 Naoki Hiratani
Naoki Hiratani Tomoki Fukai
Tomoki Fukai- 1Department of Complexity Science and Engineering, The University of Tokyo, Kashiwa, Japan
- 2Laboratory for Neural Circuit Theory, RIKEN Brain Science Institute, Wako, Japan
In the adult mammalian cortex, a small fraction of spines are created and eliminated every day, and the resultant synaptic connection structure is highly nonrandom, even in local circuits. However, it remains unknown whether a particular synaptic connection structure is functionally advantageous in local circuits, and why creation and elimination of synaptic connections is necessary in addition to rich synaptic weight plasticity. To answer these questions, we studied an inference task model through theoretical and numerical analyses. We demonstrate that a robustly beneficial network structure naturally emerges by combining Hebbian-type synaptic weight plasticity and wiring plasticity. Especially in a sparsely connected network, wiring plasticity achieves reliable computation by enabling efficient information transmission. Furthermore, the proposed rule reproduces experimental observed correlation between spine dynamics and task performance.
Introduction
The amplitude of excitatory and inhibitory postsynaptic potentials (EPSPs and IPSPs), often referred to as synaptic weight, is considered a fundamental variable in neural computation (Bliss and Collingridge, 1993; Dayan and Abbott, 2005). In the mammalian cortex, excitatory synapses often show large variations in EPSP amplitudes (Song et al., 2005; Ikegaya et al., 2013; Buzsáki and Mizuseki, 2014), and the amplitude of a synapse can be stable over trials (Lefort et al., 2009) and time (Yasumatsu et al., 2008), enabling rich information capacity compared with that at binary synapses (Brunel et al., 2004; Hiratani et al., 2013). In addition, synaptic weight shows a wide variety of plasticity which depend primarily on the activity of presynaptic and postsynaptic neurons (Caporale and Dan, 2008; Feldman, 2009). Correspondingly, previous theoretical results suggest that under appropriate synaptic plasticity, a randomly connected network is computationally sufficient for various tasks (Maass et al., 2002; Ganguli and Sompolinsky, 2012).
On the other hand, it is also known that synaptic wiring plasticity and the resultant synaptic connection structure are crucial for computation in the brain (Chklovskii et al., 2004; Holtmaat and Svoboda, 2009). Elimination and creation of dendritic spines are active even in the brain of adult mammalians. In rodents, the spine turnover rate is up to 15% per day in sensory cortex (Holtmaat et al., 2005) and 5% per day in motor cortex (Zuo et al., 2005). Recent studies further revealed that spine dynamics are tightly correlated with the performance of motor-related tasks (Xu et al., 2009; Yang et al., 2009). Previous modeling studies suggest that wiring plasticity helps memory storage (Poirazi and Mel, 2001; Stepanyants et al., 2002; Knoblauch et al., 2010). However, in those studies, EPSP amplitude was often assumed to be a binary variable, and wiring plasticity was performed in a heuristic manner. Thus, it remains unknown what should be encoded by synaptic connection structure when synaptic weights have a rich capacity for representation, and how such a connection structure can be achieved through a local spine elimination and creation mechanism, which is arguably noisy and stochastic (Kasai et al., 2010).
To answer these questions, we constructed a theoretical model of an inference task. We first studied how sparse connectivity affects the performance of the network by analytic consideration and information theoretic evaluations. Then, we investigated how synaptic weights and connectivity should be organized to perform robust inference, especially under the presence of variability in the input structure. Based on these insights, we proposed a local unsupervised rule for wiring and synaptic weight plasticity. In addition, we demonstrated that connection structure and synaptic weight learn different components under a dynamic environment, enabling robust computation. Lastly, we investigated whether the model is consistent with various experimental results on spine dynamics.
Results
Connection Structure Reduces Signal Variability in Sparsely Connected Networks
What should be represented by synaptic connections and their weights, and how are those representations acquired? To explore the answers to these questions, we studied a hidden variable estimation task (Figure 1A), which appears in various stages of neural information processing (Beck et al., 2008; Lochmann and Deneve, 2011). In the task, at every time t, one hidden state is sampled with equal probability from p number of external states st = {0,1,…,p − 1}. Neurons in the input layer show independent stochastic responses ~ N(θjμ, σX) due to various noises (Figure 1B, middle), where is the firing rate of input neuron j at time t, θjμ is the average firing rate of neuron j to the stimulus μ, and σX is the constant noise amplitude (see Table 1 for the definitions of variables and parameters). Although, we used Gaussian noise for analytical purposes, the following argument is applicable for any stochastic response that follows a general exponential family, including Poisson firing (Supplementary Figure 1). Neurons in the output layer estimate the hidden variable from input neuron activity and represent the variable with population firing {}, where i = 1,2,…N are indices of output neurons. This task is computationally difficult because most input neurons have mixed selectivity for several hidden inputs, and the responses of the input neurons are highly stochastic (Figure 1C). Let us assume that the dynamics of output neurons are written as follows:
where cij (= 0 or 1) represents connectivity from input neuron j to output neuron i, wij is its synaptic weight (EPSP size), and hw is the threshold. M and N are population sizes of the input and output layers, respectively. In the model, all feedforward connections are excitatory, and the inhibitory input is provided as the global inhibition .
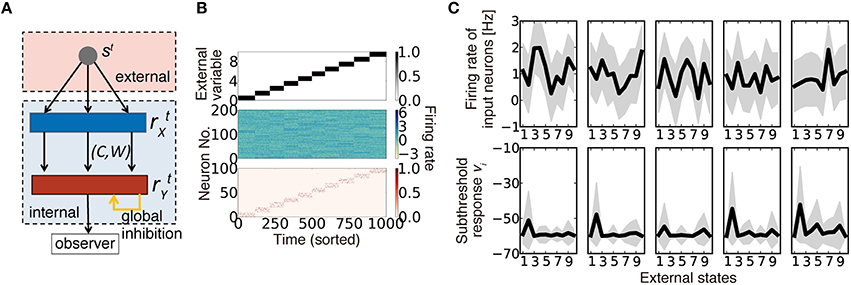
Figure 1. Description of the model. (A) Schematic diagram of the model. (B) An example of model behavior calculated at ρ = 0.16, when the synaptic connection is organized using the weight-coding scheme. The top panel represents the external variable, which takes an integer 0 to 9 in the simulation. The middle panel is the response of input neurons, and the bottom panel shows the activity of output neurons. In the simulation, each external state was randomly presented, but here the trials are sorted in ascending order. (C) Examples of neural activity in a simulation. Graphs on the top row represent the average firing rates of five randomly sampled input neurons for given external states (black lines) and their standard deviation (gray shadows). The bottom graphs are subthreshold responses of output neurons that represent the external state s = 1. Because the boundary condition for the membrane parameter was introduced as , vi is typically bounded at −vd. Note that vi is the unnormalized log-likelihood, and the units on the y-axis are arbitrary.

Table 1. Definitions of main variables and parameters.
If the feedforward connection is all-to-all (i.e., cij = 1 for all i,j pairs), by setting the weights as for output neuron i that represents external state μ, the network gives an optimal inference from the given firing rate vector , because the value qjμ represents how much evidence the firing rate of neuron j provides for a particular external state μ. (For details, see Sections Model dynamics and Gaussian Model). However, if the connectivity between the two layers is sparse, as in most regions of the brain (Potjans and Diesmann, 2014), optimal inference is generally unattainable because each output neuron can obtain a limited set of information from the input layer. How should one choose connection structure and synaptic weights in such a case? Intuitively, we could expect that if we randomly eliminate connections while keeping the synaptic weights of output neuron i that represents external state μ as wij ∝ qjμ (below, we call it as weight coding), the network still works at a near-optimal accuracy. On the other hand, even if the synaptic weight is a constant value, if the connection probability is kept at ρij∝qjμ (i.e., connectivity coding; see Section Weight Coding and Connectivity Coding for details of coding strategies), the network is expected to achieve near-optimal performance. Figure 2A describes the connection matrices between input/output layers in two strategies. In the weight coding, if we sort input neurons with their preferred external states, the diagonal components of the connection matrix show high synaptic weights, whereas in the connectivity coding, the diagonal components show dense connection (Figure 2A). Both of realizations asymptotically converge to optimal solution when the number of neurons in the middle layer is sufficiently large, though in a finite network, not strictly optimal under given constraints. In addition, both of them are obtainable through biologically plausible local Hebbian learning rules as we demonstrate in subsequent sections.
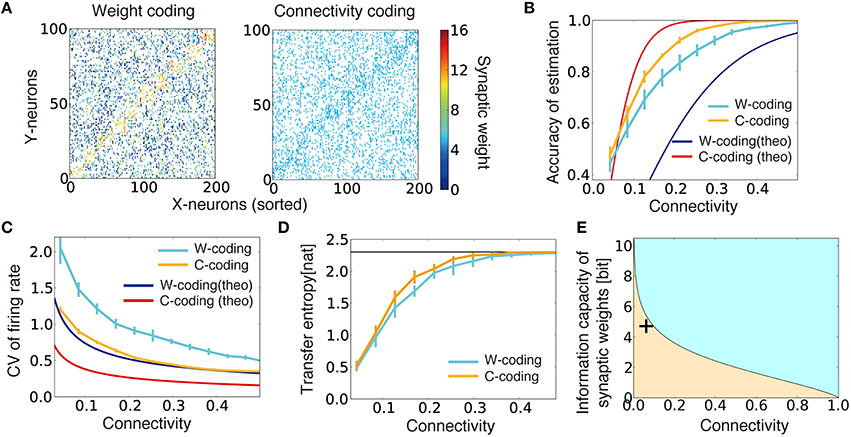
Figure 2. Performance comparison between connectivity coding and weight coding. (A) Examples of synaptic weight matrices in weight coding (W-coding) and connectivity coding (C-coding) schemes calculated at γ = 0.2. X-neurons were sorted by their selectivity for external states, and colors represent synaptic weights. (B) Comparison of the performance between connectivity coding and weight coding schemes at various sparseness of connectivity. Orange and cyan lines are simulation results. The error bars represent standard deviation over 10 independent simulations. In the following panels, error bars are trial variability over 10 simulations. Red and blue lines are analytical results. (C) Analytically evaluated coefficient of variation (CV) of output firing rate and corresponding simulation results. For simulation results, the variance was evaluated over whole output neurons from their firing rates for their selective external states. (D) Estimated maximum transfer entropy for two coding strategies. Black horizontal line is the maximal information logep. (E) Relative information capacity of connection structure vs. synaptic weight is shown at various values of synaptic connectivity. In the orange (cyan) area, the synaptic connectivity has higher (lower) information capacity than the synaptic weights. Plus symbol represents the data point obtained from CA3-to-CA1 connections.
We evaluated the accuracy of the external state estimation using a bootstrap method (Section Accuracy of Estimation) for both coding strategies. Under intermediate connectivity, both strategies showed reasonably good performance (as in Figure 1B, bottom). Intriguingly, in sparsely connected networks, the connectivity coding outperformed the weight coding, despite its binary representation (Figure 2B, cyan/orange lines). The analytical results confirmed this tendency (Figure 2B, red/blue lines; see Section Evaluation of Performances in Weight Coding and Connectivity Coding for the Details) and indicated that the firing rates of output neurons selective for the given external state show less variability in connectivity coding than in the weight coding, enabling more reliable information transmission (Figure 2C). To further understand this phenomenon, we evaluated the maximum transfer entropy of the feed forward connections: . Because of limited connectivity, each output neuron obtains information only from the connected input neurons. Thus, the transfer entropy was typically lower under sparse than under dense connections in both strategies (Figure 2D). However, in the connectivity coding scheme, because each output neuron can get information from relevant input neurons, the transfer entropy became relatively large compared to the weight coding (orange line in Figure 2D). Therefore, analyses from both statistical and information theory-based perspectives confirm the advantage of connectivity coding over the weight coding in the sparse regions.
The result above can also be extended to arbitrary feedforward networks as below. For a feedforward network of M input and N output neurons with connection probability ρ, information capacity of connections is given as IC (ρ) ≡ logMN C ρMN ≈ MN · H(ρ), where H represents the entropy function H(ρ) ≡ − ρ logρ − (1 − ρ) log (1 − ρ). Similarly, for a given connections between two layers, information capacity of synaptic weights is written as Iw(ρ) ≡ ρMN log b, where b is the number of distinctive synaptic states (Varshney et al., 2006). Therefore, when the connection probability ρ satisfies b = exp [H(ρ) ∕ ρ], synaptic connections and weights have the same information capacities. This means that, as depicted in Figure 2E, in a sparsely connected network, synaptic connections tend to have larger relative information capacity, compared to a dense network with the same b. This result is consistent with the model above, because stochastic firing of presynaptic neuron can be regarded as synaptic noise even though synaptic weights have an infinitely high resolution in the model. Furthermore, in the CA3-to-CA1 connection of mice, connection probability is estimated to be around 6% (Sayer et al., 1990), and information capacity of synaptic weight is around 4.7 bits (Bartol et al., 2015), thus the connection structure should also play an active role in neural coding in the real brain (data point in Figure 2E).
Dual Coding by Synaptic Weights and Connections Enables Robust Inference
In the section above, we demonstrated that a random connection structure highly degrades information transmission in a sparse regime to the degree that weight coding with random connection fell behind connectivity coding with a fixed weight. Therefore, in a sparse regime, it is necessary to integrate representations by synaptic weights and connections, but how should we achieve such a representation? Theoretically speaking, we should choose a connection structure that minimizes the loss of information due to sparse connectivity. This can be achieved by minimizing the KL-divergence between the distribution of the external states estimated from the all-to-all network, and the distribution estimated from a given connection structure (i.e., , see Section Optimality of Connectivity for details). However, this calculation requires combinatorial optimization, and local approximation is generally difficult (Donoho, 2006), thus expectedly the brain employs some heuristic alternatives. Experimental results indicate that synaptic connections and weights are often representing similar features. For example, the EPSP size of a connection in a clustered network is typically larger than the average EPSP size (Lefort et al., 2009; Perin et al., 2011), and a similar property is suggested to hold for interlayer connections (Yoshimura et al., 2005) (Ryan et al., 2015). Therefore, we could expect that by simply combining the weight coding and connectivity coding in the previous section, low performance at the sparse regime can be avoided, though convergence to the optimal solution is generally not achievable in this hybrid strategy even in the limit of infinitely many neurons. On the other hand, in the previous modeling studies, synaptic rewiring and resultant connection structure were often generated by cut-off algorithm in which a synapse is eliminated if the weight is smaller than the given criteria (Chechik et al., 1998; Navlakha et al., 2015). Thus, let us next compare the representation by combining the weight coding and connectivity coding (we call it as the dual coding below), with the cut-off coding strategy.
Figure 3A describes the synaptic weight distributions in the two strategies, as well as in random connection (see Section Dual Coding and Cut-Off Coding for details of the implementation) for the input structure used in Figure 3C. The light-colored distributions represent the normalized optimal synaptic weights for all-to-all connections, and the dark distributions represent the weights chosen from the light-colored distributions by each strategy. When connectivity coding and weight coding are combined (i.e., in the dual coding), connection probability becomes larger in proportion to its synaptic weight (Figure 3A middle), and the resultant distribution exhibits a broad distribution as observed in the experiments (Song et al., 2005; Ikegaya et al., 2013), whereas in the cut-off strategy, the weight distribution is concentrated at a non-zero value (Figure 3A, right). Intuitively, the cut-off strategy seems more selective and beneficial for inference. Indeed, in the original task, the cut-off strategy enabled near-optimal performance, though the dual coding also improved the performance compared to a randomly connected network (Figure 3C). However, under the presence of variability in the input layer, cut-off strategy is no longer advantageous. For instance, let us consider the case when noise amplitude σX is not constant but pre-neuron dependent. If the firing rate variability of input neuron j is given by σX, j ≡ σXexp (2ζj log σr) ∕ σr, where ζj is a random variable uniformly sampled from [0, 1), and σr is the degree of variability, in an all-to-all network, optimal inference is still achieved by setting synaptic weights as . On the contrary, in the sparse region, the performance is disrupted especially in the cut-off strategy, so that the dual coding outperformed the cut-off strategy (Figure 3D).
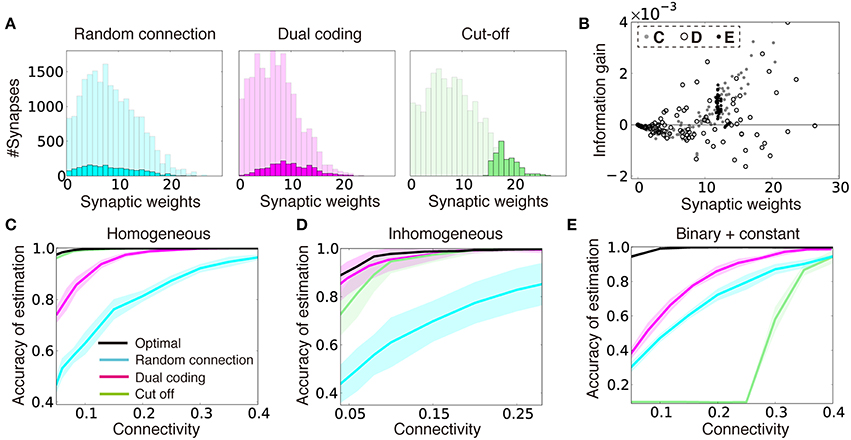
Figure 3. Dual coding yields robust information representation compared to fixed random connections and cut-off strategy. (A) Synaptic weight distributions in random connection (left), dual coding (middle), and cut-off (right) strategies in the model described (C). Light colors represent possible connections (i.e., normalized distributions of optimal synaptic weights under all-to-all connections), while dark colors show the actual connections chosen under the different strategies. Connection probability was set at ρ = 0.1. (B) Relationships between the synaptic weight and the information gain per connection for three input configurations described in (C–E). The open black circles were calculated with σr = 2.0 instead of σr = 4.0 for illustration purpose. (C–E) Comparisons of performance among different connection structure organizations for models with homogeneous input variability (C), inhomogeneous input variability (D), and the model with binary or constant input structures (E). Note that black lines represent lower bounds for the optimal performance, but not the exact optimal solutions. In (D), the means and standard deviations were calculated over 100 simulation trials instead of 10 due to intrinsic variability.
To further illustrate this phenomenon, let us next consider a case when a quarter of input neurons show a constant high response for all of the external states as and the rest of input neurons show high response for randomly selected half of external states (i.e., ), where θlow < θhigh < θconst, and with the normalization factor . Even in this case, is the optimal synaptic weights configuration in the all-to-all network, but if we create a sparse network with cut-off algorithm, the performance drops dramatically at certain connectivity, whereas in the dual coding, the accuracy is kept at some high levels even in the sparse connectivity (Figure 3E).
To get insights on why the dual coding is more robust against variability in the input layer, for three input configurations described above, we calculated the relationship between synaptic weight wij and the information gained by a single synaptic connection ΔIij. Here, we defined the information gain ΔIij by the mean reduction in the KL divergence , achieved by adding one synaptic connection cij to a randomly connected network C (see Section Optimality of Connectivity for details). In the original model, ΔIij has nearly a linear relationship with the synaptic weight wij (gray points in Figure 3B), thus by simply removing the connections with small synaptic weights, a near-optimal connection structure was acquired (Figure 3C). On the other hand, when the input layer is not homogeneous, large synapses tend to have negative (black circles in Figure 3B) or zero (black points in Figure 3B) gains. As a result, the linear relationship between the weight and the information gain is no longer observed. Thus, in these cases, the dual coding is less likely to be disrupted by non-beneficial connections.
Although our consideration here is limited to a specific realization of synaptic weights, in general, it is difficult to represent the information gain by locally acquired synaptic weight, so we could expect that the cut-off strategy is not the optimal connectivity organization in many cases.
Local Hebbian Learning of the Dual Coding
The argument in the previous section suggest that, by combining the weight coding and connectivity coding, the network can robustly perform inference especially in sparsely connected regions. However, in the previous sections, a specific connection and weight structure were given a priori, although structures in local neural circuits are expected to be obtained with local weight plasticity and wiring plasticity. Thus, we next investigate whether dual coding can be achieved through a local unsupervised synaptic plasticity rule.
Let us first consider learning of synaptic weights. In order to achieve the weight coding, synaptic weight wij should converge to when output neuron i represents external state μ, and represents the mean connectivity of the network. Thus, synaptic weight change is given as:
The second term is the homeostatic term heuristically added to constrain the average firing rates of output neurons (Turrigiano and Nelson, 2004). Note that the first term corresponds to stochastic gradient descending on , because the weight coding approximates the optimal representation by synaptic weights (Nessler et al., 2013; see Section Synaptic Weight Learning for details). We performed this unsupervised synaptic weight learning on a randomly connected network. When the connectivity is sufficiently dense, the network successfully acquired a suitable representation (Figure 4A). Especially under a sufficient level of homeostatic plasticity (Figure 4B), the average firing rate showed a narrow unimodal distribution (Figure 4C, top), and most of the output neurons acquired selectivity for one of external states (Figure 4C, bottom).
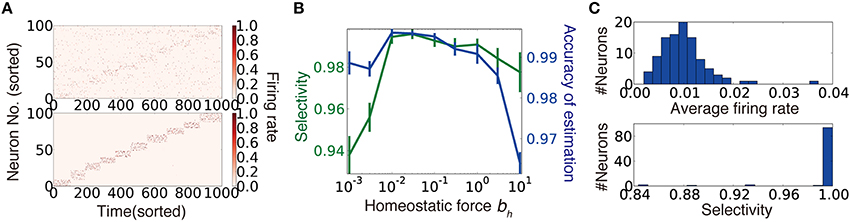
Figure 4. Synaptic weight learning on random connection structures. (A) An example of output neuron activity before (top) and after (bottom) synaptic weight learning calculated at connectivity ρ = 0.4. A diagonal line faintly observed in the upper panel reflects bias due to finite size effect (see Section Accuracy of Estimation for details) (B) Selectivity of output neurons and accuracy of estimation at various strengths of homeostatic plasticity at ρ = 0.4. Selectivity was defined as for i ∈ Ωμ. (C) Histogram of average firing rates of output neurons (top), and selectivity of each neuron calculated for the simulation depicted in (A).
We next investigated the learning of connection structures by wiring plasticity. Unlike synaptic weight plasticity, it is not yet well understood how we can achieve functional connection structure with local wiring plasticity. In particular, rapid rewiring may disrupt the network structure, and possibly worsen the performance (Chechik et al., 1998). Thus, let us first consider a simple rewiring rule, and discuss the biological correspondence later. Here, we introduced a variable ρij, for each combination (i,j) of presynaptic neuron j and postsynaptic neuron i, which represents the connection probability. If we randomly create a synaptic connection between neuron (i,j) with probability ρij/τc and eliminate it with probability (1−ρij)/τc, on average there is a connection between neuron (i,j) with probability ρij, when the maximum number of synaptic connections is bounded by 1. In this way, the total number of synaptic connections is kept constant on average, without any global regulation mechanism. Throughout the paper, when a new spine is created, we set its initial synaptic weight as , not by the value calculated from Equation (2), for biological plausibility.
From a similar argument done for synaptic weights, the learning rule for connection probability ρij is derived as:
where wo is the expected mean synaptic weight (Section Synaptic Connection Learning). Under this rule, the connection probabilities converge to the connectivity coding. Moreover, although this rule does not maximize the transfer entropy of the connections, direction of learning is on average close to the direction of the stochastic gradient on transfer entropy. Therefore, the above rule does not reduce the transfer entropy of the connection on average (see Section Dual Hebbian Rule and Estimated Transfer Entropy).
Figure 5A shows the typical behavior of ρij and wij under combination of this wiring rule (Equation 3) and the weight plasticity rule described in Equation (2) (we call this combination as the dual Hebbian rule because both Equations 2 and 3 have Hebbian forms). When the connection probability is low, connections between two neurons are rare, and, even when a spine is created due to probabilistic creation, the spine is rapidly eliminated (Figure 5A, top). In the moderate connection probability, spine creation is more frequent, and the created spine survives longer (Figure 5A, middle). When the connection probability is high enough, there is almost always a connection between two neurons, and the synaptic weight of the connection is large because synaptic weight dynamics also follow a similar Hebbian rule (Figure 5A, bottom).
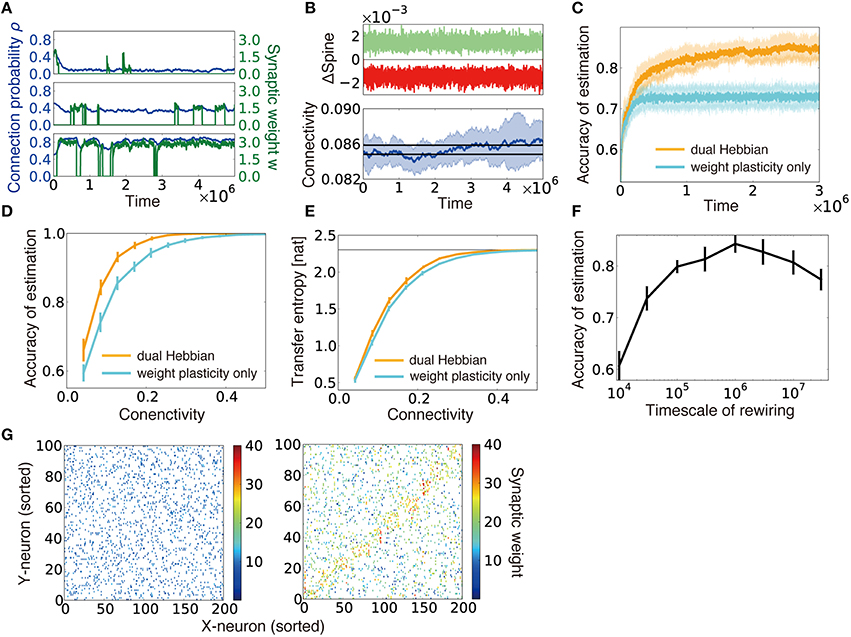
Figure 5. Dual Hebbian learning for synaptic weights and connections. (A) Examples of spine creation and elimination. In all three panels, green lines show synaptic weights, and blue lines are connection probability. When there is not a synaptic connection between two neurons, the synaptic weight becomes zero, but the connection probability can take a non-zero value. Simulation was calculated at ρ = 0.48, ηρ = 0.001, and τc = 105. (B) Change in connectivity due to synaptic elimination and creation. Number of spines eliminated (red) and created (green) per unit time was balanced (top). As a result, connectivity did not appreciably change due to rewiring (bottom). Black lines in the bottom graph are the mean connectivity at γ = 0.1 and γ = 0.101 in the model without rewiring. (C) Accuracy of estimation for the model with/without wiring plasticity. For the dual Hebbian model, the sparseness parameter was set as γ = 0.1, whereas γ = 0.101 was used for the weight plasticity model to perform comparisons at the same connectivity (see B). (D,E) Comparison of the performance (D) and the maximum estimated transfer entropy (E) after learning between the dual Hebbian model and the model implemented with synaptic plasticity only at various degrees of connectivity. Horizontal line in (E) represents the total information logep. (F) Accuracy of estimation with various timescales for rewiring τc. Note that the simulation was performed only for 5 × 106 time steps, and the performance did not converge for the model with a longer timescale. (G) Synaptic weight matrices before (left) and after (right) learning. Both X-neurons (input neuron) and Y-neurons (output neurons) were sorted based on their preferred external states.
We implemented the dual Hebbian rule in our model and compared the performance of the model with that of synaptic weight plasticity on a fixed random synaptic connection structure. Because spine creation and elimination are naturally balanced in the proposed rule (Figure 5B, top), the total number of synaptic connections was nearly unchanged throughout the learning process (Figure 5B, bottom). As expected, the dual Hebbian rule yielded better performance (Figures 5C,D) and higher estimated transfer entropy than the corresponding weight plasticity only model (Figure 5E). This improvement was particularly significant when the frequency of rewiring was in an intermediate range (Figure 5F). When rewiring was too slow, the model showed essentially the same behavior as that in the weight plasticity only model, whereas excessively frequent probabilistic rewiring disturbed the connection structure. Although a direct comparison with experimental results is difficult, the optimal rewiring timescale occurred within hours to days, under the assumption that firing rate dynamics (Equation 1) are updated every 10–100 ms. Initially, both connectivity and weights were random (Figure 5G, left), but after the learning process, the diagonal components of the weight matrix developed relatively larger synaptic weights, and, at the same time, denser connectivity than the off-diagonal components (Figure 5G, right). Thus, through dual Hebbian learning, the network can indeed acquire a connection structure that enables efficient information transmission between two layers; as a result, the performance improves when the connectivity is moderately sparse (Figures 5D,E). Although the performance was slightly worse than that of a fully-connected network, synaptic transmission consumes a large amount of energy (Sengupta et al., 2013), and synaptic connection is a major source of noise (Faisal et al., 2008). Therefore, it is beneficial for the brain to achieve a similar level of performance using a network with fewer connections.
Connection Structure Can Acquire Constant Components of Stimuli and Enable Rapid Learning
We have shown that the dual coding by synaptic weights and connections robustly helps computation in a sparsely connected network, and the desirable weight and connectivity structures are naturally acquired through the dual Hebbian rule. Although we were primary focused on sparse regions, the rule potentially provides some beneficial effects even in densely connected networks. To consider this issue, we extended the previous static external model to a dynamic one, in which at every interval T2, response probabilities of input neurons partly change. If we define the constant component as θconst and the variable component as θvar, then the total model becomes , where the normalization term is given as (Figure 6A). Below, we updated θvar at every T2 = 105 time steps. In this setting, when the learning was performed only with synaptic weights based on fixed random connections, although the performance rapidly improved, every time a part of the model changed, the performance dropped dramatically and only gradually returned to a higher level (cyan line in Figure 6B). By contrast, under the dual Hebbian learning rule, the performance immediately after the model shift (i.e., the performance at the trough of the oscillation) gradually increased, and convergence became faster (Figures 6B,C), although the total connectivity stayed nearly the same (Figure 6D). After learning, the synaptic connection structure showed a higher correlation with the constant component than with the variable component (Figure 6E; see Section Model Error). By contrast, at every session, synaptic weight structure learned the variable component better than it learned the constant component (Figure 6F). The timescale for synaptic rewiring needed to be long enough to be comparable with the timescale of the external variability T2 to capture the constant component. Otherwise, connectivity was also strongly modulated by the variable component of the external model. In Figure 6G, lines represent the model errors for three different values of T2 at various timescales of rewiring. In addition, we find that the rewiring timescale should be in an intermediate range as also observed in Figure 5F. After sufficient learning, the synaptic weight w and the corresponding connection probability ρ roughly followed a linear relationship (Figure 6H). Remarkably, some synapses developed connection probability ρ = 1, meaning that these synapses were almost permanently stable because the elimination probability (1−ρ)/τc became nearly zero.
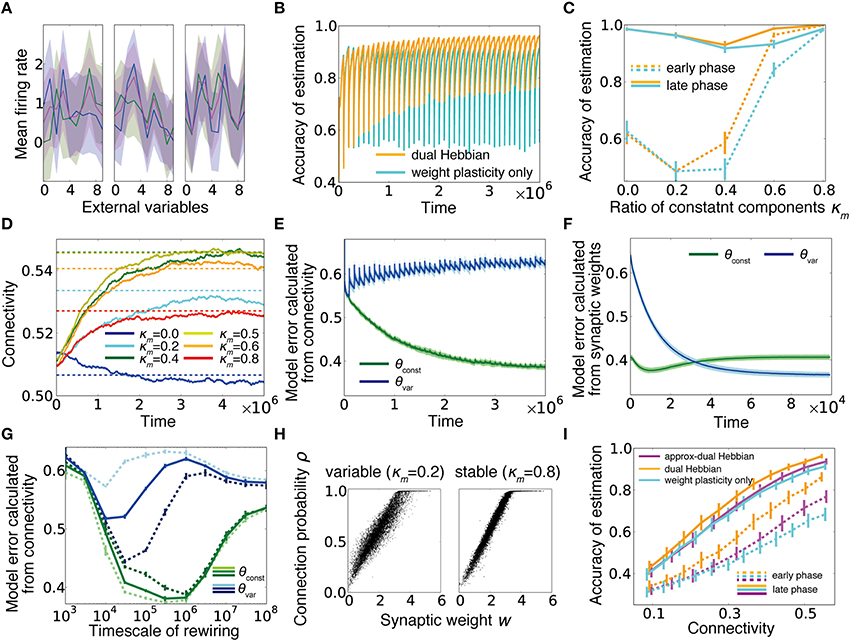
Figure 6. Dual Hebbian learning under a dynamic environment. (A) Examples of input neuron responses. Blue lines represent the constant components θconst, green lines show the variable components θvar, which are updated at every T2 time steps by sampling a new input structure from a truncated Gaussian distribution (see Section Gaussian Model), and magenta lines are the total external models θ calculated from the normalized sum. (B) Learning curves for the model with or without wiring plasticity, when the variable components change every 105 time steps. (C) Accuracy of estimation for various ratios of constant components. Early phase performance was calculated from the activity within 10,000 steps after the variable component shift, and the late phase performance was calculated from the activity within 10,000 steps before the shift. As in (B), orange lines represent the dual Hebbian model, and cyan lines are for the model with weight plasticity only. (D) Trajectories of connectivity change. Connectivity tends to increase slightly during learning. Dotted lines are mean connectivity at (κm, γ) = (0.0, 0.595), (0.2, 0.625), (0.4, 0.64), (0.5, 0.64), (0.6, 0.635), and (0.8, 0.620). In (C), these parameters were used for the synaptic plasticity only model, whereas γ was fixed at γ = 0.6 for the dual Hebbian model. (E,F) Model error calculated from connectivity (E) and synaptic weights (F). Note that the timescale of (F) is the duration in which the variable component is constant, not the entire simulation (i.e., the scale of x-axis is 104 not 106). (G) Model error calculated from connectivity for various rewiring timescales τc. For a large τc, the learning process does not converge during the simulation. Dotted lines are results for T2 = 3 × 104 (pale lines), and T2 = 3 × 105 (dark lines). Note that the splitting point of θconst and θvar shifts for the left/right sides in the pale/dark lines. (H) Relationship between synaptic weight w and connection probability ρ at the end of learning. When the external model is stable, w and ρ have a more linear relationship than that for the variable case. (I) Comparison of performances among the model without wiring plasticity (cyan), the dual Hebbian model (orange), the approximated model (magenta).
Approximated Dual Hebbian Learning Rule Reconciles with Experimentally Observed Spine Dynamics
Our results up to this point have revealed functional advantages of dual Hebbian learning. In this last section, we investigated the correspondence between the experimentally observed spine dynamics and the proposed rule. To this end, we first studied whether a realistic spine dynamics rule approximates the proposed rule, and then examined if the rule explains the experimentally known relationship between synaptic rewiring and motor learning (Xu et al., 2009; Yang et al., 2009).
Previous experimental results suggest that a small spine is more likely to be eliminated (Yasumatsu et al., 2008; Kasai et al., 2010), and spine size often increases or decreases in response to LTP or LTD respectively, with a certain delay (Matsuzaki et al., 2004; Wiegert and Oertner, 2013). In addition, though spine creation is to some extent influenced by postsynaptic activity (Knott et al., 2006; Yang et al., 2014), the creation is expected to be more or less a random process (Holtmaat and Svoboda, 2009). Thus, changes in the connection probability can be described as
By combining this rule and the Hebbian weight plasticity described in Equation (2), the dynamics of connection probability well replicated the experimentally observed spine dynamics (Yasumatsu et al., 2008; Kasai et al., 2010; Figures 7A–C). Moreover, the rule outperformed the synaptic weight only model in the inference task, although the rule performed poorly compared to the dual Hebbian rule due to the lack of activity dependence in spine creation (magenta line in Figure 6I). This result suggests that plasticity rule by Equations (2) and (4) well approximates the dual Hebbian rule (Equations 2+3). This is because, even if the changes in the connection probability are given as a function of synaptic weight as in Equation (4), as long as the weight plasticity rule follows Equation (2), wiring plasticity indirectly shows a Hebbian dependency for pre- and postsynaptic activities as in the original dual Hebbian rule (Equation 3). As a result, the approximated rule gives a good approximation of the original dual Hebbian rule.
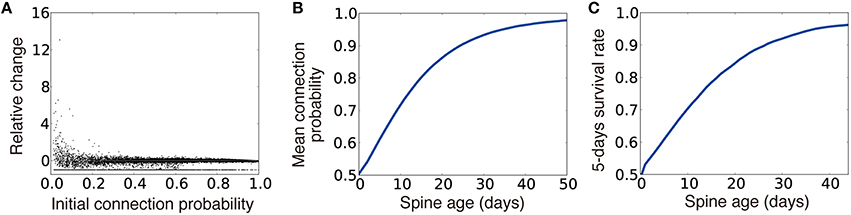
Figure 7. Spine dynamics of the approximated dual Hebbian model. (A) Relative change of connection probability in 105 time steps. If the initial connection probability is low, the relative change after 105 time steps has a tendency to be positive, whereas spines with a high connection probability are more likely to show negative changes. The line at the bottom represents eliminated spines (i.e., relative change = −1). (B,C) Relationships between spine age and the mean connection probability (B) and the 5-days survival rate (C). Consistent with the experimental results, survival rate is positively correlated with spine age. Five days survival rate was calculated by regarding 105 time steps as 1 day.
We next applied this approximated learning rule to motor learning tasks. The primary motor cortex has to adequately read-out motor commands based on inputs from pre-motor regions (Salinas and Romo, 1998; Sul et al., 2011). In addition, the connection from layer 2/3 to layer 5 is considered to be a major pathway in motor learning (Masamizu et al., 2014). Thus, we hypothesized that the input and output layers of our model can represent layers 2/3 and 5 in the motor cortex. We first studied the influence of training on spine survival (Xu et al., 2009; Figure 8A). To compare with experimental results, below we regarded 105 time steps as 1 day, and described the training and control phases as two independent external models θctrl and θtrain. We assumed that the corresponding neural circuits are already tuned and actively employed for processing certain structured inputs, even in the control animal, so that training is actually a retraining on a new input structure. Under this assumption, survival ratio of newly created and pre-existing spines exhibits a large difference, as observed in the experiment (Figure 8B). However, the difference is difficult to replicate when the control is modeled as a blank slate with unstructured inputs (Figure 8C). As observed for the control case, newly created spines were less stable than pre-existing spines, also in the training case (solid lines vs. dotted lines in Figure 8B), because older spines tended to have a larger connection probability (Figure 7B). Nevertheless, continuous training turned pre-existed spines less stable and new spines more stable than their respective counterparts in the control case (red lines vs. lime lines in Figure 8B). The 5-day survival rate of a spine was higher for spines created within a couple of days from the beginning of training compared with spines in the control case, whereas the survival rate converged to the control level after several days of training (Figure 8D). Our model also replicates the effect of varying training duration on spine stability (Yang et al., 2009). When training on new input structure θtraining was rapidly terminated and the inputs structure went back to the control θctrl, newly formed spines became less stable than those undergoing training on new input structure for a long period continuously (Figure 8E). In addition, we found that θctrl and θtrain need to be independent to observe the above results (Figure 8F).
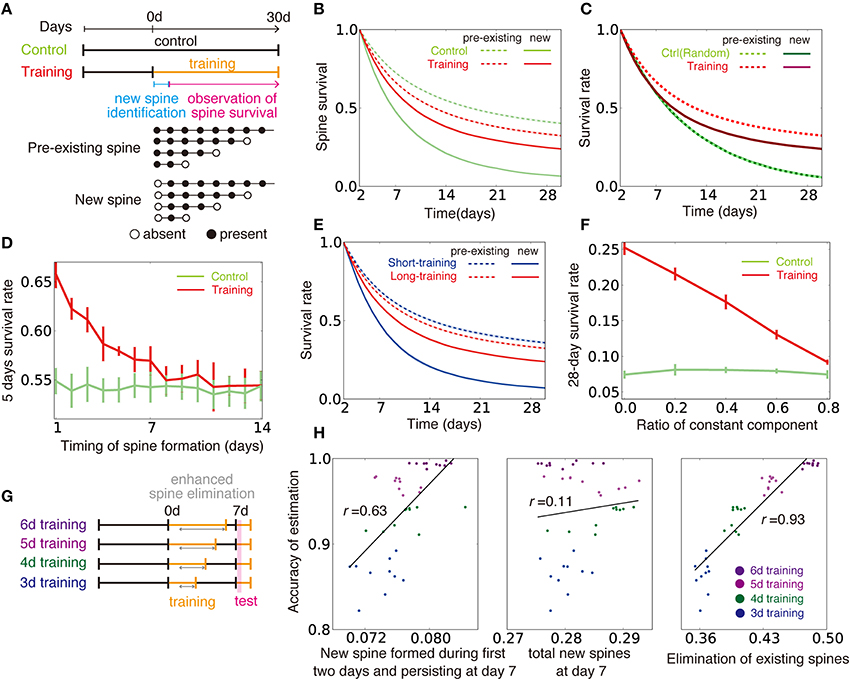
Figure 8. Influence of training on spine dynamics. (A) Schematic diagrams of the simulation protocols for (B–F), and examples of spine dynamics for pre-existing spines and new spines. (B) Spine survival rates for control and training simulations. Dotted lines represent survival rates of pre-existing spines (spines created before day 0 and existing on day 2), and solid lines are new spines created between day 0 and day 2. (C) Spine survival rates when control was modeled with random Gaussian inputs , instead of a pattern {θctrl}. Note that light-green line is hidden under dotted green line, because two lines show nearly identical dynamics. (D) The 5-day survival rate of spines created at different stages of learning. (E) Spine survival rates for short-training (2 d) and long-training (30 d) simulations. Pre-existing and new spines were defined as in (A,B). (F) Effect of similarity between the control condition and training on the new spine survival rate. The value of κm was changed as in Figure 6C to alter the similarity between the two conditions. Note that κm = 0 in (A–E,G,H). (G, H) Relationships between creation and elimination of spines and task performance. Performance was calculated from the activity within 2000–7000 time steps after the beginning of the test phase (see Section Spine Dynamics for details). In the simulation, the synaptic elimination was increased fivefold from day 1 to the end of training.
We next considered the relationship between spine dynamics and task performance (Yang et al., 2009). For this purpose, we compared task performance at the beginning of the test period among simulations with various training lengths (Figure 8G). Here, we assumed that spine elimination was enhanced during continuous training, as is observed in experiments (Xu et al., 2009; Yang et al., 2009). The performance was positively correlated with both the survival rate at day 7 of new spines formed during the first 2 days, and the elimination rate of existing spines (left and right panels of Figure 8H; see Section Spine Dynamics for details). By contrast, the performance was independent from the total ratio of newly formed spines from day 0 to 6 (middle panel of Figure 8H). These results demonstrate that complex spine dynamics are well described by the approximated dual Hebbian rule, suggesting that the brain uses a dual learning mechanism.
Discussion
In this study, we first analyzed how random connection structures impair performance in sparsely connected networks by analyzing the change in signal variability and the transfer entropy in the weight coding and the connectivity coding strategies (Figure 2). Subsequently, we showed that connection structures created by the cut-off strategy are not beneficial under the presence of input variability, due to lack of positive correlation between the information gain and weight of synaptic connections (Figure 3). Based on these insights, we proposed that the dual coding by weight and connectivity structures as a robust representation strategy, then demonstrated that the dual coding is naturally achieved through dual Hebbian learning by synaptic weight plasticity and wiring plasticity (Figures 4, 5). We also revealed that, even in a densely connected network in which synaptic weight plasticity is sufficient in terms of performance, by encoding the time-invariant components with synaptic connection structure, the network can achieve rapid learning and robust performance (Figure 6). Even if spine creation is random, the proposed framework still works effectively, and the approximated model with random spine creation is indeed sufficient to reproduce various experimental results (Figures 7, 8).
Model Evaluation
Spine dynamics depend on the age of the animal (Holtmaat et al., 2005), the brain region (Zuo et al., 2005), and many molecules play crucial roles (Kasai et al., 2010; Caroni et al., 2012), making it difficult for any theoretical models to fully capture the complexity. Nevertheless, our simple mathematical model replicated many key features (Yasumatsu et al., 2008; Xu et al., 2009; Yang et al., 2009; Kasai et al., 2010). For instance, small spines often show enlargement, while large spines are more likely to show shrinkage (Figure 7A). Older spines tend to have a large connection probability, which is proportional to spine size (Figure 7B), and they are more stable (Figure 7C). In addition, training enhances the stability of newly created spines, whereas it degrades the stability of older spines (Figure 8B).
Experimental Prediction
In the developmental stage, both axon guidance (Munz et al., 2014) and dendritic extension (Matsui et al., 2013) show Hebbian-type activity dependence, but in the adult cortex, both axons and dendrites seldom change their structures (Holtmaat and Svoboda, 2009). Thus, although recent experimental results suggest some activity dependence for spine creation (Knott et al., 2006; Yang et al., 2014), it is still unclear to what extent spine creation depends on the activity of presynaptic and postsynaptic neurons. Our model indicates that in terms of performance, spine creation should fully depend on both presynaptic and postsynaptic activity (Figure 6I). However, we also showed that it is possible to replicate a wide range of experimental results on spine dynamics without activity-dependent spine creation (Figure 8).
Furthermore, whether or not spine survival rate increases through training is controversial (Xu et al., 2009; Yang et al., 2009). Our model predicts that the stability of new spines highly depends on the similarity between the new task and control behavior (Figure 8F). When the similarity is low, new spines created in the new task are expected to be more stable than those created in the control case, because the synaptic connection structure would need to be reorganized. By contrast, when the similarity is high, the stability of the new spines would be comparable to that of the control.
Related Studies
Previous theoretical studies revealed candidate rules for spine creation and elimination (Deger et al., 2012; Zheng et al., 2013; Fauth et al., 2015), yet their functional benefits were not fully clarified in those studies. Some modeling studies considered the functional implications of synaptic rewiring (Poirazi and Mel, 2001) or optimality in regard to benefit and wiring cost (Chen et al., 2006), but the functional significance of synaptic plasticity and the variability of EPSP size were not considered in those models. In comparison, our study revealed functional roles of wiring plasticity that cooperates with synaptic weight plasticity and obeys local unsupervised rewiring rules. In addition, we extended the previous results on single-spine information storage and synaptic noise (Varshney et al., 2006) into a network, and provided a comparison with experimental results (Figure 2E).
Previous studies on associative memory models found the cut-off coding as the optimal strategy for maximizing the information capacity per synapse (Chechik et al., 1998; Knoblauch et al., 2010). Our results suggest that the above result is the outcome of the tight positive correlation between the information gain and synaptic weight in associative memory systems, and not generally applicable to other paradigms (Figures 3B,C). In addition, although cut-off strategy did not yield biologically plausible synaptic weight distributions in our task setting (Figure 3A, right), in perceptron-based models, this unrealistic situation can be avoided by tuning the threshold of neural dynamics (Brunel et al., 2004; Sacramento et al., 2015). Especially, cut-off strategy may provide a good approximation for developmental wiring plasticity (Ko et al., 2013), though the algorithm is not fully consistent with wiring plasticity in the adult animals.
Finally, our model provides a biologically plausible interpretation for multi-timescale learning processes. It was previously shown that learning with two synaptic variables on different timescales is beneficial under a dynamically changing environment (Fusi et al., 2007). In our model, both fast and slow variables played important roles, whereas in previous studies, only one variable was usually more effective than others, depending on the task context.
Methods
Model
Model Dynamics
We first define the model and the learning rule for general exponential family, and derive equations for two examples (Gaussian and Poisson). In the task, at every time t, one hidden state st is sampled from prior distribution p(st) (see Table 1 for the definitions of variables and parameters). Neurons in the input layer show stochastic response that follows probabilistic distribution f ( |st = μ):
From these input neuron activities, neurons in output layer estimate the hidden variables. Here we assume maximum likelihood estimation for decision making unit, as the external state is a discrete variable. In this framework, in order to detect the hidden signal, firing rate of neuron i should be proportional to posterior
where σi represents the index of the hidden variable preferred by output neuron i (Beck et al., 2008; Lochmann and Deneve, 2011). For instance, if output neuron i is selective for the hidden variable st = μ, then σi = μ. Note that {rX, j} represent firing rates of input neurons, whereas {rY, i} represent the rates of output neurons. Due to Bayes rule, estimation of st is given by,
where qjμ ≡ h(θjμ), . If we assume the uniformity of hidden states as log p(st = μ) : const, and , the equation above becomes
To achieve neural implementation of this inference problem, let us consider a neural dynamics in which the firing rates of output neurons follow,
where,
and hw is the threshold. If connection is all-to-all, wij = qjμ gives optimal inference, because
Note that hw is not necessary to achieve optimal inference, however, under a sparse connection, hw is important for reducing the effect of connection variability. In this formalization, even in non-all-to-all network, if the sparseness of connectivity stays in reasonable range, near-optimal inference can be performed for arbitrary feedforward connectivity by adjusting synaptic weight to wij = wμj ≡ qjμ ∕ ρμj where , and Ωμ is the set of output neurons selective for external state μ.
Weight Coding and Connectivity Coding
Let us first consider the case when the connection probability is constant (i.e., ρij = ρ). By substituting ρij = ρ into the above equations, c and w are given with Pr [cij = 1] = ρ and wij = wμj = qjμ ∕ ρ, where the mean connectivity is given as , and is the average of the normalized mean response qjμ (i.e., ). Parameter γ is introduced to control the sparseness of connections, and here we assumed that neuron i represents the external state (i.e., if , output neuron i represents the state μ). Under this configuration, the representation is solely achieved by the synaptic weights, thus we call this coding strategy as the weight coding.
On the other hand, if the synaptic weight is kept at a constant value, the representation is realized by synaptic connection structure (i.e., connectivity coding). In this case, the model is given by Pr [cij = 1] = ρμj and wij = wμj = 1∕γ, where ρμj = min(γqjμ, 1).
Dual Coding and Cut-off Coding
By combining the weight coding and connectivity coding described above, the dual coding is given as wij = wμj = qjμ∕ρ, Pr [cij = 1] = ρμj, ρμj = min(γqjμ, 1), where ρ was defined by , , as in the weight coding. Although normalization factor ρ slightly overestimates the connectivity, the resultant difference was negligibly small in our model setting. In the model with inhomogeneous input-activity variance, we instead used to suppress variability. For the cut-off coding strategy, the synaptic weight was chosen as wij = wμj = qjμ∕ρo where ρo is the mean connection probability. Based on these synaptic weights, for each output neuron, we selected Mρo largest synaptic connections, and eliminated all other connections. Thus, connection matrix C was given as , where [true]+ = 1, [false]+ = 0. When multiple connections have the same weight, we randomly selected the connections so that the total number of inbound connections becomes Mρo. Finally, in the random connection strategy, synaptic weights and connections were determined as wij = wμj = qjμ∕ρo, Pr [cij = 1] = ρo.
Synaptic Weight Learning
To perform maximum likelihood estimation from output neuron activity, synaptic weight matrix between input neurons and output neurons should provide a reverse model of input neuron activity. If the reverse model is faithful, KL-divergence between the true input and the estimated distributions would be minimized (Dayan et al., 1995; Nessler et al., 2013). Therefore, synaptic weights learning can be performed by . Likelihood is approximated as
in the second line is the average response estimated from connectivity matrix C, and weight matrix W. In the last equation, is substituted for . If we approximate the estimated parameter with by using the average connectivity ρo, a synaptic weight plasticity rule is given by stochastic gradient descending as
Especially, in a Gaussian model, the synaptic weight converges to the weight coding as , where μ is the external state that output neuron i learned to represent (i.e., i ∈ Ωμ).
As we were considering population representation, in which the total number of output neuron is larger than the total number of external states (i.e., p < N), there is a redundancy in representation. Thus, to make use of most of population, homeostatic constraint is necessary. For homeostatic plasticity, we set a constraint on the output firing rate. By combining two terms, synaptic weight plasticity rule is given as
By changing the strength of homeostatic plasticity bh, the network changes its behavior. The learning rate is divided by γ, because the mean of w is proportional to 1/γ. Although, this learning rule is unsupervised, each output neuron naturally selects an external state in self-organization manner.
Synaptic Connection Learning
Wiring plasticity of synaptic connection can be given in a similar manner. As shown in Figure 3, if the synaptic connection structure of network is correlated with the external model, the learning performance typically gets better. Therefore, by considering , the update rule of connection probability is given as
Here, we approximated wij with its average value wo. In this implementation, if synaptic weight is also plastic, convergence of DKL is no longer guaranteed, yet as shown in Figure 3, redundant representation robustly provides a good heuristic solution.
Let us next consider the implementation of the rewiring process with local spine elimination and creation based on the connection probability ρij. To keep the detailed balance of connection probability, creation probability cp(ρ) and elimination probability ep(ρ) need to satisfy
The simplest functions that satisfy above equation is cp(ρ) ≡ ρ∕τc, ep(ρ) ≡ (1−ρ)∕τc. In the simulation, we implemented this rule by changing cij from 1 to 0 with probability (1−ρ)∕τc for every connection with cij = 1, and shift cij from 0 to 1 with probability ρ∕τc for non-existing connection (cij = 0) at every time step.
Dual Hebbian Rule and Estimated Transfer Entropy
The results in the main texts suggest that non-random synaptic connection structure can be beneficial either when that increases estimated transfer entropy or is correlated with the structure of the external model. To derive dual Hebbian rule, we used the latter property, yet in the simulation, estimated transfer entropy also increased by the dual Hebbian rule. Here, we consider relationship of two objective functions. Estimation of the external state from the sampled inputs is approximated as
Therefore, by considering stochastic gradient descending, an update rule of ρij is given as
If we compare this equation with the equation for dual Hebbian rule (Equation 13), both of them are monotonically increasing function of and have the same dependence on although normalization terms are different. Thus, the change directions in dynamics given by Equation (13) and (15) have on average positive cross-correlation, hence under an adequate normalization, the inner product of change direction becomes positive on average. Therefore, although dual Hebbian learning rule does not maximize the estimated maximum transfer entropy, the rule rarely diminishes it.
Gaussian Model
We constructed mean response probabilities by following 2 steps. First, non-normalized response probabilities were chosen from a truncated normal distribution N(μM, σM) defined on [0, ∞). Second, we defined by , where . Truncated normal distribution was chosen for performing Gaussian approximation in analytical calculation (see Section Evaluation of Performances in Weight Coding and Connectivity Coding). When the noise follows a Gaussian distribution, the response functions is given as
thus functions in Equation (5) are uniquely defined as
Because , α(q) is given as . By substituting g(r) in Equation (8) with g(r) in Equation (16), the neural dynamics is given as
Thus, in this model setting, optimal inference in all-to-all connection is given by . Similarly, dual Hebbian rule becomes
Poisson Model
For Poisson model, we defined mean response probabilities from a log-normal distribution instead of a normal distribution. Non-normalized values were sampled from a truncated log-normal distribution defined on . Normalization was performed as for , where . Because the noise follows a Poisson distribution p(r|θ) = exp[−q + r log q − log r!], the response functions are given as
As a result, α(q) is defined as α(q) ≡ A(h−1(q)) = eq. By substituting them to the original equations, the neural dynamics also follows Equation (17). If connection is all-to-all, by setting wij = log(θjμ∕θo) for i ∈ Ωμ, optimal inference is achievable. Here, we normalized θj by θo, which is defined as , in order to keep synaptic weights in positive values. Note that, theoretically speaking, θo can be any value satisfying , yet here we used for numerical stability.
Learning rules for synaptic weight and connection are given as
Note that the first term of the synaptic weight learning rule coincides with a previously proposed optimal learning rule for spiking neurons (Habenschuss et al., 2013; Nessler et al., 2013). In calculation of model error, error was calculated as , where estimated parameter was given by . Here, represents the mean of true {qjμ}, and non-normalized estimator was calculated as . In Supplementary Figure 1D, estimation from connectivity was calculated from , and similarly, estimation from weights was calculated by . For parameters, we used , , , , wo = 1∕γ, , and for other parameters, we used same values with the Gaussian model.
Analytical Evaluations
Evaluation of Performances in Weight Coding and Connectivity Coding
In Gaussian model, we can analytically evaluate the performance in two coding schemes. As the dynamics of output neurons follows membrane potential variable ui, which is defined as
determines firing rates of each neuron. Because {θjμ} is normalized with , mean and variance of {θjμ} are given as
where μM and σM are the mean and variance of the original non-normalized truncated Gaussian distribution . Because both rX, j and {θjμ} approximately follow Gaussian distribution, ui is expected to follow Gaussian. Therefore, by evaluating its mean and variance, we can characterize the distribution of ui for a given external state (Babadi and Sompolinsky, 2014).
Let us first consider the distribution of ui in the weight coding. In weight coding scheme, wij and cij are defined as
where . By setting , the mean membrane potential of output neuron i selective for given signal (i.e., i ∈ Ωμ for st = μ) is calculated as,
Similarly, the variance of ui is given as
where ζj is a Gaussian random variable. On the other hand, if output neuron i is not selective for the presented stimuli (if st≠μ and i ∈ Ωμ), wij and rX, j are independent. Thus, the mean and the variance of ui are given as,
In addition to that, due to feedforward connection, output neurons show noise correlation. For two output neurons i and l selective for different states (i.e., i ∈ Ωμ and l∉Ωμ), the covariance between ui and ul satisfies
Therefore, approximately (ui, ul) follows a multivariable Gaussian distributions
In maximum likelihood estimation, the estimation fails if a non-selective output neuron shows higher firing rate than the selective neuron. When there are two output neurons, probability for such an event is calculated as
In the simulation, there are p − 1 distractors per one selective output neuron. Thus, approximately, accuracy of estimation was evaluated by . In Figure 2B, we numerically calculated this value for the analytical estimation.
Similarly, in connectivity coding, wij and cij are given as
By setting wo = μθ∕γ, from a similar calculation done above, the mean and the variance of (ui, ul) are derived as
If we compare the two coding schemes, means are the same for two coding schemes, and as γ satisfies , variance of non-selective output neuron are similar. The main difference is the second term of signal variance. In the weight coding, signal variance is proportional to 1/γ, on the other hand, in the connectivity coding, the second term of signal variance is negative, and does not depend on the connectivity. As a result, in the adequately sparse regime, firing rate variability of selective output neuron becomes smaller in connectivity coding, and the estimation accuracy is better. In the sparse limit, the first term of variance becomes dominant and both schemes do not work well, consequently, the advantage for connectivity coding disappears. Coefficient of variation calculated for signal terms is indeed smaller in connectivity coding scheme (blue and red lines in Figure 2C), and the same tendency is observed in simulation (cyan and orange lines in Figure 2C).
Optimality of Connectivity
To evaluate optimality of a given connection matrix C, we calculated the posterior probability of the external states estimated from C and rX, and compared then to that from the fully connected network Call. Below, we denote the mean KL-divergence as I(Call,C) for readability. When the true external state is st = ν, firing rates of input neurons are given by ~ N(θjν, σX), hence this I(Call,C) is approximately evaluated as
where {ζj} are Gaussian random variables, and Call represents the all-to-all connection matrix. By taking integral over Gaussian variables, the posterior probability is evaluated as
where
Thus, the KL-divergence between estimations by two connection structures Call and C is approximated as:
In the black lines in Figures 3C–E, we maximized the approximated KL-divergence I(Call, C) with a hill-climbing method from various initial conditions, thus the lines may not be the exact optimal, but rather lower bounds of the optimal performance. Information gain by a connection cij was evaluated by
where ηij is a N×M matrix in which only (i, j) element takes 1, and all other elements are 0. In Figure 3B, we took average over 1000 random connection structures with connection probability ρ = 0.1.
Model Settings
Details of Simulation
In the simulation, the external variable st was chosen from 10 discrete variables (p = 10) with equal probability (Pr [st = q] = 1/p, for all q). The mean response probability θjμ was given first by randomly chosen parameters from the truncated normal distribution N(μM, σM) in [0, ∞), and then normalized using , where . Mean weight wo was defined as . The normalization factor hw was defined as in Figures 1, 2, 4, 5, where , and as in Figures 6, 7, as the mean of θ depends on κm. In Figure 3, we used for the dual coding, and for the rest. Average connectivity was calculated from the initial connection matrix of each simulation. In the calculation of the dynamics, for the membrane parameter , a boundary condition was introduced for numerical convenience, where vd = −60 and ℓ is index for the output neurons. In addition, synaptic weight wij was bounded to a non-negative value (wij > 0), and the connection probability was defined as ρ ∈ [0, 1]. For the dynamics of synaptic weight wij in Figures 4–8, we used Equation (2), and for the dynamics of connection probability ρij, we used Equation (3) in Figures 5, 6, and Equation (4) in Figures 6I, 7, 8, unless stated otherwise. In the rest of figures, both wij and ρij were kept constants on the values described in Sections Weight Coding and Connectivity Coding and Dual Coding and Cut-Off Coding. For simulations with synaptic weight learning, initial weights were defined as , where = 0.1, and ζ is a Gaussian random variable. Similarly, in the simulation with structural plasticity, the initial condition for the synaptic connection matrix was defined as . In both the dual Hebbian rule and the approximated dual Hebbian rule, the synaptic weight of a newly created spine was given as , for a random Gaussian variable ζ ← N(0, 1). In Figure 8, simulations were initiated at −20 days (i.e., 2 × 106 steps before stimulus onset) to ensure convergence for the control condition. For model parameters, μM = 1.0, σM = 1.0, σX = 1.0, M = 200, N = 100 1.0, and 1.0 were used, and for learning-related parameters, ηX = 0.01, bh = 0.1, ηρ= 0.001, τc = 106, T2 = 105, and κm = 0.5 were used. In Figures 7, 8, ηρ = 0.0001, , and γ = 0.6 were used, unless otherwise stated.
Accuracy of Estimation
The accuracy was measured with the bootstrap method. By using data from t-To < = t' < t, the selectivity of output neurons was first decided. Ωμ was defined as a set of output neurons that represents external state μ. Neuron i belongs to set Ωμ if i satisfies
where operator [X]+ returns 1 if X is true; otherwise, it returns 0. By using this selectivity, based on data from t < = t' < t+To, the accuracy was estimated as
In this method, even if the connection structure between input and output layers is completely random, still the accuracy of estimation typically becomes slightly higher than the chance level (= 1.0/p) if output activity is not completely uniform, but the effect is almost negligible for the given model settings. In the simulation, To = 103 was used because this value is sufficiently slow compared with weight change but sufficiently long to suppress variability.
Model Error
Using the same procedure, model error was estimated as
where represents the estimated parameter. was estimated by
In Figure 6E, the estimation of the internal model from connectivity was calculated by
Similarly, the estimation from the synaptic weight in Figure 6F was performed with
Transfer Entropy
Entropy reduction caused by partial information on input firing rates was evaluated by transfer entropy:
where
Output group Ωμ was determined as described above. Here, the true model was used instead of the estimated model to evaluate the maximum transfer entropy achieved by the network.
Spine Dynamics
In Figure 8H, x-axes were calculated as follows:
Here, we denoted the connectivity at day n as cij(n−d). For instance, “total new spine at day 7” is the mean ratio of spines exist at day 7 which was absent at day 0, to spine exist at day 7. In this method, transient processes, such as elimination and recreation during day 0–7, are dismissed, but such rapid rewiring is rare in the model, and experimental observations tend to be suffered from the same problem. Hence, we used simplified calculation as described above.
Code Availability
C++ codes of the simulation program is available at ModelDB (http://modeldb.yale.edu/181913).
Author Contributions
Conceived and designed the experiments: NH, TF. Performed the experiments: NH. Analyzed the data: NH. Wrote the paper: NH, TF.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors thank Drs. Haruo Kasai and Taro Toyoizumi for their comments on the early version of the manuscript. This work was partially supported by JSPS doctoral fellowship (DC2) to NH, KAKENHI (no. 15H04265) to TF and CREST, Japan Science and Technology.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fncir.2016.00041
Supplementary Figure 1. Results in Poisson model. (A) An example of output neuron activity before (top) and after (bottom) synaptic weight learning at connectivity ρ = 0.25. (B) Synaptic weight matrices before (left) and after (right) learning. Both X-neurons and Y-neurons were sorted based on their preferred external states. (C) Accuracy of estimation at various timescale of rewiring τc. (D) Model error calculated from connectivity (left) and synaptic weights (right). (E) Comparison of performance among the model without wiring plasticity (cyan), and dual Hebbian model(orange). Corresponding results in the Gaussian model are described in Figures 4A, 5F,G, 6E,F,I, respectively.
References
Babadi, B., and Sompolinsky, H. (2014). Sparseness and expansion in sensory representations. Neuron 83, 1213–1226. doi: 10.1016/j.neuron.2014.07.035
Bartol, T. M., Bromer, C., Kinney, J. P., Chirillo, M. A., Bourne, J. N., Harris, K. M., et al. (2015). Nanoconnectomic upper bound on the variability of synaptic plasticity. eLife 4:e10778. doi: 10.7554/eLife.10778
Beck, J. M., Ma, W. J., Kiani, R., Hanks, T., Churchland, A. K., Roitman, J., et al. (2008). Probabilistic population codes for bayesian decision making. Neuron 60, 1142–1152. doi: 10.1016/j.neuron.2008.09.021
Bliss, T. V., and Collingridge, G. L. (1993). A synaptic model of memory: long-term potentiation in the hippocampus. Nature 361, 31–39. doi: 10.1038/361031a0
Brunel, N., Hakim, V., Isope, P., Nadal, J.-P., and Barbour, B. (2004). Optimal information storage and the distribution of synaptic weights: perceptron versus purkinje cell. Neuron 43, 745–757. doi: 10.1016/j.neuron.2004.08.023
Buzsáki, G., and Mizuseki, K. (2014). The log-dynamic brain: how skewed distributions affect network operations. Nat. Rev. Neurosci. 15, 264–278. doi: 10.1038/nrn3687
Caporale, N., and Dan, Y. (2008). Spike timing–dependent plasticity: a Hebbian learning rule. Annu. Rev. Neurosci. 31, 25–46. doi: 10.1146/annurev.neuro.31.060407.125639
Caroni, P., Donato, F., and Muller, D. (2012). Structural plasticity upon learning: regulation and functions. Nat. Rev. Neurosci. 13, 478–490. doi: 10.1038/nrn3258
Chechik, G., Meilijson, I., and Ruppin, E. (1998). Synaptic pruning in development: a computational account. Neural Comput. 10, 1759–1777. doi: 10.1162/089976698300017124
Chen, B. L., Hall, D. H., and Chklovskii, D. B. (2006). Wiring optimization can relate neuronal structure and function. Proc. Natl. Acad. Sci. U.S.A. 103, 4723–4728. doi: 10.1073/pnas.0506806103
Chklovskii, D. B., Mel, B. W., and Svoboda, K. (2004). Cortical rewiring and information storage. Nature 431, 782–788. doi: 10.1038/nature03012
Dayan, P., and Abbott, L. F. (2005). Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems. 1st Edn. Cambridge, MA: The MIT Press.
Dayan, P., Hinton, G. E., Neal, R. M., and Zemel, R. S. (1995). The Helmholtz machine. Neural Comput. 7, 889–904. doi: 10.1162/neco.1995.7.5.889
Deger, M., Helias, M., Rotter, S., and Diesmann, M. (2012). Spike-timing dependence of structural plasticity explains cooperative synapse formation in the neocortex. PLoS Comput. Biol. 8:e1002689. doi: 10.1371/journal.pcbi.1002689
Donoho, D. L. (2006). Compressed sensing. IEEE Trans. Inf. Theory 52, 1289–1306. doi: 10.1109/TIT.2006.871582
Faisal, A. A., Selen, L. P. J., and Wolpert, D. M. (2008). Noise in the nervous system. Nat. Rev. Neurosci. 9, 292–303. doi: 10.1038/nrn2258
Fauth, M., Wörgötter, F., and Tetzlaff, C. (2015). The formation of multi-synaptic connections by the interaction of synaptic and structural plasticity and their functional consequences. PLoS Comput. Biol. 11:e1004031. doi: 10.1371/journal.pcbi.1004031
Feldman, D. E. (2009). Synaptic mechanisms for plasticity in neocortex. Annu. Rev. Neurosci. 32, 33–55. doi: 10.1146/annurev.neuro.051508.135516
Fusi, S., Asaad, W. F., Miller, E. K., and Wang, X.-J. (2007). A neural circuit model of flexible sensorimotor mapping: learning and forgetting on multiple timescales. Neuron 54, 319–333. doi: 10.1016/j.neuron.2007.03.017
Ganguli, S., and Sompolinsky, H. (2012). Compressed sensing, sparsity, and dimensionality in neuronal information processing and data analysis. Annu. Rev. Neurosci. 35, 485–508. doi: 10.1146/annurev-neuro-062111-150410
Habenschuss, S., Puhr, H., and Maass, W. (2013). Emergence of optimal decoding of population codes through STDP. Neural Comput. 25, 1371–1407. doi: 10.1162/NECO_a_00446
Hiratani, N., Teramae, J.-N., and Fukai, T. (2013). Associative memory model with long-tail-distributed Hebbian synaptic connections. Front. Comput. Neurosci. 6:102. doi: 10.3389/fncom.2012.00102
Holtmaat, A. J. G. D., Trachtenberg, J. T., Wilbrecht, L., Shepherd, G. M., Zhang, X., Knott, G. W., et al. (2005). Transient and persistent dendritic spines in the neocortex in vivo. Neuron 45, 279–291. doi: 10.1016/j.neuron.2005.01.003
Holtmaat, A., and Svoboda, K. (2009). Experience-dependent structural synaptic plasticity in the mammalian brain. Nat. Rev. Neurosci. 10, 647–658. doi: 10.1038/nrn2699
Ikegaya, Y., Sasaki, T., Ishikawa, D., Honma, N., Tao, K., Takahashi, N., et al. (2013). Interpyramid spike transmission stabilizes the sparseness of recurrent network activity. Cereb. Cortex 23, 293–304. doi: 10.1093/cercor/bhs006
Kasai, H., Hayama, T., Ishikawa, M., Watanabe, S., Yagishita, S., and Noguchi, J. (2010). Learning rules and persistence of dendritic spines. Eur. J. Neurosci. 32, 241–249. doi: 10.1111/j.1460-9568.2010.07344.x
Knoblauch, A., Palm, G., and Sommer, F. T. (2010). Memory capacities for synaptic and structural plasticity. Neural Comput. 22, 289–341. doi: 10.1162/neco.2009.08-07-588
Knott, G. W., Holtmaat, A., Wilbrecht, L., Welker, E., and Svoboda, K. (2006). Spine growth precedes synapse formation in the adult neocortex in vivo. Nat. Neurosci. 9, 1117–1124. doi: 10.1038/nn1747
Ko, H., Cossell, L., Baragli, C., Antolik, J., Clopath, C., Hofer, S. B., et al. (2013). The emergence of functional microcircuits in visual cortex. Nature 496, 96–100. doi: 10.1038/nature12015
Lefort, S., Tomm, C., Floyd Sarria, J.-C., and Petersen, C. C. H. (2009). The excitatory neuronal network of the C2 barrel column in mouse primary somatosensory cortex. Neuron 61, 301–316. doi: 10.1016/j.neuron.2008.12.020
Lochmann, T., and Deneve, S. (2011). Neural processing as causal inference. Curr. Opin. Neurobiol. 21, 774–781. doi: 10.1016/j.conb.2011.05.018
Maass, W., Natschläger, T., and Markram, H. (2002). Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560. doi: 10.1162/089976602760407955
Masamizu, Y., Tanaka, Y. R., Tanaka, Y. H., Hira, R., Ohkubo, F., Kitamura, K., et al. (2014). Two distinct layer-specific dynamics of cortical ensembles during learning of a motor task. Nat. Neurosci. 17, 987–994. doi: 10.1038/nn.3739
Matsui, A., Tran, M., Yoshida, A. C., Kikuchi, S. S., U, M., Ogawa, M., et al. (2013). BTBD3 controls dendrite orientation toward active axons in mammalian neocortex. Science 342, 1114–1118. doi: 10.1126/science.1244505
Matsuzaki, M., Honkura, N., Ellis-Davies, G. C. R., and Kasai, H. (2004). Structural basis of long-term potentiation in single dendritic spines. Nature 429, 761–766. doi: 10.1038/nature02617
Munz, M., Gobert, D., Schohl, A., Poquérusse, J., Podgorski, K., Spratt, P., et al. (2014). Rapid Hebbian axonal remodeling mediated by visual stimulation. Science 344, 904–909. doi: 10.1126/science.1251593
Navlakha, S., Barth, A. L., and Bar-Joseph, Z. (2015). Decreasing-rate pruning optimizes the construction of efficient and robust distributed networks. PLoS Comput. Biol. 11:e1004347. doi: 10.1371/journal.pcbi.1004347
Nessler, B., Pfeiffer, M., Buesing, L., and Maass, W. (2013). Bayesian computation emerges in generic cortical microcircuits through spike-timing-dependent plasticity. PLoS Comput. Biol. 9:e1003037. doi: 10.1371/journal.pcbi.1003037
Perin, R., Berger, T. K., and Markram, H. (2011). A synaptic organizing principle for cortical neuronal groups. Proc. Natl. Acad. Sci. U.S.A. 108, 5419–5424. doi: 10.1073/pnas.1016051108
Poirazi, P., and Mel, B. W. (2001). Impact of active dendrites and structural plasticity on the memory capacity of neural tissue. Neuron 29, 779–796. doi: 10.1016/S0896-6273(01)00252-5
Potjans, T. C., and Diesmann, M. (2014). The cell-type specific cortical microcircuit: relating structure and activity in a full-scale spiking network model. Cereb. Cortex 24, 785–806. doi: 10.1093/cercor/bhs358
Ryan, T. J., Roy, D. S., Pignatelli, M., Arons, A., and Tonegawa, S. (2015). Engram cells retain memory under retrograde amnesia. Science 348, 1007–1013. doi: 10.1126/science.aaa5542
Sacramento, J., Wichert, A., and van Rossum, M. C. W. (2015). Energy efficient sparse connectivity from imbalanced synaptic plasticity rules. PLoS Comput. Biol. 11:e1004265. doi: 10.1371/journal.pcbi.1004265
Salinas, E., and Romo, R. (1998). Conversion of sensory signals into motor commands in primary motor cortex. J. Neurosci. 18, 499–511.
Sayer, R. J., Friedlander, M. J., and Redman, S. J. (1990). The time course and amplitude of EPSPs evoked at synapses between pairs of CA3/CA1 neurons in the hippocampal slice. J. Neurosci. 10, 826–836.
Sengupta, B., Stemmler, M. B., and Friston, K. J. (2013). Information and efficiency in the nervous system—a synthesis. PLoS Comput. Biol. 9:e1003157. doi: 10.1371/journal.pcbi.1003157
Song, S., Sjöström, P. J., Reigl, M., Nelson, S., and Chklovskii, D. B. (2005). Highly nonrandom features of synaptic connectivity in local cortical circuits. PLoS Biol. 3:e68. doi: 10.1371/journal.pbio.0030068
Stepanyants, A., Hof, P. R., and Chklovskii, D. B. (2002). Geometry and structural plasticity of synaptic connectivity. Neuron 34, 275–288. doi: 10.1016/S0896-6273(02)00652-9
Sul, J. H., Jo, S., Lee, D., and Jung, M. W. (2011). Role of rodent secondary motor cortex in value-based action selection. Nat. Neurosci. 14, 1202–1208. doi: 10.1038/nn.2881
Turrigiano, G. G., and Nelson, S. B. (2004). Homeostatic plasticity in the developing nervous system. Nat. Rev. Neurosci. 5, 97–107. doi: 10.1038/nrn1327
Varshney, L. R., Sjöström, P. J., and Chklovskii, D. B. (2006). Optimal information storage in noisy synapses under resource constraints. Neuron 52, 409–423. doi: 10.1016/j.neuron.2006.10.017
Wiegert, J. S., and Oertner, T. G. (2013). Long-term depression triggers the selective elimination of weakly integrated synapses. Proc. Natl. Acad. Sci. U.S.A. 110, E4510–E4519. doi: 10.1073/pnas.1315926110
Xu, T., Yu, X., Perlik, A. J., Tobin, W. F., Zweig, J. A., Tennant, K., et al. (2009). Rapid formation and selective stabilization of synapses for enduring motor memories. Nature 462, 915–919. doi: 10.1038/nature08389
Yang, G., Lai, C. S. W., Cichon, J., Ma, L., Li, W., and Gan, W.-B. (2014). Sleep promotes branch-specific formation of dendritic spines after learning. Science 344, 1173–1178. doi: 10.1126/science.1249098
Yang, G., Pan, F., and Gan, W.-B. (2009). Stably maintained dendritic spines are associated with lifelong memories. Nature 462, 920–924. doi: 10.1038/nature08577
Yasumatsu, N., Matsuzaki, M., Miyazaki, T., Noguchi, J., and Kasai, H. (2008). Principles of long-term dynamics of dendritic spines. J. Neurosci. Off. J. Soc. Neurosci. 28, 13592–13608. doi: 10.1523/JNEUROSCI.0603-08.2008
Yoshimura, Y., Dantzker, J. L. M., and Callaway, E. M. (2005). Excitatory cortical neurons form fine-scale functional networks. Nature 433, 868–873. doi: 10.1038/nature03252
Zheng, P., Dimitrakakis, C., and Triesch, J. (2013). Network self-organization explains the statistics and dynamics of synaptic connection strengths in cortex. PLoS Comput. Biol. 9:e1002848. doi: 10.1371/journal.pcbi.1002848
Keywords: synaptic plasticity, synaptogenesis, neural decoding, computational model, connectomics
Citation: Hiratani N and Fukai T (2016) Hebbian Wiring Plasticity Generates Efficient Network Structures for Robust Inference with Synaptic Weight Plasticity. Front. Neural Circuits 10:41. doi: 10.3389/fncir.2016.00041
Received: 08 December 2015; Accepted: 11 May 2016;
Published: 31 May 2016.
Edited by:
Ido Kanter, Bar Ilan University, IsraelReviewed by:
Gianluigi Mongillo, Paris Descartes University, FranceAlexantrou Serb, University of Southampton, UK
Copyright © 2016 Hiratani and Fukai. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Naoki Hiratani, bi5oaXJhdGFuaUBnbWFpbC5jb20=;
Tomoki Fukai, dGZ1a2FpQHJpa2VuLmpw