 Kenji Morita
Kenji Morita Ayaka Kato
Ayaka Kato- 1Physical and Health Education, Graduate School of Education, The University of Tokyo, Tokyo, Japan
- 2Department of Biological Sciences, School of Science, The University of Tokyo, Tokyo, Japan
A corrigendum on Figure 2Cd of
Striatal dopamine ramping may indicate flexible reinforcement learning with forgetting in the cortico-basal ganglia circuits
by Morita, K., and Kato, A. (2014). Front Neural Circuits 8:36. doi: 10.3389/fncir.2014.00036
In the preparation of organized program codes for this article (Morita and Kato, 2014) for submission to public database after the publication, we have noticed that there was an error in the code for making Figure 2Cd written by one of the authors Kenji Morita. Specifically, although RPE values at S1 for the cases with decay (i.e., the leftmost points of the three solid lines) should be proportional to the amount of reward as appeared in the formula for calculating them:
where “R” represents the amount of reward, they were incorrectly plotted as an equal value in Figure 2Cd (indicated by the red circle in the left (“Error”) panel of the figure attached to this Corrigendum) because “R” was mistakenly dropped (i.e., effectively assumed to be 1 in all the cases) in the code. We have corrected the code and made the corrected Figure 2Cd [the right (“Corrected”) panel of the figure attached to this Corrigendum]. There is no need to change the texts explaining Figure 2Cd in the Methods, Results, and the figure legend. We sincerely apologize for the inconvenience. Lastly, we would like to take this opportunity to announce that the program (MATLAB) codes for this article (with the correction described in the above) are now available on the ModelDB (Accession: 153573): http://senselab.med.yale.edu/modeldb/ShowModel.asp?model=153573
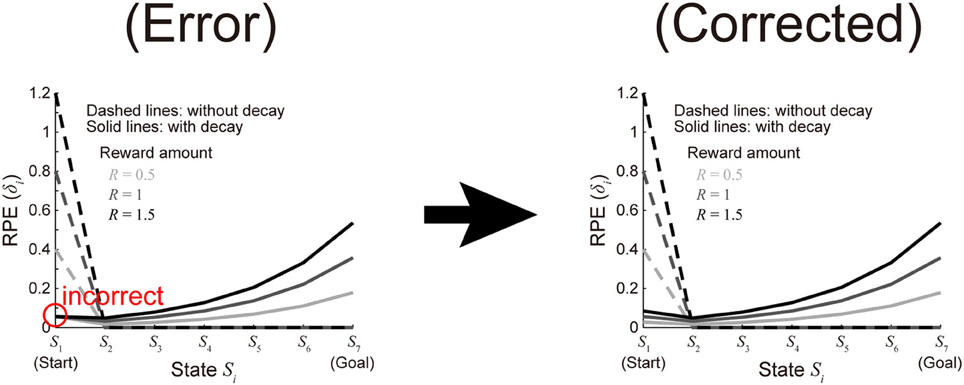
Figure 2. (C) (d) The solid lines show the eventual (asymptotic) values of RPE after the convergence of learning at all the states from the start (S1) to the goal (S7) when there are 7 states (n = 7) in the model incorporating the decay, with varying the amount of the reward obtained at the goal (R) (unvaried parameters were set as follows: a = 0.6, y = 0.8(1/6), and x = 0.75). The dashed lines show the cases of the model without decay.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Keywords: dopamine, basal ganglia, corticostriatal, synaptic plasticity, reinforcement learning, reward prediction error, flexibility, computational modeling
Citation: Morita K and Kato A (2014) Corrigendum: Striatal dopamine ramping may indicate flexible reinforcement learning with forgetting in the cortico-basal ganglia circuits. Front. Neural Circuits 8:48. doi: 10.3389/fncir.2014.00048
Received: 14 April 2014; Accepted: 23 April 2014;
Published online: 16 May 2014.
Edited and reviewed by: M. Victoria Puig, Massachusetts Institute of Technology, USA
Copyright © 2014 Morita and Kato. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence:bW9yaXRhQHAudS10b2t5by5hYy5qcA==