 Matthias J. Ehrhardt
Matthias J. Ehrhardt Zeljko Kereta
Zeljko Kereta Georg Schramm
Georg Schramm- 1Department of Mathematical Sciences, University of Bath, Bath, United Kingdom
- 2Computer Science Department, University College London, London, United Kingdom
- 3Department of Imaging and Pathology, KU Leuven, Leuven, Belgium
We investigated subset-based optimization methods for positron emission tomography (PET) image reconstruction incorporating a regularizing prior. PET reconstruction methods that use a prior, such as the relative difference prior (RDP), are of particular relevance because they are widely used in clinical practice and have been shown to outperform conventional early-stopped and post-smoothed ordered subset expectation maximization. Our study evaluated these methods using both simulated data and real brain PET scans from the 2024 PET Rapid Image Reconstruction Challenge (PETRIC), where the main objective was to achieve RDP-regularized reconstructions as fast as possible, making it an ideal benchmark. Our key finding is that incorporating the effect of the prior into the preconditioner is crucial for ensuring fast and stable convergence. In extensive simulation experiments, we compared several stochastic algorithms—including stochastic gradient descent (SGD), stochastic averaged gradient amelioré (SAGA), and stochastic variance reduced gradient (SVRG)—under various algorithmic design choices and evaluated their performance for varying count levels and regularization strengths. The results showed that SVRG and SAGA outperformed SGD, with SVRG demonstrating a slight overall advantage. The insights gained from these simulations directly contributed to the design of our submitted algorithms, which formed the basis of the winning contribution to the PETRIC 2024 challenge.
1 Introduction
1.1 Context
Positron emission tomography (PET) is a pillar of modern clinical imaging, widely used in oncology, neurology, and cardiology. Most state-of-the-art approaches for the image reconstruction problem in PET imaging can be cast as an optimization problem
where the data fidelity term measures how well the estimated data matches the acquired data and the regularizer penalizes unwanted features in the image. is a linear forward model for the PET physics, which includes effects such as scanner sensitivities or attenuation, and is the additive background term to account for scattered and random coincidences. Due to the Poisson nature of the data, the data fidelity is usually taken as the Kullback–Leibler (KL) divergence. The regularizer commonly entails non-negativity constrains and terms that promote smoothness. A particularly successful model for smoothness in PET is the relative difference prior (RDP) (1).
This paper focuses on algorithms for the fast reconstruction of . Particularly, we present our winning contribution to the 2024 PET Rapid Image Reconstruction Challenge (PETRIC) (2), where the task was to reconstruct data from various PET scanners using RDP-regularized reconstruction methods. PET image reconstructions that use the RDP are of particular current relevance because RDP is widely used in clinical practice, being implemented by a major commercial vendor, and has been shown to outperform conventional early-stopped and post-smoothed ordered subset-maximum likelihood expectation maximization (OS-MLEM) reconstructions (3–5). Although implementations based on block sequential regularized expectation maximization (BSREM) (6), they have been shown to be slower than an algorithm that uses ideas from machine learning and tailored preconditioning (7). In this paper, we outline the process used to find the winning algorithm and share the insights obtained along the way. For context, the task had to be completed within the Synergistic Image Reconstruction Framework (SIRF) (8), and speed was measured as walltime until an application-focused convergence criterion was reached.
1.2 Problem details
Traditionally, fast algorithms for PET reconstruction have been subset-based (9), meaning only a subset of the data is used in every iteration. In the last decade, algorithms using a similar strategy but derived for machine learning have entered the field and shown state-of-the-art performance (7, 10–14). They exploit the fact that the KL divergence is separable in the estimated data
where denotes the number of subsets and function is defined by
Here, denotes a subset of the data, e.g., all data associated to a “view.”
A great deal of effort has been put into finding good prior models (i.e., regularizers) for PET, including smooth and non-smooth priors, which either promote smoothness of the image to be reconstructed or encourage similarity to anatomical information (15–18). In Nuyts et al. (1), the authors proposed a smooth and convex prior that takes into account the scale of typical PET images, resulting in greater smoothness in less active regions. Mathematically, for non-negative images , the resulting regularizer can be defined by
where the first sum is over all voxels and the second sum is over all “neighbors” . Parameter allows placing more or less emphasis on edge preservation, and parameter ensures that the function is well-defined and twice continuously differentiable. Terms , , and are weight factors accounting for distances between voxels and are intended to create a uniform “perturbation response” (19). Note that the essential part of the prior is
which has two important properties. First, if the sum of activities between voxels is small compared to the scaled absolute difference , the regularizer essentially reduces to total variation: . Second, the larger the activity in both voxels, i.e., the larger , the less weight is placed on penalizing their difference, justifying the name of the regularizer. See also Appendix A1 for formulas of derivatives.
Combined with the indicator function of the non-negativity constraint,
we arrive at the regularization model used in PETRIC
This formula has to be interpreted to be for infeasible images with negative voxel values and has the finite RDP value everywhere else.
The rest of the paper is structured as follows. In Section 2, we introduce the building blocks of our algorithms and discuss proximal stochastic gradient approaches for solving Equation 1, stepsize regimes, preconditioning, and subset selection. In Section 3, we thoroughly investigate the effects of different choices of building blocks in a simulated setting. In Section 4, we present the algorithms we ended up using in PETRIC and their performance on real data. We conclude with final remarks in Sections 5 and 6.
2 Building blocks
Combining the modeling choices in Equations 1, 2, and 4, we arrive at the optimization problem
where we define and . The variety of optimization methods for solving instances of problem 5 is extensive and has grown in recent decades; see Ehrhardt et al. (13) and references therein. For linear inverse problems, such as in PET image reconstruction, the most common approaches are based on either (proximal) gradient descent or on primal-dual approaches.
In this work, we consider stochastic gradient methods for solving problem 5. They take the form
where is a stepsize, is an estimator of the gradient of the smooth part of the objective function , is a matrix that acts as a preconditioner (PC), and is the proximal operator associated with the non-negativity constraint, which can be efficiently computed entrywise, .
All three components , , and are critical for fast and stable algorithmic performance. In realistic image reconstruction settings, and in the context of the PETRIC challenge, the selection of these three components must balance accuracy and computational costs. In the remainder of this section, we review stochastic estimators, discuss their trade-offs, and address the stepsize selection and preconditioners. Finally, we consider the role of subset selection and sampling regimes, namely, how to choose the sets in Equation 2 and decide which subsets to use at each iteration of the algorithm.
2.1 Stochastic gradient methods
Let us turn our attention to the selection of gradient estimators .
Stochastic gradient descent (SGD) defines the gradient estimator by selecting a random subset index in each iteration and evaluating
to compute the update in Equation 6. Each iteration only requires storing the current iterate and computing the gradient for only one subset function. This can lead to large variances across updates, which increase with the number of subsets. To moderate this, vanishing stepsizes, satisfying
are required to ensure convergence but at the cost of convergence speed.
Stochastic averaged gradient amelioré (SAGA) controls the variance by maintaining a table of historical gradients . Each iteration uses a computed subset gradient combined with the full gradient table to update the gradient estimator
followed by updating the corresponding entry in the table
In contrast to SGD, SAGA guarantees convergence to a minimizer with constant stepsizes and preconditioners for Lipschitz-smooth problems. In its standard form, SAGA has the same computational cost as SGD, but it requires storing gradients. The memory cost is not a practical limitation for most PET problems (even for relatively large ). If this is a concern, alternative formulations of SAGA exist with other memory footprints; see Ehrhardt et al. (13) for a further discussion.
Stochastic variance reduced gradient (SVRG) also reduces the variance by storing reference images and gradients, but unlike SAGA, these are updated infrequently. Algorithmically, SVRG is usually implemented with two loops: an outer loop and an inner loop. At the start of each outer loop, subset gradients and the full gradient estimator are computed at the last iterate as
In the inner loop, the gradients are retrieved from memory and balanced against a randomly sampled subset gradient at the current iterate, giving the gradient estimator
Note the similarity between the gradient estimators of SAGA and SVRG given by Equations 7 and 8, respectively.
After iterations, the snapshot image and the full gradient estimator are updated. The update parameter is typically chosen as for convex problems.
It is most common to store only the snapshot image and the corresponding full gradient , which then requires recomputing the subset gradient at each iteration. This lowers the memory footprint (requiring only the snapshot image and the full gradient to be stored) but increases the computational costs.
2.2 Stepsizes
Theoretical convergence guarantees often require stepsizes based on , where is the Lipschitz constant of . In PET, global Lipschitz constants are usually pessimistic, yielding conservative stepsize estimates.
Many stepsize approaches exist for stochastic iterative methods, ranging from predetermined choices made before running the algorithm (constant or vanishing) to adaptive methods [e.g., Barzilai–Borwein (BB) (20) and “difference of gradients”-type (21) rules] and backtracking techniques [e.g., Armijo (22)]. Due to the constraints imposed by the challenge (where computational time is a key metric), in this work, we focus on the first two categories.
Constant is the baseline stepsize rule. The specific value requires tuning to ensure convergence.
Vanishing rules consider stepsizes of the form , which satisfy the SGD convergence conditions, for and the decay parameter that needs to balance convergence and stability: small enough to maintain speed but large enough to ensure convergence.
Adaptive stepsize tuning via the BB rule is achieved by minimizing the residual of the secant equation at the current iterate. It converges for strongly convex problems and is applicable to SGD and SVRG (20). We tested several variants of the BB rule (long and short forms, geometric mean combinations, diagonal BB, etc.) but settled on the short-form BB for its performance and stability. When applied to gradient descent, short-form BB sets the stepsizes according to , where and . When applied to SVRG, these values are computed during the iterations when the full gradient is recomputed.
2.3 Preconditioning
Preconditioners are essential for accelerating iterative reconstruction algorithms by stabilizing admissible stepsize and adapting them to individual components of the solution. Effectively, image components with large gradient variance receive smaller updates, and vice versa. This can have a dramatic effect in PET image reconstruction (and machine learning applications) due to the widely varying range of local Lipschitz constants. Motivated by Newton’s method, many preconditioners aim to approximate the inverse of the Hessian to allow for unit stepsizes. However, computing a full Hessian is impractical in high-dimensional problems, motivating the need for efficient approximations.
Preconditioners based only on data fidelity are standard in PET. The most prominent example is
which can be derived from the gradient descent interpretation of MLEM. Here, the division of the two vectors is interpreted componentwise. Since and , a small constant ensures that the every diagonal entry of the preconditioner is non-zero. tends to work well for weak priors (e.g., in low-noise scenarios). However, it often underperforms because it does not account for the strength of the prior. This can either jeopardize the convergence behavior or require significant stepsize tuning.
Let
be the inverse of the diagonal of the Hessian of the prior. In this work, we used diagonal preconditioners that combine the data fidelity and prior terms via the (scaled) harmonic mean between and . For scalars , the harmonic mean is given by
Since our preconditioners are diagonal, this concept can be readily extended to define for some
Note that it satisfies . While this may look like an ad hoc choice, if and are good approximations to their respective Hessians, then the harmonic mean will be a good approximation to Hessian of the entire smooth term . Note also that by the definition of the harmonic mean, the proposed preconditioner is diagonal with strictly positive diagonal elements. As such, standard results on convergence follow, e.g., with sufficiently small stepsizes.
We tested several alternatives to Equation 9, such as taking an componentwise minimum between and , reweighing their contributions, using the Kailath variant of the Woodbury identity (together with the diagonal approximation) to estimate the inverse of the Hessian, and other variants. The selected preconditioner provided the best balance between computational cost and algorithmic performance. Traditional second-order methods update the preconditioner in every iteration, which is costly. Preconditioner (Equation 9) is much cheaper and, as experiments show, requires updating only in the first three epochs, after which it stabilizes with no performance gain from further updates.
2.4 Subset selection and sampling
Subset-based reconstruction algorithms enhance the convergence speed of traditional iterative methods by dividing the projection data into multiple subsets and performing updates using partial measurement data. While this approach can offer significant computational advantages, careful selection of the number of subsets is critical. Using too many subsets can introduce artifacts and amplify noise, especially when subsets lack sufficient angular coverage, and increases the variance between successive updates, which can compromise the stability and convergence properties. Conversely, selecting too few subsets diminishes the acceleration benefit and causes behavior similar to classical methods, such as MLEM, which are known for their slow convergence. The number of subsets is typically chosen as a divisor of the total number of projection angles (or views), allowing the data to be partitioned evenly. Subsets are then constructed to ensure that each is representative and uniformly distributed. We found that using approximately 25 subsets provides a good trade-off between reconstruction quality and computational speed in most scenarios, given the current computational requirements and scanner configurations.
To determine the order in which subsets are accessed, we consider the following standard choices:
Herman–Meyer order (23) is a well-established deterministic choice based on the prime decomposition of the number of subsets.
Uniformly random with replacement is the most common choice in machine learning applications. In each iteration, the subset index is chosen by taking a sample from uniformly at random.
Uniformly random without replacement randomizes access to subset indices but ensures that over successive iteration cycles, all data are used by computing a permutation of in each epoch.
Importance sampling uses a weighted variant of uniform sampling with replacement. For each , we assign a probability , such that . When Lipschitz constants are known, is a common choice.
Since Lipschitz constants are unknown in PET, we propose an alternative importance sampling strategy for SVRG. Namely, when the full gradient estimator is updated, we compute , where is the current image estimate. This incurs minimal computational overhead since all subset gradients are already recomputed in SVRG.
Finally, drawing inspiration from the Herman–Meyer ordering, which is designed to maximize information gain between successive updates and incorporating the concept of random sampling without replacement to ensure full coverage of subsets in each epoch with varying order, we propose the following novel subset ordering strategy.
Cofactor order begins by identifying all generators of the cyclic group associated with the number of subsets, , which are identified as positive integers that are coprime with , meaning that they share no prime factors with it. These generators are then ranked according to their proximity to two reference points, and , to balance spread and randomness. In each epoch, the next available generator from this sorted list is selected and used to define a new traversal of the cyclic group, thereby determining the order in which subsets are accessed (i.e., one subset index per iteration). Once the list of generators has been exhausted, it is reinitialized, and the process repeats for subsequent epochs.
For example, if , the coprimes (i.e., the set of generators) are given by . The sorted list of coprimes, based on their proximity to and , is . Thus, will be the first generator, which produces the subset indices: , , , , , , , , , , , , , , and . This exhausts the set of possible indices, so the next generator is selected as 11, and the process is repeated.
3 Numerical simulation experiments
To validate and refine the algorithmic components introduced in the previous section, we conducted a comprehensive suite of fast inverse-crime simulations. By simulating a simplified yet realistic PET scanner using the pure GPU mode of parallelproj v1.10.1 (24), iterative reconstructions could be run in seconds. This enabled a systematic exploration of the effects of various factors on convergence behavior, including the choice of stochastic algorithm, preconditioner, stepsize strategy, number of subsets, subset sampling method, time-of-flight (ToF) vs. non-ToF data, count levels, and regularization strength.
3.1 Simulation setup
All experiments used a simulated cylindrical (polygonal) scanner with a diameter of 600 mm and a length of 80 mm, comprising 17 rings with 36 modules each (12 detectors per module). Simulated ToF resolution was 390 ps, and a 4-mm isotropic Gaussian kernel in image space was used to model limited spatial resolution. Emission data were binned into a span 1 sinogram (289 planes, 216 views, 353 radial bins, 25 ToF bins). A simple 3D elliptical phantom was forward-projected (accounting for water attenuation), contaminated with a smooth background sinogram, and corrupted by Poisson noise to simulate realistic emission data. Low- and high-count regimes were simulated with and true events, respectively. Reconstruction was performed at an image size of voxels with a 2.5 mm isotropic spacing.
Reference reconstructions (see Figure 1) were obtained by running 500 iterations of the preconditioned limited memory Broyden–Fletcher–Goldfarb–Shanno algorithm (L-BFGS-B) (25) with three relative regularization strengths . The regularization parameter was scaled as
This ensures that reconstructions with the same at different count levels show comparable resolution. All stochastic reconstructions were initialized with one epoch of ordered subset expectation maximization (OSEM) (with 27 subsets). Convergence was measured by the normalized root mean square error (NRMSE) excluding cold background around the elliptical phantom, normalized by the intensity of the largest background ellipsoid. In line with the NRMSE target threshold used in the PETRIC challenge, we consider the point where NRMSE was less than 0.01 as a marker of practical convergence. The data were divided into subsets by selecting every th view. Unless stated otherwise, in each epoch, subsets were drawn uniformly at random without replacement. All runs were performed using an NVIDIA RTX A4500 GPU. The code for all our simulation experiments and submissions to PETRIC is available at https://github.com/SyneRBI/PETRIC-MaGeZ. To reproduce the results, users should use the tagged versions ALG1, ALG2, ALG3, or 2024_paper_simulation_results.
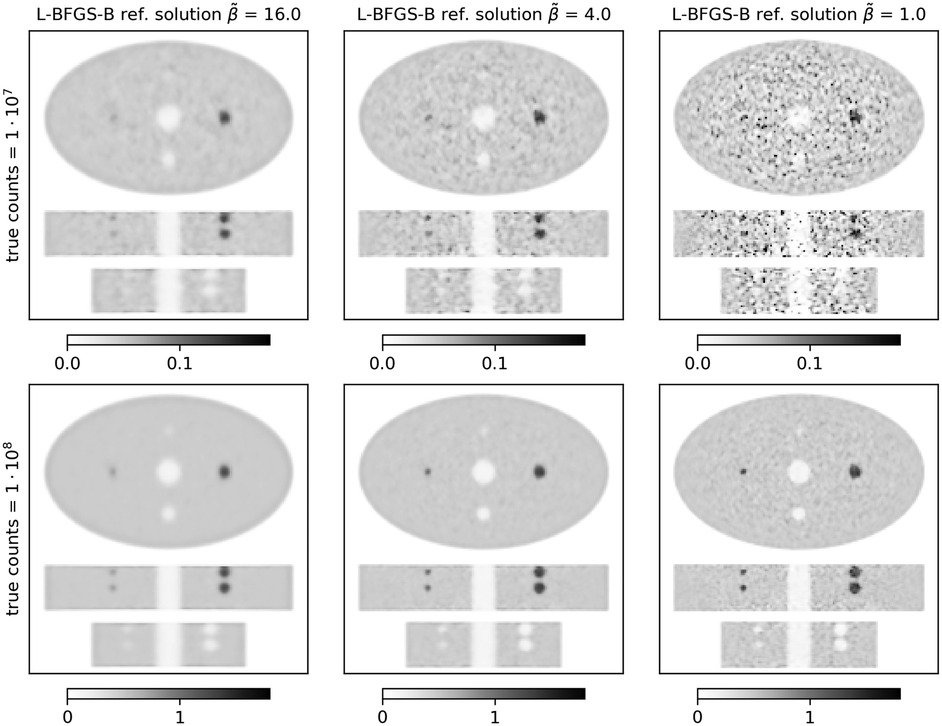
Figure 1. Stacked central transversal, coronal, and sagittal slices of L-BFGS-B reference reconstructions of the ellipse phantom. Each column shows a different level of regularization () increasing from left to right. The top row shows results for true counts, and the bottom row shows results for true counts.
3.2 Main simulation results
Algorithm and preconditioner effects (see Figure 2): When comparing SVRG, SAGA, and plain SGD under a vanishing stepsize schedule with and , we made the following observations.
• SVRG and SAGA consistently outperform SGD in all count and regularization regimes.
• The harmonic mean preconditioner (Equation 9) is crucial: under strong regularization , the classic MLEM preconditioner diverges or converges extremely slowly (depending on the chosen stepsize), whereas the harmonic mean variant converges reliably in every scenario.
• SVRG with the harmonic preconditioner, and (giving mild decay), yields the fastest convergence for medium and high . For low regularization, a slightly larger (up to or ) can accelerate convergence.
• Across all methods, convergence was slower in the case of low regularization .

Figure 2. Reconstruction performance in terms of NRMSE vs. walltime for SVRG, SAGA, and SGD, for MLEM (dashed lines) and harmonic (solid lines) PCs and three initial stepsizes () represented by different colors, using 27 subsets, a gentle stepsize decay with epochs, and subset selection without replacement. Results are shown for three levels of regularization () and two count levels. Note the logarithmic scale on the x- and y-axes. For each combination of preconditioner and , the outcome of one run is displayed. The thick solid line shows the NRMSE target threshold of used in the PETRIC challenge, and the dashed–dotted horizontal black line shows the NRMSE of the initial OSEM reconstruction.
Impact of the number of subsets (see Figure 3): Fixing the harmonic preconditioner and vanishing stepsize rule , we varied the number of subsets :
• SVRG achieves optimal walltime convergence at under medium to high . Lower benefits from using a greater number of subsets.
• Optimal values of and for SAGA depend strongly on : high favors a larger number of subsets with smaller , medium favors with , and low favors .
• Overall, SVRG with optimized settings achieves faster convergence compared to SAGA with optimized settings.

Figure 3. Performance in terms of NRMSE vs. walltime for SVRG and SAGA, for different number of subsets and initial stepsizes , using the harmonic preconditioner, a gentle stepsize decay with epochs, and subset selection without replacement. Results are shown for three levels of regularization and two count levels. For each combination of and , the outcome of one run is displayed. The thick horizontal black line shows the NRMSE target threshold of used in the PETRIC challenge.
Stability across repeated runs using different subsets orders (see Figure 4): We run five independent runs (changing the random seed used for the random subset selection) of the reconstructions using SVRG, the harmonic preconditioner, , , and . The run-to-run NRMSE variation is small, especially at , confirming low variance introduced by the stochastic subset selection in this setting.
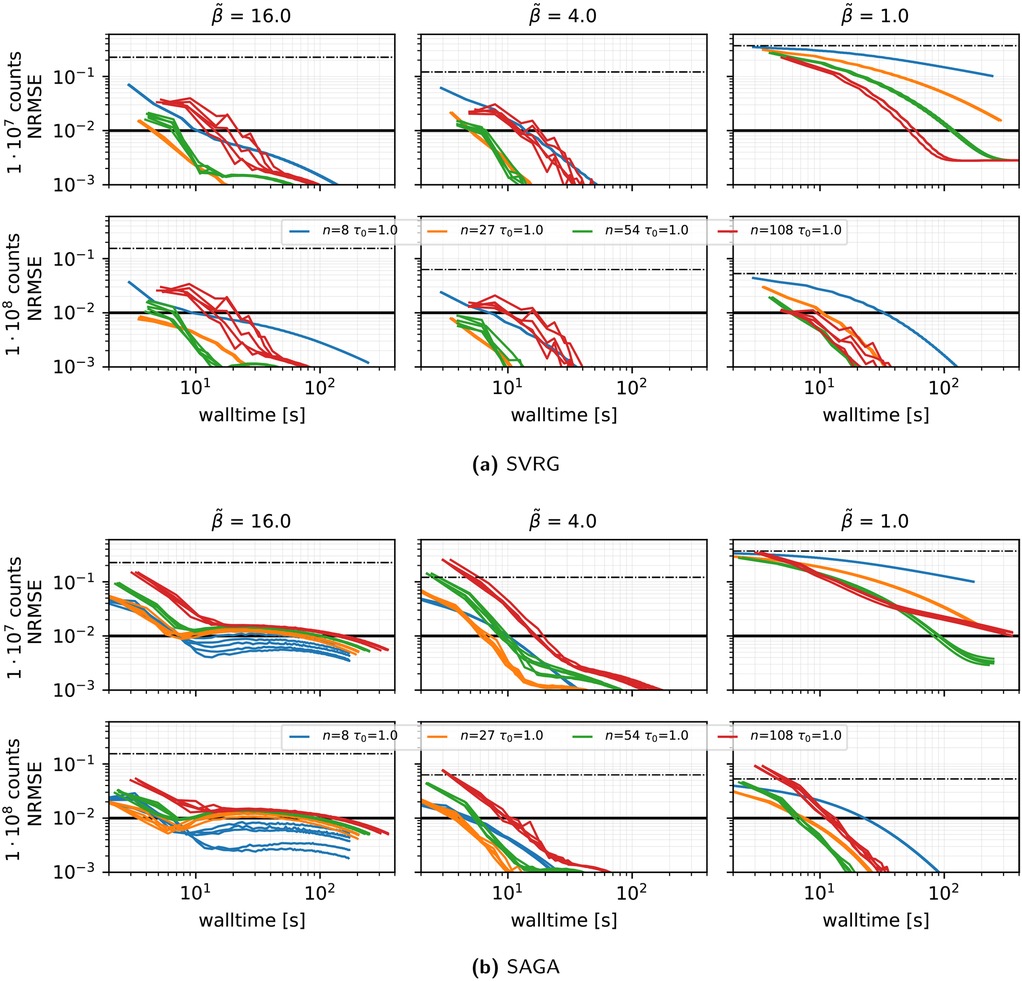
Figure 4. Same as Figure 3 showing the results of five runs, using a different random seed for the subset selection.
Subset sampling strategy (see Figure 5): Comparing the Herman–Meyer order, uniform sampling at random with and without replacement, importance sampling, and cofactor strategies for selecting the order of subsets for SVRG with , , and , we observe negligible differences between all subset selection rules in simulated scenarios, with some minor benefits for sampling without replacement and cofactor sampling.

Figure 5. Same as Figure 3 (SVRG only) showing the results for different subset sampling strategies, subsets, the harmonic preconditioner, an initial stepsize , and gentle stepsize decay using for non-ToF (top) and ToF reconstructions (bottom).
Stepsize rules (see Figure 6): We see that for SVRG, , and the harmonic preconditioner:
• At low , adaptive rules (short-form BB or heuristic ALG1) modestly outperform a simple decay.
• However, in the medium-to-high regime, a constant or decaying initialization yields superior ToF reconstruction performance compared to adaptive BB schemes.

Figure 6. Same as Figure 5 showing the results for different stepsize strategies, 27 subsets, and the harmonic preconditioner for non-ToF (top) and ToF reconstructions (bottom).
3.3 Simulation-derived conclusions
The inverse-crime simulation study motivated the design of our algorithms submitted to the PETRIC challenge in the following way:
• The harmonic mean preconditioner was essential for achieving stable convergence with across different count and regularization regimes.
• SVRG slightly outperformed SAGA in robustness and speed, and both outperformed SGD.
• A moderate number of subsets, , led to the fastest convergence times.
These guidelines directly informed our implementation choices for the three submitted algorithms, which are explained in detail in the next section.
4 Submitted algorithms and their performance
Based on the insights gained from the inverse-crime simulations in the previous section, we implemented and submitted three closely related algorithms (termed ALG1, ALG2, and ALG3) to the PETRIC challenge under the team name MaGeZ. All three algorithms use SVRG as the underlying stochastic gradient algorithm and apply the harmonic mean preconditioner (Equation 9). The pseudocode that forms the basis of all three algorithms is given in Algorithm 1 in Appendix A2. Our SVRG implementation uses in-memory snapshot gradients, adding only a small overhead compared to plain SGD or BRSEM. In the context of sinogram-based PET reconstructions of data from modern scanners, where gigabytes are devoted to storing sinograms, this extra memory requirement can be effectively neglected, as discussed in Twyman et al. (7).
The available PETRIC training datasets were primarily used to fine-tune the algorithm hyperparameters, namely, (i) the number of subsets, (ii) the subset selection strategy, (iii) the stepsize rule, and (iv) the update frequency of the preconditioner. These are the only distinguishing features among the submitted algorithms, and our choices are summarized in Table 1. ALG1 and ALG2 use the number of subsets as the divisor of the number of views closest to 25. ALG3 further modifies the subset count slightly using the divisor closest to 24.2 (with the goal of selecting a smaller number of subsets in some of the training datasets). In ALG1 and ALG2, subsets are chosen uniformly at random without replacement in each iteration of each epoch. ALG3 uses the proposed cofactor rule. ALG1 updates the preconditioner at the start of epochs 1, 2, and 3. ALG2 and ALG3 update the preconditioner at the start of epochs 1, 2, 4, and 6. ALG1 uses a fixed, piecewise stepsize schedule, while ALG2 and ALG3 employ a short BB rule for adaptive stepsize reduction, which is computed at the start of epochs 1, 2, 4, and 6.

Table 1. Key hyperparameters of the three submitted algorithms.
4.1 Performance on PETRIC test datasets
Figures 7 and 8 present the convergence behavior of all three submitted algorithms in terms of whole-object NRMSE, background NRMSE, and multiple volume-of-interest (VOI) mean absolute error metrics (AEMs). Each dataset was reconstructed three times with all three algorithms using a local NVIDIA RTX A4500 GPU. From the two figures, we observe the following:
• All algorithms converge reliably across all datasets and runs.
• ALG2 and ALG3 perform similarly and slightly outperform ALG1 in most cases. In the Vision600 Hoffman dataset, ALG1 takes almost twice as long as ALG2 and ALG3 to reach the convergence threshold.
• For the DMI4 NEMA, NeuroLF Esser, and Mediso low-count datasets, convergence is reached very quickly both in terms of walltime and epoch count, typically within four epochs.
• The Vision600 Hoffman dataset shows the slowest convergence, requiring more than 23 epochs (594 updates) for ALG2 and ALG3 and more than 47 epochs (1,184 updates) for ALG1.
• Inter-run variability is low, with timing differences between runs being within 1–2 s.
• Across all datasets, whole-object NRMSE is the slowest metric to converge, becoming the bottleneck in determining the final convergence time.
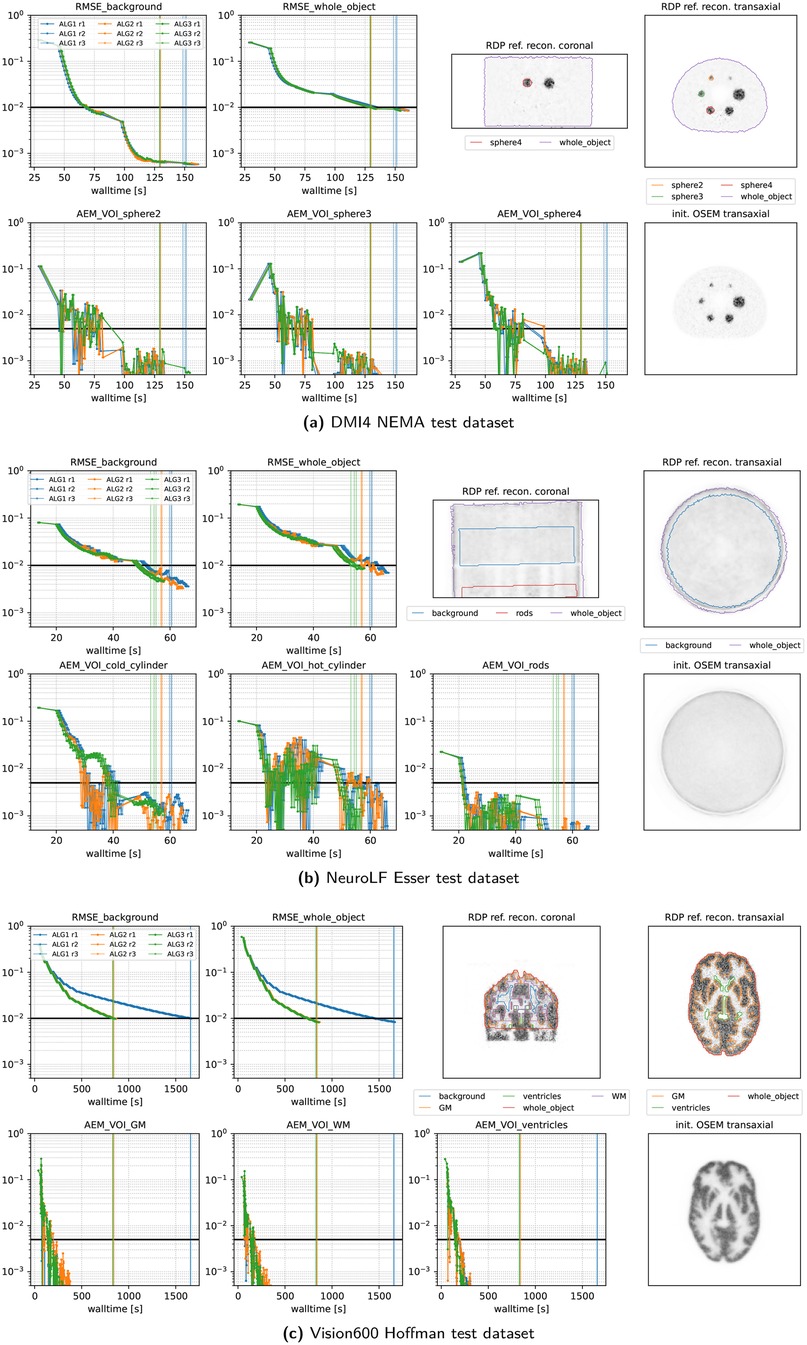
Figure 7. Performance metrics of our three submitted algorithms evaluated on three representative PETRIC test datasets using three repeated runs. The vertical lines indicate the time when the thresholds of all metrics were reached. Note the logarithmic scale on the y-axis and the linear scale on the x-axis. The top right images show coronal and transaxial slices of the reference reconstruction alongside contour lines of the volumes of interest used for the metrics. The bottom right image shows the same transaxial slice of the OSEM reconstruction used for the initialization of all algorithms.
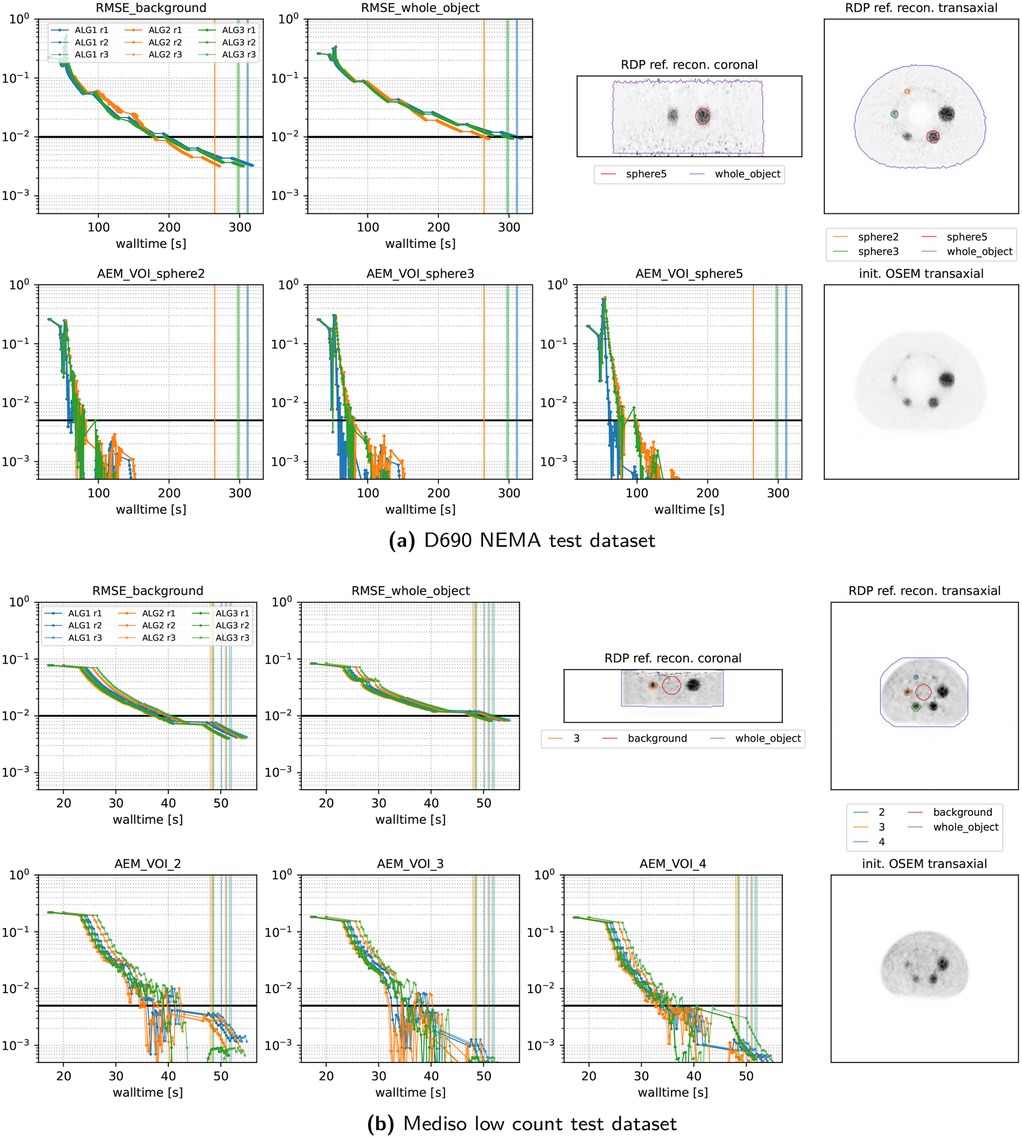
Figure 8. Same as Figure 7 for two more datasets.
A closer inspection of the stepsize behavior on the Vision600 Hoffman dataset reveals that the slower convergence of ALG1 is due to its lower final stepsize, which was implemented as a “safety feature.” After 300 updates, ALG1 reduces its to 0.5, whereas ALG2 and ALG3 continue to use since their BB-based calculated adaptive stepsizes remained larger in this dataset. This difference explains the kink observed in ALG1’s convergence curves around 450 s.
5 Discussion
We now want to discuss what we believe are the important and interesting aspects of this work.
In our view, the most important feature of our algorithms is the improved preconditioner, which takes into account Hessian information of the regularizer. This enhancement allowed for a better generalization of stepsize choices across a range of scanners, objects, noise levels, and regularization strengths. We chose SVRG as our gradient estimator, although this choice is not as clear-cut and might be different for other variants of the reconstruction problem. Our experience suggests that while a sophisticated method to control variance is important, the specific approach (e.g., SVRG or SAGA) appears to be less critical. In contrast, other factors like stepsizes and sampling strategies had a relatively minor impact, as the algorithms were not particularly sensitive to these choices.
A key aspect in our approach was to consider what could be effectively computed and what could not. For the RDP, it is easy to compute the gradient and the diagonal Hessian, but other operations such as the proximity operator or the full Hessian are much more costly. Similarly, the ideal number of subsets is largely a computational efficiency question. It has been observed numerous times that, theoretically, fewer epochs are needed with a larger number of subsets. However, practically, this means that the overhead per epoch increases, e.g., as the gradient is computed in each iteration of the epoch. These two factors must be traded off against each other.
Speaking of the RDP, we noticed a couple of interesting features that we have not exploited in our work. First, the diagonal Hessian of the RDP is very large in background regions where the activity is small. Second, while its gradient has a Lipschitz constant, similar to the total variation and its smoothed variants, algorithms that do not rely on gradients might be beneficial.
Between the three algorithms, ALG2 and ALG3 consistently performed either similarly to or better than ALG1. Comparing them to the submissions of other teams, it is worth noting that for almost all datasets, they performed far better than any of the other competitors, which lead to MaGeZ winning the challenge overall (26).
Coordination between our simulation insights and algorithm design was essential to our approach. Local testing allowed us to validate the generalization of our methods before final submission. Across datasets, we favored robustness over aggressive tuning. Refinement came from iterative testing rather than from theoretical guarantees alone. Above all, our goal was to develop an algorithm that performs well out-of-the-box.
6 Conclusions
In this paper, we presented our strategy and thought process behind designing our winning strategy for the 2024 PETRIC challenge. We identified the key parameters for PET image reconstruction algorithms using realistic yet very fast simulations. The harmonic mean preconditioner helped us to overcome the biggest roadblock of the challenge: tuning of parameters for a variety of settings with various scanner models, phantoms, and regularization strengths.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material.
Author contributions
MJE: Formal analysis, Validation, Project administration, Methodology, Data curation, Supervision, Writing – original draft, Conceptualization, Funding acquisition, Visualization, Software, Writing – review & editing, Investigation, Resources. ZK: Conceptualization, Visualization, Software, Validation, Methodology, Resources, Writing – original draft, Supervision, Formal analysis, Investigation, Funding acquisition, Data curation, Writing – review & editing, Project administration. GS: Methodology, Data curation, Supervision, Investigation, Conceptualization, Software, Writing – review & editing, Visualization, Resources, Writing – original draft, Project administration, Validation, Funding acquisition, Formal analysis.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. MJE and ZK acknowledge support from the EPSRC (EP/Y037286/1, EP/S026045/1, EP/T026693/1, and EP/V026259/1 to MJE; and EP/X010740/1 to ZK). GS acknowledges the support from NIH grant R01EB029306 and FWO project G062220N.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Generative AI was used in the creation of this manuscript. ChatGPT-4 was used for grammar and language improvements but not for content creation.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Nuyts J, Bequé D, Dupont P, Mortelmans L. A concave prior penalizing relative differences for maximum-a-posteriori reconstruction in emission tomography. IEEE Trans Nucl Sci. (2002) 49:56–60. doi: 10.1109/TNS.2002.998681
2. da Costa-Luis C, Ehrhardt MJ, Kolbitsch C, Ovtchinnikov E, Pasca E, Thielemans K, et al. Data from: Petric: PET rapid image reconstruction challenge (2025). Available online at: https://www.ccpsynerbi.ac.uk/events/petric (Accessed July 01, 2024).
3. Teoh EJ, McGowan DR, Macpherson RE, Bradley KM, Gleeson FV. Phantom and clinical evaluation of the Bayesian penalized likelihood reconstruction algorithm Q.Clear on an LYSO PET/CT system. J Nucl Med. (2015) 56:1447–52. doi: 10.2967/jnumed.115.159301
4. Teoh EJ, McGowan DR, Bradley KM, Belcher E, Black E, Gleeson FV. Novel penalised likelihood reconstruction of PET in the assessment of histologically verified small pulmonary nodules. Eur Radiol. (2016) 26:576–84. doi: 10.1007/s00330-015-3832-y
5. Ahn S, Ross SG, Asma E, Miao J, Jin X, Cheng L, et al. Quantitative comparison of OSEM and penalized likelihood image reconstruction using relative difference penalties for clinical PET. Phys Med Biol. (2015) 60:5733–51. doi: 10.1088/0031-9155/60/15/5733
6. Ahn S, Fessler JA. Globally convergent image reconstruction for emission tomography using relaxed ordered subsets algorithms. IEEE Trans Med Imaging. (2003) 22:613–26. doi: 10.1109/TMI.2003.812251
7. Twyman R, Arridge S, Kereta Z, Jin B, Brusaferri L, Ahn S, et al. An investigation of stochastic variance reduction algorithms for relative difference penalized 3D PET image reconstruction. IEEE Trans Med Imaging. (2022) 42:29–41. doi: 10.1109/TMI.2022.3203237
8. Ovtchinnikov E, Brown R, Kolbitsch C, Pasca E, Gillman AG, Thomas BA, et al. SIRF: synergistic image reconstruction framework. Comput Phys Commun. (2020) 249:107087. doi: 10.1016/j.cpc.2019.107087
9. Hudson HM, Larkin RS. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans Med Imaging. (1994) 13:601–9. doi: 10.1109/42.363108
10. Ehrhardt MJ, Markiewicz P, Schönlieb CB. Faster PET reconstruction with non-smooth priors by randomization and preconditioning. Phys Med Biol. (2019) 64:225019. doi: 10.1088/1361-6560/ab3d07
11. Kereta Ž, Twyman R, Arridge S, Thielemans K, Jin B. Stochastic EM methods with variance reduction for penalised PET reconstructions. Inverse Probl. (2021) 37:115006. doi: 10.1088/1361-6420/ac2d74
12. Schramm G, Holler M. Fast and memory-efficient reconstruction of sparse Poisson data in listmode with non-smooth priors with application to time-of-flight PET. Phys Med Biol. (2022) 67:155020. doi: 10.1088/1361-6560/ac71f1
13. Ehrhardt MJ, Kereta Z, Liang J, Tang J. A guide to stochastic optimisation for large-scale inverse problems. Inverse Probl. (2025) 41:053001. doi: 10.1088/1361-6420/adc0b7
14. Papoutsellis E, da Costa-Luis C, Deidda D, Delplancke C, Duff M, Fardell G, et al. Stochastic optimisation framework using the core imaging library and synergistic image reconstruction framework for pet reconstruction. arXiv [Preprint]. arXiv:2406.15159 (2024).
15. Bredies K, Kunisch K, Pock T. Total generalized variation. SIAM J Imaging Sci. (2010) 3:492–526. doi: 10.1137/090769521
16. Knoll F, Holler M, Koesters T, Otazo R, Bredies K, Sodickson DK. Joint MR-PET reconstruction using a multi-channel image regularizer. IEEE Trans Med Imaging. (2016) 36:1–16. doi: 10.1109/TMI.2016.2564989
17. Ehrhardt MJ, Markiewicz P, Liljeroth M, Barnes A, Kolehmainen V, Duncan JS, et al. PET reconstruction with an anatomical MRI prior using parallel level sets. IEEE Trans Med Imaging. (2016) 35:2189–99. doi: 10.1109/TMI.2016.2549601
18. Xie Z, Baikejiang R, Li T, Zhang X, Gong K, Zhang M, et al. Generative adversarial network based regularized image reconstruction for PET. Phys Med Biol. (2020) 65:125016. doi: 10.1088/1361-6560/ab8f72
19. Tsai YJ, Schramm G, Ahn S, Bousse A, Arridge S, Nuyts J, et al. Benefits of using a spatially-variant penalty strength with anatomical priors in PET reconstruction. IEEE Trans Med Imaging. (2019) 39:11–22. doi: 10.1109/TMI.2019.2913889
20. Tan C, Ma S, Dai YH, Qian Y. Barzilai-Borwein step size for stochastic gradient descent. Adv Neural Inf Process Syst. (2016) 29.
21. Ivgi M, Hinder O, Carmon Y. Dog is SGD’s best friend: a parameter-free dynamic step size schedule. In: International Conference on Machine Learning. PMLR (2023). p. 14465–99.
22. Vaswani S, Mishkin A, Laradji I, Schmidt M, Gidel G, Lacoste-Julien S. Painless stochastic gradient: interpolation, line-search, and convergence rates. Adv Neural Inf Process Syst. (2019) 32.
23. Herman GT, Meyer LB. Algebraic reconstruction techniques can be made computationally efficient (positron emission tomography application). IEEE Trans Med Imaging. (1993) 12:600–9. doi: 10.1109/42.241889
24. Schramm G, Thielemans K. PARALLELPROJ—an open-source framework for fast calculation of projections in tomography. Front Nucl Med. (2024) 3:2023. doi: 10.3389/fnume.2023.1324562
25. Byrd RH, Lu P, Nocedal J, Zhu C. A limited memory algorithm for bound constrained optimization. SIAM J Sci Comput. (1995) 16:1190–208. doi: 10.1137/0916069
26. da Costa-Luis C, Ehrhardt MJ, Kolbitsch C, Ovtchinnikov E, Pasca E, Thielemans K, et al. Data from: PETRIC: PET rapid image reconstruction challenge—leaderboard (2025). Available online at: https://petric.tomography.stfc.ac.uk/leaderboard (Accessed May 16, 2025).
Appendix
1 Gradient and Hessian of the RDP
For completeness, we present here the first and second derivatives of the RDP (Equation 3), i.e., the gradient and the diagonal of the Hessian. Both of these are used in our proposed solution.
Let , , and . Then the first derivative is given by
and the second by
2 Pseudocode for submitted preconditioned SVRG algorithm

Algorithm 1. Preconditioned SVRG algorithm.

.
Keywords: PET, MAP, preconditioning, variance reduction, stochastic gradient methods, regularization methods, image reconstruction
Citation: Ehrhardt MJ, Kereta Z and Schramm G (2025) Fast PET reconstruction with variance reduction and prior-aware preconditioning. Front. Nucl. Med. 5:1641215. doi: 10.3389/fnume.2025.1641215
Received: 4 June 2025; Accepted: 6 August 2025;
Published: 17 September 2025.
Edited by:
Yi-Hwa Liu, Yale University, United StatesReviewed by:
Alan Miranda, University of Antwerp, BelgiumDamir Seršić, Sveučilište u Zagrebu Fakultet Elektrotehnike i Računarstva, Croatia
Copyright: © 2025 Ehrhardt, Kereta and Schramm. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zeljko Kereta, ei5rZXJldGFAdWNsLmFjLnVr
†ORCID:
Matthias J. Ehrhardt
orcid.org/0000-0001-8523-353X
Zeljko Kereta
orcid.org/0000-0003-2805-0037
Georg Schramm
orcid.org/0000-0002-2251-3195