


- Department of Psychological and Brain Sciences, Johns Hopkins University, Baltimore, MD, USA
Attention selects stimuli for perceptual and cognitive processing according to an adaptive selection schedule. It has long been known that attention selects stimuli that are task relevant or perceptually salient. Recent evidence has shown that stimuli previously associated with reward persistently capture attention involuntarily, even when they are no longer associated with reward. Here we examine whether the capture of attention by previously reward-associated stimuli is modulated by the processing of current but unrelated rewards. Participants learned to associate two color stimuli with different amounts of reward during a training phase. In a subsequent test phase, these previously rewarded color stimuli were occasionally presented as to-be-ignored distractors while participants performed visual search for each of two differentially rewarded shape-defined targets. The results reveal that attentional capture by formerly rewarded distractors was the largest when both recently received and currently expected reward were the highest in the test phase, even though such rewards were unrelated to the color distractors. Our findings support a model in which value-driven attentional biases acquired through reward learning are maintained via the cognitive mechanisms involved in predicting future rewards.
Introduction
Perception is limited in its representational capacity, which gives rise to the need to perceive stimuli selectively. Selective attention controls the availability of stimuli for cognition, decision making, and action (Desimone and Duncan, 1995). Recent evidence reviewed below suggests that attentional priority is influenced by prior associations between stimuli and reward, as well as by the current reward value of stimuli. By attending to stimuli associated with the delivery of reward (e.g., nutrients), organisms maximize the opportunity to procure valuable resources that are critical to their survival and wellbeing.
The voluntary deployment of attention can be influenced by the reward value of stimuli. For example, visual search is more efficient for targets associated with the delivery of reward (e.g., Kiss et al., 2009; Kristjansson et al., 2010). Targets associated with high reward are also more robustly represented in early visual areas of the brain (Serences, 2008; Serences and Saproo, 2010).
Certain stimuli capture attention involuntarily, including physically salient stimuli (e.g., Yantis and Jonides, 1984; Theeuwes, 1992, 2010) and stimuli possessing goal-related features (e.g., Folk et al., 1992; Anderson and Folk, 2012). Recent evidence demonstrates that attention is also captured by previously rewarding stimuli. The recent delivery of high reward primes attention to a reward-associated stimulus (Hickey et al., 2010, 2011). Furthermore, we have shown that stimuli persistently capture attention after repeated pairings with reward, even when they are no longer rewarded and are otherwise inconspicuous and task-irrelevant (Anderson et al., 2011b; Anderson and Yantis, 2012, 2013).
Over the past two decades, much has been learned about the underlying neurobiology of reward. Learned reward predictions are represented in the basal ganglia (BG), such that the onset of reward-associated stimuli elicits the release of dopamine (DA) from BG neurons (Schultz et al., 1997; Waelti et al., 2001). It is also known that unexpected reward also elicits phasic DA release. Once an organism learns that a stimulus predicts reward, the receipt of the expected reward no longer produces DA release in response to the reward; instead, the omission of the expected reward depresses DA activity (Schultz et al., 1997). Thus, phasic DA activity is thought to convey a signal that represents both reward prediction and reward-prediction error.
The relationship between the underlying mechanisms for processing reward and for biasing attention in favor of reward-associated stimuli is unknown. One possibility is that reward motivates the recruitment of different cognitive processes, such as memory storage and perceptual learning, in order to establish and maintain attentional biases that prove adaptive in promoting reward procurement. By such an account, value-driven attentional biases are maintained independently of the cognitive architecture that subserves reward processing. Another possibility is that value-driven attentional priority is represented and signaled by the reward processing system, which is sensitive to current reward predictions. In the present study, we adjudicate between these two accounts by measuring the magnitude of attentional capture by previously reward-associated stimuli when different levels of reward were predicted from the current task.
The experiment was modeled after the experiments of Anderson et al. (2011b) and included a training phase and a test phase. In the training phase, participants learned to associate each of two color stimuli with different amounts of monetary reward (see Figure 1A). The training phase was followed by a test phase that was a modified version of the additional singleton paradigm (Theeuwes, 1992) in which the target of visual search was a shape singleton (see Figure 1B). Reward feedback was also provided in the test phase, and one of the shape targets (e.g., a unique circle among diamonds) was probabilistically associated with more reward than the other. This reward structure allowed participants to experience reward prediction and reward-prediction error on each trial. Each item in the test phase was rendered in a different color, but color was not relevant to the task. However, one of the non-targets was sometimes rendered in a color that was associated with reward during the preceding training phase. This design allowed us to assess the magnitude of value-driven attentional capture by previously rewarded colors in the test phase, as a function of both reward prediction and reward-prediction error. The hypothesis that value-driven attentional priority is represented and signaled by the reward processing system predicts that value-driven attentional capture should be maximal when these reward signals are the largest, even though current rewards are unrelated to the previously reward-associated stimuli.
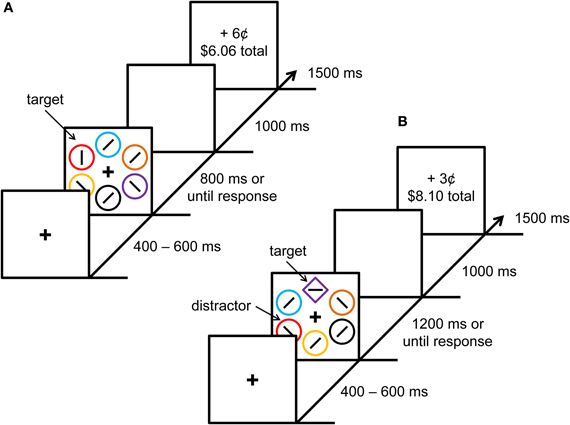
Figure 1. Experimental paradigm. Sequence of events and time course for a trial during the training phase (A) and test phase (B). Each trial was followed by a blank 1000 ms intertrial interval.
Materials and Methods
Participants
Sixteen participants were recruited from the Johns Hopkins University community. All were screened for normal or corrected-to-normal visual acuity and color vision. Participants were provided monetary compensation based on performance that varied between 12 and $15 (mean = $13.44). All procedures were approved by the Johns Hopkins University Institutional Review Board and all participants provided informed consent.
Apparatus
A Mac Mini equipped with Matlab software and Psychophysics Toolbox extensions was used to present the stimuli on a Dell P991 monitor. The participants viewed the monitor from a distance of approximately 50 cm in a dimly lit room. Manual responses were entered using a 101-key US layout keyboard.
Stimuli
Each trial consisted of a fixation display, a search array, and a feedback display (see Figure 1). The fixation display contained a white fixation cross (0.5 × 0.5° visual angle) presented in the center of the screen against a black background, and the search array consisted of the fixation cross surrounded by six shape stimuli (each with a diameter of 2.3° visual angle) placed at equal intervals on an imaginary circle with a radius of 5°. The six shapes were each rendered in a different color (red, green, blue, cyan, pink, orange, yellow, or white).
During the training phase, all six of the shapes were circles and the target was defined as the red or green circle (exactly one of which was presented on each trial). During the test phase, the six shapes consisted of either a diamond among circles or a circle among diamonds, and the target was defined as the unique shape. On 25% of the trials in the test phase, one of the non-target shapes was red and on another 25% of the trials, one of the non-target shapes was green; these constituted the formerly rewarded distractors (these two non-target shapes are referred to as “distractors”). The target was never red or green during the test phase.
Inside the target shape, a white line segment was oriented either vertically or horizontally, and inside each of the non-targets, a white line segment was tilted at 45° to the left or to the right (randomly for each non-target). The participant was required to report whether the orientation of the line segment inside the target shape was vertical or horizontal with a corresponding key press. Correct responses were followed in both phases of the experiment by a feedback display that informed participants of the monetary reward earned on that trial, as well as the total reward accumulated thus far in the experiment.
Design and Procedure
The experiment consisted of 240 trials during each of the two phases, for a total of 480 trials. Participants completed 50 practice trials prior to the training phase, and 20 practice (distractor-absent) trials prior to the test phase; behavioral data from these practice trials were not included in any analysis. In the training phase, target identity and target location were fully crossed and counterbalanced, and trials were presented in a random order. In the test phase, target identity, target location, distractor identity, and distractor location were fully crossed and counterbalanced, and trials were presented in a random order. Thus, in the test phase, the presence and identity of the distractor provided no predictive information concerning the target or reward.
In both the training and test phase, one of the two targets (e.g., red during training and diamond singleton at test) was followed by a high reward on 80% of correct trials and a low reward on the remaining 20%; the percentages were reversed for the low-reward target. High and low rewards were 6 and 2¢, respectively, during the training phase and 3 and 1¢ during the test phase (higher rewards were used in the training phase to maximize the learning of the color–reward associations). Incorrect responses or responses that were too slow were followed by feedback indicating 0¢ had been earned. Which color target and shape-singleton target was associated with high reward in their respective phase of the experiment was counterbalanced across participants, such that each combination of color and shape was used equally often. Participants were not informed of the reward contingencies, which had to be learned through experience in the task. Upon completion of the experiment, participants were given the cumulative reward they had earned.
Each trial began with the presentation of the fixation display for a randomly varying interval of 400, 500, or 600 ms. The search array then appeared and remained on screen until a response was made or the trial timed out. Trials timed out after 800 ms in the training phase and 1200 ms in the test phase. The search array was followed by a blank screen for 1000 ms, the reward feedback display for 1500 ms, and a 1000 ms intertrial interval.
Participants made a forced-choice target identification by pressing the “z” and the “m” keys for the vertically- and horizontally-orientated targets, respectively. If the trial timed out, the computer emitted a 500 ms and 1000 Hz feedback tone.
Data Analysis
Only correct responses were included in all analyses of RT, and all RTs more than three standard deviations above or below the mean of their respective condition for each participant were excluded.
Results
Training Phase
There were no significant differences in RT [t(15) = −0.16, p = 0.877] or accuracy [t(15) = −1.04, p = 0.316] to report a high-reward target compared to a low-reward target (means for high-reward target: 537 ms, 90.0%; means for low-reward target: 536 ms, 91.1%). There were also no significant differences in RT [t(15) = 1.81, p = 0.091] or accuracy [t(15) = −1.14, p = 0.272] based on the color of the target (means for red: 534 ms, 91.2%; means for green: 539 ms, 89.9%). In our prior studies on reward and attention, participants have generally been faster to respond to high-reward targets than to low-reward targets (Anderson et al., 2011a, 2012; Anderson and Yantis, 2012). The present results suggest that top–down attentional control dominated performance in the training phase, such that participants searched for the two target colors with approximately equal priority. The reward feedback allowed participants to learn the color–reward contingencies, however, and the effects of these contingencies on performance in the test phase were of primary interest.
Test Phase
We first compared RT and accuracy for trials containing a high-reward target compared to a low-reward target, as in the training phase. As in the training phase, RT [t(15) = −0.28, p = 0.785] and accuracy [t(15) = −0.26, p = 0.798] did not differ based on the value of the target (means for high-reward target: 673 ms, 89.8%; means for low-reward target: 663 ms, 90.6%). There was a highly significant effect of target shape, such that participants were substantially faster and more accurate to report circle-singleton targets compared to diamond-singleton targets [for RT: mean difference = 130 ms, t(15) = 14.26, p < 0.001, d = 3.57; for accuracy: mean difference = 8.9%, t(15) = 4.59, p < 0.001, d = 1.15]. This suggests that the circle singleton was more physically salient than the diamond singleton.
Next, to assess the effect of distractor presence, trials during the test phase were sorted according to whether they contained a non-target formerly associated with high reward (high-value distractor, 25% of trials), a non-target formerly associated with low reward (low-value distractor, 25% of trials), or neither (50% of trials). A repeated measures ANOVA revealed that RT in the three distractor conditions differed significantly [Table 1, F(2, 30) = 16.63, p < 0.001, η2p = 0.526]. Neither the color that was associated with high reward during training [F(2, 24) = 2.93, p = 0.073] nor the shape singleton that was associated with high reward at test (F < 1) interacted significantly with the effect of distractor condition on RT, and the three-way interaction was also not significant [F(2, 24) = 1.08, p = 0.357], so we collapsed across these two factors. A post-hoc contrast revealed that RT was slower when a previously rewarded color distractor was present compared to the distractor-absent condition, indicating the presence of value-driven attentional capture by formerly rewarded but now irrelevant colors [t(15) = 5.72, p < 0.001, d = 1.72]; RT did not differ between the high- and low-value distractor conditions [t(15) = −0.63, p = 0.537], and the distractors captured attention regardless of their color [both t's > 4.50, p's < 0.001]. Accuracy did not differ significantly among the three conditions (F < 1), nor did the effect of distractor condition on accuracy interact with the color associated with high-reward during training [F(2, 24) = 2.03, p = 0.153] or the shape singleton associated with high-reward at test (F < 1), and the three-way interaction was also not significant (F < 1).
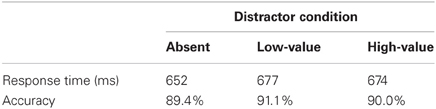
Table 1. Response time and accuracy by condition in the test phase.
According to reward-prediction error accounts, a representation of current expected reward develops based on a trial's former context (e.g., Nakahara et al., 2004). We therefore next examined how the magnitude of predicted reward on a given trial (based on the target's shape) modulated the degree to which the formerly rewarded color distractors captured attention. The predicted reward on a given trial was defined as the mean reward received over the previous five trials in which the current shape-singleton target served as the target. This computed value was used rather than the actual reward probabilities assigned to the singleton target, as previous research has shown that participants are highly sensitive to recent reward history (e.g., Serences, 2008), and this method better accounts for trials in the early part of the test phase in which participants have had little experience with the current reward contingencies. The mean reward received in the last 5 trials is, of course, highly correlated with the actual reward probabilities. But estimated value can vary considerably given the stochastic fluctuations in actual reward delivery, and so this method provides a potentially more sensitive index of the influence of experienced value on performance. We calculated value-driven attentional capture (slowing of RT on distractor present vs. absent trials) separately for trials on which the current shape singleton's predicted reward fell into one of four equally-spaced ranges as shown in Figure 2A. The magnitude of value-driven capture differed significantly for different amounts of predicted reward [F(3, 45) = 2.96, p = 0.042, η2p = 0.165], and the data were well accounted for by a linear trend in which the magnitude of capture becomes greater as predicted reward increases [F(1, 15) = 6.97, p = 0.019, η2p = 0.317].
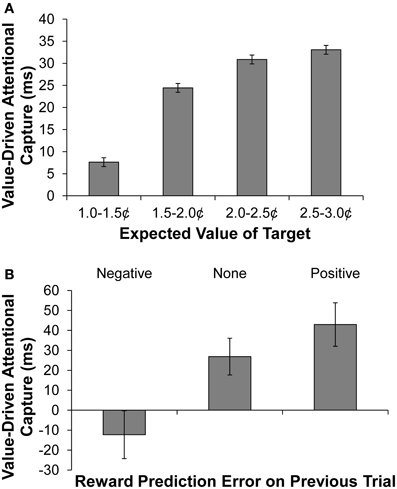
Figure 2. Behavioral results. (A) Value-driven attentional capture (defined as the mean difference in RT between distractor-present and distractor-absent trials) as a function of the value of the search context (defined as the mean reward obtained on the previous 5 trials in which the current shape singleton served as the target). (B) Value-driven attentional capture as a function of the reward-prediction error experienced on the previous trial. The error bars reflect the within-subjects SEM.
RT on distractor-absent trials did not differ based on predicted reward (F < 1), meaning that the observed changes in the magnitude of value-driven attentional capture as a function of predicted reward were not the consequence of baseline shifts in RT (the mean RTs on distractor-absent trials as a function of increasingly high predicted reward were 652, 646, 640, and 664 ms). Neither did the magnitude of value-driven attentional capture differ based on the mean reward received over the previous 5 trials without respect to the current target (F < 1), meaning that the effect of predicted reward on attentional capture did not reflect a more global consequence of recently received rewards.
In addition to the mean reward received over the last few trials a given stimulus was a target, another potentially salient reward-related signal concerns recent reward-prediction error. Positive reward-prediction error occurs when more reward is received than predicted, and negative reward-prediction error when less reward is received than expected. Reward-prediction errors are thought to provide a teaching signal that adjusts subsequent reward predictions to reduce the discrepancy between previously predicted and received reward (e.g., Waelti et al., 2001). Therefore, the representation of reward on a given trial can be expressed in terms of the reward-prediction error realized on the preceding trial, with the magnitude being larger following positive reward-prediction error and smaller following negative reward-prediction error.
A positive reward-prediction error was taken to occur when participants received a high reward following a singleton target that typically yields low reward, and a negative reward-prediction error was taken to occur when participants received a low reward following a singleton target that usually yields high reward. We found that the magnitude of value-driven attentional capture differed significantly following the three possible outcomes of reward prediction on the previous trial (positive prediction error, negative prediction error, and no prediction error) [Figure 2B, F(2, 30) = 4.63, p = 0.018, η2p = 0.236]. In particular, value-driven capture was significantly greater following a positive reward-prediction error than following a negative reward-prediction error [t(15) = 2.63, p = 0.019, d = 0.66]; the former produced substantial value-driven attentional capture, while the latter produced no evidence of attentional capture. RT on distractor-absent trials did not differ based on the reward-prediction error on the preceding trial (F < 1), meaning that the observed changes in the magnitude of value-driven attentional capture were not the consequence of baseline shifts in RT (the mean RTs on distractor-absent trials following negative, no, and positive reward-prediction error were 658, 653, and 641 ms, respectively). This provides further evidence that the attentional bias toward stimuli with learned value varies as a function of ongoing task-related reward processing.
Discussion
Attention selects stimuli for perceptual and cognitive processing. By attending to stimuli associated with the delivery of reward, organisms maximize the opportunity to procure valuable resources. We have previously shown that valuable stimuli capture attention involuntarily (Anderson et al., 2011a,b, 2012; Anderson and Yantis, 2012, 2013). The present study tested the hypothesis that this attentional bias for valuable stimuli is maintained via the cognitive mechanisms involved in processing rewards.
Using two different measures of ongoing reward processing, we found strong influences of both currently expected reward and recent reward-prediction error on the magnitude of value-driven attentional capture by formerly rewarded distractors. The greater the reward prediction on a given trial, the greater the distraction caused by previously rewarded but currently irrelevant stimuli. This finding is surprising because one might hypothesize participants to be most resistant to distraction when a high reward target was available to motivate goal-directed performance. Value-driven attentional capture was also more pronounced following positive reward-prediction error (i.e., when more reward was received than expected) than following negative reward-prediction error. This finding is also somewhat surprising because one might hypothesize that the reward-prediction errors would increase attention to the target, rather than to the distractor. Instead, this result shows that when an unexpectedly high reward has been obtained, stimuli that predict high reward in both the current and past contexts tend to capture attention.
Interestingly, value-driven attentional capture was small or non-existent when predicted reward was low and recent reward-prediction error was negative, respectively. This contrasts with the magnitude of value-driven attentional capture typically observed without reward feedback during the test phase (e.g., Anderson et al., 2011a,b; Anderson and Yantis, 2012, 2013). This suggests that relatively small rewards are experienced as disappointing and result in a reduction in the attentional bias afforded to reward-associated stimuli, consistent with the small or even negative priming observed following a low reward (e.g., Della Libera and Chelazzi, 2006; Hickey et al., 2010, 2011).
These behavioral results suggest the existence of a common mechanism that represents both reward predictions and reward-prediction error, and signals incentive salience (i.e., attentional priority for formerly rewarded stimuli). One candidate for this mechanism is the phasic DA signal in the BG (Schultz et al., 1997; Waelti et al., 2001). This is consistent with recent evidence showing that the visual representation of a reward-associated cue is modulated by the receipt of unrelated reward and corresponding reward-related DA activity (Arsenault et al., 2013). If value-based attentional priority is signaled via mechanisms that overlap with the signaling of current reward, modulating the representation of current reward should produce concurrent modulations in value-driven attentional capture. By relating ongoing reward processing to value-driven attentional capture in this way, our findings provide further insight into the mechanisms underlying attentional capture by reward-associated stimuli, which, in turn, has important implications for theories linking reward learning to attentional control (e.g., Della Libera and Chelazzi, 2006, 2009; Serences, 2008; Peck et al., 2009; Raymond and O'Brien, 2009; Hickey et al., 2010, 2011; Krebs et al., 2010; Serences and Saproo, 2010; Anderson et al., 2011a,b, 2012; Della Libera et al., 2011; Anderson and Yantis, 2012, 2013; Hickey and van Zoest, 2012).
It is worth noting that in the present study, the magnitude of attentional capture by stimuli previously associated with reward did not depend on the magnitude of prior reward value experienced during training (i.e., RT did not differ between the high- and low-value distractor conditions). One possibility is that the reward associated with the color distractors was influenced by the reward received in the test phase, which was unrelated to color. Both color targets were associated with reward outcome in the training phase of present study, and the extent to which persistent reward-related attentional biases acquired through learning should scale with the magnitude of prior reward is unclear. Previous studies show that reward associations play a direct and important role in the development of attentional biases for former targets (Anderson et al., 2011a,b, 2012; Anderson and Yantis, 2013), which, together with the observed influence of ongoing rewards, suggests that the observed attentional biases for former targets reflects an effect of reward history.
Our findings also provide further evidence for a mode of attentional control that is distinct from the well-documented stimulus-driven and goal-directed mechanisms (e.g., Folk et al., 1992; Theeuwes, 1992, 2010; Yantis, 2000; Connor et al., 2004). We show that previously reward-predictive but currently irrelevant stimuli capture attention even when they are not task relevant and not physically salient, replicating previous results (Anderson et al., 2011b; Anderson and Yantis, 2012, 2013). Our data also reveal that motivating current task goals with reward potentiates rather than minimizes attentional capture by previously valuable but currently irrelevant stimuli. If value-driven attentional capture merely reflected difficulty overcoming a previously motivated selection strategy, it would not be expected to be modulated in this way and might instead be better overcome by the motivation provided by currently expected reward. Thus, our results provide direct evidence that learned value influences attentional control in a way that does not depend on either physical salience or ongoing goals, and is instead mediated by the cognitive mechanisms involved in reward processing.
Attentional biasing of reward-associated stimuli is adaptive in many circumstances, facilitating the procurement of future rewards. However, previous reward learning and ongoing goals will at times conflict, as they do, for example, in the case of desired abstinence from a substance of abuse. Visual cues for a substance of abuse can involuntary capture attention in drug-dependent populations (e.g., Lubman et al., 2000; Marissen et al., 2006; Field and Cox, 2008), much as the previously reward-associated distractors capture attention in the present study. This drug-related attentional bias is thought to play an important role in contributing to relapse following periods of abstinence (see Field and Cox, 2008, for a review). Our findings have implications for theories of such disordered attentional control in addiction by demonstrating that reward-related attentional biases are mediated specifically by the brain mechanisms involved in processing rewards, which are known to be directly affected by drugs of abuse (e.g., Berridge and Robinson, 1998).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank J. Halberda and V. Stuphorn for helpful comments and E. Wampler for assistance with data collection. The research was supported by U.S. National Institutes of Health grant R01-DA013165 to Steven Yantis and fellowship F31-DA033754 to Brian A. Anderson.
References
Anderson, B. A., and Folk, C. L. (2012). Dissociating location-specific inhibition and attention shifts: evidence against the disengagement account of contingent capture. Attn. Percept. Psychophys. 74, 1183–1198. doi: 10.3758/s13414-012-0325-9
Anderson, B. A., Laurent, P. A., and Yantis, S. (2011a). Learned value magnifies salience-based attentional capture. PLoS ONE 6:11. doi: 10.1371/journal.pone.0027926
Anderson, B. A., Laurent, P. A., and Yantis, S. (2011b). Value-driven attentional capture. Proc. Natl. Acad. Sci. U.S.A. 108, 10367–10371. doi: 10.1073/pnas.1104047108
Anderson, B. A., Laurent, P. A., and Yantis, S. (2012). Generalization of value-based attentional priority. Vis. Cogn. 20, 647–658. doi: 10.1080/13506285.2012.679711
Anderson, B. A., and Yantis, S. (2012). Value-driven attentional and oculomotor capture during goal-directed, unconstrained viewing. Attn. Percept. Psychophys. 74, 1644–1653. doi: 10.3758/s13414-012-0348-2
Anderson, B. A., and Yantis, S. (2013). Persistence of value-driven attentional capture. J. Exp. Psychol. Hum. Percept. Perform. 39, 6–9. doi: 10.1037/a0030860
Arsenault, J. T., Nelissen, K., Jarraya, B., and Vanduffel, W. (2013). Dopaminergic reward signals selectively decrease fMRI activity in primate visual cortex. Neuron 77, 1174–1186. doi: 10.1016/j.neuron.2013.01.008
Berridge, K. C., and Robinson, T. E. (1998). What is the role of dopamine in reward: hedonic impact, reward learning, or incentive salience? Brain Res. Rev. 28, 309–369. doi: 10.1016/S0165-0173(98)00019-8
Connor, C. E., Egeth, H. E., and Yantis, S. (2004). Visual attention: bottom-up vs. top-down. Curr. Biol. 14, 850–852. doi: 10.1016/j.cub.2004.09.041
Della Libera, C., and Chelazzi, L. (2006). Visual selective attention and the effects of monetary reward. Psychol. Sci. 17, 222–227. doi: 10.1111/j.1467-9280.2006.01689.x
Della Libera, C., and Chelazzi, L. (2009). Learning to attend and to ignore is a matter of gains and losses. Psychol. Sci. 20, 778–784. doi: 10.1111/j.1467-9280.2009.02360.x
Della Libera, C., Perlato, A., and Chelazzi, L. (2011). Dissociable effects of reward on attentional learning: from passive associations to active monitoring. PLoS ONE 6:4. doi: 10.1371/journal.pone.0019460
Desimone, R., and Duncan, J. (1995). Neural mechanisms of selective visual attention. Annu. Rev. Neurosci. 18, 193–222. doi: 10.1146/annurev.ne.18.030195.001205
Field, M., and Cox, W. M. (2008). Attentional bias in addictive behaviors: a review of its development, causes, and consequences. Drug Alcohol Depend. 97, 1–20. doi: 10.1016/j.drugalcdep.2008.03.030
Folk, C. L., Remington, R. W., and Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. J. Exp. Psychol. Hum. Percept. Perform. 18, 1030–1044. doi: 10.1037/0096-1523.18.4.1030
Hickey, C., Chelazzi, L., and Theeuwes, J. (2010). Reward changes salience in human vision via the anterior cingulate. J. Neurosci. 30, 11096–11103. doi: 10.1523/JNEUROSCI.1026-10.2010
Hickey, C., Chelazzi, L., and Theeuwes, J. (2011). Reward has a residual impact on target selection in visual search, but not on the suppression of distractors. Vis. Cogn. 19, 117–128.
Hickey, C., and van Zoest, W. (2012). Reward creates oculomotor salience. Curr. Biol. 22, R19–R20. doi: 10.1016/j.cub.2012.02.007
Kiss, M., Driver, J., and Eimer, M. (2009). Reward priority of visual target singletons modulates event-related potential signatures of attentional selection. Psychol. Sci. 20, 245–251. doi: 10.1111/j.1467-9280.2009.02281.x
Krebs, R. M., Boehler, C. N., and Woldorff, M. G. (2010). The influence of reward associations on conflict processing in the Stroop task. Cognition 117, 341–347. doi: 10.1016/j.cognition.2010.08.018
Kristjansson, A., Sigurjonsdottir, O., and Driver, J. (2010). Fortune and reversals of fortune in visual search: reward contingencies for pop-out targets affect search efficiency and target repetition effects. Attn. Percept. Psychophys. 72, 1229–1236. doi: 10.3758/APP.72.5.1229
Lubman, D. I., Peters, L. A., Mogg, K., Bradley, B. P., and Deakin, J. F. W. (2000). Attentional bias for drug cues in opiate dependence. Psychol. Med. 30, 169–175.
Marissen, M. A. E., Franken, I. H. A., Waters, A. J., Blanken, P., van den Brink, W., and Hendriks, V. M. (2006). Attentional bias predicts heroin relapse following treatment. Addiction 101, 1306–1312. doi: 10.1111/j.1360-0443.2006.01498.x
Nakahara, H., Itoh, H., Kawagoe, R., Takikawa, Y., and Hikosaka, O. (2004). Dopamine neurons can represent context-dependent prediction error. Neuron 47, 129–141.
Peck, C. J., Jangraw, D. C., Suzuki, M., Efem, R., and Gottlieb, J. (2009). Reward modulates attention independently of action value in posterior parietal cortex. J. Neurosci. 29, 11182–11191. doi: 10.1523/JNEUROSCI.1929-09.2009
Raymond, J. E., and O'Brien, J. L. (2009). Selective visual attention and motivation: the consequences of value learning in an attentional blink task. Psychol. Sci. 20, 981–988. doi: 10.1111/j.1467-9280.2009.02391.x
Schultz, W., Dayan, P., and Montague, P. R. (1997). A neural substrate of prediction and reward. Science 275, 1593–1599.
Serences, J. T. (2008). Value-based modulations in human visual cortex. Neuron 60, 1169–1181. doi: 10.1016/j.neuron.2008.10.051
Serences, J. T., and Saproo, S. (2010). Population response profiles in early visual cortex are biased in favor of more valuable stimuli. J. Neurophysiol. 104, 76–87. doi: 10.1152/jn.01090.2009
Theeuwes, J. (1992). Perceptual selectivity for color and form. Percept. Psychophys. 51, 599–606. doi: 10.3758/BF03211656
Theeuwes, J. (2010). Top-down and bottom-up control of visual selection. Acta Psychol. 135, 77–99. doi: 10.1016/j.actpsy.2010.02.006
Waelti, P., Dickinson, A., and Schultz, W. (2001). Dopamine responses comply with basic assumptions of formal learning theory. Nature 412, 43–48. doi: 10.1038/35083500
Yantis, S. (2000). “Goal-directed and stimulus-driven determinants of attentional control,” in Attention and Performance XVIII, eds S. Monsell and J. Driver (Cambridge, MA: MIT Press), 73–103.
Keywords: selective attention, attentional capture, reward learning, reward prediction, incentive salience
Citation: Anderson BA, Laurent PA and Yantis S (2013) Reward predictions bias attentional selection. Front. Hum. Neurosci. 7:262. doi: 10.3389/fnhum.2013.00262
Received: 14 March 2013; Accepted: 23 May 2013;
Published online: 11 June 2013.
Edited by:
Simone Vossel, University College London, UKReviewed by:
Clayton M. Hickey, VU University Amsterdam, NetherlandsChiara D. Libera, University of Verona, Italy
Copyright © 2013 Anderson, Laurent and Yantis. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and subject to any copyright notices concerning any third-party graphics etc.
*Correspondence: Brian A. Anderson, Department of Psychological and Brain Sciences, Johns Hopkins University, 3400 N. Charles St., Baltimore, MD 21218-2686, USA e-mail:YmFuZGVyMzNAamh1LmVkdQ==
†Present address: Brain Corporation, San Diego, USA