 Xiaohong Cui
Xiaohong Cui Jihai Xiao
Jihai Xiao Dandan Li
Dandan Li Yan Niu
Yan Niu Jie Xiang
Jie Xiang- College of Information and Computer, Taiyuan University of Technology, Taiyuan, China
At present, the diagnosis of brain disease is mainly based on the self-reported symptoms and clinical signs of the patient, which can easily lead to psychiatrists' bias. The purpose of this study is to develop a brain network clustering model to accurately identify brain diseases based on resting state functional magnetic resonance imaging (fMRI) in the absence of clinical information. We use cosine similarity and sub-network kernels to measure attribute similarity and structure similarity, respectively. By integrating the structure similarity and attribute similarity into one matrix, spectral clustering is used to achieve brain network clustering. Finally, we evaluate this method on three diseases: Alzheimer's disease, Bipolar disorder patients, and Schizophrenia. The performance of methods is evaluated by measuring clustering consistency. Clustering consistency is similar to clustering accuracy, which is used to evaluate the consistency between the clustering labels and clinical diagnostic labels of the subjects. The experimental results show that our proposed method can significantly improve clustering performance, with a consistency of 60.6% for Alzheimer's disease, with a consistency of 100% for Schizophrenia, with a consistency of 100% for Bipolar disorder patients.
Introduction
In recent years, graph mining has become a popular research field and has been widely used in computer networks (Zou et al., 2017), social network analysis (Halder et al., 2016) and computational biology (Zhang et al., 2017). In addition, many new kinds of data can be represented as graphs, such as functional magnetic resonance imaging (fMRI) data. Using fMRI data we can construct the brain functional connectivity network in which each node represents a brain region and each edge represents the functional connectivity between two brain regions (Kong and Yu, 2014). These brain networks provide us with a means to explore the function of the human brain and provide valuable information for clinical diagnosis of neurological diseases, such as Alzheimer's disease (AD), Bipolar disorder patients (BD), and Schizophrenia (SC). Therefore, brain network analysis based on graph mining has become a new research hotspot and attracted increasingly more researchers.
In brain science studies, some brain network of subjects were given, some of whom suffered from certain brain diseases (such as AD or BD), while the other group was a normal control group without any brain disease. The next task is to distinguish the two types of subjects accurately. In this problem, most of the researchers are based on the assumption that brain networks with similar structures have similar functional characteristics. Therefore, the key problem is how to measure the similarity of brain network.
The existing similarity measure of brain networks can be classified into two main classes (Mheich et al., 2019): (1) the statistical comparison, where various graph theoretical metrics (such as efficiency and betweenness) can also be estimated at node or edge level of the compared networks (Bullmore and Bassett, 2011). These metrics are then quantitatively compared between two groups of networks via statistical tests. (2) Graph matching, where the main purpose is to quantify a similarity score between two brain networks by considering structure distance. This method includes: edit distances, hamming distance (Gao et al., 2010) and kernel methods (Shervashidze et al., 2011).
In this paper, by combining the above two class methods, a similarity measurement method of brain network based on node attribute similarity and structural similarity is proposed, and the method is applied to the clustering of brain network. We use cosine similarity and sub-network kernels to measure attribute similarity and structure similarity, respectively. By integrating the structure similarity and attribute similarity into one matrix, spectral clustering is used to achieve brain network clustering.
This framework is illustrated in Figure 1. Specifically, for each brain connectivity network, we first preprocess the fMRI data and construct a minimum spanning tree (MST) network of the Default Mode Network (DMN), then compute two different types of similarity (attribute similarity and structure similarity) and effectively integrate these for spectral clustering. Finally, we evaluate the proposed method on three datasets. One dataset was from Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. The other two dataset were selected from the UCLA Consortium for Neuropsychiatric Phenomics LA5c Study, and the study was approved by the UCLA Institutional Review Board. Cluster consistency is used to evaluate the performance of the method. The cluster consistency is similar to the clustering accuracy, which reflects the consistency between the cluster results and the clinical diagnosis results. It can be seen from the experimental results that the consistency of the proposed brain network clustering algorithm is high, which shows that the clustering of the brain network can be accurately realized without the clinical diagnosis information.
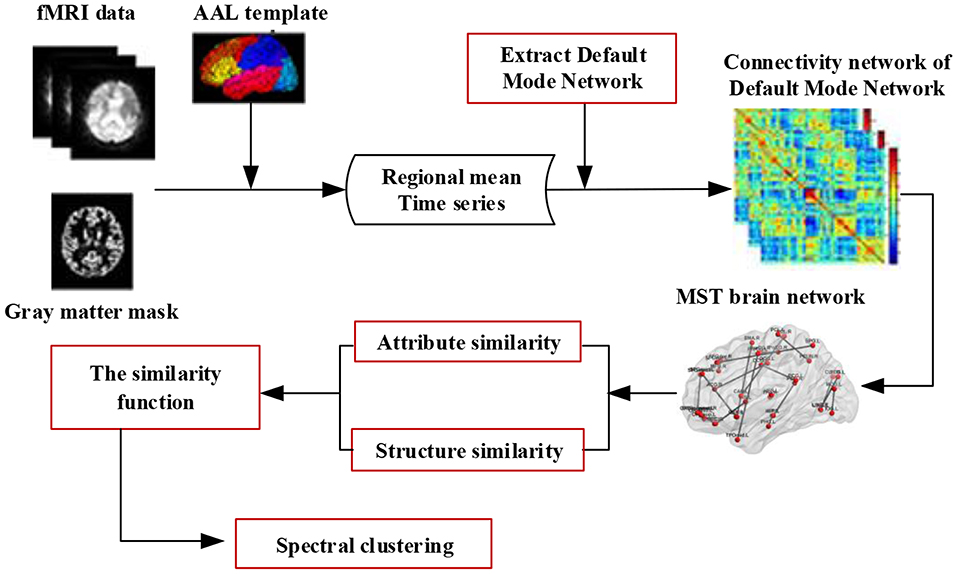
Figure 1. The framework of spectral clustering based on brain network. Firstly, the fMRI data is preprocessed, and the minimum spanning tree (MST) network of the default mode network (DMN) is constructed. Then, two different types of similarity (attribute similarity and structural similarity) are calculated. Finally, the two kinds of similarity are effectively combined and the brain network clustering is carried out.
Materials and Methods
Data Acquisition and Preprocessing
The data used in this study was from three datasets. One was the Alzheimer's Disease Neuroimaging Initiative (ADNI) database (http://adni.loni.usc.edu/). The other two were obtained from a public database, openfMRI dataset (https://www.openfmri.org/). Its accession number is ds000030.
In the ADNI database, 109 subjects (48 AD patients and 61 NC) were selected for analysis. Of these, 55 participants (26 AD patients and 29 NCS) were selected from ADNI-2. These data meet the following parameter settings: repetition time (TR) = 3,000 ms; echo time (TE) = 30 ms; slice thickness = 3.3 mm; flip angle = 80°; slice number = 48 and 140 time points. During scanning, all the subjects were instructed to keep their eyes closed. Another 54 participants (22 AD patients and 32 NCs) were selected from ADNI-3. These data meet the following parameter settings: repetition time (TR) = 3,000 ms; echo time (TE) = 30 ms; slice thickness = 3.4 mm; flip angle = 90°; slice number = 48 and 197 time points. Table 1 shows the demographic information of the participants.
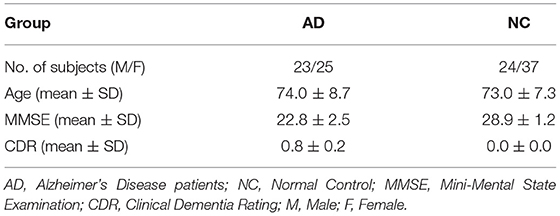
Table 1. Demographic information of study participants.
In openfMRI database, 49 bipolar disorder patients (BD), 50 schizophrenia (SC) and 49 age- and gender-matched normal subjects (NC) were selected for analyzing. Data meets the following parameter settings: repetition time (TR) = 2,000 ms; echo time (TE) = 30 ms; slice thickness = 4 mm; flip angle = 90°; slice number = 34 and 152 time points. The detailed demographics and clinical features of the patients and normal controls are described in Table 2.
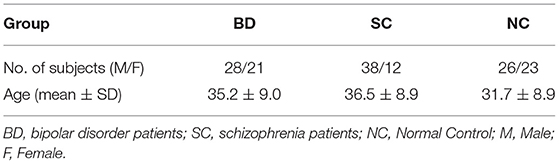
Table 2. Demographic information of study participants.
Many preprocessing steps for the fMRI images were performed using Data Processing Assistant for Resting-State fMRI (DPARSF, http://pub.restfmri.net/) (Chao-Gan and Yu-Feng, 2010), Statistical Parametric Mapping (SPM12) (http://www.fil.ion.ucl.ac.uk/spm), and the Resting-State fMRI Data Analysis Toolkit (REST 1.8) packages (Song et al., 2011). These steps include slice time correction, brain skull removal, and motion correction followed by temporal pre-whitening, spatial smoothing, global drift removal, and band pass filtering. Specifically, the first 10 time points of each subject were removed; slice-timing correction and image realignment were carried out on the remaining time points. Because the brain size, shape, orientation, and gyral anatomy of each subject is different, the fMRI data of each subject was usually normalized into the Montreal Neurological Institute (MNI) space (resampled into 3 × 3 × 3 mm3 voxels) by using a unified segmentation on the T1 image. Then, the linear trends of the time courses were removed, and the effect of nuisance covariates was removed by signal regression using the global signal, the six motion parameters, the cerebrospinal fluid (CSF) and white matter (WM) signals. Temporal filtering (0.01 Hz < f < 0.08 Hz) was applied. Lastly, since we used only gray matter (GM) tissue to construct the functional connectivity network, the gray matter mask was used to mask the corresponding fMRI images to eliminate the possible effects from CSF and WM.
Method
The core of our proposed method is listed below and will be described comprehensively in the following sections:
(1) Labeling the DMN and generating the MST brain functional network.
(2) Brain network similarity assessment.
(3) Spectral clustering algorithm based on brain networks.
Labeling the DMN and Generating the MST Brain Network
Many studies have confirmed that the Default Mode Network (DMN) maintains a relatively stable state in the whole brain network, which is suitable for the study of the abnormality of the brain function network connections. In addition, a large number of studies have confirmed that AD patients have abnormal functional connections in the DMN (Mevel et al., 2011; Garcés et al., 2014). The connection abnormality is mainly reflected in the decrease of functional connections in the Posterior Cingulate Cortex (PCC) and Hippocampus (HIP), and the degree of reduction is positively correlated with the degree of episodic memory impairment. With the development of the disease, the impairment of DMN is aggravated gradually. Previous studies have confirmed that Bipolar disorder (Öngür et al., 2010), Schizophrenia (Mingoia et al., 2010; Tang et al., 2013) patients have abnormal functional connections in the DMN. Therefore, the connection abnormality of the DMN could provide an imaging marker for monitoring AD, BP, and SC.
(1) Labeling the DMN
In this paper, according to the Automated Anatomical Labeling (AAL) (Tzourio-Mazoyer et al., 2002) atlas in concordance with another study (Ciftçi, 2011), the DMN consisted of 32 locations and are shown in Table 3. These 32 locations were defined as the nodes of the brain network, and node time series were obtained by averaging the corresponding voxel time series in the anatomical areas. Then, with the Pearson correlation coefficients between pairs of nodes as connectivity weights, a functional full connected network was finally constructed for each subject.
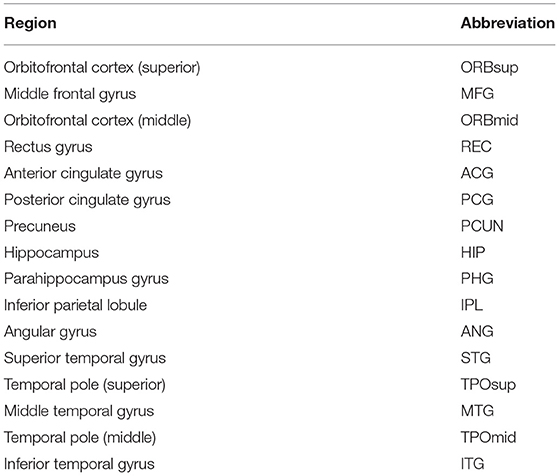
Table 3. AAL structures forming the DMN.
(2) Constructing the MST brain network
When building a brain network, the traditional approach is to convert a fully connected network into a binary network by setting a threshold. And there is no gold standard for the selection of thresholds. In addition, because different thresholds get different binary networks, this will affect the results of subsequent analysis to a certain extent. In order to avoid the threshold selection problem and preserve the structure of the brain network, we adopt the minimum spanning tree network correction scheme to construct the unbiased brain network. The MST method not only preserves the core framework of the network and ensures the neural interpretability of the network, but also eliminates the influence of the threshold. The MST network correction scheme has been widely applied to construct brain networks. For example, Guo et al. (2017) constructed minimum spanning tree high-order functional connectivity networks to identify AD from NC. van Dellen et al. (2018) constructed the MST structural brain networks of healthy adults, and concluded that MST was a feasible method to analyze structural brain networks. Cui et al. (2018) constructed the MST functional brain network for AD, MCI, and NC, analyzed the difference of topological structure among them, and classified them by using topological structural features.
In this paper, we constructed the MST brain network based on the full connected network by employing Kruskal's algorithm (Kruskal, 1956). The details of the algorithm used in this study are as follows: (1) order the weights of the full connected network in descending order; (2) link the nodes with maximal weight until all the nodes are linked in a loopless subgraph; (3) skip the link if the addition of this link leads to a loop.
In this study, the number of nodes in the topology of MST was 32 and the number of edges was 31.
Brain Network Similarity Measure
A brain network has not only attribute features but also topological features. So the similarity of brain networks was evaluated by their attribute similarity and structural similarity. The brain network clustering framework is shown in Figure 2.
1. Brain network attribute similarity
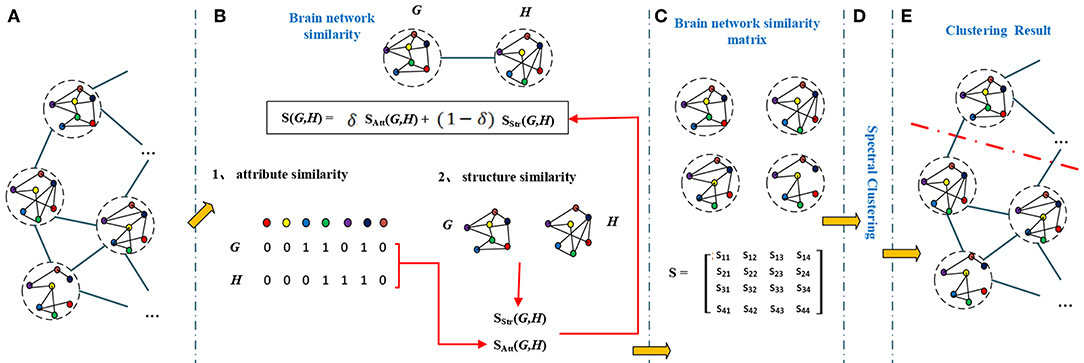
Figure 2. The brain network clustering framework. A graph (A) contains a number of inter-connected nodes, each node represents a brain network, different color represent different brain region. To calculate similarities between brain networks (G and H), we first find similarity between brain networks by taking node attributes (attribute similarity) and structures (structure similarity) into consideration (B). The similarity matrix (C) is formed by the effective combination of attribute similarity and structural similarity. Similarity matrix and spectral clustering (D) results in final clustering results in (E).
Betweenness is an important graph theoretical metrics in MSTs. In clinical application, betweenness centrality was used to compare brain networks of healthy subjects and patients with schizophrenia, depression and Alzheimer diseases (van den Heuvel et al., 2010; Yao et al., 2010; Becerril et al., 2011). Hence, the attribute similarity of brain networks is evaluated by measuring the similarity of betweenness. Betweenness of nodes is defined as the number of shortest paths through a node.
The betweenness bi of the node i is defined as (Tewarie et al., 2015):
where ρhj is the number of shortest paths between node h and j; is the number of shortest paths between node h and j through the node i; V is the set of nodes; and n is the number of nodes.
The attribute similarity satt(G, H) is calculated using the cosine similarity method (Nguyen et al., 2011). The formula is as follows:
where bm(G) is the betweenness of the m-th node in the brain network G, bm(H) is the betweenness of the m-th node in brain network H, and n is the number of nodes in the brain network.
2. Brain network structure similarity
A kernel can be seen as a measure of similarity between a pair of subjects. When a kernel is used for graph data, called a graph kernel, the data is mapped from the original graph space to the feature space and further measures the similarity between two graphs by comparing their topological structure (Shervashidze et al., 2011).
In this paper, sub-network kernels (Jie et al., 2018) were used to measure the topological structure similarity of brain networks. Compared with traditional graph kernels, sub-network kernels not only take into account the uniqueness of each node in brain networks, but also capture the multi-level topological properties of the brain network nodes.
The detailed process of sub-network kernels is summarized as follows:
(1) We construct a set of sub-networks on each node to reflect the connectivity of the brain network at multiple levels.
Specifically, G = (V, E) and H = (V, E′) represent a pair of brain networks, where V represents the node set for the networks. E and E′ represent the edge sets for G and H, respectively. Because the brain has the same brain area they share the same nodes.
To reflect the multi-level topological properties of brain networks, we first define two sets of sub-networks on each node Vi in the networks G and H,
where ,,, and s(·, vi) is the length of the shortest-path between node Vi and the other node. Here, h determines the maximum of s(·, vi) and also defines the number of sub-networks in the set and .
According to Equation (3), for a brain network of n nodes, we can obtain n sets of sub-networks:
(2) We can calculate the kernel of brain networks G and H by calculating the similarity of all sub-network groups from the same node. The kernel of brain networks G and H is defined as:
with
and
where |·| is the determinant, and are the corresponding covariance matrices which are defined on the sub-networks and by Equation (7) (Shrivastava and Li, 2014), respectively, d represents the number of power iterations, n denotes the number of nodes in the brain network, and is defined in Equation (8).
where CϵRd × d is a covariance matrix, d is the number of power iterations, cov denotes the covariance between two vectors, W denotes the adjacency matrix for the sub-network, e is the vector of all ones, and ‖·‖1 denotes the l1 norm of a vector. Here, the set of power iterations on a given vector e,{e, We, W2e, …, Wde}, is known as the “d-order Krylov subspace” which contains sufficient information to describe the adjacency matrix W for some appropriately chosen d.
Finally, the topological structural similarity between two brain networks G and H is equal to the kernel of the two brain networks G and H, and is defined as:
3. Brain network similarity
Because the similarity of brain networks includes two parts (attribute similarity and structure similarity), it is necessary to combine them into one similarity. For this combination, we use a weight δ to control the degree of contribution of each part. In addition, since attribute similarity and structure similarity are two different types, normalization must be performed before combining them. The normalization is defined as:
The similarity sG,H of two brain networks G and H is defined as follows:
So similarity matrix for all brain networks S is defined as follows:
where sgh represents the similarity between brain networks G and H, and n represents the number of brain networks. sgh ranges between 0 (no similarity at all) to 1 (fully similar / same network).
Spectral Clustering Algorithm Based on Brain Networks
With the similarity matrix S obtained in the above section, we can formulate the clustering of brain networks as a spectral clustering (Ng et al., 2002; von Luxburg, 2007) problem, in which brain networks with a higher similarity tend to be grouped into the same cluster.

Algorithm 1: Spectral clustering algorithm based on brain networks
Methodology
In all algorithms, we set the number of clusters to 2 for classifying the patients and the healthy controls. In addition, there were certain parameters that needed to be set in the proposed algorithm: (1) We apply grid search to find the optimal value for δ. We do grid search for δ in {0.1, 0.2, … 0.9}. (2) In the sub-network kernels, the parameters h and d are set to 3 and 3 for AD, the parameters h and d are set to 3 and 1 for SC and BP, respectively.
To evaluate the consistency between the clustering labels and clinical diagnostic labels of the subjects, we defined clustering consistency as similar to clustering accuracy (Wang et al., 2010), which can be used to discover one to one relationships between clusters and clinical classes and can measure the extent to which each cluster contains data points from the corresponding class.
Clustering consistency sums up the entire matching degree between all pair class clusters. Clustering consistency can be computed as
where Cm denotes the m-th (m[{1, 2}) cluster in the final results, and Lp is the diagnostic p-th (p[{1, 2}) group (patient group and control group). T(Cm, Lp) is the number of samples that belong to group p and are assigned to cluster m. n represents the number of brain networks. Consistency is the maximum sum of T(Cm, Lp) for all pairs of clusters and groups, and these pairs have no overlaps.
Results
The minimum spanning tree brain network of the default mode network was constructed using Kruskal's algorithm. Then, According to a certain proportion, the attribute similarity matrix and the structure similarity matrix were combined to form a similarity matrix which is used for clustering. Finally the clustering of the brain network was completed by spectral clustering.
Clustering Performance
In order to evaluate the clustering performance of our proposed method, we compared our method with methods that use a different similarity measure for the same dataset, including:
(1) Spectral clustering algorithm based on node attributes: It is an existing similarity measure of brain networks only considering node attribute similarity. We first constructed the similarity matrix only based on node betweenness and then used the similarity matrix as the input for normalized spectral clustering.
(2) Spectral clustering algorithm based on kernel method (Jie et al., 2018): It is an existing similarity measure of brain networks only considering structure distance between two brain networks. We first constructed the similarity matrix for graphs based on the kernel method and then used the similarity matrix as the input for normalized spectral clustering.
(3) Spectral clustering algorithm based on SimiNet (Mheich et al., 2018): SimiNet takes into account the physical locations of nodes and the weight difference of edge when computing similarity between two brain graphs. We first constructed the similarity matrix for graphs based on SimiNet and then used the similarity matrix as the input for normalized spectral clustering.
In all experiments, we evaluate the performance of methods by measuring clustering consistency. Clustering consistency is used to find one-to-one relationships between clusters and clinical classes of the subject, and to measure the extent to which each cluster contains data points from the same class. Table 4 shows the clustering performances of the different methods with the same dataset. The results showed that our proposed method achieved the best clustering performance, with a consistency of 60.6% for AD, with a consistency of 100% for SC, with a consistency of 100% for BP.
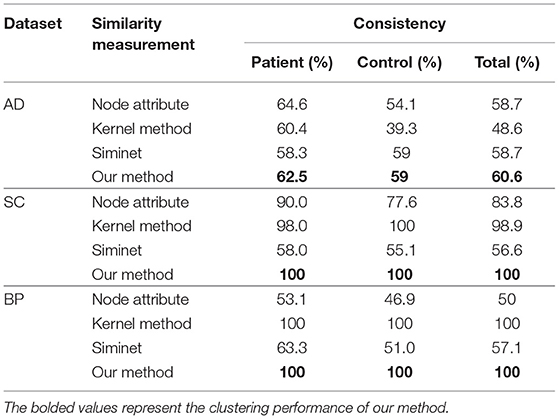
Table 4. Clustering performance of different similarity measure.
Discussion
Performance Evaluations
The clustering performance of four different similarity measurement methods is listed in Table 4. When the consistency is 100%, the clustering label of all subjects is consistent with the clinical diagnostic label, and the clustering accuracy is 100%. When the consistency is 0%, the clustering label of all subjects is inconsistent with the clinical diagnosis label, and the clustering accuracy is 0%.
As shown in Table 4, among the four similarity measure methods, our method performed the best on the three datasets in terms of consistency. The node attribute and the kernel methods achieved a slightly better result.
The node attribute method directly used the node attributes of a brain network for calculating the similarity between each pair of brain networks, which was utilized for the final brain network clustering. The result shows that the similarity of the brain network cannot be more accurately determined from the node attributes (betweenness) alone. The result shows that the brain disorders are associated with alterations in the hubs. Many studies have also demonstrated that the hubs of the human brain are generally implicated with brain disorders (He et al., 2008; Lynall et al., 2010), such as AD and SC.
The kernel method computed the similarity matrix by performing sub-network kernels on the brain network. The result means that when the attributes of the network change, this will affect the global connection structure of the network. Therefore, the description of the global structure has a great effect on the clustering.
SimiNet measures the similarity between the two graphs according to the node and edge attributes under the spatial constraints related to the physical position of the nodes. The key feature of this algorithm is that it takes into account the physical locations of the network nodes. However, in the not-weight brain network constructed with rs-fMRI (resting state fMRI) data, the position of the nodes is the same, so the advantages of the algorithm are not fully reflected. As shown in Table 4, we can see that this method achieved a slightly better result.
Different to the above methods, our method combines both the attribute similarity and structure similarity, where the attribute similarity captures the topological characteristics of brain networks and the structure similarity captures the structure distance. In addition, sub-network kernels were used to measure the structural similarity of brain networks. It not only takes into account the uniqueness of each node, but also captures the multi-level topological properties of nodes in the networks, which are essential for defining the similarity measure. These results indicated that the attribute features and the interior-node structure were important for graph clustering. So, the similarity measurement method based on the combination of attributes and structure can accurately describe the similarity of the brain network, thus improving the clustering performance.
In addition, the results show that when the method is applied to different data sets, the clustering performance is also different, which indicates that the clustering performance is affected by the data to a certain extent. This is because we choose DMN as regions of interesting to construct brain network in this study. The damage degree of DMN is different in different brain diseases, which affects the performance of clustering.
Effect of Parameters δ, d, and h
To compute the similarity of two graphs, the parameters δ, d, and h need to be set. d controls the number of power iterations, and h is the size of a sub-network set. The weight δ is used to control the degree of contribution of attribute similarity and structure similarity. In this section, we explore the effect of parameters δ, d, and h on clustering performance. To analyze the effect of these parameters on our method, we set different values for d ∈ {3, 4, 5, 6, 7, 8} and h ∈ {1, 2, 3}, and δ was set from 0.1 to 0.9 with a step of 0.1. Figures 3–5 shows the clustering results of AD, SC, and BP with respect to different values of these parameters.
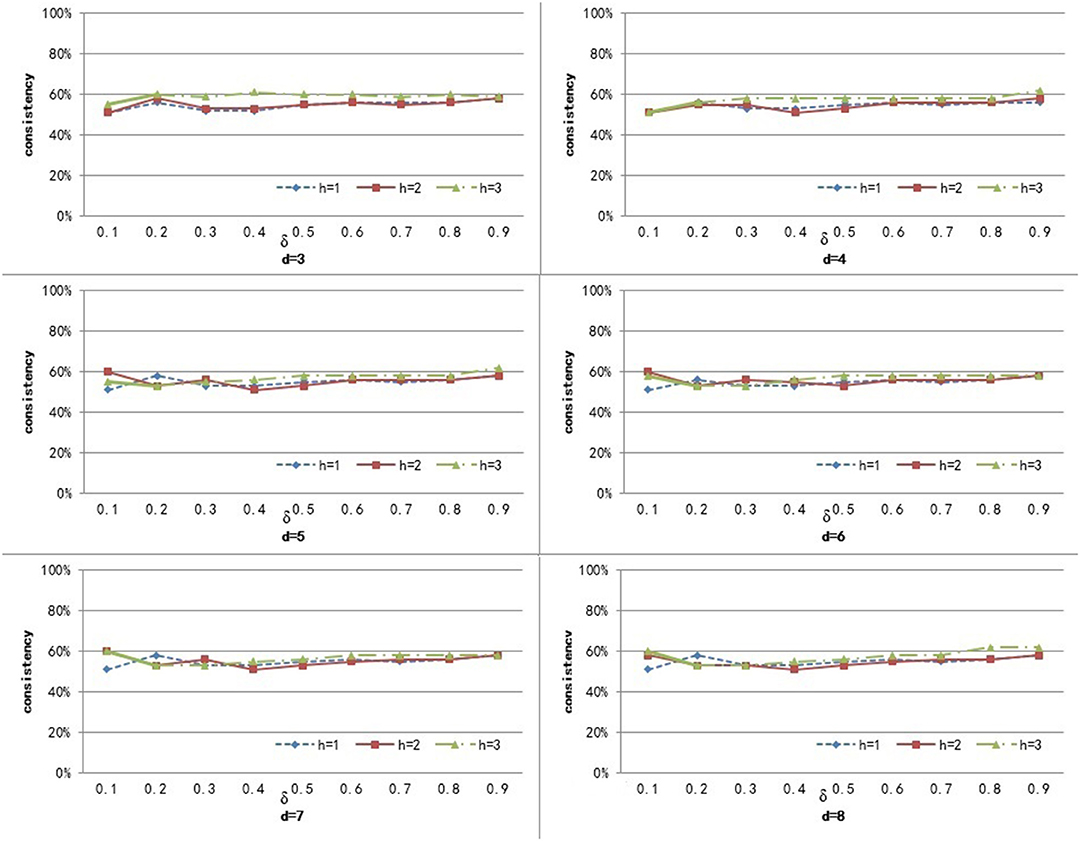
Figure 3. The cluster result of AD with respect to different values of parameter δ, h, and d.
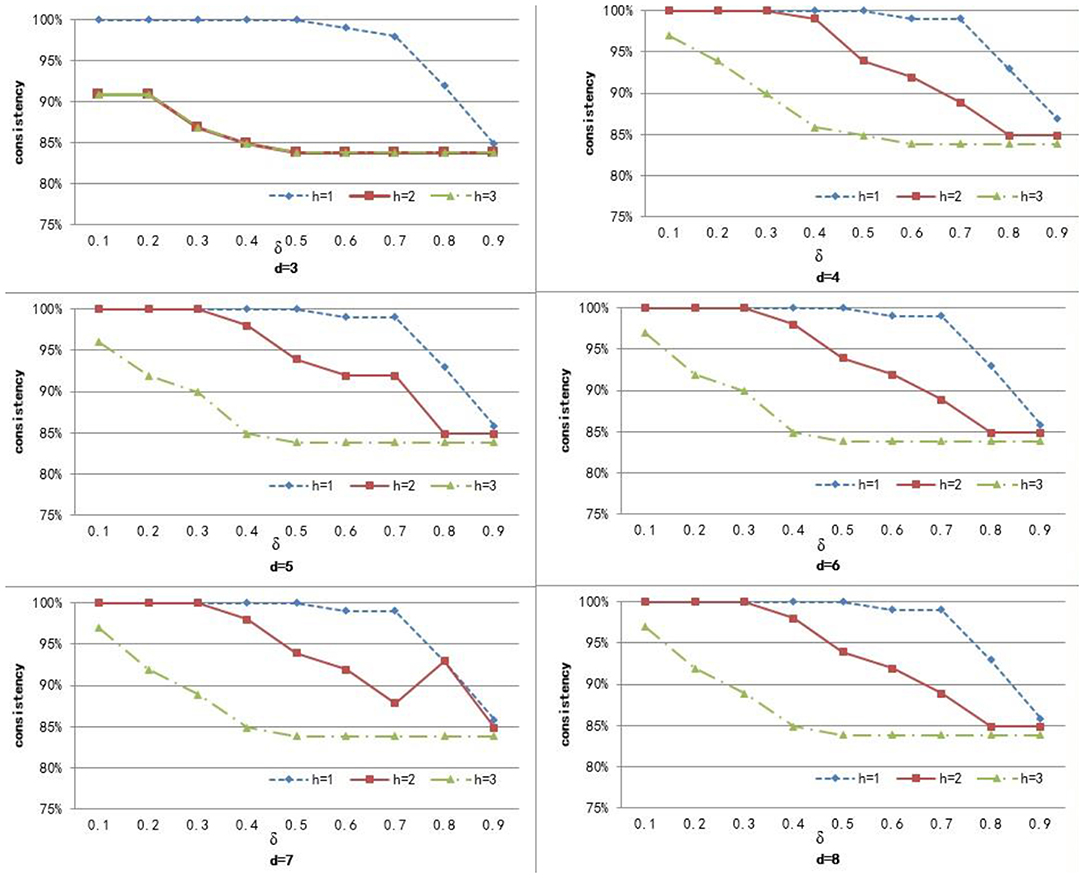
Figure 4. The cluster result of SC with respect to different values of parameter δ, h, and d.
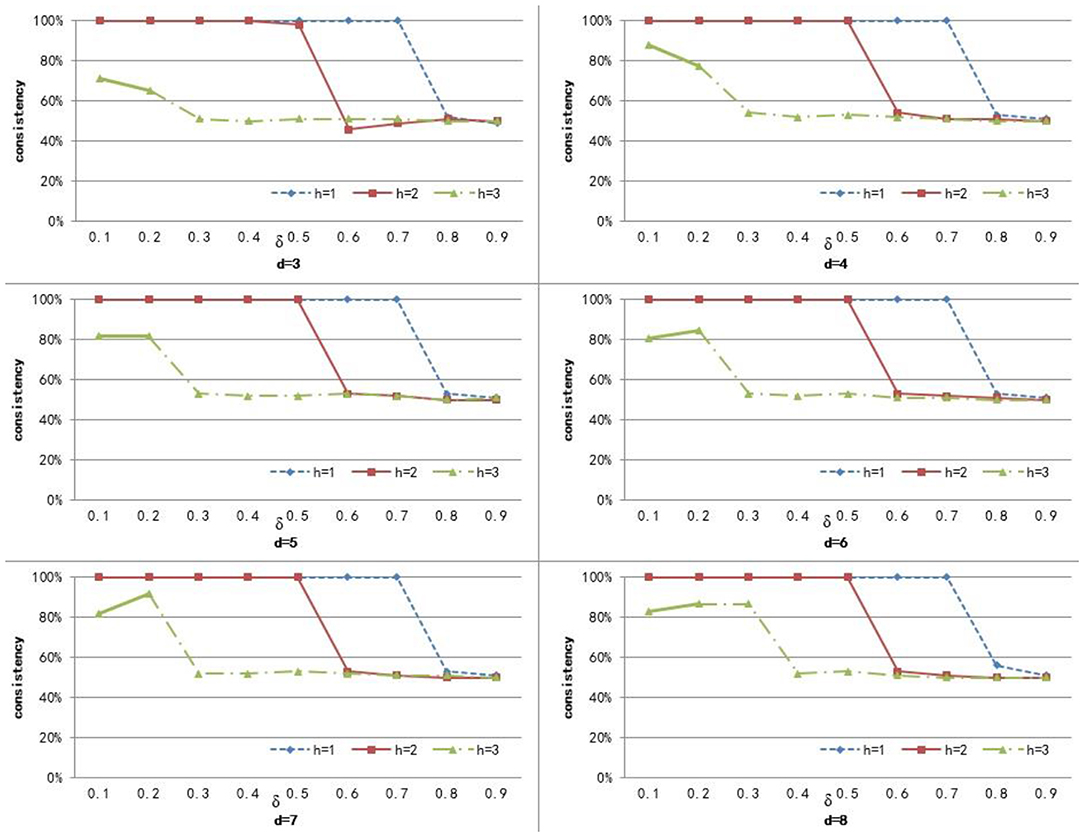
Figure 5. The cluster result of BP with respect to different values of parameter δ, h, and d.
From Figure 3 we can see that the consistency for AD is between 51 and 60.6%. The best clustering performance was obtained when h = 3 and δ = 0.9, with the consistency of 60.6%. From Figure 4 we can see that the consistency is between 84 and 100% for SC. The best clustering performance was obtained when h = 1 and ∈ [0.1, 0.7], with the consistency of 100%. From Figure 5 we can see that the consistency is between 50 and 100% for BP. The best clustering performance was obtained when h = 1 and δ ∈ [0.1, 0.7], with the consistency of 100%.
Figures 3–5 shows that, with a fixed h, the curves varied with the value of d are very smooth, which shows that our method is very robust to the parameter d. Moreover, we can observe that, given a fixed d, the clustering performance is largely affected by different values of h. When h = 1, our method obtains the best clustering performance for SC and BP. When h = 3, our method obtains the best clustering performance for AD. These results imply that the selection of h is critical for our proposed method. This is reasonable since the number h controls the size of a sub-network set for each node in a brain network, and thus affects the similarity measurement of brain networks. In additional, these results imply that the selection of δ is critical for our proposed method. It is because that δ controls the degree of contribution of attribute similarity and structure similarity.
The experimental results showed that the topological structure and the attribute features of brain networks play important roles in clustering brain networks. The setting of parameters is related to the experimental data.
Limitation
Although the proposed method is effective, when this method is applied to different datasets, the clustering performance is different, which indicates that the clustering performance is affected by the data to a certain extent. In addition, the proposed method does not take into account a priori knowledge of the subject, such as Mini-Mental State Examination and Clinical Dementia Rating. A large number of studies have shown that making full use of a priori knowledge in the process of searching for clusters can significantly improve the performance of the clustering algorithm (Jiao et al., 2012). Therefore, it will be meaningful to combine this knowledge with spectral clustering.
Conclusion
In this paper, we proposed a framework for spectral clustering based on attribute feature similarity and topological structure similarity. Specifically, we use cosine similarity to measure the attribute similarity between brain networks. Then, we use sub-network kernels to calculate the structure similarity between brain networks. Finally, according to an optimal parameter δ, the similarity matrix was obtained by integrating the structure similarity and attribute similarity, and spectral clustering is carried out. Hence, this new similarity matrix considers both the global and local similarity of brain networks. In experiments with the AD, BP, and SC dataset, we demonstrated that our proposed method can significantly improve clustering performance in terms of consistency. In our future work, we will explore the combination of a priori knowledge and spectral clustering and carry out further research in this area.
Data Availability Statement
The data used in this study was from three datasets. (1) Alzheimer's Disease Neuroimaging Initiative (ADNI) database, accessible at: http://adni.loni.usc.edu/. (2) Obtained from the public database openfMRI, accessible at: https://www.openfmri.org/).
Ethics Statement
The grantee organization of ADNI project is the Northern California Institute for Research and Education (NCIRE), and the study is coordinated by the Alzheimer's Therapeutic Research Institute (ATRI) at the University of Southern California. ADNI data are disseminated by the Laboratory of Neuro Imaging at the University of Southern California. This research was also supported by NIH grants P30 AG010129 and K01 AG030514. All ADNI subjects together with their legal representatives should have written informed consent before collecting clinical, genetic and imaging data.
The OpenfMRI project is managed by the Poldrack Lab and Center for Reproducible Neuroscience at Stanford University, with computing resources provided by the Texas Advanced Computing Center and Amazon.com. It is funded by grants from the National Science Foundation, National Institute for Drug Abuse, and Laura and John Arnold Foundation.
Author Contributions
XC proposed a framework of spectral clustering based on brain network. JXiao, YN, and DL processed data and made experiment. JXian, BW, HG, and JC gave the proof of results.
Funding
This study was supported by research grants from the National Natural Science Foundation of China (61672374, 61873178, 61876124, 61906130), Key Research and Development Plan of Shanxi Province (International Scientific and Technical Cooperation) (201803D421047), Key Research and Development Plan of Shanxi Province (201803D31043), Youth Fund Project of Shanxi Province (201901D211075, 201701D221119), Natural Science Foundation of Shanxi Province (201801D121135). The sponsors had no role in the design or execution of the study, the collection, management, analysis, and interpretation of the data, or preparation, review, and approval of the manuscript.
Conflict of Interest
This manuscript has not been published or presented elsewhere in part or in entirety, and is not under consideration by any another journal. Meanwhile, all the authors have read through the manuscript, approved it for publication, and declared no conflict of interest.
References
Becerril, K. E., Repovs, G., and Barch, D. M. (2011). Error processing network dynamics in schizophrenia. Neuroimage 54, 1495–1505. doi: 10.1016/j.neuroimage.2010.09.046
Bullmore, E. T., and Bassett, D. S. (2011). Brain graphs: graphical models of the human brain connectome. Soc. Sci. Electron. Pub. 7, 113–140. doi: 10.1146/annurev-clinpsy-040510-143934
Chao-Gan, Y., and Yu-Feng, Z. (2010). DPARSF: a MATLAB toolbox for “pipeline” data analysis of resting-state fMRI. Front. Syst. Neurosci. 4:13. doi: 10.3389/fnsys.2010.00013
Ciftçi, K. (2011). Minimum spanning tree reflects the alterations of the default mode network during Alzheimer's disease. Ann. Biomed. Eng. 39, 1493–1504. doi: 10.1007/s10439-011-0258-9
Cui, X., Xiang, J., Guo, H., Yin, G., Zhang, H., Lan, F., et al. (2018). Classification of Alzheimer's disease, mild cognitive impairment, and normal controls with subnetwork selection and graph kernel principal component analysis based on minimum spanning tree brain functional network. Front. Comput. Neurosci. 12:31. doi: 10.3389/fncom.2018.00031
Gao, X., Xiao, B., and Tao, D. (2010). A survey of graph edit distance. Pattern Anal Appl. 13, 113–129. doi: 10.1007/s10044-008-0141-y
Garcés, P., Angel Pineda-Pardo, J., Canuet, L., Aurtenetxe, S., López, M. E., Marcos, A., et al. (2014). The Default Mode Network is functionally and structurally disrupted in amnestic mild cognitive impairment - a bimodal MEG-DTI study. Neuroimage Clin. 6, 214–221. doi: 10.1016/j.nicl.2014.09.004
Guo, H., Liu, L., Chen, J., Xu, Y., and Jie, X. (2017). Alzheimer classification using a minimum spanning tree of high-order functional network on fMRI dataset. Front. Neurosci. 11:639. doi: 10.3389/fnins.2017.00639
Halder, S., Samiullah, M., and Lee, Y. K. (2016). Supergraph based periodic pattern mining in dynamic social networks. Expert Syst. Appl. 72, 430–442. doi: 10.1016/j.eswa.2016.10.033
He, Y., Chen, Z., and Evans, A. (2008). Structural insights into aberrant topological patterns of large-scale cortical networks in Alzheimer's disease. J. Neurosci. 28, 4756–4766. doi: 10.1523/JNEUROSCI.0141-08.2008
Jiao, L. C., Shang, F., Wang, F., and Liu, Y. (2012). Fast semi-supervised clustering with enhanced spectral embedding. Pattern Recognit. 45, 4358–4369. doi: 10.1016/j.patcog.2012.05.007
Jie, B., Liu, M., Zhang, D., and Shen, D. (2018). Sub-network kernels for measuring similarity of brain connectivity networks in disease diagnosis. IEEE Trans. Image Process 27, 2340–2353. doi: 10.1109/TIP.2018.2799706
Kong, X., and Yu, P. S. (2014). Brain network analysis: a data mining perspective. ACM SIGKDD Explor. Newslett. 15, 30–38. doi: 10.1145/2641190.2641196
Kruskal, J. B. (1956). On the shortest spanning subtree of a graph and the traveling salesman problem. Proc. Am. Math. Soc. 7, 48–50. doi: 10.1090/S0002-9939-1956-0078686-7
Lynall, M. E., Bassett, D. S., Kerwin, R., McKenna, P. J., Kitzbichler, M., Muller, U., et al. (2010). Functional connectivity and brain networks in schizophrenia. J. Neurosci. 30, 9477–9487. doi: 10.1523/JNEUROSCI.0333-10.2010
Mevel, K., Chételat, G., Eustache, F., and Desgranges, B. (2011). The default mode network in healthy aging and Alzheimer's disease. Int. J. Alzheimer's Dis. 2011:535816. doi: 10.4061/2011/535816
Mheich, A., Hassan, M., Khalil, V., Gripon, V., Dufor, O., and Wendling, F. (2018). SimiNet: a novel method for quantifying brain network similarity. IEEE Trans. Pattern Anal. Mach. Intell. 40, 2238–2249. doi: 10.1109/TPAMI.2017.2750160 Available online at: https://arxiv.xilesou.top/ftp/arxiv/papers/1908/1908.10592.pdf
Mheich, A., Wendling, F., and Hassan, M. (2019). Brain network similarity: methods and applications. arXiv [Preprint]. arXiv:1908.10592.
Mingoia, G., Wagner, G., Langbein, K., Maitra, R., Dietzek, M., and Burmeister, H. R. (2010). Altered default-mode network activity in schizophrenia: a resting state fmri study. Schizophr. Res. 117, 355–356. doi: 10.1016/j.schres.2010.02.624
Ng, A. Y., Jordan, M. I., and Weiss, Y. (2002). On spectral clustering: analysis and an algorithm. Adv. Neural Inf. Process. Syst. 14, 849–856.
Nguyen, D. T., Chen, L., and Chan, C. K. (2011). Clustering with multiviewpoint-based similarity measure. IEEE Trans. Knowl. Data Eng. 24, 988–1001. doi: 10.1109/TKDE.2011.86
Öngür, D., Lundy, M., Greenhouse, I., Shinn, A. K., Menon, V., Cohen, B. M., et al. (2010). Default mode network abnormalities in bipolar disorder and schizophrenia. Psychiatry Res. 183, 59–68. doi: 10.1016/j.pscychresns.2010.04.008
Shervashidze, N., Schweitzer, P., van Leeuwen, E. J., Mehlhorn, K., and Borgwardt, K. M. (2011). Weisfeiler-lehman graph kernels. J. Mach. Learn. Res. 12, 2539–2561. Available online at: http://www.jmlr.org/papers/volume12/shervashidze11a/shervashidze11a.pdf
Shrivastava, A., and Li, P. (2014). “A new space for comparing graphs,” in 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (Beijing: ASONAM), 62–71.
Song, X. W., Dong, Z. Y., Long, X. Y., Li, S. F., Zuo, X. N., Zhu, C. Z., et al. (2011). REST: a toolkit for resting-state functional magnetic resonance imaging data processing. PLoS ONE 6:e25031. doi: 10.1371/journal.pone.0025031
Tang, J., Liao, Y., Song, M., Gao, J. H., Zhou, B., Tan, C., et al. (2013). Aberrant default mode functional connectivity in early onset schizophrenia. PLoS ONE 8:e71061. doi: 10.1371/journal.pone.0071061
Tewarie, P., van Dellen, E., Hillebrand, A., and Stam, C. J. (2015). The minimum spanning tree: an unbiased method for brain network analysis. Neuroimage 104, 177–188. doi: 10.1016/j.neuroimage.2014.10.015
Tzourio-Mazoyer, N., Landeau, B., Papathanassiou, D., Crivello, F., Etard, O., Delcroix, N., et al. (2002). Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 15, 273–289. doi: 10.1006/nimg.2001.0978
van Dellen, E., Sommer, I. E., Bohlken, M. M., Tewarie, P., Draaisma, L., Zalesky, A., et al. (2018). Minimum spanning tree analysis of the human connectome. Hum. Brain Mapp. 39,2455–2471. doi: 10.1002/hbm.24014
van den Heuvel, M. P., Mandl, R. C., Stam, C. J., Kahn, R. S., and Hulshoff Pol, H. E. (2010). Aberrant frontal and temporal complex network structure in schizophrenia: a graph theoretical analysis. J. Neurosci. 30, 15915–15926. doi: 10.1523/JNEUROSCI.2874-10.2010
von Luxburg, U. (2007). A tutorial on spectral clustering. Stat. Comput. 17, 395–416. doi: 10.1007/s11222-007-9033-z
Wang, F., Zhao, B., and Zhang, C. (2010).Linear time maximum margin clustering. IEEE Trans. Neural Netw. 21:319–332. doi: 10.1109/TNN.2009.2036998
Yao, Z., Zhang, Y., Lin, L., Zhou, Y., Xu, C., Jiang, T., et al. (2010). Abnormal cortical networks in mild cognitive impairment and alzheimer's disease. PLoS Comput. Biol. 6:e1001006. doi: 10.1371/journal.pcbi.1001006
Zhang, D., Tu, L., Zhang, L. J., Jie, B., and Lu, G. M. (2017). Subnetwork mining on functional connectivity network for classification of minimal hepatic encephalopathy. Brain Imaging Behav. 12, 1–11. doi: 10.1007/s11682-017-9753-4
Keywords: graph mining, similarity, sub-network kernels, spectral clustering, Alzheimer's disease
Citation: Cui X, Xiao J, Guo H, Wang B, Li D, Niu Y, Xiang J and Chen J (2020) Clustering of Brain Function Network Based on Attribute and Structural Information and Its Application in Brain Diseases. Front. Neuroinform. 13:79. doi: 10.3389/fninf.2019.00079
Received: 15 January 2019; Accepted: 24 December 2019;
Published: 07 February 2020.
Edited by:
Xi-Nian Zuo, Institute of Psychology (CAS), ChinaReviewed by:
Daoqiang Zhang, Nanjing University of Aeronautics and Astronautics, ChinaSam Neymotin, Nathan Kline Institute for Psychiatric Research, United States
Yi Su, Banner Alzheimer's Institute, United States
Copyright © 2020 Cui, Xiao, Guo, Wang, Li, Niu, Xiang and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Junjie Chen, Y2hlbmpqQHR5dXQuZWR1LmNu; Jie Xiang, eGlhbmdqaWVAdHl1dC5lZHUuY24=