 Hengyi Zhang
Hengyi Zhang- College of Animal Science and Technology, Northwest A&F University, Yangling, China
Classification is widely used in gene expression data analysis. Feature selection is usually performed before classification because of the large number of genes and the small sample size in gene expression data. In this article, a novel feature selection algorithm using approximate conditional entropy based on fuzzy information granule is proposed, and the correctness of the method is proved by the monotonicity of entropy. Firstly, the fuzzy relation matrix is established by Laplacian kernel. Secondly, the approximately equal relation on fuzzy sets is defined. And then, the approximate conditional entropy based on fuzzy information granule and the importance of internal attributes are defined. Approximate conditional entropy can measure the uncertainty of knowledge from two different perspectives of information and algebra theory. Finally, the greedy algorithm based on the approximate conditional entropy is designed for feature selection. Experimental results for six large-scale gene datasets show that our algorithm not only greatly reduces the dimension of the gene datasets, but also is superior to five state-of-the-art algorithms in terms of classification accuracy.
Introduction
The development of DNA microarray technology has brought about a large number of gene expression data. It is a hot topic in bioinformatics to analyze and mine the knowledge behind these data (Sun et al., 2019b). As the most basic data mining method, classification is widely used in the analysis of gene expression data. Due to the small sample size and high dimensionality of gene expression data, the traditional classification methods are often ineffective when applied to gene expression data directly (Fu and Wang, 2003; Mitra et al., 2011; Phan et al., 2012; Konstantina et al., 2015). It has become a consensus in the academic community to reduce the dimensionality before classification. Feature selection is the most widely used dimensionality reduction method in gene expression data because it can maintain the biological significance of each feature. Feature selection can not only reduce the time and space complexity of classification learning algorithm, avoid dimensionality disaster, and improve the prediction accuracy of classification, but also help to explain biological phenomena.
Feature selection methods are generally divided into three categories: filter, wrapper, and embedded method (Hu et al., 2018). The filter method obtains the optimal subset of features by judging the similarity between the features and the objective function based on the statistical characteristics of data. The wrapper method uses a specific model to carry out multiple rounds of training. After each round of training, several features are removed according to the score of the objective function, and then the next round of training is carried out based on the new feature set. In this way, recursion is repeated until the number of remaining features reaches the required number. The embedded method uses machine learning algorithm to get the weight coefficient of each feature in the first place, and then selects the feature according to the weight coefficient from large to small. Wrapper and embedded methods have heavy computational burden and are not suitable for large-scale gene data sets. Our feature selection method belongs to the filter method, in which a heuristic search algorithm is used to find an optimal subset of features using approximate conditional entropy based on fuzzy information granule for gene expression data classification.
Attribute reduction is a fundamental research topic and an important application of granular computing (Dong et al., 2018; Wang et al., 2019). Attribute reduction can be used for feature selection. Granular computing is a new concept and new computing paradigm of information processing, which is mainly used to deal with fuzzy and uncertain information (Qian et al., 2011).
Pawlak (1982) proposed the rough set theory. Rough set theory is a new mathematical tool to deal with fuzziness and uncertainty. Granular computing is one of the important research contents of rough set theory. On the basis of equivalence relation, rough set theory is only suitable for dealing with discrete data widely existing in real life. When dealing with attribute reduction problem of continuous data in classical rough set theory, discretization method is often used to convert continuous data into discrete data, but the discretization will inevitably lead to information loss (Dai and Xu, 2012). To overcome this drawback, Hu et al. proposed a neighborhood rough set model (Hu et al., 2008, 2011). Using neighborhood rough set model to select attribute of decision table containing continuous data can keep classification ability well and need not discretize it. The existing neighborhood rough set attribute reduction methods are based on the perspective of algebra or information theory. The definition of attribute significance based on algebra theory only describes the influence of attributes on the definite classification subset contained in the universe. The definition of attribute significance based on information theory only describes the influence of attributes on uncertain classification subsets contained in the universe. A single perspective is not comprehensive (Jiang et al., 2015).
Zadeh (1979) proposed the concept of information granulation based on fuzzy sets theory. Objects in the universe are granulated into a set of fuzzy information granules by a fuzzy-binary relation (Tsang et al., 2008; Jensen and Shen, 2009).
In this article, a heuristic feature selection algorithm based on fuzzy information granules and approximate conditional entropy is designed to improve the classification performance of gene expression data sets. The experimental results for several gene expression data sets show that the proposed algorithm can find optimal reduction sets with few genes and high classification accuracy.
The remainder of this article is organized as follows. Section “Materials and Methods” gives the gene expression datasets for the experiment and our feature selection algorithm. Section “Experimental Results and Analysis” shows and analyzes the experimental results. Section “Conclusion and Discussion” summarizes this study and discusses future research focus.
Materials and Methods
Gene Expression Data Sets
The following six gene expression datasets are used in this article.
(1) Leukemia1 dataset consists of 7129 genes and 72 samples with two subtypes: patients and healthy people (Sun et al., 2019a).
(2) Leukemia2 dataset consists of 5327 genes and 72 samples with three subtypes: ALL-T (acute lymphoblastic leukemia, T-cell), ALL-B (acute lymphoblastic leukemia, B-cell), and AML (acute myeloid leukemia) (Dong et al., 2018).
(3) Brain Tumor dataset consists of 10,367 genes and 50 samples with four subtypes (Huang et al., 2017).
(4) 9_Tumors dataset consists of 5726 genes and 60 samples with nine subtypes: non-small cell lung cancer, colon cancer, breast cancer, ovarian cancer, leukemia, kidney cancer, melanoma, prostate cancer, and central nervous system cancer (Ye et al., 2019).
(5) Robert dataset consists of 23,416 genes and 194 samples with two subtypes: Musculus CD8+T-cells and L1210 cells (Kimmerling et al., 2016).
(6) Ting dataset consists of 21,583 genes and 187 samples with seven subtypes: GMP cells, MEF cells, MP cells, nb508 cells, TuGMP cells, TuMP cells, and WBC cells (Ting et al., 2014).
The six gene expression datasets are summarized in Table 1.
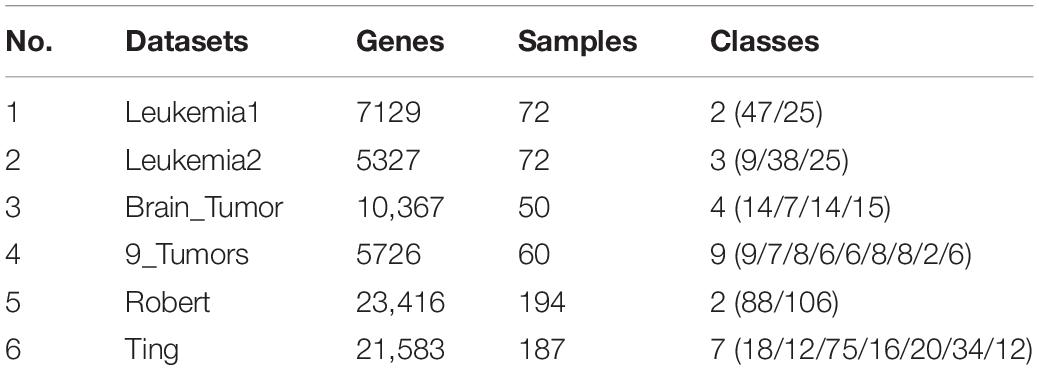
Table 1. Description of six experimental datasets.
Fuzzy Sets and Fuzzy-Binary Relation
Let U = {x1, x2, …, xn} be a nonempty finite set and denote a universe, I = [0, 1], IU denotes all fuzzy sets on U.
Fuzzy sets are regarded as the extensions of classical sets (Zadeh, 1965).
F is a fuzzy set on U, i.e., F: U → I, then F(xi) is the membership degree of xi to F.
The cardinality of F ∈ IU is .
Fuzzy-binary relation are fuzzy sets on two universes. IU×U denotes all fuzzy-binary relations on U × U.
Fuzzy-binary relation R can be represented by
where rij = R(xi, xj) ∈ I is the similarity of xi and xj.
Information Systems and Rough Sets
Definition 2.1 (Li et al., 2017). Let Ube a set of objects and A a set of attributes. Suppose that U and A are finite sets. If each attribute a ∈ A determines an information function a:U→Va, where Va is the set of function values of attribute a, then the pair (U, A) is called an information system.
Moreover, if A = C⋃D, C is a condition attribute set and D is a decision attribute set, then the pair (U, A) is called a decision information system.
If (U, A) is an information system and P ⊆ A, then an equivalence relation (or indiscernibility relation) ind(P) can be defined by (x, y) ∈ ind(P)⇔∀a ∈ P, a(x) = a(y).
Obviously, .
For P ⊆ A and x ∈ U, denote [x]ind(P) = {y|(x, y) ∈ ind(P)} and U/ind(P) = {[x]ind(P)|x∈U}.
Usually, [x]ind(P) and U/ind(P) are briefly denoted by [x]P and U/P, respectively.
According to the rough set theory, for P ⊆ A, X ⊆ U is characterized by and , where and .
and are referred to as the lower and upper approximations of X, respectively.
X is crisp if and X is rough if .
The Approximately Equal Relation on Fuzzy Sets
Given F,G ∈ IU. For x ∈ U, F(x) and G(x) are the membership degrees of x belonging to fuzzy sets F and G, respectively. F(x) and G(x) ∈ [0,1]. Actually, it is very difficult to ensure that the equation F(x) = G(x) holds. For this reason, we propose the following approximately equal relation of fuzzy sets.
Definition 2.2 Given A,B ∈ IU. If there exists k ∈ N(k≥2) such that for any x ∈ U, A(x),B(x) ∈ [0,1/k) or A(x),B(x) ∈ [1/k,2/k)…or A(x),B(x) ∈ [(k−1)/k,1], then we say that A is approximately equal to B, and denote it by , where k is regarded as a threshold value.
Definition 2.3 For each a ∈ U, define xR:U→[0,1],xR(a) = R(x,a)(x ∈ U), xR is referred to as a fuzzy set that means the membership degree of a to x.
Definition 2.4 , [x]Ris referred to as the fuzzy equal class of x induced by the fuzzy relation R on U.
Definition 2.5 [xi]R(i = 1,2,…,|U|) is named as the fuzzy information granule induced by the fuzzy relation R on U.
Definition 2.6G(R) = {[x1]R,[x2]R,…,[xn]R} is referred to as the fuzzy-binary granular structure of the universe U induced by R.
It is easy to prove: , .
Fuzzy-Binary Relation Based on Laplacian Kernel
Hu et al. (2010) found that there are some relationships between rough sets and Gaussian kernel method, so Gaussian kernel is used to obtain fuzzy relations. Compared with Gaussian kernel, Laplacian kernel has higher peak, faster reduction and smoother tail. Therefore, Laplacian kernel is better than Gaussian kernel in describing the similarity between objects. In this article, we use Laplacian kernel to extract the similarity between two objects from decision information system, where ||xi−xj|| is the Euclidean distance between two objects xi and xj. In general, σ is a given positive value.
Obviously, k(xi, xj) satisfies:
(1) k(xi, xj)∈(0,1].
(2) k(xi, xj) = k(xj,xi).
(3) k(xi, xi) = 1.
Let R = (k(xi, xj))n×n, then R is called the fuzzy relation matrix induced by Laplacian kernel.
Feature Selection Using Approximate Conditional Entropy Based on Fuzzy Information Granule
Approximate Accuracy and Approximate Conditional Entropy
Definition 2.7 Given a decision information system (U, C⋃D), ∀X ⊆ U, X ≠ ϕ (ϕ is an empty set), then the approximate accuracy of X is defined as
where |.| denotes the cardinality of set. Obviously, 0≤a(X)≤1.
Definition 2.8 Given a decision information system (U,C⋃D), ∀B ⊆ C, the fuzzy information granule of object x under B is [x]R_B, the partition of U derived from D is {X1,X2,…,Xk}, then the conditional entropy of D relative to B is defined as
where RB denotes the fuzzy relation based on attribute set B and log is a base-2 logarithm.
The approximate accuracy can effectively measure the imprecision of the set caused by the boundary region, while the conditional entropy can effectively measure the knowledge uncertainty caused by the information granularity. We combine the two to propose approximate conditional entropy.
Definition 2.9 Let (U,C⋃D) be a decision information system, ∀B ⊆ C, the fuzzy information granule of object x under B is [x]R_B, the partition of U derived from D is {X1,X2,…,Xk}, aB(Xi) is the approximate accuracy of Xi under RB, then the approximate conditional entropy of D relative to B is defined as
Theorem 2.1 Let (U,C⋃D) be a decision information system, ∀B ⊆ C, the fuzzy information granule of object x under B is [x]R_B, the partition of U derived from D is {X1,X2,…,Xk}.
(1) Hace(D/B) gets the maximum value |U|log|U| if and only if [xi]RB = U(i = 1,2,…,n) and |Xj| = 1(j = 1,2,…,k = n).
(2) Hace(D/B)gets the minimum value 0 if and only if [xi]RB ⊆ [xi]RD(i = 1,2,…,n).
Proof. (1) Due to [xi]RB = U(i = 1,2,…,n) and |Xj| = 1(j = 1,2,…,k), we have aB(Xj) = 0(j = 1,2,…,k) according to Definition 2.7.
Thus, log(2−aB(Xj)) = 1(j = 1,2,…,k).
Clearly, .
By Definition 2.9, we have Hace(D/B) = |U|log|U|.
The converse is also true.
(2) Due to [xi]RB ⊆ [xi]RD(i = 1,2,…,n), we have aB(Xj) = 1(j = 1,2,…,k) according to Definition 2.7. Thus log(2−aB(Xj)) = 0(j = 1,2,..,k). Obviously, Hace(D/B) = 0 according to Definition 2.9.
The converse is also true.
Theorem 2.2 Let (U,C⋃D) be a decision information system, ∀L,M ⊆ C, if M ⊆ L, then Hace(D/M)≥Hace(D/L).
Proof. Due to M ⊆ L ⊆ C, we have and .
Then aM(X)≤aL(X) according to Definition 2.7.
By M ⊆ L and U/D = {X1,X2,…,Xk}, we have
Consequently, Hace(D/M)≥Hace(D/L) according to Definition 2.9.
Theorem 2.2 shows that Hace(D/B) decreases monotonically with the increase of the number of attributes in B, which is very important for constructing forward greedy algorithm of attributes reduction.
Definition 2.10 Let (U,C⋃D) be a decision information system and B ⊆ C, if Hace(D/B) = Hace(D/C) and Hace(D/(B−{b})) > Hace(D/C)(∀b ∈ B), then B is called a reduction of C relative to D.
The first condition guarantees that the selected attribute subset has the same amount of information as the whole attribute set. The second condition guarantees that there is no redundancy in the attribute reduction set.
Definition 2.11 Assume that (U,C⋃D) be a decision information system, ∀c ∈ C, define the following indicator,
then IIA(c,C,D) is called the importance of internal attribute of c in C relative to D.
Definition 2.12 Assume that (U,C⋃D) be a decision information system, ∀c ∈ C, if IIA(c,C,D) > 0, then attribute c is called a core attribute of C relative to D.
Definition 2.13 Assume that (U,C⋃D) be a decision information system, B ⊆ C, ∀d ∈ C−B, define the following indicator,
then IEA(d,B,C,D) is called the importance of external attribute of d to B relative to D.
IEA(d,B,C,D) shows the change of approximate conditional entropy after adding attribute d. The larger IEA(d,B,C,D) is, the more important d is to B relative to D.
Feature Selection Algorithm Using Approximate Conditional Entropy
In this article, a novel feature selection algorithm using approximate conditional entropy (FSACE) is proposed and described as follows.

Experimental Results and Analysis
All experiments are performed on a personal computer running Windows 10 with an Intel(R) Core(TM) i7-4790 CPU operating at 3.60 GHz with 8 GB memory using MATLAB R2019a. The classifiers (KNN, CART, and SVM) are selected to verify the classification accuracy, where the parameter k=3 in KNN and Gaussian kernel function is selected in SVM. Other parameters of the three algorithms are the default values of the software.
Influence of Different Values of σ on Classification Performance
In this part, the classification accuracy of different Laplacian kernel parameters values of σ is tested. For gene expression data, feature selection aims to improve classification accuracy by eliminating redundant genes. The different values of σ influence the size of granulated gene data, which affects the classification accuracy of selected genes. Therefore, the different values of σ should be set in the process of feature selection of gene expression data sets. Moreover, the different values of σ also affect the composition of the selected gene subset. To obtain a suitable σ and a good gene subset, the classification accuracy of the selected gene subset for different values of σ should be discussed in detail.
The corresponding experiments are performed to graphically illustrate the classification accuracy of FSACE under different values of σ. The results are shown in Figure 1, where the horizontal axis denotes σ ∈ [0.05,1] at intervals of 0.05, and the vertical axis represents the classification accuracy.
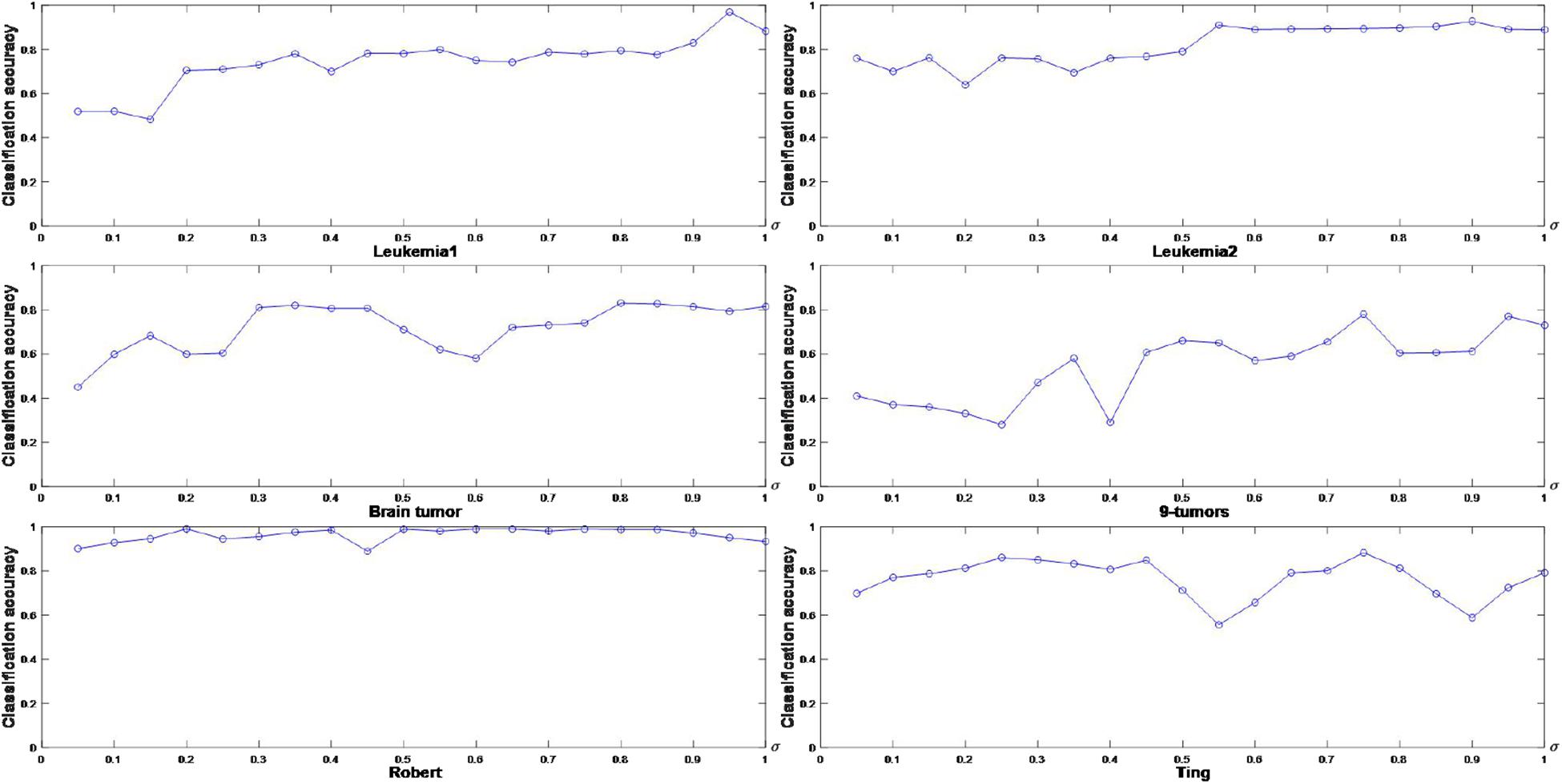
Figure 1. Classification accuracy for six gene expression data sets with different values of σ.
Figure 1 shows that σ greatly influences the classification performance of FSACE. σ is usually set to make the classification accuracy highest. Thus, the appropriate parameter values of σ can be obtained for each data set from Figure 1. In Figure 1A, for Leukemia1 data set, when σ is 0.95, the classification accuracy is the highest. In Figure 1B, for Leukemia2 data set, when σ is 0.55, the classification accuracy is the highest. In Figure 1C, for Brain tumor data set, when σ is 0.80, the classification accuracy is the highest. In Figure 1D, for 9-tumors data set, when σ is 0.75, the classification accuracy is the highest. In Figure 1E, for Robert data set, when σ is 0.60, the classification accuracy is the highest. In Figure 1F, for Ting data set, when σ is 0.75, the classification accuracy is the highest. Therefore, the appropriate values of σ for different data sets are determined.
The Feature Selection Results and Classification Performance of FSACE
The classification results obtained from the three classifiers (KNN, CART, and SVM) with 10-fold cross-validation are shown in Table 2 on the test data by FSACE.
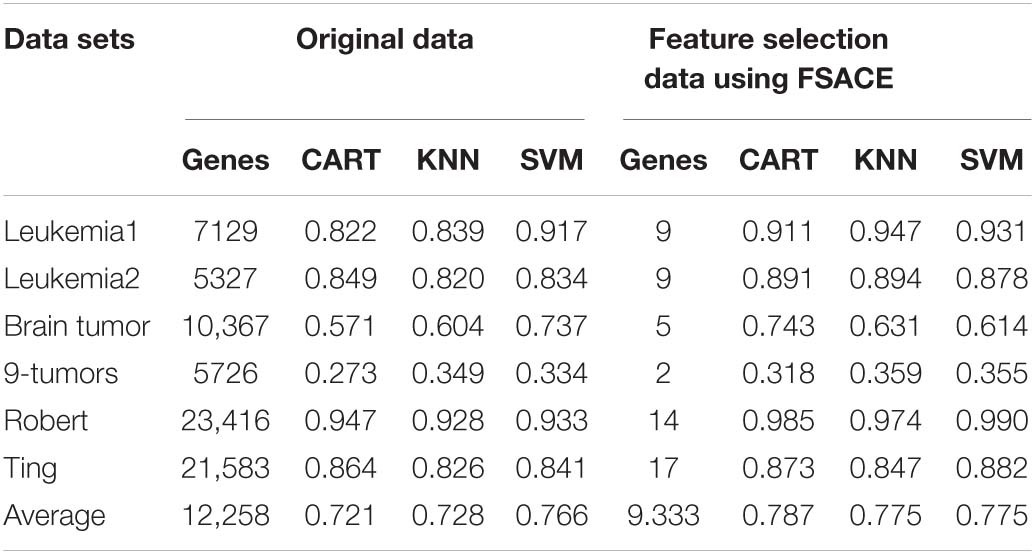
Table 2. Classification results of six gene expression data sets.
Table 2 shows that FSACE not only greatly reduces the dimensionality of all six gene expression data sets, but also improves the classification accuracy.
The results of feature genes selection from six gene expression data sets are shown in Table 3 using FSACE.

Table 3. The selected feature genes on six gene expression data sets using FSACE.
Comparison of the Classification Performance of Several Entropy-Based Feature Selection Algorithms
To evaluate the performance of FSACE in terms of classification accuracy, FSACE algorithm is compared with several state-of-the-art feature selection algorithms, including EGGS (Chen et al., 2017), EGGS-FS (Yang et al., 2016), MEAR (Xu et al., 2009), Fisher (Saqlain et al., 2019), and Lasso (Tibshirani, 1996). According to the change trend of Fisher scores of six gene datasets, we select the top-200 genes as the reduction set for Fisher algorithm.
Tables 4–9 show the experimental results of six gene expression data sets using six different feature selection methods.
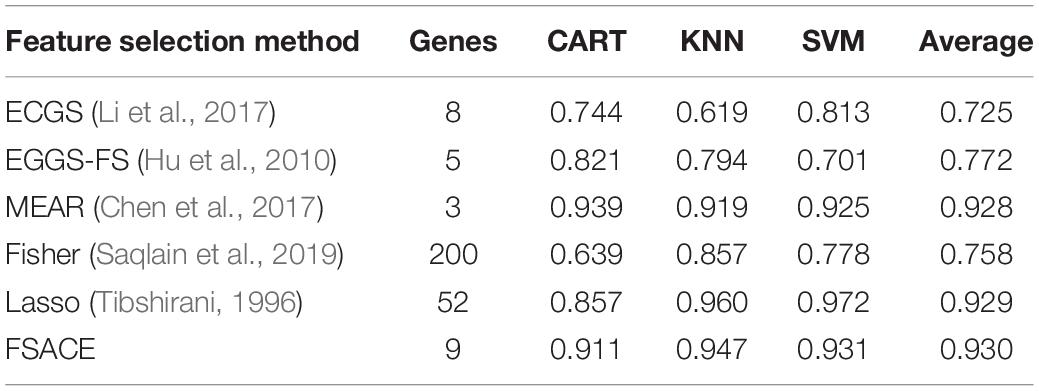
Table 4. Classification accuracy of Leukemia1 using six different feature selection algorithms.
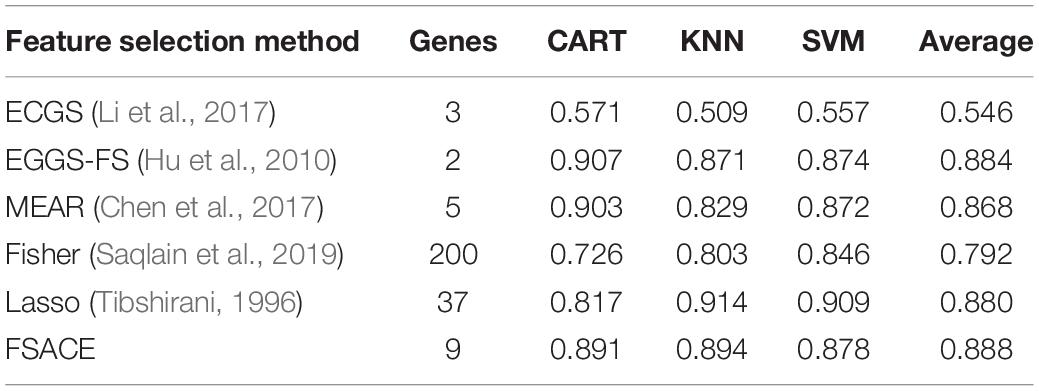
Table 5. Classification accuracy of Leukemia2 using six different feature selection algorithms.
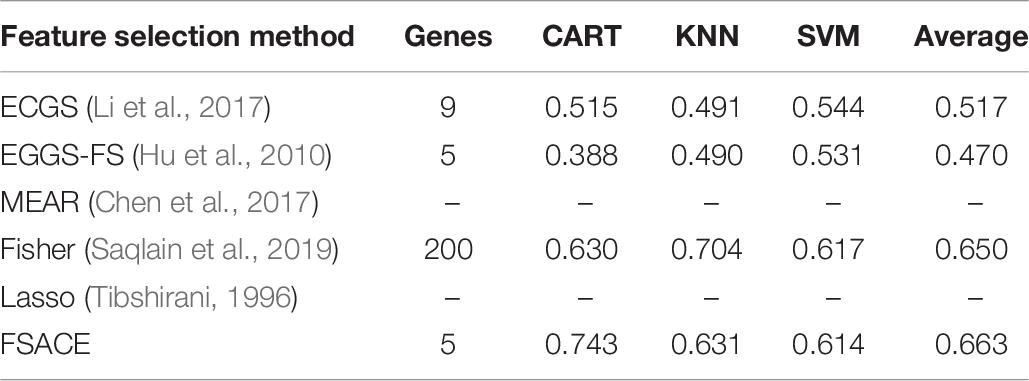
Table 6. Classification accuracy of Brain tumor using six different feature selection algorithms.
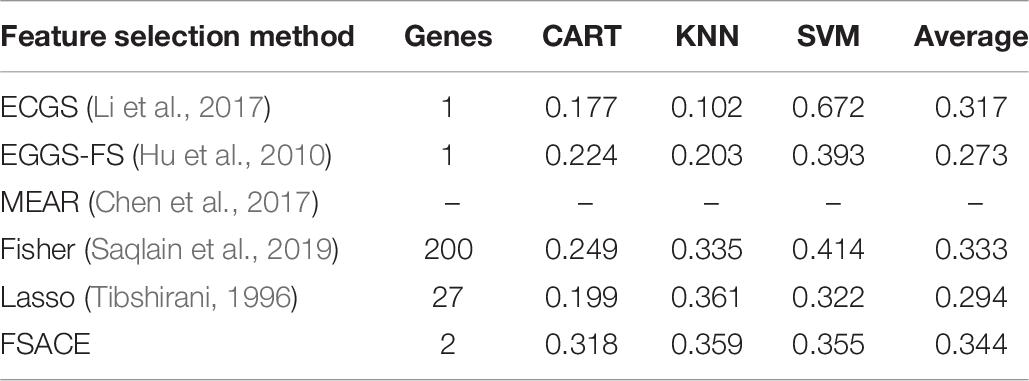
Table 7. Classification accuracy of 9-tumors using six different feature selection algorithms.
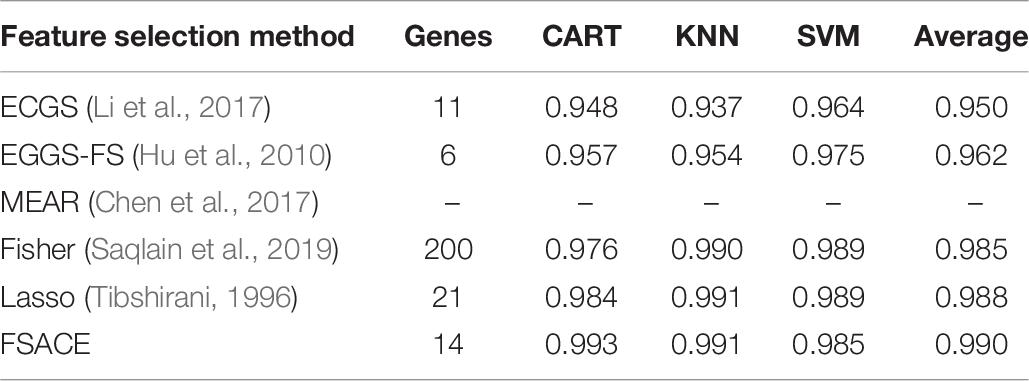
Table 8. Classification accuracy of Robert using six different feature selection algorithms.
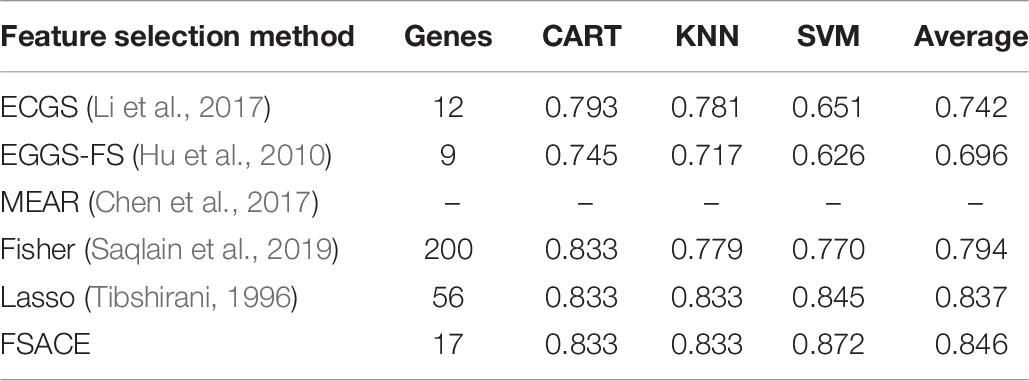
Table 9. Classification accuracy of Ting using six different feature selection algorithms.
As shown in Tables 4, 5, FSACE has the highest average classification accuracy for Leukemia1 and Leukemia2, and exhibits better classification performance than the other five algorithms.
As shown in Tables 6, 7, MEAR cannot work on Brain Tumor data set and 9-tumors data set, its results are denoted by the sign –. FSACE obtains the highest average classification accuracy among the five feature selection algorithms for Brain Tumor data set and 9-tumors data set.
Tables 8, 9 shows that MEAR still can not work on Robert data set and Ting data set, which indicates that the algorithm is not stable. Our algorithm still has the highest classification accuracy among all the algorithms. Although the classification accuracy of our algorithm is only a little higher than lasso algorithm, the number of attributes reduced by our algorithm is much less than lasso algorithm.
Tables 4–9 show that the average number of attributes reduced by our algorithm is slightly more than that of MEAR, ECGS, and EGGS-FS, but the average classification accuracy is much higher than that of these three algorithms.
Therefore, FSACE can not only effectively remove noise and redundant data from the original data, but also improve the classification accuracy of gene expression data sets.
Conclusion and Discussion
Firstly, the concept of approximate conditional entropy is given and its monotonicity is proved in this article. Approximate conditional entropy can describe the uncertainty of knowledge from two aspects of boundary and information granule. And then, a novel feature selection algorithm FSACE is proposed based on the approximate conditional entropy. Finally, the effectiveness of the proposed algorithm is verified on several gene expression data sets. Experimental results show that compared with several state-of-the-art feature selection algorithms, the proposed feature selection algorithm not only can obtain compact features, but also improve classification performance. The time complexity of FSACE is O(|U|2|C|2). Because the gene expression data sets usually contain a large number of genes, the time complexity of FSACE is high. In addition, FSACE does not consider the interaction between attributes. Therefore, reducing the time complexity of FSACE and seeking more efficient feature selection algorithm considering interaction between attributes are two issues that we will study in the future.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://portals.broadinstitute.org/cgi-bin/cancer/datasets.cgi (cancer Program Legacy Publication Resources).
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Chen, Y., Zhang, Z., Zheng, J., Ying, M., and Yu, X. (2017). Gene selection for tumor classification using neighborhood rough sets and entropy measures. J. Biomed. Inform. 67, 59–68. doi: 10.1016/j.jbi.2017.02.007
Dai, J., and Xu, Q. (2012). Approximations and uncertainty measures in incomplete information systems. Inf. Sci. 198, 62–80. doi: 10.1016/j.ins.2012.02.032
Dong, H., Li, T., Ding, R., and Sun, J. (2018). A novel hybrid genetic algorithm with granular information for feature selection and optimization. Appl. Soft Comput. 65, 33–46. doi: 10.1016/j.asoc.2017.12.048
Fu, X., and Wang, L. (2003). Data dimensionality reduction with application to simplifying RBF network structure and improving classification performance. IEEE Trans. Syst. Man Cybern. Part B Cybern. 33, 399–409. doi: 10.1109/tsmcb.2003.810911
Hu, L., Gao, W., Zhao, K., Zhang, P., and Wang, F. (2018). Feature selection considering two types of feature relevancy and feature interdependency. Expert Syst. Appl. 93, 423–434. doi: 10.1016/j.eswa.2017.10.016
Hu, Q., Yu, D., Liu, J., and Wu, C. (2008). Neighborhood rough set based heterogeneous feature subset selection. Inf. Sci. 178, 3577–3594. doi: 10.1016/j.ins.2008.05.024
Hu, Q., Zhang, L., Chen, D., Witold, P., and Daren, Y. (2010). Gaussian kernel based fuzzy rough sets: model, uncertainty measures and applications. Int. J. Approx. Reason. 51, 453–471. doi: 10.1016/j.ijar.2010.01.004
Hu, Q., Zhang, L., Zhang, D., Wei, P., Shuang, A., and Witold, P. (2011). Measuring relevance between discrete and continuous features based on neighborhood mutual information. Expert Syst. Appl. 38, 10737–10750. doi: 10.1016/j.eswa.2011.01.023
Huang, X., Zhang, L., Wang, B., Li, F. Z., and Zhang, Z. (2017). Feature clustering based support vector machine recursive feature elimination for gene selection. Appl. Intell. 48, 1–14.
Jensen, R., and Shen, Q. (2009). New approaches to fuzzy-rough feature selection. IEEE Trans. Fuzzy Syst. 17, 824–838. doi: 10.1109/tfuzz.2008.924209
Jiang, F., Wang, S., Du, J., and Sui, Y. F. (2015). Attribute reduction based on approximation decision entropy. Control and Decis. 30, 65–70. doi: 10.3390/e20010065
Kimmerling, R., Szeto, G., Li, J., Alex, S. G., Samuel, W. K., Kristofor, R. P., et al. (2016). A microfluidic platform enabling single-cell RNA-seq of multigenerational lineages. Nat. Commun. 7:10220.
Konstantina, K., Themis, P., Konstantinos, P. E., Michalis, V. K., and Dimitrios, I. F. (2015). Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 13, 8–17. doi: 10.1016/j.csbj.2014.11.005
Li, Z., Liu, X., Zhang, G., Xie, N., and Wang, S. (2017). A multi-granulation decision-theoretic rough set method for distributed fc-decision information systems: an application in medical diagnosis. Appl. Soft Comput. 56, 233–244. doi: 10.1016/j.asoc.2017.02.033
Mitra, S., Das, R., and Hayashi, Y. (2011). Genetic networks and soft computing. IEEE/ACM Trans. Comput. Biol. Bioinform. 8, 94–107.
Phan, J., Quo, C., and Wang, M. (2012). Cardiovascular genomics: a biomarker identification pipeline. IEEE Trans. Inf. Technol. Biomed. 16, 809–822. doi: 10.1109/titb.2012.2199570
Qian, Y., Liang, J., Wu, W., and Dang, C. (2011). Information granularity in fuzzy binary GrC model. IEEE Trans. Fuzzy Syst. 19, 253–264. doi: 10.1109/tfuzz.2010.2095461
Saqlain, S. M., Sher, M., Shah, F. A., Khan, I., Ashraf, M. U., Awais, M., et al. (2019). Fisher score and Matthews correlation coefficient-based feature subset selection for heart disease diagnosis using support vector machines[J]. Knowl. Inf. Syst. 58, 139–167. doi: 10.1007/s10115-018-1185-y
Sun, L., Wang, L., Xu, J., and Zhang, S. (2019a). A neighborhood rough sets-based attribute reduction method using Lebesgue and entropy measures. Entropy 21, 1–26.
Sun, L., Zhang, X., Qian, Y., Xu, J., and Zhang, S. (2019b). Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Inf. Sci. 502, 18–41. doi: 10.1016/j.ins.2019.05.072
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Series B Stat. Methodol. 58, 267–288. doi: 10.1111/j.2517-6161.1996.tb02080.x
Ting, D., Wittner, B., Ligorio, M., Brian, W. B., Ajay, M. S., Xega, K., et al. (2014). Single-cell RNA sequencing identifies extracellular matrix gene expression by pancreatic circulating tumor cells. Cell Rep. 8, 1905–1918. doi: 10.1016/j.celrep.2014.08.029
Tsang, E., Chen, D., Yeung, D., Wang, X. Z., and Lee, J. W. T. (2008). Attributes reduction using fuzzy rough sets. IEEE Trans. Fuzzy Syst. 16, 1130–1141. doi: 10.1109/tfuzz.2006.889960
Wang, C., Shi, Y., Fan, X., and Shao, M. W. (2019). Attribute reduction based on k-nearest neighborhood rough sets. Int. J. Approx. Reason. 106, 18–31. doi: 10.1016/j.ijar.2018.12.013
Xu, F., Miao, D., and Wei, L. (2009). Fuzzy-rough attribute reduction via mutual information with an application to cancer classification. Comput. Math. Appl. 57, 1010–1017. doi: 10.1016/j.camwa.2008.10.027
Yang, J., Liu, Y., Feng, C., and Zhu, G. Q. (2016). Applying the fisher score to identify Alzheimer’s disease-related genes. Genet. Mol. Res. 15, 1–9.
Ye, C., Pan, J., and Jin, Q. (2019). An improved SSO algorithm for cyber-enabled tumor risk analysis based on gene selection. Future Gener. Comput. Syst. 92, 407–418. doi: 10.1016/j.future.2018.10.008
Keywords: feature selection, Laplacian kernel, fuzzy information granule, fuzzy relation matrix, approximate conditional entropy
Citation: Zhang H (2021) Feature Selection Using Approximate Conditional Entropy Based on Fuzzy Information Granule for Gene Expression Data Classification. Front. Genet. 12:631505. doi: 10.3389/fgene.2021.631505
Received: 20 November 2020; Accepted: 12 March 2021;
Published: 30 March 2021.
Edited by:
Wilson Wen Bin Goh, Nanyang Technological University, SingaporeCopyright © 2021 Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hengyi Zhang, emhhbmdoZW5neWkyMDAwQDE2My5jb20=