 Junjie Ke
Junjie Ke Tianhao Zhang
Tianhao Zhang Yilin Wang
Yilin Wang Peyman Milanfar1
Peyman Milanfar1 Feng Yang
Feng Yang- 1Google Research, Mountain View, CA, United States
- 2Google, Mountain View, CA, United States
No-reference video quality assessment (NR-VQA) for user generated content (UGC) is crucial for understanding and improving visual experience. Unlike video recognition tasks, VQA tasks are sensitive to changes in input resolution. Since large amounts of UGC videos nowadays are 720p or above, the fixed and relatively small input used in conventional NR-VQA methods results in missing high-frequency details for many videos. In this paper, we propose a novel Transformer-based NR-VQA framework that preserves the high-resolution quality information. With the multi-resolution input representation and a novel multi-resolution patch sampling mechanism, our method enables a comprehensive view of both the global video composition and local high-resolution details. The proposed approach can effectively aggregate quality information across different granularities in spatial and temporal dimensions, making the model robust to input resolution variations. Our method achieves state-of-the-art performance on large-scale UGC VQA datasets LSVQ and LSVQ-1080p, and on KoNViD-1k and LIVE-VQC without fine-tuning.
1 Introduction
Video quality assessment (VQA) has been an important research topic in the past years for understanding and improving perceptual quality of videos. Conventional VQA methods mainly focus on full reference (FR) scenarios where distorted videos are compared against their corresponding pristine reference. In recent years, there has been an explosion of user generated content (UGC) videos on social media platforms such as Facebook, Instagram, YouTube, and TikTok. For most UGC videos, the high-quality pristine reference is inaccessible. This results in a growing demand for no-reference (NR) VQA models, which can be used for ranking, recommending and optimizing UGC videos.
Many NR-VQA models (Li et al., 2019; You and Korhonen, 2019; Tu et al., 2021; Wang et al., 2021; Ying et al., 2021) have achieved significant success by leveraging the power of deep-learning. Most existing deep-learning approaches use convolutional neural networks (CNNs) to extract frozen frame-level features and then aggregate them in the temporal domain to predict the video quality. Since frozen frame-level features are not optimized for capturing spatial-temporal distortions, this could be insufficient to catch diverse spatial or temporal impairments in UGC videos. Moreover, predicting UGC video quality often involves long-range spatial-temporal dependencies, such as fast-moving objects or rapid zoom-in views. Since convolutional kernels in CNNs are specifically designed for capturing short-range spatial-temporal information, they cannot capture dependencies that extend beyond the receptive field (Bertasius et al., 2021). This limits CNN models’ ability to model complex spatial-temporal dependencies in UGC VQA tasks, and therefore it may not be the best choice to effectively aggregate complex quality information in diverse UGC videos.
Recently, architectures based on Transformer (Vaswani et al., 2017) have been proven to be successful for various vision tasks (Carion et al., 2020; Arnab et al., 2021; Chen et al., 2021; Dosovitskiy et al., 2021), including image quality assessment (Ke et al., 2021). Unlike CNN models that are constrained by limited receptive fields, Transformers utilize the multi-head self-attention operation which attends over all elements in the input sequence. As a result, Transformers can capture both local and global long-range dependencies by directly comparing video quality features at all space-time locations. This inspires us to apply Transformer on VQA in order to effectively model the complex space-time distortions in UGC videos.
Despite the benefits of Transformers, directly applying Transformers on VQA is challenging because VQA tasks are resolution-sensitive. Video recognition models like ViViT (Arnab et al., 2021) use fixed and relatively small input size, e.g., 224 × 224. This is problematic for VQA since UGC videos with resolution smaller than 224 are very rare nowadays [less than 1% in LSVQ (Ying et al., 2021)]. Such downsampling leads to missing high-frequency details for many videos. As shown in Figure 1, some visible artifacts in the high resolution video are not obvious when the video is downsampled. Human perceived video quality is affected by both the global video composition, e.g., content, video structure and smoothness and local details, e.g., texture and distortion artifacts. But it is hard to capture both global and local quality information when using fixed resolution inputs. Similarly for image quality assessment, Ke et al. (2021) showed the benefit of applying the Transformer architecture on the image at the original resolution. Although processing the original high-resolution input is affordable for a single image, it is computationally infeasible for videos, due to Transformer’s quadratic memory and time complexity.
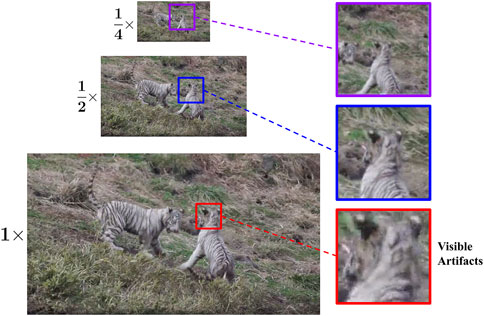
FIGURE 1. Video quality is affected by both global video composition and local details. Although downsampled video frames provide the global view and are easier to process for deep-learning models, some distortions visible on the original high resolution videos may disappear when resized to a lower resolution.
To enable high-resolution views in video Transformers for a more effective VQA model, we propose to leverage the complementary nature of low and high resolution frames. We use the low-resolution frames for a complete global composition view, and sample spatially aligned patches from the high-resolution frames to complement the high-frequency local details. The proposed Multi-REsolution Transformer (MRET) can therefore efficiently extract and encode the multi-scale quality information from the input video. This enables more effective aggregation of both global composition and local details of the video to better predict the perceptual video quality.
As illustrated in Figure 2, we first group the neighboring frames to build a multi-resolution representation composed of lower-resolution frames and higher-resolution frames. We then introduce a novel and effective multi-resolution patch sampling mechanism to sample spatially aligned patches from the multi-resolution frame input. These multi-resolution patches capture both the global view and local details at the same location, and they serve as the multi-resolution input for the video Transformer. In addition to preserving high-resolution details, our proposed MRET model also aligns the input videos at different resolutions, making the model more robust to resolution variations. After the multi-resolution tokens are extracted, a factorized spatial and temporal encoder is employed to efficiently process the large number of spatial-temporal tokens.
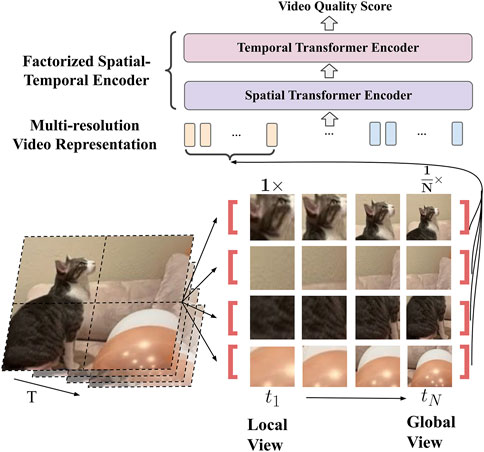
FIGURE 2. The proposed multi-resolution Transformer (MRET) for VQA. To capture both global composition and local details of video quality, we build a multi-scale video representation with patches sampled from proportionally resized frames with different resolutions.
The major contributions of this paper are summarized into three folds.
• We propose a multi-resolution Transformer for video quality assessment (MRET), which makes it possible to preserve high-resolution quality information for UGC VQA.
• We propose a novel multi-resolution patch sampling mechanism, enabling the Transformer to efficiently process both global composition information and local high-resolution details.
• We apply MRET on large-scale UGC VQA datasets. It outperforms the previous state-of-the-art methods on LSVQ (Ying et al., 2021) and LSVQ-1080p (Ying et al., 2021). It also achieves state-of-the-art performance on KoNViD-1k (Hosu et al., 2017) and LIVE-VQC (Sinno and Bovik, 2018) without fine-tuning, demonstrating its robustness and generalization capability.
2 Related work
Video Quality Assessment: Video quality assessment aims to quantify video quality. FR-VQA methods measure quality changes from pristine videos, and NR-VQA methods measure video quality without a pristine reference. For UGC videos that lack high-quality pristine reference, NR-VQA metrics are more applicable. Conventional NR metrics (Saad et al., 2014; Mittal et al., 2015; Li et al., 2016; Korhonen, 2019; Sinno and Bovik, 2019; Dendi and Channappayya, 2020; Tu et al., 2021) utilize distortion-specific features and low-level features like natural scene statistics (NSS). These feature-based NR-VQA methods mainly rely on hand-crafted statistical features summarized from limited data and are harder to generalize to diversified UGC videos. In the past few years, CNN-based NR metrics (Li et al., 2019; You and Korhonen, 2019; Wang et al., 2021; Ying et al., 2021) achieve great success in VQA using features extracted with CNNs. The features are then aggregated temporally with pooling layers or recurrent units like LSTM. The PVQ (Ying et al., 2021) method learns to model the relationship between local video patches and the global original UGC video. It shows that exploiting both global and local information can be beneficial for VQA. Recent CNN-Transformer hybrid methods (Jiang et al., 2021; Li et al., 2021; Tan et al., 2021; You, 2021) show the benefit of using Transformer for temporal aggregation on CNN-based frame-level features. Since all these methods use CNN for spatial feature extraction, they suffer from CNN’s limitation, i.e., a relatively small spatial receptive field. Moreover, these frame-level features are usually extracted from either fixed size inputs or a frozen backbone without VQA optimization. Our method is a pure Transformer-based VQA model and can be optimized end-to-end. Unlike models that use fixed small input, our proposed MRET model enables high-resolution inputs. The proposed multi-resolution input representation allows the model to have a full spatial receptive field across multiple scales.
Vision Transformers: The Transformer (Vaswani et al., 2017) architecture was first proposed for NLP tasks and has recently been adopted for various computer vision tasks (Carion et al., 2020; Arnab et al., 2021; Chen et al., 2021; Dosovitskiy et al., 2021; Ke et al., 2021). The Vision Transformer (ViT) (Dosovitskiy et al., 2021) first proposes to classify an image by treating it as a sequence of patches. This seminal work has inspired subsequent research to adopt Transformer-based architectures for other vision tasks. For video recognition, ViViT (Arnab et al., 2021) examines four designs of spatial and temporal attention for the pretrained ViT model. TimeSformer (Bertasius et al., 2021) studies five different space-time attention methods and shows that a factorized space-time attention provides better speed-accuracy tradeoff. Video Swin Transformer (Liu et al., 2022) extends the local attention computation of Swin Transformer (Liu et al., 2021) to temporal dimension, and it achieves state-of-the-art accuracy on a broad range of video recognition benchmarks such as Kinetics-400 (Kay et al., 2017) and Kinetics-600 (Kay et al., 2017). Since video recognition tasks are less sensitive to input resolution than VQA, most of the video Transformers proposed for video recognition tasks use relatively small resolution and fixed square input, e.g., 224 × 224. The objective for the VQA task is sensitive to both global composition and local details, and it motivates us to enable video Transformers to process frames in a multi-resolution manner, capturing both global and local quality information.
3 Multi-resolution transformer for video quality assessment
3.1 Overall architecture
Understanding the quality of UGC videos is hard because they are captured under very different conditions like unstable cameras, imperfect camera lens, varying resolutions and frame rates, different algorithms and parameters for processing and compression. As a result, UGC videos usually contain a mixture of spatial and temporal distortions. Moreover, the way viewers perceive the content and distortions also impact the perceptual quality of the video. Sometimes transient distortions such as sudden glitches and defocusing can significantly impact the overall perceived quality, which makes the problem even more complicated. As a result, both global video composition and local details are important for accessing the quality of UGC videos.
To capture video quality at different granularities, we propose a multi-resolution Transformer (MRET) for VQA which embeds video clips as multi-resolution patch tokens as shown in Figure 3. MRET is comprised of two major parts, namely, 1) a multi-resolution video embedding module (Section 3.2), and 2) a space-time factorized Transformer encoding module (Section 3.3).
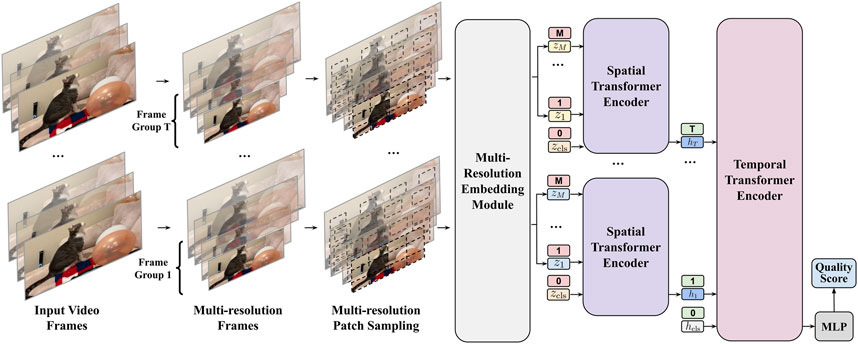
FIGURE 3. Model overview for MRET. Neighboring video frames are grouped and rescaled into a pyramid of low-resolution and high-resolution frames. Patches are sampled from the multi-resolution frames and encoded as the Transformer input tokens. The spatial Transformer encoder takes the multi-resolution tokens to produce a representation per frame group at its time step. The temporal Transformer encoder then aggregates across time steps. To predict the video quality score, we follow a common strategy in Transformers to prepend a “classification token” (zcls and hcls) to the sequence to represent the whole sequence input and to use its output as the final representation.
The multi-resolution video embedding module aims to encode the multi-scale quality information in the video, capturing both global video composition from lower resolution frames, and local details from higher resolution frames. The space-time factorized Transformer encoding module aggregates the spatial and temporal quality from the multi-scale embedding input.
3.2 Multi-resolution video representation
Since UGC videos are highly diverse, we need to design an effective multi-resolution video representation for capturing the complex global and local quality information. To achieve that, we first transform the input video into groups of multi-resolution frames. As shown in Figure 3, the input frames are divided into groups of N. N is the number of scales in the multi-resolution input. We then resize the N frames into a pyramid of low-resolution and high-resolution frames. We preserve the aspect ratios of the frames during resizing, and we control the shorter-side length for each frame (Figure 4). Assuming the shorter-side length for the largest resolution is L, the resulting pyramid of frames will have shorter-side length
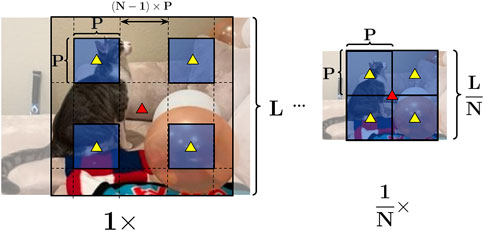
FIGURE 4. Multi-resolution patch sampling. We first rescale the N frames to
After obtaining the multi-resolution frames, we need a way to effectively and efficiently encode them as input tokens to the Transformer. Although low-resolution frames can be processed efficiently, processing the high-resolution frames in its entirety can be computationally expensive. For the higher-resolution frames, we propose to sample patches instead to save computation. Intuitively, the lower-resolution frames provide global views of the video composition, while the higher-resolution ones provide complementary local details. We want a patch sampling method that can best utilize the complementary nature of these multi-scale views. To achieve that, we propose to sample spatially aligned grids of patches from the grouped multi-resolution frames. In short, we use the lowest resolution frame for a complete global view, and we sample local patches at the same location from the higher-resolution frames to provide the multi-scale local details. Since the patches are spatially aligned, the Transformer has access to both the global view and local details at the same location. This allows it to better utilize the complementary multi-scale information for learning video quality.
Figures 4, 5 demonstrate how we sample spatially aligned grids of patches. Firstly, we choose a frame center, as shown by the red triangle in Figure 4. During training, the frame center is chosen randomly along the middle line for the longer-length side. For inference, we use the center of the video input. After aligning the frames, we then sample center-aligned patches from the frames. P is the patch size. For the smallest frame, we continuously sample the grid of patches to capture the complete global view. For larger frames, we sample linearly spaced-out patches to provide multi-scale local details. The center for the patches remain aligned at the same location, as shown by the yellow triangles in Figure 4. For the ith frame (i = 1, …, N), the distance between patches can be calculated as (N − i) × P. Since the patches are center-aligned, they form a “tube” of multi-resolution patches for the same location. As a result, those multi-resolution patches provide a gradual “zoom-out” view, capturing both the local details and global view at the same location.
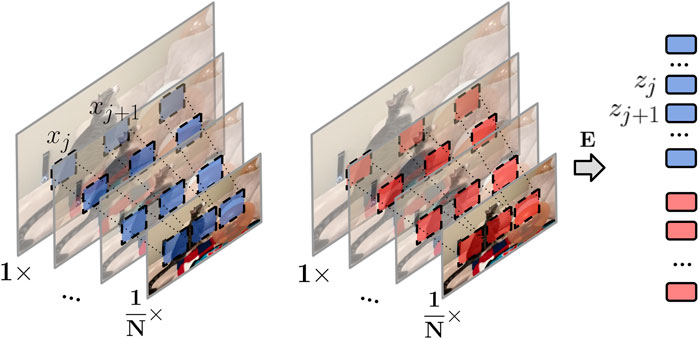
FIGURE 5. Multi-resolution video frames embedding. We extract center-aligned multi-resolution patches, and then linearly project the spatially aligned “tubes” of patches to 1D tokens.
As shown in Figure 5, we then linearly project each tube of multi-resolution patch xi to a 1D token
3.3 Factorized spatial temporal transformer
As shown in Figure 3, after extracting the multi-resolution frame embedding, we apply a factorization of spatial and temporal Transformer encoders in series to efficiently encode the space-time quality information. Firstly, the spatial Transformer encoder takes the tokens from each frame group to produce a latent representation per frame group. It serves as the representation at this time step. Secondly, the temporal Transformer encoder models temporal interaction by aggregating the information across time steps.
3.3.1 Spatial transformer encoder
The spatial Transformer encoder aggregates the multi-resolution patches extracted from the entire frame group to a representation
3.3.2 Temporal transformer encoder
The temporal Transformer encoder models the interactions between tokens from different time steps. We use the zcls token position output from the spatial Transformer encoder as the frame group level representation. As shown in Figure 3, each group of frames will be encoded as a single token ht, t = 1, …, T. We then prepend a
Q is the number of layers for the temporal Transformer encoder. v is output from the hcls token position from the temporal encoder, which is used as the final video representation.
3.4 Video quality prediction
To predict the final quality score, we add an MLP layer on top of the final video representation v. The output of the MLP layer is regressed to the video mean opinion score (MOS) label associated with each video in VQA datasets. The model is trained end-to-end with L2 loss.
3.5 Initialization from pretrained models
Vision Transformers have been shown to be only effective when trained on large-scale datasets (Arnab et al., 2021; Dosovitskiy et al., 2021) as they lack the inductive biases of 2D image structures, which needs to be imposed during pretraining. However, existing video quality datasets are several magnitudes smaller than large-scale image classification datasets, such as ILSVRC-2012 ImageNet (Russakovsky et al., 2015) (we refer to it as ImageNet in what follows) and ImageNet-21k (Deng et al., 2009). As a result, training Transformer models from scratch using VQA datasets is extremely challenging and impractical. We therefore also choose to initialize the Transformer backbone from pretrained image models.
Unlike the 3D video input, the image Transformer models only need 2D projection for the input data. To initialize the 3D convolutional filter E from 2D filters Eimage in pretrained image models, we adopt the “central frame initialization strategy” used in ViViT (Arnab et al., 2021). In short, E is initialized with zeros along all temporal positions, except at the center ⌊N/2⌋. The initialization of E from pretrained image model can therefore be formulated as:
4 Experimental results
4.1 Datasets
We run experiments on four UGC VQA datasets, including LSVQ (Ying et al., 2021), LSVQ-1080p (Ying et al., 2021), KoNViD-1k (Hosu et al., 2017), and LIVE-VQC (Sinno and Bovik, 2018). LSVQ (excluding LSVQ-1080p) consists of 38,811 UGC videos and 116,433 space-time localized video patches. The original and patch videos are all annotated with MOS scores in [0.0, 100.0], and it contains videos of diverse resolutions. LSVQ-1080p contains 3,573 videos with 1080p resolution or higher. Since our model does not make a distinction between original videos and video patches, we use all the 28.1k videos and 84.3k video patches from the LSVQ training split to train the model and evaluate the model on full-size videos from the testing splits of LSVQ and LSVQ-1080p. KoNViD-1k contains 1,200 videos with MOS scores in [0.0, 5.0] and 960p fixed resolution. LIVE-VQC contains 585 videos with MOS scores in [0.0, 100.0] and video resolution from 240p to 1080p. We use KoNViD-1k and LIVE-VQC for evaluating the generalization ability of our model without fine-tuning. Since no training is involved, we use the entire dataset for evaluation.
4.2 Implementation details
We set the number of multi-resolution frames in each group to N = 4. The shorter-side length L is set to 896 for the largest frame in the frame group. Correspondingly, the group of frames are rescaled with shorter-side length 896, 672, 448, and 224. We use patch size p = 16 when generating the multi-resolution frame patches. For each frame, we sample a 14 × 14 grid of patches. Unless otherwise specified, the input to our network is a video clip of 128 frames uniformly sampled from the video.
The hidden dimension for Transformer input tokens is set to d = 768. For the spatial Transformer, we use the ViT-Base (Dosovitskiy et al., 2021) model (12 Transformer layers with 12 heads and 3072 MLP size), and we initialize it from the checkpoint trained on ImageNet-21K (Deng et al., 2009). For the temporal Transformer, we use 8 layers with 12 heads, and 3072 MLP size. The final model has 144M parameters and 577 GFLOPs.
We train the models with the synchronous SGD momentum optimizer, a cosine decay learning rate schedule from 0.3 and a batch size of 256 for 10 epochs in total. All the models are trained on TPUv3 hardware. Spearman rank ordered correlation (SRCC) and Pearson linear correlation (PLCC) are reported as performance metrics.
4.3 Comparison with the state-of-the-art
4.3.1 Results on LSVQ and LSVQ-1080p
Table 1 shows the results on full-size LSVQ and LSVQ-1080p datasets. Our proposed MRET outperforms other methods by large margins on both datasets. Notably, on the higher resolution test dataset LSVQ-1080p, our model is able to outperform the strongest baseline by 7.8% for PLCC (from 0.739 to 0.817). This shows that for high-resolution videos, the proposed multi-resolution Transformer is able to better aggregate local and global quality information for a more accurate video quality prediction.
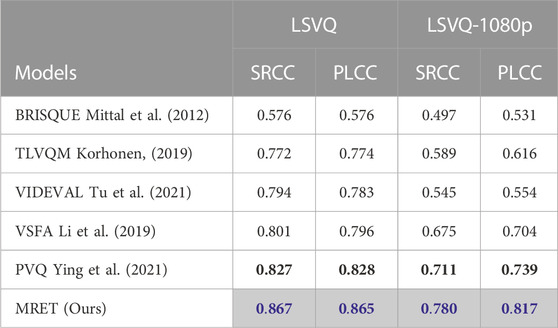
TABLE 1. Results on full-size videos in LSVQ and LSVQ-1080p test sets. Blue and black numbers in bold represent the best and second best respectively. We take numbers from (Ying et al., 2021) for the results of the reference methods. Our final method is marked in gray.
4.3.2 Performance on cross dataset
Since existing VQA datasets are magnitudes smaller than popular image classification datasets, VQA models are prone to overfitting. Therefore, it is of great interest to obtain a VQA model that can generalize across datasets. To verify the generalization capability of MRET, we conduct a cross-dataset evaluation where we train the model using LSVQ training set and separately eval on LIVE-VQC and KoNViD-1k without fine-tuning. As shown in Table 2, MRET is able to generalize very well to both datasets, and it performs the best among methods without fine-tuning. Moreover, its performance is even as good as the best ones that are fine-tuned on the target dataset. This demonstrates the strong generalization capability of MRET. Intuitively, the proposed multi-resolution input aligns the videos at different resolutions. Not only does it provide a more comprehensive view of the video quality, but it also makes the model more robust to resolution variations. As a result, MRET can learn to capture quality information for UGC videos under different conditions.
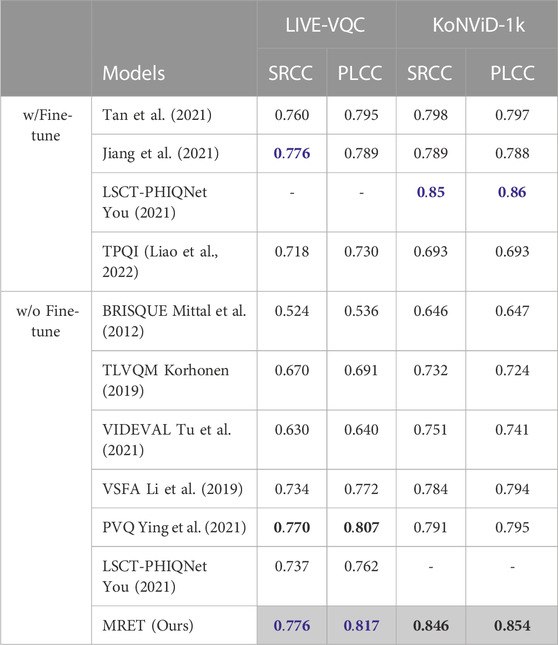
TABLE 2. Performance on KoNViD-1k and LIVE-VQC. Methods except LSCT-PHIQNet (You, 2021) in “w/o Fine-tune” group are trained on LSVQ. Blue and black numbers in bold represent the best and second best respectively. We take numbers from (Ying et al., 2021; Jiang et al., 2021; You, 2021; Tan et al., 2021; Liao et al., 2022) for the results of the reference methods. Our final method is marked in gray.
4.4 Ablation studies
4.4.1 Spatial temporal quality attention
To understand how MRET aggregates spatio-temporal information to predict the final video quality, we visualize the attention weights on spatial and temporal tokens using Attention Rollout (Abnar and Zuidema, 2020). In short, we average the attention weights of the Transformer across all heads and then recursively multiply the weight matrices of all layers. Figure 6 visualizes temporal attention for each input time step and spatial attention for selected frames. As shown by temporal attention for the video, the model is paying more attention to the second section when the duck is moving rapidly across the grass. The spatial attention also shows that the model is focusing on the main subject, i.e., duck in this case. This verifies that MRET is able to capture spatio-temporal quality information and utilize it to predict the video quality.
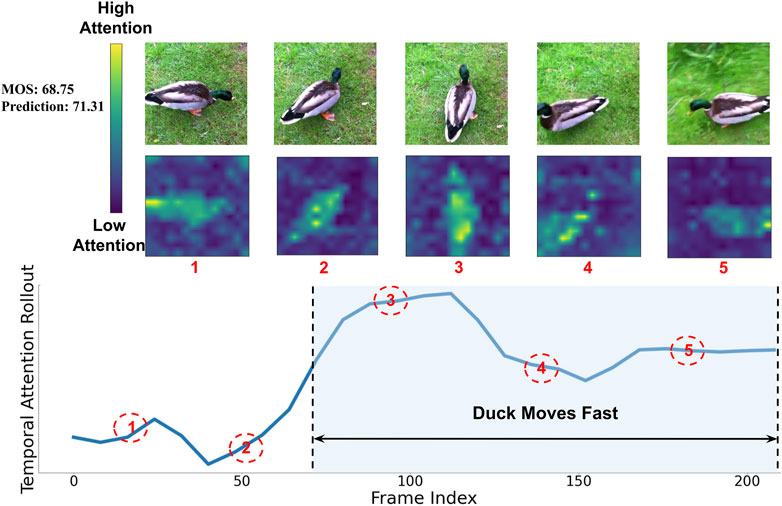
FIGURE 6. Visualization of spatial and temporal attention from output tokens to the input. The heat-map on the top shows the spatial attention. The chart on the bottom shows the temporal attention. Higher attention values correspond to the more important video segments and spatial regions for prediction. The model is focusing on spatially and temporally more meaningful content when predicting the final video quality score.
4.4.2 Effectiveness of multi-resolution frame inputs
To verify the effectiveness of the proposed multi-resolution input representation, we run ablations by not using the multi-resolution input. The comparison result is shown in Table 3 as “MRET” and “w/o Multi-resolution” for with and without the multi-resolution frames respectively. For MRET, we resize the frames to [896, 672, 448, 224] for shorter-side lengths. For the method “w/o Multi-resolution”, we resize all the frames in the frame group to the same shorter-side length (224). The GFLOPs is the same for both models because the patch size and number of patches are the same. The multi-resolution frame input brings 1%–2% boost in SRCC on LSVQ and 2%–3% boost in SRCC on LSVQ-1080p. The gain is larger on LSVQ-1080p because the dataset contains more high-resolution videos, and therefore more quality information is lost when resized statically to a small resolution. Armed with the multi-resolution input representation, MRET is able to utilize both global information from lower-resolution frames and detailed information from higher-resolution frames. The results demonstrate that the proposed multi-resolution representation is indeed effective for capturing the complex multi-scale quality information that can be lost when using statically resized frames. Table 3 also shows that MRET performance improves with the increase of number of input frames since more temporal information is preserved.
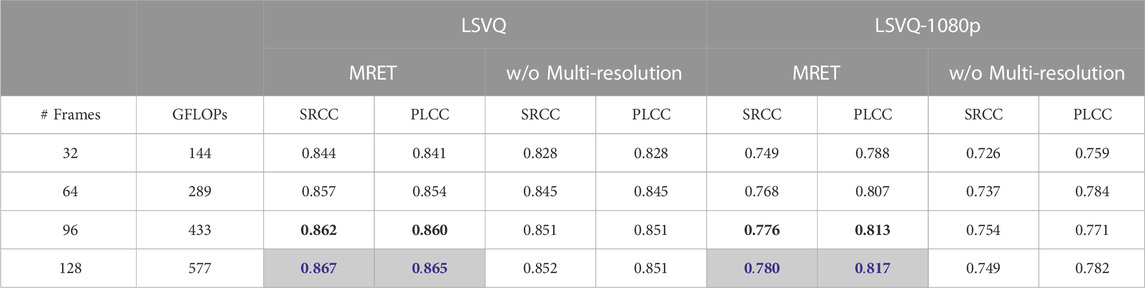
TABLE 3. Ablation study results for multi-resolution input on LSVQ and LSVQ-1080p dataset. MRET uses multi-resolution input while “w/o Multi-resolution” uses fixed-resolution frames. Both models grouped the frames by N =4 when encoding video frames into tokens. Blue and black numbers in bold represent the best and second best respectively on the same dataset. Our final method is marked in gray.
After verifying that the multi-resolution representation is indeed more effective than fixed resolution, we also run ablations with different multi-resolution patch sampling methods (Table 4). For “Random”, we first resize the frames to the 4-scale multi-resolution input, and then randomly sample the same number of patches from each resolution. For “High-res Patch on Last Frame”, we use low-resolution patches for the first 3 frames (224×), and only sample high-resolution patches from the last frame (896×). MRET samples center-aligned patches from the 4-scale input, and it performs the best. This shows the proposed sampling method can more effectively utilize the complementary nature of the multi-resolution views. With the center-aligned multi-resolution patches, MRET is able to better aggregate both the global view, and the multi-resolution local details.
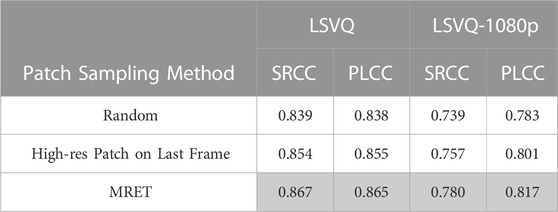
TABLE 4. Ablation for multi-resolution patch sampling method. Our final method is marked in gray.
4.4.3 Number of grouped multi-resolution frames N
In Table 5 we run ablations on the number of grouped frames N when building the multi-resolution video representation. The experiment is run with 60 frames instead of 128 since smaller N increases the number of input tokens for the temporal encoder and introduces high computation and memory cost. For MRET, we use multi-resolution input for the grouped frames and for “w/o Multi-resolution”, we resize all the frames to the same 224 shorter-side length. For all N, using multi-resolution input is better than a fixed resolution. It further verifies the effectiveness of the proposed multi-resolution input structure. For multi-resolution input, the performance improves when increasing N from 2 to 5, but the gain becomes smaller as N grows larger. There is also a trade-off between getting higher resolution views and the loss of spatio-temporal information with the increase of N, since the area ratio of sampled patches becomes smaller as resolution increases Overall, we find N = 4 to be a good balance between performance and complexity.
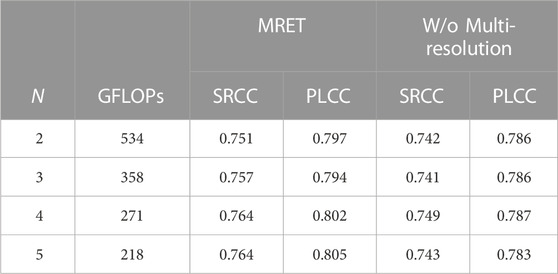
TABLE 5. Ablation study results for number of grouped frames N on the LSVQ-1080p dataset. MRET uses multi-resolution input while “w/o Multi-resolution” use fixed resolution frames. Models here are trained with 60 input frames instead of 128.
4.4.4 Pretrained checkpoint selection
Compared to CNNs, Transformers impose less restrictive inductive biases which broadens their representation ability. On the other hand, since Transformers lack the inductive biases of the 2D image structure, it generally needs large datasets for pretraining to learn the inductive priors. In Table 6, we try initializing the spatial Transformer encoder in MRET model with checkpoints pretrained on different image datasets, including two image classification (Class.) datasets, and one image quality assessment (IQA) dataset. ImageNet-21k is the largest and it performs the best, showing that large-scale pretraining is indeed beneficial. This conforms with the findings in previous vision Transformer works (Arnab et al., 2021; Dosovitskiy et al., 2021). LIVE-FB (Ying et al., 2020) is an IQA dataset on which PVQ (Ying et al., 2021) obtain their 2D frozen features. Since IQA is a very relevant task to VQA, pretraining on this relatively small IQA dataset leads to superior results than ImageNet. This shows that relevant task pretraining is beneficial when large-scale pretraining is not accessible.

TABLE 6. Results for initializing MRET model from checkpoints pretrained on different image datasests. Our final method is marked in gray.
4.4.5 Frame sampling strategy
We run ablations on the frame sampling strategy in Table 7. For our default “Uniform Sample”, we sample 128 frames uniformly throughout the video. For “Front Sample”, we sample the first 128 frames. For “Center Clip” we take the center clip of 128 frames from the video. On LSVQ and LSVQ-1080p dataset, uniformly sampling the frames is the best probably because there is temporal redundancy between continuous frames and uniformly sampling the frames allows the model to see more diverse video clips. Since most of the videos in the VQA dataset are relatively short, uniformly sampling the frames is good enough to provide a comprehensive view.
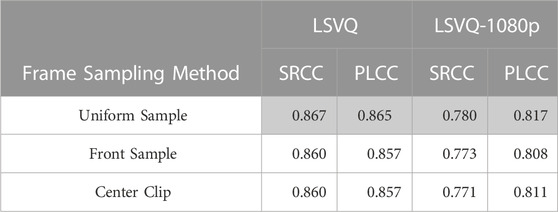
TABLE 7. Ablation study results for frame sampling method. Our final method is marked in gray.
5 Conclusion and future work
We propose a multi-resolution Transformer (MRET) for VQA, which integrates multi-resolution views to capture both global and local quality information. By transforming the input frames to a multi-resolution representation with both low and high resolution frames, the model is able to capture video quality information at different granularities. To effectively handle the variety of resolutions in the multi-resolution input sequence, we propose a multi-resolution patch sampling mechanism. A factorization of spatial and temporal Transformers is employed to efficiently model spatial and temporal information and capture complex space-time distortions in UGC videos. Experiments on several large-scale UGC VQA datasets show that MRET can achieve state-of-the-art performance and has strong generalization capability, demonstrating the effectiveness of the proposed method. MRET is designed for VQA, and it can be extended to other scenarios where the task labels are affected by both video global composition and local details. The limitation of Transformers is that it can be computationally expensive, and thus costly to make predictions on long videos. In this paper, we focus on improving the performance of the VQA model and we leave it as future work to improve its efficiency and to lower the computation cost. One potential direction is to use more efficient Transformer variants, such as Reformer (Kitaev et al., 2020) and Longformer (Beltagy et al., 2020) where the attention complexity has been greatly reduced. Those efficient Transformers can be adopted as a drop-in replacement for the current spatial and the temporal Transformer used in MRET.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author contributions
The authors confirm contribution to the paper as follows: design and implementation: JK, TZ, and FY; draft manuscript preparation: JK, TZ, YW, and FY. All authors contributed to the article and approved the submitted version.
Conflict of interest
JK, PM, and FY were employed by the Google Research. TZ and YW were employed by the Google.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abnar, S., and Zuidema, W. (2020). Quantifying attention flow in transformers. arXiv preprint arXiv:2005.00928.
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., and Schmid, C. (2021). “Vivit: A video vision transformer,” in Proceedings of the IEEE/CVF international conference on computer vision (IEEE), 6836–6846.
Beltagy, I., Peters, M. E., and Cohan, A. (2020). Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
Bertasius, G., Wang, H., and Torresani, L. (2021). Is space-time attention all you need for video understanding? Int. Conf. Mach. Learn. (ICML) 2, 4.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., and Zagoruyko, S. (2020). “End-to-end object detection with transformers,” in European conference on computer vision. Glasgow, UK (Springer International Publishing).
Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., et al. (2021). “Pre-trained image processing transformer,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Nashville, TN (IEEE/CVF), 12299–12310.
Dendi, S. V. R., and Channappayya, S. S. (2020). No-reference video quality assessment using natural spatiotemporal scene statistics. IEEE Trans. Image Process. 29, 5612–5624. doi:10.1109/tip.2020.2984879
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., and Fei-Fei, L. (2009). “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20-25 June 2009 (IEEE), 248–255.
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2019). “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, NAACL-HLT 2019, minneapolis, MN, USA, june 2-7, 2019, volume 1 (long and short papers). Editors J. Burstein, C. Doran, and T. Solorio Minneapolis, Minnesota (Association for Computational Linguistics), 4171–4186. doi:10.18653/v1/n19-1423
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., et al. (2021). “An image is worth 16x16 words: Transformers for image recognition at scale,” in International conference on learning representations. Virtual Event (ICLR).
Hosu, V., Hahn, F., Jenadeleh, M., Lin, H., Men, H., Szirányi, T., et al. (2017). “The konstanz natural video database (konvid-1k),” in 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May 2017 - 02 June 2017 (IEEE), 1–6.
Jiang, J., Wang, X., Li, B., Tian, M., and Yao, H. (2021). Multi-dimensional feature fusion network for no-reference quality assessment of in-the-wild videos. Sensors 21, 5322. doi:10.3390/s21165322
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., et al. (2017). The kinetics human action video dataset. arXiv preprint arXiv:1705.06950.
Ke, J., Wang, Q., Wang, Y., Milanfar, P., and Yang, F. (2021). “Musiq: Multi-scale image quality transformer,” in Proceedings of the IEEE/CVF international conference on computer vision. Nashville, TN (IEEE/CVF), 5148–5157.
Kitaev, N., Kaiser, Ł., and Levskaya, A. (2020). Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451.
Korhonen, J. (2019). Two-level approach for no-reference consumer video quality assessment. IEEE Trans. Image Process. 28, 5923–5938. doi:10.1109/tip.2019.2923051
Li, D., Jiang, T., and Jiang, M. (2019). “Quality assessment of in-the-wild videos,” in Proceedings of the 27th ACM international conference on multimedia. New York (Association for Computing Machinery), 2351–2359.
Li, X., Guo, Q., and Lu, X. (2016). Spatiotemporal statistics for video quality assessment. IEEE Trans. Image Process. 25, 3329–3342. doi:10.1109/tip.2016.2568752
Li, Y., Feng, L., Xu, J., Zhang, T., Liao, Y., and Li, J. (2021). “Full-reference and no-reference quality assessment for compressed user-generated content videos,” in 2021 IEEE international conference on multimedia and expo workshops (ICMEW) (IEEE), 1–6.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., et al. (2021). “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision. Nashville, TN (IEEE/CVF), 10012–10022.
Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., et al. (2022). “Video swin transformer,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. IEEE/CVF (IEEE/CVF), 3202–3211.
Mittal, A., Moorthy, A. K., and Bovik, A. C. (2012). No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 21, 4695–4708. doi:10.1109/tip.2012.2214050
Mittal, A., Saad, M. A., and Bovik, A. C. (2015). A completely blind video integrity oracle. IEEE Trans. Image Process. 25, 289–300. doi:10.1109/tip.2015.2502725
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 115, 211–252. doi:10.1007/s11263-015-0816-y
Saad, M. A., Bovik, A. C., and Charrier, C. (2014). Blind prediction of natural video quality. IEEE Trans. Image Process. 23, 1352–1365. doi:10.1109/tip.2014.2299154
Sinno, Z., and Bovik, A. C. (2018). Large-scale study of perceptual video quality. IEEE Trans. Image Process. 28, 612–627. doi:10.1109/tip.2018.2869673
Sinno, Z., and Bovik, A. C. (2019). “Spatio-temporal measures of naturalness,” in 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22-25 September 2019 (IEEE), 1750–1754.
Tan, Y., Kong, G., Duan, X., Wu, Y., and Long, H. (2021). No-reference video quality assessment for user generated content based on deep network and visual perception. J. Electron. Imaging 30, 053026. doi:10.1117/1.jei.30.5.053026
Tu, Z., Wang, Y., Birkbeck, N., Adsumilli, B., and Bovik, A. C. (2021). Ugc-vqa: Benchmarking blind video quality assessment for user generated content. IEEE Trans. Image Process. 30, 4449–4464. doi:10.1109/tip.2021.3072221
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). “Attention is all you need,” in Advances in neural information processing systems. Long Beach, CA (Curran Associates Inc), 5998–6008.
Wang, Y., Ke, J., Talebi, H., Yim, J. G., Birkbeck, N., Adsumilli, B., et al. (2021). “Rich features for perceptual quality assessment of ugc videos,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Nashville, TN (IEEE/CVF), 13435–13444.
Ying, Z., Mandal, M., Ghadiyaram, D., and Bovik, A. (2021). “Patch-vq:’patching up’the video quality problem,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Nashville, TN (IEEE/CVF), 14019–14029.
Ying, Z., Niu, H., Gupta, P., Mahajan, D., Ghadiyaram, D., and Bovik, A. (2020). “From patches to pictures (paq-2-piq): Mapping the perceptual space of picture quality,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Seattle, WA (IEEE/CVF), 3575–3585.
You, J., and Korhonen, J. (2019). “Deep neural networks for no-reference video quality assessment,” in 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22-25 September 2019 (IEEE), 2349–2353.
Keywords: video quality assessment, transformer, no-reference, multi-resolution, user-generated content
Citation: Ke J, Zhang T, Wang Y, Milanfar P and Yang F (2023) MRET: Multi-resolution transformer for video quality assessment. Front. Sig. Proc. 3:1137006. doi: 10.3389/frsip.2023.1137006
Received: 03 January 2023; Accepted: 13 March 2023;
Published: 29 March 2023.
Edited by:
Chang-Wen Chen, Hong Kong Polytechnic University, Hong Kong SAR, ChinaReviewed by:
Tiesong Zhao, Fuzhou University, ChinaKe Gu, Beijing University of Technology, China
Ekrem Çetinkaya, University of Klagenfurt, Austria
Copyright © 2023 Ke, Zhang, Wang, Milanfar and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Junjie Ke, anVuamlla0Bnb29nbGUuY29t