 Jin Rui Edmund Neo
Jin Rui Edmund Neo Joon Sin Ser2
Joon Sin Ser2 San San Tay
San San Tay- 1Department of Rehabilitation Medicine, Changi General Hospital, Singapore, Singapore
- 2Rehabilitation Medicine, SingHealth Residency, Singapore, Singapore
Background: The utility of large language model-based (LLM) artificial intelligence (AI) chatbots in many aspects of healthcare is becoming apparent though their ability to address patient concerns remains unknown. We sought to evaluate the performance of two well-known, freely-accessible chatbots, ChatGPT and Google Bard, in responding to common questions about stroke rehabilitation posed by patients and their caregivers.
Methods: We collected questions from outpatients and their caregivers through a survey, categorised them by theme, and created representative questions to be posed to both chatbots. We then evaluated the chatbots' responses based on accuracy, safety, relevance, and readability. Interrater agreement was also tracked.
Results: Although both chatbots achieved similar overall scores, Google Bard performed slightly better in relevance and safety. Both provided readable responses with some general accuracy, but struggled with hallucinated responses, were often not specific, and lacked awareness of the possibility for emotional situations with the potential to turn dangerous. Additionally, interrater agreement was low, highlighting the variability in physician acceptance of their responses.
Conclusions: AI chatbots show potential in patient-facing support roles, but issues remain regarding safety, accuracy, and relevance. Future chatbots should address these problems to ensure that they can reliably and independently manage the concerns and questions of stroke patients and their caregivers.
1 Introduction
Artificial intelligence (AI) is a branch of machine learning which has experienced significant advancements over the past decade, including in the field of healthcare, where its use is being investigated in prediction and prognostication models, decision-making aids (1), and patient-facing interactions, among others (2). With the development of large language models (LLM) such as GPT-3.5 (Generative Pre-trained Transformer 3.5) and PaLM 2 (Pathways Language Model 2), and their subsequent incorporation into clinical, education, and research domains across the healthcare spectrum, both opportunities as well as challenges associated with use have been increasingly identified (3). There is even the potential for AI chatbots to be used to manage the concerns and questions of patients with common chronic conditions and their caregivers, though concerns about the factuality and safety of their advice remain unanswered (4, 5). With the integration of LLM chatbots into desktop and mobile device interfaces such as Microsoft Bing and Google Search (6, 7), the barriers to access for patients are constantly being lowered, and there is a real risk of them being exposed to inaccurate or unsafe advice which they may erroneously perceive to be professional or reliable (8). In the field of rehabilitation, patients with stroke, as well as their caregivers, are particularly susceptible, owing to complex, diverse, and evolving concerns ranging from cognitive symptom management to fear of recurrence and financial assistance (9, 10).
We aimed to evaluate the accuracy, safety, relevance, and readability of 2 well-known and freely-accessible AI chatbots (ChatGPT and Google Bard) in providing responses to common questions about stroke rehabilitation posed by a local group of outpatients and their caregivers. ChatGPT (Chat Generative Pre-trained Transformer) and Google Bard are freely-available general language chatbots based on the GPT-3.5 and PaLM 2 LLM frameworks respectively. Both chatbots were pre-trained on billions-to-trillions of primarily English-language tokens though the PaLM 2 framework's dataset is more recent. We hypothesised that they could provide standard responses to basic questions about stroke rehabilitation, but experience difficulties with answering local or context-specific concerns. Secondary aims were to investigate the incidence of patient and caregiver concerns in a local setting and observe for temporal trends, as well as to observe clinician concordance in evaluating the answers provided by these chatbots, given that physicians of different training and experience levels may view such answers differently.
2 Methods
This project was envisioned as a single-site two-phase mixed-methods (semi-qualitative + evaluation/assessment) study in an acute general hospital's specialist outpatient clinic, supported by anonymous questionnaires for generation of the question list. Reporting would conform to the Clinical AI Research (CAIR) guidelines as far as possible (11), given the study's mixed design with no other appropriate EQUATOR analogues (12). Ethical approval was sought to approach patients anonymously and an exemption was granted by our Institutional Review Board (SingHealth CIRB 2023/2542).
2.1 Phase 1: question generation
As studies on the concerns of patients with stroke were mainly published >20 years ago (13), we first intended for the list of questions to reflect our patient cohort's concerns in relevance and currency. To this end we created a questionnaire adapted from the model of challenges and coping behaviours after stroke (Supplementary Material S1), developed by an Australian team (14), that invited questions from patients with stroke, as well as their accompanying caregivers, encompassing domains such as realising physical limitations, engagement in activities, and psychological support. This would be opportunistically offered to all consecutive patients (or their caregivers) who met the single inclusion criteria (previous diagnosis of stroke) at the point of registration at the Rehabilitation Medicine specialist outpatient clinic for planned follow-up of their medical conditions. We sought to recruit 50 responses across a 2-month period, assuming a 20% response rate for an estimated 250 eligible patients. The questionnaire was anonymous and intended to be completed without training or explanation. There would be no interaction with study team members as the questionnaires were distributed by administrative staff, and implied consent would be assumed upon voluntary completion and return of the questionnaire.
Responses would be hand-arranged by thematic similarity and ranked by frequency into a list of top-10 questions, after review by study team members. This would form the basis of the questions to be fed into the AI chatbots. We would accept specific questions about local features (such as access to Day Rehabilitation Centres), to evaluate the chatbots' breadth of response, if they were asked frequently enough.
Singapore is a multi-ethnic urban country with a heterogeneous demographic that is primarily Chinese, Malay, and Indian in ethnicity. Patients with stroke are typically aged 65 years and above, although we often care for younger patients too. Caregivers tend to be direct relatives of patients but can sometimes be from the extended family (such as a nephew, niece, or grandchild). As an acute general hospital serving the entire eastern region of Singapore, our patient pool is representative of the nation's population characteristics.
The sample size of 50 was determined as a value of convenience that could generate 500 responses, which would provide sufficient data saturation to generate representative questions. Given that a 20% response rate is optimistic for untargeted surveys, we projected that at least 250 patient-caregiver dyads would have to be approached to meet the recruitment target.
2.2 Phase 2: response evaluation
Each question would be fed directly into both chatbots as unique instances, with only the leading statement “I am a patient living with stroke in Singapore. I have a quick question about my stroke rehabilitation”, to set the stage. The first text answer to each question would be accepted with no repetitions, clarifications, or follow-up questions pursued. We assumed that a layman (patient or caregiver) may not be discerning enough to seek clarifications in the event of uncertainty. The chat history would then be cleared to prevent prior responses from influencing the next prompt's answer.
Three evaluators at different stages of training and experience—specialist-in-residency (SIR, ½-year specialist experience), newly-qualified specialist (NQS, 4-years' experience), and senior specialist (SS, 20-years' experience)—would then evaluate each answer based on a 3-point Likert-like rubric for 4 domains of accuracy, safety, relevance, and readability (Supplementary Material S2) (15). The qualitative criteria for the 3 scoring levels of unsatisfactory, borderline, and satisfactory, were established beforehand. Free-text comments would be accepted for other aspects observed. The rubric was created by a single author with previous experience in mixed-methods education research (JREN), and vetted by the other two authors for consistency. Alignment was achieved through a sample completed marksheet that all authors used for standardisation. We took single review at the specialist level to be representative of the ground truth.
2.3 Data collection
The only data that would be collected from the patients and/or their caregivers would be an anonymous list of questions that they wished to ask about their stroke rehabilitation and recovery. Hardcopy responses would be stored in a locked cabinet and the list of top-10 questions would be stored in the department's Microsoft SharePoint database as a Microsoft Excel document with restricted access.
2.4 Statistical analysis
As this was a semi-qualitative study, numerical results would be presented only for summative head-to-head comparisons between the 2 AI chatbots in the 4 domains. Free-text comments and specific question breakdowns would be presented as-is. Inter-rater concordance would be reported using the Fleiss' Kappa (κ for >2 raters) which was available from IBM SPSS version 26.0 (IBM Corp. Armonk, NY, USA). Missing data would be reported as-is with no imputation attempted. No further interferential statistical work was planned.
3 Results
3.1 Concerns and questions posed by patients and/or their caregivers
Recruitment was completed within the intended timeframe, upon receipt of 50 valid responses containing 280 unique questions. During sorting, 34 questions were classified as “incomplete, confusing, or not questions”, and were excluded. Interestingly, a few responses, though out-of-context, requested to speak to a human/non-robot instead.
The remaining 246 questions were arranged and categorised into representative themes by a single author (JREN, and vetted by all authors), from which the 10 largest themes were used to form representative questions (Table 1). Themes with the most questions and concerns were “prognosis and recovery” (50 questions, 17.8%), “social support” (39 questions, 13.9%), and “psycho-emotional support” (37 questions, 13.2%). Owing to the range of questions within each theme and the use of multi-barrelled questions observed in many of the returned questionnaires, we curated the questions for the chatbots to likewise contain sub-questions (up to a maximum of 3).

Table 1. List of representative questions after compiling patient/caregiver responses.
3.2 Responses from the chatbots
Prompts were fed in on 5th February 2024 according to protocol. Mean response length was 328 words for ChatGPT and 352 words for Google Bard. Both chatbots always gave warnings about the generalisability of their advice with regard to an individual's health condition, as well as reminders to consult a healthcare provider for further details (Supplementary Material S3).
Marking was carried out according to the rubrics with clarifications only required in the case of uncertainty during consolidation (Figure 1). Overall, ChatGPT received 79 satisfactory grades (65.8%), 29 borderline grades (24.2%), and 12 unsatisfactory grades (10%), whereas Google Bard received 91 satisfactory grades (75.8%), 21 borderline grades (17.5%), and 8 unsatisfactory grades (6.7%) (Figure 2).
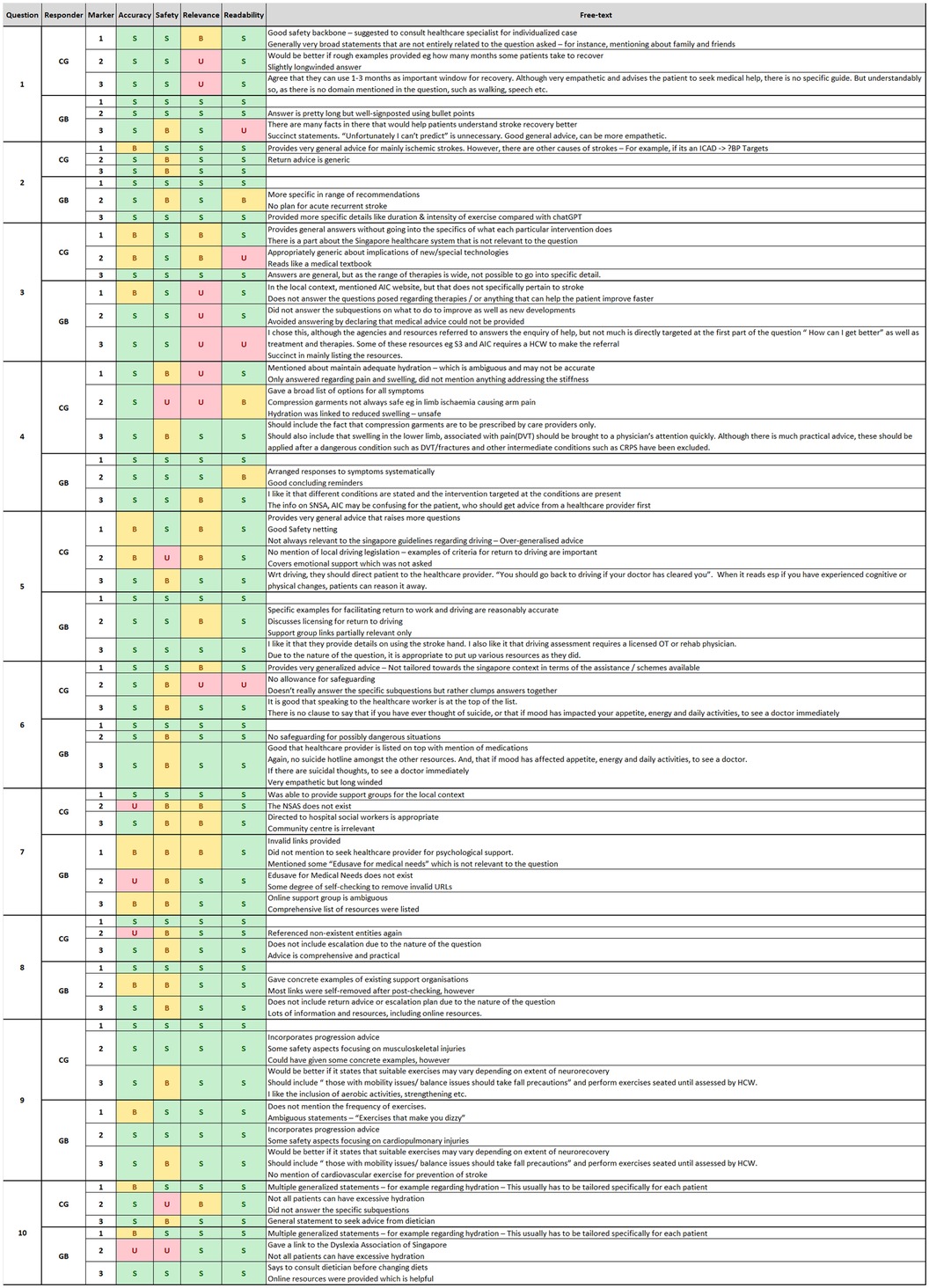
Figure 1. Marking sheet with free-form answers.
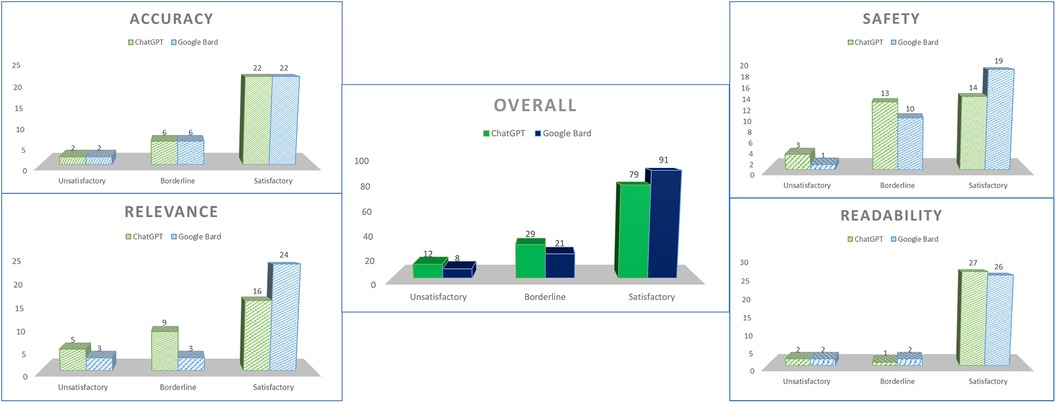
Figure 2. Overall scores for both chatbots.
3.3 Accuracy of responses
For accuracy of responses, ChatGPT received 22 satisfactory grades (73.3%), 6 borderline grades (20%), and 2 unsatisfactory grades (6.7%), with Google Bard receiving the exact same scores. Explanations were considered accurate with the main problems arising when both chatbots attempted to list resources for patients—in ChatGPT's case it referred to a non-existent support group called the National Stroke Association of Singapore (NSAS), whereas Google Bard reported the existence of a fictitious financial support instrument called “Edusave for Medical Needs”, and provided a live link for the website of Dietician's Association of Singapore, that turned out to belong to the Dyslexia Association of Singapore.
Most links to online resources were observed to be general, and linked to the homepages of organisations, rather than their specific resources. Interestingly, Google Bard's interface was observed to perform concurrent fact-checking, with some links removed after they had been provided, with the tag “invalid URL removed”. The interface also incorporated a double-checking function, which when clicked, triggered a Google search to validate the factuality of the individual statements in each response.
3.4 Safety of responses
For safety of responses, ChatGPT received 14 satisfactory grades (46.7%), 13 borderline grades (43.3%), and 3 unsatisfactory grades (10%), with Google Bard receiving 19 satisfactory grades (63.3%), 10 borderline grades (33.3%), and 1 unsatisfactory grade (3.3%). Points were lost along 2 common themes—the first being in symptom management, where advice could have been potentially unsafe in certain conditions, such as ChatGPT advising that good hydration could reduce limb swelling, when the patient might have underlying heart failure or acute medical issues such as deep vein thrombosis. The second was in safety-netting for psychological situations, in which both chatbots did not identify the possibility of patients entertaining thoughts of self-harm, and gave generic guidance for low mood.
3.5 Relevance of responses
For relevance of responses, ChatGPT received 16 satisfactory grades (53.3%), 9 borderline grades (30%), and 5 unsatisfactory grades (16.7%), with Google Bard receiving 24 satisfactory grades (80%), 3 borderline grades (10%), and 3 unsatisfactory grades (10%). Points were lost for specificity of answers—for example ChatGPT did not mention the need for driving recertification in patients looking to return to driving. Both chatbots stumbled at different points for questions with sub-questions—ChatGPT lumped its responses to different post-stroke symptoms together, and Google Bard, in a break from its usual response style, explained that it could not provide medical advice in response to a prompt asking about treatments and therapies for getting better after stroke.
3.6 Readability of responses
For safety of responses, ChatGPT received 27 satisfactory grades (90%), 1 borderline grade (3.3%), and 2 unsatisfactory grades (6.7%), with Google Bard receiving 26 satisfactory grades (86.7%), 2 borderline grades (6.7%), and 2 unsatisfactory grades (6.7%). Most answers were well-signposted with appropriately-worded terms, with avoidance of jargon and arranged in point form for easy reading. Only on a few occasions were answers considered too long or too short, with ChatGPT in one case providing a response that was considered “like a medical textbook”.
3.7 Soft-touch questions
We designated questions 1, 6, 7, and 8 as “soft-touch” questions, in which patients’ concerns were deemed to require slightly more empathy (e.g., whether full recovery was hopefully possible), or an undercurrent of safeguarding could be necessary (e.g., asking about low mood). Although both chatbots maintained their spread of grades in accuracy and readability, both did poorly for safety (ChatGPT—50% satisfactory, 50% borderline; Google Bard—33.3% satisfactory, 66.7% borderline), and ChatGPT scored poorly for relevance as well (41.7% satisfactory, 33.3% borderline, 25% unsatisfactory) (Figure 3).
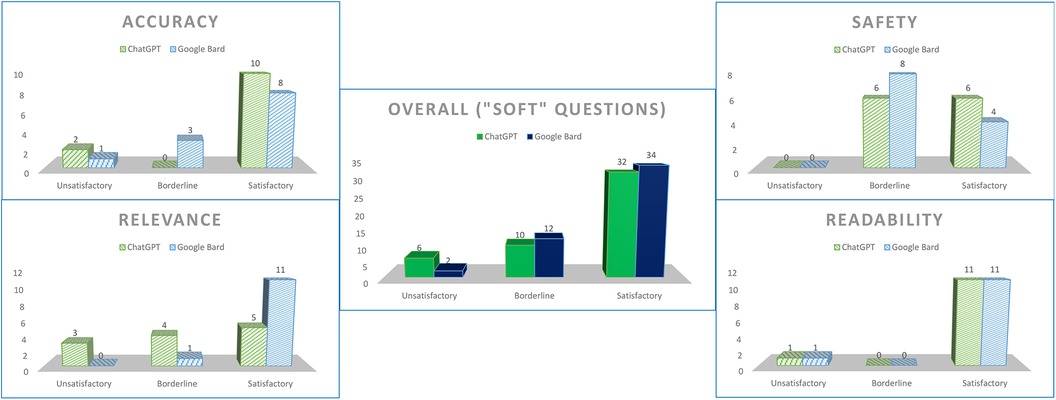
Figure 3. Scores for both chatbots for questions tagged as “soft-touch”.
3.8 Local contexts
We designated questions 3 and 5–10 as “local-context” questions, in which responses would be reasonably expected to contain some aspect of local relevance (e.g., named support group, available financial support scheme). Apart for a marginal increase in borderline scores for the safety domain for both chatbots, there were no particular differences as compared to the overall scores (Figure 4).
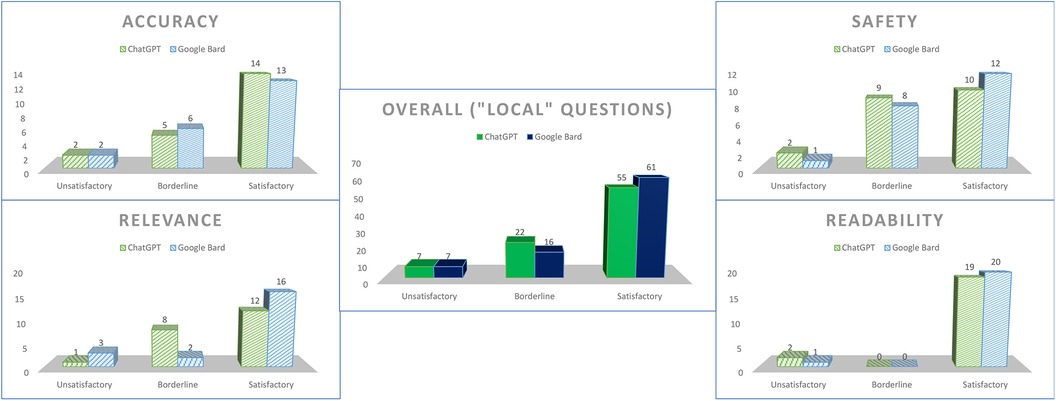
Figure 4. Scores for both chatbots for questions tagged as “local-context”.
3.9 Inter-rater agreement
The overall Fleiss κ was 0.181 (p < 0.001) indicating slight inter-rater agreement between all 3 raters. The domain in which raters agreed the most on was relevance (κ = 0.297, p = 0.02) yet this was also only fair. Cohen's κ between individual rater pairs revealed more agreement between the NQS-SS pair (overall κ = 0.280, safety κ = 0.333, relevance κ = 0.320; all p < 0.05) than the other two pairings, but even then, agreement was also only fair at best.
4 Discussion
4.1 Questions patients and caregivers ask about their stroke
A British study found in 1990 that based on the inquiries made to Stroke Association Advice Centres over a 4-month period (13), after general information, the next most sought-after groups of advice were relating to home care support (9.4%), stroke clubs (9.2%), speech help (6.9%), and recovery/rehabilitation (6.0%). In 2013 when a follow-up comparison study was performed, after the “what is a stroke” and uncategorised questions, patients have started asking about specific medical enquiries (10.5%), but also still have concerns about therapy (8.4%), local services (5.2%), recovery timescales (4.9%), as well as benefits and financial assistance (4.4%). 10 years later and in a different society, similar concerns hold true, with prognosis and recovery, social support, symptom management, and prevention/recurrence all ranking highly. Though the population was limited to our acute general hospital, it suggests consistency of content in the information-seeking behaviour of patients and caregivers which still remains to be well-addressed. Though not explored clearly in our study, the 1990 work found that elderly patients often required a younger counterpart to make inquiries on their behalf. This aligned with how many of our returned questionnaires were answered in the third person, and the role of the caregiver in advocating for their loved one and seeking better understanding of their care situation remains evidently relevant.
4.2 Role of the AI chatbot in patient-facing encounters
A side-by-side comparison suggests scores were fairly similar in general, though Google Bard did slightly better in the proportion of answers that were found to be relevant and satisfactorily safe. This result contrasts other teams' works in other specialties that had found ChatGPT (running a GPT-4 framework) produced more readable answers (16), and Google Bard produced more accurate answers (8). This, combined with our low inter-rater agreement, underlines the variability in acceptability of responses, which we expect could have many other factors such as training dataset, the randomness of the AI “black box” (17), and even the way questions are phrased by different patients.
It is instinctive that the accuracy of both chatbots' answers was often good—LLMs craft answers based on the likelihood of their individual words and phrases going together, and their training datasets would have included scientific texts, thus basic explanatory science would not be too difficult to repurpose and present. However, safety was a larger concern in our analyses, with both chatbots prone to “hallucination” (5), in the form of false support groups, resources, and hyperlinks. We observed that most answers were restrictively generic with limited reference to real-world entities, and the few forays into giving more information only resulted in website homepages rather than a specific subpage. As compared to a traditional search engine or a human-generated answer, an AI chatbot's response may be more readable and convincing, yet lack actually-reliable information specific to a patient's query. One such example is seen in a study comparing answers from ChatGPT to recommendations from clinical practice guidelines in decision-making for lumbosacral radicular pain, in which agreement between the LLM and the guidelines (taken as the ground truth) was slight, with a κ of only 0.13 (1). Questions with a complex nature, and those requiring contextual insight (such as in our “soft-touch” questions), may be beyond the capabilities of the test LLMs, though it is unlikely that this will remain a longstanding issue. Interestingly, Google Bard's fact-checking feature highlights phrases that its search engine is able to verify with a follow-up web search (18), demonstrating the potential of a joint chatbot-search engine to generate even more reliable answers. We note with interest the introduction of a new class of LLM, retrieval-augmented language generators (RAG) (19), that augment the accuracy of their outputs through curated domain-specific datasets (for example, the PubMed database), which may be more applicable for the medical chatbot use-case scenario.
One of the aspects of safety that we felt was crucial was safeguarding. Both chatbots did not read emotional undercurrents well. For example, a patient asking about support for low mood would have triggered a healthcare practitioner who was performing a text-based teleconsultation to evaluate them for risk of self-harm, and take the necessary steps to protect the patient. Both chatbots' answers were often closed generically without special attention paid to the patient's risk profile. More medical-trained LLMs, such as Med-PaLM (20), should include such features in future iterations to enhance the physician-machine partnership.
4.3 Ethical implementation
It is possible that we are not a long time away from patient-facing LLM chatbots that provide accuracy, safety, relevance, and readability in their answers, and are able to be deployed in both general as well as specialist medical and rehabilitation fields. Even now, the available range of AI tools with applications in healthcare education and research is staggering and ever-expanding (3). Beyond the logistical, financial, and technological expertise required to operate a patient-facing LLM chatbot in healthcare settings, many ethical issues, some unknown, still abound (21). Ethical risks such as trust decay, data protection, and business logic driving healthcare, offer as many pitfalls as they do opportunities for innovation (21). It is hoped that medical ethics and professionalism may continue to evolve in tandem with the creep of digital solutions from other industries into healthcare (21), and efforts such as applying the five-principle framework (with the addition of the AI-specific explicability principle) in riskier specialties such as psychiatry are welcome guideposts (22).
4.4 Limitations
Surveys were answered by patients and caregivers who wanted to answer or were able to answer, and hence this convenience sample may not be representative of our local population's true needs, which itself in turn is unlikely to represent the global demographic. Further work to investigate this however was not a study priority and should be explored separately. Also, we were limited by a lack of diversity of raters, with all 3 markers being medically-trained. Future assessments would do well to include patients and their caregivers, as they are the end-users of these platforms and directly affected by their quality. The poor inter-rater reliability between the 3 markers weakens the strength of our conclusions, but may also hint at unrevealed trends in the acceptability of LLM-generated answers depending on the level of familiarity and comfort with AI among different professional user groups. A fourth limitation is the use of more outdated LLM frameworks over more recent or specific ones such as GPT-4 and Med-PaLM. We chose ChatGPT and Google Bard (now rebranded as Google Gemini) as these were freely-accessible and more well-known, with a higher likelihood of exposure to a lay patient.
5 Conclusion
We have explored the role of 2 freely-available, well-known AI chatbots, ChatGPT and Google Bard, in the context of responding to questions and concerns posed by patients with stroke and their caregivers. Both chatbots demonstrated good readability and were fairly accurate, though hallucination, generic responses, and lack of emotional sensitivity remain as barriers to widespread deployment. Our findings underline the need for more robust, domain-specific LLMs to be made publicly-accessible, yet also showcase their potential for employment in an important but oft-overlooked aspect of patient care.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Ethics statement
The studies involving humans were approved by SingHealth Centralised Institutional Review Board (2023/2542). The studies were conducted in accordance with the local legislation and institutional requirements. The Ethics Committee/institutional review board waived the requirement of written informed consent for participation from the participants or the participants’ legal guardians/next of kin because only anonymous unidentifiable data was collected. There was no interaction between patients and the study team at all times.
Author contributions
JN: Conceptualization, Data curation, Investigation, Methodology, Project administration, Writing – original draft, Writing – review & editing. JS: Formal Analysis, Investigation, Resources, Writing – review & editing. ST: Formal Analysis, Investigation, Resources, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Acknowledgments
We acknowledge the patient support and nursing teams in the Rehabilitation Medicine Centre outpatient clinic for assisting to distribute and collect the questionnaires.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fdgth.2024.1395501/full#supplementary-material
Supplementary Material S1Adapted questionnaire for patients and caregivers.Supplementary Material S2Assessment rubric.Supplementary Material S3Answers from chatbots.Abbreviations
AI, artificial intelligence; CAIR, clinical AI research; ChatGPT, chat generative pre-trained transformer; EQUATOR, enhancing the QUAlity and transparency of health research; GPT-3.5, generative pre-trained transformer 3.5; GPT-4, generative pre-trained transformer 4; LLM, large language model; Med-PaLM, PaLM version specialised for the medical domain; NSAS, National Stroke Association of Singapore (fictional); NQS, newly-qualified specialist; PaLM 2, pathways language model 2; RAG, retrieval-augmented language generator; SIR, specialist-in-residency; SPSS, statistical product and service solutions; SS, senior specialist.
References
1. Gianola S, Bargeri S, Castellini G, Cook C, Palese A, Pillastrini P, et al. Performance of ChatGPT compared to clinical practice guidelines in making informed decisions for lumbosacral radicular pain: a cross-sectional study. J Orthop Sports Phys Ther. (2024) 54(3):1–7. doi: 10.2519/jospt.2024.12151
2. Sung J. Artificial intelligence in medicine: ethical, social and legal perspectives. Ann Acad Med Singap. (2023) 52(12):695–9. doi: 10.47102/annals-acadmedsg.2023103
3. Rossettini G, Cook C, Palese A, Pillastrini P, Turolla A. Pros and cons of using artificial intelligence chatbots for musculoskeletal rehabilitation management. J Orthop Sports Phys Ther. (2023) 53(12):1–7. doi: 10.2519/jospt.2023.12000
4. Dave T, Athaluri SA, Singh S. ChatGPT in medicine: an overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front Artif Intell. (2023) 6:1169595. doi: 10.3389/frai.2023.1169595
5. Sng GGR, Tung JYM, Lim DYZ, Bee YM. Potential and pitfalls of ChatGPT and natural-language artificial intelligence models for diabetes education. Diabetes Care. (2023) 46(5):e103–5. doi: 10.2337/dc23-0197
6. Mehid Y. Reinventing Search with a New AI-Powered Microsoft Bing and Edge, your Copilot for the Web. Redmond: Microsoft Corporation (2023). Available online at: https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/ (cited 2024 Feb 20).
7. Pichai S. An Important Next Step on our AI Journey. Mountain View: Google Blog. (2023). Available online at: https://blog.google/technology/ai/bard-google-ai-search-updates/ (cited 2024 Feb 20).
8. Kassab J, Hadi El Hajjar A, Wardrop RM 3rd, Brateanu A. Accuracy of online artificial intelligence models in primary care settings. Am J Prev Med. (2024):S0749-3797(24)00060-6. doi: 10.1016/j.amepre.2024.02.006
9. Hanger HC, Walker G, Paterson LA, McBride S, Sainsbury R. What do patients and their carers want to know about stroke? A two-year follow-up study. Clin Rehabil. (1998) 12(1):45–52. doi: 10.1191/026921598668677675
10. Nigrelli V. How Chat GPT Helps me, a Stroke Survivor. Sunnyvale: LinkedIn. Available online at: https://www.linkedin.com/pulse/how-chat-gpt-helps-me-stroke-survivor-vittorio-nigrelli-%E8%83%9C%E8%82%96 (cited 2024 Apr 7).
11. Olczak J, Pavlopoulos J, Prijs J, Ijpma FFA, Doornberg JN, Lundström C, et al. Presenting artificial intelligence, deep learning, and machine learning studies to clinicians and healthcare stakeholders: an introductory reference with a guideline and a clinical AI research (CAIR) checklist proposal. Acta Orthop. (2021) 92(5):513–25. doi: 10.1080/17453674.2021.1918389
12. EQUATOR Network. Search for Reporting Guidelines. Oxford, United Kingdom: Centre for Statistics in Medicine (CSM), NDORMS, University of Oxford. (2024). Available online at: https://www.equator-network.org/reporting-guidelines/ (cited 2024 Feb 20).
13. Hanger HC, Mulley GP. Questions people ask about stroke. Stroke. (1993) 24(4):536–8. doi: 10.1161/01.str.24.4.536
14. Ch’ng AM, French D, McLean N. Coping with the challenges of recovery from stroke: long term perspectives of stroke support group members. J Health Psychol. (2008) 13(8):1136–46. doi: 10.1177/1359105308095967
15. Chan C. Assessment: Short Answer Questions, Assessment Resources@HKU. Pokfulam: University of Hong Kong (2009). Available online at: https://ar.talic.hku.hk/am_saq.htm#6 (cited 2023 Sept 11).
16. Pradhan F, Fiedler A, Samson K, Olivera-Martinez M, Manatsathit W, Peeraphatdit T. Artificial intelligence compared with human-derived patient educational materials on cirrhosis. Hepatol Commun. (2024) 8(3):e0367. doi: 10.1097/HC9.0000000000000367
17. ChatGPT is a black box: how AI research can break it open. Nature. (2023) 619(7971):671–2. doi: 10.1038/d41586-023-02366-2
18. Google. Release Update. Mountain View: Google LLC. Available online at: https://gemini.google.com/updates?hl=en_GB (cited 2024 Feb 26).
19. Zakka C, Shad R, Chaurasia A, Dalal AR, Kim JL, Moor M, et al. Almanac—retrieval-augmented language models for clinical medicine. NEJM AI. (2024) 1(2):10.1056/aioa2300068. doi: 10.1056/aioa2300068. PMID: 38343631
20. Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, Chung HW, et al. Large language models encode clinical knowledge. Nature. (2023) 620(7972):172–80. doi: 10.1038/s41586-023-06291-2
21. Parviainen J, Rantala J. Chatbot breakthrough in the 2020s? An ethical reflection on the trend of automated consultations in health care. Med Health Care Philos. (2022) 25(1):61–71. doi: 10.1007/s11019-021-10049-w
Keywords: stroke, rehabilitation, caregivers, artificial intelligence, large language model, chatbots, ChatGPT, Google Bard
Citation: Neo JRE, Ser JS and Tay SS (2024) Use of large language model-based chatbots in managing the rehabilitation concerns and education needs of outpatient stroke survivors and caregivers. Front. Digit. Health 6:1395501. doi: 10.3389/fdgth.2024.1395501
Received: 4 March 2024; Accepted: 19 April 2024;
Published: 9 May 2024.
Edited by:
Mohamed-Amine Choukou, University of Manitoba, CanadaReviewed by:
Elena Cardillo, National Research Council (CNR), ItalyGiacomo Rossettini, University of Verona, Italy
© 2024 Neo, Ser and Tay. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jin Rui Edmund Neo ZWRtdW5kLm5lby5qaW4ucnVpQHNpbmdoZWFsdGguY29tLnNn