Abstract
How the neocortex works is a mystery. In this paper we propose a novel framework for understanding its function. Grid cells are neurons in the entorhinal cortex that represent the location of an animal in its environment. Recent evidence suggests that grid cell-like neurons may also be present in the neocortex. We propose that grid cells exist throughout the neocortex, in every region and in every cortical column. They define a location-based framework for how the neocortex functions. Whereas grid cells in the entorhinal cortex represent the location of one thing, the body relative to its environment, we propose that cortical grid cells simultaneously represent the location of many things. Cortical columns in somatosensory cortex track the location of tactile features relative to the object being touched and cortical columns in visual cortex track the location of visual features relative to the object being viewed. We propose that mechanisms in the entorhinal cortex and hippocampus that evolved for learning the structure of environments are now used by the neocortex to learn the structure of objects. Having a representation of location in each cortical column suggests mechanisms for how the neocortex represents object compositionality and object behaviors. It leads to the hypothesis that every part of the neocortex learns complete models of objects and that there are many models of each object distributed throughout the neocortex. The similarity of circuitry observed in all cortical regions is strong evidence that even high-level cognitive tasks are learned and represented in a location-based framework.
Introduction
The human neocortex learns an incredibly complex and detailed model of the world. Each of us can recognize 1000s of objects. We know how these objects appear through vision, touch, and audition, we know how these objects behave and change when we interact with them, and we know their location in the world. The human neocortex also learns models of abstract objects, structures that don’t physically exist or that we cannot directly sense. The circuitry of the neocortex is also complex. Understanding how the complex circuitry of the neocortex learns complex models of the world is one of the primary goals of neuroscience.
Vernon Mountcastle was the first to propose that all regions of the neocortex are fundamentally the same. What distinguishes one region from another, he argued, is mostly determined by the inputs to a region and not by differences in intrinsic circuitry and function. He further proposed that a small volume of cortex, a cortical column, is the unit of replication (Mountcastle, 1978). These are compelling ideas, but it has been difficult to identify what a column could do that is sufficient to explain all cognitive abilities. Today, the most common view is that the neocortex processes sensory input in a series of hierarchical steps, extracting more and more complex features until objects are recognized (Fukushima, 1980; Riesenhuber and Poggio, 1999). Although this view explains some aspects of sensory inference, it fails to explain the richness of human behavior, how we learn multi-dimensional models of objects, and how we learn how objects themselves change and behave when we interact with them. It also fails to explain what most of the circuitry of the neocortex is doing. In this paper we propose a new theoretical framework based on location processing that addresses many of these shortcomings.
Over the past few decades some of the most exciting advances in neuroscience have been related to “grid cells” and “place cells.” These neurons exist in the hippocampal complex of mammals, a set of regions, which, in humans, is roughly the size and shape of a finger, one on each side of the brain. Grid cells in combination with place cells learn maps of the world (O’Keefe and Dostrovsky, 1971; Hafting et al., 2005; Moser et al., 2008). Grid cells represent the current location of an animal relative to those maps. Modeling work on the hippocampus has demonstrated the power of these neural representations for episodic and spatial memory (Byrne et al., 2007; Hasselmo et al., 2010; Hasselmo, 2012), and navigation (Erdem and Hasselmo, 2014; Bush et al., 2015). There is also evidence that grid cells play a role in more abstract cognitive tasks (Constantinescu et al., 2016; Behrens et al., 2018).
Recent experimental evidence suggests that grid cells may also be present in the neocortex. Using fMRI (Doeller et al., 2010; Constantinescu et al., 2016; Julian et al., 2018) have found signatures of grid cell-like firing patterns in prefrontal and parietal areas of the neocortex. Using single cell recording in humans (Jacobs et al., 2013) have found more direct evidence of grid cells in frontal cortex (Long and Zhang, 2018), using multiple tetrode recordings, have reported finding cells exhibiting grid cell, place cell, and conjunctive cell responses in rat S1. Our team has proposed that prediction of sensory input by the neocortex requires a representation of an object-centric location to be present throughout the sensory regions of the neocortex, which is consistent with grid cell-like mechanisms (Hawkins et al., 2017).
Here we propose that grid cell-like neurons exist in every column of the neocortex. Whereas grid cells in the medial entorhinal cortex (MEC) primarily represent the location of one thing, the body, we suggest that cortical grid cells simultaneously represent the location of multiple things. Columns in somatosensory cortex that receive input from different parts of the body represent the location of those inputs in the external reference frames of the objects being touched. Similarly, cortical columns in visual cortex that receive input from different patches of the retinas represent the location of visual input in the external reference frames of the objects being viewed. Whereas grid cells and place cells learn models of environments via movement of the body, we propose that cortical grid cells combined with sensory input learn models of objects via movement of the sensors.
Although much is known about the receptive field properties of grid cells in MEC and how these cells encode location (Rowland et al., 2016), the underlying mechanisms leading to those properties is not known. Experimental results suggest that grid cells have unique membrane and dendritic properties (Domnisoru et al., 2013; Schmidt-Hieber et al., 2017). There are two leading computational candidates, oscillatory interference models (O’Keefe and Burgess, 2005; Burgess et al., 2007; Giocomo et al., 2007, 2011; Burgess, 2008) and continuous attractor models (Fuhs and Touretzky, 2006; Burak and Fiete, 2009). The framework proposed in this paper assumes that “cortical grid cells” exhibit similar physiological properties as grid cells in MEC, but the framework is not dependent on how those properties arise.
Throughout this paper we refer to “cortical columns.” We use this term similarly to Mountcastle, to represent a small area of neocortex that spans all layers in depth and of sufficient lateral extent to capture all cell types and receptive field responses. For this paper, a cortical column is not a physically demarked entity. It is a convenience of nomenclature. We typically think of a column as being about one square millimeter of cortical area, although this size is not critical and could vary by species and region.
How Grid Cells Represent Location
To understand our proposal, we first review how grid cells in the entorhinal cortex are believed to represent space and location, Figure 1. Although many details of grid cell function remain unknown, general consensus exists on the following principles. A grid cell is a neuron that becomes active at multiple locations in an environment, typically in a grid-like, or tiled, triangular lattice. A “grid cell module” is a set of grid cells that activate with the same lattice spacing and orientation but at shifted locations within an environment (Stensola et al., 2012). As an animal moves, the active grid cells in a grid cell module change to reflect the animal’s updated location. This change occurs even if the animal is in the dark, telling us that grid cells are updated using an internal, or “efference,” copy of motor commands (Hafting et al., 2005; McNaughton et al., 2006; Moser et al., 2008; Kropff et al., 2015). This process, called “path integration,” has the desirable property that regardless of the path of movement, when the animal returns to the same physical location, then the same grid cells in a module will be active.
FIGURE 1
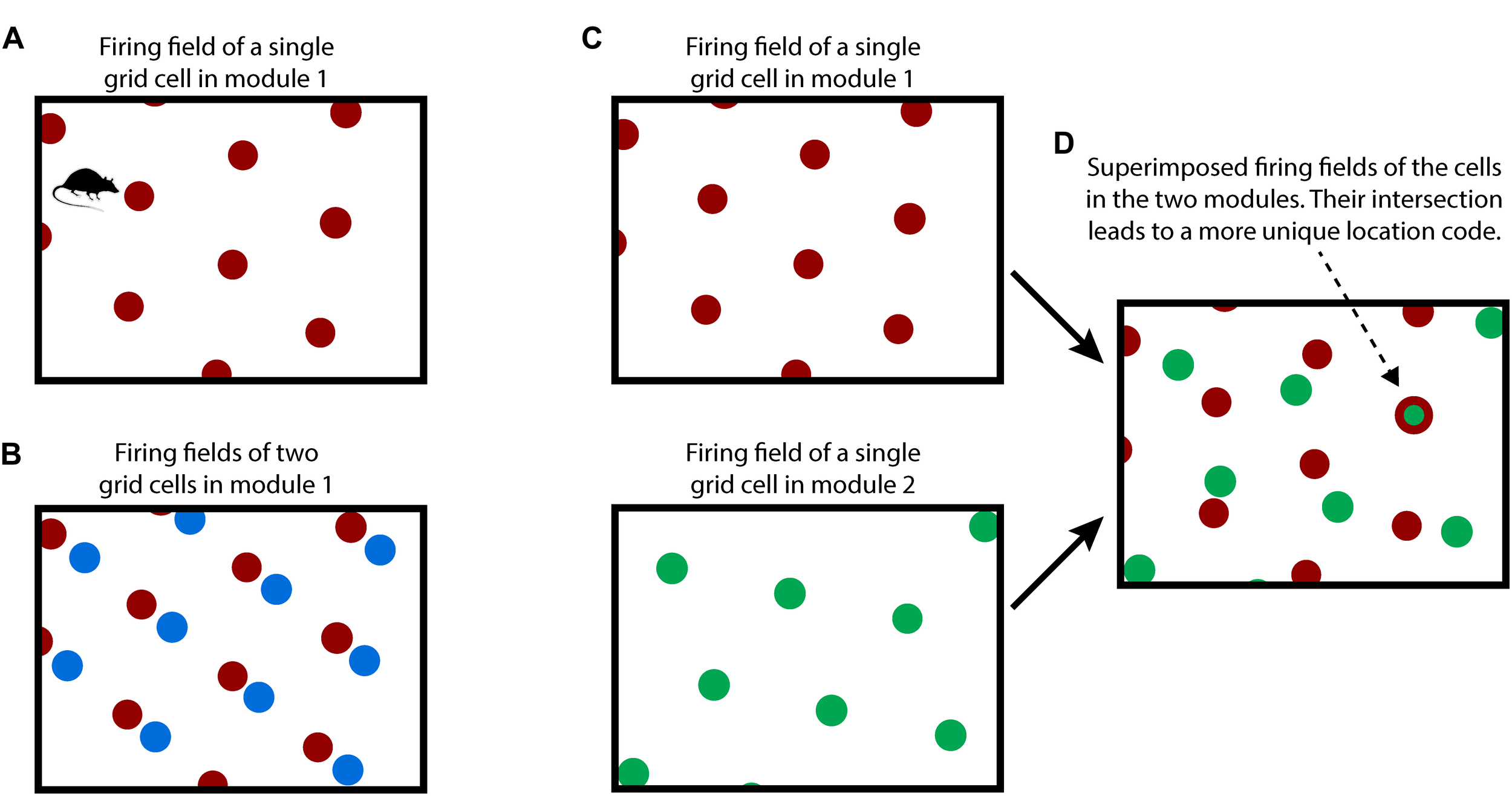
How grid cells represent location. (A) An individual grid cell becomes active at multiple locations (red circles) as an animal moves about an environment (rectangle). The locations of activation form a periodic grid-like lattice. The activation locations are always the same for any particular environment. (B) A grid cell module is a set of grid cells that activate at the same spacing and orientation but at different positions in the environment. The activation locations for two grid cells in a grid cell module are shown (red and blue dots). Every location in an environment will activate one or more grid cells in a module. Because of the periodic activation of grid cells, a single grid cell module cannot represent unique locations. (C) Multiple grid cell modules (two shown, top and bottom) tile the same space at different orientations and/or spacings. (D) Although a single module cannot represent unique locations in an environment, the activity across multiple modules can. This rectangle shows the superimposed firing fields of the two grid cells from C). Note that when the two cells (red and green) fire together, only one location is possible (indicated by arrow). The number of locations that can be represented increases exponentially with the number of modules.
Due to tiling, a single grid cell module cannot represent a unique location. To form a representation of a unique location requires looking at the active cells in multiple grid cell modules where each grid cell module differs in its tile spacing and/or orientation relative to the environment, Figures 1C,D. For example, if a single grid cell module can represent twenty different locations before repeating, then 10 grid cell modules can represent approximately 2010 different locations before repeating (Fiete et al., 2008). This method of representing location has several desirable properties:
- (1)
Large representational capacity:
The number of locations that can be represented by a set of grid cell modules is large as it scales exponentially with the number of modules.
- (2)
Path integration works from any location:
No matter what location the network starts with, path integration will work. This is a form of generalization. The path integration properties have to be learned once for each grid cell module, but then apply to all locations, even those the animal has never been in before.
- (3)
Locations are unique to each environment:
Every learned environment is associated with a set of unique locations. Experimental recordings suggest that upon entering a learned environment, entorhinal grid cell modules “anchor” differently (Rowland and Moser, 2014; Marozzi et al., 2015). (The term “anchor” refers to selecting which grid cells in each module should be active at the current location.) This suggests that the current location and all the locations that the animal can move to in that environment will, with high certainty, have representations that are unique to that environment (Fiete et al., 2008; Sreenivasan and Fiete, 2011).
Combining these properties, we can now broadly describe how grid cells represent an environment such as a room, Figure 2A. An environment consists of a set of location representations that are related to each other via path integration (i.e., the animal can move between these location representations). Each location representation in the set is unique to that environment and will not appear in any other environment. An environment consists of all the locations that the animal can move among, including locations that have not been visited, but could be visited. Associated with some of the location representations are observable landmarks.
FIGURE 2
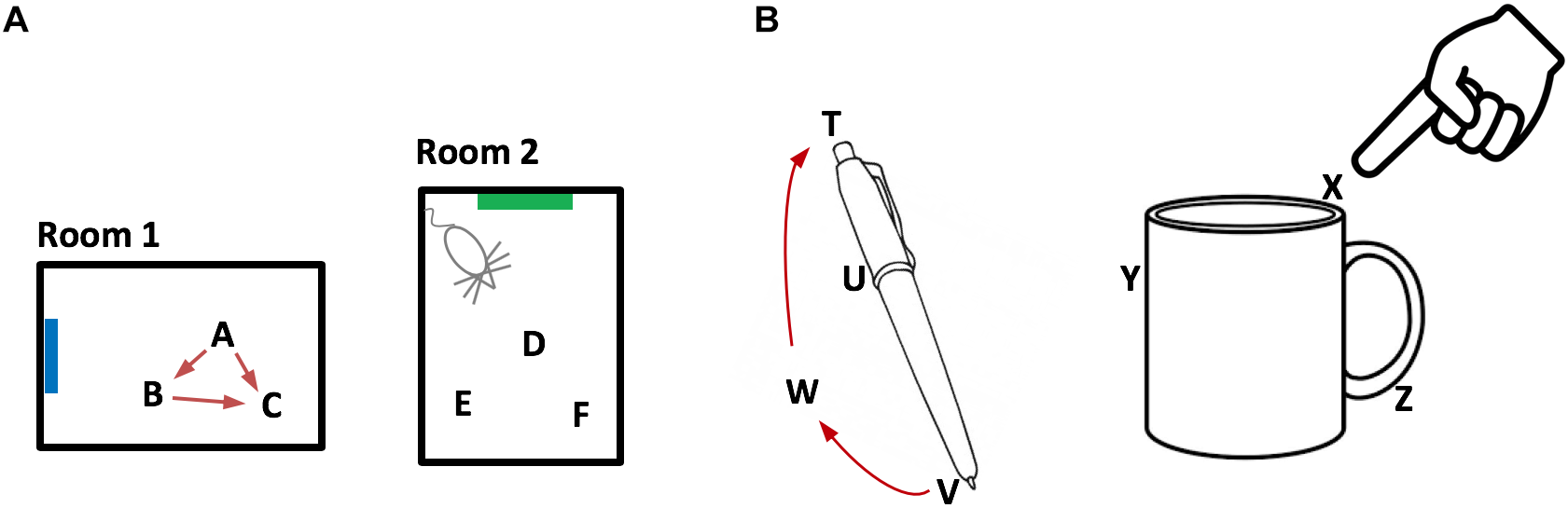
Representing objects as location spaces. We propose that the neocortex learns the structure of objects in the same way that the entorhinal cortex and hippocampus learn the structure of environments. (A) Two rooms that a rodent has learned. Because of distinct landmarks (suggested by blue and green rectangles) an animal will perceive these as different rooms. Locations in a room are represented by the activity in a set of grid cell modules in the entorhinal cortex. Three locations are shown for each room (A,B,C and D,E,F). Representations of location are unique to both the location in a room and the room. Therefore, if an animal can determine it is in location A, then it knows what room it is in (Room1) and its location in the room. The locations associated with a room are united via movement and path integration. As an animal moves, the representation of location is updated (red arrows) based on an internal copy of its motor behavior. By exploring a room, the animal learns the features associated with locations in the room. (B) We propose that objects such as a pen or coffee cup are similarly defined by a set of locations (four labeled for the pen and three labeled for the cup). Grid cells in the neocortex represent the location of a sensor patch (for example, tip of finger) in the location space of the object. Locations in an object’s space are unique to the object and the location relative to the object. An object’s space includes locations that can be moved to but don’t necessarily have an associated feature. For example, location W is part of the pen because a finger can move from V to W to T via path integration. By moving and exploring the object, the neocortex learns the features associated with locations of the object.
Grid Cells in the Neocortex
Now let us consider a patch of neocortex that receives input from the tip of a finger, Figure 2B. Our proposal is that some of the neurons in that patch of cortex represent the location of the fingertip as it explores an object. When the finger moves, these cortical grid cells update their representation of location via a motor efference copy and path integration. Objects, such as a coffee cup, have an associated set of locations, in the same way that environments, such as a room, have an associated set of locations. Associated with some of the object’s locations are observable features. The cortical area receiving input from the fingertip tracks the location of the sensory input from the fingertip in the location space of the object. Through movement and sensation, the fingertip cortical area learns models of objects in the same way that grid cells and place cells learn models of environments. Whereas the entorhinal cortex tracks the location of the body, different areas of the neocortex independently track the location of each movable sensory patch. For example, each area of somatosensory cortex tracks the location of sensory input from its associated body part. These areas operate in parallel and build parallel models of objects. The same basic method applies to vision. Patches of the retina are analogous to patches of skin. Different parts of the retina observe different locations on an object. Each patch of cortex receiving visual input tracks the location of its visual input in the location space of the object being observed. As the eyes move, visual cortical columns sense different locations on an object and learn parallel models of the observed object.
We have now covered the most basic aspects of our proposal:
- (1)
Every cortical column has neurons that perform a function similar to grid cells. The activation pattern of these cortical grid cells represents the location of the column’s input relative to an external reference frame. The location representation is updated via a motor efference copy and path integration.
- (2)
Cortical columns learn models of objects in the world similarly to how grid cells and place cells learn models of environments. The models learned by cortical columns consist of a set of location representations that are unique to each object, and where some of the locations have observable features.
A Location-Based Framework for Cortical Computation
Our proposal suggests that cortical columns are more powerful than previously assumed. By pairing input with a grid cell-derived representation of location, individual columns can learn complex models of structure in the world (see also Lewis et al., 2018). In this section we show how a location-based framework allows neurons to learn the rich models that we know the neocortex is capable of.
Object Compositionality
Objects are composed of other objects arranged in a particular way. For example, it would be inefficient to learn the morphology of a coffee cup by remembering the sensory sensation at each location on the cup. It is far more efficient to learn the cup as the composition of previously learned objects, such as a cylinder and a handle. Consider a coffee cup with a logo on it, Figure 3A. The logo exists in multiple places in the world and is itself a learned “object.” To represent the cup with the logo we need a way of associating one object, “the logo,” at a relative position to another object, “the cup.” Compositional structure is present in almost all objects in the world, therefore cortical columns must have a neural mechanism that represents a new object as an arrangement of previously-learned objects. How can this functionality be achieved?
FIGURE 3
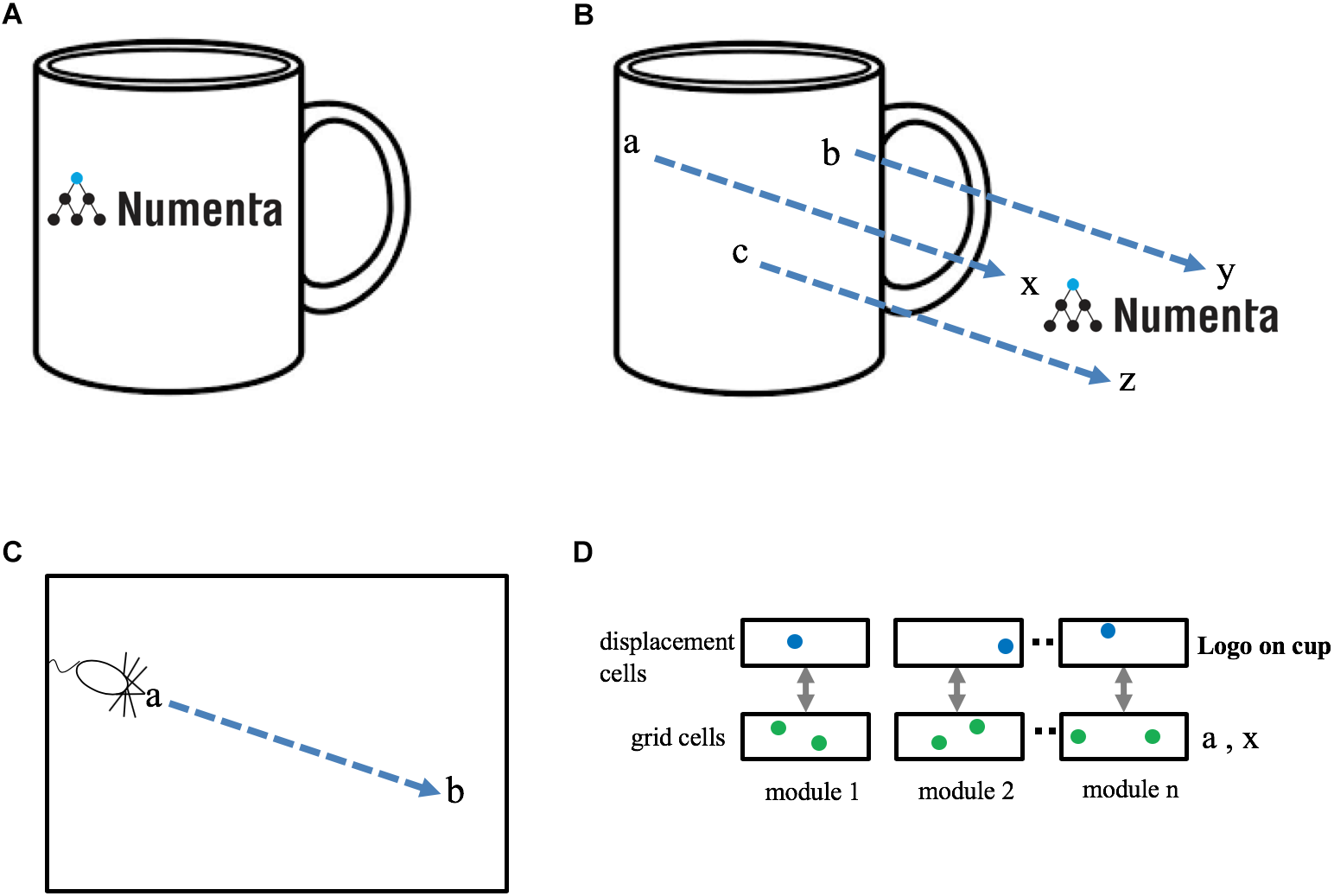
Representing objects as compositions of other objects. (A) The neocortex can learn an object, such as a “coffee cup with logo,” as a composition of two previously learned objects, “cup” and “logo.” The goal is to represent this relationship efficiently, without any relearning. (B) The cup and the logo each have their own unique set of locations. Three locations are shown in cup space (a, b, c) and three locations are shown in logo space (x, y, z). When the logo is placed on the cup there is a fixed one-to-one mapping between locations in cup space and locations in logo space. This relationship can be represented as a displacement vector between the two spaces (blue arrows). (C) Animals exploring an environment can determine the direction and distance from their current location, a, to a previously visited target location, b, even if they have never taken this path before. Determining the displacement between two locations in the same space (e.g., a to b in C) is equivalent to determining the displacement between two locations in separate spaces (e.g., a to x in B). (D) A method to determine the displacement between two locations. Each grid cell module is paired with a displacement cell module. Cells in a displacement cell module (blue dots) respond to a particular displacement between pairs of grid cells (green dots). Any two pairs of grid cells with the same displacement in physical space will activate the same displacement cell. Displacement cells cannot represent a unique displacement in the same way that grid cells cannot represent a unique location. However, the set of active cells in multiple displacement cell modules (three shown) will represent a unique displacement. Because the set of active grid cells in multiple grid cell modules is unique to objects (cup and logo), the set of active displacement cells will also be unique (to both the cup and logo). Thus, a set of active displacement cells can represent the relative placement of two specific objects (location of logo on cup).
We have proposed that each object is associated with a set of locations which are unique to the object and comprise a space around the object. If a finger is touching the coffee cup with the logo, then the cortical grid cells representing the location of the finger can at one moment represent the location of the finger in the space of the coffee cup and at another moment, after re-anchoring, represent the location of the finger in the space of the logo. If the logo is attached to the cup, then there is a fixed, one-to-one, relationship between any point in the space of the logo and the equivalent point in the space of the cup, Figure 3B. The task of representing the logo on the cup can be achieved by creating a “displacement” vector that converts any point in cup space to the equivalent point in logo space.
Determining the displacement between two objects is similar to a previously-studied navigation problem, specifically, how an animal knows how to get from point a to point b within an environment, Figure 3C. Mechanisms that solve the navigation problem (determining the displacement between two points in the same space) can also solve the object composition problem (determining the displacement between two points in two different spaces).
Displacement Cells
Several solutions have been proposed for solving the point-to-point navigation problem using grid cells. One class of solutions detects the difference between two sets of active grid cells across multiple grid cell modules (Bush et al., 2015) and another uses linear look-ahead probes using grid cells for planning and computing trajectories (Erdem and Hasselmo, 2014). We suggest an alternate but related solution. Our proposal also relies on detecting differences between two sets of active grid cells, however, we propose this is done on a grid cell module by grid cell module basis. We refer to these cells as “displacement cells” (see Supplementary Material for a more thorough description). Displacement cells are similar to grid cells in that they can’t on their own represent a unique displacement. (In the Supplementary Material example, a displacement cell that represents a displacement of “two to the right and one up,” would also be active for “five over and four up.”) However, the cell activity in multiple displacement cell modules represents a unique displacement in much the same way as the cell activity in multiple grid cell modules represents a unique location, Figure 3D. Hence, a single displacement vector can represent the logo on the coffee cup at a specific relative position. Note, a displacement vector not only represents the relative position of two objects, it also is unique to the two objects. Complex objects can be represented by a set of displacement vectors which define the components of an object and how they are arranged relative to each other. This is a highly efficient means of representing and storing the structure of objects.
This method of representing objects allows for hierarchical composition. For example, the logo on the cup is also composed of sub-objects, such as letters and a graphic. A displacement vector placing the logo on the cup implicitly carries with it all the sub-objects of the logo. The method also allows for recursive structures. For example, the logo could contain a picture of a coffee cup with a logo. Hierarchical and recursive composition are fundamental elements of not only physical objects but language, mathematics, and other manifestations of intelligent thought. The key idea is that the identity and relative position of two previously-learned objects, even complex objects, can be represented efficiently by a single displacement vector.
Grid Cells and Displacement Cells Perform Complementary Operations
Grid cells and displacement cells perform complementary operations. Grid cells determine a new location based on a current location and a displacement vector (i.e., movement). Displacement cells determine what displacement is required to reach a new location from a current location.
If the two locations are in the same space, then grid cells and displacement cells are useful for navigation. In this case, grid cells predict a new location based on a starting location and a given movement. Displacement cells would represent what movement is needed to get from Location1 to Location2.
If the two locations are in different spaces (that is the same physical location relative to two different objects) then grid cells and displacement cells are useful for representing the relative position of two objects. Grid cells convert a location in one object space to the equivalent location in a second object space based on a given displacement. In this case, displacement cells represent the relative position of two objects.
We propose that grid cells and displacement cells exist in all cortical columns. They perform two fundamental and complementary operations in a location-based framework of cortical processing. By alternating between representations of locations in a single object space and representations of locations in two different object spaces, the neocortex can use grid cells and displacement cells to learn both the structure of objects and generate behaviors to manipulate those objects.
The existence of grid cells in the entorhinal cortex is well-documented. We propose they also exist in all regions of the neocortex. The existence of displacement cells is a prediction introduced in this paper. We propose displacement cells are also present in all regions of the neocortex. Given their complementary role to grid cells, it is possible that displacement cells are also present in the hippocampal complex.
Object Behaviors
Objects may exhibit behaviors. For example, consider the stapler in Figure 4. The top of the stapler can be lifted and rotated. This action changes the stapler’s morphology but not its identity. We don’t perceive the open and closed stapler as two different objects even though the overall shape has changed. The movement of a part of an object relative to other parts of an object is a “behavior” of the object. The behaviors of an object can be learned, and therefore they must be represented in the neural tissue of cortical columns. We can represent behaviors in a location-based framework, again using displacement vectors. The top half and bottom half of the stapler are two components of the stapler. The relative position of the top and bottom is represented by a displacement vector in the same way as the relative position of the logo and the coffee cup. However, unlike the logo on the coffee cup, the two halves of the stapler can move relative to each other. As the stapler top rotates upward, the displacement of the stapler top to bottom changes. Thus, the rotation of the stapler top is represented by a sequence of displacement vectors. By learning this sequence, the system will have learned this behavior of the object.
FIGURE 4
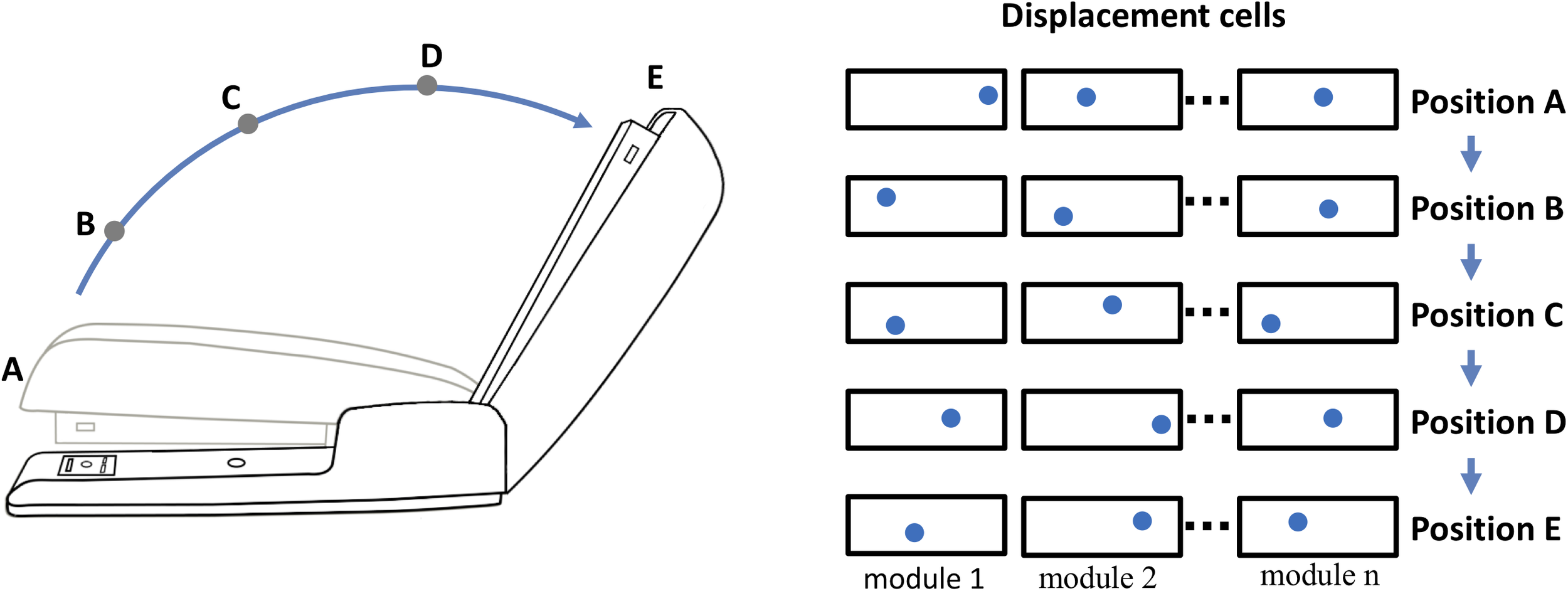
Representing behaviors of objects. Objects have “behaviors,” they can change their shape and features over time. The neocortex can learn these changes, but how? For example, a stapler has several behaviors, one is rotating the top relative to the base. If the top of the stapler is a component object of the stapler, with its own location space, then its position relative to the stapler base is represented by a displacement vector as illustrated in Figure 3. (The top and base of the stapler are analogous to the logo and the cup. Unlike the logo on the cup, the location of the stapler top relative to the base can change.) The closed position is represented by displacement A and the fully open position is represented by displacement E. As the stapler top hinges from the closed to open position, the displacement vector will continually change. (Five positions, A to E, and corresponding displacement vectors are shown.) To learn this behavior, the neocortex only needs to learn the sequence of displacement vectors as the top rotates.
Opening and closing the stapler are different behaviors yet they are composed of the same displacement elements, just in reverse order. These are sometimes referred to as “high-order” sequences. Previously we described a neural mechanism for learning high-order sequences in a layer of neurons (Hawkins and Ahmad, 2016). This mechanism, if applied to the displacement modules, would allow the learning, inference, and recall of complex behavioral sequences of objects.
“What” and “Where” Processing
Sensory processing occurs in two parallel sets of neocortical regions, often referred to as “what” and “where” pathways. In vision, damage to the “what,” or ventral, pathway is associated with the loss of ability to visually recognize objects whereas damage to the “where,” or dorsal, pathway is associated with the loss of ability to reach for an object even if it has been visually identified. Equivalent “what” and “where” pathways have been observed in other sensory modalities, thus it appears to be general principle of cortical organization (Goodale and Milner, 1992; Ungerleider and Haxby, 1994; Rauschecker, 2015). “What” and “where” cortical regions have similar anatomy and therefore we can assume they operate on similar principles.
A location-based framework for cortical function is applicable to both “what” and “where” processing. Briefly, we propose that the primary difference between “what” regions and “where” regions is that in “what” regions cortical grid cells represent locations that are allocentric, in the location space of objects, and in “where” regions cortical grid cells represent locations that are egocentric, in the location space of the body. Figure 5 shows how a displacement vector representing movement could be generated in “what” and “where” regions. The basic operation, common to all, is that a region first attends to one location and then to a second location. The displacement cells will determine the movement vector needed to move from the first location to the second location. In a “what” region, Figure 5C, the two locations are in the space of an object, therefore, the displacement vector will represent the movement needed to move the finger from the first location on the object to the second location on the object. In this example, the “what” region needs to know where the finger is relative to the cup, but it does not need to know where the cup or finger is relative to the body. In a “where” region, Figure 5B, the two locations are in the space of the body, therefore, the displacement vector will represent how to move from one egocentric location to a second egocentric location. The “where” region can perform this calculation not knowing what object may or may not be at the second location. A more detailed discussion of processing in “where” regions is beyond the scope of this paper. We only want to point out that it is possible to understand both “what” and “where” processing using similar mechanisms by assuming different location spaces.
FIGURE 5
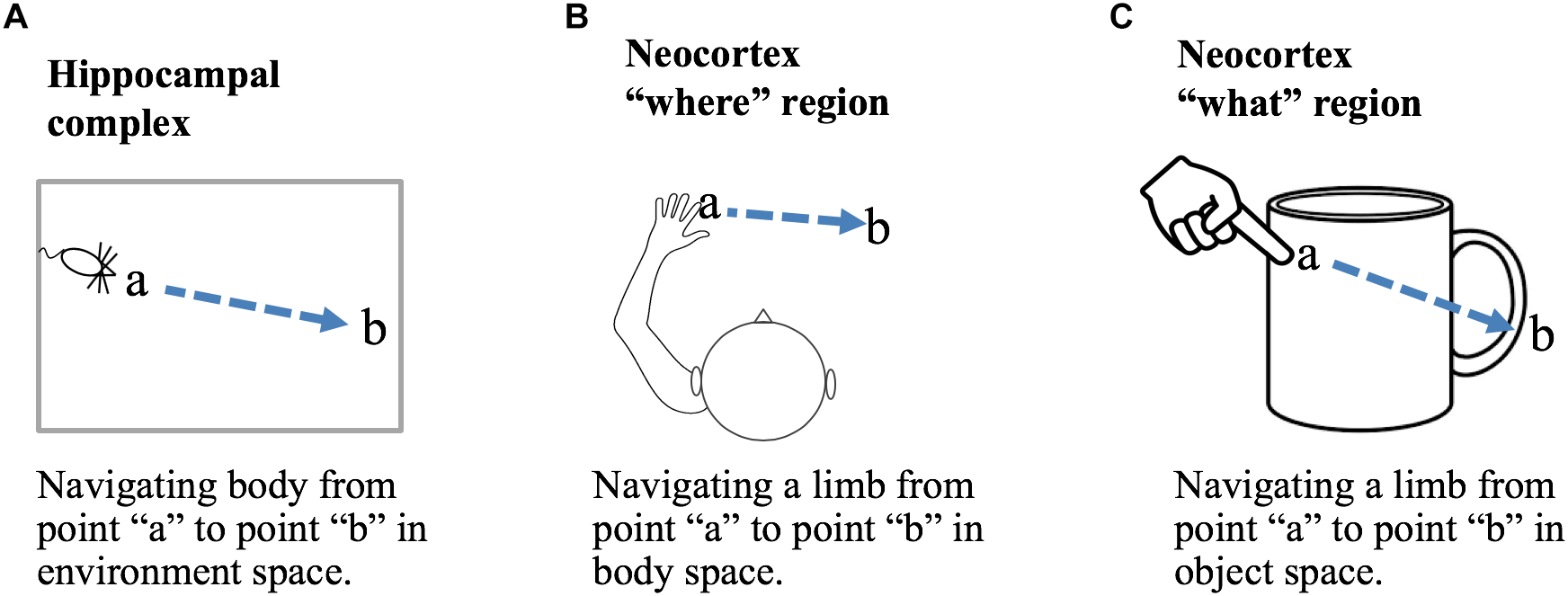
Location processing in different areas of the brain. Grid cells and displacement cells (see text) can be applied to different tasks in different areas of the brain. (A) If grid cell modules in the hippocampal complex are anchored by cues in an environment, then grid cell activation patterns will represent locations relative to that environment. Given two locations, a and b, displacement cells will calculate the movement vector needed to move the body from point a to point b. (B) If cortical grid cell modules are anchored relative to the body, then they will represent locations in body space. Given two locations, displacement cells will calculate the movement vector needed to move a body part from its current location to a desired new location relative to the body. (C) If cortical grid cell modules are anchored by cues relative to an object, then they will represent locations in the object’s space. Displacement cells will calculate the movement vector needed to move a limb or sensory organ from its current location to a new location relative to the object. Operations performed in (B,C) are associated with “where” and “what” regions in the neocortex.
Rethinking Hierarchy, the Thousand Brains Theory of Intelligence
Regions of the neocortex are organized in a hierarchy (Felleman and Van Essen, 1991; Riesenhuber and Poggio, 1999; Markov et al., 2014). It is commonly believed that when sensory input enters the neocortex the first region detects simple features. The output of this region is passed to a second region that combines simple features into more complex features. This process is repeated until, several levels up in the hierarchy, cells respond to complete objects (Figure 6A). This view of the neocortex as a hierarchy of feature extractors also underlies many artificial neural networks (LeCun et al., 2015).
FIGURE 6
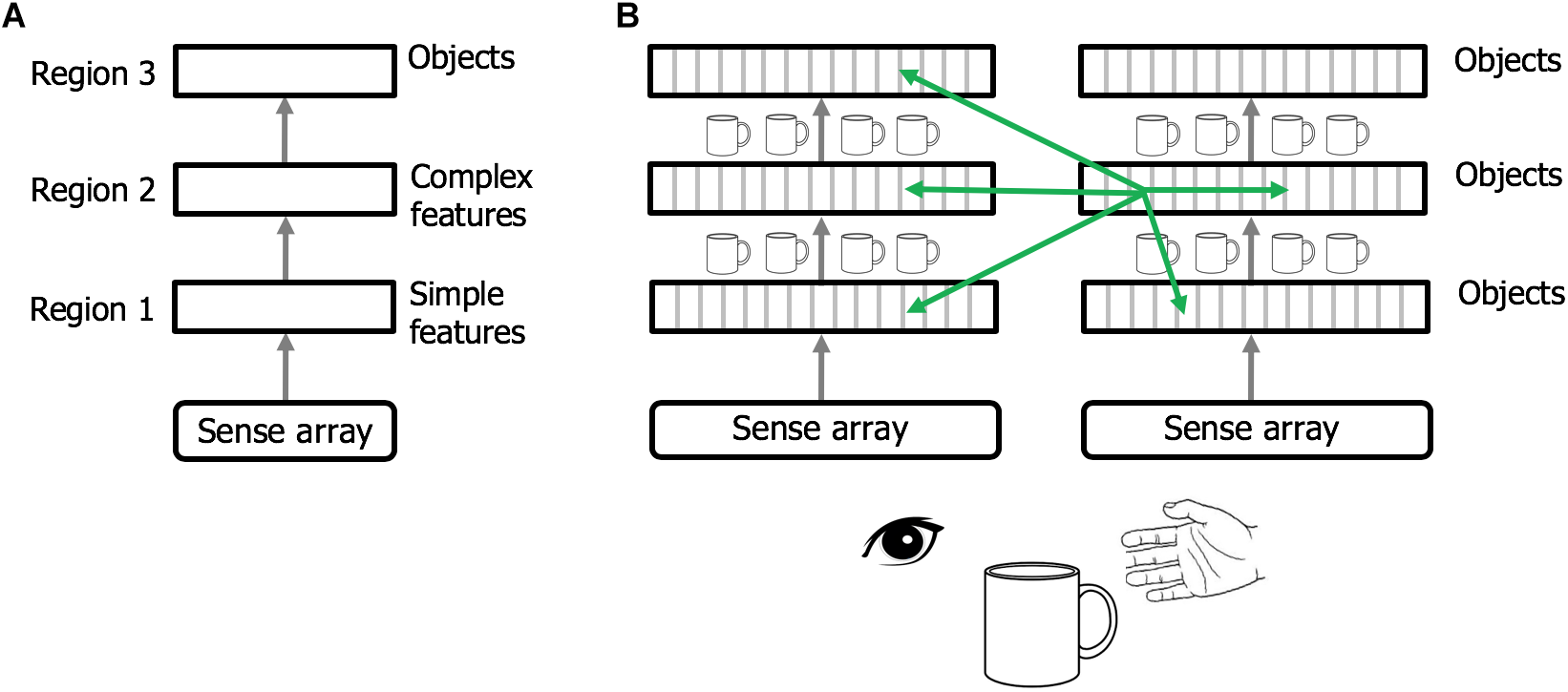
Rethinking cortical hierarchy. (A) Commonly held view of cortical hierarchy. Sensory input is processed in a hierarchy of cortical regions. The first region detects simple features. The next region combines simple features into more complex features. This is repeated until a region at the top of the hierarchy forms representations of complete objects. (B) Modified view of cortical hierarchy. Every column in every region learns complete models of objects. (Columns learn complete models by combining sensory input with an object-centric location of that input and integrating over movements of the sensor.). Shown are two sensory hierarchies, one for vision and one for touch, both sensing the same object, a cup. There are multiple models of an object within each region, in different regions within a sensory modality, and in different sensory modalities. Although there are many models of the same object (suggested by the small cup images), the models are not identical, as each model is learned via a different subset of the sensory arrays. The green arrows denote the numerically-large cortical-cortical connections that are not hierarchical in nature. The non-hierarchical connections project within the region of origin, across hierarchical levels, across modalities, and between hemispheres. Typically, many columns will be simultaneously observing the same object. The non-hierarchical connections between columns allow them to rapidly infer the correct object (see text). Although learning objects requires movement of the sensors, inference often occurs without movement due to the non-hierarchical connections.
We propose that cortical columns are more powerful than currently believed. Every cortical column learns models of complete objects. They achieve this by combining input with a grid cell-derived location, and then integrating over movements (see Hawkins et al., 2017; Lewis et al., 2018 for details). This suggests a modified interpretation of the cortical hierarchy, where complete models of objects are learned at every hierarchical level, and every region contains multiple models of objects (Figure 6B).
Feedforward and feedback projections between regions typically connect to multiple levels of the hierarchy (only one level of connection is shown in Figure 6). For example, the retina projects to thalamic relay cells in LGN, which then project to cortical regions V1, V2, and V4, not just V1. This form of “level skipping” is the rule, not the exception. Therefore, V1 and V2 are both, to some extent, operating on retinal input. The connections from LGN to V2 are more divergent suggesting that V2 is learning models at a different spatial scale than V1. We predict that the spatial scale of cortical grid cells in V2 will similarly be larger than those in V1. The level of convergence of input to a region, paired with the spatial scale of its grid cells, determines the range of object sizes the region can learn. For example, imagine recognizing printed letters of the alphabet. Letters at the smallest discernable size will be recognized in V1 and only V1. The direct input to V2 will lack the feature resolution needed. However, larger printed letters would be recognized in both V1 and V2, and even larger letters may be too large for V1 but recognizable in V2. Hierarchical processing still occurs. All we are proposing is that when a region such as V1 passes information to another region such as V2, it is not passing representations of unclassified features but, if it can, it passes representations of complete objects. This would be difficult to observe empirically if objects are represented by population codes as proposed in Hawkins et al. (2017). Individual neurons would participate in many different object representations and if observed in isolation will appear to represent sensory features, not objects. The number of objects that a cortical column can learn is large but limited (Hawkins et al., 2017). Not every column can learn every object. Analysis of system capacity requires a more thorough understanding of hierarchical flow and is beyond the scope of this paper.
There are many cortical-cortical projections that are inconsistent with pure hierarchical processing (Figure 6B, green arrows). For example, there are long range projections between regions in the left and right hemispheres (Clarke and Zaidel, 1994), and there are numerous connections between regions in different sensory modalities, even at the lowest levels of the hierarchy (Schroeder and Foxe, 2005; Driver and Noesselt, 2008; Suter and Shepherd, 2015). These connections may not be hierarchical as their axons terminate on cells located outside of cellular layers associated with feedforward or feedback input. It has been estimated that 40% of all possible region-to-region connections actually exist which is much larger than a pure hierarchy would suggest (Felleman and Van Essen, 1991). What is the purpose of these long-range non-hierarchical connections? In Hawkins et al. (2017) we proposed that cell activity in some layers (e.g., L4 and L6) of a column changes with each new sensation, whereas, cell activity in other layers (e.g., L2/3), representing the observed “object,” are stable over changing input. We showed how long-range associative connections in the “object” layer allow multiple columns to vote on what object they are currently observing. For example, if we see and touch a coffee cup there will be many columns simultaneously observing different parts of the cup. These columns will be in multiple levels of both the visual and somatosensory hierarchies. Every one of these columns has a unique sensory input and a unique location, and therefore, long-range connections between the cells representing location and input do not make sense. However, if the columns are observing the same object, then connections between cells in the object layer allow the columns to rapidly settle on the correct object. Thus, non-hierarchical connections between any two regions, even primary and secondary sensory regions in different sensory modalities, make sense if the two regions often observe the same object at the same time (see Hawkins et al., 2017 for details).
One of the classic questions about perception is how does the neocortex fuse different sensory inputs into a unified model of a perceived object. We propose that the neocortex implements a decentralized model of sensor fusion. For example, there is no single model of a coffee cup that includes what a cup feels like and looks like. Instead there are 100s of models of a cup. Each model is based on a unique subset of sensory input within different sensory modalities. There will be multiple models based on visual input and multiple models based on somatosensory input. Each model can infer the cup on its own by observing input over movements of its associated sensors. However, long-range non-hierarchical connections allow the models to rapidly reach a consensus of the identity of the underlying object, often in a single sensation.
Just because each region learns complete models of objects does not preclude hierarchical flow. The main idea is that the neocortex has 100s, likely 1000s, of models of each object in the world. The integration of observed features does not just occur at the top of the hierarchy, it occurs in every column at all levels of the hierarchy. We call this “The Thousand Brains Theory of Intelligence.”
Discussion
Crick (1979) wrote an essay titled, “Thinking about the Brain.” In it he wrote, “In spite of the steady accumulation of detailed knowledge, how the human brain works is still profoundly mysterious.” He posited that over the coming years we would undoubtedly accumulate much more data about the brain, but it may not matter, as “our entire way of thinking about such problems may be incorrect.” He concluded that we lacked a “theoretical framework,” a framework in which we can interpret experimental findings and to which detailed theories can be applied. Nearly 40 years after Crick wrote his essay, his observations are still largely valid.
Arguably, the most progress we have made toward establishing a theoretical framework is based on the discovery of place cells and grid cells in the hippocampal complex. These discoveries have suggested a framework for how animals learn maps of environments, and how they navigate through the world using these maps. The success of this framework has led to an explosion of interest in studying the entorhinal cortex and hippocampus.
In this paper we are proposing a theoretical framework for understanding the neocortex. Our proposed cortical framework is a derivative of the framework established by grid cells and place cells. Mechanisms that evolved for learning the structure of environments are now applied to learning the structure of objects. Mechanisms that evolved for tracking the location of an animal in its environments are now applied to tracking the location of limbs and sensory organs relative to objects in the world. How far this analogy can be taken is uncertain. Within the circuits formed by the hippocampus, subiculum, and entorhinal cortex are grid cells (Hafting et al., 2005), place cells (O’Keefe and Dostrovsky, 1971; O’Keefe and Burgess, 2005), head direction cells (Taube et al., 1990; Giocomo et al., 2014; Winter et al., 2015), border cells (Lever et al., 2009), object vector cells (Deshmukh and Knierim, 2013), and others, plus many conjunctive cells that exhibit properties that are combinations of these (Sargolini et al., 2006; Brandon et al., 2011; Stensola et al., 2012; Hardcastle et al., 2017). We are currently exploring the idea that the neocortex contains cells that perform equivalent functions to the variety of cells found in the hippocampal complex. The properties of these cells would only be detectable in an awake animal actively sensing learned objects. The recent work of Long and Zhang (2018) suggests this might be true.
Orientation
In the entorhinal cortex, and elsewhere in the brain, are found head direction cells (Taube et al., 1990; Sargolini et al., 2006; Brandon et al., 2011; Giocomo et al., 2014; Winter et al., 2015; Raudies et al., 2016). These cells represent the allocentric orientation of an animal relative to its environment. Inferring where you are via sensation, predicting what you will sense after moving, and determining how to move to get to a new location all require knowing your current orientation relative to your environment. In the models reviewed in Hasselmo (2009) and Hasselmo et al. (2010) head direction cells are critical for accurately transitioning between spatial locations. The same need for orientation exists throughout the neocortex. For example, knowing that a finger is at a particular location on a coffee cup is not sufficient. The finger also has an orientation relative to the cup (which way it is rotated and its angle at contact). Predicting what the finger will sense when it contacts the cup or what movement is required to reach a new location on the cup requires knowing the finger’s orientation relative to the cup in addition to its location. Therefore, we predict that within each cortical column there will be a representation of orientation that performs an analogous function to head direction cells in the hippocampal complex. How orientation is represented in the cortex is unknown. There could be a set of orientation cells each with a preferred orientation, similar to head direction cells, but we are not aware of any evidence for this. Alternately, orientation could be represented via a population code, which would be more difficult to detect. For example, in somatosensory regions orientation could be represented by activating a sparse subset of egocentric orientation detectors (Hsiao et al., 2002; Bensmaia et al., 2008; Pruszynski and Johansson, 2014). How orientation is represented and interacts with cortical grid cells and displacement cells is largely unknown. It is an area we are actively studying.
Prediction
A long standing principle behind many theories of cortical function is prediction (Lashley, 1951; Rao and Ballard, 1999; Hawkins and Blakeslee, 2004; Lotter et al., 2018). By representing the location of a sensor, a cortical column can associate sensory information within the location space of each object, similar to the way place cells associate sensory information with locations (O’Keefe and Nadel, 1978; Komorowski et al., 2009). This enables a column to build powerful predictive models. For example, when moving your finger from the bottom of a cup to the top, it can predict the sensation regardless of how the cup is rotated with respect to the sensor. Representing composite objects using displacement cells enables a column to generalize and predict sensations even when encountering a novel object. For example, suppose we see a cup with a familiar logo (Figure 3A) and that portions of the logo are obscured. Once a column has recognized the logo and the cup, it can make predictions regarding the entire logo in relation to the cup even if that combined object is new. Building such predictive models would be much harder without an explicit representation of location. In previous papers we proposed dendritic mechanisms that could serve as the neural basis for predictive networks (Hawkins and Ahmad, 2016; Hawkins et al., 2017). Overall, prediction underlies much of the framework discussed in this paper.
Attention
One of the key elements of a location-based framework for cortical processing is the ability of an area of cortex to rapidly switch between object spaces. To learn there is a logo on the coffee cup we need to alternate our attention between the cup and the logo. With each shift of attention, the cortical grid cells re-anchor to the location space of the newly attended object. This shift to a new object space is necessary to represent the displacement between two objects, such as the logo and the cup. It is normal to continuously shift our attention between the objects around us. With each newly attended object the cortical grid cells re-anchor in the space of the new object, and displacement cells represent where the new object is relative to the previously attended object. Changing attention is intimately tied to movement of the sensor, re-anchoring of grid cells, and, as widely believed, feedback signals to the thalamus (Crick, 1984; McAlonan et al., 2006), presumably to select a subset of input for processing. How these elements work together is poorly understood and represents an area for further study.
Uniqueness of Location Code
Our proposal is based on the idea that a set of grid cell modules can encode a very large number of unique locations. There are some observations that suggest that grid cells, on their own, may not be capable of forming enough unique codes. For example, because each grid cell exhibits activity over a fairly large area of physical space (Hafting et al., 2005), the activation of the cells in a grid cell module is not very sparse. Sparsity is helpful for creating easily discernable unique codes. The lack of sparsity can be overcome by sampling the activity over more grid cell modules, but not enough is known about the size of grid cell modules and how many can be realistically sampled (Gu et al., 2018) have shown that grid cell modules are composed of smaller sub-units that activate independently, which would also increase the representation capacity of grid cells. Another factor impacting capacity is conjunctive cells. In the entorhinal cortex there are more conjunctive cells than pure grid cells. Conjunctive cells exhibit some combination of “gridness” plus orientation and/or other factors (Sargolini et al., 2006). Conjunctive cells may have a sparser activation than pure grid cells and therefore would be a better basis for forming a set of unique location codes. If the neocortex has cells similar to conjunctive cells, they also might play a role in location coding. Not enough is known about how grid cells, orientation cells, and conjunctive cells work together to suggest exactly how locations are encoded in the neocortex. As we learn more about location coding in the neocortex, it is important to keep these possibilities in mind.
Where Are Grid Cells and Displacement Cells in the Neocortex?
The neocortex is commonly divided into six layers that run parallel to the surface. There are dozens of different cell types, therefore, each layer contains multiple cell types. Several lines of evidence suggest that cortical grid cells are located in L6 [specifically L6 cortical-cortical neurons (Thomson, 2010)] and displacement cells are located in L5 (specifically L5 thick-tufted neurons) (Figure 7).
FIGURE 7
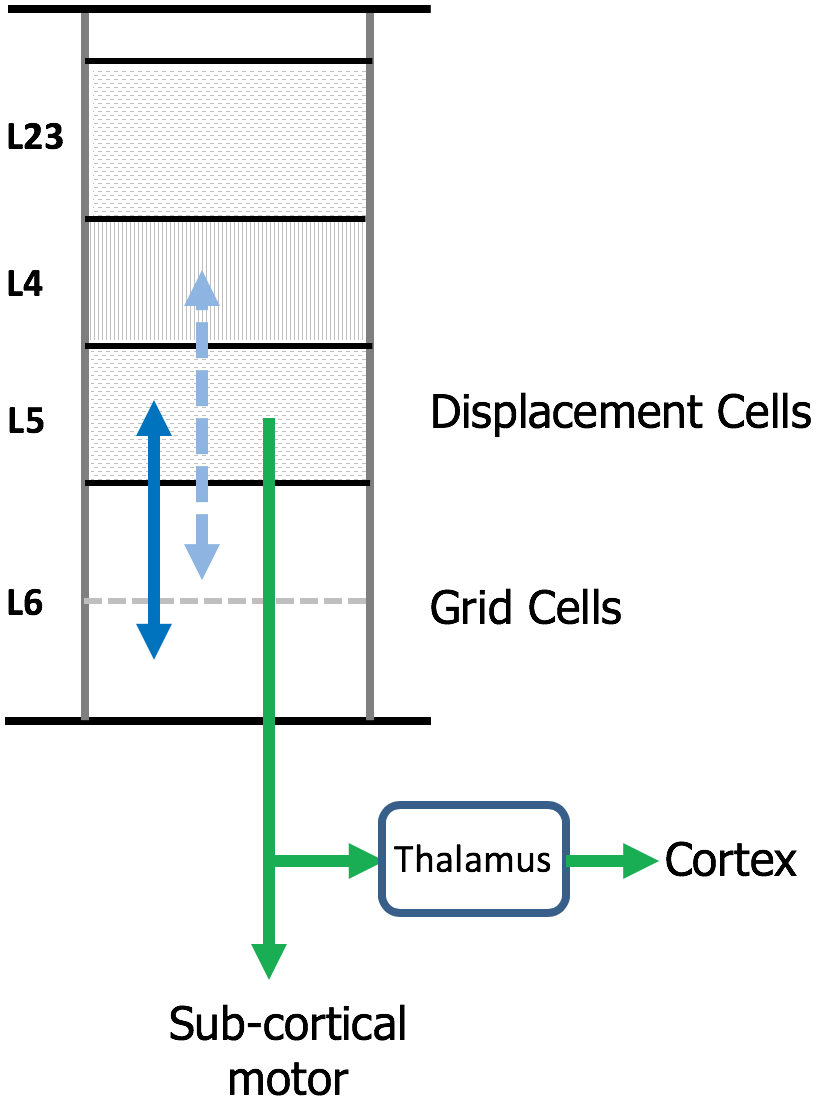
Location of grid cells and displacement cells in the neocortex. The neocortex contains dozens of cell types commonly organized into six cellular layers. Here, we show a simple drawing of a cortical column. We propose cortical grid cells are located in layer 6 and displacement cells are in layer 5. A requirement of our proposal is that cortical grid cells make bi-lateral connections with displacement cells (solid blue line). Another requirement is that, when combined with a representation of orientation, they make bi-lateral connections with cells in layer 4 (dashed blue line). This is how the column predicts the next input into layer 4. Displacement cells match the unusual connectivity of layer 5 “thick tufted” neurons, which are the motor output cells of the neocortex. These neurons send their axon down into the white matter where the axon splits (green arrows). One branch terminates in sub-cortical structures responsible for motor behavior. The second axon branch terminates on relay cells in the thalamus which become the feedforward input to a hierarchically-higher cortical region. As explained in the text, displacement cells can alternate between representing movements and representing the composition of multiple objects. We propose that L5 thick tufted cells alternate between these two functions which aligns with their unusual connectivity.
One piece of evidence suggesting cortical grid cells are in L6 is the unusual connectivity between L4 and L6. L4 is the primary input layer. However, feed forward input forms less than 10% of the synapses on L4 cells (Ahmed et al., 1994, 1997; Sherman and Guillery, 2013), whereas approximately 45% of the synapses on L4 cells come from L6a cortical-cortical neurons (Ahmed et al., 1994; Binzegger et al., 2004). Similarly, L4 cells make large numbers of synapses onto those same L6 cells (McGuire et al., 1984; Binzegger et al., 2004; Kim et al., 2014). Also, the connections between L6 and L4 are relatively narrow in spread (Binzegger et al., 2004). The narrow connectivity between L6 and L4 is reminiscent of the topologically-aligned bidirectional connectivity between grid cells in MEC and place cells in hippocampus (Rowland et al., 2013; Zhang et al., 2013). We previously showed how the reciprocal connections between L6 and L4 can learn the structure of objects by movement of sensors if L6 represents a location in the space of the object (Lewis et al., 2018). For a column to learn the structure of objects in this fashion requires bidirectional connections between cells receiving sensory input and cells representing location. L6a is the only known set of cells that meet this requirement. Also, grid cells use motor input to update their representations for path integration. Experiments show significant motor projections to L6 (Nelson et al., 2013; Leinweber et al., 2017). The current experimental evidence for the presence of grid cells in the neocortex is unfortunately mute on what cortical layers contain grid cells. It should be possible to experimentally determine this in the near future. Our prediction is they will be in L6.
The main evidence for displacement cells being in L5 is again connectivity. A subset of L5 cells (known as “L5 thick-tufted cells”) that, as far as we know exists in all cortical regions, projects sub-cortically to brain regions involved with motor behavior. (For example, L5 cells in the visual cortex project to the superior colliculus which controls eye movements.) These L5 cells are the motor output cells of the neocortex. However, the same L5 cells send a branch of their axon to thalamic relay nuclei, which then project to hierarchically higher cortical regions (Douglas and Martin, 2004; Guillery and Sherman, 2011; Sherman and Guillery, 2011). It is difficult to understand how the same L5 cells can be both the motor output and the feedforward input to other regions. One interpretation put forth by Guillery and Sherman is that L5 cells represent a motor command and that the feedforward L5 projection can be interpreted as an efference copy of the motor command (Guillery and Sherman, 2002, 2011).
We offer a possible alternate interpretation. The L5 cells in question are displacement cells and they alternately represent movements (sent sub-cortically) and then represent compositional objects (sent to higher regions via thalamic relay cells). As described above, displacement cells will represent a movement vector when comparing two locations in the same space and will represent composite objects when comparing two locations in two different spaces. These two rapidly-changing representations could be disambiguated at their destination either by phase of an oscillatory cycle or by physiological firing patterns (Burgess et al., 2007; Hasselmo, 2008; Hasselmo and Brandon, 2012). Although we are far from having a complete understanding of what the different cellular layers do and how they work together, a location-based framework offers the opportunity of looking anew at the vast body of literature on cortical anatomy and physiology and making progress on this problem.
Location-Based Framework for High-Level Thought and Intelligence
We have described our location-based framework using examples from sensory inference. Given that the anatomy in all cortical regions is remarkably similar, it is highly likely that everything the neocortex does, including language and other forms of high-level thought, will be built upon the same location-based framework. In support of this idea, the current empirical evidence that grid cells exist in the neocortex was collected from humans performing what might be called “cognitive tasks,” and it was detected in cortical regions that are far from direct sensory input (Doeller et al., 2010; Jacobs et al., 2013; Constantinescu et al., 2016).
The location-based framework can be applied to physical structures, such as a cup, and to abstract concepts, such as mathematics and language. A cortical column is fundamentally a system for learning predictive models. The models are learned from inputs and movements that lead to changes in the input. Successful models are ones that can predict the next input given the current state and an anticipated movement. However, the “inputs” and “movements” of a cortical column do not have to correspond to physical entities. The “input” to a column can originate from the retina or it can originate from other regions of the neocortex that have already recognized a visual object such as a word or a mathematical expression. A “movement” can represent the movement of the eyes or it can represent an abstract movement, such as a verb or a mathematical operator.
Success in learning a predictive model requires discovering the correct dimensionality of the space of the object, learning how movements update locations in that space, and associating input features with specific locations in the space of the object. These attributes apply to both sensory perception and high-level thought. Imagine a column trying to learn a model of a cup using visual input from the retina and movement input from a finger. This would fail, as the location spaced traversed by the finger would not map onto the feature space of the object as evidenced by the changing inputs from the eyes. Similarly, when trying to understand a mathematical problem you might fail when using one operator to manipulate an equation but succeed by switching to a different operator.
Grid cells in the neocortex suggests that all knowledge is learned and stored in the context of locations and location spaces and that “thinking” is movement through those location spaces. We have a long way to go before we understand the details of how the neocortex performs cognitive functions, however, we believe that the location-based framework will not only be at the core of the solutions to these problems, but will suggest solutions.
Conclusion
It is sometimes said that neuroscience is “data rich and theory poor.” This notion is especially true for the neocortex. We are not lacking empirical data as much as lacking a theoretical framework that can bridge the gap between the heterogeneous capabilities of perception, cognition, and intelligence and the homogeneous circuitry observed in the neocortex. The closest we have to such a framework today is hierarchical feature extraction, which is widely recognized as insufficient.
One approach to developing a theory of neocortical function is to build in-silico models of a cortical column based on detailed anatomical data (Helmstaedter et al., 2007; Markram et al., 2015). This approach starts with anatomy and hopes to discover theoretical principles via simulation of a cortical column. We have used a different method. We start with a detailed function that we know the neocortex performs (such as sensory-motor learning and inference), we deduce neural mechanisms that are needed to perform those functions (such as cells that represent location), and then map those neural mechanisms onto detailed biological data.
Based on this method, this paper proposes a new framework for understanding how the neocortex works. We propose that grid cells are present everywhere in the neocortex. Cortical grid cells track the location of inputs to the neocortex in the reference frames of the objects being observed. We propose the existence of a new type of neuron, displacement cells, that complement grid cells, and are similarly present throughout the neocortex. The framework shows how it is possible that a small patch of cortex can represent and learn the morphology of objects, how objects are composed of other objects, and the behaviors of objects. The framework also leads to a new interpretation of how the neocortex works overall. Instead of processing input in a series of feature extraction steps leading to object recognition at the top of the hierarchy, the neocortex consists of 1000s of models operating in parallel as well as hierarchically.
Introspection can sometimes reveal basic truths that are missed by more objective experimental techniques. As we go about our day we perceive 1000s of objects, such as trees, printed and spoken words, buildings, and people. Everything is perceived at a location. As we attend to each object we perceive the distance and direction from ourselves to these objects, and we perceive where they are relative to each other. The sense of location and distance is inherent to perception, it occurs without effort or delay. It is self-evident that the brain must have neural representations for the locations of objects and for the distances between the objects as we attend to them in succession. The novelty of our claim is that these locations and distances are calculated everywhere in the neocortex, they are the principal data types of cortical function, perception, and intelligence.
Statements
Author contributions
JH, together with ML, MK, SP, and SA conceived of the overall theory and mapping to neuroscience. JH, together with SA, wrote the majority of the manuscript. ML, MK, and SP participated in writing, editing, and revising the manuscript.
Funding
Numenta is a privately held company. Its funding sources are independent investors and venture capitalists.
Acknowledgments
We thank the reviewers for many helpful and detailed comments which have significantly improved the overall manuscript. We thank David Eagleman, Weinan Sun, Michael Hasselmo, and Mehmet Fatih Yanik for their feedback and help with this manuscript. We also thank numerous collaborators at Numenta over the years for many discussions, especially Donna Dubinsky, Christy Maver, Celeste Baranski, Luiz Scheinkman, and Teri Fry. We also note that a version of this paper has been posted to the preprint server bioRxiv (Hawkins et al., 2018).
Conflict of interest
JH, ML, MK, SP, and SA were employed by Numenta, Inc. Numenta has some patents relevant to the work. Numenta has stated that use of its intellectual property, including all the ideas contained in this work, is free for non-commercial research purposes. In addition Numenta has released all pertinent source code as open source under an AGPL V3 license (which includes a patent peace provision).
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncir.2018.00121/full#supplementary-material
References
1
AhmedB.AndersonJ. C.DouglasR. J.MartinK. A.NelsonJ. C. (1994). Polyneuronal innervation of spiny stellate neurons in cat visual cortex.J. Comp. Neurol.34116–24. 10.1002/cne.903410103
2
AhmedB.AndersonJ. C.MartinK. A.NelsonJ. C. (1997). Map of the synapses onto layer 4 basket cells of the primary visual cortex of the cat.J. Comp. Neurol.380230–242. 10.1002/(SICI)1096-9861(19970407)380:2<230::AID-CNE6>3.0.CO;2-4
3
BehrensT. E. J.MullerT. H.WhittingtonJ. C. R.MarkS.BaramA. B.StachenfeldK. L.et al (2018). What is a cognitive map? Organizing knowledge for flexible behavior.Neuron100490–509. 10.1016/J.NEURON.2018.10.002
4
BensmaiaS. J.DenchevP. V.DammannJ. F.CraigJ. C.HsiaoS. S. (2008). The representation of stimulus orientation in the early stages of somatosensory processing.J. Neurosci.28776–786. 10.1523/JNEUROSCI.4162-07.2008
5
BinzeggerT.DouglasR. J.MartinK. A. C. (2004). A quantitative map of the circuit of cat primary visual cortex.J. Neurosci.248441–8453. 10.1523/JNEUROSCI.1400-04.2004
6
BrandonM. P.BogaardA. R.LibbyC. P.ConnerneyM. A.GuptaK.HasselmoM. E. (2011). Reduction of theta rhythm dissociates grid cell spatial periodicity from directional tuning.Science332595–599. 10.1126/SCIENCE.1201652
7
BurakY.FieteI. R. (2009). Accurate path integration in continuous attractor network models of grid cells.PLoS Comput. Biol.5:e1000291. 10.1371/journal.pcbi.1000291
8
BurgessN. (2008). Grid cells and theta as oscillatory interference: theory and predictions.Hippocampus181157–1174. 10.1002/hipo.20518
9
BurgessN.CaswellB.O’KeefeJ. (2007). An oscillatory interference model of grid cell firing.Hippocampus17801–812. 10.1002/hipo
10
BushD.BarryC.MansonD.BurgessN. (2015). Using grid cells for navigation.Neuron87507–520. 10.1016/j.neuron.2015.07.006
11
ByrneP.BeckerS.BurgessN. (2007). Remembering the past and imagining the future: a neural model of spatial memory and imagery.Psychol. Rev.114340–375. 10.1037/0033-295X.114.2.340
12
ClarkeJ. M.ZaidelE. (1994). Anatomical-behavioral relationships: Corpus callosum morphometry and hemispheric specialization.Behav. Brain Res.64185–202. 10.1016/0166-4328(94)90131-7
13
ConstantinescuA. O.O’ReillyJ. X.BehrensT. E. J. (2016). Organizing conceptual knowledge in humans with a gridlike code.Science3521464–1468. 10.1126/science.aaf0941
14
CrickF. (1984). Function of the thalamic reticular complex: the searchlight hypothesis.Proc. Natl. Acad. Sci. U.S.A.814586–4590. 10.1073/pnas.81.14.4586
15
CrickF. H. (1979). Thinking about the brain.Sci. Am.241219–232. 10.1038/scientificamerican0979-219
16
DeshmukhS. S.KnierimJ. J. (2013). Influence of local objects on hippocampal representations: landmark vectors and memory.Hippocampus23253–267. 10.1002/hipo.22101
17
DoellerC. F.BarryC.BurgessN. (2010). Evidence for grid cells in a human memory network.Nature463657–661. 10.1038/nature08704
18
DomnisoruC.KinkhabwalaA. A.TankD. W. (2013). Membrane potential dynamics of grid cells.Nature495199–204. 10.1038/nature11973
19
DouglasR. J.MartinK. A. C. (2004). Neuronal circuits of the neocortex.Annu. Rev. Neurosci.27419–451. 10.1146/annurev.neuro.27.070203.144152
20
DriverJ.NoesseltT. (2008). Multisensory interplay reveals crossmodal influences on ‘sensory-specific’ brain regions, neural responses, and judgments.Neuron5711–23. 10.1016/J.NEURON.2007.12.013
21
ErdemU. M.HasselmoM. E. (2014). A biologically inspired hierarchical goal directed navigation model.J. Physiol. Paris10828–37. 10.1016/j.jphysparis.2013.07.002
22
FellemanD. J.Van EssenD. C. (1991). Distributed hierarchical processing in the primate cerebral cortex.Cereb. Cortex11–47. 10.1093/cercor/1.1.1
23
FieteI. R.BurakY.BrookingsT. (2008). What grid cells convey about rat location.J. Neurosci.286858–6871. 10.1523/JNEUROSCI.5684-07.2008
24
FuhsM. C.TouretzkyD. S. (2006). A spin glass model of path integration in rat medial entorhinal cortex.J. Neurosci.10436–447. 10.1523/jneurosci.4353-05.2006
25
FukushimaK. (1980). Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.Biol. Cybern.36193–202. 10.1007/BF00344251
26
GiocomoL. M.MoserM. B.MoserE. I. (2011). Computational models of grid cells.Neuron71589–603. 10.1016/j.neuron.2011.07.023
27
GiocomoL. M.StensolaT.BonnevieT.Van CauterT.MoserM.-B.MoserE. I. (2014). Topography of head direction cells in medial entorhinal cortex.Curr. Biol.24252–262. 10.1016/J.CUB.2013.12.002
28
GiocomoL. M.ZilliE. A.FransénE.HasselmoM. E. (2007). Temporal frequency of subthreshold oscillations scales with entorhinal grid cell field spacing.Science3151719–1722. 10.1126/science.1139207
29
GoodaleM. A.MilnerA. D. (1992). Separate visual pathways for perception and action.Trends Neurosci.1520–25. 10.1016/0166-2236(92)90344-8
30
GuY.LewallenS.KinkhabwalaA. A.DomnisoruC.YoonK.GauthierJ. L.et al (2018). A map-like micro-organization of grid cells in the medial entorhinal cortex.Cell175736–750.e30. 10.1016/j.cell.2018.08.066
31
GuilleryR. W.ShermanS. M. (2002). The thalamus as a monitor of motor outputs.Philos. Trans. R. Soc. B Biol. Sci.3571809–1821. 10.1098/rstb.2002.1171
32
GuilleryR. W.ShermanS. M. (2011). Branched thalamic afferents: what are the messages that they relay to the cortex?Brain Res. Rev.66205–219. 10.1016/j.brainresrev.2010.08.001
33
HaftingT.FyhnM.MoldenS.MoserM.-B.MoserE. I. (2005). Microstructure of a spatial map in the entorhinal cortex.Nature436801–806. 10.1038/nature03721
34
HardcastleK.GanguliS.GiocomoL. M. (2017). Cell types for our sense of location: where we are and where we are going.Nat. Neurosci.201474–1482. 10.1038/nn.4654
35
HasselmoM. (2012). How we Remember: Brain Mechanisms of Episodic Memory.Cambridge, MA: MIT Press.
36
HasselmoM. E. (2008). Grid cell mechanisms and function: contributions of entorhinal persistent spiking and phase resetting.Hippocampus181213–1229. 10.1002/hipo.20512
37
HasselmoM. E. (2009). A model of episodic memory: mental time travel along encoded trajectories using grid cells.Neurobiol. Learn. Mem.92559–573. 10.1016/j.nlm.2009.07.005
38
HasselmoM. E.BrandonM. P. (2012). A model combining oscillations and attractor dynamics for generation of grid cell firing.Front. Neural Circuits6:30. 10.3389/fncir.2012.00030
39
HasselmoM. E.GiocomoL. M.BrandonM. P.YoshidaM. (2010). Cellular dynamical mechanisms for encoding the time and place of events along spatiotemporal trajectories in episodic memory.Behav. Brain Res.215261–274. 10.1016/j.bbr.2009.12.010
40
HawkinsJ.AhmadS. (2016). Why neurons have thousands of synapses, a theory of sequence memory in neocortex.Front. Neural Circuits10:23. 10.3389/fncir.2016.00023
41
HawkinsJ.AhmadS.CuiY. (2017). A theory of how columns in the neocortex enable learning the structure of the world.Front. Neural Circuits11:81. 10.3389/FNCIR.2017.00081
42
HawkinsJ.BlakesleeS. (2004). On Intelligence.New York, NY: Times Books.
43
HawkinsJ.LewisM.KlukasM.PurdyS.AhmadS. (2018). A framework for intelligence and cortical function based on grid cells in the neocortex.bioRxiv [Preprint]. 10.1101/442418
44
HelmstaedterM.de KockC. P. J.FeldmeyerD.BrunoR. M.SakmannB. (2007). Reconstruction of an average cortical column in silico.Brain Res. Rev.55193–203. 10.1016/J.BRAINRESREV.2007.07.011
45
HsiaoS. S.LaneJ.FitzgeraldP. (2002). Representation of orientation in the somatosensory system.Behav. Brain Res.13593–103. 10.1016/S0166-4328(02)00160-2
46
JacobsJ.WeidemannC. T.MillerJ. F.SolwayA.BurkeJ. F.WeiX. X.et al (2013). Direct recordings of grid-like neuronal activity in human spatial navigation.Nat. Neurosci.161188–1190. 10.1038/nn.3466
47
JulianJ. B.KeinathA. T.FrazzettaG.EpsteinR. A. (2018). Human entorhinal cortex represents visual space using a boundary-anchored grid.Nat. Neurosci.21191–194. 10.1038/s41593-017-0049-1
48
KimJ.MatneyC. J.BlankenshipA.HestrinS.BrownS. P. (2014). Layer 6 corticothalamic neurons activate a cortical output layer, layer 5a.J. Neurosci.349656–9664. 10.1523/JNEUROSCI.1325-14.2014
49
KomorowskiR. W.MannsJ. R.EichenbaumH. (2009). Robust conjunctive item-place coding by hippocampal neurons parallels learning what happens where.J. Neurosci.299918–9929. 10.1523/JNEUROSCI.1378-09.2009
50
KropffE.CarmichaelJ. E.MoserM.-B.MoserE. I. (2015). Speed cells in the medial entorhinal cortex.Nature523419–424. 10.1038/nature14622
51
LashleyK. S. (1951). “The problem of serial order in behavior.” in Cerebral Mechanisms in Behavior; the Hixon Symposium, ed.JeffresL. A. (New York, NY: Wiley), 112–131.
52
LeCunY.BengioY.HintonG. (2015). Deep learning.Nature521436–444. 10.1038/nature14539
53
LeinweberM.WardD. R.SobczakJ. M.AttingerA.KellerG. B. (2017). A sensorimotor circuit in mouse cortex for visual flow predictions.Neuron951420–1432.e5. 10.1016/j.neuron.2017.08.036
54
LeverC.BurtonS.JeewajeeA.O’KeefeJ.BurgessN. (2009). Boundary vector cells in the subiculum of the hippocampal formation.J. Neurosci.299771–9777. 10.1523/JNEUROSCI.1319-09.2009
55
LewisM.PurdyS.AhmadS.HawkinsJ. (2018). Locations in the neocortex: a theory of sensorimotor object recognition using cortical grid cells.bioRxiv [Preprint]. 10.1101/436352
56
LongX.ZhangS.-J. (2018). A novel somatosensory spatial navigation system outside the hippocampal formation.bioRxiv [Preprint]. 10.1101/473090
57
LotterW.KreimanG.CoxD. (2018). A neural network trained to predict future video frames mimics critical properties of biological neuronal responses and perception.arXiv [Preprint]. arXiv:1805.10734
58
MarkovN. T.VezoliJ.ChameauP.FalchierA.QuilodranR.HuissoudC.et al (2014). Anatomy of hierarchy: feedforward and feedback pathways in macaque visual cortex.J. Comp. Neurol.522225–259. 10.1002/cne.23458
59
MarkramH.MullerE.RamaswamyS.ReimannM. W.AbdellahM.SanchezC. A.et al (2015). Reconstruction and simulation of neocortical microcircuitry.Cell163456–492. 10.1016/j.cell.2015.09.029
60
MarozziE.GinzbergL. L.AlendaA.JefferyK. J. (2015). Purely translational realignment in grid cell firing patterns following nonmetric context change.Cereb. Cortex254619–4627. 10.1093/cercor/bhv120
61
McAlonanK.CavanaughJ.WurtzR. H. (2006). Attentional modulation of thalamic reticular neurons.J. Neurosci.264444–4450. 10.1523/JNEUROSCI.5602-05.2006
62
McGuireB. A.HornungJ. P.GilbertC. D.WieselT. N. (1984). Patterns of synaptic input to layer 4 of cat striate cortex.J. Neurosci.43021–3033. 10.1523/JNEUROSCI.04-12-03021.1984
63
McNaughtonB. L.BattagliaF. P.JensenO.MoserE. I.MoserM.-B. (2006). Path integration and the neural basis of the “cognitive map”.Nat. Rev. Neurosci.7663–678. 10.1038/nrn1932
64
MoserE. I.KropffE.MoserM.-B. (2008). Place cells, grid cells, and the brain’s spatial representation system.Annu. Rev. Neurosci.3169–89. 10.1146/annurev.neuro.31.061307.090723
65
MountcastleV. (1978). “An organizing principle for cerebral function: the unit model and the distributed system,” inThe Mindful Brain, edsEdelmanG.MountcastleV. (Cambridge, MA: MIT Press), 7–50.
66
NelsonA.SchneiderD. M.TakatohJ.SakuraiK.WangF.MooneyR. (2013). A circuit for motor cortical modulation of auditory cortical activity.J. Neurosci.3314342–14353. 10.1523/JNEUROSCI.2275-13.2013
67
O’KeefeJ.BurgessN. (2005). Dual phase and rate coding in hippocampal place cells: theoretical significance and relationship to entorhinal grid cells.Hippocampus15853–866. 10.1002/hipo.20115
68
O’KeefeJ.DostrovskyJ. (1971). The hippocampus as a spatial map. Preliminary evidence from unit activity in the freely-moving rat.Brain Res.34171–175. 10.1016/0006-8993(71)90358-1
69
O’KeefeJ.NadelL. (1978). The Hippocampus as a Cognitive Map.Oxford: Oxford University Press. 10.1017/CBO9781107415324.004
70
PruszynskiJ. A.JohanssonR. S. (2014). Edge-orientation processing in first-order tactile neurons.Nat. Neurosci.171404–1409. 10.1038/nn.3804
71
RaoR. P. N.BallardD. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nat. Neurosci.279–87. 10.1038/4580
72
RaudiesF.HinmanJ. R.HasselmoM. E. (2016). Modelling effects on grid cells of sensory input during self-motion.J. Physiol.5946513–6526. 10.1113/JP270649
73
RauscheckerJ. P. (2015). Auditory and visual cortex of primates: a comparison of two sensory systems.Eur. J. Neurosci.41579–585. 10.1111/ejn.12844
74
RiesenhuberM.PoggioT. (1999). Hierarchical models of object recognition in cortex.Nat. Neurosci.21019–1025. 10.1038/14819
75
RowlandD. C.MoserM. B. (2014). From cortical modules to memories.Curr. Opin. Neurobiol.2422–27. 10.1016/j.conb.2013.08.012
76
RowlandD. C.RoudiY.MoserM.-B.MoserE. I. (2016). Ten years of grid cells.Annu. Rev. Neurosci.3919–40. 10.1146/annurev-neuro-070815-013824
77
RowlandD. C.WeibleA. P.WickershamI. R.WuH.MayfordM.WitterM. P.et al (2013). Transgenically targeted rabies virus demonstrates a major monosynaptic projection from hippocampal area CA2 to medial entorhinal layer II neurons.J. Neurosci.3314889–14898. 10.1523/JNEUROSCI.1046-13.2013
78
SargoliniF.FyhnM.HaftingT.McNaughtonB. L.WitterM. P.MoserM. B.et al (2006). Conjunctive representation of position, direction, and velocity in entorhinal cortex.Science312758–762. 10.1126/science.1125572
79
Schmidt-HieberC.ToleikyteG.AitchisonL.RothA.ClarkB. A.BrancoT.et al (2017). Active dendritic integration as a mechanism for robust and precise grid cell firing.Nat. Neurosci.201114–1121. 10.1038/nn.4582
80
SchroederC. E.FoxeJ. (2005). Multisensory contributions to low-level, “unisensory” processing.Curr. Opin. Neurobiol.15454–458. 10.1016/j.conb.2005.06.008
81
ShermanS.GuilleryR. (2013). Thalamocortical Processing: Understanding the Messages that Link the Cortex to the World.Cambridge, MA: MIT Press.
82
ShermanS. M.GuilleryR. W. (2011). Distinct functions for direct and transthalamic corticocortical connections.J. Neurophysiol.1061068–1077. 10.1152/jn.00429.2011
83
SreenivasanS.FieteI. (2011). Grid cells generate an analog error-correcting code for singularly precise neural computation.Nat. Neurosci.141330–1337. 10.1038/nn.2901
84
StensolaH.StensolaT.SolstadT.FrølandK.MoserM. B.MoserE. I. (2012). The entorhinal grid map is discretized.Nature49272–78. 10.1038/nature11649
85
SuterB. A.ShepherdG. M. G. (2015). Reciprocal interareal connections to corticospinal neurons in mouse M1 and S2.J. Neurosci.352959–2974. 10.1523/JNEUROSCI.4287-14.2015
86
TaubeJ. S.MullerR. U.RanckJ. B. (1990). Head-direction cells recorded from the postsubiculum in freely moving rats. I. Description and quantitative analysis.J. Neurosci.10420–435. 10.1212/01.wnl.0000299117.48935.2e
87
ThomsonA. M. (2010). Neocortical layer 6, a review.Front. Neuroanat.4:13. 10.3389/fnana.2010.00013
88
UngerleiderL. G.HaxbyJ. V. (1994). “What” and “where” in the human brain.Curr. Opin. Neurobiol.4157–165. 10.1016/0959-4388(94)90066-3
89
WinterS. S.ClarkB. J.TaubeJ. S. (2015). Disruption of the head direction cell network impairs the parahippocampal grid cell signal.Science347870–874. 10.1126/science.1259591
90
ZhangS.-J.YeJ.MiaoC.TsaoA.CerniauskasI.LedergerberD.et al (2013). Optogenetic dissection of entorhinal-hippocampal functional connectivity.Science340:1232627. 10.1126/science.1232627
Summary
Keywords
neocortex, grid cell, neocortical theory, hierarchy, object recognition, cortical column
Citation
Hawkins J, Lewis M, Klukas M, Purdy S and Ahmad S (2019) A Framework for Intelligence and Cortical Function Based on Grid Cells in the Neocortex. Front. Neural Circuits 12:121. doi: 10.3389/fncir.2018.00121
Received
20 October 2018
Accepted
24 December 2018
Published
11 January 2019
Volume
12 - 2018
Edited by
Robert C. Froemke, New York University, United States
Reviewed by
Michael E. Hasselmo, Boston University, United States; Srikanth Ramaswamy, École Polytechnique Fédérale de Lausanne, Switzerland
Updates
Copyright
© 2019 Hawkins, Lewis, Klukas, Purdy and Ahmad.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jeff Hawkins, jhawkins@numenta.com
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.