 Tian Xia
Tian Xia Pedro Sanchez
Pedro Sanchez Chen Qin
Chen Qin Sotirios A. Tsaftaris
Sotirios A. Tsaftaris- 1School of Engineering, University of Edinburgh, Edinburgh, United Kingdom
- 2The Alan Turing Institute, London, United Kingdom
- 3Department of Electrical and Electronic Engineering, Imperial College London, London, United Kingdom
Due to the limited availability of medical data, deep learning approaches for medical image analysis tend to generalise poorly to unseen data. Augmenting data during training with random transformations has been shown to help and became a ubiquitous technique for training neural networks. Here, we propose a novel adversarial counterfactual augmentation scheme that aims at finding the most effective synthesised images to improve downstream tasks, given a pre-trained generative model. Specifically, we construct an adversarial game where we update the input conditional factor of the generator and the downstream classifier with gradient backpropagation alternatively and iteratively. This can be viewed as finding the ‘weakness’ of the classifier and purposely forcing it to overcome its weakness via the generative model. To demonstrate the effectiveness of the proposed approach, we validate the method with the classification of Alzheimer’s Disease (AD) as a downstream task. The pre-trained generative model synthesises brain images using age as conditional factor. Extensive experiments and ablation studies have been performed to show that the proposed approach improves classification performance and has potential to alleviate spurious correlations and catastrophic forgetting. Code: https://github.com/xiat0616/adversarial_counterfactual_augmentation
1. Introduction
Deep learning has been playing an increasingly important role in medical image analysis in the past decade, with great success in segmentation, diagnosis, detection, etc (1). Although deep-learning based models can significantly outperform traditional machine learning methods, they heavily rely on the large size and quality of training data (2). In medical image analysis, the availability of large dataset is always an issue, due to high expense of acquiring and labelling medical imaging data (3). When only limited training data are available, deep neural networks tend to memorise the data and cannot generalise well to unseen data (4, 5). This is known as over-fitting (4). To mitigate this issue, data augmentation has become a popular approach. The aim of data augmentation is to generate additional data that can help increase the variation of the training data.
Conventional data augmentation approaches mainly apply random image transformations, such as cropping, flipping, and rotation etc. to the data. Even though such conventional data augmentation techniques are general, they may not transfer well from one task to another (6). For instance, color augmentation could prove useful for natural images but may not be suitable for MRI images which are presented in greyscale images (3). Furthermore, traditional data augmentation methods may introduce distribution shift, i.e., the change of the joint distribution of inputs and outputs, and consequently adversely impact the performance on non-augmented data during inference1 (i.e., during the application phase of the learned model) (7).
Some recently developed approaches learn parameters for data augmentation that can better improve downstream task, e.g. segmentation, detection, diagnosis, etc., performance (6, 8, 9) or select the hardest augmentation for the target model from a small batch of random augmentations for each traning sample (10). However, these approaches still use conventional image transformations and do not consider semantic augmentation (11), i.e., creating unseen samples by changing semantic information of images such as changing the background of an object or changing the age of a brain image. Semantic augmentation can complement traditional techniques and improve the diversity of augmented samples (11).
One way to achieve semantic augmentation is to train a deep generative model to create counterfactuals, i.e., synthetic modifications of a sample such that some aspects of the original data remain unchanged (12–16). However, these approaches mostly focus on the training stage of generative models and randomly generate samples for data augmentation, without considering which counterfactuals are more effective for downstream tasks, i.e. data-efficiency of the generated samples. Ye et al. (17) use a policy based reinforcement learning (RL) strategy to select synthetic data for augmentation with reward as the validation accuracy. Xue et al. (18) propose a cGAN based model to augment classification of histopathology images with a selective strategy based on assigned label confidence and feature similarity to real data. By contrast, our approach focuses on finding the weakness (i.e. the hard counterfactuals) of a downstream task model (e.g. a classifier) and forces it to overcome its weakness. Similarly, Ye et al. (17) use a policy based reinforcement learning (RL) strategy to select synthetic data for augmentation, with reward as the validation accuracy, but the instability of RL training could perhaps hinder the utility of their approach. Wang et al. (11), Li et al. (19), Chen and Su (20) proposed to augment the data in the latent space of the target deep neural network, by estimating the covariance matrix of latent features obtained from latent layers of the target deep neural network for each class (e.g., car, horse, tree, etc.) and sampling directions from the feature distributions. These directions should be semantic meaningful such that changing along one direction can manipulate one property of the image, e.g. color of a car. However, there is no guarantee that the found directions will be semantically meaningful, and it is hard to know which direction controls a particular property of interest.
In this work, we consider the scenario that we have a classifier which we want to improve (e.g. an image-based classifier of Alzheimer’s Disease (AD) given brain images). We are also given some data and a pre-trained generative model that is able to create new data given an image as input and conditioning factors that can alter corresponding attributes in the input. For example, the generative model can alter the brain age of the input. We propose an approach to guide a pre-trained generative model to generate the most effective counterfactuals via an adversarial game between the input conditioning factor of the generator and the downstream classifier, where we use gradient backpropagation to update the conditioning factor and the classifier alternatively and iteratively. A schematic of the proposed approach is shown in Figure 1.
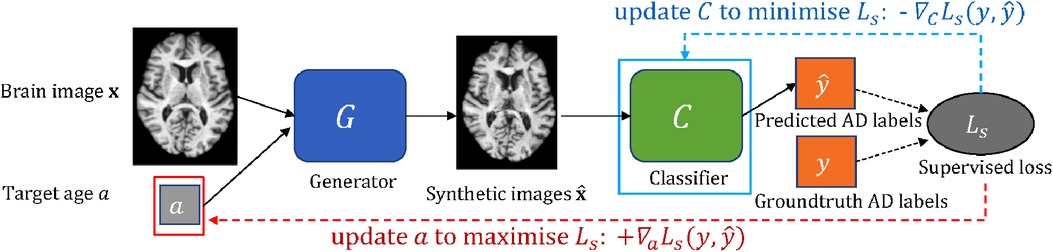
Figure 1. A schematic of the adversarial classification training. The pre-trained generator takes a brain image and a target age as input and outputs a synthetically aged image that corresponds to the target age . The classifier aims to predict AD label for a given brain image. To utilise to improve , we formulate an adversarial game between (in red box) and (in cyan box), where and are updated alternatively and iteratively using and , respectively (see Section 2.3). Note is frozen.
Specifically, we choose the classification of AD as the downstream task and utilise a pre-trained brain ageing synthesis model to improve the AD classifier. The brain ageing generative model used in this paper is adopted from a recent work (21), which takes a brain image and a target age as inputs and outputs an aged brain image.2 We show that the proposed approach can improve the test accuracy of the AD classifier. We also demonstrate that it can be used in a continual learning3 context to alleviate catastrophic forgetting, i.e. deep models forget what they have learnt from previous data when training on new given data, and can be used to alleviate spurious correlations, i.e. two variables appear to be causally related to one another but in fact they are not. Our contributions can be summarised as follows:
1. We propose an approach to utilise a pre-trained generative model for a classifier via an adversarial game between conditional input and the classifier. To the best of our knowledge, this is the first approach that formulates such an adversarial scheme to utilise pre-trained generators in medical imaging.
2. We improve a recent brain ageing synthesis model by involving Fourier encoding to enable gradient backpropagation to update conditional factor and demonstrate the effectiveness of our approach on the task of AD classification.
3. We consider the scenario of using generative models in a continual learning context and show that our approach can help alleviate catastrophic forgetting.
4. We apply the brain ageing synthesis model for brain rejuvenation synthesis and demonstrate that the proposed approach has the potential to alleviate spurious correlations.
2. Methodology
2.1. Notations and problem overview
We denote an image as , and a conditional generative model that takes an image and a conditional vector as input and generates a counterfactual that corresponds to : . For each , there is a label . We define a classifier that predicts the label for given : . In this paper, is a brain image, is the AD diagnosis of , and represents the target age and AD diagnosis on which the generator is conditioned. We select age and AD status to be conditioning factors as they are major contributors to brain ageing. We use a 2D slice brain ageing generative model as , and a VGG4-based (22) AD classification model as . In Xia et al. (21), the brain ageing generative model is evaluated in multiple ways, including several quantitative metrics: Structural Similarity (SSIM), Peak Signal-to-Noise Ratio (PSNR) and Mean Squared Error (MSE) between the synthetically aged brain images and the ground-truth follow-up images, and Predicted Age Difference (PAD), i.e. difference between the predicted age by a pre-trained age predictor and the desired target age. For more details of the evaluation metrics, please refer to Xia et al. (21), Section 4. Note that we only change the target age in this paper, thus we write the generative process as for simplicity.
Suppose a pre-trained and a are given, the question we want to answer is: “How can we use to improve in a (data) efficient manner”? To this end, we propose an approach to utilise to improve via an adversarial game with gradient backpropagation to update and alternatively and iteratively.
2.2. Fourier encoding for conditional factors
The proposed approach requires backpropagation of gradient to the conditional factor to find the hard counterfactuals. However, the original brain ageing synthesis model (21) used ordinal encoding to encode the conditional age and AD diagnosis, where the encoded vectors are discrete in nature and need to maintain a certain shape, which hinders gradient backpropagation to update these vectors. Imagine a 5-dimensional ordinal vector representing the number 3 as . If we compute gradients with respect to the vector to update it, and the gradients multiplied by alpha happen to be [ −0.3, −0.1, 0.1, 0.2, − 0.3] (for example), then the resulting vector would be , −0.3], which is not a ordinal vector anymore. Converting this to obey ordinal rules will require that we first quantize to and then check for ordinal order preservation of the 1 digits. Both are not easily differentiable.
To enable gradient backpropagation to update the conditional vectors, we propose to use Fourier encoding (23, 24) to encode the conditional attributes, i.e., age and heath state (diagnosis of AD). The effectiveness of Fourier encoding has been experimentally shown in Tancik et al. (23), Mildenhall et al. (24). We also compared the generative model using Fourier v.s. Ordinal encoding using the quantitative metrics briefly introduced in Section 2.1, as presented in Table 1. We observe that the generator using Fourier encoding achieves very similar quantitative results as the generator using ordinal encoding, demonstrating effectiveness of Fourier encoding to encode age and health status.
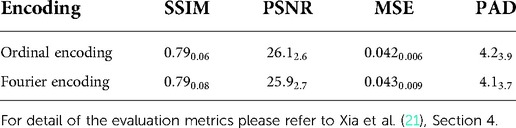
Table 1. Quantitative results of brain ageing model using ordinal encoding and Fourier encoding.
The key idea of Fourier encoding is to map low-dimensional vectors to a higher dimensional domain using a set of sinusoids. For instance, if we have a d-dimensional vector which is normalised into , , then the encoded vector can be represented as Tancik et al. (23):
where can be viewed as the Fourier basis frequencies, and the Fourier series coefficients.
In this work, the vector represents the target age and the health status (AD diagnosis), and . In our experiments, we set for , and are independently and randomly sampled from a Gaussian distribution, , where is set to 10. We set and the resulting is 200-dimensional. After encoding, the generator takes the encoded vector as input.
The use of Fourier encoding offers two advantages. First, Xia et al. (21) encoded age and health state into two vectors and had to use two MLPs to embed the encoded vectors into the model. This may not be a big issue when the number of factors is small. However, extending the generative model to be conditioned on tens or hundreds of factors will increase the memory and computation costs significantly. With Fourier encoding, we can encode all possible factors into a single vector, which offers more flexibility to scale the model to multiple conditional factors. Second, Fourier encoding allows us to compute the gradients with respect to the input vector or certain elements of , since the encoding process is differentiable. As such, we replace the ordinal encoding with Fourier encoding for all experiments. The generative model takes as input: , where represents target age and health state. Since we only change the target age in this paper, we write the generative process as for simplicity.
2.3. Adversarial counterfactual augmentation
Suppose we have a conditional generative model and a classification model . The goal is to utilise to improve the performance of . To this end, we propose an approach consisting of three steps: pre-training, hard sample selection and adversarial classification training. A schematic of the adversarial classification training is presented in Figure 1. Algorithm 1 summarises the steps of the method. Below we describe each step in detail.

Algorithm 1:. Adversarial counterfactual augmentation with a pre-trained G.
2.3.1. Pre-training
The generative model is pre-trained using the same losses as in Xia et al. (21) except that we use Fourier encoding to encode age and AD diagnosis. Consequently, we obtain a pre-trained that can generate counterfactuals conditioned on given target ages : .
The classification model is a VGG-based network (22) trained to predict the AD diagnosis from brain images, optimised by minimising:
where is a supervised loss (binary cross-entropy loss in this paper), is a brain image, and is its ground-truth AD label. To note that if the pre-trained and are available in practice, we could avoid the pre-training step.
2.3.2. Hard sample selection
Liu et al. (25), Feldman and Zhang (26) suggested that training data samples have different influence on the training of a supervised model, i.e., some training data are harder for the task and are more effective to train the model than others. Liu et al. (25) propose to up-sample, i.e. duplicate, the hard samples as a way to improve the model performance. Based on these observations, we propose a similar strategy to Liu et al. (25) to select these hard samples: we record the classification errors of all training samples for the pre-trained and then select samples with the highest errors. The selected hard samples are denoted as : .
2.3.3. Adversarial classification training
Bowles et al. (14), Frid-Adar et al. (27), Dar et al. (28) augmented datasets by randomly generating a number of synthetic data with pre-trained generators. Similar to training samples, some synthetic data could be more effective for downstream tasks than others. Here we assume that if a synthetic data sample is hard, then it is more effective for training. We propose an adversarial game to find the hard synthetic data to boost .
Specifically, let us first define the classification loss for synthetic data as:
where is a generated sample conditioned on the target age : , and is the ground-truth AD label for . Here we assume that changing target age does not change the AD status, thus and have the same AD label.
Since the encoding of age is differentiable (see Section 2.2), we can obtain the gradients of with respect to as: , and update in the direction of maximising by: , where is the step size (learning rate) for updating . Formally, the optimization function of can be written as:
Then we could obtain a set of synthetic data using the updated : where , denoted as .
The classifier is updated by optimising:
where : is a combined dataset consisting of the training dataset and synthetic dataset: . Similar to Liu et al. (25), we update on instead of as we found updating only on can cause catastrophic forgetting (29).
The adversarial game is formulated by alternatively and iteratively updating and classifier via Eqs. 4 and 5, respectively. In practice, to prevent from going to unsuitable ages, we clip it to be in [60, 90] after every update.
2.3.4. Updating vs. updating
Note here the adversarial game is formulated between and , instead of and . This is because training against allows to change its latent space without considering image quality, and the output of could be unrealistic. Please refer to Section 4.1.2 for more details and results.
2.3.5. Counterfactual augmentation vs. conventional augmentation
Here we choose to augment data counterfactually instead of applying conventional augmentation techniques. This is because that the training and testing data are already pre-processed and registered to MNI 152, and in this case conventional augmentations do not introduce helpful variations. Please refer to Section 4.1.3 for more details and results.
2.4. Adversarial classification training in a continual learning context
Most previous works (14, 27, 28, 30–32) that used pre-trained deep generative models for augmentation focused on generating a large number of synthetic samples, and then merged the synthetic data with the original dataset and trained the downstream task model (e.g. a classifier) on this augmented dataset. However, this requires training the task model from scratch, which could be inconvenient. Imagine that we are given a pre-trained classifier, and we have a generator at hand which may or may not be pre-trained on the same dataset. We would like to use the generator to improve the classifier, or transfer the knowledge learnt by the generator to the classifier. The strategy of previous works is to use the generative model to produce a large amount of synthetic data that cover the knowledge learnt by the generator, and then train the classifier on both real and synthetic data from scratch, which would be expensive. However, in this work, we consider the task of transferring knowledge from the generator to the classifier in the continual learning context, by considering synthetic data as new samples. We want the classifier to learn new knowledge from these synthetic data without forgetting what it has learnt from the original classification training set. We will show how our approach can help in the continual learning context.
In Section 2.3, after we obtain the synthetic set , we choose to update the classifier on the augmented dataset , instead of (stage 6 in Algorithm 1). This is because re-training the classifier only on the would result in catastrophic forgetting (29), i.e. a phenomenon where deep neural networks tends to forget what it has learnt from previous data when being trained on new data samples. To alleviate catastrophic forgetting, efforts have been devoted to developing approaches to allow artificial neural networks to learn in a sequential manner (33, 34). These approaches are known as continual learning (33, 35, 36), lifelong learning (37, 38), sequential learning (39, 40), or incremental learning (41, 42). Despite different names and focuses, the main purpose of these approaches is to overcome catastrophic forgetting and to learn in a sequential manner.
If we consider the generated data as new samples, then the update of the pre-trained classifier can be viewed as a continual learning problem, i.e. how to learn new knowledge from the synthetic set without forgetting old knowledge that is learnt from the original training data . To alleviate catastrophic forgetting, we re-train the classifier on both the synthetic dataset and the original training dataset . This strategy is known as memory replay in continual learning (43, 44) and was also used in other augmentation works (25). The key idea is to store previous data in a memory buffer and replay the saved data to the model when training on new data. However, it could be expensive to store and revisit all the training data, especially when the data size is large (44). In Section 4.2, we perform experiments where we only provide a portion () of training data to the classifier when re-training with synthetic data (to simulate the memory buffer). In this case, we only create synthetic data from the memory bank. We want to see whether catastrophic forgetting would happen or not when only a portion () of training data is provided, and if so, how much it affects the test accuracies. Algorithm 2 summarises the steps of the method in the continual learning context.

Algorithm 2:. Adversarial classification learning with Dstore.
3. Experimental setup
3.1. Data
We use the ADNI dataset (45) for experiments. We select 380 AD and 380 CN (control normal) T1 volumes between 60 and 90 years old. We split the AD and CN data into training/validation/testing sets with 260/40/260 volumes, respectively. All volumetric data are skull-stripped using DeepBrain5, and linearly registered to MNI 152 space using FSL-FLIRT (46). We normalise brain volumes by clipping the intensities to , where is the largest intensity value within each volume, and then rescale the resulting intensities to the range [−1, +1]. We select the middle 60 axial slices from each volume and crop each slice to the size of , resulting in 31,200 training, 4,800 validation and 9,600 testing slices.
3.2. Implementation
The generator is trained the same way as in Xia et al. (21), except we replace ordinal encoding with Fourier encoding. We pre-train the classifier for 100 epochs. The experiments are performed using Keras and Tensorflow. We train pre-trained classifiers with Adam with a learning rate of 0.00001 and decay of 0.0001. During adversarial learning, the step size of is tuned to be 0.01, and the learning rate for is 0.00001. The experiments are performed using a NVIDIA Titan X GPU.
3.3. Comparison methods
We compare with the following baselines:
1. Naïve: We directly use the pre-trained for comparison as the lower bound.
2. RSRS: Random Selection + Random Synthesis. We randomly select samples from the training set , denoted as , and then use the generator to randomly generate synthetic samples for each sample in , denoted as . Then we train the classifier on the combined dataset for steps. This is the typical strategy used by most previous works (14, 27, 28).
3. HSRS: Hard Selection + Random Synthesis. We select hard samples from based on their classification errors of , denoted as , and then use the generator to randomly generate synthetic samples for each sample in , denoted as . Then we train the classifier on the combined dataset for steps.
4. RSAT: Random Selection + Adversarial Training. We randomly select samples from the training set , denoted as , and then use the adversarial training strategy to update the classifier , as described in Section 2.3. The difference between RSAT and our approach is that we select hard samples for generating counterfactuals, while RSAT uses random samples.
5. JTT: Just Train Twice (25) record samples that are misclassified by the pre-trained classifier, obtaining an error set. Then they construct an oversampled dataset that contain examples in the error set times and all other examples once. Finally, they train the classifier on the oversampled dataset . In this paper, we set as we found large results in bad performance. We also found the original learning rate (0.01) used for the second training stage results in very bad performance and set it to be 0.00001.
4. Results and discussion
4.1. Improving the performance of classifiers
4.1.1. Comparison with baselines
We first compare our method with baseline approaches by evaluating the test accuracy of the classifiers. We set and in experiments. We pre-train for 100 epochs and as described in Section 3. The weights of the pre-trained and the pre-trained are the same for all methods. For a fair comparison, the total number of synthetically generated samples is fixed to 500 for RSRS, HSRS, RSAT and our approach. For JTT, there are 2,184 samples mis-classified by and oversampled. We initialize randomly between real ages of original brain images and maximal age (90 yrs old).
From Table 2 we can observe that our proposed procedure achieves the best overall test accuracy, followed by baseline RSAT. This demonstrates the advantage of adversarial training between the conditional factor (target age) and the classifier. On top of that, it shows that selecting hard examples for creating augmented synthetic results helps, which is also demonstrated by the improvement of performance of HSRS over Naïve. We also observe that JTT (25) improves the classifier performance over Naïve, showing the benefit of up-sampling hard samples. In contrast, baseline RSRS achieves the lowest overall test accuracy, even lower than that of Naïve. This shows that randomly synthesising counterfactuals from randomly selected samples could result in synthetic images that are harmful to the classifier.

Table 2. Average test accuracies of models trained via our procedure and baselines.
Furthermore, we observe that for all methods, the worst-group performances are achieved on the 80–90 CN group. A potential reason could be: as age increases, the brains shrink, and it is harder to tell if the ageing pattern is due to AD or caused by normal ageing. Nevertheless, we observe that for this worst group, our proposed method still achieves the best performance, followed by . This shows that adversarial training can be helpful to improve the performance of the classifier, especially for hard groups. The next best results are achieved by HSRS and JTT, which shows that finding hard samples and up-sampling or augmenting them was helpful to improve the worst-group performance. We also observe the improvement of worst-group performance for RSRS over Naïve, but the improvement is small compared to other baselines. Figure 2 presents histograms of original ages for training subjects and the target ages after adversarial training, where we can see how the adversarial training aims to balance the data.
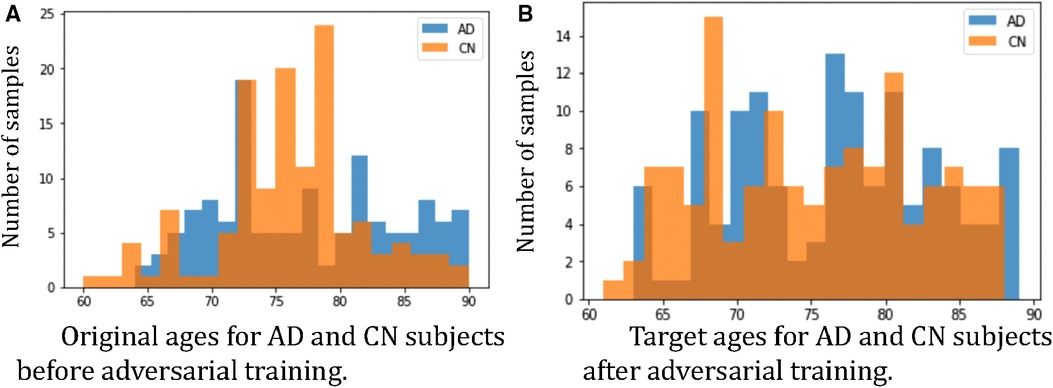
Figure 2. Histograms of ages of subjects before and after adversarial learning. We can observe that adversarial training aims to balance the data.
We also report the precision and recall for all methods, as presented in Table 3. We can observe that our approach achieves the highest overall precision and recall results.
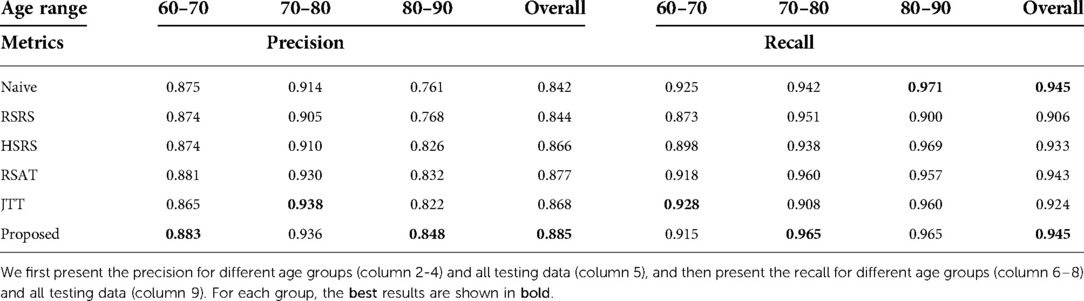
Table 3. The test precision and recall values for all methods.
In summary, the quantitative results show that it is helpful to find and utilise hard counterfactuals for improving the classifier.
4.1.2. Train G against C
We choose to formulate an adversarial game between the conditional generative factor (the target age) and the classifier , instead of between the generator and the classifier . This is because we are concerned that an adversarial game between and could result in unrealistic outputs of . In this section, we perform an experiment to investigate this.
Specifically, we define an optimization function:
where we aim to train in the direction of maximising the loss of the classifier on the synthetic data .
After every update of , we construct a synthetic set by generating 100 synthetic images from , and update on via Equation 5. The adversarial game vs. is formulated by alternatively optimising Equations 6 and 5 for 10 epochs.
In Figure 3, we present the synthetic brain ageing progression of a CN subject before and after the adversarial training of vs. . We can observe that after the adversarial training, the generator produces unrealistic results. This could be because there is no loss or constraint to prevent the generator from producing low-quality results. The adversarial game only requires the generator to produce images that are hard for the classifier , and naturally, images of low quality would be hard for . A potential solution could be to involve a GAN loss with a discriminator to improve the output quality, but this would make the training much more complex and require more memory and computations. We also measure the test accuracy of the classifier after training against to be , which is much lower than the Naïve method () and our approach () in Table 2. The potential reason is that is misled by the unrealistic samples generated by .
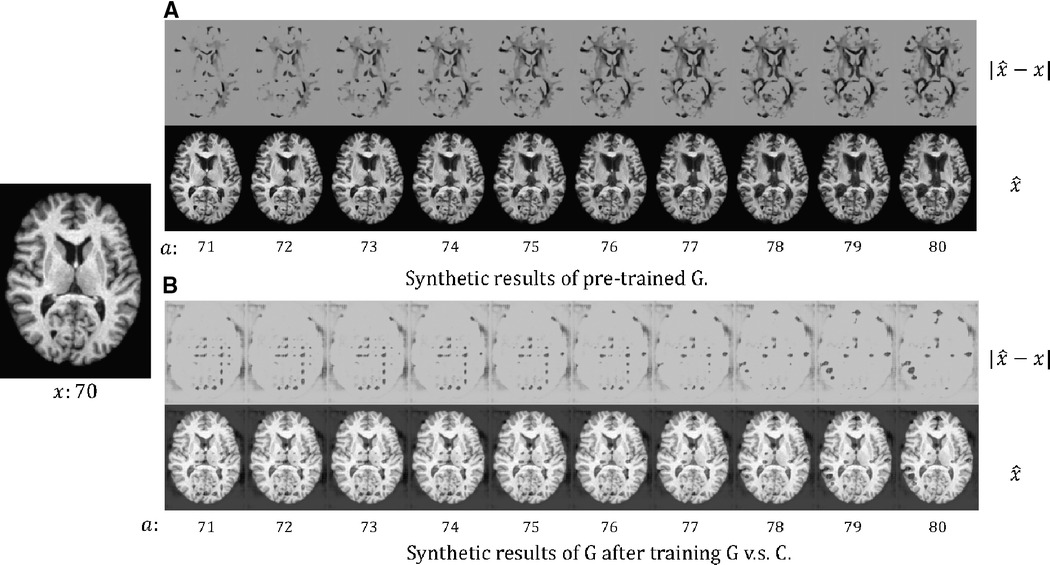
Figure 3. The synthetic results for a healthy (CN) subject at age 70: (A) the results of the pre-trained , i.e. before we train against ; (B) the results of after we train against . We synthesise aged images at different target ages . We also visualise the difference between and , . For more details see text.
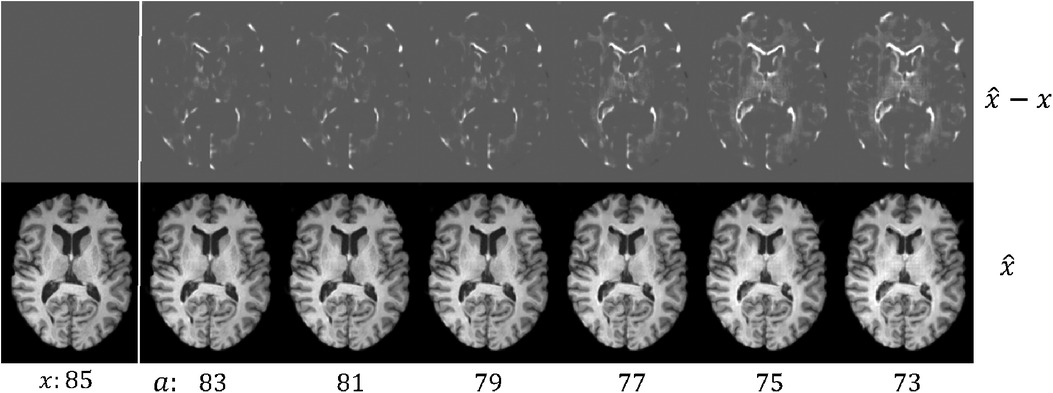
Figure 4. Example results of brain rejuvenation for an image () of a 85 year old CN subject. We synthesise rejuvenated images at different target ages . We also show the differences between and , . For more details see text.
4.1.3. Effect of conventional augmentations for registered brain MRI data
In this section, we test the effect of applying several commonly used conventional augmentations, e.g. rotation, shift, scale and flip, to the training of the AD classifier. These are typical conventional augmentation techniques applied to computer vision classification task. Specifically, we train the classifier the same way as Naïve, except we augment training data with conventional augmentations.
Interestingly, we find that after applying rotation (range 10 degrees), shift (range 0.2), scale (range 0.2), and flip to augment the training data, the accuracy of the trained classifier drops from to . We then measure accuracies when trained with each augmentation to be (rotation), (shift), (scale), and (flip). We also trained the classifier with random gamma correction (gamma ranges from 0.2 to 1.8), and the resulting test accuracy is . This could be because both training and testing data are already pre-processed, including registered to MNI 152 and contrast normalisation, and these conventional augmentations do not introduce helpful variations to the training data but distract the classifier from focusing on subtle differences between AD and CN brains.
We also tried to train the classifier with MaxUp (10) with conventional augmentations. The idea of MaxUp is to generate a small batch of augmented samples for each training sample and train the classifier on the worst-performance augmented sample. The overall test accuracy is . This could be because that MaxUp tends to select the augmentations that distract the classifier from focusing on subtle AD features the most.
The results with conventional augmentations (+MaxUp) suggest that for the task of AD classification, when training and testing data are pre-processed well, conventional data augmentation techniques seem to not help improve the classification performance. Instead, these augmentations distract the classifier from identifying subtle changes between CN and AD brains. By contrast, the proposed procedure augment data in terms of semantic information, which could alleviate data imbalance and improve classification performance.
4.2. Adversarial counterfactual augmentation in a continual learning context
4.2.1. Results when re-training with a portion () of training data
Suppose we have a pre-trained classifier and a pre-trained generator , and we want to improve by using for data augmentation. However, after pre-training, we only store () of the training dataset, denoted as . During the adversarial training, we synthesise samples using the generator , denoted as . Then we update the classifier on , using Equation 5 where . The target ages are initialised and updated the same way as in Section 4.1. Algorithm 2 illustrates the procedure in this section.
Table 4 presents the test accuracies of our approach and baselines when changes. For Naïve-100, the results are then same as in Table 2. For JTT, the original paper Liu et al. (25) retrained the classifier using the whole training set. Here we first randomly select training samples as and find misclassified data within to up-sample, then we retrain the classifier on the augmented set. We can observe that when decreases, catastrophic forgetting happens for all approaches. However, our method suffers the least from catastrophic forgetting, especially when is small. With of training data for retraining, our approach achieves better results than Naïve. This might be because the adversarial training between and tries to detect what is missing in and tries to recover the missing data by updating towards those directions. We observe that RSAT achieves the second best results, only slightly worse than the proposed approach. Moreover, HSRS and JTT are more affected by catastrophic forgetting and achieve worse results. This might be because the importance of selecting hard samples declines as decreases, since the becomes smaller.
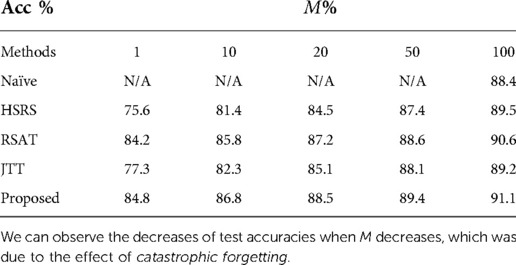
Table 4. Test accuracies of our approach and baselines when the ratio of the size vs. the size of changes.
These results demonstrate that our approach could alleviate catastrophic forgetting. This could be helpful in cases where we want to utilise generative models to improve pre-trained classifiers (or other task models) without revisiting all the training data (a continual learning context).
4.2.2. Results when number of samples used for synthesis () changes
We also performed experiments where we changed , i.e. the number of samples used for generating counterfactuals. Specifically, we set , i.e. only of original training data are used for re-training , to see how many synthetic samples are needed to maintain good accuracy, especially when there are only a few training data stored in . This is to see how efficient the synthetic samples are in terms of training and alleviating catastrophic forgetting. The results are presented in Table 5.
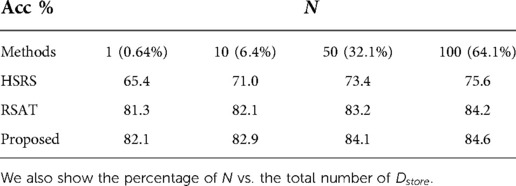
Table 5. Test accuracies when changes () of our approach and baselines.
From Table 5, we can observe that the best results are achieved by our method, followed by RSAT. Even with only one sample for synthesis, our method could still achieve a test accuracy of . This is probably because the adversarial training of vs. guides to generate hard counterfactuals, which are efficient to train the classifier. The results demonstrate that our approach could help alleviate catastrophic forgetting even with a small number of synthetic samples used for augmentation. This experiment could also be viewed as a measurement of the sample efficiency, i.e. how efficient a synthetic sample is in terms of re-training a classifier.
4.3. Can the proposed procedure alleviate spurious correlations?
Spurious correlation occurs when two factors appear to be correlated to each other but in fact they are not (47). Spurious correlation could affect the performance of deep neural networks and has been actively studied in computer vision field (25, 48–51) and in medical imaging analysis field (52, 53). For instance, suppose we have an dataset of bird and bat photos. For bird photos, most backgrounds are sky. For bat photos, most backgrounds are cave. If a classifier learns this spurious correlation, e.g. it classifies a photo as bird as long as the background is sky, then it will perform poorly on images where bats are flying in the sky. In this section, we investigate if our approach could correct such spurious correlations by changing to generate hard counterfactuals.
Here we create a dataset where 7860 images between 60 and 75 yrs old are AD, and 7,680 images between 75 and 90 yrs old are healthy, denoted as . This is to construct a spurious correlation: and (in reality older people have higher chances of getting AD (54)). Then we pre-train on . The brain ageing model proposed in Xia et al. (21) only considered simulating ageing process, but did not consider brain rejuvenation, i.e., the reverse of ageing. To utilise old CN data, we pre-train another generator in the rejuvenation direction, i.e.,generating younger brain images from old ones. As a result, we obtain two generators that are pre-trained on , denoted as and , where is trained to simulate the rejuvenation process. Figure 4 shows visual results of . After that, we select 50 CN and 50 AD hard images from , denoted as and perform the adversarial classification training using for old CN samples and for young AD samples. The target ages are initialized as real ages of .
After we obtain and , we select 50 CN and 50 AD images from that result in highest training errors, denoted as . Note that the selected CN images are between 75 and 90 yrs old, and the AD images are between 60 and 75 yrs old. Then we generate synthetic images from using for old CN samples and for young AD samples. The target ages are initialized as their ground-truth ages. Finally, we perform the adversarial training between and the classifier . Here we want to see if the adversarial training can detect the spurious correlations purposely created by us, and more importantly, we want to see if the adversarial training between and can break the spurious correlations.
Table 6 presents the test accuracies of our approach and baselines. For Naïve, we directly use the classifier pre-trained on . For HSRS, we randomly generate synthetic samples from for augmentation. For JTT, we simply select mis-classified samples from and up-sample these samples.
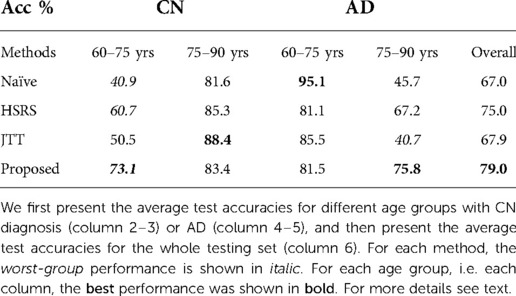
Table 6. Test accuracies for our procedure and baselines when pre-trained on .
We can observe from Table 6 that the pre-trained on (Naïve) achieves much worse performance ( accuracy) compared to that of Table 2 ( accuracy). Specifically, it tends to misclassify young CN images as AD and misclassify old AD images as CN. This is likely due to the spurious correlations that we purposely create in : and . We notice that for Naïve, the test accuracies of AD groups are higher than that of CN groups. This is likely due to the fact we have more AD training data, and the classifier is biased to classify a subject to AD. This can be viewed as another spurious correlation. Overall, we observe that our method achieves the best results, followed by HSRS. This shows that the synthetic results generated by the generators are helpful to alleviate the effect of spurious correlations and improve downstream tasks. The improvement of our approach over HSRS is due to the adversarial training between and , which guides the generator to produce hard counterfactuals. We observe JTT does not improve the test accuracies significantly. A potential reason is that JTT tries to find “hard” samples in the training dataset. However, in this experiment, the “hard” samples should be young CN and old AD samples which do not exist in the training dataset . By contrast, our procedure could guide to generate these samples, and HSRS could create these samples by random chance.
Figure 5 plots the histograms of the target ages before and after the adversarial training. From Figure 5 we can observe that the adversarial training pushes towards the hard direction, which could alleviate the spurious correlations. For instance, in and the AD subjects are all in the young group, i.e. 60–75 yrs old, and the classifier learns the spurious correlation: , but in Figure 5A we can observe that the adversarial training learns to generate AD synthetic images in the range of 75–90 yrs old. These old AD synthetic images can help alleviate the spurious correlation and improve the performance of . Similarly, we can observe are pushed towards young for CN subjects in Figure 5B.
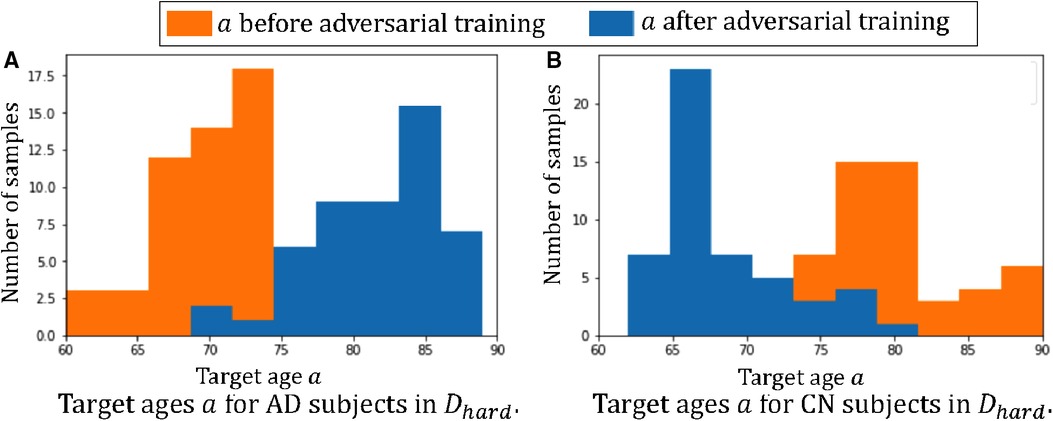
Figure 5. Histograms of target ages before and after adversarial training: (A) the histogram of for the 50 AD subjects in ; (B) the histogram of for the 50 CN subjects in . Here we show histograms of before (in orange) and after (in blue) the adversarial training.
5. Conclusion
We presented a novel adversarial counterfactual scheme to utilise conditional generative models for downstream tasks, e.g. classification. The proposed procedure formulates an adversarial game between the conditional factor of a pre-trained generative model and the downstream classifier. The synthesis model used in this work uses two generators for ageing and rejuvenation. Others have shown that one model can handle both tasks albeit in another dataset and with less conditioning factors (55). We do highlight though that our approach is agnostic to the generator used and since could benefit from advances in (conditional) generative modelling. In this paper, we demonstrate that several conventional augmentation techniques are not helpful for registered MRI. However, there might be other heuristic-based augmentation techniques that will improve performance, and it is worth trying to combine our semantic augmentation strategy with such conventional augmentation techniques to further boost performance. The proposed adversarial counterfactual scheme could be applied to generative models that produced other types of counterfactuals rather than the ageing brain, e.g. the ageing heart (55, 56), future disease outcomes (57), existence of pathology (58, 59), etc. The way we updated the conditional factor (target age) could be improved. Instead of a continuous scalar (target age), we can consider extending the proposed adversarial counterfactual augmentation to update other types of conditional factors, e.g., discrete factor or image. The strategy that we used to select hard samples may not be the most effective and could be improved.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://adni.loni.usc.edu.
Ethics statement
Ethical review and approval was not required for this study in accordance with the local legislation and institutional requirements.
Author contributions
TX, PS, CQ and SAT contributed to the conceptualization of this work. TX, PS, CQ and SAT designed the methodology. TX developed the software tools necessary for preprocessing and analysing images files and for training the model. TX drafted this manuscript. All authors contributed to the article and approved the submitted version.
Acknowledgments
This work was supported by the University of Edinburgh, the Royal Academy of Engineering and Canon Medical Research Europe via PhD studentships of Pedro Sanchez (grant RCSRF1819\8\25). S.A. Tsaftaris acknowledges the support of Canon Medical and the Royal Academy of Engineering and the Research Chairs and Senior Research Fellowships scheme (grant RCSRF1819\8\25).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1An example could be when training and testing brain MRI data are already well-registered, traditional augmentations, e.g. rotation, shift, etc., on the training data will hurt the performance of the trained model on testing data. See Section 4.1.3 for more details.
2Code is available at https://github.com/xiat0616/BrainAgeing
3Deep models continuously learn based on input of new data while preserving previously learnt knowledge.
4A popular deep learning neural network that has widely been used for classification.
5https://github.com/iitzco/deepbrain
References
1. Shen D, Wu G, Suk H-I. Deep learning in medical image analysis. Annu Rev Biomed Eng. (2017) 19:221–48. doi: 10.1146/annurev-bioeng-071516-044442
2. Chlap P, Min H, Vandenberg N, Dowling J, Holloway L, Haworth A. A review of medical image data augmentation techniques for deep learning applications. J Med Imaging Radiat Oncol. (2021) 65:545–63. doi: 10.1111/1754-9485.13261
3. Shorten C, Khoshgoftaar TM. A survey on image data augmentation for deep learning. J Big Data. (2019) 6:1–48. doi: 10.1186/s40537-019-0197-0
4. Dietterich T. Overfitting, undercomputing in machine learning. ACM Comput Surv (CSUR). (1995) 27:326–7. doi: 10.1145/212094.212114
5. Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res. (2014) 15:1929–58. doi: 10.5555/2627435.2670313
6. Cubuk ED, Zoph B, Mane D, Vasudevan V, Le QV. Autoaugment: learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision, Pattern Recognition (2019). p. 113–123. Long Beach, CA, USA: IEEE
7. Gong C, Wang D, Li M, Chandra V, Liu Q. Keepaugment: a simple information-preserving data augmentation approach. In Proceedings of the IEEE/CVF Conference on Computer Vision, Pattern Recognition (2021). p. 1055–1064. Nashville, TN, USA: IEEE
8. Chen C, Qin C, Ouyang C, Wang S, Qiu H, Chen L, et al. Enhancing mr image segmentation with realistic adversarial data augmentation [Preprint] (2021). Available at: http://arxiv.org/2108.03429.
9. Gao Y, Tang Z, Zhou M, Metaxas D. Enabling data diversity: efficient automatic augmentation via regularized adversarial training. In International Conference on Information Processing in Medical Imaging. Springer (2021). p. 85–97.
10. Gong C, Ren T, Ye M, Liu Q. Maxup: lightweight adversarial training with data augmentation improves neural network training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021). p. 2474–2483. Nashville, TN, USA: IEEE
11. Wang Y, Huang G, Song S, Pan X, Xia Y, Wu C. Regularizing deep networks with semantic data augmentation. IEEE Trans Pattern Anal Mach Intell. (2021) 44(7):3733–48.
12. Zhang X, Wang Z, Liu D, Lin Q, Ling Q. Deep adversarial data augmentation for extremely low data regimes. IEEE Trans Circuits Syst Video Technol. (2020) 31:15–28. doi: 10.1109/TCSVT.2020.2967419
13. Shamsolmoali P, Zareapoor M, Shen L, Sadka AH, Yang J. Imbalanced data learning by minority class augmentation using capsule adversarial networks. Neurocomputing. (2021) 459:481–93. doi: 10.1016/j.neucom.2020.01.119
14. Bowles C, Chen L, Guerrero R, Bentley P, Gunn R, Hammers A, et al. GAN augmentation: augmenting training data using generative adversarial networks [Preprint] (2018). Available at: http://arxiv.org/1810.10863.
15. Oh K, Yoon JS, Suk H-I. Learn-explain-reinforce: counterfactual reasoning, its guidance to reinforce an Alzheimer’s disease diagnosis model [Preprint] (2021). Available at: http://arxiv.org/2108.09451.
16. Dash S, Balasubramanian VN, Sharma A. Evaluating, mitigating bias in image classifiers: a causal perspective using counterfactuals. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (2022). p. 915–924. Waikoloa, HI, USA: IEEE.
17. Ye J, Xue Y, Long LR, Antani S, Xue Z, Cheng KC, et al. Synthetic sample selection via reinforcement learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer (2020). p. 53–63.
18. Xue Y, Ye J, Zhou Q, Long LR, Antani S, Xue Z, et al. Selective synthetic augmentation with histogan for improved histopathology image classification. Med Image Anal. (2021) 67:101816. doi: 10.1016/j.media.2020.101816
19. Li S, Gong K, Liu CH, Wang Y, Qiao F, Cheng X. Metasaug: meta semantic augmentation for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021). p. 5212–5221. Nashville, TN, USA: IEEE.
20. Chen J, Su B. Sample-specific and context-aware augmentation for long tail image classification (2021). Available at: https://openreview.net/forum?id=34k1OWJWtDW.
21. Xia T, Chartsias A, Wang C, Tsaftaris SA, Initiative ADN, et al. Learning to synthesise the ageing brain without longitudinal data. Med Image Anal. (2021) 73:102169. doi: 10.1016/j.media.2021.102169
22. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. ICLR, San Diego, CA, USA (2015).
23. Tancik M, Srinivasan PP, Mildenhall B, Fridovich-Keil S, Raghavan N, Singhal U, et al. Fourier features let networks learn high frequency functions in low dimensional domains. NeurIPS, British Columbia, Canada (2020).
24. Mildenhall B, Srinivasan PP, Tancik M, Barron JT, Ramamoorthi R, Ng R. NeRF: representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision. Springer (2020). p. 405–421.
25. Liu EZ, Haghgoo B, Chen AS, Raghunathan A, Koh PW, Sagawa S, et al. Just train twice: improving group robustness without training group information. In International Conference on Machine Learning. PMLR (2021). p. 6781–6792.
26. Feldman V, Zhang C. What neural networks memorize and why: discovering the long tail via influence estimation [Preprint] (2020). Available at: http://arxiv.org/2008.03703.
27. Frid-Adar M, Diamant I, Klang E, Amitai M, Goldberger J, Greenspan H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing. (2018) 321:321–31. doi: 10.1016/j.neucom.2018.09.013
28. Dar SU, Yurt M, Karacan L, Erdem A, Erdem E, Çukur T. Image synthesis in multi-contrast MRI with conditional generative adversarial networks. IEEE Trans Med Imaging. (2019) 38(10):2375–88.30835216
29. Kirkpatrick J, Pascanu R, Rabinowitz N, Veness J, Desjardins G, Rusu AA, et al. Overcoming catastrophic forgetting in neural networks. Proc Natl Acad Sci. (2017) 114:3521–6. doi: 10.1073/pnas.1611835114
30. Antoniou A, Storkey A, Edwards H. Data augmentation generative adversarial networks [Preprint] (2018). Available at: http://arxiv.org/.org/1711.04340.
31. Frid-Adar M, Klang E, Amitai M, Goldberger J, Greenspan H. Synthetic data augmentation using GAN for improved liver lesion classification. In 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018). IEEE (2018). p. 289–293.
32. Shin H-C, Tenenholtz NA, Rogers JK, Schwarz CG, Senjem ML, Gunter JL, et al. Medical image synthesis for data augmentation and anonymization using generative adversarial networks. In International Workshop on Simulation and Synthesis in Medical Imaging. Springer (2018). p. 1–11.
33. Delange M, Aljundi R, Masana M, Parisot S, Jia X, Leonardis A, et al. A continual learning survey: defying forgetting in classification tasks. IEEE Trans Pattern Anal Mach Intell. (2021) 44(7):3366–85.
34. Parisi GI, Kemker R, Part JL, Kanan C, Wermter S. Continual lifelong learning with neural networks: a review. Neural Netw. (2019) 113:54–71. doi: 10.1016/j.neunet.2019.01.012
35. Chaudhry A, Rohrbach M, Elhoseiny M, Ajanthan T, Dokania PK, Torr PHS, et al. Continual learning with tiny episodic memories. CoRR (2019). abs/1902.10486.
36. Lopez-Paz D, Ranzato M. Gradient episodic memory for continual learning. Adv Neural Inf Process Syst. (2017) 30:6467–76. doi: 10.5555/3295222.3295393
38. Aljundi R, Chakravarty P, Tuytelaars T. Expert gate: lifelong learning with a network of experts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017). p. 3366–3375. Honolulu, Hawaii: IEEE.
39. McCloskey M, Cohen NJ. Catastrophic interference in connectionist networks: the sequential learning problem. In Psychology of Learning and Motivation, Vol. 24. Elsevier (1989). p. 109–165.
40. Aljundi R, Rohrbach M, Tuytelaars T. Selfless sequential learning. In International Conference on Learning Representations (2018). Vancouver, BC, Canada.
41. Chaudhry A, Dokania PK, Ajanthan T, Torr PH. Riemannian walk for incremental learning: understanding forgetting and intransigence. In Proceedings of the European Conference on Computer Vision (ECCV) (2018). p. 532–547. Munich, Germany: Springer.
42. Gepperth A, Karaoguz C. A bio-inspired incremental learning architecture for applied perceptual problems. Cognit Comput. (2016) 8:924–34. doi: 10.1007/s12559-016-9389-5
43. Robins A. Catastrophic forgetting, rehearsal and pseudorehearsal. Conn Sci. (1995) 7:123–46. doi: 10.1080/09540099550039318
44. van de Ven GM, Siegelmann HT, Tolias AS. Brain-inspired replay for continual learning with artificial neural networks. Nat Commun. (2020) 11:1–14. doi: 10.1038/s41467-020-17866-2
45. Petersen RC, Aisen P, Beckett LA, Donohue M, Gamst A, Harvey DJ, et al. Alzheimer’s disease neuroimaging initiative (ADNI): clinical characterization. Neurology. (2010) 74:201–9. doi: 10.1212/WNL.0b013e3181cb3e25
46. Woolrich MW, Jbabdi S, Patenaude B, Chappell M, Makni S, Behrens T, et al. Bayesian analysis of neuroimaging data in FSL. Neuroimage. (2009) 45:S173–86. doi: 10.1016/j.neuroimage.2008.10.055
47. Simon HA. Spurious correlation: a causal interpretation. J Am Stat Assoc. (1954) 49:467–79. doi: 10.1080/01621459.1954.10483515
48. Sagawa S, Raghunathan A, Koh PW, Liang P. An investigation of why overparameterization exacerbates spurious correlations. In International Conference on Machine Learning. PMLR (2020). p. 8346–8356.
49. Sagawa S, Koh PW, Hashimoto TB, Liang P. Distributionally robust neural networks for group shifts: on the importance of regularization for worst-case generalization [Preprint] (2019). Available at: http://arxiv.org/1911.08731.
50. Youbi Idrissi B, Arjovsky M, Pezeshki M, Lopez-Paz D. Simple data balancing achieves competitive worst-group-accuracy [E-prints] (2021). Available at: http://arxiv.org/–2110.
51. Goel K, Gu A, Li Y, Ré C. Model patching: closing the subgroup performance gap with data augmentation. ICLR, Vienna, Austria (2021).
52. Mahmood U, Shrestha R, Bates DDB, Mannelli L, Corrias G, Erdi YE, et al. Detecting spurious correlations with sanity tests for artificial intelligence guided radiology systems. Front Digit Health (2021) 3:671015. doi: 10.3389/fdgth.2021.671015
53. DeGrave AJ, Janizek JD, Lee S-I. AI for radiographic COVID-19 detection selects shortcuts over signal. Nat Mach Intell (2021) 53:1–10.
54. Goedert M, Spillantini MG. A century of Alzheimer’s disease. Science. (2006) 314:777–81. doi: 10.1126/science.1132814
55. Campello VM, Xia T, Liu X, Sanchez P, Martín-Isla C, Petersen SE, et al. Cardiac aging synthesis from cross-sectional data with conditional generative adversarial networks. Front Cardiovasc Med. (2022) 9:983091. doi: 10.3389/fcvm.2022.983091
56. Qiao M, Basaran BD, Qiu H, Wang S, Guo Y, Wang Y, et al. Generative modelling of the ageing heart with cross-sectional imaging and clinical data. arXiv preprint arXiv:2208.13146. (2022). doi: 10.48550/arXiv.2208.13146
57. Kumar A, Hu A, Nichyporuk B, Falet J-PR, Arnold DL, Tsaftaris S, et al. Counterfactual image synthesis for discovery of personalized predictive image markers. MICCAI Workshop on Medical Image Assisted Blomarkers’ Discovery, MICCAI Workshop on Artificial Intelligence over Infrared Images for Medical Applications. Springer (2022). p. 113–24.
58. Xia T, Chartsias A, Tsaftaris SA. Pseudo-healthy synthesis with pathology disentanglement and adversarial learning. Med Image Anal. (2020) 64:101719. doi: 10.1016/j.media.2020.101719
59. Basaran BD, Qiao M, Matthews PM, Bai W. Subject-specific lesion generation and pseudo-healthy synthesis for multiple sclerosis brain images. In: Zhao C, Svoboda D, Wolterink JM, Escobar M, (editors). Simulation and Synthesis in Medical Imaging. SASHIMI 2022. Lecture Notes in Computer Science, vol 13570. Chem: Springer (2022). p. 1–11. doi: 10.1007/978-3-031-16980-9_1
Keywords: Alzheimer’s disease, generative model, classification, counterfactuals, data efficiency
Citation: Xia T, Sanchez P, Qin C and Tsaftaris SA (2022) Adversarial counterfactual augmentation: application in Alzheimer’s disease classification. Front. Radio 2:1039160. doi: 10.3389/fradi.2022.1039160
Received: 7 September 2022; Accepted: 7 November 2022;
Published: 30 November 2022.
Edited by:
Yang Song, University of New South Wales, AustraliaReviewed by:
Kayhan Batmanghelich, University of Pittsburgh, United StatesYuan Xue, Johns Hopkins University, United States
© 2022 Xia, Sanchez, Qin and Tsaftaris. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tian Xia dGlhbi54aWFAZWQuYWMudWs=
Specialty Section: This article was submitted to Artificial Intelligence in Radiology, a section of the journal Frontiers in Radiology