 Brendyn Miller1†
Brendyn Miller1† Samuel J. Coeyman
Samuel J. Coeyman Carina M. C. Mels
Carina M. C. Mels William J. Richardson
William J. Richardson- 1Institute for Regenerative Medicine, Wake Forest University, Winston-Salem, NC, United States
- 2Ralph E. Martin Department of Chemical Engineering, University of Arkansas, Fayetteville, AR, United States
- 3Hypertension in Africa Research Team, North-West University, Potchefstroom, South Africa
- 4MRC Research Unit for Hypertension and Cardiovascular Disease, North-West University, Potchefstroom, South Africa
Introduction: Cardiovascular disease (CVD) remains the leading global cause of mortality, with hypertension (HT) being a significant contributor, responsible for 56% of CVD-related deaths. Masked hypertension (MHT), a condition where patients exhibit normotensive blood pressure (BP) in clinical settings but elevated BP in out-of-clinic measurements, poses an elevated risk for cardiovascular complications and often goes undiagnosed. Current diagnostic methods, such as ambulatory BP monitoring (ABPM) and home BP monitoring (HBPM), have limitations in feasibility and accessibility.
Methods: This study aimed to address these challenges by leveraging machine learning (ML) models to predict MHT based on clinical data from a single outpatient visit. Utilizing a dataset from the African-PREDICT study, which included comprehensive clinical, biomarker, body composition, and physical activity data from a young, healthy cohort (aged 20–30 years) in South Africa, we developed a predictive framework for MHT detection.
Results: The ML models demonstrated the potential to enhance early identification and treatment of MHT, reducing reliance on resource-intensive methods like ABPM. Specifically, we found that utilizing a Least Absolute Shrinkage and Selection Operator (LASSO) feature selection method with an extreme gradient boosting model had an accuracy of 0.83 and a ROC AUC score of 0.86 while relying predominantly on four features: systolic blood pressure, body weight, left ventricular mass at systole, and circulating levels of dehydroepiandrosterone sulfate.
Discussion: This approach could enable targeted interventions, particularly in resource-limited settings, thereby mitigating the progression of MHT and its associated risks. These findings underscore the importance of integrating advanced computational techniques into clinical practice to address global health challenges.
1 Introduction
Cardiovascular disease (CVD) is the leading cause of death globally, claiming approximately 17.9 million lives annually (World Health Organization, 2023; Mathers et al., 2009). Hypertension (HT) is one of the strongest risk factors for CVD and is associated with coronary disease, left ventricular hypertrophy, valvular heart disease, cardiac arrhythmias, cerebral stroke, and renal failure (Kjeldsen, 2018). HT accounts for approximately 56% of all CVD-related deaths (10 million) and is incredibly prevalent, affecting an estimated 1.3 billion people worldwide (World Heart Federation, 2022). This number has been increasing and is expected to reach 1.56 billion deaths annually by the year 2025 due to multiple factors, including population aging, increased prevalence of chronic kidney disease (CKD), diabetes mellitus, and obesity, suboptimal clinical treatments, and poor adherence to treatment plans (Kearney et al., 2005; Hunter et al., 2021). HT is defined clinically as a blood pressure (BP) of 140/90 mmHg or higher and can be prevented or managed through lifestyle and pharmacological interventions (Messerli et al., 2007; Nguyen et al., 2010).
While HT can be managed, it often remains untreated as several population studies have found 12.7%–37.3% of all cases of HT were not diagnosed clinically (Huguet et al., 2021; Shukla et al., 2015; Essa et al., 2022). This is due in part to a subset of these patients (10% of the general population) having normotensive BP measurements within the clinic while their out-of-clinic BP as measured by ambulatory BP monitoring is elevated to the point of being considered hypertensive (Pickering et al., 2007). This condition has been classified as masked hypertension (MHT) and has been shown to have equal, if not increased, risk for adverse cardiovascular morbidity due to the lack of any clinical diagnosis and corresponding clinical intervention (Stergiou et al., 2014; Thakkar et al., 2020; Bobrie et al., 2008). Furthermore, this condition has been associated with increased organ damage, altered cardiovascular dysfunction and structural changes, and higher incidence of cardiovascular and cerebral events (including stroke and cognitive decline) (Bobrie et al., 2008; Trachsel et al., 2015; Fujiwara et al., 2018).
One recent meta-analysis has suggested that nearly one in three patients who have normotensive office blood pressure measurements have MHT. While this condition is more commonly present in older populations, MHT has even been identified in young and apparently healthy populations in the absence of clinically relevant risk factors (such as dyslipidemia, hyperglycemia, obesity, etc.) (Bobrie et al., 2008). Other studies have also reported similar findings, with one study reporting that approximately 11% of children under the age of 15 had MHT (Stergiou G. S. et al., 2005) and another study reported the prevalence of MHT in young to middle-aged adults (44 ± 19 years of age) to be 23% (Bendov et al., 2005). Other studies found MHT present in populations that appeared to be in peak physical condition, such as endurance runners and professional soccer players (Trachsel et al., 2015; Berge et al., 2013). These studies demonstrate the need to monitor the out-of-office BP of the general population to diagnose and treat MHT in a timely and effective manner. The most common methods for detecting MHT are ambulatory BP monitoring (ABPM) and home BP monitoring (HBPM), however both methods come with significant drawbacks (Hermida et al., 2015; Anstey et al., 2018). HBPM, while convenient and easy to obtain, has been shown to have a reduced ability to detect MHT when compared to ABPM and research published by Stergiou et al., suggests that HBPM should only be used in conjunction with ABPM to detect MHT (Stergiou G. et al., 2005). ABPM, on the other hand, has been shown to successfully detect MHT with a high degree of accuracy; however, it requires the use of cumbersome equipment that may not be available to certain population groups, particularly in children or in populations in low-and-middle income countries (Flynn et al., 2022; Shimbo et al., 2015; Stergiou et al., 2021; Abdalla, 2017). Thus, the feasibility of ABPM for population-level detection of MHT is unknown (Abdalla, 2017). One potential alternative would be to develop a method for assessing risk for MHT based on clinical measurements obtained from a single outpatient visit. This could serve as a preliminary screening method that would allow the patients most at risk for MHT to be identified while reducing the need for all patients to undergo ABPM. Patients that are classified as being at risk for MHT could then undergo ABPM to confirm the presence of MHT and the need for further medical and lifestyle intervention to prevent the advent of CVD.
Several studies have recently developed machine learning (ML) models to predict adverse cardiovascular events such as coronary heart disease, heart failure, and stroke that have shown potential to assist clinicians in early disease detection and diagnosis (Krittanawong et al., 2020; Sevakula et al., 2020). These models evaluate clinical features to determine which patients are most at risk for these events using a combination of statistical methods and computational algorithms that can be automatically fine-tuned to these specific applications based on the input data. Researchers have found that these data-driven models can outperform traditional models in applications involving a multitude of different variables due to their inherent ability to capture the non-linear relationships between these features and the variable that is being predicted (Sevakula et al., 2020; Motwani et al., 2016; Churpek et al., 2016). ML models are also useful for establishing a predictive model in which an experimentally validated model is not readily available. The goal of this study was to develop an ML model to detect patients with MHT in the hopes of improving MHT detection, diagnosis, and treatment in a young and relatively healthy population.
2 Materials and methods
2.1 Patient data acquisition
The dataset used in this model was derived from the African-PREDICT study, which aims at preemptively identifying cardiovascular disease in young adults from South Africa (Mokwatsi, 2022). The African-PREDICT study design and specific research methods used to collect the data have been described previously (Schutte et al., 2019). In brief, a total of 1202 black (N = 606) and white (N = 596) young men and women (aged 20–30 years) in South Africa were screened to be healthy and clinically normotensive and without complicating factors such as pregnancy or previous self-reported diagnosis of any chronic diseases. Different clinical measures relevant to hypertension were collected from each patient. Each of the measured features could be broadly categorized into the following groups:
1. Questionnaire data (e.g., medical history, social status, diet, psychosocial profile)
2. Biomarker data (e.g., lipids, glucose, multiplex cytokines, RAS-Fingerprint, adipokines, oxidative stress, nitric oxide and coagulation markers, urinary sodium, metabolomics, proteomics)
3. Body composition data (physical measurements)
4. Physical activity (vigorous, moderate, and sedentary activity levels)
5. BP (office, 24-h cuff monitoring, central, reactivity)
6. Target organ damage (arterial stiffness, carotid wall thickness, electrocardiography, echocardiography, retinal microvasculature, renal function).
Each data type was obtained at a single time-point upon patient enrollment in the study, with no follow-up data included in the present analysis. Office BP was measured 4 times, twice on both arms; 24-h BP was obtained over a single 24-h period; biomarker samples were obtained once, but appropriate duplicate/triplicate readings were used for biochemical panel measurements. All measurements were conducted in accordance with current gold standard methodologies and were carried out by trained research nurses, postgraduate students, and academic staff. The necessary ethical clearance was obtained from the Health Research Ethics Committee of North-West University (ethics number: NWU-00001–12-A1), with all participants providing written informed consent prior to data collection; the study is registered on ClinicalTrials.gov (Identifier: NCT03292094).
2.2 Machine learning model overview
Figure 1 depicts the overall process implemented during machine learning model development. The original African-PREDICT dataset contains health records with 526 different features from a cohort of 1,202 de-identified patients. This dataset was preprocessed prior to modeling and then split into a training set for constructing the ML model and a testing set for validating the model. One of five different feature selection strategies was then applied to the training set to identify the relevant features in the dataset and eliminate the unnecessary features. The relevant features were used to train the model using four different classification models as well as a stacked model assembled with all the base models combined. This resulted in 25 different pipelines in total (5 feature selection algorithms x five different ML classification models).
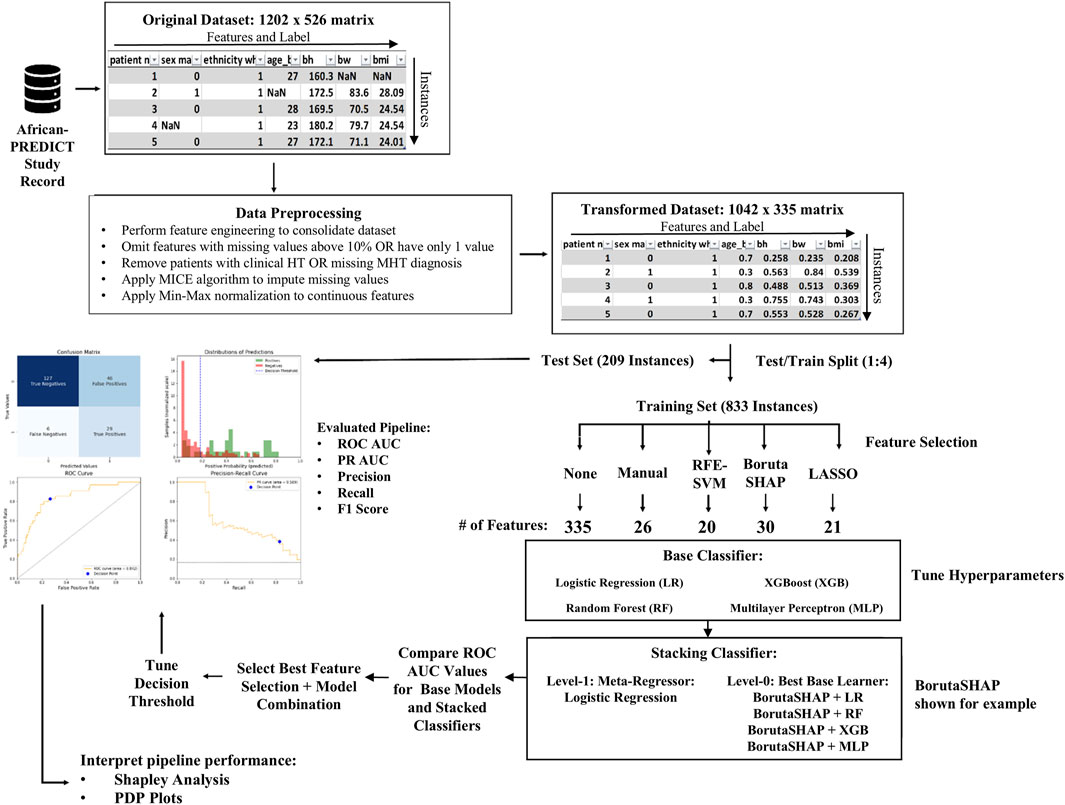
Figure 1. Overview of pipeline development process. The original dataset was imported as a 1202 × 526 matrix. It underwent preprocessing that consisted of feature engineering, data cleaning, imputation, and scaling to make a transformed dataset that was a 1042 × 335 matrix. The data was split into testing and training sets using a 1:4 split ratio. Five feature selection methods were evaluated on four different base ML models and a fifth ensemble ML model, resulting in 25 different pipelines (feature selection algorithm + ML model). The best performing pipelines were evaluated and SHAP analysis was used in conjunction with PDP plots to interpret the pipeline predictions.
The overall goal was to correctly classify patients with MHT. In this cohort, MHT was defined as the absence of hypertension in clinical measurements (i.e., clinic systolic blood pressure <140 mmHg and diastolic blood pressure <90 mmHg based on European Society of Hypertension guidelines) combined with high blood pressure in 24-h ambulatory cuff monitoring (i.e., systolic blood pressure ≥130 mmHg and/or diastolic blood pressure ≥80 mmHg). These ambulatory blood pressure measurements were acquired by fitting a cuff to participants’ non-dominant arms, and instructions given to ensure successful inflations. The cuff was programmed for readings every 30 min during the day and every 60 min during the night. Successful blood pressure readings were averaged across the measurement period and then compared to the systolic and diastolic pressure thresholds.
The model performance for each feature selection strategy was compared using the area under their receiver operating characteristic curve (ROC AUC). The classifier with the highest ROC AUC was then tuned, and the results of the final model were reported. Shapley Additive explanations (SHAP) values were used to investigate the individual contributions of each feature to the model predictions, and partial dependence plots (PDPs) were created to assess the relationship between each feature and the predicted outcome (Gramegna and Giudici, 2022).
2.3 Data preprocessing
The first step in building the ML model was to load the de-identified patient data and store it as a data frame in Python (version 3.12.2) using an open-source integrated development environment (IDE) (Visual Studio Code V1.93). The dataset was first cleaned by dropping any patient who was clinically diagnosed with hypertension, any patient who was missing more than 10% of feature measurements, and any feature that was missing in more than 10% of patients. Any features that contained only one unique value in the dataset were also dropped.
After cleaning the data, the next preprocessing step was to drop irrelevant features and perform feature engineering to reduce the number of features in the dataset. The purpose of this step was two-fold: first, reducing the number of features in the dataset by removing unnecessary features helps to improve model performance and reduce computational cost (Guyon and De, 2003), and second, this step helps to improve the overall interpretability of the model. Several features in the original dataset were not considered relevant to the model based on the intended use case for the model. These features could be broadly classified as ambulatory blood pressure measurements and certain questionnaire features. Next, we performed a literature review of known risk factors for HT (Franklin et al., 2015; Franklin et al., 2016; Booth et al., 2016; du Toit et al., 2023). Of these, several categorical features were identified that could be determined from numerical features in the dataset. Given that these categorical features could potentially help improve the performance of certain ML models and potentially serve as important predictors of MHT, these features were created using the criteria outlined in Table 1 and were included as additional features in the data frame.
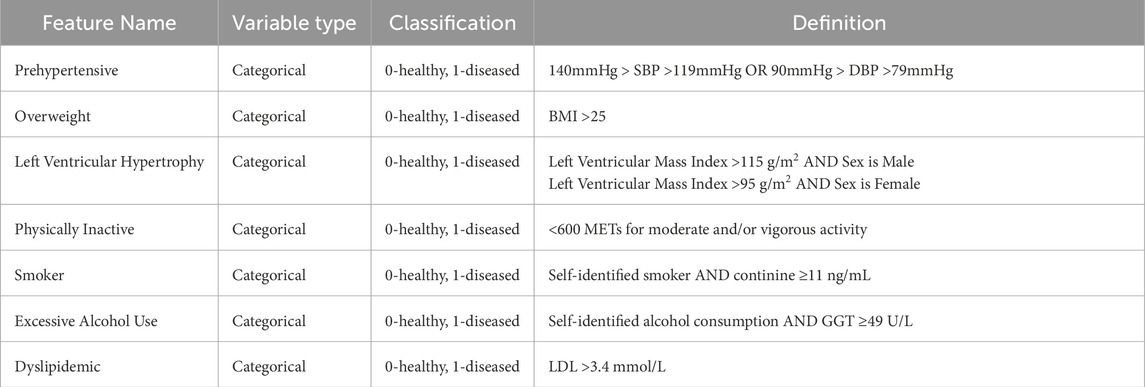
Table 1. List of engineered categorical features and corresponding definitions based on previous analyses (Franklin et al., 2015; Franklin et al., 2016; Booth et al., 2016; du Toit et al., 2023).
Once the dataset had been cleaned and feature engineering had been conducted, there was a total of 335 features across 1042 patients. Next, any remaining missing numerical values in the dataset were imputed using the Multivariate Imputation by Chained Equations (MICE) algorithm (van Buuren and Groothuis-Oudshoorn, 2011). The MICE algorithm assumes that the missing values are missing at random without any underlying relationship between the instances where features are missing and a detailed explanation of the algorithm has been described by Azur et al., (Azur et al., 2011). For this work, MICE imputation was implemented using the iterative imputer class in scikit-learn. More details of how this algorithm was implemented in the scikit-learn library are described elsewhere (van Buuren and Groothuis-Oudshoorn, 2011; Pedregosa, 2011). For the categorical features, missing values were filled in using the mode of the entire column.
After imputing missing values in the dataset, the final step in the data preprocessing stage was to scale the continuous features to increase model efficiency and prevent feature bias from occurring in the ML algorithms that weigh feature importance based on Euclidean distance measures. This is a crucial step for those ML algorithms, as features of high magnitude can be biased toward higher weights than features of lower magnitude (Jadhav et al., 2019). Scaling the dataset was implemented using a MinMaxScaler class from the scikit-learn.preprocessing library (scikit-learn v. 1:3:0) (Pedregosa, 2011).
2.4 Feature selection
The next step in ML model development was to perform feature selection, which is a crucial to preparing a dataset for training a ML model (Kumar, 2014). This phase was especially important in the present study because of a high participant-to-variable ratio (1042:335). Feature selection enabled a drastic reduction in the number of features fed into the subsequent ML models, which can improve training performance. For this work, a total of five different feature selection methods were explored:
1. RFE-SVM–a wrapper feature selection method known as recursive feature elimination which utilizes a support vector machine classifier
2. BorutaSHAP–a wrapper feature selection method which utilizes the Boruta algorithm wrapped around an extreme gradient boosted classifier (XGB) to select features based on their SHapley Additive exPlanation (SHAP) values
3. LASSO - an embedded feature selection method that uses an L1 regularization technique to eliminate unimportant features by shrinking the coefficients of these features to zero and effectively removing them from the model, known as Least Absolute Shrinkage and Selection Operator regression.
4. Manual–features based on relevant predictors reported in scientific literature
5. None–all features included
RFE-SVM is a popular wrapper feature selection method that has been used in multiple previous studies to select important features using the backward feature elimination algorithm in conjunction with a SVM linear classifier (Samb et al., 2012). SVM classifiers are a class of generalized linear classifiers that operate under the guiding principle of simultaneously minimizing classification error and maximizing the geometric margin by identifying the hyperplane that maximizes the Euclidian distance between the plane and the dataset features in a multidimensional space (Brereton and Lloyd, 2010). For this study, the Recursive Feature Elimination was implemented using the RFE class in the scikit-learn.feature_selection library.
The second automatic feature selection technique that was evaluated for this study was the Boruta-SHAP technique. Briefly, the Boruta method determines feature importance by comparing the relevance of real features in the dataset to randomized copies of the features. A more detailed overview of the Boruta algorithm has been described previously by Kursa et al., (Kursa et al., 2010). For this study, the standard Boruta-SHAP algorithm was slightly modified to utilize SHAP values as the metric for importance scoring. This metric was selected based on previous research which has evaluated different automatic feature selection techniques and found that feature selection techniques based on SHAP values are more stable (less lightly to alter selected features for different permutations of the training data) and can improve overall model performance compared to other automatic feature selection techniques (Gramegna and Giudici, 2022; Ma and Huang, 2008). The Boruta-SHAP feature selection algorithm was implemented in python using the BorutaSHAP function BorutaSHAP library (BorutaSHAP v. 1.0.17) (Keany, 2020). A Random Forest Classifier class from the scikit-learn.ensemble library was fit to a training dataset containing all the features and implemented as the wrapper for the BortuaSHAP instance.
The third and final automatic feature selection method that was assessed in this study was LASSO regression. At a high level, LASSO regression performs feature selection by shrinking the coefficient of unimportant features in the regression model towards zero through the introduction of an L1 regularization penalty term (Ranstam and Cook, 2018). LASSO regression feature selection was implemented using the LassoCV class in the scikit-learn.linear_model library.
For the manual feature selection, a literature review was conducted to determine which features in the original dataset were correlated with the incidence of MHT. Features from our dataset that were found to be relevant to MHT are shown in Table 2.
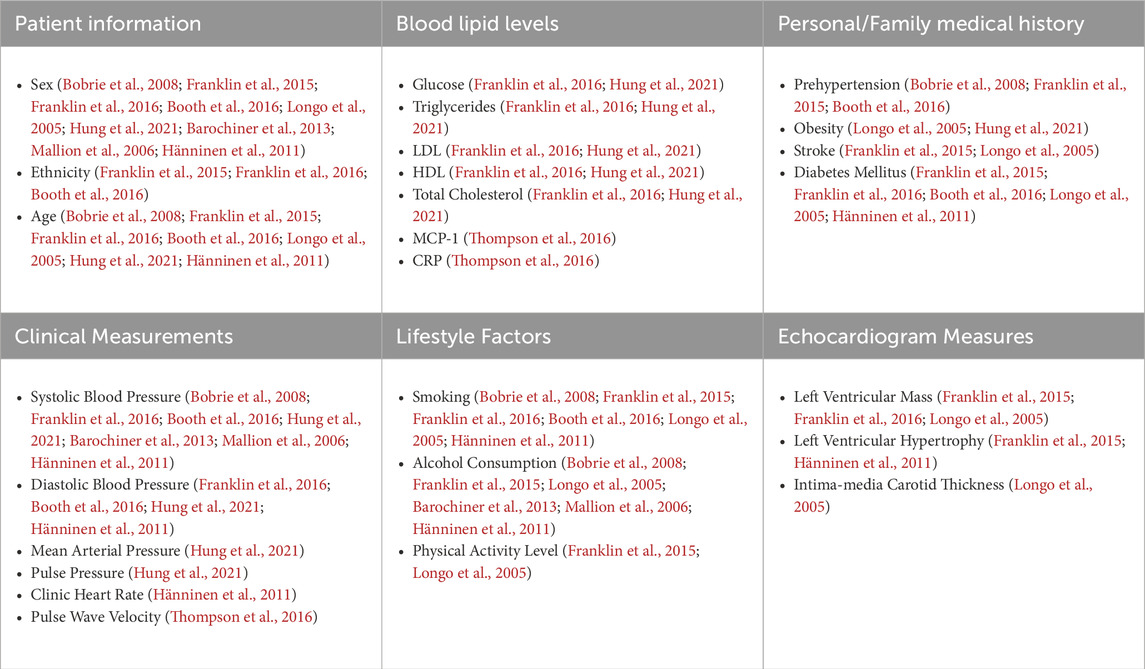
Table 2. Manual selected features based on literature reviews.
2.5 Machine learning models
The overall goal of this model was to detect patients that were at risk for MHT, so patient classification was the ML task chosen to be modeled using the African-PREDICT dataset. Several ML classifier algorithms were employed and evaluated for this purpose using the features from each feature selection strategy. These algorithms included:
1. Multivariate logistic regression (LR) classifier
2. Random forest (RF) classifier
3. Extreme Gradient Boosting (XGB) classifier
4. Artificial Neural Network (ANN) classifier
5. Stacking (STK) classifier
2.6 Hyperparameter & decision threshold tuning
A Bayesian Optimization grid search strategy was employed to evaluate a range of hyperparameters for each model (Table 3). Hyperparameters in a set were mapped to a corresponding score probability to create a probabilistic model that enabled the grid search to converge to the optimal hyperparameter values, rather than blindly testing each combination of values individually. A more detailed discussion of this algorithm is presented by Wu et al. (2019). Five-fold cross-validation was used for hyperparameter tuning and model training to help improve how the fitted values would generalize to a test dataset.
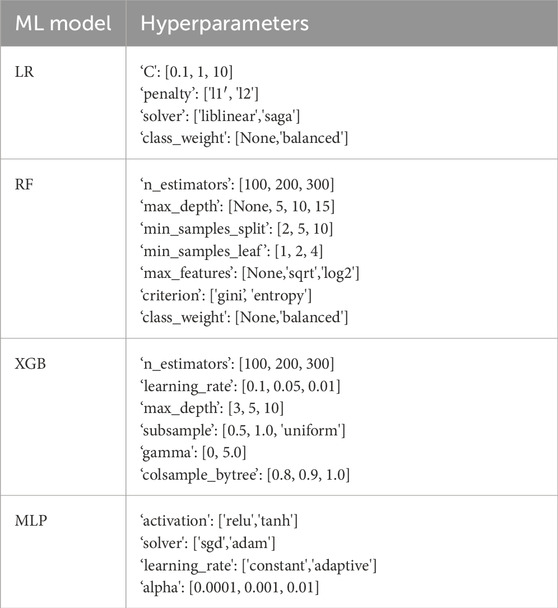
Table 3. List of ML models and their associated sets of evaluated hyperparameters.
The final step in constructing the overall pipelines was to tune the decision threshold value for classifying patients as “at risk” for MHT. For every model, the predicted MHT probability for each patient was calculated. This decision threshold was again cross-validated with a ten-fold repetitive split of the training data.
2.7 Evaluation metrics
This study evaluated several classification metrics commonly used to evaluate the performance of an ML model on an imbalanced dataset. These metrics include the accuracy, precision, recall (also known as sensitivity or true positive rate), specificity (equal to one minus the false positive rate), the F1 score, area under the receiver operator characteristic curve (ROC AUC), area under the precision-recall curve (PR AUC), and the odds ratio. Each of these metrics provides information on how well the model was able to identify patient outcomes based on the features in the dataset. ROC AUC is one of the most common evaluation metrics for binary classification problems and is constructed by plotting the true positive rate (TPR) vs. the false positive rate (FPR) for a range of decision thresholds between 0 and one and then calculating the area under the resulting curve.
2.8 Model interpretation
Model interpretability is a key factor when developing a ML model for clinical applications as end users, such as clinicians and other medical professionals, need to be able to understand how a prediction was made in order to confirm that the prediction is valid and aligns with their own medical knowledge and understanding. Thus, a method for helping model end users to make sense of the model is imperative when the final model involves more complex ML algorithms (Cinà, 2022). Two common methods used in ML model development include SHAP Values and Partial Dependence Plots (PDPs). SHAP values are used to access the contribution of a feature to a model’s predicted outcome for a particular instance is a concept rooted in game theory (Hart, 1989). In its original context, Shapley values were created as a means of evaluating a player’s contribution to a game’s outcome. It has since been applied in the field of ML as a model-agnostic means of interpreting how a model operates (Shih et al., 2022). In this case, each feature in the model is considered a player in the game and the model prediction is the outcome.
PDPs are a valuable tool for interpreting and explaining the behavior of ML models by providing insights into how the model’s predicted outcome changes as a function of a specific feature while holding other features constant. By isolating the effect of a single feature on the model’s predictions, PDPs highlight the relationship between that feature and the output feature in an intuitive and visual manner. These plots can then be used to identify trends, patterns, and potential nonlinearities that might not be evident from simple summary statistics or coefficients. PDPs can also facilitate the detection of interaction effects between variables, showcasing how their combined influence impacts the model’s output.
3 Results
3.1 Feature selection and relative importance of selected features
Five different feature selection strategies were evaluated in this study: RFE-SVM, BorutaSHAP, LASSO, manual, and none (all features). The number of selected features for each feature selection strategy are reported in Figure 2A with common features found across the selection strategies shown in Figure 2B. Of all the feature selection strategies that were evaluated, the LASSO method produced the highest ROC AUC value using the XGB classifier, with a total of 21 features selected. Dyslipidemic, LV posterior wall thickness at diastole, phosphorus, prehypertensive, medication for alimentary tract and metabolism, socio-economic education, socio-economic household income, and socio-economic skill were unique to LASSO; body weight, chromium, blood pressure grades, c-peptide, and LV posterior wall thickness at systole were shared between LASSO and BorutaSHAP; participant age, alcohol consumption, ethnicity, obesity, and sex were shared between LASSO and the manual selections; LV mass at systole and dehydroepiandrosterone sulfate (DHEA-S) was shared between the LASSO, RFE-SVM and BorutaSHAP strategies; and systolic blood pressure was shared by all strategies. It is important to note that this selection includes a variety class of features from biochemical analyses, general questionnaire, and anthropometry measurements.
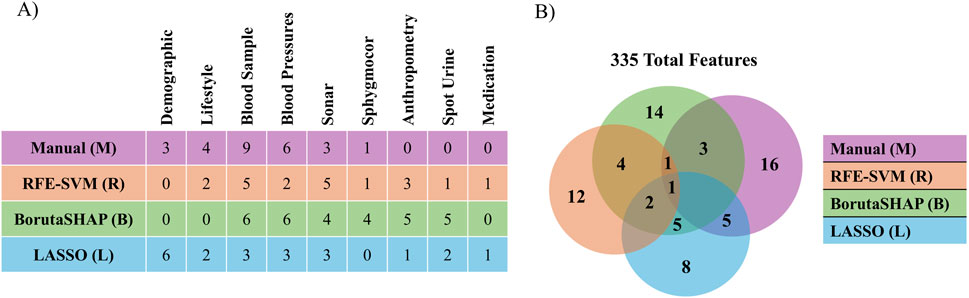
Figure 2. Comparison of features selected by each selection method. (A) The number of features selected by each method for each patient data category. (B) The number of features selected by and shared by each method.
3.2 Comparison of classifiers across different feature selection strategies
Each permutation of feature selection strategy and machine learning algorithm was implemented to create a total of 25 different MHT classifier pipelines. Five-fold cross-validation was used to obtain the mean and standard deviation of the ROC AUC for each model, seen in Figure 3. The LASSO feature selection strategy combined with a XGB classifier obtained the highest average ROC AUC score out of the entire set of models when evaluated on the test set, with a ROC AUC of 0.89 ± 0.03. Conversely, the ANN classifier tuned using the features selected with LASSO obtained the lowest average ROC AUC score out of the entire set of models when evaluated on the test set, with a ROC AUC of 0.44 ± 0.22.
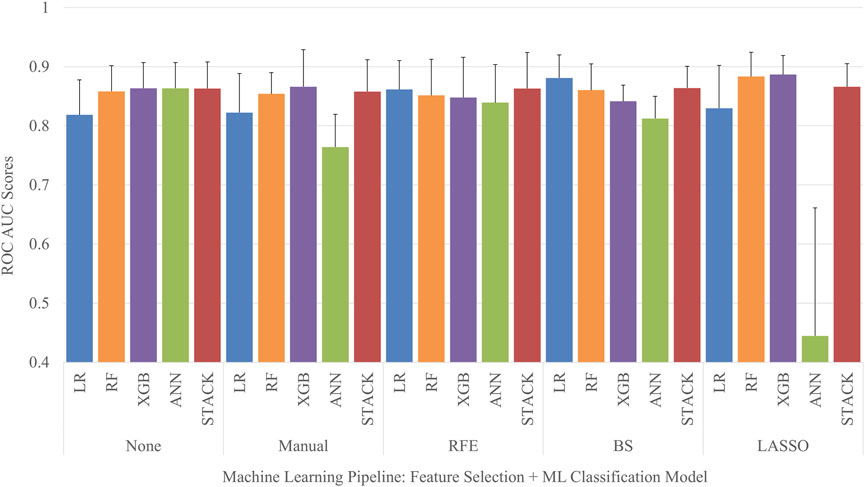
Figure 3. ROC AUC comparison of machine learning models.
3.3 Evaluation of final model performance
After examining all ROC AUC scores, the XGB classifier with LASSO feature selection strategy was chosen as the final pipeline for the MHT classifier due to it having the highest ROC AUC score. To assess the overall model performance, the pipeline’s accuracy, ROC AUC, PR AUC, F1 score, sensitivity, specificity, and odds ratio within the test set were calculated. We also compared these performance metrics to a binary prediction model previously proposed by Thompson et al. that classified MHT risk based on a simple cutoff for office systolic blood pressure greater than 120 mmHg (Thompson et al., 2016). The results of the comparison are outlined in Table 4 and Figure 4. The XGB classifier with LASSO features outperformed the binary classifier across all metrics evaluated, except for sensitivity where the binary had a slightly better sensitivity.
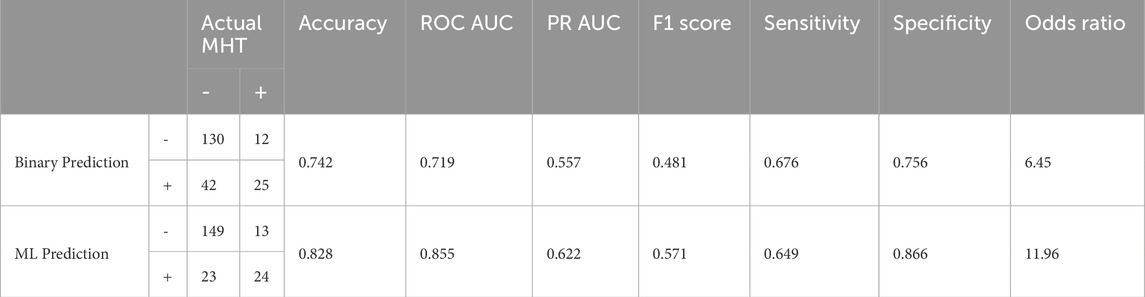
Table 4. ML model evaluation metrics vs. simple binary classifier evaluation metrics.
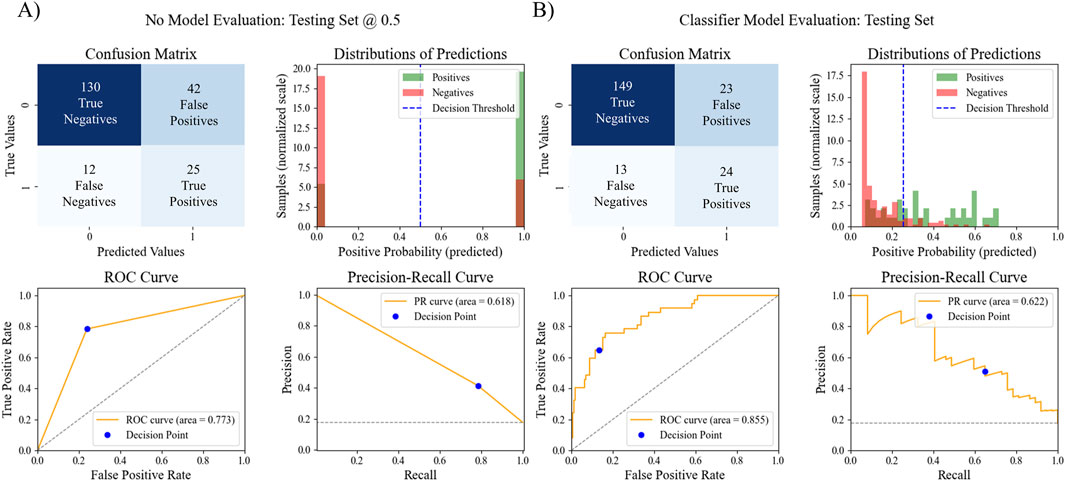
Figure 4. Comparison of MHT ML model performance vs. MHT binary model performance. The confusion matrix, distribution of predictions, ROC AUC, and PR AUC for (A) the simple binary classifier and (B) the best ML pipeline.
3.4 Model explanation
SHAP analysis was used to evaluate the overall contribution of each selected feature to the predictions made by the best five pipelines. SHAP values were calculated for each feature for each instance in the optimized dataset. The absolute value of each SHAP value for a particular feature across all instances were summed together, averaged, and normalized to indicate the importance of the feature relative to the other features in the optimized dataset. The normalized values were aggregated across the five pipelines with the highest test ROC AUC, and the top 15 features are shown in Figure 5. Plots of original and normalized values for each of the five best pipelines can be seen in supplemental figures, along with ‘bee swarm’ plots for each model. The top five features used in the best pipeline (LASSO XGB) were the same as the top five features across the aggregate of the five best pipelines: systolic BP, prehypertensive diagnosis, body weight, DHEA-S, and LV mass.
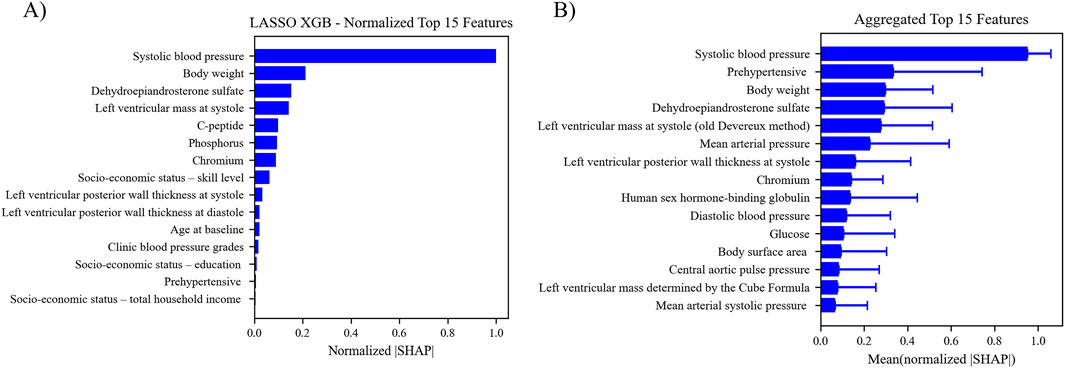
Figure 5. (A) Features ranking according to the mean absolute SHAP value. The absolute SHAP value of each feature for each instance was calculated and averaged to get the relative feature importance. (B) Aggregated feature ranking for features across the five top performing pipelines.
The relationship between the predicted outcome of the model using each of the top 15 LASSO XGB features, and the top 15 aggregated features were also assessed with PDPs (Figure 6). This analysis indicated that the best pipelines’ chances of classifying a patient with MHT increased in conjunction with elevated BPs, body weight, body surface area, LV mass/thickness, and several biochemical markers (DHEA-S, chromium, human sex hormone-binding globulin). Conversely, the risk of MHT decreased in conjunction with elevated glucose levels. Individual PDPs for each of the five best pipelines can be seen in the Supplementary Material.
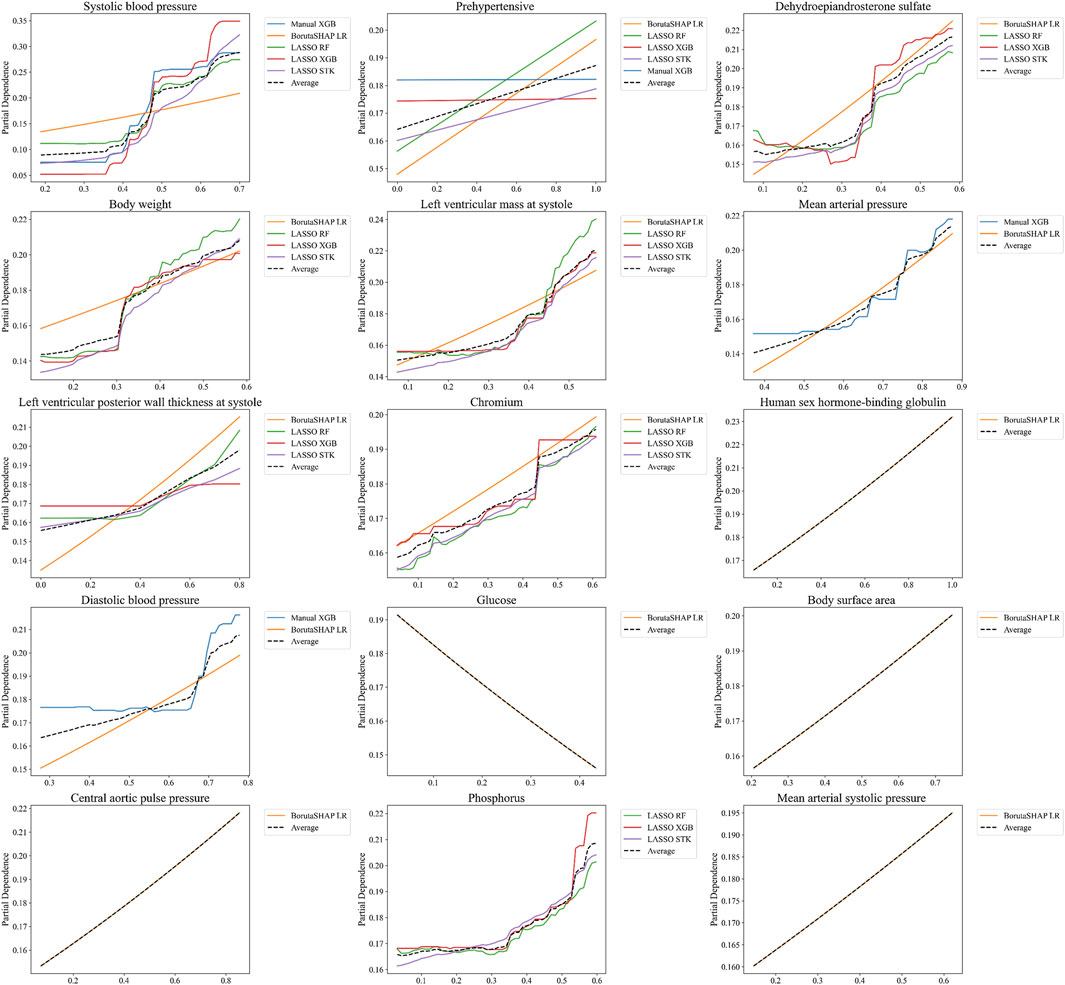
Figure 6. Partial Dependence Plots for features selected from the aggregated rankings. PDPs are shown for only the top 15 most important features determined by SHAP values in Figure 5, averaged for the five best ML pipelines. Note that not every one of these features was included in the top five pipelines, which is why some features only include 1, 2, or 4 PDP curves.
4 Discussion
The aim of this study was to develop a machine learning pipeline that would be able to detect MHT in a seemingly young and healthy individual from the African-PREDICT cohort. To develop the pipeline, several popular feature selection methods and ML algorithms were evaluated. The results of this study found that the LASSO feature selection strategy in conjunction with a XGB classifier resulted in a ML model that had the highest ROC AUC score out of the set of 25 different pipelines that were constructed. The final ML pipeline was compared to a simple binary classifier that served as a “rule-of-thumb” for evaluating a patient’s risk for MHT in LMIC and was found to perform much better in each evaluation metric that was considered, except for sensitivity where the binary model had a slightly better performance (Thompson et al., 2016). SHAP analysis and PDP plots were also implemented to help interpret the contributions of different features to the model predictions. SHAP analysis revealed that the most important predictors of MHT for this ML model were related to systolic blood pressure and patient body weight. Individual patient analysis using this model could be used to identify which of these features need to be focused on and could help clinicians in implementing a clinical action plan. Overall, the results of this study show that an ML pipeline could be utilized to identify patients most at risk for MHT and highlight which features provide the greatest predictive value.
The final model’s performance was evaluated on the test set, resulting in an accuracy of 0.828, a ROC AUC score of 0.855, a PR AUC score of 0.622, a precision score of 0.511, a sensitivity score of 0.649, a specificity score of 0.866, and an F1 score of 0.571. These evaluation metrics are comparable to the reported evaluation metrics for other recently published ML models for MHT (Hung et al., 2021; Shih et al., 2022; Lip et al., 2021) or better (Bae et al., 2022; Meng et al., 2022). In a previous study that evaluated the African-PREDICT dataset, an office measurement of systolic blood pressure over 120 mmHg could be used as a cut-off value for classifying someone as at-risk for MHT (Thompson et al., 2016). Therefore, for comparison with this study, a simple binary model was created that classified patients as having MHT if they had an office systolic blood pressure of 120 mmHg. With just this single predictor alone, this basic classification model resulted in an accuracy of 0.742, a ROC AUC score of 0.719, a PR AUC score of 0.557, an F1 score of 0.481, a sensitivity score of 0.676, a specificity score of 0.756, and precision score of 0.373. While the simple binary model performed fairly well, the ML pipeline did perform better in all aspects except for sensitivity. The primary strength to the new pipeline, and the potential argument for clinical adoption of this model, is the number of individuals that were successfully identified as not having MHT. When comparing the ML model results with the binary systolic pressure cutoff model, the ML model was able to correctly classify 19 more individuals as true negatives, while the simple binary model incorrectly classified those individuals as false positives. That means 19 people might have been prescribed unnecessary treatment or follow-up monitoring based on the binary prediction, resulting in wasted financial costs, potential side-effects, etc.
Model interpretability is crucial for promoting clinical use because it provides the clinician and patient with insight into why the model makes a particular prediction one way or the other. In addition, model explanations help point to potential underlying physiological relationships that provide a deeper understanding of the pathology and possible interventional strategies. Using SHAP analysis, it was shown that the five most important features for the best ML pipeline (LASSO + XGB) were the same five most important on average across the five best ML pipelines. These features included systolic BP measured in the clinic, a prehypertensive designation (based on clinic BP measurements), body weight, circulating serum levels of DHEA-S, and LV mass at systole measured with echocardiography. These features are all noninvasive measurements that could be performed in any clinic. It is important to note that four of these five features (BPs, DHEA-S, and LV mass) have all been directly linked to physiological stress and sympathetic control, and the fifth feature (body weight) is often related to waist circumference which has also been linked to physiological stress (Grassi et al., 2018; Borovac et al., 2020; Maninger et al., 2009; Kühnel et al., 2023; Tryon et al., 2013). During acute mental stress, DHEA-S levels typically increase transiently, peaking immediately after stress exposure and then gradually returning to baseline within about an hour - however, long-term or chronic psychosocial stress is associated with reduced basal levels of DHEA-S and a diminished capacity to produce DHEA-S during acute stress, suggesting an impaired adrenal response and potential link to adverse health outcomes and accelerated aging (Lennartsson et al., 2013). SBP increases during physiological stress due to sympathetic nervous system activation, causing vasoconstriction and increased cardiac output. The magnitude of SBP reactivity to stress varies among individuals and can be influenced by factors such as sex and lifestyle. For example, in women, higher DHEA-S levels have been linked to greater blood pressure reactivity to stress (Hirokawa et al., 2016). Chronic stress-induced hemodynamic load can also promote left ventricular hypertrophy, reflecting the cumulative impact of stress on cardiac structure (Wentzel et al., 2025). The fact that these factors played large roles in our ML model supports a connection between MHT and a possible pathological mechanism related to underlying stress–a relationship worth testing more directly in future studies. Further, interventions aimed at mitigating stress control could be a route to reduce MHT risk even without pharmacological interventions. Of course, it is important to note that SHAP values and PDPs indicate feature importance in modeling predictions but do not necessarily imply causal relationships.
There are several limitations to this study that are worth highlighting. First, the number of participants in the dataset was relatively small for the number of features that were evaluated, and it is likely that the model performance would increase given a larger set of training data. A broader population would especially improve the model’s predictive capabilities for more focused demographic subgroups based on sex, race, age, etc. Secondly, the model was not validated on a test set from an external cohort; thus, the general utility of this model has not been tested. Thirdly, our analyses are cross-sectional, and temporal ordering cannot be established. The reported findings should not be interpreted as causal and should be confirmed in future prospective analysis. Still, the ML approach enables efficient pattern discovery by identifying multivariate and nonlinear associations between clinical variables and outcomes, which conventional statistics may miss. This enables discovery of novel risk markers or biomarker combinations relevant to disease prediction or prognosis–even when cross sectional data is used. In application, this ML pipeline can be integrated into electronic health records or clinical decision support systems to provide physicians with data-driven risk assessments or intervention recommendations for conditions influenced by vascular and endocrine profiles. For example, an algorithm predicting elevated cardiometabolic risk based on a cross-sectional panel (including DHEA-S, blood pressure, and other labs) could prompt early lifestyle or pharmacological intervention, improving patient outcomes at both the individual and population level. Of course, some of the key features identified in this study are more feasible from a data collection perspective, so the ultimate utility of these types of tools will depend on practice cost-benefit analyses in real-world contexts.
5 Conclusion
This study proposed an XGB framework with LASSO feature selection as a ML model for predicting the incidence of MHT in a young, apparently healthy population from a LMIC. The proposed model achieved a higher ROC AUC and demonstrated higher scoring metrics compared to the current “rule-of-thumb” classifier for MHT. SHAP analysis found that the office measurements of blood pressure, body weight, DHEA-S biochemical levels, and LV mass were the most important predictors of MHT. PDP revealed the relationships between each LASSO selected feature and the prediction of MHT. Overall, this study demonstrated the promise of using LASSO with an XGB framework model to detect MHT and further development of the model could potentially lead to a viable tool for aiding clinicians in identifying which patients are most at risk for MHT.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: Data sharing is restricted to the terms of the African-PREDICT collaborator network. Requests to access these datasets should be directed to CM,Q2FyaW5hLkNNQG53dS5hYy56YQ==.
Ethics statement
The studies involving humans were approved by Health Research Ethics Committee of North-West University (ethics number: NWU-00001–12-A1). The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements.
Author contributions
BM: Writing – original draft, Writing – review and editing. SC: Writing – original draft, Writing – review and editing. AW: Writing – review and editing. CM: Writing – review and editing. WR: Writing – review and editing, Writing – original draft.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. The research funded in this manuscript is part of an ongoing research project financially supported by the South African Medical Research Council (SAMRC) with funds from National Treasury under its Economic Competitiveness and Support Package; the South African Research Chairs Initiative (SARChI) of the Department of Science and Technology and National Research Foundation (NRF) of South Africa; the Strategic Health Innovation Partnerships (SHIP) Unit of the SAMRC with funds received from the South African National Department of Health, GlaxoSmithKline R&D, the UK Medical Research Council and with funds from the UK Government’s Newton Fund; as well as corporate social investment grants from Pfizer (South Africa), Boehringer-Ingelheim (South Africa), Novartis (South Africa), the Medi Clinic Hospital Group (South Africa) and in kind contributions of Roche Diagnostics (South Africa).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2025.1684693/full#supplementary-material
References
Abdalla M. (2017). Ambulatory blood pressure monitoring: a complementary strategy for hypertension diagnosis and management in low-income and middle-income countries. Cardiol. Clin. 35 (1), 117–124. doi:10.1016/j.ccl.2016.08.012
Anstey D. E., Muntner P., Bello N. A., Pugliese D. N., Yano Y., Kronish I. M., et al. (2018). Diagnosing masked hypertension using ambulatory blood pressure monitoring, home blood pressure monitoring, or both? Hypertension 72 (5), 1200–1207. doi:10.1161/HYPERTENSIONAHA.118.11319
Azur M. J., Stuart E. A., Frangakis C., Leaf P. J. (2011). Multiple imputation by chained equations: what is it and how does it work? Int. J. Methods Psychiatric Res. 20 (1), 40–49. doi:10.1002/mpr.329
Bae S., Samuels J. A., Flynn J. T., Mitsnefes M. M., Furth S. L., Warady B. A., et al. (2022). Machine learning–based prediction of masked hypertension among children with chronic kidney disease. Hypertension 79 (9), 2105–2113. doi:10.1161/HYPERTENSIONAHA.121.18794
Barochiner J., Cuffaro P. E., Aparicio L. S., Alfie J., Rada M. A., Morales M. S., et al. (2013). Predictors of masked hypertension among treated hypertensive patients: an interesting association with orthostatic hypertension. Am. J. Hypertens. 26 (7), 872–878. doi:10.1093/ajh/hpt036
Bendov I., Benarie L., Mekle J., Bursztyn M. (2005). Clinical practice, masked hypertension is as common as isolated clinic hypertension: predominance of younger men. Am. J. Hypertens. 18 (5), 589–593. doi:10.1016/j.amjhyper.2004.11.036
Berge H. M., Andersen T. E., Solberg E. E., Steine K. (2013). High ambulatory blood pressure in male professional football players. Br. J. Sports Med. 47 (8), 521–525. doi:10.1136/bjsports-2013-092354
Bobrie G., Clerson P., Ménard J., Postel-Vinay N., Chatellier G., Plouin P.-F. (2008). Masked hypertension: a systematic review. J. Hypertens. 26 (9), 1715–1725. doi:10.1097/HJH.0b013e3282fbcedf
Booth J. N., Muntner P., Diaz K. M., Viera A. J., Bello N. A., Schwartz J. E., et al. (2016). Evaluation of criteria to detect masked hypertension. J. Clin. Hypertens. 18 (11), 1086–1094. doi:10.1111/jch.12830
Borovac J. A., D’Amario D., Bozic J., Glavas D. (2020). Sympathetic nervous system activation and heart failure: current state of evidence and the pathophysiology in the light of novel biomarkers. World J. Cardiol. 12 (8), 373–408. doi:10.4330/wjc.v12.i8.373
Brereton R. G., Lloyd G. R. (2010). Support Vector Machines for classification and regression. Analyst 135 (2), 230–267. doi:10.1039/B918972F
Churpek M. M., Yuen T. C., Winslow C., Meltzer D. O., Kattan M. W., Edelson D. P. (2016). Multicenter comparison of machine learning methods and conventional regression for predicting clinical deterioration on the wards. Crit. Care Med. 44 (2), 368–374. doi:10.1097/CCM.0000000000001571
Cinà G. (2022). Why we do need explainable ai for healthcare. arXiv Prepr. arXiv:2206.15363. doi:10.48550/arXiv.2206.15363
du Toit W. L., Kruger R., Gafane-Matemane L. F., Schutte A. E., Louw R., Mels C. M. C. (2023). Markers of arterial stiffness and urinary metabolomics in young adults with early cardiovascular risk: the African-PREDICT study. Metabolomics 19 (4), 28. doi:10.1007/s11306-023-01987-y
Essa E., Shitie D., Yirsaw M. T., Wale M. Z. (2022). Undiagnosed hypertension and associated factors among adults in Debre Markos town, North-West Ethiopia: a community-based cross-sectional study. SAGE Open Med. 10, 20503121221094223. doi:10.1177/20503121221094223
Flynn J. T., Urbina E. M., Brady T. M., Baker-Smith C., Daniels S. R., Hayman L. L., et al. (2022). Ambulatory blood pressure monitoring in children and adolescents: 2022 update: a scientific statement from the American heart Association. Hypertension 79 (7), e114–e124. doi:10.1161/HYP.0000000000000215
Franklin S. S., O’Brien E., Thijs L., Asayama K., Staessen J. A. (2015). Masked hypertension: a phenomenon of measurement. Hypertension 65 (1), 16–20. doi:10.1161/HYPERTENSIONAHA.114.04522
Franklin S. S., O’Brien E., Staessen J. A. (2016). Masked hypertension: understanding its complexity. Eur. Heart J. 38, 1112–1118. doi:10.1093/eurheartj/ehw502
Fujiwara T., Yano Y., Hoshide S., Kanegae H., Kario K. (2018). Association of cardiovascular outcomes with masked hypertension defined by home blood pressure monitoring in a Japanese general practice population. JAMA Cardiol. 3 (7), 583–590. doi:10.1001/jamacardio.2018.1233
Gramegna A., Giudici P. (2022). Shapley feature selection. FinTech 1 (1), 72–80. doi:10.3390/fintech1010006
Grassi G., Pisano A., Bolignano D., Seravalle G., D’Arrigo G., Quarti-Trevano F., et al. (2018). Sympathetic nerve traffic activation in essential hypertension and its correlates: systematic reviews and meta-analyses. Hypertension 72 (2), 483–491. doi:10.1161/HYPERTENSIONAHA.118.11038
Guyon I., De A. M. (2003). An introduction to variable and feature selection André Elisseeff. J. Mach. Learn. Res. 3. doi:10.5555/944919.944968
Hänninen M.-R. A., Niiranen T. J., Puukka P. J., Mattila A. K., Jula A. M. (2011). Determinants of masked hypertension in the general population: the Finn-Home study. J. Hypertens. 29 (10), 1880–1888. doi:10.1097/HJH.0b013e32834a98ba
Hermida R. C., Smolensky M. H., Ayala D. E., Portaluppi F. (2015). Ambulatory Blood Pressure Monitoring (ABPM) as the reference standard for diagnosis of hypertension and assessment of vascular risk in adults. Chronobiology Int. 32 (10), 1329–1342. doi:10.3109/07420528.2015.1113804
Hirokawa K., Ohira T., Nagayoshi M., Kajiura M., Imano H., Kitamura A., et al. (2016). Dehydroepiandrosterone-sulfate is associated with cardiovascular reactivity to stress in women. Psychoneuroendocrinology 69, 116–122. doi:10.1016/j.psyneuen.2016.04.005
Huguet N., Larson A., Angier H., Marino M., Green B. B., Moreno L., et al. (2021). Rates of undiagnosed hypertension and diagnosed hypertension without anti-hypertensive medication Following the Affordable Care Act. Am. J. Hypertens. 34 (9), 989–998. doi:10.1093/ajh/hpab069
Hung M.-H., Shih L.-C., Wang Y.-C., Leu H.-B., Huang P.-H., Wu T.-C., et al. (2021). Prediction of masked hypertension and masked uncontrolled hypertension using machine learning. Front. Cardiovasc. Med. 8, 778306. doi:10.3389/fcvm.2021.778306
Hunter P. G., Chapman F. A., Dhaun N. (2021). Hypertension: current trends and future perspectives. Br. J. Clin. Pharmacol. 87 (10), 3721–3736. doi:10.1111/bcp.14825
Jadhav A., Pramod D., Ramanathan K. (2019). Comparison of performance of data imputation methods for numeric dataset. Appl. Artif. Intell. 33 (10), 913–933. doi:10.1080/08839514.2019.1637138
Keany E. (2020). BorutaShap: a wrapper feature selection method which combines the Boruta feature selection algorithm with Shapley values. Zenodo. doi:10.5281/zenodo.4247610
Kearney P. M., Whelton M., Reynolds K., Muntner P., Whelton P. K., He J. (2005). Global burden of hypertension: analysis of worldwide data. Lancet 365 (9455), 217–223. doi:10.1016/S0140-6736(05)17741-1
Kjeldsen S. E. (2018). Hypertension and cardiovascular risk: general aspects. Pharmacol. Res. 129, 95–99. doi:10.1016/j.phrs.2017.11.003
Krittanawong C., Virk H. U. H., Bangalore S., Wang Z., Johnson K. W., Pinotti R., et al. (2020). Machine learning prediction in cardiovascular diseases: a meta-analysis. Sci. Rep. 10 (1), 16057. doi:10.1038/s41598-020-72685-1
Kühnel A., Hagenberg J., Knauer-Arloth J., Ködel M., Czisch M., Sämann P. G., et al. (2023). Stress-induced brain responses are associated with BMI in women. Commun. Biol. 6 (1), 1031. doi:10.1038/s42003-023-05396-8
Kumar V. (2014). Feature Selection: a literature Review. Smart Comput. Rev. 4 (3). doi:10.6029/smartcr.2014.03.007
Kursa M. B., Jankowski A., Rudnicki W. R. (2010). Boruta – a System for feature selection. Fundam. Inf. 101 (4), 271–285. doi:10.3233/FI-2010-288
Lennartsson A.-K., Theorell T., Kushnir M. M., Bergquist J., Jonsdottir I. H. (2013). Perceived stress at work is associated with attenuated DHEA-S response during acute psychosocial stress. Psychoneuroendocrinology 38 (9), 1650–1657. doi:10.1016/j.psyneuen.2013.01.010
Lip S., Mccallum L., Reddy S., Chandrasekaran N., Tule S., Bhaskar R. K., et al. (2021). Machine learning based models for predicting white-coat and masked patterns of blood pressure. J. Hypertens. 39 (Suppl. 1), e69. doi:10.1097/01.hjh.0000745092.07595.a5
Longo D., Dorigatti F., Palatini P. (2005). Masked hypertension in adults. Blood Press. Monit. 10 (6), 307–310. doi:10.1097/00126097-200512000-00004
Ma S., Huang J. (2008). Penalized feature selection and classification in bioinformatics. Briefings Bioinforma. 9 (5), 392–403. doi:10.1093/bib/bbn027
Mallion J.-M., Clerson P., Bobrie G., Genes N., Vaisse B., Chatellier G. (2006). Predictive factors for masked hypertension within a population of controlled hypertensives. J. Hypertens. 24 (12), 2365–2370. doi:10.1097/01.hjh.0000251895.55249.82
Maninger N., Wolkowitz O. M., Reus V. I., Epel E. S., Mellon S. H. (2009). Neurobiological and neuropsychiatric effects of dehydroepiandrosterone (DHEA) and DHEA sulfate (DHEAS). Front. Neuroendocrinol. 30 (1), 65–91. doi:10.1016/j.yfrne.2008.11.002
Mathers C. D., Boerma T., Ma Fat D. (2009). Global and regional causes of death. Br. Med. Bull. 92 (1), 7–32. doi:10.1093/bmb/ldp028
Meng H., Guo L., Kong B., Shuai W., Huang H. (2022). Nomogram based on clinical features at a single outpatient visit to predict masked hypertension and masked uncontrolled hypertension: a study of diagnostic accuracy. Medicine 101 (49), e32144. doi:10.1097/MD.0000000000032144
Messerli F. H., Williams B., Ritz E. (2007). Essential hypertension. Lancet 370 (9587), 591–603. doi:10.1016/S0140-6736(07)61299-9
Mokwatsi G. G. (2022). South Africa – the African-PREDICT Study. Blood Press. Monit. 27 (Suppl. 1), e11. doi:10.1097/01.mbp.0000905264.52874.97
Motwani M., Dey D., Berman D. S., Germano G., Achenbach S., Al-Mallah M. H., et al. (2016). Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: a 5-year multicentre prospective registry analysis. Eur. Heart J. 38, 500–507. doi:10.1093/eurheartj/ehw188
Nguyen Q., Dominguez J., Nguyen L., Gullapalli N. (2010). Hypertension management: an update. Am. Health and Drug Benefits 3 (1), 47–56.
Pedregosa F. (2011). Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12. doi:10.5555/1953048.2078195
Pickering T. G., Eguchi K., Kario K. (2007). Masked hypertension: a review. Hypertens. Res. 30 (6), 479–488. doi:10.1291/hypres.30.479
Samb M. L., Camara F., Ndiaye S., Slimani Y., Esseghir M. A. (2012). A novel RFE-SVM-based feature selection approach for classification. Int. J. Adv. Sci. Technol. 43.
Schutte A. E., Gona P. N., Delles C., Uys A. S., Burger A., Mels C. M., et al. (2019). The African prospective study on the Early Detection and Identification of cardiovascular disease and Hypertension (African-PREDICT): design, recruitment and initial examination. Eur. J. Prev. Cardiol. 26 (5), 458–470. doi:10.1177/2047487318822354
Sevakula R. K., Au-Yeung W. M., Singh J. P., Heist E. K., Isselbacher E. M., Armoundas A. A. (2020). State-of-the-Art machine learning techniques aiming to improve patient outcomes pertaining to the cardiovascular System. J. Am. Heart Assoc. 9 (4), e013924. doi:10.1161/JAHA.119.013924
Shih L.-C., Wang Y.-C., Hung M.-H., Cheng H., Shiao Y.-C., Tseng Y.-H., et al. (2022). Prediction of white-coat hypertension and white-coat uncontrolled hypertension using machine learning algorithm. Eur. Heart J. - Digital Health 3 (4), 559–569. doi:10.1093/ehjdh/ztac066
Shimbo D., Abdalla M., Falzon L., Townsend R. R., Muntner P. (2015). Role of ambulatory and home blood pressure monitoring in clinical practice: a narrative review. Ann. Intern. Med. 163 (9), 691–700. doi:10.7326/M15-1270
Shukla A. N., Madan T., Thakkar B. M., Parmar M. M., Shah K. H. (2015). Prevalence and predictors of undiagnosed hypertension in an apparently healthy Western Indian population. Adv. Epidemiol. 2015, 1–5. doi:10.1155/2015/649184
Stergiou G. S., Palatini P., Parati G., O’Brien E., Januszewicz A., Lurbe E., et al. (2021). 2021 European Society of Hypertension practice guidelines for office and out-of-office blood pressure measurement. J. Hypertens. 39 (7), 1293–1302. doi:10.1097/HJH.0000000000002843
Stergiou G. S., Yiannes N. J., Rarra V. C., Alamara C. v. (2005a). White-coat hypertension and masked hypertension in children. Blood Press. Monit. 10 (6), 297–300. doi:10.1097/00126097-200512000-00002
Stergiou G., Salgami E., Tzamouranis D., Roussias L. (2005b). Masked hypertension assessed by ambulatory blood pressure versus home blood pressure monitoring: is it the same phenomenon? Am. J. Hypertens. 18 (6), 772–778. doi:10.1016/j.amjhyper.2005.01.003
Stergiou G. S., Asayama K., Thijs L., Kollias A., Niiranen T. J., Hozawa A., et al. (2014). Prognosis of white-coat and masked hypertension: international Database of HOme blood pressure in relation to Cardiovascular outcome. Hypertension 63 (4), 675–682. doi:10.1161/HYPERTENSIONAHA.113.02741
Thakkar H. V., Pope A., Anpalahan M. (2020). Masked hypertension: a systematic review. Heart, Lung Circulation 29 (1), 102–111. doi:10.1016/j.hlc.2019.08.006
Thompson J. E. S., Smith W., Ware L. J., M C Mels C., van Rooyen J. M., Huisman H. W., et al. (2016). Masked hypertension and its associated cardiovascular risk in young individuals: the African-PREDICT study. Hypertens. Res. 39 (3), 158–165. doi:10.1038/hr.2015.123
Trachsel L. D., Carlen F., Brugger N., Seiler C., Wilhelm M. (2015). Masked hypertension and cardiac remodeling in middle-aged endurance athletes. J. Hypertens. 33 (6), 1276–1283. doi:10.1097/HJH.0000000000000558
Tryon M. S., Carter C. S., DeCant R., Laugero K. D. (2013). Chronic stress exposure may affect the brain’s response to high calorie food cues and predispose to obesogenic eating habits. Physiology and Behav. 120, 233–242. doi:10.1016/j.physbeh.2013.08.010
van Buuren S., Groothuis-Oudshoorn K. (2011). Mice: multivariate imputation by chained equations in R. J. Stat. Softw. 45. doi:10.18637/jss.v045.i03
Wentzel A., Smith W., Jansen van Vuren E., Kruger R., Breet Y., Wonkam-Tingang E., et al. (2025). Allostatic load and cardiometabolic health in a young adult South African population: the African-PREDICT study. Am. J. Physiology-Heart Circulatory Physiology 328 (3), H581–H593. doi:10.1152/ajpheart.00845.2024
World Health Organization (2023). World health Organization cardiovascular disease. Available online at: https://www.who.int/health-topics/cardiovascular-diseases#tab=tab_1.
World Heart Federation (2022). World heart Federation. Available online at: https://world-heart-federation.org/news/world-hypertension-day-taking-action-against-the-silent-epidemic-of-high-blood-pressure/.
Keywords: machine learning, masked hypertension, African-PREDICT, cardiovascular disease, predictive modeling
Citation: Miller B, Coeyman SJ, Wentzel A, Mels CMC and Richardson WJ (2025) Machine learning model for detecting masked hypertension in young adults. Front. Physiol. 16:1684693. doi: 10.3389/fphys.2025.1684693
Received: 12 August 2025; Accepted: 20 October 2025;
Published: 17 November 2025.
Edited by:
Lisheng Xu, Northeastern University, ChinaReviewed by:
Tomer Gazit, Tel Aviv Sourasky Medical Center, IsraelDu Jinsong, Zaozhuang University, China
Copyright © 2025 Miller, Coeyman, Wentzel, Mels and Richardson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: William J. Richardson, d3IwMTNAdWFyay5lZHU=
†Denotes equal co-first author contributions