 Marcia Mendes
Marcia Mendes Adrian Schwaninger
Adrian Schwaninger Stefan Michel
Stefan Michel- 1School of Applied Psychology, University of Applied Sciences and Arts Northwestern Switzerland (FHNW), Olten, Switzerland
- 2Center for Adaptive Security Research and Applications (CASRA), Zürich, Switzerland
This paper describes a study where a new X-ray machine for security screening featuring motion imaging (i.e., 5 views of a bag are shown as an image sequence) was evaluated and compared to single view imaging available on conventional X-ray screening systems. More specifically, it was investigated whether with this new technology X-ray screening of passenger bags could be enhanced to such an extent that laptops could be left inside passenger bags, without causing a significant impairment in threat detection performance. An X-ray image interpretation test was created in four different versions, manipulating the factors packing condition (laptop and bag separate vs. laptop in bag) and display condition (single vs. motion imaging). There was a highly significant and large main effect of packing condition. When laptops and bags were screened separately, threat item detection was substantially higher. For display condition, a medium effect was observed. Detection could be slightly enhanced through the application of motion imaging. There was no interaction between display and packing condition, implying that the high negative effect of leaving laptops in passenger bags could not be fully compensated by motion imaging. Additional analyses were carried out to examine effects depending on different threat categories (guns, improvised explosive devices, knives, others), the placement of the threat items (in bag vs. in laptop) and viewpoint (easy vs. difficult view). In summary, although motion imaging provides an enhancement, it is not strong enough to allow leaving laptops in bags for security screening.
Introduction
A secure air transportation system is vital for society and economy. Aviation security measures have been increased substantially in response to several successful and attempted terrorist attacks since September 11, 2001. One major aspect in this field is the mandatory process of baggage screening using X-ray machines. Before entering the secure area of an airport, all passengers, as well as members of airline and airport staff have to pass the security checkpoints to have themselves and all their belongings screened. The security checkpoint is a socio-technical system consisting of human and technical elements, working together. The goal is that no threat items are brought past security checkpoints and onto an airplane. Strong efforts are being made in order to improve and further develop X-ray screening equipment. Yet, the final decision whether threat items are contained in the baggage still relies on human operators (screening officers) who visually inspect the X-ray images provided by the machine. As a consequence, man-machine system performance depends on human factors and display technology (e.g., Bolfing et al., 2008; Koller et al., 2008; von Bastian et al., 2008, 2010; Michel and Schwaninger, 2009; Graves et al., 2011). When evaluating new technological developments with regard to their added value for security screening purposes, this should be taken into account appropriately (see also Yoo and Choi, 2006; Yoo, 2009).
In X-ray screening, three image-based factors have been identified as relevant for human operators to detect threat items in X-ray images (Schwaninger, 2003b; Hardmeier et al., 2005, 2006; Schwaninger et al., 2005a). The first one is the view difficulty of an object, resulting from the position of a threat item in a bag (effect of viewpoint). The second factor is the superposition of an item by other objects contained in the bag (effect of superposition). The third factor refers to the complexity of a bag, which depends on the number and type of objects in the bag (effect of bag complexity). The intensity with which X-rays can penetrate through materials in a bag depends on the specific material density of a substance (e.g., Brown et al., 1995). Therefore, the material density of the items contained in a bag will also affect the factors superposition and bag complexity and thus will influence the difficulty to detect threat items. Schwaninger et al. (2005b) have developed algorithms to automatically estimate X-ray image difficulty based on viewpoint, superposition, and bag complexity. Their algorithms were highly correlated with human perception of the above mentioned image-based factors and could well predict human threat detection performance (see also Schwaninger et al., 2007; Bolfing et al., 2008).
State-of-the-art X-ray screening equipment is able to provide high quality images with good image resolution. Yet, the detection of threat items in X-ray images remains a challenging task for screening officers and becomes even more difficult when dense objects, such as large electronic devices, are contained in the baggage. Due to their compact construction, electronic devices (e.g., laptops) are hard to penetrate. Hence, they can conceal other parts of luggage or could be used to intentionally hide threat items (e.g., an improvised explosive device, IED). Especially when single view X-ray systems are used or even multi-view systems, if the additional views do not provide enough meaningful information, the inspection becomes difficult. Threat items which are behind, in front of, or hidden inside a laptop case become very challenging or even impossible for human operators to recognize (see also von Bastian et al., 2008). In a previous paper, Mendes et al. (2012) documented how threat detection can be substantially impaired when laptops are not taken out of passenger bags and a threat item (e.g., an IED) is placed either behind, in front of, or within a laptop. The present paper extends these results by investigating how a new technology which allows presenting bags in multiple views as an image sequence (i.e., motion imaging) could possibly reduce such an impairment.
Considering the large number of views which can be produced by a single object, the question arises how objects can be recognized when presented in unusual views. In the object recognition literature, two types of theories can be distinguished (see Peissig and Tarr, 2007; Kravitz et al., 2008): viewpoint-invariant theories (e.g., Marr, 1982; Biederman, 1987) and viewpoint-dependent theories (e.g., Poggio and Edelman, 1990; Bülthoff and Edelman, 1992; Tarr, 1995). Most viewpoint-invariant theories assume that objects are stored in visual memory by their component parts and their spatial relationship (see Marr and Nishihara, 1978; Biederman, 1987). Once a particular object has been stored, recognition of that object should be unaffected by the viewpoint (including novel viewpoints), given that the necessary features can be recovered from this view (Burgund and Marsolek, 2000). The viewpoint-dependent theories propose that objects are not stored in memory as rotation invariant structural descriptions, but in a viewer centered format. Thus, if an object has never been seen from a certain viewpoint and is therefore not stored in visual memory, recognition is impaired if view-invariant features are not available (Kosslyn, 1994; Bülthoff and Bülthoff, 2006; Schwaninger, 2005). Several studies on viewpoint-dependent theories could show that viewpoint can strongly affect recognition performance (e.g., Bülthoff and Edelman, 1992; Edelman and Bülthoff, 1992; Humphrey and Khan, 1992; Graf et al., 2002). Even though our visual perception can be considered highly robust with respect to changes of viewpoint, we are more facile with certain views relative to others, such as often encountered views and views that make larger numbers of surfaces available (Palmer et al., 1981; Blanz et al., 1999). Such views have also been referred to as “canonical” views. Research in aviation security X-ray screening has shown that threat items are easier to identify when depicted in frontal (canonical) views than when horizontally or vertically rotated (e.g., Michel et al., 2007; Bolfing et al., 2008; Koller et al., 2008). Consequently, having machines featuring multiple X-ray images of the same bag from different viewpoints could ease recognition of threat items in passenger bags for screening officers.
At present, most of the machines deployed at airports provide single view images, which do not allow screening officers to analyze an image from different viewpoints. A human operator will only be able to identify a threat item and make a correct decision if the threat can be recognized in the provided single view image (Schwaninger, 2003b; Schwaninger et al., 2005a; Graves et al., 2011). Considering the above mentioned image based factors (viewpoint, superposition and bag complexity) and the density of electronic devices, it becomes evident why most international and national regulations specify that portable computers and other large electronic devices shall be removed from passenger bags and screened separately at security checkpoints (e.g., the current regulation of the European Comission, 2010). Based on the model by Schwaninger et al. (2005b) one would predict that leaving laptops in passenger bags results in decreases of threat detection performance due to increases of superposition and bag complexity. Threat items placed behind, in front of, or inside a laptop could become very challenging for human operators to detect. Moreover, recognition would become additionally challenging if in the provided X-ray image the threat item would be depicted from a difficult viewpoint (e.g., vertically or horizontally rotated).
This study was conducted to examine the above mentioned effects by comparing conventional single view display technology to a new technology. More specifically, a new X-ray screening machine featuring “motion imaging” was tested. “Motion imaging” means that five images are available, which are rotated around the vertical axis. These can be either displayed in a short video sequence or can each be statically viewed. In relation to the initial image (0°), the angles of the five images are −25°, −12.5°, 0°, 12.5°, 25° (see Figure 1).
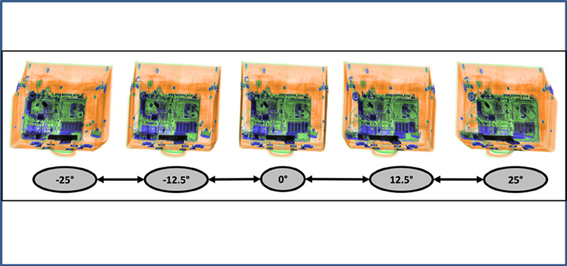
Figure 1. Example of motion imaging X-ray images provided by the machine evaluated in this study. The image in the middle shows the initial image (0°).
One could hypothesize that through the application of motion imaging and the availability of multiple views, recognition of certain objects could become easier. There are several possible advantages dynamic displays may confer over static ones (Vuong and Tarr, 2004). For example, object motion may enhance the recovery of information about shape (e.g., Ullmann, 1979). Furthermore, it may provide observers with additional views of objects (Pike et al., 1997), or it may allow observers to anticipate views of objects (Mitsumatsu and Yokosawa, 2003). Moreover, when objects rotate in depth, certain features can become visible while others become obscured (Vuong and Tarr, 2004). Thus, objects could become less superimposed and could possibly be displayed from an easier viewpoint (i.e., from a more canonical perspective).
The first goal of our study was to determine whether motion imaging improves detection of threat items in passenger bags. The second goal was to investigate whether leaving laptops in passenger bags results in a decrease of detection performance (effect of superposition and bag complexity), while the third goal was to evaluate whether such an effect can be compensated when motion imaging is available. Additional analyses were carried out to examine effects depending on different threat categories (guns, IEDs, knives, others), the placement of the threat items (in bag vs. in laptop) and the viewpoint effect (easy vs. difficult view).
Methods and Materials
An image interpretation test containing bags and laptops was created in four versions to examine the factors display condition (single vs. motion imaging) and packing condition (laptops inside vs. laptops outside). Each test version differed with regard to these two factors (see section Experimental Design). Four experimental groups with certified screening officers were formed. Each group conducted one of the test versions. Detection performance scores and reaction times (RTs) of all groups were compared to evaluate the effects of the above mentioned factors.
Participants
The study was conducted with 80 airport security screening officers employed at an international European airport. All participants were certified screeners, meaning they were all qualified, trained and certified according to the standards set by the national appropriate authority (civil aviation administration) and consistent with the European Regulation (European Comission, 2010). The screening officers were randomly distributed into four different experimental groups (A, B, C, and D, 20 per group). Figure 2 illustrates the experimental design. In order to verify that all experimental groups were comparable with regard to the screeners' X-ray image interpretation competency, all participants conducted the X-Ray Competency Assessment Test (X-Ray CAT) before the main experiment was carried out. The X-Ray CAT for cabin baggage screening is a standardized instrument to measure X-ray image interpretation competency of airport security screening officers and has been applied in several previous scientific studies (Koller and Schwaninger, 2006; Michel et al., 2007; Koller et al., 2008). It is currently used for screener certification at several European airports. The test consists of 256 trials and is based on 128 different color X-ray images of passenger bags, which are each used twice: once without (non-threat image) and once containing a threat object (threat image). For more information on the X-Ray CAT see Koller and Schwaninger (2006). Average detection performance scores (A′)1 of all four groups were compared using post-hoc pairwise comparisons with Bonferroni correction. No significant differences between the groups could be found (all p values >0.05), implying that they were comparable regarding their image interpretation competency. The average age of the participants was M = 40.69 years (SD = 10.78), with a range between 22 and 58 years. 53% of the participants were female. The average amount of job experience was M = 4.95 years (SD = 4.49, range: 0.5–23 years). Between-participants analyses of variance showed no differences between the experimental groups with regard to age [F(3, 76) = 1.57, p = 0.204, η2 = 0.058] or job experience [F(3, 74) = 0.66, p = 0.579, η2 = 0.026].
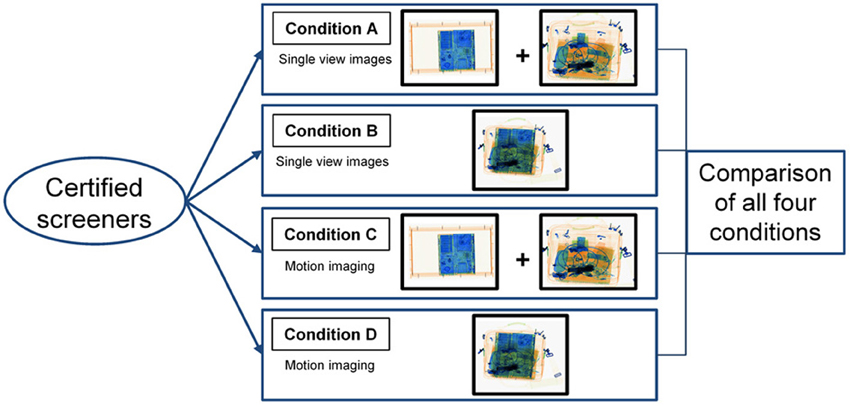
Figure 2. Experimental design (between-participants) for the comparison of the four different conditions.
Experimental Design
All experimental groups conducted a computer-based X-ray image interpretation test. During the test, color X-ray images of passenger bags and laptops were displayed, sometimes containing threats (threat images) and sometimes without any threat items (non-threat images). Images were displayed in random order. All participants were exposed to every image and had to decide whether the bags and laptops could be regarded as harmless (OK) or whether they contained a threat item (NOT OK). Each test condition differed with regard to the factors display condition (single view vs. motion imaging) and packing condition (laptops inside vs. outside of passenger bags). Figure 2 displays the experimental design of the study. The following four different experimental conditions were conducted and compared to examine the effects and interactions of the above mentioned two factors using a between-participants design:
(A) Single view images, laptops and passenger bags screened separately.
(B) Single view images, laptops are left inside the passenger bags.
(C) Motion imaging, laptops and passenger bags screened separately.
(D) Motion imaging, laptops are left inside the passenger bags.
In all test conditions the same bags were presented to the screening officers. Originally, every bag contained a laptop. In conditions A and C the laptops were taken out of the bag and screened separately, whereas in conditions B and D the laptops were left inside the passenger bags. This allowed examining the effects of superposition and bag complexity caused by laptops. Figure 2 illustrates the two different packing conditions (laptop inside vs. laptop outside).
In conditions A and B, images of the baggage and laptop could only be seen from one single viewpoint. Conditions C and D allowed examining the images from different viewpoints through motion imaging. As explained in the introduction, one important objective of this study was to test whether motion imaging could enhance the inspection of passenger bags to such an extent that laptops could be left inside passenger bags without affecting detection performance negatively. Would detection performance scores still be significantly higher in condition A compared to D, one could conclude that the detection of threat items is significantly impaired when laptops are left inside passenger bags, even when motion imaging is available.
Image Interpretation Test
The image interpretation test was based on a representative set2 of 96 passenger bags (defined by screening experts from a specialized police organization), all of which originally contained laptops. All test images were recorded with the machine evaluated in this study. The test images were created and recorded in collaboration with aviation security experts from a specialized police organization and former airport security screening officers now employed by CASRA. As explained above, in conditions A and C the laptops were taken out of the bags and recorded separately, whereas in conditions B and D the laptops were left inside the bags. Each bag/laptop-combination was used twice, once containing a threat item in either the bag or the laptop, and once without any threat item. The test contained a representative sample of threat items selected and developed (the IEDs in laptops) by experts from an airport police department. These could be divided into four different threat categories: guns, IEDs, knives and other threat items (e.g., electric shock devices, etc.). For all categories except guns, in half of the cases the threat items were placed in the bag, while in the other half of the cases the threat items were placed within the laptop (see Figure 3). Due to their size, it would not have been realistic to place guns inside a laptop. Moreover, the factor viewpoint was included in the test design. For those threat items placed inside the bags, half were positioned in easy views and half in difficult views. Easy view means that threat items were depicted from a frontal/canonical view in the X-ray image, while for difficult view the threat items were horizontally or vertically rotated. All the threat items placed inside the laptop cases were positioned in easy views. As laptops are comparably flat, it would have been difficult to place threat items in vertically or horizontally rotated positions. The IEDs which were placed inside the laptops were specifically built into the cases. It must be considered that since an IED consists of several component parts, it becomes more difficult to determine what the canonical view and thus an easy view would be. Each threat category contained 24 items. Therefore, the number of test images for the conditions were the following:
- Tests A and C (laptops and bags screened separately):
4 × 24 threat images (60 bags and 36 laptops)
+96 non threat BAG images
+96 non threat LAPTOP images
= 288 test images - Tests B and D (laptops inside bags):
4 × 24 combined threat images (60 threats in bags and 36 threats in laptops)
+96 combined non threat images
= 192 test images
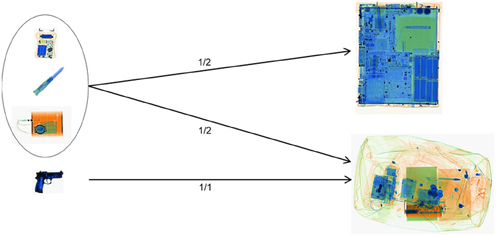
Figure 3. Placement of the threat items.
Procedure
All participants were invited to the experimenters' facilities to conduct the test. Four computer workstations with the corresponding consoles of the tested machine and 19′ TFT monitors were set up in a normally lit room. X-ray images covered about 2/3 of the computer screen. The distance to the monitor was ~60 cm. Four participants at a time were tested. Before the test started, all participants received a short introduction by the test supervisor, explaining the test procedure and introducing the new technology of motion imaging. All participants were able to try out the console and view test images for ~20 min, in order to become familiar with the images, the technology and the handling of the console. Pre-testing had shown that this amount of time was enough to get well acquainted with the console and it was also recommended by the manufacturer. After a break of 10 min the actual test started. Tests were conducted quietly and individually, and under supervision. The test images remained on the screen until the participant either pressed the “OK” or “NOT OK” and the “move belt forward” button. RTs were measured in milliseconds and correspond to the amount of time it took for a screening officer to come to a decision and press the “OK” or “NOT OK” button after the first image pixel of the bag/laptop appeared on the screen. There was no time limit set for viewing an image. However, participants were instructed to inspect the images as quickly and accurately as possible. Breaks of 10 min were taken in 30 minute-cycles, to avoid eyestrain and fatigue, and to make sure that especially those participants conducting tests A and C (288 images instead of 192 images, see section Image Interpretation Test) would not become too tired toward the end. All participants completed the test in less than 2 h, including breaks.
Results and Discussion
According to signal detection theory (Green and Swets, 1966), there are four possible outcomes to a screener's response when judging an X-ray image as either OK or NOT OK: hit, false-alarm, correct rejection and miss (Schwaninger, 2003a; Hofer and Schwaninger, 2004). In this study, A′ was applied as a measure for detection performance (Pollack and Norman, 1964). A′ is a measure of sensitivity which is commonly used for a variety of tasks including screener certification and competency assessments (Hofer and Schwaninger, 2004; Koller and Schwaninger, 2006; Michel et al., 2010). It considers the hit rate as well as the false-alarm rate and can be calculated using the following formula (Grier, 1971):
H is the hit rate and F the false alarm rate. If performance is below chance, i.e., when H < F, equation (2) must be used (Aaronson and Watts, 1987).
Due to the security confidential nature of performance values, these are not displayed in this paper. In order to provide meaningful results, relative differences and effect sizes are reported. All reported effect sizes are interpreted based on Cohen (1988). For t-tests, d between 0.20 and 0.49 represents a small effect size; d between 0.50 and 0.79 represents a medium effect size; d ≥ 0. 80 represent a large effect size. For analysis of variance (ANOVA) statistics, η2 between 0.01 and 0.05 represents a small effect size; η 2 between 0.06 and 0.13 represents a medium effect size; η2 ≥ 0.14 represents a large effect size.
Comparison of Detection Performance by Condition
Figure 4 shows a comparison of detection performance scores by condition (A, B, C, and D)3. Most remarkable seems to be the effect of packing condition. Performance was much better in conditions A and C, where laptops and bags were screened separately, compared to conditions B and D, where laptops were left inside the passenger bags. The graph also suggests that performance was slightly better when motion imaging was available (condition C compared to A and condition D compared to C, respectively). The ANOVA with the between-participants factors display condition (no motion vs. motion) and packing condition (laptop separate vs. laptop in bag) revealed a large main effect for packing condition, F(1, 76) = 105.22, p < 0.001, η2 = 2.0, and a medium main effect for display condition, F(1, 76) = 5.05, p < 0.05, η2 = 2.0. There was no interaction between display and packing condition, F(1, 76) = 0.361, p = 0.55, η2 = 2.0. Thus, although motion imaging enhanced detection performance slightly, it could not compensate the negative effects on detection performance resulting from leaving laptops inside bags. Further, the direct comparison of condition D (motion imaging available, laptops in bags) and condition A (no motion imaging available, laptops and bags screened separately) revealed a highly significant effect, t(26) = 5.89, p < 0.001, d = 1.86. This also shows that although motion imaging did improve detection performance (as shown by the main effect in the ANOVA), the large negative effect of packing condition could not be compensated.
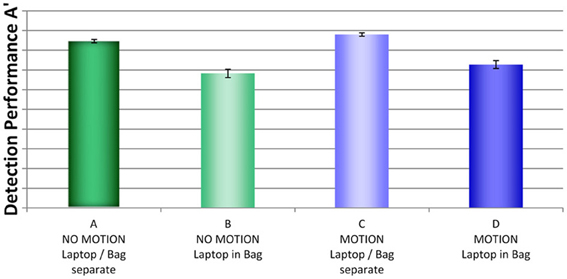
Figure 4. Mean detection performance A' with standard errors of the mean for all four conditions (A–D). For security reasons, actual A' performance scores are not reported.
In sum, the results imply that the packing condition had a high impact on detection performance. Motion imaging resulted in better detection but could not fully compensate the effect of packing condition (i.e., impaired detection when leaving laptops in passenger bags). The large main effect for packing condition is consistent with the assumption that the well-documented effects of superposition and bag complexity (Schwaninger et al., 2005a,b, 2007; Hardmeier et al., 2005, 2006; Bolfing et al., 2008; von Bastian et al., 2008) increase when laptops are left in passenger bags, resulting in impairments of threat detection performance.
A more detailed analysis was conducted by looking at each threat category separately. As can be seen in Figure 5, large differences between conditions, but also between threat categories were found. A mixed-design ANOVA with the within-participants factor threat category (guns, IEDs, knives, others) and the between-participants factors display condition (no motion vs. motion) and packing condition (laptop separate vs. laptop in bag) revealed large significant main effects for the factors threat category and packing condition and a medium effect for display condition (for details, see Table 1A). The interaction between threat category and packing condition was also highly significant, implying that leaving laptops in passenger bags affected performance differently, depending on threat category. None of the other interactions reached statistical significance. As Figure 5 indicates, IEDs and other threats were most difficult to detect, especially in conditions B and D. In general, a slight advantage of motion imaging could be observed (compare condition C to A, and D to B), which according to Figure 5 was most evident for guns.
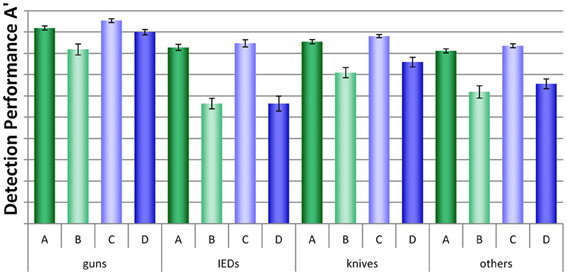
Figure 5. Mean detection performance A' with standard errors of the mean for all four conditions (A–D) and each threat category (guns, IEDs, knives, others).

Table 1. Results of the ANOVAs conducted with detection performance (A′) as dependent variable4.
Additionally, we conducted direct comparisons between conditions D (motion imaging available, laptops in bags) and A (no motion imaging available, laptops and bags screened separately) for each threat category, to further examine whether for certain threat types the negative effect on detection performance of leaving laptops in bags could be fully compensated by motion imaging. For all threat categories except guns, large significant differences were revealed (see Table 2). This further indicates that even though motion imaging did improve detection performance (as shown by the main effect in the ANOVA, see above), it could not compensate the large negative effect of packing condition. Only for the detection of guns, motion imaging seemed to have helped to compensate the negative effect of leaving laptops in bags (which could explain the marginally significant interaction (p = 0.09) between threat category and display condition in Table 1A).
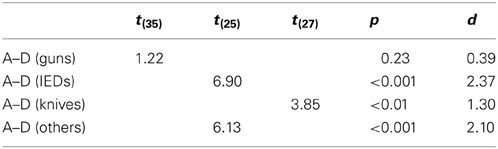
Table 2. Results of the two-tailed independent samples t-tests comparing detection performance A′ between conditions A and D for each threat category (guns, knives, IEDs, others)5.
As described earlier, half of the threat items were placed inside laptops and half were placed inside the bags (except for guns, which could not be place inside laptops). Figure 6 displays how detection performance differed for each condition with regard to threat category and the placement of threat items. Again, threat items were detected better when the bags and laptops were screened separately (conditions A and C). Planned comparisons were conducted for each condition and threat category (except for guns, as all guns were placed inside the bags), to compare the differences between detection performance with regard to the placement of threats for each condition (see Table 3). Biggest differences were found for IEDs. For each condition, detection performance was worse when the IEDs were built into the laptops, compared to when they were placed inside the bags. However, while for conditions A and C detection performance was still relatively high, the scores achieved in conditions B and D were much lower for the IEDs within the laptops. For the threat categories knives and others, in most conditions detection performance was higher when these were placed inside the laptops. This could be explained by the fact that all threat items placed within the laptops were positioned in easy views (see Method section), and thus were easier to recognize. For IEDs, this effect was not observed. As the IEDs were specifically built into the laptops and since an IED consists of several component parts, it becomes more difficult to determine what actually the canonical/frontal view and thus an easy view would be (see Method section).
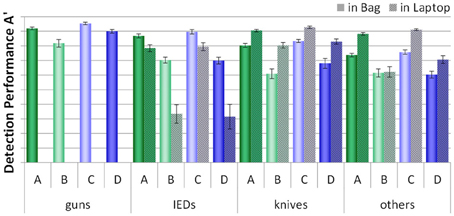
Figure 6. Mean detection performance A' with standard errors of the mean for all four conditions (A–D) with regard to the placement of a threat item (in bag vs. in laptop) for each threat category (guns, IEDs, knives, others).
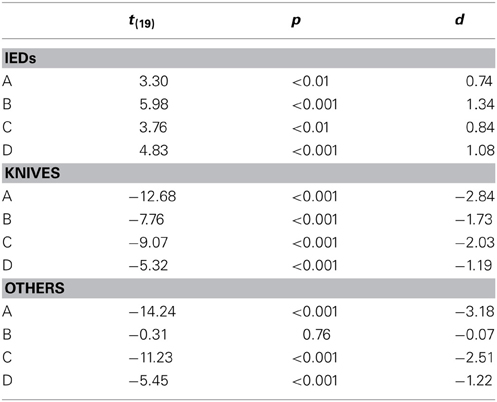
Table 3. Results of two-tailed paired samples t-tests comparing the detection performance A' with regard to the placement of each threat item (in laptop vs. in bag) for each threat category (guns, IEDs, knives, others) and each condition (A–D).
In order to examine the viewpoint effect and whether this effect was influenced by condition, detection performance scores of all conditions were compared, broken up by easy vs. difficult view (see Figure 7). Since all threat items placed inside the laptop cases were positioned in easy views, this analysis was only conducted for the threat items placed inside the bags. A mixed-design ANOVA with the within-participants factors view difficulty (easy vs. difficult view) and threat category (guns, IEDs, knives, others) and the between-participants factor condition (A, B, C, D) revealed large significant main effects for all three factors (see Table 1B). There was no significant interaction between view difficulty and condition, while all other interactions were significant. Therefore, a viewpoint effect could clearly be observed, which differed with regard to threat category. However, view difficulty was not significantly affected by condition. Interestingly, as Figure 7 indicates, throughout all conditions guns, IEDs and knives were detected better when depicted in easy views, while for the category others this was the other way around. The category others contained a very heterogeneous group of threat items (e.g., pepper spray, taser, throwing star, etc.). Hence, it could have been that the screening officers were more familiar with those threat items positioned in difficult views, and therefore recognized these more easily. As Figure 7 further indicates, for the category guns, motion imaging seemed to have been of help to reduce the viewpoint effect (see conditions C and D). This is consistent with the results reported above (see Table 2) and makes sense if one takes into account that guns change their shape more drastically than other objects when rotated. Thus, motion imaging can be more effective for supporting the recognition of guns.
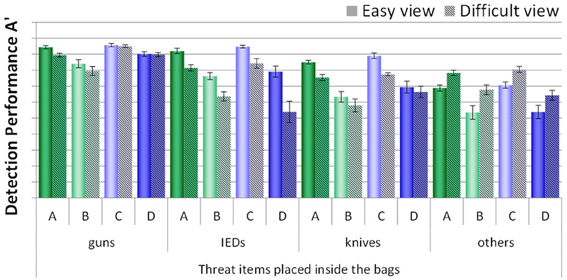
Figure 7. Mean detection performance A' with standard errors of the mean for all four conditions (A–D) with regard to the view difficulty (easy vs. difficult view) for each threat category (guns, IEDs, knives, others). Only threat items which were placed inside the bags are included.
Comparison of Reaction Times by Condition
Figure 8 shows the average reaction times (RTs, converted into seconds) for all conditions and threat categories. For all categories, a similar pattern can be observed: More time was needed in conditions B and D where laptops were left inside the bags. Most time was needed in condition D, where motion imaging was available. As Figure 8 implies, remarkable differences can be observed between the threat categories and conditions. A repeated-measures ANOVA (see Table 4) revealed large significant main effects for the factors threat category (guns, IEDs, knives, others) and condition (A, B, C, D). The interaction between both factors was also significant, implying that the size of the differences in RTs between the conditions varied with regard to threat category. As displayed in Figure 8, all conditions achieved fastest RTs for the category guns, while longest RTs are clearly observed for the category IEDs.
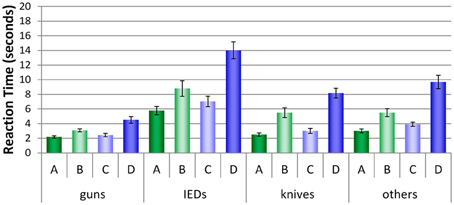
Figure 8. Mean reaction times (s) with standard errors of the mean for all four conditions (A–D) broken up by threat categories (guns, knives, IEDs, others).
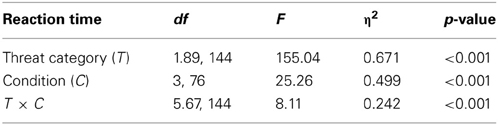
Table 4. Results of the repeated-measures ANOVA conducted with reaction time (RT).
To determine which condition actually took the longest time to complete the test all RTs for each security screener in each condition were summed and averaged across screening officers. Figure 9 displays these results. As described in the Method section, for test conditions A and C where laptops and bags were displayed separately, 288 images were displayed. In test conditions B and D, 192 images were shown. Even though fewer images were viewed in condition D, compared to conditions A and C, altogether, more time was needed to inspect these test images. While conditions A, B, and C did not differ from each other significantly, large differences were observed between each of these three conditions with condition D (see Table 5). These results indicate that even though fewer images had to be viewed when laptops were kept in passenger bags, altogether more time was needed to apply motion imaging and investigate these images thoroughly. Thus, while motion imaging provides a security advantage, it comes with a certain cost of efficiency.
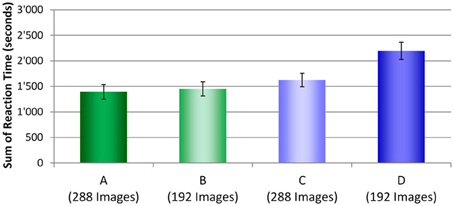
Figure 9. Sum of reaction times (s) averaged across participants with standard errors of the mean for all four conditions (A–D).
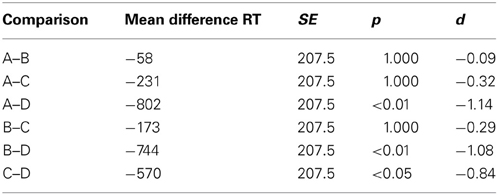
Table 5. Results of pairwise comparisons with Bonferroni correction for the sums of reaction times (in seconds) of all four conditions (SPSS Bonferroni adjusted p-values are quoted).
Summary and Conclusions
The benefits of an X-ray machine featuring a new technology offering multiple views of X-ray images and motion imaging were evaluated and compared to single view imaging. In specific, it was investigated whether leaving laptops inside passenger bags resulted in a decrease of detection performance and whether such an effect could be compensated by motion imaging. The results revealed that threat detection performance was much better when laptops and bags were screened separately (see also Mendes et al., 2012). Leaving laptops inside passenger bags resulted in a clear decrease of threat detection performance, supporting the view that increases in superposition and bag complexity affect detection performance negatively (Schwaninger et al., 2005b, 2007; Bolfing et al., 2008). Motion imaging technology could slightly improve threat detection performance. Yet, it could not compensate the negative effect of leaving laptops inside bags. Highest detection performance was achieved when motion imaging was available and laptops and bags were screened separately.
More detailed analyses indicate that performance differed remarkably with regard to the different threat categories [guns, improvised explosive devices (IEDs), knives, others]. IEDs and the others threat category were most difficult to detect, especially when laptops were not removed from passenger bags. Only a small advantage of motion imaging was observed. Merely for the detection of guns, motion imaging seemed to be of substantial benefit. Further analyses regarding the placement of threat items (in bag vs. in laptop) indicated that IEDs were particularly difficult to detect when these were built into the laptop cases. Specifically when laptops were left inside the bags, threat detection performance was quite low compared to when the laptops were displayed separately. Thus, when no automatic explosives detection is available and laptops are not removed from passenger bags, the detection of explosives and bombs, in particular, is impaired. For the categories knives and others, detection performance was higher when these were placed inside the laptops. This could be due to the fact that—for practical reasons—all threat items placed inside the laptops had to be positioned in easy views (canonical views). In general, threat items depicted in more difficult views were harder to detect. These findings are consistent with previous research on viewpoint effects, which showed that recognition of items depicted in frontal/canonical view is easier (e.g., Michel et al., 2007; Bolfing et al., 2008; Koller et al., 2008). Only for the category others, this effect was the other way round. As the category others contained a very heterogeneous group of threat items, possibly screening officers were more familiar with the items positioned in difficult views and thus detected these better. Results also showed that in general more time was needed to inspect the images when laptops were left inside the bags. Longest RTs were found when laptops were not removed from bags and motion imaging was applied. Thus, providing additional views is paid for by increasing RT (see also von Bastian et al., 2008). Even though fewer images were viewed when laptops were left inside the passenger bags, altogether more time was needed to apply motion imaging and inspect these images properly. Keeping factors such as throughput and efficiency at security checkpoints in mind, screening time is an important point to consider.
Technology for security screening will constantly be developed further. Yet, the final decision on whether threat items are contained in luggage still rely on human operators, who inspect the luggage based on an image provided by a machine. The presented study underlines the importance of thoroughly evaluating any new technological features with regard to their added value provided to the screening officers, prior to implementing these in the airport environment. In this study, only a slight benefit of motion imaging technology was revealed. No real advantage could be observed for the detection of IEDs, while the results do suggest that for certain objects such as guns, the rotation and availability of different viewpoints through motion imaging could improve identification. As previous research has shown (e.g., Michel et al., 2007) guns change their shape more drastically than other objects when rotated. Thus, one could assume that motion imaging would possibly be more helpful also for the detection of other threat types if larger rotations and more views are available (or even fully rotatable 3D images, see below).
All in all, the detection of threat items in cabin baggage screening currently still seems more reliable when laptops are taken out of passenger bags. Therefore, the outcomes of this study underline the appropriateness and importance of current regulations specifying that portable computers should be removed from passenger bags for X-ray screening. However, this might be reconsidered if effective and efficient automatic threat detection is available, which is particularly important for IEDs (see e.g., Singh and Singh, 2003; Eilbert, 2009; Mery et al., 2013). Furthermore, if more rotation in depth would be available, higher benefits could possibly be expected, which is of particular importance regarding new technological developments such as computer tomography offering 3D views. Effects of superposition and viewpoint could be reduced further and RTs could be decreased if screening officers can directly navigate to their preferred view of a bag image. In combination with automated threat detection this could possibly result in substantially higher human-machine system performance (see e.g., Flitton et al., 2010; Megherbi et al., 2010). However, this would have to be examined in further studies.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We are thankful to aviation security experts from the German Federal Police Technology Center for providing their valuable expertise and support for the creation and recording of x-ray images. We thank Zurich State Police, Airport Division, for providing screeners and supporting this study.
Footnotes
- ^For details on the calculation of A′ see section Results and Discussion.
- ^The set was based on a two-month data collection, assessing the contents and types of bags that were passing through the security checkpoints at an international European airport.
- ^Due to the packing condition, the proportion of target present and target absent trials differed for conditions A/C and B/D (in conditions A and C the ratio is 1:2; in conditions B and D the ratio is 1:1). According to signal detection theory (Green and Swets, 1966), different ratios of target present and target absent trials can result in a criterion shift (i.e., changes in hit and false alarm rates). Measures of detection performance in terms of sensitivity such as d' and A' are thought to be relatively independent of criterion shifts, which could also be shown in studies on target prevalence (e.g., Gur et al., 2003; Wolfe et al., 2007; Wolfe and Van Wert, 2010). Therefore, it can be assumed that the different proportions on target present trials in conditions A/C and B/D did not affect detection performance (A′) results in this study.
- ^In all analyses of variance in this study were Mauchly's test indicated that the assumption of sphericity had been violated, the degrees of freedom were corrected using Greenhouse-Geisser estimates of sphericity.
- ^In all t-tests of this study where Levene's test indicated unequal variances, degrees of freedom were adjusted using the default procedure in SPSS.
References
Aaronson, D., and Watts, B. (1987). Extension of Grier's computational formulas for A' and B” to below-chance performance. Psychol. Bull. 102, 439–442. doi: 10.1037/0033-2909.102.3.439
Biederman, I. (1987). Recognition-by-components: a theory of human image understanding. Psychol. Rev. 94, 115–147. doi: 10.1037/0033-295X.94.2.115
Blanz, V., Tarr, M. J., Bülthoff, H. H., and Vetter, T. (1999). What object attributes determine canonical views? Perception 28, 575–600. doi: 10.1068/p2897
Bolfing, A., Halbherr, T., and Schwaninger, A. (2008). “How image based factors and human factors contribute to threat detection performance in X-ray aviation security screening,” in HCI and Usability for Education and Work Lecture Notes in Computer Science, Vol. 5298, ed A. Holzinger (Berlin; Heidelberg: Springer-Verlag), 419–438. doi: 10.1007/978-3-540-89350-9_30
Brown, W., Emery, T., Gergory, M., Hackett, R., Yates, C., and Ling, J. (1995). Advanced Physics: Practical Guide. Harlow: Longman.
Bülthoff, H. H., and Edelman, S. (1992). Psychophysical support for a two-dimensional view interpolation theory of object recognition. Proc. Natl. Acad. Sci. U.S.A. 89, 60–64. doi: 10.1073/pnas.89.1.60
Bülthoff, I., and Bülthoff, H. H. (2006). “Objektwahrnehmung,” in Handbuch der Allgemeinen Psychologie – Kognition, eds J. Funke and P. A. Frensch (Göttingen: Hogrefe Verlag), 165–172.
Burgund, E. D., and Marsolek, C. J. (2000). Viewpoint-invariant and viewpoint-dependent object recognition in dissociable neural subsystems. Psychon. Bull. Rev. 7, 480–489. doi: 10.3758/BF03214360
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences. New York, NY: Erlbaum, Hillsdale.
Edelman, S., and Bülthoff, H. H. (1992). Orientation dependence in the recognition of familiar and novel views of three-dimensional objects. Vision Res. 32, 2385–2400. doi: 10.1016/0042-6989(92)90102-O
Eilbert, R. F. (2009). “Chapter 6 – X-ray technologies,” in Aspects of Explosives Detection, eds M. M. Marshall and J. C. Oxley (Oxford: Elsevier), 89–130. doi: 10.1016/B978-0-12-374533-0.00006-4
European Comission. (2010). Commission regulation (EU) No 185/2010 of March 2010 laying down detailed measures for the implementation of the common basic standards on aviation security. Official J. Eur. Union 53, 1–55.
Flitton, G. T., Breckon, T. P., and Bouallagu, N. M. (2010). “Object recognition using 3D SIFT in complex CT volumes,” in Proceedings of the British Machine Vision Conference, eds F. Labrosse, R. Zwiggelaar, Y. Liu, and B. Tiddeman (BMVA Press), 1–12. doi: 10.5244/C.24.11
Graf, M., Schwaninger, A., Wallraven, C., and Bülthoff, H. H. (2002). Psychophysical Results from Experiments on Recognition and Categorisation. Information Society Technologies (IST) Programme, Cognitive Vision Systems CogVis (IST-2000–29375), Tübingen: Max Planck Institute for Biological Cybernetics.
Graves, I., Butavicius, M., Mac Leod, V., Heyer, R., Parsons, K., Kuester, N., et al. (2011). “The role of the human operator in image-based airport security technologies,” in Innovations in Defence Support Systems – Socio-Technical Systems, Studies in Computational Intelligence, Vol. 338, eds L. C Jain, E. V. Aidman, and C. Abeynake (Berlin; Heidelberg: Springer Verlag), 147–181. doi: 10.1007/978-3-642-17764-4_5
Green, D. M., and Swets, J. A. (1966). Signal Detection Theory and Psychophysics. New York, NY: Wiley.
Grier, J. B. (1971). Nonparametric indexes for sensitivity and bias: computing formulas. Psychol. Bull. 75, 424–429. doi: 10.1037/h0031246
Gur, D., Rockette, H. E., Armfield, D. R., Blachar, A., Bogan, J. K., Brancatelli, G., et al. (2003). Prevalence effect in a laboratory environment1. Radiology 228, 10–14. doi: 10.1148/radiol.2281020709
Hardmeier, D., Hofer, F., and Schwaninger, A. (2005). The x-ray object recognition test (x-ray ort) – a reliable and valid instrument for measuring visual abilities needed in x-ray screening. IEEE ICCST Proc. 39, 189–192.
Hardmeier, D., Hofer, F., and Schwaninger, A. (2006). “Increased detection performance in airport security screening using the X-Ray ORT as pre-employment assessment tool” in Proceedings of the 2nd International Conference on Research in Air Transportation, ICRAT 2006 (Belgrade), 393–397.
Hofer, F., and Schwaninger, A. (2004). Reliable and valid measures of threat detection performance in X-ray screening. IEEE ICCST Proc. 38, 303–308.
Humphrey, G. K., and Khan, S. C. (1992). Recognizing novel views of three-dimensional objects. Can. J. Psychol. 46, 170–190. doi: 10.1037/h0084320
Koller, S., and Schwaninger, A. (2006). “Assessing X-ray image interpretation competency of airport security screeners,” Proceedings of the 2nd International Conference on Research in Air Transportation, ICRAT 2006 (Belgrade), 399–402.
Koller, S. M., Hardmeier, D., Michel, S., and Schwaninger, A. (2008). Investigating training, transfer, and viewpoint effects resulting from recurrent CBT of X-ray image interpretation. J. Transp. Secur. 1, 81–106. doi: 10.1007/s12198-007-0006-4
Kosslyn, S. M. (1994). Image and Brain. The Resolution of the Imagery Debate. Cambridge, MA: MIT Press.
Kravitz, D. J., Vinson, L. D., and Baker, C. I. (2008). How position dependent is visual object recognition? Trends Cogn. Sci. 12, 114–122. doi: 10.1016/j.tics.2007.12.006
Marr, D., and Nishihara, H. K. (1978). Representation and recognition of the spatial organization of three-dimensional shapes. Proc. R. Soc. Lond. B 200, 269–294. doi: 10.1098/rspb.1978.0020
Megherbi, N., Flitton, G. T., and Breckon, T. P. (2010). “A classifier based approach for the detection of potential threats in CT based baggage screening,” in Proceedings of the 17th IEEE International Conference on Image Processing (ICIP), (Hong Kong), 1833–1836. doi: 10.1109/ICIP.2010.5653676
Mendes, M., Schwaninger, A., Strebel, N., and Michel, S. (2012). “Why laptops should be screened separately when conventional x-ray screening is used,” in Proceedings of the 46th IEEE International Carnahan Conference on Security Technology (Boston, MA). doi: 10.1109/CCST.2012.6393571
Mery, D., Mondragon, G., Riffo, V., and Zuccar, I. (2013). Detection of regular objects in baggage using multiple X-ray views. Insight 55, 16–20. doi: 10.1784/insi.2012.55.1.16
Michel, S., de Ruiter, J. C., Hogervorst, M., Koller, S. M., Moerland, R., and Schwaninger, A. (2007). “Computer-based training increases efficiency in X-ray image interpretation by aviation security screeners,” in Proceedings of the 41st Carnahan Conference on Security Technology (Ottawa).
Michel, S., Mendes, M., and Schwaninger, A. (2010). “Can the difficulty level reached in computer-based training predict results in x-ray image interpretation tests?,” in Proceedings of the 44th Carnahan Conference on Security Technology (San Jose, CA).
Michel, S., and Schwaninger, A. (2009). “Human machine interaction in X-ray screening,” in Proceedings of the 43rd IEEE International Carnahan Conference on Security Technology (Zurich). doi: 10.1109/CCST.2009.5335572
Mitsumatsu, H., and Yokosawa, K. (2003). Efficient extrapolation of the view with a dynamic and predictive stimulus. Perception 32, 969–983. doi: 10.1068/p5068
Palmer, S., Rosch, E., and Chase, P. (1981). “Canonical perspective and the perception of objects,” in Attention and Performance IX, eds J. Long and A. Baddeley (Hillside, NJ: Lawrence Erlbaum), 135–151.
Peissig, J. J., and Tarr, M. J. (2007). Visual object recognition: do we know more than we did 20 years ago? Annu. Rev. Psychol. 58, 75–96. doi: 10.1146/annurev.psych.58.102904.190114
Pike, G. E., Kemp, R. I., Towell, N. A., and Phillips, K. C. (1997). Recognizing moving faces: the relative contribution of motion and perspective view information. Vis. Cogn. 4, 409–437. doi: 10.1080/713756769
Poggio, T., and Edelman, S. (1990). A network that learns to recognize three-dimensional objects. Nature 343, 263–266. doi: 10.1038/343263a0
Pollack, I., and Norman, D. A. (1964). A non-parametric analysis of recognition experiments. Psychon. Sci. (75), 125–126.
Schwaninger, A. (2005). “Objekterkennung und Signaldetektion,” in Praxisfelder der Wahrnehmungspsychologie, ed B. Kersten (Bern: Huber), 108–132.
Schwaninger, A., Hardmeier, D., and Hofer, F. (2005a). Aviation security screeners visual ablilities and visual knowledge measurement. IEEE Aerosp. Electron. Syst. 20, 29–35.
Schwaninger, A., Michel, S., and Bolfing, A. (2005b). Towards a model for estimating image difficulty in x-ray screening. IEEE ICCST Proc. 39, 185–188. doi: 10.1109/CCST.2005.1594875
Schwaninger, A., Michel, S., and Bolfing, A. (2007). “A statistical approach for image difficulty estimation in X-ray screening using image measurements,” in Proceedings of the 4th Symposium on Applied Perception in Graphics and Visualization (New York, NY: ACM Press), 123–130. doi: 10.1145/1272582.1272606
Singh, S., and Singh, M. (2003). Explosives detection systems (EDS) for aviation security. Signal Process. 83, 31–55. doi: 10.1016/S0165-1684(02)00391-2
Tarr, M. J. (1995). Rotating objects to recognize them: a case study on the role of viewpoint dependency in the recognition of three-dimensional objects. Psychon. Bull. Rev. 2, 55–82. doi: 10.3758/BF03214412
von Bastian, C. C., Schwaninger, A., and Michel, S. (2008). Do multi-view X-ray systems improve X-ray image interpretation in airport security screening? Zeitschrift für Arbeitswissenschaft 3, 166–173.
von Bastian, C. C., Schwaninger, A., and Michel, S. (2010). Color impact on security screening. Aerospace Electron. Syst. Mag. 25, 33–38. doi: 10.1109/MAES.2010.5631724
Vuong, Q. C., and Tarr, J. T. (2004). Rotation direction affects object recognition. Vision Res. 44, 1717–1730. doi: 10.1016/j.visres.2004.02.002
Wolfe, J. M., Horowitz, T. S., Van Wert, M. J., Kenner, N. M., Place, S. S., and Kibbi, N. (2007). Low target prevalence is a stubborn source of errors in visual search tasks. J. Exp. Psychol. Gen. 136, 623–638. doi: 10.1037/0096-3445.136.4.623
Wolfe, J. M., and Van Wert, M. J. (2010). Varying target prevalence reveals two dissociable decision criteria in visual search. Curr. Biol. 20, 121–124. doi: 10.1016/j.cub.2009.11.066
Yoo, K. E. (2009). “Screening on the ground, security in the sky,” in Protecting Airline Passengers in the Age of Terrorism, eds P. Seidenstat and F. X. Splane (Santa Barbara, CA: Praeger Security International), 63–85.
Keywords: aviation security, X-ray screening, threat detection, human factors, motion imaging, multiple views, laptop screening
Citation: Mendes M, Schwaninger A and Michel S (2013) Can laptops be left inside passenger bags if motion imaging is used in X-ray security screening? Front. Hum. Neurosci. 7:654. doi: 10.3389/fnhum.2013.00654
Received: 31 May 2013; Paper pending published: 22 July 2013;
Accepted: 19 September 2013; Published online: 18 October 2013.
Edited by:
Andrea Szymkowiak, University of Abertay Dundee, UKReviewed by:
Elena Rusconi, University College London, UKLynne M. Coventry, Northumbria University, UK
Copyright © 2013 Mendes, Schwaninger and Michel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Adrian Schwaninger, School of Applied Psychology, Institute Humans in Complex Systems, University of Applied Sciences and Arts Northwestern Switzerland, Riggenbachstrasse 16, 4600 Olten, Switzerland e-mail:YWRyaWFuLnNjaHdhbmluZ2VyQGZobncuY2g=