 Yang Liu
Yang Liu Wei Mo1,2†
Wei Mo1,2†- 1Endocrinology, The Fifth Clinical College of Guangzhou University of Chinese Medicine, Guangzhou, China
- 2Endocrinology, Guangdong Provincial Second Hospital of Traditional Chinese Medicine, Guangzhou, China
Background: Diabetic ketoacidosis (DKA) is a frequent acute complication of diabetes mellitus (DM). It develops quickly, produces severe symptoms, and greatly affects the lives and health of individuals with DM.This article utilizes machine learning methods to examine the baseline characteristics that significantly contribute to the development of DKA. Its goal is to identify and prevent DKA in a targeted and early manner.
Methods: This study selected 2382 eligible diabetic patients from the MIMIC-IV dataset, including 1193 DM patients with ketoacidosis and 1186 DM patients without ketoacidosis. A total of 42 baseline characteristics were included in this research. The research process was as follows: Firstly, important features were selected through Pearson correlation analysis and random forest to identify the relevant physiological indicators associated with DKA. Next, logistic regression was used to individually predict DKA based on the 42 baseline characteristics, analyzing the impact of different physiological indicators on the experimental results. Finally, the prediction of ketoacidosis was performed by combining feature selection with machine learning models include logistic regression, XGBoost, decision tree, random forest, support vector machine, and k-nearest neighbors classifier.
Results: Based on the importance analysis conducted using different feature selection methods, the top five features in terms of importance were identified as mean hematocrit (haematocrit_mean), mean hemoglobin (haemoglobin_mean), mean anion gap (aniongap_mean), age, and Charlson comorbidity index (charlson_comorbidity_index). These features were found to have significant relevance in predicting DKA. In the individual prediction using logistic regression, these five features have been proven to be effective, with F1 scores of 1.000 for hematocrit mean, 0.978 for haemoglobin_mean, 0.747 for age, 0.692 for aniongap_mean and 0.666 for charlson_comorbidity_index. These F1 scores indicate the effectiveness of each feature in predicting DKA, with the highest score achieved by mean hematocrit. In the prediction of DKA using machine learning models, including logistic regression, XGBoost, decision tree, and random forest demonstrated excellent results, achieving an F1 score of 1.000. Additionally, by applying feature selection techniques, noticeable improvements were observed in the experimental performance of the support vector machine and k-nearest neighbors classifier.
Conclusion: The study found that hematocrit, hemoglobin, anion gap, age, and Charlson comorbidity index are closely associated with ketoacidosis. In clinical practice, these five baseline characteristics should be given with the special attention to achieve early detection and treatment, thus reducing the incidence of the disease.
1 Introduction
Diabetic ketoacidosis (DKA) is a potentially life-threatening metabolic complication associated with diabetes mellitus (DM). DKA is characterized by a severe lack of insulin and increased levels of counter-regulatory hormones, which can cause the accumulation of ketones in the body. If not promptly diagnosed and treated, DKA can lead to serious complications and even death. Therefore, it is critical to closely monitor DM and take appropriate measures to prevent DKA from developing or to swiftly manage it (1). DKA can develop rapidly, often taking place within 24 hours (2). It can even occur earlier in patients treated with short-acting insulin, such as Humalog, with metabolic changes potentially occurring 1.5 to 2 hours sooner (3). Infection is a frequent precipitating factor for DKA worldwide and accounts for approximately 30-50% of DKA cases. Among potential infections, urinary tract infections and pneumonia are among the most commonly associated with DKA. Other factors that can trigger DKA include concurrent health conditions such as surgical procedures, trauma, myocardial ischemia, and pancreatitis. Psychological stress and medication non-compliance, particularly with insulin therapy, can also contribute to the development of DKA (4).
One of the main triggers for DKA is insufficient insulin. In the absence of adequate insulin, blood glucose levels rise, leading to increased breakdown of triglycerides in adipose tissue and release of a large amount of free fatty acids. More free fatty acids enter the kidneys through the liver, causing an increase in gluconeogenesis in the liver and releasing more glucose into the bloodstream. In an environment of high blood glucose and insufficient insulin, the liver begins to excessively produce ketone bodies, including beta-hydroxybutyric acid, acetoacetate, and acetone. The accumulation of ketone bodies in the blood results in increased blood acidity, ultimately leading to ketoacidosis. Ketoacidosis is one of the most significant physiological effects of DKA. Excessive ketone bodies cause an increase in blood acidity, affecting acid-base balance and potentially leading to an acidotic state. Due to increased urine output caused by high blood glucose and ketoacidosis, patients may experience severe dehydration. This can lead to electrolyte imbalances, reduced blood volume, and blood concentration. Dehydration and hyperglycemia may result in disturbances of sodium, potassium, and other electrolytes, potentially triggering arrhythmias and other severe physiological problems. DKA can negatively impact multiple organs, including the heart, kidneys, and nervous system. Recent progress in medical technology has led to significant advances in treatment options for DM. However, despite these developments, the incidence and mortality rates associated with DKA remain high. As the global prevalence of DM continues to rise, the incidence of DKA is also increasing year by year (5). A study involving 28,770 individuals under the age of 20 with DM found that among these participants, 94% did not experience DKA, 5% had a single episode of DKA, and 1% had at least two episodes of DKA (6). The mortality rate for DKA varies between 1% and 5%, with the highest mortality rates typically observed among elderly individuals and those with complications related to their diabetes (7). It is worth noting that cerebral edema, a complication that can occur as a result of DKA, is the leading cause of death among individuals under the age of 24 with DM (8).
Research has shown that there are 100,000 hospitalization cases of DKA in the United States every year, accounting for 4-9% of all discharge records of diabetic patients (4). The treatment of DKA requires a significant amount of healthcare resources. In adult type 1 diabetes patients in the United States, direct medical care costs account for 1/4 of the total expenses (9). Indeed, effective control and prevention of DKA are paramount in reducing healthcare costs. The emergence of computer technology has opened up new avenues for utilizing machine learning techniques to support doctors in disease diagnosis. By leveraging these technologies, healthcare professionals can potentially enhance their diagnostic accuracy and efficiency, leading to improved patient care and cost-effectiveness. Furthermore, given the high risk and poor prognosis associated with DKA, the development of a risk prediction model specifically for this condition is of great importance. Such a model can aid in identifying patients who are at higher risk of experiencing DKA, allowing for targeted interventions and preventive measures. By implementing a risk prediction model, healthcare providers can potentially reduce the incidence of DKA episodes, improve patient outcomes, and mitigate the economic burden on both the healthcare system and patients (10).
This study combines the existing public dataset MIMIC-IV with machine learning techniques for healthcare analysis. By employing feature selection methods (random forest, Spearman correlation analysis), baseline characteristics are optimized to identify five baseline characteristics highly correlated with DKA. Based on the abnormality of these five highly correlated baseline characteristics, early warning can be given in the early stages of the disease, assisting clinicians in clinical diagnosis, providing more effective treatment plans, and reducing the incidence of the disease and patients’ suffering. Meanwhile, this study utilizes six machine learning methods to establish a risk prediction model based on DKA, including logistic regression, XGBoost, decision tree, random forest, support vector machine, and k-nearest neighbors classifier. Experimental results demonstrate the effectiveness of feature selection, as the five optimized baseline characteristics can accurately predict the risk of DKA. The research process of this paper is as depicted in Figure 1.
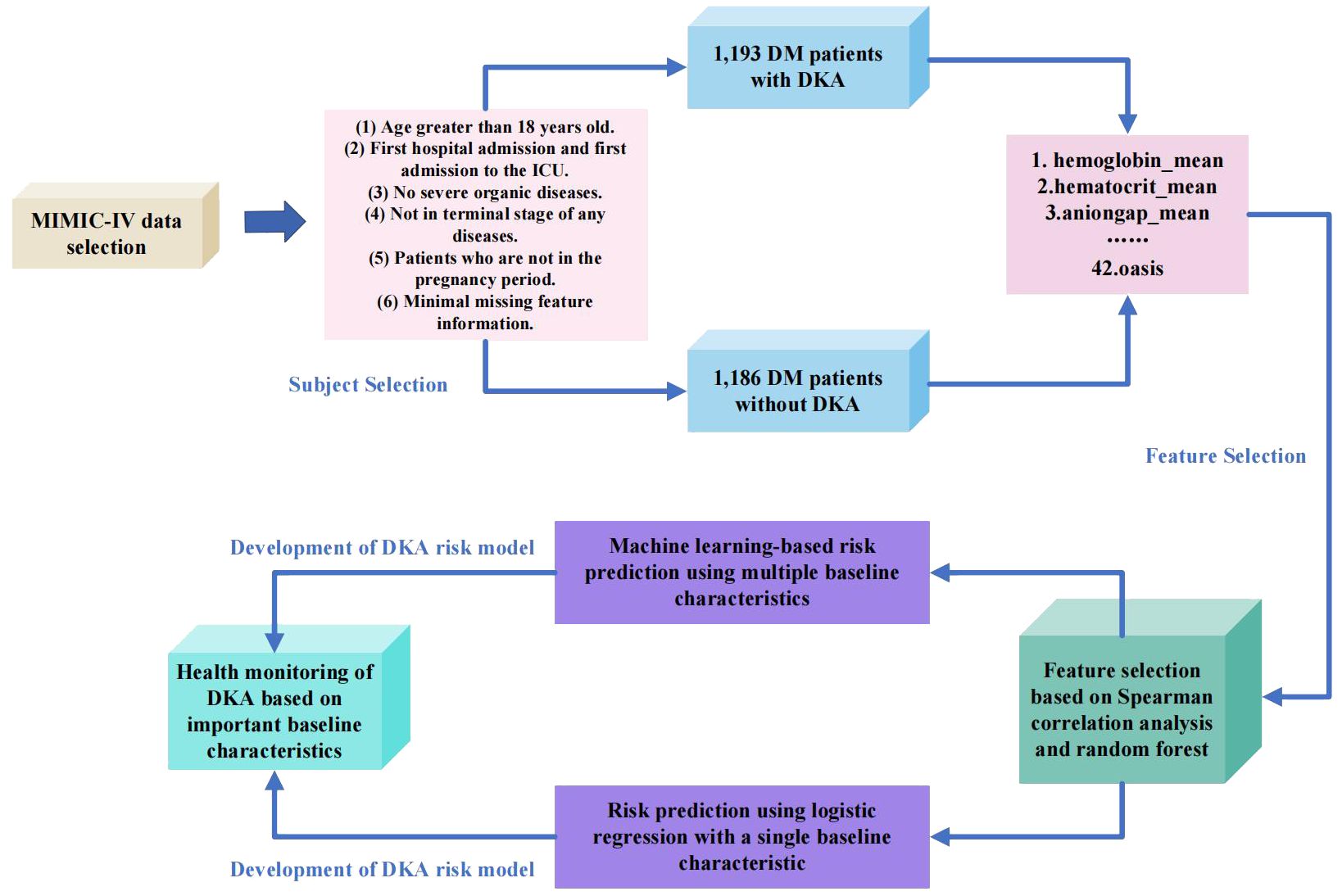
Figure 1 Flow chart of this study.
2 Method
2.1 Databaset
The MIMIC dataset was established in 2003 with the support of the National Institutes of Health in the United States. It was jointly created by the MIT Laboratory for Computational Physiology, the Beth Israel Deaconess Medical Center (BIDMC) affiliated with Harvard Medical School, and Philips Healthcare (10). The dataset utilized in this study is known as the ‘Medical Information Mart for Intensive Care IV’ (MIMIC-IV). It encompasses a wide range of data, including demographic information, disease diagnoses, vital signs, laboratory tests, treatment details, survival status, and other comprehensive clinical records. Compared to its predecessor, MIMIC-III, the scope of the MIMIC-IV dataset has been extended to cover the period from 2008 to 2019, providing a broader range of data for analysis and research.
2.2 Participant selection criteria
In this study, a total of 2379 patients were chosen from the MIMIC-IV dataset. Among them, 1193 patients had DKA and 1186 patients had DM without ketosis. The participants in this study were required to meet the following criteria: The participants in this study needed to meet the following criteria: (1) Age over 18 years. (2) First admission and first admission to the ICU. (3) Absence of other serious organic diseases. (4) Exclude late-stage disease. (5) Non-pregnant patients. (6) Minimal missing characteristic information.
2.3 Selection of indicators and data preprocessing
This study excluded baseline characteristics with missing data greater than 30% in MIMIC-IV, such as C-reactive protein, procalcitonin, height, and serum albumin. At the same time, Structured Query Language (SQL) was used to extract data of DKA patients from MIMIC-IV. The baseline characteristics selected in this study included demographic features, vital signs, laboratory indicators, comorbidity indicators, and scoring system indicators. Demographic features included gender, age, weight, and ethnicity. Vital signs included heart rate (heart_rate_mean), respiratory rate (resp_rate_mean), body temperature (temperature_mean), peripheral oxygen saturation (SPO2_mean), systolic blood pressure (SBP_mean), diastolic blood pressure (DBP_mean), and mean blood pressure (mbp_mean). Laboratory indicators included blood urea nitrogen (bun_mean), creatinine (creatinine_mean), urine output, sodium (sodium_mean), potassium (potassium_mean), calcium (calcium_mean), anion gap (anioinga_mean), hematocrit (haematocrit_mean), hemoglobin (haemoglobin_mean), white blood cell count (wbc_mean), absolute neutrophil count (abs_neutrophils_mean), absolute lymphocyte count (abs_lymphocytes_mean), platelets (platelets_mean), mean corpuscular hemoglobin (mch_mean), red blood cells (rbc_mean), red cell distribution width (rdw_mean), glucose (glucose_mean), and chloride (chloride_mean). Comorbidity indicators included hypertension, obesity, myocardial infarction, congestive heart failure, peripheral vascular disease, chronic pulmonary disease, liver disease, and renal disease. Scoring system indicators included lods, charlson, and oasis.
All data were analyzed using IBM SPSS Statistics 25. Two-sided statistical analyses were conducted, and a significance level of p ≤ 0.05 was used for interpretation of statistical significance. Normality was assessed for continuous variables, which were presented as mean ± standard deviation (SD), while categorical data are summarized as counts or percentages. Group comparisons were performed using the chi-square test for categorical variables and analysis of variance, and the Kruskal-Wallis test for continuous variables. The detailed baseline characteristics are shown in Table 1.
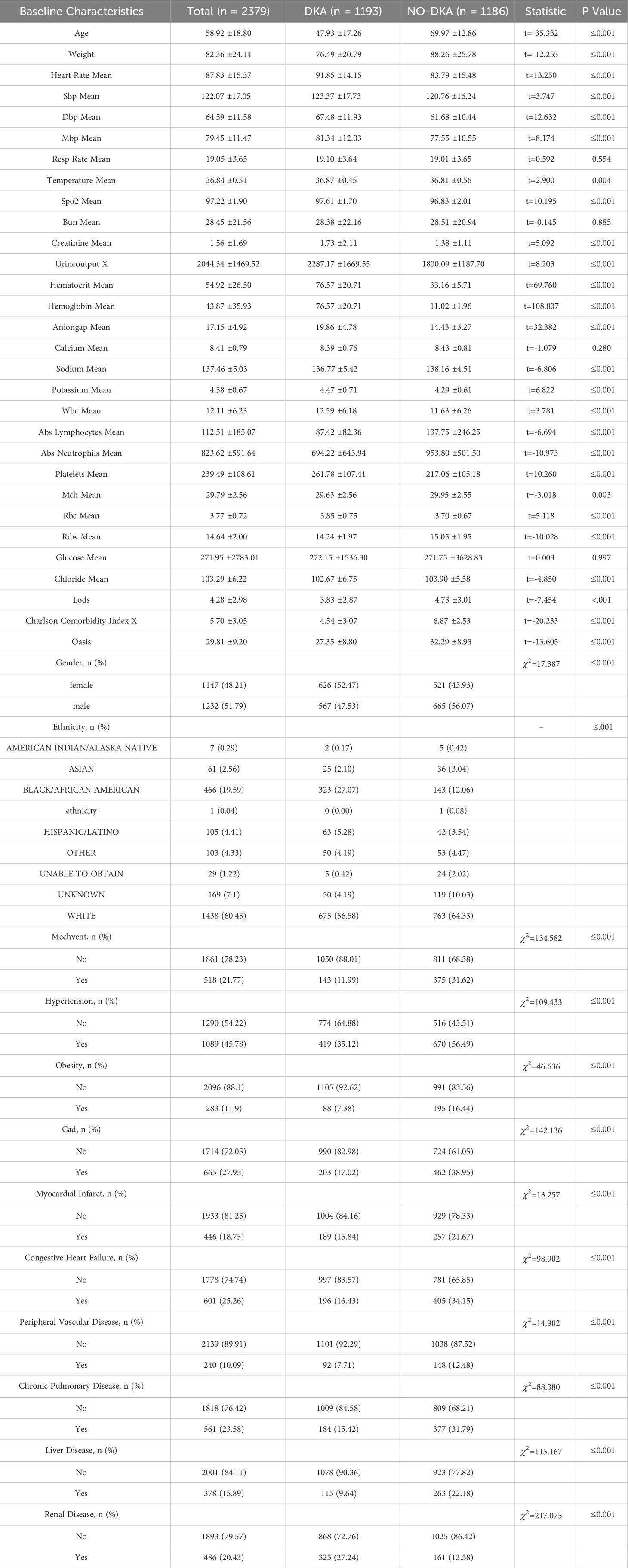
Table 1 Baseline characteristics between DKA and non-DKA group.
The LODS (Logistic Organ Dysfunction System) is a medical scoring system commonly used to assess the degree of organ dysfunction in patients. This scoring system evaluates and quantifies the functional status of multiple organ systems based on clinical indicators such as blood pressure, respiratory rate, and oxygen saturation to determine the presence of organ dysfunction in patients.
In the field of home healthcare, OASIS (Outcome and Assessment Information Set) commonly refers to an assessment tool used to collect and document clinical information and functional status data of patients in a home care setting. OASIS assessment covers multiple domains, including activities of daily living, medical history, pain assessment, medication management, emotional status, and more.
The Charlson Comorbidity Index is a scoring system used to assess the burden of comorbidities or other chronic medical conditions in a patient. It assigns a score to various comorbidities based on their association with one-year mortality. The scores are summed to calculate a total score, which is used as an indicator of the patient’s overall health status and the risk of future complications or mortality.
Before carrying out feature selection and developing a DKA risk prediction model, we used mean imputation to handle missing values in the data set. Mean imputation is a commonly used method where the missing values are replaced with the mean or mode of the available data. The formula (Equation 1) for mean imputation can be represented as:
The symbols indicating whether an answer is provided represent the number of samples. In this study, mean imputation was performed for missing values in neutrophil and lymphocyte counts.
2.4 Feature selection
The study employed two feature selection methods to screen important baseline characteristics related to DKA, including Spearman correlation analysis and random forest. Spearman correlation analysis is used to assess the monotonic relationship between two continuous or ordinal variables. It is used to describe the correlation between two variables that have ordinal variables or distribution characteristics that cannot be described by mean and standard deviation. The formula (Equation 2) can be represented as:
Where N represents the total number of observations, ρ ranges from -1 to 1. [-1, 0) represents a negative correlation, and (0, 1] represents a positive correlation. A correlation of 0.8-1.0 indicates a very strong correlation, 0.6-0.8 indicates a strong correlation, 0.4-0.6 indicates a moderate correlation, 0.2-0.4 indicates a weak correlation, and 0.0-0.2 indicates a very weak or no correlation. It is worth noting that to better reflect the correlation, we took the absolute value of all correlation coefficients. The top 20 baseline characteristics in terms of correlation strength are shown in Table 2.
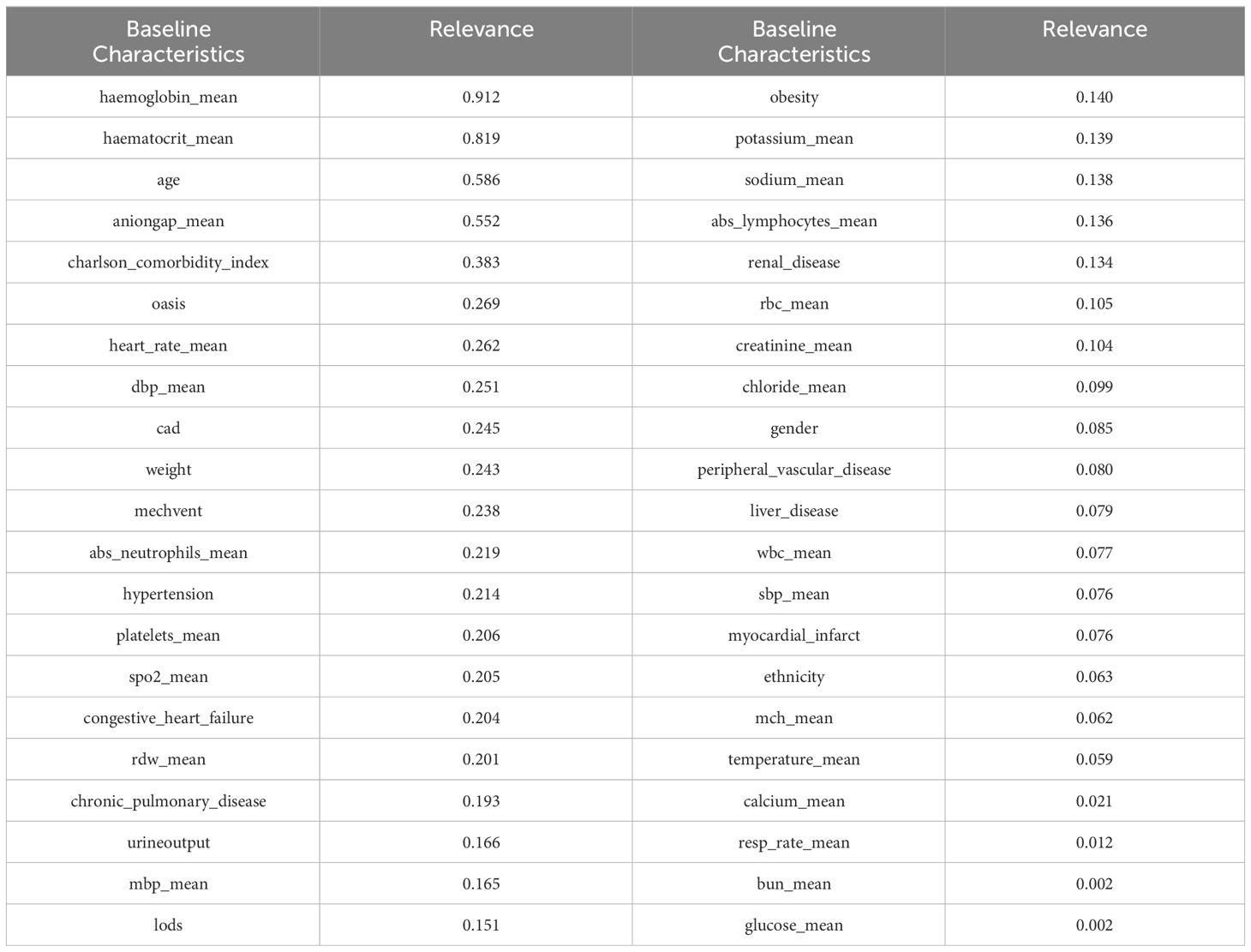
Table 2 Top 20 baseline characteristics based on Spearman correlation analysis.
To enhance the reliability of the experimental results, we also incorporated a feature selection method based on random forests. Random forest is a collection classifier composed of multiple decision trees. The classifier ensemble of the random forest is RF = {h(X, θk),k = 1,2,3,···K}, where K is the number of decision trees, and θk is a random variable that follows an independent distribution. Under the known conditions of the independent variables, all classifiers are weighted to obtain the optimal selection result. We had a total of 10,000 decision trees, with a training set to test set ratio of 8.5:1.5. Random forest performed repeated sampling on the replaced dataset to obtain 10,000 data subsets, and each subset generate a corresponding decision tree, ultimately forming the DKA important baseline characteristics ensemble. The importance of random forest in selecting relevant indicators is shown in Table 3.
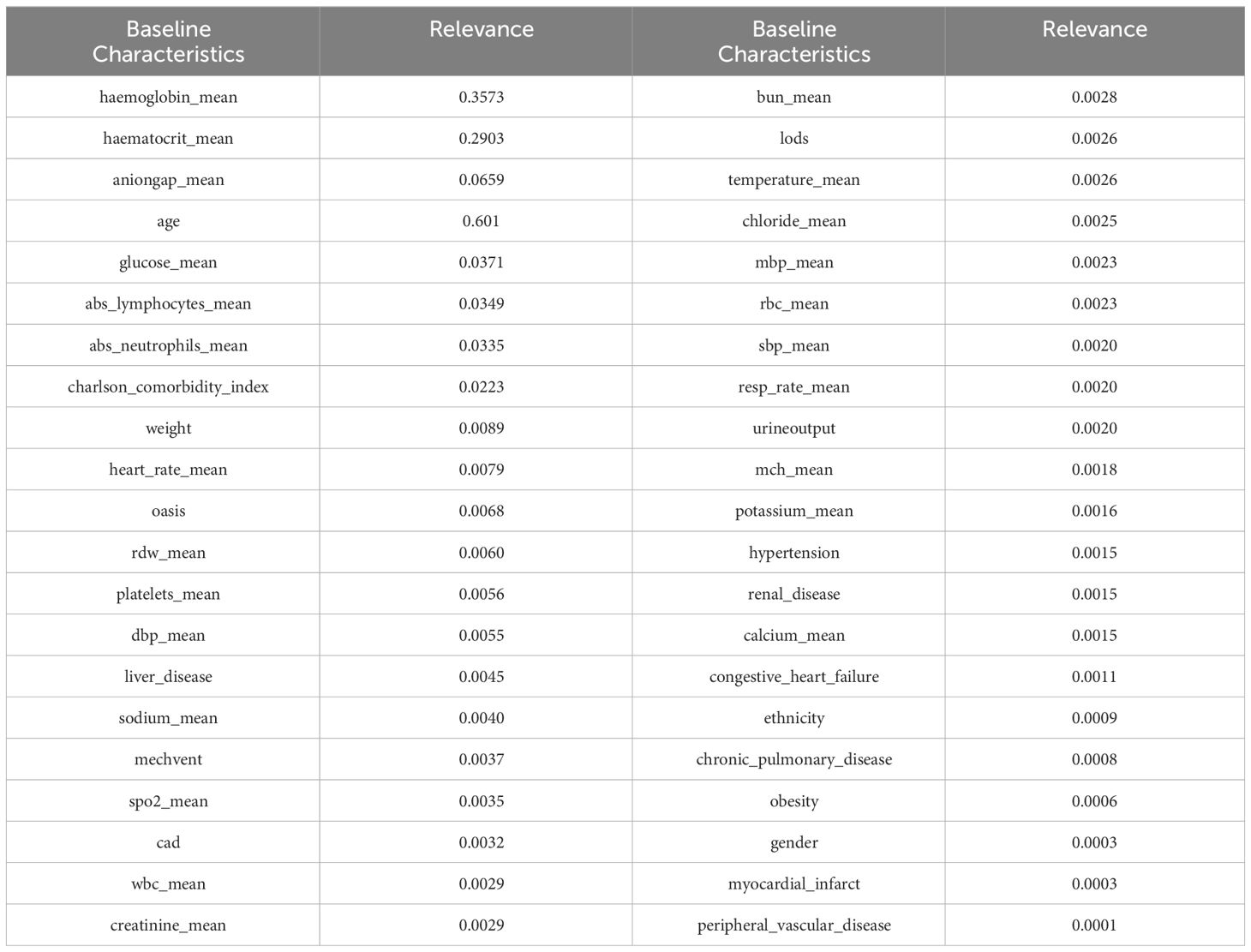
Table 3 Top 20 baseline characteristics based on feature selection method using random forest.
After conducting correlation analysis using two feature selection methods, it was discovered that certain baseline characteristics exhibited high levels of correlation. By combining the importance rankings of baseline characteristics from the two feature selection methods, the top five strongly correlated baseline characteristics were selected based on their smallest sum of importance rankings. These five baseline characteristics include hemoglobin_mean, haematocrit_mean, aniongap_mean, age, and Charlson_comorbidity_index.
2.5 Establishing a risk prediction model for DKA
The study utilized supervised machine learning models for the prediction of DKA risk. The experiments were divided into two parts: the first part focused on risk prediction using logistic regression with a single baseline characteristic, while the second part utilized xgboost, decision trees, random forests, support vector machines, and k-nearest neighbors classifiers with multiple baseline characteristics for risk prediction. The complete dataset for the study was divided into training and testing sets, with a ratio of 0.85:0.15. The experiments were then conducted using five-fold cross-validation. The performance evaluation metrics used for the experiments included the area under the curve (AUC) of the receiver operating characteristic (ROC) curve, accuracy, and F1-score. These metrics were utilized to assess the predictive performance of the models, overall accuracy, and the balance between precision and recall in predicting DKA risk.
2.5.1 Risk prediction based on logistic regression with a single baseline characteristic
The study aimed to predict DKA risk independently for each baseline characteristic using logistic regression. Based on Table 4, the experimental results were categorized into three levels according to the F1 score: F1 scores higher than 80, F1 scores between 80 and 60, and F1 scores lower than 60. A total of two baseline characteristics, hematocrit mean and hemoglobin_mean, achieved an F1 score greater than 80. There were 20 baseline characteristics (Age, weight, heart_rate_mean, resp_rate_mean, temperature_mean, anioingap,dbp_mean, abs_neutrophils_mean, congestive_heart_failure, platelets_mean, glucose_mean, obesity, myocardial_infarct, peripheral_vascular_disease, chronic_pulmonary_disease, renal_disease, oasis, cad, mechvent, charlson_comorbidity_index) with F1 scores between 60 and 80. The prediction results demonstrated a significant similarity with the feature selection results, highlighting the strong performance of hematocrit mean and hemoglobin_mean compared to other baseline characteristics. This indicated the importance of these two features in predicting DKA risk.
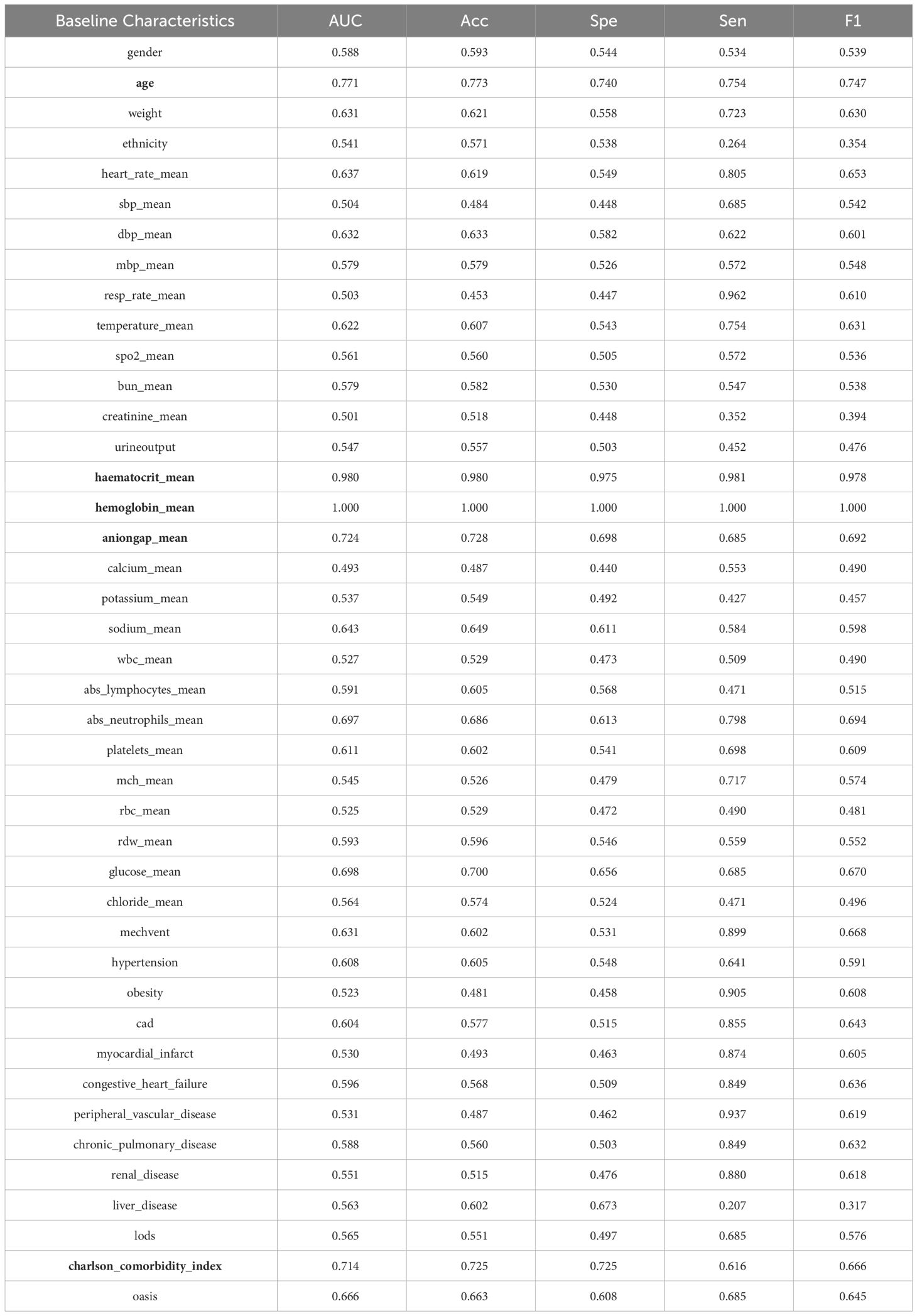
Table 4 Characteristic at baseline between DKA and non-DKA group.
2.5.2 Risk prediction based on multiple baseline characteristics using xgboost, decision trees, random forests, support vector machines, and k-nearest neighbors classifiers
To predict DKA, we utilized all 42 baseline characteristics and employed various machine learning algorithms, including xgboost, decision trees, random forests, support vector machines, and k-nearest neighbors classifiers. The specific algorithm parameter details for xgboost were as follows: a learning rate of 0.01, 3000 iterations, a tree depth of 4, and a minimum sum of leaf node sample weight of 5. The decision tree classifier used the Gini coefficient as the splitting criterion and was constructed with a maximum depth of 50. The random forest classifier employs 8 decision trees, each with a maximum depth of 50.The support vector machine classifier used the radial basis function (RBF) kernel. The k-nearest neighbors classifier was configured to use 5 nearest neighbors, and the algorithm for selecting the nearest neighbors was the automatic optimization algorithm available in the scikit-learn library.
The experimental resulted in Table 5 indicate that xgboost, decision trees, and random forests achieve an AUC, accuracy, and F1-score of 1, which demonstrates their ability to accurately identify DKA patients. However, the performance of the support vector machine and k-nearest neighbors classifiers was comparatively weaker.
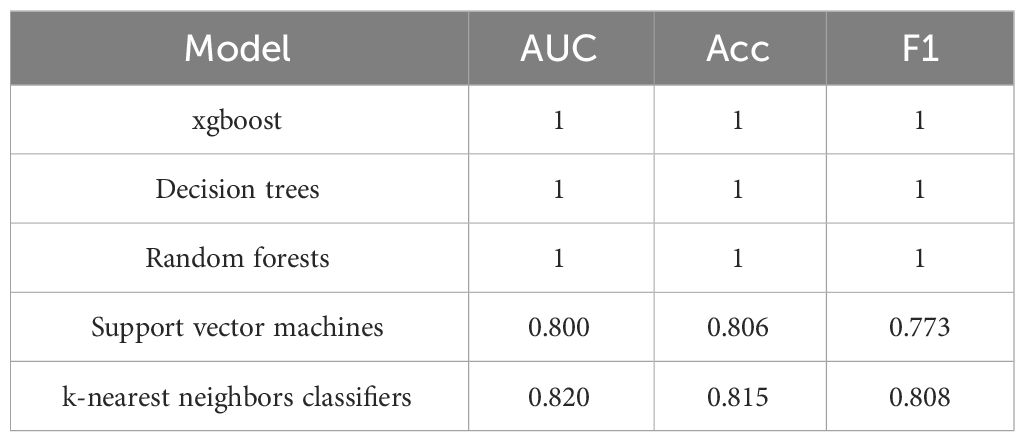
Table 5 DKA risk prediction based on all baseline characteristics.
We believe that the reason support vector machines and k-nearest neighbors classifiers cannot accurately identify DKA is due to some baseline characteristics interfering with the model’s decision-making. To further predict DKA, we used feature selection to select five baseline characteristics (namely hemoglobin mean, hematocrit mean, aniongap mean, age, and Charlson comorbidity index).
The experimental resulted in Table 6 demonstrated a significant improvement in the performance of support vector machines and k-nearest neighbors classifiers, validating the effectiveness of the feature selection method and the five important features.We also provided accuracy change plots for support vector machines and k-nearest neighbors classifiers based on both the full set of features and the important features. These plots, labeled as Figures 2–5, demonstrate the variation in accuracy for the different feature sets. The learning curve illustrated the impact of the number of training samples on the model’s performance. The results indicated that the machine learning approach adopted by the research institute did not exhibit overfitting or underfitting phenomena. The model had essentially reached a performance bottleneck, and there was no need to supplement the data for further training.
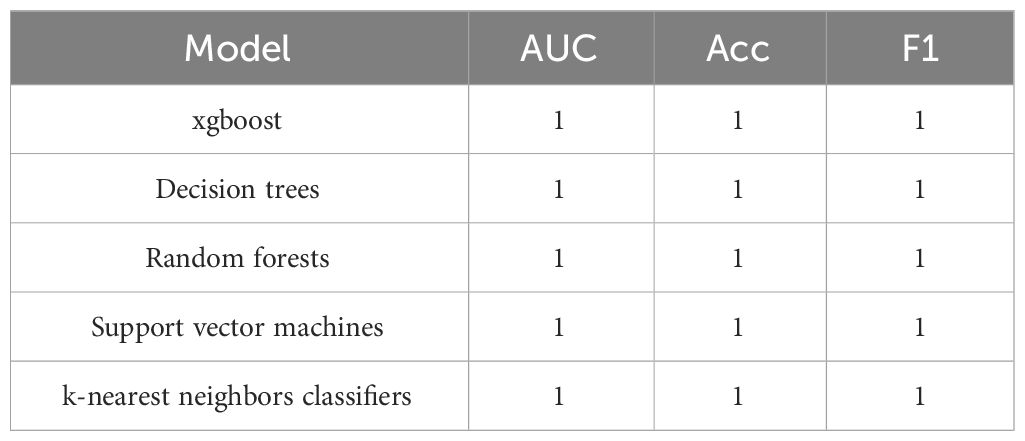
Table 6 DKA risk prediction based on feature selection.
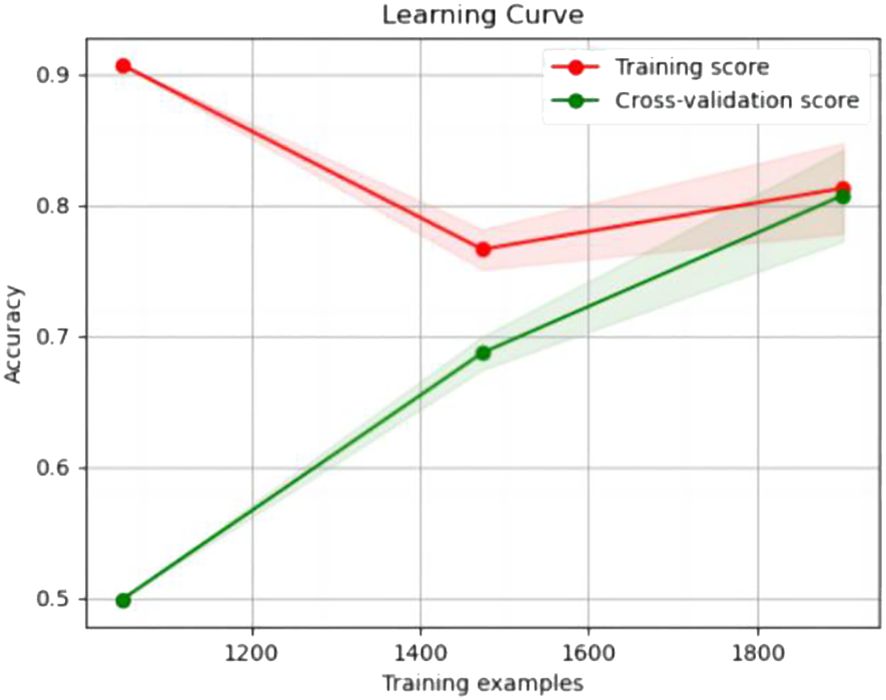
Figure 2 Accuracy change plot of support vector machines based on all features.
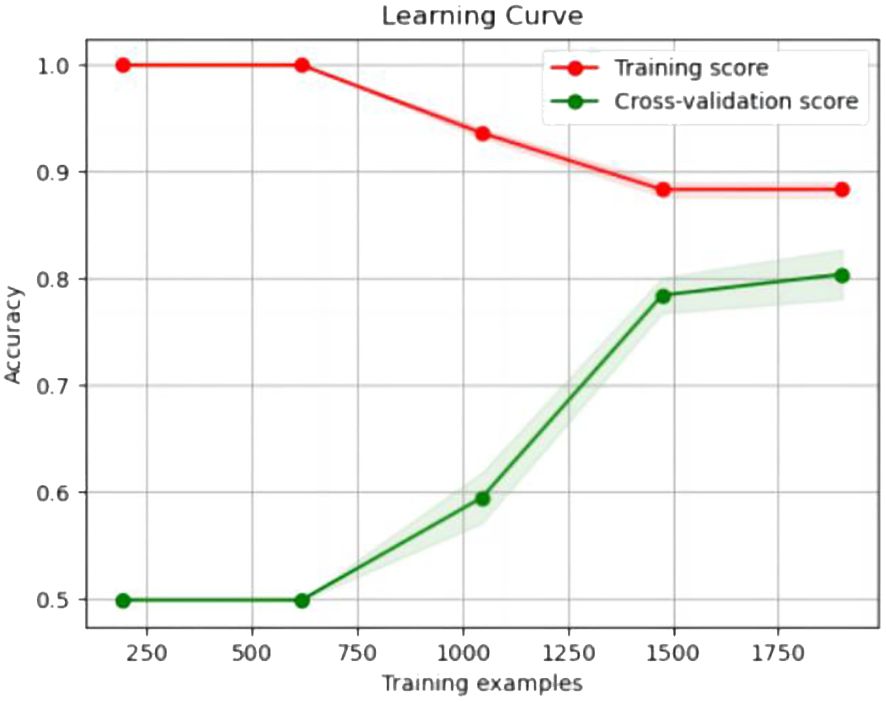
Figure 3 Accuracy change plot of k-nearest neighbors classifier based on all features.
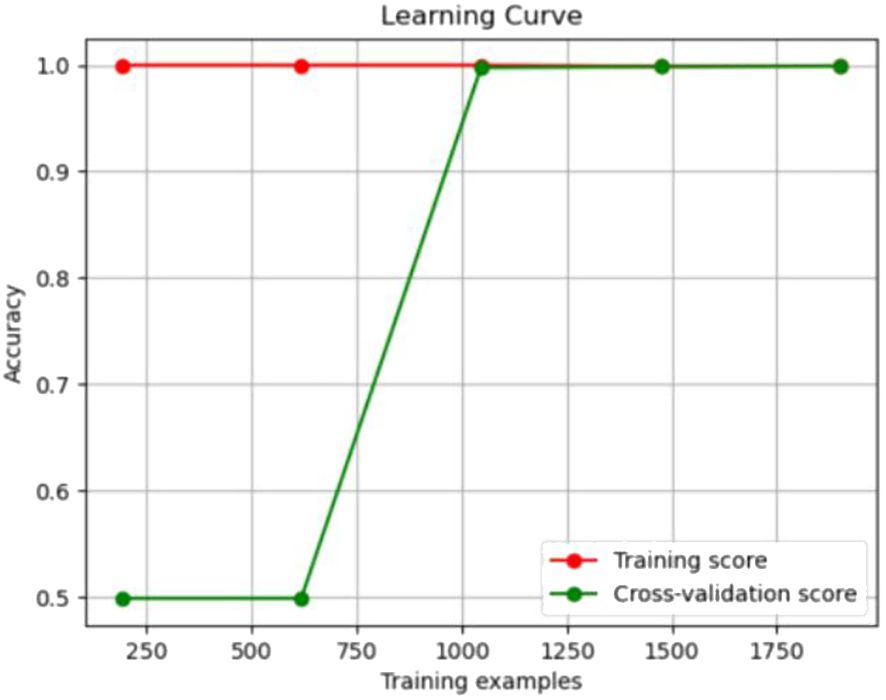
Figure 4 Accuracy change plot of support vector machine based on important features.
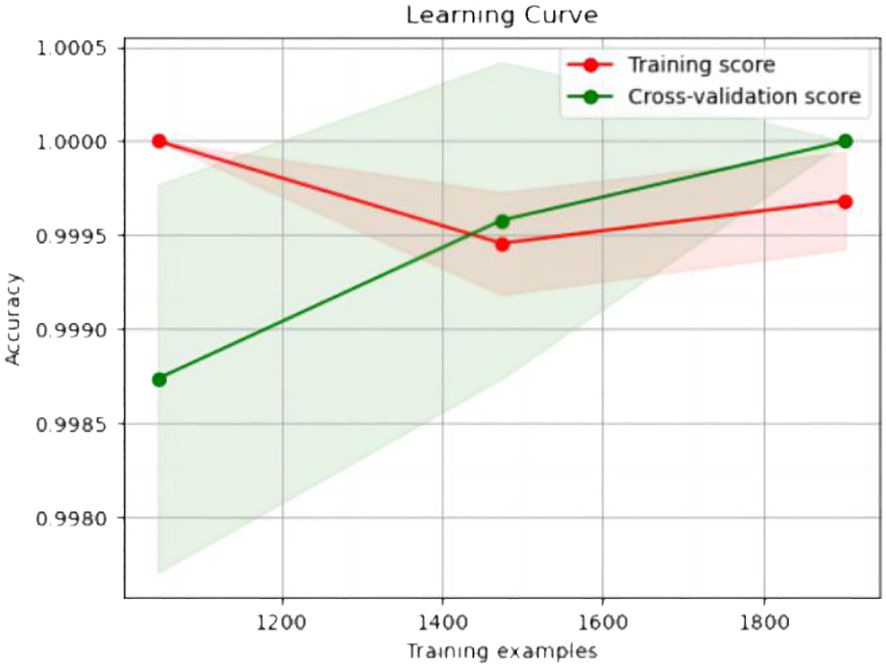
Figure 5 Accuracy change plot of k-nearest neighbors classifier based on important features.
3 Discussion
Discussion on the importance of baseline characteristics
The occurrence of DKA is attributed to the relative or absolute deficiency of insulin, along with the presence of excessive counter-regulatory hormones such as glucagon, cortisol, catecholamines, and growth hormone. These factors lead to hyperglycemia, glucosuria, dehydration, acidosis, and varying degrees of hyperosmolarity (11). When blood glucose levels elevated, especially in individuals with diabetes, the body is unable to effectively utilize glucose as energy and instead begins to break down fats to provide energy. One of the byproducts of this process is acetoacetic acid. Acetoacetic acid is a ketone body, and when it accumulates excessively in the body, it can lead to ketonemia, which triggers DKA (12). DKA can affect the chemical balance of the blood, including the acid-base balance. It also impacts various parameters related to the blood, such as hemoglobin and hematocrit.
Hemoglobin_mean refers to the mean value of hemoglobin (Hb). Hb is a protein presenting in red blood cells, primarily responsible for carrying and delivering oxygen to various tissues in the body (13). In the state of DKA, due to insufficient insulin or resistance to insulin by cells, is blood glucose levels rise. High blood glucose can lead to excessive urine production by the kidneys, causing significant loss of fluids in the body (14). Inadequate insulin prevents cells from properly utilizing glucose as an energy source. As a result, the body resorts to breaking down fats, leading to an excessive production of ketones in the liver (13). These excess ketones are excreted in urine along with a significant amount of urine, resulting in fluid loss. Glucose is an osmotically active substance, and in a state of high blood glucose, the osmotic pressure of the blood increases, leading to further dehydration of cells. These changes in the body can cause blood to become concentrated, resulting in an increase in the concentration of hemoglobin per unit volume of blood (15). In DKA state, there is a significant increase in acidic substances in the blood. The body utilizes the buffering agents in the blood to neutralize the excess acid, thereby maintaining the acid-base balance of the blood (16). Hemoglobin, a basic protein, can serve as a buffer and increase compensatively in response to acidosis. Thus, changes in HB can effectively reflect the condition of DKA.
Hematocrit_mean represents the mean value of hematocrit (Hct). Hct refers to the proportion of red blood cells in the volume of blood. In clinical practice, Hct is an important indicator for assessing blood concentration and determining blood volume status (17). DKA’s hyperglycemia and ketoacidosis characteristic result in osmotic diuresis and significant depletion of fluid and electrolytes in the intracellular and extracellular fluid compartments (18). The elevated blood glucose and increased urine output caused by DKA lead to dehydration within the body (14) (13). Dehydration-induced blood concentration can cause an increase in Hct. In DKA, the elevated blood glucose and increased concentration of glucose in the blood lead to increased blood viscosity, resulting in an elevated Hct. Therefore, there is a close relationship between Hct and the state changes in DKA.
Hemoglobin and hematocrit are both based on whole blood and therefore depend on plasma volume. If a patient is severely dehydrated, the hemoglobin and hematocrit levels will be higher compared to the normal blood volume (18). An increase in hemoglobin and hematocrit may indicate dehydration and blood concentration (19). Hematocrit and hemoglobin can play a supportive role in evaluating DKA. Given the data from these hematological parameters, such as an increase in red blood cell volume and hemoglobin concentration, they may be useful indicators of inadequate extracellular fluid volume in DKA. Meanwhile, it had been mentioned earlier that cerebral edema was a crucial factor contributing to the increased mortality rate in DKA, primarily due to the most severe complication of excessive or rapid fluid administration. Therefore, accurately assessing the degree of dehydration before initiating fluid therapy in DKA patients was of paramount importance. However, this is not a straightforward estimation, as dehydration did not directly correlate with the severity assessment of DKA based on blood gas values. In this context, hematological parameters can be employed, and two examples were hematocrit (Hct) and hemoglobin (Hb) concentration (10). However, they have limitations in predicting the occurrence of DKA (20), but physiologically, it is reasonable to consider them as useful indicators.
The term ‘anion_gap_mean’ refers to the mean value of anion gap, w hich is used to measure the difference between undetermined anions and undetermined cations in the blood. It is calculated by measuring the concentrations of anions (such as chloride ions) and cations (such as sodium ions, potassium ions) in the blood (21). The formula for anion gap is as follows: Anion Gap = [Na+]-([Cl-] + [HCO3-]) (22). In normal conditions, the anion gap typically falls between 8-16 mmol/L. The anion gap is commonly used to evaluate acid-base balance, and it can be easily calculated from routine laboratory data. It has the widest application in the diagnosis of various forms of metabolic acidosis (23). DKA possesses its unique physiological characteristics, including the generation and elimination of ketones, hyperglycemia, and fluid loss. This combination directly influences the biochemical parameters of patients with DKA, particularly the anion gap and total carbon dioxide levels Mifsud and Salem (11). In the state of DKA, metabolic disturbances in the body lead to the production and accumulation of a large number of ketones, such as beta-hydroxybutyrate, acetoacetate, and acetone. Ketones are metabolic byproducts of fatty acid metabolism, and their breakdown metabolism generates anions, especially beta-hydroxybutyrate. These anions are not accounted for in routine electrolyte analysis and are not included in the sum of cations (such as sodium, potassium) or measured anions (such as chloride) (24). D-lactic acid is a product of methylglyoxal (MG) metabolism through the glyoxalase pathway (25). In a state of hyperglycemia, the production of MG can significantly increase (26). Therefore, in hyperglycemic conditions, the blood concentration of D-lactic acid should also increase significantly. Research has shown that in the state of DKA, the increase in D-lactic acid also contributes to the generation of anion gap during acidosis. Therefore, in DKA, the increase in ketones and D-lactic acid leads to the accumulation of unmeasured anions, r esulting in an increase in the anion gap (24). Therefore, measuring changes in the anion gap can be helpful in diagnosing and monitoring the severity of DKA.
A significant correlation exists between an individual’s age and the likelihood of developing DKA. A study analyzing 4,807 cases of DKA revealed the incidence rate was 14% for those above 70 years old, 23% within the age group of 51 to 70 years, 27% within the age group of 30 to 50 years, and 36% for individuals under 30 years old (5). Based on this data, it is evident that younger patients have a higher incidence rate, with DKA commonly being observed in children and adolescents with both type 1 and type 2 diabetes (27). This is believed to be due to several factors commonly found in patients within this age group, including a higher rate of growth and development, increased metabolic rate, and greater insulin requirements. Furthermore, children and adolescents may have less developed self-management skills for diabetes and may be more susceptible to neglecting or inadequately controlling their blood glucose levels, thus increasing the risk of developing DKA. DKA can affect individuals of all age groups, with older individuals who have additional comorbidities often experiencing higher mortality rates. However, DKA is the leading cause of death among diabetes patients younger than 24 years old, with cerebral edema commonly induced by DKA being the most common cause (8). Middle-aged and elderly patients in this age group may have coexisting chronic conditions such as hypertension, coronary heart disease, and renal failure. These conditions may increase the risk of mortality in DKA and can affect treatment options. Furthermore, elderly patients may have decreased physiological reserves and require careful monitoring of fluid balance and insulin therapy (5). Healthcare providers should develop personalized treatment plans for patients of different age groups, taking into account their physiological characteristics, medical history, and risk of complications. As a result, age plays a crucial role in guiding the management and treatment strategies for DKA. Relevant studies indicate that a mixed state of ketoacidosis and hyperosmolarity is observed in 30% of presentations of hyperglycemic emergencies in diabetes. While both age and the degree of hyperosmolarity influence the mortality rate, only age emerges as an independent predictor of mortality Feldman (12). Poor blood glucose control disproportionately affects young patients with a detrimental impact on DKA. Hence, we emphasize the need for a better understanding of the role of age in diabetes intervention, especially in the context of DKA.
The Charlson Comorbidity Index (CCI), also known as the Charlson Index, is a frequently used instrument for evaluating the burden and risk of comorbidities in patients. It assigns scores to various diseases, depending on a patient’s medical history and diagnoses, and these scores are then combined to generate a composite score (28). CCI offers useful insights into a patient’s overall health status and can assist healthcare professionals in assessing and anticipating the effects of comorbidities on patient outcomes. A high CCI score indicates that the patient is significantly affected by multiple diseases, indicating a greater burden of comorbidities and a higher risk of illness (29). It is widely recognized that many adults with diabetes also experience concurrent chronic conditions such as chronic heart failure, chronic obstructive pulmonary disease, renal disease, and depression (30). In a comprehensive study on medical insurance, it was discovered that the presence of multiple comorbidities can complicate a patient’s condition. The study identified congestive heart failure (CHF), pneumonia (CKD), and chronic obstructive pulmonary disease (COPD) as the most frequent conditions leading to readmission within 30 days after discharge (31). As a result, the proportion of DKA patients with comorbidities such as CHF, CKD, and COPD may be higher, indicating that these conditions commonly coexist in individuals with diabetes, potentially leading to a higher readmission rate for DKA patients. Furthermore, research has suggested that a Hospital Admission Index (HAI) with a CCI score of 3 or higher can serve as a predictive factor for DKA readmission. As previously mentioned, the presence of comorbidities complicates the treatment of diabetes patients, thereby increasing the risk of readmission. Thus, active monitoring and treatment of DKA patients with comorbidities can contribute to enhancing DKA management (32).
The diagnosis of DKA itself is prone to misdiagnosis, and the indicators used are often influenced by the underlying diabetes, making early prediction challenging. The five features we have selected exhibit strong stability, contributing to a comprehensive assessment of the patient’s overall physiological status, not just the diabetes-related physiological changes. In the prodromal stage of DKA, when the values of blood glucose and ketone bodies have not reached diagnostic thresholds, we can complementarily analyze the five features to achieve a comprehensive analysis and provide assistance in predicting DKA. Our intention is not to replace the diagnostic indicators for DKA but rather to serve as an auxiliary indicator to help doctors diagnose more quickly and accurately.
For young patients or those with multiple complications, it is crucial to provide enhanced education and guidance on insulin or medication therapy (33). During the diagnostic and treatment process, it is essential to promptly monitor indicators such as hemoglobin, hematocrit, anion gap, age, and Charlson comorbidity index in DM patients who present with relevant symptoms.Early intervention should be implemented to reduce the incidence of the disease. By closely monitoring these indicators and promptly intervening, the occurrence rate of the disease can be reduced.
4 Conclusion
This study was based on the MIMIC-IV dataset and utilized feature selection and machine learning methods to construct a risk prediction model for DKA. Five potential baseline characteristics highly correlated with DKA have been identified, which include hemoglobin_mean, haematocrit_mean, aniongap_mean, age, and Charlson_comorbidity_index. Furthermore, we utilized machine learning methods to accurately predict the incidence of DKA in patients and demonstrated the effectiveness of important baseline characteristics. This study holds the following significant values: (1) Early warning: DKA typically develops gradually rather than occurring suddenly. By continuously monitoring important baseline characteristics and utilizing a machine learning prediction model, it is possible to identify the risk of DM patients progressing to DKA at an early stage, thereby providing early warning signals. This enables doctors to intervene in a timely manner, adjust the patient’s treatment plan, and prevent the occurrence of DKA. (2) Optimization resource allocation: Establishing a DKA risk prediction model can assist hospitals and healthcare institutions in better allocating resources. For instance, for high-risk patients, more attention and resources can be allocated to their monitoring and treatment to reduce the risk of DKA occurrence. This targeted allocation of resources ensures that those at higher risk receive the necessary support and intervention, optimizing the overall healthcare delivery system. (3) Reduction healthcare costs: Treatment for DKA typically requires hospitalization and is associated with high medical expenses. By utilizing important baseline characteristics and predictive models, it is possible to effectively reduce the frequency of DKA episodes, resulting in significant cost savings for patients with recurrent DKA. This cost reduction is achieved through proactive management and prevention strategies based on risk assessment, ultimately improving the overall economic efficiency of healthcare delivery.
There are some limitations associated with this study: (1) Data Quality: The model’s performance heavily relies on the quality of the data used. If there are errors, missing information, or biases in the input data, the model may be influenced by quality variations, impacting its predictive capabilities. (2) Sample Bias: If the samples in the training data are insufficient or do not adequately represent the diversity in the real world, the model may exhibit bias in future practical applications. The representativeness of the samples is crucial for the model’s generalization ability. (3) Concept Drift: If the data distribution changes over time or space, the model may struggle to effectively adapt to the new data distribution. This could result in a decline in the model’s performance in real-world applications. (4) Uncertainty: Machine learning models typically provide probabilities or scores for predictions rather than deterministic outcomes. In the medical field, for certain situations, patients and doctors may prefer to understand the uncertainty of the model rather than just binary predictive results.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://about.citiprogram.org/.
Ethics statement
The manuscript presents research on animals that do not require ethical approval for their study.
Author contributions
YL: Writing – original draft, Writing – review & editing, Methodology. WM: Formal analysis, Methodology, Writing – review & editing. HW: Methodology, Writing – review & editing. ZS: Data curation, Investigation, Writing – review & editing. YZ: Data curation, Writing – review & editing. JB: Data curation, Formal analysis, Methodology, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Guangdong Province Famous Traditional Chinese Medicine (TCM) Doctor (Wang He) Studio Construction Project.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Lorente L, Martín MM, Argueso M, Solé-Violán J, Perez A, Ramos JAMY, et al. Association between red blood cell distribution width and mortality of covid-19 patients. Anaesthesia Crit Care Pain Med. (2021) 40:100777. doi: 10.1016/j.accpm.2020.10.013
2. Kitabchi AE, Umpierrez GE, Murphy MB, Barrett EJ. Hyperglycemic crises in diabetes. Diabetes Care. (2004) 27:S94. doi: 10.2337/diacare.27.2007.S94
3. Reichel A, Rietzsch H, Köhler H, Pfützner A, Gudat U, Schulze J. Cessation of insulin infusion at night-time during csii-therapy: comparison of regular human insulin and insulin lispro. Exp Clin Endocrinol Diabetes. (1998) 106:168–72. doi: 10.1055/s-0029-1211971
4. Umpierrez GE, Kitabchi AE. Diabetic ketoacidosis: risk factors and management strategies. Treatments Endocrinol. (2003) 2:95–108. doi: 10.2165/00024677-200302020-00003
5. Henriksen OM, Røder ME, Prahl JB, Svendsen OL. Diabetic ketoacidosis in Denmark: incidence and mortality estimated from public health registries. Diabetes Res Clin Pract. (2007) 76:51–6. doi: 10.1016/j.diabres.2006.07.024
6. Fritsch M, Rosenbauer J, Schober E, Neu A, Placzek K, Holl RW, et al. Predictors of diabetic ketoacidosis in children and adolescents with type 1 diabetes. experience from a large multicentre database. Pediatr Diabetes. (2011) 12:307–12. doi: 10.1111/pdi.2011.12.issue-4pt1
7. Wang J, Williams DE, Narayan KV, Geiss LS. Declining death rates from hyperglycemic crisis among adults with diabetes, us 1985–2002. Diabetes Care. (2006) 29:2018–22. doi: 10.2337/dc06-0311
8. Bialo SR, Agrawal S, Boney CM, Quintos JB. Rare complications of pediatric diabetic ketoacidosis. World J Diabetes. (2015) 6:167. doi: 10.4239/wjd.v6.i1.167
9. Kitabchi AE, Umpierrez GE, Miles JM, Fisher JN. Hyperglycemic crises in adult patients with diabetes. Diabetes Care. (2009) 32:1335. doi: 10.2337/dc09-9032
10. Johnson AE, Bulgarelli L, Shen L, Gayles A, Shammout A, Horng S, et al. Mimic-iv, a freely accessible electronic health record dataset. Sci Data. (2023) 10:1. doi: 10.1038/s41597-023-01945-2
13. Giardina B, Messana I, Scatena R, Castagnola M. The multiple functions of hemoglobin. Crit Rev Biochem Mol Biol. (1995) 30:165–96. doi: 10.3109/10409239509085142
15. Liamis G, Liberopoulos E, Barkas F, Elisaf M. Diabetes mellitus and electrolyte disorders. World J Clin Cases: WJCC. (2014) 2:488. doi: 10.12998/wjcc.v2.i10.488
16. De Marchi S, Cecchin E, Basile A, Donadon W, Lippi U, Quaia P, et al. More on the increase of hemoglobin ai in chronic renal failure: the role of acidosis. Nephron. (1983) 35:49–53. doi: 10.1159/000183044
17. Van Beaumont W. Evaluation of hemoconcentration from hematocrit measurements. J Appl Physiol. (1972) 32:712–3. doi: 10.1152/jappl.1972.32.5.712
18. Dhatariya KK, Vellanki P. Treatment of diabetic ketoacidosis (dka)/hyperglycemic hyperosmolar state (hhs): novel advances in the management of hyperglycemic crises (uk versus usa). Curr Diabetes Rep. (2017) 17:1–7. doi: 10.1007/s11892-017-0857-4
19. Billett HH. “Hemoglobin and Hematocrit”. In: Walker HK, Hall WD, Hurst JW, editors. Clinical Methods: The History, Physical, and Laboratory Examinations. 3rd edition. Boston: Butterworths (1990). Chapter 151.
20. Wolfsdorf JI, Glaser N, Agus M, Fritsch M, Hanas R, Rewers A, et al. Ispad clinical practice consensus guidelines 2018: Diabetic ketoacidosis and the hyperglycemic hyperosmolar state. Pediatr Diabetes. (2018) 19:155–77. doi: 10.1111/pedi.2018.19.issue-S27
21. Kraut JA, Madias NE. Serum anion gap: its uses and limitations in clinical medicine. Clin J Am Soc Nephrol. (2007) 2:162–74. doi: 10.2215/CJN.03020906
22. Lolekha PH, Vanavanan S, Lolekha S. Update on value of the anion gap in clinical diagnosis and laboratory evaluation. Clinica chimica Acta. (2001) 307:33–6. doi: 10.1016/S0009-8981(01)00459-4
23. Oh MS, Carroll HJ. The anion gap. New Engl J Med. (1977) 297:814–7. doi: 10.1056/NEJM197710132971507
24. Lu J, Zello GA, Randell E, Adeli K, Krahn J, Meng QH. Closing the anion gap: contribution of d-lactate to diabetic ketoacidosis. Clinica Chimica Acta. (2011) 412:286–91. doi: 10.1016/j.cca.2010.10.020
25. Han Y, Randell E, Vasdev S, Gill V, Curran M, Newhook LA, et al. Plasma advanced glycation endproduct, methylglyoxal-derived hydroimidazolone is elevated in young, complication-free patients with type 1 diabetes. Clin Biochem. (2009) 42:562–9. doi: 10.1016/j.clinbiochem.2008.12.016
26. Thornalley PJ. Pharmacology of methylglyoxal: formation, modification of proteins and nucleic acids, and enzymatic detoxification-a role in pathogenesis and antiproliferative chemotherapy. Gen Pharmacol: Vasc System. (1996) 27:565–73. doi: 10.1016/0306-3623(95)02054-3
27. Randall L, Begovic J, Hudson M, Smiley D, Peng L, Pitre N, et al. Recurrent diabetic ketoacidosis in inner-city minority patients: behavioral, socioeconomic, and psychosocial factors. Diabetes Care. (2011) 34:1891–6. doi: 10.2337/dc11-0701
28. Wang C, Zhang X, Li B, Mu D. A study of factors impacting disease based on the charlson comorbidity index in uk biobank. Front Public Health. (2023) 10:1050129. doi: 10.3389/fpubh.2022.1050129
29. Austin SR, Wong Y-N, Uzzo RG, Beck JR, Egleston BL. Why summary comorbidity measures such as the charlson comorbidity index and elixhauser score work. Med Care. (2015) 53:e65. doi: 10.1097/MLR.0b013e318297429c
30. Soh JGS, Wong WP, Mukhopadhyay A, Quek SC, Tai BC. Predictors of 30-day unplanned hospital readmission among adult patients with diabetes mellitus: a systematic review with meta-analysis. BMJ Open Diabetes Res Care. (2020) 8:e001227. doi: 10.1136/bmjdrc-2020-001227
31. Jencks SF, Williams MV, Coleman EA. Rehospitalizations among patients in the medicare fee-for-service program. New Engl J Med. (2009) 360:1418–28. doi: 10.1056/NEJMsa0803563
32. Shaka H, Aguilera M, Aucar M, El-Amir Z, Wani F, Muojieje CC, et al. Rate and predictors of 30-day readmission following diabetic ketoacidosis in type 1 diabetes mellitus: a us analysis. J Clin Endocrinol Metab. (2021) 106:2592–9. doi: 10.1210/clinem/dgab372
Keywords: diabetic ketoacidosis, diabetes mellitus, MIMIC-IV, feature selection, risk prediction
Citation: Liu Y, Mo W, Wang H, Shao Z, Zeng Y and Bi J (2024) Feature selection and risk prediction for diabetic patients with ketoacidosis based on MIMIC-IV. Front. Endocrinol. 15:1344277. doi: 10.3389/fendo.2024.1344277
Received: 25 November 2023; Accepted: 26 February 2024;
Published: 27 March 2024.
Edited by:
Jian Ma, Harbin Medical University, ChinaReviewed by:
Weizhou Yue, Northeastern University, United StatesNingning Zheng, China Medical University Hospital, Taiwan
Pan Yang, Harvard Medical School, United States
Copyright © 2024 Liu, Mo, Wang, Shao, Zeng and Bi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jianlu Bi, 116706379@qq.com
†These authors have contributed equally to this work and share first authorship