 Kexin Ning
Kexin Ning Qingguo Lü
Qingguo Lü Xiaofeng Liao
Xiaofeng Liao- College of Computer Science, Chongqing University, Chongqing, China
In this study, we focus on investigating a nonsmooth convex optimization problem involving the l1-norm under a non-negative constraint, with the goal of developing an inverse-problem solver for image deblurring. Research focused on solving this problem has garnered extensive attention and has had a significant impact on the field of image processing. However, existing optimization algorithms often suffer from overfitting and slow convergence, particularly when working with ill-conditioned data or noise. To address these challenges, we propose a momentum-based proximal scaled gradient projection (M-PSGP) algorithm. The M-PSGP algorithm, which is based on the proximal operator and scaled gradient projection (SGP) algorithm, integrates an improved Barzilai-Borwein-like step-size selection rule and a unified momentum acceleration framework to achieve a balance between performance optimization and convergence rate. Numerical experiments demonstrate the superiority of the M-PSGP algorithm over several seminal algorithms in image deblurring tasks, highlighting the significance of our improved step-size strategy and momentum-acceleration framework in enhancing convergence properties.
1 Introduction
In the field of image deblurring, the solution of inverse problems can usually be attributed to the solution of constrained optimization problems; thus, the development of optimization solvers for inverse problems with constraints has been a subject of intense research interest. Significantly, the constrained optimization problems arising from image restoration tasks, i.e., denoising, inpainting, and deblurring, can be defined as follows (Bonettini et al., 2008):
where f(x) is a convex function measuring the divergence between the restored and measured data. Due to the ill-posedness of the image restoration problem, a composite regularized function, given by the sum of a fit-to-data function and a penalty function, can be considered to achieve a trade-off between data fidelity and iteration convergence (Tang et al., 2023). Due to the sparsity of image issues, the penalty term generally uses a nonsmooth function, i.e., the l1-norm; then, the regularized optimization problem can be formed as (Malitsky and Mishchenko, 2024):
where f(x) is the discrepancy term, which could be smooth, and g(x) is the nonsmooth penalty term. To address this regularized and nonsmooth optimization problem, the proximal gradient method (PGM) is regarded as a robust and efficient approach. PGM is particularly effective in large-scale and high-dimensional composite optimization problems, with wide applications in signal processing (Wang, 2025) and image restoration (Liu et al., 2019). To address the composite optimization problem (Equation 2), the PGM combines gradient descent with a proximal operator on the penalty term, as shown as follows (Parikh and Boyd, 2014):
where αk > 0 is the step size for gradient descent, and the proximal operator for the penalty function g is defined as follows:
By invoking the proximal operator, the PGM effectively manages non-smooth components and promotes sparse solutions, thus outperforming traditional gradient-based techniques in non-smooth optimization contexts (Aravkin et al., 2022). Classically, the two-step iterative shrinkage thresholding (TwIST) algorithm extends the PGM by introducing a momentum term that relies on the two previous iterations, leading to faster convergence rates for ill-conditioned problems (Bioucas-Dias and Figueiredo, 2007). Thereafter, the fast iterative shrinkage thresholding (FISTA) algorithm was proposed, which improves the PGM by incorporating the Nesterov momentum term and an adaptive step size, thereby accelerating the global convergence rate (Beck and Teboulle, 2009). Moreover, optimization problems in practical applications are often constrained by domain-specific requirements, which motivate the development of the gradient projection method (GPM) to address constrained optimization problems (Zhou et al., 2025). For solving Equation 1, the GPM combines gradient descent with a projection operator, leading to the following iteration:
in which the projection operator of a vector x ∈ ℝN onto the region set is defined as follows:
The projection operation can achieve minimal computational expense while restricting the iterative vector onto the feasible set . This is evident in the specific case of problem (Equation 2), i.e., lasso regression and ridge regression, where projection can be computed in linear time (Maroni et al., 2025). Consequently, the GPM and its improvements stand as credible schemes to address image deblurring tasks, thanks to their low per-iteration computational overhead (Chen et al., 2025).
Through an optimized fusion of PGM and GPM, a scaled gradient projection (SGP) algorithm was proposed to address the constrained composite problem (Equation 2) (Bonettini and Prato, 2015). The SGP algorithm introduces a scaling matrix Dk during the proximal gradient descent; that is,
Compared with the FISTA algorithm, SGP demonstrates superior convergence rates and enhances deblurring performance. Recently, aiming to accelerate the solution of the composite optimization method, an optimal accelerated composite optimization (OptISTA) algorithm to solve Equation 2 was developed, which improves FISTA by optimizing the step size via a double-function method and theoretically establishes an exact matching lower bound for composite optimization problems (Jang et al., 2025). Afterwards, the improved OptISTA (IOptISTA) algorithm was proposed, which incorporates a weighting matrix technique and achieves superior numerical performance in image deblurring tasks (Wang et al., 2025).
To accelerate convergence during optimization, the Barzilai-Borwein rules, which serve as adaptive step-size strategies that determine step sizes without relying on online searches, have been widely investigated and improved (He et al., 2023). Serving as an effective and seminal step-size selection strategy, the Barzilai-Borwein (BB) step-size selection rules have garnered significant attention, which approximate the Hessian matrix inverse in a quasi-Newton manner, providing a step size that can adaptively adjust to the descent direction of the problem, which leads to faster convergence rates (Barzilai and Borwein, 1988). Recently, in the context of l1-regularized problems, a novel step-size selection rule within the proximal gradient framework was proposed, which achieves acceleration by preemptively identifying the optimal redundant components using the spectral properties of the BB step size (Crisci et al., 2024). Beyond step-size improvement, momentum methods provide additional convergence acceleration (Zhang et al., 2023). Classically, the Heavy-Ball (HB) algorithm leverages momentum from past gradients to amplify descent directions, thereby improving convergence rates in ill-conditioned optimization landscapes (Polyak, 1964). Afterwards, Nesterov proposed an Accelerated Gradient (NAG) algorithm, which achieves faster convergence by calculating the gradient at an extrapolated future position based on current momentum (Nesterov, 1983). Building upon foundational momentum techniques, a series of momentum frameworks has been developed to achieve enhanced convergence properties. In Yang et al. (2016), a unified framework was developed to implement a range of momentum acceleration variants by altering related parameters. Recently, another unified paradigm was proposed, which features two momentum-based algorithm variants for decentralized stochastic gradient descent (Du et al., 2024).
Motivated by the effectiveness of the SGP algorithm in combining PGM and GPM and inspired by acceleration strategies involving step-size rules and momentum techniques, we focus on developing a solver for the constrained l1-regularized optimization problem, aiming to accelerate convergence while preserving optimization performance in image deblurring.
The main contributions in this study are summarized below.
We propose a momentum-based proximal scaled gradient projection (M-PSGP) algorithm that combines the procedure of the SGP algorithm with a unified momentum framework (UM). Numerical experiments demonstrate the effectiveness of UM in stabilizing and accelerating the convergence rate of our algorithm.
• We design a new step-size selection rule BB2* and apply it in the M-PSGP algorithm. The BB2* rule can be regarded as an enhancement of the BB-like step-size rule proposed by Crisci et al. (2024). By combining it with UM, a dual acceleration effect could be achieved. Numerical experiments illustrate the superiority of BB2* by comparing it with other rules in terms of accelerating the convergence rate.
• Compared with other seminal proximal gradient projection algorithms, the M-PSGP algorithm can accelerate the convergence rate of l1-regularized optimization problems. Meanwhile, the M-PSGP algorithm can achieve better performance in image deblurring tasks, particularly when applied to images generated by convolving a Gaussian blur with originally astronomical or medical images and adding Gaussian white noise.
Organization: In Section 2, we describe the constrained l1-regularized optimization problem by presenting the image formation and the principle of image deblurring. In Section 3, we present the SGP algorithm in detail and propose the M-PSGP algorithm. In Section 4, we perform a convergence analysis for the M-PSGP algorithm. In Section 5, we conduct a series of comparative experiments and demonstrate the effectiveness of the M-PSGP algorithm. In Section 6, our final remarks and future work are given.
Notation: Throughout the article, is a vector stacked from the two-dimensional original image X ∈ ℝN, N = n × n. Similarly, the vector is stacked from the observed image Y ∈ ℝN, and the vector is stacked from the background additive noise B ∈ ℝN. A ∈ ℝN × N is a given matrix modeling the blur effect. The symbol λ is a regularization coefficient. The symbol is the l1-norm of x. ||x|| denotes the standard Euclidean norm for x, indicates the D-norm, where D is a symmetric positive definite matrix. ∇f(x) is the gradient of the continuous function f at x, and ∂g(x) is the subdifferential of the semicontinuous function g at x.
2 Problem description
2.1 Image formation and deblurring modeling
In this work, we note that the image blur is caused by out-of-focus blur during detection. Under the assumption that the blur is uniform across the original image, the blurring process can be modeled as a convolution process:
where A is the blur kernel, Y is the blurred image, X is the original image, and B represents background additive noise.
The goal of image deblurring is to recover the original image X from the observed Y. Due to the extreme ill-conditioning of A, the original image cannot be directly obtained through matrix operations. Hence, we employ the Bayesian approach, which uses prior information about the original object, to model the solution process of this inverse problem. The Bayes formula provides the conditional probability of xi given the value yi:
Assume that the blur kernel A and the background noise B follow Gaussian distributions; then, the distribution of blurred pixel values yi is given by the following:
where σ is the standard deviation of B. Then, the likelihood is estimated as follows:
Assume that X is a Gibbs random field with a distribution:
where Z is a normalization constant, and g(x) is a given function, usually called the penalization function. By taking the negative logarithm of PY(yi|xi)PX(xi) and considering the maximum estimation of the posterior probability distribution, the image deblurring can be modeled as an optimization problem of the form:
in which f(x) is the simplified negative logarithm of Equation 4 defined as follows:
2.2 Problem formulation
Let ⊆ ℝN be a closed convex set. For arbitrary x ∈ , f(x): → ℝ is a convex, continuously differentiable function and g(x): → ℝ is a convex and lower semicontinuous function. Following Equation 5, we consider the constrained optimization problem as follows:
in which, under the assumption that the blur kernel and background noise follow Gaussian distributions, following estimation (Equation 4) and its simplified negative logarithm (Equation 6), we let f(x) be a least squares function and choose the l1-norm to serve as g(x). Under these conditions, F(x) is convex and the gradient ∇f(x) = A⊤(Ax − b), which implies that for any x, y ∈ :
Thus, ∇f(x) is L-Lipschitz continuous with .
In the following, we will provide some related definitions and basic properties.
Definition 1 (Stationary point). Given a closed convex set ⊆ ℝN and a proper, convex function F: → ℝ, a point x* ∈ is the stationary point of F if 0 ∈ ∂F(x*).
Below, the definition of subdifferential for a general function is provided.
Definition 2 (Limiting subdifferential). Given a closed convex set ⊆ ℝN and a convex and lower semicontinuous function g: → ℝ, the limiting subdifferential at a point x ∈ is:
In the situation, the subdifferential of g(x) = λ||x||1 can be computed by:
In our study, the proximal operator is applied based on the definition 3.
Definition 3 (Proximal operator). Given a closed convex set ⊆ ℝN and a threshold L > 1, let , the proximal operator associated with a non-negative parameter α is defined as:
The Lipschitz continuity property of the operator (Equation 9) is stated in Lemma 1:
Lemma 1. (Bauschke and Combettes, 2017) If g: → ℝ is convex, proper and lower semicontinuous, for any x, y ∈ , it satisfies:
Definition 4 (Projection operator). Given a closed convex set ⊆ ℝN and a threshold L > 1, let , the projection operator is defined as follows:
The Lipschitz continuity property of the operator (Equation 10) is stated as Lemma 2:
Lemma 2. (Bonettini et al., 2008) If D ∈ DL and x, y ∈ , then:
Naturally, corresponding to the progress of gradient descent, the stationary point can be confirmed by the iterative value, as in Lemma 3:
Lemma 3. (Bonettini and Prato, 2015) A vector x* ∈ is a stationary point of Equation 7 if and only if
3 Methods
3.1 The SGP algorithm
The SGP algorithm (Bonettini and Prato, 2015) combines the scaled gradient descent method (Equation 3) with a line search procedure, resulting in the following iteration:
It employs a symmetric positive definite matrix Dk in front of ∇f(xk) during the process of gradient descent, and the entries in are defined as:
where L is an appropriate threshold, customarily chosen as the Lipschitz constant of the objective function. Based on the BB rules, αk is confirmed as follows:
where sk−1 = xk − xk−1 and zk−1 = ∇f(xk)−∇f(xk−1). Further, the step-size αk in Equation 12 is adaptively alternated based on or .
Specifically, if the iterate yk obtained from the projection is identical to the current iterate xk, then xk is recognized as a stationary point. If yk ≠ xk, a descent direction is defined as dk = yk − xk, and it is incorporated into the update procedure specified in Equation 12, where λk is the step-size for the descent iteration.
3.2 The proposed M-PSGP algorithm: momentum-based proximal scaled gradient projection algorithm
The update direction of PGM is solely determined by the negative gradient of the continuous part of the objective function, which could lead to oscillations during the iteration. The SGP invokes the scaled matrix Dk before the negative gradient, which enhances the descent step size but also raises the oscillations. To address such circumstances, momentum methods can mitigate oscillations by incorporating a velocity term that averages past gradients, thereby leveraging inertia to stabilize direction in the face of perturbations (Xie et al., 2025). Moreover, by leveraging historical gradient information, the momentum method could maintain large updates even in low-curvature areas, indicating the acceleration effect on the convergence rate (Loizou and Richtárik, 2020).
Considering the effects of acceleration and stability on momentum methods, we integrate a unified momentum framework, UM (Yang et al., 2016), within SGP, resulting in the M-PSGP algorithm for the problem (Equation 7). Setting α > 0, β ∈ [0, 1], and s ≥ 0, the update process of UM is described as follows:
• When s = 0, the update is reduced to the HB method:
• When s = 1, the update is exactly the form of the NAG method:
• When , the update of xk+1 is essentially a gradient method (GM) to achieve acceleration:
By incorporating the UM (Equation 16) into the procedure (Equations 11, 12), the M-PSGP algorithm is delineated in Algorithm 1. For clarity, we also provide the exact flow diagram of Algorithm 1 in Figure 1.
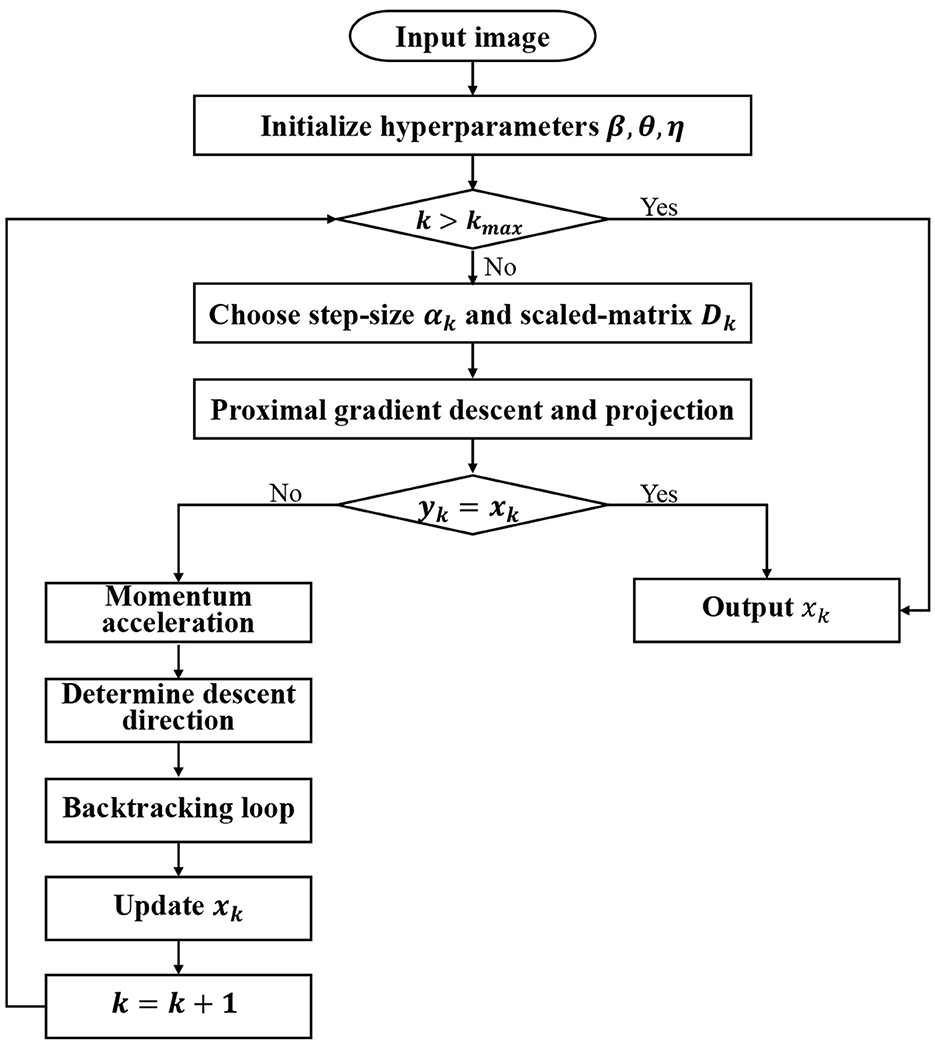
Figure 1. The flow diagram of the Algorithm 1.

Algorithm 1. M-PSGP.
As illustrated in Figure 1, beyond parameter initialization, the algorithm primarily consists of four key computational phases, including proximal gradient descent and projection, momentum acceleration, determining the descent direction, and the backtracking loop. In the proximal gradient descent and projection step, the M-PSGP computes a gradient descent step on the smooth component f(x), then applies the proximal operator to account for the non-smooth regularizer g(x) in line 6. Subsequently, line 7 applies the projection operator to ensure constraint satisfaction. In the momentum acceleration step, the M-PSGP first computes the next intermediate position mk, as shown in line 10. The calculation of momentum vk is defined as mk − mk−1, and to satisfy the non-negative constraint, it should be projected as in line 11. The value vk captures the change between successive intermediate positions during the optimization process. Thus, in line 12, the M-PSGP incorporates information about the past gradients into the update step, which helps accelerate and stabilize convergence toward the stationary point. Here, η is a hyperparameter that modulates the effect of momentum on the update direction. Subsequently, the descent direction is formally defined as the vector difference between the current iterate and the momentum-corrected candidate point in line 14. Finally, a backtracking line search loop in line 19 is executed to find an appropriate step size along this direction, which recalls the generalized non-monotone Armijo-type line search proposed by Zhang (2010).
In Figure 2, we present a schematic diagram of a single iteration for both the M-PSGP and SGP algorithms. To provide a more intuitive explanation, we present Table 1, which specifies the definitions of all nodes and vectors, along with their correspondences to the key steps of Algorithm 1. Based on the explanations provided in Table 1, we can conclude from Figure 2 that, under identical initial conditions, the E node (obtained by the M-PSGP algorithm) moves closer to the stationary point of F(x) after one iteration than the F node (obtained by the SGP algorithm). This observation further verifies, from a vector operation perspective, the acceleration effect of the M-PSGP algorithm. Additionally, it should be noted that, for the sake of clarity and conciseness, we have omitted explicit emphasis on projection operations, as all vectors are assumed to be constrained within the feasible domain by default. Likewise, nodes C and vector M3 are also presented as the results obtained after applying the proximal operator.
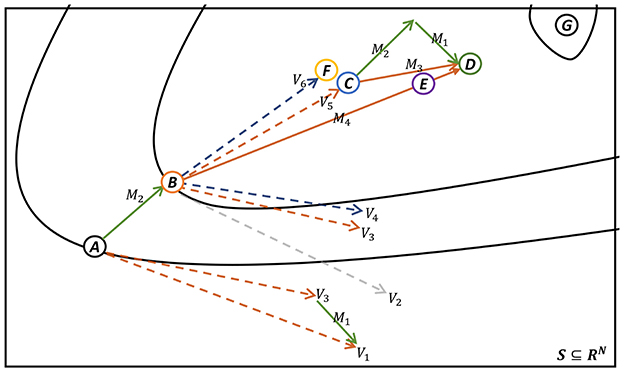
Figure 2. Iteration process of M-PSGP (accelerated by NAG) and SGP Algorithms. Nodes and vectors are noted in Table 1.
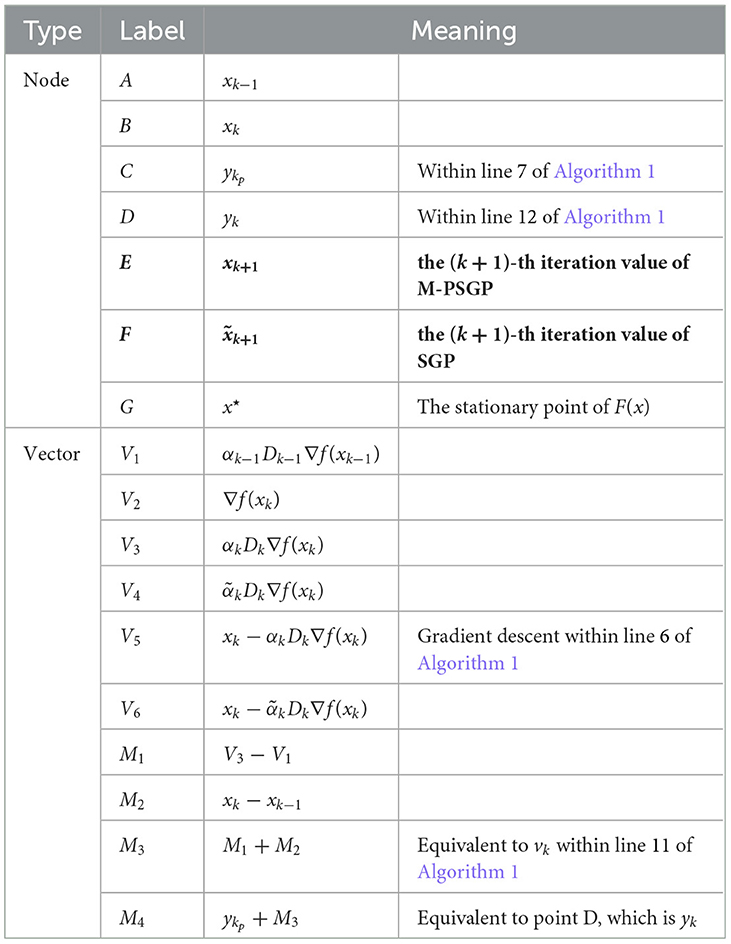
Table 1. Notation of nodes and vectors in Figure 2.
3.3 The improved step-size selection rule
In Algorithm 1, line 6 shows the proximal scaled gradient descent process under projection. Denote tk = αkDk, which governs descent distance and affects the convergence rate during the solving process. In M-PSGP, we are committed to enhancing the selection strategy for the descent parameter tk. The confirmation of Dk in M-PSGP corresponds to the rule (Equation 13) in SGP, which implies that an innovative tk is contingent on a novel αk strategy. In M-PSGP, tailored to the l1-regularized problem (Equation 7), we propose a step-size rule BB2* and a related SS* rule to determine αk, meanwhile, the descent parameter tk is modified. As mentioned by Crisci et al. (2024), we consider the following partition of the index set during the iteration:
where i denotes the index of the zero component in xk. By invoking this partition in Algorithm 1, the iteration is carried out:
in which tk = xk − αkDk ∇ f(xk). Naturally, the vector sk can be separated as:
and the difference between the corresponding gradients zk can be reformulated as:
Applying Equations 20, 21 to the BB rules (Equation 14) and (Equation 15), we can obtain the following:
Inspired by the BB2-like rule for box-constrained problems proposed by Crisci et al. (2019), we develop a new variant, which is termed the BB2* rule, as follows:
Intuitively, the optimization process is accelerated by preemptively eliminating the optimal zero components, as the reciprocal of 1/αk only depends on non-zero components. By excluding these zero components, the step-size calculation can focus on the active subspace, thereby improving the accuracy of curvature estimation, reducing redundant projections, and ultimately enhancing convergence efficiency. Furthermore, motivated by the SGP algorithm, which alternatively chooses αk to balance convergence acceleration with algorithmic robustness, we determine αk by switching between and adaptively. Thereafter, the comprehensive step-size selection rule, which we termed the SS* rule, is defined as follows:
where τ is the threshold determining the translation.
It is remarked that, since we propose a larger step-size rule BB2* (Equation 24) than BB2 (Equation 15), it is possible that the ykp after gradient descent and projection yields an opposite increase. In this situation, a monotone line search, which enforces the sequence f(xk) to be strictly decreasing, might lead to multiple computation loops during backtracking. That results in a dissipation of the acceleration effect achieved by our BB2* rule. Thus, equipping a non-monotone line search procedure is significant for the M-PSGP algorithm to adapt to the inherent non-monotonic nature of our step-size rules.
4 Computational complexity analysis and convergence analysis
In this section, we will focus on the computational complexity analysis and convergence analysis for the M-PSGP algorithm.
4.1 Computational complexity analysis
In our image deblurring problem, the dimension of the optimization variable is n = N = 65, 536 for 256 × 256 images. The point spread function (PSF) matrix A is typically a block circulant matrix with circulant blocks (BCCB). For such structured matrices, the matrix-vector product Ax can be computed with (nlogn) complexity by employing the fast Fourier transform (FFT) (Davis, 1979). Thus, the computational cost of major operations in one iteration of our M-PSGP algorithm is analyzed as follows:
• Gradient computation (T∇): Computing requires two FFT-based operations, yielding (nlogn) complexity.
• Function evaluation (Tf): Evaluating also requires FFT operations, with (nlogn) complexity.
• BB step-size computation (TBB): Calculating αk involves vector differences and inner products, requiring (n) operations.
• Diagonal scaling (TD): Applying the diagonal scaling matrix Dk to vectors is an element-wise operation with (n) complexity.
• Proximal/projection operations (Tproj): Both the proximal operator for the ℓ1-norm and the projection onto the non-negative orthant are element-wise operations with (n) complexity.
• Backtracking evaluations (Nbt): The average number of function evaluations during backtracking line search.
• Proximal calls (Cprox): The number of proximal/projection calls per iteration (typically Cprox = 2 in M-PSGP).
The overall per-iteration computational complexity can be expressed as follows:
Substituting the respective complexities:
Therefore, the per-iteration time complexity of the proposed M-PSGP algorithm is:
The (nlogn) term dominates due to the FFT-based gradient and function evaluations, while all other operations maintain linear (n) complexity. This complexity is significantly more efficient than the (n2) complexity required by direct matrix operations, making our algorithm suitable for high-dimensional image processing problems.
4.2 Convergence analysis
In this section, we will focus on the convergence analysis for the M-PSGP algorithm. The main convergence guarantee of M-PSGP in the case of heavy-ball momentum acceleration is presented in Theorem 1, and its proof is based on a series of basic properties that we state in the following lemmas.
Lemma 4. Assume that yk ≠ xk, then, the dk = yk − xk is a strict descent direction for the function f at xk, that is, .
Proof. The proof of this lemma is detailed in Appendix A. □
Lemma 5. Define ek = mk − xk, where mk = xk − sαkDk ∇ f(xk), it has:
for ||Dk|| ≤ L, αk ∈ [αmin, αmax] and G = maxx ∈ ||∇f(x)||.
Proof. The proof of this lemma is detailed in Appendix B.
Lemma 6. Consider a Lyapunov function , where F(x) is constructed as Equation 7 and ||ek|| is defined as (29). There exist constants σ, ρ > 0 such that:
Proof. The proof of this lemma is detailed in Appendix C.
Lemma 7. Let β ∈ (0, 1) and θ ∈ (0, 1) be fixed constants. For any iteration k, the nonmonotone backtracking line search terminates in a finite number of trials; that is, there exists wk > 0 such that the following inequality holds:
where fmax = max0 ≤ j ≤ min(k, M−1)f(xk−j).
Proof. The proof of this lemma is detailed in Appendix D.
Theorem 1. Consider the composite convex minimization problem (Equation 7) and suppose the sequence {xk} is generated by the M-PSGP algorithm under the assumption that the level set {x:F(x) ≤ F(x0)} is bounded. Then the sequence {xk} converges to a stationary point x* of F over = {x : x ≥ 0}, i.e.,
Proof. The proof of this theorem is detailed in Appendix E.
5 Results
In this section, we conduct simulation experiments to confirm the superiority of the M-PSGP algorithm in solving l1-regularized optimization problems, with a focus on its application to image deblurring. All algorithms are implemented in Python 3.8.10, and the experiments are conducted on a computer equipped with a 12th Gen Intel(R) Core(TM) processor at 2.30 GHz.
First, we compare the performance of different BB-like step-size rules within the framework of the SGP algorithm, demonstrating the superiority of SS* rules in accelerating the convergence rate and enhancing deblurring effectiveness. For the sake of convenience in notation, we name the method that incorporates SS* into SGP as the SGP* algorithm. Then, we combine the unified momentum framework UM with the SGP* algorithm, which serves as the M-PSGP algorithm. The comparison between the SGP* and M-PSGP demonstrates the notable advantage of momentum acceleration. Moreover, we compare M-PSGP with other seminal methods and present its excellence.
5.1 Experiment settings and performance measures
All of the algorithms are tested on problem (Equation 7). The test examples are generated by convolving the original 256 × 256 images with the Gaussian kernels of different noise levels (σ2 = 5 and σ2 = 10; higher σ values result in stronger blurring effects), followed by additive white noise with a Gaussian distribution (σ2 = 0.01). To ensure an objective and consistent evaluation of the proposed M-PSGP algorithm and its comparison with the baseline SGP method, we adopted the test examples used in Bonettini and Prato (2015); Federica et al. (2015) and selected two representative CT images. Furthermore, to comprehensively evaluate the generalization capability and robustness of the M-PSGP algorithm, we also selected four images of different types from the standard image processing benchmark dataset Set12 proposed by Zhang et al. (2017) as supplementary test examples. The complete set of selected test examples is presented in Figure 3.

Figure 3. Test examples. The first row displays the original images, the second row displays the deblurred images with σ2 = 5, the third row displays the deblurred images with σ2 = 10. The test images are sequentially labeled as: (A) NGC7027; (B) SATELLITE; (C) CHAOS; (D) OASIS; (E) CAMERAMAN; (F) HOUSE; (G) FISHSTAR; (H) PARROT.
To evaluate and compare the effectiveness of different algorithms, we measure the number of convergence iterations (ITER), the corresponding runtime (TIME) to achieve convergence, relative reconstruction error (RRE) (Bonettini et al., 2008), peak signal-to-noise ratio (PSNR) (Liao et al., 2025), and structural similarity (SSIM) (Liao et al., 2024). These indicators are defined as follows:
where x is the original image and is the deblurred image, M and N denote the sizes along the two dimensions of the image. μx and are the pixel-wise averages, σx and are the variances of x and , is the covariance between x and , and c1 and c2 are stability constants.
In all simulations, we set the maximum number of iterations as 200, , , and α0 = 1.3. The step size threshold τ is set as 0.15. In the backtracking loop step, the line search parameters are θ = 10−4, β = 0.95. The initial iteration value x0 is set as follows: where y are the observed values.
5.2 Comparison of step-size rules in SGP
In this subsection, we inspect the performance in practical implementations of those different step-size rules:
• BB1: , where is defined as the rule (Equation 14).
• BB2: , where is defined as the rule (Equation 15).
• SS: αk is defined following the SS algorithm proposed by Bonettini and Prato (2015).
• BB2*: αk is defined following the rule (Equation 24).
• SS*: αk is defined following the rule (Equation 25).
Here, the BB2* and SS* are our proposed rules. To adhere to the principle of a single variable, thereby enhancing the referential value of the experimental outcomes, we uniformly implement these rules in the SGP algorithm.
The numerical results are reported in Table 2 and Figure 4. Table 2 shows that for all test images, SS* could achieve the highest PSNR and SSIM on all test images, indicating the best optimization effect and the highest quality of the reconstructed images. As shown in the curve in Figure 4, it can be concluded that SS* and BB2* require fewer iterations to achieve the same effect compared to other rules at the preliminary iteration stage, which means that the SS* and BB2* rules can improve the convergence rate more than other rules. Across the comprehensive optimization stages, SS* achieves the lowest RRE (the highest negative logarithm of RRE), demonstrating the dual advantages of SS* in accelerating convergence while enhancing optimization accuracy. Indeed, the SGP algorithm employing the SS* method is equivalent to the M-PSGP algorithm operating without its momentum acceleration, which can be denoted as the SGP* algorithm.
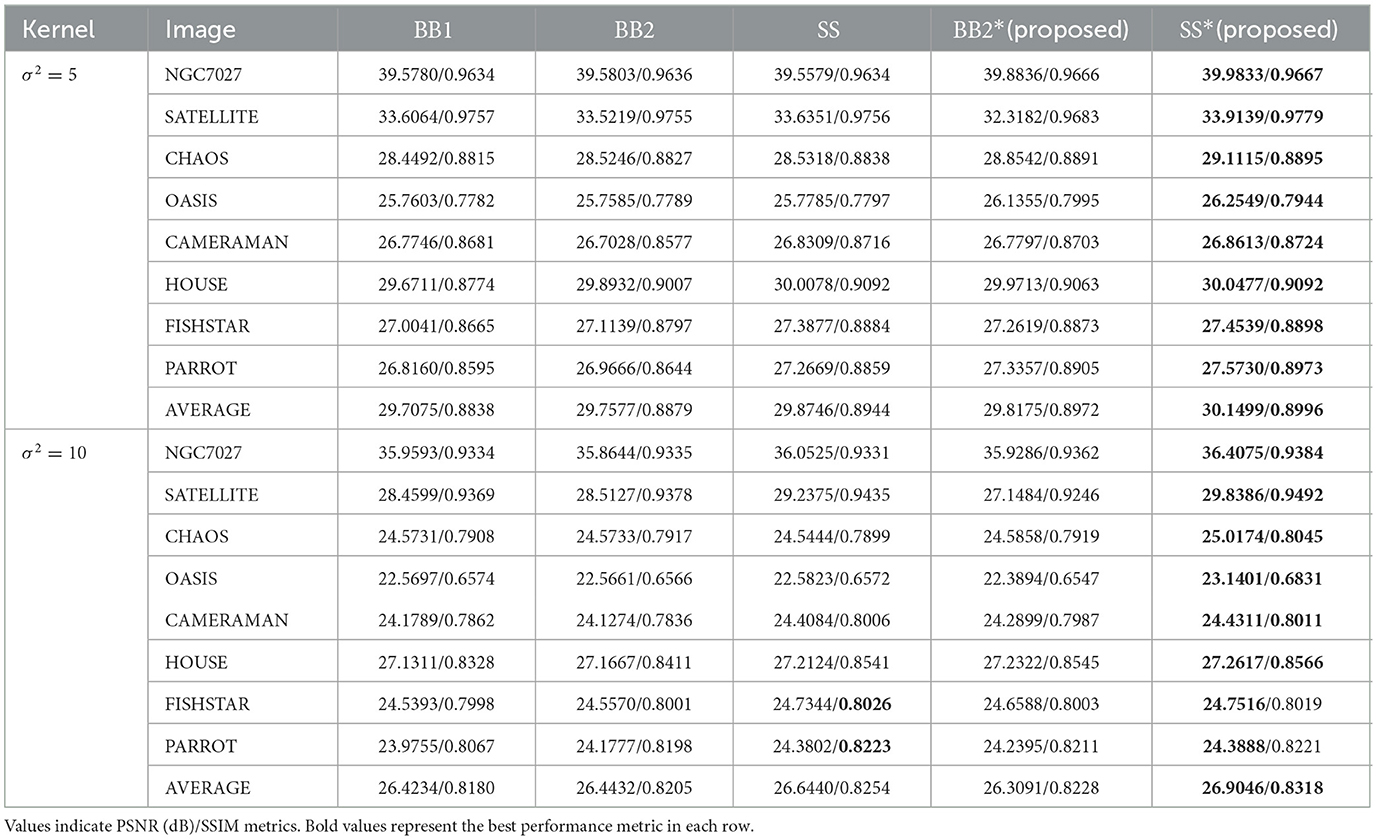
Table 2. Performance comparison of different step-size rules under various noise levels (σ2 = 5 and σ2 = 10).
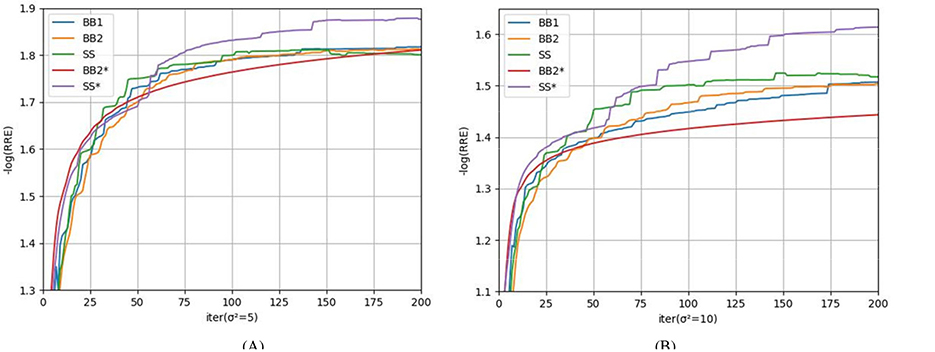
Figure 4. Comparison of different step-size rules in terms of the average negative logarithm of RRE: (A) σ2 = 5; (B) σ2 = 10.
5.3 Comparison between SGP* and M-PSGP
Aiming to study the acceleration and stability effects of the unified momentum framework UM (Equation 16), we compare the M-PSGP algorithm with the SGP* algorithm (M-PSGP without its momentum acceleration) in this subsection. Table 3 presents the numerical performance of SGP* and M-PSGP variants (accelerated by HB, NAG, and GM). The results demonstrate that all M-PSGP variants can produce more efficient results than SGP*. From Figure 5, we can observe that the M-PSGP variants consistently outperform SGP* in convergence speed across noise levels, achieving faster RRE reduction and earlier stabilization. Furthermore, as shown in Equation 16, the selection of parameter η must satisfy the range required for the convergence of the algorithms, and then within this range, values that yield higher performance metrics are chosen. To demonstrate the sensitivity of η, using the NGC7027 case with a blur level of σ2 = 5 as an example, we investigated the performance of three accelerated variants (HB: s = 0, NAG: s = 1, and GM: s = 1/1 − η) under different values of the parameter η. Using the NGC7027 case with a blur level of σ2 = 5 as an example. The experimental results are presented in Figure 6.
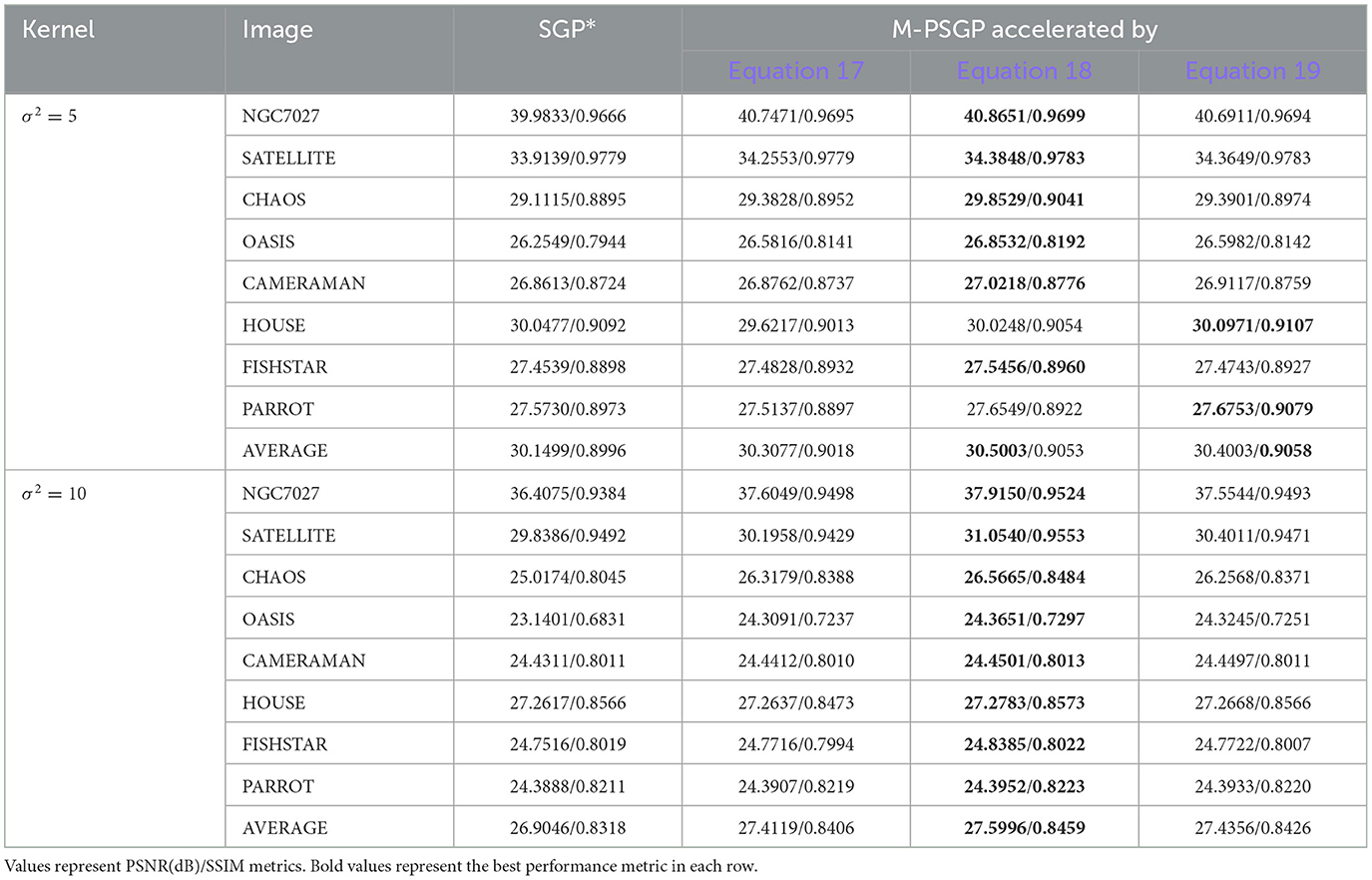
Table 3. Performance comparison between SGP* and M-PSGP accelerated variants under different noise levels (σ2 = 5 and σ2 = 10).
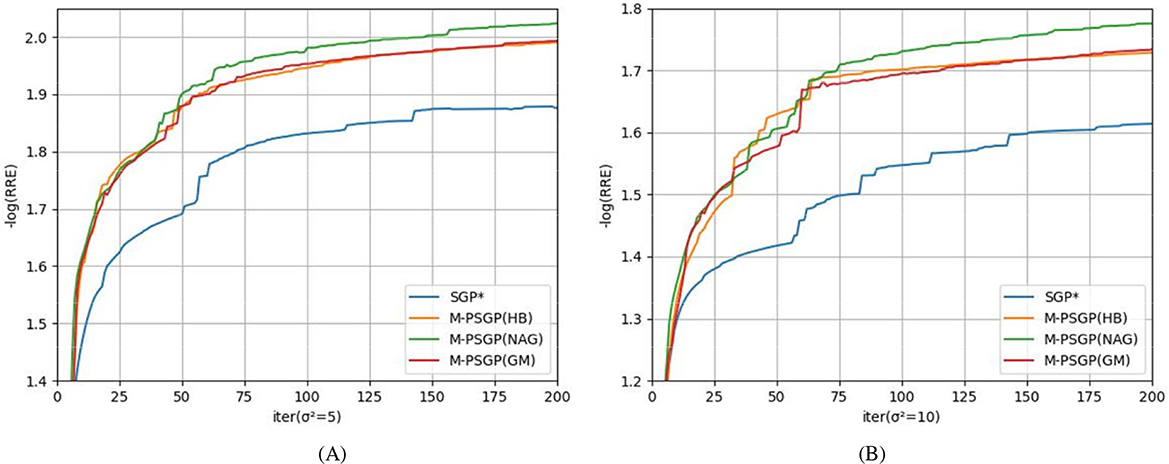
Figure 5. Comparison between SGP* and M-PSGP accelerated variants in terms of the average negative logarithm of RRE: (A) σ2 = 5; (B) σ2 = 10.
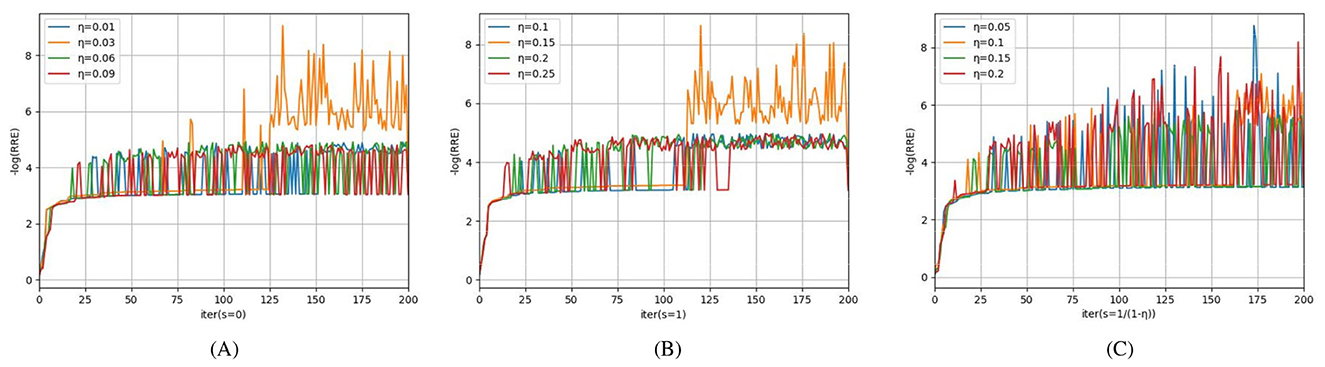
Figure 6. Sensitivity and optimal choice of η for M-PSGP accelerated variants: (A) s = 0; (B) s = 1; (C) s = 1/(1 − η).
5.4 Comparison of M-PSGP with other algorithms
In this subsection, we present the comparison of the M-PSGP algorithm with other algorithms, including TwIST (Bioucas-Dias and Figueiredo, 2007), FISTA (Beck and Teboulle, 2009), SGP (Bonettini and Prato, 2015), OptISTA (Jang et al., 2025), and IOptISTA (Wang et al., 2025). Table 4 presents the performance metrics of M-PSGP and other seminal algorithms, from which we can conclude that M-PSGP achieves the highest PSNR and SSIM, among others. On 12 out of the 16 test examples, the M-PSGP algorithm achieved satisfactory deblurring performance in less time, which is attributed to its requiring fewer iterations to converge. On the remaining four test images, M-PSGP achieved better deblurring performance under the same iteration limit, albeit at the expense of a longer total runtime. In Figure 7, based on the average variations in curvature depicted, we further substantiate that the M-PSGP algorithm can accelerate convergence during the optimization process more than others. In Figure 8, we present a magnified view of the deblurring effects on test images under the Gaussian noise level σ2 = 5, which allows for a visual assessment of the M-PSGP and other algorithms. The magnified details demonstrate the superior capabilities of the M-PSGP algorithm in enhancing the overall effect of image deblurring, as well as in preserving and clarifying edges.
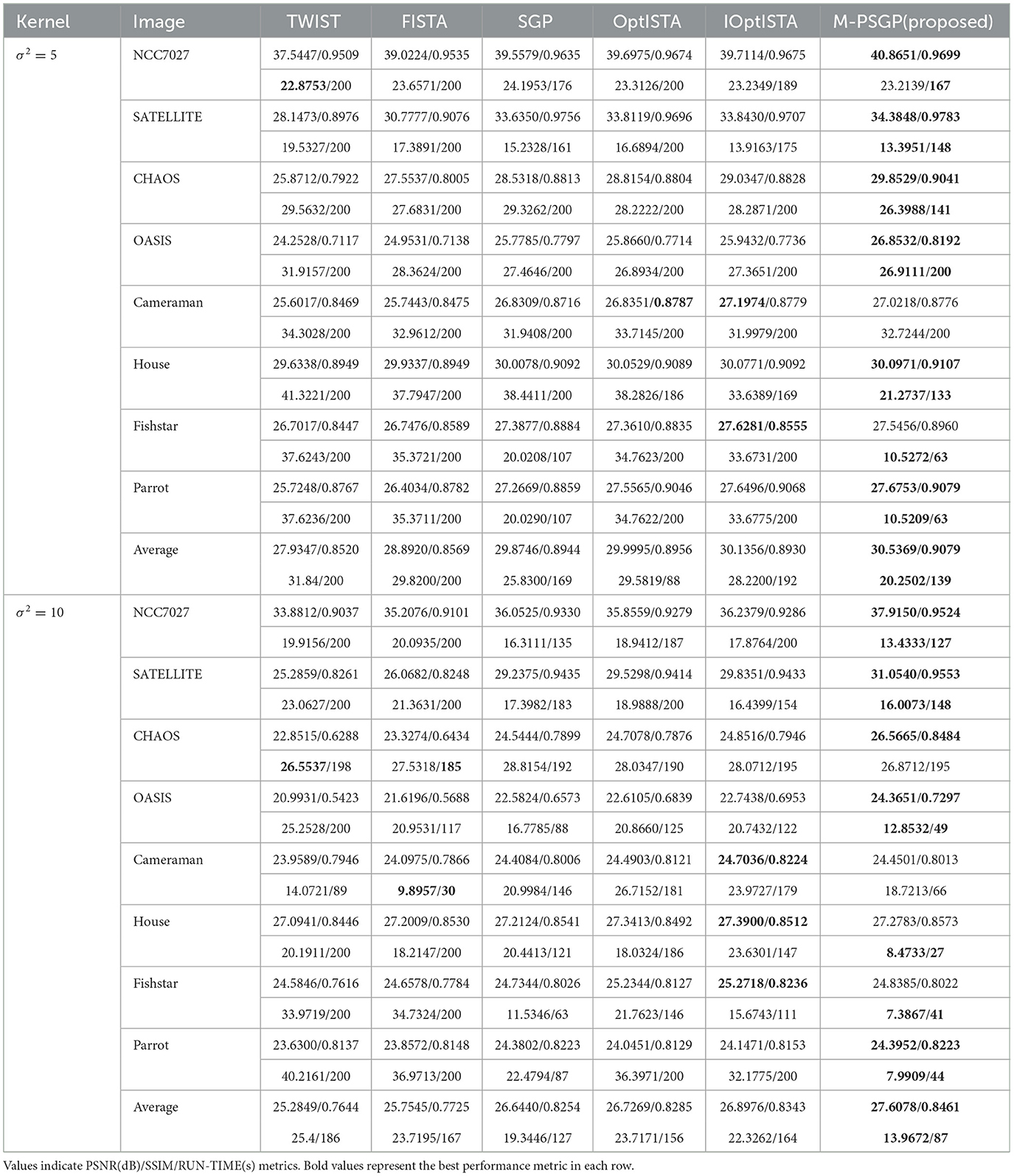
Table 4. Performance comparison of different deblurring algorithms under various noise levels (σ2 = 5 and σ2 = 10).
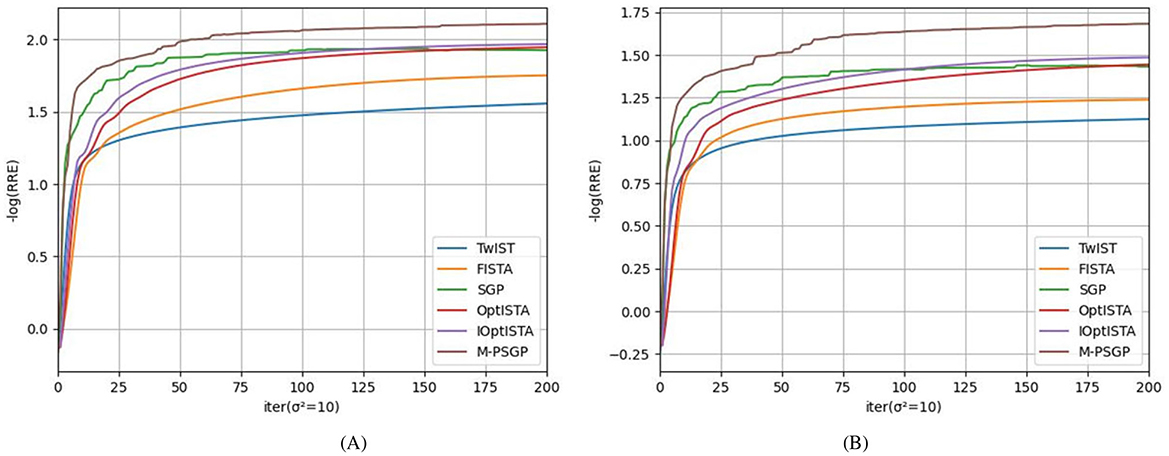
Figure 7. Comparison of TwIST, FISTA, SGP, OptISTA, IoptISTA and M-PSGP in terms of the average negative logarithm of RRE: (A) σ2 = 5; (B) σ2 = 10.

Figure 8. Visual reconstructed results from blurred test images (σ2 = 5). The images shown from left to right are (A) blurred images; (B) TWIST-deblurred images; (C) FISTA-deblurred images; (D) SGP-deblurred images; (E) OptISTA-deblurred images; (F) IoptISTA-deblurred images; (G) M-PSGP-deblurred images.
6 Conclusion and discussion
In this study, we propose the M-PSGP algorithm and demonstrate its significant improvement in optimizing l1-regularized problems, with applications to image deblurring. The integration of the improved step-size rule BB2* and the unified momentum framework UM has led to accelerated convergence rates and improved performance in image deblurring tasks. Numerical experiments have demonstrated that the M-PSGP algorithm outperforms existing proximal gradient projection algorithms, TwIST, FISTA, SGP, OptISTA, and IOptISTA. The M-PSGP algorithm has presented a credible alternative to conventional techniques in image deblurring and has demonstrated potential applications in other domains, where l1-regularized optimization problems are prevalent. In the future, we will endeavor to apply the M-PSGP algorithm to other optimization problems, such as ridge regression and non-convex optimization, thereby enhancing its applicability to a broader range of signal processing tasks. Furthermore, with the potential to provide novel perspectives for tackling large-scale optimization problems, the application of the M-PSGP algorithm to parameter training in machine learning is also a significant research topic.
While this study presents a promising optimization framework, its practical deployment may face certain limitations that warrant further discussion. First, the performance of the method depends on the selection of several hyperparameters (e.g., η). Although the algorithm incorporates adaptive mechanisms, its sensitivity to these settings may present challenges in practical applications, where parameter tuning is limited or robustness is essential. Second, the convergence analysis and numerical experiments are conducted under standard assumptions. The method's performance in non-Gaussian or heavy-tailed noise environments remains an open question. Such conditions are common in real-world data (e.g., sensor data), and the robustness of momentum acceleration and line search strategies in these settings warrants further investigation. Acknowledging these aspects would provide a more comprehensive view of the method's operational scope and guide future research toward enhancing its practical robustness and applicability.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
KN: Formal analysis, Investigation, Methodology, Visualization, Writing – original draft, Writing – review & editing. QL: Conceptualization, Formal analysis, Investigation, Methodology, Supervision, Writing – original draft, Writing – review & editing. XL: Funding acquisition, Resources, Supervision, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported in part by the Natural Science Foundation of Chongqing (Innovation and Development Joint Fund) under Grants CSTB2023NSCQ-LZX0149 and CSTB2025NSCQ-LZX0085, in part by the Graduate Research and Innovation Foundation of Chongqing under Grant CYB25038, and in part by the National Natural Science Foundation of China under Grants 62576053 and 62302068.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fdata.2025.1704189/full#supplementary-material
References
Aravkin, A., Baraldi, R., and Orban, D. (2022). A proximal quasi-newton trust-region method for nonsmooth regularized optimization. SIAM J. Optim. 32, 900–929. doi: 10.1137/21M1409536
Barzilai, J., and Borwein, J. (1988). Two-point step size gradient methods. IMA J. Numer. Anal. 8, 141–148. doi: 10.1093/imanum/8.1.141
Bauschke, H., and Combettes, P. (2017). Correction to: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Cham: Springer. doi: 10.1007/978-3-319-48311-5
Beck, A., and Teboulle, M. (2009). A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2, 183–202. doi: 10.1137/080716542
Bioucas-Dias, J., and Figueiredo, M. (2007). A new twist: two-step iterative shrinkage/thresholding algorithms for image restoration. IEEE Trans. Image Process 16, 2992–3004. doi: 10.1109/TIP.2007.909319
Bonettini, S., and Prato, M. (2015). New convergence results for the scaled gradient projection method. Inverse Probl. 31:095008. doi: 10.1088/0266-5611/31/9/095008
Bonettini, S., Zanella, R., and Zanni, L. (2008). A scaled gradient projection method for constrained image deblurring. Inverse Probl. 25:015002. doi: 10.1088/0266-5611/25/1/015002
Chen, X., Cheng, D., and Feng, J. (2025). Matrix projection and its application in image processing. Digital Signal Process 163:105231. doi: 10.1016/j.dsp.2025.105231
Crisci, S., Rebegoldi, S., Toraldo, G., and Viola, M. (2024). Barzilai-borwein-like rules in proximal gradient schemes for l1-regularized problems. Optim. Methods. Softw. 39, 601–633. doi: 10.1080/10556788.2023.2285489
Crisci, S., Ruggiero, V., and Zanni, L. (2019). Steplength selection in gradient projection methods for box-constrained quadratic programs. Appl. Math. Comput. 356, 312–327. doi: 10.1016/j.amc.2019.03.039
Du, H., Cheng, C., and Ni, C. (2024). A unified momentum-based paradigm of decentralized sgd for non-convex models and heterogeneous data. Artif. Intell. 332:104130. doi: 10.1016/j.artint.2024.104130
Federica, P., Marco, P., and Luca, Z. (2015). A new steplength selection for scaled gradient methods with application to image deblurring. J. Sci. Comput. 65, 895–919. doi: 10.1007/s10915-015-9991-9
He, C., Zhang, Y., Zhu, D., Cao, M., and Yang, Y. (2023). A mini-batch algorithm for large-scale learning problems with adaptive step size. Digit. Signal Process 143:104230. doi: 10.1016/j.dsp.2023.104230
Jang, U., Gupta, S., and Ryu, E. (2025). Computer-assisted design of accelerated composite optimization methods: optista. Math. Programm. 1–109. doi: 10.1007/s10107-025-02258-5
Liao, X., Wei, X., Zhou, M., Li, Z., and Kwong, S. (2024). Image quality assessment: measuring perceptual degradation via distribution measures in deep feature spaces. IEEE Trans. Image Process. 33, 4044–4059. doi: 10.1109/TIP.2024.3409176
Liao, X., Wei, X., Zhou, M., Wong, H., and Kwong, S. (2025). Image quality assessment: Exploring joint degradation effect of deep network features via kernel representation similarity analysis. IEEE Trans. Pattern Anal. Mach. Intell. 47, 2799–2815. doi: 10.1109/TPAMI.2025.3527004
Liu, R., Sun, W., Hou, T., Hu, C., and Qiao, L. (2019). Block coordinate descent with time perturbation for nonconvex nonsmooth problems in real-world studies. Front. Inform. Technol. Electron. Eng. 20, 1390–1403. doi: 10.1631/FITEE.1900341
Loizou, N., and Richtárik, P. (2020). Momentum and stochastic momentum for stochastic gradient, newton, proximal point and subspace descent methods. Comput. Optim. Appl. 77, 653–710. doi: 10.1007/s10589-020-00220-z
Malitsky, Y., and Mishchenko, K. (2024). “Adaptive proximal gradient method for convex optimization,” in Proc Adv Neural Inf Process Syst (Red Hook, NY Curran Associates, Inc), 100670–100697. doi: 10.52202/079017-3193
Maroni, G., Cannelli, L., and Piga, D. (2025). Gradient-based bilevel optimization for multi-penalty ridge regression through matrix differential calculus. Eur. J. Control. 81, 101150. doi: 10.1016/j.ejcon.2024.101150
Nesterov, Y. (1983). A method for solving the convex programming problem with convergence rate o(1/k2). Proc. Dokl. Akad. Nauk. SSSR 269543.
Parikh, N., and Boyd, S. (2014). Proximal algorithms. Found. Trends Optim. 1, 127–239. doi: 10.1561/2400000003
Polyak, B. (1964). Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 4, 1–17. doi: 10.1016/0041-5553(64)90137-5
Tang, X., Zhao, X., Liu, J., Wang, J., Miao, Y., Zeng, T., et al. (2023). “Uncertainty-aware unsupervised image deblurring with deep residual prior,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9883–9892. doi: 10.1109/CVPR52729.2023.00953
Wang, D. (2025). Monotonically accelerated proximal gradient for nonnegative tensor decomposition. Digital Signal Process 161, 105097. doi: 10.1016/j.dsp.2025.105097
Wang, Q., Xu, S., Tong, X., and Zeng, T. (2025). An improved optimal proximal gradient algorithm for non-blind image deblurring. arXiv [preprint]. arXiv:2502.07602. doi: 10.48550/arXiv:2502.07602
Xie, Z., Liu, L., Chen, Z., and Wang, C. (2025). Proximal gradient algorithm with dual momentum for robust compressive sensing MRI. Signal Process. 230:109817. doi: 10.1016/j.sigpro.2024.109817
Yang, T., Lin, Q., and Li, Z. (2016). Unified convergence analysis of stochastic momentum methods for convex and non-convex optimization. arXiv [preprint]. arXiv:1604.03257. doi: 10.48550/arXiv.1604.03257
Zhang, J. (2010). “On the non-monotone armijo-type line search algorithm,” in Proc Int Conf on Inf and Comput., Vol. 3 (Wuxi: IEEE), 308–311. doi: 10.1109/ICIC.2010.263
Zhang, J., Zhang, G., Liang, Z., and Liao, L. (2023). Momentum acceleration-based matrix splitting method for solving generalized absolute value equation. Appl. Math. Comput. 42:300. doi: 10.1007/s40314-023-02436-1
Zhang, K., Zuo, W., Chen, Y., Meng, D., and Zhang, L. (2017). Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 26, 3142–3155. doi: 10.1109/TIP.2017.2662206
Keywords: momentum acceleration, adaptive step-size, Barzilai–Borwein rules, proximal gradient descent, nonsmooth constrained optimization
Citation: Ning K, Lü Q and Liao X (2025) M-PSGP: a momentum-based proximal scaled gradient projection algorithm for nonsmooth optimization with application to image deblurring. Front. Big Data 8:1704189. doi: 10.3389/fdata.2025.1704189
Received: 12 September 2025; Accepted: 03 November 2025;
Published: 24 November 2025.
Edited by:
Feng Chen, Dallas County, United StatesReviewed by:
Hewa Majeed Zangana, University of Duhok, IraqNur Alamsyah, Universitas Informatika dan Bisnis Indonesia, Indonesia
Copyright © 2025 Ning, Lü and Liao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qingguo Lü, cWdsdkBjcXUuZWR1LmNu; Xiaofeng Liao, eGZsaWFvQGNxdS5lZHUuY24=