev. 31, 236–250. doi: 10.1016/S0165-0173(99)00040-5
Molinari, H. H., Schultze, K. E., and Strominger, N. L. (1996). Gracile, cuneate, and spinal trigeminal projections to inferior olive in rat and monkey. J. Comp. Neurol. 375, 467–480. doi: 10.1002/(SICI)1096-9861(19961118)375:3<467::AID-CNE9>3.0.CO;2-0
Morishita, W., and Sastry, B. R. (1996). Postsynaptic mechanisms underlying long-term depression of GABAergic transmission in neurons of the deep cerebellar nuclei. J. Neurophysiol. 76, 59–68.
Nakano, E., Imamizu, H., Osu, R., Uno, Y., Gomi, H., Yoshioka, T., et al. (1999). Quantitative examinations of internal representations for arm trajectory planning: minimum commanded torque change model. J. Neurophysiol. 81, 2140–2155.
Nieus, T., Sola, E., Mapelli, J., Saftenku, E., Rossi, P., and D'Angelo, E. (2006). LTP regulates burst initiation and frequency at mossy fiber–granule cell synapses of rat cerebellum: experimental observations and theoretical predictions. J. Neurophysiol. 95, 686. doi: 10.1152/jn.00696.2005
Ohyama, T., Nores, W. L., Medina, J. F., Riusech, F. A., and Mauk, M. D. (2006). Learning-induced plasticity in deep cerebellar nucleus. J. Neurosci. 26, 12656–12663. doi: 10.1523/JNEUROSCI.4023-06.2006
Ouardouz, M., and Sastry, B. R. (2000). Mechanisms underlying LTP of inhibitory synaptic transmission in the deep cerebellar nuclei. J. Neurophysiol. 84, 1414–1421.
Porrill, J., and Dean, P. (2007). Cerebellar motor learning: when is cortical plasticity not enough. PLoS Comput. Biol. 3:e197. doi: 10.1371/journal.pcbi.0030197
Porrill, J., Dean, P., and Stone, J. V. (2004). Recurrent cerebellar architecture solves the motor-error problem. Proc. R. Soc. Lond. B 271, 789–796. doi: 10.1098/rspb.2003.2658
Pugh, J. R., and Raman, I. M. (2006). Potentiation of mossy fiber EPSCs in the cerebellar nuclei by NMDA receptor activation followed by postinhibitory rebound current. Neuron 51, 113–123. doi: 10.1016/j.neuron.2006.05.021
Racine, R., Wilson, D., Gingell, R., and Sunderland, D. (1986). Long-term potentiation in the interpositus and vestibular nuclei in the rat. Exp. Brain Res. 63, 158–162. doi: 10.1007/BF00235658
Roggeri, L., Rivieccio, B., Rossi, P., and D'Angelo, E. (2008). Tactile stimulation evokes long-term synaptic plasticity in the granular layer of cerebellum. J. Neurosci. 28, 6354–6359. doi: 10.1523/JNEUROSCI.5709-07.2008
Roitman, A. V., Pasalar, S., and Ebner, T. J. (2009). Single trial coupling of Purkinje cell activity to speed and error signals during circular manual tracking. Exp. Brain. Res. 192, 241–251. doi: 10.1007/s00221-008-1580-9
Rossi, P., Sola, E., Taglietti, V., Borchardt, T., Steigerwald, F., Utvik, K., et al. (2002). Cerebellar synaptic excitation and plasticity require proper NMDA receptor positioning and density in granule cells. J. Neurosci. 22, 9687–9697.
Rothganger, F. H., and Anastasio, T. J. (2009). Using input minimization to train a cerebellar model to simulate regulation of smooth pursuit. Biol. Cybern. 101, 339–359. doi: 10.1007/s00422-009-0340-7
Saint-Cyr, J. (1983). The projection from the motor cortex to the inferior olive in the cat: an experimental study using axonal transport techniques. Neuroscience 10, 667–684. doi: 10.1016/0306-4522(83)90209-9
Sawtell, N. B. (2010). Multimodal integration in granule cells as a basis for associative plasticity and sensory prediction in a cerebellum-like circuit. Neuron 66, 573–584. doi: 10.1016/j.neuron.2010.04.018
Schweighofer, N., Arbib, M. A., and Dominey, P. F. (1996a). A model of the cerebellum in adaptive control of saccadic gain. I. The model and its biological substrate. Biol. Cybern. 75, 19–28. doi: 10.1007/BF00238736
Schweighofer, N., Arbib, M. A., and Dominey, P. F. (1996b). A model of the cerebellum in adaptive control of saccadic gain. II. Simulation results. Biol. Cybern. 75, 29–36. doi: 10.1007/BF00238737
Schweighofer, N., Arbib, M. A., and Kawato, M. (1998a). Role of the cerebellum in reaching movements in humans. I. Distributed inverse dynamics control. Eur. J. Neurosci. 10, 86–94. doi: 10.1046/j.1460-9568.1998.00006.x
Schweighofer, N., Spoelstra, J., Arbib, M. A., and Kawato, M. (1998b). Role of the cerebellum in reaching movements in humans. II. A neural model of the intermediate cerebellum. Eur. J. Neurosci. 10, 95–105. doi: 10.1046/j.1460-9568.1998.00007.x
Schweighofer, N., Doya, K., and Lay, F. (2001). Unsupervised learning of granule cell sparse codes enhances cerebellar adaptive control. Neuroscience 103, 35–50. doi: 10.1016/S0306-4522(00)00548-0
Shadmehr, R., and Brashers-Krug, T. (1997). Functional stages in the formation of human long-term motor memory. J. Neurosci. 17, 409–419.
Shadmehr, R., and Holcomb, H. H. (1997). Neural correlates of motor memory consolidation. Science 277, 821–825. doi: 10.1126/science.277.5327.821
Shadmehr, R., and Krakauer, J. W. (2008). A computational neuroanatomy for motor control. Exp. Brain Res. 185, 359–381. doi: 10.1007/s00221-008-1280-5
Shadmehr, R., and Mussa-Ivaldi, S. (2012). Biological Learning and Control: How the Brain Builds Representations, Predicts Events, and Makes Decisions. Cambridge, MA: Mit Press.
Siciliano, B., and Khatib, O. (2008). Springer Handbook of Robotics; Part G. Human-Centered and Life-like Robotics. New York, NY: Springer-Verlag New York Inc. doi: 10.1007/978-3-540-30301-5
Sola, E., Prestori, F., Rossi, P., Taglietti, V., and D'Angelo, E. (2004). Increased neurotransmitter release during long-term potentiation at mossy fibre-granule cell synapses in rat cerebellum. J. Physiol. 557, 843. doi: 10.1113/jphysiol.2003.060285
Solinas, S., Nieus, T., and D'Angelo, E. (2010). A realistic large-scale model of the cerebellum granular layer predicts circuit spatio-temporal filtering properties. Front. Cell. Neurosci. 4:12. doi: 10.3389/fncel.2010.00012
Spencer, R. M. C., Ivry, R. B., and Zelaznik, H. N. (2005). Role of the cerebellum in movements: control of timing or movement transitions. Exp. Brain Res. 161, 383–396. doi: 10.1007/s00221-004-2088-6
Spitzer, M. (2000). “Hidden layers,” in The Mind Within the Net: Models of Learning, Thinking and Acting, ed M. Spitzer (Cambridge, MA: The MIT press), 115–136.
Spoelstra, J., Schweighofer, N., and Arbib, M. A. (2000). Cerebellar learning of accurate predictive control for fast-reaching movements. Biol. Cybern. 82, 321–333. doi: 10.1007/s004220050586
Swain, R. A., Kerr, A. L., and Thompson, R. F. (2011). The cerebellum: a neural system for the study of reinforcement learning. Front. Behav. Neurosci. 5:8. doi: 10.3389/fnbeh.2011.00008
Thach, W. (1996). On the specific role of the cerebellum in motor learning and cognition: clues from PET activation and lesion studies in man. Behav. Brain Sci. 19, 411–433. doi: 10.1017/S0140525X00081504
Todorov, E. (2004). Optimality principles in sensorimotor control (review). Nat. Neurosci. 7, 907–915. doi: 10.1038/nn1309
Tolu, S., Vanegas, M., Garrido, J. A., Luque, N. R., and Ros, E. (2013). Adaptive and predictive control of a simulated robot arm. Int. J. Neural Syst. 23, 1–15. doi: 10.1142/S012906571350010X
Tseng, Y. W., Diedrichsen, J., Krakauer, J. W., Shadmehr, R., and Bastian, A. J. (2007). Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J. Neurophysiol. 98, 54–62. doi: 10.1152/jn.00266.2007
Uno, Y., Kawato, M., and Suzuki, R. (1989). Formation and control of optimal trajectory in human multijoint arm movement. Minimum torque-change model. Biol. Cybern. 61, 89–101. doi: 10.1007/BF00204593
van der Smagt, P. (2000). Benchmarking cerebellar control. Rob. Auton. Syst. 32, 237–251. doi: 10.1016/S0921-8890(00)00090-7
Van Kan, P. L., Houk, J. C., and Gibson, A. R. (1993). Output organization of intermediate cerebellum of the monkey. J. Neurophysiol. 69, 57.
Wallman, J., and Fuchs, A. F. (1998). Saccadic gain modification: visual error drives motor adaptation. J. Neurophysiol. 80, 2405–2416.
Wang, J., Dam, G., Yildirim, S., Rand, W., Wilensky, U., and Houk, J. C. (2008). Reciprocity between the cerebellum and the cerebral cortex: nonlinear dynamics in microscopic modules fop generating voluntary motor commands. Complexity 14, 29–45. doi: 10.1002/cplx.20241
Weiss, E. J., and Flanders, M. (2011). Somatosensory comparison during haptic tracing. Cereb. Cortex 21, 425–434. doi: 10.1093/cercor/bhq110
Wolpert, D. M., and Ghahramani, Z. (2000). Computational principles of movement neuroscience. Nat. Neurosci. 3, 1212–1217. doi: 10.1038/81497
Wolpert, D. M., Miall, R. C., and Kawato, M. (1998). Internal models in the cerebellum. Trends Cogn. Sci. 2, 338–347. doi: 10.1016/S1364-6613(98)01221-2
Wulff, P., Schonewille, M., Renzi, M., Viltono, L., Sassoè-Pognetto, M., Badura, A., et al. (2009). Synaptic inhibition of Purkinje cells mediates consolidation of vestibulo-cerebellar motor learning. Nat. Neurosci. 12, 1042–1049. doi: 10.1038/nn.2348
Xu-Wilson, M., Chen-Harris, H., Zee, D. S., and Shadmehr, R. (2009). Cerebellar contributions to adaptive control of saccades in humans. J. Neurosci. 29, 12930–12939. doi: 10.1523/JNEUROSCI.3115-09.2009
Yamazaki, T., and Nagao, S. (2012). A computational mechanism for unified gain and timing control in the cerebellum. PLoS ONE 7:e33319. doi: 10.1371/journal.pone.0033319
Yamazaki, T., and Tanaka, S. (2005). Neural modeling of an internal clock. Neural Comput. 17, 1032–1058. doi: 10.1162/0899766053491850
Yamazaki, T., and Tanaka, S. (2007). The cerebellum as a liquid state machine. Neural Netw. 20, 290–297. doi: 10.1016/j.neunet.2007.04.004
Yamazaki, T., and Tanaka, S. (2009). Computational models of timing mechanisms in the cerebellar granular layer. Cerebellum 8, 423–432. doi: 10.1007/s12311-009-0115-7
Zhang, W., and Linden, D. J. (2006). Long-term depression at the mossy fiber–deep cerebellar nucleus synapse. J. Neurosci. 26, 6935–6944. doi: 10.1523/JNEUROSCI.0784-06.2006
Appendix A. Ideal Torque Values and Final Synaptic Weights
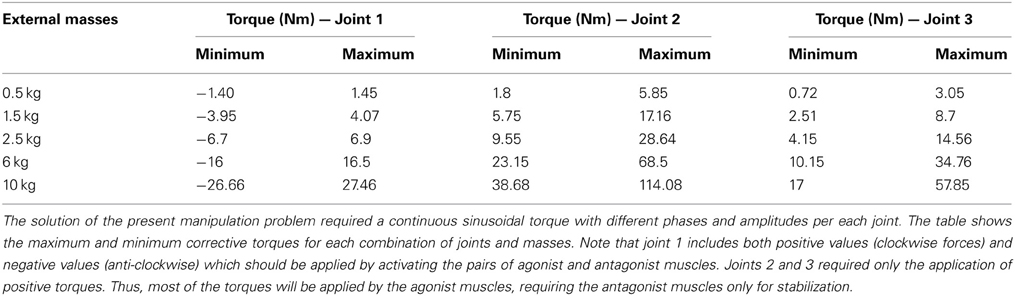
Table A1. Theoretical torque values when manipulating different masses.
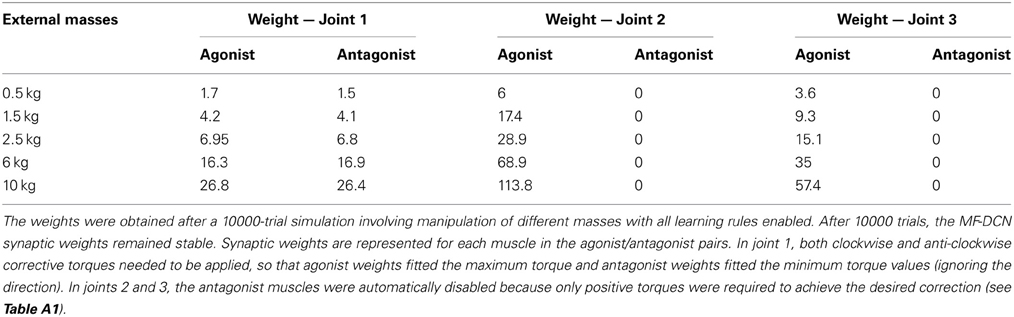
Table A2. MF-DCN synaptic weights.
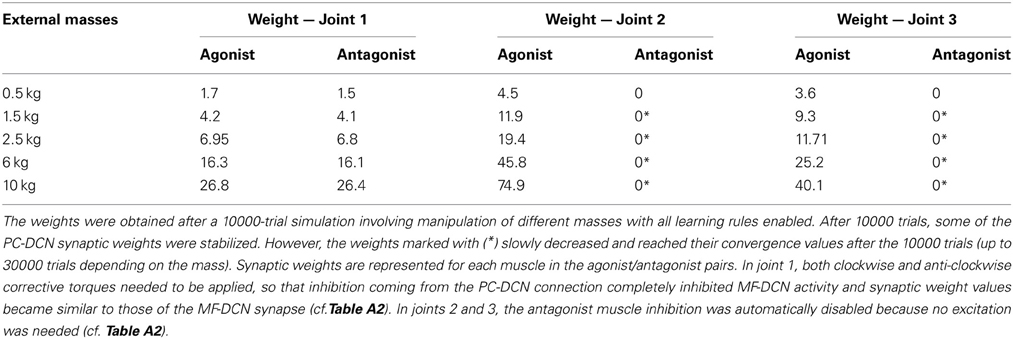
Table A3. PC-DCN synaptic weights.
Appendix B. Robotic Arm Description
The inverse dynamic equation defining the lightweight robot (LWR) is given by the expression:
where τ is the torque value vector to be applied by the robot joints, Q, , and are vectors representing the positions, velocities, and accelerations of the joints, and [Q2] being vectors defined as follows:
where n represents the number of links included in the robotic arm, M(Q) represents the inertia matrix (the mass matrix), C(Q) is the Coriolis matrix, D(Q) represents the matrix of centrifugal coefficients, G(Q) is the gravity action on the joints and finally F(Q, ) represents the friction term. The friction term is crucial in controlling LWR arms with high-ratio gear boxes since conventional methodologies fail to control these robots without a massive modeling (van der Smagt, 2000). At the same time, the friction term can be differentiated in two terms; dry and viscous friction components obtaining:
where FD(Q, ) and FV(Q, ) are the dry/viscous friction matrices, respectively. The first four terms of Equation B1 mainly include the inherent robot dynamic parameters (inertia matrix, Coriolis/centrifugal matrix, and gravitational force vector). These parameters are up to eleven per joint (inertia matrix is symmetrical):
1. Inertia tensor terms: (xxj, xyj, xzj, yyj, yzj, zzj)
2. Center of Mass: (mxj, myj, mzj)
3. Mass: (Mj)
4. Motor Inertia: (Ij)
where j ranges from 1 to the number of joints (3 in our model). These parameters are usually grouped according to these four categories in order to make the computational task easier (Khalil and Dombre, 2004). For our particular LWR (Albu-Schäffer et al., 2007), the nominal values obtained applying parametric methods (Bona and Curatella, 2005) are shown in Tables B1–B3.
Table B1. Inertia tensor parameters (kg · m2).

Table B2. Centers of masses (m), masses (kg) and motor inertias (kg · m2).

Table B3. Friction parameters: dry friction (N · m) and viscous friction (N · m · s/rad).
Keywords: cerebellar nuclei, long-term synaptic plasticity, gain control, learning consolidation, modeling
Citation: Garrido JA, Luque NR, D'Angelo E and Ros E (2013) Distributed cerebellar plasticity implements adaptable gain control in a manipulation task: a closed-loop robotic simulation. Front. Neural Circuits 7:159. doi: 10.3389/fncir.2013.00159
Received: 04 June 2013; Accepted: 17 September 2013;
Published online: 09 October 2013.
Edited by:
Chris I. De Zeeuw, Erasmus Medical Center, NetherlandsReviewed by:
Christopher H. Yeo, University College London, UKGuy Cheron, Université Libre de Bruxelles, Belgium
Copyright © 2013 Garrido, Luque, D'Angelo and Ros. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jesús A. Garrido and Egidio D'Angelo, Brain Connectivity Center, IRCCS Istituto Neurologico Nazionale C. Mondino, Via Mondino 2, Pavia, I-27100, Italy e-mail:amVzdXMuZ2Fycmlkb0B1bmlwdi5pdA==;ZGFuZ2Vsb0B1bmlwdi5pdA==
†These authors have contributed equally to this work.