 Phuong N. Chau
Phuong N. Chau Rasa Zalakeviciute2
Rasa Zalakeviciute2 Ilias Thomas
Ilias Thomas Yves Rybarczyk
Yves Rybarczyk- 1School of Information and Engineering, Dalarna University, Falun, Sweden
- 2Grupo de Biodiversidad Medio Ambiente y Salud, Universidad de Las Américas, Quito, Ecuador
Weather Normalized Models (WNMs) are modeling methods used for assessing air contaminants under a business-as-usual (BAU) assumption. Therefore, WNMs are used to assess the impact of many events on urban pollution. Recently, different approaches have been implemented to develop WNMs and quantify the lockdown effects of COVID-19 on air quality, including Machine Learning (ML). However, more advanced methods, such as Deep Learning (DL), have never been applied for developing WNMs. In this study, we proposed WNMs based on DL algorithms, aiming to test five DL architectures and compare their performances to a recent ML approach, namely Gradient Boosting Machine (GBM). The concentrations of five air pollutants (CO, NO2, PM2.5, SO2, and O3) are studied in the city of Quito, Ecuador. The results show that Long-Short Term Memory (LSTM) and Bidirectional Recurrent Neural Network (BiRNN) outperform the other algorithms and, consequently, are recommended as appropriate WNMs to quantify the effects of the lockdowns on air pollution. Furthermore, examining the variable importance in the LSTM and BiRNN models, we identify that the most relevant temporal and meteorological features for predicting air quality are Hours (time of day), Index (1 is the first collected data and increases by one after each instance), Julian Day (day of the year), Relative Humidity, Wind Speed, and Solar Radiation. During the full lockdown, the concentration of most pollutants has decreased drastically: −48.75%, for CO, −45.76%, for SO2, −42.17%, for PM2.5, and −63.98%, for NO2. The reduction of this latter gas has induced an increase of O3 by +26.54%.
Introduction
In recent years, millions of deaths around the world have been caused by the polluted environment due to toxic emissions from industries, traffic, and the growing human population (Piqueras and Vizenor, 2016; WHO, 2021a,b). Among the most common atmospheric pollutants are carbon monoxide (CO), nitrogen oxides (NO and NO2), sulfur dioxide (SO2), ozone (O3) and particulate matter (PM), predominantly fine particulate matter (with aerodynamic diameter ≤ 2.5 μm, PM2.5). These pollutants, at certain established concentration levels, can damage respiratory and cardiovascular systems (Pope et al., 2012; Lelieveld et al., 2015). Furthermore, recent studies have shown that bad air quality could aggravate the symptoms of the coronavirus disease 2019 (COVID-19) (Gardiner et al., 2020; Wu et al., 2020).
In 2020, while the COVID-19 spread throughout the world, Ecuador was one of the most affected countries, with 50,183 confirmed cases and 4,199 deaths, reported on June 21st (WHO, 2020). To reduce the disease spread, the country implemented the first exceptionally strict lockdown between March 15 and June 2, 2020, and from thereon, has been progressively relaxing the security measures (until September 2020)1. This situation makes Quito, the capital city of Ecuador, an excellent case study to assess the effects of different levels of lockdown.
The simplest approach to assessing the impact of the COVID-19 lockdowns on air quality is to compare the average concentration of a pollutant before and during the lockdown (Gkatzelis et al., 2019; Zalakeviciute et al., 2020). More advanced methods consist of developing a model to predict the pollution level assuming a business as usual (BAU) scenario and quantifying the lockdown effects. Air quality prediction is traditionally based on the application of atmospheric chemical transport models (CTMs), which provide a mathematical framework for the description of emission patterns, meteorology, chemical transformations, and removal processes (Seinfeld and Pandis, 2016). Such CTMs can be combined with higher resolution dispersion models to provide local air quality levels in street canyons (Gidhagen et al., 2021). More recently, statistical methods, such as Machine Learning (ML) (Barré et al., 2021; Betancourt et al., 2021; Lovrić et al., 2021; Nitheesh et al., 2021; Rybarczyk and Zalakeviciute, 2021), have proven their efficiency and reliability in predicting the concentrations of pollutants in the atmosphere.
Meteorological normalization is a method that uses meteorological features to predict the concentrations of air contaminants under BAU conditions (Grange et al., 2018). Since we take into account the actual meteorological condition during the lockdown, it allows us to obtain Weather Normalized Models (WNMs). So far, the WNMs have been built from ML algorithms, such as Random Forest and Gradient Boosting Machine (GBM). Grange et al. (2018) proposed WNMs based on Random Forest algorithm for PM10 analysis. Afterwards, Rybarczyk and Zalakeviciute (2021) and Barré et al. (2021) used GBM for developing the WNMs to quantify the effects of COVID-19 lockdowns on air quality.
More recently, DL algorithms have shown a better performance than ML on several predicting problems. For example, Convolution Neural Network (CNN) fits well for image and signal processing (LeCun et al., 1998; Qin et al., 2019). Long-Short Term Memory (LSTM) is more adapted for time series prediction (Kuremoto et al., 2014; Ong et al., 2016) and natural language processing (NLP) (Hochreiter and Schmidhuber, 1997). Bidirectional Recurrent Neural Network (BiRNN) is mainly applied for timeseries data (Li et al., 2019), signal processing (Schuster and Paliwal, 1997), automated translation (Sundermeyer et al., 2014), NLP (Liwicki et al., 2007), and bioinformatics (Pollastri and McLysaght, 2005). In addition to that, the architecture of each DL method can be customized to improve model accuracy. In recent years, DL has received much attention for developing air quality prediction models. Recurrent Neural Network (RNN) has been applied for air quality monitoring (Kristiani et al., 2020) and air quality classification (Fan et al., 2017; Zhao et al., 2018). CNN has been used for air pollution index prediction and NO2 estimation (Ragab et al., 2020). Meanwhile, LSTM was applied for predicting CO, NO2, O3, PM10, SO2 and pollen concentrations in Madrid (Navares and Aznarte, 2020), and for modeling air quality in India (Krishan et al., 2019). Finally, some studies used DL for predicting air quality with BiRNN (Tong et al., 2019), Gated Recurrent Unit (GRU) (Athira et al., 2018) and multi-source data for forecasting PM2.5 (Sun et al., 2021). Considering that DL has the potential to provide higher accuracy, we propose DL-based WNMs by testing five DL architectures. Another motivation for using a DL-based approach is its modeling flexible, such as new data can be included in the training without having to scan the whole dataset.
This paper aims to develop WNMs based on DL for studying the effect of COVID-19 on air quality. The accuracy of GBM and five DL algorithms is compared to identify the best models for predicting air pollution under BAU conditions. The objective is to obtain a more accurate assessment of the effect of the lockdowns (strict and relaxing) on air quality, using the capital city of Ecuador as a case study. Five representative pollutants of the urban air quality are studied: NO2, SO2, CO, O3, and PM2.5. Afterwards, we use SHapley Additive exPlanations (SHAP)2 to discover the feature importance of the inputs for the best model, which can reveal the interrelations between predictors and pollutant concentrations. Finally, the impacts of the COVID-19 lockdown are quantified by calculating the difference between the real and predicted values of the pollutant concentrations under the BAU assumption.
In summary, the main goals of this study are outlined as follows:
• Developing WNMs based on DL to estimate air pollution for the five most representative urban pollutants.
• Assessing the impacts of the COVID-19 lockdowns on air quality in Quito by selecting the best WNMs.
• Identifying the feature importance for the best WNMs and analyzing the relationship between temporal, meteorological features, and air pollutants.
The remainder of this paper is organized into three sections. Section Materials and Methods includes a description of the site and instrumentation, data collection, data processing, and implemented methods. Section Results and Discussions presents the results and discussion. Our conclusions and future work are presented in the final section.
Materials and Methods
Site Description and Instrumentation
The Ecuadorian capital, Quito, is located in South America right on the equator. The climate is mild and stable in terms of daily temperature variations, with wet (September–May) and dry (June–August) seasons (Zalakeviciute et al., 2018a). It is a high elevation city in the Andes mountains at 2,850 meters above mean sea level (m.a.s.l.), housing a population of 2.2 million people (EMASEO, 2011; INEC, 2011). Due to the reduced availability of oxygen (70%) at this altitude (Andes mountains), and poor-quality diesel and gasoline, the city is known for its long-term air pollution problems (Zalakeviciute et al., 2018a,b).
The city successfully manages a long-term air quality monitoring network, functioning in accordance with the requirements of the Environmental Protection Agency of the United States (U.S. EPA) (Secretaria de Ambiente, dd). The study site - Belisario (m.a.s.l 2,835 m, coord. 78°29'24” W, 0°10'48” S) is in a central traffic-busy district and is the best representative of the capital city of Ecuador.
Air quality monitoring instruments were set on the patio of a local school. A ThermoFisher Scientific 48i instrument was used to acquire the concentrations of CO (EPA method No. RFCA-0981-054). A ThermoFisher Scientific 43i was used for SO2 (EPA method No. EQSA-0486-060). ThermoFisher Scientific 49i was used for O3 (EPA method No. EQOA-0880-047). ThermoFisher Scientific 42i was used for NO2 (EPA method No. RFNA-1289-074). Finally, Thermo Scientific FH62C14-DHS was used to obtain PM2.5 concentrations (EPA No. EQPM-0609-183). Apart from the air quality data, meteorological parameters were also measured in the same monitoring station. For that, a complete automatic weather station was used. Wind speed and direction were measured using a MetOne instrument. Relative humidity, temperature and precipitation were measured by Thies Clima equipment. Finally, a Kipp Zonen radiometer measured solar radiation, and Vaisala equipment measured atmospheric pressure.
Data
The data include meteorological, temporal variables, and five air pollutant concentrations. The seven meteorological features are: Solar Radiation (SR), Wind Direction (WD), Wind Speed (WS), Atmospheric Pressure (p), Precipitation (Prec), Temperature (T) and Relative Humidity (RH). The four temporal variables are Julian Day (or Day of the Year), Weekday, Hours (or Time of Day), and Index (the index is started from 1 January 2016 and incremented by one at each instance). These temporal variables are additional variables in WNMs, not directly affecting the atmospheric concentration, but reflecting cyclic emission patterns. Hours account for emissions at rush hours. The Julian Day is a periodic term that represents seasonal emissions. The Weekday reflects the difference in human mobility between weekends and weekdays. The Index variable is denoted as a trending feature. The predicted features are the concentrations of NO2, SO2, CO, O3, and PM2.5.
The dataset includes 4 years and 9 months of hourly data between 2016 and 2020. Instances with empty values for certain features are eliminated from the cleaned dataset. Afterwards, we divided the data into three parts. The first part is the training set, from 1 January 2016 to 15 January 2020 (2 months before the COVID-19 lockdown). The second part, which is the testing set, is from 16 January 2020 to 15 March 2020 (the day of the national lockdown). In WNMs, the months before the application of interventions are commonly used for the testing set (Petetin et al., 2020; Barré et al., 2021; Rybarczyk and Zalakeviciute, 2021). The third part is the full lockdown (from 16 March to 1 June 2020) and partial lockdown (from 2 June to 30 September 2020) periods, which is used to quantify the change of pollutant concentration, through the best WNM models.
Figure 1 illustrates the distribution of the seven meteorological features for the training and testing sets. From this figure, we can identify three groups. The first group of variables indicates that the median of testing data is higher than that on training data (Figures 1A,E–G). On the contrary, the second group includes WS and WD (Figures 1B,C). The median of these features in testing sets is lower than the median in the training data. The last group consists of Prec features, where the boxes are small in both training and testing sets (Figure 1D). This feature is skewed, which can be caused by the weather characteristics in Quito with wet and dry seasons. Overall, most distributions of the meteorological features on the training sets are able to cover the distributions of the meteorological features on the testing set.
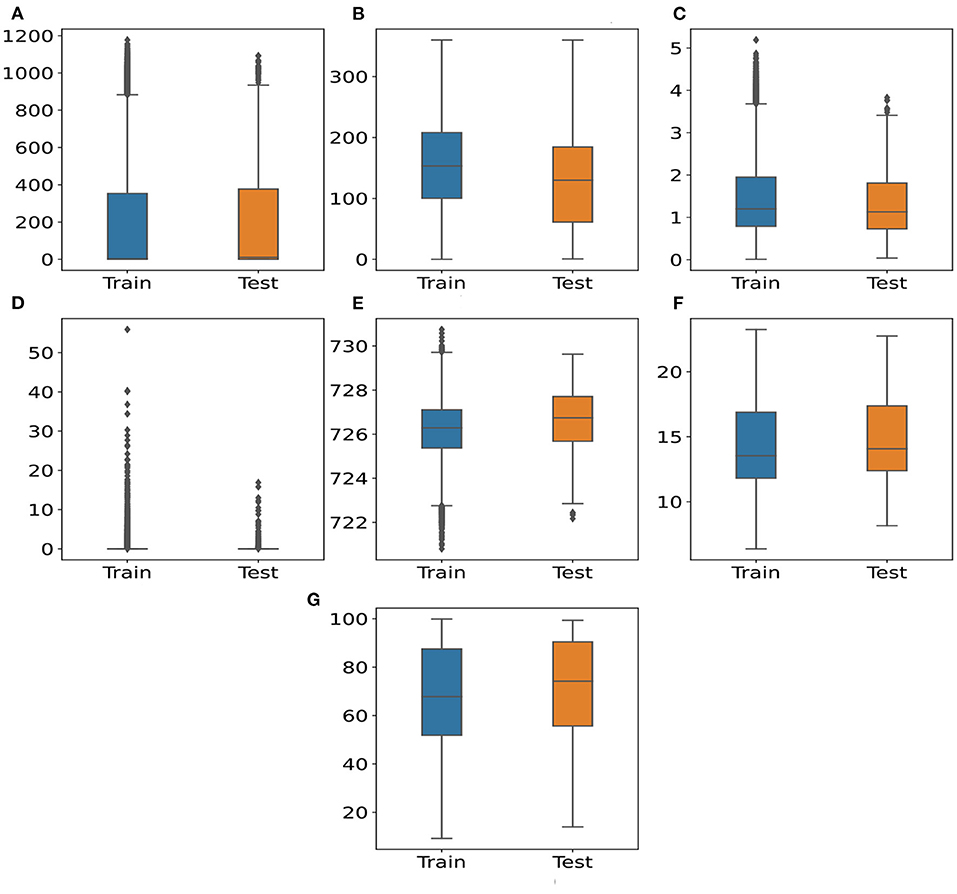
Figure 1. Distributions of meteorological features between training and testing set. (A) SR (W/m2) (B) WD (°) (C) WS (m/s) (D) Prec (mm) (E) p (mb) (F) temperature (°C) (G) RH (%).
Figure 2 depicts the distributions of five pollutant concentrations. There are several outliers in the data. The outliers consist of data points that are higher than 1.5 times the interquartile range (IQR). Meanwhile, outlier levels in air pollutants should be different from 1.5*IQR (Schmid et al., 2000). Additionally, it can be seen that the median and height of the boxes in training and testing data are sharply similar. This observation allows us to retain all original pollutant data to develop WNMs and assess the effects of COVID lockdowns.
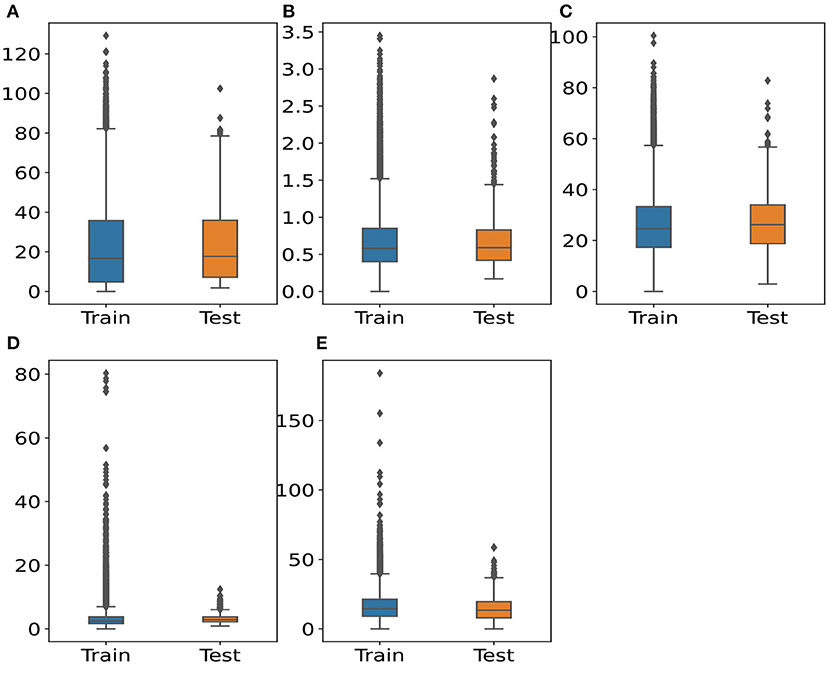
Figure 2. Distributions of pollutant concentrations between training and testing set. (A) O3 (μg/m3) (B) CO (mg/m3) (C) NO2 (μg/m3) (D) SO2 (μg/m3) (E) PM2.5 (μg/m3).
Method
Figure 3 represents an overview of our research method. First, we eliminated empty values and split the data into training and testing sets. Second, we used the training and testing data to develop and evaluate the performance of GBM and DL models. The architecture and implementation of the GBM and DL models are described in Sections Gradient Boosting Machine and DL Models. The experimental setups describe how to tune the parameters of GBM and DL algorithms (Section Experimental Setups). Third, all models are evaluated to select the best WNMs, based on the two metrics explained in Section Evaluation Metrics. Afterwards, the best WNMs are used for “Variable Importance” and “Assessment of Air Quality Changes”. The respective importance of each feature for the best WNMs is obtained by using the SHAP values method (Section SHapley Additive exPlanations for Model Explanation). Finally, the best WNMs is used to quantify the pollution change in Quito during the COVID-19 lockdown. The predicted values from the best WNMs are considered as pollution levels of contaminants under BAU conditions. The air quality changes are the differences between the predicted and the actual values during the lockdown periods.
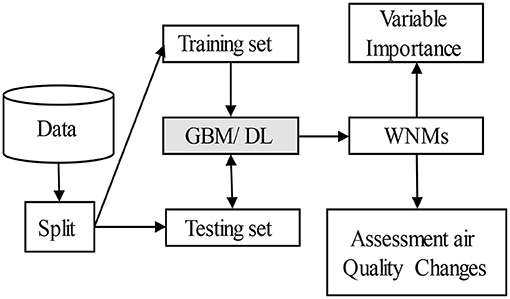
Figure 3. Workflow of the data analysis.
Gradient Boosting Machine
GBM is a powerful method of decision tree-based ensemble learning (Friedman, 2001). It was used in the previous study for assessing the effect of the COVID-19 lockdown on air quality (Barré et al., 2021; Rybarczyk and Zalakeviciute, 2021). The generalization of the algorithm is a stage-wise additive model of n individual regression trees following the algorithm presented in Table 1. GBM sequentially builds regression trees for all the data set features in a fully distributed way, which means that the trees are built in parallel. At each iteration from 1 to M, the instructions defined at line 2(a–d) are repeated K times. Equation (1) is used to obtain the outputs.

Table 1. GBM procedure in H2O library.
DL Models
In recent years, five kinds of DL methods (CNN, LSTM, RNN, BiRNN, and GRU) have been widely used in the literature (LeCun et al., 1998; Ong et al., 2016; Athira et al., 2018; Jogin et al., 2018; Qin et al., 2019; Tong et al., 2019; Kristiani et al., 2020; Navares and Aznarte, 2020). Each of these algorithms has its advantages and drawbacks. For this reason, the proposed approach aims to compare their performance for air quality prediction. Once the best model is identified, it is used to assess pollution changes caused by the different levels of lockdown.
The proposed DL models are based on the five layers presented in Figure 4. First, an input layer adapts the temporal and meteorological features to the DL layer. This layer transforms the original data into three-dimensional data with Min-Max Scaler based on the number of features and the number of “Timesteps.” Second, the DL layer is set up for capturing the characteristics of the data. CNN, LSTM, RNN, BiRNN and GRU are used to compare the performance of each of the DL architectures. Third, a “Drop out” layer is introduced after the DL layer to reduce the risk of over-fitting. Since the outputs are real numbers, a Dense layer is added afterwards to adapt the output of the “Drop out” layer to the predicted targets. Then, the weights of the WNM are adjusted from the predictive feature to obtain the best model. Although more complex DL models could be implemented (e.g., CNN-LSTM or LSTM-LSTM), the intended scope of this study is to focus on a DL layer for a fair comparison between the DL architectures.
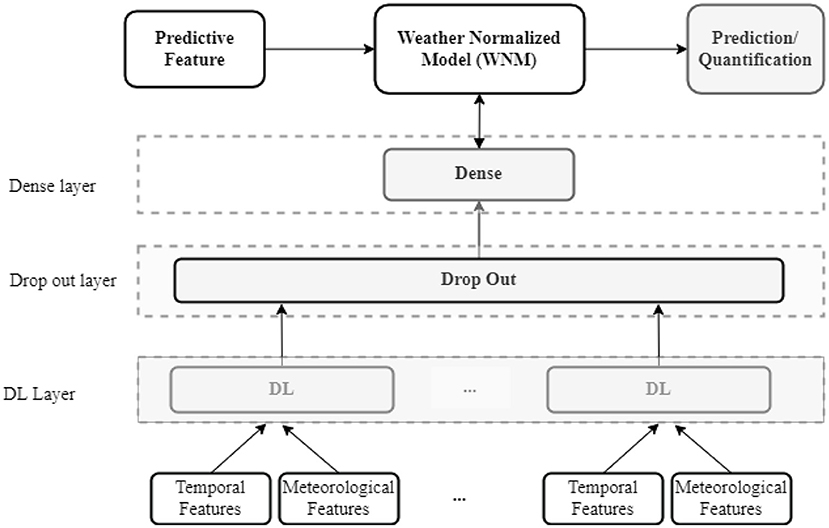
Figure 4. The model with general DL layer.
The architectures, advantages, and disadvantages of five DL methods (CNN, LSTM, RNN, BiRNN, and GRU) are described in detail in the rest of this section.
Convolution Neural Network
There are two basic types of CNN architecture: CNN1D and CNN2D. While the former can be used for sequence data, the latter is applied to image or high dimensional data. Figure 5A shows the connections inside the CNN1D layer. The CNN1D cells receive and learn from the inputs. Afterwards, the outputs of CNN1D are sent to the MaxPooling1D cells. The MaxPooling1D cells decrease the number of parameters to learn and support the internal presentations in the CNN1D layer. The outputs from the MaxPooling1D cells are sent to the “Drop Out” layer. In the CNN1D layer, there is no connection between the CNN cells.
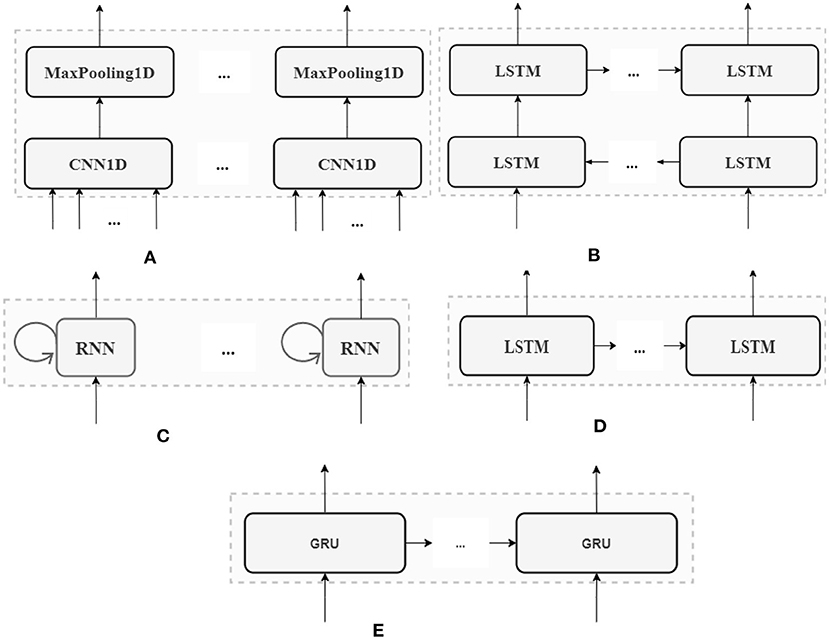
Figure 5. Five DL architectures. (A) CNN1D layer (B) BiRNN layer (C) RNN layer (D) LSTM layer (E) GRU layer.
Recurrent Neural Network Based Architectures
In the RNN architecture, instead of being connected to each other, the cells are connected to the former sequence of the input itself (Figure 5C). For example, at time t, the RNN cells link to the previous state of themselves at the time (t−1). There are many ways of using RNN efficiently. For the sake of a fair comparison between the different DL architectures tested here, only one-layer RNN is used as in Figure 5C.
The LSTM layer is used in the same layer as CNN or RNN. However, the LSTM cells work differently. The LSTM has two outputs at time t. The first output is connected to the “Drop Out” layer in the DL model. The second output forwards information to the next LSTM cell, and the cell also receives the input from the previous LSTM cell (Figure 5D).
BiRNN combines two hidden LSTM layers, and each LSTM layer has an opposite direction. Hence, the BiRNN can get backward or forward information (Figure 5B). This is a powerful DL architecture for sequence data with bidirectional context. However, BiRNN is slower than LSTM, because it runs in both forward and backward recursion (Li et al., 2019).
GRU is a new version of LSTM with fewer gates inside. The gates can keep or reject the information from the inputs. Additionally, the internal structure of GRU is simpler, and its performance is faster than LSTM because it has fewer computational operations to update the parameters of the hidden layers. In our model, the GRU layer is similar to the LSTM layer, with LSTM cells replaced by GRU cells (Figure 5E).
Experimental Setups
We conducted the experiments on Dell Precision 7550. The computer has 16 CPUs with Intel Core I7-10875H@2.3 GHz, with 8 cores and 128 GB memory. Additionally, it includes Nvidia Quadro T2000 with 4 GB memory. Since the DL models require GPU devices, our experiments used the whole memory of the Nvidia card on the computer with the “Timesteps” = 12. The configuration of each method is described in the rest of this section.
GBM Tuning
GBM is implemented using the H2O library for Python. The parameters of the model are shown in Table 2. We set the tuning of “ntrees” parameters by maximizing 15,000 trees. The learning rate was tuned to 0.05, in order to satisfy the convergence criterion quickly. If the GBM model cannot improve, the model will stop after the “stopping_round” iterations. The other parameters were used as the sample in the H2O library. These parameters are similar to a previous study (Rybarczyk and Zalakeviciute, 2021).

Table 2. Parameters for GBM in H2O library.
DL Tuning
All DL models are run with the TensorFlow library (version 2.3.0) on Python programming language. The parameters for all the DL models are listed in Table 3. We tuned “Timesteps” and “The number of nodes” to find the best model for each pollutant. “Epochs” is a parameter used as a condition for stopping the model. Specifically, the DL stops after 300 iterations if no global optimization is reached. Otherwise, the Early Stopping Strategy is applied, based on the “Patience” parameter. This means that the training model finishes after 20 iterations (Patience = 20) if the performance cannot improve. The “Drop out” (0.25) eliminates 25% of connections to reduce the overfitting. The learning rate is 0.05, which increases the speed of convergence in DL models. “Batch size” controls the gradient error in the models. CNN requires two additional parameters, which are the kernel size and polling size. If “Timesteps” is one, these parameters are one, and they should be tuned to three if “Timesteps” is greater or equal to three. A total of 30 models (five “Timesteps” × six “The number of nodes”) for each DL architecture were created.
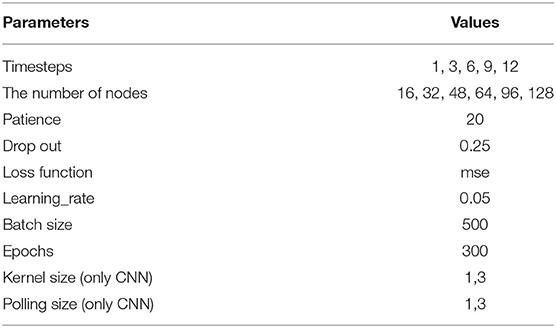
Table 3. Parameters for all DL models.
Evaluation Metrics
Two metrics were used to evaluate and compare the performance of the GBM and WNMs (DL-based models): Root Mean Square Error (RMSE) and coefficient of determination (R2). RMSE and R2 were computed according to Equations (2) and (3), respectively. RMSE ranges from zero to plus infinity, and R2 ranges from 0 to 1. In both equations, yi are predicted values and yi are actual values of sample i, and p is the size of the testing set; are mean of actual values. To obtain the best evaluation, the RMSE must be as close as possible to zero and the R2 as close as possible to one.
SHapley Additive exPlanations for Model Explanation
DL has been applied in many research areas, because of its high performance. On the other hand, DL is considered as a black box, which makes it difficult to explain why a model has a good prediction. Nevertheless, the important values for input features can be disclosed by using SHAP (Lundberg and Lee, 2017). This method is based on Equation (4). In this equation, φj(val) is the SHAP value for feature j; when a feature has higher φj(val), it is assessed as a stronger contributor for the model; S is the set of features in the model or predictors; p is the number of input variables; xj is the vector values of feature j; and val(S) is the output variable with the set S or pollutant concentrations.
SHAP values are used for interpreting the correlations between the input and output features. The higher the value is, the higher the importance is. SHAP values can provide a deeper understanding of the contribution of meteorological and temporal variables to pollutant concentrations.
Results and Discussions
In Section Performance, the performance of five DL architectures and GBM is compared, based on the lowest RMSE and highest R2. In order to look into the black boxes, the variable importance for the best WNMs is carried out in Section Variable Importance. Finally, these latter models are used for assessing the effects of COVID-19 lockdowns on air quality in Quito (Section Quantifying Air Quality Changes).
Performance
The performance of WNMs before the lockdown is presented in Table 4. Overall, the accuracy of the proposed DL models is better than that of the GBM. Particularly, BiRNN and LSTM outperform the GBM algorithm for predicting pollution concentrations. While BiRNN yields the best results with respect to O3 concentrations (RMSE = 7.1854; R2 = 0.8628), NO2 concentrations (RMSE = 7.3644; R2 = 0.5772) and CO concentrations (RMSE = 0.1830; R2 = 0.7148), the LSTM gives the best results with respect to SO2 (RMSE = 1.0506; R2 = 0.4702) and PM2.5 concentrations (RMSE = 6.7677; R2 = 0.4310). Consequently, three BiRNNs and two LSTMs models are used for the second part of the study, which consists of identifying variable importance and assessing the impacts of COVID-19 lockdown on air quality.
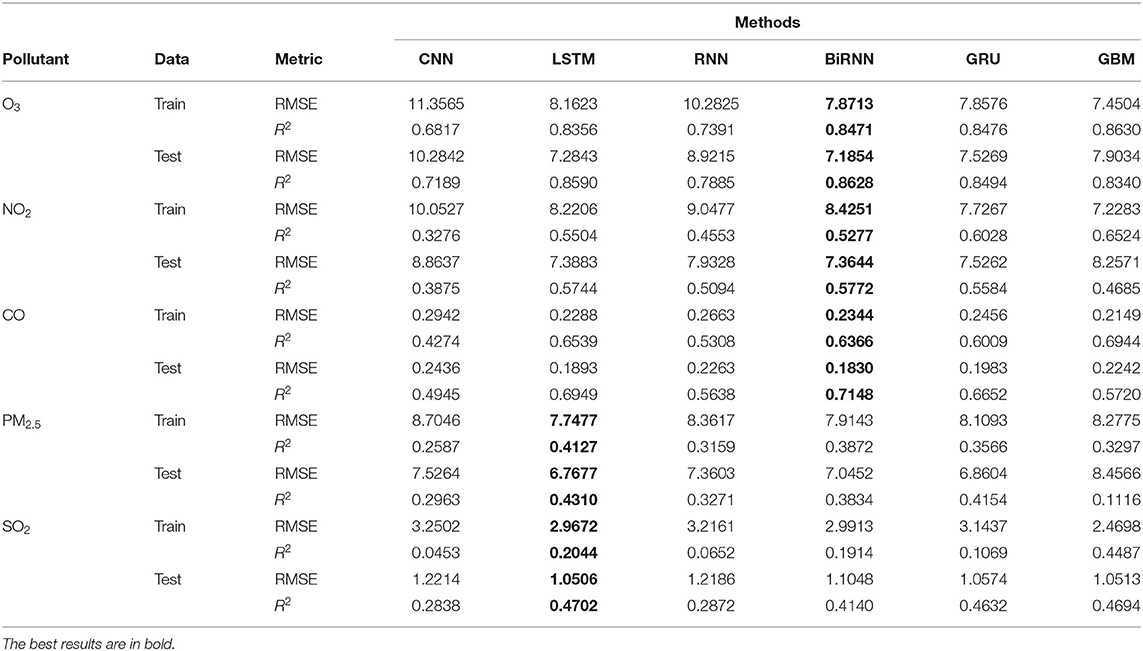
Table 4. Performance of GBM and five DL models for evaluation period.
Additionally, the predicted performance of the models for O3 (R2= 0.8628), CO (R2= 0.7148) and NO2 (R2= 0.5772) is better than SO2 (R2= 0.4702) and PM2.5 (R2= 0.4310). This can be affected by the distributions and outliers of the data in Figure 2. The outliers in training data are more than the testing data with all pollutants. Especially, these outliers are much higher in SO2 and PM2.5 than other pollutants. Although R2 of SO2 and PM2.5 is under 0.5, the RMSE of these pollutants with LSTM architecture is also lower than other algorithms during the testing period. This performance suggests that the WNMs are reliable in estimating the BAU and, consequently, can provide accurate quantification of the air pollution change during the lockdowns.
It is to note that the errors in the training set are higher than the errors in the test set. Besides the outliers on the data as mentioned above, this can be caused by the “Drop Out” layer and Early Stopping strategy in DL models. On one hand, the “Drop Out” of the TensorFlow library helps the model to reduce the overfitting on the training data, but it is not active in the testing phase. Therefore, the testing error is lower than the training error in some situations. On the other hand, the Early Stopping strategy selects the best parameter setting with the lowest testing error (Fathi and Shoja, 2018).
Variable Importance
SHAP provided an in-depth method for analyzing the contribution of each feature to predict pollutant concentrations in the ML and DL models. Figure 6 shows the mean of SHAP values of the input features with five best models for O3 (Figure 6A), CO (Figure 6B), NO2 (Figure 6C), SO2 (Figure 6D) and PM2.5 (Figure 6E). The higher SHAP value means that the feature is more important in predicting the outputs. If we consider the top four variables, both meteorological and temporal features contributed to the best models. Hours, Index, RH and SR, are more important than other variables in the Ozone estimation model (Figure 6A). Ozone is a secondary pollutant that is issued from photochemical reactions, confirming the importance of SR and RH in the concentrations of this feature. Secondly, while SR, WS and Hours have crucial contributions to NO2 models (Figure 6C), Index, WS and SR play an important role in predicting SO2 concentrations (Figure 6D). WS is a significant feature in most of the best WNMs. This is due to the fact that the wind tends to clean the atmosphere through a ventilation effect. RH is also a good predictor of four pollutants NO2, O3, SO2, and CO. The NO2 and CO concentrations are emitted from motorized vehicles and RH tends to worsen engine efficiency, especially in high altitude cities (Zalakeviciute et al., 2018a). Thirdly, the Hours feature was the most significant variable in estimating NO2, O3, and PM2.5 concentrations. It can be explained by the existence of two significant concentration peaks at the rush hours (around 8:00 a.m. and 6:00 p.m.) in the city (Rybarczyk and Zalakeviciute, 2018). The SHAP values of “Hours” are over 0.05 in O3, around 0.01 in NO2 and over 0.002 in PM2.5. Finally, the Julian Day (seasonal) feature is the highest contributor for the PM2.5 model (SHAP value ≈ 0.0042). Since the PM2.5 emitted from traffic is very sensitive to humidity, the existence of dry and wet seasons can explain the importance of “Julian Day” in the prediction of these latter pollutants (Kleine Deters et al., 2017).
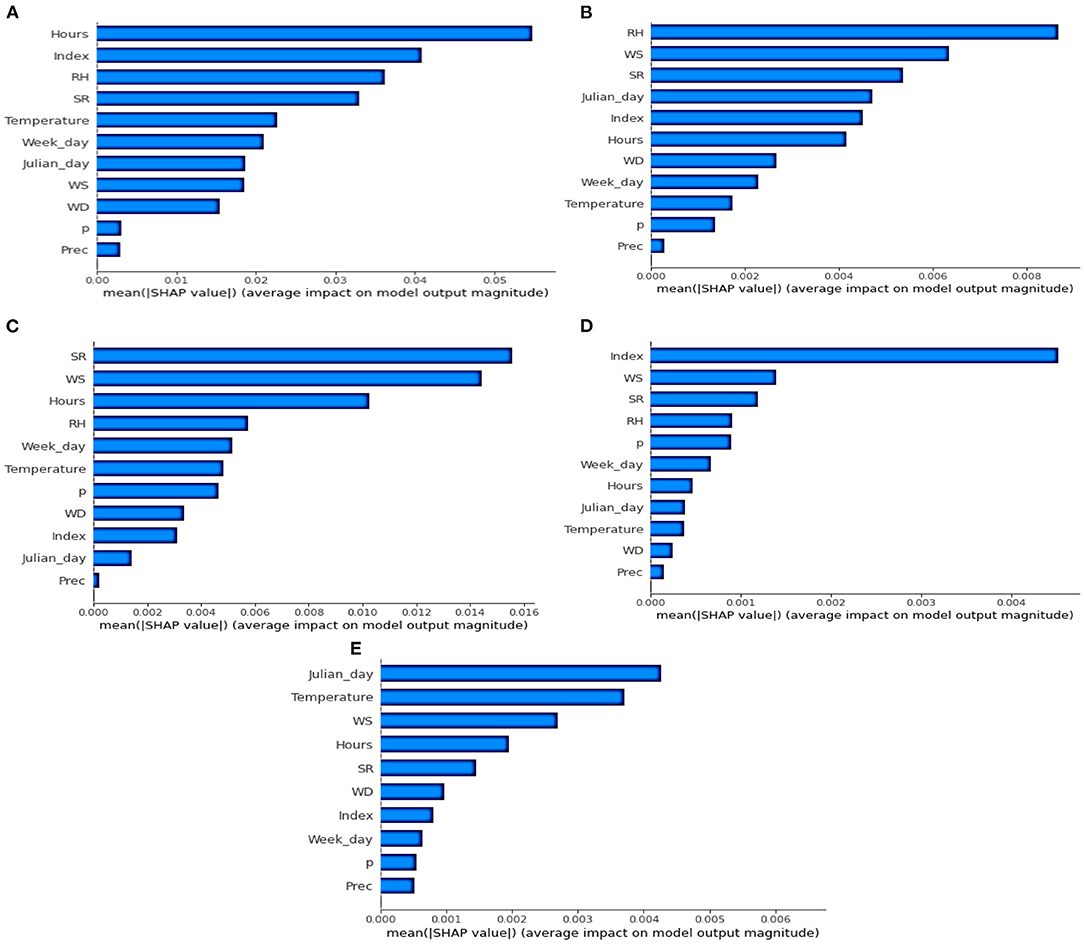
Figure 6. Variable importance with mean (|SHAP value|) for the five best models. (A) O3 (B) CO (C) NO2 (D) SO2 (E) PM2.5.
Quantifying Air Quality Changes
Figure 7 shows the concentration of PM2.5, NO2, CO, SO2, and O3 from 16 January 2020 to 30 September 2020. For the 2 months before lockdown (green area represents the model evaluation period), the estimated values are closer to observations. This confirms that the best models (LSTM for PM2.5, SO2 and BiRNN for O3, NO2, CO) provided accurate referential values for quantifying the concentration of contaminants without lockdown (BAU scenario). On the contrary, the concentration of pollutants decreases drastically during the lockdown period (red area in Figure 7). The largest drop, −63.98%, is observed for NO2 (Table 5). Meanwhile, CO concentration is reduced by −48.75%. The decline is a bit lower for PM2.5 and SO2 with −42.17 and −45.76%, respectively. These improvements in air quality can be explained by the substantial reduction in the use of public and private transportations. These results are in line with a previous study (Rybarczyk and Zalakeviciute, 2021), showing that traffic is the main source of pollution in the city center of Quito.
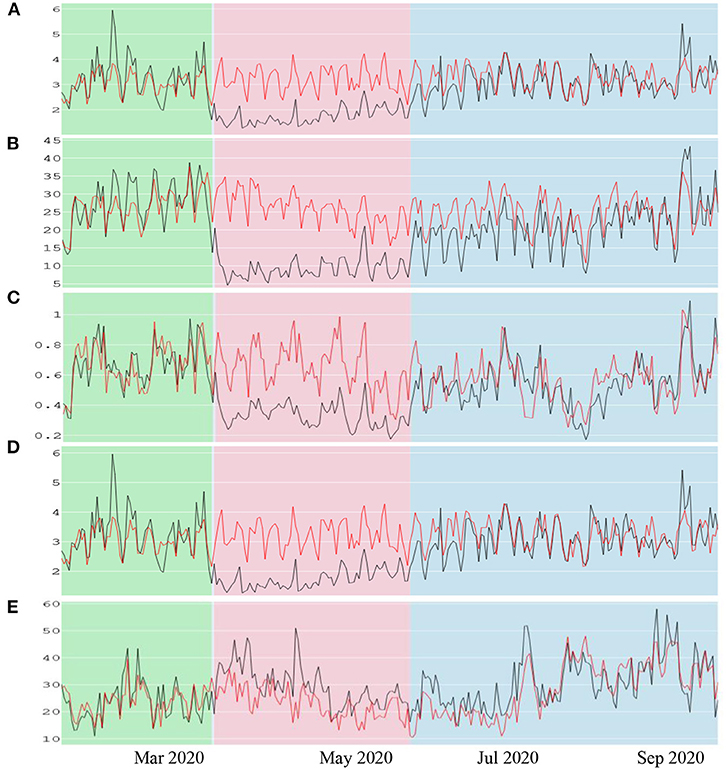
Figure 7. Observed and predicted concentrations of pollutants during the pre-lockdown (green area or validation period), full lockdown (pink area) and partial relaxation (blue area). The black and red lines are the observed and modeled values, respectively. (A) represents PM2.5 concentrations. (B) represents NO2 concentrations. (C) represents CO concentrations. (D) represents SO2 concentrations. (E) represents O3 concentrations.
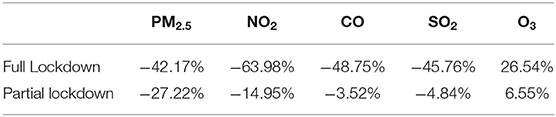
Table 5. The effects of two levels of restriction on five pollutants concentrations.
In contrast to the other pollutants, the concentration of the secondary pollutant, O3, increased by 26.54% during the full lockdown. This is due to the weakness of NOx-O3 titration process (Cazorla et al., 2021). When the concentration of NOx/NO2 decreased, the concentration of O3 tends to increase because of the higher ozone production rates. This is a common urban effect noticed during weekends when anthropogenic activities decrease (Huryn and Gough, 2014).
Finally, during the partial lockdown, the pollutant concentrations displayed in the blue area shows that the BAU values tend to overlap with the observed concentrations. As shown in Table 5, the difference of pollutant concentrations between the actual and predicted values during the partial lockdown is significantly reduced, especially for O3 (6.55%), CO (−3.52%), and SO2 (−4.84%). This is due to the gradual intensification of anthropogenic activities as businesses started opening up, and more and more people started circulating by using their motorized fleets.
Conclusions and Future Work
In this research, we proposed WNMs based on DL for quantifying the air quality changes during the full and partial lockdowns due to the COVID-19 pandemic in Quito, Ecuador. In the context of the BAU conditions, the results indicated that DL models are appropriate for assessing the changes in anthropogenic pollutant concentrations. DL is more accurate in predicting the concentration of contaminants than the ML algorithms used in previous studies, namely Random Forest (Lovrić et al., 2021) and GBM (Petetin et al., 2020; Rybarczyk and Zalakeviciute, 2021). Among the DL algorithms, the LSTM and BiRNN are the best architectures for simulating the BAU conditions and can be considered as a promising standard method for assessing air quality.
The study has also demonstrated that our WNMs can capture the correlations among meteorological and temporal variables on five contaminants before the COVID-19 lockdown period. SHAP library allows us to look into the DL black-box and estimate the weights of the input features in the final models. This additional analysis shows that both meteorological and temporal features are relevant in developing the best WNMs. Among the top four variables, we can identify WS, SR and RH for meteorological features and Hours, Index, Julian Day for temporal features.
Our study shows that the concentration of the pollutants decreased by 63.98, 48.75, 45.76, and 42.17% for NO2, CO, SO2, and PM2.5, respectively, during the full lockdown. An increase in O3 concentration (26.54%) was attributed to the decline in the NO2 concentrations, also known as the weekend effect. On the other hand, as soon as the partial lockdown was implemented and the relaxed regulations on license plate-based circulation were introduced, the pollution concentrations increased gradually up to the BAU level. This fact suggests a short inertia between the alteration of the human mobility and its impact on the air quality of the city.
Even if DL provides better performance than ML, this study is still facing some limitations. First, we do not apply any transformation (e.g., normalization) and remove outliers from the dataset, considering the similar distribution between training and testing sets. However, outliers and skewed data can affect the performance of our models. Second, the error rate is higher in the training set than in the testing set, which suggests further tuning for the Drop Out rate and Patience parameters of DL models. Finally, more advanced algorithms seem necessary to improve the prediction of SO2 and PM2.5 (R2 <0.5). Therefore, future work will focus on overcoming these limitations, such as developing WNMs that combine several DL architectures (i.e., LSTM+BiRNN or LSTM+GRU), and normalizing PM2.5 and SO2 concentrations.
To sum up, the outcome of the present study highlights the fact that air quality in Quito is directly and highly dependent on the mobility of its population. It suggests further research to explore and understand the correlations between traffic, anthropogenic activities, and air pollution. Finally, the general contribution of this work is to propose a new method, DL-based WNMs, allowing an accurate assessment of the effect of any natural event or human intervention on air quality.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
PC and YR contributed to the conception and design of the study. RZ organized the database. PC implemented the codes, re-processed data and experiments, and wrote the first draft of the manuscript. PC, YR, RZ, and IT contributed to manuscript revision, read, edit, and approved the submitted version. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank the Secretariat of the Environment of the Municipality of the Metropolitan District of Quito for providing us with the air quality and meteorological data. We also thank the supports from Jorge H. Amorim for this manuscript.
Footnotes
References
Athira, V., Geetha, P., Vinayakumar, R., and Soman, K. (2018). Deepairnet: applying recurrent networks for air quality prediction. Proc. Comput. Sci. 132, 1394–1403. doi: 10.1016/j.procs.2018.05.068
Barré, J., Petetin, H., Guevara, M., Pérez García-Pando, C., Bowdalo, D., and Jorba Casellas, O. (2021). Estimating lockdown-induced European NO2 changes using satellite and surface observations and air quality models. Atmos. Chem. Phys. 21, 7373–7394. doi: 10.5194/acp-21-7373-2021
Betancourt, C., Stomberg, T., Stadtler, S., Roscher, R., and Schultz, M. G. (2021). AQ-Bench: a benchmark dataset for machine learning on global air quality metrics. Earth Syst. Sci. Data Discuss. 13, 3013–3033. doi: 10.5194/essd-2020-380
Cazorla, M., Herrera, E., Palomeque, E., and Saud, N. (2021). What the COVID-19 lockdown revealed about photochemistry and ozone production in < city>Quito < /city>, Ecuador. Atmos. Pollut. Res. 12, 124–133. doi: 10.1016/j.apr.2020.08.028
EMASEO (2011). De Quito, Municipio del Distrito Metropolitano. Plan de desarrollo 2012-2022. Quito: Municipio de Quito.
Fan, J., Li, Q., Hou, J., Feng, X., Karimian, H., and Lin, S. (2017). A spatiotemporal prediction framework for air pollution based on deep RNN. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 4, 15. doi: 10.5194/isprs-annals-IV-4-W2-15-2017
Fathi, E., and Shoja, B. M. (2018). “Deep neural networks for natural language processing,” in Handbook of Statistics, Vol. 38, eds V. N. Gudivada and C. R. Rao (Amsterdam: Elsevier), 229–316.
Friedman, J. H.. (2001). Greedy function approximation: a gradient boosting machine. Ann. Stat. 1189–1232. doi: 10.1214/aos/1013203451
Gardiner, F. W., Gillam, M., Churilov, L., Sharma, P., Steere, M., Hannan, M., et al. (2020). Aeromedical retrieval diagnostic trends during a period of Coronavirus 2019 lockdown. Intern. Med. J. 50, 1457–1467. doi: 10.1111/imj.15091
Gidhagen, L., Krecl, P., Targino, A. C., Polezer, G., Godoi, R. H. M., Felix, E., et al. (2021). An integrated assessment of the impacts of PM2.5 and black carbon particles on the air quality of a large Brazilian city. Air Qual. Atmos. Health. 14, 1455–1473. doi: 10.1007/s11869-021-01033-7
Gkatzelis, G. I., Gilman, J. B., Brown, S. S., Eskes, H., Gomes, A. R., Lange, A. C., et al. (2019). The global impacts of COVID-19 lockdowns on urban air pollution: a critical review and recommendations. Elementa Sci. Anthrop. 7:46. doi: 10.1525/elementa.2021.00176
Grange, S. K., Carslaw, D. C., Lewis, A. C., Boleti, E., and Hueglin, C. (2018). Random forest meteorological normalisation models for Swiss PM 10 trend analysis. Atmos. Chem. Phys. 18, 6223–6239. doi: 10.5194/acp-18-6223-2018
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Huryn, S. M., and Gough, W. A. (2014). Impact of urbanization on the ozone weekday/weekend effect in Southern Ontario, Canada. Urban Clim. 8, 11–20. doi: 10.1016/j.uclim.2014.03.005
INEC (2011). Superficie (km2), Densidad Poblacional a Nivel Parroquial. Quito. Available online at: https://www.ecuadorencifras.gob.ec/search/Poblaci%C3%B3n,+superficie+(km2),+densidad+poblacional+a+nivel+parroquial/
Jogin, M., Madhulika, M. S., Divya, G. D., Meghana, R. K., and Apoorva, S. (2018). “Feature extraction using convolution neural networks (CNN) and deep learning,” in 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT) (Bangalore: IEEE), 2319–2323.
Kleine Deters, J., Zalakeviciute, R., Gonzalez, M., and Rybarczyk, Y. (2017). Modeling PM2.5 urban pollution using machine learning and selected meteorological parameters. J. Elect. Comp. Eng. 5106045, 1–14. doi: 10.1155/2017/5106045
Krishan, M., Jha, S., Das, J., Singh, A., Goyal, M. K., and Sekar, C. (2019). Air quality modelling using long short-term memory (LSTM) over NCT-Delhi, India. Air Qual. Atmos. Health 12, 899–908. doi: 10.1007/s11869-019-00696-7
Kristiani, E., Lee, C.-F., Yang, C.-T., Huang, C.-Y., Tsan, Y.-T., and Chan, W.-C. (2020). Air quality monitoring and analysis with dynamic training using deep learning. J. Supercomput. 77, 5586–5605. doi: 10.1007/s11227-020-03492-8
Kuremoto, T., Kimura, S., Kobayashi, K., and Obayashi, M. (2014). Time series forecasting using a deep belief network with restricted Boltzmann machines. Neurocomputing 137, 47–56. doi: 10.1016/j.neucom.2013.03.047
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. doi: 10.1109/5.726791
Lelieveld, J., Evans, J. S., Fnais, M., Giannadaki, D., and Pozzer, A. (2015). The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 525, 367–371. doi: 10.1038/nature15371
Li, Q., Ness, P. M., Ragni, A., and Gales, M. J. (2019). “Bi-directional lattice recurrent neural networks for confidence estimation” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Brighton: IEEE), 6755–6759.
Liwicki, M., Graves, A., Fernàndez, S., Bunke, H., and Schmidhuber, J. (2007). “A novel approach to on-line handwriting recognition based on bidirectional long short-term memory networks,” in Proceedings of the 9th International Conference on Document Analysis and Recognition, ICDAR (Parana).
Lovrić, M., Pavlović, K., Vuković, M., Grange, S. K., Haberl, M., and Kern, R. (2021). Understanding the true effects of the COVID-19 lockdown on air pollution by means of machine learning. Environ. Pollut. 274, 115900. doi: 10.1016/j.envpol.2020.115900
Lundberg, S. M., and Lee, S.-I. (2017). “A unified approach to interpreting model predictions,” Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, CA).
Navares, R., and Aznarte, J. L. (2020). Predicting air quality with deep learning LSTM: towards comprehensive models. Ecol. Inform. 55, 101019. doi: 10.1016/j.ecoinf.2019.101019
Nitheesh, M. G., Gokulakrishnan, R., and Devadas, P. (2021). “Air prediction by given attribute based on supervised with classification machine learning approach,” in Advances in Electronics, Communication and Computing, eds P. K. Mallick, A. K. Bhoi, G. S. Chae and K. Kalita (Singapore: Springer), 413–420.
Ong, B. T., Sugiura, K., and Zettsu, K. (2016). Dynamically pre-trained deep recurrent neural networks using environmental monitoring data for predicting PM 2.5. Neural Comp. Appl. 27, 1553–1566. doi: 10.1007/s00521-015-1955-3
Petetin, H., Bowdalo, D., Soret, A., Guevara, M., Jorba, O., Serradell, K., et al. (2020). Meteorology-normalized impact of the COVID-19 lockdown upon NO2 pollution in Spain. Atmosp. Chem. Phys. 20, 11119–11141. doi: 10.5194/acp-20-11119-2020
Piqueras, P., and Vizenor, A. (2016). The Rapidly Growing Death Toll Attributed to Air Pollution: A Global Sresponsibility. Policy Brief for GSDR. WHO, 1–4. Available online at: https://sdgs.un.org/documents/brief-gsdr-rapidly-growing-death-toll-21621
Pollastri, G., and McLysaght, A. (2005). Porter: a new, accurate server for protein secondary structure prediction. Bioinformatics 21, 1719–1720. doi: 10.1093/bioinformatics/bti203
Pope, C. A., Ezzati, M., and Dockery, D. W. (2012). Validity of observational studies in accountability analyses: the case of air pollution and life expectancy. Air Qual. Atmos. Health 5, 231–235. doi: 10.1007/s11869-010-0130-3
Qin, D., Yu, J., Zou, G., Yong, R., Zhao, Q., and Zhang, B. (2019). A novel combined prediction scheme based on CNN and LSTM for urban PM 2.5 concentration. IEEE Access 7, 20050–20059. doi: 10.1109/ACCESS.2019.2897028
Ragab, M. G., Abdulkadir, S. J., Aziz, N., Al-Tashi, Q., Alyousifi, Y., Alhussian, H., et al. (2020). A novel one-dimensional CNN with exponential adaptive gradients for air pollution index prediction. Sustainability 12, 10090. doi: 10.3390/su122310090
Rybarczyk, Y., and Zalakeviciute, R. (2018). “Regression models to predict air pollution from affordable data collections,” in Machine Learning – Advanced Techniques and Emerging Applications, ed F. Hamed (London: IntechOpen), 15–48.
Rybarczyk, Y., and Zalakeviciute, R. (2021). Assessing the COVID-19 impact on air quality: a machine learning approach. Geophys. Res. Lett. 48:e2020GL091202. doi: 10.1029/2020GL091202
Schmid, H. P., Grimmond, C. S. B., Cropley, F., Offerle, B., and Su, H. B. (2000). Measurements of CO2 and energy fluxes over a mixed hardwood forest in the mid-western United States. Agric. For. Meteorol. 103, 357–374. doi: 10.1016/S0168-1923(00)00140-4
Schuster, M., and Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transact. Signal Process. 45, 2673–2681. doi: 10.1109/78.650093
Seinfeld, J. H., and Pandis, S. N. (2016). Atmospheric Chemistry and Physics: From Air Pollution to Climate Change. Hoboken, NJ: John Wiley & Sons.
Sun, Q., Zhu, Y., Chen, X., Xu, A., and Peng, X. (2021). A hybrid deep learning model with multi-source data for PM2.5 concentration forecast. Air Qual. Atmos. Health 14, 503–513. doi: 10.1007/s11869-020-00954-z
Sundermeyer, M., Alkhouli, T., Wuebker, J., and Ney, H. (2014). “Translation modeling with bidirectional recurrent neural networks,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Doha).
Tong, W., Li, L., Zhou, X., Hamilton, A., and Zhang, K. (2019). Deep learning PM2.5 concentrations with bidirectional LSTM RNN. Air Qual. Atmos. Health 12, 411–423. doi: 10.1007/s11869-018-0647-4
WHO (2020). Coronavirus Disease. Available online at: https://www.who.int/docs/default-source/coronaviruse/situation-reports/20200621-covid-19-sitrep-153.pdf?sfvrsn=c896464d_2 (accessed March 09, 2021).
WHO (2021a). Air Pollution. Available online at: https://www.who.int/health-topics/air-pollution#tab=tab_1 (accessed March 09, 2021).
WHO (2021b). Public Health and Environment. Available online at: https://www.who.int/data/gho/data/themes/public-health-and-environment (accessed March 09, 2021).
Wu, Y., Xu, X., Chen, Z., Duan, J., Hashimoto, K., Yang, L., et al. (2020). Nervous system involvement after infection with COVID-19 and other coronaviruses. Brain Behav. Immun. 87, 18–22. doi: 10.1016/j.bbi.2020.03.031
Zalakeviciute, R., López-Villada, J., and Rybarczyk, Y. (2018a). Contrasted effects of relative humidity and precipitation on urban PM2.5 pollution in high elevation urban areas. Sustainability 10:2064. doi: 10.3390/su10062064
Zalakeviciute, R., Rybarczyk, Y., López-Villada, J., and Diaz Suarez, M. V. (2018b). Quantifying decade-long effects of fuel and traffic regulations on urban ambient PM2.5 pollution in a mid-size South American city. Atmos. Pollut. Res. 9, 66–75. doi: 10.1016/j.apr.2017.07.001
Zalakeviciute, R., Vasquez, R., Bayas, D., Buenano, A., Mejia, D., Zegarra, R., et al. (2020). Drastic improvements in air quality in Ecuador during the COVID-19 outbreak. Aerosol Air Qual. Res. 20, 1783–1792. doi: 10.4209/aaqr.2020.05.0254
Keywords: air pollution, machine learning, deep learning - artificial neural network (DL-ANN), data-driven modeling and optimization, COVID-19
Citation: Chau PN, Zalakeviciute R, Thomas I and Rybarczyk Y (2022) Deep Learning Approach for Assessing Air Quality During COVID-19 Lockdown in Quito. Front. Big Data 5:842455. doi: 10.3389/fdata.2022.842455
Received: 23 December 2021; Accepted: 14 February 2022;
Published: 04 April 2022.
Edited by:
Forrest M. Hoffman, Oak Ridge National Laboratory (DOE), United StatesReviewed by:
Alex Jung, Aalto University, FinlandJianwu Wang, University of Maryland, United States
Copyright © 2022 Chau, Zalakeviciute, Thomas and Rybarczyk. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Phuong N. Chau, Y25wQGR1LnNl; Yves Rybarczyk, eXJ5QGR1LnNl