 Steve N'Guyen
Steve N'Guyen Charles Thurat
Charles Thurat Benoît Girard
Benoît Girard- 1Sorbonne Universités, UPMC Univ Paris 06, UMR 7222, ISIR, Paris, France
- 2CNRS, UMR 7222, ISIR, Paris, France
- 3LPPA, Collège de France, CNRS UMR 7152, Paris, France
The Basal Ganglia (BG) is a central structure involved in multiple cortical and subcortical loops. Some of these loops are believed to be responsible for saccade target selection. We study here how the very specific structural relationships of these saccadic loops can affect the ability of learning spatial and feature-based tasks. We propose a model of saccade generation with reinforcement learning capabilities based on our previous BG and superior colliculus models. It is structured around the interactions of two parallel cortico-basal loops and one tecto-basal loop. The two cortical loops separately deal with spatial and non-spatial information to select targets in a concurrent way. The subcortical loop is used to make the final target selection leading to the production of the saccade. These different loops may work in concert or disturb each other regarding reward maximization. Interactions between these loops and their learning capabilities are tested on different saccade tasks. The results show the ability of this model to correctly learn basic target selection based on different criteria (spatial or not). Moreover the model reproduces and explains training dependent express saccades toward targets based on a spatial criterion. Finally, the model predicts that in absence of prefrontal control, the spatial loop should dominate.
1. Introduction
The basal ganglia (BG) are a set of interconnected subcortical nuclei (Redgrave, 2007), which are thought to be central in the performance of action selection (Mink, 1996; Redgrave et al., 1999).
The BG are traditionally described as being composed of various parallel subcircuits with identical internal wiring, implied in different functions (from motor to cognitive ones), and belonging to a set of parallel cortico-baso-thalamo-cortical loops (Alexander et al., 1986), as schematized in Figure 1A. However, the BG also participate in purely subcortical loops (Groenewegen and Berendse, 1994; McHaffie et al., 2005, 2006; May, 2006), which are wired a bit differently as the input to the BG is relayed through the thalamus and the BG output projects directly to the considered subcortical structures (Figure 1B), and which rely on different thalamic nuclei (pulvinar, lateral posterior, rostral, and caudal intralaminar). They do, in particular, participate in loops with the superior colliculus (SC), well-known for its laminar structure, its mapping of the visual field and its involvement in gaze orientation movements, including saccadic eye movements (Moschovakis et al., 1996; Lynch and Tian, 2006).
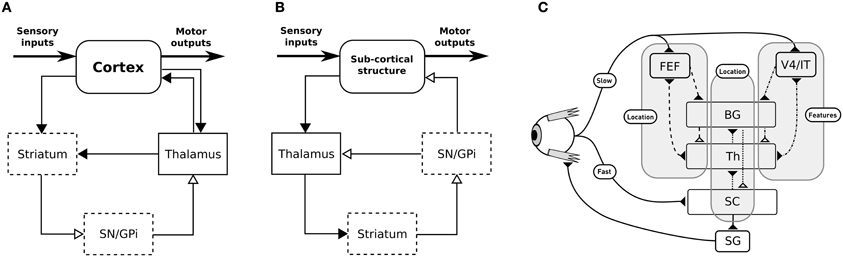
Figure 1. (A) General organization for cortical loops. (B) General organization for subcortical loops. Filled arrow heads are exitatory connexions, empty arrow heads are inhibitory connexions. Dashed block are inhibitory structures. Note that the concerned thalamus nuclei are differents between (A) (ventral anterior, ventrolateral, medial dorsal) and (B) (pulvinar, lateral posterior, rostral and caudal intralaminar). (A,B) Adapted from McHaffie et al. (2005). (C) Schematic representation of the relationships between the three modeled loops, note the type of information processed (either location or features of targets) and the delays (slow or fast).
We propose here a computational model of the interactions of subcortical and cortical BG loops in primates, processing either target position (spatial) information or target feature information, in the well investigated framework of saccadic eye movements (Hikosaka et al., 2000). Indeed, cortico-basal loops dealing with the location of potential targets in the visual field, on the one hand, or with the detection of features of potential targets, on the other hand, have long been identified. The SC (and thus the tecto-basal loop) is a bottleneck receiving all this information for the final decision, however it also receives target location information earlier than the cortically processed information, through direct projections from the retina.
We thus study the effects imposed by this hierarchical structure—where the highest level modules have longer latencies, while the lowest level module has a lower latency shortcut, but specific to location information, Figure 1C—on performance and saccadic reaction time in space-based and/or feature-based selection tasks, in order to identify predictions specific to this organization. These predictions stand for dorsolateral prefrontal cortex (dlPFC) deprived animals as it is not included in our model and as we can expect the inhibitory control from the dlPFC on the SC to allow additional control on unwanted short-latency saccades (Koval et al., 2011).
We show that the fact that a purely spatial selection and learning system operate at the last level predicts that:
• in spatial tasks only should the saccadic reaction times decrease with learning, allowing the generation of express saccades and causing short latency activations in the FEF,
• performance in feature-based tasks should be lower than in spatial tasks, because of the perturbations caused by the subcortical spatial loop,
• in conjunction tasks, where spatial and feature-based information determine the good choice, errors are unavoidable when no choice should be made.
2. Materials and Methods
2.1. Global Architecture
The subcortical loop (Figure 2, dotted circuit) has access to visual inputs directly conveyed from the retina to the superficial layers of the SC, with a low latency. These retinal projections provide relatively rich visual information (Girman and Lund, 2007), but no color information. As the SC layers are organized as piled retinotopic maps of the visual field, and given the spatial receptive fields of the BG output neurons projecting to the SC (Hikosaka and Wurtz, 1983), it can be assumed that the competition among targets is here based on spatial position. This loop is a good candidate neural substrate to explain the accumulating evidence [see for example McPeek and Keller (2002); McPeek et al. (2003); McPeek and Keller (2004), among many others since 2000] that the SC performs target selection on its own, rather than solely executing cortical decisions.
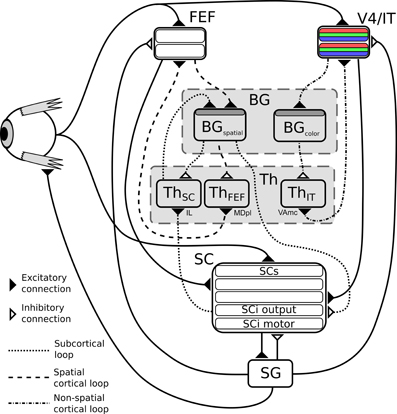
Figure 2. Structure of the model. BG, Basal ganglia; FEF, frontal eye fields; SG, saccade generators; SC, superior colliculus; Th, thalamus; V4|IT, Feature perception area including IT (TE region) interacting with V4 visual cortex area. Dark gray shaded layers on BG modules are input layers with reinforcement learning capabilities.
Two cortical loops, projecting to the SC as a common output, are considered. A first one (Figure 2, dashed circuit), comprising the frontal eye fields (FEF), also operates on the spatial domain, but contributes to saccade generation with longer latencies than the SC. This loop is known to be a common pathway for “cognitive” saccades, where working memory or sequence generation are involved, however these are not included in the proposed model (indeed no SEF and pre-SEF have been included). We hypothesize that the BG subcircuit involved in this loop is shared with the subcortical one (i.e., there is only one BG subcircuit dedicated to spatial selection of targets). This choice of converging input has been made based on known anatomy as it seems that FEF projects to the “Oculomotor Striatum” (central/longitudinal Caudate) (Stanton et al., 1988).
The second one (Figure 2, dash-dot circuit) comprises V4 and IT and deals with the selection of targets exhibiting specific features (only color will be used here for simplicity). V4 is known to be selective to shape and color (Ogawa and Komatsu, 2004) and visuotopically organized (Gattass et al., 1988). Moreover, this region exhibits strong recurrent connections with IT (in particular the TE area) (Ungerleider et al., 2008). The TE region of IT has been shown to be selective to features (and colors) and not visuotopically organized (activity doesn't depend on object position) (Tompa and Sáry, 2010). More importantly, this TE area forms a loop with the BG (Middleton and Strick, 1996), thus it seems somewhat reasonable to hypothesize that colors and features could be selected through a cortical IT-BG-Th loop in a non-spatial fashion and then projected back to V4. In particular, the TE region, projects to the “Visual Striatum” (tail of Caudate and caudal/ventral portion of Putamen) (Middleton and Strick, 1996), supporting the separation between the spatial and the feature loop. The SC is known to receive numerous projections from cortical areas amongst which V4 (Fries, 1984; Lock et al., 2003). This mechanism is compatible with feature/color sensitivity with a longer latency than luminance signal observed in intermediate layers of SC (SCi) (White et al., 2009; White and Munoz, 2011).
So to summarize, in this model two parallel mechanisms compete for target selection (Figure 1C). The first one is “location” based and comprises two cooperating loops, both cortical and subcortical. The second one is “feature” based and comprises one cortical loop. The detail of the equations are given below.
2.2. Model Description
The proposed model is intended to learn to generate saccades toward targets selected based on their color and location in the visual field (cf. Figure 2), depending on the reward contingencies experienced during interaction with the environment.
As said before, it is composed of three main loops going through the BG, which interact in both competitive and cooperative ways. The subcortical one corresponds to the SC-Th-BG circuit (dotted connexions on Figure 2), it gets its inputs from the direct projections from the retina to the superficial layers of the superior colliculus along with activity of deep layers, and it selects among targets competing on a purely spatial dimension. This loop passes through the Intralaminar nucleus (IL) thalamic relay (McHaffie et al., 2005).
The cortical ones also comprise a circuit dedicated to spatial competition (FEF-BG-Th, dashed connexions on Figure 2), which shares its BG circuit with the subcortical loop but with a different thalamic relay (the paralamellar portion of the mediodorsal thalamic nuclei, MDpl) (Alexander et al., 1986; Tian and Lynch, 1997) and another dedicated to features (namely color) selection (IT-BG-Th, dot-dashed connexions on Figure 2) via VAmc (Middleton and Strick, 1996).
Retinal information is transmitted to SC, FEF, and V4|IT with different latencies according to the literature, SCs input latency is fixed to 41 ms (type I neurons) (Rizzolatti and Buchtel, 1980). FEF to 91 ms and IT to 122 ms (average over all TE sub-regions) (Lamme and Roelfsema, 2000).
The FEF module contains an input and an output retinotopic map sensible to luminance. The V4|IT module contains one input and one output retinotopic maps for each color. SC module also contains several retinotopic maps, dealing with direct retinal input (SCs), FEF input, V4|IT input, summed activity of SCs, FEF and V4|IT (SCi output) and motor activity (SCi motor). For each of these structures a selection loop through BG occurs.
We use rate-coding models of neurons [based on locally projected dynamical systems, lPDS, (Girard et al., 2008)], which are defined as follows:
where I(t) represents the external inputs, τ the time constant, and Π[0, max] a projection operator ensuring that the neuron activity x(t) will remain within [0, max].
The projection operator Π[0, max] is simply an operator acting on ẋ ensuring that the variable x remains within a specified range of values. In our case (Euler integration with 1 ms timestep) we end up with a discrete update operating as follows :
This method is very similar to the classical way of converting the computed activity x into a non-negative one y = max(0.0, x) but here the non-linear “transfer function” is applied inside the differential equation at the cost of making it a non-longer a classical ordinary differential equation but with some over benefits such as “contraction” i.e., stability.
The BG model we use here (Girard et al., 2008) was formulated in this framework, so as to formally ensure its dynamical stability. For the sake of consistency, we thus use it for the rest of the model presented here. Only the external input part [I(t)] and the time constant (τ) of this equation have to be specified to define such a neuron model. Thus, to simplify the writing, only I(t) will be given in the next section providing a detailed description of the model, while the time constants and other model parameters are provided in supplemental data section.
The BG exert an inhibitory influence on their target circuits, which prevents them from generating actions. Even without any inputs, the BG converge to a given level of inhibition, GPi|SNrrest, sufficient to enforce this control. As previously proposed in Arai et al. (1994, 1999); Das et al. (1996), we modeled the effect of the basal ganglia inhibition as modulating the excitatory inputs of the targeted systems. To ensure that, at rest, no action can be generated, this inhibitory gain modulation is normalized with regards to the GPi|SNrrest constant. Thus, the contributions of the BG outputs to the circuits they target will take the general following form in the equations of the next section:
Where IE is the excitatory input controlled by the BG inhibition, GPi|SNr is the output of the BG neurons projecting to the considered circuit.
The feedback from the SC, which signals the end of the execution of a saccade, is also modeled as modulating.
Most of the components of the model are 70 × 70 2D maps of lPDS neurons for each hemifield, respecting the complex-logarithmic geometry of the macaque SC, as modeled by Ottes et al. (1986). Unless specified, neurons of one map project to those of another map in a one-to-one manner. Visual inputs are simulated as gaussian activities spreading over a hundred of neurons.
2.2.1. Cortical and subcortical loops
Color information is processed by the cortical V4|IT-BG-Th loop. As stated previously, the V4 structure contains several retinotopic maps each encoding for a specific color (3 are used here, red, green, and blue). In order to deal with non-spatial color channels, activity in each map is summed, providing a reduced number of independent channel. These channels are amplified in an closed loop manner by the interaction of IT with BG and Th (Figure 3).
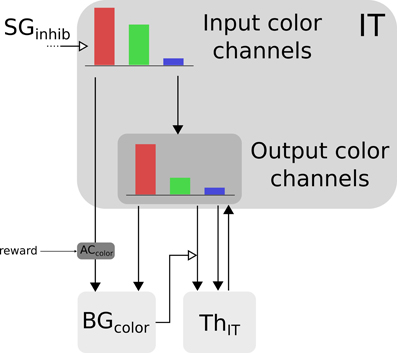
Figure 3. Selection loop for color channels. Black arrow heads are exitatory connexions, empty arrow heads are inhibitory connexions.
Thus, the BG selection occurring in the V4|IT-BG-Th loop deals with non-spatial color information only. Then these channels are transformed back into retinotopic maps (cf. Figure 4) and the resulting map (V4 output map) is then projected to SCi. Activity fed to the channels is computed as follows:
with c ∈ [red, green, blue], ITinc the visual input channel for color c, IToutc the activity of the IT layer connected with ThIT and SGinhib the ascending inhibition from saccade generators. Thalamic activity depends on IToutc and on BG output nuclei GPi|SNrcolor. The BG output thus gates a part of the transmission between ITout and ThIT with a modulating inhibition. TRNIT is the activity of the globally inhibiting inputs from the thalamic reticular nucleus and ITh a constant tonic activity. ITinc is fed to the reinforcement learning module for the color (ACcolor). Details of the reinforcement learning are given below (Section 2.2.3). Then, the resulting channels along with IToutc are given as inputs to the BG. For full details about Th and BG model see Girard et al. (2008).
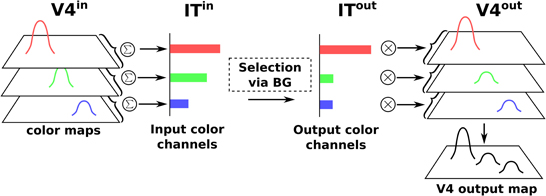
Figure 4. Spatial-color transformation.
Spatial information is processed by two cooperating loops. In the cortical FEF-BG-Th loop, FEF receives visual information in its input map with a long latency (91 ms). This map is then fed to the selection loop (cf. Figure 5) and the resulting activity is computed as follows:
with (i, j) ∈ [0, n]2, FEFin the visual input and FEFout the activity of the FEF layer connected with ThFEF.
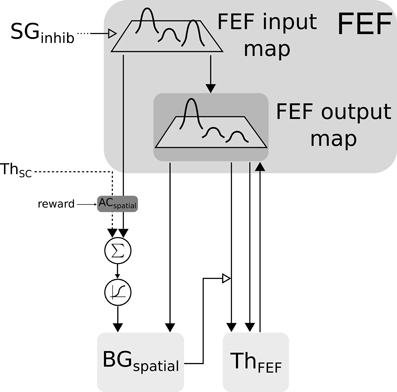
Figure 5. Closed loop selection-amplification of spatial FEF map. Black arrow heads are exitatory connexions, empty arrow heads are inhibitory connexions.
The two maps (ThSC and FEFin) are concatenated and fed to the reinforcement learning module. We decided to keep both maps concatenated in order to preserve the full learning capabilities and then to merge back the resulting weighted maps at the BGspatial input level before BG selection.
The merge is done by summing and passing these maps through a sigmoid , inducing a non-linearity and a minimal salience threshold. Similarly to the color loop, the resulting map along with FEFin are given as inputs to the BG.
In the SC-Th-BG loop, SCi receives inputs from V4|IT, FEF and retina (via SCs). These inputs are weighted summed and fed to the selection loop (cf. Figure 6). As stated previously the BGspatial module is the same than in the FEF-BG-Th loop. The resulting activity is computed as follow:
with (i, j) ∈ [0, n]2, SCs the visual input from the superficial layer of SC, GPi|SNr the inhibition from the output nucleus of BG projecting to SC.
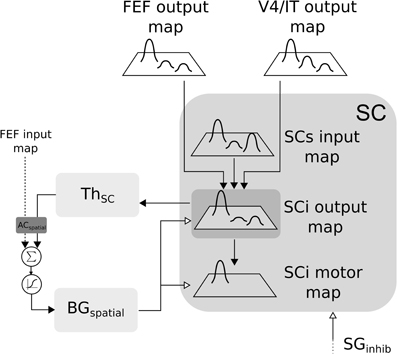
Figure 6. Closed loop selection-amplification of spatial SC map. Black arrow heads are exitatory connexions, empty arrow heads are inhibitory connexions.
2.2.2. Basal ganglia
The BG model used here was first described in Girard et al. (2008) and is depicted in Figure 7A for cortical loops. Notice that for the subcortical loop the connectivity is slightly different for the position of the Thalamus (cf. Figure 7B).
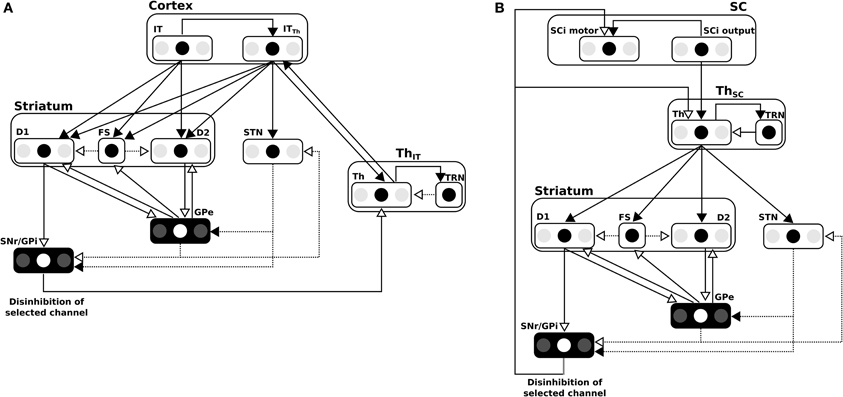
Figure 7. (A) Details of the BG model in the cortical loop (here, IT-BG-Th is shown but an identical structure is used for FEF-BG-Th). Only 3 channels are represented, the middle one being the most salient. SNr/GPi and GPe are color inverted as channels activity in these structures are opposed (middle channel which is the most activated in input, is the weakest in these structures). Thalamus structure (Th) is composed of a ventral anterior nucleus and of reticular nucleus (TRN) which constitute a population without segregated channels. Striatum is composed of D1 and D2 types of dopaminergic neurons and of a population of fast discharge inter-neurons (FS). Filled arrow heads are exitatory connexions and empty arrow heads are inhibitory. Filled lines represents one-to-one connexions and dotted lines represents one-to-all connexions. Adapted from Girard et al. (2008). (B) Details of the BG model in the subcortical loop (SC-Th-BG). Same model than in (A) except for the position of the Thalamus.
The parameters of the BG circuit involved in the spatial loop have been adapted so as to cope with the selection of 630 channels (see Supplemental Data).
The n × n inputs from the spatial maps (here with n = 70 for each hemifields) converge on the m × m inputs (here m = 18 for each hemifield) by the Gaussian Pyramids method. Input map size is reduced by first convolving it with a 5 × 5 gaussian kernel:
with In the input map, G the normalized gaussian kernel and (i, j) ∈ [0, n]2. Then it is 2 × 2 binned in order to divide dimensions by 2.
This operation is repeated 2 times in order to reduce the input map by a factor 16. The opposite operation is computed to upscale the output activity of BG in order to match the projection toward other structures. This dimensionality reduction is inspired by the anatomy of cortico-striatal connections (Zheng and Wilson, 2002).
As seen on Figure 4, the color BG circuit receives the sums of the activity of the color maps, and thus operates selection among three channels:
with WBGITc a normalization constant. The output of the same circuit thus affects the whole color maps in the following manner:
with the normalized activity of the input map for color c, = V4inci, j/max(V4inc) and IToutc the output activity for a whole channel c.
2.2.3. Actor critic
The input to the BG circuits is biased by reward using the classical “Actor-Critic” TD(λ) learning algorithm (Sutton, 1988; Montague et al., 1996; Sutton and Barto, 1998).
TD-error δ is computed according to
Rt being the reward at time t, Vt the estimated value function, WCritic the learned weights of the Critic, Inputt the input matrix (spatial or color) and γ the discount factor.
Critic's weights are then updated using eligibility traces ECritic:
η being the learning rate and λ the “forgetting” factor of eligibility traces. The size of the Critic's weights vector is N, the same as Input so here connexions are “all-to-one” type. Actions vector (weighted inputs) is computed as following:
and Actor's weights are computed as following:
Actor's weights matrix is of size N × N so here, connexion are “all-to-all” type.
Compared to classical reinforcement learning (cf. Figure 8, left) we can see that “States” are inputs to be selected and “Actions” are weighted inputs. Here, the BG compute a selection of these weighted inputs – thus playing the role of the “winner-takes-all” (cf. Figure 8, right) – and then disinhibit some structure (i.e., SC) which eventually will trigger a real action.
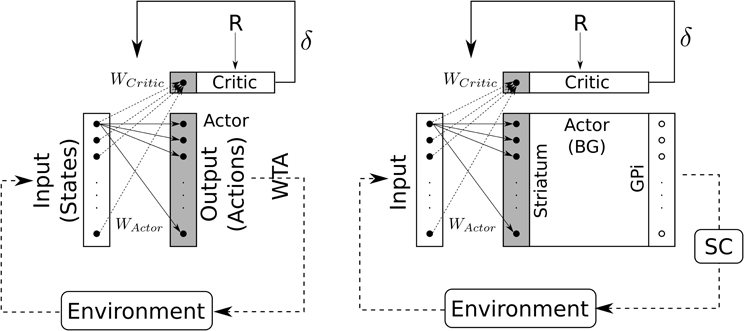
Figure 8. Schematic representation of the Actor-Critic reinforcement learning algorithm. Left: classical Actor-Critic, involving a winner-takes-all (WTA) selection mechanism. Right: Actor-Critic with BG as selection mechanism.
Actor's weights are initialized to an identity matrix in order to allow for an initial “standard” behavior (direct unweighted projection). A minimum value for Actor's weights diagonal has been implemented (WActormin = 0.6) in order to prevent the system to from losing the ability to trigger saccades. Critics weights are initialized to a random matrix with values ∈ [0, 0.01].
The exploration, which is important for RL convergence, is caused here by a perceptual noise only. This perceptual noise is implemented in the following manner: one input has an amplitude of 1 and the other of 0.95. This 5% difference is sufficient for the system to select the most “intense” input, before learning adds its own biases to the selection, and is randomly alternated between cues in order to ensure the absence of a systematic bias.
2.2.4. Spatio-temporal transformation
In order to compute the so-called “spatio-temporal transformation” (STT) required to convert a spatially coded target into a saccade burst generators (SBGs) temporal sequence, we used the model first described in Tabareau et al. (2007) (cf. Figure 9). This model includes a visual map (SCi output map described above) and a motor map (SC motor map) with a log-complex mapping along with colliculi gluing mechanism. The motor layer is projected to the saccade generators and both are controlled by a strong inhibition from omnipause neuron (OPN).
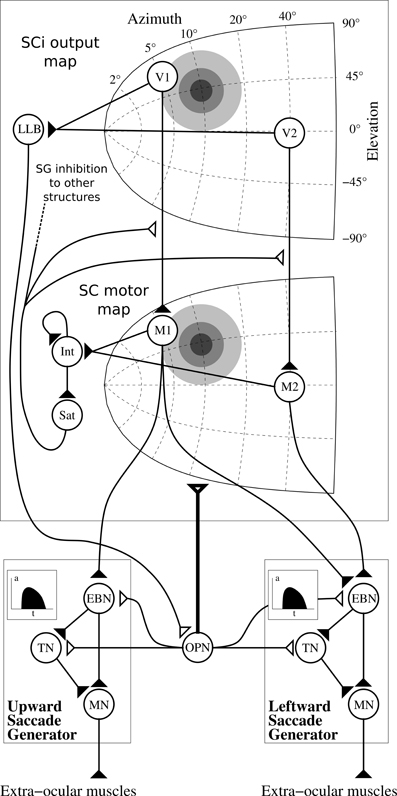
Figure 9. Architecture of the motor layer of SC. Only one colliculus (right hemifield) and two SBG are represented (without cross projections) along with two neurons by map (V1 and V2 in the SCi output map, M1 and M2 in the motor map). Gray discs represents gaussian activity produced by a visual target (coordinate (10°, 10°), thus R = 10°, θ = 45°), insets in the saccade generator represent the temporal coding in EBNs generated to control muscles. Filled triangles are for excitatory connexions, empty triangles are for inhibitory connexions. Bold connexion affect the whole map. Adapted from Tabareau et al. (2007).
We can notice than we slightly modified the “integrating-saturating” mechanism (Int and Sat in Figure 9). This mechanism no longer inhibits the whole motor map in a subtractive manner, but now modulates the visual map to motor map projection in a multiplicative manner:
with Imotor the input activity of motor layer, SCiout the activity of SCiout map described in section 2.2.1, OPN the output activity of the OPN and (i, j) ∈ [0, n]2.
This modification has the advantage of generating more realistic burst activities, more similar to the gamma functions used in van Opstal and Goossens (2008).
Notice that Sat is used as the ascending inhibitory signal SGinhib in other structures, which signals the execution of a saccade (Sommer and Wurtz, 2002).
2.2.5. Model parameterization
The parameters of the model were hand-tuned, these tuning operations were performed, as much as possible, by considering the various subsystems (BG models, generation of the motor command, convergence of the inputs on the SC, and reinforcement learning) in isolation and enforcing their correct operation.
The parameters of the spatial BG loop had to be modified compared to the initial parameterization of (Girard et al., 2008), as the number of competing channels is much higher. This drastically affects the effects of diffuse projections, like those of the STN on the GPe and GPi. When 630 channels are exciting the GPi, rather than 6, the strength of this excitation has to be reduced, so as to avoid saturating the GPi neurons, and so as to allow one-to-one inhibitions from the Striatum to be strong enough to conteract excitation and thus allow selection. These modifications were made as follows: the BG model was isolated from the rest of the system, and provided with 2D Gaussian inputs similar to those used in the tasks, with varied amplitudes. The parameters were adjusted until the selection of a single target with an amplitude between 0.6 and 1 was restored. Finer adjustment were then made so that one or two distractors of inferior amplitudes would not disturb the selection process, and that the simultaneous selection of multiple targets occurred only when they have very close amplitudes.
The parameters of the motor layers of the SC, and of the saccade generators, which operate the spatio-temporal transformation, were almost identical to those of (Tabareau et al., 2007), except slight modifications in the integration rate of the saturating mechanism, so as to adjust the duration of the motor bursts to more realistic values.
The parameters adjusting the strength of the contributions of all the different maps to the final SCi layer were adjusted so that: (1) imposing an input from the spatial system only, or from the color one only, would generate the corresponding saccade, and (2) simultaneously imposing a given target position in the spatial system and another one in the color system, would result in an averaging saccade.
Finally, the parameters driving the temporal integration of reward in the learning modules –namely the discount factors γ and the eligibility trace λ– had to be large enough, so that learning could occur despite the relatively long delay between the appearance of a target and the effective reward delivery (≈500 ms). The learning rates were adjusted so that the learning would converge to the best possible level of performance in approximately 20–25 sessions. The relative difference between ηspatial and ηcolor has to be considered in the light of: 1) the huge difference in the number of input weights to be adjusted in each system (1587600 in the spatial domain vs. 9 in the color one), and (2) the different extent of the input stimulations corresponding to one target (a 2D Gaussian input spreading over a hunded of channels in the spatial domain vs. one single channel in the color domain).
2.3. Simulated Tasks
We simulated 3 target selection tasks where the system has to trigger a saccade toward one of the two displayed cues (cf. Figure 10).
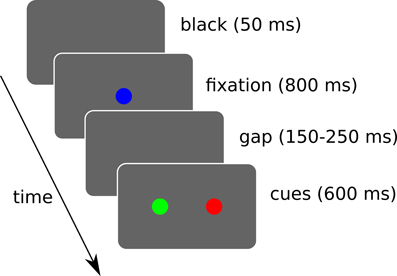
Figure 10. Simulated sequence of visual stimuli. A black screen of 50 ms is followed by a fixation cue for 800 ms. Then a random gap time (between 150 and 250 ms) is followed by the two cues. The cues are displayed for a maximum of 600 ms and loops back. During this interval, if a saccade of sufficient amplitude (>2.5° from the center) is detected, the trial ends and loops back. Rewards are given when the trial ends, which may be triggered by the timer or a saccade depending on the task.
A “spatial task” is aimed at verifying its ability to learn to choose a target based on spatial information only. A “color task” for color information only. And a “conjunction task” to study interactions between these two. 10 runs were done and each experimental run is composed of 40 sessions of 12 trials.
3. Results
3.1. Spatial Task
In the spatial task, the rewarded cue only depends on its position on the visual field. So the system has to learn to ignore the color information and to favor the spatial one.
We can see that the model is able to learn the task with a performance reaching ≈90–95% (Figure 11A), this means that it is possible to find a parameterization of the model allowing for a good level of performance after learning
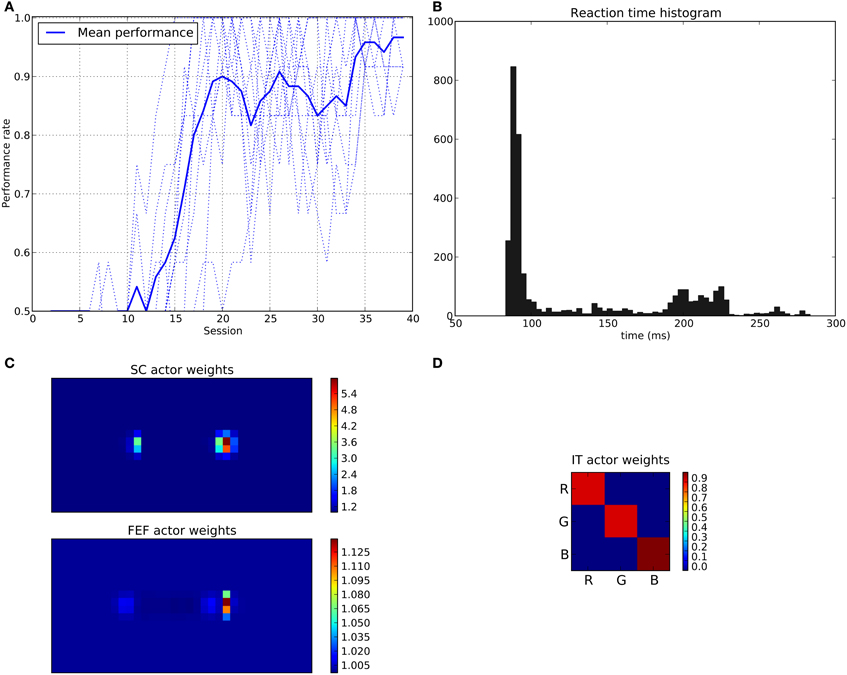
Figure 11. Results of the spatial task. The rewarded cue is the right one regardless its color. (A) Performance across sessions (bold line is the mean performance of the 10 runs represented with dotted lines). (B) Distribution of saccadic reaction time (SRT) for the whole experiment. (C) Learned weights (averaged over 10 runs) for the Actor part of the spatial loop; for readability reasons, the multidimensional weight matrix has been projected on the output: it represents, for each unit, the sum of the input weights coming from the whole map, for the SC (top) and the FEF (bottom), note also the different intensity scale between SC and FEF. (D) Learned weights (averaged over 10 runs) for Actor part of the color loop.
The distribution of SRT is bimodal, with a very sharp peak of low latency (≈88 ms) and a second bump centered around ≈200 ms (cf. Figure 11B). This behavior is very similar to that of “express saccades” for short latencies and “regular saccades” for longer ones described in Fischer and Weber (1993). Looking at details of the evolution of these SRT, it appears that for the first half of the experiment (first 20 sessions = first 240 trials) saccade latencies mainly fall within the 200 ms mode (cf. Figure 12). These saccades reflect the baseline timings of the system without any selection bias from learning.
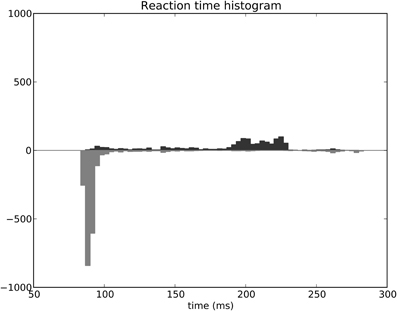
Figure 12. Spatial task reaction time histogram with separated first half of the experiment (top) and second half (bottom).
For the second half of the experiment (where performance is close to 90%), saccade latencies fall within the 88 ms mode.
Associated weights for the color loop (Figure 11D) indicates that the colors of targets (red or green) have not been learned: they have similar weights values of ≈0.8 in the diagonal.
In contrast, the weights of the spatial loop (Figure 11C) show a strong bias toward the right target (the rewarded one), especially in the weight map corresponding to the SC (≈5.5, while the FEF ones are around 1.1). These weights causes a strong activity on the spatial loop with a quick disinhibition from the SNr as soon as the direct retina-to-SC signal appears. Then, activity is transmitted to the motor layer even before visual information reaches the cortical visual areas and rapidly triggers a saccade. This kind of saccade thus differs from “standard” ones as they only rely on the direct retina-to-SC pathway. Indeed, before learning, the retina-to-SC input is not sufficient to trigger a saccade alone in our model and needs either FEF or V4|IT input, thus explaining the longer SRT.
If we look at the details of neural activity in normal and express saccades (Figure 13), what appears for the spatial task (after learning) is that direct retinal input induces activity in the spatial loop, which is quickly dis-inhibited by the BG (thanks to the strong weights) and activates the SCi motor map. Moreover, as the same BG module is shared between the subcortical and the cortical loops, this dis-inhibition also affects the cortical loop and thus induces activity in FEF before visual information reaches it. This induced activity depends in facts on the baseline level of the Thalamus and is a prediction of the model due to our choice of a single shared spatial BG module. The activity in the SC causes a disinhibition in the spatial BG circuit, which then disinhibits also the thalamo-FEF loop. As this loop is auto-excitatory and as the thalamus has a baseline activity, this trigger a resonance between Cortex and Thalamus. Thus the observed short latency activity in FEF is not caused directly by visual input but indirectly by subcortical visual activity.
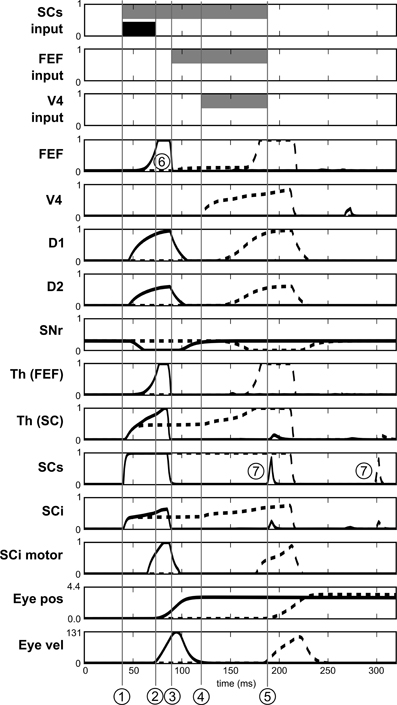
Figure 13. Activities of different neurons of the target channel in the spatial task. Target appears at t = 0. Dashed line: before leaning. Solid line: after learning. SCs input, FEF input and V4 input represent the presence of the visual cue in the receptive field before learning (gray) and after learning (black). 1: Visual activity reaching SCs. 2: Beginning of the express saccade (after learning). 3: Visual activity reaching FEF. 4: Visual activity reaching V4|IT. 5: Beginning of the saccade before learning. 6: Indirect short latency activity in FEF provoked by SC activity. 7: Small burst of post-saccadic visual activity provoked by the end of inhibition from SGinhib.
Yet, express saccades depend only on the SC loop and FEF only has a marginal impact on it. Nevertheless, simulations with a FEF inactivation (after learning) extends SRT of ≈15 ms, this FEF resonant activity thus contributes to the global behavior.
Notice that Figure 13 also exhibits some very short bursts of post-saccadic visual activity (better seen for SCs but the mechanism is the same for all the structures). These bursts are provoked by the residual retinal activity reaching each visual region due to the latencies, whereas eyes have already moved. This behavior is probably not significant as it may be canceled by a different choice of parameters for SGinhib for example.
3.2. Color Task
In the color task, the rewarded cue only depends on its color. So the system has to learn to ignore the spatial information and to favor the color one.
Here, the average performance only reaches about 75% (cf. Figure 14A), so the system can learn the task but errors are still made at a rather consistent rate. The performance is thus lower that in the spatial task, an effect which is most probably caused by the structure of the BG loops themselves, a point we discuss further in section 4.2.
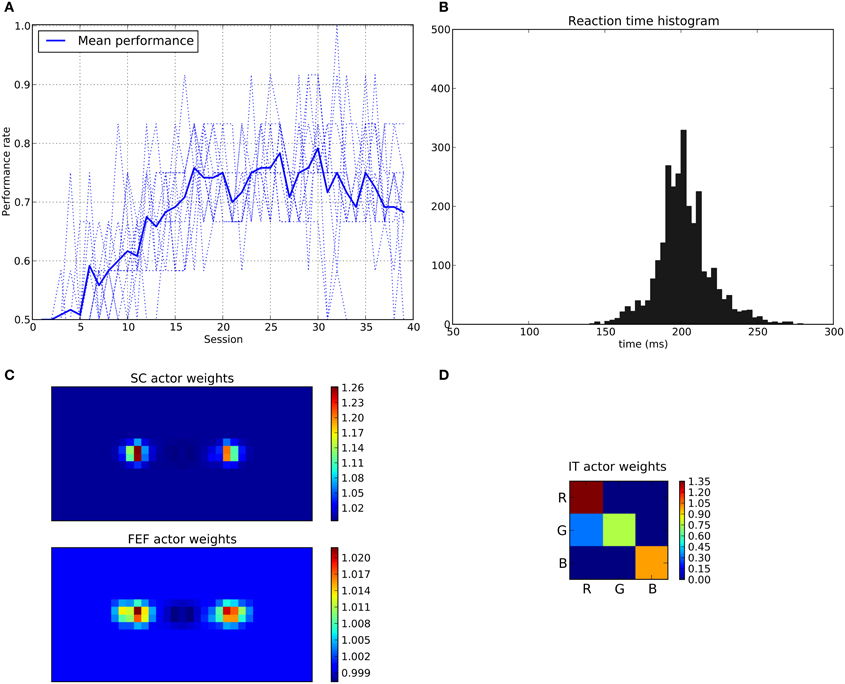
Figure 14. Results of the color task. The rewarded cue is the red one regardless its position. (A–D) Same as Figure 11.
Color learning is very sensitive to noise in the spatial domain. Indeed, most of the time (≈95%) these errors occur when the distractor (object with the wrong color) is the most intense (“intensity” is imposed to be 1.0 or 0.95 by the perceptual noise). It means that even with learned weights favoring the good color in average (cf. Figure 14D) and spatial ones almost symmetric (cf. Figure 14C, the intensity scale indicates very small variations), the color loop is sometimes unable to impose its choice when a competition occurs between the spatial and the color loop. This is explained by the fact that the subcortical circuit, which operates exclusively on spatial information, can take decisions faster than the color loop. It thus can impose a choice based on spatial information even before the cortical color loop converges to a decision.
The SRT for this task mainly consists on a single mode histogram centered around 200 ms, easily explained by the longer latency of the color loop (122 ms). No reduction of these latencies by learning were to be expected, as no faster pathway operating on colors is available.
3.3. Conjunction Task
In the conjunction task, the rewarded cue depends on both position and color (e.g., red disk at the right position). When this conjunction is not presented (No conjunction case), the system is rewarded only if the eye position stays within a 2.5° circle around the center (“Good average” behavior).
Here, the average performance for the conjunction case reaches levels similar to those of the spatial task (around 95%, Figure 15A) but for the “No conjunction case” the rewarded behavior (“Good average”) is rarely performed. We can see that the errors made in this case tend to be mostly “color errors” i.e., a saccade toward the good location but with the wrong color (around 90% of errors at the end of the experiment). “Spatial errors” occurred when a saccade is triggered toward the good color but at the wrong position. However, we can see that at the beginning of the learning and until half of the experiment, the system is still able to produce a small number of “good average” (≈15%). This behavior progressively disappears as the spatial loops learn and become faster, thanks to its subcortical component, making it more difficult for the color loop to select due to its longer latency.
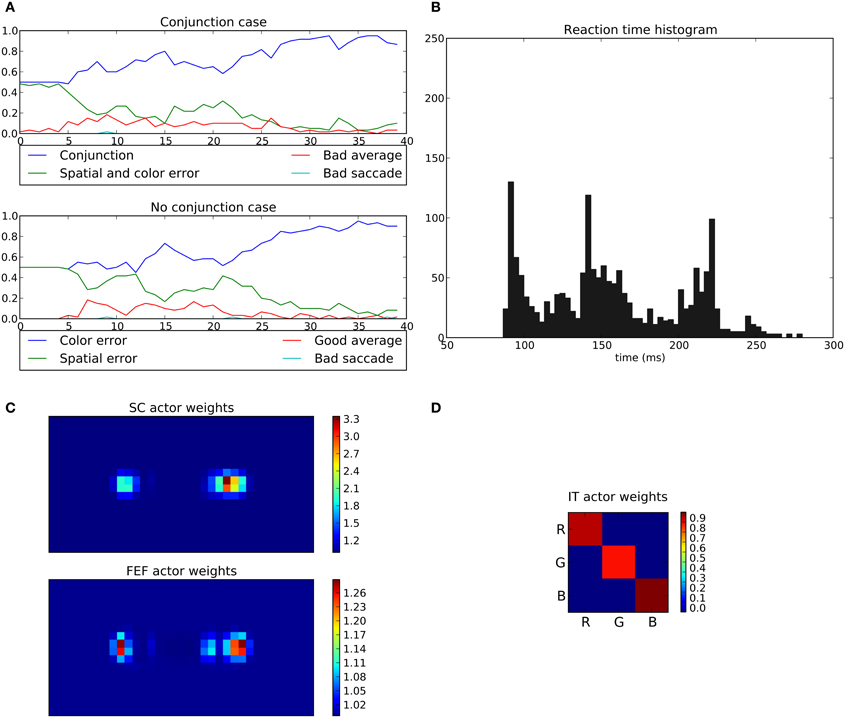
Figure 15. Results of the conjunction task. The rewarded cue is the right red one; if not present, reward is given for fixating the center area. (A) Average choices, in the conjonction (top) and no conjunction (bottom) case. In the conjunction case, “conjunction” represents the good choice, “spatial and color error” a movement toward the wrong cue, “bad average” an averaging saccade (both targets selected simultaneously) and “bad saccade” (saccades that fall neither within a 2.5 radius from the center or any cue). In the no conjunction case, “good average” is a rewarded saccade keeping the eyes on the fixation point, “spatial” and “color” errors respectively represent movements to the green target on the right and to the red target on the left, and “bad saccade” in any other position (generally between fixation and cue but outside the 2.5 radius). (B–D) Same as Figures 11, 14.
What appears at the end of the experiment is that the behavior of the system is mainly dominated by the spatial loop with almost no weighting from the color loop.
The learned weights correspond well to the task as the right position is favored compared to left one with (cf. Figure 15C) but the red color is only slightly favored compared to green (cf. Figure 15D).
The saccade reaction time is more complicated here. In fact we can see three modes (≈88 ms, ≈140 ms and ≈220 ms). These three modes are in fact explained by the respective latencies imposed for the three pathways, SC (41 ms), FEF (91 ms), and V4|IT (122 ms). Similarly to the spatial task, most of the 88 ms saccades occurred on the second half of the experiment reflecting the specialization toward spatial selection. In fact, saccade latencies shift from the 220 ms mode roughly at the first tier of the experiment, to the 140 ms mode at the second tier and then to the 88 ms mode. This gradual shift of timing thus explains the lack of influence of the color loop, whose pathway latency is of 122 ms. A saccade may be triggered by the spatial loops before feature information even reaches the color loop. Again, this effect is not specific to a given parameterization: the advantage of the spatial decisions, caused by a subcortical circuit with earlier access to information, and thus with faster learning, is structural. It is to be noted that the 140 ms peak did not appear in the spatial task, as the learning is fast enough to allow the system to quickly switch to an “express saccade expert.” This is also explained by the information “redundancy” in our model between SC and FEF, the latter dealing with the same spatial information only with a longer latency. In the conjunction task, this peak appears as the “difficulty” slows down the learning, and thus the shift to an “express saccade expert.”
4. Discussion
We described a model of the saccadic system with some very specific structural features:
• the cortico-basal circuits operate in various dimensions (selection based on spatial position, or on target features), with sensory inputs provided with a given latency,
• the subcortico-basal circuit operates on spatial information only, and with a shorter latency,
• all these circuits are subject to reinforcement learning at the level of the input of the BG,
We claim that this structure predicts very specific behaviors, especially in feature-based and space-and-feature-based decisions:
• In the spatial decision task, an ability to switch, from long-latency to short latency saccades (thanks to the learning of the subcortical circuit). An effect experimentally described in Fischer et al. (1984).
• In this task, after the learning of the subcortical shortcut, an early burst of activity in the FEF appears, caused by resonant activity in the spatial circuit. This burst slightly contributes to the reduction of the saccade latency.
• In the color decision task, the concurrently learning subcortical circuit reduces the efficiency of learning, when compared to the spatial task. In normal animals, this effect could be canceled by a external cognitive brake, for example the dlPFC, acting on the subcortical circuit. Thus we predict that this deficit observed in simulation should be observed only in animals with prefrontal cortex deactivation.
• In the conjunction color-and-space-based task, again with the same prefrontal cortex deactivation, space should dominate in the sense that when the cunjunction is not presented, (1) inhibiting the response should be difficult and disappear with learning, (2) the resulting errors should be preferentially directed toward the correct position in space rather than toward the target with the correct color, (3) the saccade latencies should decrease as in the purely spatial task, a clear clue that the subcortical spatial circuit has taken full control of the decisions.
4.1. Previous Models
Very few models have investigated the operation of multiple basal ganglia circuits in saccadic decision and learning (Girard and Berthoz, 2005), and even fewer took into account the existence of a purely subcortical loop.
The seminal model of Dominey and Arbib (1992, 1995) is quite complete, with memory and sequence learning that we have not yet replicated. Nevertheless, some of its aspects seem now rather outdated. First, their model lacks the subcortical SC-Th-BG loop which is now clearly identified: they only integrated cortical loops. This subcortical loop can operate faster than the cortical circuit and one aim of our work is to explore their interactions. Second, the BG model they used is oversimplified. Indeed it is only based on the direct/indirect interpretation of the BG connectivity, from which they keep the direct pathway only. Consequently, concurrent channels cannot interact in the BG circuitry which make target selection problematic. Their SC motor layer thus requires an ad hoc winner-takes-all mechanism, where our more complete BG model solves these problems.
The model proposed in Brown et al. (2004) includes a cortical loop dedicated to saccade strategy selection, and a subcortical loop dedicated to target selection. They also include a working memory mechanisms we have not yet included. Their cortical “strategy” loop explicitly selects whether the target of a saccade will be based on the fixation cue, target position or target feature. Their subcortical loop lacks any thalamic relay and is entirely controlled by the cortical loop, making it unable to learn and make saccades without it. Finally, the details of their BG circuitry suffer from limitations, discussed in details in Girard and Berthoz (2005).
Chambers et al. (2005) proposed a model integrating both the subcortical and cortical pathways without learning capabilities, where a single up-to-date BG model dedicated to location-based selection integrates FEF and SC inputs. Using the various positive feedback loops of this circuitry, they show that manipulating the level of dopamine in their BG model generate reaction time and saccade size modifications reminiscent of Parkinson's disease patient behavior. This model is equivalent to our spatial circuits, and does not explore learning and competition between cortical loops.
The model described in Guthrie et al. (2013) integrates two cortical loops (“cognitive” and “motor”) interacting through different associative structures at both cortical and striatal level. They store in a sub-part of the Striatum all the possible spatial and feature combinations, which could create an obvious combinatorial problem in a realistic model with a full field of view representation and a rich feature space. This model has shown the ability to learn to select targets based on conjunction of information between the two loops but does not include SC and does not specify how the selection in the BG is transformed in a motor command. The associative striatal structure is dependent on the associative cortical one and provides a mean of information transfer between loops. However, the BG architecture used is quite simplified, lacking GPe and GPe-STN connectivity. Finally this model does not include any subcortical loop and thus did not study possible interactions between cortical and subcortical loops.
4.2. Spatial Dominance
Our results show that the system is able to learn basic behaviors such as the “spatial task” and the “color task.” Moreover, we observed quite different abilities for these tasks. A first difference appeared on the color task performance which only rises to about 75%. This difference can be explained by the very structure of the model where the spatial loop intrinsically dominates the system as it includes the SCi output map and has access to information before the color one. Thus, it can learn before the color loop processes information and, has the last word on selection. This characteristic is confirmed in the “conjunction task” where the system finally learned a “spatial task.” What is quite clear with this architecture is that subcortical spatial choice should prevail when opposed to a color one. This characteristic was also observed in a previous work with a simpler model without the cortical spatial loop (N'Guyen et al., 2010) and seems to be a prediction of this architecture. Such a prediction could be tested on animals with dlPFC inactivation in a task where both a spatial and feature criterion contradict each other as we expect the dlPFC to inhibit impulsive subcortical behavior. This prediction wouldn't be hold for the model proposed by Guthrie et al. (2013) as they explicitly represent conjunction information in the Striatum, and this allows for an experimental discrimination between the two models.
4.3. Express Saccades
Moreover, another stable outcome of this model relates to the saccade reaction time. We observed what resembles to “express saccades” for the spatial task. These short latency saccades occurred only after a period of learning in our case. This training dependent behavior is in accordance with previous observations on monkeys (and humans) (Fischer et al., 1984; Fischer and Ramsperger, 1986). However it appears that monkeys are also able to trigger some rare and spontaneous express saccades without learning that our model cannot reproduce. This behavior may be viewed as a kind of exploratory one, clearly lacking in our model.
These express saccades are only performed toward learned locations and never toward learned features. This suggests that this behavior is location dependent and not feature dependent, which is in accordance with results in monkeys (Fischer et al., 1984; Schiller and Haushofer, 2005). Indeed, imposed sensory pathways latencies exclude the ability of express saccade for the cortical color loop (122 ms) which easily explains the lack of such saccade in the color task. Therefore, the intrinsic architecture of the model predicts that correct express saccades cannot occur based on feature information. Moreover in our system this spatial dependency is encoded in a retinocentric reference frame and so doesn't depend on the location of target in space which is also in accordance with previous results (Schiller and Haushofer, 2005).
Furthermore it seems that these express saccades are not dependent on FEF as simulations done with FEF inactivation on a learned system, only lengthen them of about 15 ms which seems to be quite in accordance with what was observed in lesion studies (Schiller et al., 1987).
Interestingly, we observed a short latency burst of activity in FEF prior to the execution of the express saccade. This activity is not caused by a direct visual input (it appears before visual input reaches FEF) but by an indirect SC activity causing the a resonating activity in the cortical loop. Although a SC to FEF projection, either direct or through the Thalamus, has been hypothesized (Sommer and Wurtz, 1998; Everling and Munoz, 2000), this induced activity through BG disinhibition seems to be a new prediction of our model.
Notice that the express saccades we obtained could be theoretically shortened even more with a pre-disinhibition of BG which could be viewed as a preparatory activity. Doing so it should be possible to shorten latency by tens of milliseconds maybe explaining the observed range of timings from 70 to 90 ms in living animals. For example a preparatory activity in FEF during the gap period which could either facilitate or even elicit disinhibition of BG (Everling and Munoz, 2000). Whether this pre-disinhibition exists or not remains a question to be answered experimentally. However this phenomenon was not observed in our system and may require some memory capacity that we did not implement.
If we look further at the SRT distributions, what is commonly observed in primates is a bimodal distribution of reaction time for a detection task (only one cue) which can be related to our spatial task. These two modes are in the range of 80–100 ms and 130–160 ms. Moreover, as said before these timings keeps quite unmodified after a FEF lesion but are drastically changed after a SC lesion (Schiller et al., 1987). Our model produces a compatible bimodal distribution but with a longer latency for the second mode which involves the color loop. So it seems that our model doesn't capture the exact mechanism explaining this precise timing.
In contrast, a unimodal distribution is observed in primates for a discrimination task (where the animal has to choose a cue based on a feature) which can be related to our color task. In this case the distribution is wider and in the range of 160–200 ms without express saccades. Once again, this distribution remains unchanged after FEF lesion but is modified after a SC lesion (Schiller et al., 1987). Here the mechanism proposed by our model seems quite consistent with the experimental data.
Unfortunately to the best of our knowledge there is no data on a spatial-feature conjunction task in the literature, but it is to be noted that a similar three peaks distribution was observed in a quite different task where the primate had to choose between two targets (both rewarded) presented with a 50 ms offset (Schiller et al., 2004).
4.4. Exploration
Noise is necessary in the system to allow the generation of saccades toward one target among two with similar predicted values, rather than systematically resulting in averaging saccades. While averaging saccades sometimes happen in behaving animals (Ottes et al., 1984) they are quite rare and not as systematic as our model would produce them without perceptual noise. This is because the output of our BG does not represent a probability distribution of possible targets but indeed a direct control that requires a unique choice. Yet, our solution is probably a bit simplistic, a more plausible one would be to produce a selection with more competition between targets such as “race models” (Bundesen, 1987; Ludwig et al., 2007). These mechanisms would most of the time allow a selection of a unique target between two perfectly identical cues. Moreover these mechanisms could also produce an attentional engagement/disengagement behavior which could produce the “gap effect” (Saslow, 1967; Braun and Breitmeyer, 1988) that our model cannot replicate.
4.5. Multiple Loops
In our model we have chosen to include only one SC-Th-BG loop but McHaffie et al. (2005) have identified at least two (maybe three) different loops involving different layers of the SC.
The first one linking the SC superficial layers (SCs) to the BG via lateral posterior (LP) and pulvinar nuclei of thalamus and ending back to the SC superficial layers (and possibly also deep layers). According to the fact that SCs activity is mainly driven by direct retinal projection, it seems reasonable to think that this loop could be responsible of selection of these retinal inputs. We didn't implement this loop that appeared redundant in our model as we included a SCs to SCi projection but we can imagine a different mechanism with for example a SCs to SCi pathway gated by SNr inhibition.
The second loop—that we implemented in our model—links the SC deep layers (SCi) to BG via intralaminar thalamus nuclei (both caudal and rostral, which represent segregated regions with different type of contact to striatal medium spiny neurons and thus may in fact describe two parallel loops). The deep layers of the SC are known to receive afferent connections from multiple areas (sensory, premotor, motor, but also multisensory…) (May, 2006) thus probably conveying much higher level information. Moreover, as good evidences indicate a SCs to SCi projection (Lee et al., 1997; Isa, 2002), it seems reasonable to think that this loop could be involved in selection of sensory (or high order) targets for orienting behavior as described in this work.
4.6. Associative Map
The conjunction task clearly requires the ability to select and combine feature and location, but we built our model with the conservative assumption that these different types of information were treated independently by strictly separating feature and spatial loops in the learning stage. We thus stick to the assumption of parallel functionally segregated loops as described in Alexander et al. (1986). Moreover this choice was also driven by anatomical considerations as the TE region of IT seems to projects to the “Visual Striatum” (Middleton and Strick, 1996) while the FEF seems to project to the “Oculomotor Striatum” (Stanton et al., 1988). This architecture should make learning quicker and learning generalization easier (i.e., we can directly learn that a color is rewarded regardless of its position rather than learn each color/location combination). This assumption has also the clear advantage to keep the system simple without the need to learn all possible combinations of features and locations which would causes a problem of combinatorial explosion. But the disadvantage is that the system has no means to directly associate the couple feature/location and can only separately learn both, explaining the relatively poor performances for this task.
We hoped that each loop could learn to select separately and then produce the desired behavior while combined back at SC level. However, with this architecture the only mean to perform the correct behavior (trigger a saccade only if the good cue appears at the good position) is by triggering an average saccade between the two cues in the “no conjunction” case and thus keeping fixation close to the center. In our model, it becomes less and less probable as learning progresses, because the spatial loop becomes quicker than the feature one, thus feature information cannot be included in the decision anymore. Notice that with an external brake (such as inhibition from dlPFC) limiting the expression of express saccades, the task could probably be learned.
Different architectures can be proposed to alleviate this problem in more realistic ways. It is possible to combine all the information at different levels. FEF is known to receive inputs from multiple areas (Schall et al., 1995), being a convergence structure for ventral and dorsal visual stream. In particular in our case, IT (TE) is known to project to FEF (Schall et al., 1995) and we can imagine that FEF already combines spatial and non-spatial information. This combination could occur after feature selection and then explain the observed salience map (Thompson et al., 2001).
Another possibility could be a combination at the Striatum level allowing the possibility to learn combination of inputs as done in Guthrie et al. (2013). The disadvantage is to multiply the size of the input vector as stated above. If we have N spatial channels and M color channels the input size is N × M and the all-to-all weight matrix (N × M)2. Even if Guthrie et al. (2013) invoked interesting biological bases, one can question if this kind of combination is a problem in biological systems. The predictions we make about the conjunction case could help deciding based on experimental data, which architecture (separated or merged loops) is correct.
Finally, interaction between loops can also happen at the Thalamus level. Even if FEF and IT loops doesn't share the same Thalamic nuclei (VAmc for IT and MDpl for FEF) this mechanism could still be possible.
Funding
This research is funded by the HABOT project (Emergence(s) Ville de Paris program).
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fncom.2014.00048/abstract
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Alexander, G. E., DeLong, M. R., and Strick, P. L. (1986). Parallel organization of functionally segregated circuits linking basal ganglia and cortex. Ann. Rev. Neurosci. 9, 357–381. doi: 10.1146/annurev.ne.09.030186.002041
Arai, K., Das, S., Keller, E. L., and Aiyoshi, E. (1999). A distributed model of the saccade system: simulations of temporally perturbed saccades using position and velocity feedback. Neural Netw. 12, 1359–1375. doi: 10.1016/S0893-6080(99)00077-5
Arai, K., Keller, E., and Edelman, J. (1994). Two-dimensional neural network model of the primate saccadic system. Neural Netw. 7, 1115–1135. doi: 10.1016/S0893-6080(05)80162-5
Braun, D., and Breitmeyer, B. (1988). Relationship between directed visual attention and saccadic reaction times. Exp. Brain Res. 1988, 546–552. doi: 10.1007/BF00406613
Brown, J., Bullock, D., and Grossberg, S. (2004). How laminar frontal cortex and basal ganglia circuits interact to control planned and reactive saccades. Neural Netw. 17, 471–510. doi: 10.1016/j.neunet.2003.08.006
Bundesen, C. (1987). Visual attention: race models for selection from multielement displays. Psychol. Res. 49, 113–121. doi: 10.1007/BF00308676
Chambers, J. M., Gurney, K., Humphries, M., and Prescott, T. (2005). “Mechanisms of choice in the primate brain: a quick look at positive feedback,” in Modelling Natural Action Selection, eds J. Bryson, T. Prescott, and A. Seth (Brighton: AISB Press), 45–52.
Das, S., Keller, E. L., and Arai, K. (1996). A distributed model of the saccadic system: the effects of internal noise. Neurocomputing 11, 245–269. doi: 10.1016/0925-2312(95)00068-2
Dominey, P., and Arbib, M. (1995). A model of corticostriatal plasticity for learning oculomotor associations and sequences. J. Cogn. Neurosci. 7, 311–336. doi: 10.1162/jocn.1995.7.3.311
Dominey, P. F., and Arbib, M. (1992). A cortico-subcortical model for generation of spatially accurate sequential saccades. Cereb. Cortex 2, 153–175. doi: 10.1093/cercor/2.2.153
Everling, S., and Munoz, D. P. (2000). Neuronal correlates for preparatory set associated with pro-saccades and anti-saccades in the primate frontal eye field. J. Neurosci. 20, 387–400.
Fischer, B., Boch, R., and Ramsperger, E. (1984). Express-saccades of the monkey: effect of daily training on probability of occurrence and reaction time. Exp. Brain Res. 55, 232–242.
Fischer, B., and Ramsperger, E. (1986). Human express saccades: effects of randomization and daily practice. Exp. Brain Res. 64, 569–578. doi: 10.1007/BF00340494
Fischer, B., and Weber, H. (1993). Express saccades and visual attention. Behav. Brain Sci. 16, 553. doi: 10.1017/S0140525X00031575
Fries, W. (1984). Cortical projections to the superior colliculus in the macaque monkey: a retrograde study using horseradish peroxidase. J. Comp. Neurol. 230, 55–76. doi: 10.1002/cne.902300106
Gattass, R., Sousa, A. P. B., and Gross, C. G. (1988). Organization and extent of V3 and V4 of the macaque. J. Neurosci. 8, 1831–1845.
Girard, B., and Berthoz, A. (2005). From brainstem to cortex: computational models of saccade generation circuitry. Prog. Neurobiol. 77, 215–255. doi: 10.1016/j.pneurobio.2005.11.001
Girard, B., Tabareau, N., Pham, Q. C., Berthoz, a., and Slotine, J.-J. (2008). Where neuroscience and dynamic system theory meet autonomous robotics: a contracting basal ganglia model for action selection. Neural Netw. 21, 628–641. doi: 10.1016/j.neunet.2008.03.009
Girman, S. V., and Lund, R. D. (2007). Most superficial sublamina of rat superior colliculus: neuronal response properties and correlates with perceptual figure-ground segregation. J. Neurophysiol. 98, 161–77. doi: 10.1152/jn.00059.2007
Groenewegen, H. J., and Berendse, H. W. (1994). The specificity of the “nonspecific” midline and intralaminar thalamic nuclei. Trends Neurosci. 17, 52–57. doi: 10.1016/0166-2236(94)90074-4
Guthrie, M., Leblois, A., Garenne, A., and Boraud, T. (2013). Interaction between cognitive and motor cortico-basal ganglia loops during decision making: a computational study. J. Neurophysiol. 109, 3025–3040. doi: 10.1152/jn.00026.2013
Hikosaka, O., Takikawa, Y., and Kawagoe, R. (2000). Role of the basal ganglia in the control of purposive saccadic eye movements. Physiol. Rev. 80, 953–978.
Hikosaka, O., and Wurtz, R. H. (1983). Visual and oculomotor functions of monkey substantia nigra pars reticulata. IV relation of substantia nigra to superior colliculus. J. Neurophysiol. 49, 1285–1301.
Isa, T. (2002). Intrinsic processing in the mammalian superior colliculus. Curr. Opin. Neurobiol. 12, 668–677. doi: 10.1016/S0959-4388(02)00387-2
Koval, M., Lomber, S., and Everling, S. (2011). Prefrontal cortex deactivation in macaques alters activity in the superior colliculus and impairs voluntary control of saccades. J. Neurosci. 31, 8659–8668. doi: 10.1523/JNEUROSCI.1258-11.2011
Lamme, V. A., and Roelfsema, P. R. (2000). The distinct modes of vision offered by feedforward and recurrent processing. Trends Neurosci. 23, 571–579. doi: 10.1016/S0166-2236(00)01657-X
Lee, P. H., Helms, M. C., Augustine, G. J., and Hall, W. C. (1997). Role of intrinsic synaptic circuitry in collicular sensorimotor integration. Proc. Natl. Acad. Sci. U.S.A. 94, 13299–13304. doi: 10.1073/pnas.94.24.13299
Lock, T. M., Baizer, J. S., and Bender, D. B. (2003). Distribution of corticotectal cells in macaque. Exp. Brain Res. 151, 455–470. doi: 10.1007/s00221-003-1500-y
Ludwig, C. J. H., Mildinhall, J. W., and Gilchrist, I. D. (2007). A population coding account for systematic variation in saccadic dead time. J. Neurophysiol. 97, 795–805. doi: 10.1152/jn.00652.2006
Lynch, J., and Tian, J.-R. (2006). Cortico-cortical networks and cortico-subcortical loops for the higher control of eye movements. Prog. Brain Res. 151, 461–491. doi: 10.1016/S0079-6123(05)51015-X
May, P. J. (2006). The mammalian superior colliculus: laminar structure and connections. Prog. Brain Res. 151, 321–378. doi: 10.1016/S0079-6123(05)51011-2
McHaffie, J., Jiang, H., May, P., Coizet, V., Overton, P., Stein, B., et al. (2006). A direct projection from superior colliculus to substancia nigra pars compacta in the cat. Neuroscience 138, 221–234. doi: 10.1016/j.neuroscience.2005.11.015
McHaffie, J. G., Stanford, T. R., Stein, B. E., Coizet, V., and Redgrave, P. (2005). Subcortical loops through the basal ganglia. Trends Neurosci. 28, 401–407. doi: 10.1016/j.tins.2005.06.006
McPeek, R., Han, J., and Keller, E. (2003). Competition between saccade goals in the superior colliculus produces saccade curvature. J. Neurophysiol. 89, 2577–2590. doi: 10.1152/jn.00657.2002
McPeek, R., and Keller, E. (2004). Deficits in saccade target selection after inactivation of superior colliculus. Nat. Neurosci. 7, 757–763. doi: 10.1038/nn1269
McPeek, R. M., and Keller, E. L. (2002). Saccade target selection in the superior colliculus during a visual search task. J. Neurophysiol. 88, 2019–2034.
Middleton, F. A., and Strick, P. L. (1996). The temporal lobe is a target of output from the basal ganglia. Proc. Natl. Acad. Sci. U.S.A. 93, 8683–8687. doi: 10.1073/pnas.93.16.8683
Mink, J. W. (1996). The basal ganglia: focused selection and inhibition of competing motor programs. Progress Neurobiol. 50, 381–425. doi: 10.1016/S0301-0082(96)00042-1
Montague, P. R., Dayan, P., and Sejnowski, T. J. (1996). A framework for mesencephalic dopamine systems based on predictive hebbian learning. J. Neurosci. 16, 1936–1947.
Moschovakis, A., Scuddert, C., and Highstein, S. (1996). The microscopic anatomy and physiology of the mammalian saccadic system. Prog. Neurobiol. 50, 133–254. doi: 10.1016/S0301-0082(96)00034-2
N'Guyen, S., Pirim, P., Meyer, J.-A., and Girard, B. (2010). “An integrated neuromimetic model of the saccadic eye movements for the psikharpax robot,” in SAB2010 - Simulation of Adaptive Behavior: From Animals to Animats 11, (Paris).
Ogawa, T., and Komatsu, H. (2004). Target selection in area V4 during a multidimensional visual search task. J. Neurosci. 24, 6371–6382. doi: 10.1523/JNEUROSCI.0569-04.2004
Ottes, F., Gisbergen, J., and Eggermont, J. (1986). Visuomotors fields of the superior colliculus: a quantitative model. Vision Res. 26, 857–873. doi: 10.1016/0042-6989(86)90144-6
Ottes, F. P., Van Gisbergen, J. A., and Eggermont, J. J. (1984). Metrics of saccade responses to visual double stimuli: two different modes. Vision Res. 24, 1169–1179. doi: 10.1016/0042-6989(84)90172-X
Redgrave, P., Prescott, T. J., and Gurney, K. (1999). The basal ganglia: a vertebrate solution to the selection problem? Neuroscience 89, 1009–1023. doi: 10.1016/S0306-4522(98)00319-4
Rizzolatti, G., and Buchtel, H. (1980). Neurons with complex visual properties in the superior colliculus of the macaque monkey. Exp. Brain Res. 42, 37–42.
Saslow, M. G. (1967). Effects of components of displacement-step stimuli upon latency for saccadic eye movement. J. Opt. Soc. Am. 57, 1024–1029. doi: 10.1364/JOSA.57.001024
Schall, J., Morel, A., King, D. J., and Bullier, J. (1995). Topography of visual cortex connections with frontal eye field in macaque: convergence and segregation of processing streams. J. Neurosci. 15, 4464–4487.
Schiller, P. H., and Haushofer, J. (2005). What is the coordinate frame utilized for the generation of express saccades in monkeys? Exp. Brain Res. 167, 178–186. doi: 10.1007/s00221-005-0037-7
Schiller, P. H., Haushofer, J., and Kendall, G. (2004). An examination of the variables that affect express saccade generation. Visual Neurosci. 21, 119–127. doi: 10.1017/S0952523804042038
Schiller, P. H., Sandell, J. H., and Maunsell, J. H. (1987). The effect of frontal eye field and superior colliculus lesions on saccadic latencies in the rhesus monkey. J. Neurophysiol. 57, 1033–1049.
Sommer, M. A., and Wurtz, R. H. (1998). Frontal eye field neurons orthodromically activated from the superior colliculus. J. Neurophysiol. 80, 3331–3335.
Sommer, M. A., and Wurtz, R. H. (2002). A pathway in primate brain for internal monitoring of movements. Science 296, 1480–1482. doi: 10.1126/science.1069590
Stanton, G., Goldberg, M. E., and Bruce, C. J. (1988). Frontal eye field efferents in the macaque monkey: I. Subcortical pathways and topography of striatal and thalamic terminal fields. J. Comp. Neurol. 271, 473–492. doi: 10.1002/cne.902710402
Sutton, R. (1988). Learning to predict by the methods of temporal differences. Mach. Learn. 3, 9–44. doi: 10.1007/BF00115009
Sutton, R. S., and Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge, MA: The MIT Press.
Tabareau, N., Bennequin, D., Berthoz, A., Slotine, J.-J., and Girard, B. (2007). Geometry of the superior colliculus mapping and efficient oculomotor computation. Biol. Cybern. 97, 279–292. doi: 10.1007/s00422-007-0172-2
Thompson, K., Bichot, N., and Schall, J. (2001). “From attention to action in frontal cortex,” in Visual Attention and Cortical Circuits, eds J. Braun, C. Koch, and J. Davies (Cambridge: MIT), 137–157.
Tian and Lynch, J. C. (1997). Subcortical input to the smooth and saccadic eye movement subregions of the frontal eye field in Cebus monkey. J. Neurosci. 17, 9233–9247.
Tompa, T., and Sáry, G. (2010). A review on the inferior temporal cortex of the macaque. Brain Res. Rev. 62, 165–182. doi: 10.1016/j.brainresrev.2009.10.001
Ungerleider, L. G., Galkin, T. W., Desimone, R., and Gattass, R. (2008). Cortical connections of area V4 in the macaque. Cereb. Cortex 18, 477–499. doi: 10.1093/cercor/bhm061
van Opstal, A. J., and Goossens, H. H. L. M. (2008). Linear ensemble-coding in midbrain superior colliculus specifies the saccade kinematics. Biol. Cybern. 98, 561–577. doi: 10.1007/s00422-008-0219-z
White, B. J., Boehnke, S. E., Marino, R. A., Itti, L., and Munoz, D. P. (2009). Color-related signals in the primate superior colliculus. J. Neurosci. 29, 12159–12166. doi: 10.1523/JNEUROSCI.1986-09.2009
White, B. J., and Munoz, D. P. (2011). Separate visual signals for saccade initiation during target selection in the primate superior colliculus. J. Neurosci. 31, 1570–1578. doi: 10.1523/JNEUROSCI.5349-10.2011
Keywords: basal ganglia, superior colliculus, saccades, decision making, reinforcement learning
Citation: N'Guyen S, Thurat C and Girard B (2014) Saccade learning with concurrent cortical and subcortical basal ganglia loops. Front. Comput. Neurosci. 8:48. doi: 10.3389/fncom.2014.00048
Received: 05 August 2013; Accepted: 02 April 2014;
Published online: 23 April 2014.
Edited by:
David Hansel, University of Paris, FranceReviewed by:
Thomas Boraud, Universite de Bordeaux, FranceArthur Leblois, Centre National pour la Recherche Scientifique, France
Copyright © 2014 N'Guyen, Thurat and Girard. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Steve N'Guyen, Sorbonne Universités, UPMC Univ Paris 06, CNRS, UMR 7222, ISIR, 4, Place Jussieu, 75252 Paris Cedex 05, France e-mail:c3RldmUubmd1eWVuQGNvbGxlZ2UtZGUtZnJhbmNlLmZy