 Peisen Sun
Peisen Sun Haoming Wang
Haoming Wang Guanglin Li1,2*
Guanglin Li1,2*- 1Key Laboratory of Ministry of Education for Medicinal Plant Resource and Natural Pharmaceutical Chemistry, Shaanxi Normal University, Xi’an, China
- 2College of Life Sciences, Shaanxi Normal University, Xi'an, China
- 3College of Plant Protection, Northwest A&F University, Yangling, China
Circular RNA (circRNA), which has a closed-loop structure, is a special type of endogenous RNA that plays important roles in many biological processes. With improvements in next-generation sequencing technology and bioinformatics methods, some tools have been published for circRNA detection based on RNA-seq. Here, we developed the R package “Rcirc” for further analyses of circRNA after its detection. Rcirc identifies the coding ability of circRNA and visualizes various aspects of this feature. It also provides general visualization for both single circRNAs and meta-features of thousands of circRNAs. Rcirc was designed as a user-friendly tool that provides many highly automated functions without requiring the user to perform many complicated processes. It is available on GitHub (https://github.com/PSSUN/Rcirc) under the license GPL 3.0.
Introduction
Circular RNA (circRNA) is an abundant functional RNA molecule with a highly conserved closed-loop structure that is generated by back-splicing with no 5′ cap or 3′ poly (A) tails (Vicens and Westhof, 2014). Single-stranded circRNAs appear to play a role in endogenous cells, such as immune regulation and cancer and RNA-binding protein regulation (Li et al., 2018). In the medical field, circRNAs are often used as biomarkers to identify the occurrence of cancer because of their ring structure, which is difficult for RNase R to degrade in the liquid phase (Bonizzato et al., 2016; Kulcheski et al., 2016).
In addition, circRNA has translation capabilities and important biological significance (Pamudurti et al., 2017). Organisms contain a large number of short peptides (<100 aa) that play important roles in many regulatory pathways (Slavoff et al., 2013; Delcourt et al., 2018). Recently, many studies have shown multiple pieces of evidence that strongly support circRNA translation, such as the specific association of circRNAs with translating ribosomes (Pamudurti et al., 2017). This means that a large number of circRNAs also have a small open reading frame (ORF) that can be translated to produce functional peptides. However, it is difficult for the traditional RNA-seq technique to accurately identify these short peptides from transcripts. In recent years, the increasing maturity of ribosome profiling technology, which provides strong evidence for translation events, has enabled accurate identification of short peptides. In contrast to the traditional RNA-seq technique, ribosome profiling can confirm the specific translation region of mRNAs (Brar and Weissman, 2015).
Feature analysis is also a very important area in the field of circRNA, and most published circRNAs have been analyzed. In particular, the numerous machine learning studies for identifying new circRNAs have left no doubt that a large number of possible features are needed, including the types of shear signal, the length of circRNAs, the frequency of triplet codons, and the location of different back-splice junctions on the genome; however, there is currently no tool for the characterization and subsequent visualization of circRNAs.
Based on high-throughput sequencing data, various tools have been developed for circRNA detection, including circRNA finder (Westholm et al., 2015), find_circ (Memczak et al., 2013), CIRCexplorer (Zhang et al., 2014), and CIRI (Gao et al., 2015). Additionally, numerous databases for circRNA that are based on those detection tools have also been published (Hansen et al., 2016).
However, most published software programs are designed to predict circRNAs, and only two software programs can identify their coding capability (Meng et al., 2017; Sun and Li, 2019). There is no tool that focuses on the downstream analyses and visualization of features or on mapping for circRNAs after the prediction process. circtools can help design primers but cannot perform large-scale analysis and visualize read mapping (Jakobi et al., 2018). Here, we developed Rcirc, an R package. It can not only identify candidate circRNAs but also recognize the translation ability of circRNAs. Rcirc also performs many feature analyses and data visualization. Through a display of diversity, users can easily see the various sequence features of a certain data set and determine whether a feature is representative.
Implementation
Currently, Rcirc contains 10 functions for the analysis of circRNAs. Rcirc covers three main parts for circRNA research (Figure 1): circRNA detection, coding ability identification, and feature visualization. The users can run any functions from those parts individually or run all functions of the whole pipeline.
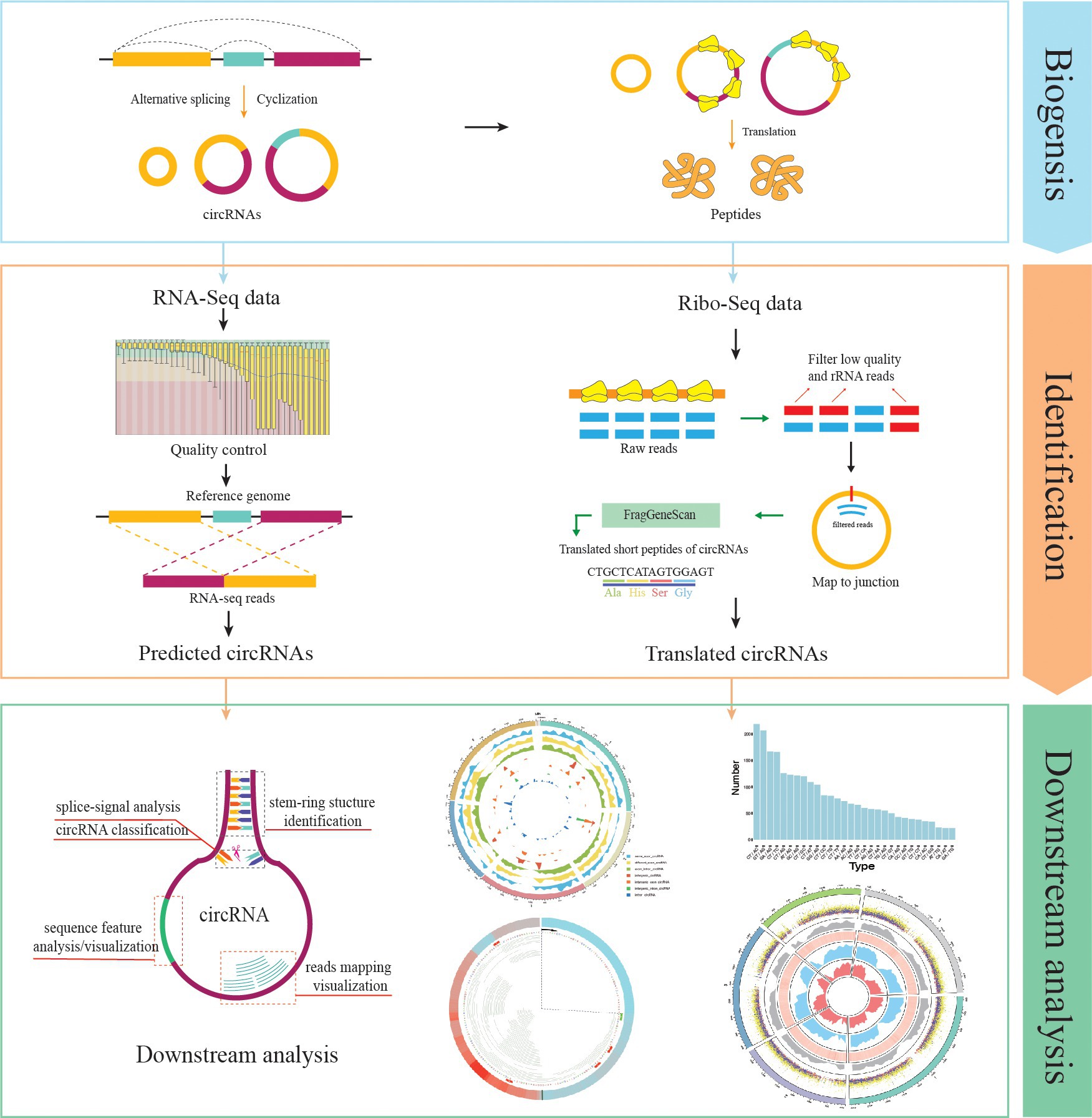
Figure 1. Rcirc workflow. From top to bottom are shown the identification of circRNAs, identification of circular RNA (circRNA) translation ability, and downstream analysis/visualization of circRNA. The right column represents the analyses that Rcirc can perform at the corresponding stage.
circRNA Detection and Coding Ability Identification
Users can make a de novo prediction for circRNAs based on RNA-seq data by using the function predictCirc, which aids in fundamental quality control for RNA-seq data and circRNA prediction by calling CIRI2 (Gao et al., 2018). Finally, a predicted fasta file and a prediction report in csv format are outputted to an appointed file.
The function translateCirc can help to identify the coding capability from the given circRNAs based on Ribo-seq data. Because the ribosome needs to span the back-splice junction composed of the 3′ end and the 5′ end during translation, if a circRNA exhibits translational behavior, the Ribo-seq reads can be mapped to the back-splice junction, which provides the criterion for the translation of circRNA (Sun and Li, 2019).
Since, the sequence spanning the back-splice junction in circRNA is spliced from the 3′ and 5′ ends, it cannot be directly obtained. Therefore, in Rcirc, we completely copy each circRNA sequence and concatenate it in the original sequence. Later, the linear sequence is used to simulate the real situation of the circRNA at the back-splice junction. After that, the reads of the ribosomal maps are aligned to this linear sequence.
Compared to traditional RNA-seq data, ribosome profiling data require further processing to remove the rRNA sequence in addition to for the routine quality control process (removing the linker and filtering the low-quality fragments) because the fragments of rRNA during sequencing may also be mixed in the final data, causing interference with the results. Since, the length of the reads obtained by the ribosome data is relatively short (generally less than 50 bp), even if there is a successful comparison of the reads to the back-splice junction, it is not enough to indicate that the reads are from this position because they may also originate from any similar area of the transcriptome.
To avoid this issue, Rcirc first aligns all processed Ribo-seq reads back to the rRNA sequence and reference genome, removing all reads that can be aligned to the rRNA and linear transcripts and leaving only reads that were not successfully aligned. This step ensures that all remaining reads have no similar regions on the rRNA and the linear transcript. Then, Rcirc aligns these reads to the previously simulated back-splice junction to cheek for matches and then counts the number of reads that can align to the back-splice junction. The circRNA is finally identified as a translated circRNA if there are no less than three Ribo-seq reads on its back-splice junction.
Downstream Analysis and Visualization
In this section, we introduce four commonly used functions. The mappingPlot function is one of the important functions in Rcirc. Most next-generation sequencing (NGS) data visualization browser tools, such as IGV, help to view the mapping between reads and sequences. This method of expression is more vivid and intuitive than files in text formats such as the SAM/BAM format and thus helps researchers better study the problem in the interval of interest. However, it is impossible for these tools to view mapping results on circRNA because of its end-to-end ring structure, which is different from linear structures. In combination with the makeGenome function, users can use the mappingPlot function to visualize the alignment of circRNA. The makeGenome function automatically connects the 5′ end and 3′ end of circRNA as a ring and produces a data frame in R that contains all the mapping information of each circRNA. The makeGenome function generates a new sequence file. All circRNA sequences in this sequence file are connected end to end. By aligning Ribo-seq reads to this sequence file, users can use the mappingPlot function to visualize the alignment file, the mapping of Ribo-seq data on each junction can be revealed clearly by a ring diagram, which simulates the real circular form of circRNA in cells. This visualization includes the reads covered region, reads covered density, highlighted bases, start codons, and stop codons. Moreover, users can enlarge the mapping region by adjusting an optional parameter. The detailed usage of mappingPlot can be found in the Rcirc user documents.
circRNAs are generally classified by the location of the back-splice junction. Here, we use classByType to classify a given circRNA. According to the position of the back-splice junction, we divide the circRNA into seven categories: same_exon, different_exon, intron_exon, intron, intron_intergenic, exon_intergenic, and intergenic. After completing the classification, classByType can give a classification table and a ring density map of the distribution of different types of circRNAs on different chromosomes. A specific demonstration can be seen in Figure 2B. Users need to enter only an annotation file of the genome and a BED (Browser Extensible Data) format file of circRNAs, which can be easily analyzed.
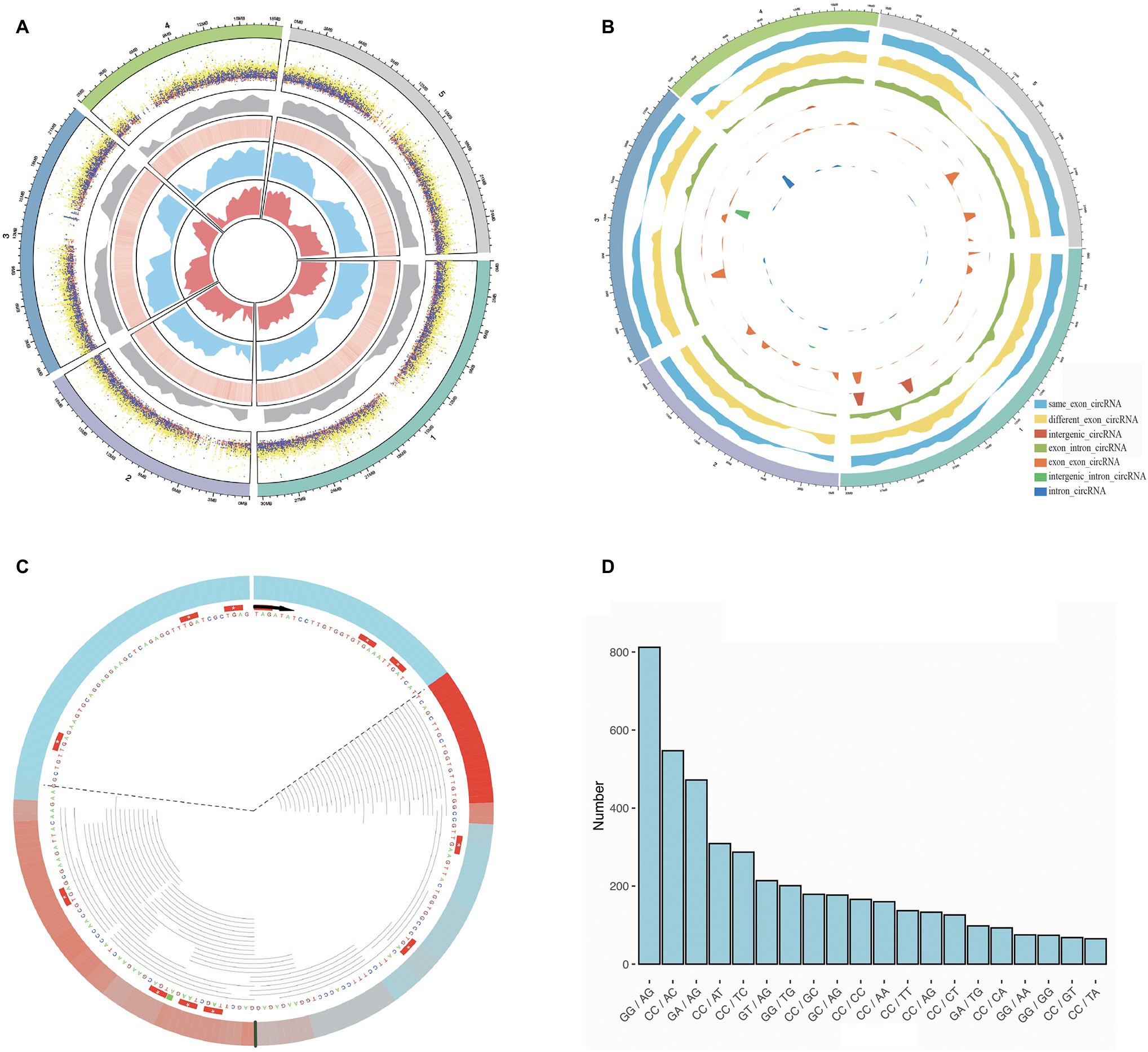
Figure 2. Some characterizations of Arabidopsis thaliana were performed using Rcirc. (A) An overview of the characteristics of all candidate circRNAs in A. thaliana. From the outside to the inside are shown a distribution of different types of circRNAs of different lengths in dot plot (the height of the dots represents the length of the circRNA, and different colors represent different types of circRNA; orange, green, light blue, cyan, dark blue, purple, light yellow represent: same_exon_circ, diff_exon_circ, exon_intron_circ, intron_circ, interg_circ, interg_exon_circ, interg_intron_circ, respectively); a density distribution of all the circRNAs; a heatmap of GC content for the genome, wherein red reveals the high GC content regions and white reveals the low GC content regions; the RNA-seq read coverage density (blue); and the Ribo-seq read coverage density (red). (B) Classification of circRNAs and plot density profiles. Different colors represent different types of circRNAs. High density indicates a large amount of circRNA, and low density indicates a small amount. (C) A visual analysis of the Ribo-seq reads mapping of one of the circRNAs. The black line represents the back-splice junction. The color change in the outermost circle represents the coverage density of the reads at the site. Red indicates high coverage of Ribo-seq reads in this location, and blue indicates low coverage. Each green line inside represents a Ribo-seq read. The area within the dashed line represents the full length covered by the reads, and the area outside of dashed line represents the area without read coverage. (D) Splice signals of all circRNAs were analyzed by Rcirc, and the resulting histograms are shown.
The stemRing function can help to determine the possible stem-ring structure for the given circRNAs in BED format. It extracts the sequence upstream and downstream of each circRNA and performs a local alignment between the downstream sequence and the reverse complement of the sequence upstream. Finally, stemRing outputs the result in a csv format file that contains the position information of each circRNA and the local upstream and downstream alignment information. Using stemRing and looking at the results, it is possible to conduct a large-scale investigation of circRNA stem-ring structures and construct a corresponding expression vector containing reverse complementary paired sequences to help circRNA circularize in cells.
The showOverview function provides an overview of all circRNAs, including a large amount of information, in one circle. It includes the distribution of circRNAs of different lengths on different chromosomes and the density distribution of circRNAs on different chromosomes. The high-GC and low-GC regions of the genome are labeled with different colors, allowing users to find connections between different features.
In addition, Rcirc includes many other functions. For example, it can also perform joint analysis on thousands of circRNAs to analyze and visualize their distribution as a function of lengths, type, and splice signal.
Software Construction
Rcirc is an R-based toolkit, and all code is written in R language. In the prediction phase, we predict the circRNA by calling the external program CIRI2. The main program of CIRI2 is already included in Rcirc without the user having to download and install it. In the identification phase of translation capabilities, we call STAR, bowtie, and trimmomatic to filter and align Ribo-seq data. In the analysis and visualization section, the R packages we use are circlize (Gu et al., 2014), ggplot2 (Hadley, 2016), Biostrings (Pagès et al., 2019), IRanges (Lawrence et al., 2013), and others.
Most of the features included in Rcirc are introduced in Table 1. More details are provided in the Rcirc user manual.
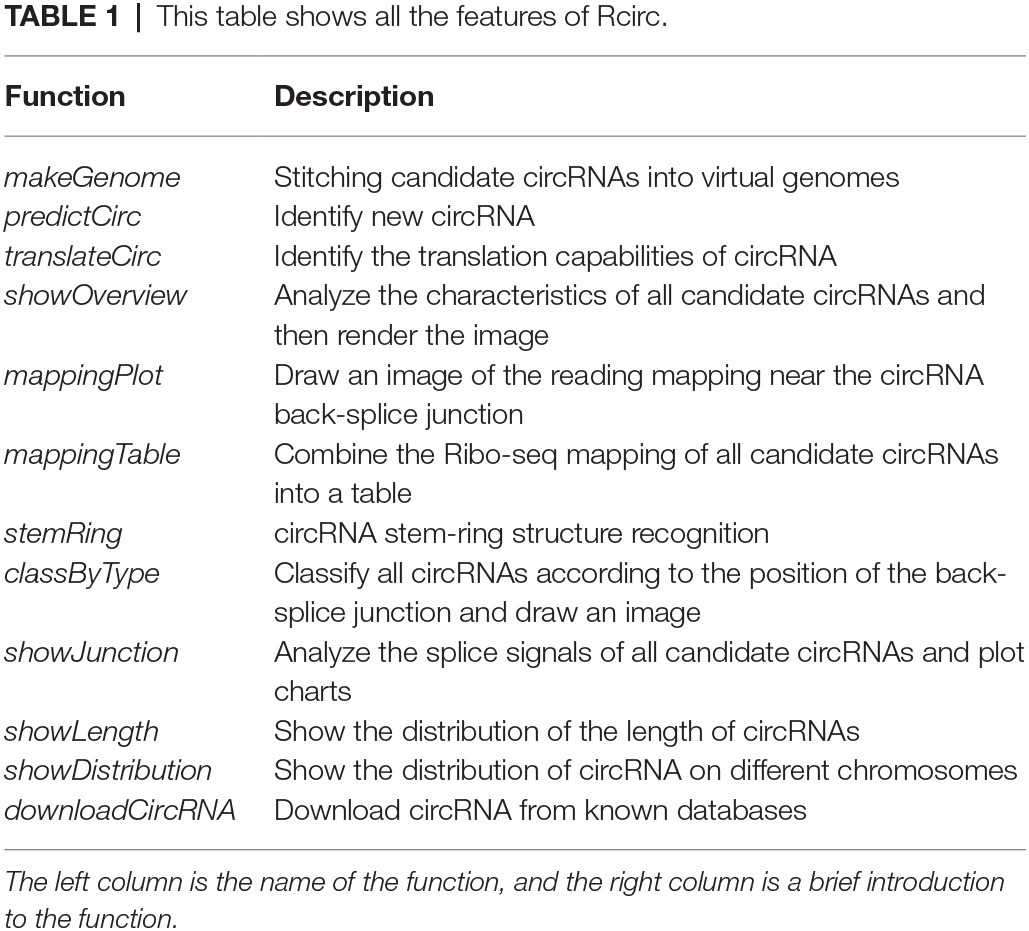
Table 1. This table shows all the features of Rcirc.
Results
To demonstrate the Rcirc analysis process, we downloaded circRNAs of Arabidopsis thaliana from Plantcircbase (Chu et al., 2017), analyzed these circRNAs, and visualized the results. The results of the partial analysis are shown in Figure 2.
In Figure 2A, we classified circRNAs by different types and lengths and compared them with the GC content of the genome, transcript abundance, and translation abundance.
The circRNAs of A. thaliana are mostly distributed at both ends of the chromosome, and the number of parts near the centromere is small. Compared with the genome, the number of circRNAs in regions with high GC content is small. In terms of length, the intergenic-intron-type circRNA has the longest average length, and the exon-type circRNA has the shortest average length. Exon-type circRNA is more regularly distributed on the chromosome and has higher consistency with transcript abundance and translation abundance, while the distribution of intron-type circRNA and intergenic-type circRNA has strong randomness and transcription. This abundance has no obvious correlation.
To visualize the ribosome footprint on circRNA, we used Rcirc to align Ribo-seq reads to these circRNAs and randomly selected a circRNA with Ribo-seq read coverage for display (Figure 2C). The green line representing the reads of Ribo-seq in the figure shows how the ribosome moves on the back-splice site of this circRNA. In contrast to text-based alignment files, Rcirc provides this intuitive visual function for users.
The circRNA cleavage signal refers to the arrangement and combination of two bases upstream and downstream of the circRNA back-splice site. In circRNA research, the cleavage signal is often regarded as an important feature of circRNAs in a species. Analysis of Arabidopsis circRNA splice signals showed that GG/AG, CC/AC, and GA/AG accounted for most of the signals (Figure 2D).
Discussion
Most of the currently published software is used to predict circRNA (Hansen et al., 2016), while no software for characterization of circRNA is available. Similar software such as circtools provides partial analysis and visualization functions such as primer design, but its visualization of the back-splice junction is applicable only for the linear structure, which is less intuitive than the circular structure (Table 2). Another important feature of Rcirc is to fill the gap in this field. In the circRNA literature, many articles have analyzed the characteristics of circRNA from multiple angles, generally including its length distribution, chromosome distribution, classification, and shearing according to the location of its back-splice junction in linear transcripts, the shear signal distribution of the back-splice junction, etc. We have summarized these analyses and added as much of the downstream analysis as possible in Rcirc. Software that is complicated to use imposes a high cost in learning time on the user. In Rcirc, we simplified all the analysis processes as much as possible. To perform the above analysis, users did not need to write complex code. The design principle of Rcirc is to complete one analysis using only one line of code. Therefore, Rcirc is an easy-to-use R package for circRNA investigation.
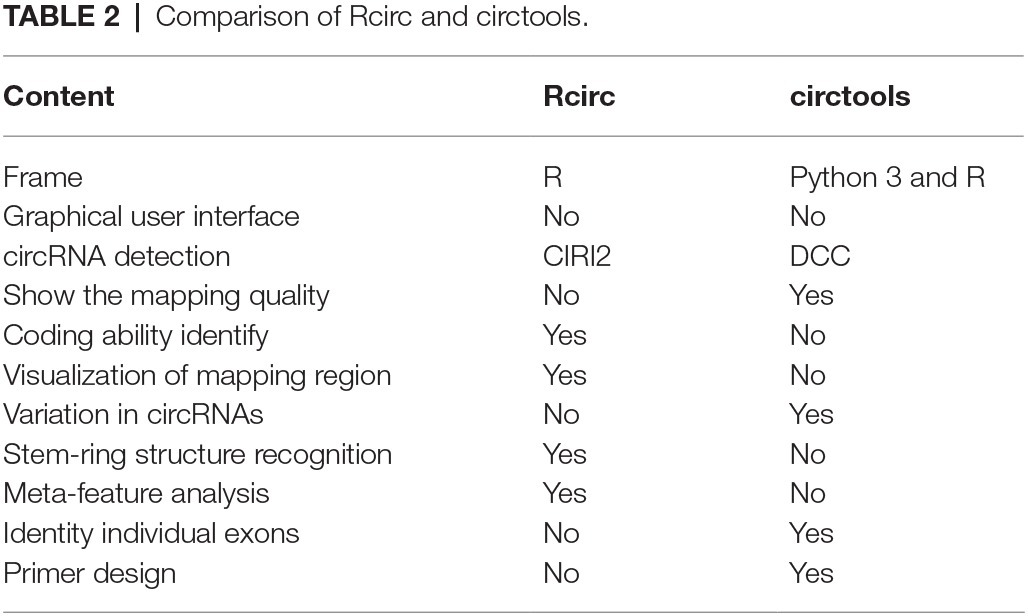
Table 2. Comparison of Rcirc and circtools.
To simplify Rcirc use for feature investigation and visualization, we eliminated a large number of possible input parameters and made the functions highly modular. The user needs only to enter the necessary file path to obtain the final analysis results. This design reduces the use threshold of Rcirc, allowing the user to execute the desired analysis without much learning time. However, due to the lack of customizability of the analysis results, the analysis process cannot be directly defined by modifying the parameters. To improve the customizability while simplifying the use as much as possible, we have added some parameters for modifying the way in which the results are displayed, all of which are set to default values for the user to call when needed.
We tested the two most time-consuming functions when running in R, “circ_summary” and “circ.plot”, by applying them to handle a 5.4 Mb virtual genome and 501,691 Ribo-seq reads. We ran both functions with a single thread on PC equipment with eight CPU cores at a clock rate of 2.3 GHz and 8 GB of RAM. The running times were 4.14 and 1.53 s, respectively. However, these two functions in Rcirc are not available in other tools, such as circtools.
Conclusion
With increasingly intensive research on circRNA, an increasing number of studies have proven that it plays an important role in the body. However, the corresponding analysis tools for circRNA have not been developed. The main goal of our study was to develop a user-friendly tool that covers the main demands for circRNA research. Rcirc is a capable and user-friendly package based on the R language. The package provides numerous analyses for both upstream and downstream research, including circRNA detection, coding ability identification, single feature analyses, and the visualization of meta-features. Furthermore, the users can visualize the read mapping for each back-splice junction of circRNA by using Rcirc with sequencing data. With increasing attention on circRNA, Rcirc will become an auxiliary tool to encourage researchers to proceed with further analyses on circRNA, and we will add the most common features into Rcirc in future releases. All the details of usage are included in the Rcirc documents in the GitHub online pages.
Availability and Requirements
Rcirc is available at https://github.com/PSSUN/Rcirc; operating system(s): Linux; programming language: R; other requirements: bowtie, STAR, R packages (circlize, ggplot2, Biostrings, GenomicAlignments, GenomicFeatures, GenomicRanges, and IRanges). The installation packages for all of the required software are available on the Rcirc homepage. Users do not need to download the required software individually. The Rcirc home page also provides detailed user manuals for reference. The tool is freely available. There are no restrictions on use by nonacademics.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://bis.zju.edu.cn/plantcircnet/Data/Download/ath.gtf.
Author Contributions
PS and HW developed the software package under the guidance of GL, and PS performed all analyses in the manuscript. PS and GL drafted and revised the manuscript. All the authors read and approved the final manuscript.
Funding
This work was supported by grants from the National Natural Science Foundation of China (Grant No.31770333, No.31370329, and No.11631012), the Program for New Century Excellent Talents in University (NCET-12-0896) and the Fundamental Research Funds for the Central Universities (No. GK201403004). The funding agencies had no role in the study, its design, the data collection and analysis, the decision to publish, or the preparation of the manuscript. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Bonizzato, A., Gaffo, E., Te Kronnie, G., and Bortoluzzi, S. (2016). CircRNAs in hematopoiesis and hematological malignancies. Blood Cancer J. 6:e483. doi: 10.1038/bcj.2016.81
Brar, G. A., and Weissman, J. S. (2015). Ribosome profiling reveals the what, when, where and how of protein synthesis. Nat. Rev. Mol. Cell Biol. 16, 651–664. doi: 10.1038/nrm4069
Chu, Q., Zhang, X., Zhu, X., Liu, C., Mao, L., Ye, C., et al. (2017). PlantcircBase: A Database for Plant Circular RNAs. Mol. Plant 10, 1126–1128. doi: 10.1016/j.molp.2017.03.003
Delcourt, V., Staskevicius, A., Salzet, M., Fournier, I., and Roucou, X. (2018). Small proteins encoded by unannotated ORFs are rising stars of the proteome, confirming shortcomings in genome annotations and current vision of an mRNA. Proteomics 18:1700058. doi: 10.1002/pmic.201700058
Gao, Y., Wang, J., and Zhao, F. (2015). CIRI: an efficient and unbiased algorithm for de novo circular RNA identification. Genome Biol. 16:4. doi: 10.1186/s13059-014-0571-3
Gao, Y., Zhang, J., and Zhao, F. (2018). Circular RNA identification based on multiple seed matching. Brief. Bioinform. 19, 803–810. doi: 10.1093/bib/bbx014
Gu, Z., Gu, L., Eils, R., Schlesner, M., and Brors, B. (2014). Circlize implements and enhances circular visualization in R. Bioinformatics 30, 2811–2812. doi: 10.1093/bioinformatics/btu393
Hadley, W. (2016). ggplot2: Elegant graphics for data analysis . New York: Springer-Verlag. Available at: https://ggplot2.tidyverse.org
Hansen, T. B., Venø, M. T., Damgaard, C. K., and Kjems, J. (2016). Comparison of circular RNA prediction tools. Nucleic Acids Res. 44:e58. doi: 10.1093/nar/gkv1458
Jakobi, T., Uvarovskii, A., and Dieterich, C. (2018). Circtools—a one-stop software solution for circular RNA research. Bioinformatics 35, 2326–2328. doi: 10.1093/bioinformatics/bty948
Kulcheski, F. R., Christoff, A. P., and Margis, R. (2016). Circular RNAs are miRNA sponges and can be used as a new class of biomarker. J. Biotechnol. 238, 42–51. doi: 10.1016/j.jbiotec.2016.09.011
Lawrence, M., Huber, W., Pagès, H., Aboyoun, P., Carlson, M., Gentleman, R., et al. (2013). Software for computing and annotating genomic ranges. PLoS Comput. Biol. 9:e1003118. doi: 10.1371/journal.pcbi.1003118
Li, X., Yang, L., and Chen, L.-L. (2018). The biogenesis, functions, and challenges of circular RNAs. Mol. Cell 71, 428–442. doi: 10.1016/j.molcel.2018.06.034
Memczak, S., Jens, M., Elefsinioti, A., Torti, F., Krueger, J., Rybak, A., et al. (2013). Circular RNAs are a large class of animal RNAs with regulatory potency. Nature 495, 333–338. doi: 10.1038/nature11928
Meng, X., Chen, Q., Zhang, P., and Chen, M. (2017). CircPro: an integrated tool for the identification of circRNAs with protein-coding potential. Bioinformatics 33, 3314–3316. doi: 10.1093/bioinformatics/btx446
Pagès, H., Aboyoun, P., Gentleman, R., and DebRoy, S. (2019). Biostrings: Efficient manipulation of biological strings. R package version 2.54.0.
Pamudurti, N. R., Bartok, O., Jens, M., Ashwal-Fluss, R., Stottmeister, C., Ruhe, L., et al. (2017). Translation of CircRNAs. Mol. Cell 66, 9.e7–21.e7. doi: 10.1016/j.molcel.2017.02.021
Slavoff, S. A., Mitchell, A. J., Schwaid, A. G., Cabili, M. N., Ma, J., Levin, J. Z., et al. (2013). Peptidomic discovery of short open reading frame–encoded peptides in human cells. Nat. Chem. Biol. 9, 59–64. doi: 10.1038/nchembio.1120
Sun, P., and Li, G. (2019). CircCode: a powerful tool for identifying circRNA coding ability. Front. Genet. 10:981. doi: 10.3389/fgene.2019.00981
Vicens, Q., and Westhof, E. (2014). Biogenesis of circular RNAs. Cell 159, 13–14. doi: 10.1016/j.cell.2014.09.005
Westholm, J. O., Miura, P., Olson, S., Shenker, S., Joseph, B., Celniker, S. E., et al. (2015). Genomewide analysis of Drosophila circular RNAs reveals their structural and sequence properties and age-dependent neural accumulation. Cell Rep. 9, 1966–1980. doi: 10.1016/j.celrep.2014.10.062
Keywords: bioinformatics, circular RNAs, visualization, R package, coding potential, ribosome profiling
Citation: Sun P, Wang H and Li G (2020) Rcirc: An R Package for circRNA Analyses and Visualization. Front. Genet. 11:548. doi: 10.3389/fgene.2020.00548
Edited by:
Yun Xiao, Harbin Medical University, ChinaReviewed by:
Wei Vivian Li, Rutgers, The State University of New Jersey, United StatesShaoli Das, National Institutes of Health (NIH), United States
Copyright © 2020 Sun, Wang and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guanglin Li, Z2xsaUBzbm51LmVkdS5jbg==