


- 1Department of Psychology, Humboldt-Universität zu Berlin, Berlin, Germany
- 2Berlin School of Mind and Brain, Humboldt-Universität zu Berlin, Berlin, Germany
The richness of semantic representations associated with individual words has emerged as an important variable in reading. In the present study we contrasted different measures of semantic richness and explored the time course of their influences during visual word processing as reflected in event-related brain potentials (ERPs). ERPs were recorded while participants performed a lexical decision task on visually presented words and pseudowords. For word stimuli, we orthogonally manipulated two frequently employed measures of semantic richness: the number of semantic features generated in feature-listing tasks and the number of associates based on free association norms. We did not find any influence of the number of associates. In contrast, the number of semantic features modulated ERP amplitudes at central sites starting at about 190 ms, as well as during the later N400 component over centro-parietal regions (300–500 ms). Thus, initial access to semantic representations of single words is fast and word meaning continues to modulate processing later on during reading.
Introduction
Extracting meaning from words and texts is the ultimate goal of written language comprehension. Yet, semantic representations and the mechanisms underlying semantic processing remain elusive. Accordingly, many models of visual word recognition, even though assuming a role for semantic representations, have restricted explicit computational implementations to orthographic and phonological processes (Seidenberg and McClelland, 1989; Plaut et al., 1996; Coltheart et al., 2001; but see Harm and Seidenberg, 2004). One way to approach the issue how meaning is represented and retrieved during reading is to examine influences of semantic richness, that is, how differences between words in the amount of associated semantic information modulate word processing (Buchanan et al., 2001; Locker et al., 2003; Yates et al., 2003; Balota et al., 2004; Adelman et al., 2006; Pexman et al., 2007; Duñabeitia et al., 2008; Mirman and Magnusson, 2008; Pexman et al., 2008; Grondin et al., 2009; Yap et al., 2011). Investigating, which of the various measures proposed to quantify semantic richness influence word processing, and at what point in time these influences take place (absolutely as well as in relation to other lexical processes), helps to specify the nature of semantic representation and to come closer to an understanding of the processes taking place when meaning is extracted from print. As yet, evidence on the time course of semantic richness effects during reading is scarce and inconsistent (Kounios et al., 2009; Müller et al., 2010; Amsel, 2011; see below). Exploiting the high temporal resolution provided by event-related brain potentials (ERPs), we aimed to further clarify this issue.
Measures of the richness of semantic representations have been based, for example, on word co-occurrences in text corpora (Buchanan et al., 2001), contextual dispersion across different content areas (Adelman et al., 2006), and the number of semantic features generated in feature-listing tasks (McRae et al., 2005). However, Pexman et al. (2008) reported different patterns of contributions for these different measures of semantic richness to the latencies of lexical decisions and semantic categorizations. Hence, semantic richness seems not to be a unitary phenomenon and distinct mechanisms may underlie the influences of different facets of this variable. Here, we directly contrasted two important measures of the richness of semantic representations, the number of semantic features and associates, as described below.
Many influential models and theories assume semantic features to play a crucial role in meaning representation (e.g., Collins and Loftus, 1975; Plaut and Shallice, 1993; Harm and Seidenberg, 2004); the number of semantic features determining a word's meaning thus seems to be a key indicator of semantic richness. Indeed, words with many semantic features (e.g., desk) are processed faster in lexical decision and semantic categorization tasks than words with fewer features (e.g., cork; Pexman et al., 2002, 2003; Grondin et al., 2009). In the present study the number of semantic features was manipulated based on the elaborate norms by McRae et al. (2005) where more than 700 participants had listed semantic features for 541 concrete words (e.g., mouse—“is small,” “has legs,” etc.).
Another relevant and frequently used measure of semantic richness is the number of different first associations generated across participants in free-association tasks (Nelson et al., 2004). In the study by Nelson et al. (2004), participants produced the first word that came to their mind upon hearing a specific cue word. Subsequently, the number of different first associations to this cue word was counted, excluding idiosyncratic associations (i.e., associated words produced by a single participant only). Based on the assumption that every first free association to a cue word is an associate in semantic memory, the number of different first free associations has been referred to as the number of associates. For simplicity, we will use the term number of associates throughout the manuscript. Words with many associates have been found to be processed faster than words with few associates in tasks such as lexical decision, semantic categorization, reading aloud, perceptual identification, and online sentence reading (Buchanan et al., 2001; Pexman et al., 2007; Duñabeitia et al., 2008). However, it is important to note that a recent study did not find any influences of the number of associates when controlling for other lexical and semantic variables such as e.g., the number of features (Yap et al., 2011). Thus, the available evidence concerning independent influences of the number of associates is controversial.
An important step toward understanding the mechanisms underlying the extraction of meaning from print, and ultimately specifying these mechanisms in explicit computational models, is to investigate the time course of influences of semantic richness, that is, at which time it affects word processing and how the timing of semantic richness effects relates to influences of other lexical variables. A number of studies have investigated the temporal dynamics of different aspects of semantic processing, and recent evidence suggests that lexical semantic access may start as early as within the first 200 ms of word processing (e.g., Skrandies, 1998; Hauk et al., 2006; Penolazzi et al., 2007; Kiefer et al., 2008; Dambacher et al., 2009; Pulvermüller et al., 2009; Segalowitz and Zheng, 2009; Kiefer and Pulvermüller, 2011; Rabovsky et al., 2011a). However, evidence on the time course of the above-mentioned effects of semantic richness is restricted to three recent ERP studies, two focusing on semantic features (Kounios et al., 2009; Amsel, 2011) and the other on associates (Müller et al., 2010).
Kounios et al. (2009) aimed at a graded manipulation of semantic richness, ranging from abstract words with presumably rather poor representations in semantic space (Paivio, 1986; Plaut and Shallice, 1993), over concrete words with few semantic features, to concrete words with many semantic features (cf. McRae et al., 2005). In this study, participants were presented with word pairs, which could be semantically related or unrelated. Whereas no responses were to be given to the first words of the pairs (the experimental items), the second words of the pairs had to be judged for their relatedness to the preceding word. Significant effects of semantic richness were obtained in the ERPs between 200 and 800 ms after stimulus onset, but the theoretically most extreme comparison (between abstract words and concrete words with many semantic features) was not significant in any segment. Furthermore, ERP amplitudes did not show a monotonic ordering according to the presumably graded variation of semantic richness. In line with previous evidence (Kounios and Holcomb, 1994; West and Holcomb, 2000), N400 amplitudes to both types of concrete words were larger as compared to abstract words; however, concrete words with few features unexpectedly tended to elicit larger N400 amplitudes than those with many semantic features. Because this result is at variance with predictions, Kounios et al. (2009) concluded that semantic richness either has a non-monotonic effect on neural activity or that, alternatively, their manipulation of semantic richness was confounded with some other factor.
In a study by Amsel (2011), participants read words silently and subsequently made two judgments, at first about the extent to which the word elicited mental imagery and then concerning the extent to which this imagery was based on specific personal memories. In contrast to Kounios et al. (2009), Amsel indeed found more negative amplitudes for words with more semantic features starting at about 320 ms. Furthermore, this study reported significant influences of the number of features between 200 and 300 ms, and an additional short-lived effect already at 120 ms. Thus, available evidence on influences of the number of features is rather mixed concerning both timing and direction.
Müller et al. (2010) manipulated the number of associates in a lexical decision task and observed larger N400 amplitudes for words with more associates. This seems in line with the finding of enhanced negativity for words with many features at about 320 ms (Amsel, 2011) but in disagreement with the observation of Kounios et al. (2009) that concrete words with fewer semantic features elicited larger N400 amplitudes. It seems important to note that part of the inconsistency may be due to the use of different measures of semantic richness, as the relation of the different variables is currently not clear. Furthermore, in line with theories assuming a feature-based organization of semantic memory (Plaut and Shallice, 1993; Harm and Seidenberg, 2004; McRae, 2004), recent evidence suggests that the number of associates may not yield independent contributions to semantic richness effects when other relevant variables are controlled for (Yap et al., 2011). In sum, the evidence concerning the temporal evolvement of semantic richness effects during reading is far from conclusive.
It seems especially interesting to pinpoint the moment when semantic richness effects first arise during reading, and to determine the temporal delay between initial access to form-related lexical information and the activation of the corresponding semantic representations. Access to orthographic representations has been proposed to be reflected in the left-lateralized N1 component of the ERP peaking at about 160 ms, presumably corresponding to hemodynamic activation in an area within the left fusiform gyrus assumed to be specialized in visual word form processing (e.g., McCandliss et al., 2003; Maurer et al., 2005; Brem et al., 2009). As activation of orthographic representations may enable the retrieval of the corresponding semantic information, the subsequent components (P2 and N2) seem to be interesting candidates for initial influences of semantic richness. Indeed, these components seem to be modulated, for example, by semantic context (van den Brink et al., 2001; Kandhadai and Federmeier, 2010; Barber et al., 2011).
Aiming to specify the temporal relationship between word form and meaning processing, we compared the onset of semantic richness effects with the onset of lexicality effects: as pseudowords do not match any pre-existing visual word form representation, ERP differences between words and pseudowords may already arise at the level of orthographic processing, preceding possible effects at the semantic level.
In sum, we recorded ERPs while participants performed visual lexical decisions. Within the word stimuli, we orthogonally manipulated two prominent measures of semantic richness, namely the number of semantic features (McRae et al., 2005) and associates (Nelson et al., 2004) to assess independent contributions of each variable. Based on the evidence for early lexical semantic modulations described above, we examined influences of semantic richness not only on the N400 component, which has often been related to semantic processes (Kutas and Federmeier, 2011), but also on earlier ERP components.
Materials and Methods
Participants
Twenty-four native English speakers (from Australia, New Zealand, the UK, and the USA) were paid 7€ per hour to participate in the study. Half of them were male; their age ranged from 19 to 32 (M = 25) years. All participants had normal or corrected-to-normal vision, 20 were right-handed. Written informed consent was obtained before the experiment.
Materials
Stimuli were 160 concrete English nouns (40 per condition combination) and 160 pseudowords. Within the word stimuli, the number of semantic features (McRae et al., 2005) and the number of associates (Nelson et al., 2004) were orthogonally manipulated across two levels each. The four condition combinations did not differ in familiarity, concreteness, word length, word frequency, bigram frequency, or in the number of orthographic neighbors, phonological neighbors, phonemes, and syllables (all Fs < 1; please see Table 1). We report the measures for number of associates and concreteness based on Nelson et al. (2004). The word frequency values represent log-transformed frequencies based on the HAL corpus (Lund and Burgess, 1996), according to the English Lexicon Project (ELP; Balota et al., 2007). Values for the remaining word characteristics are taken from McRae et al. (2005). Pseudowords were constructed by recombining the letters of the word stimuli (e.g., “osnop” from “spoon”). They were orthographically less typical than the words as indicated by bigram and trigram frequency values retrieved from the ELP (Balota et al., 2007).
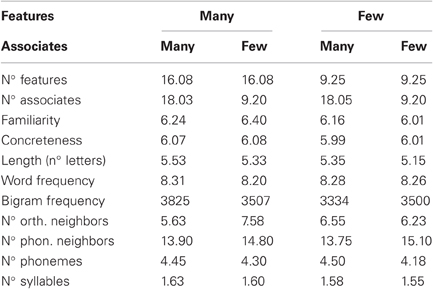
Table 1. Stimulus characteristics.
Procedure
Participants were seated in a dimly lit, sound-attenuated, and electrically shielded chamber. Stimuli were presented in black in 24 point Arial font on a light blue screen, 1 m in front of the participants. Each trial began with a fixation cross, presented for 1.5 s, and followed by a letter string, terminated by the response or after 3 s. The next trial started immediately thereafter, with a constant response-stimulus interval of 1.5 s. Participants were instructed to restrict eye blinks to the periods during which the fixation cross was visible. Participants were to indicate as fast and accurately as possible whether the letter string was a word or not by pressing a button to the left or right with the corresponding index finger. Response hand-to-stimulus assignments were counterbalanced across participants. Stimuli were presented in a different random order for each participant. In all, the experiment comprised 320 trials, separated by seven short breaks.
EEG Recording and Analysis
The EEG was recorded with Ag/AgCl electrodes from 62 scalp sites according to the extended 10–20 system, and referenced to the left mastoid. Electrode impedance was kept below 5 kΩ. Bandpass of amplifiers (Brainamps) was 0.032–70 Hz, and sampling rate was 500 Hz. Offline, the EEG was transformed to average reference. Eye blink artifacts were removed with a spatio-temporal dipole modeling procedure using BESA software (Berg and Scherg, 1991). After applying a 30 Hz low pass filter, the continuous EEG was segmented into epochs of 1 s, with a 200 ms pre-stimulus baseline. Trials with remaining artifacts and with incorrect or missing responses were discarded.
Early parts of the ERP waves were segmented based on measures of global map dissimilarity (GMD; Lehmann and Skrandies, 1980; Brandeis et al., 1992). GMD values reflect dissimilarities of topographies across adjacent time points so that GMD peaks indicate transitions between periods of relative topographical stability, which indicate ongoing processes in similar brain areas (Lehmann and Skrandies, 1980). GMD values based on ERPs averaged across all experimental conditions peaked at 80, 130, 180, and 240 ms (see Figure 1D). These moments of transition were taken as borders for ERP segmentation; thus, subsequent analyses focused on segments between 80–130, 130–180, and 180–240 ms. As word processing continues during later parts of the ERP, transitions between brain states as indicated by GMD measures become less clear-cut (see Figure 1D). Thus, a further segment between 300 and 500 ms, corresponding to the N400 component, was chosen based on the literature (e.g., Kutas and Federmeier, 2011).
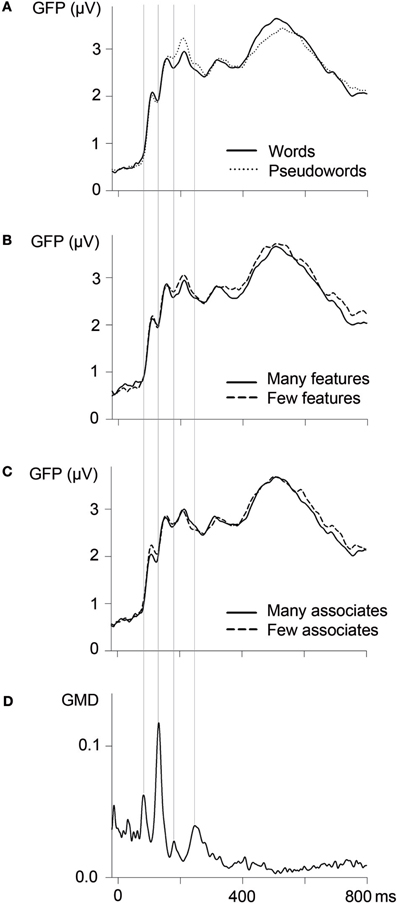
Figure 1. Global field power (GFP; n = 24; 62 channels) as a function of lexicality (A), the number of semantic features (B), and the number of associates (C). Vertical lines indicate borders of ERP segmentation, based on measures of global map dissimilarity (GMD; D).
Amplitudes were averaged within these selected epochs. We first analyzed amplitudes of global field power (GFP; Lehmann and Skrandies, 1980), reflecting the average activity across all electrodes (see Figures 1A–C). By providing a global measure of activity across the scalp, GFP analyses diminish the risk of obtaining false positive results, which may be entailed by focusing on a few electrode sites only. Furthermore, for each segment, these global analyses were complemented by analyses focusing on electrode sites at relevant regions of interest (ROIs). For early components with sharp and clearly localized peaks, these complementary analyses focused on electrodes with maximal amplitudes (averaged across all experimental conditions) and their contralateral counterparts: PO7/PO8 for the segment between 80 and 130 ms, corresponding to the P1 component, and PO9/PO10 for the segment between 130 and 180 ms, corresponding to the N1 component. The segment between 180 and 240 ms corresponds to the P2/N2 complex, with a negative maximum at posterior sites and a positive maximum over the vertex, so that we analyzed ERPs both at posterior (PO9/PO10) and at central (C1, Cz, CPz, C2) sites. For the N400 component, which has a broad maximum over centro-parietal regions (Kutas and Federmeier, 2011), we analyzed a larger electrode cluster (C1, Cz, C2, CP1, CPz, CP2, P1, Pz, P2) between 300 and 500 ms.
Even with painstaking controls of perceptual factors the use of different words for different experimental conditions always induces the risk that obtained effects may be due to sensory confounds. Especially when focusing on early visual components, this is a serious issue. In order to control for such possible confounds, pseudowords were categorized according to the semantic richness condition of the words they were derived from. As pseudowords were constructed by recombining the letters of the word stimuli (e.g., “osnop” from “spoon”), they were identical to their base words in terms of the basic visual features contained in the letters, but differed from their base words in that they did not convey meaning. Hence, we applied the ERP analyses run on the word stimuli in an analogous way to the pseudoword stimuli. Thus, obtaining semantic richness effects for the words but not for the pseudowords provides evidence against an interpretation of the obtained semantic richness effects in terms of a sensory confound.
In addition to semantic richness effects, we also analyzed differences between words and pseudowords. As effects of semantic richness can be analyzed only within words, data were thus submitted to two types of ANOVAs. One focused on word stimuli only and included the factors Features (many vs. few) and Associates (many vs. few), while the other was applied to all stimuli and included the factor Lexicality (words vs. pseudowords). Post-hoc tests were Bonferroni-corrected.
In an attempt to capture the temporal delay between the influences of lexicality and semantic richness, we calculated t-tests for each time point between GFP amplitudes to words vs. pseudowords (lexicality effect), as well as between GFP amplitudes to words with many vs. few semantic features (feature effect). Onsets were defined as the points in time when an effect first started to be significant (for df = 23 p < 0.05 if t > 2.069) over five successive sampling points.
In order to compare the scalp topographies of the effects across time windows, difference waves were scaled to the individual GFP within the relevant time windows for each participant; that is, the amplitude at each electrode was divided by GFP. This was done in order to omit differences in overall amplitude since only the shape of the distributions was to be compared.
Results
Performance
For each subject, we excluded trials deviating from the subject's mean RT by more than 2 SDs. Response latencies were significantly shorter for words (M = 682 ms) than for pseudowords (M = 759 ms), F1 (1,23) = 20.25, p < 0.001, F2 (1,318) = 123.1, p < 0.001, but were not affected by the semantic richness factors, F1s < 1, F2s < 1. Analyses of error rates did not reveal significant effects, with overall very high accuracy for both words (M = 1.8%) and pseudowords (M = 2.0%).
Electrophysiology
GFP amplitudes as a function of lexicality, the number of features, and the number of associates are depicted in Figures 1A–C. F-values and significance levels for analyses of GFP amplitudes and for the complementary analyses of ERP amplitudes at specific ROIs (see below for details) are reported in Table 2.
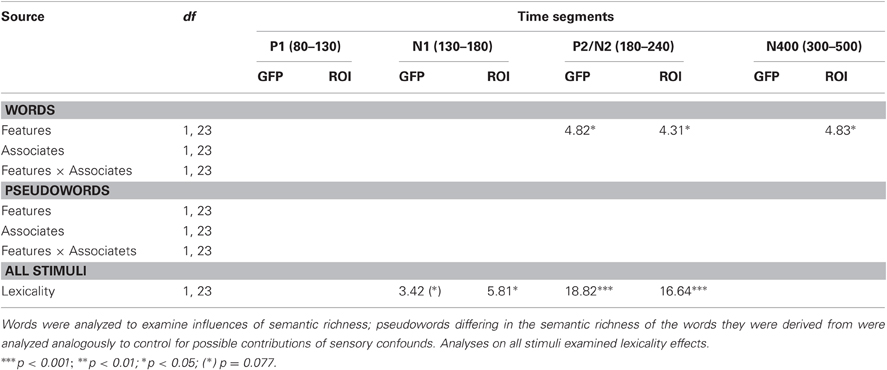
Table 2. F-values and significance levels from analyses of variance on GFP amplitudes and on ERP amplitudes at relevant electrode sites (ROIs; see Methods and Results for details).
Between 80 and 130 ms, in the segment corresponding to the P1 component, neither analyses of GFP amplitudes nor analyses focusing on the electrodes with maximal P1 amplitudes (PO7/PO8) showed significant effects.
Between 130 and 180 ms, corresponding to the N1 time window, analyses of electrodes with maximal N1 amplitudes (PO9/PO10) revealed a significant influence of Electrode Site, F(1,23) = 16.16, p = 0.001, indicating left-lateralization as typically observed for the N1 to visual words (e.g., McCandliss et al., 2003). In addition, there was a significant influence of lexicality (with a corresponding trend in the GFP analysis), indicating larger N1 amplitudes for pseudowords than words (see Figures 1 and 2).
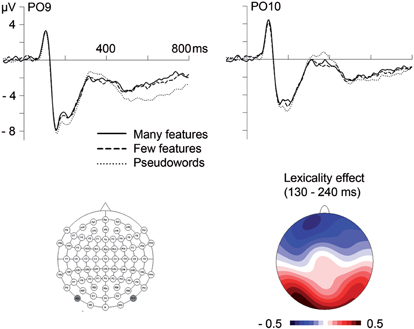
Figure 2. Top. Influences of lexicality and the number of semantic features on event-related brain potentials at posterior electrode sites. Bottom. At left is a map of electrode locations with the depicted sites PO9 and PO10 highlighted in dark gray. To the right is the topographical distribution of the lexicality effect (words minus pseudowords) between 130 and 240 ms.
In the segment between 180 and 240 ms, corresponding to the P2/N2 complex, analyses of GFP amplitudes showed continued influences of lexicality, which could be confirmed at the posterior sites PO9 and PO10, F(1,23) = 16.64, p < 0.001 (F < 1 at C1, Cz, CPz, C2). Comparison of topographical distributions of lexicality effects between the earlier (130–180 ms) and later (180–240 ms) segment revealed no significant difference, F(1,23) = 1.17, p = 0.32. Importantly, during the segment between 180 and 240 ms, GFP analyses also revealed significant influences of the number of features (see Figure 1 and Table 2). Feature effects could be confirmed over the vertex, F(1,23) = 4.31, p < 0.05 at C1, Cz, CPz, C2 (please see Figure 3), but were not significant over posterior areas, F(1,23) = 1.82, p = 0.19.
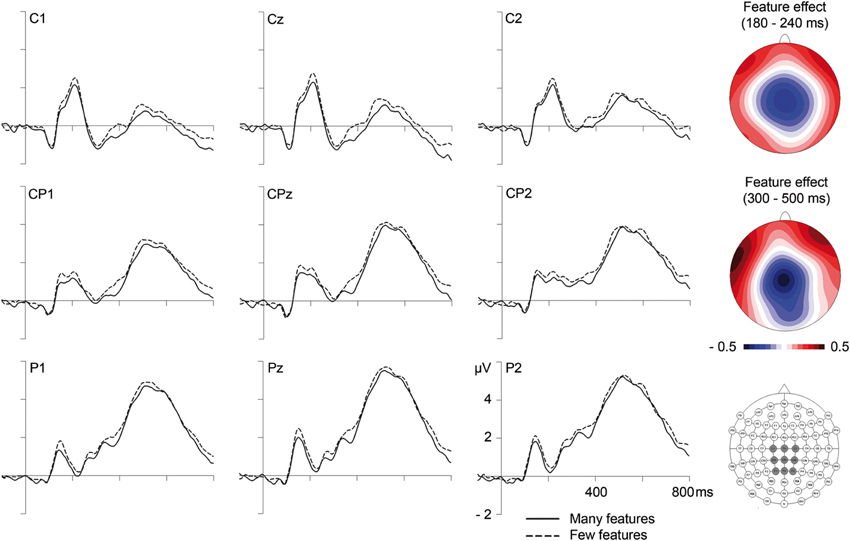
Figure 3. Influences of the number of semantic features on event-related brain potentials at centro-parietal electrode sites. On the right are topographical distributions of feature effects (many minus few semantic features) between 180 and 240 (top) and between 300 and 500 ms (middle), as well as a map of electrode locations with the depicted sites highlighted in dark gray.
Running t-tests on GFP amplitudes (see Methods) indicated lexicality effects to start at 164 ms while feature effects arose at 190 ms, suggesting that semantic features are activated only about 20–30 ms after form-related properties during word reading.
During the N400 segment, GFP analyses did not reveal significant results. However, the complementary analysis focusing on centro-parietal sites (C1, Cz, C2, CP1, CPz, CP2, P1, Pz, P2), providing increased sensitivity, revealed a significant influence of the number of features, F(1,23) = 4.83, p < 0.05. As can be seen in Figure 3, amplitudes were more negative for words with more semantic features (and even though not statistically reliable, this tendency is also observable in GFP amplitudes depicted in Figure 1). A comparison of topographical distributions of semantic feature effects between the earlier (180–240) and later (300–500) time windows revealed no significant difference (F < 1).
Analogous analyses of ERPs to pseudowords categorized according to the semantic richness of their base words did not reveal any significant differences (see Table 2).
Discussion
The present study investigated the time course of semantic richness effects during visual word recognition by means of ERPs. We focused on two different measures of semantic richness, namely the number of semantic features (McRae et al., 2005) and the number of associates (Nelson et al., 2004). Of primary interest were, whether, and how these measures contribute to semantic richness effects during word reading, and to disentangle their relative contributions. In addition, we related the onset of semantic influences to the onset of lexicality effects in order to obtain relative temporal information on the time course of word form and meaning access. The number of semantic features modulated ERP amplitudes starting at about 190 ms, shortly after the onset of lexicality effects during the N1 segment at about 164 ms. Later on, in the N400 segment, the number of semantic features enhanced negative amplitudes at centro-parietal sites. In contrast, we did not find any influence of the number of associates. We will detail and discuss these findings below.
Early ERP Components
The first ERP component found to be modulated was the posterior left-lateralized N1, presumably reflecting visual word form processing within the fusiform gyrus (McCandliss et al., 2003; Maurer et al., 2005; Brem et al., 2009; see Figure 2). Mean amplitudes at posterior sites in the N1 segment (130–180 ms) were modulated by lexicality, with larger amplitudes for pseudowords than for words. This lexicality effect is in line with PET studies showing stronger left fusiform activations for pseudowords than for real words (Brunswick et al., 1999; Fiez et al., 1999). More generally, it fits well with the assumption that the left-lateralized N1 component in reading indicates orthographic activation in the visual word form area (e.g., McCandliss et al., 2003), which seems to be hierarchically organized to code orthographic representations of increasing complexity from individual letters over bigrams and trigrams to whole words (Vinckier et al., 2007). Please note that due to our orthographically untypical pseudowords, the ERP difference between words and pseudowords obtained here may arise at an orthographic locus beneath the whole word level.
Shortly after the N1, an effect of the number of semantic features was observed during the P2/N2 segment (180–240 ms) while the lexicality effect continued (see Figures 1,2,3). Thus, semantic access seems to start quickly, within the first 200 ms of reading, in line with recent evidence as discussed in the introduction (Skrandies, 1998; Hauk et al., 2006; Penolazzi et al., 2007; Kiefer et al., 2008; Dambacher et al., 2009; Pulvermüller et al., 2009; Segalowitz and Zheng, 2009; Kiefer and Pulvermüller, 2011; Rabovsky et al., 2011a). Running t-tests on GFP amplitudes (see Methods) indicated lexicality effects to start at 164 ms, while feature effects arose at 190 ms.
As noted above, because the pseudowords were orthographically untypical, our lexicality effect may arise at an orthographic level below access to whole word representations already. Therefore, the temporal delay between access to whole word representations and semantics may be even shorter than the observed 20–30 ms. This suggests that word form activation initially precedes the activation of semantic features by no more than 20–30 ms, and that form-related and semantic properties are subsequently processed in parallel. These results are incompatible with theories assuming discrete and modular processing stages in reading, where processing at a lower orthographic level needs to be completed in order to enable the activation of higher-level semantic representations. Instead, our data support partial information transmission and temporal overlap between processes at different levels of representations in reading (Seidenberg and McClelland, 1989; Plaut and Shallice, 1993; Harm and Seidenberg, 2004).
N400 Component
As to be expected, the number of semantic word features also affected ERP amplitudes during the time window of the N400 component, which has been related to semantic processing (Kutas and Hillyard, 1980; Kutas and Federmeier, 2000, 2011). Words with many semantic features elicited larger N400 amplitudes at centro-parietal sites than words with fewer features (see Figure 3), in line with Amsel (2011), reporting an enhanced negativity for words with many features from about 320 ms onwards. Furthermore, our results fit well with findings that concrete words—considered to contain richer semantic representations—produce larger N400 amplitudes than abstract words (Kounios and Holcomb, 1994; West and Holcomb, 2000; Kounios et al., 2009), and that newly learned objects and their written names elicit larger N400 amplitudes when they are associated with in-depth as compared to minimal semantic information (Abdel Rahman and Sommer, 2008; Rabovsky et al., 2011a).
On the other hand, our finding of enhanced N400 amplitudes for words with more semantic features is at variance with the results of Kounios et al. (2009) who observed a trend for larger N400 amplitudes for words with fewer semantic features. However, the authors themselves found it surprising that their semantic feature effect was in the opposite direction as the commonly observed concreteness effect that they had also replicated in their study, and accordingly discussed the possibility that their semantic richness manipulation might have been confounded with some other factor. Clearly, further research seems desirable. In any case, the present result of enhanced N400 amplitudes for words with many semantic features is in line with feature effects reported by Amsel (2011) as well as ERP effects of concreteness (Kounios and Holcomb, 1994; West and Holcomb, 2000; Kounios et al., 2009) and the amount of newly acquired semantic information (Abdel Rahman and Sommer, 2008; Rabovsky et al., 2011a).
In principle, our finding of larger N400 amplitudes for words with many semantic features would seem to be also compatible with the enhanced negativity in the N400 window for words with more associates reported by Müller et al. (2010). However, although both the number of features and associates measure some facet of semantic richness, and would thus be expected to elicit similar influences, it seems somewhat surprising that we only found effects of the number of features and no influences of the number of associates. On the other hand, our results are in line with Yap et al. (2011) who did find independent influences of the number of features but not the number of associates when controlling for other relevant semantic and lexical variables. Notably, Müller et al. (2010) focused on the number of associates, but did not control for the number of features. As the number of features and associates are positively correlated if not intentionally disentangled as done here, it is possible that the effect of number of associates reported by Müller et al. was at least partly due to the number of semantic features. Furthermore, their stimuli with high and low numbers of associates also differed in imageability, with significantly higher imageability values for words with more associates (see p. 458 and Table 1 in Müller et al., 2010); N400 amplitude enhancements as in the study by Müller et al. have also been found for words with high imageability (Kounios and Holcomb, 1994; Holcomb et al., 1999; West and Holcomb, 2000; Swaab et al., 2002). On the other hand, the discrepancy may also be due to the manipulation of the number of associates being rather modest in our study (mean difference of nine associates between the groups) as compared to the manipulation by Müller and colleagues (mean difference of 24 associates).
Another possibly relevant factor is that the present study employed a lexical decision task with orthographically rather untypical pseudowords; hence, semantic access presumably contributed little to successful task performance. It has been repeatedly shown that semantic influences on word processing depend on task demands (West and Holcomb, 2000; Pexman et al., 2008). The semantic influences elicited in our task were presumably restricted to those influences, which take place automatically when presented with a visual word, and were not induced by task demands and intentional semantic processing. This may also be responsible for the absence of behavioral facilitation for words with richer semantic representations1, which might have been expected based on previous evidence (Buchanan et al., 2001; Pexman et al., 2007; Duñabeitia et al., 2008; Grondin et al., 2009).
For these reasons, even though it is an interesting topic whether the organization of the semantic system is based on semantic features, associations, or both (Lucas, 2000; Hutchison, 2003; Yee et al., 2009), we would not want to base too strong of a claim on the absence of ERP effects of the number of associates. Still, it seems interesting to note that our findings converge with Yap et al. (2011) in suggesting that the number of associates may not independently contribute to semantic richness effects on (concrete) word processing when other relevant semantic and lexical variables are controlled for. Notably, the amount of semantic features modulated the ERPs in both early and later time windows in spite of the above-mentioned constraints, in line with automatic task-independent activation of semantic features during reading.
At present it seems difficult to draw clear conclusions concerning the functional basis of the N400 modulation. Possibly it reflects some continued reverberation and settling still related to lexical semantic access. On the other hand, the N400 effect may also reflect additional post-lexical semantic processing or implicit memory formation (see e.g., Schott et al., 2002; Rabovsky et al., 2011b). In any case, the present observation of feature effects being present already between 180 and 240 ms seems to converge with earlier suggestions that N400 effects occur too late to represent the first phase of lexical semantic access (van den Brink et al., 2001; Sereno and Rayner, 2003; Hauk et al., 2006; Dambacher et al., 2009).
Conclusions
In sum, initial access to semantic features associated with visual words is fast: ERP modulations set in already at about 190 ms, in close temporal succession to orthographic activation as indicated by lexicality effects in the N1, starting at about 164 ms. Furthermore, the amount of semantic features enhanced N400 amplitudes, indicating continued influences of word meaning during reading.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by a scholarship from the Berlin School of Mind and Brain to Milena Rabovsky, and the German Research Foundation Grants AB 277/4 and 5 to Rasha Abdel Rahman. We would like to thank Melih Bakirtas for assisting in data acquisition.
Footnotes
- ^While in our performance data, neither ANOVAs nor multiple regression analyses did reveal significant effects of the number of features or associates, multiple regression analyses (but not ANOVAs) on RTs to the same stimuli as retrieved from the ELP showed the expected facilitating influence of the number of features (p < 0.05; one-sided) but not associates (p = 0.17; one-sided).
References
Abdel Rahman, R., and Sommer, W. (2008). Seeing what we know and understand: how knowledge shapes perception. Psychon. Bull. Rev. 15, 1055–1063.
Adelman, J. S., Brown, G. D., and Quesada, J. F. (2006). Contextual diversity, not word frequency, determines word-naming and lexical decision times. Psychol. Sci. 17, 814–823.
Amsel, B. D. (2011). Tracking real-time neural activation of conceptual knowledge using single-trial event-related potentials. Neuropsychologia 49, 970–983.
Balota, D. A., Cortese, M. J., Sergent-Marshall, S. D., Spieler, D. H., and Yap, M. (2004). Visual word recognition of single-syllable words. J. Exp. Psychol. Gen. 133, 283–316.
Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson, G. B., and Treiman, R. (2007). The English Lexicon Project. Behav. Res. Methods 39, 445–459.
Barber, H. A., Ben-Zvi, S., Bentin, S., and Kutas, M. (2011). Parafoveal perception during sentence reading? An ERP paradigm using rapid serial visual presentation (RSVP) with flankers. Psychophysiology 48, 523–531.
Berg, P., and Scherg, M. (1991). Dipole modeling of eye activity and its application to the removal of eye artefacts from the EEG and MEG. Clin. Phys. Physiol. Meas. 12, 49–54.
Brandeis, D., Naylor, H., Halliday, R., Callaway, E., and Yano, L. (1992). Scopolamine effects on visual information processing, attention, and event-related potential map latencies. Psychophysiology 29, 315–336.
Brem, S., Halder, P., Bucher, K., Summers, P., Martin, E., and Brandeis, D. (2009). Tuning of the visual word processing system: distinct developmental ERP and fMRI effects. Hum. Brain Mapp. 30, 1833–1844.
Brunswick, N., McCrory, E., Price, C. J., Frith, C. D., and Frith, U. (1999). Explicit and implicit processing of words and pseudowords by adult developmental dyslexics. Brain 122, 1901–1917.
Buchanan, L., Westbury, C., and Burgess, C. (2001). Characterizing semantic space: neighborhood effects in word recognition. Psychon. Bull. Rev. 8, 531–544.
Collins, A. M., and Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychol. Rev. 82, 407–428.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., and Ziegler, J. (2001). DRC: a dual route cascaded model of visual word recognition and reading aloud. Psychol. Rev. 108, 204–256.
Dambacher, M., Rolfs, M., Göllner, K., Kliegl, R., and Jacobs, A. M. (2009). Event-related potentials reveal rapid verification of predicted visual input. PLoS One 4, e5047. doi: 10.1371/journal.pone.0005047
Duñabeitia, J. A., Áviles, A., and Carreiras, M. (2008). NoA's ark: influence of the number of associates in visual word recognition. Psychon. Bull. Rev. 15, 1072–1077.
Fiez, J. A., Balota, D. A., Raichle, M. E., and Petersen, S. E. (1999). Effects of lexicality, frequency, and spelling-to-sound consistency of the functional anatomy of reading. Neuron 24, 205–218.
Grondin, R., Lupker, S. J., and McRae, K. (2009). Shared features dominate semantic richness effects for concrete concepts. J. Mem. Lang. 60, 1–19.
Harm, M., and Seidenberg, M. S. (2004). Computing the meanings of words in reading: cooperative division of labor between visual and phonological processes. Psychol. Rev. 111, 662–720.
Hauk, O., Davis, M. H., Ford, M., Pulvermüller, F., and Marslen-Wilson, W. D. (2006). The time course of visual word recognition as revealed by linear regression analysis of ERP data. Neuroimage 30, 1383–1400.
Holcomb, P. J., Kounios, J., Anderson, J. E., and West, W. C. (1999). Dual-coding, context-availability, and concreteness effects in sentence comprehension: an electrophysiological investigation. J. Exp. Psychol. Learn. Mem. Cogn. 25, 721–742.
Hutchison, K. A. (2003). Is semantic priming due to association strength or feature overlap? A microanalytic review. Psychon. Bull. Rev. 10, 785–813.
Kandhadai, P., and Federmeier, K. D. (2010). Automatic and controlled aspects of lexical associative processing in the two cerebral hemispheres. Psychophysiology 47, 774–785.
Kiefer, M., and Pulvermüller, F. (2011). Conceptual representations in mind and brain: theoretical developments, current evidence, and future directions. Cortex. Advance online publication.
Kiefer, M., Sim, E. J., Herrnberger, B., Grothe, J., and Hoenig, K. (2008). The sound of concepts: four markers for a link between auditory and conceptual brain systems. J. Neurosci. 28, 12224–12230.
Kounios, J., Green, D. L., Payne, L., Fleck, J. I., Grondin, R., and McRae, K. (2009). Semantic richness and the activation of concepts in semantic memory: evidence from event-related potentials. Brain Res. 1282, 95–102.
Kounios, J., and Holcomb, P. J. (1994). Concreteness effects in semantic processing: ERP evidence supporting dual-coding theory. J. Exp. Psychol. Learn. Mem. Cogn. 20, 804–823.
Kutas, M., and Federmeier, K. D. (2000). Electrophysiology reveals semantic memory use in language comprehension. Trends Cogn. Sci. 4, 463–470.
Kutas, M., and Federmeier, K. D. (2011). Thirty years and counting: finding meaning in the N400 component of the event-related brain potential (ERP). Annu. Rev. Psychol. 62, 14.1–14.27.
Kutas, M., and Hillyard, S. A. (1980). Reading senseless sentences: brain potentials reflect semantic incongruity. Science 207, 203–205.
Lehmann, D., and Skrandies, W. (1980). Reference-free identification of components of checkerboard-evoked multichannel potential fields. Electroencephalogr. Clin. Neurophysiol. 48, 609–621.
Locker, L. Jr., Simpson, G. B., and Yates, M. (2003). Semantic neighborhood effects on the recognition of ambiguous words. Mem. Cognit. 31, 505–515.
Lucas, M. (2000). Semantic priming without association: a meta-analytic review. Psychon. Bull. Rev. 7, 618–630.
Lund, K., and Burgess, C. (1996). Producing high-deimensional semantic spaces from lexical co-occurrence. Behav. Res. Methods Instrum. Comput. 28, 203–208.
Maurer, U., Brandeis, D., and McCandliss, B. D. (2005). Fast, visual specialization for reading in English revealed by the topography of the N170 ERP response. Behav. Brain Funct. 1, 13.
McCandliss, B. D., Cohen, L., and Dehaene, S. (2003). The visual word form area: expertise for reading in the fusiform gyrus. Trends Cogn. Sci. 7, 293–299.
McRae, K. (2004). “Semantic memory: some insights from feature-based connectionist attractor networks,” in Psychology of Leaning and Motivation: Advances in Research and Theory, Vol. 45, ed Ross, B. H. (San Diego, CA: Academic Press), 41–86.
McRae, K., Cree, G. S., Seidenberg, M. S., and McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behav. Res. Methods Instrum. Comput. 37, 547–559.
Mirman, D., and Magnusson, J. S. (2008). Attractor dynamics and semantic neighborhood density: processing is slowed by near neighbors and speeded by distant neighbors. J. Exp. Psychol. Learn. Mem. Cogn. 34, 65–79.
Müller, O., Duñabeitia, J. A., and Carreiras, M. (2010). Orthographic and associative neighborhood density effects: what is shared, what is different? Psychophysiology 47, 455–466.
Nelson, D. L., McEvoy, C. L., and Schreiber, T. A. (2004). The University of South Florida free association, rhyme, and word fragment norms. Behav. Res. Methods Instrum. Comput. 36, 402–407.
Paivio, A. (1986). Mental Representations: A Dual Coding Approach. New York: Oxford University Press.
Penolazzi, B., Hauk, O., and Pulvermüller, F. (2007). Early semantic context integration and lexical access as revealed by event-related brain potentials. Biol. Psychol. 74, 374–388.
Pexman, P. M., Hargreaves, I. S., Siakaluk, P. D., Bodner, G. E., and Pope, J. (2008). There are many ways to be rich: effects of three measures of semantic richness on visual word recognition. Psychon. Bull. Rev. 15, 161–167.
Pexman, P. M., Hargreaves, I. S., Edwards, J. D., Henry, L. C., and Goodyear, B. G. (2007). The neural consequences of semantic richness. When more comes to mind, less activation is observed. Psychol. Sci. 18, 401–406.
Pexman, P. M., Lupker, S. J., and Hino, Y. (2002). The impact of feedback semantics on visual word recognition: number-of-features effects in lexical decision and naming tasks. Psychon. Bull. Rev. 9, 542–549.
Pexman, P. M., Holyk, G. G., and MonFils, M. H. (2003). Number-of-features effects and semantic processing. Mem. Cognit. 31, 842–855.
Plaut, D. C., McClelland, J. L., Seidenberg, M. S., and Patterson, K. (1996). Understanding normal and impaired word reading: computational principles in quasi-regular domains. Psychol. Rev. 103, 56–115.
Plaut, D. C., and Shallice, T. (1993). Deep dyslexia – a case-study of connectionist neuropsychology. Cogn. Neuropsychol. 10, 377–500.
Pulvermüller, F., Shtyrov, Y., and Hauk, O. (2009). Understanding in an instant: neurophysiological evidence for mechanistic language circuits in the brain. Brain Lang. 110, 81–94.
Rabovsky, M., Sommer, W., and Abdel Rahman, R. (2011a). Depth of conceptual knowledge modulates visual processes during word reading. J. Cogn. Neurosci. Advance online publication.
Rabovsky, M., Sommer, W., and Abdel Rahman, R. (2011b). Implicit word learning benefits from semantic richness: electrophysiological and behavioral evidence. J. Exp. Psychol. Learn. Mem. Cogn. Advance online publication.
Schott, B., Richardson-Klavehn, A., Heinze, H. J., and Düzel, E. (2002). Perceptual priming versus explicit memory: dissociable neural correlates at encoding. J. Cogn. Neurosci. 14, 578–592.
Segalowitz, S., and Zheng, X. (2009). An ERP study of category priming: evidence of early lexical semantic access. Biol. Psychol. 80, 122–129.
Seidenberg, M. S., and McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychol. Rev. 96, 523–568.
Sereno, S. C., and Rayner, K. (2003). Measuring word recognition in reading: eye movements and event-related potentials. Trends Cogn. Sci. 7, 489–493.
Skrandies, W. (1998). Evoked potential correlates of semantic meaning – A brain mapping study. Brain Res. Cogn. Brain Res. 6, 173–183.
Swaab, T. Y., Baynes, K., and Knight, R. T. (2002). Separable effects of priming and imageability on word processing: an ERP study. Brain Res. Cogn. Brain Res. 15, 99–103.
van den Brink, D., Brown, C. M., and Hagoort, P. (2001). Electrophysiological evidence for early contextual influences during spoken-word recognition: N200 versus N400 effects. J. Cogn. Neurosci. 13, 967–985.
Vinckier, F., Dehaene, S., Jobert, A., Dubus, J. P., Sigman, M., and Cohen, L. (2007). Hierarchical coding of letter strings in the ventral stream: dissecting the inner organization of the visual word form system. Neuron 55, 143–156.
West, W. C., and Holcomb, P. J. (2000). Imaginal, semantic, and surface-level processing of concrete and abstract words: an electrophysiological investigation. J. Cogn. Neurosci. 12, 1024–1037.
Yap, M. J., Tan, S. E., Pexman, P. M., and Hargreaves, I. S. (2011). Is more always better? Effects of semantic richness on lexical decision, speeded pronunciation, and semantic classification. Psychon. Bull. Rev. 18, 742–750.
Yates, M., Locker, L. Jr., and Simpson, G. B. (2003). Semantic and phonological influences on the processing of words and pseudohomophones. Mem. Cogn. 31, 856–866.
Keywords: word meaning, semantic richness, visual word recognition, ERPs, N400
Citation: Rabovsky M, Sommer W and Abdel Rahman R (2012) The time course of semantic richness effects in visual word recognition. Front. Hum. Neurosci. 6:11. doi: 10.3389/fnhum.2012.00011
Received: 21 November 2011; Accepted: 23 January 2012;
Published online: 14 February 2012.
Edited by:
Penny M. Pexman, University of Calgary, CanadaReviewed by:
Ian S. Hargreaves, University of Calgary, CanadaBen Amsel, University of California, San Diego, USA
Copyright: © 2012 Rabovsky, Sommer and Abdel Rahman. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Milena Rabovsky, Department of Psychology, Humboldt-Universität zu Berlin, Rudower Chaussee 18, 12489 Berlin, Germany. e-mail:bWlsZW5hLnJhYm92c2t5QGh1LWJlcmxpbi5kZQ==