

- Laboratoire Psychologie de la Perception, Centre Attention Vision, CNRS UMR 8158, Université Paris Descartes, Paris, France
Our perception starts with the image that falls on our retina and on this retinal image, distant objects are small and shadowed surfaces are dark. But this is not what we see. Visual constancies correct for distance so that, for example, a person approaching us does not appear to become a larger person. Interestingly, an artist, when rendering a scene realistically, must undo all these corrections, making distant objects again small. To determine whether years of art training and practice have conferred any specialized visual expertise, we compared the perceptual abilities of artists to those of non-artists in three tasks. We first asked them to adjust either the size or the brightness of a target to match it to a standard that was presented on a perspective grid or within a cast shadow. We instructed them to ignore the context, judging size, for example, by imagining the separation between their fingers if they were to pick up the test object from the display screen. In the third task, we tested the speed with which artists access visual representations. Subjects searched for an L-shape in contact with a circle; the target was an L-shape, but because of visual completion, it appeared to be a square occluded behind a circle, camouflaging the L-shape that is explicit on the retinal image. Surprisingly, artists were as affected by context as non-artists in all three tests. Moreover, artists took, on average, significantly more time to make their judgments, implying that they were doing their best to demonstrate the special skills that we, and they, believed they had acquired. Our data therefore support the proposal from Gombrich that artists do not have special perceptual expertise to undo the effects of constancies. Instead, once the context is present in their drawing, they need only compare the drawing to the scene to match the effect of constancies in both.
Introduction
Visual perception is our main access to the outside, “distal”, world which we experience consciously at the end of a long chain of processes. The image projected on our retina is the proximal stimulus, the original data on which these processes operate. If we should see the world as it is represented on the retina, objects would change size as they moved toward or away from us, change color as they moved into different lights, be cut into pieces as they moved behind other objects, and jump to and fro every time we moved our eyes. But instead of perceiving this ever-changing world, we have a coherent, invariant visual representation of objects: we experience visual constancy, that is, our conscious percept is to a large extent in accordance with the distal object’s properties whatever the proximal stimulus projected on our retina.
However, visual artists when rendering an object or a scene on a canvas return to a representation that is closer to the proximal image, depicting distant objects as smaller and nearby objects as larger. Clearly, compared to non-artists, artists are able to depict scenes and objects much more accurately. What is the basis of their expertise? One aspect is of course motor skill but the other of interest to us is the ability to see the proximal pattern of light and dark – to ignore the corrections, the visual constancies, underlying our everyday perception. The artist can pick the right dark pigment for depicting an object in a shadow, a pigment much darker than our subjective impression of the object; can make the distant object the correct size even though it is experienced as not very small. A number of studies have addressed these issues (Cohen and Bennett, 1997; Kozbelt, 2001; Cohen, 2005; Mitchell et al., 2005; Kozbelt and Seeley, 2007; Cohen and Jones, 2008; Matthews and Adams, 2008) showing indeed that drawing accuracy is correlated to perceptual performances: subjects who made more accurate drawings also showed less effect of context and visual constancies. According to Kozbelt (2001), artists are “experts in visual cognition.” The present study addresses whether the expertise of visual artists lies in their ability to access their proximal representation better than non-artists. Have years of experience changed their visual processing and their ability to access early levels of representation? Such plasticity in visual processing as a result of visual experience is seen in many contexts (Hubel and Wiesel, 1970; Goldstone, 1998; Ostrovsky et al., 2006; Green and Bavelier, 2008).
The idea that artists have direct access to early representations has been strongly criticized by the art historian Gombrich (1987). Gombrich agreed with Ruskin (1912) that artists do use special techniques to depict the proximal stimulus but he felt that their training could not lead them to get an “innocent eye”: the “innocent eye is a myth” (Gombrich, 1987, p. 251). Instead, “making comes before matching” (Gombrich, 1987, p. 99), and artists have to deal with their biased perception by drawing sketches according to it, and then make corrections in order to match it with the objective model they wish to represent. In this view, image-making is a hypothesis-testing process, a continuous back, and forth between production and correction. This “copyist” approach is an alternative explanation for the representational skills of artists. That is, artists may experience the same visual constancies as non-specialists but learn to make corrections in the context of the drawing itself as it progresses. Specifically, once sufficient context is present in the drawing, they only have to match the sizes and colors they see in their artwork to the perceived sizes and colors they see in the scene being depicted; the similarity of context in both will impose the same constancies.
To examine whether artists have developed visual expertise or copyist expertise, we tested three different constancies: size, lightness, and shape, all of which must be undone or bypassed for figurative artists to create an accurate copy of a scene. Two of the experiments use matching-to-standard tasks while the third is a visual search task. In all of these tasks, we will use context, perspective grids, shadows, and occlusion to trigger the application of visual constancies (Day, 1972; Todorovic, 2002, 2010), and see whether the artists are less influenced by the context than non-artists. If artists are indeed able to access, or recover their initial retinal image (closer to the proximal stimulus), they would be less affected by context than non-artists. However, this finding would not tell us whether the greater accuracy was due to perception that was uncorrected by visual constancies (Ruskin, 1912) or to skill in undoing the corrections (Gombrich, 1987). The critical factor to distinguish these two possibilities is speed: access to the uncorrected proximal image ought to allow for rapid response whereas the reversal of the corrections should require extra time. To test the speed of access, we use a visual search task for partial shapes in occluded or unoccluded presentation (He and Nakayama, 1992; Rensink and Enns, 1998). If artists are able to access the initial uncorrected image then their processing rates for the occluded versions will be more rapid than those of non-artists.
In these experiments, context is introduced in order to trigger the corrections of visual constancies and we assume that, without any instruction, both artists and non-artists would probably experience these context effects to the same degree. However, the subjects were not asked to judge the perceived size, or lightness, or shape, they were asked to ignore the context, to bypass constancy, and report the “real” size or luminance, or shape of the test. This is a critical point in the procedure: subjects are asked explicitly to report what corresponds to their retinal image. Can artists do this better than non-artists?
Experiment: Size Constancy
Size constancy refers to the accurate perception of an object’s size despite the fact that a distant object will have a smaller size on our retina than a near object. In order to provide such a “veridical perception” (Todorovic, 2002), the visual system needs to infer the object’s size by correcting its size on the retina (in visual angle) for the perceived distance (Figure 1). Because size constancy is related to distance perception, it must be directly dependent on the various cues to depth (Leibowitz and Harvey, 1967; Day, 1972). For example, the influence of monocular cues (perspective grids) on size constancy has been shown in several experiments (Stuart et al., 1993; Aks and Enns, 1996; Bennett and Warren, 2002). Nevertheless, our perception is not limited strictly to corrected distal image; for example, Rock (1983) suggested that we are aware of both retinal size and actual size of the object, even if we generally do not pay attention to retinal size. However, even when asked to judge an object’s retinal size (say, compare a distant building to our thumb held out beside it), there are residual effects of the actual size in the world (Carlson, 1960, 1962). This suggests that artists may be able to access the uncorrected retinal size of objects, ignoring to some extent the real world sizes of the objects; perhaps, they may do this more effectively than non-artists.

Figure 1. In the left panel, the man in the background appears to be about the same height as the woman in the foreground. This perception corresponds to visual constancy. However, in the right panel, the man’s image is moved so that he appears to be adjacent to the woman, and the now appears much smaller than he does on the left. This is the correction for distance that underlies size constancy and we, non-artists, are unable to ignore it even though we know that the two images of the man have identical size on the picture plane (measure them to check). Can artists register that the two images of the man have identical size in the picture plane?
In this first experiment, perceived depth was induced by linear perspective cues of a receding hallway in the context condition. Here, size constancy should make the test stimulus look larger in the hallway than when it is seen against the flat grid (Figure 2), and we assume that, without any instruction, both artists and non-artists would probably experience this effect to the same degree. However, the subjects were asked to adjust the size to match the physical size of a standard (presented on a blank field below) as if they were using their fingers to measure the size directly on the screen. In other words, subjects were encouraged to ignore the context and report the “real” size of the test.
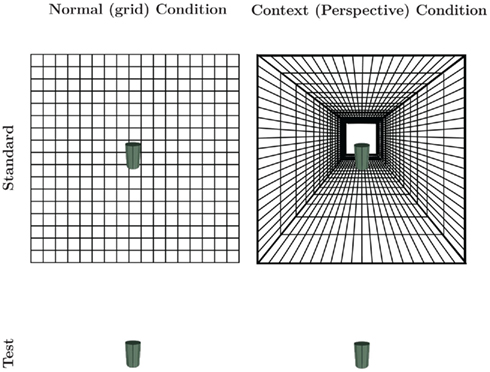
Figure 2. Size task conditions. Subjects were asked to adjust the size of the test cylinder so that it matched the actual size of the standard cylinder, imagining that they were using their fingers to judge the size of both cylinders on the screen. There were two randomly counterbalanced conditions: “normal” condition where the cylinder was displayed on a simple 16 × 16 grid, and “context” condition where the cylinder appears in linear perspective represented by a hallway.
Materials and Methods
Subjects
For the three experiments, the subjects were subdivided in three groups: art students, professional artists, and non-artists. The first were recruited from high-ranked Major Art School [n = 9, six females and three males, age = 22 ± 1.7]. Professional artists were recruited from galleries, workshops, and international artists associations [n = 14, nine females and female males, age = 39 ± 12.9]. Non-artists subjects were recruited from the internal network of Cognitive Science (RISC), a database of voluntary subjects, except for two subjects from our laboratory [n = 14, nine females and five males, age = 23 ± 2.8]. The non-artists reported having no particular drawing skills or specific training in visual arts. All subjects had normal or corrected-to-normal vision and those from outside our laboratory were paid 10€ for their participation. They were informed about the purpose of the experiment and were naïve about our hypotheses. They all gave their informed consent before passing the experiment.
Materials
All the experiments took place in a dark room and used the same materials. Also, the subject’s head was always held by a chinrest so that his or her eyes were approximately 52 cm from the center of the screen. The stimuli were projected on a 22″ CRT screen (LaCie, Electron 22 blue IV), with a resolution of 1024 × 768 pixels and with a refresh frequency of 100 Hz. The monitor’s luminance was linearized with a gamma correction. The experiments were programmed with MATLAB Psychtoolbox (version 3.0.8), and were run on an Apple computer.
The screen was divided in two equal vertical halves (21° × 16°). In the top half (“standard”), two possible texture gradients could be displayed: a simple 16 × 16 black line-drawn grid simulating a vertical wall, or a black line-drawn perspective grid representing a hallway with a central perspective (with a unique vanishing point in the center). The targets were two green cylinders, one in each half (see Figure 2). The cylinders were drawn with Adobe Photoshop CS4, and their color saturation was set at 10% in order to avoid any distracting salience. All the visual elements (texture gradients and cylinders) were presented against a white background.
Procedure
Participants were told, “Adjust the size of the cylinder, at the bottom of the screen, so that it matches the size of the standard cylinder at the top. Make your adjustment as if you were using your fingers to measure the size directly on the screen.” They pressed the right arrow on the keyboard to increase the lower cylinder’s size, or the left arrow to decrease it, and then pressed the space button to register the setting. There was no time pressure but the time they took to make their setting was recorded.
The standard cylinder displayed in the top half of the screen could be presented either on a simple grid or on a texture gradient representing a hallway. The former corresponded to the normal condition, while the latter corresponded to the context condition. The two conditions were presented equally often with the order randomized across trials. The standard cylinder could have six possible heights (1.5°, 1.6°, 1.7°, 1.8°, 1.9°, and 2° of visual angle), which were randomized across trials, and the test cylinder could begin randomly either 50% smaller or bigger than the standard.
Each participant started the experiment with a block of 10 practice trials. The conditions in the test block were the texture gradient (normal/context) and the possible heights of the referential cylinder. There were 5 trials per condition for a total amount of 60 trials for the test bloc (5 × 6 × 2).
Results
Subjects settings increased proportionally with the standard size and we summarized each subject’s settings by their means across the six standard sizes. We then computed a ratio between the context mean response and the normal mean response for each subject (group mean ratios are plotted in Figure 3). These ratios are a measure of the context effect on the subject’s judgment. Ratios close to 1 mean that there was no effect of the context, while ratios significantly greater than 1 would suggest such an effect, that is, that subjects have overestimated the standard size when presented in the hallway context.
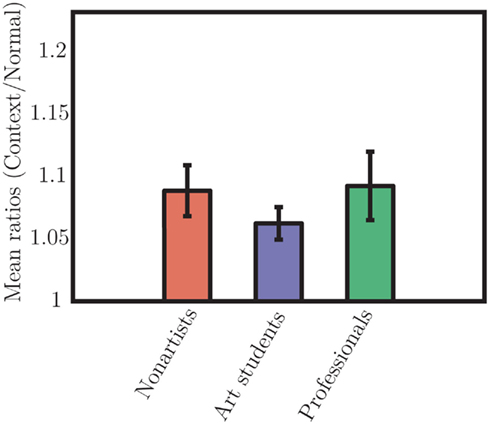
Figure 3. Group mean ratios. Ratios were computed by dividing the subject’s mean response in the context condition by that obtained in the normal condition. The art students showed a numerically smaller ratio, but this difference was not significant. Nevertheless, all ratios were significantly greater than 1, demonstrating the presence of significant constancy effects in all subjects.
We ran a one-way ANOVA on those ratios with Groups (non-artist, art students, professional artists) as factor. This test showed no significant difference in the effect of context vs. normal conditions across groups [F(2,34) = 0.37, p = 0.69]. Nevertheless, all ratios were significantly greater than 1 [t(36) = 6.36, p < 0.000]. The average ratio was 1.08, where a ratio of 1 would indicate no effect of context. There was therefore no evidence in our results suggesting that artists are better than non-artists at ignoring context in accessing stimulus size. One of our other questions was whether artists’ performances would vary with experience. To address that point, we analyzed the correlation between the context effect expressed as the ratio described above and subjects’ years of art experience. We fixed non-artists’ experience to 0, since they were not supposed to have followed an art training, and used the self-reported years of art training as the other variable in the correlation. The correlation was not significant (Pearson’s r = 0.08, ns).
Finally, we analyzed the response time for each subject to evaluate the effort the subjects put into making their settings in each settings in each condition. A longer time would suggest more effort. We found a significant main effect of Groups [F(2,219) = 22.59, p < 0.001, η2 = 0.17], as well as a main effect of the condition [F(1,219) = 5.89, p < 0.016, η2 = 0.03], but no interaction between Condition and Groups [F(2,219) = 0.357]. A Post hoc analysis showed that surprisingly, art students, like professional artists, spent more time on each trial, 15.37 and 15.95 s, respectively, almost twice as much as non-artists 8.60 s (both p < 0.001). There was no difference between art students and professional artists. This result is the opposite of our expectation that artists would find this task easier.
In summary, size perception was influenced by visual context for all subjects, showing an increase in the estimated size of the standard by in an average of 8% in the context condition compared to the normal condition. We also found no correlation between the degree of context’s influence and the subject’s experience, suggesting that experience and training do not play a crucial role in artists’ performance. In sum, we find no evidence of an advantage for artists in ignoring context when judging object size.
The instructions were of critical importance in this task: if we had asked subjects to match the apparent size, we would expect that size constancy would apply equally to all, independently of their art training. But instead, we were encouraging subjects to ignore the context and evaluate the size of the standard and comparison as if they were measuring them on the screen with their fingers. Our adjustment procedure also allowed subjects time to engage various strategies; this is of particular interest to us as it should bring into play explicit strategies that artists have learned in drawing class as well as the implicit ones acquired through long practice.
Despite these aspects of the experiment that should have favored the artists if they did have special perceptual expertise, we found that the artists were as bound to the context effects as non-artists. Moreover, response time analysis showed that both art students and professional artists spent much more time on each trial than non-artists. We had expected artists to take less time, given their expertise. This opposite result suggests that the artists felt some pressure, as experts in visual perception, to perform well on these tasks, to engage the strategies that they had been taught to correct size perception and to overcome context effect. But despite the instructions to ignore context and despite the longer duration the artists spent on the task, they showed the same extent of constancy as non-artists.
Experiment: Lightness Constancy
We perceive objects via the light they reflect back to our retina. The received light is determined by two components: the object’s surface reflectance and the illumination falling on it. The reflectance corresponds to the proportion of the incident light that is reflected at different wavelengths of the spectrum and fully depends on the surface material. It is a property of the object and remains constant whatever the intensity or wavelength distribution of the illumination falling on the object. The amount of light arriving at the retina (the proximal property) is the product of the object’s reflectance (its “color,” the distal property) and the illumination. Here we will focus on achromatic property of the object’s surface – whether it is light or dark, and in the case of the achromatic test patches we use, white, gray, or black. We will use “lightness” as the perceived reflectance (white vs. black surface) and “brightness” or luminance as the perceived luminance (the product of illumination and reflectance). According to those definitions, lightness constancy designates the invariance of the surface’s perceived reflectance despites changes in illumination (Gilchrist, 1988; Moore and Brown, 2001).
To recover the surface reflectance of an object, most authors assume a process that can discount the illumination falling on it. To do so, the visual system must estimate the illumination. A number of proposals have been made for this process (Gilchrist, 1988, 2006; Adelson, 1993, 2000; Arend and Spehar, 1993a,b; Agostini and Galmonte, 2002). Although lightness constancy has often been explained in terms of low-level mechanisms (simultaneous contrast effect caused by lateral inhibition in retina’s ganglion cells), it now appears that in some cases, a high-level computation of spatial relationships of surfaces and light is required. For example, a cast shadow on a surface can be recognized by the visual system because it is darker, its borders are unrelated to object borders, the surrounding texture continues into the shadow area with a reduction of luminance but not contrast, and it appears to have no volume of its own (Cavanagh and Leclerc, 1989). Thus the visual system would attribute change of luminance within the shadow limits to a change in illumination, not reflectance (Gilchrist, 1988).
However, a painter can only vary the reflectance of the paint used to depict the object and so this one pigment must correspond to the luminance coming from the real object where the luminance is the product of the object’s reflectance and the illumination falling on it. Can normal observers make these luminance judgments with any accuracy (brightness) – how well could they pick a paint to match it? For instance, when a cast shadow falls on a test surface it leads the observer to perceive the object’s surface as lighter (Figure 4). Can artists ignore the perceived reflectance and “see” the actual luminance any better than normal observers?
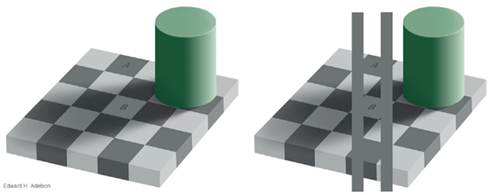
Figure 4. Lightness constancy and shadows (Adelson, 1993). Squares A and B have identical luminance as shown by the vertical gray stripes that contact both in the right hand panel. However, B appears to lie in a shadowed region indicating a reduction in illumination, Once the visual system compensates for the illumination difference, B appears to be a lighter (whiter) surface than A.
To examine this we introduce a cast shadow into a simple scene (Figure 5) where lightness constancy should make the test stimulus look lighter, more white, when the shadow falls on it even though its luminance remains the same. We assume that, without any instruction, both artists and non-artists would probably experience this effect to the same degree. However, the subjects were not asked to judge the perceived surface lightness (light or dark) but to judge the amount of light as if the shadow were not present or they could look at the gray patch through a tube. In other words, subjects were encouraged to ignore the context, to bypass lightness constancy and report the “real” luminance of the test.
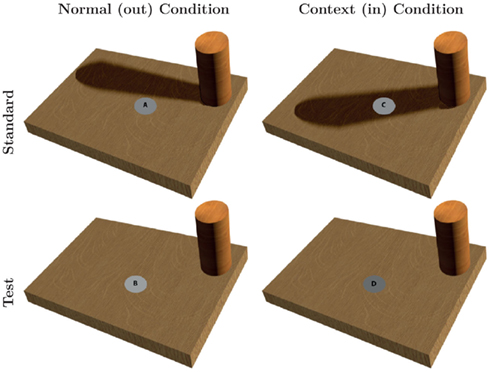
Figure 5. Brightness task conditions. The task was to adjust the brightness (luminance) of the test ellipse (B and D) so that it corresponded to the actual brightness of the standard ellipse (A and C). Two conditions were randomly presented to the subject: the “normal” condition where the standard was outside the shadow, and the “context” condition where the standard was within the shadow.
Materials and Methods
Stimuli
For this experiment, the screen was divided in two vertical halves having the same height and width (21° × 16°). In those two half-screens were displayed two identical boards textured with a wood surface and on which a piece of wood shaped as a cylinder was lying, each of them was made with Adobe Photoshop CS4. The wood surface’s average luminance was 9.60 ± 0.12 cd/m2 (mean and SD), while the white background’s luminance was 68.4 cd/m2.
On the top board that served as standard, a cast shadow was rendered to correspond to the effect of a light source on the right. Within the shadow, the wood surface’s luminance was 3.04 ± 0.10 cd/m2 and then rose gradually to the adjacent value to simulate a shadow penumbra. Also, the shadow could have two possible locations covering or not the ellipse position. The target stimuli were two ellipses (2° × 1.5°) colored with middle gray and were presented with the same luminance whether or they fell in the shadow region.
Procedure
The subjects were asked to adjust the luminance of the test ellipse, so that it corresponded to the actual luminance of the standard ellipse. More particularly, subjects were told “adjust the luminance of the test ellipse, at the bottom of the screen, so that it matches the luminance of the standard ellipse, that at the top. Focus on the standard ellipse’s inside, as if there was no cast shadow, and ignore the context of the scene.” They pressed the right arrow for increasing the luminance and the left arrow for decreasing it. Once the subject was satisfied with the adjustment he or she pressed the space key to register the choice. The subject had all the time he or she wanted to give a response.
The standard ellipse could have six possible luminance levels randomized across the trials (14, 16.5, 19, 21.8, 24.6, 27.6; values given in cd/m2), while the test ellipse’s luminance could be initially and randomly (before the subject’s adjustment) either 25% smaller or bigger than the standard luminance. On the half of the trials, the standard ellipse was outside the shadow, and in the other half, it was inside. The ellipse’s position was randomized across the trials.
Each subject started the task with a block of 10 practice trials to ensure that he or she had understood instructions. Conditions that composed the test block were the six possible luminance levels of the standard ellipse and the two positions of the shadow. There were 5 trials per condition, and so 60 trials in the test block (5 × 6 × 2).
Results
As in the first experiment’s analyses, we averaged the mean response for each subject over the stimulus conditions and computed a ratio between the mean in the context and normal conditions (Figure 6). A one-way ANOVA was run on the individual ratios with Groups (non-artists, art students, professional artists) as factor. There was no significant main effect of group [F(2,34) = 1.65, p = 0.21]. Nevertheless, all ratios were significantly greater than 1 [t(36) = 14.48, p < 0.000]. The average ratio was 1.35, where a ratio of 1 would indicate no effect of context and a ratio of 3.16 would indicate complete lightness constancy. As in the first experiment, we asked whether context’s effect on perceptual performance, quantified by ratios, varies with experience. The correlation between ratios, expressing the context effect, and individual self-reported years of art training was not significant (r = 0.02, ns).
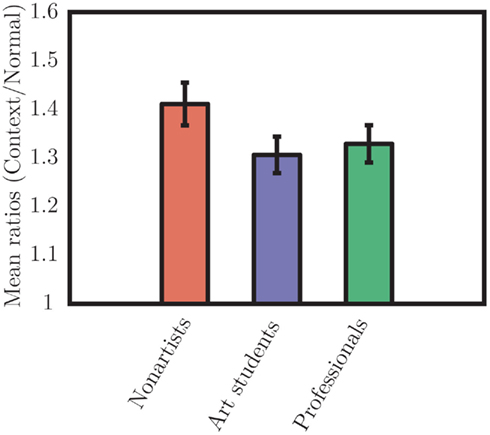
Figure 6. Group mean ratios for brightness. Both art students and professional artists had numerically smaller ratios than non-artists, but these differences were not significant. Nevertheless, their ratios were about 1.32, showing a strong influence of visual context in all cases.
Finally we analyzed the subjects’ response time to evaluate the effort the subject made to perform the task. We found a significant main effect of Groups [F(2,219) = 18.91, p < 0.001, η2 = 0.15], and a significant main effect of condition [F(1,219) = 25.53, p < 0.001, η2 = 0.10]. There was no interaction between both factors. Post hoc comparisons showed that non-artists spent less time (9.67 s) than art students (11.44 s, p < 0.003), and the professional artists were slower still (14.31 s, p < 0.03).
Our present findings revealed that non-artists, art students, and professional artists were all strongly affected in their brightness (luminance) judgment when a cast shadow was overlapping the position of the standard ellipse. Subjects perceived the standard about 30% brighter than it was, and thus showed a strong effect of lightness constancy (all ratios were significantly greater than 1) despite being asked to ignore the shadow context.
As was the case for the size task, art students and professional artists again took significantly longer than non-artists to make their setting on each trial, suggesting that they put more efforts into doing the task. Nevertheless, this extra effort, and their substantial expertise did not allow them to overcome lightness constancy. Finally and consistently with our first experiment’s results, we found no correlation between the effect of context and the subject’s art experience.
Experiment: Amodal Completion
Amodal completion, another instance of perceptual constancy (e.g., Rock, 1983), is a phenomenal completion of an object’s shape even though some of its parts are occluded by another, intermediate object (e.g., Kanizsa, 1979). Despite the lack of information concerning the occluded parts of the far object, our perception of this object seems to remain complete so that, even if the object is separated into two visible parts by the occluder, we know that the different parts belong to the same object (Kanizsa, 1985). These completion phenomena have been explained in terms of Gestalt configuration laws, such as collinearity (good continuation, e.g., Kellman and Shipley, 1991), similarity, and so forth. Such laws are largely implemented by low-level mechanisms (e.g., edge detection, line orientation, and size discrimination in V1; problem-solving of “border-ownership” in V2 complex cells, e.g., Bruno et al., 1997; Rensink and Enns, 1998; Tse, 1999; Wolfe and Horowitz, 2004).
The processing of visual shape proceeds principally from an analysis of the parts (mosaic stage) to that of the whole (completion stage) where independence from vantage point and completion of missing details emerge. Surprisingly, our conscious access to the object does not seem to follow the same sequence, but rather the reverse (Hochstein and Ahissar, 2002). Several visual search studies have demonstrated that the individual parts of an object are accessed after the percept of the whole object, even when the whole object is not presented (it is partially hidden, He and Nakayama, 1992; Rensink and Enns, 1998; Wolfe and Horowitz, 2004). For example, He and Nakayama (1992) reported that searching for an L-shape is more difficult when it appeared touching an adjacent square. In this case, subjects seem to see not an L-shape but a square completed behind the occluder, thus camouflaging the L (Figure 7). Similar results have been found by Rensink and Enns (1998), where searching for a notched square touching a circle led to greater reaction times and to search slopes that were steeper than when it was isolated.
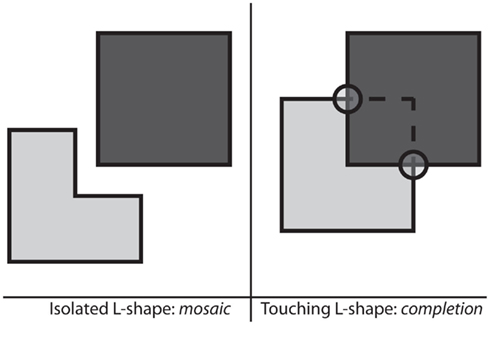
Figure 7. Amodal completion. When the L-shape touches the square, it is harder to find as it is no longer seen as an L but as the visible part of an occluded square. The T-junctions (here, circled) ordinarily suggest the presence of occlusion, and thus presence of depth. On the basis of these cues, the visual system extends the contours until they meet together (showed with the dashed lines) to form a square.
If object-level descriptions are the first representations available to conscious perception (Tse, 1999; Lee and Vecera, 2005), any task that requires access to an object’s parts requires that the object be “unbundled,” a step that requires extra time (Hochstein and Ahissar, 2002). Can visual artists better ignore the completed form of the object’s representation and then access the “mosaic” image that would be present on our retina? In our task, subjects were instructed to locate the notched square (Figure 8) so, if the notch contacted the adjacent circle, it would normally be completed and appear as a partially hidden square, camouflaging the notched square shape. If artists have any special expertise in accessing early representations, prior to the completion step, they should find these targets faster than non-artists.
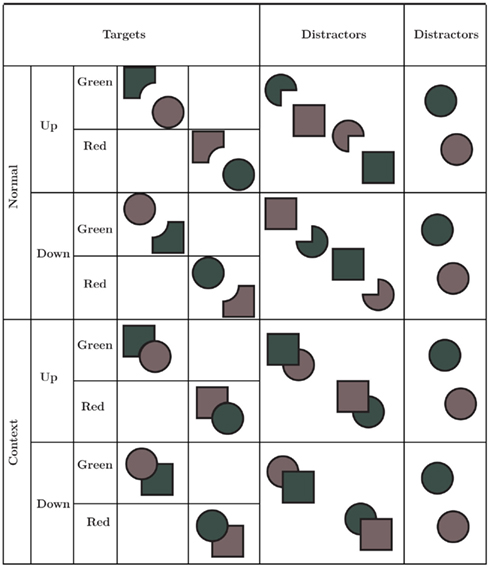
Figure 8. Shape task, stimuli, and conditions. The target was a notched square that could be either green or red. In “normal” condition, the target was free, while distractors were Pacman-like circles with a square as companion. In “context” condition, the target was bounded with an “occluding” circle, whereas distractors were squares overlapping a circle. In both conditions, target, and distractors had the same overall size, and there were six isolated circles as supplementary distractors to prevent subjects from searching for a circle overlapping a square.
Materials and Methods
Stimuli
We designed a visual search task based on Rensink and Enns’ (1998) experiment using amodal completion. The target was a notched square generated by subtracting a circle shape overlapping a square (see Figure 8) and that could possibly be either red or green. For both colors we decreased the saturation by 90% so that neither seemed more salient than the other while remaining discriminable. The distractors were circles with a missing quarter sector (which was generated by subtracting a square shape overlapping a circle), which could also be green or red of the same saturation as the target. An item could accompany the target as the distractors. This added item was a green/red circle for the target, whereas it was a green/red square for the distractors. Depending on the condition, those paired items had a specific spatial relationship, either adjacent (mosaic condition) or touching (occlusion condition). The overall size spanned by the pair was 1.5° in the mosaic condition (notched square separated from the accompanying circle), and of 1.13° in the occlusion condition (notched square touching with the circle).
All the items were projected in a 12° × 8° visual array centered on the screen. Their position was randomly distributed within a 6 × 4 invisible grid. The set number was randomly chosen between 2, 8, or 12 items, and all the displayed elements were jittered by ±0.5° to avoid the item collinearity that could help the subject to find the target. To avoid alternative cues to the target pair, we added six isolated circles that were either green of red. The circles’ size was approximately 0.77°.
Procedure
The subject had to find a specific target presented among a set of distractors. A target was present on all trials, but could have one of two colors: red or green. The subject had to report the color of the target by pressing the “Z” key on the keyboard if the target was red, or the “N” key if it was green. Subjects were asked to use their two hands, one per key.
The target could have two different orientations: either upright or upside-down. In the mosaic condition, the target was isolated, that is not bounded to another item, whereas in the occlusion condition, the target was attached to a circle so that it appeared as a square occluded by a circle. In the former condition, the distractors were a Pacman-like shape accompanied by a square, while in the latter condition they were a circle occluded by a square. Distractors were designed so that the shapes of those of the mosaic condition corresponded to those of the occlusion condition.
The task was divided in a practice block and a test block. The practice block consisted of 30 trials to ensure that the subjects had well understood the instructions and that they were able to discriminate the colors (green/red). The test block was designed as follows: at the beginning of each trial a black fixation cross was displayed at the center of the stimulus array for 1000 ms and the subject had to look at it. After its disappearance, the items were displayed for a maximum of 12 s, the time interval within which the subject had to respond. If the subject took too much time to respond, the message “too long” appeared and the experiment moved to the next trial.
The subjects had to respond as quickly as possible but keep the error rate below 10%. Each time they made an error, feedback including the current error rate was shown (computed on the basis of the total number of the errors they made over the total number of trials). Their reaction times were the dependent variable we measured.
The conditions were the spatial relationship between the target and its companion-item (mosaic/occlusion), the number of items (2, 8, or 12), the target’s color (green/red), and the target’s orientation (upright, up-down). There were 15 trials per condition, and hence 360 trials per subject (2 × 3 × 2 × 2 × 15). Those 360 trials were divided into two equal parts of 180 trials, and a short break between them was proposed to the subject.
Results
We first analyzed the reaction times of the subject as a function of the number of displayed items (target and distractors) and we then computed linear regression slopes (Figure 9). The linear regression slopes show that subjects’ reaction times linearly increased with the number of items (R2 = 0.67 ± 0.01) and that the slopes in both context (occlusion) and no-context (mosaic) conditions were steep, with an average of 178 ms/item for the context case, and 89 ms/item for the no-context case. This difference between conditions was significant [F(1,34) = 173.47, p < 0.001, η2 = 0.84], showing a strong effect of context; however, there was no effect of Groups [F(2,34) = 1.74, p = 0.19] or interaction between Groups and Conditions [F(2,34) = 1.31]. A similar pattern of results held for the intercepts of these linear regressions. Because of the absence of the group effects and of interactions in the regression analysis, we could proceed to an analysis of the mean response times, as we had in the two previous experiments, calculating a ratio between mean in the context conditions and in the normal condition for each group (Figure 10). We ran a one-way ANOVA on the individual ratios with Groups (non-artists, art students, professional artists). This analysis revealed no main effect of Groups [F(2,34) = 0.30, p = 0.74]. This result is consistent with the absence of interaction between Groups and Conditions in the slope and intercept analyses. It suggests once again that artists (students and professionals) were not better than non-artists at accessing the raw image data of the target’s L-shape. Nevertheless, again all ratios were significantly greater than 1 [t(36) = 17.88, p < 0.000] indicating a strong effect of context. The average ratio was 1.50, where a ratio of 1 would indicate no effect of context.
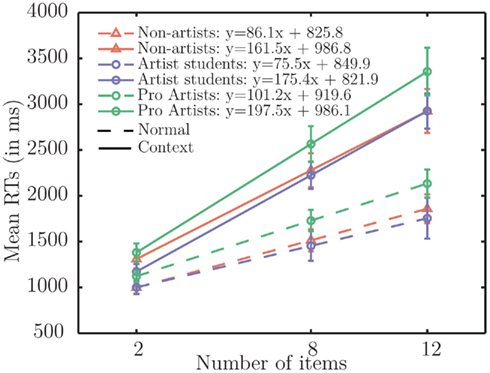
Figure 9. Reaction times as a function of number of items in display with group regression slopes and intercepts for normal and context conditions. While non-artists and art students did not show differences between their slopes, professional artists were numerically slower in both conditions. But this was not significant. No main effect of groups was found for either the slopes or the intercepts.
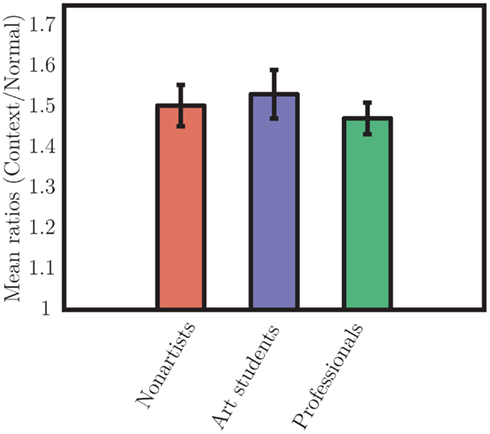
Figure 10. Group mean ratios for shape. Neither professional artists nor art students showed different ratios from those of non-artists. All the subjects were similarly affected by the “occlusion” condition where the target appeared to be a visible part of an occluded square.
In order to address the question whether artists’ ability to overcome the effect of context can be explained by their years of art training, we analyzed the correlation between the individual ratios and the individual self-reported experience. As in the two first experiments, we found no correlation between ratios and subjects’ experience (r = −0.13, ns).
Visual search tasks allow us to quantify approximately the time that attention spends on every visual object (e.g., Treisman and Gormican, 1988; Wolfe, 1998; Wolfe and Horowitz, 2004; Nakayama and Martini, 2011). Previous articles have shown that accessing the visible part of an occluded object takes more time than when the partial shape is isolated (He and Nakayama, 1992; Rensink and Enns, 1998). Consistent with these earlier results, we also find that visual search for a notched square was slower when the notch was contacting a circle than when it was isolated indicating a strong effect of context even though subjects were instructed to ignore it and look for L-shapes. Finally, as in the two first experiments, ratios between the mean response times in the context and normal conditions did not correlate with subject’s experience.
General Discussion
Visual constancies, such as those of size, lightness, or shape, are known to depend on both low-level, automatic mechanisms and high-level, attentive processing. Our conscious perception emerges with appropriate corrections for the context in the scene (Hochstein and Ahissar, 2002; Ahissar and Hochstein, 2004). This makes sense since we need to recognize objects for what they are, bypassing the particular details of how they arrived on our retina. Although this top-first strategy may be useful for our action in everyday life, visual artists have different goals. They must capture exactly those low-level details that broadly match what lands on our retina. Our present study asked whether visual artists like painters and draftsmen can really access this proximal representation or if they are as much affected by visual context and visual constancies as non-artists, even when asked explicitly to ignore context. One could expect that the intensive training of artists might modify the functional organization of the visual brain to allow artists faster access to the early visual information that they need to reproduce in their artwork.
Indeed, several previous studies have reported that visual artists outperformed non-artists in many visual tasks: mental imagery (e.g., Calabrese and Marucci, 2006), object recognition, visual search for embedded shape and Gestalt completion (Kozbelt, 2001). Other studies have shown that artists were also less influenced by shape constancy in a drawing task, as well as in a perceptual task (Mitchell et al., 2005; Cohen and Jones, 2008). Both Mitchell et al. (2005) and Cohen and Jones (2008) have related reduced effects of shape constancy to drawing accuracy. All those findings would suggest that, because artists are more accurate in depicting objects, they should be less influenced by their conceptual knowledge, and perhaps they would rely more on their present raw, early level representation than on their past knowledge.
However, the results of our three experiments, two matching-to-standard tasks and one visual search task, showed that art students and professionals do not differ from non-artists in their ability to ignore perceptual context. Indeed, in all of the three tasks, all the groups’ ratios were significantly greater than 1, showing a significant effect of visual context on their settings. In the first two cases, we found that judgments for size were shifted an average 8 and 35% from veridical by the context (perspective and cast shadow). In the third, the amodal completion context slowed visual search by 50%.
These results argue against theories that suggested that artists’ drawing accuracy is solely due to perceptual expertise. Moreover, all three experiments showed similar, significant effects of context for all groups even though the subjects were instructed to ignore context. There is no evidence here for plasticity in the visual systems of artists. It is possible that we might find some significant differences between artists and non-artists if we had more than the 23 artist and 14 non-artist subjects we tested here; or if we changed our tasks and insisted even more strongly that the subjects ignore the context and report what was on the screen. However, even so, there would not be much joy for those who would want to see artists with an access to early representations. Our data did show significant large effects of context and the best the artists did at reducing this was a non-significant decrease in context effect of about 10% compared to the non-artists’ ratio in the second experiment (lightness). This is far from the 100% reduction that would be required to be able to paint based on “seeing the proximal image.”
Although there is little evidence of any visual system plasticity from all those years of training, there is evidence that their training did affect their performance in the matching tasks but in a different way: they took a very long time to make their settings compared to non-artists. The tasks were not easier for them as we would expect if they had special perceptual expertise. It suggests instead that artists may have found the tasks a personal challenge to their self-image as artists and so they spent more time, perhaps trying to apply specific strategies that they had learned to deal with depicting size and lightness. But to no avail. The visual search task also showed no advantage for artists, again giving no support to the possibility of a direct, more rapid access to a low-level visual representation.
According to the Gombrich (1987) model of schemata, artists act as copyists, starting with a rough approximation to the scene they are painting. They then compare the depiction with the original and make corrections so that they look the same. This interpretation of the skills of artists does not require them to “see” their retina, the proximal stimulus. Yes, they may make initial errors in selecting a paint, having chosen a value that is more in line with what they “see,” affected as it is by visual constancies. They can quickly correct it once it is in play on the canvas and subject to the same constancies from the context surround it on the canvas, just as the original object is surrounded by its context in the world.
Nevertheless, our results have only examined perceptual factors. In contrast, the visual arts are not only visual but also motor as they involve the drawing task itself. Isolating the perceptual factor allowed us to argue against perceptual expertise as a contributing factor to the difference in drawing skills between artists and non-artists. However, the expertise of visual artists may only emerge in tasks that call on artists’ to actually produce works of art. Further research should assess the role of visual factors in tasks where artists produce artworks.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was supported by a Chaire d’Excellence grant to Patrick Cavanagh.
References
Adelson, E. H. (1993). Perceptual organization and the judgment of brightness. Science 262, 2042–2044.
Adelson, E. H. (2000). “Lightness perception and lightness illusions,” in The New Cognitive Neurosciences, Vol. 3, ed. M. Gazzaniga (Cambridge, MA: MIT Press), 339–351.
Agostini, T., and Galmonte, A. (2002). Perceptual organization overcomes the effects of local surround in determining simultaneous lightness contrast. Psychol. Sci. 13, 89–93.
Ahissar, M., and Hochstein, S. (2004). The reverse hierarchy theory of visual perceptual learning. Trends Cogn. Sci. (Regul. Ed.) 8, 457–464.
Aks, D. J., and Enns, J. T. (1996). Visual search for size is influenced by a background texture gradient. J. Exp. Psychol. Hum. Percept. Perform. 22, 1467–1481.
Arend, L. E., and Spehar, B. (1993a). Lightness, brightness, and brightness contrast: 1. Illuminance variation. Percept. Psychophys. 54, 446–456.
Arend, L. E., and Spehar, B. (1993b). Lightness, brightness, and brightness contrast: 2. Reflectance variation. Percept. Psychophys. 54, 457–468.
Bennett, D. J., and Warren, W. (2002). Size scaling: retinal or environmental frame of reference? Percept. Psychophys. 64, 462–477.
Bruno, N., Bertamini, M., and Domini, F. (1997). Amodal completion of partly occluded surfaces: is there a “mosaic” stage? J. Exp. Psychol. Hum. Percept. Perform. 23, 1412.
Calabrese, L., and Marucci, F. S. (2006). The influence of expertise level on the visuo-spatial ability: differences between experts and novices in imagery and drawing abilities. Cogn. Process. 7, 118–120.
Carlson, V. R. (1962). Size-constancy judgments and perceptual compromise. J. Exp. Psychol. 63, 68–73.
Cavanagh, P., and Leclerc, Y. G. (1989). Shape from shadows. J. Exp. Psychol. Hum. Percept. Perform. 15, 3–27.
Cohen, D. J. (2005). Look little, look often: the influence of gaze frequency on drawing accuracy. Percept. Psychophys. 67, 997–1009.
Cohen, D. J., and Bennett, S. (1997). Why can’t most people draw what they see? J. Exp. Psychol. Hum. Percept. Perform. 23, 609–621.
Cohen, D. J., and Jones, H. E. (2008). How shape constancy relates to drawing accuracy. Psychol. Aesthet. Creat. Arts 2, 8–19.
Day, R. H. (1972). The basis of perceptual constancy and perceptual illusion. Invest. Ophthalmol. 11, 525–532.
Gilchrist, A. L. (1988). Lightness contrast and failures of constancy: a common explanation. Percept. Psychophys. 43, 415–424.
Gombrich, E. H. (1987). Art and Illusion: A Study in the Psychology of Pictorial Representation. Oxford: Phaidon.
Green, C. S., and Bavelier, D. (2008). Exercising your brain: a review of human brain plasticity and training-induced learning. Psychol. Aging 23, 692–701.
Hochstein, S., and Ahissar, M. (2002). View from the top: hierarchies and reverse hierarchies in the visual system. Neuron 36, 791–804.
Hubel, D. H., and Wiesel, T. N. (1970). The period of susceptibility to the physiological effects of unilateral eye closure in kittens. J. Physiol. (Lond.) 206, 419–436.
Kellman, P. J., and Shipley, T. F. (1991). A theory of visual interpolation in object perception. Cogn. Psychol. 23, 141–221.
Kozbelt, A., and Seeley, W. P. (2007). Integrating art historical, psychological, and neuroscientific explanations of artists’ advantages in drawing and perception. Psychol. Aesthetics Creativity Arts 1, 80–90.
Lee, H., and Vecera, S. P. (2005). Visual cognition influences early vision: the role of visual short-term memory in amodal completion. Psychol. Sci. 16, 763–768.
Leibowitz, H., and Harvey, L. O. Jr. (1967). Size matching as a function of instructions in a naturalistic environment. J. Exp. Psychol. 74, 378.
Matthews, W. J., and Adams, A. (2008). Another reason why adults find it hard to draw accurately. Perception 37, 628–630.
Mitchell, P., Ropar, D., Ackroyd, K., and Rajendran, G. (2005). How perception impacts on drawings. J. Exp. Psychol. Hum. Percept. Perform. 31, 996–1003.
Moore, C. M., and Brown, L. E. (2001). Preconstancy information can influence visual search: the case of lightness constancy. J. Exp. Psychol. Hum. Percept. Perform. 27, 178–194.
Ostrovsky, Y., Andalman, A., and Sinha, P. (2006). Vision following extended congenital blindness. Psychol. Sci. 17, 1009–1014.
Rensink, R. A., and Enns, J. T. (1998). Early completion of occluded objects. Vision Res. 38, 2489–2505.
Stuart, G. W., Bossomaier, T. R., and Johnson, S. (1993). Preattentive processing of object size: implications for theories of size perception. Perception 22, 1175–1193.
Todorovic, D. (2010). Context effects in visual perception and their explanations. Rev. Psychol. 17, 17–32.
Treisman, A., and Gormican, S. (1988). Feature analysis in early vision: evidence from search asymmetries. Psychol. Rev. 95, 15–48.
Wolfe, J. M. (1998). “Visual search,” in Attention 1, Vol. 15, ed. H. Pashler (London: University College London Press), 77–84.
Keywords: art, vision, visual constancy, visual search, scene perception
Citation: Perdreau F and Cavanagh P (2011) Do artists see their retinas? Front. Hum. Neurosci. 5:171. doi: 10.3389/fnhum.2011.00171
Received: 16 June 2011; Accepted: 12 December 2011;
Published online: 30 December 2011.
Edited by:
Luis M. Martinez, Universidad Miguel HernándezReviewed by:
Luis M. Martinez, Universidad Miguel HernándezMartin Banks, University of California Berkeley, USA
Peter Thompson, University of York, UK
Copyright: © 2011 Perdreau and Cavanagh. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Florian Perdreau, Laboratoire Psychologie de la Perception, Centre Attention Vision, CNRS UMR 8158, Université Paris Descartes, Paris, France. e-mail:Zmxvcmlhbi5wZXJkcmVhdUBwYXJpc2Rlc2NhcnRlcy5mcg==