 Zifei Liang
Zifei Liang Jiangyang Zhang
Jiangyang Zhang- Department of Radiology, Center for Biomedical Imaging, New York University, New York, NY, United States
Introduction: The resolution of magnetic resonance imaging is often limited at the millimeter level due to its inherent signal-to-noise disadvantage compared to other imaging modalities. Super-resolution (SR) of MRI data aims to enhance its resolution and diagnostic value. While deep learning-based SR has shown potential, its applications in MRI remain limited, especially for preclinical MRI, where large high-resolution MRI datasets for training are often lacking.
Methods: In this study, we first used high-resolution mouse brain auto-fluorescence (AF) data acquired using serial two-photon tomography (STPT) to examine the performance of deep learning-based SR for mouse brain images.
Results: We found that the best SR performance was obtained when the resolutions of training and target data were matched. We then applied the network trained using AF data to MRI data of the mouse brain, and found that the performance of the SR network depended on the tissue contrast presented in the MRI data. Using transfer learning and a limited set of high-resolution mouse brain MRI data, we were able to fine-tune the initial network trained using AF to enhance the resolution of MRI data.
Discussion: Our results suggest that deep learning SR networks trained using high-resolution data of a different modality can be applied to MRI data after transfer learning.
1. Introduction
Magnetic resonance imaging (MRI) is a non-invasive imaging technique with many applications in neuroscience research, both in humans and animals, due to its rich soft tissue contrasts. For example, T1- and T2-weighted MRI are commonly used to examine brain structures, and diffusion MRI (dMRI) is sensitive to tissue microstructure and useful for detecting acute stroke (1). Compared to other imaging techniques, such as optical imaging, MRI is inherently a low signal-to-noise (SNR) technique, and as a result, its spatial resolution is limited at the millimeter (mm) or sub-mm level. Advances in high-field MRI and high-performance gradient systems have greatly improved the spatial resolution of MRI but these approaches are facing increasing challenges associated with the high complexity and cost of such systems (2–5).
A promising approach to improving resolution is using super-resolution (SR) to transform a low-resolution image into a high-resolution image. The conventional machine-learning-based image SR takes multiple images acquired with sub-voxel spatial shifts and produces images with higher spatial resolution (6–12). For example, in order to improve the resolution along the slice direction, multiple images can be acquired, each shifted by a known sub-voxel distance along the slice direction, and images with enhanced through-plane resolution can be reconstructed (13). To improve in-plane resolution, acquiring multiple images with rotated scans has also been reported (14, 15). Also, some work incorporated extra information from inter-scan subject motions or image distortions to achieve SR (6, 16). These MRI SR methods have many applications, such as generating finer maps of metabolic activities of the brain (9), improving brain structure segmentation (6), or visualizing small white matter tract (17). However, the need to acquire multiple images increases the total imaging time and makes the technique susceptible to motions (11). An alternative SR approach is based on sparse representation (18–20), but is sensitive to noise and is computationally expansive.
When conventional and sparse representation-based SR are not applicable, deep learning-based SR has been proposed as an alternative (21). Leveraging large amounts of training data, many reports have demonstrated the success of this approach using generic images. Early work used the Feed-Forward neural networks, including the convolutional neural network (CNN) [e.g., the LeNet5 proposed in 1998 by LeCun et al. (22)], to achieve image SR (21), but used moderate numbers of layers and neurons, which limited its performance. Later, the ResNet further improved the performance by using “skip connections” to avoid the problem of vanishing gradients in very deep (>100) networks (23). Recent development based on generative adversarial network (GAN) provided additional improvements (24). Deep learning based SR of MRI data has been demonstrated recently using CNN, ResNet, and GAN-based networks (25–29), which showed success in improving results from low-field MRI systems (30), dMRI studies (31, 32), as well as coronary MR angiography (33).
Although deep-learning-based SR has made a lot of progress in recent years, especially on generic images, it is still not fully understood how image contrast and resolution affect the performance of SR. Some work already analyzed the effects of resolution on deep learning performance (e.g., 34), on diagnosis or image labeling tasks. There have been several reports that took advantage of multiple MRI contrasts for a variety of tasks including image segmentation, diagnosis, and lesion detection (35–39), using the multi-contrast information to train a neural network. Many SR methods take multi-contrast MRI data to train a neural network or use them as a prior/constraint for SR (40–43). This approach allows the network to learn the different characteristics of each contrast and how they relate to the task at hand, such as (40), which used high-resolution T1-weighted MRI data to enhance the resolution of low resolution T2-weighted MRI data.
Large collections of high-resolution MRI data of the human brain, such as the Human Connectome Project (HCP) (44), which contain hundreds of MRI data acquired with identical resolutions and contrasts, made it possible to train deep learning network to perform SR (45, 46). In contrast, studies involving the mouse brain often have a much smaller sample size, and pooling data from multiple studies is not a viable option due to variations in imaging resolution and contrasts caused by differences in study designs and MRI systems. While similar MRI resources for the mouse brain still do not exist, more than 1,700 three-dimensional (3D) mouse brain auto-fluorescence (AF) images acquired using optical imaging techniques [e.g., serial two-photon tomography (STPT)] are available from the Allen mouse brain connectivity atlas (AMBCA) (47). In this study, using the large collection of 3D AF data, we examined how much improvement deep learning based SR can provide for mouse brain data and whether we can leverage the AMBCA mouse brain AF data to enhance the resolution of mouse brain MRI data. We also examined the effects of contrasts and resolution of the training data on deep learning-based SR. Specifically, we investigated the difference between training using low and high-resolution AF data, applying SR networks trained using AF data to MRI data, and using transfer learning to adapt networks trained using AF data to different MRI contrasts.
2. Method and material
2.1. Auto-fluorescence (AF) data of the mouse brain
High-resolution 3D auto-fluorescence AF data (n = 100), with a spatial resolution of 25 µm × 25 µm × 25 µm were downloaded from AMBCA (http://help.brain-map.org/display/mousebrain/API). These data were used as the training and testing data in the following sections. 3D AF data were down-sampled by averaging the corresponding patch voxels to various resolutions (Figure 1).

Figure 1. Representative down-sampled AF images of a mouse brain. This axial section was selected from a 3D AF volume.
2.2. Animals MRI
We acquired multi-contrast mouse brain MRI data to examine the performance of SR networks trained using 3D AF data. All animal experiments have been approved by the Institute Animal Care and Use Committee at New York University. Inbred C57BL/6 mice (Jackson Laboratories, 4 months old, female, n = 10) were fixed by trans-cardiac perfusion of 4% paraformaldehyde in phosphate buffered saline (PBS) for ex vivo MRI. After fixation, mouse heads were removed and immersed in 4% PFA in PBS for 24 h at 4°C before being transferred to PBS. Before ex vivo MRI, specimens were placed into 10 ml syringes, which were filled with Fomblin (Fomblin Profludropolyether, Ausimont, Thorofare, New Jersey, USA) for susceptibility matching and prevention of dehydration.
Images were acquired on a 7 Tesla MRI system (Bruker Biospin, Billerica, MA, USA) using a quadrature volume excitation coil (72 mm inner diameter) and a receive-only 4-channel phased array cryogenic coil. The specimens were imaged with the skull intact and placed in a syringe filled with Fomblin (perfluorinated polyether, Solvay Specialty Polymers USA, LLC, Alpharetta, GA, USA) to prevent tissue dehydration. 3D diffusion MRI data were acquired using a modified 3D diffusion-weighted gradient- and spin-echo (DW-GRASE) sequence (48) with the following parameters: echo time (TE)/repetition time (TR) = 30/400 ms; two signal averages; field of view (FOV) = 12.8 mm × 10 mm × 18 mm, resolution = 0.1 mm × 0.1 mm × 0.1 mm; two non-diffusion weighted images (b0s); 30 diffusion encoding directions; and b = 2,000 and 5,000 s/mm2, total 60 diffusion-weighted images (DWIs). Maps of fractional anisotropy (FA) were generated by tensor fitting using MRtrix (49). Co-registered T2-weighted (T2w) MRI data were acquired using a rapid acquisition with relaxation enhancement (RARE) sequence with the same FOV, resolution, and signal averages as the diffusion MRI acquisition and the following parameters: TE/TR = 50/3,000 ms, acceleration factor = 8; The total imaging time was approximately 12 h for each specimen.
2.3. Conventional CNN (cCNN), ResNet, and GAN based SR networks
In our study, we compared the performance of three SR networks: cCNN, ResNet, and GAN. The basic architectures of the three types of networks are shown in Figure 2 and explained below.
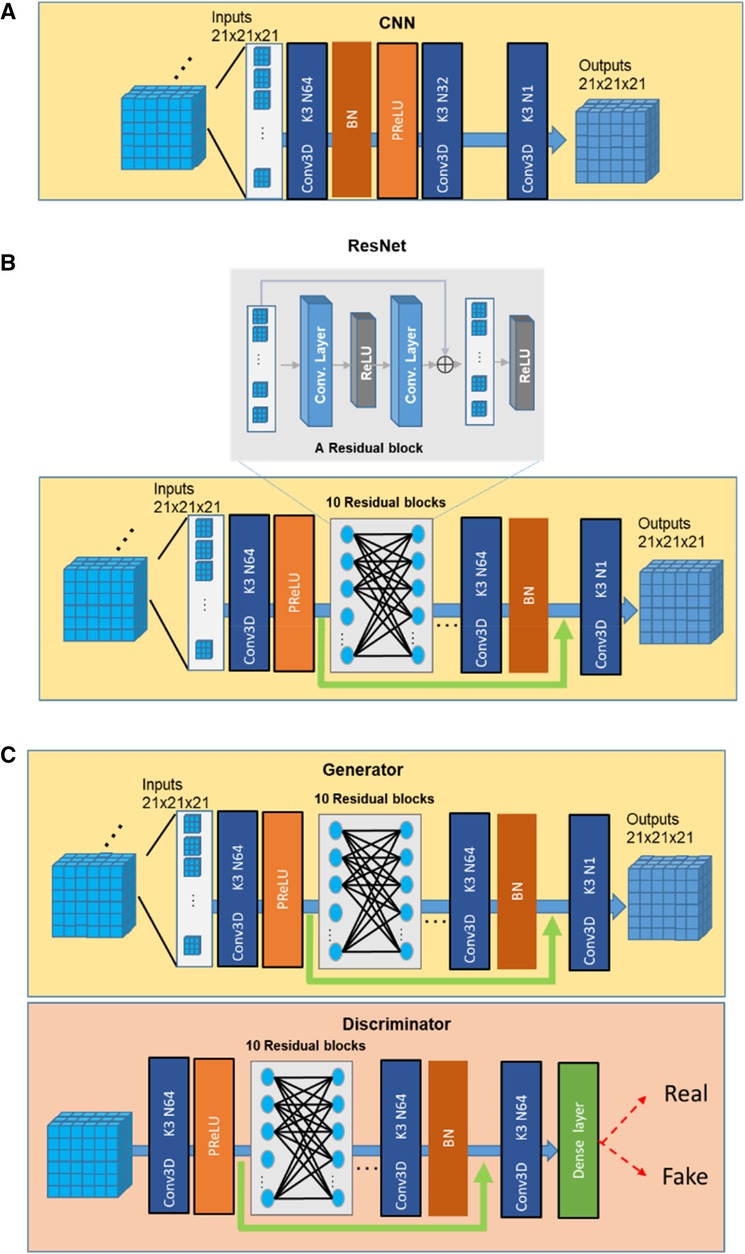
Figure 2. Basic network layouts of the cCNN (A), resNet (B), and GAN (C).
2.3.1. cCNN
The classical CNN models for SR used by previous studies (21) correspond to a specific parameterization of the baseline neural network architecture with 3 convolution layers, with two-dimensional (2D) kernel size 9, 1, 5 and channels 64, 32, 1, separately. In this study, we used the same architecture with the same number of channels but with 3D kernels with size of 3 for all layers (Figure 2A).
2.3.2. Resnet
We followed the description in (23) to build a ResNet SR network. To achieve a balance between the performance and the cost of time and space, we used 10 Residual blocks and 64 channels for the convolution layer (50) and 3 × 3 × 3 filter size (Figure 2B). One residual block is composed of two convolutions, two ReLU with one additional layer.
2.3.3. GAN
A typical GAN network consists of a generator and a discriminator (Figure 2C). In this study, we used the ResNet as the generator. The discriminator was composed of 10 Residual blocks and necessary dense, and Sigmoid layers (64 channels and 3 × 3 × 3 kernels in each layer). The discriminator was trained to identify the real high-resolution data from those generated from the Generator (51, 52).
One important consideration is the size of the input when training deep neural networks. Previous studies (e.g., 32), considered 2D and 3D training inputs separately. In our work, we used 2D data to test the effects of training samples size and 3D data to test the performance of SR as our MRI data were acquired in 3D. For training with 3D data, we chose 21 × 21 × 21 as the size of the input following the suggestion of (18). As for loss function, many previous works had used perception loss (5), which fits the human visual system. Nevertheless, considering the criteria of keeping the fidelity of image details, here we employed the simple mean square error (MSE) loss.
Due to the size difference between low and high-resolution images, up-sampling is necessary. With conventional camera picture super-resolution, many deep learning models incorporated transposed convolution for up-sampling under the assumption that natural scenery is locally continuous and smooth (10, 32, 53). However, considering the small input size used here, to minimize the edge effects, we up-sampled the 3D MRI volume before input to the neural network with cubic interpolation.
2.3.4. Transfer learning
In order to fine-tune the network trained using mouse brain AF data and apply it on MRI data, we used transfer learning. This is necessary because high-resolution MRI data is scarce. We used transfer learning to obtain a specific network for the FA maps from diffusion MRI, by refining the ResNet network trained using AF data. By freezing most of the network layers' parameters while adjusting the last three layers weights by training with high-resolution FA maps from 6 mouse brains.
2.3.5. Hyper-parameters for training
Other choices of hyper-parameters and tricks used during training procedures are primarily referring to practical considerations in (25). Rectified linear unit (ReLU) is used as the activation function that has the form f=max(0,x). The network is initialized with glorot_normal initialization (54) to encourage the weights to learn different input features. Glorot_normal initialization essentially draws form either a normal or uniform distribution, which is expressed in math formula as ( is the number of columns in W, U is a uniform distribution), and keeps weights in a reasonable range across the entire network. The Adam method (55) is adopted for stochastic optimization in this study with beta1 of 0.9, beta2 of 0.999, epsilon of 1 × 10−08, and a learning rate of 0.001. The number of epochs is initialized as 1,000, but to prevent overfitting, early stopping is also employed when monitoring the validation set loss not decreasing in 100 epochs. The input data are preprocessed to standardize each input with the form of ranging [0, 1].
2.3.6. Testing
We kept 10 from the 100 AF dataset for testing in AF SR experiments and 4 from 10 MRI data for testing in MRI SR experiments. All the testing data were not included in the training group. The testing was performed by dividing the brain into many 3D patches, with the size as the input of the deep neural network required, and recombine them together to reconstructive the entire 3D volumes. The quantitative evaluation was calculated based on selecting several group of brain slices with valid information from the reconstructed subjects and comparing with the corresponding high-resolution data.
2.3.7. A ResNet network trained using human brain MRI data
We also conducted a study to evaluate whether a neural network trained using human brain MRI data can also be applied to mouse brain MRI data. We downloaded 60 3D humanbrain magnetization prepared rapid gradient echo (MPRAGE) MRI data from the HCP online database (https://humanconnectome.org/) (44) and down-sampled the data from the original 0.8 mm × 0.8 mm × 0.8 mm resolution to 1.6 mm × 1.6 mm × 1.6 mm resolution to train the ResNet network as described above. We tested the performance of the ResNet network on a separate group of down-sampled MPRAGE data (n = 5) and found the network can significantly improve the resolution of the images using the original data as the ground truth (Supplementary Figure S1). The SR performance of our network was comparable to previous reports.
2.4. Image quality and statistical analysis
We used root mean square error (RMSE) and structural similarity index (SSIM) to evaluate the difference between SR and reference images. RMSE was calculated by evaluating the absolute differences between two images (6), which rates pixel value fidelity, while SSIM appraises structure level fidelity (6).
We also used the open-access, parameter-free image resolution estimation tool developed by Descloux et al. (56) (https://github.com/Ades91/ImDecorr.git) to evaluate the effective image resolution. The algorithm utilizes image partial phase autocorrelation and uses the local maximum of the highest normalized frequency coefficient K (also termed cut-off frequency) to determine the effective resolution (effective resolution = voxel size/K).
Paired t-test in GraphPad Prism 9.0 (www.GraphPad.com) was used to test whether there was a significant difference between the RMSE/SSIM of images generated using different SR methods. Correlation analysis of AF and MRI signals was also performed using GraphPad Prism. Welch's ANOVA test in GraphPad was used to evaluate if the multiple population means are equal, and ultimately to assess whether the variable among different groups is a significant factor to the super-resolution.
3. Results
3.1. Comparisons of cCNN, ResNet, and GAN and required training dataset
Using the large collection of 3D AF data from AMBCA, we first compared the performances of the three types of SR networks. We down-sampled the 3D mouse brain AF data from their native 25 µm resolution to 100 µm resolution and then to 200 µm resolution (Figure 1). We chose the 200 mm resolution here because in vivo MRI experiments often have spatial resolutions between 100 and 200 µm. After we completed training the networks using 20,000 21 × 21 × 21 patches of AF data (200 µm data as inputs and corresponding 100 µm data as training targets), a separate set of down-sampled 3D AF data (200 µm resolutions) (Figure 2, LR) were used for testing with the corresponding 100 µm resolution 3D AF data as the ground truth (Figure 3, Reference HR). Visually, the structural details in the SR results still did not match those in the reference 100 µm images. For example, the internal structures in the hippocampus were less clear in the SR results than in the reference (Figure 3, bottom row). The SR results generated by ResNet and GAN were closer to the reference 100 µm images than the results generated by cubic interpolation and cCNN.
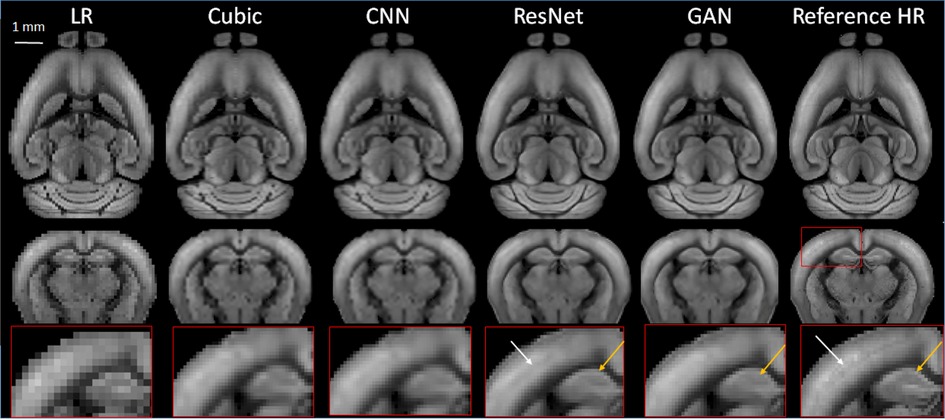
Figure 3. Representative SR images generated from down-sampled low-resolution images (LR, 200 µm isotropic) using cubic interpolation (cubic), cCNN, resNet, and GAN are compared with the reference image at 100 µm isotropic resolution. Top and middle panels: horizontal and axial images. Bottom panel: enlarged views of a region containing part of the cortex and hippocampus, as indicated by the red box in the axial reference image.
RMSE analysis indicated ResNet produced the lowest RMSE, significantly outperforming cubic interpolation, GAN, and cCNN (Figure 4A). GAN yielded significantly lower RMSE values compared to cubic interpolation and cCNN. Regarding SSIM analysis, ResNet produced significantly higher SSIM values than cubic interpolation and cCNN, but no significant improvement over GAN (Figure 4A).
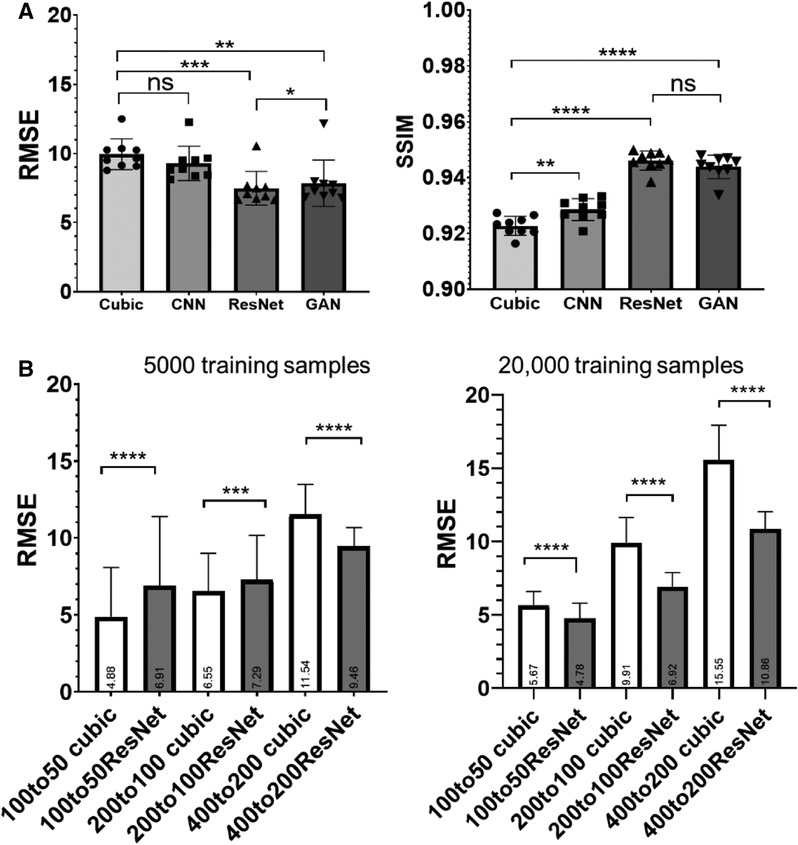
Figure 4. (A) Quantitative measurements (RMSE and SSIM) corresponding to Figure 3. (B) RMSE results by training and testing on various resolution/amount of auto fluorescence datasets. Left, results with 5,000 training samples. Right, results with 20,000 training samples.
We also compared the ResNet SR results at different resolutions and training data size (listed in Table 1). With 5,000 training samples, the ResNet only out-performed cubic interpolation in terms of RMSE at the 400 µm resolution (p < 0.0001) and was out-performed by cubic interpolation at the 100 and 200 µm resolutions (Figure 4B). After increasing the number of training samples to 20,000, ResNet out-performed cubic interpolation at all three resolution levels (Figure 4B).

Table 1. Design and results of training on various resolution datasets.
3.2. The role of training data resolution in SR
Next, we tested the generalization ability of SR networks trained at different resolutions. We trained three ResNet networks using data at 50–25, 100–50, and 200–100 µm, respectively, and tested their performances on 200 µm data. Visually, the network trained using 200–100 µm data performed better than networks trained using data at other resolutions (Figure 5A). Quantitative assessment showed that ResNet-based SR produced the best results when the resolution of the training data matched the resolution of actual data (Figures 5B,C). ResNet networks trained using higher resolution data did not produce significant improved RMSE and SSIM scores over cubic interpolation. The results generated by the ResNet network trained with matching resolution (200–100 µm) improved RMSE and SSIM significantly (ANOVA, p = 0.0019, F = 7), highlighting the importance of resolution for training data.
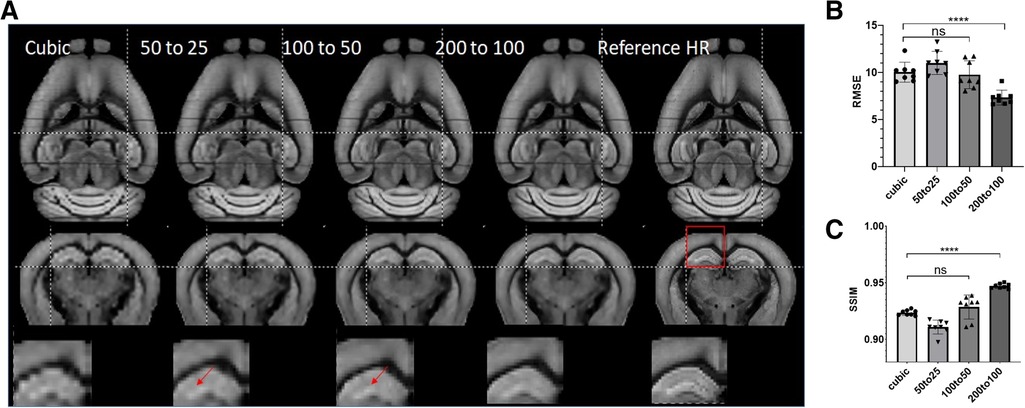
Figure 5. (A) Representative SR images generated from down-sampled low-resolution images (LR, 200 µm isotropic) using cubic interpolation (cubic) and resNet trained with images at three different resolutions and the reference image at 100 µm isotropic resolution. Top and middle panels: horizontal and axial images. Bottom panel: enlarged views of a region containing part of the cortex and hippocampus, as indicated by the red box in the axial reference image. (B, C) Quantitative measurements (RMSE and SSIM) of SR results in (A).
3.3. Cross-modality transfer learning SR
Although the previous results showed effective SR using the 3D AF data from AMBCA, using the same approach to SR mouse brain MRI data remained challenging due to the lack of a large high-resolution mouse brain MRI dataset. One question is whether we can use the network trained on the 3D AF data to SR mouse brain MRI data. To test this approach, we down-sampled 3D T2-weighted (T2w) and FA MR images of the mouse brain from 100 µm resolution to 200 µm resolution and applied the ResNet network trained using 200–100 µm 3D AF data. The results were compared to the original 100 µm FA and T2w MR images. Visually, the ResNet results were better than cubic interpolation results for both FA and T2w (Figures 6A,B), comparing the jagged edges in cubic interpolated results with smooth edges in ResNet results. Quantitative assessment showed that the ResNet T2w MRI results indeed had higher effective resolution, measured using a toolbox in (56), and lower RMSE than the cubic interpolated T2w MRI data (Figures 6C–E). However, the RMSE of the SR FA data showed no improvement over the cubic interpolation results (Figure 6E). The difference between T2w and FA images might be explained by the difference in MR contrasts. After co-register the FA and T2w data with the 3D AF data, the AF signals showed a positive correlation with normalized T2w (R = 0.72, p < 0.0001) and a negative correlation with FA values (R = 0.69, p < 0.0001), as shown in Figures 6F,G.
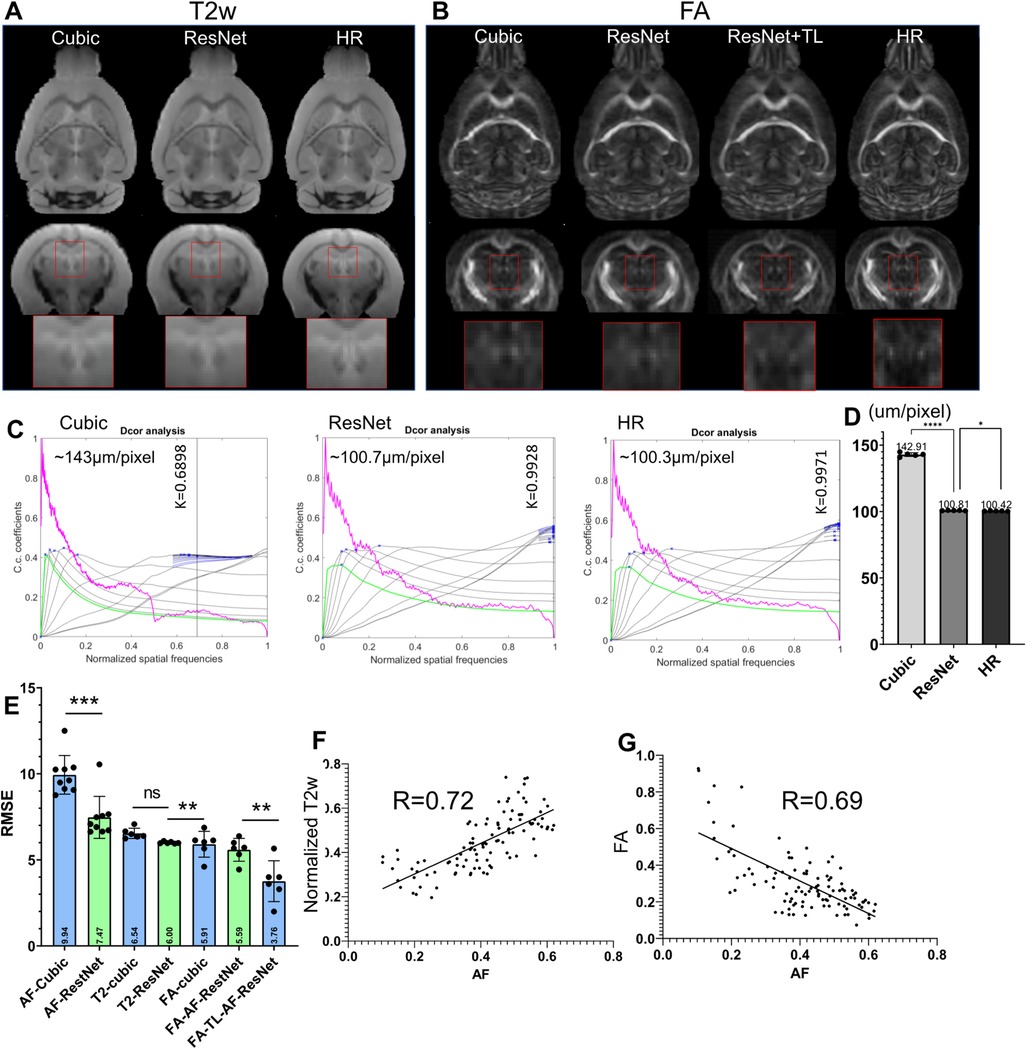
Figure 6. Super-resolution of T2-weighted (T2w) and FA images of the mouse brain. (A) T2w MRI SR using the ResNet trained using the 3D AF data compared with cubic interpolation results and high-resolution (HR) data; (B) results of FA SR using the ResNet trained on the AF data (ResNet) and transfer learning (ResNet + TL) compared with cubic interpolation results and HR data. (C) Estimation of the effective resolutions of the cubic interpolation, ResNet SR, and HR T2w images shown in (A). The magenta lines: radial average of log of the absolute value of Fourier transform from T2w images; the gray lines: all high-pass filtered decorrelation functions; blue to black lines: decorrelation functions with refined mask radius and high-pass filtering range. Blue crosses: all local maxima. K is the max of all maxima (shown as a vertical line) and the cut-off frequency. The effective resolution was calculated as nominal resolution (100 µm here) divided by K. (D) Effective resolution of the cubic-interpolation, ResNet SR, and native HR images (n = 5). (E) RMSE results of selected images shown in (A,B). (F,G) Voxel-wise correlations between AF and normalized T2w as well as between AF and FA signals.
We then used transfer learning by keeping on training the last three layers of the neural network while fixing the rest of the network. Compared with results from directly applying the network trained using AF data, the SR result from transfer learning showed significantly reduced RMSE (Figure 6E). This result suggests that transfer learning may allow us to use SR network trained using 3D AF data to SR MRI data.
3.4. Training from human MRI and application on mouse MRI
As there have been many reports on human brain MRI SR (26, 57, 58), it is worth accessing whether the SR networks trained using human brain MRI data can be applied to mouse brain MRI data. Apply the ResNet network trained using HCP MPRAGE data to the mouse brain T2w MRI data generated sharper results than cubic interpolation (Figure 7), but also introduced some ringing artifacts (indicated by the orange arrows in Figure 7A). Quantitative evaluations using PSNR, SSIM, and RMSE suggested that the human ResNet results were significantly worse than cubic interpolation (Figure 7B).
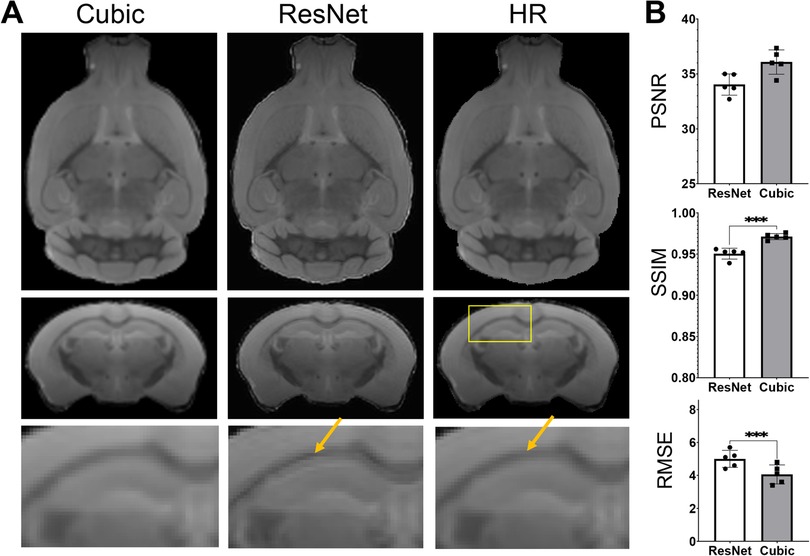
Figure 7. Super-resolution of T2w images of the mouse brain using the resNet trained using HCP MPRAGE data. (A) T2w MRI SR using the ResNet trained using the 3D AF data compared with cubic interpolation results and high-resolution (HR) data; (B) the PSNR, SSIM, and RMSE of the results from cubic-interpolation and ResNet.
4. Discussion
The goal of our study is to investigate whether deep learning-based SR can enhance the resolution of mouse brain MRI data. Acquiring high-resolution MRI data of the mouse brain or human brain is technically challenging and requires lengthy acquisition. For example, Wang et al. recently demonstrated dMRI of the mouse brain at 25 µm isotropic resolution, which took 95 h even with compressed sensing (59). Prolonged MRI acquisition is expensive and impractical due to the constant drift of the magnetic field as well as sample stability. Moreover, the available resolution also depends on the MRI contrast. For example, certain MRI acquisition techniques (e.g., dMRI) inherently require lengthy acquisition and have lower signal-to-noise (SNR) than conventional T1- and T2-weighted MRI. As a result, MRI data acquired using such techniques often have limited spatial resolutions and could benefit from SR methods.
In this study, we compared three types of deep learning networks for SR. As expected, ResNet and GAN outperformed cCNN in this study. This is because cCNNs require a large number of parameters to accommodate all potential features in images, which can lead to overfitting, as reported in previous studies (52, 60). The finding that ResNet outperformed GAN, however, was surprising to us because GAN has shown improved performances in many conventional image processing tasks including realistic image generation (61), inpainting (62), and image repairing (63). One possible explanation is that the loss functions used by the generator and discriminator here were not designed specifically to minimize the RMSE. In a previous study (52), a GAN network similar to the one used in this study generated visually realistic results but had lower RMSE and SSIM values against the ground truth than ResNet. Recent developments in GAN networks, such as conditional GAN (64), Cycle GAN (65), and the use of more sophisticated loss functions instead of the simple MSE loss function, may improve the performance of GAN for SR in the future.
Previous work on SR of generic images did not consider the effects of actual image resolution as the training and testing images were often acquired under a wide range of settings (e.g., multiple subjects in a scene and varying image sizes). However, for MRI and medical imaging, imaging resolution can be precisely defined by the field of view and image dimension and is an important parameter for evaluating its diagnostic value. Our results based on the mouse brain AF data demonstrate that the resolutions of the training data need to match the target resolution in order to achieve optimal SR performance and mismatches between the resolutions of training and target data resulted in reduced SR performance. In MRI data, structural details visible at different resolutions may have distinct statistical characteristics. For example, at low resolution (200–400 µm), we can only see major white matter tracts in the mouse brain, but as the resolution improves, smaller white matter tracts and other structural features emerge. Although it is possible to train a network with data of multiple resolutions, doing so will result in increased network complexity and require more training data.
We showed that increasing the training data size from 5,000 to 20,000 improved the network performance, but there is no hard threshold as the amount of training data needed depends on the network as well as the data pattern. For generic image SR, an early report on CNN-based SR used only 91 images, divided into 24,800 training samples, and the authors claimed that the training set already captured enough nature images features to avoid overfitting (23). Another study (43) used 5,744 slices to train a GAN-based SR network. In our case, the ResNet had about more than 10,000 parameters, and the 20,000 training samples were likely to capture all the mouse brain features to prevent overfitting. However, given the large number of optical data in AMBCA, we can potentially further increase the number of the training dataset.
As there is a lack of large collections (100 or more subjects) of high-resolution mouse brain MRI data, we investigated whether the extensive set of AMBCA mouse brain optical data could be used for SR of mouse brain MRI data. However, we found that the direct application of the SR network trained using AF to MRI data did not work well and transfer learning was required. Our results indicate that direct training on AF data can enhance the T2w MRI data, but provides limited improvement in the resolution of FA images. This may be due to the anisotropic microstructure organization characterized by FA, which may not be captured by the AF images. Transfer learning may have worked in this case because FA and AF images share links to some common features. It has also been reported that the contrast in AF mainly reflects tissue myelin content, and as myelinated white matter structures have anisotropic microstructure, there is a potential indirect link between AF and FA contrasts. However, it is important to note that high-resolution MRI data still needs to be collected to train the network.
One critical question of deep learning-based SR is whether it can be extended to human brain MRI data. Several studies have used SR techniques to improve the resolution of human brain images. For example, in (66), SR was used to enhance the low-resolution spectroscopic images of the human brain to detect the metabolic features. Other studies, such as (67), have proposed to apply SR models trained using lower resolution data (e.g., 2.5–1.25 mm) to high resolution data (1.25 mm or higher). However, our results in Sections 3.2 and 3.4 demonstrate that the SR becomes ineffective once the resolution and contrast discrepancy between the training and target data increases beyond a certain extent. For the current deep learning SR methods, the lack of high-resolution training data remains a significant challenge, which may be alleviated by using images acquired from postmortem brain specimens, taking into consideration the differences in MRI signals between in vivo and post-mortem MRI. Future studies are needed to explore the generalizability of deep learning-based SR methods to human brain MRI data with different image contrasts and imaging protocols, as well as the potential of using transfer learning and data augmentation techniques to enhance the performance of SR models.
In summary, we demonstrated that a deep learning network trained using AF data acquired from the mouse brain using serial two photon microscopy can improve the resolution of mouse brain MRI data via transfer learning. Our results suggest that the deep learning network can achieve better MRI SR than conventional cubic interpolation. This approach potentially allows us to leverage the large collection of mouse brain data from AMBCA and reduce the requirement on available high-resolution MRI data.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The animal study was reviewed and approved by New York University, Memorial Sloan Kettering Cancer Center, and Johns Hopkins University.
Author contributions
ZL: conceptualization, data curation, formal analysis, investigation, methodology, project administration, resources, software, validation, visualization, writing—original draft, writing—review and editing. JZ: conceptualization, project administration, resources, writing—review and editing data availability statement. All authors contributed to the article and approved the submitted version.
Funding
Eunice Kennedy Shriver National Institute of Child Health and Human Development (R01HD074593) JZ. National Institute of Neurological Disorders and Stroke (R01NS102904) JZ.
Conflict of interest
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author ZL declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fradi.2023.1155866/full#supplementary-material.
References
1. Moseley ME, Kucharczyk J, Mintorovitch J, Cohen Y, Kurhanewicz J, Derugin N, et al. Diffusion-weighted MR imaging of acute stroke: correlation with T2-weighted and magnetic susceptibility-enhanced MR imaging in cats. AJNR Am J Neuroradiol. (1990) 11(3):423–9. Available at: https://www.ncbi.nlm.nih.gov/pubmed/21616122161612
2. Tardif CL, Schafer A, Trampel R, Villringer A, Turner R, Bazin PL. Open science CBS neuroimaging repository: sharing ultra-high-field MR images of the brain. Neuroimage. (2016) 124(Pt B):1143–8. doi: 10.1016/j.neuroimage.2015.08.042
3. Ladd ME, Bachert P, Meyerspeer M, Moser E, Nagel AM, Norris DG, et al. Pros and cons of ultra-high-field MRI/MRS for human application. Prog Nucl Magn Reson Spectrosc. (2018) 109:1–50. doi: 10.1016/j.pnmrs.2018.06.001
4. Balchandani P, Naidich TP. Ultra-high-field MR neuroimaging. AJNR Am J Neuroradiol. (2015) 36(7):1204–15. doi: 10.3174/ajnr.A4180
5. Huang SY, Witzel T, Keil B, Scholz A, Davids M, Dietz P, et al. Connectome 2.0: developing the next-generation ultra-high gradient strength human MRI scanner for bridging studies of the micro-, meso- and macro-connectome. Neuroimage. (2021) 243:118530. doi: 10.1016/j.neuroimage.2021.118530
6. Zifei Liang XH, Teng Q, Wu D, Qing L. 3D MRI image super-resolution for brain combining rigid and large diffeomorphic registration. IET Image Process. (2017) 11:1291–301. doi: 10.1049/iet-ipr.2017.0517
7. Farsiu S, Robinson MD, Elad M, Milanfar P. Fast and robust multiframe super resolution. IEEE Trans Image Process. (2004) 13(10):1327–44. doi: 10.1109/TIP.2004.834669
8. Marquina A, Osher SJ. Image super-resolution by TV-regularization and bregman iteration. J Sci Comput. (2008) 37:367–82. doi: 10.1007/s10915-008-9214-8
9. Abd-Almajeed A, Langevin F. Sub-pixel shifted acquisitions for super-resolution proton magnetic resonance spectroscopy (1H MRS) mapping. Magn Reson Imaging. (2015) 33(4):448–58. doi: 10.1016/j.mri.2015.01.002
10. Poot DH, Jeurissen B, Bastiaensen Y, Veraart J, Van Hecke W, Parizel PM, et al. Super-resolution for multislice diffusion tensor imaging. Magn Reson Med. (2013) 69(1):103–13. doi: 10.1002/mrm.24233
11. Van Reeth E, Tham IW, Tan CH, Poh CL. Super-resolution in magnetic resonance imaging: a review. Magn Reson A. (2012) 40A(6):306–25. doi: 10.1002/cmr.a.21249
12. Liang ZF, He XH, Wang ZY, Tao QC. Combining coarse and fine registration for video frame super-resolution reconstruction (in English). J Electron Imaging. (2014) 23(6):063018. doi: 10.1117/1.Jei.23.6.063018
13. Greenspan H, Oz G, Kiryati N, Peled S. MRI inter-slice reconstruction using super-resolution. Magn Reson Imaging. (2002) 20(5):437–46. doi: 10.1016/s0730-725x(02)00511-8
14. Nicastro M, Jeurissen B, Beirinckx Q, Smekens C, Poot DHJ, Sijbers J, et al. To shift or to rotate? Comparison of acquisition strategies for multi-slice super-resolution magnetic resonance imaging. Front Neurosci. (2022) 16:1044510. doi: 10.3389/fnins.2022.1044510
15. Plenge E, Poot DHJ, Bernsen M, Kotek G, Houston G, Wielopolski P, et al. Super-resolution methods in MRI: can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time? (in English). Magnet Reson Med. (2012) 68(6):1983–93. doi: 10.1002/mrm.24187
16. Shi F, Cheng J, Wang L, Yap PT, Shen D. Longitudinal guided super-resolution reconstruction of neonatal brain MR images. Spatiotemporal Image Anal Longitud Time Ser Image Data (2014). (2015) 8682:67–76. doi: 10.1007/978-3-319-14905-9_6
17. Peled S, Yeshurun Y. Superresolution in MRI: application to human white matter fiber tract visualization by diffusion tensor imaging. Magn Reson Med. (2001) 45(1):29–35. doi: 10.1002/1522-2594(200101)45:1-29::aid-mrm1005%3E3.0.co;2-z
18. Wang Y-H, Qiao J, Li J-B, Fu P, Chu S-C, Roddick JF. Sparse representation-based MRI super-resolution reconstruction. Measurement. (2014) 47:946–53. doi: 10.1016/j.measurement.2013.10.026
19. Yoldemir B, Bajammal M, Abugharbieh R. Dictionary based super-resolution for diffusion MRI. MICCAI Workshop on Computational Diffusion MRI. (2014).
20. Deka B, Mullah HU, Datta S, Lakshmi V, Ganesan R. Sparse representation based super-resolution of MRI images with non-local total variation regularization (in English). Pattern Recognit Mach Intell Premi. (2019) 11942:78–86. doi: 10.1007/978-3-030-34872-4_9
21. Dong C, Loy CC, He K, Tang X. Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell. (2016) 38(2):295–307. doi: 10.1109/TPAMI.2015.2439281
22. Lecun L, Bottou Y, Bengio Y, Haffne P. Gradient-based learning applied to document recognition. Proc IEEE. (1998) 86(11):2278–324. doi: 10.1109/5.726791
24. Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial networks. Proceedings of the international conference on neural information processing systems (NIPS 2014)). p. 2672–80
25. Pham CH, Tor-Díez C, Meunier H, Bednarek N, Fablet R, Passat N, et al. Multiscale brain MRI super-resolution using deep 3D convolutional networks. Comput Med Imaging Graph. (2019) 77:101647. doi: 10.1016/j.compmedimag.2019.101647
26. Chen YXY, Zhou Z, Shi F, Christodoulou AG, Li D. Brain MRI super resolution using 3D deep densely connected neural networks. 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018); Washington, DC (2018). p. 739–42. doi: 10.1109/ISBI.2018.8363679
27. Feng CM, Wang K, Lu SJ, Xu Y, Li XL. Brain MRI super-resolution using coupled-projection residual network (in English). Neurocomputing. (2021) 456:190–9. doi: 10.1016/j.neucom.2021.01.130
28. Song LY, Wang Q, Liu T, Li HW, Fan JC, Yang J, et al. Deep robust residual network for super-resolution of 2D fetal brain MRI (in English). Sci Rep-Uk. (2022) 12(1):406. doi: 10.1038/s41598-021-03979-1
29. Wang JC, Chen YH, Wu YF, Shi JB, Gee J. Enhanced generative adversarial network for 3D brain MRI super-resolution (in English). IEEE Wint Conf Appl (2020). p. 3616–25. Available at: WOS:000578444803073.
30. den Bouter MLD, Ippolito G, O'Reilly TPA, Remis RF, van Gijzen MB, Webb AG. Deep learning-based single image super-resolution for low-field MR brain images (in English). Sci Rep-Uk. (2022) 12(1):6362. doi: 10.1038/s41598-022-10298-6
31. Li H, Liang Z, Zhang C, Liu R, Li J, Zhang W, et al. SuperDTI: ultrafast DTI and fiber tractography with deep learning. Magn Reson Med. (2021) 86(6):3334–47. doi: 10.1002/mrm.28937. Epub 2021 Jul 26. PMID: 34309073 34309073
32. Elsaid NMH, Wu YC. Super-resolution diffusion tensor imaging using SRCNN: a feasibility study. Annu Int Conf IEEE Eng Med Biol Soc. (2019) 2019:2830–4. doi: 10.1109/EMBC.2019.8857125
33. Kustner T, Munoz C, Psenicny A, Bustin A, Fuin N, Qi HK, et al. Deep-learning based super-resolution for 3D isotropic coronary MR angiography in less than a minute (in English). Magnet Reson Med. (2021) 86(5):2837–52. doi: 10.1002/mrm.28911
34. Sabottke CF, Spieler BM. The effect of image resolution on deep learning in radiography (in English). Radiol-Artif Intell. (2020) 2(1):e190015. doi: 10.1148/ryai.2019190015
35. Zhang T, Shi MY. Multi-modal neuroimaging feature fusion for diagnosis of Alzheimer's disease (in English). J Neurosci Meth. (2020) 341:108795. doi: 10.1016/j.jneumeth.2020.108795
36. Lin AL, Laird AR, Fox PT, Gao JH. Multimodal MRI neuroimaging biomarkers for cognitive normal adults, amnestic mild cognitive impairment, and Alzheimer's disease (in English). Neurol Res Int. (2012) 2012:907409. doi: 10.1155/2012/907409
37. Goubran M, Leuze C, Hsueh B, Aswendt M, Ye L, Tian Q, et al. Multimodal image registration and connectivity analysis for integration of connectomic data from microscopy to MRI. Nat Commun. (2019) 10(1):5504. doi: 10.1038/s41467-019-13374-0
38. Su R, Liu JH, Zhang DY, Cheng CD, Ye MQ. Multimodal glioma image segmentation using dual encoder structure and channel spatial attention block (in English). Front Neurosci-Switz. (2020) 14:586197. doi: 10.3389/fnins.2020.586197
39. Urban G, Bendszus M, Hamprecht F, Kleesiek J. Multi-modal brain tumor segmentation using deep convolutional neural networks. MICCAI Workshop on multimodal brain tumor segmentation challenge (BRATS); Boston, Massachusetts (2014).
40. Zeng K, Zheng H, Cai CB, Yang Y, Zhang KH, Chen Z. Simultaneous single- and multi-contrast super-resolution for brain MRI images based on a convolutional neural network (in English). Comput Biol Med. (2018) 99:133–41. doi: 10.1016/j.compbiomed.2018.06.010
41. Rousseau F, s A, Neuroimaging D. A non-local approach for image super-resolution using intermodality priors (in English). Med Image Anal. (2010) 14(4):594–605. doi: 10.1016/j.media.2010.04.005
42. Zheng H, Qu XB, Bai ZJ, Liu YS, Guo D, Dong JY, et al. Multi-contrast brain magnetic resonance image super-resolution using the local weight similarity (in English). Bmc Med Imaging. (2017) 17:6. doi: 10.1186/s12880-016-0176-2
43. Lyu Q, Shan H, Wang G. MRI super-resolution with ensemble learning and complementary priors. IEEE Trnas Comput Imaging. (2020) 6:615–24. doi: 10.1109/TCI.2020.2964201
44. Marcus DS, Harms MP, Snyder AZ, Jenkinson M, Wilson JA, Glasser MF, et al. Human connectome project informatics: quality control, database services, and data visualization. Neuroimage. (2013) 80:202–19. doi: 10.1016/j.neuroimage.2013.05.077
45. Li BM, Castorina LV, Hernandez MDV, Clancy U, Wiseman SJ, Sakka E, et al. Deep attention super-resolution of brain magnetic resonance images acquired under clinical protocols (in English). Front Comput Neurosc. (2022) 16:887633. doi: 10.3389/fncom.2022.887633
46. Tanno R, Worrall DE, Kaden E, Ghosh A, Grussu F, Bizzi A, et al. Uncertainty modelling in deep learning for safer neuroimage enhancement: demonstration in diffusion MRI (in English). Neuroimage. (2021) 225:117366. doi: 10.1016/j.neuroimage.2020.117366
47. Wang Q, Ding SL, Li Y, Royall J, Feng D, Lesnar P, et al. The allen mouse brain common coordinate framework: a 3D reference atlas. Cell. (2020) 181(4):936–953.e20. doi: 10.1016/j.cell.2020.04.007
48. Wu D, Xu J, McMahon MT, van Zijl PC, Mori S, Northington FJ, et al. In vivo high-resolution diffusion tensor imaging of the mouse brain. Neuroimage. (2013) 83:18–26. doi: 10.1016/j.neuroimage.2013.06.012
49. Tournier JD, Smith R, Raffelt D, Tabbara R, Dhollander T, Pietsch M, et al. MRtrix3: a fast, flexible and open software framework for medical image processing and visualisation (in English). Neuroimage. (2019) 202:116137. doi: 10.1016/j.neuroimage.2019.116137
50. Chen C, Qi F. Single image super-resolution using deep CNN with dense skip connections and inception-ResNet. 2018 9th international conference on information technology in medicine and education (ITME); Hangzhou (2018).
51. Khan MZ, Jabeen S, Khan MUG, Saba T, Rehmat A, Rehman A, et al. A realistic image generation of face from text description using the fully trained generative adversarial networks (in English). IEEE Access. (2021) 9:1250–60. doi: 10.1109/Access.2020.3015656
52. Ledig C, Theis L, Huszar F, Caballero J, Cunningham A, Acosta A, et al. Photo-Realistic single image super-resolution using a generative adversarial network. 2017 IEEE conference on computer vision and pattern Recognition
53. Aoki R, Imamura K, Akihiro HIRANO, Yoshio MATSUDA. High-performance super-resolution via patch-based deep neural network for real-time implementation. IEICE Trans Inf Syst. (2018) E101-D(11):2808–17. doi: 10.1587/transinf.2018EDP7081
54. Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In proceedings of AISTATS Vol. 9. (2010). p. 249–56
56. Descloux A, Grussmayer KS, Radenovic A. Parameter-free image resolution estimation based on decorrelation analysis. Nat Methods. (2019) 16(9):918–24. doi: 10.1038/s41592-019-0515-7
57. Iglesias JE, Billot B, Balbastre Y, Tabari A, Conklin J, Gonzalez RG, et al. Joint super-resolution and synthesis of 1 mm isotropic MP-RAGE volumes from clinical MRI exams with scans of different orientation, resolution and contrast (in English). Neuroimage. (2021) 237:118206. doi: 10.1016/j.neuroimage.2021.118206
58. Pham CH, Tor-Diez C, Meunier H, Bednarek N, Fablet R, Passat N, et al. Multiscale brain MRI super-resolution using deep 3D convolutional networks (in English). Comput Med Imag Grap. (2019) 77:101647. doi: 10.1016/j.compmedimag.2019.101647
59. Wang N, White LE, Qi Y, Cofer G, Johnson GA. Cytoarchitecture of the mouse brain by high resolution diffusion magnetic resonance imaging. Neuroimage. (2020) 216:116876. doi: 10.1016/j.neuroimage.2020.116876
60. Yang Z, Zhang K, Liang YD, Wang JJ. Single image super-resolution with a parameter economic residual-like convolutional neural network (in English). Multimedia Modeling (Mmm 2017). (2017) 10132(Pt I):353–64. doi: 10.1007/978-3-319-51811-4_29
61. Sun YT. Generation of high-quality image using generative adversarial network (in English). Proc Spie. (2022) 12259:122595z. doi: 10.1117/12.2639479
62. Wang Q, Fan H. Image inpainting via enhanced generative adversarial network. 2021 27th international conference on mechatronics and machine vision in practice (M2VIP); Shanghai, China (2021). p. 641–6. doi: 10.1109/M2VIP49856.2021.9665009
63. Zhang QB, Zhang XH, Han HW. Backscattered light repairing method for underwater laser image based on improved generative adversarial network (in Chinese). Laser Optoelectron Prog. (2019) 56(4):041004. doi: 10.3788/Lop56.041004
65. Zhu JY, Park T, Isola P, Efros AA. “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arXiv:1703.10593 (2020).
66. Ma J, Park JM. Super-resolution hyperpolarized (13)C imaging of human brain using patch-based algorithm. Tomography. (2020) 6(4):343–55. doi: 10.18383/j.tom.2020.00037
Keywords: MRI, super-resolution (SR), deep learning, transfer learning, multi-modality image
Citation: Liang Z and Zhang J (2023) Mouse brain MR super-resolution using a deep learning network trained with optical imaging data. Front. Radiol. 3:1155866. doi: 10.3389/fradi.2023.1155866
Received: 31 January 2023; Accepted: 28 April 2023;
Published: 15 May 2023.
Edited by:
Qiang Li, Tangdu Hospital, Fourth Military Medical University, ChinaReviewed by:
Yasheng Chen, Washington University in St. Louis, United StatesMuwei Li, Vanderbilt University Medical Center, United States
© 2023 Liang and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiangyang Zhang amlhbmd5YW5nLnpoYW5nQG55dWxhbmdvbmUub3Jn