 Carl J. Nelson
Carl J. Nelson Stephen Bonner
Stephen Bonner- 1School of Physics and Astronomy, University of Glasgow, Glasgow, United Kingdom
- 2School of Computing, Newcastle University, Newcastle upon Tyne, United Kingdom
Connected networks are a fundamental structure of neurobiology. Understanding these networks will help us elucidate the neural mechanisms of computation. Mathematically speaking these networks are “graphs”—structures containing objects that are connected. In neuroscience, the objects could be regions of the brain, e.g., fMRI data, or be individual neurons, e.g., calcium imaging with fluorescence microscopy. The formal study of graphs, graph theory, can provide neuroscientists with a large bank of algorithms for exploring networks. Graph theory has already been applied in a variety of ways to fMRI data but, more recently, has begun to be applied at the scales of neurons, e.g., from functional calcium imaging. In this primer we explain the basics of graph theory and relate them to features of microscopic functional networks of neurons from calcium imaging—neuronal graphs. We explore recent examples of graph theory applied to calcium imaging and we highlight some areas where researchers new to the field could go awry.
1. Networks of Neurons—Neuronal Graphs
Organised networks occur across all scales in neuroscience. Broadly, we can categorise networks that involve neurons in two ways (Figure 1): macroscopic vs. microscopic; and functional vs. structural:
• In fMRI recordings of brain activity, macroscopic, functional networks are often extracted where entire brain regions (macroscopic) are related by their correlated activity or (anti-correlated) inhibition (functional).
• Diffusion MRI connectomics provides macroscopic, structural networks where anatomical (structural) connections are determined between regions of the brain.
• Analysis of electron microscopy can be used to extract microscopic, structural networks where neurons (microscopic) are related by their physical connections (e.g., Scheffer, 2020) synapses.
• Finally, cell-resolution calcium imaging provides microscopic, functional networks where individual neurons are related by their correlated activity or (anti-correlated) inhibition—we call these networks neuronal graphs (cells can also be grouped in to brain regions to create mesoscopic or macroscopic, functional networks).
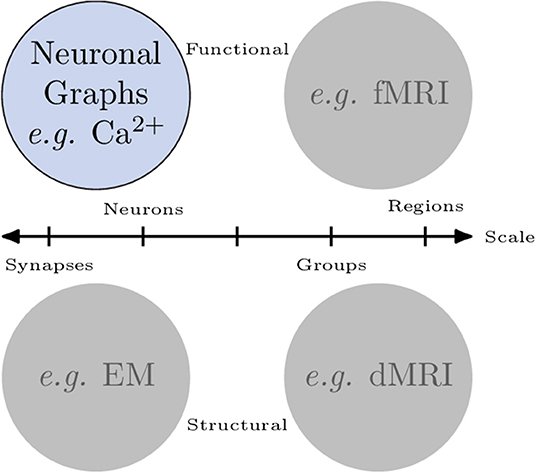
Figure 1. Networks of neurons occur across scales and can be functional or structural. Microscopic networks (left), i.e., at neuron or synapse scale, are usually recorded with calcium imaging or electron microscopy techniques. Macroscopic networks (right), i.e., recordings of indistinguishable groups of neurons or brain regions, are often recorded using MRI techniques. Neuronal Graphs are microscopic (neuron-resolved), functional networks extracted from calcium imaging experiments.
Graph theory (or network science) techniques are used for all of these network categories (Bassett et al., 2018).
This primer focusses on the application of graph theory to microscopic, functional networks of individual neurons that can be extracted from calcium imaging—we will call these neuronal graphs. Analysis of neuronal graphs has shown clear differences of organisation in brain organisation through development in zebrafish (Avitan et al., 2017) and xenopus (Khakhalin, 2019). In fact, graph theory analysis was able to reveal changes in organisation of the optic tectum under dark-rearing where past experiments that used neuronal activation statistics were not (Avitan et al., 2017). Using neuronal graphs to study development opens up greater understanding of organisational changes and, as shown by Khakhalin (2019), this knowledge can be used to develop, validate and compare models of specific neuronal computations.
Further, graph theory analysis allows the quantification of changes in functional organisation across the whole zebrafish brain due to genetic or pharmacological perturbations (Burgstaller et al., 2019). Combining light sheet microscopy and graph theory creates a pipeline that could be used for high-throughput small-molecule screening for the identification of new drugs. The use of graph theory in such cases with large and densely connected neuronal graphs provides researchers with a bank of tools for exploring changes in both local and global functional organisation.
Through this paper we will briefly explain how calcium imaging data can be processed for the extraction of neuronal graphs but will focus on the essential background needed to understand and use neuronal graphs, e.g., what types of graphs there are, i.e., weighted vs. unweighted. We will then go on to introduce some of the simpler graph theory metrics for quantifying topological structure, e.g., degree, before moving on to some of the more complex measures available, such as centrality and community detection. We will relate all of these theoretical notions to the underlying neuroscience and physiology being explored. Throughout, we will highlight possible problems and challenges that the calcium imaging community should be aware of before using these graph theory techniques. This paper will introduce common mathematical concepts from graph theory that can be applied to calcium imaging in a way that will encourage the uptake of graph theory algorithms in the field. Throughout this paper, we make use of the notation defined in Table 1.

Table 1. A list of symbols and definitions as used in this paper.
2. What Is a Graph?
A graph is fundamentally comprised of a set of nodes (or vertices), with pairs of nodes connected together via an edge. These edges can be undirected (Figure 2A), or directed edges, with implied direction between two nodes creating a “directed graph” (Figure 2B). A simple graph can be defined as one which contains no self loops (edges which connect nodes with themselves) or parallel nodes (multiple edges between two nodes).
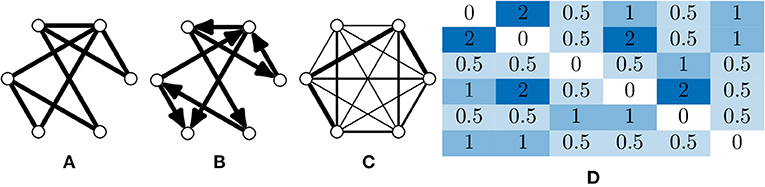
Figure 2. Types of graphs and their representation. (A) An undirected and unweighted graph; this is occasionally used for graph analyses where edge weights cannot be consider, e.g., certain community detection algorithms. (B) A directed and unweighted graph. (C) An undirected and weighted graph where the thickness of the edge indicates the weight, this is the most common graph type in calcium imaging due to the limited temporal resolution that is usually captured. Directed, weighted graphs can be produced when the temporal resolution is high enough to infer some causality between neuron activations. (D) An adjacency matrix of a weighted graph, which is an NV × NV matrix where a value in index i, j is the weight between node i and j.
Edges (and nodes) can have associated weights, often in the form of a numeric value. A graph with weighted edges can be seen in Figure 2C. These graphs are known as weighted graphs and are used to embed a greater quantity of information within the structure of a graph (Barrat et al., 2004). Working with macroscopic, functional networks, i.e., graphs with nodes representing regions on interest (Dingle et al., 2020) used average edge weight as a measure of overall connectivity.
In calcium imaging a node could represent a segmented neuron and a weighted edge the strength of correlation between two nodes. It should be noted that the term graph and network are often used interchangeably in the literature. Mathematically a simple graph can be defined as G = (V, E) where V is a finite set of nodes or nodes and E is a set of edges (Kolaczyk, 2009). The elements in E are unordered pairs {u, v} of unique nodes u, v ∈ V. The number of nodes NV = |V| and edges NE = |E| are often called the order and size of the graph G. A directed graph G can be represented where each edge in E displays an ordering to its nodes, so that (u, v) is distinct from (v, u).
Graph theory is the study of these graphs and their mathematical properties. Graph theory is a well-developed field and provides a wide spectrum of mathematical tools for exploring and quantifying graphs. Such graphs could be social networks, molecular modelling and, in our case, networks of neurons, i.e., neuronal graphs, or networks of brain regions.
A graph can be represented mathematically in several forms, common ways being the adjacency, degree and Laplacian matrices (Newman, 2010). An adjacency matrix A for a graph G, with unweighted edges, is an NV x NV matrix, where for a basic graph, the values are determined such that:
This notation can also be adjusted for the case of weighted graphs (Figure 2D) such that:
The degree ki for any node i is the total number of edges connected to that node. The degree distribution P(k) for graph G is the frequency of nodes with degree k.
Finally, the graph Laplacian L is again a matrix of size NV x NV. We can define the graph Laplacian matrix as,
One other way to consider the Laplacian matrix of a graph is that it is the degree matrix (a matrix where the diagonal values are the degree value for a certain vertex) subtracted by the adjacency matrix. Whilst seemingly simple, the graph Laplacian has many interesting properties which can be exploited to gain insights into graph structure (Chung, 1997). For example, the number of 0-eigenvalues of the Laplacian matrix corresponds with number of connected components within the graph.
3. From Calcium Imaging to Neuronal Graphs
The complexities and open challenges of extracting information about neurons from calcium imaging data could form a review in itself (e.g., Pnevmatikakis and Paninski, 2018). Here we briefly summarise the process from calcium imaging to neuronal graphs.
Calcium imaging is one of the most common ways of recording activity from large numbers of neurons at the cellular level, c.f. electrophysiological recordings with electrodes (Grienberger and Konnerth, 2012). In combination with new fluorescent reports, disease models, and optogenetics (e.g., Packer et al., 2015), calcium imaging has proved a powerful tool for exploring functional activity of neurons in vitro (e.g., Tibau et al., 2013) and in vivo (e.g., Denk et al., 1994; Grewe et al., 2010). The broad study of such data is referred to as functional connectomics (Alivisatos et al., 2012), of which neuronal graph analysis is just one aspect. Unlike electrophysiological recordings, calcium imaging can record simultaneously from hundreds or even thousands of neurons at a time (Ahrens et al., 2013), which can lead to challenging quantities of data being produced. However, calcium imaging does suffer from lower signal-to-noise ratio and lower temporal resolution when compared to electrophysiology which can cause issues in the extraction of neural assemblies (Pnevmatikakis and Paninski, 2018).
Neuronal graphs, i.e., networks of functionally connected neurons, can be extracted from calcium imaging with a variety of techniques, and research into accurate segmentation of neurons, processing of calcium signals and measurement of functional relation is an area of research full of caveats, warnings and open questions (Stetter et al., 2012). At the simplest level, it is possible to segment individual neurons, with tools such as CaImAn (Giovannucci et al., 2019), assigning each neuron as a node, vi, in our neuronal graph. It is then possible to measure the temporal correlation, using the Pearson correlation coefficient, of activity between pairs of neurons (Figure 3), assigning this value as weighted edges, E(vi, vj), in our neuronal graph (Smedler et al., 2014).
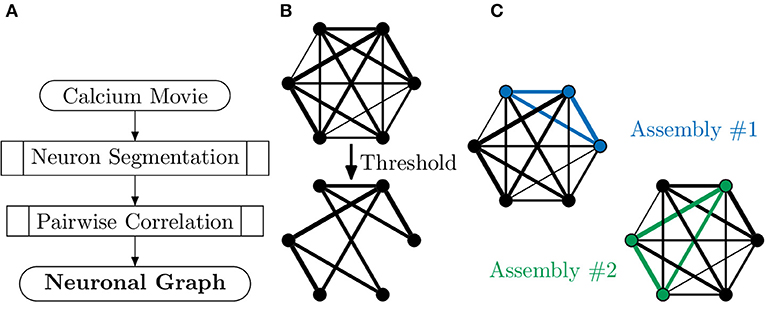
Figure 3. Extracting neuronal graphs from calcium imaging. (A) Well-developed algorithms now allow for automated neuron segmentation from calcium movies. After pairwise correlation with an appropriate metric a graph is extracted. (B) Often neuronal graphs are thresholded based on the pairwise correlation metric used, removing weak and potentially spurious edges; the remaining edges are either unweighted or weighted based on the original metrics. (C) Neuronal graphs can represent whole datasets, e.g., whole-brain calcium imaging, or sub-graphs of neural assemblies, e.g., only neurons activated by a particular stimuli, which may overlap such as in this example (blue and green subgraphs).
It is important to note that a biological network of neurons is temporally directed, i.e., the activation of one neuron causes the activation of other neurons. However, the Pearson coefficient represents a measure of correlation insensitive to causality and, as such, neuronal graphs are usually undirected. The Pearson coefficient is very suitable for most calcium imaging experiments where the temporal resolution is too low to truly measure any directionality in correlation. Very high-speed imaging of calcium dynamics (≫20 captures per second) allows the extraction of not just pairwise correlations of activity but also the propagation of calcium signalling. By using a pairwise metric that incorporates causality, e.g., transfer entropy, it is possible to extract directed graphs. In Khakhalin (2019), the author uses such an approach to create directed neuronal graphs of small numbers of neurons in the developing Xenopus tectum to investigate looming-selective networks.
Regardless of the metric of functional connectivity used, the resulting graph will have a functional connection between every pair of neurons. This densely connected graph is then typically thresholded to consider only those edges (neuron-neuron correlations) with a correlation above a set value (Betzel et al., 2019; Burgstaller et al., 2019) or above that expected in a random case (Avitan et al., 2017); this removes possibly spurious neurons and connections, as well as minimising computational requirements. Alternatively, the weakest edges are removed one-by-one until the total number of edges in the neuronal graph reaches some predetermined number (Khakhalin, 2019); this can be beneficial when comparing metrics across samples as some metrics can be skewed by the number of nodes or edges. For whole-brain calcium imaging, e.g., light sheet fluorescence microscopy in zebrafish, this neuronal graph represents all captured neurons (~80.000 in the zebrafish brain) and their relationship, i.e., all overlapping neural assemblies in the brain.
However, whole-brain calcium imaging is a relatively new technique and capturing the organisation of all neurons may not be the best way to answer a specific biological question. In many calcium studies it makes more sense to look for sub-populations of neurons that engage in concerted activity where functionally connected neurons activate in a correlated (or anti-correlated) fashion. These networks of functionally connected neurons, neural assemblies, may carry out specific functions, such as processing visual stimuli in the visual system; a neural assembly can be considered another type of neuronal graph. Within a population of neurons, each neuron may be a member of multiple assemblies, ie multiple different neuronal graphs. Neural assemblies have been demonstrated in a range of systems including the cortex (e.g., See et al., 2018), hippocampus (e.g., Harris et al., 2003) and optic tectum (e.g., Avitan et al., 2017). In particular, assemblies seen in spontaneous activity during development often demonstrate similarity to those assemblies seen in evoked stimulus processing post-development (Romano et al., 2015).
Recent work summarised and compared several methods for extracting specific neural assemblies from calcium imaging data (Mölter et al., 2018). The reader is directed to this article for further information on specific methods. Importantly, the authors show that a spectral graph clustering approach, which does not depend directly on correlations between pairs of neurons, provided results that more consistently agreed with the consensus neural assemblies across all methods (see Box 1). Each assembly could then be considered it's own neuronal graph for further analysis. This techniques illustrates that there may be many other future roles of graph theory in studying microscopic, functional networks of neurons.
Box 1. Similarity Graph Clustering for the Extraction of Neuronal Graphs.
Spectral Graph Clustering is a recently developed approach that uses powerful graph theory techniques to separate assemblies of neurons with temporally correlated activity. The technique was proposed in Avitan et al. (2017) but, briefly, comprises the following steps:
1. Segment neurons and calculate calcium fluorescence signal (compared to baseline signal).
2. Convert the calcium fluorescence signal to a binary activity pattern for each neuron, i.e., at frame t neuron n is either active (1) or not (0).
3. Identify frames where high numbers of neurons are active. Each of these frames becomes the node of a graph.
4. Calculate the cosine-distance between the activity patterns of all pairs of frames. Edges of the above graph represent this distance metric.
5. Use spectral clustering, a well-developed graph theory method that is beyond the scope of this paper, to extract the “community structure” of this graph using statistical inference to estimate the number of communities, i.e., assemblies.
6. Reject certain activity patterns and communities as noise.
7. Each neural assembly is then the average activity of all frames that belong to any kept assembly (detected community).
For the purposes of this work a “neuronal graph” refers to any graph where nodes represent neurons and edges represent some measure of functional relation between pairs of neurons.
It is worth mentioning that analysing large neuronal graphs is computationally challenging and can be very noisy for further analysis. As such, there is a large body of calcium imaging literature that groups neurons into regions of interest and using graph theory on these mesoscopic, functional networks (e.g., Betzel, 2020; Constantin et al., 2020; Vanwalleghem et al., 2020). Certain assumptions and analyses will differ between these graphs and true neuronal graphs and these assumptions will relate to how the mesoscopic networks are created, e.g., region of interest size as discussed in Dingle et al. (2020).
4. Graph Theory Metrics
Once a graph has been extracted from the imaging data then a variety of metrics can be used to explore the organisation of the network. Graph theory provides us with a range of well-defined mathematical metrics that can quantify how a graph is organised, how this evolves through time, and how the graph structure contributes to the flow of information through the network. Changes in metrics of neuronal graphs indicate changes in the functional organisation of a system. Such organisational changes may not be obvious when considering only population statistics of the system. In this section, we will define some of the more commonly used graph theory metrics and their relation to neuronal graphs; we will also signpost possible pitfalls for those new to interpreting graphs.
4.1. Node Degree
One of the most frequently used and easily interpretable metrics is the degree of a node. A node's degree is simply the number of edges connected to it (Newman, 2010). For a directed graph, a node will have both an “in” and an “out” degree which can be calculated separately or summed together to give the total degree. Often the degree of node i ∈ V is denoted by ki and for a simple graph with NV nodes, the degree in terms of an adjacency matrix A can be calculated as:
Although a simplistic metric, the graph degree alone can provide significant information about a graph. As an example of this, comparing the two unweighted graphs in Figures 4A,C, highlights that although both graphs have the same number of nodes, the mean degree of each graph is significantly different, with the higher mean degree of Figure 4C indicating that this graph is much more densely connected than Figure 4A.
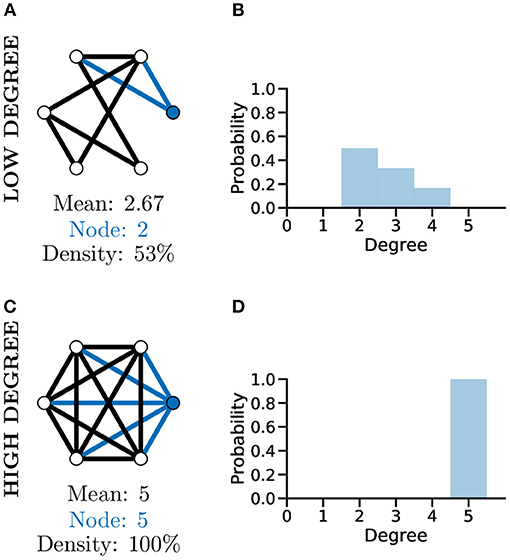
Figure 4. Graph degree, degree distribution, and density all reveal information about how connected the nodes of a graph are. More connected graphs may represent fast flow of information in a network. A not well connected graph (A) with low density and thus low mean degree and individual node degree as shown by the degree distribution (B). A “complete,” i.e., very well-connected, graph (C) with 100% density and thus high mean and node degree and a different degree distribution (D, c.f. B).
To further analyse the structure of complex graphs, the distribution of degree values is frequently used (see Figures 4B,D). The degree distribution is used to calculate the probability that a randomly selected node will have a certain degree value. It provides a natural overview of connectivity within a graph and is often plotted as a histogram with a bin size of one (Newman, 2003). In Figure 4D for example, studying the degree distribution alone would inform us that the associated graph is fully connected, known as a complete graph.
Another metric producing a single score indicating how connected nodes are within a graph is that of density. Graph density measures the number of existing edges within a graph vs. the total number of possible edges, e.g., Figures 4A,C, where the density score of 100% informs us the graph has all nodes connected to all other nodes. The interpretation of degree distribution is also important, particularly in relation to scale-free networks (see section below).
The degree of a graph has been used as a measure of the number of functional connections between neurons and used to quantify network properties in cell cultures (Smedler et al., 2014) and in vivo (Avitan et al., 2017; Burgstaller et al., 2019; Khakhalin, 2019). It's common to use the mean degree of a neuronal graph, which represents a measure of overall connectivity for a system (Avitan et al., 2017). Throughout the development of the zebrafish optic tectum the degree of the representing neuronal graphs increases during development to a mid-development peak followed by a slight decreased toward the end of development indicating that neuronal systems go through different phases of reorganisation during development (Avitan et al., 2017).
4.2. Paths in Graphs
Another common set of graph metrics to consider revolve around the concept of a path in a graph. A path is a route from one node to another through the graph, in such a way that every pair of nodes along the path are adjacent to one another. A path which contains no repeated vertices is known as a simple path. A graph for which there exists a path between every pair of nodes is considered a connected graph (Kolaczyk, 2009), which can be seen clearly in Figure 4C. Often there are many possible paths between two nodes, in which case the shortest possible path, which is the minimum number of edges needing to be traversed to connect two nodes, is often an interesting metric to consider (Bodwin, 2019). This concept is highlighted in Figures 5A,B which both illustrate paths between the same two nodes within the graph, where the first is a random path and the second is the shortest possible path.
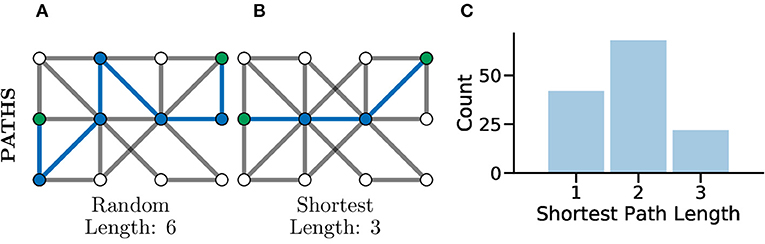
Figure 5. Paths, and especially shortest paths, in graphs give an idea of efficiency of flow or information transfer. Graphs with shorter average paths between nodes may represent networks with very efficient information transfer. (A) An example random path through a graph between the two green nodes. This is not the shortest path but just one of many potential paths. (B) An example shortest path between the same green nodes, there are multiple routes of the same shortest length, between the same two nodes in the same graph. This path represents one of the most efficient routes for information flow in a graph. (C) The distribution of shortest path lengths across all pairs of nodes in a graph can give an idea of flow efficiency in a network. A left-shifted distribution might be expected within connected brain network where neurons may be connected in a highly compact and efficient fashion for fast information processing.
In Avitan et al. (2017), the authors relate the length of a path to the potential for functional integration between two nodes. The shorter the path, the greater the potential for functional integration, i.e., a shorter average path length implies that information can be more efficiently shared across the whole network. In turn, the potential for functional integration is closely linked with efficiency communication between nodes, i.e., shorter paths between nodes indicate a smaller number of functional pathways between neurons and thus more efficient communication between neurons (Figure 5C). Although it should be noted that this being universally true has been disputed in the literature, with evidence that some information taking longer paths to retrain the correct information modality (Fornito and Bullmore, 2015).
4.2.1. Characteristic Path Length
Linked to the shortest path is the characteristic path length (CPL) or average shortest path length of a graph, as used in Burgstaller et al. (2019). The CPL is calculated by first computing the average shortest distance for all nodes to all other nodes, then taking the mean of the resulting values:
where dist is the shortest path between node i and j. The CPL represents a measure of functional integration in a neuronal graph: a lower CPL represents short functional paths throughout the network and thus improved potential for integration and parallel processing cross the graph.
4.2.2. Global Graph Efficiency
In Avitan et al. (2017), the authors use a different but related metric—global graph efficiency. Global graph efficiency again draws on the shortest path concept, and allows for a measure on how efficiently information can flow within an entire graph (Latora and Marchiori, 2001; Ek et al., 2015). It can also be used to identify the presence of small-world behaviour in the graph (see below). This metric has seen many interesting real world applications in the study of the human brain, as well as many other areas (e.g., Honey et al., 2007).
Global graph efficiency EG can be defined as:
where dist is the shortest path between node i and j.
A key benefit of using EG is that it is bounded between zero and 1, making it numerically simpler to compare between graphs.
4.3. Node Centrality
There are many use cases for which it would be beneficial to measure the relative importance of a given node within the overall graph structure, e.g., to identify key neurons in a neuronal circuit or assembly. One such way of measuring this is node centrality, within which there are numerous methods proposed in the literature which measure different aspects of topological structure, i.e., the underlying graph structure. Some of these methods originate in the study of web and social networks, with the PageRank algorithm being a famous example as it formed a key part of the early Google search algorithm (Page et al., 1999). In addition to this, some of the other frequently used centrality measures include Degree, Eigenvector, Closeness and Betweenness (Klein, 2010).
We will explore Closeness and Betweenness centrality in greater detail. Closeness centrality computes a node's importance by measuring its average “distance” to all other nodes in the graph, where the shortest path between two nodes is used as the distance metric. So for a given node i ∈ V from G(V, E), its Closeness centrality would be given as
where dist is the shortest path between i and j. This is visualised in Figure 6A, where the two nodes in the dark blue colour have the highest Closeness centrality score as they posses the lowest overall average shortest path length to the other nodes.
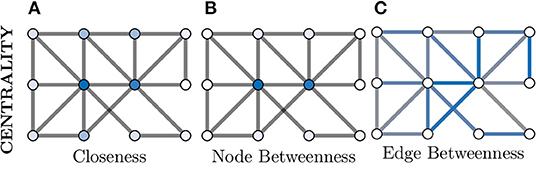
Figure 6. Centrality measures indicate the relative importance of a node within a graph. There are a great number of centrality metrics that make different assumptions and provide different insights, here we provide two example metrics. (A) Closeness centrality gives a relative importance based on the average shortest path between a node and all other nodes. The smaller the average the more important the node (darker blue) and vice versa (whiter). (B) Betweenness centrality is similar but considers how many shortest paths must pass through a node and, in this example, clearly separates the central two nodes (dark blue) as much more important than the other nodes (which appear white). (C) Centrality can also be applied to edges instead of nodes; here more blue indicates a more central role in information flow for an edge.
Additionally, Figures 6B,C demonstrates both node and edge Betweenness centrality measures respectively. Betweenness centrality exploits the concept of shortest paths (discussed earlier) to argue that nodes through which a greater volume of shortest paths pass through, are of greater importance in the graph (Freeman, 1977). Therefore, nodes with a high value of Betweenness centrality can be seen as controlling the information flow between other nodes in the graph. Edge Betweenness is a measure, which analogous to its node counterpart, counts the number of shortest paths which travel along each edge (Newman, 2010).
4.4. Graph Motifs
A more complex measure of graph local topology is that of a motif, a small and reoccurring local pattern of connectivity between nodes in a graph. It is argued that one can consider these motifs to be the building block of more complex patterns of connectivity within graphs (Shen-Orr et al., 2002). Indeed, the type and frequency of certain motifs (Figure 7C) can even be used for tasks such as graph comparison (Milenković and Pržulj, 2008) and graph classification (Huan et al., 2003).
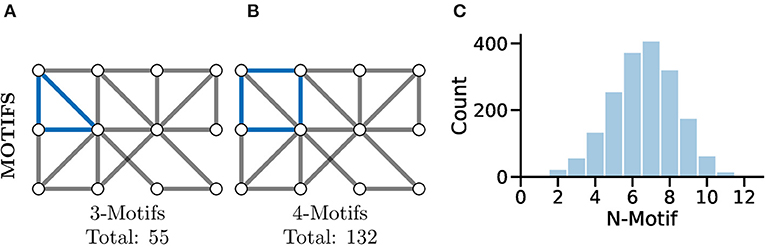
Figure 7. Motifs represent repeating highly-localised topological patterns in the graph; remember, here “local” refers to directly connected nodes in the graph and not, necessarily, physically located neurons. (A) An example 3-motif in blue; there are a total of 55 3-motifs in this graph. (B) An equivalent 4-motif in blue; there are 132 4-motifs in this graph. (C) Histograms of graph motif counts can be used to create a signature or fingerprint for graphs that can then be compared between cases. Here, we see the histogram of all n-motifs in the graph used for (A,B).
Perhaps the most fundamental motif is that of the triangle (see Figure 7A), a series of three nodes where an edge is present between all the nodes. A similar motif comprised of four nodes is highlighted in Figure 7B. The study of motifs in graphs has proved popular in fMRI studies where distributions of motifs have been used to separate clinical cases (e.g., Jiao et al., 2014; Morgan et al., 2018).
In Wanner and Friedrich (2020), the authors used motif analysis in a directed representation of mitral cell and interneuron functional connectivity in the olfactory bulb of zebrafish larvae. They found that motifs with reciprocal edges were over-represented and mediate inhibition between neurons with similar tuning. The resultant suppression of redundancy, inferred from theoretical models and tested through selective manipulations of simulations, was necessary and sufficient to reproduce a fundamental computation known as “whitening.”
4.5. Graph Clustering Coefficient
A further measure of local connectivity within a graph is that of the clustering coefficient. At the level of individual nodes, the clustering coefficient gives a measure of how connected that node's neighbourhood is within itself. For example, in Figure 8B, the nodes coloured in white have a low local clustering coefficient as their neighbourhoods are not densely connected. More concretely, for a given node v, the clustering coefficient determines the fraction of one-hop neighbours of v which are themselves connected via an edge,
where triplets refers to all possible combinations of three of neighbours of v, both open and closed (Newman, 2010). An example of a closed and open triplet in a graph is illustrated in Figure 8A.
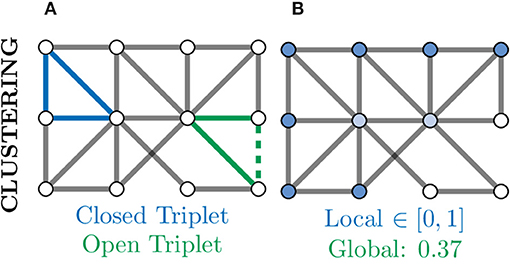
Figure 8. Clustering provides another measure of connectivity and structure in a graph based on how nodes are locally connected; remember, here “local” refers to directly connected nodes in the graph and not, necessarily, physically located neurons. (A) Based the number of closed (blue) and open (green) triplets, the clustering coefficient can be calculated locally for every node. (B) Local clustering coefficients for nodes range from zero (white) to one (blue) and may vary a lot from the global (mean) clustering coefficient. Nodes with a high clustering coefficient may be involved in general aspects of information transfer and thus form an apex for clustering.
To produce a single metric representing the overall level of connectivity within a graph, the global clustering coefficient is used CG. This is simply the mean local clustering coefficient over all nodes and can be computed as:
Clustering of a neuronal graph can be used to show differences in the functional organisation of network with graphs of high average clustering coefficient thought to be better at local information integration and robust to disruption. For example, Burgstaller et al. (2019) showed that the clustering coefficient of whole-brain graphs in wild type fish and a depression-like mutant (grs357) differ and, importantly this can be restored with the application of anti-depressant drugs. This change in local connectivity imply that depression increases local brain segregation reducing local information transfer efficiency.
4.6. Graph Communities
Community detection in graphs is a large area of interest within the literature and could be an entire review within itself. As such, we will outline the major concepts here and direct interested readers toward more in-depth reviews on community detection such as Fortunato (2010) and Yang et al. (2016).
Fundamentally, one can view communities as partitions or clusters of nodes within a graph, where the clusters typically contain densely connected nodes, with a few sparse inter-community links also being present. These global communities differ from the local, more pattern-focussed, graph motifs previously discussed. Community structures relate to specialisations within networks, e.g., a social media graph might see community structures relating to shared hobbies or interests. In graphs of brains, high-levels of community structure could indicate functional specialisation (Bullmore and Sporns, 2009).
Community detection algorithms can broadly be split into those which produce overlapping communities and those that result in non-overlapping communities (Ding et al., 2016). In a non-overlapping community each node belongs to only one community and, as such, could be used to separate a neuronal graph into distinct regions, e.g., regions of the brain or layers of the tectum. This is demonstrated in Figure 9A, where nodes in the graph belong to exactly one community. In an overlapping community, nodes may belong to multiple communities and, as such, could be used to identify neural circuits or assemblies where neurons may contribute to multiple pathways (Xie et al., 2013). This can be seen in Figure 9B, where the nodes coloured in black belong to both communities.
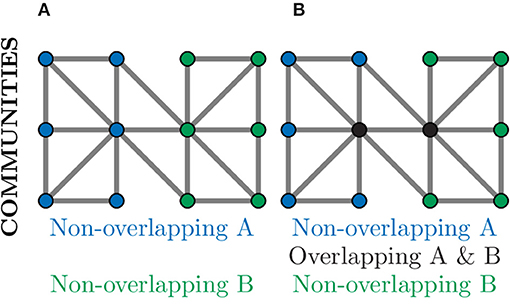
Figure 9. Community detection provides global clustering that can be either non-overlapping or overlapping depending on the algorithm used. (A) Non-overlapping communities assign each node to a community (blue or green) based on the choice of metric, often relating to number of connections. Such community detection algorithms could identify physical regions of the brain. (B) Over-lapping communities can assign a node to more than one community (black nodes) if they contribute to multiple communities. Such community detection algorithms could identify communication pathways through a network.
One of the most frequently used approaches for non-overlapping community detection in graphs is that of spectral clustering (Wang and Davidson, 2010). Here the eigenvectors and eigenvalues of the graph Laplacian matrix are used to detect connectivity based communities. The distribution of eigenvalues is indicative of the total number of clusters within the graph, and the eigenvectors indicate how to partition the nodes into their respective clusters (Nascimento and De Carvalho, 2011).
Many approaches for determining communities exploit the concept of modularity to produce their results (Devi and Poovammal, 2016). As this concept is frequently explored in conjunction with biological networks, it is explored in greater depth in the following section.
4.6.1. Graph Modularity
Strongly linked to the concept of measuring community structure within a graph, is the idea of modularity. The modularity of a graph is a more fundamental measure of the strength of interconnectivity between communities (or modules as they are commonly known in the modularity literature) of nodes (Newman, 2006). Whilst there are different measures of modularity, the majority of them aim to partition a graph in such a way that the intra-community edges are maximised, whilst the number of inter-community edges are minimised (Bordier et al., 2017). Interestingly, it has been observed that many biological networks, including networks taken from animal brains, display a high degree of modularity (Hartwell et al., 1999), perhaps indicative of functional circuits of neurons within the brain.
Modules in a graph confer robustness to networks whilst allowing for specialised processing. In the mouse auditory cortex it has been shown that neuronal graphs exhibit hierarchically modular structures (Betzel et al., 2019).
In zebrafish, brains of “depressed” fish (grs357 mutants) show an increased modularity compared to wild-type, which could be restored with anti-depressant drugs (Burgstaller et al., 2019). The combination of reduced clustering coefficient (see above) but increased modularity implies that, functionally, the brain is much less structured and organised in the disease case with more isolated communities of networks and reduced long-range communication. In Khakhalin (2019), the author used modularity, amongst other metrics, to compare looming-selective networks in the Xenopus tectum through development and with a range of computational models.
By using spectral clustering and maximising a modularity metric it is also possible to extract ensembles of strongly connections neurons, i.e., neuronal subgraphs. In Khakhalin (2019), the author did this for neurons in the optic tectum of xenopus tadpoles responding to looming stimuli. They showed that although the number of neuronal subgraphs did not significantly vary at different developmental stages, these neuronal subgraphs were spatially localised and became more distinct throughout development. This shows reorganisation and refinement of looming-selective neuronal subgraphs within the optic tectum, possibly representing the weakening of functional connections not required for this type of neural computation.
4.7. One Metric to Rule Them All?
Many of these commonly used metrics relate to “clustering,” “connectivity,” and “organisation” of the graph structure. One question the reader might ask, is “If there are so many measures of connectivity, which one do I pick?” or, later in the analysis process, “Why do different clustering/community algorithms give me markedly different results?” In truth, a change in one particular metric could be due to a variety of changes in the underlying graph (Cheng et al., 2019). As such, the answer to both of those questions depends on the hypothesis, experiment and assumptions for that particular scenario.
Scientists who are interested in exploring neuronal graphs for calcium imaging are in luck—not only is there a large body of technical mathematical literature on the subject of graphs (e.g., Newman, 2018), but there is also a significant body of more accessible, applied graph theory literature (see Fornito et al., 2016; Vecchio et al., 2017; Sporns, 2018; Farahani et al., 2019 for neuroscience-related reviews). This applied literature relates the mathematical graph theory concepts to specific real world features of networks; however, it is important to remember that these real world meanings may not map one-to-one to the biology behind neuronal graphs, even from as closely a related field as fMRI studies.
In fact, making links between graph theory analysis and real-world biological meaning requires considerable understanding of both the mathematics, experiment and neuroscience.
There are two ways the community can address this problem:
1. By working closely with graph theorists on projects to develop modified-algorithms that probe specific hypotheses and/or utilise a priori biological knowledge to reveal new information, and
2. By embedding graph theory and network science experts into groups developing and using calcium imaging techniques.
Both of these approaches create an ongoing dialogue that ensures the appropriate approaches are used and that no underlying assumptions are broken.
Additionally, many of these metrics are best used in a comparative fashion with other real experiments or with in silico controls, i.e., computationally created networks lacking true, information processing organisation.
5. Graph Models of Neurons
Exploiting graph theory to analyse neuronal graphs enables quantitative comparison between different sample groups, e.g., drug vs. no drug, by comparing metrics between graphs. Probabilistic modelling of random graphs also enables the comparison of real world neuronal graphs to an in silico control. In silico controls allow scientists to compare neuronal graphs with random graphs that have similar properties, e.g., edge, degree distribution, etc., but lack any controlled organisation. Such comparisons can be used to (a) confirm that properties of neuronal graphs are statistically significant; (b) provide a baseline from which different experiments can be compared; and (c) be used to guide the formation on new computational models that lead to a better understanding of neural mechanisms of computation (e.g., Schroeder et al., 2019).
Comparisons between the topological structure of random graphs and real graphs has been used in the study of many complex networks across diverse disciplines. In this section, we will introduce three well-established random graph models, which all display different topological structures and thus have different uses and limitations.
5.1. Random Networks—The Erdös-Rényi Model
In the Erdös-Rényi (ER) model (Erdös and Rényi, 1959; Gilbert, 1959), a graph G with NV nodes is constructed by connecting pairs of nodes, e.g., {u, v}, randomly with probability p. The creation of every edge, Eu,v, is independent from all other edges, i.e., each edge is randomly added regardless of other edges that have or have not been created (Figure 10A).
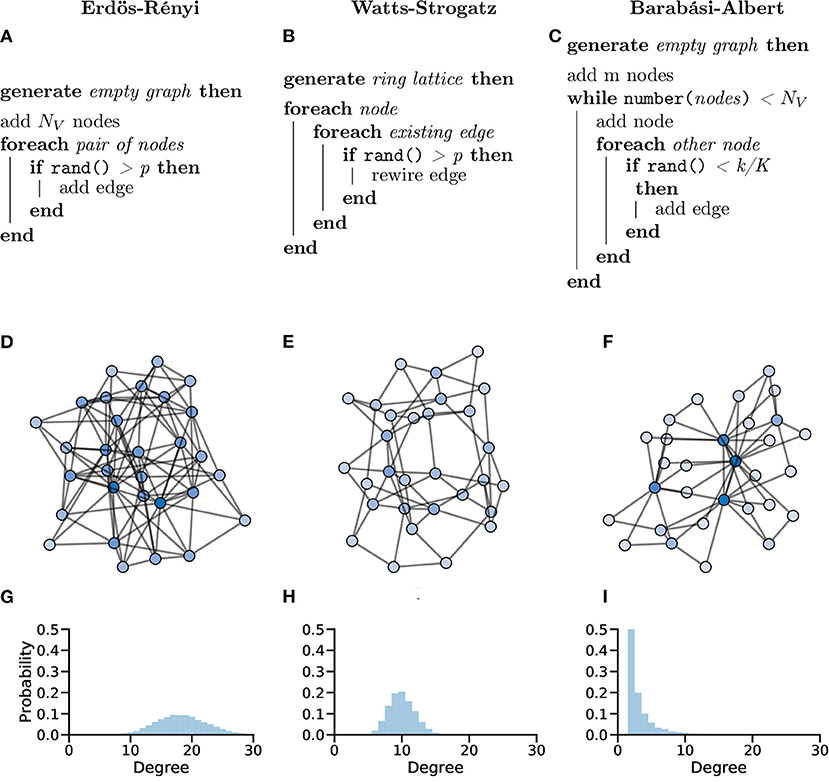
Figure 10. Random graphs, which can be used as in silico models or controls, can be generated in different ways giving the graphs different properties. Pseudocode showing the processes used to create Erdös-Rényi (A), Watts-Strogatz (B) and Barabási-Albert (C) model graphs. (D–F) Example graphs with NV = 30 showing clearly different organisations for different generation models. (G–I) Probability distributions of node degree over graphs generated with NV = 10, 000 showing lower average degree and increased tails in both the Watts-Strogatz (H) and Barabási-Albert (I) models.
The ER model generate homogenous, random graphs (Figure 10D); however, they assume that edges are independent, which is not true in biological systems. Unlike neuronal graphs, ER graphs do not display local clustering of nodes nor do they show small-world properties seen in many real-world and biological systems, as shown in the zebrafish (Avitan et al., 2017; Burgstaller et al., 2019; Figure 10G).
In fMRI data, ER graphs and functional brain networks have been compared using graph metrics and modelled temporal dynamics. Bayrak et al. (2016) showed that functional brain networks from fMRI show different topological properties to density-matched ER graphs. Further, they showed that modelling BOLD activity on both real and ER graphs showed dissimilar results, indicating the importance of network organisation on dynamic signalling. Thus ER graphs are good random graphs but don't accurately represent many graphs found in the real world (Leskovec et al., 2005).
5.2. Small-World Networks—The Watts-Strogatz Model
The Watts-Strogatz (WS) model (Watts and Strogatz, 1998) was designed to generate random graphs whilst accounting for, and replicating, features seen in real-world systems. Specifically, the WS model was designed to maintain the low average shortest path lengths of the ER model whilst increasing local clustering coefficient (compared to the ER model).
In the WS model, a ring lattice graph G (An example of such a graph is highlighted in Figure 11) with NV nodes, where each node is connected to its k nearest neighbour nodes only, is generated. For each node, each of it's existing edges is rewired (randomly) with probability β (Figure 10B).
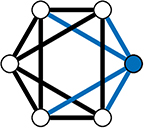
Figure 11. A 4-Regular Ring Lattice on a 6 node graph. The blue edges connected to node 1 show why this graph is 4-regular graph—all nodes have exactly 4 edges connecting them to their 4 closet neighbours.
WS graphs are heterogeneous and vary in randomness, based on parameters, usually with high modularity (Figure 10E). WS graphs show “small-world” properties, where nodes that are not neighbours are connected by a short path (c.f. Six Degrees of Kevin Bacon, Figure 10H).
Many real networks show small-world topologies. In neuroscience, small-world networks are an attractive model as their local clustering allows for highly localised processing while their low average shortest path lengths also allows for distributed processing (Bassett and Bullmore, 2016). This balance of local and distributed information processing allows small-world networks to be highly efficient for minimal wiring cost.
5.2.1. Measuring Small-Worldness
It is possible to measure how “small-world” a graph is by comparing the graph clustering and path lengths of that graph to that of an equivalent but randomly generated graph. Most simply one can calculate the small-coefficient σ (also known as the small-world quotient, Davis et al., 2003; Uzzi and Spiro, 2005),
where C and l are the clustering coefficient and average shortest path length of graph G and random graph R (Kogut and Walker, 2001). Graphs where σ > 1 are small-world. However, the small-coefficient is influenced by the size of the graph in question (Neal, 2017). Because of this, the small-coefficient is not good for comparing different graphs.
Alternatively, one can use the small-world measures ω or ω′, the latter of which provides a measure between 0 and 1. A 0 small-world measure indicates a graph is as “unsmall-worldly” as can be (given the graph size, degree, etc.), whereas 1 indicates a graph is as small-worldly as possible. The small world measure relates the properties of graph G to an equivalent lattice graph ℓ (completely ordered and non-random) and random graph R (Telesford et al., 2011),
The small-world measure is good for comparing two graphs with similar properties; however, the range of results depends on other constraints on the graph, e.g., density, degree distribution and more, and so two graphs that differ on these constraints may both have ω′ = 1 but may not be equally close to a theoretical ideal of a small world network (Neal, 2017).
An alternative measure was proposed by Neal (2015)—the small world index (SWI), defined as
Like ω, SWI ranges between 0 and 1 where 1 indicates a graph with theoretically ideal small-world characteristics given other constraints on the graph (as with ω above). Of these three metrics the SWI most closely matches the WS definition of a small-world graph.
A similar metric, the small world propensity, was proposed by Muldoon et al. (2016), defined as
where and . Both ΔC and Δℓ are bounded between 0 and 1.
Like the SWI, ϕ ranges between 0 and 1 where 1 indicates a graph with high small-world characteristics. The small world propensity was designed to provide an unbiased assessment of small world structure in brain networks regardless of graph density. The small world propensity can be extended for weighted graphs and both the weighted and unweighted variants can be used to generate model graphs.
Due to the computational constraints of large, whole-brain networks, a simplified version of small-worldliness was measured in Burgstaller et al. (2019), where the authors showed a significant difference in small-worldliness in brains of wild-type and “depressed” zebrafish (grs357 mutants) exposed to different antidepressant drugs.
It's worth noting that Muldoon et al. (2016) showed that the weighted whole-C. elegans neuronal graph did not show a high small-world propensity. The authors argue that this could be as the whole-animal neuronal graph does not just represent the head and that the organism is evolutionary simple compared to other model organisms. The authors recommend stringent examination of small-world feature across scale, physiology and evolutionary scales.
5.3. Scale-Free Networks—The Barabási-Albert Model
As the average shortest path length becomes smaller these small-world networks can begin to show scale-free properties. In a scale-free network, the degree distribution follows a power law, i.e., P(k) ~ k−γ. Scale-free networks have a small number of very connected nodes (large degree) and a large number of less connected nodes (small degree), creating a long right-tailed degree distribution (Clauset et al., 2009; Figure 10I).
The Barabási-Albert (BA) model (Albert and Barabási, 2002) was designed to generate random graphs with a scale-free (power-law) degree distribution. Specifically, the BA model incorporates a preferential attachment mechanism to generate graphs that share properties with many real-world networks, possibly including networks of neurons (Smedler et al., 2014; Avitan et al., 2017; Figure 10C).
In the BA model, a small graph of m nodes is created. Nodes are then added one at a time until the total number of nodes NV is reached. After each new node is added, an edge is created between the new node and an existing node i with probability ki/Σk, i.e., new edges are preferentially created with existing nodes with high degree (ki).
BA graphs are heterogeneous, with a small number of nodes having a relatively high number of connections (high degree), whilst the majority of nodes have a low degree. This process naturally results in a high clustering coefficients and hub-like nodes (Figure 10F).
In Avitan et al. (2017), the authors suggest that the network topology in the zebrafish optic tectum is scale-free and show that the degree distribution fits a power law. In their research, neural assemblies in the optic tectum stay scale-free throughout development and despite other changes in network topology due to dark-rearing.
Scale-free topologies have been used to predict the existence of hub nodes in neuronal assemblies of the hippocampus in mice and rats (Bonifazi et al., 2009). They showed hippocampal neuronal networks to follow a scale-free topology and demonstrated the existence of hub neurons that, using morphophysiological analyses, proved to be GABAergic interneurons.
However, there is a growing body of evidence that this type of graph is less common in real world systems (Broido and Clauset, 2019). Indeed, changing the threshold used to generate a neuronal graph can influence the degree distribution significantly, as shown in zebrafish whole-brain calcium imaging (Burgstaller et al., 2019) and neuronal cell cultures (Smedler et al., 2014). We would like to suggest caution in the interpretation of graphs as scale-free and suggest researchers follow the rigorous protocols suggested by Broido and Clauset (2019).
5.3.1. A Critique of Scale-Free Graphs
Before moving onto the identification of scale-free networks, it is worth considering the cautionary tales present in recent literature. Since the original observations made by Barabási that many empirical networks demonstrate scale-free degree distributions (Barabási and Albert, 1999), numerous other researchers have also measured the property in everything from citation to road networks (Kalapala et al., 2006).
However, there has been a growing body of work demonstrating that the scale-free property might not be as prevalent in the real world as first imagined. For example, work by Broido and Clauset (2019) has shown that in nearly one thousand empirical network datasets, constructed from data across a broad range of scientific disciplines, only a tiny fraction are actually scale-free (when using a strict definition of the property). The paper calls into question the universality of the scale-free topologies, with biological networks being one of the network classes to display the least number of scale-free examples. These ideas are not new, and earlier work has also argued against the prevalence of scale-free networks in the real world (Jones and Handcock, 2003). Conversely it has also been argued that the concept of scale-free networks can still be useful, even in light of these new discoveries (Holme, 2019).
As such, the question of how to recognise data that obeys a power law is a tricky one. Box 2 summarises the statistically rigorous process recommended by Clauset et al. (2009) for the case of a graph with degree distribution that may or may not follow a power law.
Box 2. Identifying Scale-Free Graphs.
The question of how to recognise data that obeys a power law is a tricky one. A statistically rigorous set of statistical techniques was proposed by Clauset et al. (2009), in which they also showed a number of real world data that had been miss-ascribed as scale-free.
1. First, we define our model degree distribution as,
We then estimate the power law model parameters α and kmin. kmin is the minimum number degree for which the power law applies and α is the scaling parameter. Data that follows an ideal power law across the whole domain will have kmin = 1.
2. In order to determine the lower bound kmin we compare the real data with the model above kmin using the Kolmogorov-Smirnov (KV) statistic. To calculate exactly the scaling parameter α we can use discrete maximum likelihood estimators. However, for ease of evaluation we can also approximate α where a discrete distribution, like degree distribution, is treated as a continuous distribution rounded to the nearest integer.
3. Next we calculate the goodness-of-fit between the data and the model. This is achieved by generating the a large number of synthetic datasets that follow the determined power law model. We then measure the KV statistic between the model and our synthetic data and compare this to the KV statistic between the model and our real data. The p-value is then the fraction of times that KVsynthetic is greater than KVreal. A p-value above 0.1 indicates that the power law is plausible, whilst a value below p below 0.1 indicates that the model should be rejected.
4. Finally, we compare the data to other models, e.g., exponential, Poisson or Yule distributions through likelihood ratio tests; techniques such as cross-validation or Bayesian approaches could also be used.
5.4. Machine Learning Generated Networks
The recent advances in machine learning on graphs, specifically the family of Graph Neural Network (GNN) models (Hamilton et al., 2017), has resulted in new methods for generating random graphs based on a set of input training graphs. Whilst there have, thus far, been limited possibilities for applications in biology, we briefly review some of the more prominent approaches and encourage readers to investigate further.
A family of neural-based generative models entitled auto-encoders have been adapted to generate random graphs. Auto-encoders are a type of artificial neural network which learn a low dimensional representation of input data, which is used to then reconstruct the original data (Hinton and Salakhutdinov, 2006). They are frequently combined with techniques from variational inference to create Variational Auto-Encoders (VAE), which improves the reconstruction and interpretability of the model (Kingma and Welling, 2014). Recent graph generation approaches, such as GraphVAE (Simonovsky and Komodakis, 2018), Junction Tree VAE (Jin et al., 2018), and others (Ma et al., 2018; Zhang et al., 2019), all produce a model which is trained on a given set of input graphs and can then generate random synthetic examples which have a similar topological structure to the input set.
Using an alternative approach and underlying model, GraphRNN (You et al., 2018) exploits Recurrent Neural Networks (RNN), a type of model designed for sequential tasks (Hochreiter and Schmidhuber, 1997), for graph generation. GraphRNN again learns to produce graphs matching the topologies of a set of input graphs, but this time by learning to decompose the graph generation problem into a sequence of node and edge placements.
6. Graph Analysis Tools
There are a wide range of tools for visualising and quantifying graphs. In this section, we briefly introduce a few open-source projects that may be useful for researchers who wish to explore graph theory in their work.
First, it's important to understand the possible challenges that one might face dealing with large graphs of complex data. Consider a zebrafish whole-brain calcium imaging experiment, one dataset might contain up to 100.000 neurons, so a graph of the whole brain would have 100.000 nodes. If a graph was then created with weighted edges between all nodes (a total of 10,000,000,000 edges) then the adjacency matrix alone, i.e., without any additional information such as position in the brain, would take 80 GB. Graph visualisation or analysis tools may require the loading of all or most of this data in the computer memory (RAM), thus a powerful computer is required.
This problem may be overcome by considering a subset of nodes or of edges, and many tasks can be programmed to account for memory or processing concerns.
6.1. Graph Visualisation and Analysis Software
Graph visualisation (or graph drawing) has been a large area of research in it's own right and a wide range of software and programming packages exist for calculating graph layouts and visualising massive graph data.
Two notable open-source tools are Cytoscape (Shannon et al., 2003) and Gephi (Bastian et al., 2009). Cytoscape was designed for visualising molecular networks in omics studies. Cytoscape has a wide range of visualisation tools including fast rendering and easy live navigating of large graphs. Plug-ins are available to enable graph filtering, identification of clusters, and other tasks.
Gephi is designed for a more general audience and has been used in research from social networks through digital humanities and in journalism. Like Cytoscape, Gephi is able to carry out real-time visualisation and exploration of large graphs, and has built-in tools to calculate a variety of metrics. Gephi is also supported by community-built plug-ins.
6.2. Programming With Graphs
In many cases it may be beneficial to work with neuronal graphs within existing pipelines and programming environments. There are many tools available for different programming languages that provide graph visualisation and analysis functions. Several notable Python modules exist that are open-source, are well-documented and easy to use.
NetworkX (Hagberg et al., 2008) is perhaps the most well-known and has a more gentle learning curve than the others. Many of the metrics we've described in this paper are built-in to NetworkX, along with a variety input/output options, visualisation tools and random graph generators. Importantly, NetworkX is well-documented and still in active development. However, NetworkX is designed, primarily, for small graphs and the many-edged, massive nature of some neuronal graphs may prove a challenge.
Other well-documented Python modules for the analysis of massive graphs are graph-tool (Peixoto, 2017) and NetworKit (Staudt et al., 2016). Aware of the computational challenges of processing large graphs, graph-tool makes use of the increased performance available by using algorithms implemented in C++ however, they keep the usability of a Python front-end. Similarly, NetworKit uses a combination of C++, parallelisation and heuristic algorithms to deal with computational expensive problems in a fast and parallel manner. Lastly, iGraph (Csardi and Nepusz, 2006) provides a collection of network analysis tools available in Python, Mathematica, R and C with an emphasis on analysing large graphs. As such, all of these packages can provide an alternative (or complement) to NetworkX for analysing and visualising large graphs in Python.
However, as graphs continue to grow in both complexity and size, there is an increasing need to scale graph computation from one machine to many. Parallel computation packages, such as Apache Spark (Zaharia et al., 2012), have greatly reduced many of the complexities traditionally associated with parallel programming, whilst also offering a python interface for ease of use. Apache Spark offers a selection of graph specific frameworks, such as GraphX (Gonzalez et al., 2014) and GraphFrames (Dave et al., 2016), which include implicit algorithms to extract many of the metrics discussed in the metrics section in parallel across a compute cluster. Unfortunately, for any metric not included by default, one must be coded in accordance with Spark's parallel programming model, still a non-trivial task.
Additionally, exploiting GPU technologies may bring massive changes in the speed of processing and the maximum graph sizes that can be handled. Again, these currently require custom algorithms; however, recently a new package has been released that begin to address this problem - Rapids cuGraph (RAPIDS Team, 2018).
7. Concluding Remarks
We hope that the reader can see the power of using neuronal graphs to explore network organisation as opposed to considering only population statistics. In particular we hope that the reader appreciates that the metrics presented in this paper are only the tip of the iceberg and that any interested researcher should identify and build collaborations with graph theorists and network scientists to ensure that the right metric is used to answer the question of interest (see Vicens and Bourne, 2007; Knapp et al., 2015 for best practice). Further, we hope the reader recognises that, with the use of graph models, it is possible to compare against in silico controls for null hypothesis testing in order to ensure robust and statistically rigorous conclusions are drawn. We greatly look forward to the coming years and seeing more and novel applications of graph theory in calcium imaging, and can see neuronal graphs becoming a powerful tool that helps to both answer biological questions and pose new biological hypotheses. We strongly predict that graph theory analysis on calcium imaging will lead to important new insights that allow neuroscientists to understand and model computational networks.
Author Contributions
CN conceived the idea for this instructive review. CN and SB contributed equally to the writing of this paper. All authors contributed to the article and approved the submitted version.
Funding
During this work, CN received funding by the EPSRC (EPSRC Doctoral Prize Research Fellowship EP/N509668/1).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Ahrens, M. B., Orger, M. B., Robson, D. N., Li, J. M., and Keller, P. J. (2013). Whole-brain functional imaging at cellular resolution using light-sheet microscopy. Nat. Methods 10, 413–420. doi: 10.1038/nmeth.2434
Albert, R., and Barabási, A.-L. (2002). Statistical mechanics of complex networks. Rev. Modern Phys. 74, 47–97. doi: 10.1103/RevModPhys.74.47
Alivisatos, A. P., Chun, M., Church, G. M., Greenspan, R. J., Roukes, M. L., and Yuste, R. (2012). The brain activity map project and the challenge of functional connectomics. Neuron 74, 970–974. doi: 10.1016/j.neuron.2012.06.006
Avitan, L., Pujic, Z., Mölter, J., Van De Poll, M., Sun, B., Teng, H., et al. (2017). Spontaneous activity in the zebrafish tectum reorganizes over development and is influenced by visual experience. Curr. Biol. 27, 2407.e4–2419.e4. doi: 10.1016/j.cub.2017.06.056
Barabási, A.-L., and Albert, R. (1999). Emergence of scaling in random networks. Science 286, 509–512. doi: 10.1126/science.286.5439.509
Barrat, A., Barthelemy, M., Pastor-Satorras, R., and Vespignani, A. (2004). The architecture of complex weighted networks. Proc. Natl. Acad. Sci. U.S.A. 101, 3747–3752. doi: 10.1073/pnas.0400087101
Bassett, D. S., and Bullmore, E. (2016). Small-world brain networks. Neuroscientist. 23, 499–516. doi: 10.1177/1073858416667720
Bassett, D. S., Zurn, P., and Gold, J. I. (2018). On the nature and use of models in network neuroscience. Nat. Rev. Neurosci. 19:566. doi: 10.1038/s41583-018-0038-8
Bastian, M., Heymann, S., and Jacomy, M. (2009). “Gephi: an open source software for exploring and manipulating networks,” in Third International ICWSM Conference (San Jose, CA) 361–362.
Bayrak, S., Hövel, P., and Vuksanovic, V. (2016). Comparison of functional connectivity between empirical and randomized structural brain networks. PeerJ. doi: 10.7287/peerj.preprints.1784v1
Betzel, R. F. (2020). Organizing principles of whole-brain functional connectivity in zebrafish larvae. Netw. Neurosci. 4, 234–256. doi: 10.1162/netn_a_00121
Betzel, R. F., Wood, K. C., Angeloni, C., Neimark Geffen, M., and Bassett, D. S. (2019). Stability of spontaneous, correlated activity in mouse auditory cortex. PLoS Comput. Biol. 15:e1007360. doi: 10.1371/journal.pcbi.1007360
Bodwin, G. (2019). “On the structure of unique shortest paths in graphs,” in Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms (San Diego, CA: SIAM), 2071–2089. doi: 10.1137/1.9781611975482.125
Bonifazi, P., Goldin, M., Picardo, M. A., Jorquera, I., Cattani, A., Bianconi, G., et al. (2009). Gabaergic hub neurons orchestrate synchrony in developing hippocampal networks. Science 326, 1419–1424. doi: 10.1126/science.1175509
Bordier, C., Nicolini, C., and Bifone, A. (2017). Graph analysis and modularity of brain functional connectivity networks: searching for the optimal threshold. Front. Neurosci. 11:441. doi: 10.3389/fnins.2017.00441
Broido, A. D., and Clauset, A. (2019). Scale-free networks are rare. Nat. Commun. 10, 1–10. doi: 10.1038/s41467-019-08746-5
Bullmore, E., and Sporns, O. (2009). Complex brain networks: graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 10, 186–198. doi: 10.1038/nrn2575
Burgstaller, J., Hindinger, E., Gesierich, B., and Baier, H. (2019). Light-sheet imaging and graph-theoretical analysis of antidepressant action in the larval zebrafish brain network. bioRxiv 618843. doi: 10.1101/618843
Cheng, B., Schlemm, E., Schulz, R., Boenstrup, M., Messé, A., Hilgetag, C., et al. (2019). Altered topology of large-scale structural brain networks in chronic stroke. Brain Commun. 1:fcz020. doi: 10.1093/braincomms/fcz020
Clauset, A., Shalizi, C. R., and Newman, M. E. J. (2009). Power-law distributions in empirical data. SIAM Rev. 51, 661–703. doi: 10.1137/070710111
Constantin, L., Poulsen, R. E., Favre-Bulle, I. A., Taylor, M. A., Sun, B., Goodhill, G. J., et al. (2020). Altered brain-wide auditory networks in fmr1-mutant larval zebrafish. BMC Biol. 18:125. doi: 10.1186/s12915-020-00857-6
Csardi, G., and Nepusz, T. (2006). The igraph software package for complex network research. InterJ. Complex Syst. 1695, 1–9.
Dave, A., Jindal, A., Li, L. E., Xin, R., Gonzalez, J., and Zaharia, M. (2016). “Graphframes: an integrated api for mixing graph and relational queries,” in Proceedings of the Fourth International Workshop on Graph Data Management Experiences and Systems (Redwood Shores, CA: ACM), 2. doi: 10.1145/2960414.2960416
Davis, G. F., Yoo, M., and Baker, W. E. (2003). The Small World of the American Corporate Elite, 1982-2001. Strategic Organization. doi: 10.1177/14761270030013002
Denk, W., Delaney, K. R., Gelperin, A., Kleinfeld, D., Strowbridge, B., Tank, D. W., et al. (1994). Anatomical and functional imaging of neurons using 2-photon laser scanning microscopy. J. Neurosci. Methods 54, 151–162. doi: 10.1016/0165-0270(94)90189-9
Devi, J. C., and Poovammal, E. (2016). An analysis of overlapping community detection algorithms in social networks. Proc. Comput. Sci. 89, 349–358. doi: 10.1016/j.procs.2016.06.082
Ding, Z., Zhang, X., Sun, D., and Luo, B. (2016). Overlapping community detection based on network decomposition. Sci. Rep. 6:24115. doi: 10.1038/srep24115
Dingle, Y.-T. L., Liaudanskaya, V., Finnegan, L. T., Berlind, K. C., Mizzoni, C., Georgakoudi, I., et al. (2020). Functional characterization of three-dimensional cortical cultures for in vitro modeling of brain networks. iScience 23:101434. doi: 10.1016/j.isci.2020.101434
Ek, B., VerSchneider, C., and Narayan, D. A. (2015). Global efficiency of graphs. AKCE Int. J. Graphs Combinator. 12, 1–13. doi: 10.1016/j.akcej.2015.06.001
Erdös, P., and Rényi, A. (1959). On random graphs I. Publicationes Mathematicae Debrecen 6, 290-297.
Farahani, F. V., Karwowski, W., and Lighthall, N. R. (2019). Application of graph theory for identifying connectivity patterns in human brain networks: a systematic review. Front. Neurosci. 13:585. doi: 10.3389/fnins.2019.00585
Fornito, A., and Bullmore, E. T. (2015). Reconciling abnormalities of brain network structure and function in schizophrenia. Curr. Opin. Neurobiol. 30, 44–50. doi: 10.1016/j.conb.2014.08.006
Fornito, A., Zalesky, A., and Bullmore, E. (2016). Fundamentals of Brain Network Analysis. Academic Press.
Fortunato, S. (2010). Community detection in graphs. Phys. Rep. 486, 75–174. doi: 10.1016/j.physrep.2009.11.002
Freeman, L. C. (1977). A set of measures of centrality based on betweenness. Sociometry 40, 35–41. doi: 10.2307/3033543
Giovannucci, A., Friedrich, J., Gunn, P., Kalfon, J., Brown, B. L., Koay, S. A., et al. (2019). CaImAn an open source tool for scalable calcium imaging data analysis. eLife 8:e38173. doi: 10.7554/eLife.38173
Gonzalez, J. E., Xin, R. S., Dave, A., Crankshaw, D., Franklin, M. J., and Stoica, I. (2014). “Graphx: graph processing in a distributed dataflow framework,” in 11th USENIX Symposium on Operating Systems Design and Implementation, (Broomfield, CO), 599–613.
Grewe, B. F., Langer, D., Kasper, H., Kampa, B. M., and Helmchen, F. (2010). High-speed in vivo calcium imaging reveals neuronal network activity with near-millisecond precision. Nat. Methods 7, 399–405. doi: 10.1038/nmeth.1453
Grienberger, C., and Konnerth, A. (2012). Imaging calcium in neurons. Neuron 73, 862–885. doi: 10.1016/j.neuron.2012.02.011
Hagberg, A. A., Schult, D. A., and Swart, P. J. (2008). “Exploring network structure, dynamics, and function using NetworkX,” in Proceedings of the Python in Science Conference (Pasadena, CA), 11–15.
Hamilton, W. L., Ying, R., and Leskovec, J. (2017). Representation learning on graphs: methods and applications. IEEE Data Eng. Bull. 40, 52–74.
Harris, K. D., Csicsvari, J., Hirase, H., Dragoi, G., and Buzsáki, G. (2003). Organization of cell assemblies in the hippocampus. Nature 424:552. doi: 10.1038/nature01834
Hartwell, L. H., Hopfield, J. J., Leibler, S., and Murray, A. W. (1999). From molecular to modular cell biology. Nature 402:C47. doi: 10.1038/35011540
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science 313, 504–507. doi: 10.1126/science.1127647
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Holme, P. (2019). Rare and everywhere: perspectives on scale-free networks. Nat. Commun. 10:1016. doi: 10.1038/s41467-019-09038-8
Honey, C. J., Kötter, R., Breakspear, M., and Sporns, O. (2007). Network structure of cerebral cortex shapes functional connectivity on multiple time scales. Proc. Natl. Acad. Sci. U.S.A. 104, 10240–10245. doi: 10.1073/pnas.0701519104
Huan, J., Wang, W., Washington, A., Prins, J., Shah, R., and Tropsha, A. (2003). “Accurate classification of protein structural families using coherent subgraph analysis,” in Biocomputing 2004 (World Scientific), 411–422. doi: 10.1142/9789812704856_0039
Jiao, Z.-Q., Zou, L., Cao, Y., Qian, N., and Ma, Z.-H. (2014). Effective connectivity analysis of fMRI data based on network motifs. J. Supercomput. 67, 806–819. doi: 10.1007/s11227-013-1010-z
Jin, W., Barzilay, R., and Jaakkola, T. (2018). “Junction tree variational autoencoder for molecular graph generation,” in International Conference on Machine Learning Stockholm: Stockholmsmässan, 2328–2337.
Jones, J. H., and Handcock, M. S. (2003). Social networks (communication arising): sexual contacts and epidemic thresholds. Nature 423:605. doi: 10.1038/423605a
Kalapala, V., Sanwalani, V., Clauset, A., and Moore, C. (2006). Scale invariance in road networks. Phys. Rev. E 73:026130. doi: 10.1103/PhysRevE.73.026130
Khakhalin, A. S. (2019). Graph analysis of looming-selective networks in the tectum, and its replication in a simple computational model. bioRxiv 589887. doi: 10.1101/589887
Kingma, D. P., and Welling, M. (2014). “Auto-encoding variational bayes,” in International Conference on Learning Representations ICLR. (Banff, AB).
Klein, D. (2010). Centrality measure in graphs. J. Math. Chem. 47, 1209–1223. doi: 10.1007/s10910-009-9635-0
Knapp, B., Bardenet, R., Bernabeu, M. O., Bordas, R., Bruna, M., Calderhead, B., et al. (2015). Ten simple rules for a successful cross-disciplinary collaboration. PLoS Comput. Biol. 11:e1004214. doi: 10.1371/journal.pcbi.1004214
Kogut, B., and Walker, G. (2001). The small world of Germany and the durability of national networks. Am. Sociol. Rev. 66, 317–335. doi: 10.2307/3088882
Kolaczyk, E. D. (2009). Statistical Analysis of Network Data: Methods and Models, 1st Edn. (New York, NY: Springer Publishing Company. doi: 10.1007/978-0-387-88146-1_6
Latora, V., and Marchiori, M. (2001). Efficient behavior of small-world networks. Phys. Rev. Lett. 87:198701. doi: 10.1103/PhysRevLett.87.198701
Leskovec, J., Kleinberg, J., and Faloutsos, C. (2005). “Graphs over time: densification laws, shrinking diameters and possible explanations,” in Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining (Chicago, IL), 177–187. doi: 10.1145/1081870.1081893
Ma, T., Chen, J., and Xiao, C. (2018). “Constrained generation of semantically valid graphs via regularizing variational autoencoders,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems (Red Hook, NY: Curran Associates Inc.), 7113–7124.
Milenković, T., and Pržulj, N. (2008). Uncovering biological network function via graphlet degree signatures. Cancer Inform. 6. doi: 10.4137/CIN.S680
Mölter, J., Avitan, L., and Goodhill, G. J. (2018). Detecting neural assemblies in calcium imaging data. BMC Biol. 16:143. doi: 10.1186/s12915-018-0606-4
Morgan, S. E., Achard, S., Termenon, M., Bullmore, E. T., and Vértes, P. E. (2018). Low-dimensional morphospace of topological motifs in human fMRI brain networks. Netw. Neurosci. 2, 285–302. doi: 10.1162/netn_a_00038
Muldoon, S. F., Bridgeford, E. W., and Bassett, D. S. (2016). Small-world propensity and weighted brain networks. Sci. Rep. 6:22057. doi: 10.1038/srep22057
Nascimento, M. C., and De Carvalho, A. C. (2011). Spectral methods for graph clustering–A survey. Eur. J. Operat. Res. 211, 221–231. doi: 10.1016/j.ejor.2010.08.012
Neal, Z. (2015). Making big communities small: using network science to understand the ecological and behavioral requirements for community social capital. Am. J. Commun. Psychol. 55, 369–380. doi: 10.1007/s10464-015-9720-4
Neal, Z. P. (2017). How small is it? Comparing indices of small worldliness. Netw. Sci. 5, 30–44. doi: 10.1017/nws.2017.5
Newman, M. (2010). Networks: An Introduction. Oxford: Oxford University Press. doi: 10.1093/acprof:oso/9780199206650.003.0001
Newman, M. (2018). Networks. Oxford: Oxford University Press. doi: 10.1093/oso/9780198805090.001.0001
Newman, M. E. (2003). The structure and function of complex networks. SIAM Rev. 45, 167–256. doi: 10.1137/S003614450342480
Newman, M. E. (2006). Modularity and community structure in networks. Proc. Natl. Acad. Sci. U.S.A. 103, 8577–8582. doi: 10.1073/pnas.0601602103
Packer, A. M., Russell, L. E., Dalgleish, H. W. P., and Häusser, M. (2015). Simultaneous all-optical manipulation and recording of neural circuit activity with cellular resolution in vivo. Nat. Methods 12, 140–146. doi: 10.1038/nmeth.3217
Page, L., Brin, S., Motwani, R., and Winograd, T. (1999). The Pagerank Citation Ranking: Bringing Order to the Web. Technical report, Stanford InfoLab.
Pnevmatikakis, E. A., and Paninski, L. (2018). “Analysis of functional imaging data at single-cellular resolution,” in Short Course on Functional, Structural, and Molecular Imaging, and Big Data Analysis (San Diego, CA: Society for Neuroscience), 13.
Romano, S. A., Pietri, T., Pérez-Schuster, V., Jouary, A., Haudrechy, M., and Sumbre, G. (2015). Spontaneous neuronal network dynamics reveal circuit's functional adaptations for behavior. Neuron 85, 1070–1085. doi: 10.1016/j.neuron.2015.01.027
Scheffer, L. K. (2020). Graph properties of the adult drosophila central brain. bioRxiv. doi: 10.1101/2020.05.18.102061
Schroeder, M., Bassett, D. S., and Meaney, D. F. (2019). A multilayer network model of neuron-astrocyte populations in vitro reveals mglur5 inhibition is protective following traumatic injury. bioRxiv. doi: 10.1101/798611
See, J. Z., Atencio, C. A., Sohal, V. S., and Schreiner, C. E. (2018). Coordinated neuronal ensembles in primary auditory cortical columns. eLife 7:e35587. doi: 10.7554/eLife.35587
Shannon, P., Markiel, A., Ozier, O., Baliga, N. S., Wang, J. T., Ramage, D., et al. (2003). Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 13, 2498–2504. doi: 10.1101/gr.1239303
Shen-Orr, S. S., Milo, R., Mangan, S., and Alon, U. (2002). Network motifs in the transcriptional regulation network of Escherichia coli. Nat. Genet. 31:64. doi: 10.1038/ng881
Simonovsky, M., and Komodakis, N. (2018). “Graphvae: towards generation of small graphs using variational autoencoders,” in International Conference on Artificial Neural Networks (Rhodes: Springer), 412–422. doi: 10.1007/978-3-030-01418-6_41
Smedler, E., Malmersjö, S., and Uhlén, P. (2014). Network analysis of time-lapse microscopy recordings. Front. Neural Circ. 8:111. doi: 10.3389/fncir.2014.00111
Sporns, O. (2018). Graph theory methods: applications in brain networks. Dialog. Clin. Neurosci. 20:111. doi: 10.31887/DCNS.2018.20.2/osporns
Staudt, C. L., Sazonovs, A., and Meyerhenke, H. (2016). Networkit: a tool suite for large-scale complex network analysis. Netw. Sci. 4, 508–530. doi: 10.1017/nws.2016.20
Stetter, O., Battaglia, D., Soriano, J., and Geisel, T. (2012). Model-free reconstruction of excitatory neuronal connectivity from calcium imaging signals. PLoS Comput. Biol. 8:e1002653. doi: 10.1371/journal.pcbi.1002653
Telesford, Q. K., Joyce, K. E., Hayasaka, S., Burdette, J. H., and Laurienti, P. J. (2011). The ubiquity of small-world networks. Brain Connect. 1, 367–375. doi: 10.1089/brain.2011.0038
Tibau, E., Valencia, M., and Soriano, J. (2013). Identification of neuronal network properties from the spectral analysis of calcium imaging signals in neuronal cultures. Front. Neural Circ. 7:199. doi: 10.3389/fncir.2013.00199
Uzzi, B., and Spiro, J. (2005). Collaboration and creativity: the small world problem. Am. J. Sociol. 111, 447–504. doi: 10.1086/432782
Vanwalleghem, G., Schuster, K., Taylor, M. A., Favre-Bulle, I. A., and Scott, E. K. (2020). Brain-wide mapping of water flow perception in zebrafish. J. Neurosci. 40, 4130–4144. doi: 10.1523/JNEUROSCI.0049-20.2020
Vecchio, F., Miraglia, F., and Maria Rossini, P. (2017). Connectome: graph theory application in functional brain network architecture. Clin. Neurophysiol. Pract. 2, 206–213. doi: 10.1016/j.cnp.2017.09.003
Vicens, Q., and Bourne, P. E. (2007). Ten simple rules for a successful collaboration. PLoS Comput. Biol. 3:e44. doi: 10.1371/journal.pcbi.0030044
Wang, X., and Davidson, I. (2010). “Flexible constrained spectral clustering,” in Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, DC: ACM), 563–572. doi: 10.1145/1835804.1835877
Wanner, A. A., and Friedrich, R. W. (2020). Whitening of odor representations by the wiring diagram of the olfactory bulb. Nat. Neurosci. 23, 433–442. doi: 10.1038/s41593-019-0576-z
Watts, D. J., and Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature 393:440. doi: 10.1038/30918
Xie, J., Kelley, S., and Szymanski, B. K. (2013). Overlapping community detection in networks: the state-of-the-art and comparative study. ACM Comput. Surv. 45:43. doi: 10.1145/2501654.2501657
Yang, Z., Algesheimer, R., and Tessone, C. J. (2016). A comparative analysis of community detection algorithms on artificial networks. Sci. Rep. 6:30750. doi: 10.1038/srep30750
You, J., Ying, R., Ren, X., Hamilton, W., and Leskovec, J. (2018). “GraphRNN: generating realistic graphs with deep auto-regressive models,” in International Conference on Machine Learning (Stockholm: Stockhol msmässan), 5694–5703.
Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauley, M., et al. (2012). “Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing,” in Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation (Berkeley, CA: USENIX Association), 2.
Zhang, M., Jiang, S., Cui, Z., Garnett, R., and Chen, Y. (2019). “D-vae: a variational autoencoder for directed acyclic graphs,” in Advances in Neural Information Processing Systems, Vol. 32, eds H. Wallach, H. Larochelle, A. Beygelzimer, F. D' Alché-Buc, E. Fox, R. Garnett Vancouver, BC: Curran Associates, Inc.), 1586–1598.
Keywords: brain networks, calcium imaging, graph theory, functional connectivity, network analysis, neuronal networks
Citation: Nelson CJ and Bonner S (2021) Neuronal Graphs: A Graph Theory Primer for Microscopic, Functional Networks of Neurons Recorded by Calcium Imaging. Front. Neural Circuits 15:662882. doi: 10.3389/fncir.2021.662882
Received: 01 February 2021; Accepted: 13 April 2021;
Published: 10 June 2021.
Edited by:
Blake A. Richards, Montreal Institute for Learning Algorithm (MILA), CanadaReviewed by:
Lilach Avitan, Hebrew University of Jerusalem, IsraelGerman Sumbre, École Normale Supérieure, France
Copyright © 2021 Nelson and Bonner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Carl J. Nelson, Y2hhcy5uZWxzb25AZ2xhc2dvdy5hYy51aw==