 Takashi Hayakawa
Takashi Hayakawa Takeshi Kaneko
Takeshi Kaneko Toshio Aoyagi
Toshio Aoyagi- 1Department of Morphological Brain Science, Graduate School of Medicine, Kyoto University, Kyoto, Japan
- 2CREST, Japan Science and Technology Agency, Kawaguchi, Japan
- 3Department of Applied Analysis and Complex Dynamics, Graduate School of Informatics, Kyoto University, Kyoto, Japan
A fundamental issue in neuroscience is to understand how neuronal circuits in the cerebral cortex play their functional roles through their characteristic firing activity. Several characteristics of spontaneous and sensory-evoked cortical activity have been reproduced by Infomax learning of neural networks in computational studies. There are, however, still few models of the underlying learning mechanisms that allow cortical circuits to maximize information and produce the characteristics of spontaneous and sensory-evoked cortical activity. In the present article, we derive a biologically plausible learning rule for the maximization of information retained through time in dynamics of simple recurrent neural networks. Applying the derived learning rule in a numerical simulation, we reproduce the characteristics of spontaneous and sensory-evoked cortical activity: cell-assembly-like repeats of precise firing sequences, neuronal avalanches, spontaneous replays of learned firing sequences and orientation selectivity observed in the primary visual cortex. We further discuss the similarity between the derived learning rule and the spike timing-dependent plasticity of cortical neurons.
1. Introduction
The cerebral cortex in mammalian brains plays a central role in higher-order functions such as perception, recognition, planning, and execution of goal-directed behaviors, learning and memory. However, it remains to be understood how these functions are realized through the activity of cortical neurons. Many experiments have been conducted to investigate the underlying computations in cortical circuits, and some of them have revealed the presence of characteristic activity profiles of cortical neurons. In parallel with these experimental observations, computational models have been proposed, reproducing such characteristic activities by simulating the models.
For example, simple and complex cells in the primary visual cortex (V1) of mammalian brains were found to show selective responses to visual stimuli of specific orientations (Hubel and Wiesel, 1959). The response properties of simple cells can be understood as feedforward computations acquired according to some learning principle such as the Infomax principle (Linsker, 1988; Bell and Sejnowski, 1997), the sparse coding principle (Olshausen and Field, 1997; Barlow, 2001) and independent component analysis (ICA) (for a review, see Hyvärinen et al., 2001b). The response properties of complex cells have been reproduced by extending these models of simple cells hierarchically (Hyvärinen et al., 2001a; Karklin and Lewicki, 2005). Based on these guiding learning principles, several authors have constructed biologically plausible learning algorithms in feedforward neural networks that reproduce the response properties of visual neurons including orientation selectivity (Deco and Parra, 1997; Okajima, 2001; Savin et al., 2010; Zylberberg et al., 2011; Tanaka et al., 2012). Hence, Infomax learning has been proposed as one of the candidate learning principles in V1.
Real cortical circuits consist not only of feedforward connections but also of recurrent connections (for a review, see Douglas and Martin, 2007; Kaneko, 2013). In particular, spontaneous activity in the cerebral cortex is thought to be produced by the recurrent connections in the cortical circuits. Repetition of precise firing sequences has been observed in the spontaneous activity of cortical neurons in slice cultures (Ikegaya et al., 2004). Furthermore, task-related sequential firing of cortical neurons in behaving animals and its repetition in the sleeping (Skaggs and McNaughton, 1996; Lee and Wilson, 2002) and quietly awake state (Yao et al., 2007) have been observed in vivo. As another one of the characteristic firing profiles of the spontaneous cortical activity, “neuronal avalanche” has also been reported; in certain experimental conditions, the sizes of the bursts in spontaneous bursting activity in the cerebral cortex were shown to obey a power law, and this phenomenon was named “neuronal avalanche” (Beggs and Plenz, 2003).
Historically, the emergence of stereotypical sequential firing activity was predicted in the theory of cell assembly (Hebb, 1949). Guided by this notion, previous studies have shown by simulation that certain network structures of recurrent neural networks allow the emergence of repeats of precise firing sequences and/or neuronal avalanches in the spontaneous activity of the network models (Teramae and Fukai, 2007; Tanaka et al., 2009; Teramae et al., 2012). Teramae et al. (2012) showed that sparsely distributed strong connections in a recurrent neural network lead to apparently asynchronous and irregular spontaneous activity with repeats of precise firing sequences, in accordance with experimental findings (Renart et al., 2010). From the viewpoint of learning, Izhikevich (2006) numerically demonstrated that stereotypical firing sequences appear in a recurrent neural network self-organized by spike-timing-dependent plasticity (STDP), although there is a criticism that his model requires EPSPs of unrealistic sizes to reproduce the firing sequences. Furthermore, Tanaka et al. (2009) recently revealed that the characteristics of spontaneous cortical activity in addition to orientation selectivity in V1 are acquired by self-organization of recurrent neural networks according to Infomax learning principle.
Although Tanaka et al. (2009) suggested Infomax learning as the common learning principle for the characteristics of spontaneous cortical activity and orientation selectivity, they did not show a biologically plausible learning rule for the Infomax learning. If the Infomax learning in Tanaka et al. (2009) is realized in the cortical circuits, there must be a learning rule whose components can possibly be computed through biophysical mechanisms in individual neurons or synapses. However, Tanaka et al. (2009) used a complicated learning algorithm which requires information about firing statistics of the whole network such as inverses of correlation matrices of firing activity. Neurons and synapses cannot have an access to such global information, and thus it is still unclear whether the Infomax learning formulated by Tanaka et al. (2009) in the recurrent settings is biologically plausible. Other types of biological realization of Infomax learning proposed so far (Okajima, 2001; Chechik, 2003; Toyoizumi et al., 2005) do not account for the emergence of spontaneous cortical dynamics. Although several biological mechanisms have been considered for the emergence of the dynamics observed in the cortex (Wörgötter and Porr, 2005; Izhikevich, 2006), to our knowledge, no biologically plausible learning rule in a recurrent neural network has been reported to account for the emergence of both orientation selectivity and the experimentally observed characteristics of spontaneous cortical activity. This might be due to an inherent difficulty in analytically deriving biologically plausible learning rules in recurrent neural networks. However, to understand how the cerebral cortex realizes its highly developed functions, it is the critical first step to discern such a biologically plausible learning rule.
In the present article, we construct a biologically plausible rule for the Infomax learning in a recurrent neural network, and show by numerical simulations that the learning rule reproduces repeats of precise firing sequences, neuronal avalanches, spontaneous replays of learned firing sequences, and orientation selectivity of simple cells. We further discuss the similarity of the derived learning rule to the reward-modulated STDP proposed by Florian (2007), and suggest several candidate neural substrates for its biological realization in cortical circuits.
2. Results
2.1. A Biologically Plausible Learning Rule for the Recurrent Infomax
In the present study, we consider discrete-time stochastic dynamics of recurrent neural networks similar to those of the preceding study (Tanaka et al., 2009). The recurrent neural network xt ∈ {0, 1}N consists of N simple binary neuron models xti with neuron index i and time index t, each of which takes one of the two states, 1 (fire) or 0 (quiescent). Each neuron receives an input sti from all the other neurons as sti = ∑j ≠ iwijxtj − hi at time t, and it fires at the next time step with a probability of . Here, we have denoted the logistic function as , and parametrized the maximal probability of firing transmission with pmax. The model parameters {wij}1 ≤ j ≤ N and hi represent the synaptic weights and the firing threshold of the postsynaptic neuron i, respectively, and are updated by the learning rule derived below. These settings may be understood as a discrete approximation of continuous-time neuronal dynamics (see Methods). Following the model settings in the previous studies of biologically plausible learning rules in neural networks (Savin et al., 2010; Zylberberg et al., 2011; Frémaux et al., 2013), we allow each neuron to make both of excitatory and inhibitory synapses. For the precise modeling of interactions between excitatory and inhibitory neurons, we must consider various experimental findings, such as the existence of many different kinds of inhibitory neurons (Markram et al., 2004) and excitatory axo-axonic synapses on axons of inhibitory neurons (Ren et al., 2007). Although such precise modeling is apparently intractable and beyond the scope of the current study, we can consider possible biological realization of our idealized neurons with excitatory and inhibitory synapses, for example, by replacing a single neuron with a pair of excitatory and inhibitory neurons which have the same responsiveness (see Discussion for the details). Thus, the usage of such idealized neurons does not critically affect the biological plausibility.
Originally, Infomax learning was defined as the maximization of mutual information between two groups of neural elements (Linsker, 1988; Bell and Sejnowski, 1997), and many extensions have been considered (Kay and Phillips, 2010). The mutual information was defined according to information theory (Cover and Thomas, 2012). In Tanaka et al. (2009), assuming the convergence of distributions of firing activity xt to stationary distributions ps(xt), the authors proposed to define recurrent Infomax as the maximization of mutual information between the firing activities at two successive time steps, under the constraint that the mean firing rates of neurons must be a fixed small value p0 ≪ 1:
Since the brain needs to retain information about its past activity, the above definition of the recurrent Infomax learning is straightforward.
Tanaka and colleagues did not discuss, however, plausible mechanisms for the recurrent Infomax learning in the brain. Thus, we derive a biologically plausible learning rule, which predicts possible mechanisms for the recurrent Infomax learning in real cortical circuits. Since it is thought to be impossible for a neural network to directly compute the mutual information itself, some approximation is needed. Thus, we are going to derive the learning rule from the following approximate objective function:
Here, the angle brackets with subscript ∞ represent the long-time averages of their arguments. Throughout this paper, assuming ergodicity, we identify long-time averages with corresponding ensemble averages as
The role of each term in Equation (2) is as follows (see Methods for further details of the construction of the objective function A). Predictability term A1 = ∑i log I [xti; xt − 1] represents how predictable the firing activity xt is from the firing activity at previous time steps xt − 1. In other words, this term forces neurons to fire deterministically as far as possible, that is, to fire with high probabilities near pmax in response to specific inputs, and not to fire at all for the other inputs. This term mathematically provides a lower bound of the mutual information I [xt; xt − 1] if and only if the firing of each neuron xti (1 ≤ i ≤ N) is independent. We, therefore, impose a penalty based on the sum of the pairwise correlations, correlation term , so as to bound the firing activity near the independent distribution. The correlation term A2 is also interpreted as a penalty term for population sparseness, noting that where mt = ∑ixti. Firing-rate term is a penalty term for controlling the average firing rates of all the neurons in the network to be p0. Since sti can be interpreted as an input current to the neuron i at each time step (see Methods and Figure 8), its fluctuation should be confined within a physiologically reasonable range. We therefore impose an additional penalty for excessively large fluctuation of sti with fluctuation term . The reference input strength is determined so that neurons fire with a probability of when the strength of the inputs to the neurons is s0. If excessively large fluctuation of the inputs is allowed, a kind of singularity appears in the dynamics and the approximation with the pairwise correlations fails (see Methods and Figure 7).
Then, we construct a biologically plausible learning rule as a stochastic gradient ascent algorithm for the objective function, Equation (2):
where
We remove the singularity at 〈 log {p(xti|xt − 1)/Zti} 〉T = 0 by replacing it with δ = 1.0× 10−3 if 〈 log {p(xti|xt − 1)/Zti} 〉T ≤ δ. The angle brackets with subscript τ and T are calculated recursively at each time step as, for example,
Then, is interpreted as a leaky integration of the past amounts mt − u − 1, (u ≥ 0) with a leak constant T. As T → ∞ and the process under consideration is stationary, 〈 mt〉T approaches the stationary average of mt.
In the above learning rule, we notice that all terms except γtk on the right-hand sides of Equations (3) and (4) can be computed by the postsynaptic neuron i based on its own activity and local interactions with the other neurons. Thus, these terms are biologically plausible. It should be particularly noted that the temporal integration such as can be realized locally at each synapse or each neuron, possibly with very large leak constants τ and T (phosphorylation or gene expression may be considered). In the limit of τ → ∞ and T/τ → ∞, the stochastic approximation of the gradient ascent is exact. In addition to these local processes, it suffices for the biological plausibility of the overall learning rule to assume the existence of neural substrates corresponding to the global signals γtk (1 ≤ k ≤ 4). We are able to consider a scenario for such neural substrates as follows. For γt1, γt3, and γt4, we consider a rapidly diffusing substrate emitted by each neuron (nitric oxide, neuropeptides, lipid metabolites, endcannabinoids, and so on), the sum of whose amount is γt1 − γt3 − γt4, since γtk (k = 1, 3, 4) are sums of locally computable quantities over the neuronal population. For γt2, we need to consider another substrate, since it is a non-linear function of population activity mt and its temporal integration 〈 mt〉T. As a candidate neural substrate, we can consider interneurons that are able to monitor the overall activity mt of the network and to return a non-linear feedback to pyramidal neurons. As shown in Figure 1, the action of these two types of neural substrates is to amplify the leaky integration of the past local quantities ψt − uixt − uj and ψt − ui (u ≥ 1) by their magnitudes γtk. Each neuron i realizes this amplification through its intracellular signaling pathway, receiving the neural substrates corresponding to γtk. We will discuss further detailed scenarios and their plausibility in the Discussion section. In addition, the derivation of this type of a stochastic gradient ascent method is mathematically the same as that for reward-modulated STDP, a neural implementation of reinforcement learning (Florian, 2007; Frémaux et al., 2013) (see Discussion).
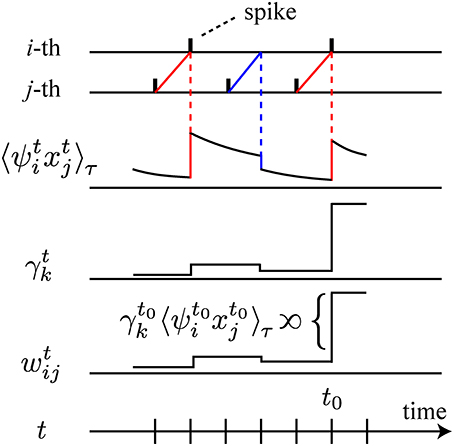
Figure 1. Schematic illustration of the learning rule. For simplicity, we illustrate only the relation between , γtk and wtij, omitting the other components of the learning rule. On the first two lines, spikes of the i-th and the j-th neurons are depicted. On the third line, decays with time constant τ, and is modulated by the interactions between the spiking activity of the i-th and the j-th neurons. When the firing of the presynaptic j-th neuron precedes the firing of the postsynaptic i-th neuron, increases (red line). If the postsynaptic neuron fails to fire, decreases (blue line). The change of the synaptic weight wij at time t0 is proportional to the product of the amount of global signal γt0k and as depicted on the fifth line.
In the following sections, we will show the results of numerical simulations of the above learning rule, in which we start from a network with weak random connections taken from a uniform distribution wij ~ [−0.1, 0.1] representing synapses in the early developmental stage just after synaptic formation is made, and with hi = log {(pmax − p0)/p0}. With these initial values, the neurons fire almost independently with probability p0. Then, we update wij and hi according to the learning rule, Equations (3) and (4). We make sure that the results in the following sections are robustly reproduced, with different series of random numbers used in the determination of initial model parameters and in the simulation. We show the learning parameters used for each simulation at the end of the corresponding figure legend. We show the learning parameters in the objective function Equation (2) with the scaled parameters cκ, cη, and cζ so that we can see their magnitudes independently of the system size and the average firing rate (see Methods for further details).
To check whether the mutual information is actually maximized, we calculate an approximate measure of the mutual information,
Here, and are empirical covariance matrices of xt and xt ⊗ xt − 1, respectively (see Methods). This estimate gauss approximates the mutual information by regarding the firing distribution ps(xt) and ps(xt, xt − 1) as Gaussian distributions. It was shown in the numerical experiment in the previous study (Tanaka et al., 2009) that these values provide a good approximation of the exact values of the mutual information.
2.2. Reproduction of Repeated Firing Sequences and Neuronal Avalanches
In this section, we reproduce repeats of precise firing sequences and neuronal avalanches similar to those observed in experimental studies (Beggs and Plenz, 2003; Ikegaya et al., 2004), which have been suggested as a consequence of the maximization of information retention in previous studies (Tanaka et al., 2009; Chen et al., 2010).
We apply the learning rule to a spontaneously firing recurrent neural network xt consisting of fifty neurons that does not receive external inputs. Then, we observe two typical behaviors of the model after learning, depending on the model parameters: maximal transmission probability pmax and average firing rate p0.
After learning with larger values of pmax and p0, we observe a variety of repeated firing sequences in apparently asynchronous and irregular firing activity of the model. According to the theory in the previous study (Tanaka et al., 2009), the relationship between the repeated precise sequences and the mutual information is understood as follows. Following the definition and the notation of entropy and conditional entropy in information theory (Cover and Thomas, 2012), the mutual information can be decomposed as
In the above equation, the first term of the right-hand side represents the abundance of firing patterns and the second term represents the predictability of firing activity xt from xt − 1. Thus, repeats of many long sequences of firing patterns are expected to emerge after the maximization of the mutual information. Here, we have defined a firing pattern as a specific configuration of firing activity xt ∈ {0, 1}N, and a sequence of firing patterns of length L as a specific configuration of a series of firing patterns {xt, xt − 1, … xt − L + 1} ∈ {0, 1}NL (illustrated in Figure 2A).
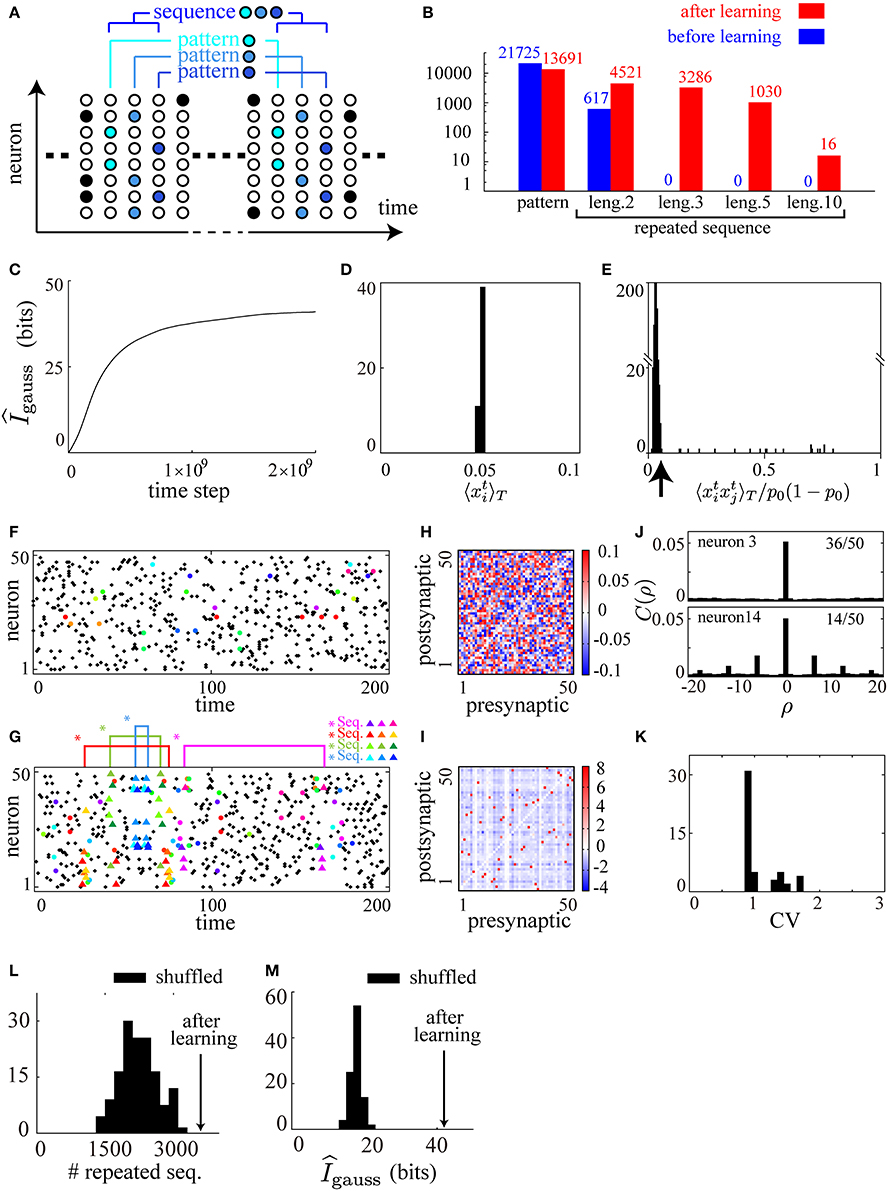
Figure 2. Cell-assembly-like repeated sequences of firing patterns are reproduced by applying the learning rule to a spontaneously firing recurrent neural network. (A) A schematic illustration of the definition of firing patterns and of sequences of firing patterns. Each color represents a unique firing pattern xt ∈ {0, 1}N. A repeated sequence of firing patterns of length 3 {xt, xt − 1, xt − 2} ∈ {0, 1}3N is also illustrated. (B) Comparison of the numbers of firing patterns and repeated sequences (repeated more than twice) of length 2, 3, 5, and 10 before and after learning, counted for a particular 50000 time steps in the simulation. (C) The approximate measure of the mutual information gauss is calculated during the course of learning. (D) A histogram of mean firing rates of the neurons in the network after learning. (E) A histogram of pairwise correlations between all the pairs of neurons in the network after learning. (F,G) Typical raster plots before (F) and after (G) learning in which repeated sequences are represented as triangles of different colors, repeated patterns as filled circles of different colors, and other spikes as black dots, according to the definition illustrated in (A). (H,I) Connection weight matrices of the network before (H) and after (I) learning in which rows correspond to connections to single postsynaptic neurons while columns correspond to connections from single presynaptic neurons. (J) Typical two examples from the autocorrelograms calculated from the activity of each neuron in the network after learning. Thirty-six of the neurons show no autocorrelation as seen in the upper figure, while fourteen show damped periodicity as seen in the lower figure. (K) A histogram of CV values calculated from the activity of each neuron in the network after learning. (L,M) Comparison of gauss (L) and the numbers of sequences of length 3 (counted for a particular 50000 time steps) (M) of the network after learning (arrows) with those of one hundred shuffled networks (histograms). The following parameters have been used in this simulation: ϵ = 0.006, cη = 1.5, cκ = 1.0, cζ = 3.0, p0 = 0.05, pmax = 0.95, N = 50, τ = 15, T = 50000.
In the numerical simulation, by counting the number of firing patterns and sequences during a particular 50000 steps, we find that the numbers of repeated sequences of length 3, 5, and 10 after learning are far larger than those before learning, while the variety of firing patterns after learning is kept high (Figure 2B). During the course of learning, we have checked that the estimate of the mutual information, Equation (6), monotonically increases and tends to saturate (Figure 2C). In addition, we have checked after learning that the average firing rate of each neuron is controlled to be p0, and that most of the pairwise correlations are controlled to be small, as shown in the histograms in Figures 2D,E. We show typical raster plots of 250 time steps before (Figure 2F) and after (Figure 2G) learning, along with matrices of the synaptic weights before (Figure 2H) and after (Figure 2I) learning. No sequence of length 3 repeats within Figure 2F, while four different repeated sequences of length 3 represented by colored triangles are found within Figure 2G, indicating the abundance of repeated sequences after learning. In contrast, the abundance of repeated patterns represented by colored circles are comparable between Figures 2F,G. These results are consistent with the theoretical consideration based on Equation (7) that a rich variety of repeated sequences should occur after the maximization of the mutual information, suggesting that our model has learned successfully.
In spite of the abundance of repeated firing sequences, the firing activity after learning is apparently asynchronous and irregular (Figure 2G) as observed in the real cortical activity (Renart et al., 2010). Examining the underlying connectivity, we find that the initial small random connections shown in Figure 2H grow into the sparsely distributed strong excitatory and inhibitory connections shown in Figure 2I. In order to quantify the asynchrony and the irregularity, we calculate autocorrelograms Figure 2J and coefficients of variation (CV) of inter-spike intervals (ISIs) Figure 2K for each neuron after learning. In the autocorrelograms, we find almost no autocorrelation for the majority (36/50) of the neurons (the upper graph in Figure 2J), and rapidly damped periodicity for the other neurons (the lower graph in Figure 2J). We find, however, that all of the CV values (Figure 2K) are greater than 1.0 (the value for a Poissonian spike train) indicating that there is no global periodicity of the network and the overall firing activity is irregular. In parallel with our results, a preceding study demonstrated that randomly connected neural networks with sparsely distributed strong synapses display asynchronous and irregular firing activity in which many precise firing sequences are embedded (Teramae et al., 2012). To compare the network after learning with networks with random connections of sparsely distributed strong synapses, we examine the activities of the network after learning and one hundred networks whose synaptic weights are shuffled sets of the original network after learning. Then, the number of repeated sequences in the original network is largest among the shuffled networks (Figure 2L) at the same time as its estimated mutual information is maximal (Figure 2M). Although we are not able to further characterize the statistical properties of the connectivity after learning because of limitations on the system size, the above result suggests that the network structure after learning is more finely tuned for efficient information transmission based on precise firing sequences than random networks with sparsely distributed strong connections.
After learning with smaller values of pmax and p0, the firing activity of the model is similar to neuronal avalanche. Following the previous theoretical and experimental studies of neuronal avalanche (Beggs and Plenz, 2003; Tanaka et al., 2009), we define a single burst as a cluster of firing partitioned by empty time steps without firing and its size as the number of spikes in that cluster (illustrated in Figure 3A). By plotting burst size s against the occurrence p(s) of bursts of that size on the log-log scale, we find that p(s) obeys a power law with a universal exponent around −3/2 for different parameters pmax = 0.4, 0.2 and different system sizes N = 50, 100, 200 after learning while p(s) before learning decreases rapidly as s increases (Figure 3B). During the process of learning, we have checked that the estimate of the mutual information, Equation (6), monotonically increases (Figure 3C), suggesting that the mutual information is successfully maximized. We show typical raster plots before (Figure 3D) and after (Figure 3E) learning. Representing different bursts in different colors, we observe that the initial random firing activity (Figure 3D) has become apparently bursty activity after learning (Figure 3E). Examining the underlying connectivity, we find that the initial small random connections in Figure 3F grow into the sparsely distributed strong excitatory and inhibitory connections shown in Figure 3G. In Figure 3G, most neurons feed two or three strong excitatory inputs to other neurons, probably reflecting the following requirement. is necessary for the emergence of neuronal avalanches, when the firing activity {xti}1 ≤ i ≤ N is controlled to be almost independent by the correlation term A2 (Zapperi et al., 1995). Then, a single firing in the network needs to evoke a single firing on average at the next time step. Given that pmax = 0.4, and that must be pmax or 0 for the maximization of the predictability term A1, each neuron needs to feed strong connections to 1/0.4 = 2.5 target neurons on average. Although these results are robustly observed for a wide range of model parameters, the power law is slightly distorted for higher maximal firing probabilities (the green plot for pmax = 0.8 in Figure 3H). When pmax is set to be near 1.0, the size distribution p(s) seems to have small multiple peaks (the blue plot for pmax = 0.95 in Figure 3H). A typical raster plot of 200 time steps after learning with this range of parameters (pmax = 0.95) is shown in Figure 3I. In the figure, as many as twelve repeated firing sequences of length 3 (for the definition of repeated firing sequences, see Figure 2A) are observed. These repeated firing sequences occupy a large fraction of the firing activity in the figure, indicating the emergence of a rich variety of stereotypical firing sequences.
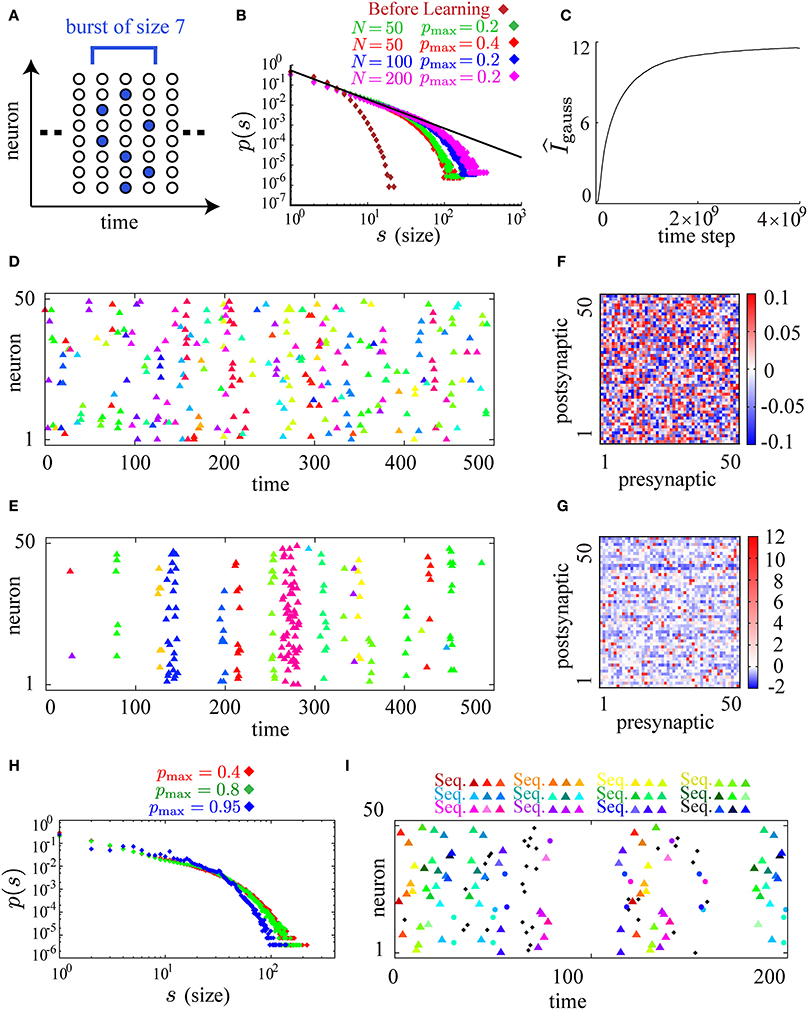
Figure 3. Neuronal avalanches are reproduced by applying the learning rule to spontaneously firing recurrent neural networks. (A) A schematic illustration of the definition of bursts and their sizes. A burst of size 7 that lasts for 3 time steps is illustrated in the figure. (B) Log-log plots of burst size s against the occurrence of bursts of that size p(s) before (brown) and after learning (red for pmax = 0.4 and N = 50, green for pmax = 0.2 and N = 50, blue for pmax = 0.2 and N = 100, and magenta for pmax = 0.2 and N = 200). The size distributions after learning fall on the straight line of slope around −3/2 (the black line). (C) The approximate measure of the mutual information gauss is calculated during the course of learning. (D,E) Typical raster plots before (D) and after (E) learning in which spikes belonging to different bursts are displayed in different colors. (F,G) Connection weight matrices of the network before (F) and after (G) learning in which rows correspond to connections to single postsynaptic neurons while columns correspond to connections from single presynaptic neurons. (H) Log-log plots of burst size s against the occurrence of bursts of that size p(s) for higher pmax ( = 0.8, 0.95) along with the plot for pmax = 0.4. (I) A typical raster plot after learning with pmax = 0.95. Colored triangles and circles indicates repeated firing sequences of length 3 and repeated firing patterns, respectively, as in Figure 2G. Repetition of as many as twelve firing sequences can be seen in the figure. The following sets of learning parameters have been used in this simulation: ϵ = 0.02, cη = 10.0, cκ = 30.0, cζ = 3.0, p0 = 0.01, pmax = 0.2, 0.4, 0.8, N = 50, τ = 10, T = 50000; ϵ = 0.01, cη = 20.0, cκ = 60.0, cζ = 4.0, p0 = 0.005, pmax = 0.2, N = 100, τ = 15, T = 50000; ϵ = 0.006, cη = 40.0, cκ = 100.0, cζ = 6.0, p0 = 0.0025, pmax = 0.2, N = 200, τ = 20, T = 50000; ϵ = 0.005, cη = 3.0, cκ = 1.0, cζ = 10.0, p0 = 0.01, pmax = 0.95, N = 50, τ = 20, T = 50000.
2.3. Reproduction of Evoked Firing Sequences and their Spontaneous Replays
In the previous section, we have demonstrated that the present learning rule reproduces repeated sequences in spontaneously firing neural networks. In experimental studies, similarities between firing sequences in spontaneous activity and firing sequences in sensory-evoked activity have been reported (Skaggs and McNaughton, 1996; Lee and Wilson, 2002; Yao et al., 2007). To investigate the relationship between firing sequences in these two types of activity, we further numerically examine the Infomax learning of a neural network driven by external inputs. We prepare a recurrent neural network (RN) consisting of fifty neurons (the 1st–50th neurons), all of which receive feedforward inputs from three external neurons (the 51st–53rd neurons (EXT)). Sensory inputs are modeled by the firing activity of these three external neurons. As represented by the squares in the diagram of Figure 4A, the external neurons fire in a fixed sequence that starts at a random timing with inter-episode intervals uniformly taken from fifty to one hundred time steps. Within the fixed sequences, the 51st neuron fires at the first time step of the sequence, the 53rd neuron at the third time step, and the 52nd neuron at the fifth time step, respectively. Given the fixed timing within the sequences, the external neurons fire stochastically and independently with a probability of 1/2, representing the variability of the environment. As a consequence, the recurrent network receives 23 − 1 = 7 kinds of slightly different input sequences with equal probabilities. Denoting the neurons in the recurrent network as xtRN ∈ {0, 1}50 and the external input neurons as xtEXT ∈ {0, 1}3, we maximize the mutual information . Although should be maximized according to the definition of the Infomax learning on recurrent networks, the present learning rule cannot directly maximize this latter mutual information. However, the above two types of mutual information are almost equal if dependence between xtEXT and xt − 1EXT is small. Hence, we have ignored the small dependence of xtEXT on xt − uEXT (1 ≤ u ≤ 4), maximizing the former information . Then, for the updates of both the recurrent connections and the feedforward connections from the external neurons in Equations (3) and (4), the index i runs through the neuron indices of RN, while the index j runs through those of both RN and EXT. Initially, we set three particular connections from the external neurons to be a large value (w1, 51, w2, 52, w3, 53 = 100) for the modeling of an established pathway of sensory signals, and the other connections to be small values (randomly taken from [−0.1, 0.1]). Then, we update both the recurrent and feedforward connections according to the present learning rule.
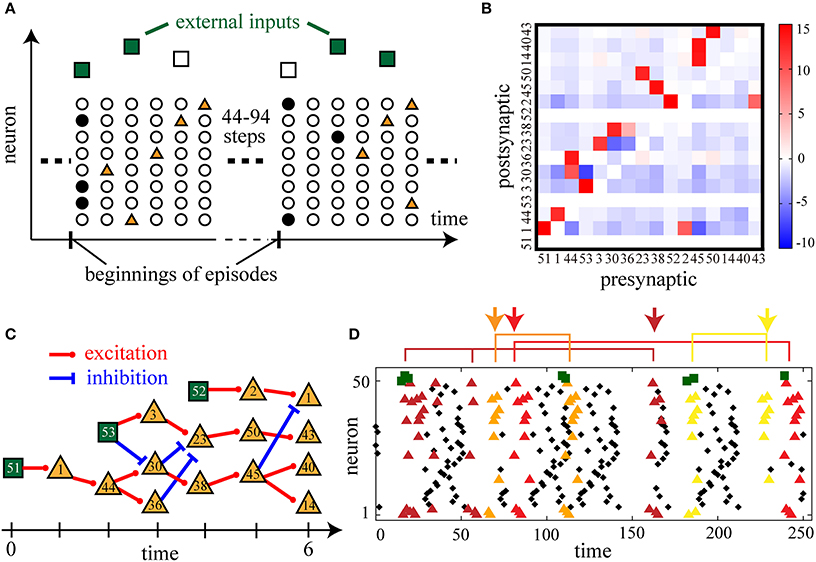
Figure 4. Sensory-evoked firing sequences and their spontaneous replays are reproduced by applying the learning rule to recurrent neural networks with external inputs. (A) A schematic illustration of the learning of external input sequences. Filled symbols represent the firing of a neuron (vertical axis) at a certain time step (horizontal axis). Once in 50–100 time steps, at the beginning of an input episode, external input neurons fire stochastically in a fixed sequence (dark green squares when fired and empty squares when not fired). In the recurrent network, neurons respond to these inputs (brown triangles). (B) A matrix of connection weights between sequence-related neurons. We picked up the sequence-related neurons until the sixth poly-synaptic transmission via strong excitation (wij > 8.0) from the firing of the 51st external input neurons. (C) A diagram of sequential firing transmission found in the weight matrix in (B). By putting t = 0 at the first time step of an external input sequence, possible strong excitation and inhibition are drawn until t = 6. (D) Typical raster plots after learning. Colored triangles are the firing of those neurons picked up in (B). Each combination of spikes of external input neurons activates a similar but distinct firing sequence indicated by triangles of a different color. Spontaneous replays of partial sequences of the evoked activity are also repeatedly observed (indicated by arrows). The following parameters have been used in this simulation: ϵ = 0.01, cη = 2.0, cκ = 3.0, cζ = 10.0, p0 = 0.02, pmax = 0.98, N = 50, τ = 15, T = 50000.
After learning, we observe that the network apparently displays several stereotypical firing sequences in response to the input sequences. Since these firing sequences are thought to be organized by sparsely distributed strong connections similarly to the cases in the previous sections, we analyze the connectivity matrix in detail. We pick up sequence-related neurons activated by poly-synaptic transmission due to strong excitatory connections (wij > 8.0) until the sixth transmission from the firing of the 51st neuron, and construct a weight matrix of the connectivity among the picked-up neurons (Figure 4B). In this weight matrix, we find sequential activation and inhibition due to the strong connections (Figure 4C) that are thought to underlie the input-evoked stereotypical firing sequences (colored triangles in Figure 4D). To be more precise, we find that three chains of strong excitatory transmission originate from either one of the three external neurons and have crosstalk with each other via strong excitatory and inhibitory transmission. Each of the seven combinations of input firing consequently activates a distinct part of the transmission cascade in Figure 4C, and results in a similar but distinct firing sequence indicated by different colors of triangles in Figure 4D. For example, when all the three external neurons fire, the evoked firing sequence is [51]→ [1]→ [53, 44]→ [3, 36]→ [52, 23]→ [2, 50]→ [1, 43] (dark brown triangles) in the order of time passage while some neurons fail to fire occasionally. This is similar to but different from the sequence activated by the combination of the 51st and 52nd neurons, [51]→ [1]→ [44]→ [30, 36]→ [52, 38]→ [2, 45]→ [14, 40] (light yellow triangles). Furthermore, such sequences are repeatedly activated in spontaneous firing between the input episodes as indicated by the arrows of different colors in Figure 4D. Thus, the present learning rule has reproduced replays of sensory-evoked firing sequences.
2.4. Reproduction of Simple-Cell-Like Receptive Field Properties
It is well known that Infomax learning is mathematically equivalent to independent component analysis (ICA) in the limit of small noise, and results in the extraction of filters similar to orientation selectivity of simple cells in V1 when it is applied to the analysis of natural images (Bell and Sejnowski, 1995, 1997). In this section, we examine numerically whether the present learning rule also achieves such feature extraction. As described in Figure 5A, a 12 × 12 pixel patch yt taken in the independently and identically distributed (i.i.d.) manner from low-pass filtered, gray-scaled and whitened natural images (Olshausen and Field, 1997) is used as an input at each time step. Similar preprocessing of input images is thought to be done in the retina and the lateral geniculate nucleus (LGN) before the processing in V1 (Atick, 1992). Following Tanaka et al. (2009), as a model of LGN, we prepare a pair of ON and OFF neurons, xti, ON and xti, OFF, for each pixel yti (1 ≤ i ≤ 144), which fire with the following probabilities proportional to positive and negative intensities of the pixel, respectively:
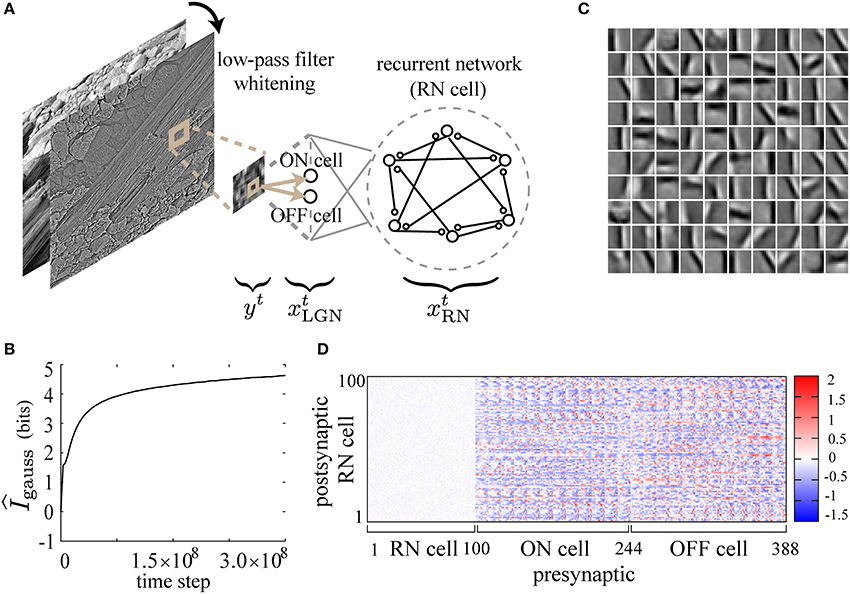
Figure 5. Feature extraction from natural images by the present learning rule. (A) Randomly taken 12× 12-pixel patches from gray-scaled, low-pass filtered and whitened natural images are used as inputs to a recurrent neural network through ON and OFF cells. (B) gauss is calculated during the course of learning. (C) STAs of input images are displayed as 10× 10 small image patches in a gray-scale (1: black, 255: white), representing the receptive field properties of the neurons in the recurrent network after learning. Each small patch corresponds to an STA due to the firing of a neuron in the recurrent network. (D) The connection weight matrix after learning is displayed on a color scale. The following parameters have been used in this simulation: ϵ = 0.02, cη = 250.0, cκ = 150.0, cζ = 1000.0, p0 = 0.0015, pmax = 0.95, N = 100, τ = 5, T = 50000.
The constant ξ is set to be 1.65 so that the mean firing rate pinput of ON- and OFF-neurons is around 0.15. Each of those input neurons feeds synaptic inputs to all the neurons xti, RN (1 ≤ i ≤ 100) in the recurrent network (RN).
Then, we apply the present learning rule to this model for the maximization of I [xt; xt − 1], denoting and (the prime symbols represent transposition of vectors). We further obtain I [xt; xt − 1] = I [xtRN ; xt − 1] because of the independence between xtLGN and xtRN, as well as the independence between xtLGN and xt − 1LGN (recall that xtLGN is generated in an i.i.d. manner from the natural images at each time step). Thus, we maximize I [xtRN ; xt − 1] instead of I [xt; xt − 1], calculating γtk with respect to only xtRN in Equations (3) and (4). For the updates of both the recurrent connections and the feedforward connections from LGN in Equations (3) and (4), the index i runs through the neuron indices of RN, while the index j runs through those of both RN and LGN.
As shown in Figure 5B, gauss increases monotonically and tends to saturate during the course of learning, suggesting that the mutual information is successfully maximized. After learning, we calculate reverse correlations by taking spike-triggered average (STA) of stimulus images (see Methods and Ringach and Shapley, 2004 for details), in order to examine the response properties of the RN neurons. As shown in STAs of Figure 5C, simple-cell-like orientation selectivity is reproduced in the simulation with a low firing rate (p0 = 0.0015) of the neurons in the recurrent network and a relatively high firing rate (pinput = 0.15) of the input neurons. The neurons acquire selectivity to edge-shaped (Gabor-function-like) contrasts of various positions, sizes, phases, frequencies, and orientations as observed in macaque V1 (Ringach, 2002). As shown in the weight matrix in Figure 5D, the synaptic weights of the recurrent connections after learning are almost zero, probably reflecting the i.i.d. presentation of the input images. In conclusion, our biologically plausible learning rule reproduces orientation selectivity of simple cells in V1 in a similar way to the previous Infomax algorithms on feedforward and recurrent neural networks (Bell and Sejnowski, 1997; Tanaka et al., 2009).
3. Discussion
In this paper, we have constructed a biologically plausible rule for the recurrent Infomax learning proposed in Tanaka et al. (2009), and reproduced the following several firing profiles of cortical neurons: (1) cell-assembly-like repeats of precise firing sequences, (2) neuronal avalanches, (3) replays of sensory-evoked firing sequences, and (4) orientation selectivity of simple cells in V1.
3.1. Biologically Plausible Learning Rule and its Similarity to STDP
In the preceding study (Tanaka et al., 2009), the learning algorithm for the recurrent Infomax was biologically implausible, which might be due to a common difficulty in considering biological realization of learning algorithms in recurrent neural networks. Actually, until recently, most learning rules proposed as biologically plausible have been limited mainly to feedforward neural networks (Savin et al., 2010; Zylberberg et al., 2011; Tanaka et al., 2012). In the present study, we have constructed a learning rule for the recurrent Infomax, according to which weight changes are computed by each postsynaptic neuron through its local interactions with other neurons and modulation by global signals γtk (1 ≤ k ≤ 4). Although the present learning rule requires the global signals γtk, we presume neural substrates for these global signals as follows. We first note that γt1 − γt3 − γt4 is a simple population sum of non-linearly transformed activities of single neurons. On the other hand, γt2 is a non-linear function of the population activity mt = ∑ixti and its temporal integration 〈 mt〉T. Thus, we should consider two different neural substrates.
For the calculation of γt1 − γt3 − γt4, before the summation over the neuronal population is taken, a complicated non-linear function of neural activity xti and sti must be computed by each of the neurons. It would be reasonable to assume that such complicated computations are realized through intracellular processes. Then, as a neural substrate for the simple summation of these intracellularly computed quantities over the neuronal population, we are able to assume a rapidly diffusing substance (for example, nitric oxide, neuropeptides, lipid metabolites, endcannabinoids, and so on) emitted by each neuron with an amount proportional to the intracellularly computed quantity. As a consequence of its rapid diffusion, its concentration in the neuronal circuit represents the population sum, that is, γt1 − γt3 − γt4. The multiplication of by γt1 − γt3 − γt4 may then be realized through the modulation of intracellular signaling in the target neuron i by the rapidly diffusing substance. On the other hand, for the calculation of γt2, the population activity mt and its temporal integration 〈 mt〉T need to be non-linearly transformed. We suggest interneurons, for example, as a neural substrate for this transformation. Some class of interneurons receives massive inputs from surrounding excitatory neurons and returns feedback to them (Markram et al., 2004). Thus, these interneurons may possibly compute the non-linear function of mt and 〈 mt〉T in γt2, and then amplify via intracellular signaling in the target neuron i by acting on the metabotropic receptors.
Hence, as we have discussed, all the processes included in Equations (3) and (4) of the present learning rule are biologically plausible in principle. It is worth noting that the above computational discussion may provides a novel perspective on the roles played by many kinds of neurotransmitters and neuromodulators and many types of inhibitory interneurons. Since the present learning rule has successfully reproduced several characteristic firing profiles of cortical neurons, we suggest the importance of experimental investigation in the candidate neural substrates for the present learning rule.
We further note similarities between the local quantity ψtixtj in the present learning rule and synaptic changes according to classical STDP (Bi and Poo, 1998). For γtk > 0, ψt − ui xt − uj (u ≥ 1) in the present learning rule represents the potentiation of synaptic weights at time t when the firing of the presynaptic neuron at time t − u precedes the firing of the postsynaptic neuron at time t − u + 1 (the red lines in Figure 1). On the other hand, when the postsynaptic neuron fails to fire after the firing of the presynaptic neuron, the synapse is depressed (the blue lines in Figure 1). When synaptic changes according to 〈 ψtixtj〉τ with γtk > 0 are measured in the same setting as classical STDP (Bi and Poo, 1998), the synaptic changes would fall on a function of relative spike timing similar to that of classical STDP. Therefore, we suggest STDP as a candidate neural substrate for the computation of ψtixtj. In addition, the present learning rule has the same mathematical structure as the reward-modulated STDP recently developed for the neural implementation of policy-gradient algorithms in reinforcement learning (Florian, 2007; Frémaux et al., 2013). From this viewpoint, ψtixtj and γtk in the present learning rule corresponds to STDP and reward/temporal-difference (TD) error signals, respectively. The reward-modulated STDP was constructed using continuous-time neuron models, and we reasonably expect that the present learning rule can be extended to a learning rule for continuous time models by a similar derivation. In the present study, however, we have taken advantage of the mathematical clarity and computational tractability of discrete-time models. We additionally note that, even if we derive an extension to a continuous time model, there will remain arbitrariness in the determination of Δ t of the corresponding objective function I [xt; xt − Δ t]. In other words, a kind of coarse-graining that determines the time scale of encoding Δ t will be essential.
As discussed above, the present learning rule is biologically plausible in principle, but it is necessary to note the following points to consider further correspondences between the present model and real cortical circuits. Firstly, in our model, single neurons can make both excitatory and inhibitory synapses, violating Dale's law. In order to settle this issue, we may consider the highly non-random connectivity among excitatory and inhibitory neurons in the cerebral cortex. The cerebral cortex has columnar structures, in which neurons with similar responsiveness are aligned in vertical strips. Thus, it would be reasonable to expect that there is a pair of excitatory and inhibitory neurons with the same responsiveness. For example, we assume that there is a local strong constraint of the internal variable sti to be the same value between the pair. Then, this pair plays the same role as the idealized single neuron in our model. Secondly, our discussion is limited to learning in local microcircuits, not to learning in wider brain regions such as the whole cerebral cortex, as we have assumed locally diffusing or cellular substrates for the calculation of the global signals γtk. This contrasts with dopamine as a global signal for the modulation of STDP in reinforcement learning (Florian, 2007; Frémaux et al., 2013). In the latter case, we can assume that dopamine is released at the same time in very wide brain regions. In the future extension of our model, on the analogy of the case of dopamine, we may consider similar monoaminergic mechanisms for the integration of local microcircuits. Thirdly, the present learning rule is not in the form of the association of firing pairs in the case of negative ψtixtj, which is different from the concept of classical STDP. This discrepancy is also common to the reward-modulated STDP (Florian, 2007), but a heuristic approximation has been proposed for the explanation of the associative LTD part of classical STDP in Florian (2007). In contrast, we have not incorporated such heuristics into the present rule so as to clearly reproduce the firing profiles of cortical neurons. Considering that the present learning rule has successfully reproduced the firing profiles observed in real cortical circuits, and that classical STDP was measured in rather artificial experimental conditions, we suggest the importance of experimental investigation for the precise form of the plasticity in physiological conditions. In this context, several different forms of STDP have recently been reported (Caporale and Dan, 2008). Actually, non-associative synaptic changes similar to negative ψtixtj in the present learning rule have recently been reported in the neural system of the electric fish (Han et al., 2000). It should further be noted that STDP is only one aspect of more complicated intracellular processes including intracellular calcium dynamics, and some researchers have explored models of these processes behind STDP (Bienenstock et al., 1982; Shouval et al., 2002; Toyoizumi et al., 2005). We intend to consider the consistency between the plasticity of real cortical neurons and analytically derived learning rules in future studies.
3.2. Reproduction of Repeated Firing Sequences and Neuronal Avalanches
There have been many computational studies on sequential firing transmission, such as precise firing sequences and neuronal avalanches, since the age of the theory of cell assembly and synfire-chain (Hebb, 1949; Abeles, 1991). Several studies have demonstrated that certain specialized network structures allow reliable sequential firing transmission (Diesmann et al., 1999; Teramae and Fukai, 2007; Teramae et al., 2012). From the viewpoint of learning, an author has numerically demonstrated that stereotypical sequences of firing are generated by STDP in recurrent neural networks and represent memory of input stimulation (Izhikevich, 2006). Several issues, however, have remained to be settled, concerning the instability of the firing sequences under the reorganization according to their learning rule and the lack of theoretical interpretability of STDP. The instability and the lack of interpretability of STDP in this context has been recognized, and a great effort has been made on the study of neural mechanisms for the stabilization of spontaneous activity self-organized by STDP (Fiete et al., 2010; Gilson and Fukai, 2011). Our approach solves this problem by realizing stable self-organization of spontaneous activity through the modulation of STDP by the global signals in the present learning rule, if we admit that STDP is the neural substrate for ψtixtj in Equation (3).
In the self-organization of spontaneous activity, the present learning rule has reproduced neuronal avalanches for small p0 and pmax values, and repeats of precise firing sequences for larger pmax values. A computational study has recently reported that recurrent neural networks with sparsely distributed strong connections display apparently asynchronous and irregular firing activity consisting of precise sequential firing transmission (Teramae et al., 2012). Such a network structure is supported by recent experimental results that magnitudes of synaptic potentials in the cerebral cortex have a skewed distribution, and only a small fraction of the synapses evokes very large excitatory postsynaptic potentials (Feldmeyer et al., 2002; Song et al., 2005). There is more supporting evidence that the firing activity of cortical neurons in behaving animals is apparently asynchronous and irregular (Renart et al., 2010). The present results are consistent with all of these previous computational and experimental results, since the firing activity with many repeated sequences in the present study is apparently asynchronous and irregular, and the underlying network structure consists of sparsely distributed strong connections. Thus, the present learning rule provides a candidate learning mechanism for the previous experimental results.
3.3. Reproduction of Replays of Sensory-Evoked Firing Sequences
We have further applied the learning rule not only to spontaneously firing neural networks but also to neural networks with external inputs. We have observed that stochastically varying external inputs reliably evoked stereotypical firing sequences in the recurrent network after learning. In the evoked activity, stochastic variation of external inputs was encoded into the activation of distinct parts of a common network structure. Such encoding of similar but distinct external inputs into a common network structure is thought to be more efficient than encoding them into different network structures. Such an efficient encoding would be preferable for limited resources in animal brains and under environmental uncertainty in the real world. Furthermore, we have found that the evoked sequences were replayed spontaneously. These results suggest that the present learning rule is a candidate learning mechanism for the emergence of sensory-evoked firing sequences and its replays in the sleeping state or in the quietly awake state (Skaggs and McNaughton, 1996; Lee and Wilson, 2002; Yao et al., 2007). Since sleep is considered to play a role in the consolidation of memory (Stickgold and Walker, 2005), the present learning rule might provide a clue to the underlying mechanisms of memory consolidation in future studies.
3.4. Reproduction of Orientation Selectivity in V1
For feedforward neural networks, several biologically plausible learning rules have been proposed to explain the emergence of orientation selectivity in V1 (Zylberberg et al., 2011; Tanaka et al., 2012). These learning rules are, however, not applicable to the dynamics of recurrent neural networks. Several computational studies have proposed STDP as a learning mechanism for independent component analysis (ICA) in the brain, and accounted for the emergence of orientation selectivity (Savin et al., 2010; Gilson et al., 2012). However, the demonstration of the performance of their learning rules has been limited to the extraction of relatively small numbers (up to 10) of features. In the context of unsupervised learning by means of STDP, Nessler et al. (2013) theoretically showed that STDP provides a mechanism for Bayesian computation and demonstrated unsupervised clustering with their learning rule, but their theory did not explain the emergence of orientation selectivity.
The present Infomax learning rule has an STDP-like component as discussed in the previous section, and Infomax learning is considered to be almost equivalent to ICA in many situations. Although the previous studies of STDP-based learning rules (Savin et al., 2010; Gilson et al., 2012) have suggested that STDP provides a learning mechanism for ICA, the present learning rule has clearly outperformed their STDP-based learning rules by reproducing one hundred simple-cell-like receptive fields of various orientations, phases, positions, and sizes, compared with the up-to-ten receptive fields reproduced in the previous studies. The difference of the present learning rule from the other STDP-based learning rules for ICA or clustering (Savin et al., 2010; Gilson et al., 2012; Nessler et al., 2013) is the correlation term A2 in Equation (2), which has been introduced for the active decorrelation of firing activity. Thus, it is expected that A2 has played a role in further penalizing residual dependence between neuronal firing, suggesting that a mechanism for active decorrelation such as A2 in addition to STDP is effective for ICA. It is noticeable that A2 also represents population sparseness, since it is a long-time average of the square of population activity. This provides an intuitive explanation of the reason for which learning according to both the Infomax and sparse coding principles leads to the extraction of similar features from natural images (Bell and Sejnowski, 1997; Olshausen and Field, 1997).
4. Methods
4.1. Construction of the Approximate Objective Function
In this section, we construct the objective function, Equation (2), that approximates Equation (1), and then derive the learning rule, Equations (3) and (4). First, the mutual information is decomposed as
The second equality is due to the conditional independence of the dynamics. The third equality holds and the mutual information is decomposed if and only if {xti}1 ≤ i ≤ N are independent. Then, we approximate the mutual information with of Equation (8) by subtracting a penalty term so as to bound the firing distribution near the independent distribution. Given that p0 ≪ 1 and positive second-order correlations are O(p20) for i ≠ j, negative second-order correlations and all multi-body correlations are necessarily O(p20). So, ignoring the negative and multi-body correlations, we use , the sum of second-order correlations as a penalty term. We further subtract the firing-rate term for the constraint of average firing rates to be p0, and the fluctuation term for the confinement of fluctuation of internal variables sti within a physiologically reasonable range. Hence, we obtain an objective function − A2 − A3 − A4. In preliminary simulations, however, we have found that the derivatives of this objective function are very small over a wide range of parameters where is relatively small, and that learning does not actually proceed (data not shown). We therefore take the logarithm of I [xti|xt − 1] in in order to accelerate learning. It provides a lower bound of , since (Jensen inequality). Maximization of this lower bound implies maximization of if I [xti; xt − 1] are equal for 1 ≤ i ≤ N, which is almost the case in the present simulation. In this way, we obtain and restate the objective function (Equation (2)):
It might also be naturally considered to use A′1 in the following equation for the acceleration of learning, taking the logarithm outside the sum of neuron-wise information terms, rather than using the lower bound A1.
In this case, we can also derive a learning rule which is biologically plausible in the same sense as Equations (3) and (4), by replacing γt1 with
In the two learning processes according to either of A1 or A′1, the values of the sum of neuron-wise information terms ∑iI [xti; xt − 1] are almost equal during the course of learning (Figure 6A). In simulations with A′1, the network actually learns to reproduce almost the same results as in the main text of this paper. For example, the same power law as in Figure 3B is reproduced after learning according to the objective function A ′ (Figure 6B). The learning rule derived from A′, however, requires three different neural substrates for the global signals. Inspecting γ′, t1, we notice that it is necessary to divide a global term ∑ilog p(xti; xt − 1)/Zti by another global term ∑i 〈 log p(xti|xt − 1)/Zti〉T. Hence, we cannot decompose γ′, t1 into neuron-wise terms, and must consider two different neural substrates for this term. We considered that the assumption of more global signals reduces biological plausibility. Thus, we do not adopt A′1 in the present study.
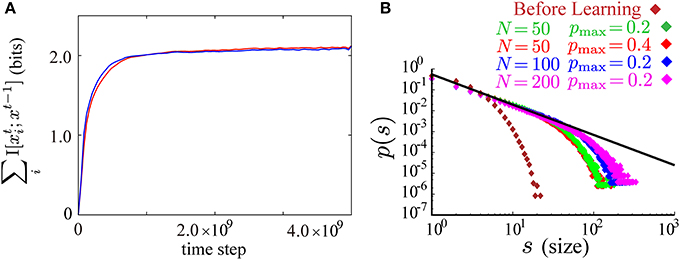
Figure 6. (A) Time evolution of the sum of the neuron-wise information terms ∑iI [xti; xt − 1] during the course of learning according to the objective function with the lower bound A1, Equation (9) (the red curve), and the modified objective function obtained by replacing A1 with A′1, Equation (10) (the blue curve). (B) The results in Figure 3B are reproduced after learning with the modified objective function and the same learning parameters as in Figure 3B. Log-log plots of size of bursts s against the occurrence of bursts of that size p(s) before (brown) and after learning (red for pmax = 0.4 and N = 50, green for pmax = 0.2 and N = 50, blue for pmax = 0.2 and N = 100, and magenta for pmax = 0.2 and N = 200). The size distributions after learning fall on the straight line of slope around −3/2 (the black line).
In a preliminary simulation, we observed that the correlation term A2 and the firing-rate term A3 successfully decorrelate neuronal activity and control mean firing rates to be p0 (see Figures 2D,E). Without the fluctuation term A4, we found that the learning proceeds successfully in the early stages (the raster plot in Figure 7A2), but overly strong positive and negative synaptic weights form nearly periodic firing patterns at later stages (the raster plots in Figures 7B2,C2). In this nearly periodic pattern of firing, the first term of Equation (8), the entropy term, would be small and thus the mutual information would not be maximized. The origin of this failure is attributed to the fact that the negative and higher-order correlations are no longer negligible in this nearly periodic firing pattern caused by the strong positive and negative connections. In fact, the many negative pairwise correlations near −p20 balance the large positive pairwise correlations in A2 as shown in the histograms of correlations in Figures 7B1,C1, thus violating the assumption on which we have constructed A2. In contrast, we have found that the objective function with the fluctuation term A4 stably decorrelates firing activity (histograms of correlations in Figures 7D1–F1 and raster plots in Figures 7D2–F2).
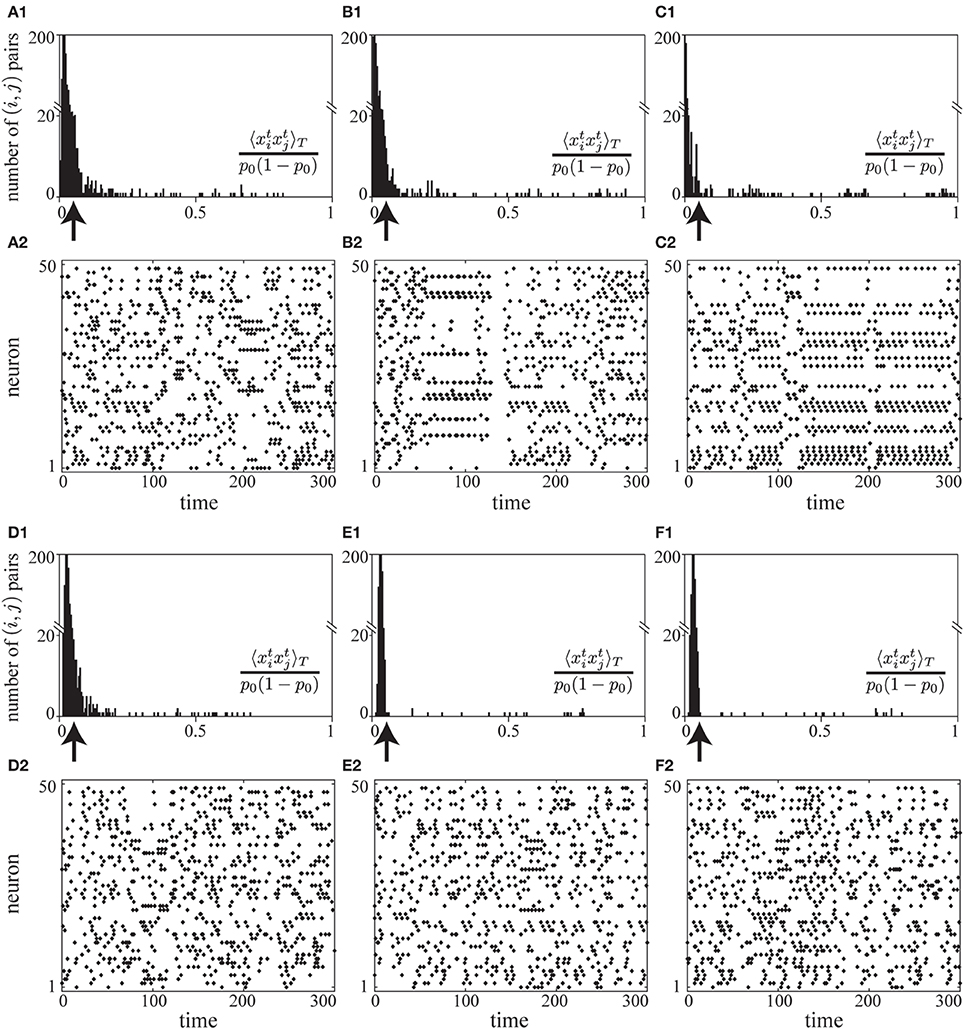
Figure 7. (A1–C2) A simulation of learning in a spontaneously firing network without the fluctuation term A4. Histograms of pairwise correlations 〈 xixj〉T/{p0(1 − p0)} (i ≠ j) (A1–C1) and raster plots (A2–C2) at different time steps during learning (the 5× 108, 1× 109, and 2× 109-th steps, respectively) are shown. The learning coefficient cζ is set to be 10000.0 so that the fluctuation term A4 does not take effect. (D1–F2) A simulation of learning in a spontaneously firing network under the effects of the fluctuation term A4. Histograms of pairwise correlations 〈 xixj〉T/{p0(1 − p0)} (i ≠ j) (D1–F1) and raster plots (D2–F2) at different time steps during learning (the 5× 108, 1× 109, and 2× 109-th steps, respectively) are shown. The learning coefficient cζ is set to be 3.0, the same value as that used in the simulation in Figure 2. In (A1–C1) and (D1–F1), the arrows indicate the value of correlation between the independent firing of xti and xtj. For the simulation in this figure, the same learning coefficients as those used in Figure 2 are used except cζ : ϵ = 0.006, cη = 1.5, cκ = 1.0, cζ = 3.0, or 10000.0, p0 = 0.05, pmax = 0.95, N = 50, τ = 15, T = 50000.
In addition, we represent the coefficients of the penalty terms in Equation (9) with the scaled parameters. Assuming that positive second-order correlations and deviations of average firing rates from p0 are O(p20), we obtain A2∝ p40 and A3∝ p20. From the numbers of terms in the summations with respect to i, j in Equation (9), we obtain that A1 ∝ N, A2 ∝ N, A3 ∝ N2, and A4 ∝ N. Thus, we have determined the scale as:
4.2. Derivation of the Biologically Plausible Learning Rule
Before deriving the learning rule, Equations (3) and (4), we first consider the maximization of a general objective function 〈 γt〉∞ with respect to model parameters wij and hi. Here, γt is an arbitrary function of firing patterns xt and xt − 1, and model parameters, wij and hi. More precisely, our aim is to calculate gradients of the following objective function for the gradient ascent method:
In the above equation, the summation has been taken over all possible firing patterns for xt − 1 and xt in {0, 1}2N. When we try to take gradients of the above quantity, we find that differentiation of the stationary distribution ps(xt − 1) is apparently intractable while differentiation of the other components is easily computed. We notice, however, that we do not need to differentiate the stationary distribution ps(xt) explicitly, assuming that the firing distribution p(xt) converges to a unique stationary distribution as time passes, and that the stationary distribution is a smooth function of the model parameters, wij and hi. On these assumptions, small changes of ps(xt − τ) for τ ≫ 1 in the objective function eventually vanish at t and t − 1, and thus the terms including the derivatives of ps(xt − τ) are negligible (see also Baxter and Bartlett, 1999). Then, we can compute the gradients as follows:
We obtain the following derivative with respect to hi in a similar way:
Calculating the gradients of the objective function, Equation (2), by repeatedly applying the above formula, Equations (13) and (14), we obtain a gradient ascent algorithm , where
The last terms in Equations (15) and (16) are due to the explicit dependence of t4 on wij and hi, and correspond to the second terms in Equations (13) and (14). Since t2 and t3 do not depend explicitly on wij and hi, the corresponding terms are zero. Although t1 depends on wij and hi explicitly, the corresponding terms turn out to vanish as follows:
Here, xt\i represents a vector consisting of the components of xt except the i-th component. At this stage, the gradient ascent algorithm, Equations (15) and (16), is not temporarily local while it is composed of synaptically local quantities modulated by biologically plausible global signals. There is, however, a natural approximation by a temporarily local learning rule that exploits the following relation. Notations for exponents and time indices can be clearly discriminated and should not be confounded in the below. For an arbitrary real-valued process qt and τ > 1, we define 〈 qt〉τ as in the Results section:
Then
Here, we put qt = 0 for t < 0. If the process under consideration is stationary, 〈 qt〉τ approaches the long-time average of qt as τ → ∞ and t/τ → ∞. Similarly, assuming that γtk has little correlation with ψt − τi for sufficiently large τ ≫ 1, and that T ≫ τ, we have
Exploiting these relations, Equations (17) and (18), instead of explicitly handling time averages, we obtain an approximation of the gradients in Equations (15) and (16) which is calculated in a temporarily local manner. Then, applying the usual stochastic approximation theory (Robbins and Monro, 1951), we obtain the temporarily local learning rule, Equations (3) and (4). Since our goal is to study biologically plausible learning rules and not to obtain rigorous convergence, we have not adjusted the value of ϵ depending on t in the simulations. For a fixed small ϵ, however, the learning has essentially stopped, probably at a local maximum.
4.3. Autocorrelograms and Coefficients of Variation
We calculated autocorrelograms and CVs of ISIs in Figures 2J,K. For this calculation, we used firing activity for a particular T0 = 50000 steps (T1 ≤ t ≤ T1 + T0) after learning. From this spike train, the autocorrelogram C(ρ) with lag ρ for the i-th neuron is calculated as
The CVs of ISIs of the i-th neuron is calculated from the collection of ISIs {lu}1 ≤ u ≤ U in the same T0 steps as
where
4.4. Image Preparation in the Learning of Natural Images
The original and preprocessed images are the same as those used in the seminal paper (Olshausen and Field, 1997). The original images are ten 512× 512 images of natural surroundings in the American northwest. Gray-scaled images are zero-centered, whitened and low-pass-filtered using a filter with the frequency response
where the cut-off frequency is fc = 200 cycles per picture. Whitening and zero-centering are due to the high-pass filtering property of f, while exp (−(f / fc)4) eliminates artifacts of higher frequency than rectangular sampling (see Atick, 1992 for further details). The images and the Matlab program codes are provided at the webpage by Olshausen (2012).
4.5. An Approximate Measure of the Mutual Information
Following the preceding study (Tanaka et al., 2009), we define an approximate measure of the mutual information . C and D are covariance matrices of xt and xt ⊗ xt − 1, respectively. Particularly, C is a N × N matrix defined as for 1 ≤ i, j ≤ N, while D is a 2N × 2N matrix defined as , and for 1 ≤ i, j ≤ N. If both of the firing distribution of xt and the joint distribution of xt and xt − 1 have Gaussian probability densities, the mutual information I [xt; xt − 1] is equal to Igauss. In the numerical simulation, we have calculated a finite-time approximation gauss by replacing the terms like 〈 xtixtj〉∞ with corresponding finite-time averages like .
4.6. Calculation of Spike Triggered Averages of Input Images
In the learning of input images, we calculated reverse correlations by taking spike-triggered average of input images presented at the previous time step of neuronal firing, as in the examination of receptive fields in physiological experiments (Ringach and Shapley, 2004). Concretely, the spike-triggered average of input images with respect to neuron i is calculated as y(i)STA, j = 〈 yt − 1j xti〉T for 1 ≤ i ≤ N and 1 ≤ j ≤ 144. Then, we linearly rescale y(i)STA, j into y*, (i)STA, j for each i so that the mean over the pixel components is 128 as , and that the maximal deviation from the mean is 127 as maxj|y*, (i)STA, j − y *,(i)mean| = 127. We have plotted the rescaled average y*, (i)STA, j as a 12× 12 pixel patch in a gray scale ranging from 1 (black) through 255 (white) in Figure 5B.
4.7. Interpretation of the Internal Variable as an Input Current
We have defined our dynamics as . The internal variable sti can be interpreted as an input current to the neuron i. To show this, we simulate an integrate-and-fire neuron model with constant input currents. We solve the following continuous-time dynamics of membrane potential V by the Euler-Maruyama method with a step size Δ t = 0.01 (ms):
In the above equation, we have added Wiener noise ξ with a constant coefficient D = 3. The membrane constant is τm = 15 (ms). If V exceeds the threshold potential θ = −50 (mV), we reset the membrane potential to the resting potential Vrest = −70 (mV) and hold it for a refractory period tref = 1, 2, or 3 (ms). We apply input currents I = −200~ 600 (mV) to this model, describing the input current in units of mV on the assumption that the input resistance is a dimensionless quantity equal to unity. Then, we find that the dependence of the firing frequency f (cycle/ms) of the neuron model on the applied current I falls on a sigmoid curve as shown in Figure 8. We further observe that the maximal firing probability depends on the length of the refractory period (Figure 8).
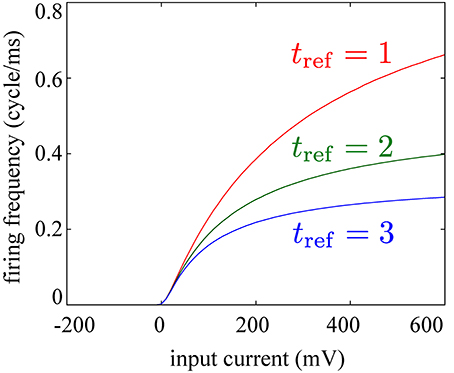
Figure 8. Dependence of firing frequencies of an integrate-and-fire model on magnitudes of constant input currents falls on a sigmoid curve. Saturating frequencies depend on the length of the refractory period tref as indicated by the differently-colored curves [red: tref = 1 (ms), green: tref = 2 (ms), blue: tref = 3 (ms)].
Funding
This study was supported by Grants-in-Aid from The Ministry of Education, Culture, Sports, Science and Technology (MEXT) for Scientific Research (22300113 and 25250006 to Takeshi Kaneko); for Exploratory Research (23650175 to Takeshi Kaneko); and for Scientific Researches on Innovative Areas “Mesoscopic Neurocircuitry” (23115101 to Takeshi Kaneko and 25115719 to Toshio Aoyagi) and “The study on the neural dynamics for understanding communication in terms of complex hetero systems” (21120002 to Toshio Aoyagi).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Takuma Tanaka for fruitful discussions and advice. We also thank Professor Bruno Olshausen for providing data and program code for the filtered natural images used in the present study.
References
Abeles, M. (1991). Corticonics: Neural Circuits of The Cerebral Cortex. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511574566
Atick, J. J. (1992). Could information theory provide an ecological theory of sensory processing? Network 3, 213–251. doi: 10.1088/0954-898X/3/2/009
Barlow, H. (2001). The exploitation of regularities in the environment by the brain. Behav. Brain Sci. 24, 602–607. doi: 10.1017/S0140525X01000024
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Baxter, J., and Bartlett, P. L. (1999). Direct Gradient-Based Reinforcement Learning: I. Gradient Estimation Algorithms. Technical Report, National University.
Beggs, J. M., and Plenz, D. (2003). Neuronal avalanches in neocortical circuits. J. Neurosci. 23, 11167–11177.
Bell, A. J., and Sejnowski, T. J. (1995). An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 7, 1129–1159. doi: 10.1162/neco.1995.7.6.1129
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Bell, A. J., and Sejnowski, T. J. (1997). The “independent components” of natural scenes are edge filters. Vision Res. 37, 3327–3338. doi: 10.1016/S0042-6989(97)00121-1
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Bi, G.-Q., and Poo, M.-M. (1998). Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type. J. Neurosci. 18, 10464–10472.
Bienenstock, E. L., Cooper, L. N., and Munro, P. W. (1982). Theory for the development of neuron selectivity: orientation specificity and binocular interaction in visual cortex. J. Neurosci. 2, 32–48.
Caporale, N., and Dan, Y. (2008). Spike timing-dependent plasticity: a Hebbian learning rule. Annu. Rev. Neurosci. 31, 25–46. doi: 10.1146/annurev.neuro.31.060407.125639
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Chechik, G. (2003). Spike-timing-dependent plasticity and relevant mutual information maximization. Neural Comput. 15, 1481–1510. doi: 10.1162/089976603321891774
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Chen, W., Hobbs, J. P., Tang, A., and Beggs, J. M. (2010). A few strong connections: optimizing information retention in neuronal avalanches. BMC Neurosci. 11:3. doi: 10.1186/1471-2202-11-3
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Cover, T. M., and Thomas, J. A. (2012). Elements of Information Theory. Hoboken, NJ: John Wiley & Sons.
Deco, G., and Parra, L. (1997). Non-linear feature extraction by redundancy reduction in an unsupervised stochastic neural network. Neural Netw. 10, 683–691. doi: 10.1016/S0893-6080(96)00110-4
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Diesmann, M., Gewaltig, M.-O., and Aertsen, A. (1999). Stable propagation of synchronous spiking in cortical neural networks. Nature 402, 529–533. doi: 10.1038/990101
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Douglas, R. J., and Martin, K. A. C. (2007). Recurrent neuronal circuits in the neocortex. Curr. Biol. 17, R496–R500. doi: 10.1016/j.cub.2007.04.024
Feldmeyer, D., Lübke, J., Silver, R. A., and Sakmann, B. (2002). Synaptic connections between layer 4 spiny neurone-layer 2/3 pyramidal cell pairs in juvenile rat barrel cortex: physiology and anatomy of interlaminar signalling within a cortical column. J. Physiol. 538, 803–822. doi: 10.1113/jphysiol.2001.012959
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Fiete, I. R., Senn, W., Wang, C. Z., and Hahnloser, R. H. (2010). Spike-time-dependent plasticity and heterosynaptic competition organize networks to produce long scale-free sequences of neural activity. Neuron 65, 563–576. doi: 10.1016/j.neuron.2010.02.003
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Florian, R. V. (2007). Reinforcement learning through modulation of spike-timing-dependent synaptic plasticity. Neural Comput. 19, 1468–1502. doi: 10.1162/neco.2007.19.6.1468
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Frémaux, N., Sprekeler, H., and Gerstner, W. (2013). Reinforcement learning using a continuous time actor-critic framework with spiking neurons. PLoS Comput. Biol. 9:e1003024. doi: 10.1371/journal.pcbi.1003024
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Gilson, M., and Fukai, T. (2011). Stability versus neuronal specialization for STDP: long-tail weight distributions solve the dilemma. PLoS ONE 6:e25339. doi: 10.1371/journal.pone.0025339
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Gilson, M., Fukai, T., and Burkitt, A. N. (2012). Spectral analysis of input spike trains by spike-timing-dependent plasticity. PLoS Comput. Biol. 8:e1002584. doi: 10.1371/journal.pcbi.1002584
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Han, V. Z., Grant, K., and Bell, C. C. (2000). Reversible associative depression and nonassociative potentiation at a parallel fiber synapse. Neuron 27, 611–622. doi: 10.1016/S0896-6273(00)00070-2
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hebb, D. (1949). The Organization of Behavior: A Neuropsychological Theory. Hoboken, NJ: John Wiley & Sons.
Hubel, D. H., and Wiesel, T. N. (1959). Receptive fields of single neurones in the cat's striate cortex. J. Physiol. 148, 574–591.
Hyvärinen, A., Hoyer, P. O., and Inki, M. (2001a). Topographic independent component analysis. Neural Comput. 13, 1527–1558. doi: 10.1162/089976601750264992
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hyvärinen, A., Karhunen, J., and Oja, E. (2001b). Independent Component Analysis. NewYork, NY: Wiley. doi: 10.1002/0471221317
Ikegaya, Y., Aaron, G., Cossart, R., Aronov, D., Lampl, I., Ferster, D., et al. (2004). Synfire chains and cortical songs: temporal modules of cortical activity. Science 304, 559–564. doi: 10.1126/science.1093173
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Izhikevich, E. M. (2006). Polychronization: computation with spikes. Neural Comput. 18, 245–282. doi: 10.1162/089976606775093882
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kaneko, T. (2013). Local connections of excitatory neurons in motor-associated cortical areas of the rat. Front. Neural Circuits 7:75. doi: 10.3389/fncir.2013.00075
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Karklin, Y., and Lewicki, M. S. (2005). A hierarchical Bayesian model for learning nonlinear statistical regularities in nonstationary natural signals. Neural Comput. 17, 397–423. doi: 10.1162/0899766053011474
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kay, J. W., and Phillips, W. A. (2010). Coherent Infomax as a computational goal for neural systems. Bull. Math. Biol. 73, 344–372. doi: 10.1007/s11538-010-9564-x
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Lee, A. K., and Wilson, M. A. (2002). Memory of sequential experience in the hippocampus during slow wave sleep. Neuron 36, 1183–1194. doi: 10.1016/S0896-6273(02)01096-6
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Linsker, R. (1988). Self-organization in a perceptual network. Computer 21, 105–117. doi: 10.1109/2.36
Markram, H., Toledo-Rodriguez, M., Wang, Y., Gupta, A., Silberberg, G., and Wu, C. (2004). Interneurons of the neocortical inhibitory system. Nat. Rev. Neurosci. 5, 793–807. doi: 10.1038/nrn1519
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Nessler, B., Pfeiffer, M., Buesing, L., and Maass, W. (2013). Bayesian computation emerges in generic cortical microcircuits through spike-timing-dependent plasticity. PLoS Comput. Biol. 9:e1003037. doi: 10.1371/journal.pcbi.1003037
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Okajima, K. (2001). An Infomax-based learning rule that generates cells similar to visual cortical neurons. Neural Netw. 14, 1173–1180. doi: 10.1016/S0893-6080(01)00091-0
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Olshausen, B. A. (2012). Sparse Coding Simulation Software. Available online at: http://redwood.berkeley.edu/bruno/sparsenet/ (Accessed July 20, 2012).
Olshausen, B. A., and Field, D. J. (1997). Sparse coding with an overcomplete basis set: a strategy employed by V1? Vision Res. 37, 15–15. doi: 10.1016/S0042-6989(97)00169-7
Ren, M., Yoshimura, Y., Takada, N., Horibe, S., and Komatsu, Y. (2007). Specialized inhibitory synaptic actions between nearby neocortical pyramidal neurons. Science 316, 758–761. doi: 10.1126/science.1135468
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Renart, A., de la Rocha, J., Bartho, P., Hollender, L., Parga, N., Reyes, A., et al. (2010). The asynchronous state in cortical circuits. Science 327, 587–590. doi: 10.1126/science.1179850
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Ringach, D., and Shapley, R. (2004). Reverse correlation in neurophysiology. Cogn. Sci. 28, 147–166. doi: 10.1207/s15516709cog2802_2
Ringach, D. L. (2002). Spatial structure and symmetry of simple-cell receptive fields in macaque primary visual cortex. J. Neurophysiol. 88, 455–463.
Robbins, H., and Monro, S. (1951). A stochastic approximation method. Ann. Math. Stat. 22, 400–407. doi: 10.1214/aoms/1177729586
Savin, C., Joshi, P., and Triesch, J. (2010). Independent component analysis in spiking neurons. PLoS Comput. Biol. 6:e1000757. doi: 10.1371/journal.pcbi.1000757
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Shouval, H. Z., Bear, M. F., and Cooper, L. N. (2002). A unified model of NMDA receptor-dependent bidirectional synaptic plasticity. Proc. Natl. Acad. Sci. U.S.A. 99, 10831–10836. doi: 10.1073/pnas.152343099
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Skaggs, W. E., and McNaughton, B. L. (1996). Replay of neuronal firing sequences in rat hippocampus during sleep following spatial experience. Science 271, 1870–1873. doi: 10.1126/science.271.5257.1870
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Song, S., Sjöström, P. J., Reigl, M., Nelson, S., and Chklovskii, D. B. (2005). Highly nonrandom features of synaptic connectivity in local cortical circuits. PLoS Biol. 3:e68. doi: 10.1371/journal.pbio.0030068
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Stickgold, R., and Walker, M. P. (2005). Memory consolidation and reconsolidation: what is the role of sleep? Trends Neurosci. 28, 408–415. doi: 10.1016/j.tins.2005.06.004
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tanaka, T., Aoyagi, T., and Kaneko, T. (2012). Replicating receptive fields of simple and complex cells in primary visual cortex in a neuronal network model with temporal and population sparseness and reliability. Neural Comput. 24, 2700–2725. doi: 10.1162/NECO_a_00341
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tanaka, T., Kaneko, T., and Aoyagi, T. (2009). Recurrent Infomax generates cell assemblies, neuronal avalanches, and simple cell-like selectivity. Neural Comput. 21, 1038–1067. doi: 10.1162/neco.2008.03-08-727
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Teramae, J.-N., and Fukai, T. (2007). Local cortical circuit model inferred from power-law distributed neuronal avalanches. J. Comput. Neurosci. 22, 301–312. doi: 10.1007/s10827-006-0014-6
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Teramae, J.-N., Tsubo, Y., and Fukai, T. (2012). Optimal spike-based communication in excitable networks with strong-sparse and weak-dense links. Sci. Rep. 2, 485. doi: 10.1038/srep00485
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Toyoizumi, T., Pfister, J.-P., Aihara, K., and Gerstner, W. (2005). Generalized Bienenstock–Cooper–Munro rule for spiking neurons that maximizes information transmission. Proc. Natl. Acad. Sci. U.S.A. 102, 5239–5244. doi: 10.1073/pnas.0500495102
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Wörgötter, F., and Porr, B. (2005). Temporal sequence learning, prediction, and control: a review of different models and their relation to biological mechanisms. Neural Comput. 17, 245–319. doi: 10.1162/0899766053011555
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Yao, H., Shi, L., Han, F., Gao, H., and Dan, Y. (2007). Rapid learning in cortical coding of visual scenes. Nat. Neurosci. 10, 772–778. doi: 10.1038/nn1895
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Zapperi, S., Lauritsen, K. B., and Stanley, H. E. (1995). Self-organized branching processes: mean-field theory for avalanches. Phys. Rev. Lett. 75, 4071–4074. doi: 10.1103/PhysRevLett.75.4071
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Zylberberg, J., Murphy, J. T., and DeWeese, M. R. (2011). A sparse coding model with synaptically local plasticity and spiking neurons can account for the diverse shapes of V1 simple cell receptive fields. PLoS Comput. Biol. 7:e1002250. doi: 10.1371/journal.pcbi.1002250
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Keywords: information maximization, biologically plausible learning rule, recurrent neural network, neuronal avalanche, precise firing sequence, orientation selectivity, spike-timing-dependent plasticity
Citation: Hayakawa T, Kaneko T and Aoyagi T (2014) A biologically plausible learning rule for the Infomax on recurrent neural networks. Front. Comput. Neurosci. 8:143. doi: 10.3389/fncom.2014.00143
Received: 17 January 2014; Accepted: 21 October 2014;
Published online: 25 November 2014.
Edited by:
Markus Diesmann, Jülich Research Centre, GermanyReviewed by:
Christian Leibold, Ludwig Maximilians University, GermanyMatthieu Gilson, Universitat Pompeu Fabra, Spain
J. Michael Herrmann, The University of Edinburgh, UK
Copyright © 2014 Hayakawa, Kaneko and Aoyagi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Takashi Hayakawa, Department of Morphological Brain Science, Graduate School of Medicine, Kyoto University, Yoshida-Konoecho, Sakyo-ku, Kyoto 6068501, Japan e-mail:aGF5YWthd2FAbWJzLm1lZC5reW90by11LmFjLmpw