


- 1 III. Institute of Physics – Biophysics, Georg–August–Universität Göttingen, Göttingen, Germany
- 2 Network Dynamics Group, Max Planck Institute for Dynamics and Self-Organization, Göttingen, Germany
- 3 Bernstein Center for Computational Neuroscience, Göttingen, Germany
- 4 Institute for Non-linear Dynamics, Georg–August–Universität Göttingen, Göttingen, Germany
Conventional synaptic plasticity in combination with synaptic scaling is a biologically plausible plasticity rule that guides the development of synapses toward stability. Here we analyze the development of synaptic connections and the resulting activity patterns in different feed-forward and recurrent neural networks, with plasticity and scaling. We show under which constraints an external input given to a feed-forward network forms an input trace similar to a cell assembly (Hebb, 1949) by enhancing synaptic weights to larger stable values as compared to the rest of the network. For instance, a weak input creates a less strong representation in the network than a strong input which produces a trace along large parts of the network. These processes are strongly influenced by the underlying connectivity. For example, when embedding recurrent structures (excitatory rings, etc.) into a feed-forward network, the input trace is extended into more distant layers, while inhibition shortens it. These findings provide a better understanding of the dynamics of generic network structures where plasticity is combined with scaling. This makes it also possible to use this rule for constructing an artificial network with certain desired storage properties.
1. Introduction
Synaptic plasticity in neural systems needs to be regulated without which unwanted effects, like overly strong growth or shrinkage, might occur, destabilizing the network function. Little is known about the underlying biophysical mechanisms which control weight growth. Learning rules (plasticity rules) usually achieve this by weight regularization terms (Bienenstock et al., 1982; Oja, 1982; Miller and MacKay, 1994; Gerstner and Kistler, 2002). A possible alternative arises when considering so-called “synaptic scaling.” This is a mechanism, discovered around 1998, by which network activity is homeostatically regulated (Turrigiano et al., 1998; Turrigiano and Nelson, 2000, 2004). Overly active networks will – on a time axis of hours up to days – down scale their activity and vice versa. This is achieved by altering the synaptic strengths usually across many neurons, which acts like a scaling mechanism (Turrigiano and Nelson, 2000). Thus, synaptic weights ω seem to be regulated by an activity dependent difference term. This term compares for every neuron – hence locally – output activity v against a terminal activity vT such that , where γ ≪ 1 is a rate factor that strongly limits this effect and thereby defines a time scale much slower than that of conventional plasticity (e.g., Hebbian plasticity Hebb, 1949 or Spike-timing dependent plasticity, STDP; Bi and Poo, 1998), which is dominated by another rate factor 1 ≫ μ > γ.
As a consequence, synaptic change needs to be described by a combination of a conventional plasticity rule together with this more slowly acting scaling rule: where G and H describe the specific instantiations of these rules (u is the presynaptic activity). For example, G would be different for a plain hebbian rule (G = uv) as compared to the BCM rule (G = uv(v − Θ)).
In a previous study (Tetzlaff et al., 2011) we have shown that such a combination of Synaptic Plasticity and Synaptic Scaling (SPaSS) leads to a rule which is globally stable for a wide variety of conditions as soon as scaling depends quadratically on the weights (H ∼ ω2). Several interesting properties were discussed. For example, a strong external input delivered to a neuron leads to large (stable) post-synaptic weights for this neuron and its direct as well as indirect target neurons. This way reliable propagation of the external signal along several stages becomes possible because all these neurons are connected with each other with strong synapses. Thus, an input trace is stored. This appears interesting as the SPaSS rule apparently allows the system to form such linked groups of neurons, which could be considered as a “cell assembly” (Hebb, 1949; Hahnloser et al., 2002; Harris et al., 2003). So far the dynamic creation and stabilization of cell assemblies has remained an enigma. While the SPaSS rule seem to achieve this (at least to some degree) so far it also remains unclear how these dynamics evolve. Thus, the goal of the current study is to analyze the dependency of size (number of neurons/stages) and strength (weights) of these input traces on the underlying connectivity and used plasticity parameters.
To this end we will use a combined rule with a hebbian plasticity term for G and the above mentioned quadratic weight dependence for H (Tetzlaff et al., 2011) between neurons i and j:
with and κ = μ/γ. In contrast to (Tetzlaff et al., 2011), we will continue to use μ and κ and not μ and γ. This is because the fixed points of such systems are only influenced by the γ to μ ratio (i.e., κ) and μ as such merely alters the time scale of our model. Additionally we assume that the output of neuron i depends linearly on the product of input and weight: vi = Σj wij·uj. Then we can adopt the results of a one synapse system from (Tetzlaff et al., 2011) and state the stable excitatory fixed point by using κ as:
or rewritten with vi = wij·uj as:
This activity value is the target activity of neuron i given input uj. This target activity becomes equal to the terminal activity vT if synaptic plasticity does not influence synaptic weights anymore (i.e., κ = 0).
Now, we want to reintroduce in more detail the results from (Tetzlaff et al., 2011) which are relevant for the current study: Figure 1A shows a schematic rendering of a network of 100 neurons that has been designed with three connections from each neuron to randomly chosen target neurons. All neurons are rate coded and we have used hebbian plasticity together with scaling as defined in equation (1). Three neurons have received strong, constant, external input, all other neurons only weak random input. This leads to two groups of neuronal descendent-lines in the network. Group 1: The three neurons receiving the strong input (input neurons) project to 9 children, 27 grandchildren, 81 great-grandchildren, etc., where – due to the randomness of the connection patterns – loops can be formed, too. Group 2: The same descendent line arises for any randomly chosen other three neurons (control neurons), too. After network relaxation we have analyzed how the fixed points of activities and weights look like for these two groups of neurons. The black lines in Figure 1B show activities (solid) and weights (dashed) for the input-descendent group; the gray lines for the control descendent group. Neurons that descend from the input neurons represent the input along at least three connection stages by producing higher activities and higher, stable weights. Thus, this network was able to store an input trace and form a “cell assembly” (Hebb, 1949). For more details concerning this result see Tetzlaff et al., 2011.
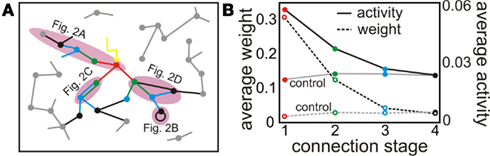
Figure 1. Given a strong external input synaptic plasticity combined with synaptic scaling (equation 1) leads to an input trace similar to a cell assembly. (A) Schematic of post-synaptic connectivity of selected neurons up to stage five. The red neuron receives a strong external input (yellow arrow). Parts of the descendent network stages are highlighted to show the general connectivity structures analyzed in this study (c.f. Figure 2). (B) Neural activities (dashed lines) and weights (solid lines) after stabilization found for the first four stages. Weights and activities of the stages linked to the external input (black) are significantly larger compared to control neurons (gray) over the first three stages representing an input trace (cell assembly).
In the current study we are going to investigate the sphere of influence of the given external input on the fixed points of weights and activities of the network dependent on the underlying connectivity. For this, we split the complex random network (c.f. Figure 1A) in smaller, more generalized parts (e.g., purple areas in Figures 1A and 2) and analyze their influence on size (number of neurons/stages) and strength (weights) of the input trace (cell assembly).
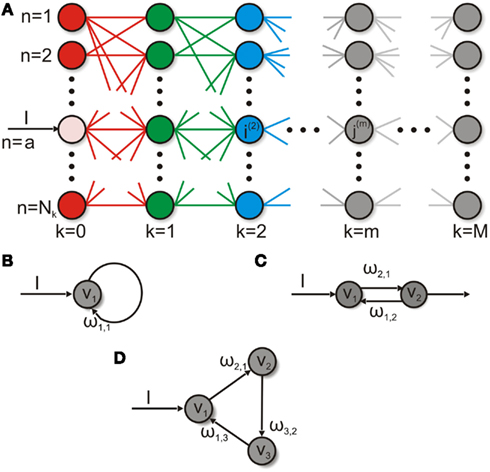
Figure 2. The different networks investigated in this study. (A) A feed-forward network consists of M layers each with Nk neurons. Each neuron j m of each layer m connects to all neurons of the source-layer m − 1 and target-layer m + 1 and has no connections within its layer. In this example neuron n = a of the first layer k = 0 (pink) receives an input ℑ while the other neurons within this layer do not. (B) The smallest recurrent system: a neuron with a self-connection receiving external input. (C) A neuron receives an external input and is recurrently connected to another neuron. (D) Three neurons build a ring structure.
First, we obtain analytical results for excitatory feed-forward networks (Figure 2A) with and without lateral connections and with feed-forward or lateral inhibition. In addition, we derive stability constraints for the maximally allowed input strength. An interesting result is that the combination of plasticity and scaling reduces lateral signal dispersion in feed-forward networks even without inhibition.
Second, we investigate recurrent network structures which are generally more difficult to handle and analytical results are hard to derive (here we mostly rely on numerics). However, we still provide analytical insights which lead to two observation: First, recurrences increase activity compared to feed-forward structures and, therefore, extend the input trace (cell assembly) within the network. Second, if we connect neurons so that they form a recurrent ring, the stability of rings of different size in a network is determined by the stability of the ring with the smallest number of neurons. All these aspects are consolidated by numerics.
To help navigating through this diversity, we provide at the end of most subsections a short paragraph that summarizes the results from this subsection. As part of the Discussion section we, finally, summarize all main findings (also in Table 1) and based on the main findings of this study give an example of a topology which results in localized cell assemblies (Figure 8).
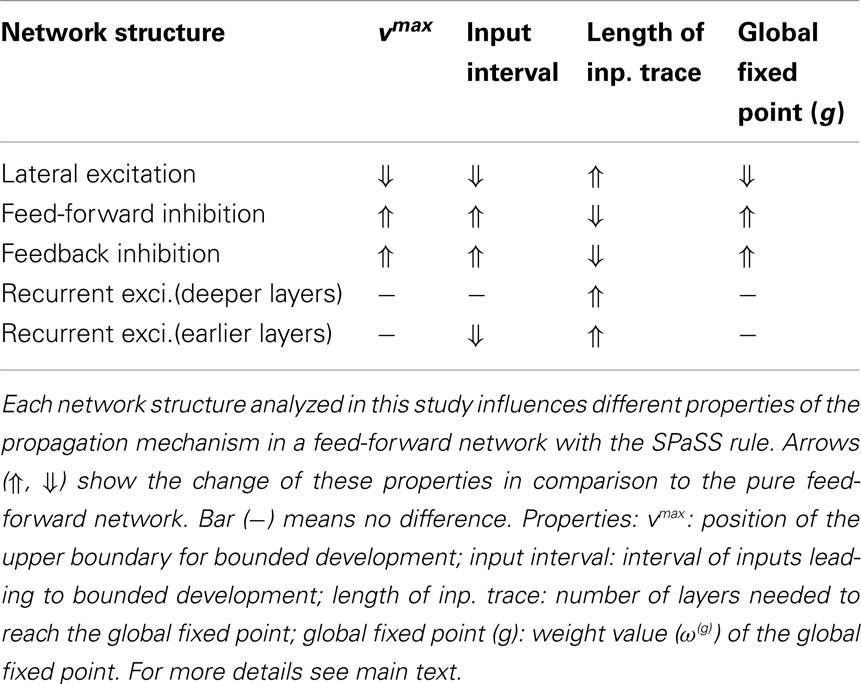
Table 1. Tabular summary of the influence of different network structures compared to a pure feed-forward network.
2. Materials and Methods
2.1. General Fixed Point Analysis
The differential equations of weights and activities for different network topologies are derived in the main text and analyzed according to their fixed point structure. This analysis is based on standard methods for a given set of differential equations determining the dynamics of ω and its fixed points ω*, where To assess the stability of these fixed points, we analytically computed the Jacobian Jγ(ω) of γ; a fixed point ω* is stable if all eigenvalues at ω = ω* are smaller than zero, and unstable otherwise. Numerics are done by solving the differential equations with the Euler method.
2.2. Feed-Forward Network
The feed-forward network (see Figure 2A) consists of M layers each with Nk neurons. Each neuron n ∈ {1, …, N} of each layer k ∈ {0, …, M − 1} has an all-to-all connection to all neurons of the target-layer k + 1 and no connection to neurons within its layer k if not stated differently. Therefore, neuron n = i(m) of layer m receives its inputs from all neurons j(m−1) of layer m − 1 with their activities via synapses of strength Thus, the output activity of neuron i(m) is the function It will be transmitted to all neurons of layer m + 1. For simplicity, in this study the function F is chosen to be the identity which does not influence the results qualitatively (Tetzlaff et al., 2011).
3. Results
3.1. Feed-Forward Networks
3.1.1. Weights and activities in feed-forward networks
The simplified structure in Figure 2A depicts how an input signal to a random network is traveling along topological stages (layers) within this network and how the network “reacts” to the input by adapting weights and activities. For this we simulate the behavior of such a feed-forward network with one neuron per stage (c.f. Figures 1A and 3) given a noisy input to layer one (activity of red neuron). As shown before (Figure 1), this activity leads to a strong post-synaptic synapse resulting in high (but not as high as red) activity at layer 1 (green neuron). This behavior is propagated until the activity vanishes in layer 4 (gray). This is the basic property of the above described input trace (cell assembly). Even if the input is reduced for a certain duration the network can re-adapt to its previous stable state very fast (c.f. Figure 3). Thus, even with a noisy external input, the network can construct a stable cell assembly along several stages.
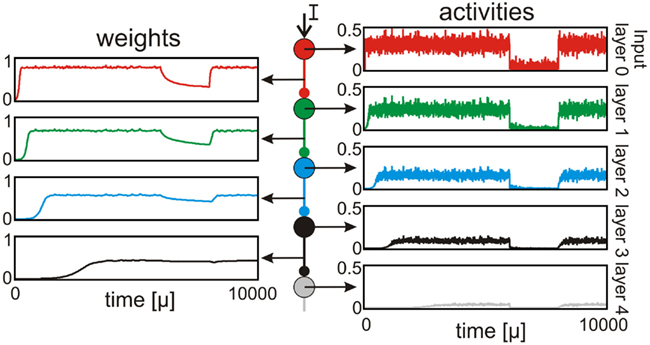
Figure 3. A noisy external input leads to propagation of activity along several stages. The first neuron (red) receives a time varying (noisy) input which leads to a strong post-synaptic synapse. Thus, the activity is transmitted to the next stage (green) resulting in high (but smaller than the input) activity and weight. This transmission occurs along several stages until the activity vanishes (gray). Even a short decrease of the input can be compensated quite fast.
In the following we analyze analytically the fixed points of weights and activities for each stage dependent on feed-forward connections and the input. We consider an input of average strength ℑ given to a neuron j(0) = a of the first layer k = 0 (pink neuron in Figure 2A), which leads then to the input activity of the first layer (the other neurons in layer k = 0 have ). Next, we calculate the weights and activities of a neuron i(1) of the next layer k = 1 assuming that the dynamics have stabilized:
Given this result, equation (1) and the dynamics for weights in the second layer write
This equation still has only one fixed point in the excitatory regime (i.e., ω > 0):
Substituting this solution into equation (4) gives
We write as this solution applies for all i(1)∈{1, …, N1} of layer k = 1 because neuron j(0) = a is connected to all neurons of layer k = 1.
All neurons of layer k = 1 have the same activity and since we use an all-to-all connectivity between each layer, neurons within each subsequent layer k ≥ 1 will have equal activity, too. Hence, the (equal) activity of each neuron in layer k = m and also the (equal) strength of each weight projecting to layer k = m merely depends on the (equal) activity of each neuron in layer k = m − 1 and the number of neurons N(m−1) in this layer:
In the next subsection we will analyze and discuss the dynamics of these equations for different parameters given the same number of neurons in each layer (N = Nk, ∀k∈{0, …, M − 1}).
3.1.2. Development of weights and activities along layers
Equations (8) and (9) describe the dynamics of weights and activities in a feed-forward network that is stimulated by just one input. When we look at the propagation of the activity (after stabilization of the weights) for different parameter values, we will find two qualitatively different scenarios: Activities will increase (divergent regime) or decrease (bounded regime) from layer to layer. As divergence should be avoided and bounded development enforced, the following relation has to be fulfilled for all neurons We now calculate lower and upper bounds for the activity and the weights so that we stay in the bounded regime.
The first inequality applies for negative firing rates. Thus, we ignore this result in the following. The second inequality defines an upper and lower bound on the activity or rather on the input ℑ:
The two constraints equations (10) and (11), and the nullcline for the weights (equation A1 in Appendix) define the weight-activity phase space (cf. Figures 4A–C) as well as the development of the fixed points of activity and weight along layers or rather stages m (cf. Figures 4D–E) in a feed-forward network. The trajectory depends on the terminal firing rate vT and the number of neurons N (c.f. Figure 4).
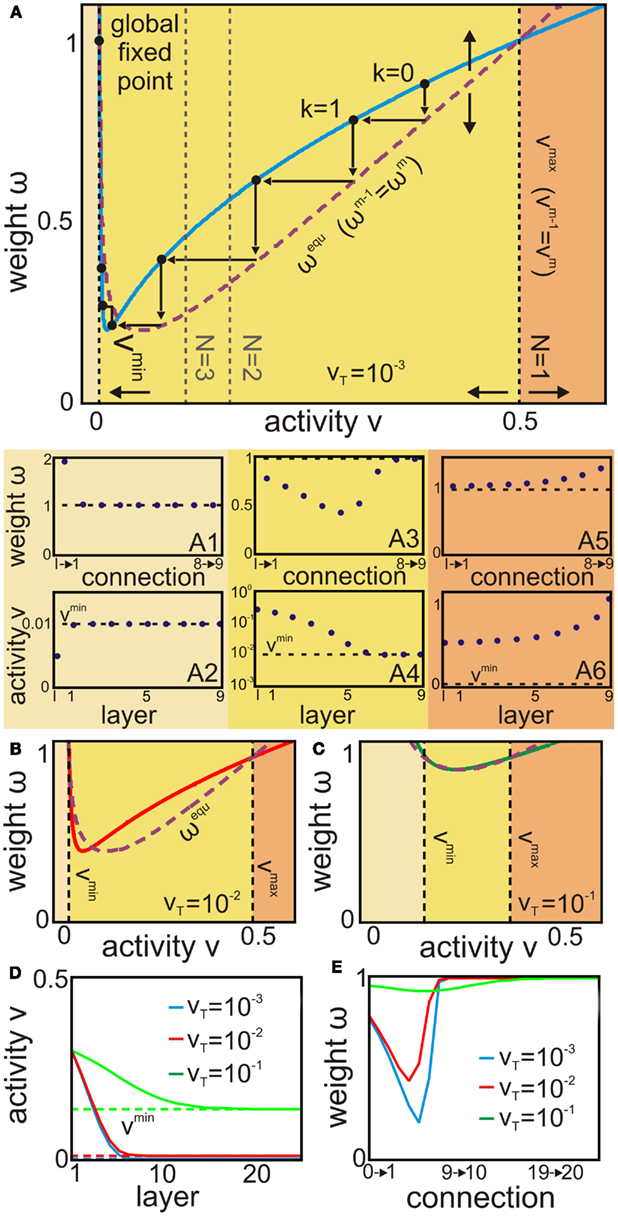
Figure 4. The phase space of a feed-forward network and how the representation of a given input depends on the parameter vT. (A–C) The constraints vmin, vmax (vertical black dashed lines), and ωequ (purple dashed line) define the direction of change of weight and activity (arrows) from layer to layer on the fixed point curve (colored continuous line). (A1–A6) The sub-panels show the fixed point values of the weights (top) and activities (bottom) of the layers at different regimes (colored according to the phase space). (D,E) Resulting from these curves the number of layers m needed to reach the global fixed point (thus, representing an input) varies for different vT. Dashed lines are the respective vmin lines. For more details see main text. Parameters: k = 2, N = 1; (A) vT = 10−3; (B) vT = 10−2; (C) vT = 10−1(D–E) ℑ = 0.3.
The phase space consists of two qualitatively different curves. The first class of curves represents the fixed points of each layer (equation 8). These fixed points do not depend on layer number k directly but on the input to this layer which is the output of the preceding layer In Figures 4A–C these fixed points are represented by the solid line. The second class of curves deals with the layer to layer fixed points of our system, i.e., with the previously calculated two constraints equations (10) and (11) and, additionally, equation (A1) for the weights. These constraints define the limits of a region within which activity stays bounded from layer to layer. In Figures 4A–C these curves are dashed lines (vertical black lines are vmin and vmax; the purple line is the nullcline ωequ for ωm = ωm−1). The constraints vmin and vmax divide the phase space into three qualitatively different regimes: if the activity of only a single layer is smaller than vmin, the activity of the next layer “jumps” to vmin and stays there for the descendant layers. If the activity is larger than vmax, activities increases from layer to layer; only if the activity stays between vmin and vmax, activities decrease from layer to layer and stay bounded (c.f. arrows in Figure 4A). Only vmax is significantly influenced by N leading to a smaller stable range as more neurons excite one neuron in the next stage.
Now we can understand how fixed points develop from layer to layer and, thus, how large a cell assembly, given input strength ℑ, gets.
First, we apply an input from the bounded regime that causes activities and weights of the first layer to converge to their fixed points which lie on the blue line (e.g., k = 0 in Figure 4A). The resulting activity v(0)* is then transmitted to the next layer and causes in turn weights of the next layer to converge. Intuitively, this is visualized by a line going downward until it reaches the weight nullcline ωequ. From here, weights together with the activity of the previous layer once again cause the activity of the next layer (k = 1) to converge, too. This is visualized by a line going leftwards to the blue fixed point curve.
This process repeats from layer to layer until the global fixed point at (v(g) = vmin, ω(g) = 1) is reached for layer k = g. Activities and weights will not change for subsequent layers k > g. In other words, the external input cannot influence layers k > g.
Thus, in a pure feed-forward network any kind of information storage can only exists for the first k layers since the system reaches its global fixed point for layers beyond k independent of the initial input (as long as the input is in the bounded regime).
3.1.3. Influence of parameters
To assess the capacity of information storage (size of input trace), we need to determine the influence of network parameters on g. It turns out that most influence on g is caused by vT. Figures 4D,E demonstrate activity and weight development for three different values of vT. Note that although the development moves along discrete layers, we plot continuous lines.
Next, we estimate the “number of jumps” from the distance between weight nullcline wequ and the blue fixed point curve (c.f. arrows between blue and purple line in Figure 4A). A smaller distance (compare Figures 4B,C) leads to smaller “jumps” from layer to layer which in turn leads to more layers toward the global fixed point. However, at the same time the difference between vmin and vmax decreases which leads to a reduced total distance between the input value and vmin.
In Figures 4A1–A6 we also show numerical results of activity and weight development when the input is chosen to be in one of each of the three different regimes; this confirms our analytical observations. For inputs greater than vmax the network diverges (Figures 4A5 and A6). For inputs less than vmin the network converges quickly to its global fixed point (v = vmin, ω = 1; Figures 4A1 and A2). Only for inputs between vmin and vmax (Figures 4A3 and A4) we notice distinctively different fixed points along several layers until at around layer eight the global fixed point is eventually reached. Thus, such a feed-forward network with inputs between vmin and vmax stores different values for activities and weights, here up to layer 7. The numerical results of A3 and A4 are qualitatively very similar to the analytical curves in Figures 4D,E.
We now define the theoretical limits of this system. On the one hand we see from Figure 4D that in order to maximize g the distance between vmax (equation 10) and vmin (equation 11) should be small and vT should then be ξ = (4κN2)−1:
Given an input between vmin and vmax, the system would need m → ∞ to reach vmin. However, with vT → (4κN2)−1 the interval (vmin, vmax) from which inputs can be chosen becomes smaller – eventually zero – and the network is specialized to “store” only a few (or one) distinct inputs. Additionally, the difference between input representation (minimum fixed point weight ωmin) and global fixed point (ω(g) = 1) also becomes smaller (green curve in Figures 4D,E). So a noisy read-out of the stored inputs is complicated as an input difference could easily fall inside the noise level. On the other hand, to get a stable read-out and at the same time to “store” a large range of different inputs, the difference between vmin and vmax should be maximized. From equations (10) and (11) we find that vT should be as negative as possible, however, in a pure feed-forward network vT < 0 would lead to a negative firing rate for v(g) = vmin < 0 which is mathematically possible but biologically implausible. Thus, vT should minimally go to zero:
To sum up, there is a trade-off, which depends on vT, between the number of layers representing an input and the stability of this representation against noise. On the one hand, a high vT ensures an extended representation over many layers, but, on the other hand, this representation is now quite susceptible to noise during the read-out process as fixed points are close to each other, and vice versa for a small vT.
3.1.4. Signal dispersion in a feed-forward network with local connectivity
Signals and therefore information in feed-forward networks are transmitted from layer to layer. If we demand that there is still information of our initial signal even after many layers, the network has to maintain the spatio-temporal integrity of inputs. Ideally, inputs should not disperse randomly both in space and in time.
We therefore test the capability of a feed-forward network (Figure 2C) for signal representation and transportation. The synapses of the network are modified by the SPaSS rule. Constant weights represent the control (to mimic, for instance, weight hard-bounds). In the first of our two scenarios we present a spatially restricted signal (transport signal) to the first layer and then measure the dispersion along layers (Figures 5A,B). In the second scenario we inject as an input two adjacent signals with a small spatial gap between them (resolution signal; Figures 5C,D). With both scenarios we are able to analyze the network’s capability to differentiate its inputs after a certain number of layers. Different from the previously analyzed network the feed-forward network is constructed as follows: each neuron projects and in turn receives synapses to and from a neuron at the same position and its two neighbors in the next and the former layer.
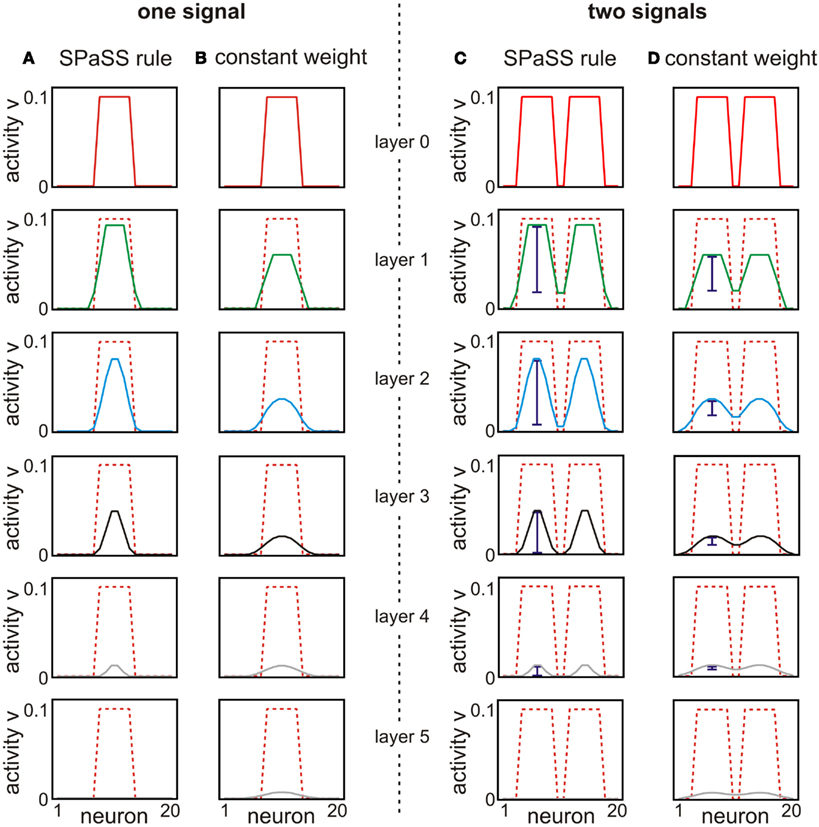
Figure 5. Signals travel along layers in a pure feed-forward network depending on the used plasticity mechanisms. (A,B) Spatial smearing of a signal is analyzed by presenting one spatially restricted input to a small group of neurons in the feed-forward network. Constant weights ωc lead to smearing (compare activity profile of given layer in red with the footprint of the original signal shown by the dashed lines). The SPaSS rule produces much less smearing and the signal propagates along layers mostly remaining inside the originally stimulated region until it vanishes. (C,D) This focusing effect of the SPaSS rule increases the resolution to distinguish two spatially distant signals in higher (e.g., blue bars of layer 1) and deeper layers (e.g., layer 3). Parameters: ωc = 0.2, κ = 2, vT = 10−2, ℑ = 0.1, ℑbackground = 10−4, N = 20, M = 10 the first six layers are shown.
If the weights are set to a constant value ωc, the input smears out with every subsequent layer. This is best visible in Figure 5B when comparing the activity profile of each layer with the dashed lines of the original signal. Additionally, the amplitude of the signal gets reduced with every subsequent layer. Although smearing is reduced by using smaller constant weights ωc, this also leads to a stronger reduction of amplitude. The SPaSS rule, on the other hand, can reduce (after weight stabilization) both smearing and amplitude reduction (cf. Figure 5A) at the same time. It is interesting to note that only in the first layer the activity of the border neurons is significantly increased. In all subsequent layers, the signal amplitude of these border neurons does not increase but merely follows the general reduction of signal amplitude.
In the second scenario smearing reduces the gap between the two initially separate signals from layer to layer (Figure 5D). For constant weights ωc the signals are difficult to distinguish after the third layer (Figure 5D). For plastic synapses the resolution decreases, too, but both signals are still distinguishable until the signal vanishes at layer five (Figure 5C). This effect has its origin in the scaling mechanism which tries to balance incoming signals. This leads to a suppression of later signals while at the same time the strong forward pathways are being maintained.
In summary, the SPaSS rule avoids a spreading or rather smearing of spatially restricted signals in deep layers of feed-forward networks. Therefore, the rule ensures that spatially distinct signals presented to a network are still distinguishable after passing several neuronal layers.
3.1.5. Feed-forward networks with excitatory and inhibitory connections
In this section we consider step by step our feed-forward network with -i- lateral excitatory connections within layers (top row in Figure 6), -ii- feed-forward inhibition (middle row in Figure 6), and -iii- feedback (self-)inhibition (bottom row in Figure 6) while all intra-layer connections stay constant. Under these constraints, analytical results can still be obtained and we state only the main equations here. All calculations – similar to those shown above – are provided in the Appendix. In principle we could also do analytics for mixtures of the structures presented in Figure 6 but calculations get lengthy and opaque then, and the same is true for plastic intra-layer connections.
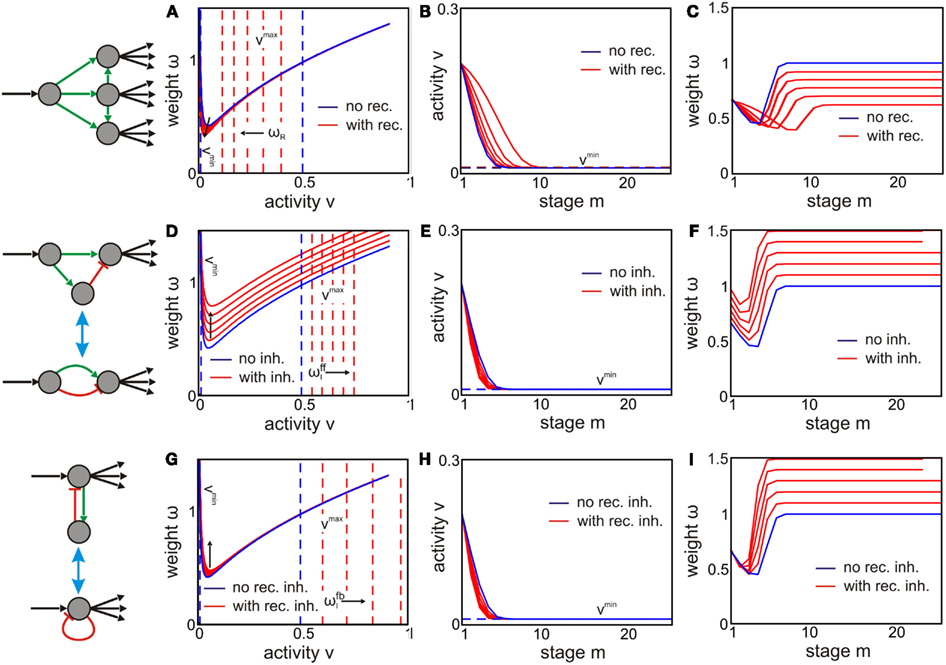
Figure 6. Inhibition and recurrent connections influence fixed points of activity and weights from layer to layer. The (A,D,G) show the phase space of the modified feed-forward networks (blue lines show the control from Figure 4A). Different structures results in different activity (B,E,H) and weight (C,F,I) development over stages m. (A–C) In the feed-forward network there are constant excitatory recurrent connections of weight ωR within each layer. These recurrences shift the constraints vmin and vmax of the fixed points and narrow the regime of possible inputs. However, the length of a trace and its difference are larger for stronger recurrences (RωR). (D–F) Fixed points with feed-forward inhibition (G–I). As (A–C), however, with inhibitory recurrent connections. Inhibition (feed-forward and feedback) enlarges the regime of inputs resulting in stable development over layers. However, length and difference of the traces are shortened. Parameters: κ = 2, vT = 10−2, N = 1, and RωR/I = 0, 0.1, …, 0.5. For (B,C,E,F,H,I) ℑ = 0.2.
3.1.5.1 Lateral excitation. First we introduce lateral excitatory connections with weights ωR (top row in Figure 6). We consider a system in which each neuron i(m) of layer m still receives input from all neurons j(m−1) of the previous layer m − 1 and, additionally, inputs from R neurons within its own layer m. As all neurons in a layer receive the same input, the activity is the same for all these neurons:
If we compare fixed point solutions (equations A2 and A3 in Appendix) and constraints (equations A4–A6 in Appendix) with those of the pure feed-forward network without lateral excitatory connections (equations 8–11; equation A1 in Appendix), we find that only the number of input neurons N is rescaled by the number of lateral excitatory connections R so that we can replace
A larger number of lateral excitatory connections R and/or stronger weights ωR increase the effective number NLat of input neurons per layer to neuron i(m). Such an increase leads to a strong decrease in vmax while the change in vmin remains negligible (dashed lines in Figure 6A). Thus, for a stable trace the inputs are now restricted to a smaller region. The positions of fixed points within a layer (continuous red lines), however, do not change much compared to the pure feed-forward network (blue line). This finding lets us expect that global convergence is reached earlier. However, this does not apply (see Figures 6B,C) as layer to layer fixed points for ω shift (not shown), too, leading to almost the same activity value. Only the weight value of the global fixed point ωglobal is reduced. This depends on the strength of the lateral excitatory connections (ωglobal ≈ 1 − RωR; see Figure 6C, constant parts of the curves). However, more layers are needed to reach this global fixed point (Figure 6B).
Thus, with respect to signal dispersion, lateral excitation in feed-forward networks leads to a reduced decay of activity from layer to layer compared to a pure feed-forward structure (Figure 5) without effecting the smearing effect much. Thus, as smearing remains limited, distinct signals are transported over more stages when lateral excitation is present.
3.1.5.2 Inhibition. Next, we introduce inhibitory lateral connections with weights ωI. As we define ωI as positive, we use a minus sign in all formulas. Inhibitory weights stay constant throughout this study and the derivative of ωI is set to zero (ωI = const.) because plasticity mechanisms for inhibitory synapses are still highly debated (Woodin et al., 2003; Haas et al., 2006; Caporale and Dan, 2008).
We investigate feed-forward and feedback inhibition; both types are equivalent to simpler structures (middle row in Figure 6, beneath the blue arrows) that are easier to analyze.
Feed-forward inhibition: Feed-forward inhibition (Figure 6, middle row) is an important structure in neuronal networks as, for instance, the ubiquitously present lateral inhibition can be approximated by multiple feed-forward structures.
Feed-forward inhibition (Figure 6 middle, above blue arrow) consists of three neurons of which one sends signals to the other two neurons. One of these two neurons in turn inhibits the second neuron. This neuron – receiving excitatory and inhibitory inputs – is defined to be the output. We simplify this structure to two neurons (Figure 6 middle, beneath blue arrow) which is identical to the original structure if the connection from the source neuron to the inhibitory neuron is set to the identity and neuronal transfer functions are, as before, linear. In the simplified structure the source neuron directly sends signals to the output neuron through a plastic excitatory synapse ωE and an inhibitory synapse with constant weight
The activity of the output neuron is then simply the difference between both weights multiplied with the activity of the source neuron u:
The results for fixed points and constraints (equations A8–A12 in Appendix) show that feed-forward inhibition increases the region of a stable input trace defined by the difference between vmax and vmin (Figure 6D). The length of the input trace (cell assembly), however, decreases (Figures 6E,F). If we compare this behavior with our pure feed-forward network, we find that feed-forward inhibition influences the dynamics similar to a change in vT toward smaller values (Figure 4). The global stable fixed point weight, however, increases with higher inhibitory weights ωI for feed-forward inhibition (Figure 6F, constant parts of the curves) but not when reducing vT; then it always stays at a value of 1 (Figure 4E).
In summary, feed-forward inhibition in a feed-forward network effects the fixed point structure in a similar way as a reduced vT in a pure feed-forward network.
Feedback inhibition: Conceptually different to feed-forward inhibition is feedback inhibition (Figure 6, bottom). Here, a neuron inhibits itself via a second neuron (Figure 6 bottom, above blue arrow). The second neuron receives excitatory input from – and in turn inhibits – the first neuron which receives inputs from preceding layers and sends signals to subsequent layers. We simplify this structure, similar to the feed-forward inhibitory structure, by setting the excitatory weight to one and, as we do anyhow by (again) using linear transfer functions for all neurons (Figure 6 bottom, beneath blue arrow). Thus, we have one neuron left which inhibits itself with constant weight only the weight ωE is plastic.
Therefore, the output activity v of the neuron is:
The equations for fixed points and constraints (equations A16–A18 in Appendix) determine the phase space of such a system (Figure 6G). The influence of feedback inhibition mainly shifts vmax to higher activity values – similar to feed-forward inhibition. This again enlarges the regime of inputs that results in a stable input trace. However, such a representation needs less layers (Figure 6H) than in a pure feed-forward network.
In summary, in a feed-forward network feedback inhibition has similar effects as feed-forward inhibition but already smaller inhibitory weights ωI yield the same results. Another difference is that the fixed point curve (equation A18 in Appendix) shifts less than for feed-forward inhibition and the dynamics of a network with feedback inhibition are more similar to the dynamics of a pure feed-forward network.
3.2. Recurrent network structures
Until now we looked only at feed-forward structures but recurrent structures are as important, for instance, to understand the dynamics of randomly connected networks. For the rest of this study we will focus on recurrent network structures. We start with presumably the simplest recurrent system: a self-connected neuron (Figure 2B) and then move on to slightly more complex ring-like structures (Figures 2C,D).
Two main results emerge from this investigation. First, the resulting activities v in different network structures after stabilization are ordered as follows: self − connected > bi − directional > three − ring > N − ring > feed − forward. Intuitively we need to consider that recurrent structures lead to a self-enhancement of activity but at the same time the number of neurons that are involved in such a recurrent ring decrease the activity if connections are on average below 1. As a consequence a second, more important observation arises: recurrent connections can be indeed stabilized by the SPaSS rule and if a recurrent structure with only a few number of neurons involved is stable, then all recurrent structures with more neurons involved will be stable, too.
3.2.1 Self-connected neurons
The simplest recurrent network is a single neuron with an input ℑ and a self-connecting synapse with weight ω (Figure 2B). The activity vt at time t of such a neuron is simply the sum of a constant external input ℑ and the weighted output of the neuron a time step before. (Instead of one time step a fixed delay term d could be used.)
To obtain stability both variables v and ω have to be constant over time, i.e., = 0 and vt = vt−1. This leads to the following dependency between activity and weight:
We insert this equation into the differential equation for weight development:
and the solutions of equation (19) are
with
These solutions have to be real (complex part equals zero) and the derivative of equation (19) at these solutions has to be smaller than zero in order to stabilize the dynamics, so parameters ℑ, κ, and vT have to be restricted. The calculations for assessing these parameters are complex and closed-forms can not be derived anymore. Therefore, the stability for a given set of parameters has to be assessed by numerical calculations of the roots. To reduce the number of parameters only the ratio of the rates (e.g., equations 8–22) κ = μ/γ is considered and we plot the maximally allowed input ℑmax that still leads to a stable weight. All smaller inputs (0 < ℑ < ℑmax) lead to a stable weight ω, too, and inputs above this value (ℑ > ℑmax) lead to divergent weight dynamics. Thus, we show the parameters which lead to stable dynamics in a κ-vT-plot with ℑmax color coded (Figure 7A). The self-connected neuron stabilizes best if γ is as large as μ (κ ≈ 1) but for the more realistic ratios of one order of magnitude difference (κ ≈ 10) stabilization is still possible for a wide regime. Furthermore, stability requires that vT is small or even negative. Here we stress that (1) negative vT does not imply negative neuronal firing rates as these systems balance plasticity and scaling ( see equation 3 and Tetzlaff et al., 2011) and (2) negative vT values can be avoided by simply adding inhibition to any of these recurrent networks (Figures 2B–D). As shown above, constant weight inhibition (Figures 6D–I) leads to a shift of the network properties toward larger allowed positive values. The general disk-like shape of the stability plot, however, does not change with inhibition added and we will thus continue to consider only excitatory recurrent networks (although vT might be negative).
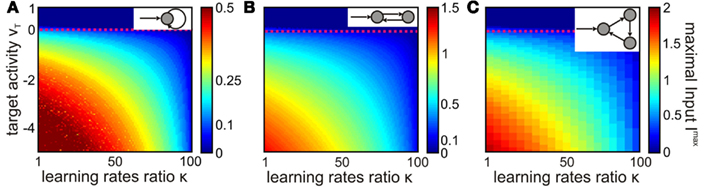
Figure 7. Different recurrent structures are stabilized by SPaSS rule. For different parameter values κ and vT the maximal input ℑmax leading to stable weights is calculated and shown in color code (note the different scale bars). (A) Self-connected neurons, (B) bi-directional structures, and (C) three-neuron rings are analyzed. If one structure is stabilized for a given parameter set (κ, vT) all other structures are stable, too. Only the maximal input decreases with more direct (less neurons) recurrences.
We have confirmed our numerical calculations with simulations up to four places after the decimal point for weight ω and activity v. (For example, for κ = 2, ℑ = 0.065, and vT = 0.01 the weight and the activity in the simulation as well as in the numerics is ω = 0.5674 and v = 0.1503 respectively).
We now compare the activity of a neuron with a self-connection vsc with the activity vff of a neuron in a feed-forward structure receiving the same input ℑ if equation (19) is simplified in the following way (see also Appendix): as ω is smaller than one, weight-dependent terms of order three (Θ(ω3)) and higher can be ignored. This leads to following neuronal activity:
which is larger than vff = ℑ.
In summary, self-connected structures in a neuronal network will raise the risk of instability. As this instability depends on the input (or rather the activity given to the self-connected neuron) this risk will decrease if a self-connected structure is in deeper layers (because activity has already declined there). However, as the resulting fixed point activity of self-connected neurons is larger than the activity of a neuron in a feed-forward structure, self-connections will extend input trace into deeper layers.
3.2.2 Simple recurrent ring networks: bi-directional and three-ring
In recurrent networks there are also other types of recurrent structures than simple self-connected neurons. Thus, in the following we derive the influence of larger recurrences on the stability and activity of neuronal networks. Equations (A19) and (A20) in Appendix show that also for the bi-directional connection the activity is increased compared to the feed-forward networks. This effect could be expected as already constant recurrences enhance network activity, but the SPaSS rule sustains the enhancement and still guarantees stable weights. Interestingly, this effect does not depend on the position of the bi-directional structure within the feed-forward network. The second neuron can be part of the feed-forward network but it can also be outside of the layered structure.
Additionally, we numerically calculated the stable regime for different parameter values and plot the results similar to the self-connected neuron. This analysis (Figure 7B) confirms the result that stability is independent of the chosen parameters vT and κ. However, we observe that the maximally allowed input ℑmax that still leads to convergence increases compared to the self-connected neuron (mind the changed color scale bars in Figures 7A,B).
For the three-neuron ring an enhancement of these observations is observed. Its equations (equation A23 in Appendix) again show that for the three-ring the activity is increased, but less, as compared to the feed-forward networks.
Furthermore, we find that the stability range for the three-ring (Figure 7C) looks similar to the one discussed above (Figures 7A,B) and the maximally allowed input ℑmax has further increased.
These considerations can be generalized in a straight-forward way for an N-ring, too (not shown).
To conclude, the results presented above confirm what we stated at the beginning of this section. First, if the smallest existing ring structure in a randomly wired recurrent network is stable, then every longer ring will be stable, too. Second, there is an ordering of the resulting activities (see Appendix):
(self − connected > bi − directional > N − ring > feed − forward). Furthermore (similar to the direct self-connection discussed above) if one neuron connects recurrently via a ring to itself, its fixed point activity is enlarged. Thus, given a feed-forward network, this fact ensures that also all following (down stream) layers will have an increased activity and, therefore, more layers are needed to reach the global fixed point. This effect is in general even stronger with the SPaSS rule than with constant weights (c.f. section 5) as the denominator of the activity depends on the input ℑ. Thus, the length of the input trace is increased with any excitatory recurrent structure.
4. Discussion
Hebb (1949) proposed that a group of interlinked neurons forms a “cell assembly.” In this study we show that the combination of synaptic scaling and hebbian plasticity can lead to such “cell assemblies.”
Synaptic scaling is a slow biological process which interacts with faster conventional synaptic plasticity (Abbott and Nelson, 2000; Turrigiano and Nelson, 2000). In a previous study (Tetzlaff et al., 2011) we showed that the (mathematical) combination of both processes leads to stable and reasonable weight growth. In the current study we have extended the analysis of this combined plasticity and scaling (SPaSS) rule to different types of feed-forward and recurrent networks. Our main goal was to try to understand why such networks are capable of forming an input trace in a stable way, with stably enhanced weights along several network stages as shown in Figure 2B. Thus, such networks are to some degree capable of learning and storing a “cell assembly” (Hebb, 1949) along the network layers.
Our main results are: (1) feed-forward networks indeed obtain a stable sequence of fixed points along several network stages, which can still be analytically calculated. This happens for a certain input range vmin < ℑ < vmax. If the network has many layers eventually a final stable fixed point is reached for all layers k > g, after which no more useful information processing takes place. Lateral connections and inhibition (feed-forward and feedback) can modify this range of information processing, hence, the extend of the input trace (see Table 1). For the lower layers one finds that networks with a SPaSS rule reduce signal dispersion as compared to networks with constant connections (see Figure 5). (2) As soon as one introduces recurrent connections, calculations become more difficult and most results have to rely on a numerical analysis. Here we find that small excitatory recurrent structures (self-connection, or small rings) are more “dangerous” than large rings as it is easier to get unstable dynamics from small as compared to large rings. Thus, if one stabilizes the smallest ring in a network, one will find that larger rings are stable, too. However, as the resulting activity from a ring is larger than in a feed-forward structure, recurrences enhance the length of an input trace and, thus, extend the influence of an external input into the deeper layers of the network. This way a larger cell assembly representing this input is formed.
Furthermore, we can take the results obtained in this study and conclude how big a cell assembly representing an external input would be and how to change its size by parameters and connectivity. For instance, a feed-forward network with one neuron per layer (also named transmission line) and recurrent (here constant) connections between layers (comparable to section 5 and 2) would lead to an input trace with stronger weights compared to a pure feed-forward network. If we introduce additionally long-range feed-forward inhibition the input trace can be “cut” after a few stages. Thus, short-range excitatory feedback together with long-range feed-forward inhibition lead to localized cell assemblies “around” the input neuron (compare black curve in Figure 8 with gray).
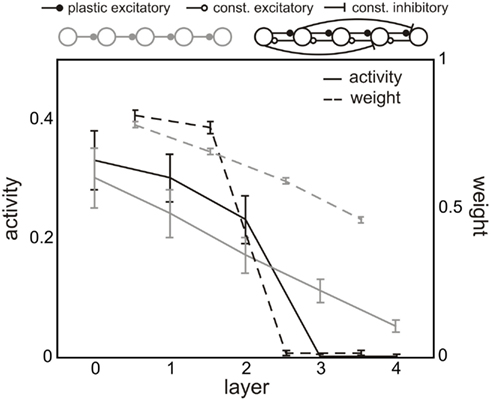
Figure 8. Connectivity shapes the size of input traces. In a pure feed-forward network (gray) an input leads to an input trace along several stages. The weights (dashed) and activities (solid) decrease from layer to layer (as already explained in section 2). On the one hand, by introducing recurrences the weights have significantly larger fixed points (see black line of the first layers), thus, the cell assembly is more stable against perturbation and more prominent in the network. Long-range inhibition, on the other hand, decreases activities and weights in a way that the cell assembly is “cut” from layer to the next (here, for instance, between 2 and 3). This an example of using the results of this study to define a connectivity which leads to strongly localized cell assemblies. Parameters: others see Figure 3.
Thus, the SPaSS rule naturally leads to spatially restricted formation of input representations. Such a representation might be indicative of a memory process, which is here reflected by the still very simple process of storing an input trace and this way forming a cell assembly. So far it has proven to be difficult to achieve stable representations of spatial-temporal patterns in time-continuous systems (c.f. Morrison et al., 2007 for STDP). In this study we analyzed mainly the spatial dispersion of such an input representation and how this dispersion is influenced by different connectivities. After stabilization removal of the input leads to slow forgetting, which however can be reversed quite fast by presenting the input again (see Figure 3). This process of forgetting and re-learning and, furthermore, the temporal aspect of the input representations has to be analyzed in future studies. However, the analysis here suggests that the combination of synaptic plasticity and synaptic scaling might be a good candidate to allow the formation of short term memories (Dudai, 2004) also in larger networks. The aspect of stable learning in attractor neural networks remains largely unresolved (Mongillo et al., 2008; Cutsuridis and Wennekers, 2009; Lansner, 2009) and we would hope that the results presented here will lead onward helping to solve this problem and leading to a better understanding of (short term) memory formation processes.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The research leading to these results has received funding from the European Community’s Seventh Framework Program FP7/2007-2013 (Specific Program Cooperation, Theme 3, Information and Communication Technologies) under grant agreement no. 270273, Xperience (Florentin Wörgötter), by the Federal Ministry of Education and Research (BMBF) by grants to the Bernstein Center for Computational Neuroscience (BCCN) – Göttingen, grant number 01GQ1005A, projects D1 and D2 (Florentin Wörgötter) and 01GQ1005B, project B3 (Marc Timme), by the Max Planck Research School for Physics of Biological and Complex Systems (Christian Tetzlaff).
References
Abbott, L. F., and Nelson, S. B. (2000). Synaptic plasticity: taming the beast. Nat. Neurosci. 3(Suppl.), 1178–1183.
Bi, G. Q., and Poo, M. M. (1998). Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type. J. Neurosci. 18, 10464–10472.
Bienenstock, E. L., Cooper, L. N., and Munro, P. W. (1982). Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. J. Neurosci. 2, 32–48.
Caporale, N., and Dan, Y. (2008). Spike timing-dependent plasticity: a hebbian learning rule. Annu. Rev. Neurosci. 31, 25–46.
Cutsuridis, V., and Wennekers, T. (2009). Hippocampus, microcircuits and associative memory. Neural Netw. 22, 1120–1128.
Dudai, Y. (2004). The neurobiology of consolidation, or, how stable is the engram? Annu. Rev. Psychol. 55, 51–86.
Gerstner, W., and Kistler, W. M. (2002). Mathematical formulations of Hebbian learning. Biol. Cybern. 87, 404–415.
Haas, J., Nowotny, T., and Abarbenel, H. D. I. (2006). Spike-timing-dependent plasticity of inhibitory synapses in the entorhinal cortex. J. Neurophysiol. 96, 3305–3313.
Hahnloser, R., Kozhevnikov, A., and Fee, M. (2002). An ultra-sparse code underlies the generation fo neural sequences in a songbird. Nature 419, 65–70.
Harris, K., Csiscvari, J., Hirase, H., Dragoi, G., and Buzsaki, G. (2003). Organization of cell assemblies in the hippocampus. Nature 424, 552–556.
Lansner, A. (2009). Associative memory models: from the cell-assembly theory to biophysically detailed cortex simulations. Trends Neurosci. 32, 178–186.
Miller, K. D., and MacKay, D. J. C. (1994). The role of constraints in Hebbian learning. Neural Comput. 6, 100–126.
Mongillo, G., Barak, O., and Tsodyks, M. (2008). Synaptic theory of working memory. Science 319, 1543–1546.
Morrison, A., Aertsen, A., and Diesmann, M. (2007). Spike-timing-dependent plasticity in balanced random networks. Neural Comput. 19, 1437–1467.
Oja, E. (1982). A simplified neuron model as a principal component analyzer. J. Math. Biol. 15, 267–273.
Tetzlaff, C., Kolodziejski, C., Timme, M., and Wörgötter, F. (2011). Synaptic scaling in combination with many generic plasticity mechanisms stabilizes circuit connectivity. Front Comput. Neurosci. 5:47. doi:10.3389/fncom.2011.00047
Turrigiano, G. G., Leslie, K. R., Desai, N. S., Rutherford, L. C., and Nelson, S. B. (1998). Activity-dependent scaling of quantal amplitude in neocortical neurons. Nature 391, 892–896.
Turrigiano, G. G., and Nelson, S. B. (2000). Hebb and homeostasis in neuronal plasticity. Curr. Opin. Neurobiol. 10, 258–364.
Turrigiano, G. G., and Nelson, S. B. (2004). Homeostatic plasticity in the developing nervous system. Nat. Rev. Neurosci. 5, 97–107.
Woodin, M., Ganguly, K., and Poo, M. M. (2003). Coincident pre- and postsynaptic activity modifies GABAergic synapses by postsynaptic changes in Cl− transporter activity. Neuron 39, 807–820.
Appendix
Nullcline of Weight Development Over Stages in Feed-Forward Networks:
which simplifies to the following nullcline for weights
Lateral Excitation in Feed-forward Networks
As defined in the main text, the activity of neuron i(m) is
leading to the stability assumption
Thus, the differential equation of the weight becomes:
The resulting positive stable weight is
with associated activity
However, to guarantee bounded development for activities of the network two constraints, comparable to the pure feed-forward network (equations 10 and 11), have to be maintained
Furthermore, the ω-nullcline is:
Feed-forward Inhibition in Feed-forward Network
Here, the activity of the output neuron is the difference between both weights multiplied with the activity of the source neuron u:
As mentioned in the main text, only the excitatory weight has a non-zero derivative
This equation has only a positive stable fixed point at
The term is approximately zero as ωI is defined to be smaller than ωE:
This leads to an output activity of
Also for this system there exists constraints defining if the output v is smaller than the input u:
Additionally, nullclines can be calculated for weights if the system consists of feed-forward inhibition motifs linked together in a feed-forward structure:
Feedback inhibition
The output activity v of the neuron is
and, thus, the dynamics of the excitatory weight is
The positive stable fixed point of this equation is
and the related output activity of this structure is
The constraints of this system for having a smaller output v than input u are
Additionally, for the weight the nullcline is
Calculations for Bi-directional and N-ring recurrences
A bi-directional system can be written as
For the stability conditions, v2 is inserted into v1 and v1 into v2 resulting in
This leads to the following weight equations
Although these equations can be solved, the solutions are complex expressions for ω1,2 and ω2,1 which are hard to interpret. However, the activity v1 of neuron 1 is larger than in a feed-forward network with the same input. On the other hand, given parameters μ = 0.01, γ = 0.005, ℑ = 0.065, and vT = 0.01 the activity v1 = 0.0746 > ℑ is still smaller than for the self-connected neuron (v = 0.1503). The activity of neuron 2 for these parameters is also larger than the activity of the second neuron in the feed-forward network (v2 = 0.0343 > 0.0290 = vk=1). This can also be shown by an approximation of thereby neglecting all terms of order and higher as they are small (ωi < 1) anyhow:
The only stable weight from this approximation that is positive is equal to the feed-forward weight ωff (equation 1) with input ℑ and N = 1 (equation 8). Thus, the activity v2 of neuron 2 is approximately
Furthermore, the activity of the first neuron receiving external input is approximately
Therefore, bi-directional connections increase the activity compared to feed-forward networks. As stated in the main text, this fact does not depend on the position of the bi-directional structure within the feed-forward network. The second neuron can be part of the feed-forward network, but it can also be outside of the layered structure.
For an N-ring with N neurons the stability conditions for the activities are
The weight ω2,1 can be again approximated by ωff if weight-dependencies of order three or even higher are neglected. Thus, the activity of neuron 1 is approximately
As all weights should be smaller than one, vnr is larger than the activity in feed-forward networks. This relation holds independent of the length (number of neurons N) of the ring structure.
Keywords: plasticity, synaptic scaling, neural network, homeostasis, synapse, signal propagation
Citation: Tetzlaff C, Kolodziejski C, Timme M and Wörgötter F (2012) Analysis of synaptic scaling in combination with Hebbian plasticity in several simple networks. Front. Comput. Neurosci. 6:36. doi: 10.3389/fncom.2012.00036
Received: 24 December 2011; Accepted: 25 May 2012;
Published online: 18 June 2012.
Edited by:
David Hansel, University of Paris, FranceReviewed by:
Harel Z. Shouval, University of Texas Medical School at Houston, USAMaurizio Mattia, Istituto Superiore di Sanità, Italy
Copyright: © 2012 Tetzlaff, Kolodziejski, Timme and Wörgötter. This is an open-access article distributed under the terms of the Creative Commons Attribution Non Commercial License, which permits non-commercial use, distribution, and reproduction in other forums, provided the original authors and source are credited.
*Correspondence: Christian Tetzlaff, Network Dynamics Group, Max Planck Institute for Dynamics and Self-Organization, Am Fassberg 17, 37077 Göttingen, Germany. e-mail:dGV0emxhZmZAcGh5c2lrMy5nd2RnLmRl