 Najmeh Nakhaei Rad1,2,3
Najmeh Nakhaei Rad1,2,3 Andriette Bekker
Andriette Bekker Mohammad Arashi
Mohammad Arashi Christophe Ley
Christophe Ley- 1Department of Mathematics and Statistics, Mashhad Branch, Islamic Azad University, Mashhad, Iran
- 2DSI-NRF Centre of Excellence in Mathematical and Statistical Sciences (CoE-MaSS), Johannesburg, South Africa
- 3Department of Statistics, University of Pretoria, Pretoria, South Africa
- 4Department of Statistics, Faculty of Mathematical Sciences, Ferdowsi University of Mashhad, Mashhad, Iran
- 5Department of Applied Mathematics, Computer Science and Statistics, Ghent University, Ghent, Belgium
This paper presents Bayesian directional data modeling via the skew-rotationally-symmetric Fisher-von Mises-Langevin (FvML) distribution. The prior distributions for the parameters are a pivotal building block in Bayesian analysis, therefore, the impact of the proposed priors will be quantified using the Wasserstein Impact Measure (WIM) to guide the practitioner in the implementation process. For the computation of the posterior, modifications of Gibbs and slice samplings are applied for generating samples. We demonstrate the applicability of our contribution via synthetic and real data analyses. Our investigation paves the way for Bayesian analysis of skew circular and spherical data.
1. Introduction
Big and complex data sets are collected from various scientific fields such as atmospheric environment, social science, psychological and biomedical studies, bioinformatics, epidemiology, digital imaging information, and machine learning, to name just a few. Big Data can refer to data with big volume or velocity, high-dimensional data (Ahmed, 2017), unstructured or unusual data (Härdle et al., 2018), complex data, etc. Therefore, there is a need for developing statistical techniques other than the traditional analytical frameworks to model, interpret, and use such data in different fields of science. Data with directions are categorized as unusual data that cannot be analyzed and modeled under the Cartesian coordinate system. With the aid of directional statistics, data science meets another level of analytical methods. In this research work, we focus on the analysis of complex directional data. Bayesian methods have received extensive attention in data science because prior information can be added to enhance modeling. Therefore, here, we consider Bayesian analysis of complex directional data.
A robust roadmap with the symmetric Fisher-von Mises-Langevin (FvML) distribution as the key element from a Bayesian perspective is briefly reviewed. According to Kikuchi's collection of directional data (Kikuchi, 1982), the first attention paid to Bayesian methods for directional data was in a paper by Mardia and El-Atoum (1976). They used the Bayesian approach to estimate the location parameter of the FvML distribution when the concentration parameter was known. The author Bagchi made several contributions in this area: (i) Bagchi (1988) formulated a conjugate prior for the mean direction and a non-informative prior for the concentration parameter of the von Mises distribution; (ii) Bagchi and Guttman (1988) focused on Bayesian inference for the multi-variate FvML distribution; (iii) Bagchi and Kadane (1991) derived the Bayes estimate for the cosine of the direction parameter of the von Mises distribution when the concentration parameter is known; and (iv) Bagchi (1994) developed empirical Bayesian techniques to estimate the mean direction of the FvML distribution (see also Guttorp and Lockhart, 1988; Dowe et al., 1996). Damien and Walker (1999) presented a full Bayesian inference for the von Mises distribution implementing a Gibbs sampler while (Rodrigues et al., 2000) provided an empirical or approximate Bayesian inference for the von Mises distribution. Nuñez-Antonio and Gutiérrez-Peña (2005) presented Bayesian analysis of the FvML distribution when all of the parameters were unknown, as well as an algorithm to generate samples from the posterior distribution based on a sampling-importance-resampling method. Muralidharan and Parikh (2007) provided Bayes estimates for both location and concentration parameters of the von Mises distribution. Bhattacharya and SenGupta (2009) presented Bayesian analysis of a generalized von Mises distribution introducing a new algorithm based on importance sampling and Markov chain Monte Carlo (MCMC) to draw samples from the posterior distribution. Mardia (2010) moved the attention to the bivariate von Mises distribution (on the torus) from a Bayesian viewpoint. Infinite mixtures of FvML distributions using standard conjugate priors for the parameters and Dirichlet priors for the mixing probabilities received attention from Bangert et al. (2010). Hornik and Grün (2013) defined conjugate and Jeffreys priors for the FvML distribution while Taghia et al. (2014) worked on Bayesian inference for the FvML mixture model. From 2017 and onwards the following contributions can be highlighted: Straub (2017) presented Bayesian analysis for the FvML distribution in 3D; Røge et al. (2017) presented Bayesian inference in the case of infinite FvML mixture model assumption; Mulder et al. (2020) provided Bayesian inference for mixtures of von Mises distributions using a reversible jump MCMC sampler and focused on non-informative priors. Lastly, the interested reader is referred to Pewsey and García-Portugués (2021) for Bayesian inference of other directional distributions.
Numerous directional data sets tend to show non-trivial features such as skewness. Therefore, the underlying distribution is not always symmetric, which emphasizes the focus on skewed directional distributions. This inspired us to investigate Bayesian analysis for the general class of skew-rotationally-symmetric distributions (Ley and Verdebout, 2017b), an asymmetric extension of all rotationally symmetric distributions, when the location, concentration, and skewness parameters are unknown.
In section 2, the skew-rotationally-symmetric distribution and special cases are described. The novel contribution is given in section 3 where the posterior distributions are obtained for the skew-FvML as the likelihood model, for four different scenarios of the prior distributions for the parameters of the model. Moreover, an algorithm is provided for generating samples from these posterior distributions. The impact of the priors is explored in section 4, by implementing the Wasserstein Impact Measure (WIM). In section 5, a synthetic data analysis is conducted to show the accuracy of the Bayes estimates based on the assumptions of the skew-FvML model. We demonstrate the applicability of the Bayesian framework for well known real datasets in section 6 for dimensions p = 2 and 3.
2. Skew-Rotationally-Symmetric Distributions
Most of the distributions on the unit hypersphere 𝕊p−1 = {v ∈ ℝp : v⊤v = 1}, p ⩾ 2, share the common feature of being rotationally-symmetric about their location μ ∈ 𝕊p−1. The distribution of a random variable X ∈ 𝕊p−1 is said to be rotationally-symmetric about μ if for any orthogonal matrix Op×p satisfying Oμ = μ it is concluded that OX is equal in distribution to X. The FvML distribution, the most common distribution in spherical studies, is obtained by conditioning on the p-variate normal distribution (see Mardia and Jupp, 2000; Ley and Verdebout, 2017a). Suppose X takes values on the non-linear manifold 𝕊p−1 and has the FvML distribution, then its probability density function (pdf) is given by
where
τ ⩾ 0 is the concentration parameter, and Iα is the modified Bessel function of order α. For τ = 0, (1) simplifies to the uniform distribution. If p = 2 in (1), it results in the von Mises distribution and when p = 3, the Fisher distribution (Fisher, 1953) is obtained.
However, in practice, all real-life phenomena cannot be represented by symmetric models. The interested reader is referred to Downs (2003) for medical research of heart disease diagnosis, Leong and Carlile (1998) for application in neurosciences, Shearman et al. (2000) for biological research on mammalian circadian rhythms, Mardia (2013) and Ameijeiras-Alonso and Ley (2020) for application in bioinformatics especially protein structure prediction, Fisher and Lee (1994) for some studies on wind direction, Ameijeiras-Alonso et al. (2021) for biomechanics studies, and Pewsey (2002) and Ley and Verdebout (2014) for animal movement studies.
Therefore, in this paper, the focus will be on the skew-rotationally-symmetric (SRS) distributions, introduced by Ley and Verdebout (2017b) as
where f(x⊤μ) is a rotationally-symmetric pdf about μ ∈ 𝕊p−1, Π : ℝ → [0, 1] is a monotone increasing function satisfying Π(−t) + Π(t) = 1 for all t ∈ ℝ, and represents the semi-orthogonal matrix such that and , where Ip is the p × p identity matrix. The parameter γ ∈ ℝp−1 is a skewness parameter vector such that γ = 0 provides the symmetric pdf f(x⊤μ) and non-zero values of γ provide skewed pdfs. This construction allows using the full potential of existing rotationally-symmetric distributions by turning them into skewed versions.
Substituting (1) in (3) and letting with Uμ(x) the sign vector which is uniformly distributed on 𝕊p−2, the skew-FvML (SFvML) distribution is obtained as
where C(τ) is defined in (2).
By using the standard cosine transformation
and choosing in (4), for p = 2, the skew-von Mises (SvM) distribution follows as
where θ, μ ∈ (−π, π], τ > 0 and γ ∈ ℝ. Here, the scalar product x⊤μ is cos(θ − μ). By choosing , x ∈ [−1, 1], in (6), the sine-skewed von Mises distribution introduced by Abe and Pewsey (2011) is obtained where γ ∈ [−1, 1].
The following lemma can be used to generate a sample from the SFvML distribution.
LEMMA 1. (Ley and Verdebout, 2017b) Generate Y from the rotationally-symmetric FvML distribution in (1). Then for any uniformly distributed sign vector Uμ(Y), Uμ; Π(Y) is defined as
where U is uniformly distributed on (0, 1) and independent of Y. Then the vector X with pdf (4) is obtained as
In the next section, Bayesian inference with the SFvML distribution as the key element is presented with all location, concentration, and skewness parameters μ, τ, and γ unknown.
3. Methodology
Let X = (X1, X2, ..., Xn) be a random sample of size n with pdf (4) where the standard normal cumulative density function (cdf) Φ replaces Π. The likelihood function is
Subsequently, four scenarios are presented to define the prior distributions for the location parameter μ, the concentration parameter τ, and the skewness parameter γ.
3.1. Prior Distributions
As above, let X denote a set of observations, and a generative model of the data be defined through a set of unknown parameters Ω = (μ, γ, τ) (see (7)). In this section the prior distributions for Ω = (μ, γ, τ) are outlined.
For the skewness vector γ the following prior distributions are proposed: (i) the multi-variate normal distribution with location parameter ξ and covariance matrix diag(σ), (ii) the multi-variate skew-normal distribution (Azzalini, 1985) with location parameter ξ, covariance matrix diag(σ) and skewness parameter λ, i.e.,
and
where , ξi ∈ ℝ, σi > 0, λi ∈ ℝ, ϕ is the standard normal pdf, ϕn and Φn are the pdf and cdf of the n-variate standard normal distribution, respectively. Next, the following priors for μ and τ are considered.
Case 1: Nuñśez-Antonio and Gutiérrez-Peñśa's Prior
In this case, we adopt the joint prior distribution of Nuñez-Antonio and Gutiérrez-Peña (2005) with direction parameter μ0, concentration parameters ζ and η for (μ, τ), i.e.,
where and 0 < η < ζ. The normalization constant can only be obtained for some special cases. Straub (2017) computed the normalization constant of (10) for ζ = 1 and p = 3.
Case 2: FvML and Gamma Prior
In this case, the FvML and gamma distributions with parameters μ0, τ0, α, and β are proposed as priors for (μ, τ) (Muralidharan and Parikh, 2007), i.e.,
where τ0, α, β > 0 and μ0 ∈ [−π, π).
3.2. Posterior Distributions
Subsequently, the posterior distribution π(Ω ∣ X) ∝ π(Ω)L(Ω ∣ X) is determined for the different prior assumptions on Ω = (μ, γ, τ). Firstly, assume the prior distribution set up as described under case 1 and different prior distributions for the skewness parameter.
Scenario 1
Assume the prior distribution of the skewness parameter, γ is given by (8), then for given X the posterior distribution of (μ, γ, τ) can be obtained by using (7), (8), and (10) as
The full conditionals for μ, γ, and τ are, respectively:
Scenario 2
If we assume the prior distribution (9) for γ, the posterior distribution of (μ, γ, τ) can be obtained by using (7), (9), and (10) as follows
The full conditionals for μ, γ, and τ are, respectively:
Scenario 3
If the prior distribution of the skewness parameter γ is given by (8), for given X, the posterior distribution of (μ, γ, τ), by using (7), (8), and (11), is
The full conditionals for μ, γ, and τ are, respectively:
Scenario 4
When the prior distribution of γ is the skew-normal distribution in (9), the posterior distribution of (μ, γ, τ) by using (7), (9), and (11) is
The full conditionals for μ, γ, and τ are, respectively:
3.3. Sampling From the Posterior Distributions
A general algorithm is presented to obtain the Bayes estimates of the parameters Ω = (μ, γ, τ) based on the modified sampling-resampling method (Smith and Gelfand, 1992) and modified Gibbs sampling.
After a sufficient burn-in period, the generated sample ((μ1, γ1, τ1), (μ2, γ2, τ2), ..., (μN, γN, τN)) is approximately distributed according to the posterior distribution of Ω = (μ, γ, τ). As can be seen in Algorithm 1, it is sufficient to generate samples of size k from prior distributions of (μ, γ, τ) which is one of the advantages of this algorithm. By increasing N and k in Algorithm 1 the approximation increases. When the joint prior distributions are not independent, Algorithm 1 still has a good performance (Muralidharan and Parikh, 2007). For the joint prior of (μ, τ) in (10), the slice sampler can be used (see McElreath, 2020).

Algorithm 1: Steps to generate samples from the posteriors by using priors and full conditionals.
4. The Wasserstein Impact Measure
The prior distributions are a crucial part in Bayesian analysis. If the sample size is small, or available data provide only indirect information about the parameters of interest, the prior distribution becomes more important (Carlin and Louis, 2008). Different criteria can be used for prior selection, we refer the reader to Vehtari et al. (2017). Ghaderinezhad et al. (2022) implemented the Wasserstein Impact Measure (WIM) as a measure of the impact of the choice of the prior in a Bayesian approach. In fact it is a convenient way for quantifying prior impact which will help us to choose between two or more priors in a given situation. Suppose Ω is the vector of parameters and F1(.) and F2(.) are two cumulative distribution functions (cdfs) of two posterior distributions π1(Ω|.) and π2(Ω|.). The Wasserstein distance between these two posteriors related to two different prior sets is obtained as follows:
with DΩ the domain of all possible values of Ω. The Wasserstein distance between two posteriors indicates, at any finite sample size n, how close the posterior distributions are and how similar the related inference will be. This is particularly interesting when considering a simple vs. a complicated, computationally intense prior; if the WIM between them is small, then one can safely use the simpler version. When n → ∞ the distance tends to 0.
In this section, a simulation study is conducted to compare the different sets of proposed priors in section 3 for p = 2 using this measure. Since the cdfs of the posteriors in (12)–(15) are not computable, Algorithm 1 and Monte Carlo integration are used to obtain the Wasserstein distance. Also, the transport package (Schuhmacher et al., 2020) in the R software offers functions for computing the Wasserstein distance between two sets of samples from different distributions. Most of the functions in this package have been designed for data with two or higher dimensions. For various combinations of the parameters we draw 200 random observations from the SvM in (6).
To compare the impact of the normal distribution and skew-normal distribution in (8) and (9) (for p = 2) as priors for the skewness parameter γ, the following steps were performed:
(1) μ and τ were considered as known parameters.
(2) For the unknown skewness parameter γ, the N(0, 5) and SN(0, 5, λ) with λ = −3, −2, −1, 1, 2, 3 were considered as priors.
(3) For a generated sample from (6) (the skewing function is the standard normal cdf), with μ = 3, τ = 1 and γ = 5, the posteriors π1(γ|.) and π2(γ|.) emanating from N(0, 5) and SN(0, 5, λ), respectively, were considered.
(4) The posteriors π1(γ|.) and π2(γ|.) were sampled using Algorithm 1, for n = 10, 15, 20, 25, 30, 35, 40, 50, 100.
(5) The Wasserstein distance between the posteriors π1(γ|.) and π2(γ|.) was estimated, using the transport package and Monte Carlo method with 1, 000 repetitions.
Figure 1 (top) shows the calculated Wasserstein distance for different values of λ and n. As expected,
• when λ is close to 0, there are no nearly differences between the posteriors π1(Ω|.) and π2(Ω|.) for different values of n.
• by increasing n, the Wasserstein distance decreases. Hence, for large values of n the difference between the posteriors is minimal.
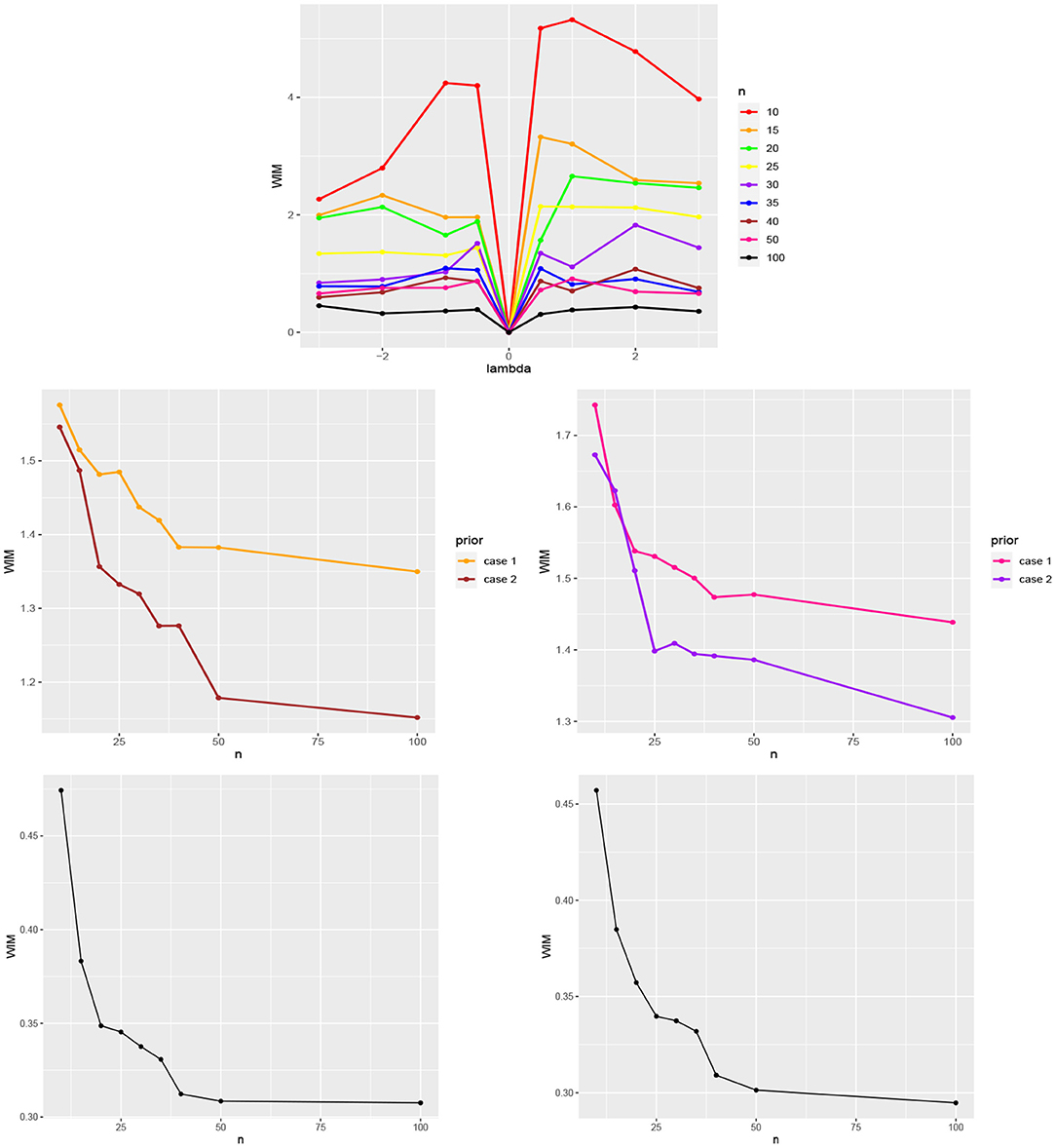
Figure 1. (Top) WIM values for comparing the normal and skew-normal distributions as priors for the skewness parameter γ for different values of λ and n. (Middle) the Wasserstein distance between the posteriors π1 and π2 (case 1) and also π1 and π3 (case 2) for μ = 2, τ = 1, γ = −1 (left) and μ = 3, τ = 0.6, γ = 1 (right) and different values of n. (Bottom) the Wasserstein distance between the posteriors π2 and π3 for μ = 2, τ = 1, γ = −1 (left) and μ = 3, τ = 0.6, γ = 1 (right) and different values of n.
To illustrate the impact of the prior selection for μ and τ the following approach was followed. Assume the normal distribution as the prior for the skewness parameter γ. The posteriors π2(Ω|.) and π3(Ω|.), emanating from the informative priors (10) (case 1) and (11) (case 2) were compared with the posterior resulting from the non-informative prior μ ~ Uniform(0, 2π) and π(τ) ∝ 1, denoted by π1(Ω|.). The posteriors were sampled using Algorithm 1 for n = 10, 15, 20, 25, 30, 35, 40, 50, 100. The Wasserstein distances were calculated between them with the transport package and Monte Carlo method with 1, 000 repetitions.
Figure 1 (middle) illustrates the obtained Wasserstein distance between the posteriors π1(Ω|.) and π2(Ω|.) (case 1) and between π1(Ω|.) and π3(Ω|.) (case 2) for μ = 2, τ = 1, γ = −1 (left) and μ = 3, τ = 0.6, γ = 1 (right). Figure 1 (bottom) shows the Wasserstein distance between the posteriors π2(Ω|.) and π3(Ω|.) for μ = 2, τ = 1, γ = −1 (left) and μ = 3, τ = 0.6, γ = 1 (right), respectively. From Figure 1 (middle and bottom) the following observations can be obtained:
• The impact of the informative priors (10) (case 1) and (11) (case 2) for μ and τ is clearly visible in comparison with the assumed non-informative priors.
• Comparatively, the posterior resulting from prior (11) (case 2) is closer to the non-informative priors.
• By increasing n, the posteriors resulting from the informative priors (10) (case 1) and (11) (case 2) tend to the case of non-informative priors.
• There is less difference between the informative priors (10) (case 1) and (11) (case 2), than with respect to the non-informative priors.
• By increasing n, the posteriors resulting from the informative priors (10) (case 1) and (11) (case 2) approach each other.
We can thus conclude that from moderate sample sizes on, both priors for all three parameters are rather similar (hence one could use the less computationally intense of both priors), but differ clearly from a non-informative one. In order to judge how large the obtained WIM values actually are, bootstrap re-sampling could be done with the original data; we leave this for future research. Our analysis here is also limited to the chosen parameter values; more simulations need to be done to get a complete picture.
A similar analysis can be performed for p = 3.
5. Synthetic Data Analysis
In this section, to assess the performance of the Bayesian approach for obtaining the estimates of Ω = (μ, τ, γ), a synthetic data analysis was conducted to obtain the Bayes estimates of the parameters of the SvM distribution (6). We generated samples of size N = 20, 50, 100, 500 from the posterior distributions (12)-(15) (scenarios 1–4) with a burn-in period of 5,000 and k = 500, using Algorithm 1 (the values of these parameters are written down in the respective tables). It is noteworthy that steps 2–7 in Algorithm 1 are combined for scenarios 1 and 2. Bayes estimates of the parameters μ, τ and γ were obtained under the squared error, absolute error and zero-one loss functions by calculating mean, median, and mode of the generated samples, respectively.
The results for p = 2 and p = 3 including the sample mean, standard deviation, quartiles, and mode of the posterior distribution are summarized in Table 1 for each of the scenarios. As can be seen in Table 1 the obtained Bayes estimates are close to the actual values of the parameters. In addition, for small sample sizes our proposed Bayesian approach still provides accurate estimates.
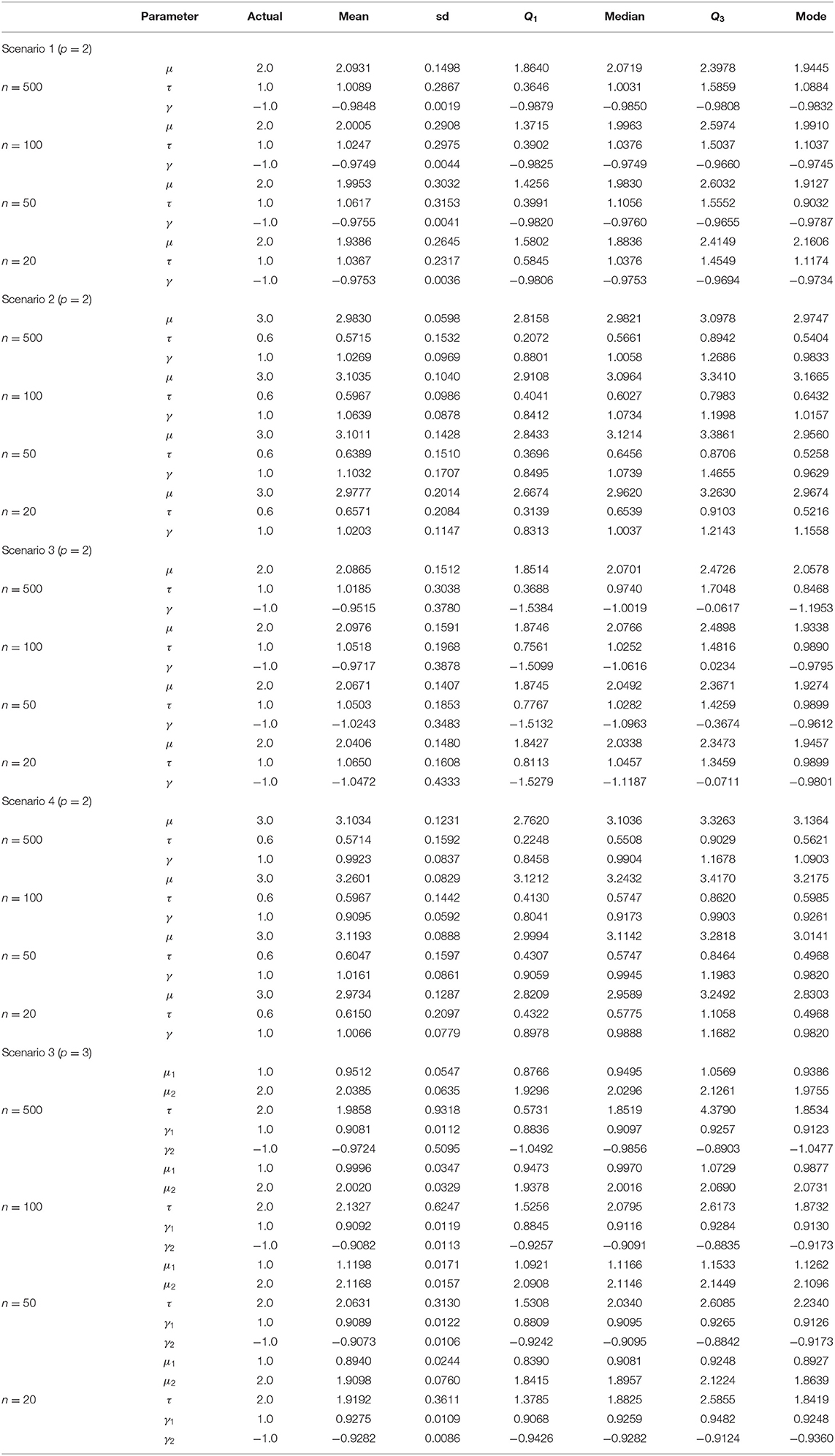
Table 1. Bayes estimates of parameters for p = 2 based on scenario 1 with prior parameters μ0 = 1, τ0 = 9, α = 0.5, β = 5, ξ = −4, σ = 1, scenario 2 with prior parameters μ0 = 1, ζ = 10, η = 0.5, ξ = 0.5, σ = 0.5, λ = −1, scenario 3 with prior parameters μ0 = 1, τ0 = 9, α = 0.5, β = 5, ξ = −4, σ = 1, and scenario 4 with prior parameters μ0 = 0.5, τ0 = 0.01, α = 0.5, β = 9, ξ = 0.5, σ = 0.5, λ = −2 and for p = 3 based on scenario 3 with prior parameters μ01 = 1, τ01 = 5, μ02 = 2, τ02 = 9, α = 12, β = 2, ξ1 = 1, σ1 = 2, ξ1 = −2, and σ1 = 2.
The traceplots of the generated samples from the posteriors, the compare-partial plots and the running mean plots are shown in Figure 2 (p = 2) and Figure 3 (p = 3) for each of the scenarios and p = 2 and 3 using the ggmcmc package in R (Fernández-i-Marın, 2016). A traceplot is an essential plot for evaluating convergence and diagnosing chain problems. It shows the time series of the sampling process and the expected outcome is to get a traceplot that looks completely random. A compare-partial plot provides overlapped kernel density plots that compare the last part of the chain (the last 10% of the values, in green) with the whole chain (in black). Ideally, the initial and final parts of the chain have to be sampling in the same target distribution, so the overlapped densities should be similar. In addition to the traceplots, the running mean plot of the chains is very useful to find within-chain convergence issues. A time series of the running mean of the chain allows to check whether the chain is slowly or quickly approaching its target distribution. The expected output is a line that quickly approaches the overall mean. Figures 2, 3 confirm the convergence of the chains and show that the modified Gibbs sampler recovers the values that actually come from the target posterior distributions.
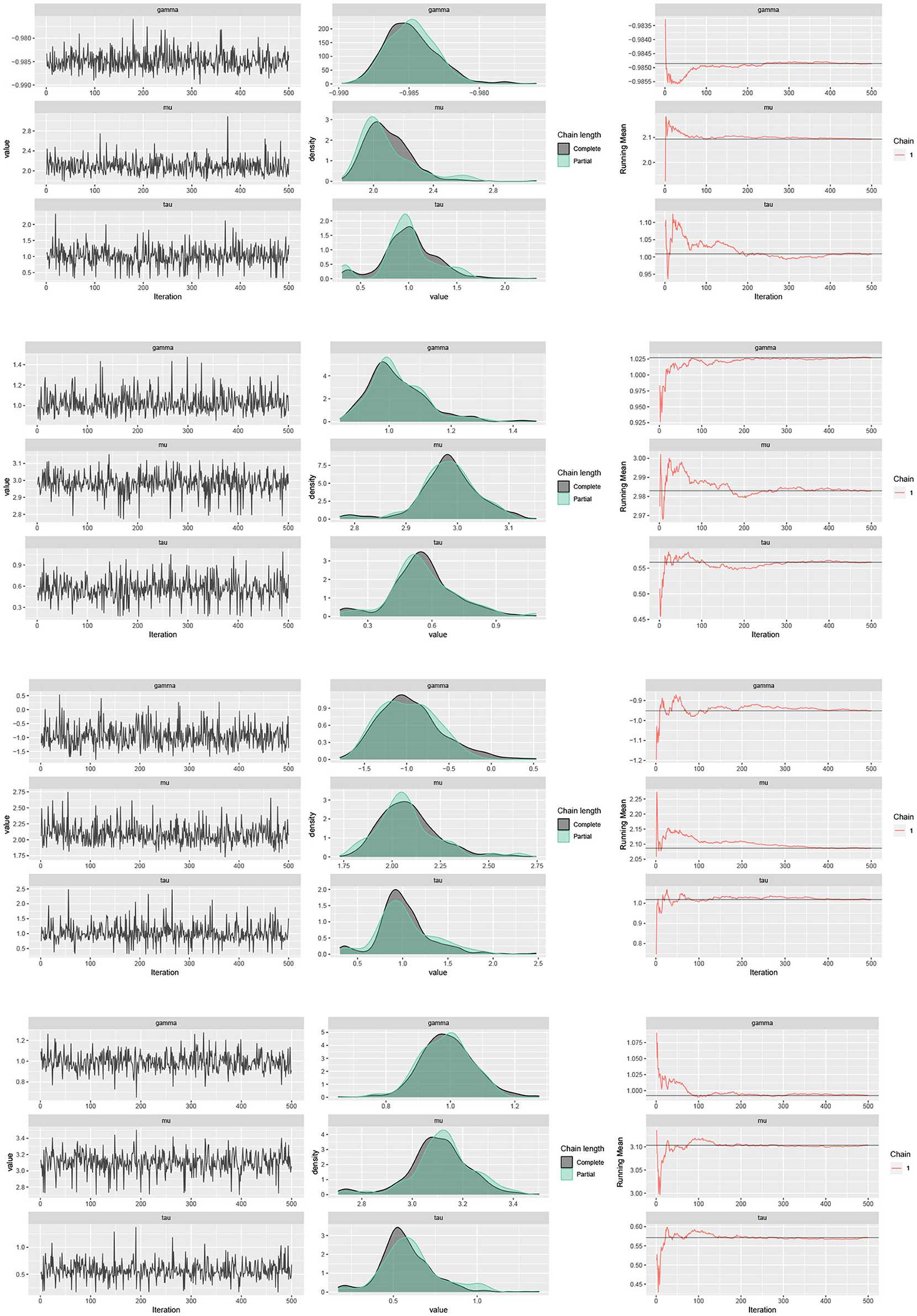
Figure 2. Traceplots, mean running and estimated posterior pdf plots of generated samples for (μ, τ, γ) in Table 1 for p = 2, n = 500 and scenario 1 (first row), scenario 2 (second row), scenario 3 (third row), and scenario 4 (fourth row).
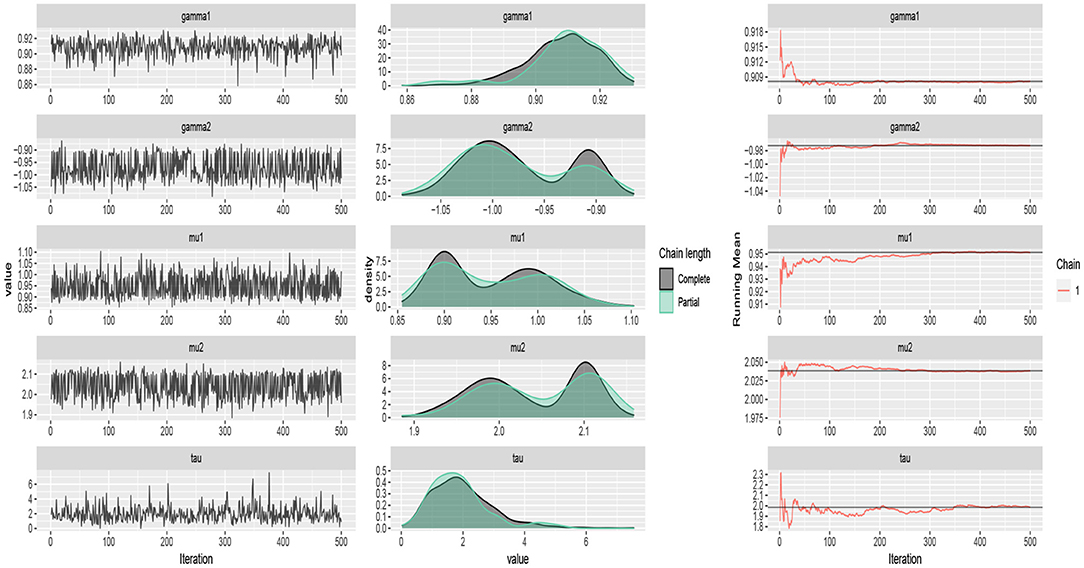
Figure 3. Traceplots, mean running and estimated posterior pdf plots of generated samples for (μ1, μ2, τ, γ1, γ2) in Table 1 for p = 3 and n = 500.
Running multiple independent chains in parallel is necessary to access the representativeness of the chains. If the multiple chains are not well mixed, the convergence of the chains is suspected (Kruschke, 2014; Vehtari et al., 2021). Therefore, four independent chains were run in parallel for scenario 3 (p = 2) in Table 1 to make the inference more robust and reliable. The results are shown in Figure 4 which confirm the convergency.
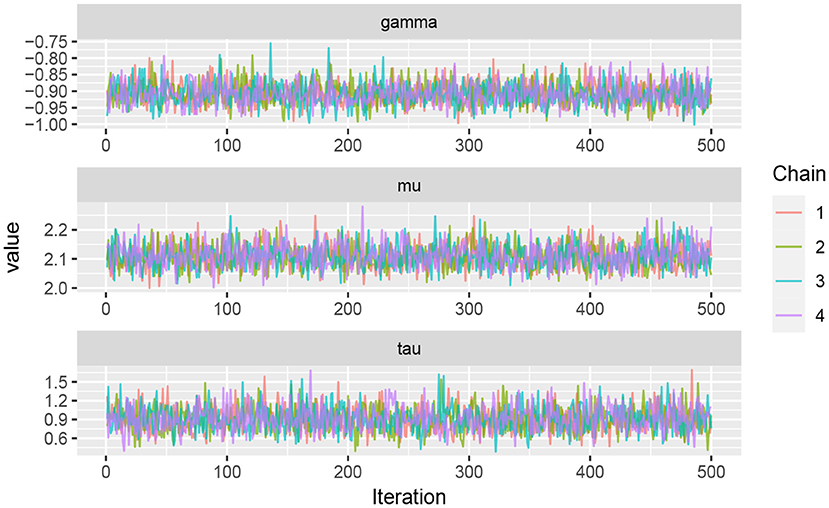
Figure 4. Traceplots of generated samples of size n = 500 from four parallel chains for (μ, τ, γ) based on scenario 3 (p = 2) in Table 1.
To compare the efficiency of Bayes estimates with respect to the maximum likelihood estimations (MLE), the mean squared errors (MSE) of MLEs and Bayes estimates of parameters under the squared error and absolute error loss functions were obtained for scenario 2 and 3 and n = 10, 20, 30, 50, 100 using a Monte Carlo simulation with 500 replications. Then, the relative efficiency (RE) was computed as
where is the MLE of Ω = (μ, τ, γ) and and are the Bayes estimates of Ω under the squared error and absolute error loss functions, respectively. The results are shown in Figure 5 for scenario 2 (top) and scenario 3 (middle) and μ = 3, τ = 0.6, γ = 1.
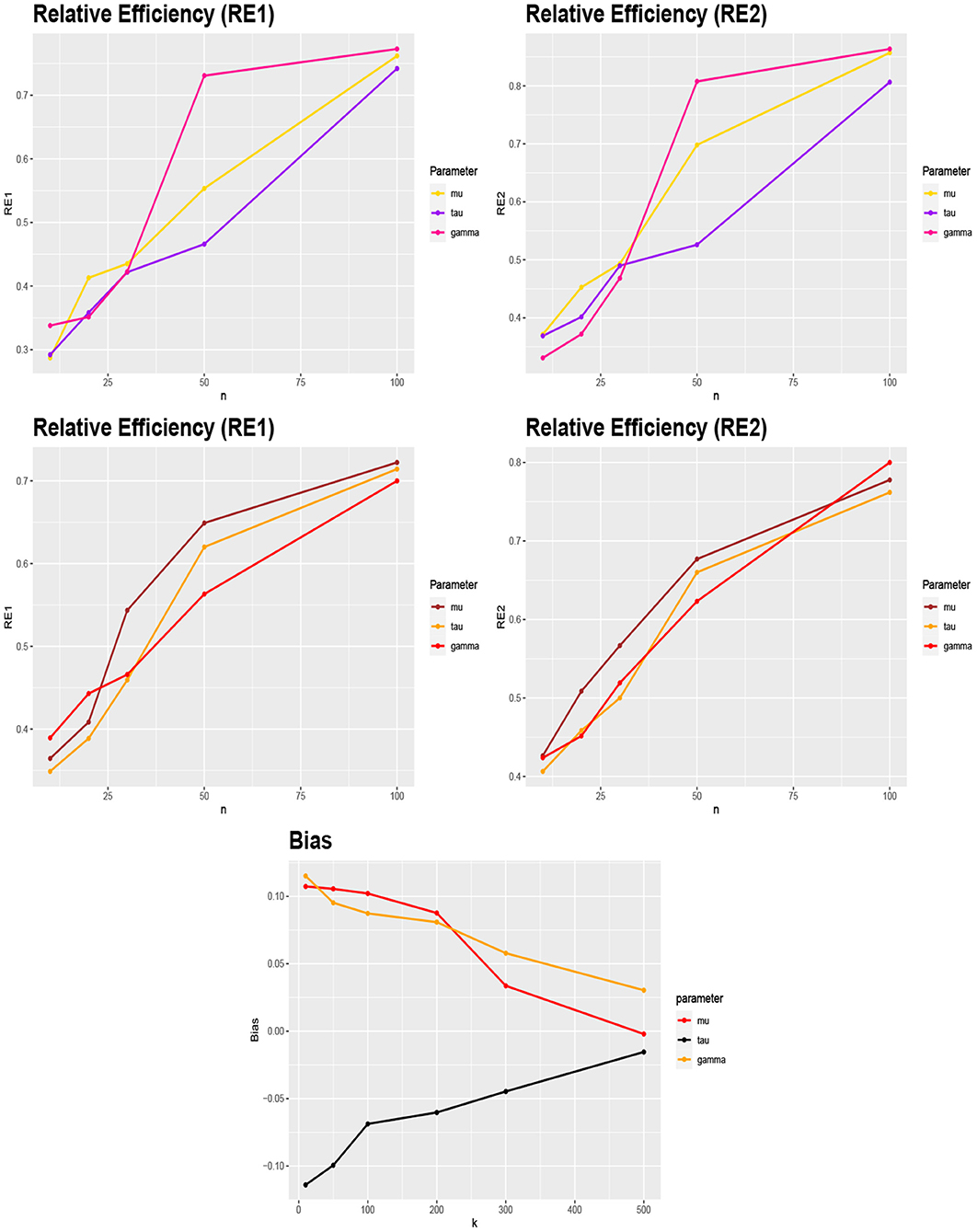
Figure 5. (Top) the RE of the Bayes estimates and MLEs of μ, τ, and γ vs. the sample size n for scenario 2. (Middle) the RE of the Bayes estimates and MLEs of μ, τ, and γ vs. the sample size n for scenario 3. (Bottom) the biases of the Bayes estimates of (μ, τ, γ) under the squared error loss function for scenario 3, p = 2, n = 100 and different values of k = 10, 50, 100, 200, 300, 500.
From Figure 5 (top and middle) the following general conclusions can be observed:
• Our proposed Bayesian approach provides more accurate estimates for parameters in comparison with the maximum likelihood method for small values of n.
• The obtained Bayes estimates under the squared error loss function have less MSE than the estimates based on absolute error loss function.
• By increasing n, our proposed Bayesian approach has a similar performance as the maximum likelihood method.
Finally, to investigate the rule of k in Algorithm 1, the biases of the Bayes estimates of (μ, τ, γ) under the squared error loss function were obtained for scenario 3 (p = 2) in Table 1, n = 100 and different values of k = 10, 50, 100, 200, 300, 500 using a Monte Carlo simulation with 500 replications. The results are shown in Figure 5 (bottom) which demonstrate that, by increasing k, the bias tends to zero and thus, the accuracy of estimates increases.
6. Data application
In what follows, the proposed Bayesian approach's performance for p = 2 is demonstrated through three datasets with different sizes n = 31, 60, 725 with the skew-von Mises distribution in (6) as assumed model. The circular boxplots (Buttarazzi et al., 2018) of the datasets are shown in Figure 6 (top) and confirm the skew pattern of the datasets.
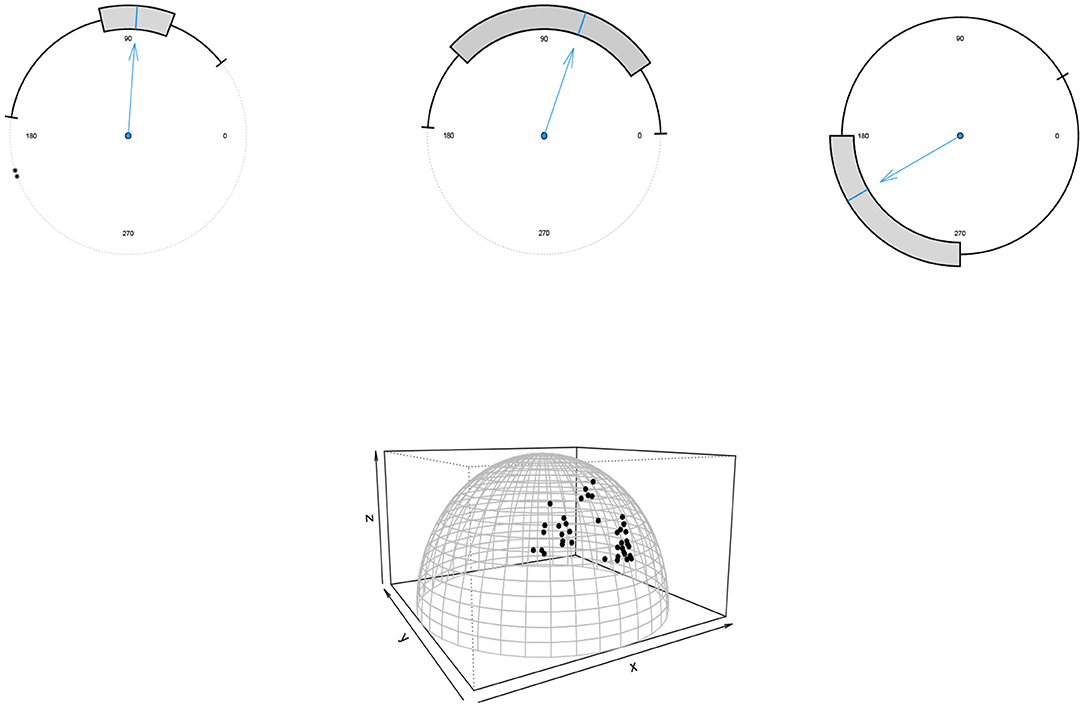
Figure 6. (Top) the boxplots of the movement of blue periwinkles (left), long-axis orientations of feldspar laths (middle) and thunder at Kew (right) datasets. (Bottom) the scatter plot of the household expenditures dataset.
The obtained results in section 5 show all the assumed scenarios provide accurate estimates for the parameters. However, based on the obtained results in section 5 with the WIM, we propose scenario 3 or 4 for obtaining the Bayes estimates to avoid time intensive computations when the sample size is not small (see Figure 7). The justification is that scenarios 1 and 2 need the slice sampler in Algorithm 1 to generate samples from the joint prior (10). Therefore, the Bayes estimates of the parameters μ, τ, and γ were obtained based on scenario 1 for the movement of blue periwinkles dataset (n = 31); scenarios 3 and 4 for the long-axis orientations of feldspar laths (n = 60) and the thunder at Kew (n = 725) datasets, respectively. See below for the description of said datasets.
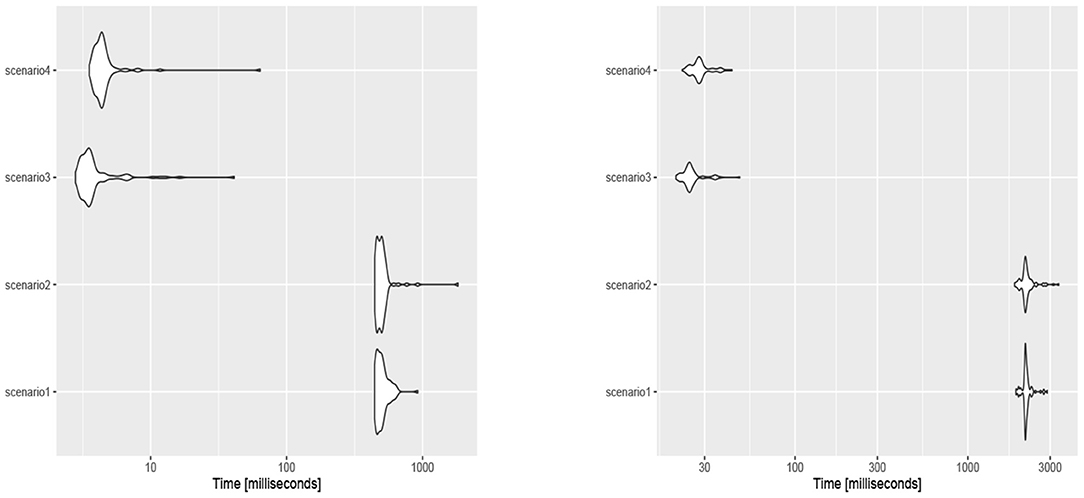
Figure 7. The execution time (in miliseconds) for generating samples of size n = 10 (left) and n = 50 (right) from the posterior density functions of each scenario.
For p = 3, a dataset of size n = 40 including the expenditures of households is considered. Figure 6 (bottom) shows the scatter plot of the data. For all the datasets to obtain the Bayes estimates we generated samples of size N = 1, 000 from the posterior distributions using Algorithm 1 with a burn-in period of 10,000 and k = 500.
In what follows, we shall describe the individual datasets in detail. Since the conclusion is more or less the same for all p = 2 settings, we already write it down here. It is observed that the proposed Bayesian approach with the skew von Mises distribution as the underlying model provides a good fit to the datasets. Generally, the obtained estimates based on the squared error and absolute error loss functions are more accurate.
6.1. Movement of Blue Periwinkles
A real dataset including the movement directions of 31 blue periwinkles, Nodilittorina unifasciata, in degrees is considered (Fisher, 1995). The data was collected from a series of experiments which were done on the distances and directions that small blue periwinkles moved after the transplantation to downshore at a specific height where they live normally. The test of Pewsey (2002) confirms that the underlying distribution for this dataset is asymmetric (p-value = 0.0000). This test is defined based on the sample second sine moment where is the sample mean direction. The large values of compared with the quantiles of the standard normal distribution lead to the rejection of symmetry. For more details see Pewsey (2002).
The Bayes estimates of parameters are obtained by using scenario 1 based on squared error, absolute error and zero-one loss functions. The results are summarized in Table 2. The traceplots of generated samples from the posterior, the compare-partial and mean running plots are shown in Figure 8 (top). The kernel density plot and histogram of the data along with the fitted curves under different loss functions are shown in Figure 8 (bottom).
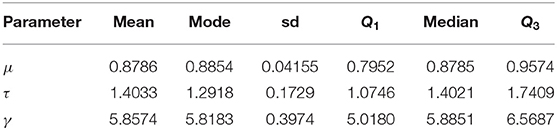
Table 2. Bayes estimates of parameters based on scenario 1 with prior parameters μ0 = 2, ζ = 2, η = 1, ξ = 5, and σ = 2 for the movement of blue periwinkles dataset.
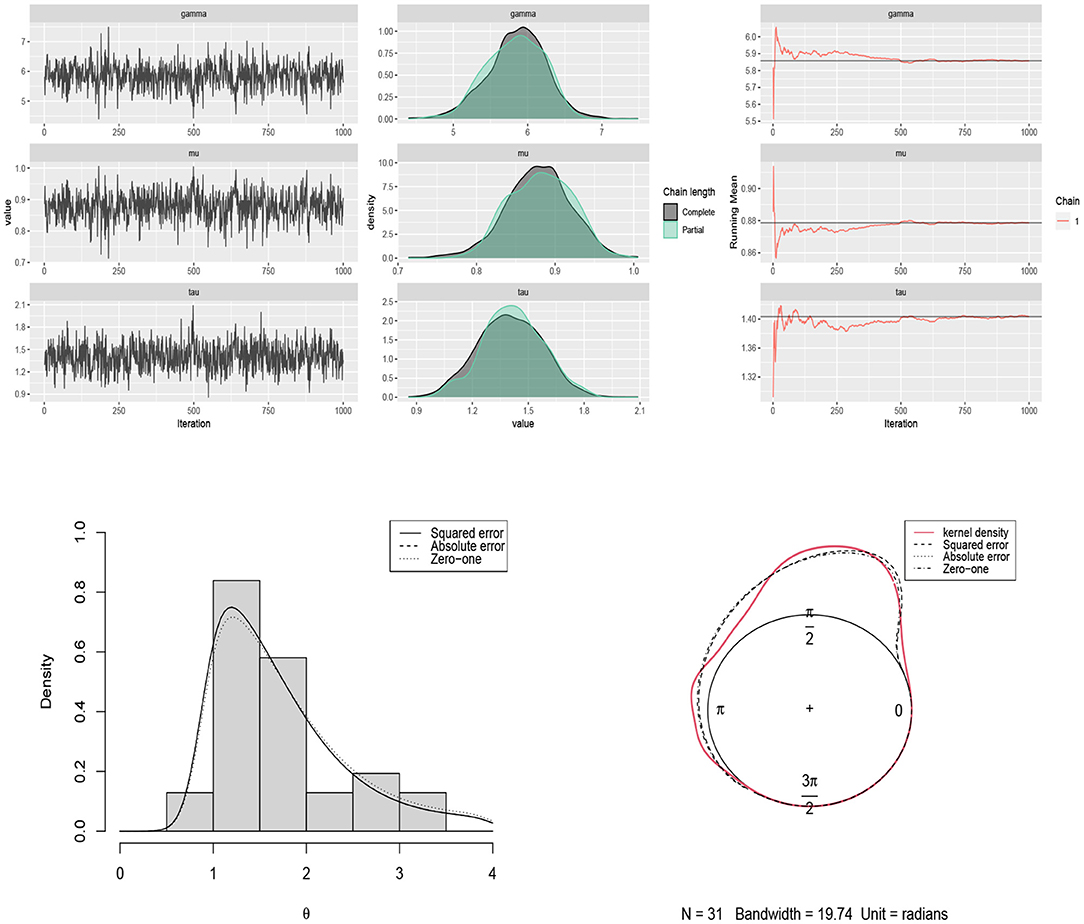
Figure 8. (Top) traceplots, mean running and estimated posterior pdf plots of generated samples for (μ, τ, γ) in Table 2 for the movement of blue periwinkles dataset. (Bottom) the histogram and kernel density plot of the data related to the movement of blue periwinkles and the fitted curves under different loss functions.
6.2. Long-Axis Orientations of Feldspar Laths
Another dataset including the measurements of long-axis orientation of 60 feldspar laths in basalt (Fisher, 1995) is considered. The symmetry test of Pewsey (2002) confirms the skew pattern of the data in Figure 6 (p-value = 0.0000). The Bayes estimates of parameters are obtained by using scenario 3 based on squared error, absolute error and zero-one loss functions. The results are summarized in Table 3. The traceplots of generated samples from the posterior, the compare-partial, and the mean running plots are shown in Figure 9 (top). The histogram and kernel density plot of the data and the fitted curves under different loss functions are shown in Figure 9 (bottom).
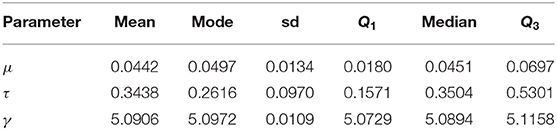
Table 3. Bayes estimates of parameters based on scenario 3 with prior parameters μ0 = 0, τ0 = 8, α = 5, β = 2, ξ = 3, σ = 1 for the long-axis orientations of feldspar laths dataset.
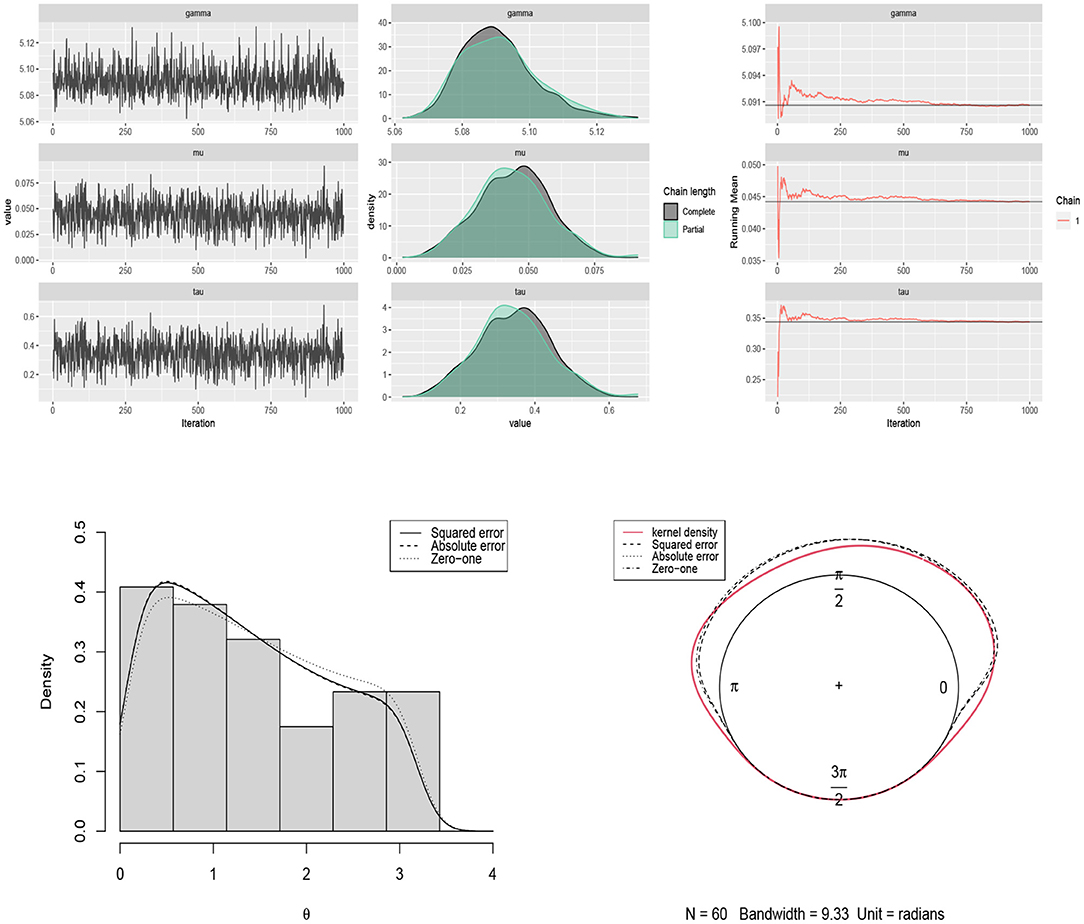
Figure 9. (Top) traceplots, mean running and estimated posterior pdf plots of generated samples for (μ, τ, γ) in Table 3 for the long-axis orientations of feldspar laths dataset. (Bottom) the histogram and kernel density plot of the data related to the long-axis orientations of feldspar laths and the fitted curves under different loss functions.
6.3. Thunder at Kew
A grouped frequency data set consisting of 725 observations about the number of times that thunder was heard at Kew (England) during each two hourly interval of the day in the summers of 1910–1935 is considered (Mardia, 1975). In this case, each 15° on the circle represents 1 h. According to the test of Pewsey (2002), the underlying distribution for this data set is not symmetric (p-value = 0.0000). The Bayes estimates of parameters are obtained by using scenario 4 based on squared error, absolute error and zero-one loss functions. The results are summarized in Table 4. The traceplots of generated samples from the posterior, the compare-partial and mean running plots are shown in Figure 10 (top). The histogram and kernel density plot of the data and the fitted curves under different loss functions are shown in Figure 10 (bottom).
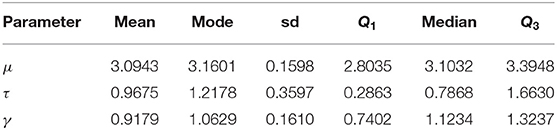
Table 4. Bayes estimates of parameters based on scenario 4 with prior parameters μ0 = 3, τ0 = 2, α = 5, β = 6, ξ = 0.5, σ = 0.5, and λ = −2 for the thunder at Kew dataset.
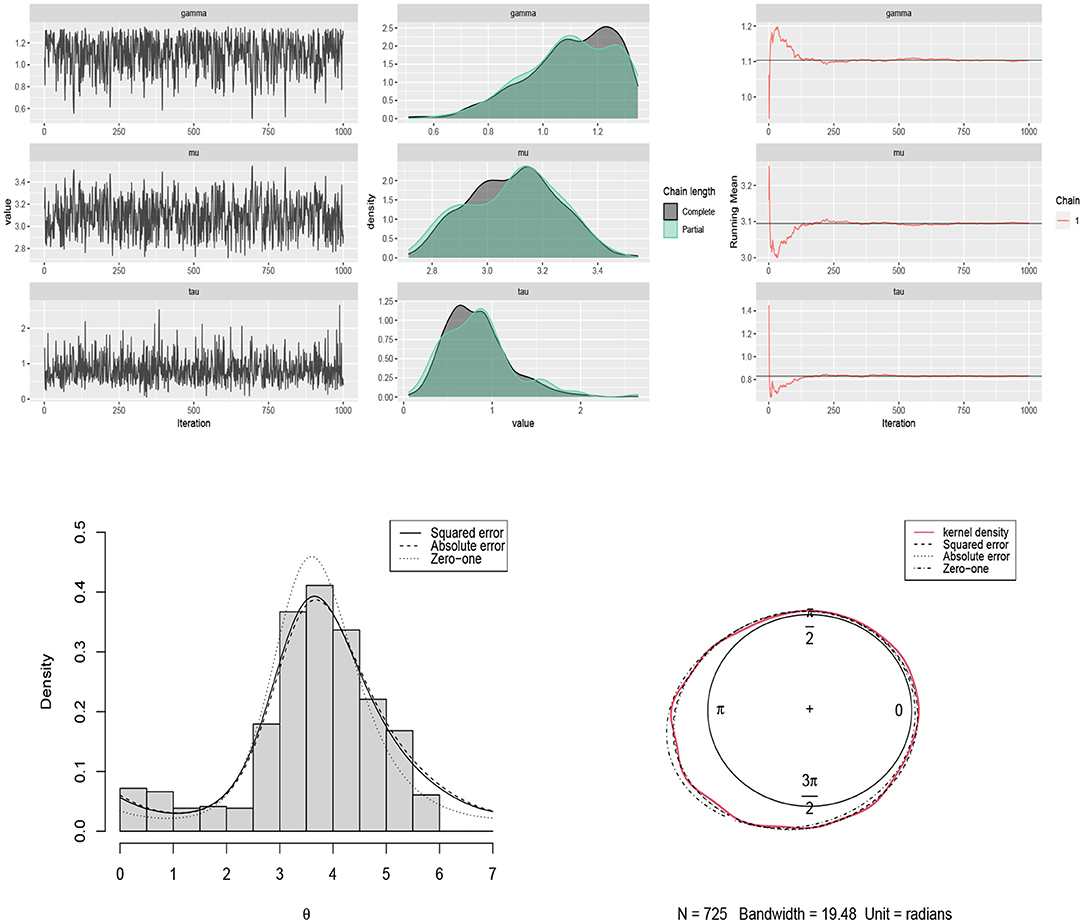
Figure 10. (Top) traceplots, mean running and estimated posterior pdf plots of generated samples for (μ, τ, γ) in Table 4 for the thunder at Kew dataset. (Bottom) the histogram and kernel density plot of the data related to the thunder at Kew and the fitted curves under different loss functions.
6.4. Household Expenditures
For p = 3, a sub data from the dataset available in the HSAUR2 package (Everitt and Hothorn, 2017) in R is considered. The entire data was collected from a survey on household expenditures in four commodity groups of housing, food, goods, and service. It includes the expenses of 20 single men and 20 single women. We considered variables housing, food, and service and normalized. After applying cosine transformation (5), the SFvML was fitted on the data and the Bayes estimates of the parameters were obtained. The results are summarized in Table 5. The traceplots of generated samples from the posterior and the compare-partial and mean running plots are shown in Figure 11 (top). The scatter plot of the data and the contour plot of the fitted distribution under different loss functions are shown in Figure 11 (bottom).
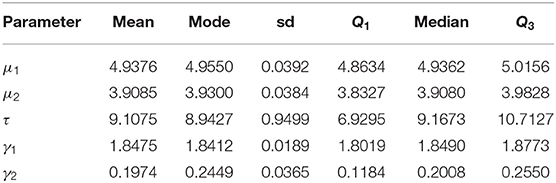
Table 5. Bayes estimates of parameters based on scenario 3 with prior parameters μ01 = 3, τ01 = 2, μ02 = 3, τ02 = 4, α = 20, β = 1, ξ1 = 0, σ1 = 3, ξ1 = 0, and σ1 = 2 for the household expenditures dataset.
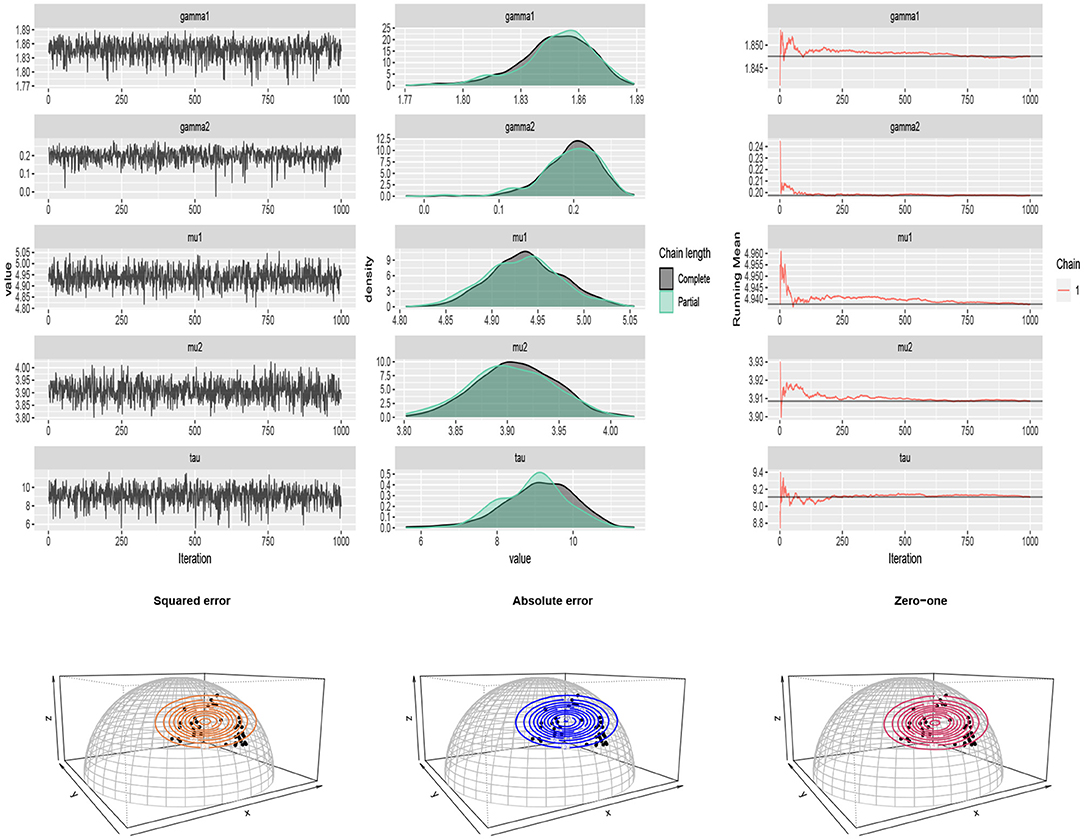
Figure 11. (Top) traceplots, mean running and estimated posterior pdf plots of generated samples for (μ1, μ2, τ, γ1, γ2) in Table 5 for the household expenditures dataset. (Bottom) the scatter plot of the household expenditures dataset and the contour plot of the fitted distribution under different loss functions.
7. Conclusion
Since the assumption that data is rotationally-symmetric is often rejected (Pewsey, 2002; Ley and Verdebout, 2014; Ameijeiras-Alonso and Ley, 2020; Ameijeiras-Alonso et al., 2021), in this paper, we have presented a Bayesian analysis for the skew-rotationally-symmetric FvML distribution. For the first time in Bayesian analysis of directional data the impact of the proposed priors in the set up has been compared using the Wasserstein Impact Measure. Using this measure can give guidance to the practitioner to avoid computationally intensive priors if a simpler prior has similar impact. An algorithm has been used based on modified Gibbs sampling and weighted bootstrap resampling for generating samples from posterior distributions. This coming together of Bayesian methods and skew distributions in the directional domain promises new research interest.
Data Availability Statement
All relevant references for data are contained within the article.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
This work was based upon research supported in part by the Visiting Professor programme, University of Pretoria and the National Research Foundation (NRF) of South Africa, SARChI Research Chair UID: 71199; Ref.: IFR170227223754 grant No. 109214; Ref.: SRUG190308422768 grant No. 120839, and DSI-NRF Centre of Excellence in Mathematical and Statistical Sciences (CoE-MaSS), South Africa. The opinions expressed and conclusions arrived at are those of the authors and are not necessarily to be attributed to the CoE-MaSS or the NRF. Christophe Ley's research is supported by the FWO Krediet aan Navorsers grant with reference number 1510391N.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We would like to thank the Associate Editor and the reviewers for their constructive comments, which improved this paper.
References
Abe, T., and Pewsey, A. (2011). Sine-skewed circular distributions. Stat. Pap. 52, 683–707. doi: 10.1007/s00362-009-0277-x
Ahmed, S. E. (2017). Big and Complex Data Analysis: Methodologies and Applications. Switzerland: Springer.
Ameijeiras-Alonso, J., and Ley, C. (2020). Sine-skewed toroidal distributions and their application in protein bioinformatics. Biostatistics. kxaa039. doi: 10.1093/biostatistics/kxaa039
Ameijeiras-Alonso, J., Ley, C., Pewsey, A., and Verdebout, T. (2021). On optimal tests for circular reflective symmetry about an unknown central direction. Stat. Pap. 62, 1651–1674. doi: 10.1007/s00362-019-01150-7
Azzalini, A. (1985). A class of distributions which includes the normal ones. Scand. J. Stat. 12, 171–178. doi: 10.6092/ISSN.1973-2201/711
Bagchi, P. (1988). Bayesian Analysis of Directional Data (Ph.D. thesis). University of Toronto, Toronto, ON, Canada.
Bagchi, P. (1994). Empirical Bayes estimation in directional data. J. Appl. Stat. 21, 317–326. doi: 10.1080/757583874
Bagchi, P., and Guttman, I. (1988). Theoretical considerations of the multivariate von Mises-Fisher distribution. J. Appl. Stat. 15, 149–169. doi: 10.1080/02664768800000022
Bagchi, P., and Kadane, J. B. (1991). Laplace approximations to posterior moments and marginal distributions on circles, spheres, and cylinders. Can. J. Stat. 19, 67–77. doi: 10.2307/3315537
Bangert, M., Hennig, P., and Oelfke, U. (2010). “Using an infinite von Mises-Fisher mixture model to cluster treatment beam directions in external radiation therapy,” in 2010 Ninth International Conference on Machine Learning and Applications (Washington, DC: IEEE), 746–751.
Bhattacharya, S., and SenGupta, A. (2009). Bayesian inference for circular distributions with unknown normalising constants. J. Stat. Plan. Inference 139, 4179–4192. doi: 10.1016/j.jspi.2009.06.008
Buttarazzi, D., Pandolfo, G., and Porzio, G. C. (2018). A boxplot for circular data. Biometrics 74, 1492–1501. doi: 10.1111/biom.12889
Damien, P., and Walker, S. (1999). A full Bayesian analysis of circular data using the von Mises distribution. Can. J. Stat. 27, 291–298. doi: 10.2307/3315639
Dowe, D. L., Oliver, J. J., Baxter, R. A., and Wallace, C. S. (1996). “Bayesian estimation of the von Mises concentration parameter,” in Maximum Entropy and Bayesian Methods, (Cambridge: Springer), 51–60.
Everitt, B. S., and Hothorn, T. (2017). Package ‘hsaur2.’ Available online at: https://CRAN.R-project.org/package=HSAUR2
Fernández-i-Marın, X. (2016). ggmcmc: analysis of mcmc samples and Bayesian inference. J. Stat. Softw. 70, 1–20. doi: 10.18637/jss.v070.i09
Fisher, N., and Lee, A. (1994). Time series analysis of circular data. J. R. Stat. Soc. Series B (Methodol.) 56, 327–339. doi: 10.1111/j.2517-6161.1994.tb01981.x
Fisher, R. A. (1953). Dispersion on a sphere. Proc. R. Soc. London Series A. Math. Phys. Sci. 217, 295–305. doi: 10.1098/rspa.1953.0064
Ghaderinezhad, F., Ley, C., and Serrien, B. (2022). The wasserstein impact measure (WIM): a generally applicable, practical tool for quantifying prior impact in Bayesian statistics. Comput. Stat. Data Anal. [Epub ahead of print].
Guttorp, P., and Lockhart, R. A. (1988). Finding the location of a signal: a Bayesian analysis. J. Amer. Stat. Assoc. 83, 322–330. doi: 10.1080/01621459.1988.10478601. [Epub ahead of print].
Hornik, K., and Grün, B. (2013). On conjugate families and Jeffreys priors for von Mises-Fisher distributions. J. Stat. Plan. Inference 143, 992–999. doi: 10.1016/j.jspi.2012.11.003
Kruschke, J. (2014). Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan. Oxford: Academic Press.
Leong, P., and Carlile, S. (1998). Methods for spherical data analysis and visualization. J. Neurosci. Methods 80, 191–200. doi: 10.1016/S0165-0270(97)00201-X
Ley, C., and Verdebout, T. (2014). Simple optimal tests for circular reflective symmetry about a specified median direction. Stat. Sinica 24, 1319–1339. doi: 10.5705/ss.2013.083
Ley, C., and Verdebout, T. (2017b). Skew-rotationally-symmetric distributions and related efficient inferential procedures. J. Multivariate Anal. 159, 67–81. doi: 10.1016/j.jmva.2017.02.010
Mardia, K. V. (1975). Statistics of directional data. J. R. Stat. Soc. Series B (Methodol.) 37, 349–393. doi: 10.1111/j.2517-6161.1975.tb01550.x
Mardia, K. V. (2010). Bayesian analysis for bivariate von Mises distributions. J. Appl. Stat. 37, 515–528. doi: 10.1080/02664760903551267
Mardia, K. V. (2013). “Some aspects of geometry driven statistical models,” in Annual LASR 2013 Proceedings (Leeds: Leeds University Press), 7–15.
Mardia, K. V., and El-Atoum, S. (1976). Bayesian inference for the von Mises-Fisher distribution. Biometrika 63, 203–206. doi: 10.1093/biomet/63.1.203
McElreath, R. (2020). Statistical Rethinking: A Bayesian Course With Examples in R and Stan. Boca Raton: CRC Press.
Mulder, K., Jongsma, P., and Klugkist, I. (2020). Bayesian inference for mixtures of von Mises distributions using reversible jump MCMC sampler. J. Stat. Comput. Simulat. 90, 1539–1556. doi: 10.1080/00949655.2020.1740997
Muralidharan, K., and Parikh, R. (2007). Some Bayesian inferences for von Mises distribution. Amer. J. Math. Manag. Sci. 27, 123–137. doi: 10.1080/01966324.2007.10737692
Nuñez-Antonio, G., and Gutiérrez-Peña, E. (2005). A Bayesian analysis of directional data using the von Mises-Fisher distribution. Commun. Stat. Simulat. Comput. 34, 989–999. doi: 10.1080/03610910500308495
Pewsey, A., and García-Portugués, E. (2021). Recent advances in directional statistics. TEST 30, 1–58. doi: 10.1007/s11749-021-00759-x
Rodrigues, J., Galvão Leite, J., and Milan, L. A. (2000). Theory & Methods: an empirical Bayes inference for the von Mises distribution. Aust. New Zealand J. Stat. 42, 433–440. doi: 10.1111/1467-842X.00140
Røge, R. E., Madsen, K. H., Schmidt, M. N., and Mørup, M. (2017). Infinite von Mises-Fisher mixture modeling of whole brain fmri data. Neural Comput. 29, 2712–2741. doi: 10.1162/neco_a_01000
Schuhmacher, D., Bähre, B., Gottschlich, C., Hartmann, V., Heinemann, F., Schmitzer, B., et al. (2020). Transport: Computation of optimal transport plans and Wasserstein distances, R package version 0.11-1. Available online at: https://cran.r-project.org/package=transport
Shearman, L. P., Sriram, S., Weaver, D. R., Maywood, E. S., Chaves, I., Zheng, B., et al. (2000). Interacting molecular loops in the mammalian circadian clock. Science 288, 1013–1019. doi: 10.1126/science.288.5468.1013
Smith, A. F., and Gelfand, A. E. (1992). Bayesian statistics without tears: a sampling–resampling perspective. Amer. Stat. 46, 84–88. doi: 10.1080/00031305.1992.10475856
Straub, J. (2017). Bayesian Inference With the Von-Mises-Fisher Distribution in 3D. Available online at: http://people.csail.mit.edu/jstraub/
Taghia, J., Ma, Z., and Leijon, A. (2014). Bayesian estimation of the von Mises-Fisher mixture model with variational inference. IEEE Trans. Pattern Anal. Mach. Intell. 36, 1701–1715. doi: 10.1109/TPAMI.2014.2306426
Vehtari, A., Gelman, A., and Gabry, J. (2017). Practical Bayesian model evaluation using leave-one-out cross-validation and waic. Stat. Comput. 27, 1413–1432. doi: 10.1007/s11222-016-9696-4
Keywords: Fisher-von Mises-Langevin distribution, Gibbs sampling, MCMC method, skew-rotationally-symmetric distributions, slice sampler, spherical data, Wasserstein Impact Measure
Citation: Nakhaei Rad N, Bekker A, Arashi M and Ley C (2022) Coming Together of Bayesian Inference and Skew Spherical Data. Front. Big Data 4:769726. doi: 10.3389/fdata.2021.769726
Received: 02 September 2021; Accepted: 27 December 2021;
Published: 08 February 2022.
Edited by:
Jian Qing Shi, Southern University of Science and Technology, ChinaReviewed by:
Daizong Ding, Fudan University, ChinaChong Zhong, Hong Kong Polytechnic University, Hong Kong SAR, China
Copyright © 2022 Nakhaei Rad, Bekker, Arashi and Ley. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Christophe Ley, Y2hyaXN0b3BoZS5sZXlAdWdlbnQuYmU=