 Thomas Risse
Thomas Risse Thomas Hélie
Thomas Hélie Fabrice Silva2
Fabrice Silva2- 1STMS Laboratory UMR 9912, IRCAM-CNRS-Sorbonne Université, Paris, France
- 2Aix Marseille University, CNRS, Centrale Med, LMA UMR 7031, Marseille, France
The vocal apparatus is a biophysical dynamic system capable of self-oscillation, which involves fluid–structure interactions and human control. This study on the sound synthesis of voiced sounds presents a physical quasi-1D model of the vocal apparatus in the port-Hamiltonian framework and its validation through numerical experiments. The modelling ensures balanced power exchanges between fluid, tissues, and human control. Fluid is represented in the larynx and in the vocal tract using a unified 1D PDE handling transverse geometry variations. A regularisation procedure is introduced to mitigate the numerically stiff behaviour of the model observed at channel closure. Vocal folds and vocal tract walls are represented by lumped element models as well as the radiation load at the lips, which consists of a first-order high-pass filter. Spatial discretisation of the fluid model and temporal discretisation of the full system are made using structure-preserving methods to ensure energy consistency (passivity). The second part of this paper focuses on numerical experiments to progressively characterise the model and assess its validity. These experiments begin with frequency response analysis of a static vocal tract under quasi-linear conditions followed by simulations of vowel transitions (diphthongs) under forced excitation. Next, self-oscillation studies are conducted on an isolated larynx where contact parameters are adjusted. Lastly, full simulations of the self-oscillating vocal apparatus with co-articulation, representing a voice synthesizer capable of articulating vowels, are presented. The dynamics are also analysed in terms of energy transfer and passivity. Finally, these results are discussed to establish a basis for future model refinements and to identify directions for enhancing the accuracy and realism of vocal synthesis.
1 Introduction
Understanding the mechanisms of voice production has been the focus of numerous studies on the physical modelling of the vocal apparatus. Highly detailed models that capture the range of physically relevant phenomena typically involve high-dimensional representations, which can be computationally intensive. Consequently, these studies often focus on specific components or aspects of the vocal apparatus (e.g., Alipour et al., 2000; Gunter, 2003; Xue et al., 2010; Guasch et al., 2013; Zhang, 2015; Valášek, 2021). In contrast, low-order models aim to replicate the qualitative behaviour of the vocal apparatus along with certain quantitative features (such as the relationship between subglottal pressure and fundamental frequency, as demonstrated in Ruty et al. (2007)) while maintaining relatively low computational costs. This computationally efficient approach has been a key focus since the early days of sound synthesis, with foundational models like the Kelly–Lochbaum model (Kelly, 1962) or digital implementations of lumped-parameter physical models (e.g., Maeda, 1982) for the vocal tract. These models are well-suited for vocal synthesizer applications or parameter studies. For the laryngeal part, low-order models (e.g., Ishizaka and Flanagan, 1972; Story and Titze, 1994; see also the review in Erath et al., 2013) typically represent the vocal folds as assemblies of lumped mass-spring-damper elements and assume a quasi-steady behaviour of fluid flow in the glottis. However, this approach introduces a one-way coupling between the flow and the vocal folds, limiting the model’s ability to accurately represent power exchanges between the fluid and tissue, and it may introduce instabilities in numerical simulations.
Recent efforts have focused on developing power-balanced, reduced-order models of voice production within the port-Hamiltonian (pH) framework first introduced in Maschke and van der Schaft (1992). Notably, Encina et al. (2015) reformulated the body-cover vocal fold model from Story and Titze (1994), and early self-oscillating power-balanced models were introduced in Hélie and Silva (2017) and Mora et al. (2018) using lumped representations of glottal flow. Subsequent research by Mora et al. (2021b) and Wetzel (2021) proposed discrete, scalable models of compressible fluid within tubes with moving boundaries, tailored for vocal tract applications. However, this set of studies primarily focused on isolated larynx models (possibly coupled with an oversimplified acoustic load) or on isolated vocal tracts under basic configurations.
This paper presents a complete simplified power-balanced model of the vocal apparatus within the pH framework, designed for the synthesis of voiced sounds. A one-dimensional distributed fluid model is developed and described as a port-Hamiltonian system of partial differential equations, accounting for compressibility, time-varying geometry, and convective acceleration. A new regularisation procedure for handling glottal closure is introduced. This model is then spatially discretised in a structure-preserving manner, from which the discrete fluid model from Mora et al. (2021b) is recovered. The vocal fold model is based on the lumped-element body-cover model from Story and Titze (1994), while the vocal tract walls are represented by a series of simpler mass-spring damper systems. At the lips, the radiation condition is modelled as an impedance load, represented by a first-order high-pass filter, tuned according to acoustic considerations and designed to be passive and compatible with time-varying configurations. Each component is formulated within the pH framework and interconnected via ports using a two-way coupling, ensuring a global power balance. Simulations are performed using an energy-preserving time integration method across various configurations, including the vocal tract alone, the larynx alone, and the complete assembly. Notably, the ability of the complete model to reproduce the co-articulation of diphthongs in self-oscillating configurations is demonstrated—an achievement that, to the best of our knowledge, is unprecedented in the context of energy-based modelling of voice production. Energy-based modelling explicitly reveals the power exchanges and dissipated power signals, which are discussed in detail.
After positioning our contributions within the existing literature on voice production modelling in Section 1, the remainder of this paper is organised as follows. Section 2 introduces the fluid and tissue models used in the experiments. Section 3 presents a series of numerical experiments based on these models, progressively increasing in complexity and realism, to assess their validity and capabilities. Finally, Section 4 discusses the results and outlines potential directions for future work.
2 Model
Energy-based models for fluid dynamics and vocal folds are proposed within the port-Hamiltonian framework. These models are subsequently interconnected, resulting in power-preserving fluid–structure interactions. Symmetry around the laryngeal midplane is assumed, allowing reduction of the problem to the case of a single vocal fold and simplifying the presentation.
2.1 Fluid flow model
The modelling of the fluid flow is proposed within the framework of port-Hamiltonian systems. It relies on the strict separation of the intrinsic behaviour of the fluid (described by means of the Hamiltonian, summing up kinetic energy and internal energy, or more specifically by the fluid behaviour law relating the pressure to the mass density) from the evolution laws (provided as mass and momentum conservation laws). As an original contribution of this paper, the latter are formulated as 1D partial differential equations under a detailed set of assumptions. Spatial discretisation is applied to obtain a discrete model, similar to that used in Mora et al. (2021b), with the change of state variables proposed in Risse et al. (2024). Here, the model with this revised set of state variables is presented. The model is constructed as a conservative system (the energy conservation naturally derives from the port-Hamiltonian systems), and lumped dissipation laws are added after spatial discretisation.
2.1.1 Formulation as a continuous 1D PDE system
The time-varying fluid domain is described in 3D cartesian space as follows:
Figure 1 presents the domain as well as its boundaries. Boundaries
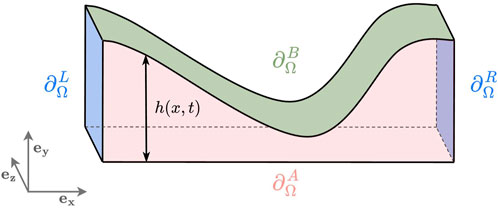
Figure 1. Fluid domain
The following assumptions are made for the fluid in
Hypothesis 1. The fluid is composed of an ideal gas (H1a) undergoing homentropic flow (i.e., constant entropy in space and time) (H1b).
Hypothesis 2. The fluid is inviscid.
Hypothesis 3. The flow is irrotational.
Let
Under Hypotheses 2 and 3, Euler equations for irrotational flow in the domain
To close the system of equations, thermodynamic considerations are used to provide expressions for functions
Hypothesis 4. The function
The corresponding expression for the specific internal energy (i.e. per unit mass)
We now explicitly consider the fluid flow in the geometry depicted in Figure 1 and perform the 1D reduction. The boundary conditions are as follows. Boundaries
Hypothesis 5.
Hypothesis 6. The fluid–structure interfaces
Hypothesis 7. The contribution of the transverse velocity
Hypothesis 8.
Hypothesis 9. The moving boundary
Mass equation: considering a cross-section
Axial momentum equation: the integration of Equation 3b and the use of Hypotheses 7 and 8 yield
The distributed state
Efforts are obtained as variational derivatives of the Hamiltonian with respect to the state variables (e.g., Olver, 1986, chapter 4, for a definition of variational derivative).
The pH formulation including the dynamics of the geometry configuration given by Hypothesis 9 then reads
where the velocity
Splitting the exchanged power into a distributed contribution
(C0) Total enthalpy control on both sides, with mass flows as power-conjugated outputs.
(C1) Mass flow control on both sides, with total specific enthalpies as power conjugated outputs.
(C2) Mixed boundary conditions—(C0) on one side, (C1) on the other.
Remark 1. The reduction from 3D equations to a 1D reduced model involved the definition of a new state variable
2.1.2 Spatial discretisation: finite differences on staggered grids
The 1D continuous equation is semi-discretised using a power-preserving finite difference approximation on a staggered grid (Trenchant et al., 2018). For the sake of brevity, only the configuration (C1) where mass flows inputs are considered at both ends of the domain is detailed here, but other configurations can be obtained using the same procedure. The 1D mesh is first presented, and then field approximations are made on that mesh. The resulting dynamics obtained from injection of these approximations in Equation 8 and integration on mesh volumes are presented using a set of chosen discrete state variables.
2.1.2.1 Meshing of the 1D domain
• The domain is divided in a primal grid of
• The dual grid is built from the primal grid. Its
A total of
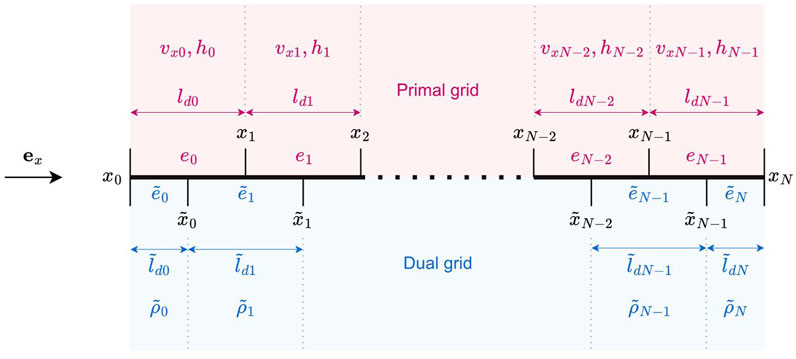
Figure 2. Staggered grid discretisation with notations for the primal grid (upper part) and dual grid (lower part).
Remark 2. We introduce the notations for Hadamard (elementwise) operations on vectors: multiplication
2.1.2.2 Approximation of the fields
• Velocity
The choice of discretisation for
• Volumetric mass density
2.1.2.3 Choice of state variables and discrete Hamiltonian
The state is chosen to be
with the degrees of freedom of velocity
The energy of the discrete fluid system is obtained by injecting field approximations in Equation 6, yielding
making use of functions of the state variables to reconstruct the volumetric mass densities in volumes of the dual grid
and provide the mass flow rates
2.1.2.4 Semi-discrete dynamical system
Injecting the field approximations in the 1D conservation equations and integrating Equation 3b on the edges of the primal grid and Equation 3a on the edges of the dual grid yields the semi-discrete dynamical system. one obtains the port-Hamiltonian formulation:
where
The power-conjugated outputs of the system are obtained by skew-symmetry as
Remark 3. Note that the reaction force
2.1.3 Lumped dissipation laws
The fluid system presented in Equation 15 has no dissipative effects. Indeed, it was first built from conservative Euler equations as it simplifies the process (Hypothesis 4 does not allow a correct representation of dissipation effects when going from 3D to 1D). Lumped dissipation laws are now introduced to account for the various effects below.
• Friction forces induced by the shear stress in the fluid. According to Stevens (1971), half4 of the net drag force for a viscous fluid flowing in a rectangular slit of section area
with
• Loss of kinetic energy due to the flow separation that can occur at the exit of the constriction, with transfer to the small scales of the velocity field in the downstream mixing region. This results in a drop in the total specific enthalpy of
• Acoustic radiation at the lips. For simplicity, we consider the approximation of the acoustic radiation impedance by a first-order high-pass filter
The dynamics of the fluid system are modified to account for these phenomena through the introduction of the dissipation matrix
where
for friction forces, to be completed by an additional term
Remark 4. In the vocal tract, visco-thermal losses and fluid–tissue coupling are relevant dissipation phenomena. A lumped tissue model for the vocal tract walls is presented in Section 2.3. Visco-thermal losses are left for future studies.
2.1.4 Equivalent circuit representation of a section of the semi-discretised model
An equivalent circuit representation of a portion of the fluid domain (more precisely to an edge of the primal grid) is depicted in Figure 3, evidencing two sub-circuits. The lower sub-circuit accounts for axial inertia and mass accumulation as in classical transmission line structures, while the upper one handles the reaction of the fluid to a change of geometry (connected to a model of tissues to be described in the next sections). Even if the two sub-circuits seem to be disconnected, they are in reality coupled through the multivariate non-separable Hamiltonian
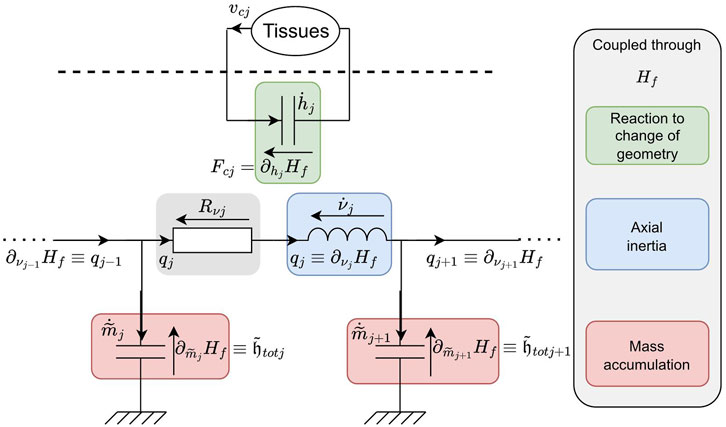
Figure 3. Equivalent circuit representation of a cell of the semi-discrete fluid model. Component laws are coupled through the Hamiltonian and thus depend on the state of the current cell and of the neighbouring sections.
2.2 Vocal fold model
The classical body-cover model of the vocal fods presented in Story and Titze (1994) is used. It consists of a body mass coupled with two cover masses. The port-Hamiltonian formulation has been developed in Encina et al. (2015).
2.2.1 Presentation
The assembly, presented in the left section of Figure 4, comprises the three masses coupled together by four springs and three dampers. Derivation of the port-Hamiltonian formulation of this assembly is recalled here. The body mass
where
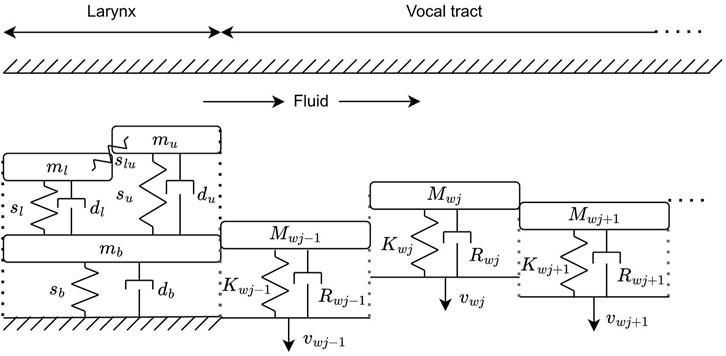
Figure 4. Tissue schematics: body cover model for the vocal fold and mass spring damper systems for vocal tract walls.
The resultant force of the springs on each mass
The total kinetic energy of the system is computed as
such that the Hamiltonian is given by
The port-Hamiltonian formulation of the dynamics including linear dissipation effects and external interactions is
with
and where dissipation coefficients
The power-conjugated output vector
2.2.2 Setting the characteristics of the springs
The above formulations leave us with the choice of potential energy functions
where
2.3 Vocal tract tissue
A better representation of low-frequency resonances of the vocal tract requires the introduction of a model for tissues of the vocal tract. We here consider a simplified local mechanical wall surface impedance
2.4 Assembly
2.4.1 Fluid–tissue connection
In the context of the numerical experiments, the models presented are tested in various configurations. The vocal tract will consist of the fluid model alone, the geometry of which will be controlled by inputs defined in order to produce articulations of different vowels. In the larynx, the fluid model will be connected to the vocal fold model by assuming the continuity of normal velocities and net forces at the fluid–structure interface. Note that several fluid cells may be connected to a single mass of the vocal folds. In this case, connected fluid cells share the same geometrical velocity, and the force received by the vocal fold mass is the result of pressure forces of all fluid cells connected to it. The resulting assembled system can be written as a new port-Hamiltonian system, the state of which is composed of the concatenation of the states of the fluid and the vocal folds.
2.4.2 Glottal closure
In many cases, self-oscillations of the vocal folds include phases of glottal closure and thus contact between the vocal folds. This phenomenon is handled in the modelling by introducing direct coupling between the vocal folds model that is only activated when the vocal folds are detected to be in contact—when the heights
Mora et al. (2021b) proposed a switching port-Hamiltonian model that disconnects the fluid from the vocal folds when
Moreover, the discrepancy
3 Numerical experiments
The energy-consistent model established in the previous section as a port-Hamiltonian system is now tested and discussed through a sequence of numerical experiments of increasing complexity. The final experiment simulates the full vocal apparatus exhibiting self-oscillations, where vowel articulation is achieved through geometrical control of the vocal tract.
3.1 General numerical setting and experimental configurations
For time discretisation, a continuous Galerkin time-stepping method is used which preserves a discrete power balance and is unconditionally stable. The method is presented in Chapter 5 of Müller (2021). Second-order polynomials are used for the projection. All simulations are run at a standard audio sampling rate
General fluid and fold physical parameters are taken as in Mora et al. (2021b) and listed in Table 1. For each numerical configuration, values of configuration-specific parameters are listed in Table 2. Four configurations are studied.
1. The frequency response of the fluid model alone in static configurations is studied. Resonance frequency convergence with respect to spatial discretisation is shown in the simple case of a straight tube. Formant frequencies obtained from the simulation of a geometry configuration corresponding to a single vowel are compared to experimental estimations.
2. Diphthong articulation: the geometry of the fluid model alone is controlled to produce the articulation of diphthongs. A synthetic glottal flow model is used to excite the vocal tract.
3. Isolated larynx: the fluid model is connected to the fold model, exhibiting self-oscillations. As the vocal tract is not modelled, this configuration corresponds to an excised larynx alone.
4. Larynx and vocal tract: the fluid model extends from the glottis to the lips and is connected to the fold model in the larynx. Again, self-oscillations are observed. The geometry of the part of the fluid model corresponding to the vocal tract is forced to produce diphthongs. This experiment yields a full self-oscillating vocal apparatus.

Table 1. General physical constants and parameters.

Table 2. Configuration specific parameters.
3.2 Frequency response
In the first experiment, the frequency response of the fluid model in static configurations is studied. Firstly, a straight tube of total length
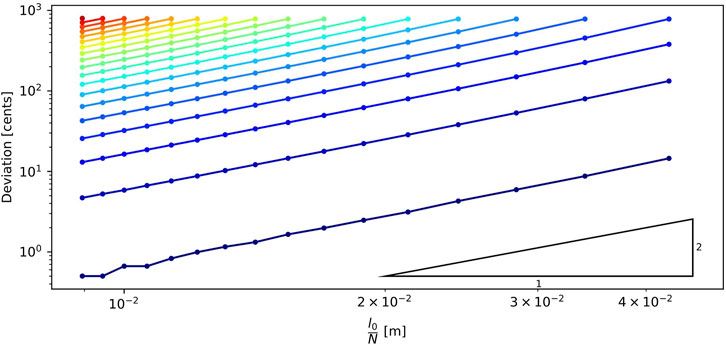
Figure 5. Convergence of resonant frequencies with the number of tracts. Deviation is expressed in cents and is computed as
Remark 5. Frequency responses are obtained from time-domain simulation of the models. The time discretisation method introduces additional frequency warping. However, in the range of studied frequencies and given the sampling frequency of
Static vocal tract configurations are now considered. The geometry is set to correspond to a vowel articulation; area functions from Story et al. (1996) are interpolated to produce a set of
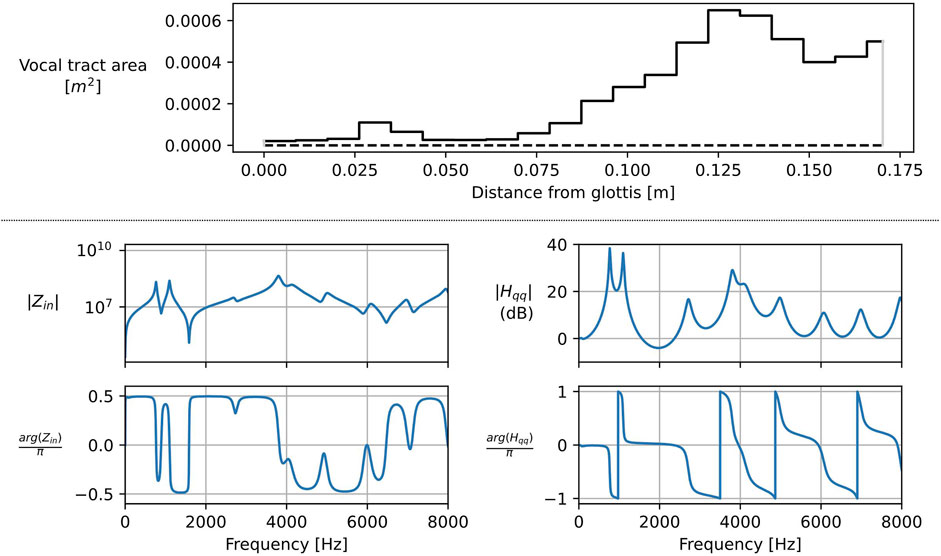
Figure 6. Discretised vocal tract area function for vowel /ɑ/ with
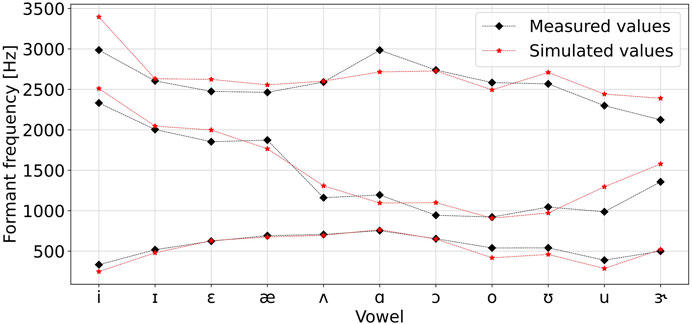
Figure 7. Comparison of the three first formant frequencies of several vowel sounds obtained from simulation of the proposed model with measurement from Story et al. (1996).
3.3 Diphthong articulation
This experiment presents the use of the model as a vocal tract with forced geometry to reproduce co-articulation of diphthongs. The general configuration is similar to the previous one, with a total length
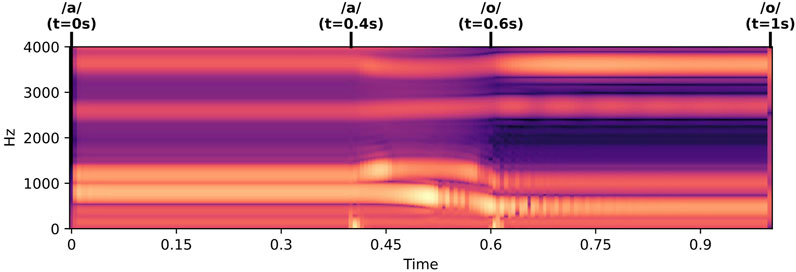
Figure 8. Wideband spectrogram of the radiated pressure for the simulation of the vowel trajectory indicated at the top of the figure. A synthetic glottal flow excitation is used.
Remark 6. The total length
3.4 Isolated larynx
One of the main objectives of this model is to be able to reproduce self-oscillations of the assembly composed of the laryngeal fluid flow and the vocal folds. We first study a configuration corresponding to an isolated larynx, with no vocal tract model or load. Note that this type of configuration is similar to that presented in Mora et al. (2021b) and can be interpreted as an excised larynx experiment. We use a total of
The subglottal total enthalpy is prescribed to be a smoothed step function (as shown in the top axis of Figure 10). An ideal boundary condition is set at the supra-glottal end, enforcing a zero total enthalpy.
3.4.1 Oscillating configuration
Physical parameters from Table 1 are used for simulation, corresponding to case C of Story and Titze (1994). Using their value of
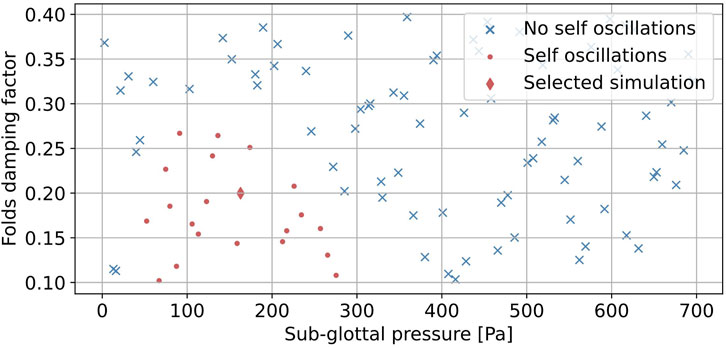
Figure 9. Cartography of oscillating regions as a function of sub-glottal pressure and folds damping factor
3.4.2 Signal analysis
Figure 10 shows the distances of the simulated masses to mid-plane and mass flow under the cover masses, obtained for the configuration indicated by a diamond marker in Figure 9. During the first
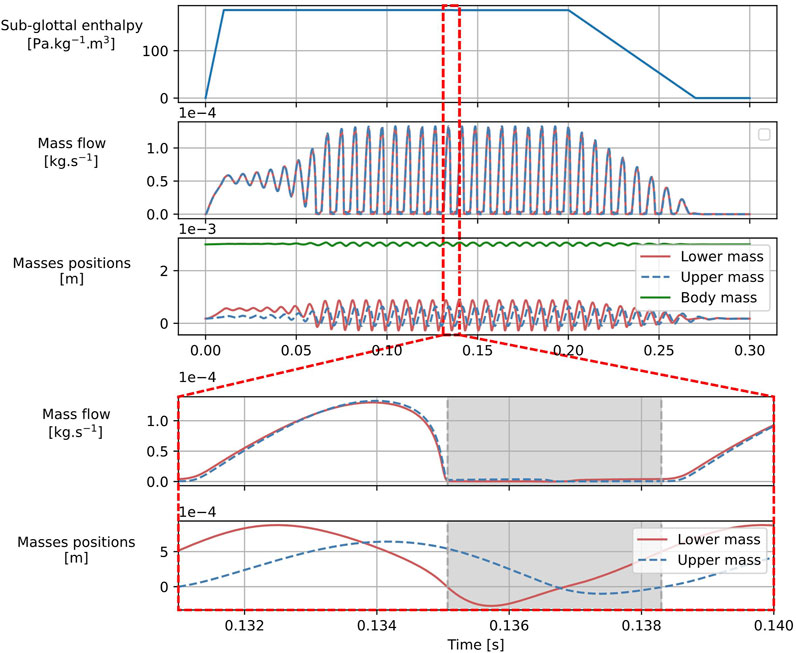
Figure 10. Simulation results in a self-oscillating configuration. Global signals (top) as well as a one-period zoom (bottom) are shown. Masses’ positions are relative to the midplane, and mass flow signals below each of the cover masses are traced. The grey zone in the zoomed signals highlights a closed glottis section of the oscillation cycle.
Time evolution of the terms of the power balance is displayed in Figure 11. The top row presents the variation of the Hamiltonian of both the fluid and tissue systems as well as dissipated power and power exchanged through the boundary at the sub-glottal end of the fluid domain5. The power balance is recovered as the sum of these three contributions vanishes (up to numerical precision). This follows from the use of the energy-balanced PDE presented in Equation 8 and of energy-preserving numerical schemes both for space and time discretisation. The bottom row decomposes the dissipated power in three contributions: loss of kinetic energy at the glottal exit (labelled jet), viscous fluid losses, and dissipation within the vocal folds. Analysis of the signals on one period (left column of the figure) provides insightful information on different portions of the cycle:
• During the opened phase (from
• During the phase of closing of the glottis (from
• During the closed phase (from
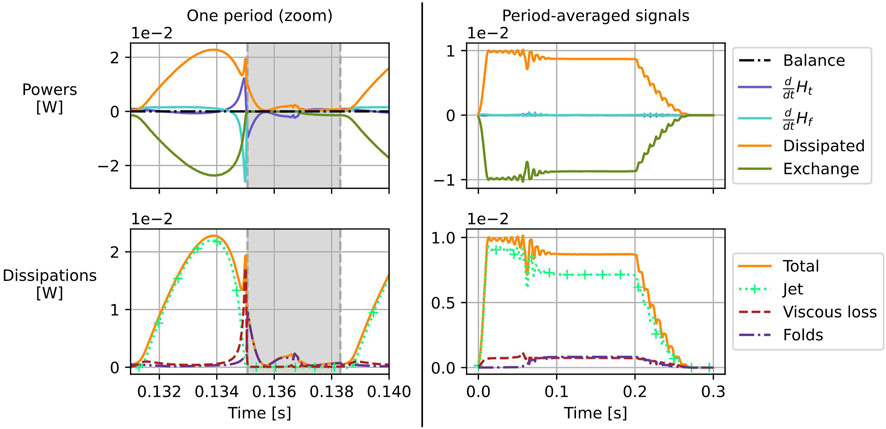
Figure 11. Power signals for the simulation presented in Figure 10. The left column shows the time series of the signals for a single period whereas the right column contains the period-averaged values of these same signals for the full simulation. Dissipated power, power exchanged with the source, and variation of the Hamiltonians of the fluid and fold systems are depicted in the top row with the power balance obtained as the sum of these four contributions. The bottom row separates the dissipated power in its different physical origins: jet dissipation at the larynx output, viscous losses, and dissipation in the folds.
The time-averaged powers are plotted on the right column of Figure 11. After establishing the periodic regime, it is clear that mean variations of the Hamiltonian are null, as expected. Kinetic energy dissipation is the most prominent source of energy loss whereas viscous losses and dissipation in the folds are of the same order of magnitude. From the energy budget of the larynx, the power received from the lower airways is mostly used to install a glottal flow able to produce flow-induced oscillations at the expensive cost of strong kinetic energy losses at the glottal exit. Once the flow is installed, a small extra effort is required to provide the power needed to compensate for viscous losses within the glottis and damping in the tissues.
3.4.3 Numerical experiment on the effect and choice of height regularisation parameters
The parameters
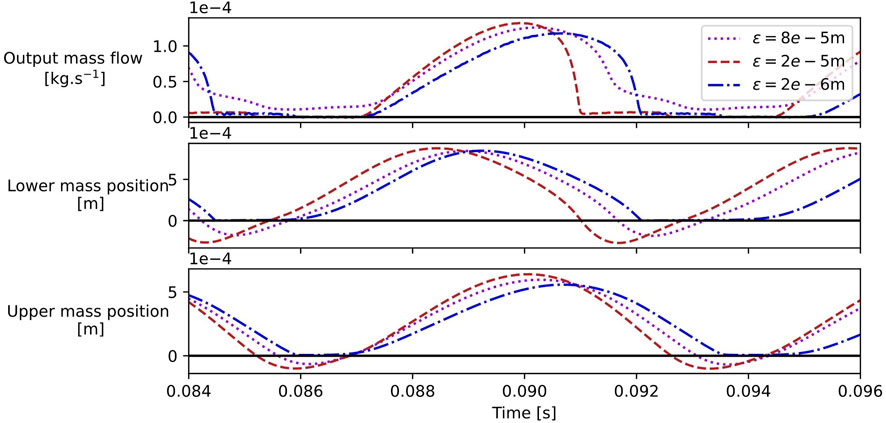
Figure 12. Snapshots of simulations of the larynx alone for different values of the effective height regularisation parameters
The following can be observed.
• For
• For
• For
It is preferable to allow folds to interpenetrate as it allows for better control of their behaviour during contact by tuning
3.5 Larynx connected to vocal tract
This last experiment focuses on the simulation of the larynx coupled to the vocal tract. This effectively represents a simplified vocal apparatus capable of self-oscillations and articulations. A total of
This configuration reproduces the concatenation of the larynx and vocal tract fluid models used in the previous experiments. The soft wall model is used in the vocal tract, and the boundary condition at the lips is set using the high-pass radiation model. Like the isolated larynx case, the sub-glottal total enthalpy serves as the control input and is set to a smoothed step function. The vocal tract geometry follows the trajectory defined in Figure 8 to produce the diphthong /ɑo/. Initial laryngeal heights are retained from Section 3.4 (see Equation 29), the damping ratio for the vocal folds set to
Time-domain results are presented in Figure 13. The top axis of the figure displays the mass flow and cover mass displacement signals over the full simulation duration. Oscillations build up at the start of the simulation, followed by a stable periodic regime, which is then modified by the transition of the vocal tract shape from /ɑ/ to /o/ between 0.4s and 0.6s. After 0.6s, the vocal tract geometry remains fixed, leading to another stable periodic regime. The output mass flow amplitude, shown in grey in the middle row, is significantly altered after the change in vocal tract shape. This change is likely due to the substantial modification in the vocal tract area at the lips, between the wide opening for /ɑ/ and the narrow opening for /o/.
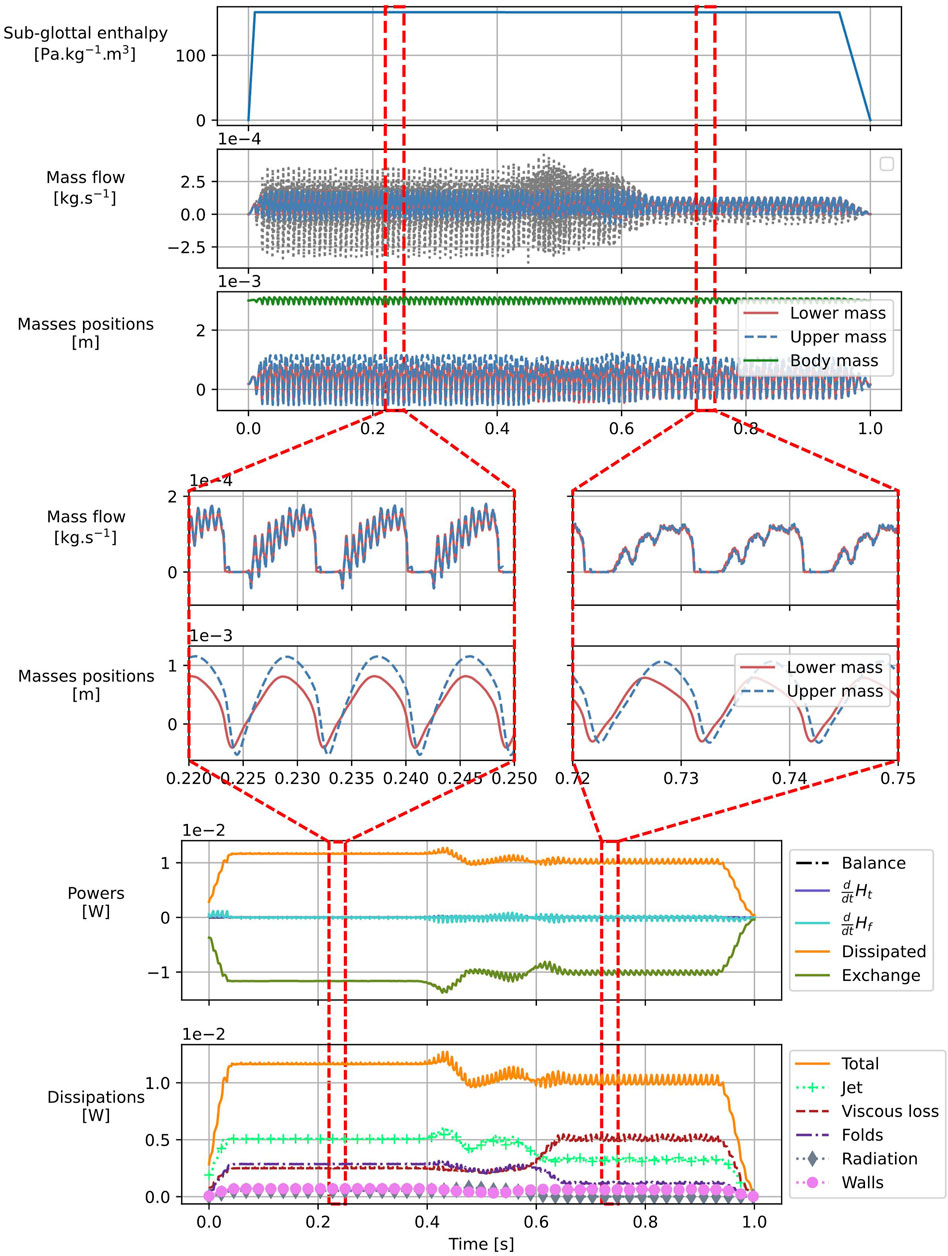
Figure 13. Simulation results for the co-articulation of diphthong /ɑo/ in self-oscillating condition. Signals of mass displacements relative to the midplane and mass flows in the larynx are traced for the full simulation time (top) and two reduced time spans corresponding to stable /ɑ/ and /o/ configurations (middle). Averaged power balance signals and dissipations are also presented (bottom).
The middle axis of the figure depicts zoomed-in views of two stable periodic regimes corresponding to vowels /ɑ/ and /o/. The mass flow signals in the glottis are strongly influenced by the vocal tract, as shown by comparisons of the respective waveforms. In addition, the fundamental frequency is noticeably lower for /o/ (99 Hz) than for /ɑ/ (119 Hz). However, the displacement of the masses is less perturbed by the acoustic coupling with the vocal tract than the mass flow signals.
Averaged power signals are shown at the bottom of the figure, with the averaging filter length set to ten periods of oscillation for configuration /ɑ/. Unfiltered signals, containing high-frequency content (amplified by the vocal tract), are not displayed; however, the global power balance is verified up to machine precision at each time step. The distinct physical origins of dissipated power—jet dissipation at the larynx output, viscous fluid losses, dissipation in the folds, radiated power at the lips, and dissipation within the vocal tract walls—have varying contributions. In particular, viscous fluid losses and fold dissipation are more important here than in cases without a vocal tract (Figure 11). Moreover, the relative contributions of each dissipation mechanism shift substantially after the vocal tract shape modification—notably the increase of the dissipated power related to viscous effects in the glottis and the vocal tract. Further investigation is needed to explain this effect.
4 Discussion and perspectives
This study demonstrates the effectiveness of a quasi-1D port-Hamiltonian model in replicating key characteristics of voice production, ensuring well-posed energy transfer dynamics between fluid, tissues, and human control. The model exhibits self-oscillatory laryngeal behaviours and incorporates a variable-geometry vocal tract. It thus serves as a simple voice synthesizer capable of articulating vowels. This positions the approach as a basis for developing a powerful tool for voice synthesis. This statement is discussed in two parts: firstly, through an analysis of the proposed model, and second, by considering motivated refinements for future model development.
4.1 Simulations of the proposed model
In Section 3, we presented several simulations of the proposed model corresponding to different configurations.
Vocal tract simulations show the evolution of formant frequencies with variations of geometry of the conduit. The incorporation of dissipative effects, such as radiation losses and wall vibrations, proved crucial for obtaining realistic formant bandwidths and frequencies—in line with Fleischer et al. (2015) and Birkholz et al. (2022). Story et al. (1996) provides a set of MRI measurements of vocal tract area functions corresponding to vowel sounds, as well as the corresponding first three formant frequencies extracted from acoustic recordings. Significant error is observed between these measured formant frequencies and our model predictions, which seems related to our choice of vocal tract wall and radiation parameters. The discrepancies observed between these measured formant frequencies and the model predictions—likely stemming from parameter choices related to vocal tract wall damping and radiation losses—highlight the need for further research to refine the modelling of dissipation mechanisms or to optimize these parameters for enhanced realism.
Simulations of the larynx alone and of the complete system show self-oscillations of the vocal folds with constant sub-glottal total enthalpy. We proposed a regularisation procedure to eliminate the unrealistic behaviour of the discrete fluid model at glottal closure. Qualitative analysis of simulation results for different values of the regularisation parameter
The reduced-dimensional approach adopted in this work also proves valuable for exploring the parameter space, particularly in determining oscillation pressure thresholds and pressure-fundamental frequency relationships (Alipour and Scherer, 2007; Ruty et al., 2007). This offers a natural extension of the work presented, allowing comparison with in vivo measurements (in the context of the ANR project AVATARS) or other models. This ability to perform parameter studies is an advantage of the low order fluid models such as that proposed here. Models with two- or three-dimensional flows are more precise but generally too expensive (days of computation for a few oscillation cycles) to perform parameter studies. Voice synthesis based on machine learning is efficient and produces very convincing results. However, any access to the physical variables involved in voice production is lost.
To facilitate future numerical experiments, the development of a fast numerical integration method is of great interest. Indeed, the current in-house iterative solver based on the method presented in Müller (2021), chapter 3 is fully implicit and results in long simulation times (in the order of 10 min of computation time for 1 s of sound). Ongoing research is focused on the development of a fast (explicit or semi-explicit) time-stepping method that satisfies a discrete power balance. Energy quadratisation techniques involving auxiliary variables, as introduced in Shen et al. (2018), have been successfully applied or extended to various problems in musical acoustics (Ducceschi et al., 2023; Bilbao et al., 2023; Castera and Chabassier, 2023; Russo et al., 2024) and show promise for enabling real-time synthesis, which remains one of our primary future objectives.
4.2 Possible refinements for future models
The use of the port-Hamiltonian (pH) framework allows the procedural connection of multiple sub-systems in a power-balanced way. In this study, subsystems for fluid dynamics, tissues in the larynx and vocal tract, and acoustic radiation were considered. Each subsystem can be refined independently without breaking the overall energy balance and passivity, offering significant flexibility for future model improvements. We propose a list of perspectives in this regard.
4.2.1 Fluid model refinements
Use of the PDE presented in 2.1.1 is, to the best of our knowledge, new in the context of vocal apparatus modelling. Unlike Bernoulli-type glottal flow solvers commonly used in the literature, this model accounts for unsteady effects and compressibility, making it suitable for representing both wave propagation in the vocal tract and glottal flow dynamics. The spatial discretisation of this equation using finite differences results in the model presented in Mora et al. (2021b). However, alternative structure-preserving discretisation methods based on a variational formulation, such as partitioned finite elements (Cardoso-Ribeiro et al., 2018; Brugnoli et al., 2020), could also be employed. Specifically, the cross-section area of the fluid domain may be discretised using methods other than piecewise constant approximations. Our intuition is that a smooth laryngeal profile is expected to improve the behaviour of the discrete fluid model during channel closure and may alleviate the need for the regularisation procedure introduced in Section 2.4.2.
A first necessary step to apply these more involved discretisation methods is to include distributed losses directly in the continuous fluid model. In the larynx, viscous friction terms can be derived from a non-homogeneous axial velocity profile on cross-sections, modelled using a boundary layer approach. This is incompatible with the homogeneity assumption (H8) on
4.2.2 Vocal fold model refinements
The vocal fold model we use is the body-cover model from Story and Titze (1994). Numerous lumped-element vocal fold models, often based on mass-spring assemblies, have been developed over the years (see Erath et al., 2013 for a review). Most of these models are straightforward to implement within the port-Hamiltonian framework and could be used with the fluid model presented here without major difficulty. The proposed framework also allows for the consideration of asymmetric vocal folds, which could be useful for studying pathological configurations (Xue et al., 2010).
Following the earlier discussion around the fluid equations, the use of “aerodynamically smooth” vocal fold models seems particularly promising. However, one of the main challenges of these lumped-element models is the identification of accurate physical parameters. Modal representations derived from the reduction of complex finite element models, as presented in Yokota et al. (2021), may help improve this.
4.2.3 Control issues
Controlling vocal fold parameters based on muscle activations is crucial for achieving realistic pitch modulation and natural vibrato mechanisms in sound synthesis. Integrating control rules, such as those proposed in Titze and Story (2002), into the current framework while maintaining the preservation of energetic properties also represents a promising avenue for future development.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
TR: Conceptualization, Formal Analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review and editing, Data curation. TH: Conceptualization, Funding acquisition, Methodology, Supervision, Writing – original draft, Writing – review and editing, Formal Analysis, Investigation. FS: Conceptualization, Methodology, Supervision, Writing – original draft, Writing – review and editing, Formal Analysis, Investigation, Visualization.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This research was funded, in whole or in part, by l’Agence Nationale de la Recherche (ANR), project AVATARS (ANR-22-CE48-0014).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frsip.2025.1525198/full#supplementary-material
Footnotes
1See Mora et al. (2021a) for port-Hamiltonian formulations of general 3D fluid mechanics
2(H6) directly provides an instantaneous relationship between
3Consider the fluid at rest state—
4As a hemilarynx is considered
5With the chosen convention, the exchanged power is the power received by the source, meaning that negative values imply a positive power transfer from the source to the system
References
Alipour, F., Berry, D. A., and Titze, I. R. (2000). A finite-element model of vocal-fold vibration. J. Acoust. Soc. Am. 108, 3003–3012. doi:10.1121/1.1324678
Alipour, F., and Scherer, R. C. (2007). On pressure-frequency relations in the excised larynx. J. Acoust. Soc. Am. 122, 2296–2305. doi:10.1121/1.2772230
Bilbao, S., Webb, C., Wang, Z., and Ducceschi, M. (2023). “Real-time gong synthesis,” in Proceedings of the 26th Conference of Digital audio effects (DAFx-23) (Copenhagen, Denmark).
Birkholz, P., Hasner, P., and Kurbis, S. (2022). “Acoustic comparison of physical vocal tract models with hard and soft walls,” in IEEE international conference on acoustics, speech and signal processing (ICASSP 2022) (IEEE), 8242–8246. doi:10.1109/ICASSP43922.2022.9746611
Brugnoli, A., Cardoso-Ribeiro, F. L., Haine, G., and Kotyczka, P. (2020). Partitioned finite element method for structured discretization with mixed boundary conditions. IFAC-PapersOnLine 53, 7557–7562. doi:10.1016/j.ifacol.2020.12.1351
Cardoso-Ribeiro, F. L., Matignon, D., and Lefèvre, L. (2018). A structure-preserving partitioned finite element method for the 2D wave equation. IFAC-PapersOnLine 51, 119–124. doi:10.1016/j.ifacol.2018.06.033
Castera, G., and Chabassier, J. (2023). Numerical analysis of quadratized schemes. Application to the simulation of the nonlinear piano string. Tech. Rep. RR-9516. Inria.
Doval, B., d’Alessandro, C., and Henrich Bernardoni, N. (2006). The spectrum of glottal flow models. Acta Acustica united Acustica 92, 1026–1046.
Ducceschi, M., Hamilton, M., and Russo, R. (2023). “Simulation of the snare-membrane collision in modal form using the scalar auxiliary variable (SAV) method,” in Proceedings of the forum acusticum 2023. doi:10.61782/fa.2023.0995
Encina, M., Yuz, J., Zanartu, M., and Galindo, G. (2015). “Vocal fold modeling through the port-Hamiltonian systems approach,” in 2015 IEEE conference on control applications (CCA) (Sydney, Australia: IEEE), 1558–1563. doi:10.1109/CCA.2015.7320832
Erath, B. D., Zañartu, M., Stewart, K. C., Plesniak, M. W., Sommer, D. E., and Peterson, S. D. (2013). A review of lumped-element models of voiced speech. Speech Commun. 55, 667–690. doi:10.1016/j.specom.2013.02.002
Flanagan, J. L. (1965). Speech analysis synthesis and perception. Berlin, Heidelberg: Springer Berlin Heidelberg. doi:10.1007/978-3-662-00849-2
Fleischer, M., Pinkert, S., Mattheus, W., Mainka, A., and Mürbe, D. (2015). Formant frequencies and bandwidths of the vocal tract transfer function are affected by the mechanical impedance of the vocal tract wall. Biomechanics Model. Mechanobiol. 14, 719–733. doi:10.1007/s10237-014-0632-2
Guasch, O., Ternstrom, S., Arnela, M., and Alıas, F. (2013). Unified numerical simulation of the physics of voice: The EUNISON project. The International Society for Computers and Their Applications (ISCA).
Gunter, H. E. (2003). A mechanical model of vocal-fold collision with high spatial and temporal resolution. J. Acoust. Soc. Am. 113, 994–1000. doi:10.1121/1.1534100
Hélie, T., and Silva, F. (2017). “Self-oscillations of a vocal apparatus: a port-Hamiltonian formulation,” in Proceedings of geometric science of information: third international conference (GSI 2017). Editors F. Nielsen,, and F. Barbaresco (Paris, France: Springer International Publishing), 375–383.
Ishizaka, K., and Flanagan, J. L. (1972). Synthesis of voiced sounds from a two-mass model of the vocal cords. Bell Syst. Tech. J. 51, 1233–1268. doi:10.1002/j.1538-7305.1972.tb02651.x
Kelly, J. L. (1962). “Speech synthesis,” in Proc. Speech communication seminar. Stockholm (Sep. 1962.
Maeda, S. (1982). A digital simulation method of the vocal-tract system. Speech Commun. 1, 199–229. doi:10.1016/0167-6393(82)90017-6
Maschke, B., and van der Schaft, A. (1992). Port-controlled Hamiltonian systems: modelling origins and systemtheoretic properties. IFAC Proc. Vol. 25, 359–365. doi:10.1016/S1474-6670(17)52308-3
Mora, L. A., Le Gorrec, Y., Matignon, D., Ramirez, H., and Yuz, J. I. (2021a). On port-Hamiltonian formulations of 3-dimensional compressible Newtonian fluids. Phys. Fluids 33, 117117. doi:10.1063/5.0067784
Mora, L. A., Ramirez, H., Yuz, J. I., Le Gorec, Y., and Zañartu, M. (2021b). Energy-based fluid–structure model of the vocal folds. IMA J. Math. Control Inf. 38, 466–492. doi:10.1093/imamci/dnaa031
Mora, L. A., Yuz, J. I., Ramirez, H., and Gorrec, Y. L. (2018). A port-Hamiltonian fluid-structure interaction model for the vocal folds this work was supported by CONICYT-PFCHA/2017-21170472, and AC3E CONICYT-basal project FB-0008. IFAC-PapersOnLine 51, 62–67. doi:10.1016/j.ifacol.2018.06.016
Müller, R. (2021). Time-continuous power-balanced simulation of nonlinear audio circuits: realtime processing framework and aliasing rejection. Sorbonne Université: Ph.D. thesis.
Olver, P. J. (1986). Applications of lie groups to differential equations, 107. New York, NY: Graduate Texts in Mathematics. doi:10.1007/978-1-4684-0274-2
Pelorson, X., Hirschberg, A., Van Hassel, R. R., Wijnands, A. P. J., and Auregan, Y. (1994). Theoretical and experimental study of quasisteady-flow separation within the glottis during phonation. Application to a modified two-mass model. J. Acoust. Soc. Am. 96, 3416–3431. doi:10.1121/1.411449
Risse, T., Hélie, T., Silva, F., and Falaize, A. (2024). Minimal port-Hamiltonian modeling of voice production: choices of fluid flow hypotheses, resulting structure and comparison. IFAC-PapersOnLine 58, 238–243. doi:10.1016/j.ifacol.2024.08.287
Russo, R., Bilbao, S., and Ducceschi, M. (2024). Scalar auxiliary variable techniques for nonlinear transverse string vibration. IFAC-PapersOnLine 58, 160–165. doi:10.1016/j.ifacol.2024.08.274
Ruty, N., Pelorson, X., Van Hirtum, A., Lopez-Arteaga, I., and Hirschberg, A. (2007). An in vitro setup to test the relevance and the accuracy of low-order vocal folds models. J. Acoust. Soc. Am. 121, 479–490. doi:10.1121/1.2384846
Shen, J., Xu, J., and Yang, J. (2018). The scalar auxiliary variable (SAV) approach for gradient flows. J. Comput. Phys. 353, 407–416. doi:10.1016/j.jcp.2017.10.021
Stevens, K. N. (1971). Airflow and turbulence noise for fricative and stop consonants: static considerations. J. Acoust. Soc. Am. 50, 1180–1192. doi:10.1121/1.1912751
Story, B. H., and Titze, I. R. (1994). Voice simulation with a body-cover model of the vocal folds. J. Acoust. Soc. Am. 97, 1249–1260. doi:10.1121/1.412234
Story, B. H., Titze, I. R., and Hoffman, E. A. (1996). Vocal tract area functions from magnetic resonance imaging. J. Acoust. Soc. Am. 100, 537–554. doi:10.1121/1.415960
Titze, I. R., and Story, B. H. (2002). Rules for controlling low-dimensional vocal fold models with muscle activation. J. Acoust. Soc. Am. 112, 1064–1076. doi:10.1121/1.1496080
Trenchant, V., Ramirez, H., Le Gorrec, Y., and Kotyczka, P. (2018). Finite differences on staggered grids preserving the port-Hamiltonian structure with application to an acoustic duct. J. Comput. Phys. 373, 673–697. doi:10.1016/j.jcp.2018.06.051
Valášek, J. (2021). Numerical simulation of fluid-structure-acoustic interaction in human phonation. Czech Technical University. Ph.D. thesis.
Wetzel, V. (2021). Lumped power-balanced modelling and simulation of the vocal apparatus: a fluid-structure interaction approach. Sorbonne Université: Ph.D. thesis.
Xue, Q., Mittal, R., Zheng, X., and Bielamowicz, S. (2010). A computational study of the effect of vocal-fold asymmetry on phonation. J. Acoust. Soc. Am. 128, 818–827. doi:10.1121/1.3458839
Yokota, K., Ishikawa, S., Takezaki, K., Koba, Y., and Kijimoto, S. (2021). Numerical analysis and physical consideration of vocal fold vibration by modal analysis. J. Sound Vib. 514, 116442. doi:10.1016/j.jsv.2021.116442
Keywords: voice, fluid–structural interaction, physical modelling, audio synthesis, port-Hamiltonian systems
Citation: Risse T, Hélie T and Silva F (2025) Voice synthesis using power-balanced simulation of a quasi-1D model of the vocal apparatus. Front. Signal Process. 5:1525198. doi: 10.3389/frsip.2025.1525198
Received: 08 November 2024; Accepted: 24 April 2025;
Published: 10 July 2025.
Edited by:
Farook Sattar, University of Victoria, CanadaReviewed by:
Robert Nickel, Bucknell University, United StatesMartin Berggren, Umeå University, Sweden
Eldad Tsabary, Concordia University, Canada
Copyright © 2025 Risse, Hélie and Silva. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Thomas Risse, dGhvbWFzLnJpc3NlQGlyY2FtLmZy