 Laurent Condat
Laurent Condat Grigory Malinovsky
Grigory Malinovsky Peter Richtárik
Peter Richtárik- Visual Computing Center, King Abdullah University of Science and Technology (KAUST), Thuwal, Saudi Arabia
We analyze several generic proximal splitting algorithms well suited for large-scale convex nonsmooth optimization. We derive sublinear and linear convergence results with new rates on the function value suboptimality or distance to the solution, as well as new accelerated versions, using varying stepsizes. In addition, we propose distributed variants of these algorithms, which can be accelerated as well. While most existing results are ergodic, our nonergodic results significantly broaden our understanding of primal–dual optimization algorithms.
1 Introduction
We propose new algorithms for the generic convex optimization problem:
where M ≥ 1 is typically the number of parallel computing nodes in a distributed setting; the
This template problem covers most convex optimization problems met in signal and image processing, operations research, control, machine learning, and many other fields, and our goal is to propose new generic distributed algorithms able to deal with nonsmooth functions using their proximity operators, with acceleration in presence of strong convexity.
1.1 Contributions
Our contributions are the following:
(1) New algorithms: We propose the first distributed algorithms to solve (Eq. 1) in whole generality, with proved convergence to an exact solution, and having the full splitting, or decoupling, property: ∇Fm,
(2) Unified framework: The foundation of our distributed algorithms consists in two general principles, applied in a cascade, which are new contributions in themselves and could be used in other contexts:
(a) We show that problem (Eq. 1) with M = 1, i.e. the minimization of F + R + H◦K, can be reformulated as the minimization of
(b) We design a non-straightforward lifting technique, so that the problem (Eq. 1), with any M, is reformulated as the minimization of
(3) New convergence analysis and acceleration: Even when M = 1, we improve upon the state of the art in two ways:
(a) For constant stepsizes, we recover existing algorithms, but we provide new, more precise, results about their convergence speed, see Theorem 1 and Theorem 5.
(b) With a particular strategy of varying stepsizes, we exhibit new algorithms, which are accelerated versions of them. We prove O(1/k2) convergence rate on the last iterate, see Theorem 3 and Theorem 4, whereas current results in the literature are ergodic, e.g. Chambolle and Pock (2016b).
1.2 Related Work
Many estimation problems in a wide range of scientific fields can be formulated as large-scale convex optimization problems (Palomar and Eldar, 2009; Sra et al., 2011; Bach et al., 2012; Bubeck, 2015; Polson et al., 2015; Chambolle and Pock, 2016a; Glowinski et al., 2016; Stathopoulos et al., 2016; Condat, 2017a; Condat et al., 2019b). Proximal splitting algorithms (Combettes and Pesquet, 2010; Boţ et al., 2014; Parikh and Boyd, 2014; Komodakis and Pesquet, 2015; Beck, 2017; Condat et al., 2019a) are particularly well suited to solve them; they consist of simple, easy to compute, steps that can deal with the terms in the objective function separately.
These algorithms are generally designed as sequential ones, for M = 1, and then they can be extended by lifting in product space to parallel versions, well suited to minimize F + R + ∑mHm ○ Km, see for instance Condat et al., 2019a, Section 8. However, it is not straightforward to adapt lifting to the case of a finite-sum








There is a vast literature on distributed optimization to minimize
When M = 1 and K = I, where I denotes the identity, Davis and Yin (2017) proposed an efficient algorithm, along with an extensive study of its convergence rates and possible accelerations. But the ability to handle a nontrivial K is behind the success of the Chambolle and Pock (2011) or \Condat (2013), Vũ (2013): they are well suited for regularized inverse problems in imaging (Chambolle and Pock, 2016a), for instance with the total variation and its variants (Bredies et al., 2010; Condat, 2014, 2017b; Duran et al., 2016); other examples are computer vision problems (Cremers et al., 2011), overlapping group norms for sparse estimation in data science (Bach et al., 2012), and trend filtering on graphs (Wang et al., 2016). Another prominent case is when H is an indicator function, so that the problem becomes: minimize F(x) + R(x) subject to Kx = b. If K is a gossip matrix like the minus graph Laplacian, decentralized optimization over a network can be tackled (Shi et al., 2015; Scaman et al., 2017; Salim et al., 2021).
When M = 1 and K is arbitrary, there exist algorithms to solve (Eq. 1) in full generality, for example, the Combettes and Pesquet (2012), Condat, (2013), Vũ (2013), PD3O (Yan, 2018) and PDDY (Salim et al., 2020) algorithms. However, their convergence rates and possible accelerations are little understood. Our main contribution is to derive new convergence rates and accelerated versions of the PD3O and PDDY algorithms, and their particular cases, including Chambolle and Pock (2011) and Loris and Verhoeven (2011) algorithms. In order to do this, we show that these two algorithms can be viewed as instances of the Davis–Yin algorithm. This reformulation technique is inspired by the recent one of O’Connor and Vandenberghe (O’Connor and Vandenberghe, 2020); it makes it possible to split the composition H°K and to derive algorithms, which call the operators proxH, K, K* separately. This technique is fundamentally different from the one in Salim et al. (2020), showing that the PD3O and PDDY algorithms are primal–dual instances of the operator version of Davis–Yin splitting to solve monotone inclusions. Notably, we can derive convergence rates with respect to the objective function and accelerations, which is not possible with the primal–dual reformulation of Salim et al. (2020). On the other hand, the latter encompasses the Condat–Vũ algorithm (Condat, 2013; Vũ, 2013), which is not the case of our approach. So, these are complementary interpretations.
1.3 Organization of the paper
In Section 2, we propose new nonstationary versions (i.e. with varying stepsizes) of several algorithms for optimization problems made of three terms, and we analyze their convergence rates. The derivation details are pushed to the end of the paper in Section 5 for ease of reading. In Section 3, we further propose distributed algorithms, which can minimize the sum of an arbitrary number of terms. Again, the derivation details are deferred to Section 6. Numerical experiments illustrating the good match between our theoretical results and practical performance are shown in Section 4.
2 Minimization of 3 Functions With a Linear Operator
Let us focus on the problem (Eq. 1) when M = 1:
where
The dual problem to (Eq. 2) is
where K* is the adjoint operator of K and G* is the convex conjugate of a function G (Bauschke and Combettes, 2017); we recall the Moreau identity:
Assumption 1There exists
2.1 Deriving the Nonstationary PD3O and PDDY Algorithms
The main difficulty in (Eq. 2) is the presence of the linear operator K. Indeed, if K = I, the Davis–Yin algorithm (Davis and Yin, 2017) is well suited to minimize F + R + H. Note that there is a minor mistake in the way Algorithm 3 in Davis and Yin (2017) is initialized. This is corrected here. Thus, the Davis–Yin algorithm is as follows:
Let
To make this algorithm applicable to K ≠ I, we reformulate the problem (Eq. 2) as follows:
(1) We choose a value η ≥‖K‖2; we recommend to set η = ‖K‖2 in practice. Then there exists a real Hilbert space
(2) Now, the problem (Eq. 2) can be rewritten as:
where
We have
Note that in O’Connor and Vandenberghe (2020), the authors use
Then, we can apply the Davis–Yin algorithm (4) to solve the problem (Eq. 5). We set F, R, H in (Eq. 4) as
Particular cases of the PD3O and PDDY algorithms, which are shown above, are the following:
(1) If K = I and η = 1, the PD3O algorithm reverts to the Davis–Yin algorithm (Eq. 4); the PDDY algorithm too, but with H and R exchanged in (Eq. 4).
(2) If F = 0, the PD3O and PDDY algorithms revert to the forms I and II (Condat et al., 2019a) of the Chambolle–Pock algorithm, a.k.a. Primal–Dual Hybrid Gradient algorithm (Chambolle and Pock, 2011), respectively.
(3) If R = 0, the PD3O and PDDY algorithms revert to the Loris–Verhoeven algorithm (Loris and Verhoeven, 2011), also discovered independently as the PDFP2O (Chen et al., 2013) and PAPC (Drori et al., 2015) algorithms; see also Combettes et al. (2014); Condat et al. (2019a) for an analysis as a primal–dual forward–backward algorithm.
(4) If F = 0 in the Davis–Yin algorithm or K = I and η = 1 in the Chambolle–Pock algorithm, we obtain the Douglas–Rachford algorihm; it is equivalent to the ADMM, see the discussion in Condat et al. (2019a).
(5) If H = 0, the PD3O and PDDY algorithms revert to the forward–backward algorithm, a.k.a. proximal gradient descent. The Loris–Verhoeven algorithm with K = I and η = 1, too.
2.2 Convergence Analysis
We first give convergence rates for the PD3O algorithm with constant stepsizes.
Theorem 1. (convergence rate of the PD3O algorithm). In the PD3O algorithm, suppose that γk ≡ γ ∈ (0, 2/LF) and η ≥‖K‖2. Then xk and uk converge to some solutions x* and u* of (2) and (3), respectively. In addition, suppose that H is continuous on an open ball centered at Kx*. Then the following hold:
Define the weighted ergodic iterate
Furthermore, if H is L-smooth for some L > 0, we have a faster decay for the best iterate so far:
Proof. The convergence of xk follows from Davis and Yin, 2017, Theorem 2.1 and the convergence of uk follows from the one of the variable
Theorem 1 applies to the particular cases of the PD3O algorithm, like the Loris–Verhoeven, Chambolle–Pock, Douglas–Rachford algorithms. Our results are new even for them.
Remark 1. We can note that the forward–backward algorithm xk+1 = proxγR(xk − γ∇F(xk)), which is a particular case of the PD3O algorithm when H = 0, is monotonic. So, the best iterate so far is the last iterate. Hence, Theorem 1 (iii) yields Ψ(xk) − Ψ(x*) = o(1/k) for the forward–backward algorithm.For the PDDY algorithm, we cannot derive a similar theorem, since
Theorem 2. (convergence of the PDDY algorithm). In the PDDY algorithm, suppose that γk ≡ γ ∈ (0, 2/LF) and η ≥‖K‖2. Then xk and
Proof. The convergence of xk and
We now give accelerated convergence results using varying stepsizes, when F or R is strongly convex; that is, μF + μR > 0. In that case, we denote by x* the unique solution to (Eq. 2).
Theorem 3. (convergence rate of the accelerated PD3O algorithm). Suppose that μF + μR > 0. Let κ ∈ (0, 1) and γ0 ∈ (0, 2(1 − κ)/LF). Set γ1 = γ0 and
Suppose that η ≥‖K‖2. Then in the PD3O algorithm, there exists c0 > 0 (whose expression is given in Section 5) such that, for every k ≥ 1,
Proof. This result follows from Davis and Yin, 2017, Theorem 3.3, stated for convenience as Lemma 1 in Section 5.□
Note that with the stepsize rule in (Eq. 7), we have k γk → 1/(μFκ + μR) as k → + ∞, so that γk = O(1/k) and γk+1/γk → 1. Also, when F = 0, LF can be taken arbitrarily small, so that we can choose any γ0 > 0.Theorem 3 is new for the PD3O and Loris–Verhoeven algorithms, but has been derived in O’Connor and Vandenberghe (2020) for the Chambolle–Pock algorithm. For the forward–backward algorithm, strong convexity yields linear convergence with constant stepsizes, so this nonstationary version does not seem interesting.Concerning the PDDY algorithm,
Theorem 4. (convergence rate of the accelerated PDDY algorithm). Suppose that μF > 0. Let κ ∈ (0, 1) and γ0 ∈ (0, 2(1 − κ)/LF). Set γ1 = γ0 and
Suppose that η ≥‖K‖2. Then in the PDDY algorithm, there exists c0 > 0 (whose expression is given in Section 5) such that, for every k ≥ 1,
Moreover, if η > ‖K‖2,
Theorem 5. (linear convergence of the PD3O and PDDY algorithms). Suppose that μF + μR > 0 and that H is LH-smooth, for some LH > 0. Let x* and u* be the unique solutions to (2) and (3), respectively. Suppose that γk ≡ γ ∈ (0, 2/LF) and η ≥‖K‖2. Then the PD3O algorithm converges linearly: there exists ρ ∈ (0, 1] such that, for every
The PDDY algorithm converges linearly too: there exists ρ ∈ (0, 1] such that, for every
Linear convergence of the other variables in the algorithms can be derived as well, see Proposition 1. Lower bounds for ρ can be derived from Theorem D.6 in the preprint version of Davis and Yin (2017). We don’t provide them, since they are not tight, as noticed in Remark D.2 of the same preprint. For instance, for the PDDY or Loris–Verhoeven algorithms with μF > 0,
If H = 0, by setting LH = 0, we get ρ = γμF(2 − γLF). But then the PDDY algorithm reverts to the forward–backward algorithm, for which it is known that
3 Distributed Proximal Algorithms
We now focus on the more general problem (Eq. 1) and we derive distributed versions of the PD3O and PDDY algorithms to solve it. For this, we develop a lifting technique: we recast the minimization of
as follows. Let
We introduce the Hilbert space
and the Hilbert space
Furthermore, we introduce


Davis–Yin algorithm when Km ≡ I and η = 1, the distributed Loris–Verhoeven algorithm when R = 0, the distributed Chambolle–Pock algorithm when Fm ≡ 0, the distributed Douglas–Rachford algorithm when Fm ≡ 0, Km ≡ I and η = 1, the (classical) distributed forward–backward algorithm when Hm ≡ 0.


We can easily translate Theorems 1–5 to these distributed algorithms; the corresponding theorems are given in Section 6. In a nutshell, we obtain the same convergence results and rates with any number of nodes M ≥ 1 as in the non-distributed setting, for any




4 Experiments
4.1 Image Deblurring Regularized With Total Variation
We first consider the non-distributed problem (Eq. 2), for the imaging inverse problem of deblurring, which consists in restoring an image y corrupted by blur and noise (Chambolle and Pock, 2016a). So, we set
where the linear operator A corresponds to a 2-D convolution with a lowpass filter, with LF = 1. The filter is approximately Gaussian and chosen so that F is μF-strongly convex with μF = 0.01. y is obtained by applying A to the classical 256 × 256 Shepp–Logan phantom image, with additive Gaussian noise. R = ı0 enforces nonnegativity of the pixel values. H°K corresponds to the classical ‘isotropic’ total variation (TV) (Chambolle and Pock, 2016a; Condat, 2017b), with H = 0.6 times the l1,2 norm and K the concatenation of vertical and horizontal finite differences.
We compare the nonaccelerated, i.e. with constant γk, and accelerated versions, with decaying γk, of the PD3O, PDDY and Condat–Vũ algorithms. We initialize the dual variables at zero and the estimate of the solution as y. We set γ0 = 1.7, κ = 0.15, η = 8 ≥‖K‖2 (except for the accelerated Condat–Vũ algorithm proposed in Chambolle and Pock (2016b), for which η = 16 and γ = 0.5).
The results are illustrated in Figure 1 (implementation in Matlab). We observe that the PD3O and PDDY algorithms have almost identical variables: the pink, red, blue curves are superimposed; we know that both algorithms are identical and revert to the Loris–Verhoeven algorithm when R = 0. Here R ≠ 0 but the nonnegativity constraint does not change the solution significantly, which explains the similarity of the two algorithms.
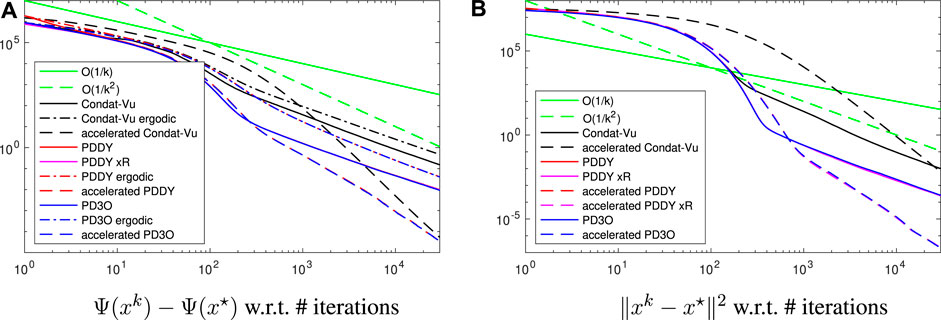
FIGURE 1. Convergence error, in log-log scale, for the experiment of image deblurring regularized with the total variation, see Section 4.1 for details.
Note that xk in the PDDY algorithm is not feasible with respect to nonnegativity, and the red curve actually shows F(xk) + H(Kxk) − Ψ(x*). In the nonaccelerated case, Ψ(xk) decays faster than O(1/k) but slower than O(1/k2), which is coherent with Theorem 1. The same holds for
The accelerated versions improve the convergence speed significantly: Ψ(xk) and ‖xk − x*‖2 decay even faster than O(1/k2), in line with Theorem 3 and Theorem 4. In all cases, the Condat–Vũ algorithm is outperformed. Also, there is no interest in considering the ergodic iterate instead of the last iterate, since the former converges at the same asymptotic rate as the latter, but slower.
4.2 Image Deblurring Regularized With Huber-TV
We consider the same deblurring experiment as before, but we make H smooth by taking the Huber function instead of the l1 norm in the total variation; that is, λ|⋅| in the latter is replaced by
for some ν > 0 and λ > 0 (set here as 0.1 and 0.6, respectively). We can also write h without branching as
The results are illustrated in Figure 2. Again, the PD3O and PDDY algorithms behave very similarly; they converge linearly, as proved in Theorem 5, and achieve machine precision in finite time. xk in the PDDY algorithm is not feasible and F(xk) + H(Kxk) − Ψ(x*) (red curve) takes negative values (not shown in log scale); so,
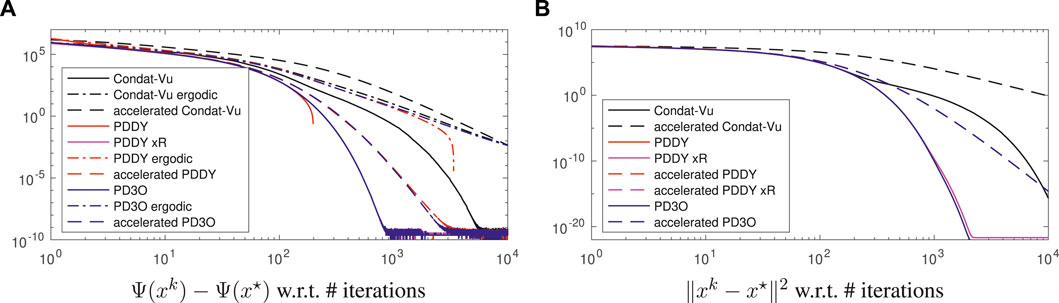
FIGURE 2. Convergence error, in log-log scale, for the experiment of image deblurring regularized with the smooth Huber-total-variation, so that linear convergence occurs, see Section 4.2 for details.
4.3 SVM With Hinge Loss
Here we consider Problem (Eq. 1) in the special case with
In particular, to train a binary classifier, we consider the classical SVM problem with hinge loss, which has the form (Eq. 9) with
For any γ > 0 we have proxγR(x) = x/(1 + γα). We could view the dot product
where
The method was implemented in Python on a single machine and tested on the dataset ‘australian’ from the LibSVM base (Chang and Lin, 2011), with d = 15 and M = 680. We set ωm ≡ 1/M, α = 0.1, γ0 = 0.1, and we used zero vectors for the initialization. The results are shown in Figure 3. Despite the oscillations, we observe that both the objective suboptimality and the squared distance to the solution converge sublinearly, with rates looking like
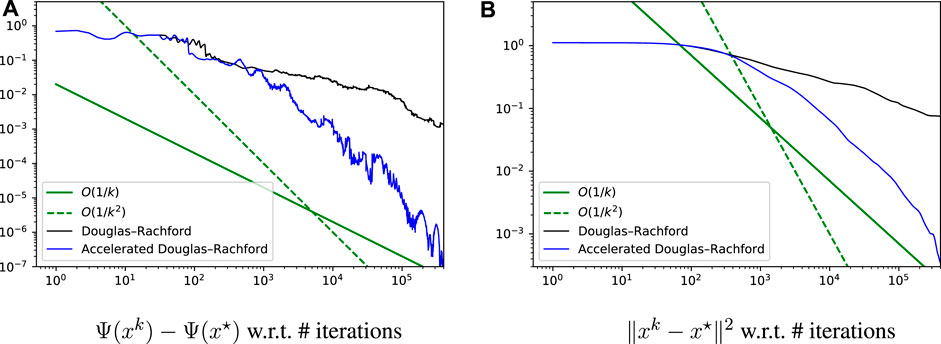
FIGURE 3. Convergence error, in log-log scale, for the SVM binary classification experiment with hinge loss, see Section 4.3 for details.
5 Derivation of the Algorithms
In this section, we give the details of the derivation of the PD3O and PPDY algorithms, and their particular cases, to solve:
with same notations and assumptions as above. Let η ≥‖K‖2, let
5.1 The Davis–Yin Algorithm
In this section, we state the results on the Davis–Yin algorithm, which we be needed to analyze the PD3O and PPDY algorithms.
The Davis–Yin algorithm to minimize the sum of 3 convex functions
Let
Equivalently, introducing the variable
Equivalently: let
In our notations, Theorem 3.3 of Davis and Yin (2017) translates into Lemma 1 as follows; we assume that
Lemma 1. (accelerated Davis–Yin algorithm). Suppose that
Then, for every k ≥ 1,
where
Note that
Lemma 2. (linear convergence of the Davis–Yin algorithm). Suppose that
Loose lower bounds for ρ are given in Davis and Yin, 2017, Theorem D.6.We have the following corollary of Lemma 2:
Proposition 1. (linear convergence of the other variables in the Davis–Yin algorithm). In the same conditions and notations as in Lemma 2, we have, for every
Also, in the form (Eq. 12) of the algorithm,
and, in the form (Eq. 10) of the algorithm,
Proof. Let
and, by nonexpansiveness of I − proxγG and
Using the same arguments, in view of the second line in (Eq. 12),
Finally, as visible in the first line of (Eq. 16), since
□
5.2 The PD3O Algorithm
We set
Let
We can remove the variable rw and the algorithm becomes: Let
After replacing CC* by ηI − KK*, the iteration becomes:
We can change the variables, so that only one call to ∇F and K* appears, which yields the algorithm: Let
When γk ≡ γ is constant, we recover the PD3O algorithm (Yan, 2018).
To derive Theorem 3 from Lemma 1, we simply have to notice that the variable
If K = I and η = 1, the PD3O algorithm reverts to the Davis–Yin algorithm, as given in (Eq. 4). In the conditions of Theorem 3, let u* be any solution of (Eq. 3); that is, u* ∈ ∂H(x*) and 0 ∈ ∂R(x*) + ∇F(x*) + u*. Then the constant c0 is
5.3 The PDDY Algorithm
The PDDY algorithm is obtained like the PD3O algorithm from the David–Yin algorithm, but after swapping the roles of
To obtain the PDDY algorithm, starting from (Eq. 10), let us first write the Davis–Yin algorithm as: Let
Equivalently: Let
We set
We can remove the variable rw and rename rx as s:
The algorithm becomes: Let
Equivalently: Let
We can write the algorithm with only one call of K* per iteration by introducing an additional variable p: Let
When γk ≡ γ is constant, we recover the PDDY algorithm (Salim et al., 2020).
Let us now derive Theorem 4 from Lemma 1. The variable
Therefore, in the conditions of Theorem 4, let u* be any solution of (Eq. 3); that is, u* ∈ ∂H(Kx*) and 0 ∈ ∂R(x*) + ∇F(x*) + K*u*. Then the constant c0 is
The last statement in Theorem 4 is obtained as follows. First, for every k ≥ 1,
If K = I and η = 1, the PDDY algorithm reverts to the Davis–Yin algorithm, as given in (Eq. 4), but with R and H exchanged. In the conditions of Theorem 4, let u* be any solution of (Eq. 3); that is, u* ∈ ∂H(x*) and 0 ∈ ∂R(x*) + ∇F(x*) + u*. Then the constant c0 is
This is the same value as in (Eq. 15), corresponding to the Davis–Yin algorithm, viewed as the PD3O algorithm, with R and H exchanged. Indeed, u* is defined differently in both cases; that is, with the exchange, u* ∈ ∂R(x*) in (Eq. 15).
5.4 R = 0: The Loris–Verhoeven Algorithm
If R = 0, the PD3O algorithm becomes: Let
whereas the PDDY algorithm becomes: Let
Equivalently,
or:
which is equivalent to (18). So, when R = 0, both the PD3O and PPDY revert to an algorithm which, for γk ≡ γ, is the Loris–Verhoeven algorithm (Loris and Verhoeven, 2011; Combettes et al., 2014; Condat et al., 2019a).
Let u* be any solution of (Eq. 3); that is, u* ∈ ∂H(Kx*) and 0 ∈ ∇F(x*) + K*u*. In the conditions of Theorem 3, c0 is:
On the other hand, in Theorem 4,
It is not clear how these two values compare to each other. They are both valid, in any case.
5.5 F = 0: The Chambolle–Pock and Douglas–Rachford Algorithms
If F = 0, the PD3O algorithms reverts to: Let
For γk ≡ γ, this is the form I (Condat et al., 2019a) of the Chambolle–Pock algorithm (Chambolle and Pock, 2011).
In the conditions of Theorem 3, let u* be any solution of (Eq. 3); that is, u* ∈ ∂H(Kx*) and 0 ∈ ∂R(x*) + K*u*. Then the constant c0 is
On the other hand, if F = 0, the PDDY algorithm reverts to: Let
which can be simplified as: Let
knowing that we can retrieve the variable xk as
For γk ≡ γ, this is the form II (Condat et al., 2019a) of the Chambolle–Pock algorithm (Chambolle and Pock, 2011).
Note that with constant stepsizes, the Chambolle–Pock form II can be viewed as the form I applied to the dual problem. This interpretation does not hold with varying stepsizes as in Theorem 3: the stepsize playing the role of γk would be 1/(γkη), which tends to + ∞ instead of 0, so that the theorem does not apply.
Note, also, that Theorem 4 does not apply, since F = 0 is not strongly convex. Finally, if the accelerated Chambolle–Pock algorithm form I is applied to the dual problem, our results do not guarantee convergence of the primal variable xk to a solution. So, we cannot derive an accelerated Chambolle–Pock algorithm form II.
If K = I,
We can rewrite the algorithm using only the meta-variable sk = xk − γkuk: Let
Using the Moreau identity, we obtain: Let
and for γk ≡ γ, we recognize the classical form of the Douglas–Rachford algorithm (Combettes and Pesquet, 2010).
In the conditions of Theorem 3, let u* be any solution of (Eq. 3); that is, u* ∈ ∂H(x*) and 0 ∈ ∂R(x*) + u*. Then the constant c0 is
On the other hand, if K = I,
Using the Moreau identity, we obtain: Let
Introducing the meta-variable
Thus, we recover exactly the Douglas–Rachford algorithm (Eq. 19), with R and H exchanged.
6 Derivation of the Distributed Algorithms
6.1 The Distributed PD3O Algorithm and its Particular Cases
Let us adopt the notations of Section 3 and precise the different operators. The gradient of
We define the linear subspace
That is,
Notably,
satisfies the condition.
The adjoint operator of
Thus,
But if F1 = ⋯ = FM, we can restrict the norm to
which is
For any ζ > 0, we have
By doing all these substitutions in the PD3O algorithm, we obtain the distributed PD3O algorithm, and all its particular cases, shown above. Theorem 1 becomes Theorem 6 as follows. The objective function is
Theorem 6. (convergence rate of the Distributed PD3O Algorithm). In the Distributed PD3O Algorithm, suppose that
Define the weighted ergodic iterate
Furthermore, if every Hm is Lm-smooth for some Lm > 0, we have a faster decay for the best iterate so far:
The theorem applies to the particular cases of the Distributed PD3O Algorithm, like the distributed Loris–Verhoeven, Chambolle–Pock, Douglas–Rachford algorithms. We can note that the distributed forward–backward algorithm is monotonic, so Theorem 6 (iii) (with Hm ≡ 0) yields Ψ(xk) − Ψ(x*) = o(1/k) for this algorithm.We now give accelerated convergence results using varying stepsizes, in presence of strong convexity. For this, we have to define the strong convexity constants
is convex. It is much weaker to require
Theorem 7. (Accelerated Distributed PD3O Algorithm). Suppose that
Suppose that
As for Theorem 5, its counterpart in the distributed setting is:
Theorem 8. (linear convergence of the Distributed PD3O Algorithm). Suppose that
We can remark that the Distributed Davis–Yin algorithm (with ωm = 1/M and γk ≡ γ) has been proposed in an unpublished paper by Ryu and Yin (Ryu and Yin, 2017), where it is named Proximal-Proximal-Gradient Method. Their results are similar to ours in Theorem 6 and Theorem 8 for this algorithm, but their condition γ < 3/(2L), with
6.2 The Distributed PDDY Algorithm
The Distributed PDDY Algorithm, shown above, is derived the same way as the Distributed PD3O Algorithm. However, the smoothness constant cannot be defined only on
and
Moreover,
except if Fm ≡ 0, in which case the Distributed PDDY Algorithm becomes the Distributed Chambolle–Pock Algorithm Form II, for which we can set
We can note that when Km ≡ I, the Distributed PDDY Algorithm reverts to a form of distributed Davis–Yin algorithm, which is different from the Distributed Davis–Yin Algorithm obtained from the PD3O algorithm, shown above. Similarly, when R = 0, we obtain a different algorithm than the Distributed Loris–Verhoeven Algorithm shown above. When Fm ≡ 0, the Distributed PDDY Algorithm reverts to the Distributed Chambolle–Pock Algorithm Form II, which is still different from the Distributed Douglas–Rachford Algorithm when Km ≡ I.
The counterpart of Theorem 2 is:
Theorem 9. (convergence of the Distributed PDDY Algorithm). In the Distributed PDDY Algorithm, suppose that γk ≡ γ ∈ (0, 2/LF) and
Theorem 10. (Accelerated Distributed PDDY Algorithm). Suppose that
Suppose that
Consequently, for every m = 1, … , M,
Moreover, if
Theorem 11. (linear convergence of the Distributed PDDY Algorithm). Suppose that
6.3 The Distributed Condat–Vũ Algorithm
We can apply our product-space technique to other algorithms; in particular, we can derive distributed versions, shown below, of the Condat–Vũ algorithm (Condat, 2013; Vũ, 2013; Condat et al., 2019a), which is a well known algorithm for the problem (Eq. 2).
The smoothness constant
Moreover, the norm of
The price to pay is a stronger condition on the parameters for convergence:
Theorem 12. (convergence of the Distributed Condat–Vũ Algorithm). Suppose that the parameters γ > 0 and σ > 0 are such that


Then xk converges to a solution x* of (1). Also,
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: LibSVM, https://www.csie.ntu.edu.tw/∼cjlin/libsvm/.
Author Contributions
GM wrote the code and generated the results for the SVM experiment in Section 4.3. PR contributed to the paper writing and to the project management. LC did all the rest.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Alghunaim, S. A., Ryu, E. K., Yuan, K., and Sayed, A. H. (2021). Decentralized Proximal Gradient Algorithms with Linear Convergence Rates. IEEE Trans. Automat. Contr. 66, 2787–2794. doi:10.1109/tac.2020.3009363
Bach, F., Jenatton, R., Mairal, J., and Obozinski, G. (2012). Optimization with Sparsity-Inducing Penalties. Found. Trends Mach. Learn. 4, 1–106. doi:10.1561/2200000015
Bauschke, H. H., and Combettes, P. L. (2017). Convex Analysis and Monotone Operator Theory in Hilbert Spaces. 2nd edn. New York: Springer.
Boţ, R. I., Csetnek, E. R., and Hendrich, C. (2014). “Recent Developments on Primal–Dual Splitting Methods with Applications to Convex Minimization,” in Mathematics without Boundaries: Surveys in Interdisciplinary Research. Editors P. M. Pardalos, and T. M. Rassias (New York: Springer), 57–99.
Bredies, K., Kunisch, K., and Pock, T. (2010). Total Generalized Variation. SIAM J. Imaging Sci. 3, 492–526. doi:10.1137/090769521
Bubeck, S. (2015). Convex Optimization: Algorithms and Complexity. FNT Machine Learn. 8, 231–357. doi:10.1561/2200000050
Cevher, V., Becker, S., and Schmidt, M. (2014). Convex Optimization for Big Data: Scalable, Randomized, and Parallel Algorithms for Big Data Analytics. IEEE Signal. Process. Mag. 31, 32–43. doi:10.1109/msp.2014.2329397
Chambolle, A., and Pock, T. (2011). A First-Order Primal-Dual Algorithm for Convex Problems with Applications to Imaging. J. Math. Imaging Vis. 40, 120–145. doi:10.1007/s10851-010-0251-1
Chambolle, A., and Pock, T. (2016a). An Introduction to Continuous Optimization for Imaging. Acta Numerica 25, 161–319. doi:10.1017/s096249291600009x
Chambolle, A., and Pock, T. (2016b). On the Ergodic Convergence Rates of a First-Order Primal-Dual Algorithm. Math. Program 159, 253–287. doi:10.1007/s10107-015-0957-3
Chang, C.-C., and Lin, C.-J. (2011). LibSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2, 27. doi:10.1145/1961189.1961199
Chen, P., Huang, J., and Zhang, X. (2013). A Primal–Dual Fixed point Algorithm for Convex Separable Minimization with Applications to Image Restoration. Inverse Probl. 29, 025011. doi:10.1088/0266-5611/29/2/025011
Combettes, P. L., Condat, L., Pesquet, J.-C., and Vũ, B. C. (2014). “A Forward–Backward View of Some Primal–Dual Optimization Methods in Image Recovery,” in Proc. Of IEEE ICIP (Paris, France: IEEE), 4141–4145.
Combettes, P. L., and Pesquet, J.-C. (2012). Primal-Dual Splitting Algorithm for Solving Inclusions with Mixtures of Composite, Lipschitzian, and Parallel-Sum Type Monotone Operators. Set-valued Anal. 20, 307–330. doi:10.1007/s11228-011-0191-y
Combettes, P. L., and Pesquet, J.-C. (2010). “Proximal Splitting Methods in Signal Processing,” in Fixed-Point Algorithms for Inverse Problems in Science and Engineering. Editors H. H. Bauschke, R. Burachik, P. L. Combettes, V. Elser, D. R. Luke, and H. Wolkowicz (New York: Springer-Verlag), 185–212.
Condat, L. (2017a). “A Convex Approach to K-Means Clustering and Image Segmentation,” in Proc. Of EMMCVPR. Lecture Notes in Computer Science. Editors M. Pelillo, and E. Hancock (Venice, Italy: Springer, 2018), Vol. 10746, 220–234.
Condat, L. (2014). A Generic Proximal Algorithm for Convex Optimization—Application to Total Variation Minimization. IEEE Signal. Process. Lett. 21(8), 985–989. doi:10.1109/LSP.2014.2322123
Condat, L. (2013). A Primal-Dual Splitting Method for Convex Optimization Involving Lipschitzian, Proximable and Linear Composite Terms. J. Optim. Theor. Appl. 158, 460–479. doi:10.1007/s10957-012-0245-9
Condat, L. (2017b). Discrete Total Variation: New Definition and Minimization. SIAM J. Imaging Sci. 10, 1258–1290. doi:10.1137/16m1075247
Condat, L., Kitahara, D., Contreras, A., and Hirabayashi, A. (2019a). Proximal Splitting Algorithms: A Tour of Recent Advances, with New Twists. Preprint arXiv:1912.00137.
Condat, L., Kitahara, D., and Hirabayashi, A. (2019b). “A Convex Lifting Approach to Image Phase Unwrapping,” in Proc. Of IEEE ICASSP (Brighton, UK: IEEE), 1852–1856. doi:10.1109/icassp.2019.8682258
Cremers, D., Pock, T., Kolev, K., and Chambolle, A. (2011). “Convex Relaxation Techniques for Segmentation, Stereo and Multiview Reconstruction,” in Markov Random Fields for Vision and Image Processing (Cambridge: MIT Press).
Davis, D., and Yin, W. (2017). A Three-Operator Splitting Scheme and its Optimization Applications. Set-valued Anal. 25, 829–858. doi:10.1007/s11228-017-0421-z
Drori, Y., Sabach, S., and Teboulle, M. (2015). A Simple Algorithm for a Class of Nonsmooth Convex-Concave Saddle-point Problems. Operations Res. Lett. 43, 209–214. doi:10.1016/j.orl.2015.02.001
Duran, J., Moeller, M., Sbert, C., and Cremers, D. (2016). Collaborative Total Variation: A General Framework for Vectorial TV Models. SIAM J. Imaging Sci. 9, 116–151. doi:10.1137/15m102873x
Gorbunov, E., Hanzely, F., and Richtárik, P. (2020). A Unified Theory of SGD: Variance Reduction, Sampling, Quantization and Coordinate Descent. Proc. Int. Conf. Artif. Intell. Stat. (Aistats), PMLR 108, 680–690.
Komodakis, N., and Pesquet, J.-C. (2015). Playing with Duality: An Overview of Recent Primal?dual Approaches for Solving Large-Scale Optimization Problems. IEEE Signal. Process. Mag. 32, 31–54. doi:10.1109/msp.2014.2377273
Konečný, J., McMahan, H. B., Yu, F. X., Richtárik, P., Suresh, A. T., and Bacon, D. (2016). “Federated Learning: Strategies for Improving Communication Efficiency,” NIPS Private Multi-Party Machine Learn. Workshop. Paper arXiv:1610.05492.
Latafat, P., Freris, N. M., and Patrinos, P. (2019). A New Randomized Block-Coordinate Primal-Dual Proximal Algorithm for Distributed Optimization. IEEE Trans. Automat. Contr. 64, 4050–4065. doi:10.1109/tac.2019.2906924
Loris, I., and Verhoeven, C. (2011). On a Generalization of the Iterative Soft-Thresholding Algorithm for the Case of Non-separable Penalty. Inverse Probl. 27, 125007. doi:10.1088/0266-5611/27/12/125007
Malinovsky, G., Kovalev, D., Gasanov, E., Condat, L., and Richtárik, P. (2020). “From Local SGD to Local Fixed point Methods for Federated Learning,” in Proceedings of the 37th International Conference on Machine Learning, PMLR, 119, 6692–6701.
O’Connor, D., and Vandenberghe, L. (2020). On the Equivalence of the Primal-Dual Hybrid Gradient Method and Douglas–Rachford Splitting. Math. Program 179, 85–108. doi:10.1007/s10107-018-1321-1
Palomar D. P., and Eldar Y. C. (Editors) (2009). Convex Optimization in Signal Processing and Communications (Cambridge: Cambridge University Press).
Parikh, N., and Boyd, S. (2014). Proximal Algorithms. FNT in Optimization 1, 127–239. doi:10.1561/2400000003
Polson, N. G., Scott, J. G., and Willard, B. T. (2015). Proximal Algorithms in Statistics and Machine Learning. Statist. Sci. 30, 559–581. doi:10.1214/15-sts530
Glowinski R., Osher S. J., and Yin W. (Editors) (2016). Splitting Methods in Communication, Imaging, Science, and Engineering (New York: Springer International Publishing).
Richtárik, P., and Takáč, M. (2014). Iteration Complexity of Randomized Block-Coordinate Descent Methods for Minimizing a Composite Function. Math. Program 144, 1–38. doi:10.1007/s10107-012-0614-z
Salim, A., Condat, L., Kovalev, D., and Richtárik, P. (2021). An Optimal Algorithm for Strongly Convex Minimization under Affine Constraints. Preprint arXiv:2102.11079.
Salim, A., Condat, L., Mishchenko, K., and Richtárik, P. (2020). Dualize, Split, Randomize: Fast Nonsmooth Optimization Algorithms. Preprint arXiv:2004.02635.
Scaman, K., Bach, F., Bubeck, S., Lee, Y. T., and Massoulié, L. (2017). Optimal Algorithms for Smooth and Strongly Convex Distributed Optimization in Networks. Proc. 34th Int. Conf. Machine Learn. (Icml) 70, 3027–3036.
Shi, W., Ling, Q., Wu, G., and Yin, W. (2015). EXTRA: An Exact First-Order Algorithm for Decentralized Consensus Optimization. SIAM J. Optim. 25, 944–966. doi:10.1137/14096668x
Sra, S., Nowozin, S., and Wright, S. J. (2011). Optimization for Machine Learning. Cambridge: The MIT Press.
Stathopoulos, G., Shukla, H., Szucs, A., Pu, Y., and Jones, C. N. (2016). Sensor Fault Diagnosis. FnT Syst. Control. 3, 249–362. doi:10.1561/2600000008
Unknown author (1972). Every Convex Function Is Locally Lipschitz. The Am. Math. Monthly 79, 1121–1124.
Vũ, B. C. (2013). A Splitting Algorithm for Dual Monotone Inclusions Involving Cocoercive Operators. Adv. Comput. Math. 38, 667–681. doi:10.1007/s10444-011-9254-8
Wang, Y.-X., Sharpnack, J., Smola, A., and Tibshirani, R. (2016). Trend Filtering on Graphs. J. Machine Learn. Res. 17, 1–41.
Keywords: convex nonsmooth optimization, proximal algorithm, splitting, convergence rate, distributed optimization
Citation: Condat L, Malinovsky G and Richtárik P (2022) Distributed Proximal Splitting Algorithms with Rates and Acceleration. Front. Sig. Proc. 1:776825. doi: 10.3389/frsip.2021.776825
Received: 14 September 2021; Accepted: 20 October 2021;
Published: 24 January 2022.
Edited by:
Hadi Zayyani, Qom University of Technology, IranCopyright © 2022 Condat, Malinovsky and Richtárik. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Laurent Condat, bGF1cmVudC5jb25kYXRAa2F1c3QuZWR1LnNh