
- 1 Department of Biology, Volen National Center for Complex Systems, Brandeis University, Waltham, MA, USA
- 2 Department of Psychology, Volen National Center for Complex Systems, Brandeis University, Waltham, MA, USA
Adults with sensory impairment, such as reduced hearing acuity, have impaired ability to recall identifiable words, even when their memory is otherwise normal. We hypothesize that poorer stimulus quality causes weaker activity in neurons responsive to the stimulus and more time to elapse between stimulus onset and identification. The weaker activity and increased delay to stimulus identification reduce the necessary strengthening of connections between neurons active before stimulus presentation and neurons active at the time of stimulus identification. We test our hypothesis through a biologically motivated computational model, which performs item recognition, memory formation and memory retrieval. In our simulations, spiking neurons are distributed into pools representing either items or context, in two separate, but connected winner-takes-all (WTA) networks. We include associative, Hebbian learning, by comparing multiple forms of spike-timing-dependent plasticity (STDP), which strengthen synapses between coactive neurons during stimulus identification. Synaptic strengthening by STDP can be sufficient to reactivate neurons during recall if their activity during a prior stimulus rose strongly and rapidly. We find that a single poor quality stimulus impairs recall of neighboring stimuli as well as the weak stimulus itself. We demonstrate that within the WTA paradigm of word recognition, reactivation of separate, connected sets of non-word, context cells permits reverse recall. Also, only with such coactive context cells, does slowing the rate of stimulus presentation increase recall probability. We conclude that significant temporal overlap of neural activity patterns, absent from individual WTA networks, is necessary to match behavioral data for word recall.
Introduction
Hearing impairment, even when mild, can cause an individual to miss critical words in everyday conversation or, in memory experiments, when asked to recall lists of spoken words. Although our focus is on effects of reduced hearing acuity this will be true as well for words partially masked by background noise. Just over 40 years ago, however, Rabbitt (1968) pointed to an additional factor attendant to memory in the presence of a degraded input. In a study of memory for short lists of eight spoken digits he found that when the final four digits in the to-be-recalled list were made difficult to recognize by presenting them masked by background noise, recall was adversely affected both for these stimuli as well as for the first four digits of the same memory set that were heard without background masking. Rabbitt suggested that the extra effort needed to identify degraded speech, whether due to noise masking or to poor hearing, draws resources that might otherwise be deployed for rehearsal or other mechanisms attendant to effective encoding of the materials in memory (Rabbitt, 1968, 1991).
Behavioral Data
The negative effect on word recall when stimulus words are made difficult to identify due to acoustic masking of the speech, or because of naturally-occurring hearing loss, has taken its place as a well-established finding (e.g., Rabbitt, 1968, 1991; Surprenant, 1999, 2007; Murphy et al., 2000). This effect of effortful perception on recall is a subtle but powerful one, especially in older adults where declines in episodic memory may further exacerbate this effect (Wingfield and Kahana, 2002; Howard et al., 2006). We have shown, for example, that recall of a sequence of just two adjacent words in a running memory task to be poorer for a group of older adults with mild-to-moderate hearing loss as compared to better hearing adults matched with the first group for age and cognitive ability (McCoy et al., 2005). The critical point in this and the above-cited studies is that this effect of degraded stimuli on word-list recall appears even when it is demonstrated that the words have been presented with adequate clarity to allow them to be correctly identified – albeit with extra effort. This general finding gives rise to the following conundrum: why is the process of laying down a memory trace of an identified word or sequence of words affected by the difficulty of identification? That is to say, once an acoustically degraded word is correctly identified, should it not be as easily remembered as any other identified word?
Rabbitt’s “effortful hypothesis” suggests an asymmetric effect of masking stimuli: the extra effort needed to identify masked stimuli detracts from resources needed to store the memory of prior clear stimuli, but does not affect a subject’s ability to identify or remember later clearly presented stimuli. Rabbitt (1968) found evidence for such asymmetry in a second context, where he tested subjects’ understanding of two successive paragraphs of text that were read in one of two alternations of masked and clear conditions. In such a context, he found that a second masked paragraph reduced subjects’ ability to recall a preceding clear paragraph, but a first masked paragraph did not affect subjects’ ability to recall a following clear paragraph.
Accounting for the negative effect of a weak sensory stimulus on subsequent recall in terms of front-end perceptual effort and memory encoding competing for a single pool of limited resources (Schneider and Pichora-Fuller, 2000; Pichora-Fuller, 2003; Wingfield et al., 2005) can be seen as an extension of a general resource argument has had long-standing descriptive utility in the general memory literature (Craik and Lockhart, 1972; Kahneman, 1973). In this paper we investigate an alternative account for the effect of reduced richness of sensory input on word recall, even when the words themselves have been correctly identified. This account centers on a transient period of reduced neural activity during the added time needed for correct word identification in response to a weak stimulus relative to a stronger one. We instantiate this account using a simplified biophysical model and we implement simulations for recall of words within a word sequence when perceptual identification of a neighboring word is slowed. because it is heard in a degraded form (e.g., McCoy et al., 2005).
Our model is based on the conditional response probabilities found in data from free recall of serial word lists (Howard and Kahana, 1999; Kahana et al., 2002), using simulations corresponding to pairs of words that could be extracted from longer lists. We test how the temporal proximity of words during presentation can allow recall of one word to promote recall of the following word or, in separate simulations, of the preceding word. We assume that poorer overall recall is a result of a reduction in the conditional response probabilities arising from weakened associations between proximal words.
Overview and Justification of the Model
Our model is based on the following biological assumptions. First, an auditory stimulus produces neuronal input that is stronger when the stimulus is clearer or in a subject with better hearing acuity. This first assumption is key to our model. Second, the input arrives at different subsets of cells according to the particular phonemes (speech sounds) present in the auditory stimulus. Third, when a word is recognized a single, word-specific group of cells maintains its activity. Fourth, the synaptic connections between active neurons change in accordance with measurements of coactive, connected neurons in brain slices.
We model the processes of word identification and word recall using a multiple-item decision-making network, comprising groups of spiking neurons, each representing a specific word. Cross-inhibition between groups ensures that once a group is sufficiently active it suppresses the neural activity of other groups, enabling only a single auditory percept at a time. Such a network configuration is known as a “winner-takes-all” network and has been used in models of both decision-making (Wang, 2001, 2002; Wong and Wang, 2006) and perception (Moreno-Bote et al., 2007). The single group of cells that ends up with high activity determines the identity of the perceived word in our model. Thus this model differs from other models of a similar task of sequential recall based on multiple-item memory (Mongillo et al., 2003), in that we simulate a circuit whose activity represents only the single perceived item at a given time (similar to models of binocular bistability, Moreno-Bote et al., 2007).
We assume the inputs that reach each group of cells are determined by how closely the sensory evidence matches the identity of the word. Even though we model presentation of just two successive stimuli from a word list, each stimulus can partially activate more than one group of cells. So to allow for the possibility of incorrect identification and incorrect recall, we include groups of cells that represent lexical alternatives to the presented words. In the case of perceptual identification, one would expect these lexical items to be those that share some phonology with the target word, with the number of such close neighbors affecting the ease (speed/accuracy) of correct identification (Luce and Pisoni, 1998). These are represented by the similar words within dashed boxes that create subsections of the word recognition network in Figure 1.
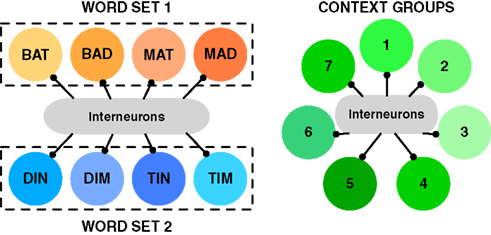
Figure 1. Schematic representation of network architecture. (Left) Winner-takes-all network of Word Groups. Each circle represents a group of 80 excitatory cells. Cells within a group receive identical input and are connected to each other by recurrent excitation. Recurrent excitation is strong enough to enable persistent activity among cells representing a single word. Each of the two dashed boxes represents a set of four words with phonological similarity (e.g., “Bat”, “Bad”, “Mat”, “Mad”). Presentation of one word from the set excites, to a degree depending on clarity of the presented word, other words in the same set. The two-word sequence consists of a stimulus from Set one then from Set two. The winner-takes all character of the word-identification network is produced by cross-inhibition between different word groups via interneurons (20 inhibitory cells per excitatory pool). The cross-inhibition is significantly stronger than weak cross-excitation (not shown) such that after presentation of a stimulus only one group of cells – typically the group most strongly activated by the stimulus – can remain significantly active. (Right) Winner-takes-all network of Context Groups. Symbols have the same meaning as for the Word Groups. Self-excitation within Context Groups is present, but less strong than for Word Groups, allowing for context to change with time while a word can be retained in memory. Seven Context Groups are simulated, again, because of cross-inhibition, just one context group is active at a time. Coupling between the two winner-takes-all networks of cells (“Word” and “Context”) is absent in the first set of simulations (Figures 2 and 3) and comprises approximately equally matched weak excitatory and weak inhibitory connections in the later simulations based on the temporal context model (Figures 4–6). See Figure S1 and Table S1 in Supplementary Material for further details of the architecture.
If the sensory input is clear, then one word is matched significantly above others, so the corresponding group of cells receives considerably greater input than other groups. However, if the sensory input is less clear, the input received by different groups of neurons is less differentiated, leading to the following three consequences. First, errors are more likely, as stochastic fluctuations can result in a group of neurons with lower sensory input becoming more active and suppressing other groups, even the group representing the actual stimulus and receiving greater sensory input. Second, the “winning” pool representing stimulus identification reaches its stable activation level more slowly, because of its weaker direct drive and greater competition from the other partially activated neuronal pools. We test whether such a slowing of the identification process for poorer stimuli (Lisper et al., 1972) contributes to a diminished association between such stimuli and other items in memory, thus reducing their ability to be recalled. Third, before settling at a stable activation level following stimulus offset, a stronger stimulus can produce a transient peak in neural activity, whose absence during a weak stimulus may also diminish the formation of associations necessary for correct recall.
Memory Formation through Synaptic Plasticity
We base our model on spiking neurons, since spikes reflect the main method of information transmission of neurons and since in vitro experimental measurements of the neural underpinnings of memory, namely long-term potentiation (LTP) and long-term depression (LTD) of synaptic strengths, can be ascribed to the temporal correlations of spiking activity in connected cells (Markram et al., 1997; Bi and Poo, 1998, 2001). Models that take into account such temporal correlations fall under the umbrella of spike- timing-dependent synaptic plasticity (STDP) (Markram et al., 1997; Bi and Poo, 1998; Song et al., 2000; Song and Abbott, 2001; Pfister and Gerstner, 2006). STDP has been established in vitro as a means of changing the strengths of connections (Sjostrom et al., 2001) between neurons, so is hypothesized to play a role in memory formation (Letzkus et al., 2007) in vivo. STDP is Hebbian (Hebb, 1949) in nature (both associative and reinforcing temporal causality) so that when spikes of one neuron precede the spikes of another, the tendency is to increase the strength of connection from the first neuron to the second. Empirical models of STDP have evolved over the years, moving beyond the attribution of plasticity to a single spike in each cell (Song et al., 2000; Song and Abbott, 2001), to include triplet terms (Pfister and Gerstner, 2006) that better fit the changes in synaptic efficacy observed in vitro when triplets and quadruplets of spikes are used in the stimulation protocol (Sjostrom et al., 2001; Sjostrom and Nelson, 2002). Importantly, the modified triplet rule produces a rate-dependence for plasticity in accordance with the Bienenstock–Cooper–Munroe rule (Bienenstock et al., 1982), such that uncorrelated presynaptic spikes correlated with high postsynaptic activity produce potentiation, but those correlated with low postsynaptic activity produce depression. In this paper, we test the effect on our network of two such triplet rules for STDP, in comparison with standard, or basic STDP.
In contrast to the vast literature on associative LTP, there are relatively few studies of associative short-term plasticity (ASTP) (but see Malenka, 1991; Castro-Alamancos and Connors, 1996; Brenowitz and Regehr, 2005; Rosanova and Ulrich, 2005; Rebola et al., 2007; Fujisawa et al., 2008; Heifets et al., 2008; Kano et al., 2009; Sun et al., 2009). Recent measurements in hippocampal slices by the group of Lisman (Erickson et al., 2009), demonstrate that a weak associative stimulation protocol produces rapid, strong synapse-specific potentiation, appearing in under 12 s and lasting for over a minute. These data match the timescale of typical sequence memory tasks, so provide the basis for our standard plasticity mechanism (ASTP). Our rule for ASTP differs from the rule for basic STDP in that it is non-linear, requiring both more than a single presynaptic spike and more than a single postsynaptic spike to produce any change at all (Erickson et al., 2009). Moreover the synaptic strengthening is large, able to produce a 40% increase from a single protocol with two presynaptic spikes, but rapidly saturates, so that once the maximal potentiation possible from a single pairing is reached, subsequent pairings of spikes produce no further change in synaptic efficacy. Finally, the mechanism only produces potentiation, but since the potentiation decays over minutes it does not disrupt the long-term stability of a network.
It is worth noting that our model of recall requires the strength of short-term plasticity (STP) to increase with firing rate of both presynaptic and postsynaptic cells – and hence be associative. STP based only on presynaptic spiking (as is the case for synaptic facilitation, Mongillo et al., 2008) cannot produce the preferential recall of successive stimuli observed behaviorally, since a strengthening of connections from one cell to all of its postsynaptic partners would provide no preference to those that had fired in temporal proximity.
The Temporal Context Model in Free Recall
The temporal context model (TCM) (Howard and Kahana, 1999, 2002; Sederberg et al., 2008), formulated by Kahana and Howard, was designed to explain the results of a wide range of serial and free recall memory tasks (Golomb et al., 2008) and has been shown to generalize to older as well as younger adults (Kahana et al., 2002; Wingfield and Kahana, 2002; Howard et al., 2006; Zaromb et al., 2006). The main suggestion is that the memory items stored in the brain are linked to a memory of the context at the time when an item was presented so that recall of a word promotes recall of the context and vice versa. While context is altered by presentation of items, unlike traditional associative learning models (Crowder, 1976; Mongillo et al., 2003) the model assumes no direct link from one memory item to the other. Rather, the item most likely to be recalled is the one whose study context is most correlated with the current context. Within TCM, context is assumed to evolve gradually over time, so that words presented closer together in time have a similar context and are more likely to promote each others recall than words separated by a wider time window. More recently, Howard et al. have demonstrated the role of context as opposed to pure temporal contiguity in the formation of preferential associations between memory items (Howard et al., 2009), lending further support to TCM.
To date, the widely successful implementations of TCM have relied on vectors and their scalar products to denote mental activity and overlap of context states. We attempt here to address the biological underpinnings of TCM, thus in our model, we assume that the firing of a certain subset of neurons comprises the neural representation of context. Therefore, in this paper, context simply means ongoing neural activity among cells connected with those cells active during auditory perception of words. We test how easily recall of specific words produces a recall of the context present during initial word presentation and how easily the recalled context can promote recall of prior or subsequent words. The key difference in connectivity between word-specific neurons and neurons representing context is a reduction in cross-inhibition, because while perception of one word should suppress perception of all other words, it does not suppress contextual activity.
We assess whether our model must include such a separate network of context cells, whose activity is not suppressed during word identification, in order to match the following three experimental findings:
(1) Weaker inputs (i.e., noise masking, hearing loss) lead to diminished probability of recall (McCoy et al., 2005);
(2) Recall is possible in reverse as well as forward order (Kahana, 1996; Howard and Kahana, 1999; Kahana et al., 2002; Kahana and Howard, 2005);
(3) Slowing the presentation rate of stimuli increases recall probability (Riggs et al., 1993; Wingfield et al., 1999).
Simulating Memory Recall
During recall, we activate one group of neurons representing one word that is already recalled, but do not provide any preferential stimulus (just a small global drive representing a general attempt to recall a word) to the neurons representing other words to be recalled. We rely on the stronger connections produced by synaptic plasticity to enable the active group to preferentially excite the desired pool of neurons. Once a subsequent group of neurons is activated by the internal network dynamics, we assume recall of the word represented by such neural activity. Thus we expect in control cases of strong stimuli, that activity of a neuronal group representing the correctly identified word should reliably follow activation of the neuronal group representing either the previous word or the following word from the prior sequence.
In the model with context groups, activation of one of the presented words should produce activity in the particular group of context cells that was active during the prior presentation. If there was insufficient synaptic plasticity, the connections to context cells could remain too indiscriminate to provoke significantly greater activity in the desired context pool and a random context pool could become active. Thus our network has the possibilities of retrieval of correct context, or incorrect context, or no retrieval of context upon word activation. Retrieval of correct context is a necessary link in a two-step process for above-chance recall of the other presented word.
Materials and Methods
Network Structure
In Figure 1, we schematically depict two winner-takes-all (WTA) networks, one for word recognition and one for context. In the figure, each circle represents a group of 100 cells that can be persistently active following stimulus offset. (100 was chosen for sufficient stability, without being computationally over-demanding nor reducing the network variability to levels below that due to noise correlations in the brain, Zohary et al., 1994). Cross-inhibition provided by the interneurons (at the center of each network) prevents more than one such group of cells in each network from maintaining activity in the absence of any external stimulus – this is the definition of winner-takes all, implementing our assumption of a single percept at a time.
While memory storage may be distributed across multiple cells in a manner such that many cells participate in multiple memories, one can think of the cells we explicitly model as those whose activity distinguishes the competing possible words. To take a specific example, we consider four pools of neurons explicitly, neurons in each pool only active to one of the four words “bat”, “bad”, “mat”, “mad”. If the stimulus input is clear, corresponding to a listener with good hearing, we assume (in our first model network) the relative level of input to these cell groups respectively as: 1, 0.05, 0.05, 0.05 during stimulus presentation. The assumption of a relative input of 0.05 to other populations is arbitrary, and the results are mostly independent of this assumption, at least in the range 0–0.5. Whereas if the stimulus input is unclear, corresponding to a subject with impaired hearing, we assume relative levels of input of: 0.35, 0.3, 0.3, 0.3. Again, the exact values are arbitrary, but chosen under the assumption that cross-inhibition maintains a relatively constant total input, but one that is more dispersed across cells. In both scenarios, the cell group corresponding to the correct word (in this case “bat”) receives greater input, enough for correct word identification (see Figure 2), but the distinction between correct and incorrect words at the input level is weaker for the hearing-impaired subject.
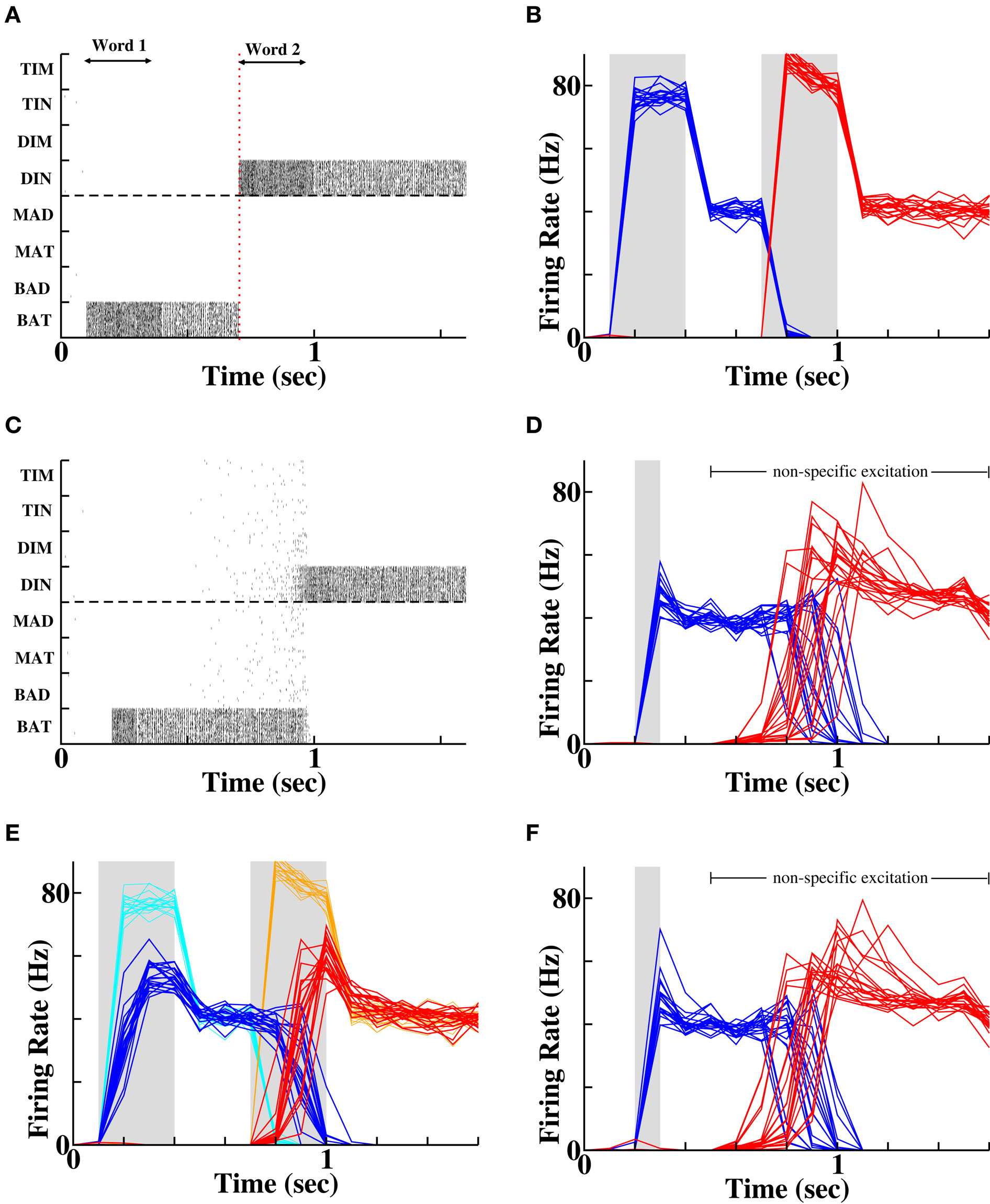
Figure 2. Forward recall via coupling between “word” populations. (A) Spike rasters during a single example of presentation of two stimuli. Each row contains the spikes of a single cell. The double-headed arrows indicate presentation of each word (via afferent Poisson input), which produces activity in a specific population that persists following stimulus offset. (B) Average firing rates of the populations of cells successively stimulated (blue = “BAT”, red = “DIN”) on each of 20 different random instantiations. (C) Spike rasters during a single instantiation demonstrating forward recall of the second word (“DIN”) following activation of the first word (“BAT”). (D) Average firing rates of the two populations across 20 independent random instantiations, demonstrating recall of “DIN” following activation of “BAT”. Gray solid bar indicates time period when first word is activated. (E) Protocol of weaker stimulation produces weaker and delayed initial activity (dark blue and red traces) compared to control (light cyan and orange traces). Twenty random instantiations of the weaker stimulation protocol produce identical final activity to controls, signifying equivalent levels of word recognition. (F) Average firing rates of the two populations with prior weak stimulation, following reactivation of the first word. Recall probability is reduced from 100% control to 75% of instantiations (15 out of 20 simulations).
All groups of neurons contain predominantly excitatory connections within the group, such that self-excitation can amplify any stimulus input and produce a short-term memory of it through persistent activity. Cross-connections between groups are both excitatory and inhibitory, but dominated by inhibition so that only one group can be fully active at a time. See Supplementary Material for the specific connections strengths.
Cells in context groups are weakly, sparsely and randomly connected with cells in the word-identification groups. Plastic excitatory connections between context and word-representing cells are necessary so that activation of a group in one WTA network can promote preferential activation of a group in the other WTA network during recall.
Protocol
The protocol for the simulations comprises three stages. In the first, “stimulus stage” inputs to the cells in the network are activated to represent auditory input. Inputs are designed to cause the cells in the network to fire at a few tens of Hz (see Figure 2), but represent activation of many cells outside the network (we assume 200 cells producing uncorrelated inputs of 45 Hz for maximal input strength, but obtained identical results when assuming 20% of that total input rate – 100 cells at 18 Hz – through synapses with conductance five times larger). In all cases these inputs cause successive activation of two pools of cells in the network, representing a sequence of two words (assumed to be within a longer list). In our subset of simulations based on the TCM, in addition, a single “context” pool of cells is activated to overlap temporally with the word stimuli.
In the second stage we calculate all of the changes in synaptic strength that arise in the first stage and update the network’s connections accordingly.
In the final, “recall stage” we activate just one pool of cells in the updated network and observe the ensuing network activity – that is, we see that given one word is recalled, how likely is a neighboring word to be recalled. Except where stated otherwise in our results, to simulate the desire for recall, we add a small, constant input to all inactive groups of cells that represent words. Without such extra input to encourage recall, our network either produces active words spontaneously and randomly (in fact in our standard network words can become spontaneously active without a stimulus) or recall becomes impossible. The constant input plays no role in determining which inactive pool becomes the next one activated, but does play a temporal role, allowing activation of a pool of cells representing a word to occur at the time when a subject attempts to recall a word. During recall, no input is provided to any context cells: any activation of context cells must be produced purely by activity in the activated word-identification cells.
In order to produce a probability of recall, for each set of parameters we produce 20 separate independent simulations (instantiations) with different random number seeds. We considered 20 as a number sufficient to demonstrate any differences between parameter sets without being so costly as to restrict the numbers of independent parameters we could test. One can think of the 20 separate instantiations as 20 separate pairs of words within lists provided for recall, or equally, as 20 separate matched subjects presented the same words (since our simulations cannot differentiate the two cases).
Single Neuron Model
We model neurons with the simplest possible of spiking models, the leaky integrate-and-fire model. Since synaptic plasticity depends on spike times (Bi and Poo, 1998; Sjostrom et al., 2001; Nelson et al., 2002), we require a level of realism that includes neural spikes, but since our model is rather general – for example, we do not know exactly in which neurons and in what activity pattern contextual information resides – generation of more sophisticated models of a particular neuronal class is unwarranted at present.
The basic equation for the membrane potential Vi of a leaky integrate-and-fire neuron labeled i follows (Tuckwell, 1988):
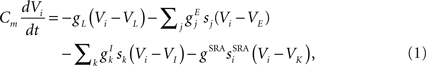
where Cm is the membrane capacitance, gL is the leak conductance, and reversal potentials for the leak current, excitatory inputs and inhibitory inputs respectively are VL, VE and VI. Maximal conductances of inputs from other excitatory cells labeled j are 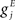 and from inhibitory cells labeled k are
and from inhibitory cells labeled k are 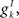 while the fractions of channels open by inputs from these cells are given by sj and sk respectively. When the membrane potential reaches a threshold, VT, the cell fires a spike at that time and the membrane potential is reset to a lower level, VR and held there for a refractory period, τR.
while the fractions of channels open by inputs from these cells are given by sj and sk respectively. When the membrane potential reaches a threshold, VT, the cell fires a spike at that time and the membrane potential is reset to a lower level, VR and held there for a refractory period, τR.
The model neurons receive excitatory and inhibitory inputs, both from other cells connected to them which are explicitly modeled within the model network and from external cells, whose firing is modeled as a random Poisson process giving feedforward input. The feedforward input arrives from a set of neurons with a constant rate, producing a low rate of noisy spontaneous activity in the modeled neurons, and from sets of cells with stimulus-dependent rates, causing higher activity in stimulus-dependent subgroups of cells within the network. Action potentials from other cells produce input in the model via a change in the relevant gating variable, si, which increases immediately following a spike by the cell labeled i according to 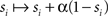 where α is the fraction of closed channels that open following a spike, and decays as dsi/dt = −si/τs between spikes.
where α is the fraction of closed channels that open following a spike, and decays as dsi/dt = −si/τs between spikes.
Spike rate adaptation is included (Dayan and Abbott, 2001) in the final term of Eq. 1 as a potassium current (with reversal potential VK) whose conductance has a maximal value of gSRA and which increases by a small fraction of its maximum 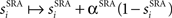 following a spike in cell i and decaying between spikes according to
following a spike in cell i and decaying between spikes according to 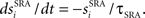
All equations were solved with C++ code, running on Intel processors, using the 2nd Order Runge–Kutta method with a time-step of 0.1 ms and linear interpolation of threshold crossing by the membrane potential, to produce spike times and with random numbers generated via the Mersenne Twister algorithm.
Plasticity Rules
We test the effects of three different plasticity rules, which we name ASTP, basic STDP (B-STDP) and triplet-STDP (3-STDP). Results presented in figures and summarized in the main text are produced with ASTP unless stated otherwise.
ASTP
Based on recent hippocampal slice data, we assume an increase in synaptic strength by up to a maximum of 40% given the concurrence of two presynaptic spikes with three postsynaptic spikes. We require the second presynaptic spike to precede the third postsynaptic spike, and given these conditions set up Gaussian temporal decays in the amount of plasticity, to ensure tight co-occurrence. Specifically, we change the synaptic weight by a fraction, ΔWASTP, given by:

where A0 = 0.4, τ+ = 30 ms, τpre = 30 ms, τpost = 30 ms, 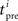 is the time of the i-th presynaptic spike and
is the time of the i-th presynaptic spike and 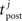 is the time of the j-th postsynaptic spike.
is the time of the j-th postsynaptic spike.
Since the precise form of the temporal window is not yet known (Erickson et al., 2009) and a Gaussian temporal dependency may be hard to justify biophysically, we also ran the simulations for ASTP based on exponential decays with a threshold. In the alternative ASTP rule, which produces the nearly identical results presented in Supplementary Material, we use:

with τ+ = 20 ms, τpre = τpost = 20 ms for tpost − tpre > 0 and no contribution for tpost − tpre < 0.
In line with the in vitro measurements of excitatory postsynaptic potentials (Erickson et al., 2009) the maximum increase across the trial using ASTP is given by A0 = 0.4 – that is, once synapses are strengthened by 40%, no further strengthening is possible.
Basic STDP
We implement STDP using standard methods (Capocchi et al., 1992; Song et al., 2000; Dayan and Abbott, 2001; Song and Abbott, 2001), assuming an exponential window for potentiation following a presynaptic spike at time tpre and for depression following a postsynaptic spike at time tpost, so that the change in connection strength, ΔW, follows:
ΔW = A+exp[(tpost − tpre)/τ+] if tpost − tpre > 0 and
ΔW = A−exp[(tpost − tpre)/τ−] if tpost − tpre < 0.
Basic STDP produces changes in synaptic weight whose sign depends only on the relative order of spikes, thus only on the relative order and direction of changes in rate, not on the absolute value of the rate.
Triplet-STDP
Given many in vitro experiments, which show that a high rate of postsynaptic firing produces potentiation, while a low rate of postsynaptic firing is more likely to produce depression (Dudek and Bear, 1993; Kirkwood and Bear, 1995), we also ran our simulations with a separate model of plasticity, produced by Pfister and Gerstner (2006), which better accounts for the measured rate-dependence of synaptic plasticity (Sjostrom et al., 2001). Their model includes triplet terms, so that recent postsynaptic spikes boost the amount of potentiation during a “pre-before-post” pairing, while recent presynaptic spikes boost the amount of depression during a “post-before-pre” pairing. Specifically when tpost − tpre > 0,
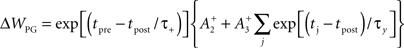
and when tpost − tpre < 0,
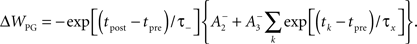
We use the two sets of values for parameters given by the full “all-to-all” model fitted to cortical data, and by the minimal model fitted to hippocampal data, as described in the paper by Pfister and Gerstner (2006), and reproduced here in the Supplementary Material.
Results
Our results are based on 20 separate instantiations, produced by simulation of the complete process of word presentation, synaptic plasticity, and test of word retrieval, for each set of parameters. These separate instantiations allowed us to produce a measure of recall probability, as would be found behaviorally via multiple word sequences and subjects. We chose a number of 20 instantiations per parameter set as sufficient that differences in results across parameter sets could be statistically significant (typically a 30% change in recall probability was significant at P < 0.05, two-tailed Binomial test) – whereas increasing the number further, while slightly improving our estimate of recall probability, would be too computationally taxing to allow us to test more than a few parameter sets.
Single Winner-Takes-All Network for Word Identification and Recall
In Figure 2, we see that the persistent firing rate of neurons representing the last word following a weak stimulus is no less than that following a strong stimulus (in fact rate is slightly higher following a weak stimulus as there is less prior adaptation and synaptic depression to suppress firing rates). Such persistent activity post-stimulus presentation on 20 of 20 trials represents active memory arising from identification of the stimulus, whether it was weak (Figure 2E) or strong (Figure 2B). However, during the strong stimulus presentation, the firing rate of the active cells increases much more rapidly and to a significantly higher peak (compare Figure 2B to Figure 2E). For the weaker stimulus, both the delayed rise to peak and the reduced magnitude of peak firing rate could result in a reduced amount of synaptic potentiation between cells active during the stimulus and those active prior to the stimulus. Upon closer examination, we find that when the weak stimulus leads to a slow rise in activity for the second word, the first word remains active for longer, leading to little change in the overall overlap of activity between the successive words (Figure 2E). In both cases the neural activity during stimulus presentation produces sufficient synaptic plasticity that on reactivation of the first word, the second word is recalled in all 20 random instantiations of the process (Figures 2D,F).
To test whether the network can produce recall in reverse order, we reactivate the second word and provide non-specific excitation to all other words (dummy words and the first word). We find no preferential reactivation of the first word following strong prior stimuli (Figure 3A) and somewhat unexpectedly, slightly better recall following weak prior stimuli (Figure 3B). For other plasticity mechanisms which, unlike associative STP, include a window for synaptic depression, synapses from the second to first word are weakened (Figure 3C), reducing probability of reverse recall to below chance (Figure 3D).
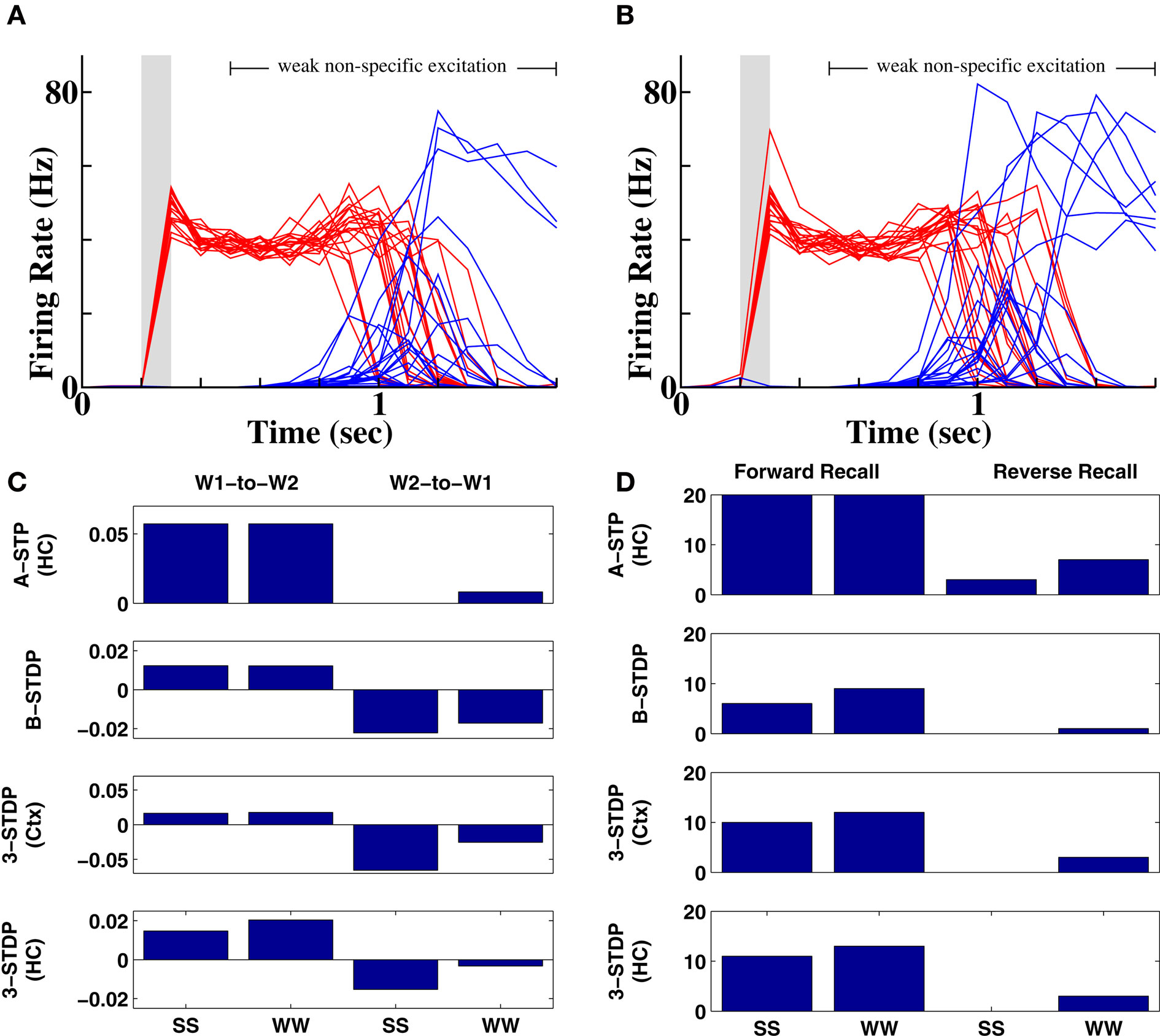
Figure 3. Impossibility of reverse recall via connections between word populations. (A) 20 separate instantiations of the memory protocol, with activation of the second word produce chance recall of other words (3 out of 20 instantiations). In the unsuccessful examples, pools that did not receive prior input become activated by chance during recall. (B) Reverse recall is slightly greater than chance following weak inputs, where temporal overlap of activity is greater. (C) Comparison of changes in mean synaptic weight as a fraction of original synaptic strength between two word pools receiving successive input, as a function of input strength and plasticity mechanism. W1 = first word; W2 = second word. Prior stimuli were either both strong (SS) or both weak (WW). Top row = associative short-term plasticity; second row = basic STDP; third row = triplet-STDP with cortical parameters; bottom row = triplet-STDP with hippocampal parameters. (D) Number of correct recalls as a function of prior input strength and plasticity mechanism. Row and column labels as in (C).
Forward and Reverse Recall VIA Reactivation of Context
If a separate group of context cells is active during the period of stimulation of the two words (Figures 4A,B) then upon subsequent reactivation of either of the words, the context cells can themselves become reactivated. The reactivation of the context cells promotes activity of the cells representing the other word, producing either forward recall (Figures 4C,D) or reverse recall (Figures 4E,F) with a success rate of 100% given sufficient initial stimulation intensity and with associative STP to modify the synapses. The ability of a separate pool of context cells to promote reliable reverse recall, that is not achievable in a single winner-take-all network, is in agreement with expectations based on the TCM for word retrieval (Howard and Kahana, 1999).
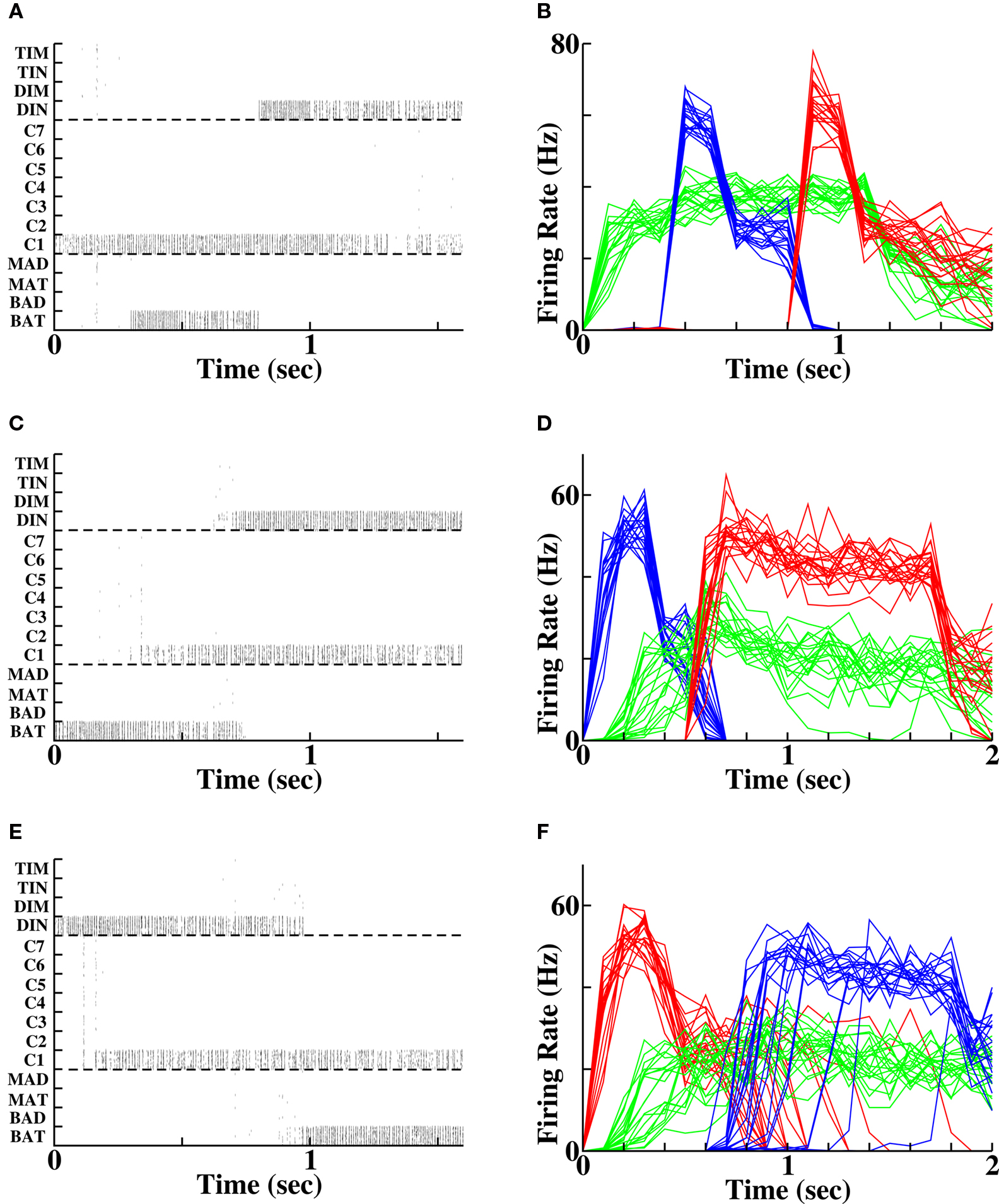
Figure 4. Forward and reverse recall in the temporal context model. (A, C, E) Spike rasters in a single instantiation, each row depicting the spikes of a single cell. (B, D, F) Population-averaged activity in each of 20 instantiations for the three populations stimulated in the protocol. Green = context population (“C1”), blue = first word population (“BAT”), red = second word population (“DIN”). (A, B) Initial stimulation protocol. The two word populations are activated at the times indicted and persist in their activity following stimulus offset. The context group is activated prior to the first word activation until 100 ms following the end of second word activation. (C, D) Forward recall. The first word, (“BAT”) is reactivated. Activity in the context pool (“C1”) is retrieved without external input. Non-specific excitation to all other word populations produces a recall of the second word (“DIN”). (E, F) Reverse recall. The second word (“DIN”) is reactivated. Activity in the population of cells retrieves activity in the context pool (“C1”), which upon non-specific excitation retrieves activity in the first word population (“BAT”).
Stimulus Strength Affects Recall Probability in A Model with Contextual Cells
The question that motivated this work was whether weaker stimuli would produce worse recall, even if the stimuli were sufficient for their identification. Our test stimuli used to address the question produced the same post-stimulus activity, as did the strong stimuli (compare dark to thin, light traces in Figure 5A), which in our model signifies equivalent ability to identify the sets of stimuli. However, upon reactivation of the first stimulus, only 35% of instantiations (7 out of 20 simulations) produced recall of the second stimulus and upon reactivation of the second stimulus, only 50% of instantiations (10 out of 20 simulations) produced recall of the first stimulus. Rather, non-specific excitation to word pools caused other lexical alternatives, which had received no prior input, to become activated (Figures 5D–F). Thus for both forward and reverse recall, the weak stimuli had no effect on the post-stimulus activity that corresponds to item identification, but recall ability was significantly reduced (P < 0.001).
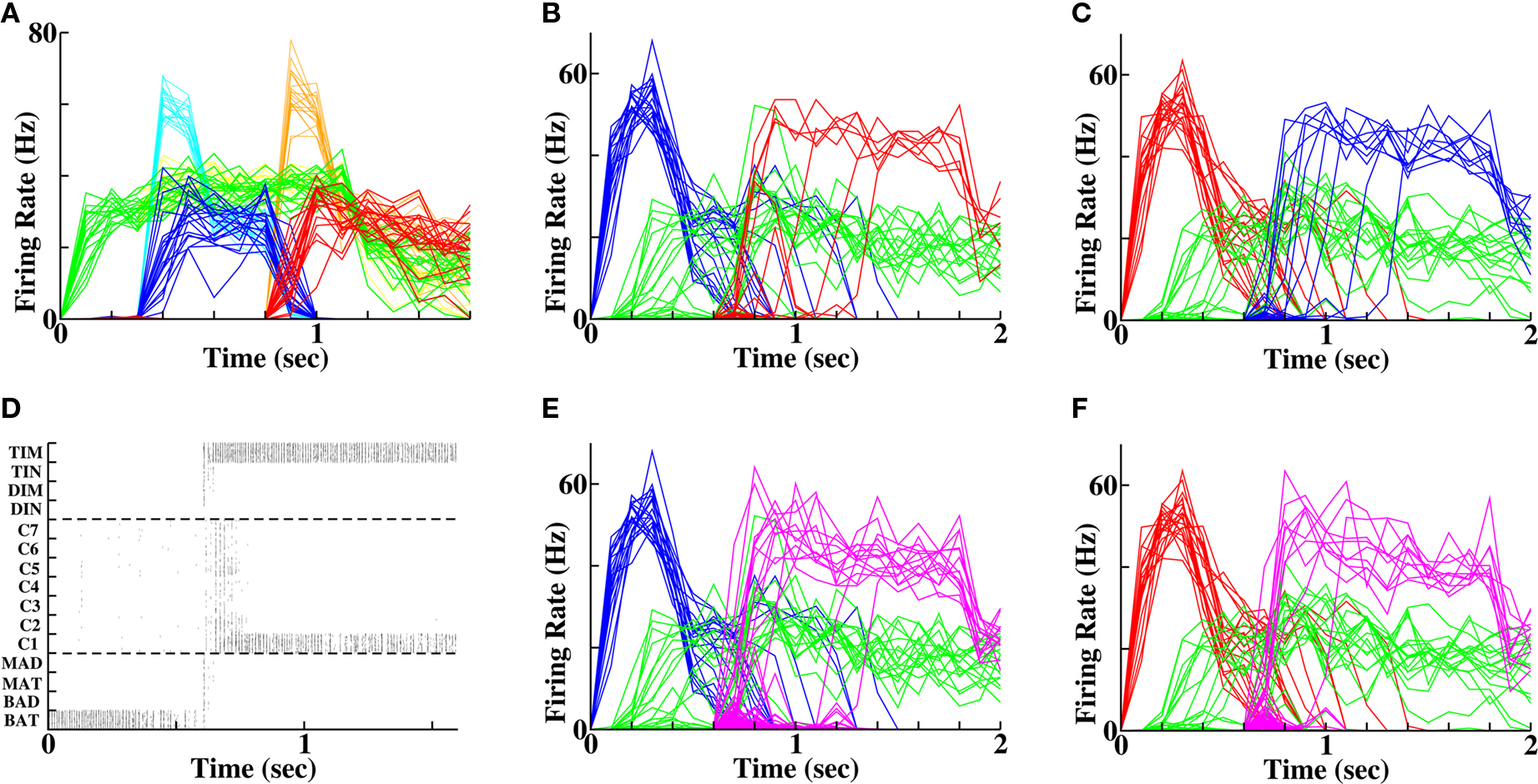
Figure 5. Diminished forward and reverse recall following weaker prior stimuli. (A) Weak stimulation protocol. Bold green, blue and red traces represent population-averaged activity of cells representing context (“C1”), first word (“BAT”) and second word (“DIN”) respectively. Faint traces in yellow, cyan and orange reproduce the traces under a strong stimulus for comparison. Note the reduced peak height, but identical final firing rates following weak stimuli. (B) Forward recall at 35% success (compare Figure 4D with identical color scheme). (C) Reverse recall at 50% success (compare Figure 4F with identical color scheme). (D) Set of spike rasters for an example error, where a population, which had not received prior stimulation, becomes activated. (E) Average activity of populations without prior stimulation (magenta) demonstrate multiple examples of error during forward recall (blue and green traces depict activity of first word, “BAT”, and context, “C1”, as in (B)). (F) Average activity of populations without prior stimulation (magenta) demonstrate multiple examples of error during reverse recall (red and green traces depict activity of second word, “DIN”, and context, “C1”, as in (C)).
Earlier behavioral experiments (Rabbitt, 1968, 1991; McCoy et al., 2005) have suggested that low stimulus quality can detrimentally affect the recall of preceding stimuli of good quality (though not the reverse effect to date). In our model we tested for such an effect on a short timescale by setting the initial two stimuli to be either weak then strong (Figure 6A) or strong then weak (Figure 6D). Using associative STP, in both protocols, the cells activated by the weak stimulus had less synaptic strengthening with the context cells. The reduced plasticity for the weak then strong stimulus protocol was both from first word cells to context cells and from context cells to first word cells (Figure 7). Similarly, when the protocol was strong then weak, the reduced plasticity was both from second word to context cells and context cells to second word cells (Figure 7). Thus having either one of the two stimuli being weak led to a reduced synaptic strengthening in one set of connections needed for recall. The diminished synaptic strengthening led to a reduction in recall probability of the word that had been weakly presented, because activation of the correct context cells was less likely to evoke activity of the cells associated with the weak stimulus. Moreover, the converse is true. Reactivation of a word that had been weakly presented was less likely to evoke the reactivation of context cells necessary for preferential recall of the other, strongly presented, word. These results hold for both forward and reverse recall, suggesting that a degraded stimulus (e.g., from noise masking or degraded hearing) would impair the recall of not only the prior word in a list, but also the following word.
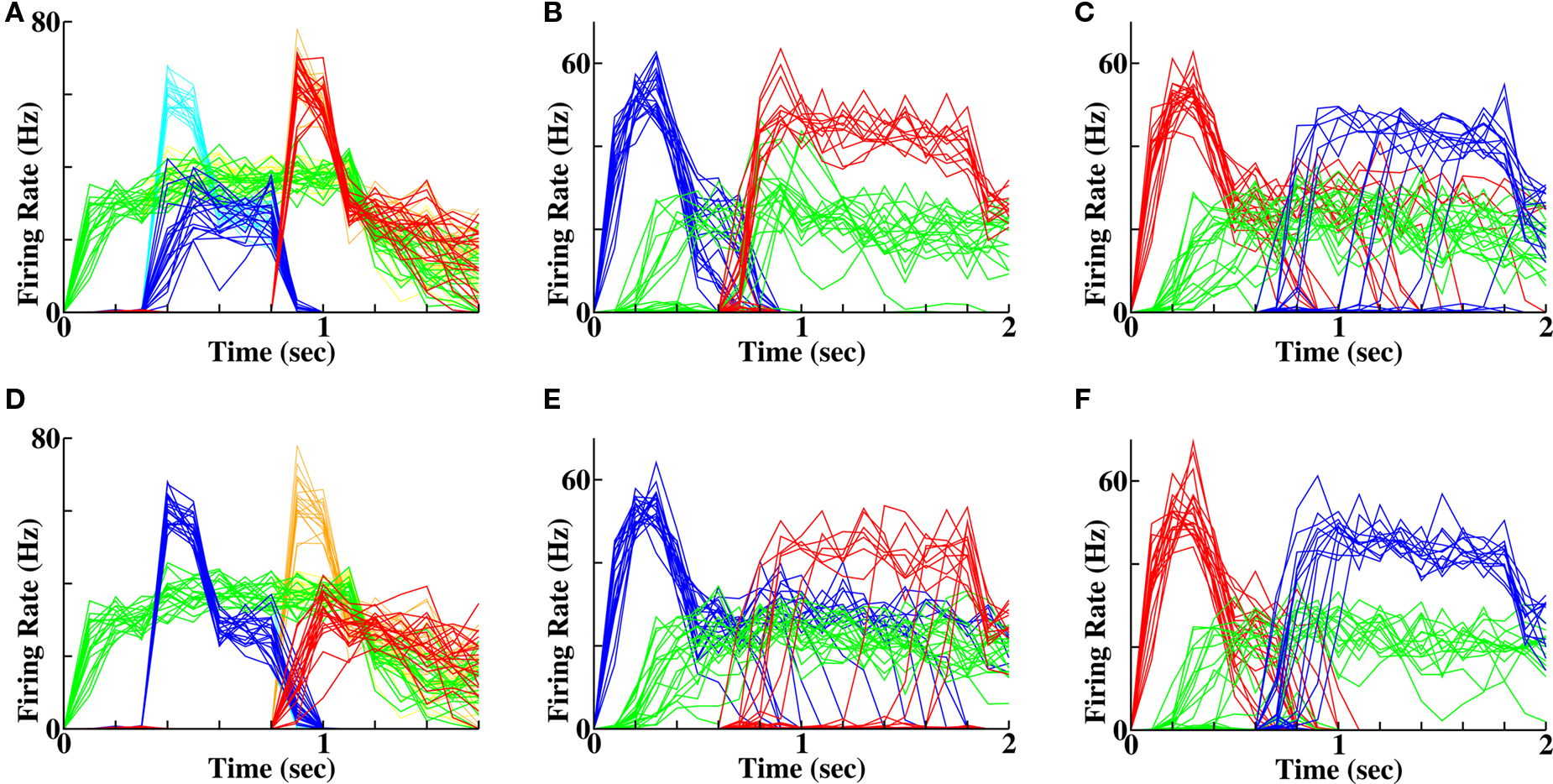
Figure 6. A single weak stimulus reduces recall probability of preceding and following words. (A) Average firing rates of stimulated word populations during a protocol of weak then strong stimulation. (Green = context, “C1”; blue = first word, “BAT”, red = second word, “DIN”; yellow, cyan, orange faint lines are activity of the same populations on all control instantiations). (B) Reduced forward recall to 55% (11 out of 20 instantiations) following a weak-then-strong protocol. (C) Reduced reverse recall to 65% (13 out of 20 instantiations) following a weak-then-strong protocol. (D) Color scheme as in (A)) but for a protocol of strong then weak stimulation. (E) Reduced forward recall to 60% (12 out of 20 instantiations) following a strong-then-weak protocol. (F) Reduced reverse recall to 65% (13 out of 20 instantiations) following a strong-then-weak protocol.
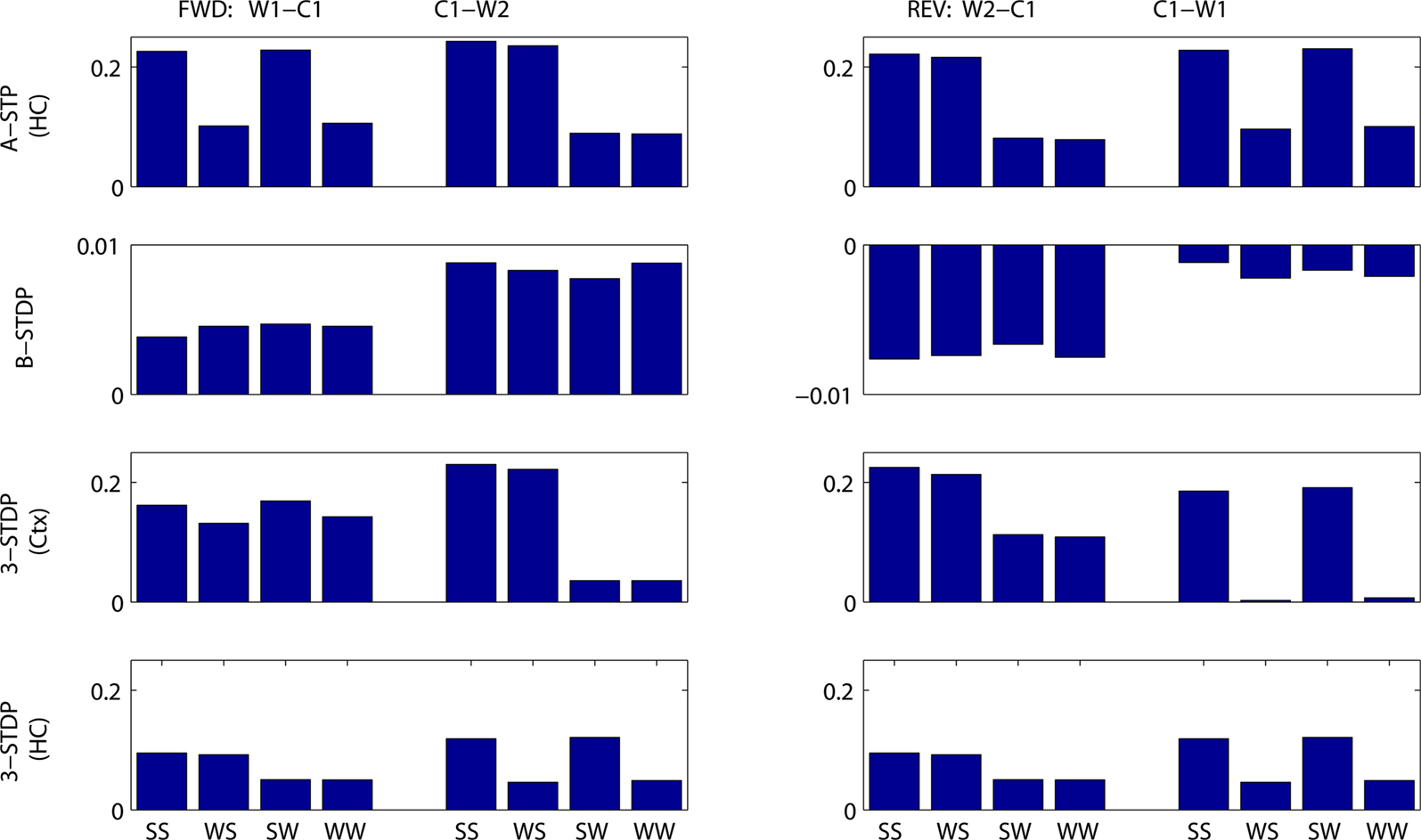
Figure 7. Mean change in synaptic weights between cell groups as a function of stimulus strengths and plasticity mechanism. Fractional change in synaptic strength is plotted. (Left) Connections needing strengthening for forward recall. W1–C1 = first word to context-1. C1–W2 = context-1 to second word. (Right) Connections needing strengthening for reverse recall. W2–C1 = second word to context-1. C1–W1 = context-1 to first word. Stimulus protocols are both strong (SS), weak then strong (WS), strong then weak (SW) or both weak (WW). Top row: associative short-term plasticity (ASTP). Second row: basic STDP. Third row: triplet-STDP (3-STDP) with parameters from cortical data (Ctx). Fourth row: triplet-STDP (3-STDP) with parameters from hippocampal data (HC).
Figures 7 and 8 summarize these results across all four plasticity mechanisms. Basic STDP was too weak to produce anything other than chance recall within our model. Both of the triplet-STDP mechanisms depend more on postsynaptic activity than presynaptic activity to produce potentiation. Thus connections from a weakly activated group of word cells to a normally activated group of context cells were often sufficiently strengthened for near-normal recall of the strong stimulus. So, in particular, the effect already seen in behavioral studies, that a weak stimulus can reduce recall probability of prior, strong stimuli, is difficult to observe if the main plasticity mechanism is either cortical or hippocampal triplet-STDP (Figure 8, reverse recall, compare SW protocol to SS protocol). However, following associative STP, which lasts over a timescale of minutes, such masking of strong stimuli is apparent in our model.
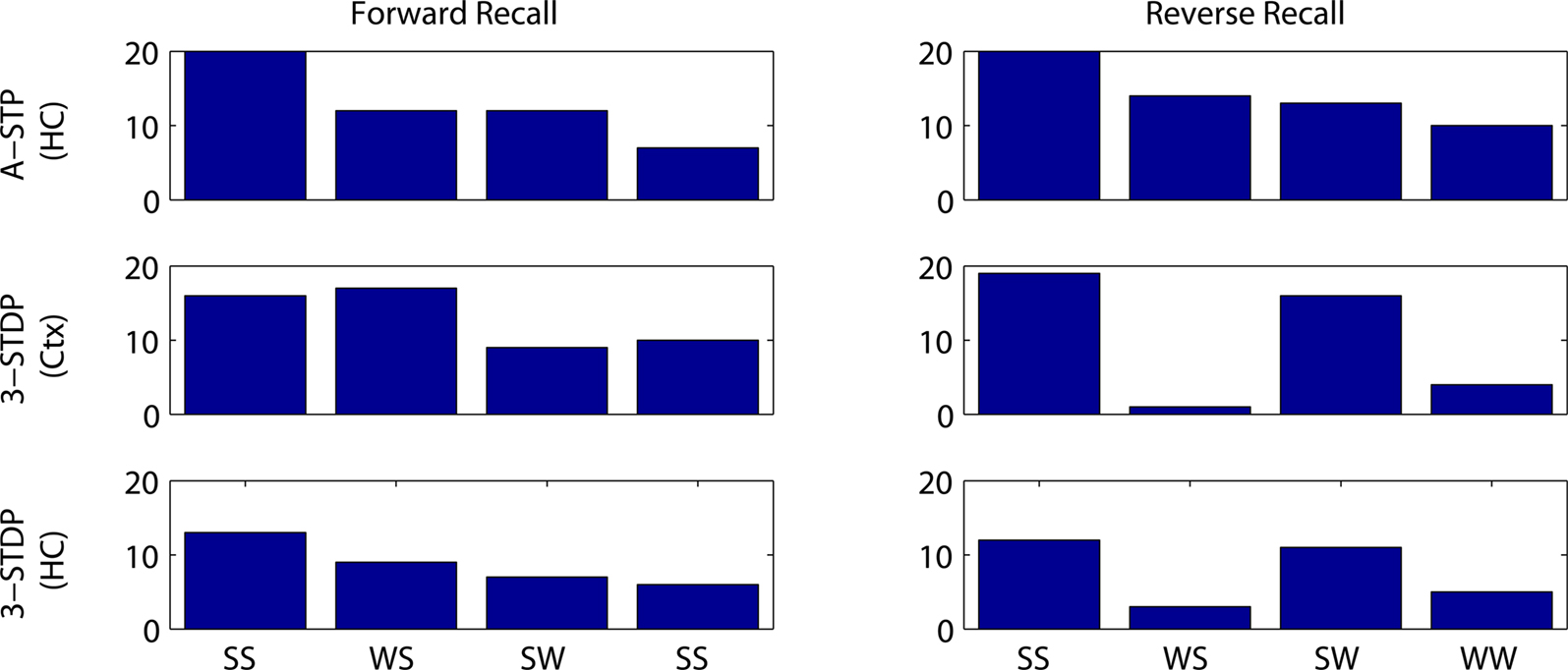
Figure 8. Number of successful recalls as a function of stimulus strengths and plasticity mechanism. Results are plotted from 20 random instantiations of each protocol. Stimulus protocols are both strong (SS), weak then strong (WS), strong then weak (SW) or both weak (WW). Top row: associative short-term plasticity (ASTP). Second row: triplet-STDP (3-STDP) with parameters from cortical data (Ctx). Third row: triplet-STDP (3-STDP) with parameters from hippocampal data (HC).
Timing of Stimulus Presentation
For those with poor hearing, reducing the rate of word presentation, for example by increasing the delay between words, can lead to better comprehension and better word recall (Stine et al., 1986; Riggs et al., 1993; Wingfield et al., 2006; Grimley, 2007). Conversely, reducing the time between words reduces intelligibility of passages, as would be expected if prior words are more often lost from memory when word frequency increases. We tested whether such an effect could be seen in our model networks.
Indeed, when context groups are present, any increase in the interval between words increases the overlap between activity representing the prior word and activity representing the context (unless the context changes). The increase in temporal overlap results in more plasticity between the cells (Figure 9) and thus greater success at recall (Figure 10). Such a result depends on the bistable nature of our word-identification network, which serves as a short-term memory of the most recent word identified. The single item in the short-term memory remains until the next item is presented. Throughout this time the corresponding neurons fire and synapses between these neurons and neurons representing context become further strengthened. If the duration of coactivity is reduced, less plasticity occurs and recall is worsened.
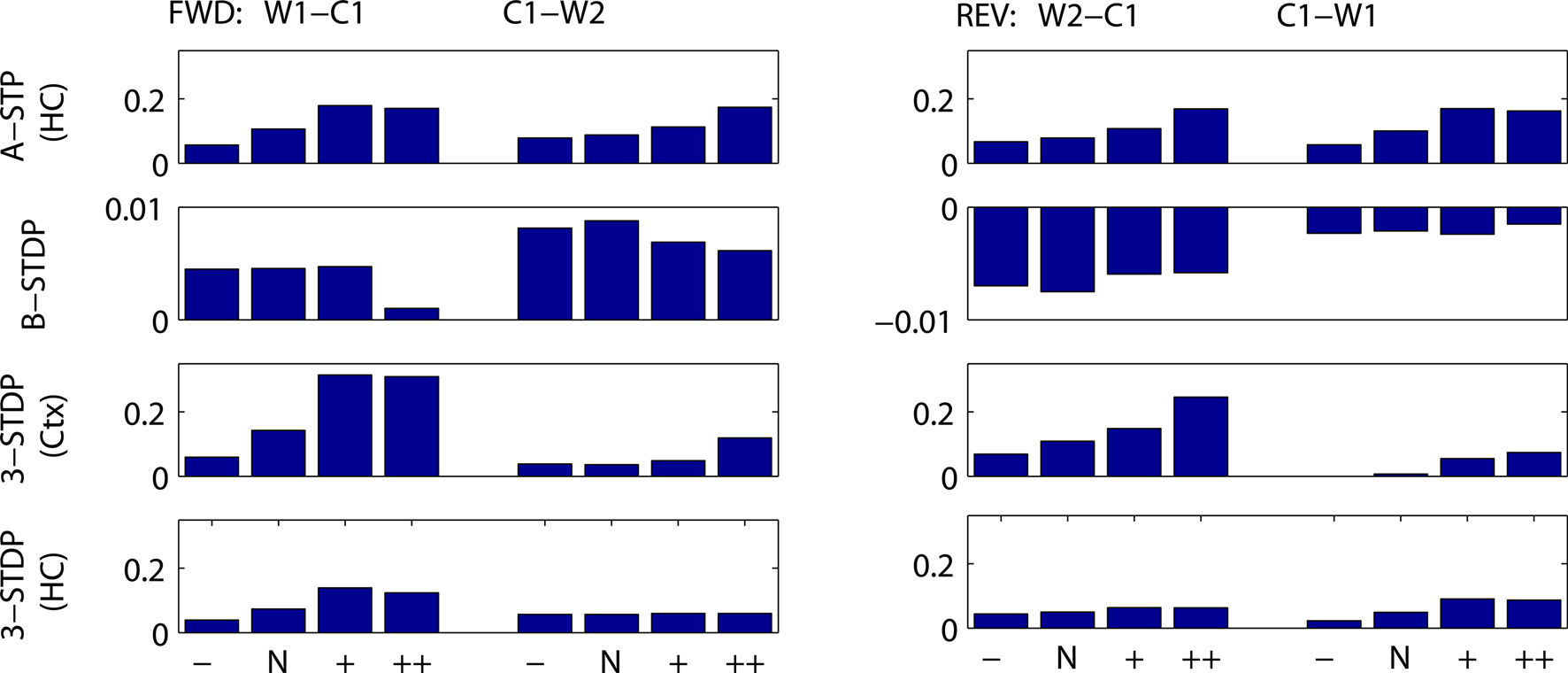
Figure 9. Mean change in synaptic weights between cell groups as a function of duration of stimulus presentation and plasticity mechanism. Fractional change in synaptic strength is plotted. (Left) Connections needing strengthening for forward recall. W1–C1 = first word to context-1. C1–W2 = context-1 to second word. (Right) Connections needing strengthening for reverse recall. W2–C1 = second word to context-1. C1–W1 = context-1 to first word. Stimulus protocols are two weak stimuli, with normal duration of other figures, 300 ms stimulus and 1000 ms between stimulus onsets (N), or 50% reduced interval between stimuli (−), or doubled interval between stimuli (+) or doubled interval and stimulus duration (++). Top row: associative short-term plasticity (ASTP). Second row: basic STDP (B-STDP). Third row: triplet-STDP (3-STDP) with parameters from cortical data (Ctx). Fourth row: triplet-STDP (3-STDP) with parameters from hippocampal data (HC).
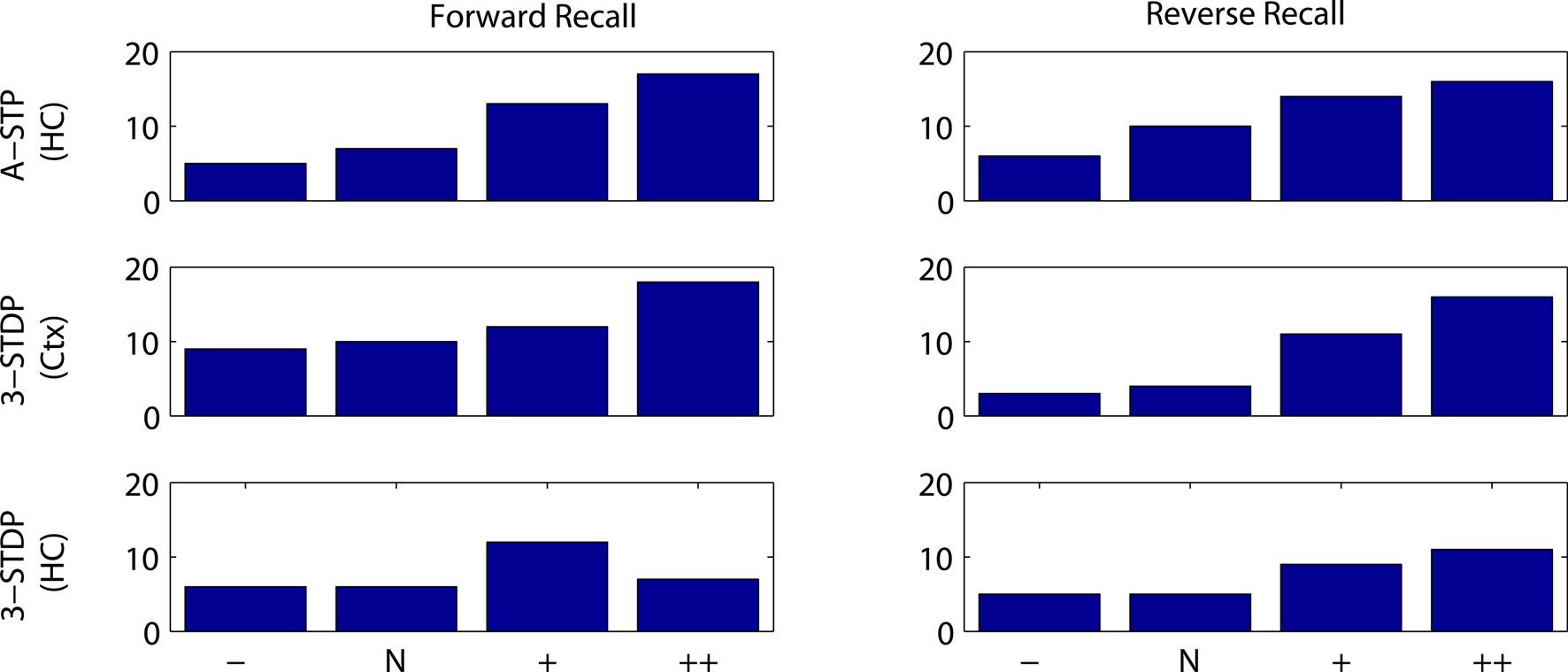
Figure 10. Number of successful recalls as a function of duration of stimulus presentation and plasticity mechanism. Results are plotted from 20 random instantiations of each plasticity mechanism. Stimulus protocols are two weak stimuli, with normal timings used in other figures, 300 ms stimulus and 1000 ms between stimulus onsets (N), or 50% reduced interval between stimuli (−), or doubled interval between stimuli (+) or doubled interval and stimulus duration (++). Top row: associative short-term plasticity (ASTP). Second row: triplet-STDP (3-STDP) with parameters from cortical data (Ctx). Third row: triplet-STDP (3-STDP) with parameters from hippocampal data (HC).
Qualitatively, such a result does not depend on the precise plasticity mechanism, but does depend on the inclusion of coactive context cells. In the model with no context cells, altering the time between stimulus presentations in the same range (500–1500 ms) has no effect on recall probability.
Asymmetry of Recall
For human subjects, forward recall is more likely than reverse recall, as demonstrated by asymmetry in the conditional response probabilities to favor following words over prior words (Howard and Kahana, 1999; Kahana et al., 2002). For our strong simulation protocols, recall is at ceiling in both forward and reverse directions, so we can observe no asymmetry. For the protocol with two successive weak stimuli, we produced extra simulations (400) to show that when using triplet-STDP with the cortical parameters, forward recall is significantly more likely than reverse recall [P(forward) = 0.33 > P(reverse) = 0. 3, Z = 3.08, P < 0.005, via two-tailed Binomial test]. Using ASTP with standard parameters for successive weak stimuli produced no significant effect on recall direction [P(forward) = 0.50, P(reverse) = 0.51]. However, given the asymmetry in connection changes, we devised an altered training protocol, where we reduced input to the contextual group to 3/8 its original level and provided input to the word groups at 2/3 the level of the strong stimulus. In this paradigm, recall probability is dominated by ability of contextual activity to retrieve appropriate word activity and produces a strong asymmetry for recall in the forward direction [P(forward) = 0.52 > P(reverse) = 0.45, Z = 1.98, P < 0.05, via two-tailed Binomial test].
In summary, all of the plasticity rules that we studied do contain an asymmetry between presynaptic and postsynaptic cells that is of the same sign as basic STDP, so favors a strengthening of connections from whichever groups of cells activity peaks earlier to the group whose activity peaks later (cf Abbott and Blum, 1996). In the limit of no contextual activity, the asymmetry in connection strengths is so strong that reverse recall is impossible. In the limit of contextual activity that is entirely constant in time, while word pools become active then become silent, there can be no asymmetry in connections to and from context cells. In our simulations, there is a strong asymmetry where the second word group becomes active, but not inactive, while the context cells remain active. That produces stronger connections from context cells to the second word group than vice versa. In simulations of lists with many more words, the temporal dynamics of activity among context pools will be key to the form and asymmetry of the conditional response probability curves.
Robustness of Results
Our results are based on simulations of 20 different randomly connected sparse networks, each slightly different in the relative excitability of different groups of cells. Connectivity parameters were constrained by the following requirements. (1) If any group of cells is too excitable, it switches on in the absence of input, due to noise fluctuations or instability of its spontaneous state. (2) If any group of cells is not excitable enough, then its activity drops to a spontaneous level immediately following stimulus offset. (3) If recurrent connections are too strong, the firing rate upon stimulus recognition is so high that following the weakest stimulus needed to produce persistent activity, plasticity is similar to that following a strong stimulus. This can result in recall at 100% following all stimuli able to produce persistent activity. (4) If excitatory cross-connections are too weak, then strengthening of those cross-connections can be insufficient to produce reliable recall. (5) If excitatory cross-connections are too strong, many cell groups can be coactive during stimulation and the winner-takes-all nature of the network is lost.
Requirements (1) and (2) relate to the width of the bistable range for groups of cells able to produce persistent activity (Amit and Brunel, 1997; Brunel, 2000). The practical range is narrower for a small group of cells because noise fluctuations can destabilize both the spontaneous and persistent state (Miller and Wang, 2006) – simulations with more cells would produce more robust results. Requirement (3) further restricts the bistable range, which is narrower when the persistent firing rate is lower. Requirements (4) and (5) limit the possible cross-connections, but these affect the excitability of each cell group, so interact with (1) and (2). In particular, the possibility of strong cross-excitation (allowing a strong effect of plasticity) combined with strong cross-inhibition (to maintain the winner-takes-all property) can require too high self-excitation (which is limited by requirement (3).
However, in spite of these requirements – which are compatible with cells firing at realistic rates of a few tens of Hz in response to preferred stimuli, but at face value restrict the parameters of the network to a much tighter range than is likely in vivo – qualitatively the results were consistent, not only using multiple plasticity protocols, but also across a number of networks, including ones where each synapse was selected randomly from a Gaussian distribution with standard deviation of 20% its mean (see Supplementary Material). It is worth noting that many of the shifts in parameters that could prevent our network’s operation, do so by producing one or more groups of cells that is either always highly active or never active. Presumably homeostatic mechanisms such as multiplicative synaptic scaling (Turrigiano and Nelson, 2000; Renart et al., 2003) could compensate to produce a functioning network.
Discussion
We have investigated a model that we believe contains the essential biological ingredients necessary for providing the neural underpinnings of sequential word identification and recall. The model is similar to others of sequential recall (Abbott and Blum, 1996; Blum and Abbott, 1996; Mongillo et al., 2003) but differs in the requirement of a single active “percept” at a time, which we implement through cross-inhibition in a winner-takes-all network for neurons representing word identity. We based our model on spiking neurons, since spikes reflect the main information transmission of neurons and measurements of the neural underpinnings of memory; namely, LTP and LTD, are based on the coincidences of spike times between cells. Within such a neurobiological framework, by generating simple patterns of neural activity to represent word identification, and providing two-word sequences, we were able to reproduce several key results found in behavioral data:
(1) We found recall in both the forward and reverse directions.
(2) Probability of recall depended on the stimulus strength, even when weak stimuli produced identical post-stimulus activity to strong stimuli as a sign of equivalent stimulus identification.
(3) A weak stimulus could reduce probability of recall of a prior stimulus.
(4) Probability of recall increased as a function of delay between stimuli on a timescale of 500–1500 ms and with the duration of the stimulus.
Moreover, we predict the corollary of result (3), that a weak stimulus can reduce the probability of recall of the following stimulus. Such a prediction has yet to be demonstrated behaviorally.
Our model contains many simplifications in order to be tractable. In particular, some cells in vivo are likely to fire in response to recognition of multiple words and the most recent word may not be encoded through persistent rapid spiking in an attractor state. Also, activity representing temporal context is likely to be continuously evolving through multiple groups of cells in multiple locations, rather than existing in one cell group before discretely switching to another. We expect that our main conclusions do not depend on these simplifications so long as the following assumptions hold. First, the set of cells with high activity at any time in response to one word is significantly different from that in response to any other word in a single list. Every single cell need not be different, just the set must be unique. Second, activity in many cells representing context must evolve slowly compared to the time between stimuli, so that contextual activity during one stimulus has significant overlap with activity at the time of a prior stimulus. This requirement ensures that retrieval of activity in context cells firing at the end of an interstimulus interval can produce activity in context cells that fired at the beginning of the interstimulus interval (and vice versa). In future work we will assess how well different models of contextual activity – differentiated by the temporal dynamics of context and the nature of couplings to cells involved in word identification – reproduce the key characteristics of recall order using simulations with more than two words.
We used an empirical model for ASTP based on recent hippocampal slice data demonstrating that synapses could be enhanced in an associative manner – requiring presynaptic and postsynaptic correlations – relatively easily and strongly, over a timescale of a minute or more. Based on the slice data, our model could produce a 40% enhancement of synaptic efficacy with optimal timing of two presynaptic and three postsynaptic spikes, but further enhancement beyond 40% could not be achieved and single spikes in each cell produced no change. By comparison, averaging multiple spike pairings, under the assumption that all pairings with equal time intervals contribute equally and sum together to produce the total change, has produced models of STDP with no threshold and no saturation. Moreover the changes produced by individual spike pairs are never greater than 1% (Markram et al., 1997; Bi and Poo, 1998; Song et al., 2000; Song and Abbott, 2001; Drew and Abbott, 2006; Pfister and Gerstner, 2006). We found that using such rules for STDP with a rate-dependent triplet term (Pfister and Gerstner, 2006) produced effects qualitatively similar, though weaker than those wrought by ASTP. These results may be expected, given the large initial strength of ASTP and its decay over minutes, in line with findings of reduced recall probabilities on the timescales of the tens of minutes of STDP measurements. To highlight the dependence of recall probability on the underlying base amplitude for plasticity, we also simulated recall using half the strength for ASTP (corresponding to a delay on the order of a minute) and with doubled strength for triplet-STDP (since parameters in vivo may differ from those in slice). Given such changes, triplet-STDP produces better performance than ASTP. It is noteworthy that, compared to ASTP, the triplet-STDP rules more reliably produced a stronger asymmetry – diminished reverse recall compared to forward recall, as is observed behaviorally (Kahana and Caplan, 2002; Howard et al., 2009) – notably when the preceding stimulus is weak (Figure 8). Thus, if our ASTP rule is a good model of plasticity over tens of seconds, while triplet-STDP is a better model for timescales larger than minutes, we would expect the strength of asymmetry in recall to increase with time from the presentation of words.
Basic STDP lacks any of the observed dependence of the sign of plasticity on firing rate, so was unable to produce the bidirectional increases in synaptic strength necessary for both forward and reverse recall of sequences – in fact reverse recall is below chance as STDP depresses the connections, whose activation is necessary for reverse recall.
We ran simulations with removal of context cells, to test their importance in our model of word recall. In these simulations, the overlap of activity of cells representing successive words could produce sufficient plasticity to generate later recall (Figure 2D). However, such recall was relatively independent of stimulus strength (Figure 2F) and could even be more probable following weaker stimuli (Figure 3D). Moreover recall in reverse order was never reliable (Figure 3) and recall probability did not depend on the interval between stimuli (data not shown). We note that if all word groups maintained strong persistent activity together in memory, as suggested by some models of multi-item memory (Lisman and Idiart, 1995; Jensen and Lisman, 1996; Amit et al., 2003; Mongillo et al., 2003), then coactive context cells would not be necessary.
Using similar methods, others have successfully modeled hippocampal place fields and their recall (Abbott and Blum, 1996; Blum and Abbott, 1996), with no need for extra temporal context cells. An important difference between models of place fields and words reflects the logical structure of words as discrete entities that are not always connected in the same way with each other, whereas location is a continuous quantity and positions have a fixed relationship with each other. Thus place fields can overlap and be coactive, since presence at a particular position means proximity to a neighboring position. For example, if “A” is near “B” and “A” is near “C” then “B” and “C” must be near each other and are often visited in temporal proximity. However, pairs of words that are often close in speech, such as “road” followed by “trip” or “road” followed by “rage” do not indicate that “trip” and “rage” would have any temporal relationship – in fact they may be exclusive, suggesting cross-inhibition in the neural circuitry. Hence, we assume mutual inhibition between cells representing different words, in line with standard attractor-based models of word recognition (Seidenberg and McClelland, 1989; Plaut et al., 1996) and perception (Moreno-Bote et al., 2007), permitting only a single word to be represented actively “in mind” at one time. This formulation omits the structure of normal speech, where one word increases the likelihood of common following words, but does reflect the structure of word lists used for multi-item memory, where successive words are completely unrelated to each other.
The conditional response probabilities found in behavioral data demonstrate the possibility of reverse recall of a series of words (Howard and Kahana, 1999; Kahana et al., 2002). Such reverse recall is only possible if the neural activity to be recalled overlaps in time during the stimulus presentation. Thus in our models, a single winner-takes-all network model for word identification does not produce reverse recall. However, inclusion of connections to separate coactive cells, our so-called “context” cells, does allow reverse recall. As an alternative mechanism, a separate multi-item short-term memory store (Lisman and Idiart, 1995; Amit et al., 2003) could play the role of the context cells of our simulations or be the locus of inter-item memory (Mongillo et al., 2003). So long as cells representing the two stimuli are coactive for sufficient time, the rate-dependent contribution to plasticity – present in all plasticity mechanisms described here, except for basic STDP – will produce bidirectional strengthening of connections and allow for reverse recall. However, it is unclear how the strength of stimulus during presentation could impact activity and influence plasticity of coactive cells in a short-term memory store.
Prior models of plasticity following overlapping sequential activity in hippocampal place cells produced forward (Abbott and Blum, 1996; Blum and Abbott, 1996), but not reverse replay of position. As well as coactivity, reverse replay also requires a plasticity mechanism that favors potentiation over depression when both presynaptic and postsynaptic cells are active in a BCM-like manner. Thus, unlike basic STDP, either ASTP or triplet-STDP could produce the more recently observed “reverse replay” in such models of hippocampal place fields, as they do in our models of word recall via temporal context.
Other models of the production and recall of sequences via synaptic plasticity have focused on hippocampal place fields (Abbott and Blum, 1996; Blum and Abbott, 1996; Hasselmo, 2008), or generation of bird song (Troyer and Doupe, 2000a,b) or other motor sequences (Nowotny et al., 2003; Stringer et al., 2003, 2007; Grossberg and Pearson, 2008; Yamashita and Tani, 2008). In the latter two cases, the period of learning contains multiple, often many hundreds, of practices of the sequence during which plasticity in the network occurs via a reinforcement signal.
Our results allow us to make some behavioral predictions for free recall of lists:
(1) The asymmetry of conditional response probability curves favoring forward-order recall is likely to increase on a timescale of minutes, where the ASTP disappears and remaining plasticity is via more asymmetric mechanisms such as triplet-STDP.
(2) In the absence of rehearsal, a single masked word will negatively affect free recall of the following as well as the prior word in a list.
(3) Not only overall recall, but also the conditional recall probability of a neighboring word given recall of the masked word should be reduced in free recall of word lists with a single masked word.
These predictions depend on word presentation being at a sufficient rate to prevent rehearsal – if attention to the masked word simply disrupts ongoing rehearsal then one expects to reproduce Rabbitt’s observations of a temporally asymmetric effect of masking on prior words.
In summary, we have shown how the dynamics of transient spiking activity of neurons in response to a stimulus determines the amount of strengthening of connections between neurons representing successive stimuli and thus the likelihood of sequential recall. Thus, given identical final activity states representing word recognition, the trajectory by which that activity state is reached affects how well a word is recalled. The strength of plasticity depends on the number of temporally proximate presynaptic and postsynaptic spikes, which is a function of both the maximum firing rate of the cells and of the amount of time they spend at a high firing rate. In particular, older adults with age-related reductions in hearing acuity are likely to have slower and weaker initial neural responses to stimuli and thus less of the synaptic plasticity needed for later recall than those with perfect hearing.
Separate “context cells” that can be coactive with cells responsive to specific words are essential in our network to produce recall of pairs of words in reverse order. Such retrieval of preceding words has been observed and characterized in behavioral data using conditional response probabilities (Kahana, 1996; Howard and Kahana, 1999). Moreover, only by including such context cells, are we able to replicate the observed improvement in recall of weak stimuli with increased time interval between successive stimuli. Finally, only with such context cells do we observe the expected reduction in recall probability as prior stimulus strength is reduced in the above-threshold range. Our simulations are limited to a winner-takes-all network for word identification, in which neural activity representing one word suppresses activity representing other words, so we can not demonstrate emphatically that serial recall in the brain can be only via context. However, taking these three results together, our simulations do provide support for the TCM – or a variation of it – as a description of memory and recall of word sequences.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported in part by NIH Grant AG019714 from the National Institute on Aging. We are grateful to John Lisman and Martha Erickson for useful discussions about their plasticity protocol. We thank Tepring Piqado for useful discussions about the auditory serial recall task.
Supplementary Material
The Supplementary Material for this article can be found online at http://www.frontiersin.org/neuroscience/systemsneuroscience/paper/10.3389/fnsys.2010.00014/
References
Abbott, L. F., and Blum, K. I. (1996). Functional significance of long-term potentiation for sequence learning and prediction. Cereb. Cortex 6, 406–416.
Amit, D. J., Bernacchia, A., and Yakovlev, V. (2003). Multiple-object working memory – a model for behavioral performance. Cereb. Cortex 13, 435–443.
Amit, D. J., and Brunel, N. (1997). Model of global spontaneous activity and local structured activity during delay periods in the cerebral cortex. Cereb. Cortex 7, 237–252.
Bi, G. Q., and Poo, M. M. (1998). Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, ad postsynaptic cell type. J. Neurosci. 18, 10464–10472.
Bi, G. Q., and Poo, M. M. (2001). Synaptic modification by correlated activity: Hebb’s postulate revisited. Annu. Rev. Neurosci. 24, 139–166.
Bienenstock, E., Cooper, L., and Munro, P. (1982). Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. J. Neurosci. 2, 32–48.
Blum, K. I., and Abbott, L. F. (1996). A model of spatial map formation in the hippocampus of the rat. Neural Comput. 8, 85–93.
Brenowitz, S. D., and Regehr, W. G. (2005). Associative short-term synaptic plasticity mediated by endocannabinoids. Neuron 45, 419–431.
Brunel, N., (2000). Persistent activity and the single-cell frequency–current curve in a cortical network model. Network 11, 261–280.
Capocchi, G., Zampolini, M., and Larson, J. (1992). Theta burst stimulation is optimal for induction of LTP at both apical and basal dendritic synapses on hippocampal CA1 neurons. Brain Res. 591, 332–336.
Castro-Alamancos, M. A., and Connors, B. W. (1996). Short-term synaptic enhancement and long-term potentiation in neocortex. Proc. Natl. Acad. Sci. U.S.A. 93, 1335–1339.
Craik, F. I., and Lockhart, R. S. (1972). Levels of processing: a framework for memory research. J. Verbal Learn. Verbal Behav. 11, 671–684.
Drew, P. J., and Abbott, L. F. (2006). Extending the effects of spike-timing-dependent plasticity to behavioral timescales. Proc. Natl. Acad. Sci. U.S.A. 103, 8876–8881.
Dudek, S. M., and Bear, M. F. (1993). Bidirectional long-term modification of synaptic effectiveness in the adult and immature hippocampus. J. Neurosci. 13, 2910–2918.
Erickson, M. A., Maramara, L. A., and Lisman, J. (2009). A single 2-spike burst induces GluR1-dependent associative short-term potentiation: a potential mechanism for short-term memory. J. Cogn. Neurosci. [Epub ahead of print].
Fujisawa, S., Amarasingham, A., Harrison, M. T., and Buzsaki, G. (2008). Behavior-dependent short-term assembly dynamics in the medial prefrontal cortex. Nat. Neurosci. 11, 823–833.
Golomb, J. D., Peelle, J. E., Addis, K. M., Kahana, M. J., and Wingfield, A. (2008). Effects of adult aging on utilization of temporal and semantic associations during free and serial recall. Mem. Cognit. 36, 947–956.
Grimley, M., (2007). An exploration of the interaction between speech rate, gender, and cognitive style in their effect on recall. Educ. Psychol. 27, 401–417.
Grossberg, S., and Pearson, L. R. (2008). Laminar cortical dynamics of cognitive and motor working memory, sequence learning and performance: toward a unified theory of how the cerebral cortex works. Psychol. Rev. 115, 677–732.
Hasselmo, M. E. (2008). Temporally structured replay of neural activity in a model of entorhinal cortex, hippocampus and postsubiculum. Eur. J. Neurosci. 28, 1301–1315.
Heifets, B. D., Chevaleyre, V., and Castillo, P. E. (2008). Interneuron activity controls endocannabinoid-mediated presynaptic plasticity through calcineurin. Proc. Natl. Acad. Sci. U.S.A. 105, 10250–10255.
Howard, M. W., Jing, B., Rao, V. A., Provyn, J. P., and Datey, A. V. (2009). Bridging the gap: transitive associations between items presented in similar temporal contexts. J. Exp. Psychol. Learn. Mem. Cogn. 35, 391–407.
Howard, M. W., and Kahana, M. J. (1999). Contextual variability and serial position effects in free recall. J. Exp. Psychol. Learn. Mem. Cogn. 25, 923–941.
Howard, M. W., and Kahana, M. J. (2002). A distributed representation of temporal context. J. Math. Psychol. 46, 269–299.
Howard, M. W., Kahana, M. J., and Wingfield, A. (2006). Aging and contextual binding: modeling recency and lag recency effects with the temporal context model. Psychon. Bull. Rev. 13, 439–445.
Jensen, O., and Lisman, J. E. (1996). Novel lists of 7 ± 2 known items can be reliably stored in an oscillatory short-term memory network: interaction with long-term memory. Learn. Mem. 3, 257–263.
Kahana, M. J., and Caplan, J. B. (2002). Associative asymmetry in probed recall of serial lists. Mem. Cognit. 30, 841–849.
Kahana, M. J., and Howard, M. W. (2005). Spacing and lag effects in free recall of pure lists. Psychon. Bull. Rev. 12, 159–164.
Kahana, M. J., Howard, M. W., Zaromb, F., and Wingfield, A. (2002). Age dissociates recency and lag recency effects in free recall. J. Exp. Psychol. Learn. Mem. Cogn. 28, 530–540.
Kano, M., Ohno-Shosaku, T., Hashimotodani, Y., Uchigashima, M., and Watanabe, M. (2009). Endocannabinoid-mediated control of synaptic transmission. Physiol. Rev. 89, 309–380.
Kirkwood, A., and Bear, M. F. (1995). Elementary forms of synaptic plasticity in the visual cortex. Biol. Res. 28, 73–80.
Letzkus, J. J., Kampa, B. M., and Stuart, G. J. (2007). Does spike timing-dependent synaptic plasticity underlie memory formation? Clin. Exp. Pharmacol. Physiol. 34, 1070–1076.
Lisman, J. E., and Idiart, M. A. P. (1995). Storage of 7 ± 2 short-term memories in oscillatory subcycles. Science 267, 1512–1515.
Lisper, L. O., Kjellberg, A., and Melin, L. (1972). Effects of signal intensity on increase of reaction time on an auditory monitoring task. Percept. Mot. Skills 34, 439–444.
Luce, P. A., and Pisoni, D. B. (1998). Recognizing spoken words: the neighborhood activation model. Ear Hear. 19, 1–36.
Malenka, R. C. (1991). Postsynaptic factors control the duration of synaptic enhancement in area CA1 of the hippocampus. Neuron 6, 53–60.
Markram, H., Lubke, J., Frotscher, M., and Sakmann, B. (1997). Regulation of synaptic efficacy by coincidence of postsynaptic APs and EPSPs. Science 275, 213–215.
McCoy, S. L., Tun, P. A., Cox, L. C., Colangelo, M., Stewart, R. A., and Wingfield, A. (2005). Hearing loss and perceptual effort: downstream effects on older adults’ memory for speech. Q. J. Exp. Psychol. A. 58, 22–33.
Miller, P., and Wang, X. J. (2006). Stability of discrete memory states to stochastic fluctuations in neuronal systems. Chaos 16, 026110.
Mongillo, G., Amit, D. J., and Brunel, N. (2003). Retrospective and prospective persistent activity induced by Hebbian learning in a recurrent cortical network. Eur. J. Neurosci. 18, 2011–2024.
Mongillo, G., Barak, O., and Tsodyks, M. (2008). Synaptic theory of working memory. Science 319, 1543–1546.
Moreno-Bote, R., Rinzel, J., and Rubin, N. (2007). Noise-induced alternations in an attractor network model of perceptual bistability. J. Neurophysiol. 98, 1125–1139.
Murphy, D. R., Craik, F. I., Li, K. Z., and Schneider, B. A. (2000). Comparing the effects of aging and background noise on short-term memory performance. Psychol. Aging 15, 323–334.
Nelson, S. B., Sjostrom, P. J., and Turrigiano, G. G. (2002). Rate and timing in cortical synaptic plasticity. Philos. Trans. R. Soc. Lond., B, Biol. Sci. 357, 1851–1857.
Nowotny, T., Rabinovich, M. I., and Abarbanel, H. D. (2003). Spatial representation of temporal information through spike-timing-dependent plasticity. Phys. Rev. E. Stat. Nonlin. Soft Matter Phys. 68, 011908.
Pfister, J. P., and Gerstner, W. (2006). Triplets of spikes in a model of spike timing-dependent plasticity. J. Neurosci. 26, 9673–9682.
Pichora-Fuller, M. K., (2003). Cognitive aging and auditory information processing. Int. J. Audiol. 42, 2S26–22S32.
Plaut, D. C., McClelland, J. L., Seidenberg, M. S., and Patterson, K. (1996). Understanding normal and impaired word reading: computational principles in quasi-regular domains. Psychol. Rev. 103, 56–115.
Rabbitt, P. M. (1968). Channel-capacity, intelligibility and immediate memory. Q. J. Exp. Psychol. 20, 241–248.
Rabbitt, P. M. A., (1991). Mild hearing loss can cause apparent memory failures which increase with age and reduce with IQ. Acta Otolaryngol. Suppl. 476, 126–141.
Rebola, N., Sachidhanandam, S., Perrais, D., Cunha, R. A., and Mulle, C. (2007). Short-term plasticity of kainate receptor-mediated EPSCs induced by NMDA receptors at hippocampal mossy fiber synapses. J. Neurosci. 27, 3987–3993.
Renart, A., Song, P., and Wang, X. J. (2003). Robust spatial working memory through homeostatic synaptic scaling in heterogeneous cortical networks. Neuron 38, 473–485.
Riggs, K. M., Wingfield, A., and Tun, P. A. (1993). Passage difficulty, speech rate, and age differences in memory for spoken text: speech recall and the complexity hypothesis. Exp. Aging Res. 19, 111–128.
Rosanova, M., and Ulrich, D. (2005). Pattern-specific associative long-term potentiation induced by a sleep spindle-related spike train. J. Neurosci. 25, 9398–9405.
Schneider, B. A., and Pichora-Fuller, M. K. (2000). “Implications of perceptual deterioration for cognitive aging research,” in The Handbook of Aging and Cognition, eds F. I. M. Craik and T. A. Salthouse (Mahwah, NJ: Lawrence Erlbaum Associates Publishers), 155–219.
Sederberg, P. B., Howard, M. W., and Kahana, M. J. (2008). A context-based theory of recency and contiguity in free recall. Psychol. Rev. 115, 893–912.
Seidenberg, M. S., and McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychol. Rev. 96, 523–568.
Sjostrom, P. J., and Nelson, S. B. (2002). Spike timing, calcium signals and synaptic plasticity. Curr. Opin. Neurobiol. 12, 305–314.
Sjostrom, P. J., Turrigiano, G. G., and Nelson, S. B. (2001). Rate, timing, and cooperativity jointly determine cortical synaptic plasticity. Neuron 32, 1149–1164.
Song, S., and Abbott, L. F. (2001). Cortical development and remapping through spike timing-dependent plasticity. Neuron 32, 339–350.
Song, S., Miller, K. D., and Abbott, L. F. (2000). Competitive Hebbian learning through spike-time-dependent synaptic plasticity. Nat. Neurosci. 3, 919–926.
Stine, E. L., Wingfield, A., and Poon, L. W. (1986). How much and how fast: rapid processing of spoken language in later adulthood. Psychol. Aging 1, 303–311.
Stringer, S. M., Rolls, E. T., and Taylor, P. (2007). Learning movement sequences with a delayed reward signal in a hierarchical model of motor function. Neural. Netw. 20, 172–181.
Stringer, S. M., Rolls, E. T., Trappenberg, T. P., and de Araujo, I. E. (2003). Self-organizing continuous attractor networks and motor function. Neural. Netw. 16, 161–182.
Sun, H. Y., Bartley, A. F., and Dobrunz, L. E. (2009). Calcium-permeable presynaptic kainate receptors involved in excitatory short-term facilitation onto somatostatin interneurons during natural stimulus patterns. J. Neurophysiol. 101, 1043–1055.
Surprenant, A. M. (1999). The effect of noise on memory for spoken syllables. Int. J. Psychol. 34, 328–333.
Surprenant, A. M. (2007). Effects of noise on identification and serial recall of nonsense syllables in older and younger adults. Neuropsychol. Dev. Cogn. B Aging Neuropsychol. Cogn. 14, 126–143.
Troyer, T. W., and Doupe, A. J. (2000a). An associational model of birdsong sensorimotor learning I. Efference copy and the learning of song syllables. J. Neurophysiol. 84, 1204–1223.
Troyer, T. W., and Doupe, A. J. (2000b). An associational model of birdsong sensorimotor learning II. Temporal hierarchies and the learning of song sequence. J. Neurophysiol. 84, 1224–1239.
Tuckwell, H. C. (1988). Introduction to Theoretical Neurobiology. Cambridge: Cambridge University Press.
Turrigiano, G. G., and Nelson, S. B. (2000). Hebb and homeostasis in neuronal plasticity. Curr. Opin. Neurobiol. 10, 358–364.
Wang, X. J. (2001). Synaptic reverberation underlying mnemonic persistent activity. Trends Neurosci. 24, 455–463.
Wang, X. J., (2002). Probabilistic decision making by slow reverberation in cortical circuits. Neuron 36, 955–968.
Wingfield, A., and Kahana, M. J. (2002). The dynamics of memory retrieval in older adulthood. Can. J. Exp. Psychol. 56, 187–199.
Wingfield, A., McCoy, S. L., Peelle, J. E., Tun, P. A., and Cox, L. C. (2006). Effects of adult aging and hearing loss on comprehension of rapid speech varying in syntactic complexity. J. Am. Acad. Audiol. 17, 487–497.
Wingfield, A., Tun, P. A., Koh, C. K., and Rosen, M. J. (1999). Regaining lost time: adult aging and the effect of time restoration on recall of time-compressed speech. Psychol. Aging 14, 380–389.
Wingfield, A., Tun, P. A., and McCoy, S. L. (2005). Hearing loss in older adulthood: what it is and how it interacts with cognitive performance. Curr. Dir. Psychol. Sci. 14, 144–148.
Wong, K. F., and Wang, X. J. (2006). A recurrent network mechanism of time integration in perceptual decisions. J. Neurosci. 26, 1314–1328.
Yamashita, Y., and Tani, J. (2008). Emergence of functional hierarchy in a multiple timescale neural network model: a humanoid robot experiment. PLoS Comput. Biol. 4, e1000220. doi: 10.1371/journal.pcbi.1000220.
Zaromb, F. M., Howard, M. W., Dolan, E. D., Sirotin, Y. B., Tully, M., Wingfield, A., and Kahana, M. J. (2006). Temporal associations and prior-list intrusions in free recall. J. Exp. Psychol. Learn. Mem. Cogn. 32, 792–804.
Keywords: plasticity, simulations, short-term plasticity, memory, temporal context model, associative learning
Citation: Miller P and Wingfield A (2010) Distinct effects of perceptual quality on auditory word recognition, memory formation and recall in a neural model of sequential memory. Front. Syst. Neurosci. 4:14. doi: 10.3389/fnsys.2010.00014
Received: 16 February 2010;
Paper pending published: 22 April 2010;
Accepted: 07 May 2010;
Published online: 03 June 2010
Edited by:
Jose Bargas, Universidad Nacional Autónoma de México, MexicoReviewed by:
Marc Howard, Syracuse University, USASen Song, Massachusetts Institute of Technology, USA
Copyright: © 2010 Miller and Wingfield. This is an open-access article subject to an exclusive license agreement between the authors and the Frontiers Research Foundation, which permits unrestricted use, distribution, and reproduction in any medium, provided the original authors and source are credited.
*Correspondence: Paul Miller, Volen National Center for Complex Systems, MS 013, Brandeis University, 415 South Street, Waltham, MA 02454, USA. e-mail:cG1pbGxlckBicmFuZGVpcy5lZHU=