 Fernando Garcia-Sanjuan
Fernando Garcia-Sanjuan Javier Jaen
Javier Jaen Vicente Nacher
Vicente Nacher- ISSI Group, Department of Computer Systems and Computation (DSIC), Universitat Politècnica de València (UPV), Valencia, Spain
Combining multiple displays in the same environment enables more immersive and rich experiences in which visualization and interaction can be improved. Although much research has been done in the field of multi-display environments (MDEs) and previous studies have provided taxonomies to define them, these have usually consisted of partial descriptions. In this paper, we propose a general taxonomy that combines these partial descriptions and complements them with new evidences extracted from current practice. The main contribution of this paper is the summarization of the key dimensions that conform MDEs and a classification of previous studies to illustrate them.
Introduction
“Prototype tabs, pads and boards are just the beginning of ubiquitous computing. The real power of the concept comes not from any one of these devices – it emerges from the interaction of all of them” (Weiser, 1991). These visionary words by Mark Weiser revealed the promising future of combining multiple displays or screens as an active research topic, mainly due to their ability to improve system capabilities in terms of both visualization and interaction. Since then, several efforts have been made to provide a definition for working environments that involve them conjointly. These settings have been named multi-display environments (MDEs) in the literature, or, more recently, multi-surface environments (MSEs). Gjerlufsen et al. (2011) define them as “ubiquitous computing environments where interaction spans multiple input and output devices and can be performed by several users simultaneously.” However, this definition does not require having any surface in the environment and emphasizes interaction being performed by several users rather than having multiple displays being accessed simultaneously. Nacenta et al. (2009), on the other hand, define them as “interactive computer system[s] with two or more displays that are in the same general space (e.g., the same room) and that are related to one another in some way such that they form an overall logical workspace.” The notion of multi-person-display ecosystems provided by Terrenghi et al. (2009) is also interesting, since they include in these environments not only the screens themselves but also the space in which they are placed and the users interacting with them. Nevertheless, none of these authors include in their definitions other devices or objects used to interact with the system as part of the environment itself. Tangible interaction mechanisms based on the manipulation of physical objects is a growing body of work (Shaer and Hornecker, 2010) that makes relevant their inclusion in the definition. We therefore propose a new definition of MDE, which arises from the combination of all the above; we consider as a multi-display or multi-surface environment a ubiquitous interactive computing system composed of several displays (or surfaces) with digital content that are located in the same physical space and have a “coupling” relationship to each other, the users interacting with the system, and the objects used for this purpose. The way surfaces are arranged and coupled determines how users perceive them as a whole, and how interactions should happen. Coutaz et al. (2003) define coupling between surfaces by denoting their mutual dependency. Two surfaces are therefore coupled “when a change of state of one surface has an impact on the state of the other.” According to this definition, the coupling would be a temporary condition between surfaces that happens when an interaction is being made; however, we would want to extend this definition to also consider different displays coupled when they have the potential of changing their mutual state, even if they are not doing so at a given moment. For this reason, we adopt the definition of coupling provided by Barralon et al. (2007), who define it as an action itself or the result of said action. In the former, coupling is “the action of binding two entities so that they operate conjointly to provide a set of functions that these entities cannot provide individually.” As the result of an action, “an assembly of the source entities, that is, a new compound entity that provides a new set of functions that the source entities, alone, cannot provide.”
Even though multiple taxonomies for MDEs do exist, they usually offer a partial view of specific technical dimensions, such as the distribution of user interfaces among the different surfaces or the transfer of elements between them. In this paper, we propose a more general taxonomy that involves how MDEs are created, how digital contents are distributed, and how one can interact with them. This taxonomy has been developed as a combination of previous ones and complemented by the analysis of MDEs found in the literature. Additionally, we provide further considerations about the context of the environment (i.e., where it is going to be implanted, by whom it is going to be used, and for what purpose) since the other technical dimensions can be affected by it. Our end goal is to provide a starting point for new designers by enabling them to identify what general key features have been tackled previously by other researchers and designers. The rest of the paper is organized as follows. Section “Historical Evolution of MDEs” explores a historical review of MDEs. Section “Previous Taxonomies to Describe MDEs” describes previous attempts to devise frameworks and ontologies to describe these environments. Section “Technical Classification of Previous Multi-Display Environments” exposes several technical dimensions extracted from the combination of previous frameworks and the analysis of previous examples of MDEs, and a classification of these works is made according to the dimensions identified. Section “Additional Considerations Related to Context” analyzes additional considerations about contexts, and our conclusions are drawn in Section “Conclusion.”
Historical Evolution of MDEs
The first MDEs date back to the late 70s/early 80s, but they were known as multi-monitor environments due to the devices that comprised them. The research in this area focused on computer screens because they were the displays normally used, and they became more popular after the introduction of Apple’s Macintosh II in 1987, which supported multi-monitor capacities as a standard feature. Early work on multi-monitor configurations deals mostly with visualization or control issues. Systems tackling the former are aimed at enlarging the virtual screen space (Choi et al., 2002; Cliburn, 2003; Mackinlay and Heer, 2004) or at using several monitors as peripheral spaces to be filled with auxiliary content (Mano et al., 1981, 1982; Grudin, 2001). Approaches regarding control issues are based on using a mouse to control the contents of the displays (Richardson et al., 1998; Benko and Feiner, 2005). These studies are mainly limited to single-user interaction, which severely restricts the possibility of inducing collaboration among users. Also, the coupling between the displays is configured manually through an application, which leads to static environments in which the number of devices is usually predetermined. In addition, the users are anchored to a specific position in space and cannot move, because the monitors are wired to computers that are not mobile.
In order to provide a more dynamic way to couple screens, approaches like the one by Ohta (2008) attach sensors to computer monitors and laptops. This means the devices can detect each other by proximity and do not require the user to manually configure the surfaces in the environment. This solution also allows certain mobility to the users, since laptops can be carried, and they do not need to be always in the same location. However, this mobility is only possible before initiating an application in the MDE because of the proximity sensors. Once the coupling has been established, the devices must not be moved during the course of the application. Equipping surfaces with external sensors, however, can be burdensome and is not very likely to be used in actual situations with non-specialists. Fortunately, the current trend is for embedding sensors in the devices themselves. In fact, handhelds, such as smartphones or tablets, now have many of these sensors built in.
With the popularity of handhelds, users can still contribute their own devices to the environment, but in a more comfortable way, since these are easier to carry than laptops. Mandryk et al. (2001) studied the impressions of teenagers playing a collaborative PDA-based game. Due to the small size of the present devices, the researchers encourage the participants to form groups by putting their PDAs together to obtain a larger visualization space. The students, however, complain of not having a sense of freedom of movements, because in order to be able to work conjointly, they cannot separate the screens during the activity. This kind of setup also presents visualization issues associated with the size of the displays and the large amount of space occupied by the device borders, which causes confusion and rejection in the players.
Other studies on MDEs using handheld displays go beyond considering these systems as large regular screens and focus more on interaction. Many of them especially attempt to provide techniques of sharing or transfer of elements. Some of them rely on pen-based interactions (Tandler et al., 2001; Hinckley et al., 2004; Lyons et al., 2009), others on pen-based as well as touch-based interactions (Geißler, 1998), whereas others on making gestures with the devices themselves (Hinckley, 2003; Marquardt et al., 2012). Handhelds’ multi-touch capabilities enable multiuser interaction, as the users can manipulate any device in the environment regardless of the other group members.
Several authors have addressed the possibility of using gestures or interactions to establish the coupling in order to avoid having to configure it manually from an application (Tandler et al., 2001; Hinckley, 2003; Hinckley et al., 2004; Ohta and Tanaka, 2012), and some have designed geometrical arrangements of the screens (or topologies) apart from the traditional rectangle or square, even allowing a surface to leave and come back to the environment in a dynamic and simple way (Hinckley et al., 2004; Ohta and Tanaka, 2012). However, most of the previous approaches still need users to maintain their devices physically together in order to avoid losing the coupling between one another. For example, only a few studies (Iwai and Sato, 2009; Maciel et al., 2010; Marquardt et al., 2012; Garcia-Sanjuan et al., 2015b) allow certain movement of the devices around the environment while keeping the displays coupled. This higher mobility can lead to freer and more natural interactions but also increases the inherent complexity.
Even though some previous works support irregular topologies, they often disregard visualization, showing different views on each display (Mano et al., 1981, 1982; Mandryk et al., 2001), or they are explored in 2D (Hinckley et al., 2004; Maciel et al., 2010; Ohta and Tanaka, 2012). The few approaches that support tridimensional compositions usually rely either on sophisticated specific-purpose hardware setups like MediaShelf (Kohtake et al., 2005, 2007), or on small cubes that can be arranged in two or three dimensions to form different shapes (Merrill et al., 2007; Goh et al., 2012). However, the cubes limit interactions, since the only way to interact with them is by reorganizing them into different figures. Besides, both approaches require the surfaces to be physically attached throughout the application so as not to lose coupling. In this respect, authors like Iwai and Sato (2009) and Marquardt et al. (2012) propose element-sharing mechanisms between surfaces, relying on proximity sensors and external cameras, respectively, which allow the screens to be on different planes. These volumetric techniques support more intuitive interactions, closer to the way people behave in the real world, but they also entail design and implementation complexity issues.
Most of the approaches described above rely on having one type of device in the MDE, namely either computer screens, PDAs, tablets, etc. There has also been substantial work on MDEs combining different types of surfaces, to take advantage of the available resources in the environment (Grudin, 2001; Johanson et al., 2002; Tan et al., 2004). In fact, authors like Gjerlufsen et al. (2011) claim that supporting different kinds of displays is a requirement for a successful multi-surface application.
Besides having several surfaces with the same purpose, or having main and secondary ones, as in Grudin (2001), this type of environment tends to favor specific functions for each type of display. As Dillenbourg and Evans (2011) point out, desktops (but also handhelds) are personal, tabletops are social, and digital whiteboards are public devices. Indeed, other authors treat small portable devices (such as smartphones or tablets) as private or personal accessories (Magerkurth et al., 2003; Sugimoto et al., 2004; Lyons et al., 2006; Gjerlufsen et al., 2011), tabletops as collaborative (Sugimoto et al., 2004; Gjerlufsen et al., 2011), and wall screens as public (Magerkurth et al., 2003; Tan and Czerwinski, 2003; Gjerlufsen et al., 2011); and, at the same time, some of these are used for visualization purposes (Rekimoto and Saitoh, 1999; Magerkurth et al., 2003; Lyons et al., 2006) and others for control (Sugimoto et al., 2004; Hunter et al., 2010; Gjerlufsen et al., 2011).
Current MDEs still have some limitations. A usual drawback is the lack of common physical or tangible objects in the interaction techniques, with a few exceptions like Rekimoto and Saitoh (1999), Sugimoto et al. (2004), Kohtake et al. (2005, 2007), which allow tangibles as information containers. This feature might enable more intuitive interactions, since people are used to manipulating physical rather than virtual objects. However, in order to track them, the designers tend to use complex hardware setups, such as ceiling-mounted cameras, which lead to complex and cumbersome configurations due to installing and calibrating this additional hardware. This also obstructs mobility and prevents MSEs being formed spontaneously. Another limitation, which especially affects MDEs based on current tablets and smartphones, is the absence of peripheral interaction, since the input usually occurs within the screens themselves. This feature is important when the interaction region of the displays is limited. Additionally, since humans can only focus on a limited spatial area at a glimpse (Smythies, 1996), having virtual content distributed among multiple displays may induce many visual attention switches, depending both on the task in hand and on the design of the input/output aspects of the system (Rashid et al., 2012).
To sum up, most of the above studies focused primarily on technical issues rather than on their possibilities of use. In fact, Yuill et al. (2013) state that, so far, little work has been conducted with tablets in group activities, and little thought has been given to their possibilities for group work, beyond the simple transfer of individual elements.
The future design of MSEs will take advantage of the capabilities of handhelds like smartphones and tablets. The increasing popularity of these devices will enable users to bring their own devices together to build these environments dynamically and virtually anywhere. In order to exploit the other advantages of these surfaces, such as mobility, it would be necessary to design coupling techniques that do not require the devices to be physically attached (unless the users so desire for reasons associated with the application). Other challenges that need to be addressed are the possibility of establishing irregular, and even tridimensional, topologies, rather than the common fixed and regular (i.e., square or rectangle). Also, considering the relatively small screen dimensions of these devices, multi-surface systems should support peripheral interactions with both fingers and tangible objects. Additionally, since these setups might require the colocated participation of users, it would be necessary to take into account cultural differences and social protocols to avoid awkward situations (Hinckley et al., 2004; Terrenghi et al., 2009).
Previous Taxonomies to Describe MDEs
Several efforts have been made to describe the defining dimensions of an MDE. Some authors propose taxonomies for these terms, but they usually focus on specific features of MDEs and do not address them in a general way. Nacenta et al. (2005, 2009) thoroughly classify element transfer and interaction techniques between displays. They mostly consider mouse interactions, and note the limitations of their taxonomy when trying to classify some previous multi-display approaches. However, they provide a common vocabulary, useful for comparing different cross-device interaction techniques. Coutaz et al. (2003) and Lachenal and Coutaz (2003) create an ontology aimed mainly at describing the physical properties of the individual surfaces that form the environment and specifying who conducts the interaction and how, focusing on terms such as surfaces, actors, and instruments. Additionally, Rashid et al. (2012) explore which visual arrangements of the surfaces influence visual attention switch in this kind of environment. Thus, their taxonomy essentially considers visualization-related aspects. Terrenghi et al. (2009) present a more general description, which includes both social and physical dimensions, all of them arranged into three main categories: (a) the size of the environment, (b) the nature of social interaction, and (c) the interaction technique that creates the coupling between surfaces and how elements are shared/transferred among them. Nevertheless, none of the above gives enough importance to the final use of the MDE or the users’ background.
Other researchers (Swaminathan and Sato, 1997; Tandler, 2001; Luyten and Coninx, 2005; Gjerlufsen et al., 2011), although not providing a taxonomy per se, also enumerate certain requirements MDEs should fulfill, from which new dimensions can be extracted. Swaminathan and Sato (1997) discuss different types of “display configurations” (i.e., how surfaces are physically arranged in the environment and which topology they form) and also different ways of manipulating content (interaction) and other visualization issues. Others delve into more technical aspects. For instance, Luyten and Coninx (2005) explore some ways of distributing graphical elements between several displays, and Gjerlufsen et al. (2011) present some requirements for multi-surface applications and divide them into application requirements (what should they do?) and development requirements (how should they do it?).
Technical Classification of Previous Multi-Display Environments
From the analysis of the above studies and building upon them, we have extracted several technical dimensions to provide a more general description of MDEs and have established a common vocabulary to serve as a summarization of previous works in the field. This section classifies these dimensions around three main axes: topology, coupling, and interaction. Concrete implementations and APIs, e.g., the ones provided in Hamilton and Wigdor (2014), Yang and Wigdor (2014), and Nunes et al. (2015) have been left out of this discussion in favor of the subjacent features they enable.
Topology of the MDE
This section describes the dimensions relative to the physical appearance of the MDE, namely the homogeneity of the surfaces in the environment, shape regularity, spatial form, size, mobility, and scalability. Table 1 provides a sample of MDEs classified according to these dimensions.
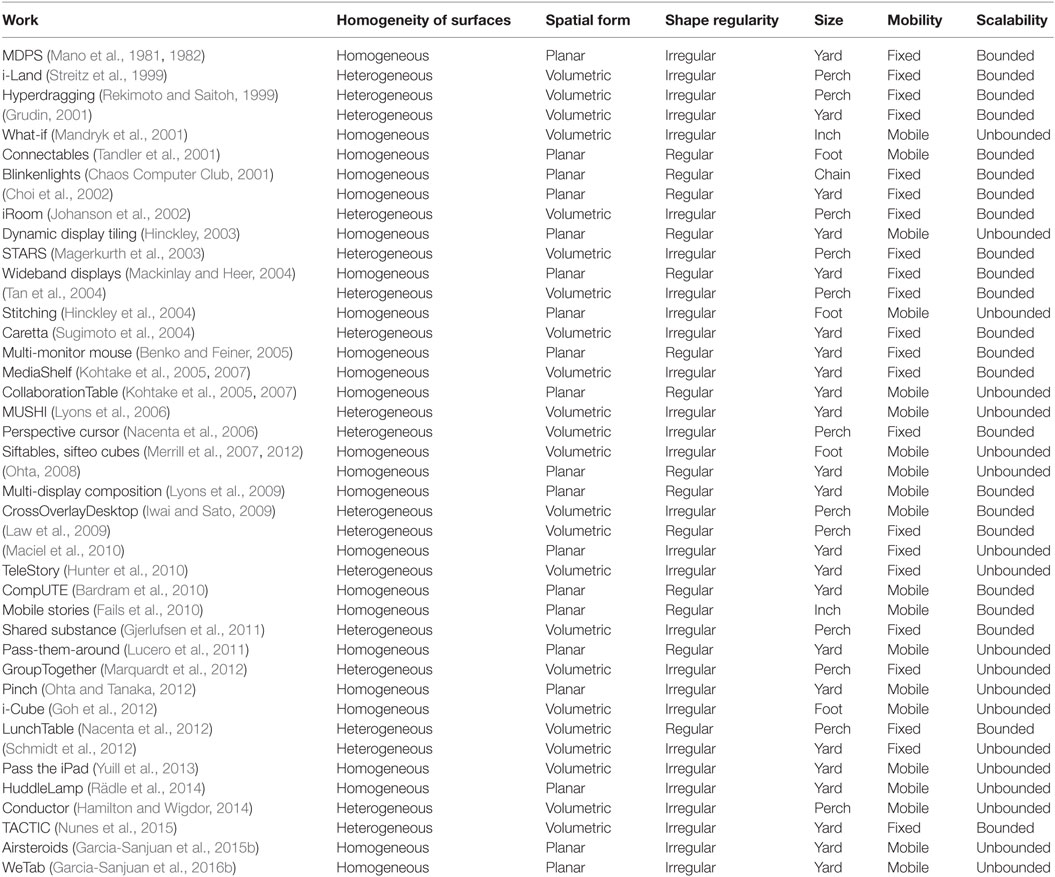
Table 1. Selection of MDEs classified by topology dimensions.
Homogeneity of Surfaces
When composing MSEs, the several devices involved can essentially be the same or have similar features [e.g., computers and laptops (Mackinlay and Heer, 2004; Benko and Feiner, 2005), smartphones and tablets (Lucero et al., 2011; Garcia-Sanjuan et al., 2015b), etc.], or can be significantly different [e.g., tablets and wall screens (Marquardt et al., 2012), tabletops and PDAs (Sugimoto et al., 2004), etc.]. Such (dis)similarity can be seen as whether the environment supports either homogeneous or heterogeneous devices. According to this, homogeneous environments are settings where all devices have similar size, technology, and interaction methods (see Figure 1), whereas heterogeneous environments are composed of displays of different shape, proportions, or even purpose (see Figure 2).

Figure 1. Example of MDE with homogeneous, planar, irregular, and yard topology [extracted from Garcia-Sanjuan et al. (2015a)].

Figure 2. Example of MDE with heterogeneous, volumetric, regular, and perch topology; and with redundant logical view [extracted from Gjerlufsen et al. (2011)].
Spatial Form
Multi-display environments are built by putting several displays in the same physical space. The way these devices are placed determines the spatial form of the environment, which can be either planar (see Figure 1) or volumetric (see Figure 2). The former are usually the traditional flat configurations formed by either computer screens (Mackinlay and Heer, 2004; Ohta, 2008) or mobile devices (Hinckley et al., 2004; Lucero et al., 2011) aimed at enlarging the visualization space of a single screen. On the other hand, volumetric forms take advantage of the third dimension in space and are usually achieved by combining heterogeneous displays (Sugimoto et al., 2004; Nacenta et al., 2006), homogeneous environments where visualization plays a minor role (Mandryk et al., 2001; Yuill et al., 2013), or devices specifically designed for this purpose (Kohtake et al., 2007; Merrill et al., 2007).
Regularity of Shape
Regardless of the spatial form of an MDE, the regularity of its shape decides whether the different surfaces are always put together the same way or whether they can support different arrangements. We differentiate between regular (see Figure 2) and irregular (see Figure 1) shapes. Regular-shaped MDEs usually are for the purpose of extending the visualization space and often present the typical rectangular form of a planar single screen (Tandler et al., 2001; Bardram et al., 2010), or the classic “L” shape of heterogeneous environments with a wall screen next to a tabletop (Nacenta et al., 2012). Irregular shapes, on the other hand, allow flexible configurations where the users can place the surfaces arbitrarily, and are present in many environments involving mobile devices that are not aimed at extending the visualization space, since they can be moved around and placed wherever the user pleases (Mandryk et al., 2001; Iwai and Sato, 2009); or in environments with a mechanism to track all the surfaces in real time (Rekimoto and Saitoh, 1999; Maciel et al., 2010; Garcia-Sanjuan et al., 2016b), so that all of them can maintain the coupling regardless of where they are placed. There are other examples of MDEs with irregular shapes that do try to extend the visualization space and rely on proximity sensors to keep the devices coupled (Goh et al., 2012; Ohta and Tanaka, 2012).
Size
Terrenghi et al. (2009) classify MDEs by size in order to study the impact of this characteristic on the users’ visual attention. They associate size with the type of movement the users must perform to see the whole visualization space. As the ecosystem gets bigger and bigger, one could expect less attention. The different sizes considered by the authors are the following:
• Inch [e.g., a smartphone-sized region (Fails et al., 2010)]: the users do not need to move their eyes (see Figure 3).
• Foot [e.g., a region the size of a laptop or a tablet (Merrill et al., 2007)]: the users can sight the entire workspace by moving their eyes (see Figure 4).
• Yard [e.g., a table-sized region (Garcia-Sanjuan et al., 2015b)]: the users must move their head (see Figure 1).
• Perch [e.g., a room (Magerkurth et al., 2003)]: the users must move their head as well as their body sometimes (see Figure 2).
• Chain [bigger spaces, >5 m (Chaos Computer Club, 2001)]: the users must move their body (see Figure 5).

Figure 3. Example of MDE with homogeneous, planar, regular, and inch topology [extracted from Fails et al. (2010)].

Figure 4. Example of MDE with homogeneous, volumetric, irregular, foot, mobile, and unbounded topology; and with discrete logical view [extracted from Merrill et al. (2007)].

Figure 5. Example of MDE with homogeneous, planar, regular, chain, fixed, and bounded topology; and with extended-continuous logical view [extracted from Chaos Computer Club (2001)].
Even though this consideration might suggest that users suffer poorer visual attention as the size of the environment increases, this would not necessarily be a drawback, since bigger ecosystems could allocate more users, as pointed out by Terrenghi et al., or it simply would not matter regarding the purpose of the system (e.g., in an MDE to foster mobility and physical exercise).
Mobility
Depending on the particular devices used to build an MDE, the resulting space can be fixed (see Figure 5) or mobile (see Figure 4). A fixed environment, e.g., one involving desktop PCs (Choi et al., 2002), tabletops and wall screens (Nacenta et al., 2012), or complex additional hardware (Marquardt et al., 2012), cannot be moved easily from one place to another, hence preventing the users to engage in an activity in an improvised way virtually anywhere. On the other hand, using other mobile devices, e.g., laptops (Bardram et al., 2010) or tablets (Yuill et al., 2013) would allow building mobile environments following a “Bring Your Own Device” (Ballagas et al., 2004) scheme, where each user offered his own surface to the environment.
Scalability
Scalability refers to the ability of the environment to grow as required. We differentiate between bounded (see Figure 5) and unbounded (see Figure 4) topologies. Bounded MDEs have a certain number of predefined surfaces and do not provide the ability to add any more in real time (Benko and Feiner, 2005; Gjerlufsen et al., 2011), whereas unbounded MDEs allow the size of the working space to be enlarged as needed (Goh et al., 2012; Rädle et al., 2014). Depending on its degree of scalability, an MDE can allocate more or less users. In the end, the number of participants of an activity should depend on its purpose, but having an unbounded system would always provide more freedom to designers. Nevertheless, scalability is tightly related to mobility, since environments relying on mobile devices are expected to be more easily scalable.
Surface Coupling in the MDE
The present section explains the dimensions relative to the coupling between surfaces to build an MDE, which are the creation, mutability, logical view of each group of surfaces, and privacy. Table 2 classifies a selection of MDEs according to these dimensions.
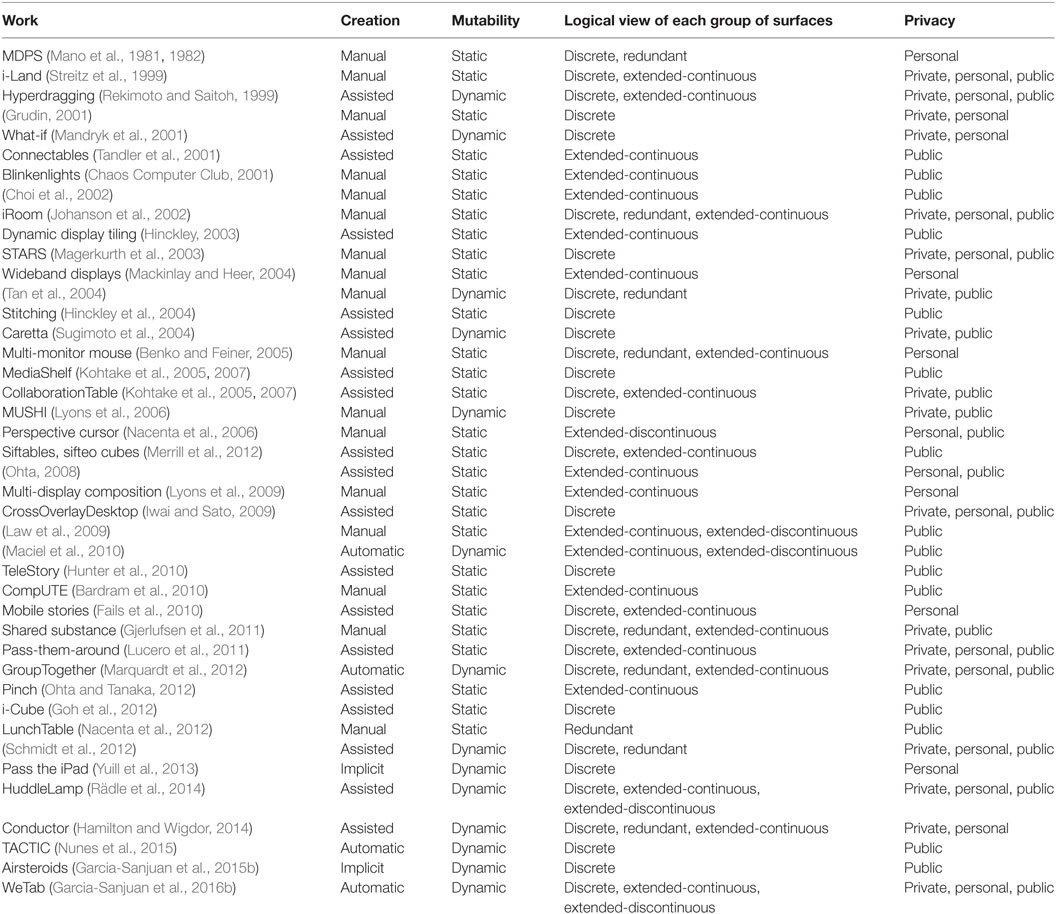
Table 2. Selection of MDEs classified by coupling dimensions.
Creation
In order to allow the different surfaces in the environment to share information, they must be coupled to one another. Terrenghi et al. (2009) write about “the type of interaction technique that enables the coupling of displays and transfer of interface elements across displays,” and classify this into three categories: synchronous human movement [the user performs a certain gesture with the surfaces, e.g., bring them closer (Hinckley, 2003), shake them together (Holmquist et al., 2001), etc.], continuous action [the user performs a continuous gesture like pick and drop (Rekimoto, 1997) or pinch (Ohta and Tanaka, 2012)], and action and infrastructure (the user configures the coupling explicitly from another device). Similarly, Barralon et al. (2007) propose several coupling mechanisms, such as proximity interaction, synchronous gestures, or physical connection. However, these are more like specific techniques than a categorization. In this respect, Luyten and Coninx (2005) describe several features to design interfaces for distributed interaction spaces (interfaces distributed among several devices). According to them, the interface distribution can be performed manually (the user indicates which devices they want to join) or automatically (the system does it by itself when a discovery service detects the devices in the environment). In our opinion, performing the interface distribution is a secondary step after performing the coupling between the devices; hence, combining the previous classifications, we classify the different ways of establishing the coupling into four broad categories, depending on the degree of involvement of the user: implicit, manual, assisted, and automatic. An implicit creation of the coupling means that the devices are completely unaware of one another, but the activity being carried out involves working with several surfaces at the same time as if they were exchanging information (Yuill et al., 2013; Garcia-Sanjuan et al., 2015b), hence, it is a sort of coupling that do not involve any link whatsoever among the surfaces but still provides the illusion of being connected; manual creation requires the user to explicitly set which devices are going to be part of the environment and where they are going to be located in the physical space (Grudin, 2001; Lyons et al., 2006); an assisted one also requires the action of the user, but they are only required to perform a gesture indicating they want to couple two or more devices together (Tandler et al., 2001; Hunter et al., 2010); and, finally, an automatic creation is completely transparent to the user and relies on a discovery service to determine which devices should be coupled (Maciel et al., 2010; Marquardt et al., 2012; Garcia-Sanjuan et al., 2016b). Whereas the first and the last methods may be more comfortable for the user, the other two involve a component of intentionality that can be useful in some contexts.
Mutability
This dimension refers to both the ability to add and remove new surfaces to the MDE as well as allowing the existing devices to move inside the environment, and having the system automatically adapt to the new situation. In a static coupling, the devices are required to stay in the same location as they were when the coupling was first made, and they cannot be moved around without losing the coupling or entering into an inconsistent state (Mano et al., 1981; Ohta and Tanaka, 2012). This definition is similar to the “fixed” coupling from Terrenghi et al. (2009), in which “displays are tightly connected but do not allow any dynamic configuration or easy re-configuration.” In contrast, a dynamic coupling allows for more freedom of movements since users can change the devices and/or move them around (Tan et al., 2004; Garcia-Sanjuan et al., 2016b), and it is similar to what Gjerlufsen et al. (2011) call “flexibility,” to the “continuous distribution” from Luyten and Coninx (2005), or the “fluid-middle” and “loose” coupling from Terrenghi et al. (2009). Dynamic coupling implies an irregular shape, because being able to move surfaces within the environment inevitably changes the shape of the topology of the surfaces.
Logical View of Each Group of Surfaces
When several surfaces are included in the same environment, they can communicate with one another and also display the contents of a logical workspace, either totally or partially. If each surface visualizes its own contents, which are different from the other devices, we say it displays a discrete logical view [e.g., Mandryk et al. (2001) and Magerkurth et al. (2003)] (see Figure 4). However, if two or more devices display partial or total views of the same workspace, we can classify the logical view of those surfaces into three groups: (a) redundant (see Figure 2), (b) extended-continuous (see Figure 5), and (c) extended-discontinuous (see Figure 6). A redundant logical view entails having the same workspace replicated on several surfaces, each of them showing the same contents although they can be graphically represented differently due to different screen sizes, resolutions, viewports, etc. (Johanson et al., 2002; Nacenta et al., 2012). In an extended-continuous logical view, the workspace is shown entirely across several surfaces, with no “empty” spaces, although the surfaces do not necessarily need to be physically joint (Ohta, 2008; Lucero et al., 2011). In contrast, an extended-discontinuous logical view allows several surfaces to represent partial views of the same workspace, but the latter does not need to be shown completely, i.e., there can be empty regions (Nacenta et al., 2006; Maciel et al., 2010). It is important to note that not all the surfaces belonging to the same environment have to support the same view; instead, there can be several workspaces that are visualized by one or many tablets and in a discrete, redundant, or extended view.
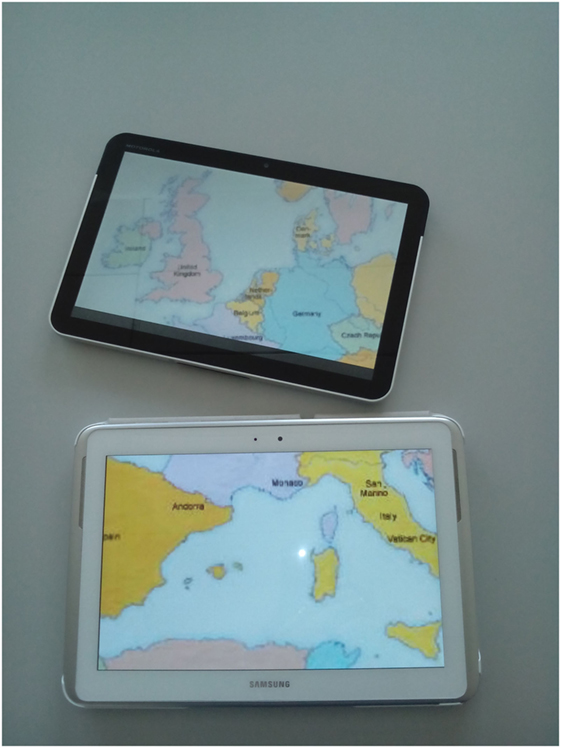
Figure 6. Example of MDE with homogeneous, planar, and irregular topology; and with extended-discontinuous logical view [extracted from Garcia-Sanjuan et al. (2016b)].
Similarly, other authors propose alternative classifications related to this dimension. Swaminathan and Sato (1997) consider “display configurations.” If the surfaces are physically joint, the configurations can be distant-contiguous or desktop-contiguous depending on whether they are located far away or near the user, respectively. If the devices are physically separated from one another, the configuration is non-contiguous, which is similar to our extended logical view, which can be continuous or separated (discontinuous). We decided to split this dimension by considering the physical component in the spatial form and shape regularity dimensions, and how the logical workspace is visualized in this dimension.
Coutaz et al. (2003) and Rashid et al. (2012) describe compatibility modes and content coordination, respectively, between the surfaces in the environment, focused on the visualization of contents. They also consider redundancy (Coutaz et al., 2003) [a.k.a., cloned coordination (Rashid et al., 2012)] when two displays show the exact same graphical components. However, Coutaz et al. (2003) consider as a different mode, called equivalency, when two displays show the same information, but due to different screen sizes or resolutions, the contents are displayed differently (e.g., a form in a tabletop is displayed differently than in a smartphone). However, our classification focuses more on the information displayed than on how that information is arranged in one display or another to improve visualization. Hence, if two screens essentially visualize the same contents, we say they work in redundancy mode. Coutaz et al. also consider two more modes: complementarity (called coordinated coordination by Rashid et al.) and assignment. In both the modes, each surface shows different graphical elements. The difference between the two emerges from the task being carried out. Several surfaces working in complementarity mode share the same purpose or tasks, and some displays act as controllers for others, whereas in assignment mode, each surface performs its own tasks. Additionally, Rashid et al. describe extended coordination, which is similar to ours, although they do not discriminate between whether there are “empty” spaces between the surfaces or not.
Privacy
Shen et al. (2003) identify three types of space in a mono-surface environment: private, where data are not visible or accessible to others; personal, where information can be visible to others but not accessible; and public, where everything is available to all users. This categorization can be applied to MDEs, where some particular devices in some situations may be private and others become personal or public, depending on the context of the application. Hence, the different environments can be classified according to which space(s) they allow to be formed. Because of their form, tabletops usually enable personal and public spaces (Johanson et al., 2002; Nacenta et al., 2006); wall screens, public (Chaos Computer Club, 2001; Kohtake et al., 2005); and handhelds, private (Streitz et al., 1999; Sugimoto et al., 2004). However, when multiple mobile devices are coupled to one another in an MDE, they often allow personal (Mandryk et al., 2001) or public (Garcia-Sanjuan et al., 2015b) regions to be created.
A similar classification is made by Luyten and Coninx (2005), but they only consider personal distributed interaction spaces if only one person is allowed to interact with the system, or collaborative if multiple users can.
Interaction with the MDE
This section deals with interaction with the MDE once the surfaces have been coupled. The dimensions identified are interaction availability, input directness, interaction medium, interaction instruments, and input continuity. Table 3 shows several example MDEs classified according to these dimensions.
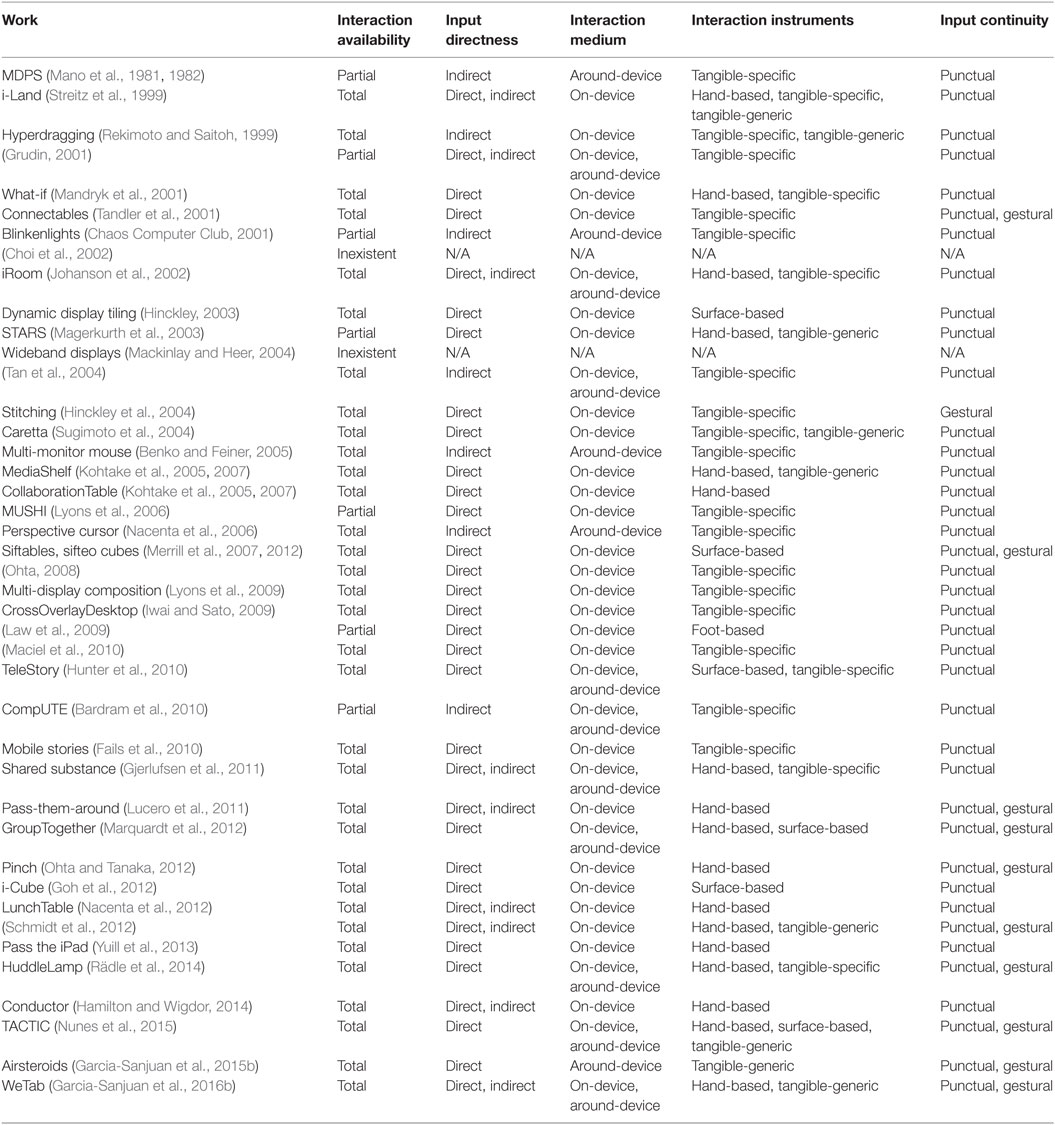
Table 3. Selection of MDEs classified by interaction dimensions.
The classification described here intends to provide a general panorama of the key issues that must be tackled regarding interaction when building an MDE. Interested readers can consult Nacenta et al. (2005, 2009) for more detailed taxonomies concerning particular aspects associated with input, such as object movement across displays.
Interaction Availability
Interaction availability refers to the capacity of the MDE to support interaction. It can be inexistent, partial, or total. If the different screens are used only for visualization or computation purposes, then we say the interaction availability is inexistent, as in Choi et al. (2002). A partial availability is present if only some of the screens allow (Bardram et al., 2010) or are used (Chaos Computer Club, 2001) for interaction at a given moment, whereas the interaction availability is total if all surfaces can be (and will be) interacted with (Hinckley et al., 2004). It is important to note the importance of context (explained below, in Section “Additional Considerations Related to Context”) to this dimension, since it is not enough to have individual displays supporting interaction to have interaction available in the environment; it also depends on the purpose of the activity being carried out.
We do not consider in this dimension whether multiple interactions can be performed at the same time because that would be a feature of each particular surface belonging to the environment (e.g., multi-touch capabilities in tablets). Instead, we focus only on interactions in the global multi-display space.
Input Directness
Depending on whether the user performs an action inside the boundaries of the same surface the interaction is directed to (Tandler et al., 2001; Yuill et al., 2013) or outside [e.g., by handling a pointer (Tan et al., 2004; Benko and Feiner, 2005)], the input modality can be direct or indirect, respectively. Although direct input can be more intuitive and natural (Shneiderman et al., 2009), indirect input presents the advantage of being able to reach distant targets, which is a very frequent need in highly integrated collaborative scenarios, according to Gutwin et al. (2006).
Rashid et al. (2012) provide a similar definition of input directness, but these authors do not attempt to describe interaction with MDEs in general, but with the graphical interfaces distributed among them, putting special emphasis on visual feedback, which may not be required in some contexts.
Swaminathan and Sato (1997) also consider input as a relevant dimension under the name “pointer movement and control,” which can be classified into (a) direct manipulation, (b) non-linear mapping with sticky controls, and (c) dollhouse metaphor. Their direct manipulation refers to the situation where, either by using fingers or laser pointers, “the user can directly point to any object in the display without having to move the pointer from a ‘current’ position to the object.” To differentiate between direct inputs from the others, this definition puts the emphasis on not having to move a pointer. Technically, using fingers and laser pointers also require moving them to the desired location; the only difference being that they do not have a constant representation on the screen (as opposed to, for instance, a mouse pointer). Non-linear mapping with sticky controls refers to speeding up the cursor when it moves through empty spaces and slowing it down near controls, thereby allowing the user to reach the whole environment with a single gesture. This feature, although interesting, is too specific for our purposes. Finally, the dollhouse metaphor, considered by these authors as the most promising, consists of a representation of the target display on another’s, smaller, screen, and map the manipulations performed on the small one to the former. Again, this metaphor is interesting, but it is too specific and could be seen as a particular indirect input technique according to our classification.
Interaction Medium
This category is concerned about where the interaction takes place, either on-device or around-device. The former considers interactions made on a device, either directly on the target (Hinckley et al., 2004; Ohta and Tanaka, 2012) or indirectly on another device (Rekimoto and Saitoh, 1999; Schmidt et al., 2012). It considers not only the interactions performed on interactive surfaces like tablets or tabletops but also those acted upon button-based devices, such as laptops, PDAs, or mobile phones.
Around-device interactions (ADI), on the other hand, refer to those made on the physical space surrounding the interactive surface (next to it, above, etc.). In colocated multiuser scenarios, on-device interactions, such as touching a screen, could cause interference problems caused by several users trying to touch the same region at the same time, and occlusion issues if the interactive device is small. ADIs allow exploiting the 3D space around the display, thereby enabling richer interactions, such as tridimensional manipulations (Hilliges et al., 2009; Kratz et al., 2012) or avoiding the issues stated above (Jones et al., 2012; Hasan et al., 2013). One possible drawback of ADIs is that they are probably less precise than on-device interactions, although, to our knowledge, this has not yet been demonstrated. However, an MDE could benefit from the combination of both, on- and around-device, media to enrich user experience. It is important to note that, according to our definition in Section “Input Directness,” direct interactions do not need to occur on the device itself but to be contained within its boundaries. Therefore, it is not only possible to have ADIs that are indirect, such as the traditional mouse-based ADIs (Benko and Feiner, 2005) or the one in Blinkenlights (Chaos Computer Club, 2001), but also to have direct ADIs like MarkAirs (Garcia-Sanjuan et al., 2015b, 2016a), which manipulate the objects of the tablet they have immediately underneath.
Interaction Instruments
Depending on what instrument is used to perform the interaction, the interaction can be body-based, surface-based, or tangible. In body-based interactions, we can differentiate between hand-based and foot-based. The former considers the users’ hands, or particularly, their fingers, as the instrument to perform the interaction with. These, including touch and mid-air gestures, are the most popular means of interaction with the available surfaces, such as tablets, and they have been shown adequate for all kinds of users, from kindergartners (Nacher et al., 2014, 2015) to the elderly (Loureiro and Rodrigues, 2011). Foot-based interactions, on the other hand, have been less explored and rely on using one’s own feet to interact, normally, with a surface on the floor (Law et al., 2009; Leo and Tan, 2010; Velloso et al., 2015). Surface-based interactions are based on manipulating the screen’s device to trigger a reaction on itself, for example, by making a gesture with it (Merrill et al., 2007) or bumping two devices together (Hinckley, 2003; Schmidt et al., 2012). Tangible interactions involve a physical object that triggers a response on the MDE, and we differentiate between interaction tangible-specific and tangible-generic. The former relies on specific-purpose peripherals, such as external keyboards (Mano et al., 1981), mice (Nacenta et al., 2006), digital pens (Hinckley et al., 2004), the keyboards themselves and the buttons of laptops and mobile phones (Fails et al., 2010), foot platforms (Sangsuriyachot et al., 2011), or using one surface simply as a remote controller of another (Hunter et al., 2010; Gjerlufsen et al., 2011). Tangible–generic interactions consider physical objects of general purpose (Kohtake et al., 2007) that can additionally be bound to digital elements or trigger-specific actions (Konomi et al., 1999; Catala et al., 2012). Coutaz et al. (2003) refer to this last type of interactions as generic “interaction resources.” In general, tangible interactions [a.k.a., tangible user interfaces (Ishii and Ullmer, 1997; Shaer and Hornecker, 2010)] offer spatial mapping, input/output unification, and the support of trial-and-error actions that can exploit innate spatial and tactile abilities, and so represent very powerful instruments for use in MDEs.
Input Continuity
Input continuity refers to how long an action lasts for the system to consider it a discrete input. The continuity can be punctual if the input is associated to a discrete contact (Mandryk et al., 2001; Hinckley, 2003; Hunter et al., 2010) or gestural if it involves a continuous gesture (Hinckley et al., 2004; Ohta and Tanaka, 2012; Garcia-Sanjuan et al., 2015b). We do not consider drag operations as gestural inputs since they involve a continuous action to trigger a continuous response, or, in other words, they can be seen as multiple discrete punctual inputs. Instead, a gestural input would be, for instance, drawing a “P” on the screen to start playing a song.
Although punctual interactions may be simpler to perform than gestural, making gestures can be quicker in some situations serving as a shortcut to a given UI element instead of having to navigate through the interface looking for it in nested collections, or they can enable richer experiences like fun (Morris et al., 2006), which could be useful in some application domains.
Additional Considerations Related to Context
Addressing the technical dimensions explored above is crucial for building an MDE since they provide an answer to what can be done with the system, and how it can be done. Yet, information about who is going to use the platform, where, and what for has often been disregarded in previous studies that offer a taxonomy for these environments. In our opinion, a great deal of attention should be paid to these considerations of the context of the environment in order to ensure building meaningful experiences, which lead to the system being well accepted. In this section, we discuss three dimensions that respond to the previous three questions about the context surrounding an MDE: user information (who?), location (where?), and purpose (what for?).
User Information
We identify five issues related to user information that should be taken into account when designing MDEs: number of users, their age, their physical and mental conditions, and sociocultural practices. However, there is a wide spectrum of other user conditions that might affect the design of MDEs. Terrenghi et al. (2009) provide some insights in this respect and explore how the number of users and the social interactions between them have an impact on some technical dimensions of the MDE, such as size. In particular, the authors state that small environments are more suitable for small groups of users because information is better managed, whereas bigger ecosystems, possibly deployed in public spaces, can allocate more users and foster productivity and social activity. Users’ age is also important to consider, for instance, MDEs built for small children or elderly people, who might have trouble working with small spaces or performing fine-grained interactions, could benefit from big and irregular topologies as well as coarse on-device and ADIs. Also, they could benefit from intuitive instruments of interaction, such as their own hands, body, and generic tangibles they are familiar with. Another important consideration is the users’ physical condition, since the system should be accessible to people with certain impairments. For example, when designing for people with reduced mobility one might not want to design perch- or chain-sized environments that would require users moving from their seat, and fixed topologies as well as static couplings might be preferred. Their mental conditions should also be taken into account because different cognitive issues may affect the perception of contents and interaction. As an example, direct, on-device, and body-based interactions might be preferred for people with certain cognitive impairments. Also, in order to avoid awkward situations, as pointed out by Terrenghi et al. (Hinckley et al., 2004; Terrenghi et al., 2009), any different cultural or social practices among the different users should also be considered, since they could affect the contents displayed on the screens or the interactions that should be supported. For example, it could affect privacy considerations and also interaction medium and instruments, because a user might not feel comfortable performing around-device gestures or certain foot-based interactions that resembled dancing in the presence of strangers.
Location
Since all MDEs must be deployed in a physical space, the physical constraints it presents should also be taken into consideration, for example, the dimensions of the room, connectivity quality, the presence or absence of seating, luminosity, etc. The size of the room will generally restrict the size of the ecosystem, and probably its mobility and scalability. Connectivity is very important for MDEs since different displays have to be in the same network in order to exchange information. The presence of low quality connectivity, or even the absence of it, could lead designers to adopt implicit coupling mechanisms, or fixed topologies in which the different devices relied on wired networks. The absence of seating might cause some discomfort in certain users, and perhaps a good solution would be opting by dynamic couplings where the users might move around and not be standing all the time in the same position. Similarly, on-device interactions on table-like surfaces would cause standing users to bend over very often; therefore, designers should consider using around-devices instead. Luminosity issues are also worth considering since they could affect the proper viewing of the contents displayed. In sum, the location where the environment is going to be deployed affects the design of MDEs. We have provided a few examples of the restrictions it can present, although the huge number of potential issues makes it impractical to enumerate them all.
Purpose
Finally, designers should keep in mind the final purpose of the ecosystem and let it drive the design of all the dimensions specified above. The different environments can have many application domains, e.g., gaming, education, entertainment, business, etc., and each one of them can be targeted to fulfill a myriad of specific purposes. For instance, in a game designed for young children, where physical exercise is encouraged, the environment should be at least perch-sized, and/or should have dynamic mutability to allow users to freely move around the environment. On the other hand, if the environment is aimed at hosting a business meeting, it should probably be yard-sized and allow different privacy policies to be defined. As another example, total interaction availability would probably be useful in gaming, but perhaps in a classroom, the teacher might want to use partial interaction availability in which they interact with a display, and the students can just watch on their own what the teacher is doing.
Conclusion
This paper reviews existing MDEs and classifies them into a common framework with the purpose of guiding future designers in identifying the dimensions of an MDE explored so far and how they could be successfully achieved. Our taxonomy builds upon previous ones that focus on specific parts or partial definitions of these ecosystems and provides a more general and wider conception. In particular, it works around three main axes: the physical topology of the environment, how the different surfaces that comprise it can be coupled and work together, and the different ways of interacting with the environment. Besides these technical features, we provide additional considerations on the context surrounding the MDE, namely, who is going to interact with it, where, and for what purpose. We argue for giving as much importance to technical dimensions as to these other considerations, because having the latter drive the design of the former will lead to meaningful technological environments suited to the users and therefore increase their chances of success.
Author Contributions
FG-S, JJ, and VN: analysis of the literature, paper writing, and conclusions.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding
This work is supported by Spanish Ministry of Economy and Competitiveness and funded by the European Development Regional Fund (EDRF-FEDER) with Project TIN2014-60077-R. It is also supported by fellowship ACIF/2014/214 within the VALi + d program from Conselleria d’Educació, Cultura i Esport (Generalitat Valenciana) and by fellowship FPU14/00136 within the FPU program from Spanish Ministry of Education, Culture, and Sport.
References
Ballagas, R., Rohs, M., Sheridan, J., and Borchers, J. (2004). “BYOD: bring your own device,” in Proceedings of the Workshop on Ubiquitous Display Environments (Nottingham: UbiComp ’04).
Bardram, J. E., Fuglsang, C., and Pedersen, S. C. (2010). “CompUTE: a runtime infrastructure for device composition,” in Proceedings of the International Conference on Advanced Visual Interfaces. AVI ’10 (New York, NY: ACM), 111–118.
Barralon, N., Coutaz, J., and Lachenal, C. (2007). “Coupling interaction resources and technical support,” in Proceedings of the 4th International Conference on Universal Access in Human-Computer Interaction: Ambient Interaction. UAHCI ’07 (Berlin, Heidelberg: Springer-Verlag), 13–22.
Benko, H., and Feiner, S. (2005). “Multi-monitor mouse,” in CHI ’05 Extended Abstracts on Human Factors in Computing Systems. CHI EA ’05 (New York, NY: ACM Press), 1208–1211.
Catala, A., Garcia-Sanjuan, F., Jaen, J., and Mocholi, J. A. (2012). TangiWheel: a widget for manipulating collections on tabletop displays supporting hybrid input modality. J. Comput. Sci. Technol. 27, 811–829. doi: 10.1007/s11390-012-1266-4
Chaos Computer Club. (2001). Project Blinkenlights. Available at: http://blinkenlights.net/
Choi, J.-D., Byun, K.-J., Jang, B.-T., and Hwang, C.-J. (2002). “A synchronization method for real time surround display using clustered systems,” in Proceedings of the Tenth ACM International Conference on Multimedia. MULTIMEDIA ’02 (New York, NY: ACM), 259–262.
Cliburn, D. C. (2003). GLUMM: an application programming interface for multi-screen programming in a windows environment. J. Comput. Sci. Colleges 18, 285–294.
Coutaz, J., Lachenal, C., and Dupuy-Chessa, S. (2003). “Ontology for multi-surface interaction,” in Proceedings of the Ninth IFIP TC13 International Conference on Human-Computer Interaction. INTERACT ’03 (Amsterdam: IOS Press).
Dillenbourg, P., and Evans, M. (2011). Interactive tabletops in education. Int. J. Comput. Support. Collab. Learn. 6, 491–514. doi:10.1007/s11412-011-9127-7
Fails, J. A., Druin, A., and Guha, M. L. (2010). “Mobile collaboration: collaboratively reading and creating children’s stories on mobile devices,” in Proceedings of the 9th International Conference on Interaction Design and Children. IDC ’10 (New York, NY: ACM), 20–29.
Garcia-Sanjuan, F., Catala, A., Fitzpatrick, G., and Jaen, J. (2015a). “Around-device interactions: a usability study of frame markers in acquisition tasks,” in Proceedings of the 15th IFIP TC.13 International Conference on Human-Computer Interaction. INTERACT’15 (Cham: Springer International Publishing), 195–202.
Garcia-Sanjuan, F., Jaen, J., Catala, A., and Fitzpatrick, G. (2015b). “Airsteroids: re-designing the arcade game using MarkAirs,” in Proceedings of the 2015 International Conference on Interactive Tabletops & Surfaces. ITS ’15 (New York, NY: ACM Press), 413–416.
Garcia-Sanjuan, F., Jaen, J., Fitzpatrick, G., and Catala, A. (2016a). “MarkAirs: around-device interactions with tablets using fiducial markers – an evaluation of precision tasks,” in Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems. CHI EA ’16 (New York, NY: ACM), 2474–2481.
Garcia-Sanjuan, F., Jaen, J., and Nacher, V. (2016b). “From tabletops to multi-tablet environments in educational scenarios: a lightweight and inexpensive alternative,” in Proceedings of the 16th International Conference on Advanced Learning Technologies. ICALT ’16 (Washington: IEEE).
Geißler, J. (1998). “Shuffle, throw or take it! Working efficiently with an interactive wall,” in CHI 98 Conference Summary on Human Factors in Computing Systems. CHI ’98 (New York, NY: ACM), 265–266.
Gjerlufsen, T., Klokmose, C. N., Eagan, J., Pillias, C., and Beaudouin-Lafon, M. (2011). “Shared substance: developing flexible multi-surface applications,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’11 (New York, NY: ACM), 3383–3392.
Goh, W. B., Chamara Kasun, L. L., Fitriani, S., Tan, J., and Shou, W. (2012). “The I-cube: design considerations for block-based digital manipulatives and their applications,” in Proceedings of the Designing Interactive Systems Conference. DIS ’12 (New York: ACM), 398–407.
Grudin, J. (2001). “Partitioning digital worlds: focal and peripheral awareness in multiple monitor use,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’01 (New York, NY: ACM), 458–465.
Gutwin, C., Subramanian, S., and Pinelle, D. (2006). Designing Digital Tables for Highly Integrated Collaboration. Technical Report HCI-TR-06-02. Saskatoon, SK: Science Department, University of Saskatchewan
Hamilton, P., and Wigdor, D. J. (2014). “Conductor: enabling and understanding cross-device interaction,” in Proceedings of the 32nd Annual ACM Conference on Human Factors in Computing Systems. CHI ’14 (New York, NY: ACM Press), 2773–2782.
Hasan, K., Ahlström, D., and Irani, P. (2013). “Ad-binning: leveraging around device space for storing, browsing and retrieving mobile device content,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’13 (New York, NY: ACM), 899–908.
Hilliges, O., Izadi, S., Wilson, A. D., Hodges, S., Garcia-Mendoza, A., and Butz, A. (2009). “Interactions in the air: adding further depth to interactive tabletops,” in Proceedings of the 22nd Annual ACM Symposium on User Interface Software and Technology. UIST ’09 (New York: ACM), 139–148.
Hinckley, K. (2003). “Synchronous gestures for multiple persons and computers,” in Proceedings of the 16th Annual ACM Symposium on User Interface Software and Technology. UIST ’03 (New York, NY: ACM), 149–158.
Hinckley, K., Ramos, G., Guimbretiere, F., Baudisch, P., and Smith, M. (2004). “Stitching: pen gestures that span multiple displays,” in Proceedings of the Working Conference on Advanced Visual Interfaces. AVI ’04 (New York, NY: ACM), 23–31.
Holmquist, L. E., Mattern, F., Schiele, B., Alahuhta, P., Beigl, M., and Gellersen, H.-W. (2001). “Smart-its friends: a technique for users to easily establish connections between smart artefacts,” in Proceedings of the 3rd International Conference on Ubiquitous Computing. UbiComp ’01 (London: Springer-Verlag), 116–122. Available at: http://dl.acm.org/citation.cfm?id=647987.741340
Hunter, S., Kalanithi, J., and Merrill, D. (2010). “Make a riddle and telestory: designing children’s applications for the siftables platform,” in Proceedings of the 9th International Conference on Interaction Design and Children. IDC ’10 (New York, NY: ACM), 206–209.
Ishii, H., and Ullmer, B. (1997). “Tangible bits: towards seamless interfaces between people, bits and atoms,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’97 (New York, NY: ACM Press), 234–241.
Iwai, D., and Sato, K. (2009). CrossOverlayDesktop: dynamic overlay of desktop graphics between co-located computers for multi-user interaction. IEICE Trans. Inform. Syst. E92-D, 2445–2453. doi:10.1587/transinf.E92.D.2445
Johanson, B., Fox, A., and Winograd, T. (2002). The interactive workspaces project: experiences with ubiquitous computing rooms. IEEE Pervasive Comput. 1, 67–74. doi:10.1109/MPRV.2002.1012339 Piscataway, NJ: IEEE Educational Activities Department
Jones, B., Sodhi, R., Forsyth, D., Bailey, B., and Maciocci, G. (2012). “Around device interaction for multiscale navigation,” in Proceedings of the 14th International Conference on Human-Computer Interaction with Mobile Devices and Services. MobileHCI ’12 (New York: ACM), 83–92.
Kohtake, N., Ohsawa, R., Yonezawa, T., Iwai, M., Takashio, K., and Tokuda, H. (2007). Self-organizable panel for assembling DIY ubiquitous computing. Pers. Ubiquitous Comput. 11, 591–606. doi:10.1007/s00779-006-0118-z London, UK: Springer-Verlag
Kohtake, N., Ohsawa, R., Yonezawa, T., Matsukura, Y., Iwai, M., Takashio, K., et al. (2005). “U-texture: self-organizable universal panels for creating smart surroundings,” in Proceedings of the 7th International Conference on Ubiquitous Computing. UbiComp 2005 (Heidelberg: Springer), 19–36.
Konomi, S., Müller-Tomfelde, C., and Streitz, N. A. (1999). “Passage: physical transportation of digital information in cooperative buildings,” in Proceedings of the Second International Workshop of Cooperative Buildings – Integrating Information, Organizations and Architecture. CoBuild ’99 (Heidelberg: Springer), 45–54.
Kratz, S., Rohs, M., Guse, D., Müller, J., Bailly, G., and Nischt, M. (2012). “PalmSpace: continuous around-device gestures vs. multitouch for 3D rotation tasks on mobile devices,” in Proceedings of the International Working Conference on Advanced Visual Interfaces. AVI ’12 (New York, NY: ACM), 181–188.
Lachenal, C., and Coutaz, J. (2003). “A reference framework for multi-surface interaction,” in Proceedings of the 10th International Conference on Human-Computer Interaction. HCI International 2003 (Mahwah, NJ: Lawrence Erlbaum Associates), 22–27.
Law, A. W., Ip, J. W., Peck, B. V., Visell, Y., Kry, P. G., and Cooperstock, J. R. (2009). “Multimodal floor for immersive environments,” in ACM SIGGRAPH 2009 Emerging Technologies. SIGGRAPH ’09 (New York, NY: ACM Press).
Leo, K. H., and Tan, B. Y. (2010). “User-tracking mobile floor projection virtual reality game system for paediatric gait & dynamic balance training,” in Proceedings of the 4th International Convention on Rehabilitation Engineering Assistive Technology. iCREATe ’10, Vol. 25, 1–25:4. Available at: http://dl.acm.org/citation.cfm?id=1926058.1926083
Loureiro, B., and Rodrigues, R. (2011). “Multi-touch as a natural user interface for elders: a survey,” in 6th Iberian Conference on Information Systems and Technologies. CISTI ’11 (Washington: IEEE), 1–6.
Lucero, A., Holopainen, J., and Jokela, T. (2011). “Pass-them-around: collaborative use of mobile phones for photo sharing,” in Proceedings of the 2011 Annual Conference on Human Factors in Computing Systems. CHI ’11 (New York: ACM Press), 1787–1796.
Luyten, K., and Coninx, K. (2005). “Distributed user interface elements to support smart interaction spaces,” in Proceedings of the Seventh IEEE International Symposium on Multimedia. ISM ’05 (Washington, DC: IEEE Computer Society), 277–286.
Lyons, K., Pering, T., Rosario, B., Sud, S., and Want, R. (2009). “Multi-display composition: supporting display sharing for collocated mobile devices,” in Proceedings of the 12th IFIP TC 13 International Conference on Human-Computer Interaction: Part I, 758–71. INTERACT ’09 (Berlin, Heidelberg: Springer-Verlag).
Lyons, L., Lee, J., Quintana, C., and Soloway, E. (2006). “MUSHI: a multi-device framework for collaborative inquiry learning,” in Proceedings of the 7th International Conference on Learning Sciences. ICLS ’06 (International Society of the Learning Sciences), 453–459. Available at: http://dl.acm.org/citation.cfm?id=1150034.1150100
Maciel, A., Nedel, L. P., Mesquita, E. M., Mattos, M. H., Machado, G. M., and Freitas, C. M. D. S. (2010). “Collaborative interaction through spatially aware moving displays,” in Proceedings of the 2010 ACM Symposium on Applied Computing. SAC ’10 (New York, NY: ACM), 1229–1233.
Mackinlay, J. D., and Heer, J. (2004). “Wideband displays: mitigating multiple monitor seams,” in Extended Abstracts of the 2004 Conference on Human Factors and Computing Systems. CHI EA ’04 (New York, NY: ACM Press), 1521–1524.
Magerkurth, C., Stenzel, R., Streitz, N., and Neuhold, E. (2003). “A multimodal interaction framework for pervasive game applications,” in Proceedings of Artificial Intelligence in Mobile Systems (New York: ACM), 1–8.
Mandryk, R. L., Inkpen, K. M., Bilezikjian, M., Klemmer, S. R., and Landay, J. A. (2001). “Supporting children’s collaboration across handheld computers,” in CHI ’01 Extended Abstracts on Human Factors in Computing Systems. CHI EA ’01 (New York, NY: ACM), 255–256.
Mano, Y., Omaki, K., and Torii, K. (1981). An intelligent multi-display terminal system towards: a better programming environment. ACM SIGSOFT Softw. Eng. Notes 6, 8–14. doi:10.1145/1010865.1010866
Mano, Y., Omaki, K., and Torii, K. (1982). “Early experiences with a multi-display programming environment,” in Proceedings of the 6th International Conference on Software Engineering. ICSE ’82 (Los Alamitos, CA: IEEE Computer Society Press), 422–423. Available at: http://dl.acm.org/citation.cfm?id=800254.807788
Marquardt, N., Hinckley, K., and Greenberg, S. (2012). “Cross-device interaction via micro-mobility and F-formations,” in Proceedings of the 25th Annual ACM Symposium on User Interface Software and Technology. UIST ’12 (New York, NY: ACM), 13–22.
Merrill, D., Kalanithi, J., and Maes, P. (2007). “Siftables: towards sensor network user interfaces,” in Proceedings of the 1st International Conference on Tangible and Embedded Interaction. TEI ’07 (New York, NY: ACM), 75–78.
Merrill, D., Sun, E., and Kalanithi, J. (2012). “Sifteo cubes,” in Proceedings of the 2012 ACM Annual Conference Extended Abstracts on Human Factors in Computing Systems Extended Abstracts. CHI EA ’12 (New York, NY: ACM), 1015–1018.
Morris, M. R., Huang, A., Paepcke, A., and Winograd, T. (2006). “Cooperative gestures: multi-user gestural interactions for co-located groupware,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’06 (New York, NY: ACM Press), 1201–1210.
Nacenta, M. A., Aliakseyeu, D., Subramanian, S., and Gutwin, C. (2005). “A comparison of techniques for multi-display reaching,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’05 (New York, NY: ACM), 371–380.
Nacenta, M. A., Gutwin, C., Aliakseyeu, D., and Subramanian, S. (2009). There and back again: cross-display object movement in multi-display environments. J. Hum. Comput. Interact. 24, 170–229. doi:10.1080/07370020902819882
Nacenta, M. A., Jakobsen, M. R., Dautriche, R., Hinrichs, U., Dörk, M., Haber, J., et al. (2012). “The LunchTable: a multi-user, multi-display system for information sharing in casual group interactions,” in Proceedings of the 2012 International Symposium on Pervasive Displays. PerDis ’12 (New York, NY: ACM Press), 1–6.
Nacenta, M. A., Sallam, S., Champoux, B., Subramanian, S., and Gutwin, C. (2006). “Perspective cursor: perspective-based interaction for multi-display environments,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’06 (New York, NY: ACM), 289–298.
Nacher, V., Jaen, J., Catala, A., Navarro, E., and Gonzalez, P. (2014). “Improving pre-kindergarten touch performance,” in Proceedings of the 9th ACM International Conference on Interactive Tabletops and Surfaces. ITS ’14 (New York: ACM), 163–166.
Nacher, V., Jaen, J., Navarro, E., Catala, A., and González, P. (2015). Multi-touch gestures for pre-kindergarten children. Int. J. Hum. Comput. Stud. 73, 37–51. doi:10.1016/j.ijhcs.2014.08.004 Elsevier.
Nunes, R., Rito, F., and Duarte, C. (2015). “TACTIC: an API for touch and tangible interaction,” in Proceedings of the Ninth International Conference on Tangible, Embedded, and Embodied Interaction – TEI ’14 (New York, NY: ACM Press), 125–132.
Ohta, T. (2008). “Dynamically reconfigurable multi-display environment for CG contents,” in Proceedings of the 2008 International Conference on Advances in Computer Entertainment Technology, 416, ACE ’08 (New York, NY: ACM).
Ohta, T., and Tanaka, J. (2012). “Pinch: an interface that relates applications on multiple touch-screen by ‘pinching’ gesture,” in Proceedings of the 9th International Conference on Advances in Computer Entertainment. ACE ’12 (Berlin, Heidelberg: Springer-Verlag), 320–335.
Rädle, R., Jetter, H.-C., Marquardt, N., Reiterer, H., and Rogers, Y. (2014). “HuddleLamp: spatially-aware mobile displays for ad-hoc around-the-table collaboration,” in Proceedings of the 9th ACM International Conference on Interactive Tabletops and Surfaces. ITS ’14 (New York, NY: ACM), 45–54.
Rashid, U., Nacenta, M. A., and Quigley, A. (2012). “Factors influencing visual attention switch in multi-display user interfaces: a survey,” in Proceedings of the 2012 International Symposium on Pervasive Displays. PerDis ’12 (New York, NY: ACM), 18:1–18:6.
Rekimoto, J. (1997). “Pick-and-drop: a direct manipulation technique for multiple computer environments,” in Proceedings of the 10th Annual ACM Symposium on User Interface Software and Technology. UIST ’97 (New York, NY: ACM), 31–39.
Rekimoto, J., and Saitoh, M. (1999). “Augmented surfaces: a spatially continuous work space for hybrid computing environments,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’99 (New York, NY: ACM), 378–385.
Richardson, T., Stafford-Fraser, Q., Wood, K. R., and Hopper, A. (1998). Virtual network computing. IEEE Internet Comput. 2, 33–38. doi:10.1109/4236.656066 Piscataway, NJ: IEEE Educational Activities Department
Sangsuriyachot, N., Mi, H., and Sugimoto, M. (2011). “Novel interaction techniques by combining hand and foot gestures on tabletop environments,” in Proceedings of the ACM International Conference on Interactive Tabletops and Surfaces. ITS ’11 (New York, NY: ACM Press), 268–269.
Schmidt, D., Seifert, J., Rukzio, E., and Gellersen, H. (2012). “A cross-device interaction style for mobiles and surfaces,” in Proceedings of the Designing Interactive Systems Conference. DIS ’12 (New York, NY: ACM Press), 318–327.
Shaer, O., and Hornecker, E. (2010). Tangible user interfaces: past, present, and future directions. Found. Trends Hum. Comput. Interact. 3, 4–137. doi:10.1561/1100000026
Shen, C., Everitt, K., and Ryall, K. (2003). “UbiTable: impromptu face-to-face collaboration on horizontal interactive surfaces,” in Proceedings of the Fifth International Conference on Ubiquitous Computing (Heidelberg: UbiComp), 218–288.
Shneiderman, B., Plaisant, C., Cohen, M., and Jacobs, S. (2009). Designing the User Interface: Strategies for Effective Human-Computer Interaction. Boston: Prentice-Hall.
Smythies, J. (1996). A note on the concept of the visual field in neurology, psychology, and visual neuroscience. Perception 25, 369–371. doi:10.1068/p250369
Streitz, N. A., Geißler, J., Holmer, T., Konomi, S., Müller-Tomfelde, C. M., Reischl, W., et al. (1999). “I-LAND: an interactive landscape for creativity and innovation,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’99 (New York, NY: ACM), 120–127.
Sugimoto, M., Hosoi, K., and Hashizume, H. (2004). “Caretta: a system for supporting face-to-face collaboration by integrating personal and shared spaces,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’04 (New York, NY: ACM), 41–48.
Swaminathan, K., and Sato, S. (1997). Interaction design for large displays. Interactions 4, 15–24. doi:10.1145/242388.242395 New York, NY: ACM
Tan, D. S., and Czerwinski, M. (2003). “Information voyeurism: social impact of physically large displays on information privacy,” in CHI ’03 Extended Abstracts on Human Factors in Computing Systems. CHI EA ’03 (New York, NY: ACM), 748–749.
Tan, D. S., Meyers, B., and Czerwinski, M. (2004). “WinCuts: manipulating arbitrary window regions for more effective use of screen space,” in CHI ’04 Extended Abstracts on Human Factors in Computing Systems, CHI EA ’04 (New York, NY: ACM), 1525–1528.
Tandler, P. (2001). “Software infrastructure for ubiquitous computing environments: supporting synchronous collaboration with heterogeneous devices,” in Proceedings of the 3rd International Conference on Ubiquitous Computing. UbiComp ’01 (London, UK: Springer-Verlag), 96–115.
Tandler, P., Prante, T., Müller-Tomfelde, C., Streitz, N., and Steinmetz, R. (2001). “Connectables: dynamic coupling of displays for the flexible creation of shared workspaces,” in Proceedings of the 14th Annual ACM Symposium on User Interface Software and Technology. UIST ’01 (New York, NY: ACM), 11–20.
Terrenghi, L., Quigley, A., and Dix, A. (2009). A taxonomy for and analysis of multi-person-display ecosystems. Pers. Ubiquitous Comput. 13, 583–598. doi:10.1007/s00779-009-0244-5 London, UK: Springer-Verlag
Velloso, E., Schmidt, D., Alexander, J., Gellersen, H., and Bulling, A. (2015). The feet in human-computer interaction: a survey of foot-based interaction. ACM Comput. Surv. 48, 21.1–21.35. doi:10.1145/2816455
Weiser, M. (1991). The computer for the 21st century. Sci. Am. 265, 66–75. doi:10.1038/scientificamerican0991-94
Yang, J., and Wigdor, D. (2014). “Panelrama: enabling easy specification of cross-device web applications,” in Proceedings of the 32nd Annual ACM Conference on Human Factors in Computing Systems. CHI ’14 (New York, NY: ACM Press), 2783–2792.
Keywords: multi-display environments, multi-surface environments, interactive surfaces, classification, taxonomy
Citation: Garcia-Sanjuan F, Jaen J and Nacher V (2016) Toward a General Conceptualization of Multi-Display Environments. Front. ICT 3:20. doi: 10.3389/fict.2016.00020
Received: 17 April 2016; Accepted: 08 September 2016;
Published: 21 September 2016
Edited by:
Teresa Romão, Universidade NOVA de Lisboa, PortugalReviewed by:
Carlos Duarte, Universidade de Lisboa, PortugalDiogo Cabral, Universidade da Madeira, Portugal
Copyright: © 2016 Garcia-Sanjuan, Jaen and Nacher. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Javier Jaen, ZmphZW5AdXB2LmVz