 John Archibald
John Archibald- Department of Linguistics, University of Victoria, Victoria, BC, Canada
In this article, I tackle the question of differential substitution in L2 phonology. A classic example of the phenomenon is learners from different L1s attempting to acquire the L2 English interdental fricative /θ/. Speakers of some languages (e.g., Japanese) tend to pronounce the /θ/ as [s] while speakers of other languages (e.g., Russian) tend to pronounce the /θ/ as [t]). Since both Japanese and Russian have both /s/ and /t/ in their phonemic inventories, it is interesting to ask why one language would choose [s] and the other [t]. What I argue in this article is that it is not a local comparison of two sounds, two features, or two phonemes that will determine why one segment rather than another is substituted. Rather, I argue that we must consider the formal representation of the entire segmental inventory (represented as a contrastive hierarchy) in order to understand why the Japanese pick the [s] but the Russian the [t] as the “best” substitute for the English /θ/. What I will demonstrate is that in the languages that substitute [s], [continuant] is the highest-ranked feature that has scope over the place and voice features in the contrastive hierarchy of phonological features. In the languages that substitute [t], the place and voice features rank above [continuant].
1. Introduction
In this article, I tackle the question of differential substitution in L2 phonology. The term was coined by Weinberger (1997), though reference to the phenomenon goes back to at least (Weinreich, 1953). A classic example of the phenomenon is learners from different L1s attempting to acquire the L2 English interdental fricative /θ/. Speakers of some languages (e.g., Japanese) tend to pronounce the /θ/ as [s] (Lombardi, 2003) while speakers of other languages (e.g., Russian) tend to pronounce the /θ/ as [t] (Weinreich, 1953; Lombardi, 2003). Since both Japanese and Russian have both /s/ and /t/ in their phonemic inventories, it is interesting to ask why one language would choose [s] and the other [t]. What I am going to argue in this article is that it is not a local comparison of two sounds, two features, or two phonemes that will determine why one segment rather than another is substituted. Rather, I will argue that we must consider the formal representation of the entire segmental inventory (either consonantal or vocalic) in order to understand why the Japanese pick the [s] but the Russian the [t] as the “best” substitute for the English /θ/. Kabak (2019) reminds us that an even broader explanatory model would need to take both external factors, such as historical patterns and language contact, and internal linguistic factors into account in looking at the difficulties that are seen in the acquisition of interdental fricatives, but in this article, I restrict myself to a strictly phonological account.
What I will argue here is that in the languages that substitute [s], [continuant] is the highest-ranked feature that has scope over the place and voice features in the contrastive hierarchy of phonological features. In the languages that substitute [t], the place and voice features rank above [continuant].
1.1. Earlier approaches
Traditional approaches (Weinreich, 1957; Stockwell and Bowen, 1965; Nemser, 1971) would say something along the lines of “learners substitute the closest sound in their inventory.” One can see the broad strokes of the argument when one considers how an L1 English speaker might substitute a [k] for a /q/. In the absence of a voiceless uvular stop [q] it seems unsurprising that a voiceless velar stop would be chosen as the “closest” match. However, previous explanations (Flege and Bohn, 2021) have struggled with independent measures of what might make one sound “closer” to another. Phonetic models such as the SLM (Flege, 1995) or PAM-L2 (Best and Tyler, 2007) have described how sounds that are similar in the L1 and the L2 tend to be assimilated (which makes it more difficult to acquire a new L2 phonetic category), while sounds that are different have been found to form new L2 phonetic categories more easily. But why is Russian [t] more like [θ] than Japanese [t] is? Conversely, why is Russian [s] less like [θ] than Japanese [s]? One can imagine detailed phonetic comparisons being the empirical data that would be drawn on to try to answer such questions. However, there is good reason to believe that substitution mechanisms (whatever they are) are not just motoric, articulatory problems because if they were we would not expect to see analogous problems of misperception [and we do; see John and Frasnelli (2023) for a discussion]. Oft times, learners who cannot produce a particular distinction also fail to perceive the contrast. Looking at phonological representation provides an explanation for both production and perception phenomena.
Brown (2000) took a more phonological view of the problem. She begins with the notion of categorical perception in phonology. Listeners hear an acoustically varied input stream and yet can assign the diverse phones from the environment to abstract phonemic categories. Let us take an example of a listener hearing a particular vowel, say [ɪ], spoken by an older male, a young adult female, and a child. The acoustics of those three vowels will be quite distinct, and yet the listener assigns them all to the category /ɪ/. Brown gives the example of English ears assigning non-English phones to English phonemes. An English speaker will have the voiceless stop phonemes /p/ and /t/ and /k/. When hearing a [q] in the input, the listener (or perhaps more accurately the parser) must assign the [q] to a phoneme. On an articulatory basis, one can argue that a uvular stop is “closer” to a velar stop than to an alveolar stop.
Rochet (1995) demonstrated that L1 English speakers substitute [u] for the L2 French /y/ while L1 Brazilian Portuguese speakers substitute [i], even though both languages have /i/ and /u/. He argues that acoustically there is more overlap with the English [u] and the French [y] (perhaps because of the fronted English [u]) than with the English [i] and the French [y] while, conversely, there is more overlap with the Brazilian Portuguese [i] and the French [y] than with the Brazilian Portuguese [u] and the French [y]. For Rochet, this means that the English speakers hear the French /y/ as [u] while the Brazilian Portuguese speakers hear the French /y/ as [i] because of the acoustic properties of the L1 and the L2 vowels. These perception issues are argued to underlie the analogous production patterns. Similarly, Brannen (2002) proposed that the explanation for differential substitution lies in phonetic rather than phonological patterns, but her model ran into problems related to this particular question in that it predicted that, for both European and Quebec French (QF), [f] should be the substitute of choice for the English /θ/ phoneme. Teasdale (1997) sought an articulatory phonetic approach to this problem by arguing that the relevant linguistic difference is in the articulation of the /s/. She noted that European French has a dental [s] and Japanese has a “flat” (or slit-type) [s] and that both of these languages substitute [s] for /θ/ while QF has an alveolar [s] so it substitutes [t]. While the correlation here is intriguing, the explanatory mechanism remains elusive.
Interestingly, James (1988) presents some data (which I will not explore in this article) that show that Dutch speakers substitute stops word-initially but fricatives word-finally (see also Collins and Mees, 1981). All I will say is that (a) contextual variation is different from differential substitution, and (b) it is not uncommon in the world's languages to have stops in onsets but fricatives in codas, but we would need to delve into Dutch syllable structure more closely before presenting a detailed analysis.
Brown's view was that the L1 phonemes act as a kind of categorical shoehorn to squeeze L2 sounds that do not quite fit into L1 categories. Brown argued that this sort of phonological funneling was impossible to overcome and that if the L1 lacked the relevant phonological feature to represent a particular contrast, that feature would never be triggered by the L2 input. González Poot (2011, 2014) demonstrated that such a position was too strong when he showed that L1 Spanish learners of L2 Yucatec Mayan had acquired a [constricted glottis] feature that is not found in L1 Spanish. The [constricted glottis] is a property of segments known as ejectives (e.g., [p'], [t'], [k]). González Poot's participants were indistinguishable from native speakers of Yucatec Mayan in their performance on a discrimination task with sound pairs like [p'a]/[pa] even though Spanish lacks ejectives and lacks the [constricted glottis] feature anywhere in its phonological inventory.
We can see that phonological features might well be involved in such a metric of closeness or similarity. Consider the substitution patterns commonly witnessed for both English interdentals /θ/ and /ð/. Crosslinguistically, we note that a /θ/ might be replaced by a [f] or a [t] or a [s]. What might lead to such variation? If we consider phonological features as the building blocks of phonemes, then Table 1 shows the relevant similarities.
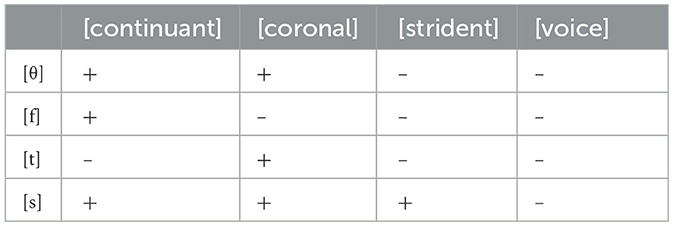
Table 1. Phonological features of interdental fricative and close comparators.
Each of the “closest” sounds matches /θ/ on three features and differs on the other; all are 75% accurate. However, such a comparison does not tell us why Russian gives precedence to the mismatch on [continuant] (to change /θ/ → [t]) while Japanese gives precedence to the mismatch on [strident] (to change /θ/ → [s]). Is there something in Russian that prioritizes a match in place of articulation while something in Japanese values a match in manner of articulation? Under this approach, the answer seems to be “no.”
Hancin-Bhatt (1994) tried to find a metric to establish a more nuanced comparison of features by looking at how many inventory contrasts each feature was involved in, and, in this way, arriving at a measure of functional load of each feature, which she called feature prominence. She adopted a model of radical underspecification (Archangeli, 1988), and then looked to see the weighting that each feature had. The first step was to generate a feature matrix showing by way of example (a selection) of Hindi phonemes in Table 2.
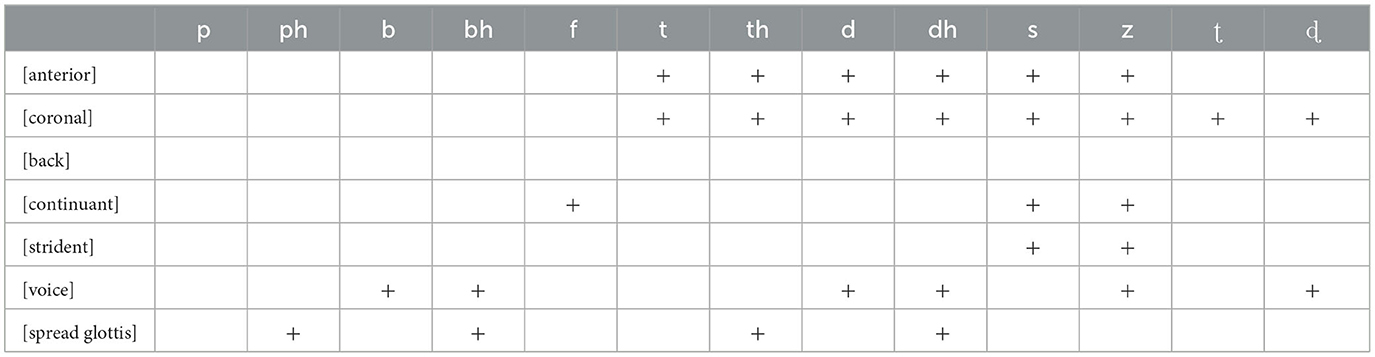
Table 2. Hancin-Bhatt's (1994) feature matrix.
She proposed a prominence score that was calculated per feature by counting the number of phonemes for which that feature was specified and dividing by the number of phonemes in the inventory. For Table 2, we could calculate the prominence values of some of the features shown in (1), where [anterior] is more prominent than [spread glottis], which in turn is more prominent than [strident].
1. Anterior = 6/13 = 0.46
Strident = 2/13 = 0.15
Spread Glottis = 4/13 = 0.31
Hancin-Bhatt reported the feature prominence ranking for Hindi features based on the full inventory shown in Table 3.
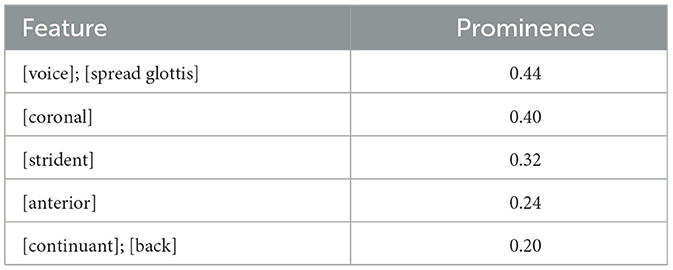
Table 3. Feature prominence rankings.
Her prediction was that features that were more prominent would be more easily perceived in the L2 input. In the above case [continuant] is of low prominence, so the listeners are predicted not to be sensitive to [continuant] cues in the input and, thus, would be predicted to substitute the stop (i.e., non-continuant) [t] for English /θ/ in a perception task. Bansal (1969) claims that this is the preferred Hindi substitution pattern. However, ultimately, Hancin-Bhatt's predictions were not always borne out. For example, she predicted that L1 Turkish speakers should substitute [s] for /θ/, but in her experiment they misperceived /θ/ as [t].
Hanuliková and Weber (2012) show that differential substitution affects perception in that when German (an [s]-language) learners of English are compared to Dutch (a [t]-language) learners of English and participants hear English words spoken with either an [s] or a [t], respectively, substituted in an English word, they fixate on the correct English [θ] word longer when the accented version matches their own substitution preference. For example, L1 German participants fixate on thick when they hear sick longer than when they hear tick, as opposed to L1 Dutch participants who would fixate more on thick when they hear tick than when they hear sick.
1.2. Possible explanations
Weinberger (1997) adopted underspecification theory to account for why L1 Japanese subjects pick [s] while L1 Russian subjects pick [t] as the substitute for English /θ/. Basically, Weinberger argues that Russian and Japanese treat the feature [continuant] differently. Japanese has /s/ unspecified for [continuant] while Russian has /t/ unspecified for [continuant]. Weinberger does not provide detailed evidence for these feature values in the respective L1s. Picard (2002, p. 88) argued that this method could not account for the difference between European and Quebec French since “both dialects have exactly the same underlying consonant inventory,” so he proposes a perception-based account. Picard acknowledges a key difference between the two French dialects as being that Canadian French has an assibilation rule that turns /t/ into [ts] before high, front vowels. He also acknowledges that with [strident] playing a role in Quebec French allophony, it seems counterintuitive (given the L1 import of [strident]) that the QF speakers do not pick the strident [s] as the substitute. When we look at contrastive hierarchy (CH) and the activity principle, we will see how the relationship works.
Smith (1997) looks at L1 Japanese (s/z), German (s/z), Turkish (t/d), and European (s/z) and Quebec (t/d) French. She focuses on the lack of the feature [distributed] in these languages. Thus, she seems to argue that they all have the same wrong phonological representation for /θ/ but the differential substitutes are the result of phonetics. Her goal is to account for the phonological cause of the misperceptions rather than the nature of which substitute is chosen.
Lombardi (2003) proposes a quite different class of solution in that she argues that the [t]-substitution occurs as the result of a high-ranked markedness constraint, thus resulting in the production of a universally less-marked stop segment, while the [s]-substitution pattern results from a high-ranked faithfulness constraint, thus resulting in the production of a form that is faithful to an L1 underlying form. As we mentioned earlier, such an output-based account has difficulty explaining the parallel perception difficulties the learners demonstrate (given the assumption of richness of the base).
Kwon (2021) presents a line of work that tackles the notion of formalizing perceptual similarity and, hence, potentially being able to predict which L1 sound is closer to the L2 interdental. She adopts an integration of the Lahiri and Reetz (2002) featurally underspecified lexicon model and Dresher's (2009) Contrastive Hierarchy (CH). Her approach generates perceptual similarity scores that argue that phonological representation, not phonetic representation, has a stronger influence on L2 perception.
Note that, with the exception of Kwon (2021), none of the previous approaches recognized constituent structure in phonological features. Some invoked feature geometry, but as Cowper and Hall (2019) remind us, “contrastive hierarchies are paradigmatic (defining systems of oppositions), and feature geometries are syntagmatic, structuring combinations of features in phonological representations.”
2. The contrastive hierarchy
I propose that using a CH approach (Dresher, 2009, 2018; Hall, 2011; Archibald, 2022a,b; Chandlee, 2023) provides just the mechanism we need to account for such differential substitution patterns. I present cross-linguistic patterns found in the existing literature and will propose a phonological explanation. I am going to focus on the interdentals [θ/ð] and their substitutes in Russian, Japanese, European French, and QF. Russian and QF tend to substitute [t] for /θ/ and [d] for /ð/ while European French and Japanese tend to substitute [s] for /θ/ and [z] for /ð/ (Gatbonton, 1978; Smith, 1997; Teasdale, 1997; Picard, 2002). However, this same machinery could be used to account for other examples of differential substitution. The CH model is a theory of ranked contrastive underspecification. Let us consider two partial phonemic inventories to see how the machinery works. Dresher (2018) gives the example of the two three-vowel systems that each use the same features but differ in feature ranking, shown in (2).
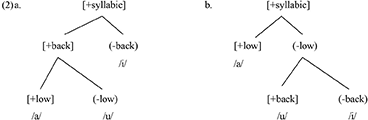
The difference between (2a) and (2b) is the ranking of features. In (2a) the inventory is first divided by the feature [back] while in (2b) the inventory is first divided by the feature [low]. In (2a) /i/ is uniquely and unambiguously represented by (non-back) so it requires no further features. In (2b), however, /i/ is represented by the feature (non-low) and the feature (non-back). Therefore, even though the two systems have the same phonemes, they may well behave differently. In the words of Dresher (2018, p. 21), “We predict that these differences in organization will be reflected in patterns of merger and neutralization.” Imagine that there was a vowel harmony process in the language; in (2a) both /a/ and /u/ would be involved in [back] harmony while in (2b) only /u/ would be involved in [back] harmony. Key elements of the model are given in Table 4 (adapted from Dresher, 2018).
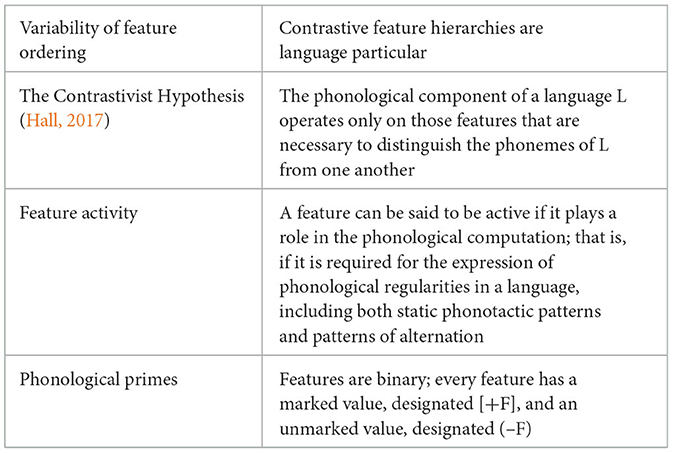
Table 4. Key properties of contrastive hierarchy theory.
Each language, therefore, will have a different ranking of features; there is no universal invariant hierarchy that governs all human languages. The features chosen by each language will also vary. Only the features represented in the CH are available for allophonic computation. For example, if a language does not represent a [round] feature in the vowel in the CH then we could not see [round] spreading occurring in adjacent segments. If features do play a role in the computational system, they are said to be active. Note that (a) this activity can be a cue to the learner as to which features to include in the CH [following what Dresher (2009) calls the successive division algorithm], and (b) not all contrastive features are active; some are there to represent phonemic contrast alone. For Dresher (2018), features are emergent from contrast and not drawn from a universal inventory. Nothing in this article hinges on this stance, so I will remain agnostic at this time. Finally, for the features that are represented, I am assuming that features are binary with a notational convention that the marked value is shown in square brackets (e.g., [+voice]) while the unmarked value is shown in parentheses [e.g., (–voice)]1. Again, this is not critical for the data and arguments in this article, but as Natvig and Salmons (2021) have shown, there is a principled difference in phonetic behavior that falls out from the markedness status (with more variation being found in the realization of the unmarked values). Archibald (in press) has shown how this input variation can be a relevant cue for the learner when setting up a new CH. Before moving on to discuss the relevance of this model to multilingualism, let me just expand slightly on the nature of the successive division algorithm (SDA). The SDA sets out the procedure by which a child or a phonologist discovers the contrastive inventory of the ambient language. At the initial stage, there are no phonemic contrasts. Then, the inventory is divided in two by introducing one feature. For example, when discovering contrastive vowels, a child may first divide the vowel inventory into [+high] and (–high) vowels. At this point they may be making a distinction between /i/ and /a/, but not between /i/ and /u/ (as they are both [+high]). Then, the SDA dictates that another feature is introduced to create a further binary distinction. For example, the [+high] vowels might be further subdivided into [+front] and (–front) vowels. At this stage, the child could represent a three-way phonemic contrast between /i/, /u/, and /a/. The division will continue successively until all the phonemes of the target language are uniquely specified.
The resulting contrastive hierarchies can also be thought of as parsing the input to which the Lx learner is exposed (where x stands for a natural number such as 1, 2, or 3). By this, I mean to indicate that this architecture can account for L1, L2, or L3 (etc.) acquisition. If we return to the previous examples discussed when introducing Brown, we can see that the Lx listener might be faced with [i/ɪ] in the input, or [k/q]. An English speaker would have a featural contrast that would allow the [i] to be assigned a different structure than the [ɪ], but would lack the structure necessary to disambiguate [k] from [q]. Consistent with the behavioral facts of Brown, the [q] would be assigned to the /k/ category, and the [ɪ] would be assigned to the /ɪ/ category. Certainly, at the initial stage of L2 learning, this explains why we speak and hear with an accent (see Archibald, 2021). The parser can also help us to understand differential substitution. Under a CH model, differential substitution is the by-product of phonological parsing of the Lx input by means of the L1 feature hierarchy. The Lx segments that are undifferentiated by an L1 parse explain both production and perception substitutions.
Let us now turn to the specific consonantal hierarchies (of English, Russian, Japanese, and European French and QF) that form the basis of my arguments. Since I am focusing on the differential substitution of the English interdentals, for reasons of space, I will limit my presentation of the features to the obstruents.
2.1. The English contrastive hierarchy
Working in the learnability tradition (Wexler and Culicover, 1983), let us begin by looking at the phonological representation of what is to be acquired in the Lx in terms of obstruent phonemes. That is to say, what are the L1 French, Japanese, and Russian speakers trying to acquire when they acquire an English /θ/ or an English /ð/ð? The English tree shown in (3) is based on the feature ranking of [supralaryngeal] > [sonorant] > [continuant] > [spread glottis] > [labial] > [posterior] > [velar]/[distributed].
3. The English Contrastive Hierarchy
I will not go into much detail as to the activity of the English features (and the role this could play in determining the acquisition path) as the focus of this article is on the initial stages of the acquisition of English interdental fricatives, and not on the restructuring stages of subsequent acquisition stages (see Archibald, 2023).
The non-supralaryngeal analysis of the English /h/ is partially motivated by such things as its exceptional behavior in a variety of phonological domains. It has special phonotactics in that it does not occur in codas or before another consonant. It can be deleted in weak metrical positions in words (Birming(h)am with an unstressed final syllable [əm]), or phrases (give it to (h)im). However, Goad and Mah (2007) argue that English /h/ is not placeless (see Rose, 1996) in that in many languages with placeless /h/, the /h/ occurs in codas but English does not allow /h/ in codas. Goad and Mah suggest that the English /h/ has a [spread glottis] feature (under laryngeal place) and this is what leads to the fact that the distribution of /h/ mirrors the distribution of aspiration (Jensen, 1993) as seen in words like (vehicular/ve(h)icle and atom/athomic).
The feature [continuant] is involved in the phonological computation system as we see allophony in forms such as delete/deletion where /t/ → [ʃ], and invade/invasion where /d/ → [ʒ]2. The feature [spread glottis] is active as we see voicing assimilation of the plural morpheme (in forms such as dog+s [z] and cat+s [s]). The feature [labial] is active as we see place assimilation of the negative prefix in forms such as im+possible. The feature [posterior] is active as we see palatalization in forms such as education where /dj/ → [dʒ]. The feature [velar] is active as we see it in cross-word assimilation in such phrases as bad guy→bag guy where /d/ → [g].
In terms of a transition theory (Cummins, 1983), Lx learners will need to adjust their L1 CH to achieve this L2 CH. The listeners would be exposed to the English phones, and would assign structure to them by parsing via the L1 CH. Ultimately, I will demonstrate that it is the variation in this parsing process that explains the phenomenon of differential substitution.
2.2. Loanword phonology
Before explicating the CH treatment of differential substitution, let me give some background in loanword phonology that will be useful. Herd (2005) shows convincingly how the CH model can account for loanword phonology. The hierarchy shown in (4) [adapted from Herd (2005)] summarizes how Hawaiian replaces English coronal obstruents and [g] with /k/ (e.g., “lettuce” → /lekuke/; “brush” → /palaki/). As one might imagine, it is difficult to come up with a rule that would turn [s] → /k/ and turn [z] → /k/ and turn [ʃ] → /k/.
4.
The key to understanding this approach is to think of the L2 input being parsed through the filter of the L1 CH. However, note that, unlike the approach of Brown (2000), this is not a segment-by-segment treatment but rather a reflection that the parsing takes place at an inventory level. Archibald (2022a,b) showed that inventory effects are clearly observed in L2 and L3 phonology. In the above example, we see that L2 [s], [z], [ʃ], and [g] are all parsed in the L1 hierarchy as [-sonorant, -labial]. Described in another way, the sounds [s], [z], [ʃ], and [g] cannot be unambiguously represented in the Hawaiian CH.
With this background, let us now turn to how the CH can provide insight into the phenomenon of differential substitution.
2.3. The European French contrastive hierarchy
First, we consider the parsing of the Lx English interdentals by speakers of European French (EF). EF speakers tend to substitute [s] for the English /θ/. The obstruent inventory of French is uncontroversial (see Walker, 1984). There is no /h/ in EF so the [supralaryngeal] contrast is not necessary. Daniel Hall (private communication) raises the issue of h-aspiré (which suggests that French does have some way of marking /h/) and that perhaps this could influence how learners represent the English /h/. However, I would suggest that the h-aspiré would have to be represented differently than the English /h/ because otherwise, the sound would not be problematic for French learners (and it is). Walker (1984, p. 41) says that h-apiré is a “morphological and lexical” issue, not a phonological one.
There is a uvular /ʁ/ in the sonorants, but that is not relevant to the question at hand. In documenting the consonantal allophonic processes, there are no processes that make use of the [strident] feature so we can assume that [strident] is inactive and non-contrastive in EF.
There is evidence for the [posterior] feature being active in EF. Niebuhr et al. (2011, p. 430) state that, “contrary to the predominant view in the literature—assimilation of place of articulation does exist in French, at least in sequences of alveolar and postalveolar sibilants.” They give the example (Kohler, 2002; Bertrand et al., 2007) of /s/ → [ʃ] in Scotch sur la bouche (“Scotch tape across the mouth”). There is also evidence that [voice] is active given the voicing assimilation (i.e., devoicing) noted in Walker (1984); for example, we see /pje/ → [pje]. The proposed CH for EF obstruents is given in (5).
5. The European French Contrastive Hierarchy
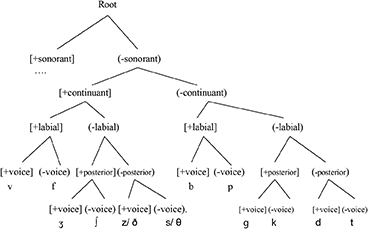
There is evidence that [continuant] is high-ranked in EF that emerges when we compare it with QF concerning the process of spirantization. The QF stop /d/ and /t/ lenite intervocalically, but they do not in EF (Colantoni et al., 2021). This differential behavior results from a difference in the ranking, as the feature does not seem to be active in either EF or QF. Having a high-ranking specified target for the stops under (-continuant) means that the articulatory targets are quite precise and would not brook much variation. Conversely, QF (which we will argue has low-ranked [continuant]) allows much more phonetic variation in the duration of the stops /d/ and /t/ because the relevant stops are unspecified for [continuant]. There is also evidence from loanword phonology in the two varieties that supports the activity of [continuant] in EF. Coté (2021) examines how English loanwords are repaired in both EF and QF. The examples that are relevant to our question include the affricates /dʒ/ and /tʃ/. The relevant borrowings and repairs are shown in Table 5.

Table 5. English loanword adaptations in European and Quebec French.
Note that the English non-continuant affricates remain as affricates in QF but the value of [continuant] changes in EF thus indicating that [continuant] is active in the phonological computation.
For ease of comparison in (4), I have included the English interdentals [θ/ð] to show how they would be parsed by the L1 EF CH. Note that the EF CH cannot disambiguate either [z/ ð] or [s/ θ]. I will not explore here how the EF hierarchy has to be changed (incrementally) to arrive at the English CH; differential substitution is our concern here. Note that the [s] substitution is driven by the highest-ranked [continuant] feature.
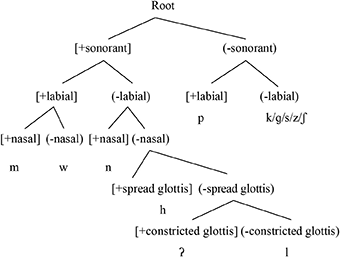
2.4. The Russian contrastive hierarchy
In tackling the question of differential substitution in Russian, I am limiting myself to presenting the CH for a subset of the Russian consonants. For reasons of space (Russian has a very complex consonantal inventory), I will only be presenting an analysis of the coronal consonants (which, after all, are the main candidates for /θ/ substitution). I base my analysis on Dresher and Hall (2020). They provide arguments for the ranking of [voice] above [continuant] in Russian; /ts/ and /tʃ/ trigger assimilatory devoicing even though they do not contrast with underlying voiced counterparts (/dz/, /dʒ/). This can be accounted for if [voice] is above [continuant] in the hierarchy. These patterns of regressive voicing assimilation evidence that [voice] is an active feature in Russian. Processes of palatalization also suggest that [sharp] is an active feature. The Russian CH is given in (6).
6. The Russian Contrastive Hierarchy
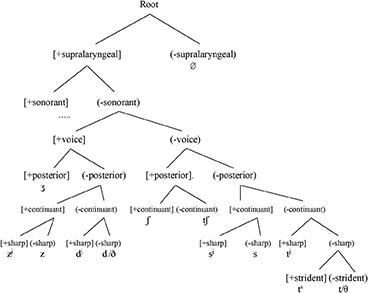
So, in Russian, [strident] is low-ranked, and is really only needed for the /ts/ vs. /t/ contrast. Crucially, [voice] is ranked above [continuant].
2.5. The Quebec French contrastive hierarchy
Walker (1984) notes that EF and QF are virtually identical in their consonantal systems (there are arguably differences in the vocalic system and certain properties of stress placement in the two varieties but those are not our concern here), and at the phonemic level this is certainly the case. There is, however, an allophonic process found in QF that is not found in EF that is directly relevant to the issue of differential substitution: assibilation. I will begin by talking about assibilation in QF and then proceed to a more general discussion. In QF there is an allophonic process that changes the phonemes /t/ and /d/ to [ts] and [dz], respectively, before the high, front vowels /i/ and /y/ (but not before /u/). Examples are given in (7).
7. ‘petit' /pəti/ → ‘battu' /baty/ ‘tout' /tu/ →
[pətsi] →[batsy] [tu]
small beaten all
‘dites' [dit] → ‘dupe' /dyp/ → ‘doute' /dut/ →
[dzit] [dzyp] [dut]
say-2sg dupe doubt
Following LaCharité (1993), I assume that affricates are strident stops. My argument is that the change from a non-strident to a strident stop indicates that the [strident] feature is active in QF. I will not get into possible spreading analyses that can motivate the phonetic change. Telfer (2006) provides an interesting account of how the following high, front vowel environment can trigger the representation of a [strident] feature. Baker and Smith (2010), I would argue, provide some indirect evidence for the activity of the [strident] feature in QF. Their article concerns the acquisition of the /y/ phoneme in L2 French by speakers from an L1 that lacks the phoneme (English). They show a correlation between people who assibilate and people who have acquired /y/. This is evidence that assibilation is an active cue (and, hence, an active feature) in QF that helps the learners to acquire the new vowel /y/. The QF CH is given in (8).
8. The Quebec French Contrastive Hierarchy
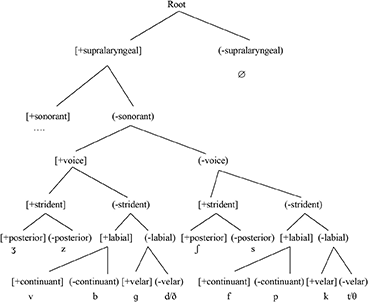
Walker (1984, p. 100) also refers to the “mellowing” of [ʃ] and [ʒ] to [x] and [ɦ] in some QF dialects (Beauce; Ottawa/Hull). Thus, the target sounds for this phonological process are [+strident, +posterior], which is consistent with both [strident] and [posterior] being active in QF.
Colantoni et al. (2021) talk about coronal stop lenition using electropalatography data on two EF and two QF speakers. Interestingly, there was a significant difference between the two dialect groups in which the QF speakers showed significantly more lenition (i.e., less contact) for both /d/ and /t/, though the effect was greater for /d/ than for the EF speakers. Note that Colantoni et al. (2021) controlled for the presence of assibilation in their data in that the lenition effects were found regardless of the following vowel (i.e., not just in the case of a following high, front vowel)3. This L1 property provides an additional reason why the QF speakers would parse the English [θ] as /t/ and the English [ð] as /d/. I would suggest that since [continuant] is low-ranked in QF (and, in fact, unspecified for the non-labials), that is what causes the lenition of the QF /t,d/ in comparison to the EF phonemic inventory, which has [continuant] highly-ranked.
2.5.1. Quebec French loanword adaptation
The discussion of loanword adaptations of English words that have been borrowed into QF is also relevant to our discussion. Hsu and Jesney (2017) provide a theoretical account of the patterns noted in Roy (1992). Many studies (Itô and Mester, 1995; Paradis and LaCharité, 1997) have revealed that loanwords often pattern differently phonologically than native vocabulary. One way to describe this is to say that there are different lexical strata and that the different strata obey different markedness restrictions. Among the patterns that Hsu and Jesney (2017) address are the following, shown in Table 64.
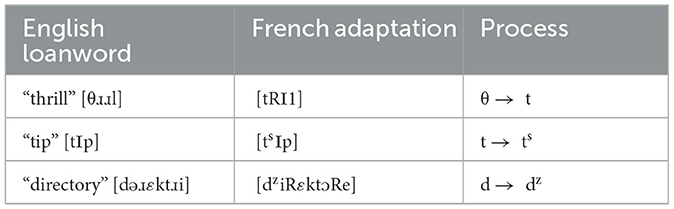
Table 6. Quebec French loanword adaptation.
Some adaptation processes apply quite uniformly, while others are more variable. Of particular interest to our discussion here, though, is the fact that words with three segments were always repaired. Those three segments were [θ], [ð], and [h]. Phonologically, for Hsu and Jesney (2017), this suggests that [θ], [ð], and [h] are the most robust markedness constraints that must be respected at all lexical strata. I would argue that the CH gives us a potential explanation of what makes these three sounds problematic. The [θ] and [ð] English inputs cannot be disambiguated by the French feature hierarchy. The [h] sound is perhaps a different story, and let me probe that question in a little more detail.
2.6. The problem of [h]
There is a considerable body of evidence that francophone learners of English have difficulty acquiring the /h/ phoneme (Janda and Auger, 1992; Brannen, 2011; White et al., 2015; Mah et al., 2016). The English /h/ tends to be deleted/omitted in production (e.g., “harm” → [arm]). Many researchers (LaCharité and Prévost, 1999; Trofimovich and John, 2011) argue that this is related to inaccurate perception. Jackson and Cardoso (2023) argue that it is the variability in the English grapheme/phoneme correspondence that accounts for the difficulty. It can be pronounced in a stressed syllable (history, inherent) but silent in an unstressed syllable (vehicle, I'd (h)ave).
Mah et al. (2016) also address the question of francophone acquisition of English /h/ in an ERP study. They begin by noting that English [h] is acoustically weak; it is made with no significant oral or pharyngeal constriction, and it has no vocal fold vibration. They suggest that the articulation of /h/ is more like a voiceless vowel. This can be supported by looking at how differently the vocal tract is positioned in the production of the /h/ in /hɑt/ compared to the /h/ in /hit/ or /hu/; a narrow phonetic transcription could well be [aɑt], [iit], and [uu]. Mah et al. further suggest that English /h/ would have the laryngeal feature [spread glottis]. French /h/ they argue is realized by just a bare laryngeal node. They are working within a feature geometry model. The relevant structures are given in (9a) for English and (9b) for French.
9.
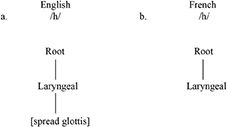
In their ERP study, they found no mismatched negativity (MMN) effect in a linguistic task but they did find an MMN effect in a non-linguistic task. This suggests that the difficulties L1 French participants are having are not at the acoustic level but rather, they argue, at the representational level. Shortly, I will provide a representational account adopting a CH model. Interestingly, production data show that francophone learners also occasionally insert an [h] in a non-target-like environment (e.g., “arm” → [h]arm). While the /h/ question may seem to be a bit removed from the differential substitution question, I hope to show that the CH approach can (a) handle the /h/ data too, (b) account for why some languages (e.g., Arabic) substitute a segment ([h]) for English /h/ rather than the French strategy of substituting Ø, and (c) show why the acquisition of an L2 phoneme that contrasts with Ø in the L1 is more difficult to acquire compared to an L2 phoneme that is realized with a different overt phone in the L1.
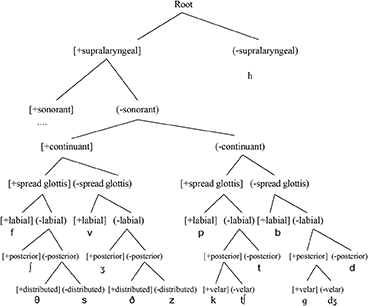
In contrast with the French problems with English /h/, let us look at the CH for Algerian Arabic. This discussion draws on Benrabah (1991) and Archibald (2022a,b), who look at the L3 English of L1 Arabic/L2 French individuals. We can see two things from this hierarchy: (1) following McCarthy (1994), Arabic gutturals (including /h/) are not placeless, and (2) the English [θ] would be parsed under the Arabic /t/. The Algerian Arabic CH is given in (10)5.
10. The Algerian Arabic Contrastive Hierarchy
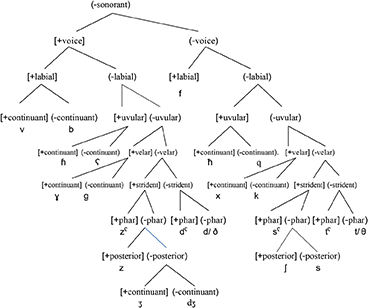
It is worth noting that in this northern African cultural context, the variety of French would tend to substitute a [s] for the English /θ/ so this substitution pattern of [t] is consistent with the transfer of the Arabic CH to represent the English obstruents. In this CH as well, we note that [voice] > [place] > [continuant], which is consistent with the [t] substitution we have already seen in Russian and QF.
However, now let us compare the learning task of Arabic learners of English to the task of French learners of English when it comes to the learning of /h/. Let us reiterate what the structure of English /h/ looks like. I will repeat the top part of the CH of (3) in (11).
11.
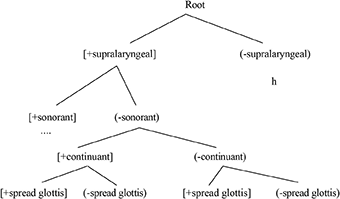
Note that in English there is a top-ranked distinction between the supralaryngeal sounds and /h/. Note too that QF lacks such a [±supralaryngeal] contrast. I repeat the top part of the CH of (8) in (12).
12.
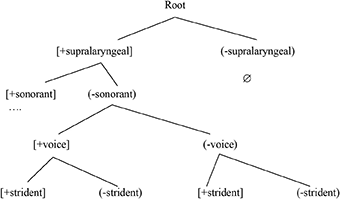
Acquiring such a high-ranked contrast, which is absent from the L1, appears to be difficult. This is consistent with what Archibald (in press) proposes in terms of a transition theory of acquiring an L2 CH where learning is conservative and incremental and begins by positing changes at the bottom of the hierarchy.
We can now contrast the English hierarchy with the high-ranked [supralaryngeal] feature with the French hierarchy, which lacks this high-ranked feature (leading to difficulty), with the Arabic hierarchy which can parse the English [h] under a place node.
The question of how L2 or L3 grammars are restructured to become more targetlike is, of course, fascinating and complex. Space precludes me from exploring it in depth here (though see Archibald, 2023 for further discussion). I will note that the work of Oxford (2015) on historical change (i.e., grammar restructuring) reveals many potential similarities in how contrastive hierarchies change over time historically and in multilinguals.
Having added this relatively brief discussion of the /h/ phenomena to the discussion of interdental differential substitution, the following general point can be made. We do not need to invoke multiple explanations for /θ/ becoming [t] in some languages and [s] in others, nor do we need to invoke special machinery to account for the difficulty of L1 French producing (and perceiving) and English [h] compared with the L1 Arabic ability to produce (and perceive) the English [h]. It can all be explained, more parsimoniously, via the machinery of a CH.
2.7. The Japanese contrastive hierarchy
Let us conclude the discussion of cross-linguistic data by looking at the interdental patterns in L1 Japanese speakers. In (13) we can see the CH for Japanese.
13. The Japanese Contrastive Hierarchy
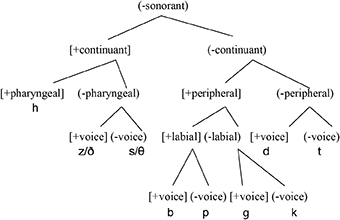
The process of spirantization in which /t/ → [s] and /d/ → [z] (Akamatsu, 1997, 2000; Labrune, 2012) indicates that [continuant] is an active feature in Japanese as shown in (14).
(14) /mikadɯki/ → [mikazɯki] “increasing moon”
Further evidence of its activity comes from Vance (1987, 2008), who notes that /b/ and /g/ spirantize to [β] and [ɤ], respectively, intervocalically. Labrune (2012, p. 64) comments that this spirantization occurs in “familiar register or fast tempo.”
There is considerable evidence that from voicing assimilation (i.e., rendaku) that [voice] is an active feature (Rice, 2005; Kubozono, 2015). For example, the [s] in sake “salmon” becomes a [z] in the phrase ʃio+zake “salted salmon.” Under this process, we see the following alternations:
/t/ → [d]
/k/ → [g]
/h/ → [b]
/s/ → [z]
Consistent with what we saw with the EF participants, having [continuant] as the highest-ranked feature leads to the substitution of the fricatives for the English interdentals. Once again, we see [continuant] > [place] > [voice]; [continuant] has scope over [place].
2.8. Summary
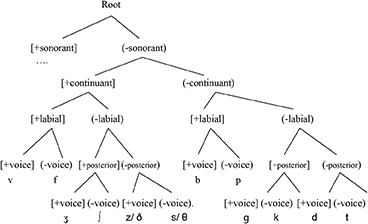
To summarize, let us recap the following three pairwise comparisons to illustrate the analyses. In (15a) and (15b), we see two [s]-substitution languages where [continuant] > [place].
15a.
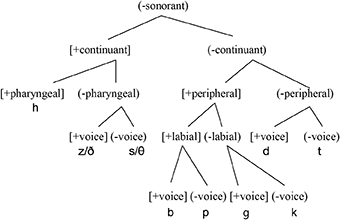
15b.
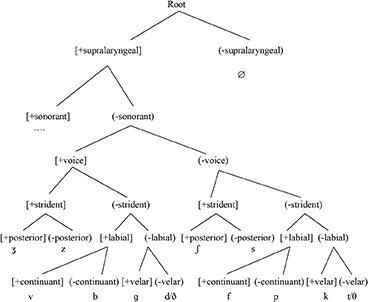
In (16a) and (16b), we see two [t]-substitution languages where [place] > [continuant].
16a.
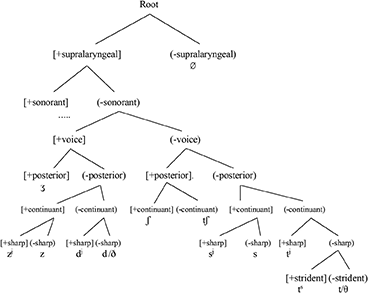
16b.
In Figures (17a) and (17b), we compare the two varieties of French where we see how one variety (EF) has [continuant] > [place] resulting in a [t] substitution while the other variety (QF) has the ranking [place] > [continuant] resulting in a [s] substitution.
17a.
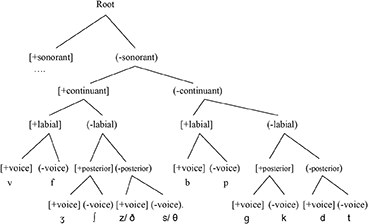
17b.
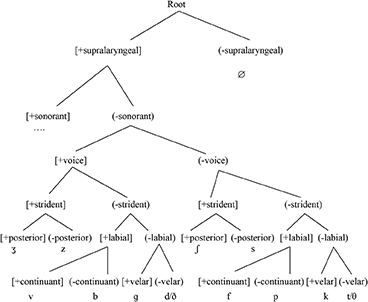
3. Conclusion
In this article, I have argued that the phenomenon of differential substitution can be explained in a principled fashion under the architectural assumption of the CH model. We see an [s] substitution for /θ/ when the [continuant] feature is the highest-ranked feature in the hierarchy (above [place] and [voice]) (e.g., Japanese and EF). In languages where [place] and [voice] features are ranked above [continuant], we see [t] as it is the completely unmarked category into which the /θ/ can be parsed (e.g., Russian and QF).
We have also proposed that parsing failures at the lowest level lead to minor ambiguities that are resolved incrementally in the learning process, while parsing failures that require the addition of a high-ranked feature are more problematic for the learners (e.g., French /h/).
The CH approach differs from Lombardi's (2003) markedness vs. faithfulness analysis in that there is a unified analysis of the two substitution options: it is all transfer of parsing procedures. Input segments that are undifferentiated by an L1-feature parse are assigned to the same phonological category. Unlike an SLM approach to equivalence classification, this is not based on surface phonetic features but rather the phonological grammar. Furthermore, unlike Lombardi (2003), this accounts for why there are perception substitutions as well as production substitutions. We must acknowledge that this is the starting point of the learning path that will require the learner to restructure the L1 CH to move incrementally closer to the L2 CH using such operations as (1) merger of an L1 contrast that is not required in the L2, (2) redeployment of an L1 contrast from one part of the L1 CH to another part of the L2 CH, or (3) triggering a new feature not found in the L1. This approach also allows for individual variation to be accounted for in a principled way (Archibald, in press) given that different learners may restructure different portions of the hierarchy in different sequences.
The CH approach recognizes that the differential substitutions fall out from inventory effects, not local surface comparisons, and further shows that the machinery of CH that has been productively used to account for L1A (Bohn and Santos, 2018), historical change (Oxford, 2015), sociolinguistics (Natvig and Salmons, 2021; Hunt Gardner and Roeder, 2022), and L3A (Archibald, 2022a,b) can also be used productively for an explanatory account of one of the oldest questions in L2 phonology: differential substitution.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Funding
This study was funded by SSHRCC grant 435-2022-1097.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^A reviewer notes that this is reminiscent of the inheritance strategy adopted in Purnell et al. (2019).
2. ^A reviewer notes that these are largely historical patterns, and may not be representative of the same type of phonological activity discussed elsewhere in the article.
3. ^They also discuss Spanish speakers in their article and the French lenition was less than the Spanish lenition, but nevertheless present.
4. ^I will not address the sonorants, only the obstruents in this article.
5. ^There might be more complexity required for the representations of /ɦ/ and /ħ/ than I am showing. The key point for the arguments in this article is that they are under a place feature node (unlike English).
References
Akamatsu, T. (2000). Japanese Phonology: A Functional Approach. Vol. 38. Lincom Studies in Asian Linguistics. Munich: Lincom Europa.
Archangeli, D. (1988). Aspects of underspecification theory. Phonology 5, 183–207. doi: 10.1017/S0952675700002268
Archibald, J. (2021). Speaking and hearing with an accent. Front. Young Minds. 9:581824. doi: 10.3389/frym.2021.581824
Archibald, J. (2022a). Segmental and prosodic evidence for property-by-property phonological transfer in L3 English in northern Africa. Languages 7, 28. doi: 10.3390/languages7010028
Archibald, J. (2022b). Phonological parsing via an integrated I-language: the emergence of property-by-property transfer effects in L3 phonology. Linguist. Approaches Biling. doi: 10.1075/lab.21017.arc
Archibald, J. (2023). “Using a contrastive hierarchy to formalize structural similarity as I- proximity in L3 phonology,” in Linguistic Approaches to Bilingualism, eds N. Kolb, N. Mitrofanova, and M. Westergaard. Special Issue. doi: 10.1075/lab.22051.arc
Archibald J. (in press). “A transition theory of L3 segmental phonology: phonological features and phonetic variation in multilingual grammars,” in Multilingual Acquisition and Learning: Towards an Eco-systemic View of Diversity, ed. E. Babatsouli (Amsterdam: John Benjamins)..
Baker, W., and Smith, C. (2010). “Acquiring the high vowel contrast in Quebec French: how assibilation helps,” in Achievements and Perspectives in SLA of Speech: New Sounds 2010, eds M. Wrembel, M. Kul, and K. Dziubalska-Kołaczyk (Brussels: Peter Lang), 279–288.
Bansal, R. K. (1969). The Intelligibility of Indian English: Measurements of the Intelligibility of Connected Speech, and Sentence and Word Material, Presented to Listeners of Different Nationalities. Hyderabad: Central Institute of English.
Benrabah, M. (1991). “Learning English segments with two languages,” in Proceedings of the International Congress of Phonetic Sciences, ed P. Romeas (Aix-en- Provence: Université de Aix-en-Provence), 334–337.
Bertrand, R., Blache, P., and R. Espesser, R. (2007). CID: corpus of interaction data. Trav. Interdiscip. Lab. Parole. Lang. d'Aix-en-Province 25, 25–55.
Best, C., and Tyler, M. (2007). “Nonnative and second-language speech perception,” in Language Experience in Second Language Speech Learning, eds O.-S. Bohn and M. Munro (Amsterdam: John Benjamins), 13–34. doi: 10.1075/lllt.17.07bes
Bohn, G., and Santos, R. (2018). The acquisition of pre-tonic vowels in Brazilian Portuguese. Alfa 62, 191–221. doi: 10.5334/jpl.184
Brannen, K. (2002). The role of perception in differential substitution. Can. J. Linguist. 47, 1–46.
Brannen, K. (2011). The Perception and Production of Interdental Fricatives in Second Language Acquisition [Unpublished doctoral dissertation]. Montréal, QC: McGill University.
Brown, C. (2000). “The interrelation between speech perception and phonological acquisition from infant to adult,” in Second Language Acquisition and Linguistic Theory, ed. J. Archibald (Oxford: Blackwell), 4–63.
Chandlee, J. (2023). Decision trees, entropy, and the contrastive feature hierarchy. Poster at the LSA. Denver Colorado. doi: 10.3765/plsa.v8i1.5465
Colantoni, L., Kochetov, A., and Steele, J. (2021). Coronal stop lenition in French and Spanish: electropalatographic evidence. Loquens 8, 1–15. doi: 10.3989/loquens.2021.080
Coté, M.-H. (2021). “L'adaptation de emprants de l'anglais en français: variation dialectale, phonologie, lexicographie,” in L'adaptation de Manlleus en Catalàien Altres Llengües Romàniques, eds M.-R. Lloret, and C. Pons-Moll (Barcelona: Publicaciones i Edicions de la Universitat de Barcelona).
Cowper, E., and Hall, D. C. (2019). “Scope variation in contrastive hierarchies of morphosyntactic features,” in Variable Properties in Language: Their Nature and Acquisition, ed. D. W. Lightfoot, and J. Havenhill (Washington, DC: Georgetown University Press), 27–41. doi: 10.2307/j.ctvfxv99p.7
Dresher, B. E. (2009). The Contrastive Hierarchy in Phonology. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511642005
Dresher, B. E. (2018). “Contrastive hierarchy theory and the nature of features,” in Proceedings of the 35th West Coast Conference on Formal Linguistics, eds W. Bennett, L. Hracs, and D. Storoshenko (Somerville, MA: Cascadilla Proceedings Project), 18–29.
Dresher, B. E., and Hall, D. C. (2020). The road not taken: the sound pattern of Russian and the history of contrast in phonology. J. Linguist. 57, 405–444. doi: 10.1017/S0022226720000377
Flege, J., and Bohn, O. (2021). “The revised Speech Learning Model (SLM-r),” in Second Language Speech Learning: Theoretical and Empirical Progress, ed. R. Wayland (Cambridge: Cambridge University Press), 3–83. doi: 10.1017/9781108886901.002
Flege, J. E. (1995). “Second language speech learning: theory, findings and problems,” in Speech Perception and Linguistic Experience: Issues in Cross-language Research, ed. W. Strange (Baltimore, MD: York Press), 233–277.
Gatbonton, E. (1978). Patterned phonetic variability in second-language speech: a gradual diffusion model. Can. Mod. Lang. Rev. 34, 335–347. doi: 10.3138/cmlr.34.3.335
Goad, H., and Mah, J. (2007). “Rethinking English /h/,” in Paper presented at Montreal-Ottawa-Toronto (MOT) Phonology Workshop. University of Ottawa.
Gonález Poot, A. (2014). “Conflict resolution in the Spanish L2 acquisition of Yucatec ejectives: L1, L2, and Universal constraints,” in Proceedings of the 2014 Annual Conference of the Canadian Linguistic Association, ed. L. Teddiman (Ottawa, ON: Canadian Linguistic Association).
González Poot, A. (2011). Conflict Resolution in the Spanish SLA of Yucatec Ejectives: L1, L2, and Universal Constraints [Ph.D. dissertation]. Calgary, AB: University of Calgary.
Hall, D. C. (2011). Phonological contrast and its phonetic enhancement: dispersedness without dispersion. Phonology 28, 1–54. doi: 10.1017/S0952675711000029
Hall, D. C. (2017). “Contrastive specification in phonology,” in Oxford Research Encyclopedia of Linguistics, ed M. Aronoff (Oxford: Oxford University Press). doi: 10.1093/acrefore/9780199384655.013.26
Hancin-Bhatt, B. (1994). Segmental transfer: a consequence of a dynamic system. Second Lang. Res. 10, 241–269. doi: 10.1177/026765839401000304
Hanuliková, A., and Weber, A. (2012). Sink positive: linguistic experience with the substitutions influences nonnative word recognition. Atten. Percept. Psychophys. 74, 613–629. doi: 10.3758/s13414-011-0259-7
Herd, J. (2005). “Loanword adaptation and the evaluation of similarity,” in Toronto Working Papers in Linguistics 24, 65–116. Available online at: https://twpl.library.utoronto.ca/index.php/twpl/article/view/6195 (accessed July 11, 2022).
Hsu, B., and Jesney, K. (2017). “Loanword adaptation in Québec French: evidence for weighted scalar constraints,” in Proceedings of the 34th West Coast Conference on Formal Linguistics. Cascadilla Proceedings Project, eds A. Kaplan, A. Kaplan, M. K. McCarvel, and E. J. Rubin (Somerville, MA: Cascadilla Proceedings Project), 249–258.
Hunt Gardner, M., and Roeder, R. (2022). Phonological mergers have systemic phonetic consequences: PALM, trees, and the low back merger shift. Lang. Var. Change 34, 29–52. doi: 10.1017/S0954394522000059
Itô, J., and Mester, A. (1995). “The core-periphery structure of the lexicon and constraints on reranking,” in Papers in Optimality Theory, eds J. Beckman, S. Urbanczyk, and L. Walsh Dickey (Amherst, MA: GLSA), 181–209.
Jackson, S., and Cardoso, W. (2023). “Orthographic interference in the acquisition of English /h/ by francophones,” in Second Language Pronunciation: Different Approaches to Teaching and Training, eds U. Alves and J. Alcanatara de Albuquerque (Berlin: De Gruyter). doi: 10.1515/9783110736120-009
Janda, R., and Auger, J. (1992). Quantitative evidence, qualitative hypercorrection, sociolinguistic variables – and French speakers' ‘eadaches with English h/ø. Lang. Commun. 12, 195–236. doi: 10.1016/0271-5309(92)90015-2
John, P., and Frasnelli, J. (2023). On the lexical source of variable L2 phoneme production. Mental Lexicon 17, 239–276. doi: 10.1075/ml.22002.joh
Kabak, B. (2019). “A dynamic equational approach to sound patterns in language change and second-language acquisition: the (un)stability of English dental fricatives illustrated,” in Patterns in Language and Linguistics: New Perspectives on a Ubiquitous Concept, eds B. Busse, and R. Moehlig-Falke (Berlin: Mouton De Gruyter), 221–254. doi: 10.1515/9783110596656-009
Kohler, K. J. (2002). “Segmental reduction in connected speech in German: phonological facts and phonetic explanations,” in Speech Production and speech Modelling, eds A. Hardcastle, and A. Marchal (Dordrecht: Springer), 69–92. doi: 10.1007/978-94-009-2037-8_4
Kubozono, H. (2015). “Introduction to Japanese phonetics and phonology,” in Handbook of Japanese Phonetics and Phonology, ed. H. Kubozono (Berlin: De Gruyter), 1–40. doi: 10.1515/9781614511984.1
Kwon, J. (2021). Defining Perceptual Similarity with Phonological Levels of Representation: Feature (Mis)match in Korean and English [Ph.D. dissertation]. Madison, WI: University of Wisconsin-Madison.
Labrune, L. (2012). The Phonology of Japanese. Oxford: Oxford University Press. doi: 10.1093/acprof:oso/9780199545834.001.0001
LaCharité, D. (1993). The Internal Structure of Affricates [Ph.D. Dissertation]. University of Ottawa, ON: University of Ottawa.
LaCharité, D., and Prévost, P. (1999). “The role of L1 and of teaching in the acquisition of English sounds by francophones,” in Proceedings of the 23rd Annual Boston University Conference on Language Development, eds A. Greenhill, H. Littlefield, and C. Taro (Somerville, MA: Cascadilla Press), 373–385.
Lahiri, A., and Reetz, H. (2002). “Underspecified recognition,” in Laboratory Phonology 7, eds C. Gussenhoven, and N. Warner (Berlin: MoutonDe Gruyter), 637–675. doi: 10.1515/9783110197105.2.637
Lombardi, L. (2003). Second language data and constraints on Manner: explaining substitutions for the English interdentals. Second Lang. Res. 18, 225–250. doi: 10.1177/026765830301900304
Mah, J., Goad, H., and Steinhauer, K. (2016). Using event-related. Brain potentials to assess perceptibility: the case of French speakers and English [h]. Front. Psychol. 7, 1469. doi: 10.3389/fpsyg.2016.01469 doi: 10.3389/fpsyg.2016.01469
McCarthy, J. (1994). “The phonetics and phonology of Semitic pharyngeals,” in Papers in Laboratory Phonology III: Phonological Structure and Phonetic Form, ed. P. Keating (Cambridge: Cambridge University Press), 191–233. doi: 10.1017/CBO9780511659461.012
Natvig, D., and Salmons, J. (2021). Connecting structure and variation in sound change. Cad. Pesqui. 2, 1–20. doi: 10.25189/2675-4916.2021.v2.n1.id314
Nemser, W. (1971). An Experimental Study of Phonological Interference in the English of Hungarians. Bloomington, IN: Indiana University Press.
Niebuhr, O., Clayards, M., and Meunier, C. Lancia, L. (2011). On place assimilation in sibilant sequences: comparing English and French. J. Phon. 39, 429–451. doi: 10.1016/j.wocn.2011.04.003
Oxford, W. (2015). Patterns of contrast in phonological change: evidence form Algonquian vowel systems. Language 91, 308–357. doi: 10.1353/lan.2015.0028
Paradis, C., and LaCharité, D. (1997). Preservation and minimality in loanword adaptation. J. Linguist. 33, 379–430. doi: 10.1017/S0022226797006786
Picard, M. (2002). The differential substitution of English /θ ð*/ in French. Lingvisticae Investig. 25, 87–96. doi: 10.1075/li.25.1.07pic
Purnell, T., Raimy, E., and Salmons, J. (2019). Old English vowels: diachrony, privativity, and phonological representations. Language 95, e447–e473. doi: 10.1353/lan.2019.0083
Rice, K. (2005). “Sequential voicing, postnasal voicing, and Lyman's Law revisited,” in Voicing in Japanese, eds J. van de Weijer, K. Nanjo, and T. Nishihara (Berlin: Mouton de Gruyter), 25–45. doi: 10.1515/9783110197686.1.25
Rochet, B. (1995). “Perception and production of second-language speech sounds by adults,” in Speech Perception and Linguistic Experience, ed. W. Strange (Baltimore, MD: York Press), 379–410.
Rose, S. (1996). Variable laryngeals and vowel lowering. Phonology 13, 73–117. doi: 10.1017/S0952675700000191
Roy, M.-J. (1992). Le role des Constraints Phonologiques dan l'adaptation d'emprunts Anglaise en Français Québécois [MA Thesis]. Quebec City: Université Laval.
Smith, L. C. (1997). “The role of L1 feature geometry in the acquisition of L2 segmental phonology: acquiring /θ/ and /ð*/ in English,” in Calgary Working Papers in Linguistics, Volume 19 (Calgary: University of Calgary), 45–70.
Stockwell, R., and Bowen, J. (1965). The Sounds of English and Spanish. Chicago, IL: University of Chicago Press.
Teasdale, A. (1997). “On the differential substitution of English [θ]: a phonetic approach,” in Calgary Working Papers in Linguistics, Volume 19 (Calgary: University of Calgary), 71–91.
Trofimovich, P., and John, P. (2011). “When three equals tree: examining the nature of phonological entries in L2 lexicons of Quebec speakers of English,” in Applying Priming Methods to L2 learning, Teaching and Research: Insights from Psycholinguistics, eds P. Trofimovich, and K. McDonough (Amsterdam: John Benjamins), 105–129. doi: 10.1075/lllt.30.09tro
Weinberger, S. H. (1997). “Minimal segments in second language phonology,” in Second-Language Speech: Structure and Process, eds A. James, and J. Leather (Berlin: Mouton de Gruyter), 263–311. doi: 10.1515/9783110882933.263
Weinreich, U. (1957). On the description of phonic interference. Word 13, 1–11. doi: 10.1080/00437956.1957.11659624
Wexler, K., and Culicover, P. (1983). Formal Principles of Language Acquisition. Cambridge, MA: MIT Press.
Keywords: contrastive hierarchy, L2 phonology, differential substitution, phonological parsing, restructuring
Citation: Archibald J (2023) Differential substitution: a contrastive hierarchy account. Front. Lang. Sci. 2:1242905. doi: 10.3389/flang.2023.1242905
Received: 19 June 2023; Accepted: 12 September 2023;
Published: 06 October 2023.
Edited by:
Alicia Luque, Nebrija University, SpainReviewed by:
Joseph Salmons, University of Wisconsin-Madison, United StatesUlrike Domahs, University of Marburg, Germany
Copyright © 2023 Archibald. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: John Archibald, am9obmFyY2hAdXZpYy5jYQ==