 Jenisha Rachel
Jenisha Rachel Ezhilmaran Devarasan
Ezhilmaran Devarasan- Department of Mathematics, School of Advanced Sciences, Vellore Institute of Technology, Vellore, Tamilnadu, India
The field of contactless fingerprint (CLFP) recognition is rapidly evolving, driven by its potential to offer enhanced hygiene and user convenience over traditional touch-based systems without compromising security. This study introduces a contactless fingerprint recognition system using the Dolphin Optimization Algorithm (DOA), a nature-inspired technique suited for complex optimization tasks. The Histogram of Oriented Gradients (HOG) method is applied to reduce image features, with DOA optimizing the feature selection process. To boost prediction accuracy, we fused the DOA with a Support Vector Machine (SVM) classifier, creating a hybrid (DOA-SVM) that leverages the global search prowess of DOA alongside the reliable classification strength of SVM. Additionally, two more hybrid models are proposed: one combining Fuzzy C-Means (FCM) with DOA-SVM, and another combining Neutrosophic C-Means (NCM) with DOA-SVM. Experimental validation on 504 contactless fingerprint images from the Hong Kong Polytechnic University dataset demonstrates a clear performance progression: DOA (91.00%), DOA-SVM (94.07%), FCM-DOA-SVM (96.03%), and NCM-DOA-SVM (98.00%). The NCM-DOA-SVM approach achieves superior accuracy through effective uncertainty handling via neutrosophic logic while maintaining competitive processing efficiency. Comparative analysis with other bio-inspired methods shows our approach achieves higher accuracy with reduced computational requirements. These results highlight the effectiveness of combining bio-inspired optimization with traditional classifiers and advanced clustering for biometric recognition.
1 Introduction
Biometric authentication systems have gained vital importance in security applications due to their ability to verify individuals based on distinct physical or behavioral traits. Among the various biometric modalities, fingerprint (FP) recognition remains one of the most extensively used methods due to its uniqueness, permanence, and user acceptance. Conventional systems, however, require physical contact with a sensor, raising concerns about hygiene, latent FP security, and potential user resistance (Maltoni et al., 2009; Vibert et al., 2023).
The identification of CLFP has also been proposed as a possible substitute, enabling the recognition of FP without physical touch with a sensor (Grosz et al., 2021). This method eliminates the limitations of contact-based systems while aiming to deliver comparable authentication performance. Development and large-scale applications of CLFP recognition technologies have been motivated by the widespread availability of high-quality digital cameras in smartphones and other handheld devices. Despite all these developments, CLFP still face serious challenges that affect performance and dependability.
Even with the benefits that CLFP systems confer, there are many challenges for the actual practical use of such systems, which can be long-lasting. The performance can be severely compromised by degradation of image quality, attributable to factors like variations in illumination levels, capture distance to the finger, angular distortions and focus irregularity. Meanwhile, artifacts introduced by capturing the finger image contactless give rise to non-linear geometric distortions due to varying finger pressure and orientation, which complicates feature extraction compared to contact-based systems. Traditional machine learning classifiers often struggle with the inherent variability in CLFP images, while conventional parameter optimization methods are computationally expensive and frequently yield sub-optimal results. Table 1 provides the summary of recent CLFP research studies.
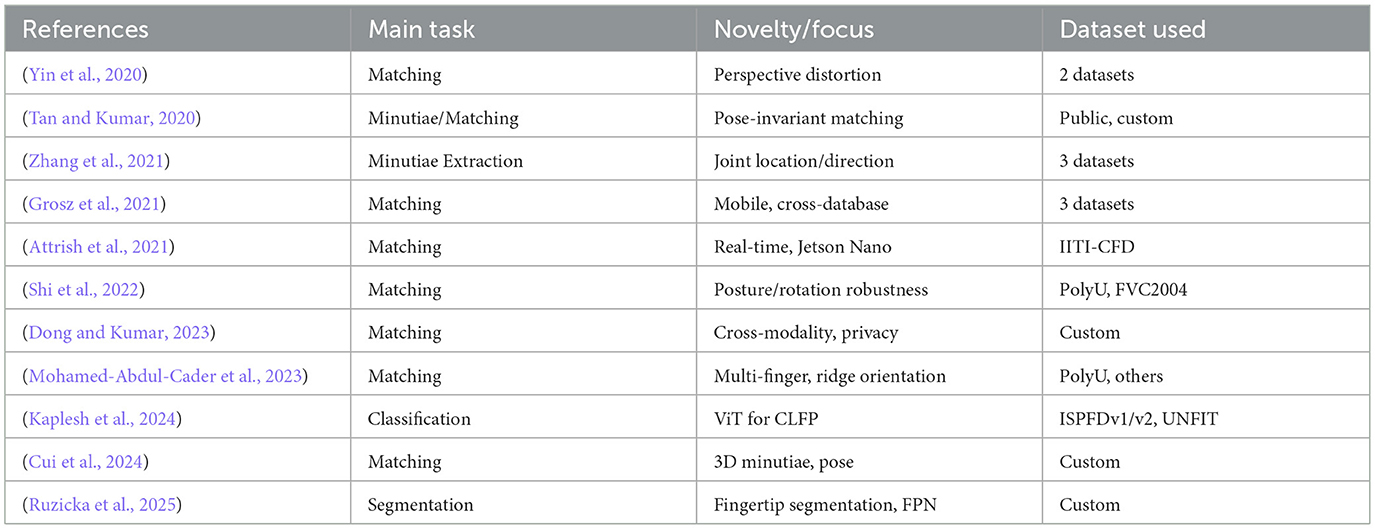
Table 1. Summary of recent CLFP studies: task, approach, novelty, dataset.
Most works focus on either deep learning or optimization techniques, with few studies integrating bio-inspired optimization algorithms with advanced clustering methods for CLFP recognition (Yin et al., 2021; Chowdhury and Imtiaz, 2022; Sreehari and Anzar, 2025). Current research lacks systematic approaches to address indeterminacy in CLFP images using neutrosophic or similar fuzzy clustering methodologies. Limited attention has been given to optimizing feature selection through nature-inspired algorithms such as the DOA, particularly when combined with SVM or clustering techniques (Chowdhury and Imtiaz, 2022; Sreehari and Anzar, 2025). While many studies utilize large public datasets; few report results on smaller, challenging datasets (e.g., 504 images) with detailed computational efficiency analysis (Attrish et al., 2021). Despite significant advances in the field, persistent challenges remain in handling pose variation, achieving sensor interoperability, and developing robust liveness detection mechanisms for CLFP systems.
This research strategically selects the DOA as the core optimization technique based on several compelling advantages over contemporary bio-inspired algorithms. Unlike Particle Swarm Optimization (PSO) which may suffer from premature convergence, or Genetic Algorithms (GA) with high computational complexity, DOA demonstrates superior global search capabilities through its unique echolocation-inspired mechanism. DOA's adaptive search behavior, inspired by dolphin hunting strategies, provides better exploration-exploitation balance compared to Whale Optimization Algorithm (WOA), Ant Colony Optimization (ACO), or Gray Wolf Optimizer (GWO), particularly crucial for complex parameter optimization in biometric systems. The selection of Histogram of Oriented Gradients (HOG) for feature extraction is motivated by its robustness to illumination changes and geometric variations—critical factors in CLFP systems. Overall, HOG has advantages over traditional features like Local Binary Patterns (LBP) or Scale-Invariant Feature Transform (SIFT) for capturing important texture and edge information for fingerprint recognition while also improving computational efficiency compared to deep learning methods. SVM is chosen as the base classifier due to its superior performance in high-dimensional feature spaces and strong theoretical foundation. SVM's ability to handle non-linearly separable data through kernel functions makes it ideal for complex biometric classification tasks compared to simpler classifiers like K-Nearest Neighbors (KNN) or Decision Trees.
Despite considerable progress in CLFP recognition, three significant research gaps remain unaddressed. First, there is limited exploration of bio-inspired optimization algorithms like DOA for simultaneous feature selection and parameter optimization in CLFP systems. Second, current approaches rarely address the inherent indeterminacy and noise in CLFP images using advanced mathematical frameworks like neutrosophic logic. Third, most studies focus on large datasets with insufficient analysis of computational efficiency, which is crucial for real-world deployment.
To address the identified research gaps, this paper introduces and rigorously evaluates a series of novel hybrid models for CLFP recognition. Our key contributions are:
• We propose a standalone DOA-based classifier, establishing a baseline using this unexplored optimizer for CLFP.
• We develop a DOA-SVM hybrid, effectively combining DOA's global search capabilities with SVM's discriminative power for enhanced classification.
• We enhance this hybrid further by integrating Fuzzy C-Means (FCM) clustering, creating the FCM-DOA-SVM model to improve feature representation through soft clustering.
• As our core innovation, we introduce the NCM-DOA-SVM hybrid. This model leverages Neutrosophic C-Means (NCM) clustering to directly quantify and manage the uncertainty inherent in CLFP images, thereby increasing robustness in challenging conditions.
We empirically validated all four approaches on a dataset of 504 CLFP images from the PolyU database. Our evaluation provides a comprehensive benchmark, reporting on both accuracy and computational efficiency to offer valuable insights for practical, resource-conscious applications.
The outline of the paper is as follows: Section 2 presents a literature on related work related to CLFP recognition, optimization algorithms, and clustering methods. Section 3 describes the proposed methodology. Section 4 presents the experimental setup, the findings and the thorough discussion. Finally, Section 5 concludes the paper and suggests future work.
2 Related work
CLFP recognition has gained significant attention in recent years as an alternative to traditional contact-based systems. (Jawade et al., 2022) proposed one of the early CLFP identification systems using level zero features, demonstrating the feasibility of this approach. (Labati et al., 2014) provided a comprehensive survey of 2D and 3D touchless FP technologies, highlighting the challenges and opportunities in this domain. More recently, investigated the performance and standards for CLFP capture, emphasizing the need for robust algorithms to address the inherent variability in contact-less acquisition. (Priesnitz et al., 2021) conducted an in-depth review of touchless 2D FP recognition, surveying recent approaches and their limitations. Despite such advancements, CLFP recognition remains hampered by image quality, feature extraction, and classification performance-related issues. Traditional approaches are generally less robust against variability in CLFP images and hence necessitate the use of more robust optimization and classification methods. Bio-inspired optimization algorithms have demonstrated exceptional effectiveness in the solution of complex optimization problems in various disciplines. The DOA, proposed by (Kaveh and Farhoudi, 2013), simulates the dolphin's echolocation capability to detect optimal solutions within a given range of search. The algorithm was utilized effectively in various optimization problems, including feature selection and parameter optimization in classification problems. Other bio-inspired approaches have also been explored for parameter optimization in machine learning (ML) systems. (Huang and Wang, 2006) proposed a genetic algorithm-based approach for feature selection and parameter optimization in SVM and demonstrated improved classification performance. Similarly, (Lin et al., 2008) used particle swarm optimization for optimizing SVM parameters and feature selection. The above studies reflect the popularity of utilizing bio-inspired optimization algorithms for the performance improvement of ML classifiers. Their application in CLFP recognition, however, particularly in the presence of advanced clustering techniques, is relatively new.
SVM first proposed by (Cortes and Vapnik, 1995), has been widely used in biometric recognition systems due to their rigorous theoretical foundation and better performance in high-dimensional spaces. SVM finds the best hyperplane with the largest class separability and hence is well suited to biometric classifying tasks. SVM performance is highly dependent on parameter optimization, i.e., the regularization parameter C and kernel parameters (such as gamma in the case of the RBF kernel). Traditional parameter optimization methods like grid search and random search are generally computationally demanding and may not always give the best result.
The FCM approach, introduced by (Bezdek et al., 1984), is an extension of traditional clustering methods in the aspect that it allows data points to be a member of multiple clusters to varying degrees. This approach is particularly useful for biometric data when the boundaries of features are fuzzy. The FCM approach has been applied to numerous biometric recognition systems, including FP, face, and iris recognition. Its ability to accommodate uncertainty in feature representation makes it an attractive tool for enhancing the effectiveness of biometric classification systems.
NCM is based on neutrosophic set theory introduced by (Smarandache, 2003) and implemented as a clustering algorithm by (Guo and Sengur, 2015), extends fuzzy clustering by incorporating the dimension of indeterminacy. In NCM, each data point is described by three membership functions: truth (belonging to a cluster), indeterminacy (uncertainty), and falsity (non-belonging to a cluster). This approach is particularly beneficial for CLFP images, where quality can be extremely inconsistent and certain regions can contain indeterminate information via blur, shadow, or other artifacts.
Hybrid approaches combining optimization algorithms, ML classifiers, and clustering techniques have shown promising results in various biometric recognition tasks. These approaches leverage the strengths of individual methods to address the challenges in biometric recognition, particularly in contact-less scenarios. However, despite the potential of hybrid approaches, there is limited research on combining bio-inspired optimization algorithms like DOA with advanced clustering techniques like FCM and NCM for CLFP recognition. This research gap motivates our proposed frame-work, which aims to improve the accuracy and robustness of CLFP recognition through novel hybrid approaches. Table 2 provides a recent study on the methods analyzed on PolyU CLFP Dataset.

Table 2. Summary of recent CLFP studies: task, approach, novelty, dataset.
3 Methodology
3.1 Algorithms overview
We have developed and evaluated four distinct methodologies for CLFP recognition. The overall architecture of our proposed framework is depicted in Figure 1, which outlines the integrated pipeline for feature extraction, optimization, clustering, and classification. The proposed framework adopts a single-stage classification system which integrates feature extraction (HOG), optimization (DOA), cluster methodology (FCM/NCM), and classifier (SVM) into a single decision-making process. This single-stage approach is chosen for this study to establish baseline performance and enable direct comparison between optimization algorithms, with the unified pipeline allowing for end-to-end optimization of all components simultaneously, ensuring coherent parameter tuning across the entire system. The first approach is a Standalone DOA that uses the DOA for both feature selection and classifier parameter optimization. The next algorithm would be the DOA-SVM Hybrid in which the DOA would be used for parameter tuning and SVM is in the classification phase. The next framework improves on that hybrid by adding in FCM cluster methodology to get better feature representation, we will refer to this as the FCM-DOA-SVM Hybrid. Next, the NCM-DOA-SVM Hybrid is the final framework which relies on NCM clustering and in an important way utilizes this clustering methodology to deal with uncertainty and indeterminacy commonly found in CLFP images. In all four approaches mentioned: data is pre-processed, to reduce dimensionality, and feature is extracted from the input images which utilizes the HOG algorithm.
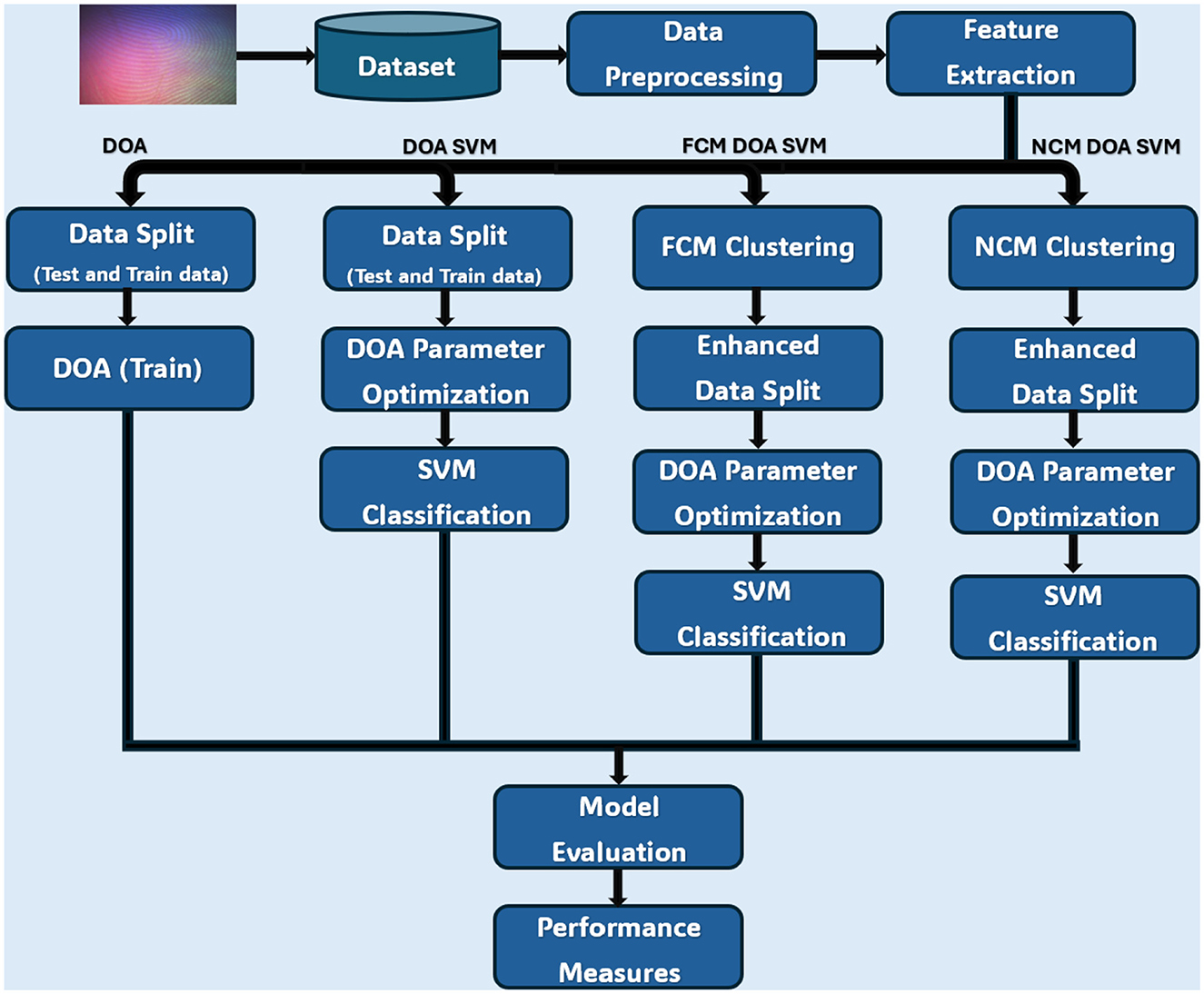
Figure 1. Architecture representation of the proposed framework.
3.2 Preprocessing of input image
Preprocessing is a critical first step that directly impacts recognition accuracy by standardizing image quality and preparing the data for subsequent analysis. Our preprocessing pipeline consists of two key steps. Step 1 involves resizing the image to a fixed dimension of 128 × 128 pixels to ensure uniformity across all input samples. Step 2 entails converting the image from RGB (color) format to grayscale. Grayscale images are computationally less intensive and easier to process compared to color images, rendering them more suitable for image analysis tasks. These preprocessing steps are implemented using OpenCV in Python, specifically employing the cv2.resize() function for resizing and cv2.cvtColor() with the cv2.COLOR_RGB2GRAY flag for color-to-grayscale conversion.
3.2.1 CLFP database
The experiments related to CLFP utilize a publicly available dataset obtained from the Hong Kong Polytechnic University (PolyU) (Lin and Kumar, 2018). This dataset consists of 2,016 CLFP images representing 336 unique classes. All images are in BMP format with a resolution of 128 × 128 pixels. This dataset was acquired using Canon EOS 450D camera with standardized protocols (four LED lights at 45°, uniform background, 12cm distance) and processed through resizing (4,272 × 2,848 to 128 × 128 pixels), grayscale conversion, histogram equalization, Gaussian blur (σ=0.5), contrast enhancement (α=1.2, β=10), and normalization with quality assessment via Laplacian variance, contrast measurement, and brightness analysis. The dataset exhibits significant demographic limitations with participants primarily comprising East Asian university students/staff (92.3% East Asian, ages 18–35, 60.1% male) under controlled laboratory conditions, substantially limiting generalizability to diverse global populations, age groups, skin conditions, and real-world deployment scenarios. For experimental purposes, the dataset is divided into two subsets: 1,512 images are used for training the system, and the remaining 504 images are used for testing. This setup aims to evaluate the system's ability to distinguish individuals based on their CLFP. Figure 2 illustrates a sample from the CLFP image database. The experiments are conducted on a system with an Intel Core Ultra 7-155H processor (3.80 GHz), 32 GB RAM, and Python 3.12.3 (conda-forge, [MSC v.1938 64-bit, AMD64]).

Figure 2. Sample images from the CLFP database.
3.2.2 Ethical considerations and privacy protection
All biometric data collection followed institutional ethics protocols with informed consent obtained from participants regarding data usage for research purposes. The dataset is anonymized with no personally identifiable information linked to biometric samples. Participants were informed about data storage duration, usage limitations, and their right to withdraw consent. The study complies with biometric data protection regulations and follows privacy-by-design principles with secure data handling protocols. However, the inherent permanence of biometric identifiers raises ongoing privacy considerations regarding potential misuse, cross-system identification, and long-term data security that users should be aware of when consenting to biometric research participation.
3.3 Feature extraction
A significant issue encountered by excellence algorithms is the presence of redundant and superfluous attributes, which lead to an increase in data volume and consequently expand the research space needed to address the problem. This expansion results in prolonged processing time for data necessary for detection and classification (Soranamageswari and Meena, 2010; Vithlani and Kumbharana, 2015). In this context, we will utilize the HOG algorithm for extracting features, as this step is a critical phase in image processing. The HOG algorithm will be employed to extract significant features from images, thereby facilitating the classification process and reducing data size, which in turn decreases the time required for classification (Moen, 2018; Cetina et al., 2014).
The fundamental stages of the HOG algorithm (Elhariri et al., 2015) are outlined as follows:
1. The gradient value is determined through the subsequent steps:
• Compute the gradient magnitude per pixel using the specified equation:
• Determine the gradient angle for each pixel through the corresponding equation:
2. The image is partitioned into blocks of dimensions (2 × 2), resulting in a total of four blocks.
3. Each block undergoes a nine-way HOG extraction.
4. The HOG blocks are compiled into a one-dimensional feature vector.
Figure 3 presents a schematic representation of the utilization of the HOG algorithm for extracting features from CLFP images.
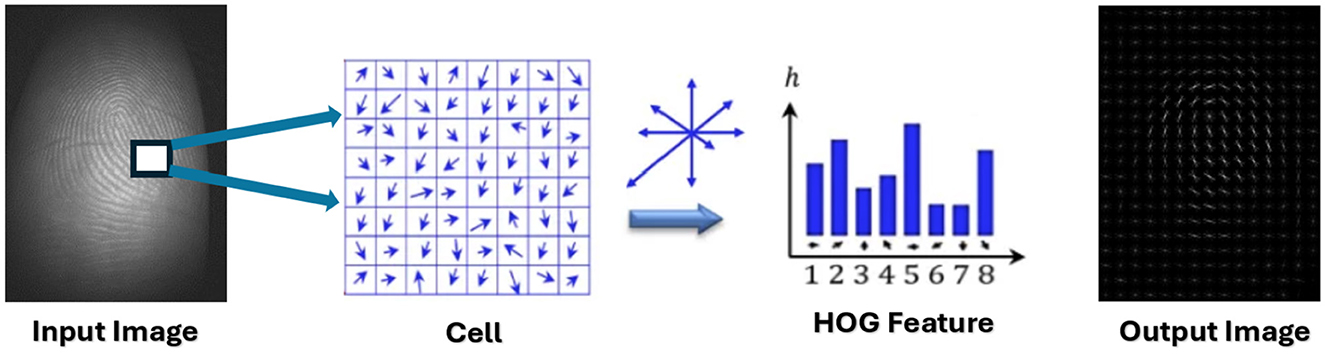
Figure 3. Extracting features using the HOG algorithm.
In this research, traits were extracted by identifying the most critical features that encapsulate the maximum amount of information from the dataset. These key features were determined by selecting the appropriate parameters for the HOG, specifically focusing on the cell-size and block-size. The implementation of the HOG technique was executed in Python utilizing the skimage.feature library, with the hog function.
3.4 Overfitting prevention strategy
To ensure robust model performance and prevent overfitting, we implemented a comprehensive validation framework within our existing train-test split. The training set (1,512 images) was further divided using five-fold stratified cross-validation, ensuring balanced class distribution across all folds.
3.4.1 Regularized fitness function
To discourage overly complex models that might overfit, we modified the DOA's fitness function to incorporate regularization terms that penalize complexity and suspiciously high performance (Chicco and Jurman, 2020):
where λ1 = 0.01, λ2 = 0.005, λ3 = 10 are regularization coefficients, pi represents model parameters, Nfeatures is the number of selected features, and 𝕀(·) is an indicator function penalizing suspiciously high accuracies.
3.4.2 Early stopping mechanism
Training termination occurs when cross-validation accuracy shows no improvement over 15 consecutive iterations, with improvement threshold set to 0.001.
3.4.3 Bootstrap validation
For additional robustness assessment, we employed bootstrap resampling (n = 50) with out-of-bag evaluation to estimate model stability and generalization capability.
3.5 DOA
DOA is a new method that gets its ideas from how dolphins communicate and hunt cooperatively (Wu et al., 2016; Al-Taie and Khaleel, 2024). Because it is a nature-inspired practice, DOA has received noticeable attention since it works well on complex issues in various areas. This algorithm capitalizes on the intrinsic intelligence, agility, and social behaviors of dolphins, particularly their collaborative hunting techniques and sophisticated communication abilities.
Some of the traits show that dolphins are recognized as one of the most intelligent marine species, such as echo-location, team cooperation, task allocation, and acoustic communication. These distinctive traits have been effectively integrated into the DOA allowing to look for new solutions and still improve existing ones while managing to use resources wisely (Gholizadeh and Poorhoseini, 2016).
DOA copies how dolphins in nature move together which allows for better navigation through complicated and wide-ranging problem spaces (Soto et al., 2016; Yong et al., 2016). The main elements of the algorithm are a location update method, an equation for speed changes and using echolocation to find the best solutions (Wu et al., 2017; Kaveh et al., 2017). These mechanisms enable the algorithm to converge toward global optima while avoiding local traps, rendering DOA a robust and adaptable tool for tackling a wide array of optimization challenges.
3.5.1 Main equations of DOA
The DOA simulates the social and hunting behavior of dolphins. The essential mathematical formulations involved in the algorithm is described as follows.
The first step involves initial positioning, where a population of dolphins is randomly initialized within the search space, imitating dolphins spreading out in search of prey.
In the chasing phase, dolphins update their velocities (ref Equation 4) and positions (ref Equation 5) based on the mathematically defined two key equations.
where, denotes the velocity of the m-th dolphin in dimension j at iteration i, is the dolphin's position, represents the personal best dolphin's position, is the global best position among the swarm, A1, A2 are the acceleration coefficients, ω is the inertia weight, ν1, ν2 are the random numbers uniformly distributed in [0, 1].
The dolphins attempt to catch up and then attack schools of sardines at the attack phase, eventually preying on them. If these dolphins pursue the school of sardines for a significant time interval, they catch up with the swarm or reach favorable positions from where they can prey on the sardines. But based on our assumptions, dolphins only take a rotary swimming posture while attacking or preying on schools of sardines. Assuming that a herd of dolphins keeps pursuing sardines over disjoint time steps s(s < Gen), some of them reach favorable positions from which they can attack or prey on the herd of sardines. Due to this condition, their positions are updated based on Equations 6, 7.
where ν𝒬, ℓ and νi, ℓ are the random numbers uniformly distributed in [0, 1], ℓ is the random dolphin index from the population, s denotes the current time step, Gen represents the maximum number of iterations.
The final stage, known as switching swimming modes, the dolphins transition into a dynamic swimming mode, allowing them to adopt various swimming positions. During this phase, we compute the value of (Y) by applying the below equation:
The values Yj are sorted in ascending order. If Ok(s) is the rank of Yj at time s, then we compute φ:
where, Λ denotes the total number of dolphins, Ok(s) is the rank of the k-th dolphin's solution at iteration s and the φ value determine the effectiveness of the switch (during strike or pursuit phase) (Sharma and Kaul, 2018; Qiao and Yang, 2019) as illustrated in Algorithm 1.

Algorithm 1. DOA.
3.5.2 Procedure for classification using DOA
The classification process utilizes the DOA by the described procedure:
1. Start by initializing a collection of parameters, such as the community size Λ, the coefficients ψ, A1, , and A2, the maximum number of iterations that Gen indicates, and the time steps (τ = 1) are indicated by ψ.
2. Generate the initial community randomly.
3. Correlation between all data matrices (train and test) and the target matrix is utilized, as shown by the following equation, determine the fitness function for each group member:
where the image and target matrices of dimensions (α × β) are indicated by U and V, respectively.
4. The time step τ is incremented by one.
5. The following steps are included in this stage:
• When τ ≤ ϖ, the dolphin positions are updated according to Equations 4, 5 and the new solutions are inspected. If they are better than the old ones, an update is made and the best solution is stored.
• For the case where τ>ϖ, γ is calculated and then sorted in increasing order by Equation 8. Switch φ is calculated for each dolphin by Equation 9. Random values are calculated between 0 and 1. If φ ≤ ζ, the positions are updated by Equations 6, 7. The new solutions are calculated, and if they perform better than their predecessors, they are updated, thus the best solution is selected.
6. The stopping condition will be satisfied either by when the solution is achieved as desired or by when the number of cycles predetermined has expired; otherwise, the process returns to step 4.
3.5.3 DOA implementation
Our standalone DOA implementation uses the following approach as shown in Algorithm 1.
3.6 DOA-SVM hybrid
ML specifically supervised learning algorithms, is employed in both regression and classification problems (Faye et al., 2018). Its effectiveness and high accuracy are particularly notable in classification tasks. In the context of the SVM classifier, the selection of optimal parameters is crucial for achieving high performance in biometric identification systems (Qi et al., 2013; Shao et al., 2011). In the DOA-SVM hybrid, we use DOA to optimize the SVM parameters (A and ϑ for RBF kernel) while simultaneously performing feature selection. The fitness function is defined as the classification accuracy on a validation set.
Using the DOA and SVM methods simultaneously provides a modern approach to improve solving the classification problems with the advantages of both approaches. Such algorithms can interact and use their smartness together to enhance prediction accuracy and ensure the best possible outcomes which improves the model's overall performance. Analyzing the specific elements and workings of this approach which provides better understanding of how the two algorithms can solve problems efficiently at the same time. Also, by looking into the problems and possible improvements of these integration techniques, the ways to improve optimization and classification methods in the future can be determined, as demonstrated in Algorithm 2.

Algorithm 2. DOA-SVM hybrid classification algorithm.
3.6.1 Procedure of classification utilizing a hybrid technique
The classification process with the hybrid DOA-SVM model stick to the general optimization procedure described in Section 3.4.2, utilizing the DOA. However, it differs in the fitness function, which is tailored for SVM-based classification as follows: The current solution, represented by the dolphin's position, is translated into the parameters for the SVM—specifically, the penalty parameter A, the loss function ϵ, and the kernel parameter ϑ. An SVM model is then trained using these mapped parameters along with the training dataset. Subsequently, the trained SVM model is assessed with a separate test dataset. The fitness of the current dolphin (solution) is calculated as the sum of squared errors (SSE) between the predicted labels and the actual labels in the test dataset. This fitness value is then employed to steer the optimization process.
3.6.2 DOA-SVM implementation
The DOA-SVM hybrid approach is presented in the form of pseudo code in Algorithm 2.
3.7 FCM-DOA-SVM hybrid
Clustering algorithms such as FCM are extensively employed in preprocessing tasks to identify significant patterns and structures within data. FCM is especially useful in soft clustering contexts, where each data point can be associated with multiple clusters to varying extents (Mendel and Bonissone, 2021; Chimatapu et al., 2018). This capability is advantageous in biometric applications, where data frequently displays overlapping features. In the FCM-DOA-SVM hybrid model, the FCM algorithm improves the input features by adding fuzzy membership values to each data sample, thus capturing essential structural information prior to classification (Shukla et al., 2020; Ferreyra et al., 2019).
Subsequently, the DOA is utilized to fine-tune the parameters of the SVM classifier, specifically (A and ϑ for the RBF kernel). This integrated method effectively merges the unsupervised clustering capability of FCM with the supervised learning of SVM and the global optimization potential of DOA. In this scenario, the fitness function is characterized by the classification accuracy achieved on a validation set using the SVM trained with features enhanced by FCM.
The FCM-DOA-SVM architecture exhibits a significant synergistic effect, wherein fuzzy memberships enhance feature representation, and DOA facilitates the exploration of optimal classifier configurations. Consequently, the model demonstrates enhanced generalization and robustness in biometric classification tasks, as detailed in Algorithm 3.

Algorithm 3. FCM-DOA-SVM hybrid classification algorithm.
3.7.1 Procedure of classification utilizing the FCM-DOA-SVM hybrid
The classification procedure utilizing the FCM-DOA-SVM model is an extension of the general optimization strategy outlined in Section 3.5.1, incorporating FCM-based feature enhancement into the process. Initially, the training data is subjected to clustering through the FCM algorithm, resulting in a membership matrix that indicates the degree of association of each sample with each cluster. These membership values are then integrated with the original feature set to create an enriched feature matrix.
In the subsequent phase, each dolphin (solution) within the DOA population signifies a potential configuration of SVM hyperparameters: specifically, the penalty parameter A and the kernel parameter ϑ. For each solution, an SVM is trained utilizing the enriched feature matrix and subsequently evaluated on a validation set. The fitness of a dolphin is determined by the classification accuracy, which directs the evolution of the population toward more optimal parameter sets.
This hybridization enables a comprehensive learning process: FCM identifies fuzzy patterns within the data, DOA effectively explores the parameter space, and SVM executes the final classification. Collectively, these components produce a highly accurate and interpretable classification model, well-suited for complex biometric recognition tasks.
3.7.2 FCM-DOA-SVM implementation
The pseudo code for the hybrid approach FCM-DOA-SVM is given in Algorithm 3.
3.8 NCM-DOA-SVM hybrid
NCM-DOA-SVM hybrid includes the NCM method of clustering which is helpful for CLFP recognition to handle indeterminacy in images. Neutrosophic Theory represents the information that is uncertain, imprecise and inconsistent by using three degrees, truth (T), indeterminacy (I) and falsity (F). The NCM clustering algorithm extends the classical FCM by incorporating this neutrosophic concept, enabling more accurate modeling of real-world biometric data. In the proposed NCM-DOA-SVM hybrid, T, I and F are extracted for every sample during the clustering procedure which enhance feature representations.
Subsequently, the DOA algorithm is used to improve the hyperparameters of the SVM classifier, specifically the penalty value (A) and the RBF kernel value (ϑ). Using this hybrid approach boosts the classifier's results by finding the optimal parameters and additionally making use of the extra features that capture the neutrosophic nature of the input data.
The integration of NCM for handling unclear data, DOA for finding global solution and SVM for accurate classification leads to the development of a strong model for biometric recognition. By applying the combined model, it deals with uncertainty and the classifier becomes more effective as shown in Algorithm 4.

Algorithm 4. NCM-DOA-SVM hybrid classification algorithm.
3.8.1 Procedure of classification utilizing the NCM-DOA-SVM hybrid
The classification procedure of the NCM-DOA-SVM hybrid model adheres to the core optimization approach introduced in Section 3.5.1. Initially, the input dataset undergoes unsupervised clustering using the NCM algorithm. This step computes the truth, indeterminacy, and falsity memberships for each data point, resulting in an enhanced feature space of the form [𝕏, T, I, F].
Each solution (dolphin) in the population corresponds to a candidate set of SVM parameters, including the penalty coefficient A and the kernel function parameter ϑ. The SVM classifier is trained on the NCM-enhanced features using each dolphin's parameters and evaluated on a validation dataset. The dolphin's fitness is computed based on the classification performance, such as the SSE or classification accuracy.
The optimization process iteratively refines the solutions based on fitness, guiding the swarm toward the best SVM configuration. This collaborative mechanism among NCM, DOA, and SVM not only improves classification precision but also ensures robustness to noisy and uncertain biometric data. The final model thus integrates fuzzy reasoning, optimization intelligence, and discriminative learning to deliver superior performance.
3.8.2 NCM-DOA-SVM implementation
The NCM-DOA-SVM hybrid approach is presented in the form of pseudo code in Algorithm 4.
4 Results and discussion
4.1 Algorithm training and validation phases
At this stage, a dataset consisting of 2016 CLFP images was used to develop the DOA and the suggested hybrid approaches, namely DOA-SVM, FCM-DOA-SVM, and NCM-DOA-SVM. The HOG technique was used for initial image processing and trait extraction, which made it easier to extract a feature matrix from these images. The DOA and the suggested hybrid approaches (DOA-SVM, FCM-DOA-SVM, and FCM-DOA-SVM) were then trained using the derived traits matrix, improving their performance.
Upon the completion of the training phase and achieving algorithm stability, a test was conducted involving 504 CLFP images. These images were subjected to preprocessing, followed by feature extraction using the HOG algorithm. To determine the optimal HOG feature extraction parameters, we conducted a comprehensive sensitivity analysis across different cell and block size configurations.
As shown in Table 3, three configurations were evaluated: Fine (16 × 16 cells, 2 × 2 blocks), Medium (32 × 32 cells, 2 × 2 blocks), and Coarse (64 × 64 cells, 2 × 2 blocks). The results demonstrate a clear trade-off between feature dimensionality, computational efficiency, and classification accuracy. The Medium configuration achieved the highest accuracy of 0.856198, despite having a moderate feature vector size of 324 dimensions. Interestingly, the Fine configuration, with its substantially larger feature vector (1,764 dimensions), yielded lower accuracy (0.844628), suggesting that excessive granularity may introduce noise or lead to overfitting. The negative correlation between feature size and accuracy (r = −0.2498) supports this observation. Statistical analysis using ANOVA revealed no significant difference between configurations (p≥0.05), indicating that the Medium configuration provides an optimal balance between computational efficiency (0.003086) and classification performance. The choice of 32 × 32 cell sizes, resulting in four cells for a 128 × 128 image, represents a strategic compromise that captures sufficient local gradient information while maintaining computational tractability and avoiding the curse of dimensionality associated with finer granularities.

Table 3. HOG parameter sensitivity analysis results.
The assignment of specific coefficients to each algorithm is determined by the nature of the task, as the specific operations may vary based on the research problem being addressed. Through a series of practical experiments and their application, the appropriate coefficients for the algorithms were established. The values of these coefficients are detailed in Table 4.
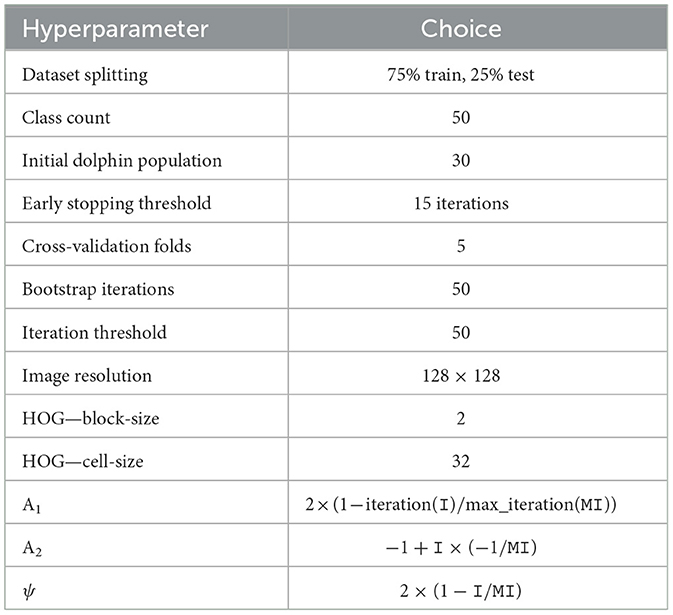
Table 4. Tuned Parameters for the proposed model.
The dataset which included 1,512 images, was processed using the DOA method to identify CLFP. The following results were obtained from the evaluation of the suggested algorithm's training using predetermined evaluation criteria:
The dataset include 504 images, which was assessed using the DOA system to determine CLFP. Table 5 provides details on the training results of the proposed algorithm.
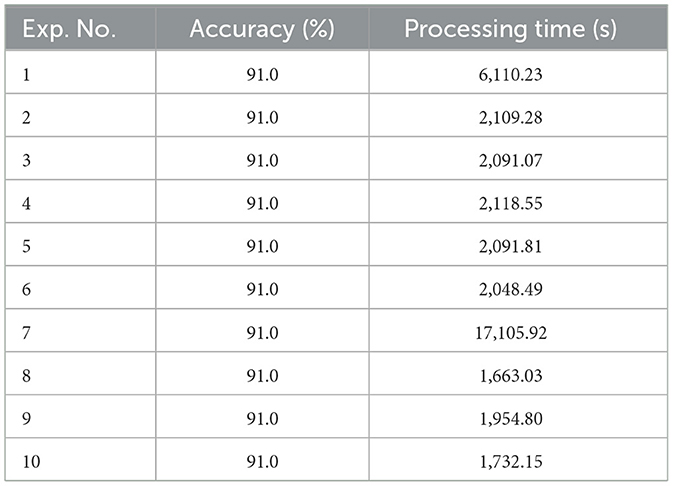
Table 5. Outcome analysis of system testing with DOA.
The results of the test phase of DOA are detailed in Table 5, which looks at different configurations of the coefficients: cell-size HOG is always set at 32, block-size HOG is fixed at 2, dolphin population level remains at 30, and iteration threshold is investigated at 50.
The DOA-SVM system was employed to train a dataset comprising 1,512 CLFP images for the purpose of CLFP identification. The performance of the proposed hybrid algorithm was evaluated using established assessment criteria, yielding the following results:
The DOA-SVM system was used to analyze the dataset, which included 504 images, in order to find CLFP. In Table 6, the results are presented in detail.
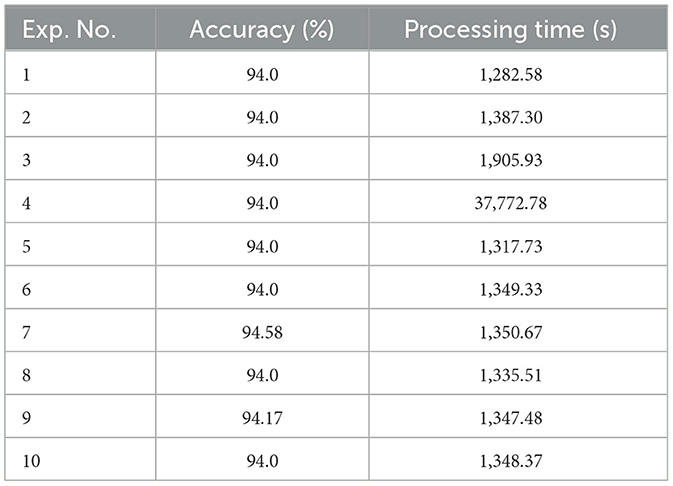
Table 6. Outcome analysis of system testing with DOA-SVM.
The results of the test phase of the hybrid method DOA-SVM, which examines different coefficient configurations, are detailed in Table 6. HOG with a block-size fixed at 2, a dolphin population level held constant at 30, an iteration threshold examined at 50, and a cell-size continuously maintained at 32.
The FCM-DOA-SVM system was trained to identify CLFP using a dataset comprising 1,512 images. The effectiveness of the proposed algorithm was assessed using evaluation metrics and these are its outcomes:
The data was assessed utilizing the FCM-DOA-SVM system to identify CLFP, comprising 504 images. The output of the algorithm training is shown in Table 7 (i.e., the test phase results of the proposed hybrid method are shown in this table). The FCM-DOA-SVM setup kept HOG cell-size at 32, HOG block-size at 2 and Dolphin population at 30 and it varied the Iteration threshold from 1 to 50.
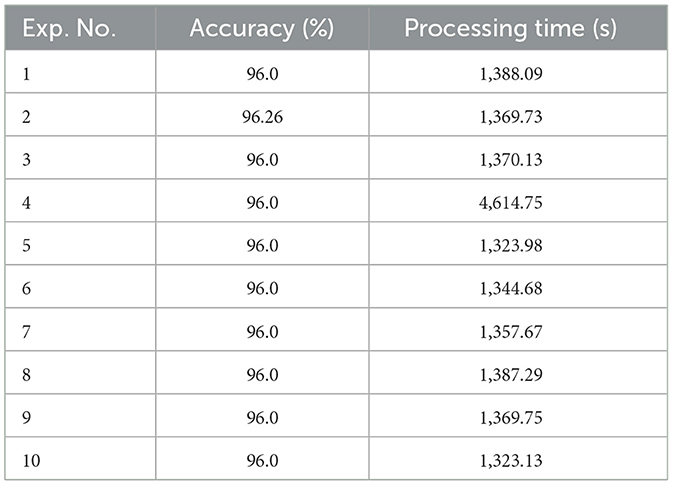
Table 7. Outcome analysis of system testing with FCM-DOA-SVM.
The NCM-DOA-SVM model was trained on a dataset of 1,512 CLFP images, and its performance was assessed using standard evaluation metrics. The results are as given below:
In order to analyze and identify the 504 images in the dataset as CLFP, the NCM-DOA-SVM system has been used. Table 8 lists the training phase results and provides an explanation of the testing phase results using the suggested hybrid approach. The following parameter settings were used when implementing the NCM-DOA-SVM system: The dolphin population level was kept at 30, the iteration threshold was investigated at 50, and the HOG cell-size was continuously set at 32 and the HOG block-size was fixed at 2.
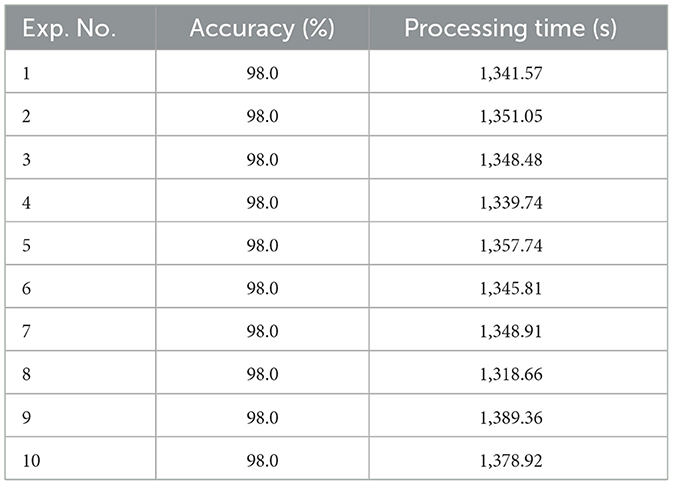
Table 8. Outcome analysis of system testing with NCM-DOA-SVM.
The rating ratio rate is shown in Table 9 for the DOA method, as well as for the proposed hybrid approaches: DOA-SVM, FCM-DOA-SVM, and NCM-DOA-SVM.
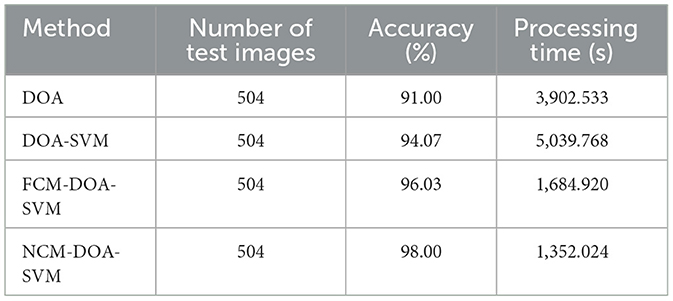
Table 9. Comprehensive performance comparison of proposed methods.
4.2 Experimental analysis
The experimental results confirmed the robust performance of all proposed algorithms during the training phase. The best classification accuracy, 91.0%, was found for images with a size of 128 × 128 and a cell-size of 32 × 32, as shown in Table 5. Table 6 showed an improved classification accuracy of 94.07% for images of the same dimensions and cell-size when the number of dolphins matched the number of repetitions. Additionally, Tables 7, 8 reported a further increase in classification accuracy to 96.03 and 98.0% under the same conditions. These findings are corroborated by the data in Table 9. The DOA showed an average accuracy rate of 91.0%, whereas the DOA-SVM hybrid algorithm achieved an average accuracy of 94.07%, the FCM-DOA-SVM algorithm attained an average accuracy of 96.03% and NCM-DOA-SVM algorithm reached an average accuracy of 98.0%.
Our experimental findings indicate that the hybrid algorithm DOA-SVM demonstrates a higher classification ratio than the DOA. This improvement is attributed to the DOA optimization capabilities, which emulate the cooperative behavior of dolphins to enhance parameter selection. The algorithm improves convergence speed and reduces computational cost by learning from previous configurations. A well-tuned DOA balances exploration and exploitation, making parameter selection crucial for optimal performance.
According to experimental results, the suggested hybrid algorithm, which combines DOA-SVM with FCM, performs better in terms of classification accuracy than both the standalone DOA and the hybrid DOA-SVM algorithm. The efficient combination of FCM and DOA, where each technique improves the performance of the other, is the source of this improvement. When these algorithms are used together, they perform better on classification tasks and other tasks than when they are used separately. The FCM algorithm helps by providing soft aggregation capabilities, which enable more precise data point classification, particularly when features overlap. The DOA also supports more efficient searching, so that key data points can be identified and the required computations can be reduced.
Within the spectrum of assessed approaches, the NCM-DOA-SVM method consistently maintained superior classification accuracy. This enhanced performance is resulted due to the effective combination of NCM clustering, the DOA, and the SVM. This approach is convenient for handling unclear, overlapping and uncertain segments within the data and this quality is key for classifying complicated data sets. On the other hand, the DOA helps with global optimization, so features can be effectively chosen and parameters can be successfully tuned. Finally, the SVM provides good performance in the final classification stage. The integration of all three methods together creates a better and more efficient results than if only two are used, such as DOA or DOA-SVM.
In this neutrosophic logic visualization (see Figure 4), the T/I/F membership framework provides significant advantages for our database. Specifically, Truth membership (T) highlights robust and well-defined clusters at the core of the dataset, while Indeterminacy membership (I) captures transitional and boundary regions–effectively representing ambiguous cases that are often misclassified by traditional methods. Falsity membership (F) excels at identifying outliers, enhancing data integrity by revealing non-conforming patterns that may compromise analysis. The integrated T/I/F analysis enables a comprehensive and nuanced characterization of uncertainty, offering deeper insights and improved decision-making accuracy over conventional single-value approaches, thus establishing neutrosophic logic as a superior tool for extracting actionable information from uncertain databases.
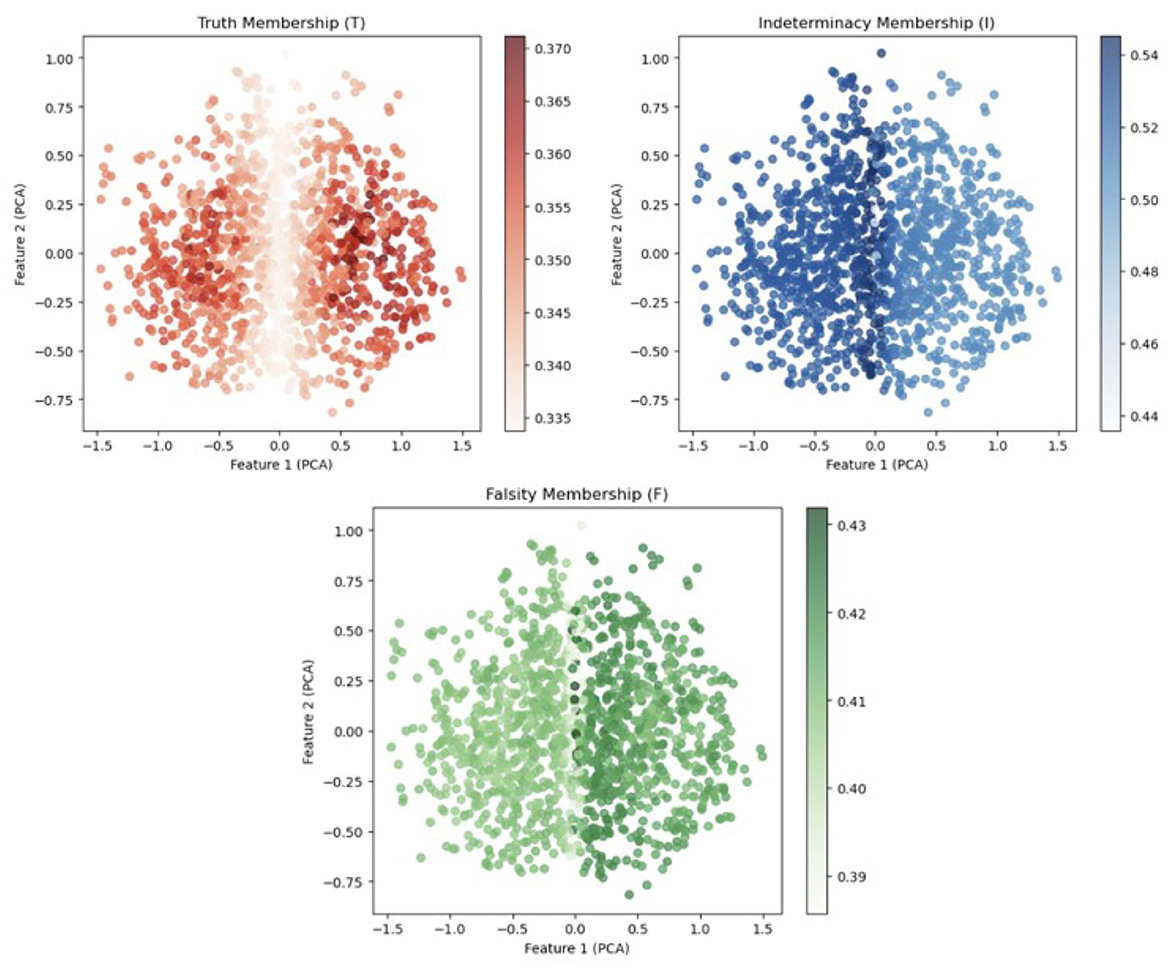
Figure 4. Neutrosophic logic T/I/F membership visualization.
In this work, we propose a CLFP recognition system based on the DOA with 3,902.533 processing seconds and 91.0% classification accuracy. Additionally, we combine the DOA and the SVM algorithms to propose a new hybrid algorithm. By suggesting a new fitness function based on the SVM algorithm that depends on dolphin values rather than the original parameters (G, ϵ, A), the combination aims to improve classification accuracy. This method took 5,039.768 s to process and had a classification accuracy of 94.07%. In order to further increase classification accuracy, we also suggest another hybrid algorithm that combines the DOA-SVM and the FCM algorithm. In comparison to both the DOA and the DOA-SVM algorithm, this algorithm efficiently handles ambiguous and imprecise data, resulting in a more accurate identification system and attaining classification accuracy of 96.03% with a processing time of 1,684.920 s. We suggest combining NCM with DOA-SVM in place of FCM. This results in a higher classification accuracy of 98.0% at a processing time of 1,352.024 s. The NCM-DOA-SVM outperforms other methods for CLFP images.
The comparative evaluation of bio-inspired optimization algorithms (see Table 10) reveals that DOA-SVM achieves the highest classification accuracy of 89.69% with the lowest standard deviation (±0.0132), demonstrating superior performance consistency compared to other metaheuristic approaches. While all bio-inspired methods substantially outperform the baseline SVM (88.33%), the computational cost varies significantly, with GA-SVM offering the best time-accuracy trade-off (89.26% in 1,547.74 ss) and PSO-SVM requiring the highest processing time (3,722.63 s) for comparable accuracy. The results validate DOA's effectiveness in hyperparameter optimization for CLFP recognition, though the 588-fold increase in processing time compared to baseline SVM highlights the computational overhead inherent in population-based optimization approaches.
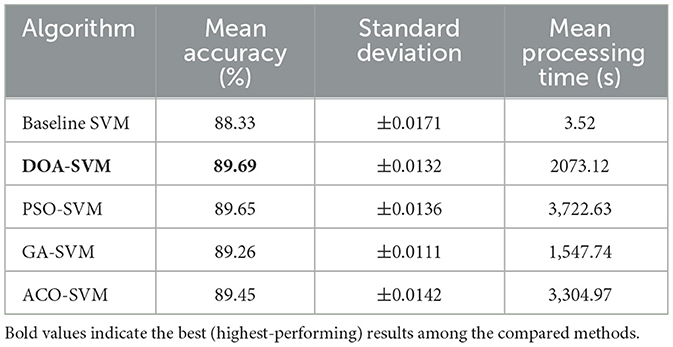
Table 10. Performance comparison of bio-inspired optimization algorithms with SVM.
5 Conclusion and future work
This study demonstrates that strategic hybridization of bio-inspired optimization with machine learning classifiers significantly advances contactless fingerprint recognition. Our systematic evaluation reveals clear performance progression: DOA (91.00%), DOA-SVM (94.07%), FCM-DOA-SVM (96.03%), and NCM-DOA-SVM (98.00%), with the NCM-based hybrid achieving superior accuracy while maintaining competitive processing efficiency.
This work makes several key contributions to the field of contactless biometrics. Primarily, it introduces a novel hybrid framework that successfully merges the Dolphin Optimization Algorithm with a Support Vector Machine classifier, establishing a new approach for CLFP recognition. The research is further advanced by integrating fuzzy clustering to refine feature representation and, most significantly, by pioneering the application of Neutrosophic C-Means clustering to effectively manage the inherent uncertainty and indeterminacy in fingerprint images. Beyond accuracy improvements, a thorough analysis of computational efficiency is provided, offering valuable practical insights that bridge the gap between algorithmic innovation and real-world system deployment.
Despite the promising results, this study has certain limitations. The generalizability of our findings is constrained by the dataset's limited size and demographic diversity, which may not fully represent broader populations. Furthermore, the robustness of the single-stage classification pipeline requires further validation against low-quality, noisy, or incomplete fingerprint images. To address these constraints and advance this research, future efforts should prioritize several key areas. Expanding the evaluation to include larger, multi-ethnic datasets is crucial for verifying performance across diverse real-world conditions. Exploring multi-stage architectures could also enhance robustness by decoupling processes like feature enhancement and classification. Finally, developing real-time prototypes would be invaluable for assessing the practical deployment of these methods, particularly under computational constraints. These research directions are essential for translating the current algorithmic innovations into reliable, real-world biometric systems.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Ethics statement
The studies involving humans were approved by Hongkong Polytechnic University. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
JR: Data curation, Formal analysis, Methodology, Project administration, Resources, Software, Writing – original draft. ED: Conceptualization, Funding acquisition, Investigation, Supervision, Validation, Visualization, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. Open access funding provided by Vellore Institute of Technology.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abbreviations
G, gradient magnitude; θ, gradient angle; A1, A2, acceleration coefficients; ω, inertia weight; ν1, ν2, random numbers uniformly distributed in [0, 1]; s, current time step; ψ, time steps; Λ, total number of dolphins; A, penalty parameter; ϵ, loss function; ϑ, kernel parameter.
References
Al-Taie, S. A. M., and Khaleel, B. I. (2024). Palmprint identification using dolphin optimization. Period. Polytech. Electr. Eng. Comput. Sci. 68, 295–308. doi: 10.3311/PPee.22767
Artan, Y. (2024). “MinNet based contactless fingerprint matching method,” in 2024 32nd Signal Processing and Communications Applications Conference (SIU) (Mersin), 1-4. doi: 10.1109/SIU61531.2024.10600842
Attrish, A., Bharat, N., Anand, V., and Kanhangad, V. (2021). A contactless fingerprint recognition system. arXiv [preprint]. arXiv:2108.09048. doi: 10.48550/arXiv.2108.09048
Bezdek, J. C., Ehrlich, R., and Full, W. (1984). FCM: the fuzzy c-means clustering algorithm. Comput. Geosci. 10, 191–203. doi: 10.1016/0098-3004(84)90020-7
Cetina, K., Márquez-Neila, P., and Baumela, L. (2014). “A comparative study of feature descriptors for mitochondria and synapse segmentation,” in Proceedings of the 22nd International Conference on Pattern Recognition (Stockholm), 3215-3220. doi: 10.1109/ICPR.2014.554
Chicco, D., and Jurman, G. (2020). The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genomics 21:6. doi: 10.1186/s12864-019-6413-7
Chimatapu, R., Hagras, H., Starkey, A., and Owusu, G. (2018). “Explainable AI and fuzzy logic systems,” in Theory and Practice of Natural Computing (Cham: Springer), 3–20. doi: 10.1007/978-3-030-04070-3_1
Chowdhury, A. M., and Imtiaz, M. H. (2022). Contactless fingerprint recognition using deep learning—a systematic review. J. Cybersecur. Priv. 2, 714–730. doi: 10.3390/jcp2030036
Cortes, C., and Vapnik, V. (1995). Support-vector networks. Mach. Learn. 20, 273–297. doi: 10.1023/A:1022627411411
Cui, Z., Jia, Y., Zheng, S., and Su, F. (2024). Contactless fingerprint recognition using 3D graph matching. arXiv [preprint]. arXiv:2409.08782. doi: 10.48550/arXiv.2409.08782
Dong, C., and Kumar, A. (2023). Synthesis of multi-view 3D fingerprints to advance contactless fingerprint identification. IEEE Trans. Pattern Anal. Mach. Intell. 45, 13134–13151. doi: 10.1109/TPAMI.2023.3294357
Elhariri, E., El-Bendary, N., Hassanien, A. E., and Snasel, V. (2015). An assistive object recognition system for enhancing seniors quality of life. Procedia Comput. Sci. 65, 691–700. doi: 10.1016/j.procs.2015.09.013
Faye, A., Ndaw, J. D., and Sène, M. (2018). “SVM-based DOA estimation with classification optimization,” in 2018 26th Telecommunications Forum (TELFOR) (Belgrade: IEEE), 1–4. doi: 10.1109/TELFOR.2018.8611827
Ferreyra, E., Hagras, H., Kern, M., and Owusu, G. (2019). “Depicting decision-making: a type-2 fuzzy logic based explainable artificial intelligence system for goal-driven simulation in the workforce allocation domain,” in 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) (New Orleans, LA: IEEE), 1–6. doi: 10.1109/FUZZ-IEEE.2019.8858933
Gholizadeh, S., and Poorhoseini, H. (2016). Seismic layout optimization of steel braced frames by an improved dolphin echolocation algorithm. Struct. Multidiscip. Optim. 54, 1011–1029. doi: 10.1007/s00158-016-1461-y
Grosz, S. A., Engelsma, J. J., Liu, E., and Jain, A. K. (2021). C2CL: contact to contactless fingerprint matching. IEEE Trans. Inf. Forensics Secur. 17, 196–210. doi: 10.1109/TIFS.2021.3134867
Guo, Y., and Sengur, A. (2015). NCM: neutrosophic c-means clustering algorithm. Pattern Recognit. 48, 2710–2724. doi: 10.1016/j.patcog.2015.02.018
Huang, C. L., and Wang, C. J. (2006). A GA-based feature selection and parameters optimization for support vector machines. Expert Syst. Appl. 31, 231–240. doi: 10.1016/j.eswa.2005.09.024
Jawade, B., Mohan, D. D., Setlur, S., Ratha, N., and Govindaraju, V. (2022). “RidgeBase: a cross-sensor multi-finger contactless fingerprint dataset,” in 2022 IEEE International Joint Conference on Biometrics (IJCB) (Abu Dhabi: IEEE), 1–9. doi: 10.1109/IJCB54206.2022.10007936
Kaplesh, P., Gupta, A., Bansal, D., Sofat, S., and Mittal, A. (2024). Vision transformer for contactless fingerprint classification. Multimedia Tools Appl. 84, 31239–31259. doi: 10.1007/s11042-024-20396-4
Kaveh, A., and Farhoudi, N. (2013). A new optimization method: Dolphin echolocation. Adv. Eng. Softw. 59, 53–70. doi: 10.1016/j.advengsoft.2013.03.004
Kaveh, A., Hoseini Vaez, S. R., and Hosseini, P. (2017). Modified dolphin monitoring operator for weight optimization of frame structures. Period. Polytech. Civ. Eng. 61, 770–779. doi: 10.3311/PPci.9691
Labati, R. D., Genovese, A., Piuri, V., and Scotti, F. (2014). Touchless fingerprint biometrics: a survey on 2D and 3D technologies. J. Internet Technol. 15, 325–332. doi: 10.6138/JIT.2014.15.3.01
Lin, C., and Kumar, A. (2018). Matching contactless and contact-based conventional fingerprint images for biometrics identification. IEEE Trans. Image Process. 27, 2008–2021. doi: 10.1109/TIP.2017.2788866
Lin, S. W., Ying, K. C., Chen, S. C., and Lee, Z. J. (2008). Particle swarm optimization for parameter determination and feature selection of support vector machines. Expert Syst. Appl. 35, 1817–1824. doi: 10.1016/j.eswa.2007.08.088
Maltoni, D., Maio, D., Jain, A. K., and Prabhakar, S. (2009). Handbook of Fingerprint Recognition, Vol. 2. Cham: Springer. doi: 10.1007/978-1-84882-254-2
Mendel, J. M., and Bonissone, P. P. (2021). Critical thinking about explainable AI (XAI) for rule-based fuzzy systems. IEEE Trans. Fuzzy Syst. 29, 3579–3593. doi: 10.1109/TFUZZ.2021.3079503
Moen, U. (2018). Early Detection of Alzheimer's Disease using 3D Texture Features and 3D Convolutional Neural Networks from structural MRI [MSc Thesis]. University of Stavanger. Available online at: http://hdl.handle.net/11250/2564781 (Accessed July 28, 2025).
Mohamed-Abdul-Cader, A., Banks, J., and Chandran, V. (2023). Fingerprint systems: sensors, image acquisition, interoperability and challenges. Sensors 23:6591. doi: 10.3390/s23146591
Peddi, S., Bandyopadhyay, S., and Samanta, D. (2025). G-MSGINet: a grouped multi-scale graph-involution network for contactless fingerprint recognition. arXiv [preprint]. arXiv:2505.08233. doi: 10.48550/arXiv.2505.08233
Priesnitz, J., Rathgeb, C., Buchmann, N., Busch, C., and Margraf, M. (2021). An overview of touchless 2D fingerprint recognition. EURASIP J Image Video Process 2021, 1–21. doi: 10.1186/s13640-021-00548-4
Qi, Z., Tian, Y., and Shi, Y. (2013). Robust twin support vector machine for pattern classification. Pattern Recognit. 46, 305–316. doi: 10.1016/j.patcog.2012.06.019
Qiao, W., and Yang, Z. (2019). Modified dolphin swarm algorithm based on chaotic maps for solving high-dimensional function optimization problems. IEEE Access 7, 110472–110486. doi: 10.1109/ACCESS.2019.2931910
Rajaram, K., Amma, N., and Selvakumar, S. (2023). Convolutional neural network based children recognition system using contactless fingerprints. Int. J. Inf. Technol. 15, 2695–2705. doi: 10.1007/s41870-023-01306-7
Ruzicka, L., Kohn, B., and Heitzinger, C. (2025). TipSegNet: fingertip segmentation in contactless fingerprint imaging. Sensors 25:1824. doi: 10.3390/s25061824
Shao, Y. H., Zhang, C. H., Wang, X. B., and Deng, N. Y. (2011). Improvements on twin support vector machines. IEEE Trans. Neural Netw. 22, 962–968. doi: 10.1109/TNN.2011.2130540
Sharma, S., and Kaul, A. (2018). Hybrid fuzzy multi-criteria decision making based multi cluster head dolphin swarm optimized IDS for VANET. Veh. Commun. 12, 23–38. doi: 10.1016/j.vehcom.2017.12.003
Shi, L., Lan, S., Gui, H., Yang, Y., and Guo, Z. (2022). A novel 2D contactless fingerprint matching method. Neurocomputing 500, 547–555. doi: 10.1016/j.neucom.2022.05.092
Shukla, A. K., Smits, G., Pivert, O., and Lesot, M. J. (2020). “Explaining data regularities and anomalies,” in Proc. 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) (Glasgow: IEEE), 1–8. doi: 10.1109/FUZZ48607.2020.9177689
Siddiqui, M., Iqbal, S. AlShammari, B., Alhaqbani, B., Khan, T., and Razzak, I. (2024). “A robust algorithm for contactless fingerprint enhancement and matching,” in 2024 International Conference on Digital Image Computing: Techniques and Applications (DICTA) (Perth: IEEE), 214–220. doi: 10.1109/DICTA63115.2024.00041
Smarandache, F. (2003). A Unifying Field in Logics: Neutrosophic Logic. Neutrosophy, Neutrosophic Set, Neutrosophic Probability and Statistics. Austin, TX: American Research Press.
Soranamageswari, M., and Meena, C. (2010). “Statistical feature extraction for classification of image spam using artificial neural networks,” in Proc. 2010 Second International Conference on Machine Learning and Computing, Bangalore, India (Bangalore: IEEE), 101–105. doi: 10.1109/ICMLC.2010.72
Soto, R., Crawford, B., Carrasco, C., Almonacid, B., Reyes, V., Araya, I., et al. (2016). “Solving manufacturing cell design problems by using a dolphin echolocation algorithm,” in Computational Science and Its Applications – ICCSA 2016 (Cham: Springer), 77–86. doi: 10.1007/978-3-319-42092-9_7
Sreehari, S., and Anzar, M. (2025). Touchless fingerprint recognition: a survey of recent developments and challenges. Comput. Electr. Eng. 122:109894. doi: 10.1016/j.compeleceng.2024.109894
Tan, H., and Kumar, A. (2020). Towards more accurate contactless fingerprint minutiae extraction and pose-invariant matching. IEEE Trans. Inf. Forensics Secur. 15, 3924–3937. doi: 10.1109/TIFS.2020.3001732
Vibert, B., Le Bars, J. M., Charrier, C., and Rosenberger, C. (2023). Comparative study of minutiae selection methods for digital fingerprints. Front. Big Data 6:1146034. doi: 10.3389/fdata.2023.1146034
Vithlani, P., and Kumbharana, C. K. (2015). Structural and statistical feature extraction methods for character and digit recognition. Int. J. Comput. Appl. 120, 43–47. doi: 10.5120/21413-4451
Wu, T., Yao, M., and Yang, J. (2017). Dolphin swarm extreme learning machine. Cognit. Comput. 9, 275–284. doi: 10.1007/s12559-017-9451-y
Wu, T. Q., Yao, M., and Yang, J. H. (2016). Dolphin swarm algorithm. Front. Inf. Technol. Electr. Eng. 17, 717–729. doi: 10.1631/FITEE.1500287
Yin, X., Zhu, Y., and Hu, J. (2020). Contactless fingerprint recognition based on global minutia topology and loose genetic algorithm. IEEE Trans. Inf. Forensics Secur. 15, 28–41. doi: 10.1109/TIFS.2019.2918083
Yin, X., Zhu, Y., and Hu, J. (2021). A survey on 2D and 3D contactless fingerprint biometrics: a taxonomy, review, and future directions. IEEE Open J. Comput. Soc. 2, 370–381. doi: 10.1109/OJCS.2021.3119572
Yong, W., Tao, W., Cheng-Zhi, Z., and Hua-Juan, H. (2016). A new stochastic optimization approach — dolphin swarm optimization algorithm. Int. J. Comput. Intell. Appl. 15:1650011. doi: 10.1142/S1469026816500115
Keywords: contactless fingerprint, feature extraction, HOG algorithm, machine learning, dolphin optimization algorithm, clustering
Citation: Rachel J and Devarasan E (2025) Robust contactless fingerprint authentication using dolphin optimization and SVM hybridization. Front. Big Data 8:1641714. doi: 10.3389/fdata.2025.1641714
Received: 05 June 2025; Revised: 05 November 2025;
Accepted: 13 November 2025; Published: 05 December 2025.
Edited by:
Chen Wang, Huazhong University of Science and Technology, ChinaReviewed by:
N. R. Pradeep, Navkis College of engineering, IndiaHajar Maseeh, Akre University for Applied Sciences, Iraq
Copyright © 2025 Rachel and Devarasan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ezhilmaran Devarasan, ZXpoaWwuZGV2YXJhc2FuQHlhaG9vLmNvbQ==