 Murtaza Saifee1
Murtaza Saifee1 Jian Wu1,2Yingna Liu1Ping Ma1,3Jutima Patlidanon1,4Yinxi Yu5
Jian Wu1,2Yingna Liu1Ping Ma1,3Jutima Patlidanon1,4Yinxi Yu5 Gui-Shuang Ying5
Gui-Shuang Ying5 Ying Han1,6*
Ying Han1,6*- 1Department of Ophthalmology, University of California, San Francisco, San Francisco, CA, United States
- 2Beijing Ophthalmology and Visual Science Key Lab, Beijing Tongren Eye Center, Beijing Tongren Hospital, Beijing Institute of Ophthalmology, Capital Medical University, Beijing, China
- 3Department of Ophthalmology, Shandong Provincial Hospital, Shandong First Medical University, Jinan, China
- 4Department of Ophthalmology, Bhumibol Adulyadej Hospital, Bangkok, Thailand
- 5Center for Preventive Ophthalmology and Biostatistics, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, United States
- 6Ophthalmology Section, Surgical Service, San Francisco Veterans Affairs Medical Center, San Francisco, CA, United States
Purpose: To introduce and validate hvf_extraction_script, an open-source software script for the automated extraction and structuring of metadata, value plot data, and percentile plot data from Humphrey visual field (HVF) report images.
Methods: Validation was performed on 90 HVF reports over three different report layouts, including a total of 1,530 metadata fields, 15,536 value plot data points, and 10,210 percentile data points, between the computer script and four human extractors, compared against DICOM reference data. Computer extraction and human extraction were compared on extraction time as well as accuracy of extraction for metadata, value plot data, and percentile plot data.
Results: Computer extraction required 4.9-8.9 s per report, compared to the 6.5-19 min required by human extractors, representing a more than 40-fold difference in extraction speed. Computer metadata extraction error rate varied from an aggregate 1.2-3.5%, compared to 0.2-9.2% for human metadata extraction across all layouts. Computer value data point extraction had an aggregate error rate of 0.9% for version 1, <0.01% in version 2, and 0.15% in version 3, compared to 0.8-9.2% aggregate error rate for human extraction. Computer percentile data point extraction similarly had very low error rates, with no errors occurring in version 1 and 2, and 0.06% error rate in version 3, compared to 0.06-12.2% error rate for human extraction.
Conclusions: This study introduces and validates hvf_extraction_script, an open-source tool for fast, accurate, automated data extraction of HVF reports to facilitate analysis of large-volume HVF datasets, and demonstrates the value of image processing tools in facilitating faster and cheaper large-volume data extraction in research settings.
Introduction
Within ophthalmology, large volume data analysis requires structured data to perform. Data extraction and structuring are often a critical and overlooked aspect of such projects. Especially with the advent of machine learning and other “large data” processing techniques, there is a strong need for fast, cheap, and reliable data extraction to develop large databases for analysis and academic research, for data such as automated perimetry reports or ophthalmic imaging data (1). Indeed, some of the data can be extracted via manufacture-provided licensed software (2), but they are often expensive and can be cost prohibitive for many institutions and practices. Alternatively, study data can be manually transcribed by trained researchers, but this is costly and tedious with high risk for human error (3–5), which limits the types and scope of research projects that can be done.
Static automated perimetry exemplifies this issue well. Perimetry data involves large volume of quantitative data for each location tested, often done serially to track longitudinal progression in conditions such as glaucoma or neuro-ophthalmic disease. Such data can be analyzed using a variety of analysis techniques with both global and localized metrics (6, 7). One challenge in managing the large volume of perimetry data is obtaining accurate and detailed data points from each test (8). Therefore, most recent studies rely on small and single institution datasets containing hundreds of eyes (9). Few studies examining automated perimetry have datasets up to 2,000-3,000 eyes or more, with one study requiring the development of an in-house data extraction software system (10, 11). These studies indicate that there is an unmet need to develop methods to automatically and accurately extract large volume of perimetry studies, which is critical to building massive perimetry datasets for future detection and progression study in the ophthalmology field.
To solve this need in the field of automated perimetry, we have developed and validated a software platform for extraction of Humphrey® Visual Field (HVF) reports, a form of static automated perimetry used widely in clinical environments. Our aim in developing this platform was to automate HVF report data extraction in a fast, accurate way to facilitate (1) development of large-volume datasets for clinical research and (2) novel methodologies in computational analysis of perimetry data.
Methods
Description and Development of Platform
The software platform was developed by the author (MS) using Python 3.6.4 (12). The software leverages OpenCV 3.4.3 (13), an open source computer vision library, for image processing and figure detection, Tesseract 4.1.1 (14), an open source optical character recognition library, for metadata extraction, and Fuzzywuzzy (15), a fuzzy regular expression library for text matching. DICOM file reading was done using PyDICOM, an open-source DICOM reading package (16). Development and testing was performed on a MacBook Air (mid-2013) running Catalina 10.15.2 (Apple Inc, Cupertino, CA, USA).
In broad detail, this software platform takes as input HVF report image files, “extracts” data from the report image, and outputs structured, digital data represented in that report (Figure 1). The data on the HVF report image is categorized into three data types: metadata, value plot data, and percentile plot data.
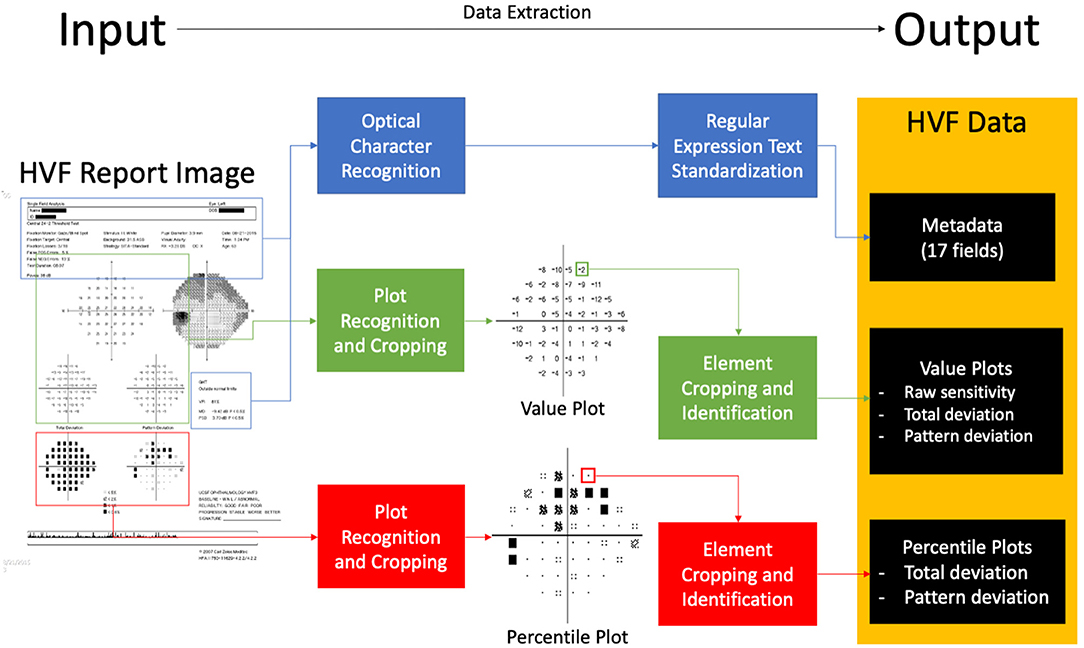
Figure 1. Block diagram of extraction software. An input visual field report identifies areas of metadata, value plots and percentile plots, processes and extracts data, and outputs structured data.
Metadata is defined as any data to be extracted not included within visual field plots. Within HVF reports, 17 fields are identified to be extracted by the platform:
1. Name
2. ID
3. Date of birth
4. Test date
5. Laterality (right or left)
6. Foveal sensitivity
7. False positive rate
8. False negative rate
9. Fixation loss rate
10. Test duration
11. Field size
12. Test strategy
13. Pupil diameter
14. Refraction used
15. Mean deviation
16. Pattern standard deviation
17. Visual Field Index (VFI).
To extract the data, the software first crops the image containing the metadata of interest and applies optical character recognition (OCR) using Tesseract. The resulting text data is then processed using regular expressions and string matching to structure and standardize the text data into the expected metadata fields.
Value plots are defined as plots with numerical perimetry data, that is, raw sensitivity plot data, total deviation value plot data, and pattern deviation value plot data (Figure 1). To extract data, the software locates the plot by identifying the plot axes and subsequently crops the plot image. It then aligns the plot to a 10 × 10 grid, and each cell is processed using a custom-built optical character recognition system (based on template matching) in order to determine and extract the value of the cell.
Percentile plots were defined as plots percentile sensitivity data values, that is, total deviation percentile plot data and pattern deviation percentile plot data (Figure 1). Percentile plots are processed in an identical fashion to value plots, but each cell is processed using a separate template-matching based system to determine the icon of the cell.
Data processed by the platform is represented and stored in an object-oriented format and can be used for further processing within the Python environment.
In addition to HVF report images, the software platform can also accept other types of input such as ophthalmic visual field (OPV) DICOM files containing HVF data and text serialization files in Javascript Object Notation (JSON) format that have been outputted by the software platform. An example of the output text file is shown in Figure 2.
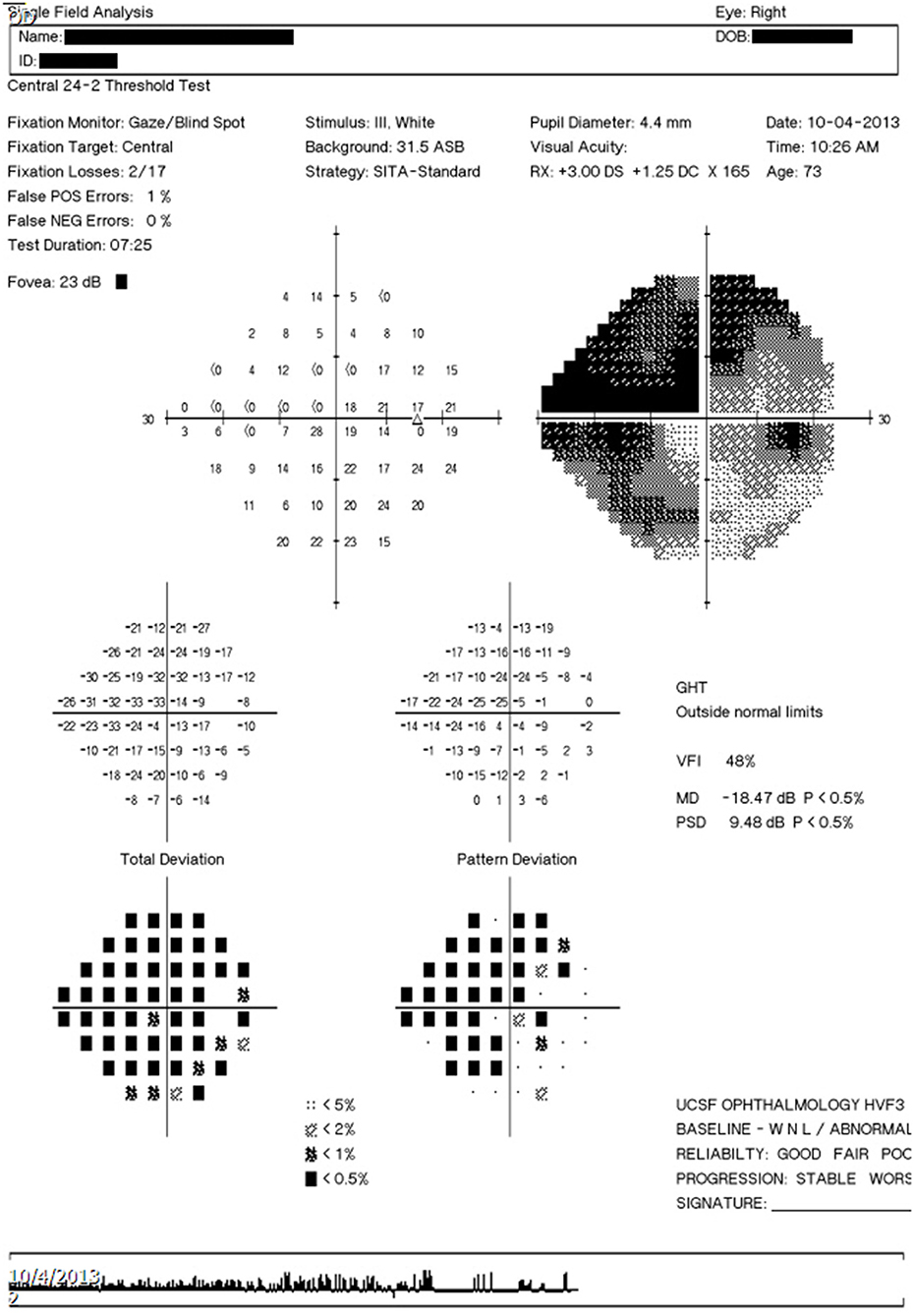
Figure 2. Example output text file. Example output text file corresponding to the image report seen in Figure 3C.
The perimetry data processed by the platform can be analyzed and processed internally within the Python environment, output as a JSON text file (e.g., to be re-imported and processed by the software platform at a different time) or output as a tab-delimited file to be imported into a spreadsheet processing software.
The software scripting platform was open-sourced under the GPL 3.0 license (17).
Extraction Platform Validation
This study was compliant with the Health Insurance Portability and Accountability Act and the Declaration of Helsinki for research involving human participants. Institutional Review Board approval was obtained from the University of California, San Francisco Human Research Protection Program.
Visual Field Testing
All VF examinations and reports were done by a Humphrey VF analyzer (HFA2 or HFA3) (Carl Zeiss Ophthalmic Systems, Inc., Dublin, CA) on a 10-2, 24-2 or 30-2 test pattern, size III white stimulus, with a Swedish Interactive Threshold Algorithm (SITA) strategy. Reports were exported as a.PNG image to the ophthalmology department picture archiving and communication system (PACS) server and downloaded from the server.
HVF Report Dataset Collection—Selection, Inclusion, and Exclusion Criteria
Three different types of HVF report resolution/layout formats (version 1, 2, and 3 layouts) present in the PACS system of our institution were identified. Examples of these layouts are shown in Figure 3. Image dimensions for these layouts are:
Version 1: 650 pixels by 938 pixels (HFA2, low resolution)
Version 2: 2,400 pixels by 3,180 pixels (HFA2, high resolution)
Version 3: 3,726 pixels by 5,262 pixels (HFA3, high resolution)

Figure 3. Humphrey Visual Field report layout types. (A) Version 1 layout. (B) Version 2 layout. (C) Version 3 layout.
A total of 90 HVF report images, with 30 HVFs for each layout version, was collected for validation. The sample size was determined by preliminary extraction tests to ensure valid statistical comparisons. Based on preliminary extraction runs, a human extraction accuracy of 98% and a computer extraction accuracy of 99.3% was assumed. At an alpha level of 0.05 and a power of 90%, assuming a 1:1 study ratio, sample size calculations determined a minimum of 1,808 data points was needed to detect a statistically significant difference; this equates to a minimum of 18 visual field reports. A set size of 30 was chosen to meet and exceed this minimum requirement.
All HVF reports were collected from patients seen at the University of California, San Francisco Ophthalmology Visual Field Testing Clinic. For version 1 layout, 30 historical HVF reports were taken from consecutive patients 2014 or prior. For version 2 layout, 30 HVF reports were selected from consecutive patients seen from March 4, 2019 to March 5, 2019. For version 3, 30 HVF reports taken from consecutive patients seen from August 30, 2019 onward.
A maximum of two HVFs per patient were selected (one for each eye). Only HVFs with strategy SITA-Standard, SITA-Fast or SITA-Faster were included; HVFs performed with a Full-Threshold strategy or any other strategy were excluded. There was no inclusion or exclusion criteria based on patient diagnosis, reliability indices, mean deviation, or type of defect noted.
Data Extraction and Accuracy Measurements
Four human extractors, all ophthalmologists familiar with reading HVF reports, were selected. Each extractor manually recorded the data from each HVF report into a spreadsheet, as well as time required for extraction. Each extractor was allowed to perform extraction independently, without proctoring, in an environment they selected as optimal. In addition to manual human extraction, each HVF report image was processed using the data extraction software script.
Each set of extracted data (from human extractors and software extractions script) was compared against data obtained from the DICOM OPV file representing the report of interest, obtained from the Humphrey Field Analyzer device. A custom testing platform, written in Python, was developed to compare these outputs.
Metadata fields were compared on a per-field basis; field were considered correct if the computer image extraction matched exactly to the DICOM reference. Two types of inaccuracy were determined by a masked grader who was blind to human or software data extraction (YH). Formatting inconsistencies were defined as when the extracted data was different from the DICOM reference in a minor way, such that the data still provided correct information; examples include case inconsistencies, whitespace differences, and differences in date reporting. True errors were defined as all other field inequalities that did not represent the correct data.
Data points from value plots and percentile plots were compared on a per data point basis, among all non-empty value data points within value plots. Data points were considered correct if the value from the extraction exactly matched the DICOM reference value.
Statistical Analysis
For each HVF record, we calculated the total number of errors for extracting metadata, value plot data, percentile plot by using computer script, and four human extractors. We summarized the errors using total number of errors from all records of each HVF layout (e.g., aggregate errors), aggregate error rate (calculated as aggregate errors divided by the total number of fields tested) and its 95% binomial confidence intervals, and median (inter-quartile) of number of errors in each HVF record. For each of HVF layout, we compared between computer script and each of four human extractors in the mean time used for data extraction using repeated measures one-way analysis of variance and in the number of errors per HVF record using Friedman's Chi-Square test due to skewed distribution. All the statistical analyses were performed in SAS v9.4 (SAS Institute Inc., Cary, NC), and two-sided p < 0.05 was considered to be statistically significant.
Results
The HVF extraction program was developed in line with the specifications outlined in the Methods section. It is available free for access and usage at https://pypi.org/project/hvf-extraction-script/. Its source code can be found at https://github.com/msaifee786/hvf_extraction_script.
Characteristics of the HVF reports for each layout version is shown in Table 1. A total of 1,530 metadata fields, 15,536 value plot data points, and 10,210 percentile data points were tested over three layout version groups. Each group included a similar number of right and left eyes and included at least one report from each field size test. There was representation from each severity of visual field defect based on mean deviation magnitude.
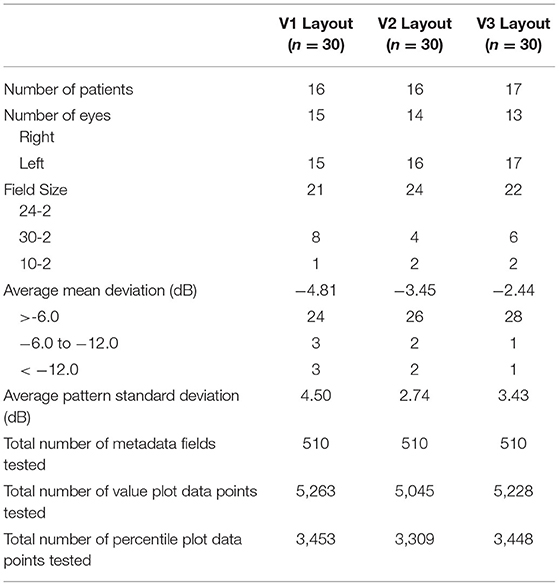
Table 1. Characteristics of validation set visual field reports.
Validation was performed between the computer extraction and human extraction for each HVF layout, measuring extraction times (Table 2), metadata error rates (Table 3A) and format inconsistencies (Table 3B), value plot error rates (Table 4) and percentile plot error rates (Table 5). Notably, minor post-processing editing was done on the human extraction datasets in order to standardized formatting prior to validation testing. Human extractor P2 mislabeled three files in the V1 layout data due to a skip in the sequential numbering; this was corrected prior to the validation comparison. Human extractor P4 skipped a column field in the extracted dataset, which was added in (with blank values) to standardized format prior to validation comparison. Lastly, datasets for P3 and P4 required trivial substitutions of characters (e.g., upper to lower case conversion).
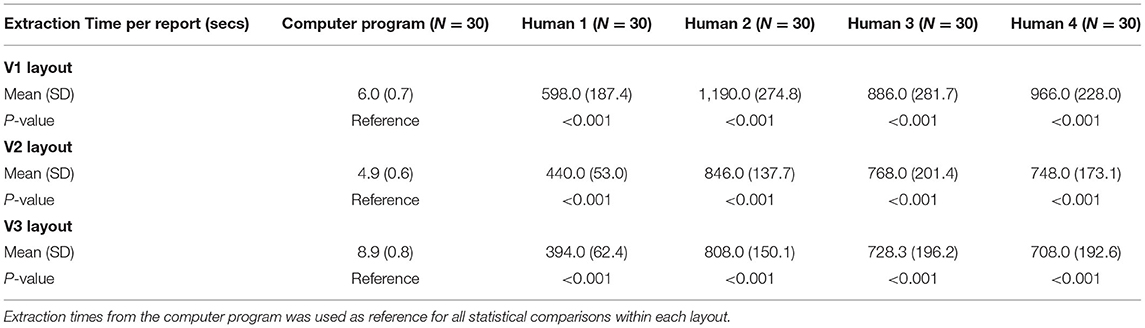
Table 2. Extraction times for each resolution layout.

Table 3A. Comparison between computer program and human metadata extraction (Metadata errors).
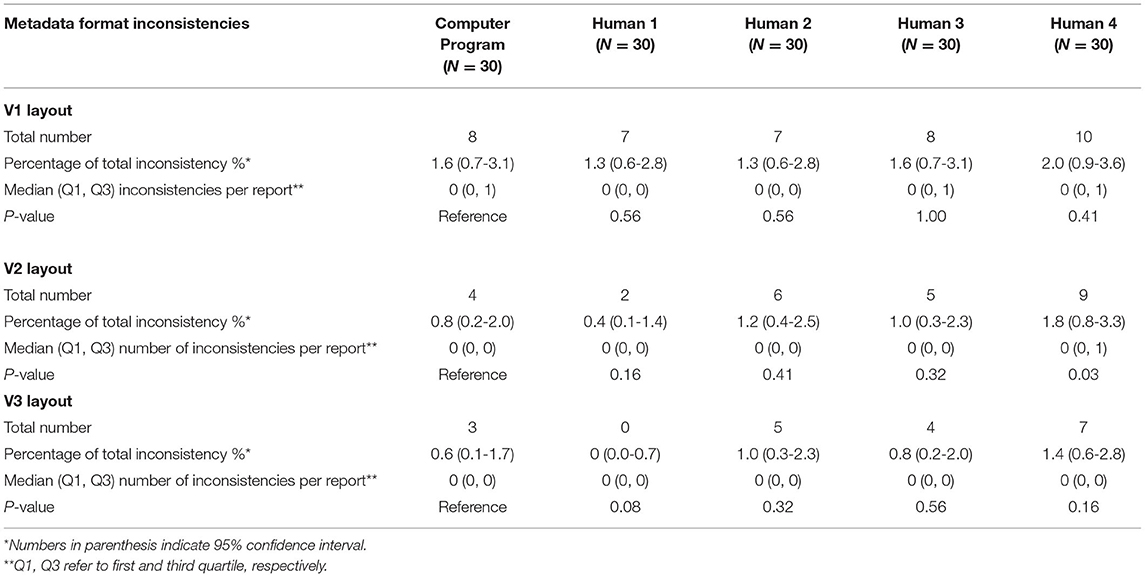
Table 3B. Comparison between computer program and human metadata extraction (format inconsistencies).
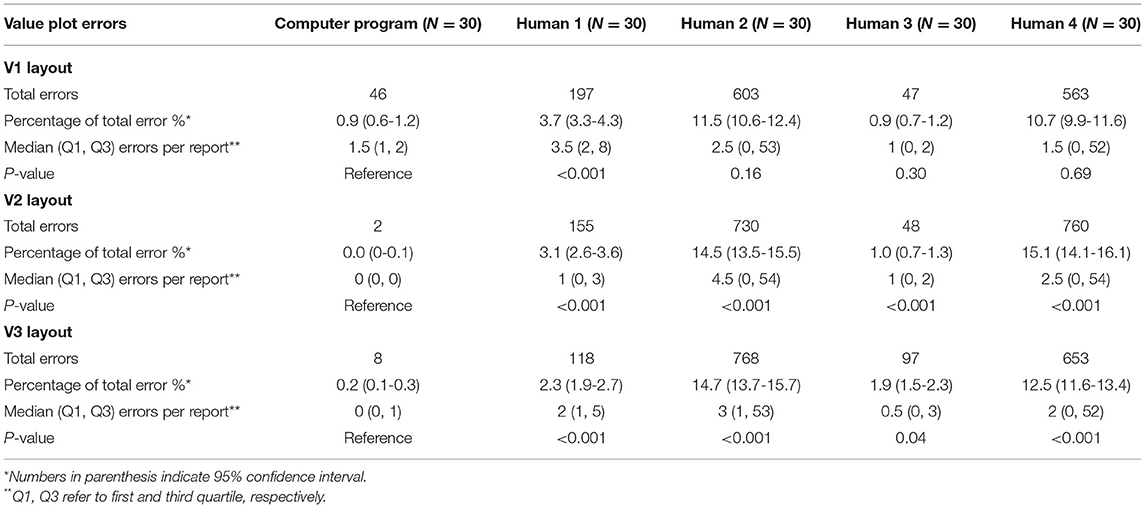
Table 4. Comparison between computer program and human on value plot extraction errors.
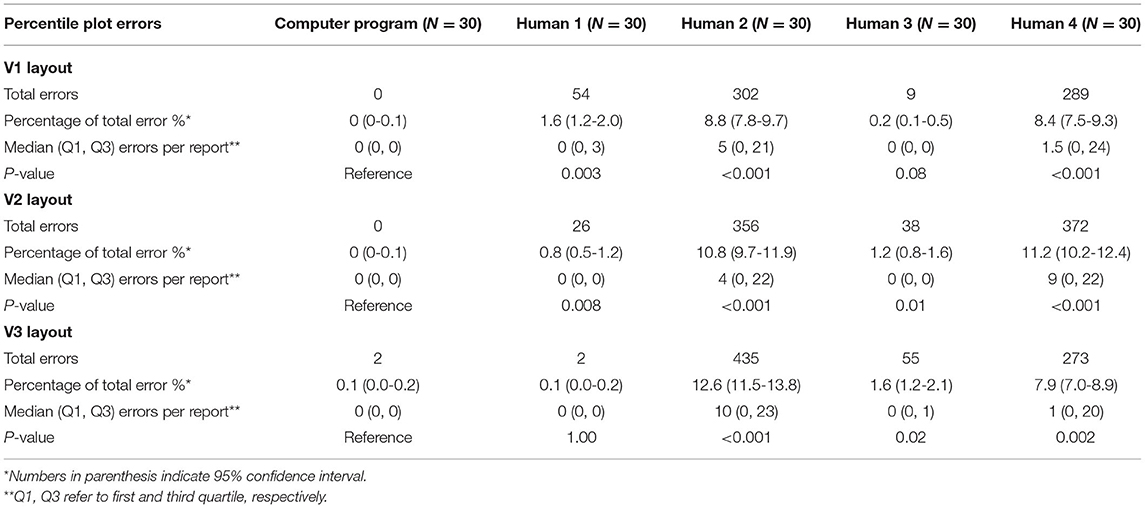
Table 5. Comparison between computer program and human on percentile plot extraction errors.
Extraction Times
Average extraction time for the computer platform varied from 4.9 to 8.9 s, with minimal variation between the different layouts (Table 2). The highest resolution V3 layout had the longest average computer extraction time. Human extractors had average extraction times varying from 394 to 1,190 s for all three versions, with a statistically significant longer time in comparison to computer extraction (p < 0.001). There was no clear difference in human extraction time among different versions. In general, the computer platform performed extractions on the order of 50-100 times faster than human extractions.
Metadata Extraction
Within the computer extraction group, there were a total of 32 metadata extraction errors across all three layouts, with a per-layout error rate varying from 1.2-3.5%, with the highest error rate occurring the V1 layout group (Table 3A). The highest frequency of extraction errors was due to incorrect character recognition (seven errors). Among all four human extractors, the average per-layout error rate varied from 2.5-4.4%. Examples of metadata extraction errors that occurred in this study are shown in Table 6.
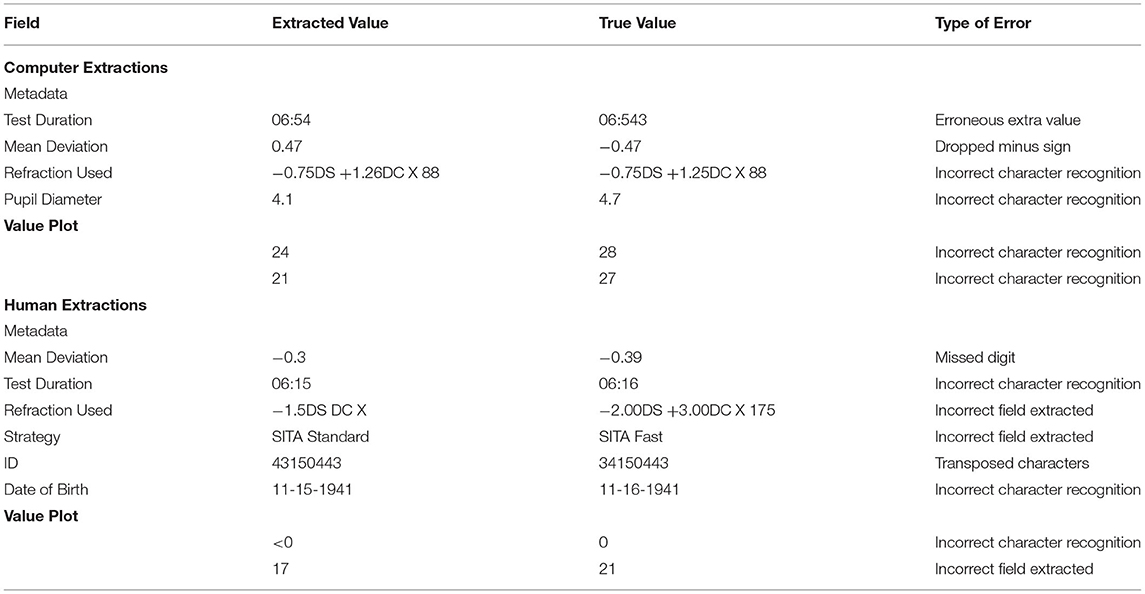
Table 6. Examples of extraction errors.
Computer extraction overall performed similarly to human extraction for metadata. In V1 layout, there was no difference between the computer and human extractors. Computer had a lower number of metadata errors than P2 and P3 in V2 layout and P3 in V3 layout, while P4 had less metadata errors than computer in V2 and V3 layouts. There was nearly no significant difference between format inconsistencies between the computer and human extractions in any version layout (Table 3B).
Value Plot Extraction
For every layout, value plot extraction errors were less for computer extraction than every human extractor (Table 4). These comparisons were statistically significant in layouts V2 and V3. The highest number of value plot errors among human extractors were due to P2 and P4; a large number of these errors occurred due to a frame shift error for all left eyes. Examples of value plot errors that occurred in this study are shown in Table 6.
Computer extraction value plot errors occurred predominantly within the V1 layout extraction; most of the errors occurred as a misidentification between 4, 6, and 8, as well as between 1 and 7 (Table 6). Majority of these occurred in the raw value plot, while the remaining errors occurred in the total deviation value plot. These errors occurred in scattered parts of the plot with no association to a specific location. In the V2 and V3 layout value plot extraction, all errors occurred in the raw value plot along the horizontal midline in the temporal field (i.e., corresponding to the area of the physiologic blind spot). Almost uniformly for these errors, the areas had a reduced sensitivity value (often “0” or “ <0”) and an adjacent open triangle icon (or fragment thereof) near the value.
Percentile Plot Extraction
Overall, percentile plot extraction errors occurred rarely in the computer extraction (Table 5). No computer extraction percentile plot extraction errors occurred in the V1 and V2 layout. Two errors occurred in the V3 layout in total deviation percentile plots. The computer performed nominally lower than every human extractor for every layout; all but two of these comparisons (P3 in V1 and P1 in V3) were statistically significant.
Discussion
To our knowledge, this is the first open-source data extraction software script for perimetry output in the literature. The main purpose of the development of this platform is to improve our ability to research and analyze perimetry data and ultimately to better guide treatment of vision-threatening diseases. To that end, this code has been made available through the Python Package Index (PyPi), and its source code has been published as open source, available through GitHub. We encourage anyone to utilize this program, scrutinize its effectiveness, improve upon it and adapt it for their own uses.
The method employed to extract data from HVF perimetry reports in this script is optical character recognition (OCR) technology, which has been available since the 1950s (18). Recently, this technology has improved significantly with improved image processing techniques and the advent of neural networks. In the literature, studies that have specifically used OCR technology for medical data exaction tasks mostly focus on scanned reports for clinical laboratory tests, with reasonably high accuracy (19–21). Adamo et al. utilized Tesseract OCR (the same OCR platform as used in our script) to achieve an accuracy of 95% in their extraction system (19). Another team was able to achieve a similar accuracy of 92.3-95.8% using a custom neural network model on multilingual reports containing Chinese and Latin characters (20, 21). Our script shows a nominally higher accuracy rate than these systems; this is likely due to our study utilizing standardized digital report images rather than scanned documents. Nonetheless, these studies highlight the value of computer vision and OCR tools in the data extraction of medical reports.
Our script offers specific value in ophthalmology, especially in the field of glaucoma, by facilitating access to structured perimetry data. Static automated perimetry is an integral component in the management and monitoring of glaucoma, and numerous studies in the literature have examined various perimetry metrics in search of an optimal marker of diagnosis or progression (22). In recent years, machine learning and neural networks have also been used in perimetry research (9); these algorithms are heavily dependent on well-categorized, large volume datasets. Thus, developing new perimetry metrics is an important focus of research in glaucoma (23), and access to structured perimetry is critical in facilitating this research (23). Our program was designed to offer a versatile option to generate structured HVF data for analysis from DICOM files or images files (such as JPG or PNG formats). With this, the program can serve as an avenue to several opportunities for perimetry data analysis. Additionally, this platform can potentially be used in conjunction with other analysis platforms such as the R package visualField (an open source module for analysis of visual field data), with the appropriate software to interface the two systems (24). Our platform has been used in a published study on HVFs in glaucoma patients undergoing glaucoma tube shunt implantation (25). Other research teams have performed studies with large volumes of HVFs for metric analysis and machine learning using in-house extraction software (6, 11); however, their script was not published and validation cannot be compared with ours.
One of the main strengths of computer extraction is the speed of extraction. Not only does the computer script offer more than a 50-fold increase in extraction speed, but also allows the extraction process to be automated for a large number of reports. Thus, the computer script can free up researchers for other tasks, and overall help reduce the cost and effort of data extraction. In institutions where structured digital perimetry data are not easily available straight from the acquisition devices, the computer extraction script offers an effective alternative to costly human extraction.
The validation results show an overall low error rate for the computer extraction data. Most errors occurred in metadata extraction, which has the most variability in the type and structure of the extracted data fields. As expected, the error rate increases with lower resolution images; this is due to the nature of image detection and OCR technology, which we used heavily in metadata extraction. Despite this correlation, metadata error rates remain low and similar to human extraction error rates, regardless of resolution of input image.
The error rate for computer extracted value and percentile data was very low and were statistically significantly better than human extraction except for value plot extractions in the low-resolution layout V1. Misidentification of similar appearing numbers in low-resolution images and interference of the open triangle icon in the area of the physiologic blind spot within the raw sensitivity plot were the main reasons for errors. The accuracy of the computer script in value and percentile plot data shows one of its main strengths, especially in the face of significant error rates in human extraction.
A notable result in our validation study is the high frequency of errors that arises from manual, human data extraction. Data errors in medical research have been studied in the past; one study showed error rates ranging from 2.3-26.9% in separately maintained clinical research databases at a single institution, due to a combination of presumed transcription and cognitive errors (26). This compares similarly to our study, with human extraction error rates as high as 10-15% in some categories. The substantially high error rate among human extraction in our study is possibly related to the display of plot data within HVF reports, which contain a high density of values within an area. This is supported by prior studies that show that displaying a high volume of data in the source document is correlated with transcription errors (4). Additionally, human extraction data tends to be variably formatted, especially when several different people contribute to the extracted datasets; this variability of data often requires standardization prior to further processing. Overall, understanding the relative strengths and weaknesses of human vs. computer extraction is important to improving research data integrity.
Lastly, it should be noted that while the computer program extraction is faster and more accurate than human extraction, it does not have 100% accuracy. Human validation of the extracted data may be needed to correct any computer errors. Understanding the limitations of computer data extraction and common areas of errors can help guide human validation of the data to speed up the process.
There are a few limitations of this validation study. First, the report layouts were limited to three distinct resolutions; while the different resolutions demonstrate the correlation of accuracy with resolution, the limited resolution layouts may not capture the full spectrum of image resolutions in use in the community. The limited number of reports per trial and selection methodology may not fully represent the spectrum of visual field defects possible, which may limit the generalizability of the error rates to specific HVF reports.
In summary, in this paper we introduce and validate a computer program for the extraction of HVF data from report images. In comparison to human extraction, computer extraction is faster and more accurate; however, human validation of the computer extraction data may be necessary for situations that require high fidelity of data. Overall, this program can help reduce the cost of data analysis for research institutions where HVF data is otherwise inaccessible.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Ethics Statement
This study was compliant with the Health Insurance Portability and Accountability Act and the Declaration of Helsinki for research involving human participants. Institutional Review Board approval was obtained from the University of California, San Francisco Human Research Protection Program.
Author Contributions
MS developed software platform and contributed to study design, data collection, and analysis. JW, YL, PM, and JP contributed to data collection and analysis. YY and G-SY contributed to data analysis and statistical calculations. YH contributed to study design, data analysis, and statistical calculations. All authors contributed to manuscript preparation.
Funding
NEI EY028747-01 funding to YH, NEI P30 EY002162 Core Grant for Vision Research, and an unrestricted grant from Research to Prevent Blindness, New York, NY.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Armstrong GW, Lorch AC. A(eye): a review of current applications of artificial intelligence and machine learning in ophthalmology. Int Ophthalmol Clin. (2020) 60:57-71. doi: 10.1097/IIO.0000000000000298
2. Carl Zeiss Meditec AG. DICOM Conformance Statement - Forum Version 3.2. Available online at: https://www.zeiss.com/content/dam/Meditec/downloads/pdf/DICOM/DICOM_Conformance_Statement_FORUM_v3.2.pdf (accessed November 3, 2020).
3. Norman DA. Design rules based on analyses of human error. Commun ACM. (1983) 26:254-8. doi: 10.1145/2163.358092
4. Soboczenski F. The Effect of Interface Elements on Transcription Tasks to Reduce Number-Entry Errors. (2014). Availble online at: http://etheses.whiterose.ac.uk/11775/1/thesis.pdf (accessed November 3, 2020).
5. Thimbleby H, Cairns P. Reducing number entry errors: solving a widespread, serious problem. J R Soc Interface. (2010) 7:1429-39. doi: 10.1098/rsif.2010.0112
6. Saeedi OJ, Elze T, D'Acunto L, Swamy R, Hegde V, Gupta S, et al. Agreement and predictors of discordance of 6 visual field progression algorithms. Ophthalmology. (2019) 126:822-8. doi: 10.1016/j.ophtha.2019.01.029
7. Nouri-Mahdavi K, Caprioli J. Measuring rates of structural and functional change in glaucoma. Br J Ophthalmol. (2015) 99:893-8. doi: 10.1136/bjophthalmol-2014-305210
8. Zheng C, Johnson TV, Garg A, Boland MV. Artificial intelligence in glaucoma. Curr Opin Ophthalmol. (2019) 30:97-103. doi: 10.1097/ICU.0000000000000552
9. Mursch-Edlmayr AS, Ng WS, Diniz-Filho A, Sousa DC, Arnold L, Schlenker MB, et al. Artificial intelligence algorithms to diagnose glaucoma and detect glaucoma progression: translation to clinical practice. Transl Vis Sci Technol. (2020) 9:55. doi: 10.1167/tvst.9.2.55
10. Yousefi S, Kiwaki T, Zheng Y, Sugiura H, Asaoka R, Murata H, et al. Detection of longitudinal visual field progression in glaucoma using machine learning. Am J Ophthalmol. (2018) 193:71-9. doi: 10.1016/j.ajo.2018.06.007
11. Wen JC, Lee CS, Keane PA, Xaio S, Rokem AS, Chen PP, et al. Forecasting future Humphrey visual fields using deep learning. PLoS ONE. (2019) 14:e0214875. doi: 10.1371/journal.pone.0214875
12. Welcome to python.org. Available online at: https://www.python.org/ (accessed November 3, 2020).
13. OpenCV. Available online at: https://opencv.org/ (accessed November 3, 2020).
14. tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository). Available online at: https://github.com/tesseract-ocr/tesseract (accessed November 3, 2020).
15. seatgeek/fuzzywuzzy: Fuzzy String Matching in Python. Available online at: https://github.com/seatgeek/fuzzywuzzy (accessed November 3, 2020).
16. pyDICOM. Available online at: https://github.com/pydicom/pydicom (accessed November 3, 2020).
17. The GNU General Public License v3.0 - GNU Project - Free Software Foundation. Available online at: https://www.gnu.org/licenses/gpl-3.0.en.html (accessed November 3, 2020).
18. Chaudhuri A, Mandaviya K, Badelia P, Ghosh KS. Optical Character Recognition Systems. In: Optical Character Recognition System for Different Languages With Soft Computing, Studies in Fuzziness and Soft Computing. Cham: Springer (2017). doi: 10.1007/978-3-319-50252-6_2
19. Adamo F, Attivissimo F, Di Nisio A, Spadavecchia M. An automatic document processing system for medical data extraction. Meas J Int Meas Confed. (2015) 61:88-99. doi: 10.1016/j.measurement.2014.10.032
20. Xue W, Li Q, Zhang Z, Zhao Y, Wang H. Table analysis and information extraction for medical laboratory reports. In: Proc - IEEE 16th Int Conf Dependable, Auton Secur Comput IEEE 16th Int Conf Pervasive Intell Comput IEEE 4th Int Conf Big Data Intell Comput IEEE 3. Athens (2018) 200-7. Available online at: https://ieeexplore.ieee.org/document/8511886
21. Xue W, Li Q, Xue Q. Text detection and recognition for images of medical laboratory reports with a deep learning approach. IEEE Access. (2020) 8:407-16. doi: 10.1109/ACCESS.2019.2961964
22. Nouri-Mahdavi K, Nassiri N, Giangiacomo A, Caprioli J. Detection of visual field progression in glaucoma with standard achromatic perimetry: a review and practical implications. Graefe's Arch Clin Exp Ophthalmol. (2011) 249:1593-1616. doi: 10.1007/s00417-011-1787-5
23. Brusini P, Johnson CA. Staging functional damage in glaucoma: review of different classification methods. Surv Ophthalmol. (2007) 52:156-79. doi: 10.1016/j.survophthal.2006.12.008
24. Marín-Franch I, Swanson WH. The visualFields package : a tool for analysis and visualization of visual fields. J Vis. (2013) 13:1-12. doi: 10.1167/13.4.10
25. Liu Q, Saifee M, Yu Y, Ying G-S, Li S, Zhong H, et al. Evaluation of long-term visual field function in patients undergoing glaucoma drainage device implantation. Am J Ophthalmol. (2020) 216:44-54. doi: 10.1016/j.ajo.2020.03.025
Keywords: glaucoma, visual field, neuroophthalmogy, optical character reader, computer vision and image processing
Citation: Saifee M, Wu J, Liu Y, Ma P, Patlidanon J, Yu Y, Ying G-S and Han Y (2021) Development and Validation of Automated Visual Field Report Extraction Platform Using Computer Vision Tools. Front. Med. 8:625487. doi: 10.3389/fmed.2021.625487
Received: 03 November 2020; Accepted: 31 March 2021;
Published: 29 April 2021.
Edited by:
Soosan Jacob, Dr. Agarwal's Eye Hospital, IndiaReviewed by:
Haotian Lin, Sun Yat-sen University, ChinaSaif Aldeen AlRyalat, The University of Jordan, Jordan
Copyright © 2021 Saifee, Wu, Liu, Ma, Patlidanon, Yu, Ying and Han. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ying Han, eWluZy5oYW5AdWNzZi5lZHU=