 Matthew B. Fitzgerald1*
Matthew B. Fitzgerald1* Varsha Mysore Athreya1
Varsha Mysore Athreya1 Majd Srour2
Majd Srour2 Jwala P. Rejimon1
Jwala P. Rejimon1 Soumya Venkitakrishnan3
Soumya Venkitakrishnan3 Achintya K. Bhowmik1,2Robert K. Jackler1Kristen K. Steenerson1,4
Achintya K. Bhowmik1,2Robert K. Jackler1Kristen K. Steenerson1,4 David A. Fabry2
David A. Fabry2- 1Department of Otolaryngology – Head and Neck Surgery, Stanford University, Stanford, CA, United States
- 2Starkey Hearing Technologies, Eden Prairie, MN, United States
- 3Department of Communication Sciences and Disorders, California State University – Sacramento, Sacramento, CA, United States
- 4Department of Neurology and Neurological Sciences, Stanford University, Stanford, CA, United States
Introduction: Traditional approaches to improving speech perception in noise (SPIN) for hearing-aid users have centered on directional microphones and remote wireless technologies. Recent advances in artificial intelligence and machine learning offer new opportunities for enhancing the signal-to-noise ratio (SNR) through adaptive signal processing. In this study, we evaluated the efficacy of a novel deep neural network (DNN)-based algorithm, commercially implemented as Edge Mode™, in improving SPIN outcomes for individuals with sensorineural hearing loss beyond that of conventional environmental classification approaches.
Methods: The algorithm was evaluated using (1) objective KEMAR-based performance in seven real-world scenarios, (2) aided and unaided speech-in-noise performance in 20 individuals with SNHL, and (3) real-world subjective ratings via ecological momentary assessment (EMA) in 20 individuals with SNHL.
Results: Significant improvements in SPIN performance were observed on CNC+5, QuickSIN, and WIN, but not NST+5, likely due to the use of speech-shaped noise in the latter, suggesting the algorithm is optimized for multi-talker babble environments. SPIN gains were not predicted by unaided performance or degree of hearing loss, indicating individual variability in benefit, potentially due to differences in peripheral encoding or cognitive function. Furthermore, subjective EMA responses mirrored these improvements, supporting real-world utility.
Discussion: These findings demonstrate that DNN-based signal processing can meaningfully enhance speech understanding in complex listening environments, underscoring the potential of AI-powered features in modern hearing aids and highlighting the need for more personalized fitting strategies.
Introduction
Approximately 15% of adults in the United States report some difficulty hearing (Blackwell et al., 2014), and by 2050 nearly 2.5 billion individuals are projected to have some degree of hearing loss (Chadha et al., 2021). The most common complaint associated with hearing loss is difficulty communicating in background noise (Pichora-Fuller, 1997; Gatehouse and Noble, 2004; Hannula et al., 2011; Le Prell and Clavier, 2017; Jorgensen and Novak, 2020; Carr and Kihm, 2022). For individuals with sensorineural hearing loss that cannot be treated medically or surgically, hearing aids (HA) are the most common recommendation, and these devices have helped millions of people to hear and communicate more effectively. Despite the many benefits of hearing aids, difficulty understanding speech in noise (SPIN) remains a common complaint. These difficulties (e.g., “they don't work”) are a common reason given by individuals who obtain hearing aids, and either return them within the trial period, or do not wear them consistently (McCormack and Fortnum, 2013; Hong et al., 2014; Humes, 2003; Hickson et al., 2014; Jilla et al., 2020; Powers and Rogin, 2020; Aazh et al., 2015). Consistent with these self-reports, speech in noise abilities correlate with hearing aid satisfaction (Saunders and Forsline, 2006; Davidson et al., 2021; Walden and Walden, 2004), and are worse in patients who tried and returned hearing aids when compared to individuals who kept their hearing aids (Humes, 2021a). Thus, while hearing aids benefit millions of individuals each year, difficulties with SPIN persist in many patients, leading to dissatisfaction, and even discontinuation in some cases.
Speech in noise abilities not only deteriorate with increasing hearing loss, but are also highly variable between individuals with similar hearing thresholds, even when the signal is audible (Wilson, 2011; Fitzgerald et al., 2023; Smith et al., 2024). These suprathreshold deficits in speech understanding are particularly noteworthy given that current procedures for fitting of hearing aids is focused primarily on maximizing audibility without exceeding uncomfortable loudness levels. This approach is at the heart of prescriptive procedures such as the “Desired Sensation Level” (DSL; Seewald et al., 1985; Scollie et al., 2005; Bagatto et al., 2005), those from the National Acoustics Laboratories (NAL; Byrne and Tonisson, 1976; Byrne and Dillon, 1986; Byrne et al., 2001; Keidser et al., 2011), and with proprietary prescriptive fitting methods developed by hearing aid manufacturers (e.g., Keidser et al., 2003). Thus, addressing the SPIN difficulties faced by patients requires solutions beyond making sounds audible.
Conventional approaches to improving the signal-to noise ratio (SNR) in users of hearing aids has routinely focused on directional microphones or the use of wireless remote microphones (Gnewikow et al., 2009). These approaches, while beneficial in many regards, do not directly manipulate the signal itself in an effort to improve the SNR. Conventional approaches to noise management based on spectral subtraction or modulation-based noise reduction systems are primarily shown to improve listening comfort with little to no improvement in speech understanding (Mueller et al., 2006; Bentler et al., 2008). In recent years, however, there has been a revolution in the use of artificial intelligence (AI) and machine learning (ML) technologies to understand and manipulate auditory signals (Bishop and Nasrabadi, 2006; LeCun et al., 2015; Zhang et al., 2018; Fabry and Bhowmik, 2021). Deep neural networks have been trained to simulate cochlear and nerve fiber outputs (Baby et al., 2021; Nagathil et al., 2021; Drakopoulos et al., 2021), and to compensate for impaired cochlea (Bondy et al., 2004; Diehl et al., 2023). To date, most ML efforts to improve SPIN abilities attempt to remove noise from the speech to improve the SNR (Soni et al., 2023; Healy and Yoho, 2016; Healy et al., 2017; Zhao et al., 2018; Alexander, 2021; Fischer et al., 2021; Fabry and Bhowmik, 2021). While promising, the integration of these approaches into conventional hearing aids has been limited until recently due to challenges such as the need for specialized computational processing hardware, constraints in power consumption, insufficient training data for these models, and other technological variables (Zou, 2025).
In the present study, our goal was to evaluate the effectiveness of a novel signal processing technique based on deep neural networks. This signal processing algorithm was implemented in a hearing aid feature called Edge Mode™. Here, this algorithm was evaluated in three ways, including (1) objective evaluation of SNR improvements in laboratory testing, (2) clinical evaluation of SNR benefits for individuals with sensorineural hearing loss, and (3) subjective assessment using ecological momentary assessment (EMA) questions during use in their daily life.
Methods
Data were collected in two phases. The first phase consisted of objective laboratory evaluation of changes in the SNR on a KEMAR mannequin. The second phase consisted of both behavioral and subjective data obtained in participants with sensorineural hearing loss. These phases are described below.
Procedures
Phase I
In this phase, changes in SNR with the Edge Mode™ algorithm, relative to the default “Personal” program (Adaptive Directionality enabled with Speech in Noise default setting) were evaluated on a Knowles Electronics Manakin for Acoustic Research (KEMAR) using a pair of Starkey Genesis AI receiver-in-canal (RIC) hearing aids fitted with occluding power dome ear tips. The devices were programmed to meet prescriptive targets for a gently sloping (N3) mild-to-moderate sensorineural hearing loss (Figure 1). The KEMAR was positioned at the center of an 8-speaker array in a sound-treated room, with loudspeakers spaced 45° apart and placed 1 meter away (Figure 2).
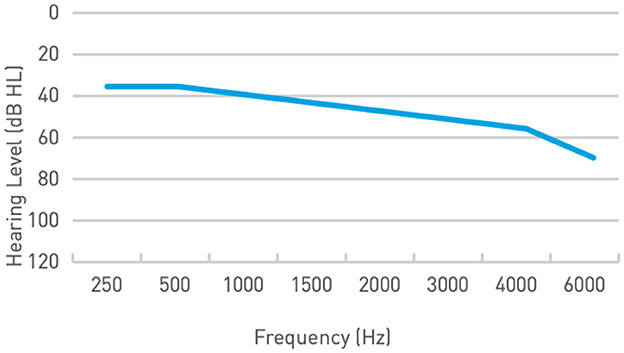
Figure 1. Audiogram for a gently sloping (N3) mild-to-moderate SNHL, used for the objective measurements in Phase I of the study.
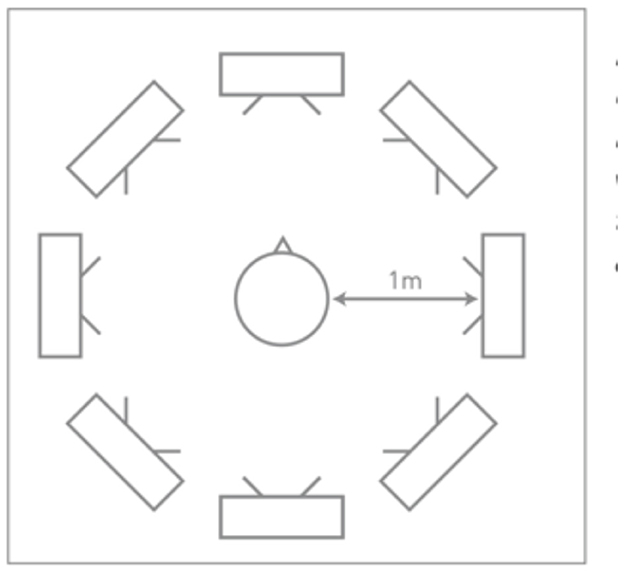
Figure 2. Overview of the laboratory setup with a KEMAR in the middle of an 8-speaker array, with the speakers placed 45-degrees apart and 1 m equidistant from the KEMAR.
Seven acoustic scenes designed to stimulate real-world listening environments were evaluated: bar, shopping mall, restaurant, construction, indoor crowd, outdoor crowd, and city noise. To stimulate diffuse noise, commonly experienced by hearing aid users (Wu et al., 2018), uncorrelated noise snippets from the same recording were played simultaneously from all 8 speakers, with speech presented from the front (0° azimuth) speaker. Each condition began with 30 s of noise alone, followed by 30 s of speech-in-noise (SPIN). The speech level was fixed at 70 dB SPL and the noise at 73 dB SPL, creating a challenging −3 dB SNR environment. These values were chosen as they approximate conversational speech levels and a SNR that that would normally yield poor speech recognition for individuals with hearing loss or perceived hearing difficulties (Fitzgerald et al., 2023, 2024; Smith et al., 2024; Wilson, 2011).
The “Personal” program uses a machine-learning algorithm to perform acoustic environmental classification (AEC). In this process, the AEC algorithm monitors and categorizes the listening environment into one of the seven acoustic environments listed above. Based on the results of the classification, the program automatically applies necessary hearing aid features (e.g., frequency-specific gain, output limitation, multiple-channel compression, omni and directional microphones, multiple channel continuous or transient noise management, and wind noise suppression). In contrast, the Edge Mode™ algorithm applies a user-initiated “acoustic snapshot” that provides an additional analysis of the soundscape across the seven acoustic scenes. This analysis results in more aggressive offsets than the default “Personal” program.
The Edge Mode™ algorithm is executed directly on the hearing aid's processor chip, which features a custom-designed integrated hardware accelerator optimized for deep neural network (DNN) operations under low-power, real-time conditions. As a result, no smartphone or cloud connectivity is required. Figure 3 presents a schematic comparison between traditional noise reduction architectures in hearing aids and the advanced sound-processing framework incorporating onboard DNN processing.
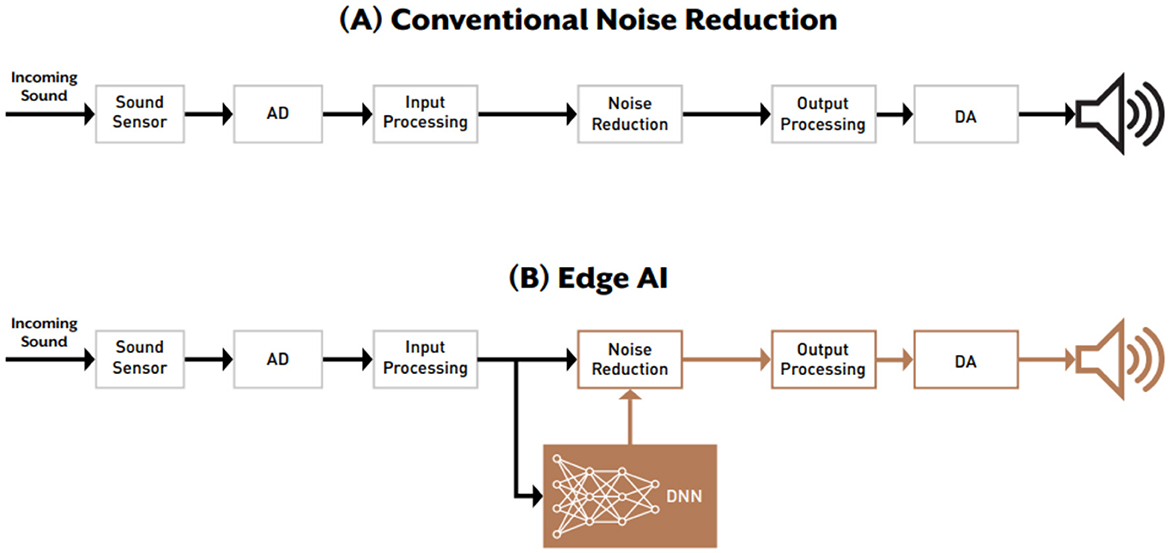
Figure 3. Schematic diagram comparing (A) conventional noise reduction in traditional hearing aids and (B) Edge Mode™ where a DNN is used to inform the noise reduction.
Measurements were made using the Hagerman method (Hagerman and Olofsson, 2004), a well-established procedure that may be used for evaluating hearing aids' noise reduction systems. It is based on the phase inversion technique, where multiple recordings take place and the phase of one signal is inverted between the measurements. This phase inversion method separates signal and noise at the hearing aid output, enabling accurate calculate of SNR improvement by isolating the processed signals from the recorded mixed signal. For a given condition, Speech Intelligibility Index (SII) computations may be used to estimate the audibility and relative importance of speech information across different bands from Hagerman measurements to calculate SNR and predicted SPIN measurements in humans.
Phase II
In this phase, we determined whether behavioral or subjective improvements were observed in hearing-aid users when Edge Mode™ algorithm was active relative to the default “Personal” program. Here, 20 human participants (11 female) with an average age of 77 years (SD = 6.8 years) were recruited from patients seen at the Stanford Ear Institute, or from a residential living facility. Demographic information for this sample is provided in Table 1. All participants first began with pure-tone audiometric assessments, including measurement of air- and bone-conduction thresholds using the modified Hughson-Westlake method (Carhart and Jerger, 1959). Inter-octave thresholds at 3,000 and 6,000 Hz were always obtained, with other inter-octave thresholds measured when thresholds differed by ≥ 20 dB HL between octaves (Wilson and McArdle, 2014).
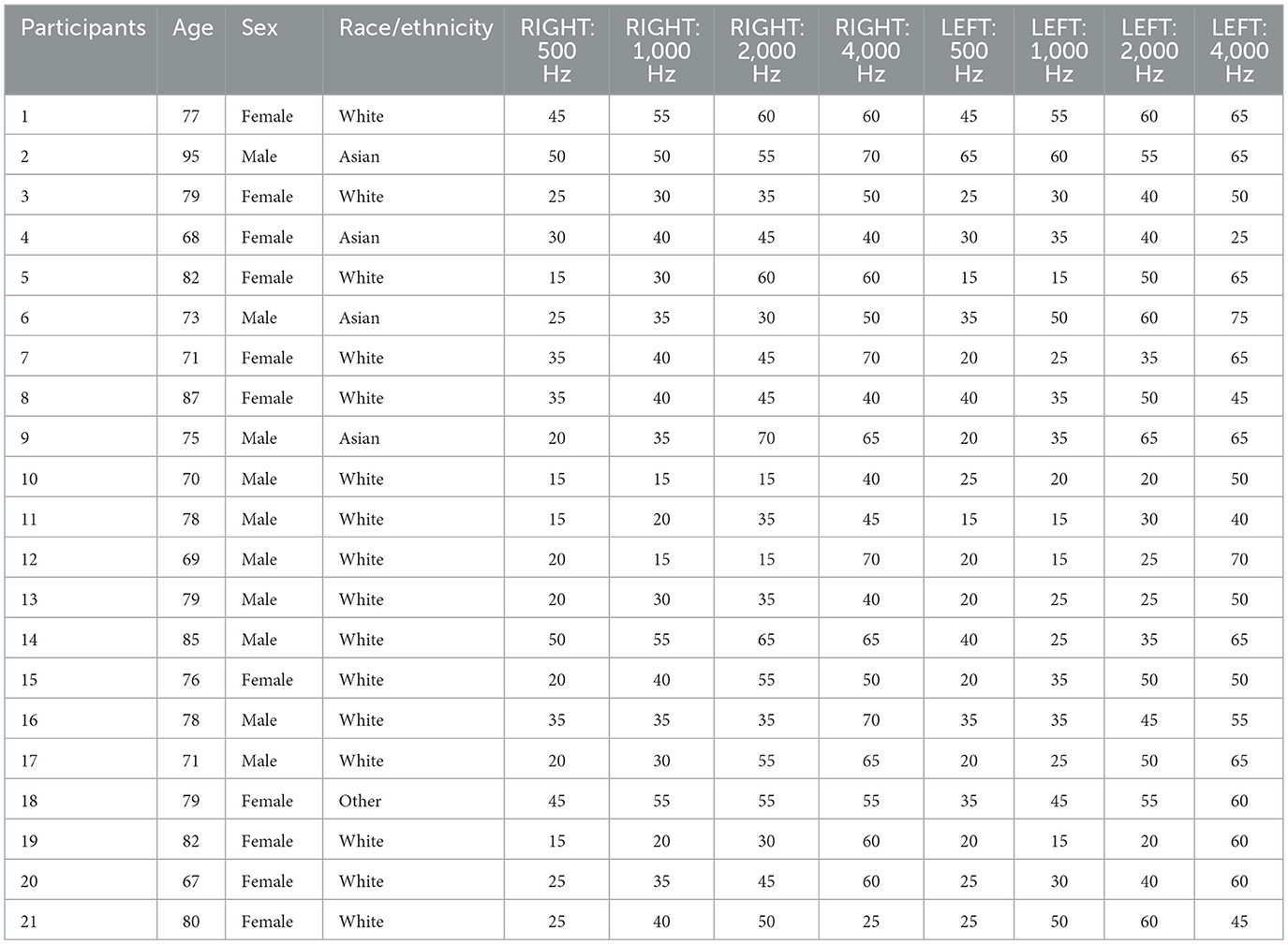
Table 1.
Unaided speech recognition in background noise was assessing using four speech-in-noise tasks. The first task consisted of Consonant-Nucleus-Consonant (CNC) words (Peterson and Lehiste, 1962). Scores were obtained using a single 50-word list presented in the presence of multi-talker babble with a signal-to-noise ratio (SNR) of +5 dB. Performance was scored in percent correct using whole words and individual phonemes. The second measure was the QuickSIN (Killion et al., 2004), which measures the SNR at which 50% of key words in low-context sentences can be repeated in the presence of multi-talker babble. Each QuickSIN list consists of six low-context sentences, with each sentence containing five key words, presented in decreasing SNR steps from +25 dB to 0 dB in 5 dB steps (Killion et al., 2004). The third SPIN measure was the Words in Noise (WIN) test (Wilson, 2003; Wilson et al., 2003). In this measure monosyllabic words are presented at different SNR values beginning at +24 dB and decreasing to 0 dB. As with the QuickSIN, the output of this test is the SNR at which 50% of words can be correctly repeated. The final SPIN measure was the Non-sense Syllable Test (NST, Kuk et al., 2010). In this measure, 115 phonetically balanced non-sense words were presented in the presence of continuous speech-weighted noise with a 5 dB SNR, and the percent correct was recorded.
All SPIN assessments were conducted using a three–speaker array centered at 0-, 135-, and 225-degrees azimuth. In all tests, speech was presented at 0 degrees azimuth. In the CNC, WIN and NST tests, the noise was delivered through the 135- and 225-degree azimuth speakers. For the QuickSIN test, the noise was also presented at 0 degrees azimuth. Speech stimuli across all conditions were presented at a fixed level of 75 dB SPL.
All participants first completed the SPIN tests in an unaided condition. Following baseline testing, participants were fit with Starkey Genesis AI RIC RT hearing aids. All fits were verified using real-ear measures with the NAL-NL2 fitting formula and were within 5 dB of target at all frequencies. Participants were then provided with the hearing aids to use in their daily life for 4 weeks. They were instructed by the research team how to manually activate “Edge Mode™” and were encouraged to use the devices during all waking hours. Datalogging was monitored weekly. If average daily use fell below four hours, participants returned to the lab for re-instruction and device reprogramming, and their trial was extended by 1 week. All participants met this requirement without exception. After completing the 4-week field trial, participants returned to the lab and repeated the SPIN measures in an aided condition. In the post-fitting SPIN measures, each test was repeated twice, once with Edge Mode™ active, and once with it deactivated (i.e., using default “Personal” program).
To determine the subjective benefits of the Edge Mode™ algorithm, we examined participant preferences during the take-home field testing period. During this four-week timeframe, participants were required to wear the devices for at least 4 h each day in the default Personal program, and to use the on-demand Edge Mode™ program at least twice daily. Subsequently, subjects answered a total of six questions (Appendix 1) regarding their subjective preference for the Personal program or Edge Mode™ via survey or ecological momentary assessment questionnaire through a smartphone mobile application. This allowed assessment of subject participants' overall preference, ease of use, and the perceived listening environment when either the personal program or Edge Mode™ was used. Subjects were blinded to the use of EMA “catch” trials (randomized to 30%) that used an audible indicator but did not apply acoustic changes when the on-demand feature was activated.
Statistical analysis
Our primary objective in this phase was to assess the influence of a speech enhancement algorithm on improving speech understanding abilities in noise. For each SPIN measure, we compared performance with the algorithm active vs. inactive via a paired t-test. We then examined the relationship between the magnitude of improvement (if any) and the degree of hearing loss by completing a linear regression on the difference between active and inactive modes vs. the degree of hearing loss as determined by the High-Frequency Pure Tone Average (HFPTA; average at 1, 2, and 4 kHz). Finally, we examined the relationship between the magnitude of improvement (if any) on a given SPIN test when the algorithm was active relative to the pre-fitting unaided performance on that test.
For the subjective ratings obtained in Phase II, we calculated the percentage of improvement, no change, or worsening of speech understanding after turning on the Edge Mode™, and the percentage of preference for Edge Mode™ or automatic mode, stratified by environment or noise level. We used a one-sample binomial test to determine (1) whether the observed proportion of improvement is statistically significant compared to the random 50–50% chance; (2) whether the observed proportion of improvement is significantly different from that of worsening when Edge Mode™ was turned on, in each environment and at each noise level and all scenarios combined. The same test was used to test the preference for Edge Mode™ or automatic mode. P-values < 0.05 was deemed to be statistically significant under two-tailed test.
Results
Phase I
Results from Hagerman and SII computations indicate that in comparison to baseline amplification conditions with omnidirectional microphones and no noise reduction, the default Personal program provided an SNR improvement of over 7 dB in challenging listening environments (e.g., “bar” or “construction” environments), and up to 13 dB SNR improvement (vs. the base condition) when Edge Mode™ was enabled (Figure 4). The magnitude of benefit varied across the seven “real-life” conditions, but each showed predicted SPIN and SNR improvements for the Edge Mode™ conditions over the default Personal program conditions. Additionally, the magnitude of benefit will vary with acoustic coupling used (e.g., occluded vs. vented domes or earmolds) under “real world” conditions.
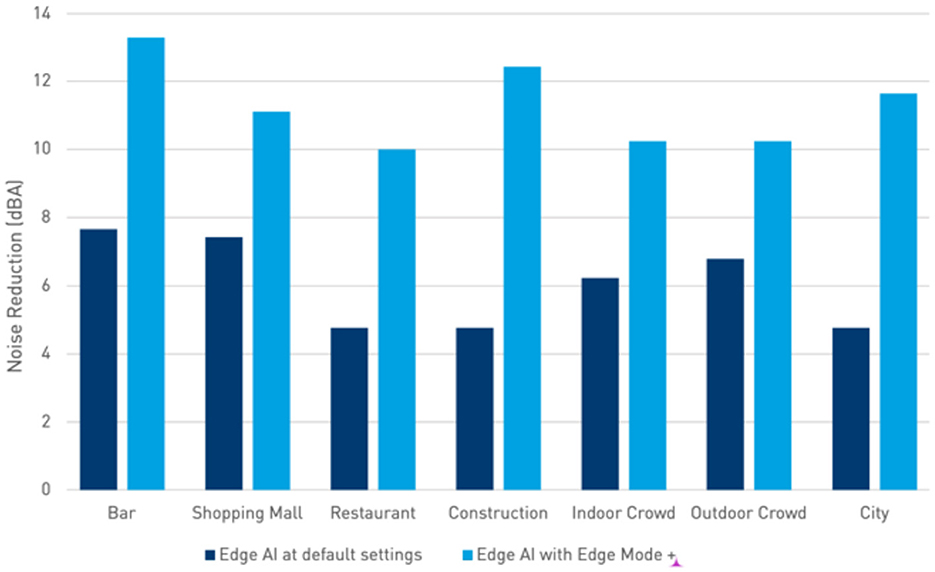
Figure 4. SII-weighted SNR improvement with a variety of challenging diffuse noise environments with Edge Mode™ hearing aids. The bars show comparison between the automatic default Personal program (dark blue) and Edge Mode™ (light blue), vs. the baseline condition of omnidirectional microphone and noise reduction disabled.
Phase II: behavioral SPIN performance
Taken together, our results show improvements with activation of the signal processing algorithm on the CNC +5 SNR, the QuickSIN and the WIN, but not on the NST +5 SNR. In all instances, these improvements were independent both degree of hearing loss and the unaided pre-fitting performance. Figure 5 shows group performance on the CNC+5 condition when the algorithm was active or inactive (left panel), while individual improvements are depicted in the right panel. Here a significant improvement in performance was observed when the algorithm was active (t20 = 5.30, p < 0.001). A moderate relationship was observed with performance when the algorithm was on and off (p = 0.007; R2 = 0.46), with the slope of the line suggesting that greater improvements were more likely to be observed when performance without the algorithm was lower. Finally, the magnitude of these improvements was unrelated to both the degree of hearing loss (p = 0.33; R2 = 0.05) and the unaided performance (p = 0.69; R2 = 0.01).
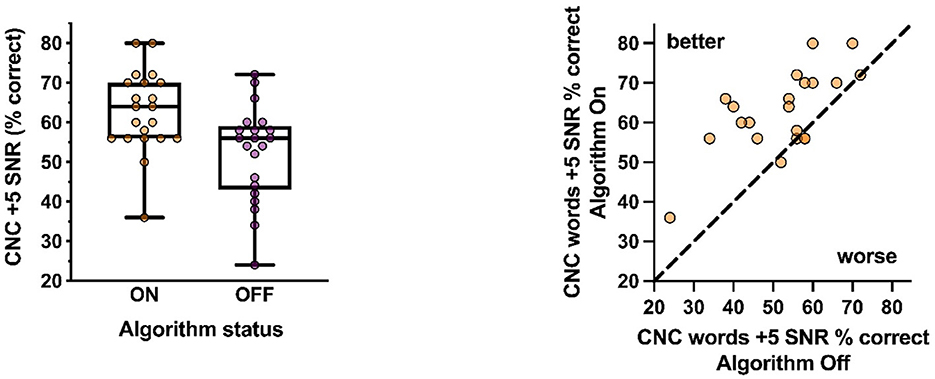
Figure 5. Group performance in the CNC+5 condition with the algorithm active or inactive (Left) and individual improvements (Right). Significant improvement was observed with the algorithm active.
Similar results were observed for the QuickSIN (Figure 6). Small, but statistically significant improvements were observed on the QuickSIN when the algorithm was active vs. not (t20 = 3.59, p = 0.002). A strong relationship was observed between the algorithm on vs. off conditions (p < 0.001; R2 = 0.87), with the slope of the line suggesting that the magnitude of improvement was similar regardless of the performance without the algorithm. As with the CNC+5 SNR, these improvements were not related to the degree of hearing loss (p = 0.93; R2 = 0.001) nor the unaided QuickSIN performance (p = 0.2; R2 = 0.09).
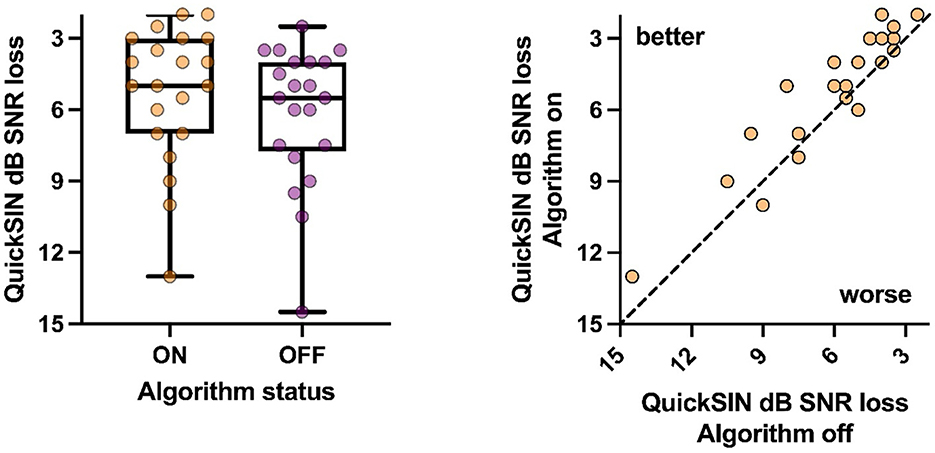
Figure 6. Group (Left) and individual (Right) performance on QuickSIN with the algorithm active and inactive were significant.
As with the QuickSIN, small, but statistically significant improvements were observed with the WIN (Figure 7) when the algorithm was active relative to when it was not (t20 = 2.12, p = 0.046). A strong relationship was again observed between the algorithm on and off conditions (p < 0.001; R2 = 0.73), with the slope of the line suggesting that, when improvements are observed, their magnitude was similar regardless of the performance without the algorithm. Any improvements were once again unrelated to the degree of hearing loss (p = 0.48; R2 = 0.03), and the unaided performance (p = 0.45; R2 = 0.03).
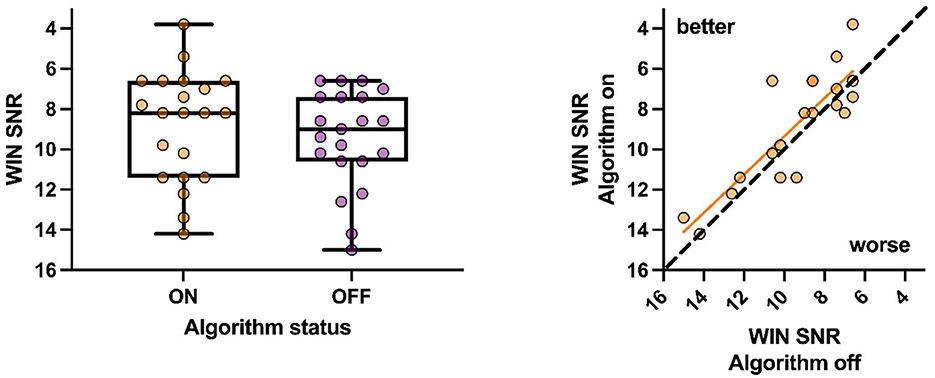
Figure 7. Group (Left) and individual (Right) performance on WIN with the algorithm active and inactive were significant.
Unlike the previous SPIN tests, there were no differences observed on the NST+5 SNR (Figure 8) when the algorithm was active or inactive regardless of whether the test was scored as whole words (t20 = 0.26, p = 0.81) or phonemes (t20 = 0.82, p = 0.42). A significant relationship between NST performance with the algorithm on and off was observed (p < 0.001; R2 = 0.59), consistent with the idea that better or worse performance without the algorithm is unchanged when the algorithm is active. Finally, no relationship was found between the magnitude of improvement (if any) and the degree of hearing loss (p = 0.79; R2 = 0.003), or the unaided performance on the NST (p = 0.72; R2 = 0.007).
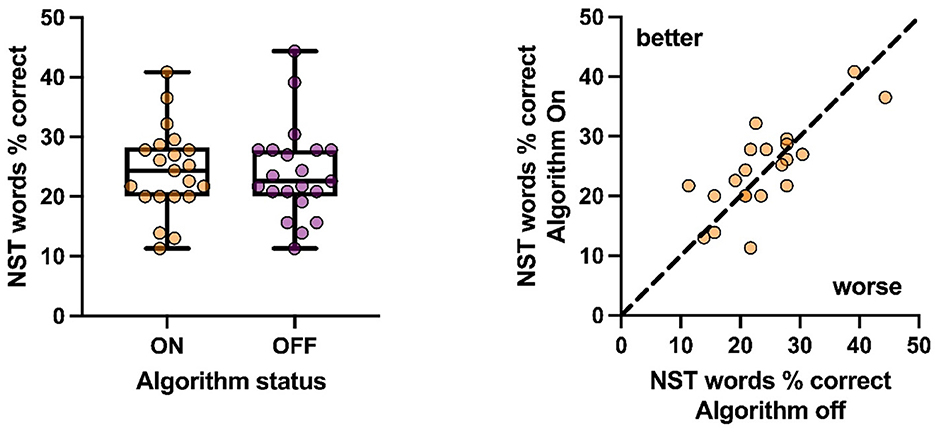
Figure 8. Group (Left) and individual (Right) performance on NST words with active and inactive algorithm were not significant.
Phase II: subjective ratings
The primary objective in this phase was to assess whether the measured laboratory benefits from Phase I and clinical benefits in Phase II were perceived as beneficial by participants during take-home testing using EMA and subjective testing. Here, significant improvements when Edge Mode™ was active were reported across all listening environments (Figure 9). Even after accounting for the catch trials, participants reported significant improvements (p < 0.001) for the questions asking about improvements in speech understanding and reduction in listening effort. Finally, when asked about listening preference between Edge Mode™ and the Personal program (Figure 10), participants were more likely to prefer listening with the Edge Mode™ active (p < 0.001) when in noisy environments.
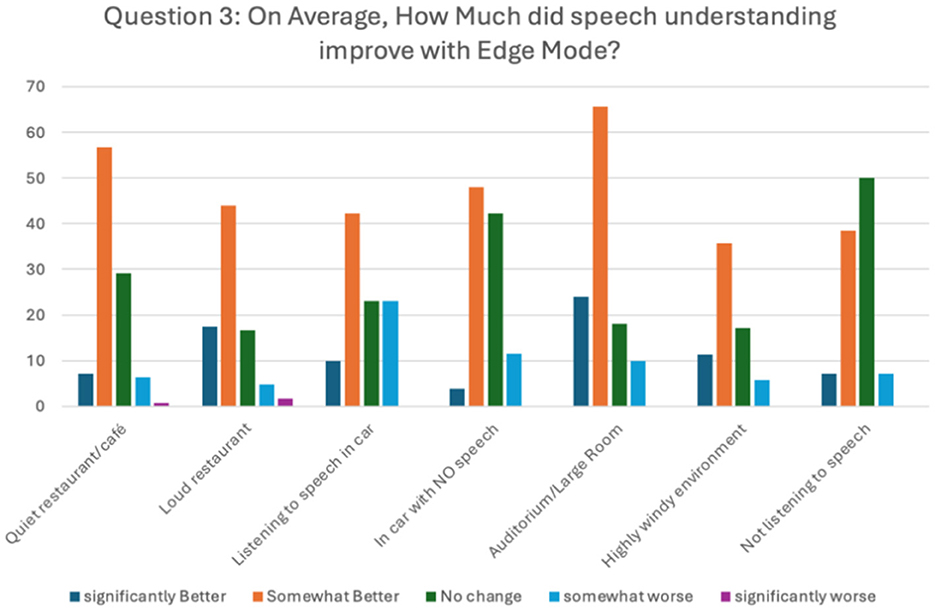
Figure 9. Subjective results from take-home testing comparing preference for the default Personal program vs. Edge Mode™ for seven quiet and noisy listening environments.
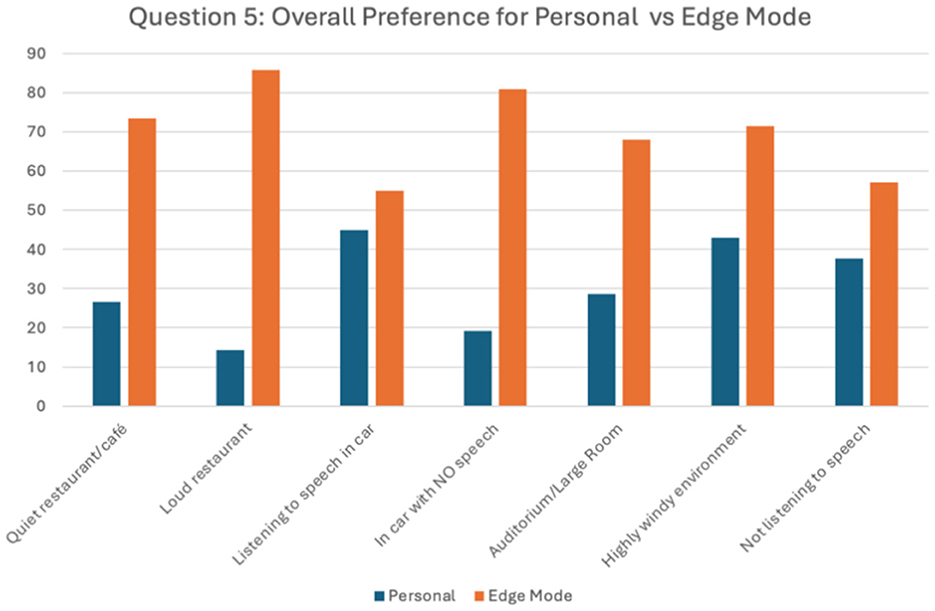
Figure 10. Overall preference for Personal vs. Edge Mode™ programs reported from take-home testing for seven quiet and noisy listening environments.
Discussion
In this multiphase assessment of a DNN-based on-demand hearing aid feature (Edge Mode™), we demonstrated strong support in Phase I for the theoretical benefits in laboratory conditions using the Hagerman method and via predicted audibility represented by SII computations. In Phase II we also observed significant improvements in both lab-based measures of speech perception in noise, and subjective benefit in real-world environments as measured by EMA questionnaires. However, these benefits were observed on some tests (CNC + 5 SNR, QuickSIN and WIN), but not others (NST + 5 SNR). When observed, these benefits were independent of the degree of hearing loss and unaided pre-fitting performance. Taken together, these results suggest that this algorithm results in small, but significant improvements in the SNR relative to current signal processing techniques, but that these benefits may vary between individuals and may not be present with all types of background noise.
One of the most striking results observed here is that the algorithm improved SPIN abilities for all tests except for the NST+5 SNR. The most likely reason for this result reflects the differences in noise types between the two tests. Here, the NST used a speech-shaped noise, while the other tests utilized multi-talker babble. By this logic, the algorithm was most likely trained on various types of multi-talker babble and was subsequently unable to generalize any improvements to the speech-shaped noise. If so, these data suggest that this algorithm needs to be further refined to optimize the SNR in different acoustic environments. An alternative, less likely information is that the NST+5 required additional cognitive resources for optimal performance than the other tests, and the additional cognitive load obscured any improvement in SNR elicited by the algorithm. Single-word or phoneme tests are often thought to rely more heavily on auditory cues because of their lack of context than sentence-based tests. Thus, one might expect that a non-sense syllable test should require the participant to focus more on purely auditory cues. However, participants may have attempted to assign meaning to the non-sense word and confused it with similar-sounding real words. If so, it may be possible that this process required additional cognitive load which obscured any benefits in SNR brought about by the algorithm.
One implication of observing benefits for some SPIN tests but not others is that it suggests that the benefits observed here are not resulting solely from a directional microphone. If this were the case, then we should have observed improvements in all SPIN tests. However, the fact that the same speaker configuration was used for all tests, and that differences were only observed for the test which used speech-shaped noise instead of multi-talker babble, suggests that other factors in the signal processing algorithm than microphone directionality accounted for the small but significant improvements observed here.
While significant improvements were observed in three of the four SPIN tests used here, it is worth noting that the improvements were on average relatively small on average (~1 dB for the QuickSIN and WIN, and 10% for the CNC+5), and often varied between individuals. For example, the smallest effect size was observed for the WIN (Cohen's d = 0.42, indicating a small effect), while the effect sizes were larger for the QuickSIN and CNC+5 (0.78 and 1.16, respectively). One possibility is that the smaller effect size with the WIN reflects the test administration. In this test, the noise level is fixed, and the level of the signal is systematically reduced. In contrast, the signal level is fixed with the QuickSIN and the CNC+5 tests, and the noise level is varied in the QuickSIN. One implication of this difference is that for some participants, there may have been a reduction of audibility for some signals, which could have hindered the effectiveness of the algorithm. Such confounds are less likely with the QuickSIN or the CNC+5 as the speech level and thus audibility was fixed in these measures, and this may help account for the reduced effect size for the WIN.
Another possibility is that the between-participant variability observed here regarding the effectiveness of the algorithm reflects individual differences between participants regarding distortions of peripheral encoding or executive function. For example, when measured in thousands of patients, performance on the QuickSIN and WIN has been shown to vary considerably between individuals with similar amounts of hearing loss (Fitzgerald et al., 2023; Wilson, 2011; Smith et al., 2024). In some instances, these between-subject differences are often attributed to differences in peripheral encoding of the signal. These include, and are not limited to, deficits in spectral-temporal modulation (Bernstein et al., 2013; Mehraei et al., 2014; Bernstein et al., 2016), temporal fine structure (Moore et al., 2008; Lorenzi et al., 2006; Hopkins et al., 2008; Viswanathan et al., 2021), the encoding of the fundamental frequency (Coffey et al., 2017; Mepani et al., 2021), synaptopathy (Liberman et al., 2016; DiNino et al., 2022), and the distortion of tonotopicity (Parida and Heinz, 2022a,b). In other instances, differences in executive function capacity have been put forth as predictors of SPIN abilities. For example, reducing working memory capacity is consistently associated with poor performance on SPIN measures in elderly patients (Humes, 2021b; Akeroyd, 2008; Janse and Jesse, 2014; Souza and Arehart, 2015; Nagaraj, 2017; Vermeire et al., 2019; Yeend et al., 2019; Humes, 2020). Other aspects of executive function, such as cognitive flexibility, are also associated with SPIN abilities in adults (Rosemann and Thiel, 2020; Helfer et al., 2020). Regarding the present data, it is possible that the algorithm used here may facilitate improvements in the SNR for some types of deficits in peripheral encoding or executive function, but not others. For example, some older adults may be more sensitive to distortions of the speech signal caused by some types of hearing aid signal processing (Arehart et al., 2013), and that these differences can be mediated or influenced by spectral distortion of between-subject variance in executive function capacity (Davies-Venn and Souza, 2014; Souza et al., 2015; Rallapalli et al., 2021; Windle et al., 2023; Rallapalli et al., 2024). By this logic, the algorithm used here may be more effective for some individuals than others, but the pre-test and fitting procedures used here were insufficient to predict which individuals would be most likely to benefit.
Another key result from this study is that, when improvements were observed on behavioral SPIN abilities, they were not related to the degree of hearing loss, or the unaided performance on any of the SPIN measures tested here. The most likely interpretation of these results is that the signal-processing algorithm used here results in enhancement of speech features for all signals, and that participant-specific factors (e.g., differences in peripheral encoding or executive-function abilities) determined the extent to which they could make use of the enhancements elicited by the algorithm. Such data speaks to the need for improved-prefitting measures to allow for greater precision in fitting of hearing aids beyond maximizing audibility according to pre-specified formulae such as NAL or DSL.
In addition to the behavioral improvements in SPIN performance observed with the Edge Mode™ algorithm, these participants also reported significant subjective improvements when the algorithm was active. These preferences were observed in both quiet and noisy listening environments, and were almost uniformly in favor of the Edge Mode™ algorithm. This subjective preference is consistent with a recent report indicating that improved SPIN performance was associated with a reduction in perceived auditory disability in a large cohort of more than 1600 patients (Fitzgerald et al., 2024). Moreover, SPIN abilities correlate with hearing aid satisfaction (Saunders and Forsline, 2006; Davidson et al., 2021; Walden and Walden, 2004), such that patients with better SPIN abilities are happier with their devices. Conversely, SPIN abilities are often worse in patients who return their hearing aids (Humes, 2021a), and difficulties with SPIN are commonly reported to be responsible for inconsistent hearing aid use, or discontinuing use altogether (McCormack and Fortnum, 2013; Hong et al., 2014; Humes, 2003; Hickson et al., 2014; Jilla et al., 2020; Powers and Rogin, 2020; Aazh et al., 2015). Taken together, these data suggest that even relatively small improvements in SNR over conventional signal processing can be noted by patients and result in improved preference. Thus, these data suggest that the future potential for DNN-assisted noise management has significant potential to further improve the communication abilities of individuals with hearing difficulties.
Conclusions
Here we evaluated the efficacy of a DNN-based hearing aid signal processing algorithm in improving speech perception in noise (SPIN) in 20 participants with hearing loss, in addition to objective evaluations in a laboratory setting. We observed significant improvement in SPIN abilities on the CNC+5 SNR, QuickSIN, and WIN tests but not on the NST+5 SNR. We speculate that the lack of improvement on the NST+5 SNR is likely due to its use of speech-shaped noise, unlike the multi-talker babble in other tests. This suggests that the algorithm may have been optimized for speech understanding in the presence of competing talkers and would need to be refined for other listening conditions. The benefits observed here were somewhat variable between individuals and were independent of the degree of hearing loss unaided SPIN abilities. These results likely reflect between-participant differences in as peripheral encoding and executive function which influence the ability of individuals to benefit from the signal processing used here. Finally, these SPIN improvements were reflected in the subjective preferences of these participants when using devices in their daily lives. Taken together, they suggest that artificial intelligence driven algorithms can elicit significant improvements in SNR in hearing aids, and that more precise tools are needed to improve pre-fitting measures to better tailor hearing aids to individual users.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Stanford University, Institutional Review Board. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
MF: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. VA: Formal analysis, Visualization, Writing – review & editing. MS: Project administration, Resources, Software, Writing – review & editing. JR: Data curation, Investigation, Project administration, Visualization, Writing – review & editing. SV: Data curation, Formal analysis, Investigation, Methodology, Visualization, Writing – review & editing. AB: Conceptualization, Funding acquisition, Project administration, Resources, Supervision, Writing – review & editing. RJ: Funding acquisition, Investigation, Resources, Supervision, Writing – review & editing. KS: Funding acquisition, Investigation, Project administration, Resources, Supervision, Writing – review & editing. DF: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Writing – original draft.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This research was supported by a grant from Starkey Hearing Technologies to Stanford University. In addition, Starkey provided equipment and technical support. Varsha Athreya was funded by donation from Mona Taliaferro.
Acknowledgments
We would like to thank Bryn Griswold for collecting these data.
Conflict of interest
MS, AB, and DF were employed by Starkey Hearing Technologies.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fauot.2025.1677482/full#supplementary-material
References
Aazh, H., Prasher, D., Nanchahal, K., and Moore, B. C. (2015). Hearing-aid use and its determinants in the UK National Health Service: a cross-sectional study at the Royal Surrey County Hospital. Int. J. Audiol. 54, 152–161. doi: 10.3109/14992027.2014.967367
Akeroyd, M. A. (2008). Are individual differences in speech reception related to individual differences in cognitive ability? A survey of twenty experimental studies with normal and hearing-impaired adults. Int. J. Audiol. 47(Suppl. 2), S53–S71. doi: 10.1080/14992020802301142
Alexander, J. M. (2021). Hearing aid technology to improve speech intelligibility in noise. Semin. Hear. 42, 175–185. doi: 10.1055/s-0041-1735174
Arehart, K. H., Souza, P., Baca, R., and Kates, J. M. (2013). Working memory, age, and hearing loss: susceptibility to hearing aid distortion. Ear Hear. 34, 251–260. doi: 10.1097/AUD.0b013e318271aa5e
Baby, D., Van Den Broucke, A., and Verhulst, S. (2021). A convolutional neural-network model of human cochlear mechanics and filter tuning for real-time applications. Nat. Mach. Intell. 3, 134–143. doi: 10.1038/s42256-020-00286-8
Bagatto, M., Moodie, S., Scollie, S., Seewald, R., Moodie, S., Pumford, J., et al. (2005). Clinical protocols for hearing instrument fitting in the Desired Sensation Level method. Trends Amplif. 9, 199–226. doi: 10.1177/108471380500900404
Bentler, R., Wu, Y. H., Kettel, J., and Hurtig, R. (2008). Digital noise reduction: outcomes from laboratory and field studies. Int. J. Audiol. 47, 447–460. doi: 10.1080/14992020802033091
Bernstein, J. G., Danielsson, H., Hällgren, M., Stenfelt, S., Rönnberg, J., and Lunner, T. (2016). Spectrotemporal modulation sensitivity as a predictor of speech-reception performance in noise with hearing aids. Trends Hear. 20:2331216516670387. doi: 10.1177/2331216516670387
Bernstein, J. G., Mehraei, G., Shamma, S., Gallun, F. J., Theodoroff, S. M., and Leek, M. R. (2013). Spectrotemporal modulation sensitivity as a predictor of speech intelligibility for hearing-impaired listeners. J. Am. Acad. Audiol. 24, 293–306. doi: 10.3766/jaaa.24.4.5
Bishop, C. M., and Nasrabadi, N. M. (2006). Pattern Recognition and Machine Learning, Vol. 4. New York, NY: Springer.
Blackwell, D. L., Luca, J. W., and Clarke, T. C. (2014). Summary health statistics for US adults: national health interview survey 2012. National Center for Health Statistics. Vital Health Stat. 10, 1–161.
Bondy, J., Becker, S., Bruce, I., Trainor, L., and Haykin, S. (2004). A novel signal-processing strategy for hearing-aid design: neurocompensation. Sig. Process. 84, 1239–1253. doi: 10.1016/j.sigpro.2004.04.006
Byrne, D., and Dillon, H. (1986). The National Acoustic Laboratories' (NAL) new procedure for selecting the gain and frequency response of a hearing aid. Ear Hear. 7, 257–265. doi: 10.1097/00003446-198608000-00007
Byrne, D., Dillon, H., Ching, T., Katsch, R., and Keidser, G. (2001). NAL-NL1 procedure for fitting nonlinear hearing aids: characteristics and comparisons with other procedures. J. Am. Acad. Audiol. 12, 37–51. doi: 10.1055/s-0041-1741117
Byrne, D., and Tonisson, W. M. (1976). Selecting the Gain of Hearing Aids for Persons with Sensorineural Hearing Impairments. Scand. Audiol. 5, 51–59. doi: 10.3109/01050397609043095
Carhart, R., and Jerger, J. F. (1959). Preferred method for clinical determination of pure-tone thresholds. J. Speech Hear. Disord. 24, 330–345. doi: 10.1044/jshd.2404.330
Carr, K., and Kihm, J. (2022). marketrak-tracking the pulse of the hearing aid market. Semin. Hear. 43, 277–288. doi: 10.1055/s-0042-1758380
Chadha, S., Kamenov, K., and Cieza, A. (2021). The world report on hearing, 2021. Bull. World Health Organ. 99, 242A−242A. doi: 10.2471/BLT.21.285643
Coffey, E. B. J., Chepesiuk, A. M. P., Herholz, S. C., Baillet, S., and Zatorre, R. J. (2017). Neural correlates of early sound encoding and their relationship to speech-in-noise perception. Front. Neurosci. 11:479. doi: 10.3389/fnins.2017.00479
Davidson, A., Marrone, N., Wong, B., and Musiek, F. (2021). Predicting hearing aid satisfaction in adults: a systematic review of speech-in-noise tests and other behavioral measures. Ear Hear. 42, 1485–1498. doi: 10.1097/AUD.0000000000001051
Davies-Venn, E., and Souza, P. (2014). The role of spectral resolution, working memory, and audibility in explaining variance in susceptibility to temporal envelope distortion. J. Am. Acad. Audiol. 25, 592–604. doi: 10.3766/jaaa.25.6.9
Diehl, P. U., Singer, Y., Zilly, H., Schönfeld, U., Meyer-Rachner, P., Berry, M., et al. (2023). Restoring speech intelligibility for hearing aid users with deep learning. Sci. Rep. 13:2719. doi: 10.1038/s41598-023-29871-8
DiNino, M., Holt, L. L., and Shinn-Cunningham, B. G. (2022). Cutting through the noise: noise-induced cochlear synaptopathy and individual differences in speech understanding among listeners with normal audiograms. Ear Hear. 43, 9–22. doi: 10.1097/AUD.0000000000001147
Drakopoulos, F., Baby, D., and Verhulst, S. (2021). A convolutional neural-network framework for modelling auditory sensory cells and synapses. Commun. Biol. 4, 1–17. doi: 10.1038/s42003-021-02341-5
Fabry, D. A., and Bhowmik, A. K. (2021). Improving speech understanding and monitoring health with hearing aids using artificial intelligence and embedded sensors. Semin. Hear. 42, 295–308. doi: 10.1055/s-0041-1735136
Fischer, T., Caversaccio, M., and Wimmer, W. (2021). Speech signal enhancement in cocktail party scenarios by deep learning based virtual sensing of head-mounted microphones. Hear. Res. 408:108294. doi: 10.1016/j.heares.2021.108294
Fitzgerald, M. B., Gianakas, S. P., Qian, Z. J., Losorelli, S., and Swanson, A. C. (2023). Preliminary guidelines for replacing word-recognition in quiet with speech in noise assessment in the routine audiologic test battery. Ear. Hear. 44, 1548–1561. doi: 10.1097/AUD.0000000000001409
Fitzgerald, M. B., Ward, K. M., Gianakas, S. P., Smith, M. L., Blevins, N. H., and Swanson, A. P. (2024). Speech-in-noise assessment in the routine audiologic test battery: relationship to perceived auditory disability. Ear Hear. 45, 816–826. doi: 10.1097/AUD.0000000000001472
Gatehouse, S., and Noble, W. (2004). The speech, spatial and qualities of hearing scale (SSQ). Int. J. Audiol. 43, 85–99. doi: 10.1080/14992020400050014
Gnewikow, D., Ricketts, T., Bratt, G. W., and Mutchler, L. C. (2009). Real-world benefit from directional microphone hearing aids. J. Rehabil. Res. Dev. 46, 603–618. doi: 10.1682/JRRD.2007.03.0052
Hagerman, B., and Olofsson, A. (2004). A method to measure the effect of noise reduction algorithms using simultaneous speech and noise. Acta Acustica United Acustica 90, 356–361.
Hannula, S., Bloigu, R., Majamaa, K., Sorri, M., and Mäki-Torkko, E. (2011). Self-reported hearing problems among older adults: prevalence and comparison to measured hearing impairment. J. Am. Acad. Audiol. 22, 550–559. doi: 10.3766/jaaa.22.8.7
Healy, E. W., Delfarah, M., Vasko, J. L., Carter, B. L., and Wang, D. (2017). An algorithm to increase intelligibility for hearing-impaired listeners in the presence of a competing talker. J. Acoust. Soc. Am. 141, 4230–4239. doi: 10.1121/1.4984271
Healy, E. W., and Yoho, S. E. (2016). Difficulty understanding speech in noise by the hearing impaired: underlying causes and technological solutions. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2016, 89–92. doi: 10.1109/EMBC.2016.7590647
Helfer, K. S., Poissant, S. F., and Merchant, G. R. (2020). Word identification with temporally interleaved competing sounds by younger and older adult listeners. Ear Hear. 41, 603–614. doi: 10.1097/AUD.0000000000000786
Hickson, L., Meyer, C., Lovelock, K., Lampert, M., and Khan, A. (2014). Factors associated with success with hearing aids in older adults. Int. J. Audiol. 53, S18–S27. doi: 10.3109/14992027.2013.860488
Hong, J. Y., Oh, I. H., Jung, T. S., Kim, T. H., Kang, H. M., and Yeo, S. G. (2014). Clinical reasons for returning hearing aids. Korean J. Audiol. 18, 8–12. doi: 10.7874/kja.2014.18.1.8
Hopkins, K., Moore, B. C. J., and Stone, M. A. (2008). Effects of moderate cochlear hearing loss on the ability to benefit from temporal fine structure information in speech. J. Acoust. Soc. Am. 123, 1140–1153. doi: 10.1121/1.2824018
Humes, L. E. (2003). Modeling and predicting hearing aid outcome. Trends Amplif. 7, 41–75. doi: 10.1177/108471380300700202
Humes, L. E. (2020). Associations between measures of auditory function and brief assessments of cognition. Am. J. Audiol. 29, 825–837. doi: 10.1044/2020_AJA-20-00077
Humes, L. E. (2021a). Differences between older adults who do and do not try hearing aids and between those who keep and return the devices. Trends Hear. 25:23312165211014329. doi: 10.1177/23312165211014329
Humes, L. E. (2021b). Factors underlying individual differences in speech-recognition threshold (SRT) in noise among older adults. Front. Aging Neurosci. 13:702739. doi: 10.3389/fnagi.2021.702739
Janse, E., and Jesse, A. (2014). Working memory affects older adults' use of context in spoken-word recognition. Q. J. Exp. Psychol. 67, 1842–1862. doi: 10.1080/17470218.2013.879391
Jilla, A. M., Johnson, C. E., Danhauer, J. L., Anderson, M., Smith, J. N., Sullivan, J. C., et al. (2020). Predictors of hearing aid use in the advanced digital era: an investigation of benefit, satisfaction, and self-efficacy. J. Am. Acad. Audiol. 31, 87–95. doi: 10.3766/jaaa.18036
Jorgensen, L., and Novak, M. (2020). Factors influencing hearing aid adoption. Semin. Hear. 41, 6–20. doi: 10.1055/s-0040-1701242
Keidser, G., Brew, C., and Peck, A. (2003). Proprietary fitting algorithms compared with one another and with generic formulas. Hear. J. 56, 28–32. doi: 10.1097/01.HJ.0000293014.56004.ee
Keidser, G., Dillon, H., Flax, M., Ching, T., and Brewer, S. (2011). The NAL-NL2 prescription procedure. Audiol. Res. 1:e24. doi: 10.4081/audiores.2011.e24
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., and Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 116, 2395–2405. doi: 10.1121/1.1784440
Kuk, F., Lau, C. C., Korhonen, P., Crose, B., Peeters, H., and Keenan, D. (2010). Development of the ORCA nonsense syllable test. Ear Hear. 31, 779–795. doi: 10.1097/AUD.0b013e3181e97bfb
Le Prell, C. G., and Clavier, O. H. (2017). Effects of noise on speech recognition: challenges for communication by service members. Hear. Res. 349, 76–89. doi: 10.1016/j.heares.2016.10.004
LeCun, Y., Bengio, Y., and Hinton, G. (2015). Deep learning. Nature 521, 436–444. doi: 10.1038/nature14539
Liberman, M. C., Epstein, M. J., Cleveland, S. S., Wang, H., and Maison, S. F. (2016). Toward a differential diagnosis of hidden hearing loss in humans. PLoS ONE 11:e0162726. doi: 10.1371/journal.pone.0162726
Lorenzi, C., Gilbert, G., Carn, H., Garnier, S., and Moore, B. C. (2006). Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proc. Natl. Acad. Sci. U. S. A. 103, 18866–18869. doi: 10.1073/pnas.0607364103
McCormack, A., and Fortnum, H. (2013). Why do people fitted with hearing aids not wear them? Int. J. Audiol. 52, 360–368. doi: 10.3109/14992027.2013.769066
Mehraei, G., Gallun, F. J., Leek, M. R., and Bernstein, J. G. (2014). Spectrotemporal modulation sensitivity for hearing-impaired listeners: dependence on carrier center frequency and the relationship to speech intelligibility. J. Acoust. Soc. Am. 136, 301–316. doi: 10.1121/1.4881918
Mepani, A. M., Verhulst, S., Hancock, K. E., Garrett, M., Vasilkov, V., Bennett, K., et al. (2021). Envelope following responses predict speech-in-noise performance in normal-hearing listeners. J. Neurophysiol. 125, 1213–1222. doi: 10.1152/jn.00620.2020
Moore, B. C., Stone, M. A., Füllgrabe, C., Glasberg, B. R., and Puria, S. (2008). Spectro-temporal characteristics of speech at high frequencies, and the potential for restoration of audibility to people with mild-to-moderate hearing loss. Ear Hear. 29, 907–922. doi: 10.1097/AUD.0b013e31818246f6
Mueller, H. G., Weber, J., and Hornsby, B. W. Y. (2006). The effects of digital noise reduction on the acceptance of background noise. Trends Amplif. 10, 83–93. doi: 10.1177/1084713806289553
Nagaraj, N. K. (2017). Working memory and speech comprehension in older adults with hearing impairment. J. Speech Lang. Hear. Res. 60, 2949–2964. doi: 10.1044/2017_JSLHR-H-17-0022
Nagathil, A., Göbel, F., Nelus, A., and Bruce, I. C. (2021). “Computationally efficient DNN-based approximation of an auditory model for applications in speech processing,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Toronto, ON: IEEE), 301–305. doi: 10.1109/ICASSP39728.2021.9413993
Parida, S., and Heinz, M. G. (2022a). Distorted tonotopy severely degrades neural representations of connected speech in noise following acoustic trauma. J. Neurosci. 42, 1477–1490. doi: 10.1523/JNEUROSCI.1268-21.2021
Parida, S., and Heinz, M. G. (2022b). Underlying neural mechanisms of degraded speech intelligibility following noise-induced hearing loss: the importance of distorted tonotopy. Hear. Res. 426:108586. doi: 10.1016/j.heares.2022.108586
Peterson, G. E., and Lehiste, I. (1962). Revised CNC lists for auditory tests. J. Speech Hear. Disord. 27, 62–70. doi: 10.1044/jshd.2701.62
Pichora-Fuller, M. K. (1997). Language comprehension in older listeners. J. Speech-Lang. Pathol. Audiol. 21, 125–142.
Powers, T. A., and Rogin, C. (2020). MarkeTrak 10: history and methodology. Semin. Hear. 41, 3–5. doi: 10.1055/s-0040-1701241
Rallapalli, V., Ellis, G., and Souza, P. (2021). Effects of directionality, compression, and working memory on speech recognition. Ear Hear. 42, 492–505. doi: 10.1097/AUD.0000000000000970
Rallapalli, V., Freyman, R., and Souza, P. (2024). relationship between working memory, compression, and beamformers in ideal conditions. Ear Hear. 46, 523–536. doi: 10.1097/AUD.0000000000001605
Rosemann, S., and Thiel, C. M. (2020). Neural signatures of working memory in age-related hearing loss. Neuroscience 429, 134–142. doi: 10.1016/j.neuroscience.2019.12.046
Saunders, G. H., and Forsline, A. (2006). The Performance-Perceptual Test (PPT) and its relationship to aided reported handicap and hearing aid satisfaction. Ear Hear. 27, 229–242. doi: 10.1097/01.aud.0000215976.64444.e6
Scollie, S., Seewald, R., Cornelisse, L., Moodie, S., Bagatto, M., Laurnagaray, D., et al. (2005). The desired sensation level multistage input/output algorithm. Trends Amplif. 9, 159–197. doi: 10.1177/108471380500900403
Seewald, R. C., Ross, M., and Spiro, M. K. (1985). Selecting amplification characteristics for young hearing-impaired children. Ear Hear. 6, 48–53. doi: 10.1097/00003446-198501000-00013
Smith, M. L., Winn, M. B., and Fitzgerald, M. B. (2024). A large-scale study of the relationship between degree and type of hearing loss and recognition of speech in quiet and noise. Ear Hear. 45, 915–928. doi: 10.1097/AUD.0000000000001484
Soni, S., Yadav, R. N., and Gupta, L. (2023). State-of-the-art analysis of deep learning-based monaural speech source separation techniques. IEEE Access 11, 4242–4269. doi: 10.1109/ACCESS.2023.3235010
Souza, P., and Arehart, K. (2015). Robust relationship between reading span and speech recognition in noise. Int. J. Audiol. 54, 705–713. doi: 10.3109/14992027.2015.1043062
Souza, P., Arehart, K., and Neher, T. (2015). Working memory and hearing aid processing: literature findings, future directions, and clinical applications. Front. Psychol. 6:1894. doi: 10.3389/fpsyg.2015.01894
Vermeire, K., Knoop, A., De Sloovere, M., Bosch, P., and van den Noort, M. (2019). Relationship between working memory and speech-in-noise recognition in young and older adult listeners with age-appropriate hearing. J. Speech Lang. Hear. Res. 62, 3545–3553. doi: 10.1044/2019_JSLHR-H-18-0307
Viswanathan, V., Bharadwaj, H. M., Shinn-Cunningham, B. G., and Heinz, M. G. (2021). Modulation masking and fine structure shape neural envelope coding to predict speech intelligibility across diverse listening conditions. J. Acoust. Soc. Am. 150:2230. doi: 10.1121/10.0006385
Walden, T. C., and Walden, B. E. (2004). Predicting success with hearing aids in everyday living. J. Am. Acad. Audiol. 15, 342–352. doi: 10.3766/jaaa.15.5.2
Wilson, R. H. (2003). Development of a speech-in-multitalker-babble paradigm to assess word-recognition performance. J. Am. Acad. Audiol. 14, 453–470. doi: 10.1055/s-0040-1715938
Wilson, R. H. (2011). Clinical experience with the words-in-noise test on 3430 veterans: comparisons with pure-tone thresholds and word recognition in quiet. J. Am. Acad. Audiol. 22, 405–423. doi: 10.3766/jaaa.22.7.3
Wilson, R. H., Abrams, H. B., and Pillion, A. L. (2003). A word-recognition task in multitalker babble using a descending presentation mode from 24 dB to 0 dB signal to babble. J. Rehabil. Res. Dev. 40, 321–327. doi: 10.1682/JRRD.2003.07.0321
Wilson, R. H., and McArdle, R. (2014). A treatise on the thresholds of interoctave frequencies: 1500, 3000, and 6000 Hz. J. Am. Acad. Audiol. 25, 171–186. doi: 10.3766/jaaa.25.2.6
Windle, R., Dillon, H., and Heinrich, A. (2023). A review of auditory processing and cognitive change during normal ageing, and the implications for setting hearing aids for older adults. Front. Neurol. 14:1122420. doi: 10.3389/fneur.2023.1122420
Wu, Y. H., Stangl, E., Chipara, O., Hasan, S. S., Welhaven, A., and Oleson, J. (2018). Characteristics of real-world signal to noise ratios and speech listening situations of older adults with mild to moderate hearing loss. Ear Hear. 39, 293–304. doi: 10.1097/AUD.0000000000000486
Yeend, I., Beach, E. F., and Sharma, M. (2019). Working memory and extended high-frequency hearing in adults: diagnostic predictors of speech-in-noise perception. Ear Hear. 40, 458–467. doi: 10.1097/AUD.0000000000000640
Zhang, M., Mary Ying, Y.-L., and Ihlefeld, A. (2018). Spatial release from informational masking: evidence from functional near infrared spectroscopy. Trends Hear. 22:2331216518817464. doi: 10.1177/2331216518817464
Zhao, Y., Wang, D., Johnson, E. M., and Healy, E. W. (2018). A deep learning based segregation algorithm to increase speech intelligibility for hearing-impaired listeners in reverberant-noisy conditions. J. Acoust. Soc. Am. 144:1627. doi: 10.1121/1.5055562
Keywords: hearing aids, audiology, speech in noise, deep neural network, artificial intelligence, ecological momentary assessment
Citation: Fitzgerald MB, Athreya VM, Srour M, Rejimon JP, Venkitakrishnan S, Bhowmik AK, Jackler RK, Steenerson KK and Fabry DA (2025) Effectiveness of deep neural networks in hearing aids for improving signal-to-noise ratio, speech recognition, and listener preference in background noise. Front. Audiol. Otol. 3:1677482. doi: 10.3389/fauot.2025.1677482
Received: 31 July 2025; Accepted: 22 September 2025;
Published: 20 October 2025.
Edited by:
Jorge Humberto Ferreira Martins, Escola Superior de Saúde do Alcoitão, PortugalReviewed by:
Antonio Vasco Oliveira, Polytechnic Institute of Porto, PortugalDiogo Costa Ribeiro, New University of Lisbon, Portugal
Copyright © 2025 Fitzgerald, Athreya, Srour, Rejimon, Venkitakrishnan, Bhowmik, Jackler, Steenerson and Fabry. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Matthew B. Fitzgerald, Zml0em1iQHN0YW5mb3JkLmVkdQ==