 Dimitri Probst1†
Dimitri Probst1† Mihai A. Petrovici1†*
Mihai A. Petrovici1†* Ilja Bytschok1
Ilja Bytschok1 Johannes Bill2
Johannes Bill2 Dejan Pecevski2
Dejan Pecevski2 Johannes Schemmel1
Johannes Schemmel1 Karlheinz Meier1
Karlheinz Meier1- 1Kirchhoff Institute for Physics, University of Heidelberg, Heidelberg, Germany
- 2Institute for Theoretical Computer Science, Graz University of Technology, Graz, Austria
The means by which cortical neural networks are able to efficiently solve inference problems remains an open question in computational neuroscience. Recently, abstract models of Bayesian computation in neural circuits have been proposed, but they lack a mechanistic interpretation at the single-cell level. In this article, we describe a complete theoretical framework for building networks of leaky integrate-and-fire neurons that can sample from arbitrary probability distributions over binary random variables. We test our framework for a model inference task based on a psychophysical phenomenon (the Knill-Kersten optical illusion) and further assess its performance when applied to randomly generated distributions. As the local computations performed by the network strongly depend on the interaction between neurons, we compare several types of couplings mediated by either single synapses or interneuron chains. Due to its robustness to substrate imperfections such as parameter noise and background noise correlations, our model is particularly interesting for implementation on novel, neuro-inspired computing architectures, which can thereby serve as a fast, low-power substrate for solving real-world inference problems.
1. Introduction
The ability of the brain to generate predictive models of the environment based on sometimes ambiguous, often noisy and always incomplete sensory stimulus represents a hallmark of Bayesian computation. Both experimental (Yang and Shadlen, 2007; Berkes et al., 2011) and theoretical studies (Rao, 2004; Deneve, 2008; Buesing et al., 2011) have explored this highly intriguing but also hotly debated hypothesis. These approaches have, however, remained rather abstract, employing highly idealized neuron and synapse models.
In this study, we explore how recurrent networks of leaky integrate-and-fire (LIF) neurons—a standard neuron model in computational neuroscience—can calculate the posterior distribution of arbitrary Bayesian networks over binary random variables through their spike response. Our work builds upon the findings of three previous studies: In Buesing et al. (2011), it was shown how the spike pattern of networks of abstract model neurons can be understood as Markov Chain Monte Carlo (MCMC) sampling from a well-definded class of target distributions. The approach was extended in a follow up paper (Pecevski et al., 2011) to Bayesian networks by identifying appropriate network architectures. The theoretical foundation for taking the step from abstract neurons to more realistic networks of LIF neurons was developed recently in Petrovici et al. (2013). In this paper, we follow and extend the approach from Petrovici et al. (2013) to the network architectures proposed by Pecevski et al. (2011). In particular, we describe a blueprint for designing spiking networks that can perform sample-based inference in arbitrary graphical models.
We thereby provide the first fully functional implementation of Bayesian networks with realistic neuron models. This enables studies in two complementary fields. On one hand, the development of network implementations for Bayesian inference contributes to the open debate on its biological correlate by exploring possible realizations in the brain. These can subsequently guide both targeted experimental research and computational modeling. Furthermore, additional physiological investigation is now made possible, e.g., of the influence of specific neuron and synapse parameters and dynamics or the embedding in surrounding networks. On the other hand, the finding that networks of LIF neurons can implement parallelized inference algorithms provides an intriguing application field for novel computing architectures. Much effort is currently invested into the development of neuro-inspired, massively parallel computing platforms, called neuromorphic devices (Indiveri et al., 2006; Schemmel et al., 2010; Furber et al., 2013). These devices typically implement models of LIF neurons which evolve in parallel and without a central clock signal. This paper offers a concrete concept for the application of neuromorphic hardware as powerful inference machines. Interestingly, questions similar to the ones mentioned above in a biological context arise for artificial systems as well: the effect of parameter noise or limited bandwidth on functional network models is, for example, the subject of active research (Petrovici et al., 2014).
The document is structured as follows. In Section 2, we review and adapt the theories from Buesing et al. (2011); Pecevski et al. (2011) and Petrovici et al. (2013) to build a complete framework for embedding sampling from probability distributions into the structure and dynamics of networks of LIF neurons. In Section 3, we provide the required translation rules and demonstrate the feasibility of the approach in computer simulations. We further compare the effect of different synaptic coupling dynamics and present a mechanism based on interneuron chains which significantly improves the sampling quality. Finally, we study robustness to parameter distortions and to correlations in the background noise, as these are likely to be present in any physical substrate, be it biological or artificial. In Section 4, we discuss these results and their implications for biological and neuro-inspired computing architectures.
For the simulations with LIF neurons, we used PyNN (Davison et al., 2008) with NEST (Diesmann and Gewaltig, 2001) or NEURON (Hines and Carnevale, 2003) as back-end. The simulations with networks of abstract model neurons were conducted in Python.
2. Materials and Methods
2.1. Bayesian Networks as Boltzmann Machines
The joint distribution defined by a Bayesian graph is the product of conditional distributions, one for each random variable (RV), with its value conditioned on the values of its parent variables. For a graph with K binary RVs Zk, the joint probability distribution is given by
where zk represents the state vector of the variables Zk in Φk, which we henceforth call principal RVs, and pak represents the state vector of the parents of Zk. Z is a normalizing constant; w.l.o.g., we assume Φk > 1. The factor p(zk|pak) is called an nth-order factor if it depends on n RVs or rather |pak| = n − 1.
Such a Bayesian network can be transformed into a second-order Markov random field (i.e., an MRF with a maximum clique size of 2). Here, we follow the recipe described in Pecevski et al. (2011). First and second-order factors are easily replaceable by potential functions Ψk(Zk) and Ψk(Zk1, Zk2), respectively. For each nth-order factor Φk with n > 2 principal RVs, we introduce 2n auxiliary binary RVs Xzk ∈ 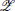 kk, where k is the set of all possible assignments of the binary vector Zk (Figure 1C). Each of these RVs “encode” the probability of a possible state zk within the factor Φk by introducing the first-order potential functions Ψzkk(Xzkk = 1) = Φk(Zk = zk). The factor Φk(Zk) is then replaced by a product over potential functions
kk, where k is the set of all possible assignments of the binary vector Zk (Figure 1C). Each of these RVs “encode” the probability of a possible state zk within the factor Φk by introducing the first-order potential functions Ψzkk(Xzkk = 1) = Φk(Zk = zk). The factor Φk(Zk) is then replaced by a product over potential functions
where an auxiliary RV Xzkk is active if and only if the principal RVs Zk are active in the configuration zk. Formally, this corresponds to the assignment: χzkki(Zki, Xzkk) = 1 − Xzkk (1 − δZki,zki). In the graphical representation, this amounts to removing all directed edges within the factors and replacing them by undirected edges from the principal to the auxiliary RVs. It can then be verified (Pecevski et al., 2011) that the target probability distribution can be represented as a marginal over the auxiliary variables.
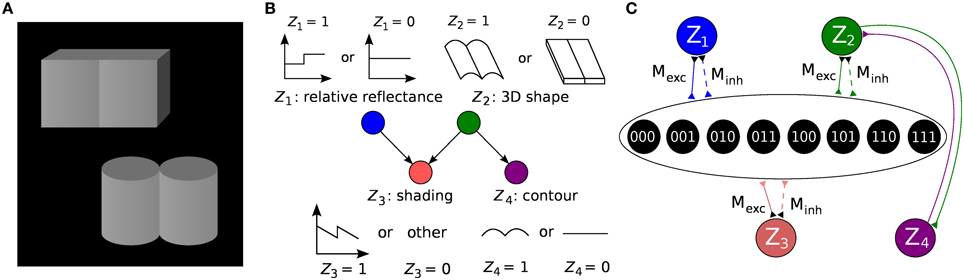
Figure 1. Formulation of an example inference problem as a Bayesian network and translation to a Boltzmann machine. (A) Knill-Kersten illusion from Knill and Kersten (1991). Although the four objects are identically shaded, the left cube is perceived as being darker than the right one. This illusion depends on the perceived shape of the objects and does not occur for, e.g., cylinders. (B) The setup can be translated to a Bayesian network with four binary RVs. The (latent) variables Z1 and Z2 encode the (unknown) reflectance profile and 3D shape of the objects, respectively. Conditioned on these variables, the (observed) shading and 2D contour are encoded by Z3 and Z4, respectively. Figure modified from Pecevski et al. (2011). (C) Representation of the Bayesian network from (B) as a Boltzmann machine. Factors of order higher than 2 are replaced by auxiliary variables as described in the main text. The individual connections with weights Mexc, Minh → ∞ between each principal and auxiliary variable have been omitted for clarity.
As the resulting graph is a second-order MRF, its underlying distribution can be cast in Boltzmann form:
where the (symmetric) weight matrices W, V and bias vectors b, a are defined as follows:
all other matrix and vector elements being zero. L1(·) represents the L1 norm. In the theoretical model, Mexc = ∞ and Minh = −∞, but they receive finite values in the concrete implementation (Section 2.4). From here, it is straightforward to create a corresponding classical Boltzmann machine. We therefore use a simplified notation from here on: we consider the vector Z to include both principal and auxiliary RVs and the Boltzmann distributions over Z are henceforth defined by the block diagonal weight matrix W and the bias vector b.
2.2. Neural Sampling: An Abstract Model
Gibbs sampling is typically used to update the states of the units in a Boltzmann machine. However, in a spiking network, detailed balance is not satisfied, since spiking neurons do not incorporate reversible dynamics due to the existence of refractory mechanisms. While a non-refractory neuron can always be brought into the refractory state with sufficient stimulation, the reverse transition is, in general, not possible. It is possible, however, to understand the dynamics of a network of stochastic neurons as MCMC sampling. In the following, we use the model proposed in Buesing et al. (2011) for sampling from Boltzmann distributions (Equation 3).
In this model, the spike response of a neuron is associated to the state zk of an RV Zk and a spike is interpreted as a state switch from 0 to 1. Each spike is followed by a refractory period of duration τ, during which the neuron remains in the state Zk = 1. The so-called neural computability condition (NCC) provides a sufficient condition for correct sampling, wherein a neuron's “knowledge” about the state of the rest of the network - and therefore its probability to spike - is encoded in its membrane potential:
where Z\k(t) denotes the vector of all other variables Zi with i ≠ k. By solving for Zk(t) = 1, one obtains a logistic neural activation function (Figure 2D), which is reminiscent of the update rules in Gibbs sampling:
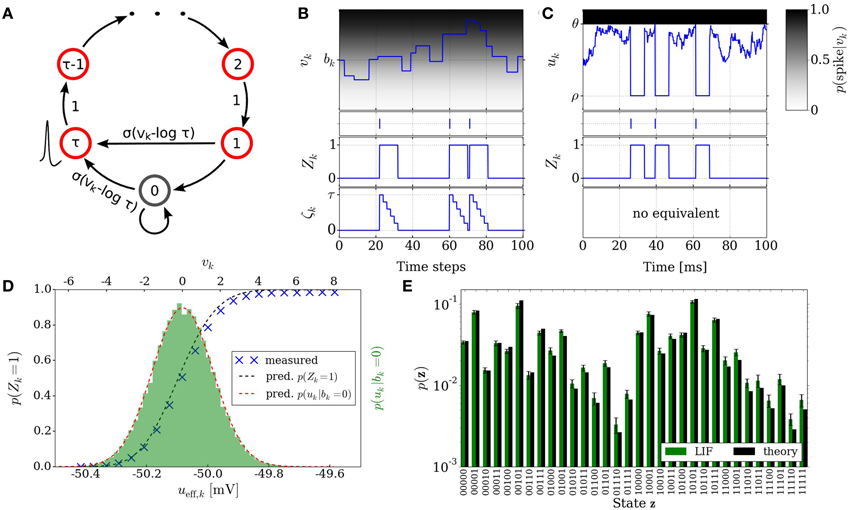
Figure 2. Neural sampling: abstract model vs. implementation with LIF neurons. (A) Illustration of the Markov chain over the refractory variable ζk in the abstract model. Figure taken from Buesing et al. (2011). (B) Example dynamics of all the variables associated with an abstract model neuron. (C) Example dynamics of the equivalent variables associated with an LIF neuron. (D) Free membrane potential distribution and activation function of an LIF neuron: theoretical prediction vs. experimental results. The blue crosses are the mean values of 5 simulations of duration 200 s. The error bars are smaller than the size of the symbols. Table 1 lists the used parameter values of the LIF neuron. (E) Performance of sampling with LIF neurons from a randomly chosen Boltzmann distribution over 5 binary RVs. Both weights and biases are chosen from a normal distribution  (μ = 0, σ = 0.5). The green bars are the results of 10 simulations of duration 100 s. The error bars denote the standard error.
(μ = 0, σ = 0.5). The green bars are the results of 10 simulations of duration 100 s. The error bars denote the standard error.
In order for a neuron to be able to track its progression through the refractory period, a refractory variable ζk is introduced for each neuron, which assumes the value τ following a spike at time t and decreases linearly toward 0 at time t + τ. The transition probability to the state ζk only depends on the previous state ζ′k. The resulting sequence of states ζk(t = 0), ζk(t = 1), ζk(t = 2),… is a Markov chain. Figure 2A illustrates the transition of the state variable ζk. A neuron with ζk ∈ {0, 1} elicits a spike with probability σ(vk − log τ). This defines the stochastic neuron model in Buesing et al. (2011).
For the particular case of a Boltzmann distribution with weight matrix W and bias vector b, the NCC (Equation 8) is satisfied by neurons with the membrane potential represented by a sum of rectangular postsynaptic potentials (PSPs):
Figure 2B illustrates the time courses of the membrane potential vk, the state variable Zk and the refractory variable ζk of an abstract model neuron.
2.3. Neural Sampling with LIF Neurons
In contrast to the abstract model described above, biological neurons exhibit markedly different dynamics. Most importantly, the firing times of individual neurons are not stochastic: in-vitro single neuron experiments show how a fixed stimulus sequence triggers a fixed spike train reliably over multiple trials (Mainen and Sejnowski, 1995). Also, their interaction is not mediated by rectangular PSPs. In-vivo, however, neurons often receive diffuse synaptic stimulus that alters their dynamics in several important ways (Destexhe et al., 2003). As demonstrated in Petrovici et al. (2013) and described below, under such conditions, deterministic neurons can attain the required stochastic dynamics to sample from arbitrary Boltzmann distributions.
A widely used neuron model that captures the abovementioned characteristics of biological neurons is the leaky integrate-and-fire (LIF) model, which defines neuron membrane dynamics as follows:
where Cm, gl and El represent the membrane capacitance, the membrane leakage conductance and the membrane leakage potential, respectively, and Iext represents an external stimulus current. Whenever u crosses a threshold θ, it is pulled down to a reset value ρ, where it stays for refractory time τref. For a given τref of the LIF neuron and a number τ of refractory time steps of the abstract model from Section 2.2, the state interpretation between the two domains can be aligned by interpreting an MCMC update step as a time interval Δt, such that τref = τ Δt. The synaptic interaction current Isyn denotes:
where wsyni represents the weight of the ith afferent synapse, Erevi its reversal potential and τsyn the synaptic time constant. Figure 2C illustrates exemplary time courses of the membrane potential uk and of the corresponding state variable Zk of a LIF neuron.
In the regime of diffuse synaptic background noise, it can be shown that the temporal evolution of the membrane potential is well approximated by an Ornstein-Uhlenbeck (OU) process with a mean and variance that can be computed analytically (Petrovici et al., 2013). This regime is achieved by intense synaptic bombardment from independent Poissonian spike sources with high firing rates νsyn and low synaptic weights. This allows calculating the temporal evolution of the membrane potential distribution p(u|u0), as well as the mean first-passage time T(u1, u2) of the membrane potential from u1 to u2. With this, the activation function of a single LIF neuron can be expressed as
where Pn represents the probability of an n-spike burst and Tn the average period of silence following such a burst. Both of these terms be expressed with recursive integrals that can be evaluated numerically (Petrovici et al., 2013).
Denoting by ueff the effective membrane potential (i.e., the average membrane potential under constant external stimulus other than the synaptic noise), this yields a sigmoidal activation function (ueff) (see Figure 2D), which can be linearly transformed to the logistic activation function σ(v) to match the abtract model in Section 2.2:
where 〈u〉0 represents the value of ueff for which p(Z = 1) = 1/2. The factor α denotes a scaling factor between the two domains and is equal to 4 [d/dueff(〈u〉0)]−1. From here, a set of parameter translation rules between the abstract and the LIF domain follow, which are explained in more detail in Section 2.5. Figure 2E shows the result of sampling with LIF neurons from an example Boltzmann distribution together with the target probability values.
2.4. Characterization of the Auxiliary Neurons
In the mathematical model in Section 2.1, the weights between principal and auxiliary RVs are Mexc = ∞ and Minh = −∞, to ensure a switching of the joint state whenever one of the auxiliary variables changes its assignment. In a concrete implementation, infinite weights are unfeasible. Here, we set the connection strengths Mexc,k = −Minh,k = γ · max [Φk (zk)], where γ is a fixed number between 5 and 10. Neurons with a bias of Mexc,k (Minh,k) will effectively spike at maximum rate (remain silent), unless driven by afferent neurons with similarly high synaptic weights.
The individual values of the factor Φk (zk) are introduced through the bias of the auxiliary neurons:
where the factor μ/ minzk [Φk (zk)] ensures that the argument of the logarithm stays larger than 0 for all possible assignments zk.
Observed variables are clamped to fixed values 0 or 1 by setting the biases of the corresponding principal neurons to very large values (±20), to ensure that they spike either at maximum rate or not at all. This mimics the effect of strong excitatory or inhibitory stimulation.
2.5. Parameter Translation between Distributions and Networks
In the LIF domain, the bias b can be set by changing the leak potential El such that the neuron is active with σ(b) for Z\k = 0:
where gtot represents the total synaptic conductance and ubeff is the effective membrane potential that corresponds to the bias b: (ubeff) = σ (b).
For the translation of synaptic weights, we use the approximate PSP shape of an LIF neuron with conductance-based synapses in the high-conductance state (HCS) (Petrovici et al., 2013):
where, wki denotes the synaptic weight from neuron i to neuron k and τeff = Cm/〈gtot〉 the effective membrane time constant. For both the LIF domain and the abstract domain, a presynaptic spike is intended to have the same impact on the postsynaptic neuron, which is approximately realized by matching the average value of the LIF PSPs within a refractory period with the theoretically optimal constant value:
Evaluating the integral in Equation (18) yields the weight translation factor between the abstract and the LIF domain: wki = β · Wki, where
Figure 3A shows the shape of such an LIF PSP with parameter values taken from Table 1. The shape is practically exponential, due to the extremely short effective membrane time constant in the HCS. We will later compare the performance of the LIF implementation to two implementations of the abstract model from Section 2.2: neurons with theoretically optimal rectangular PSPs of duration τref, the temporal evolution of which is defined as
and neurons with alpha-shaped PSPs with the temporal evolution
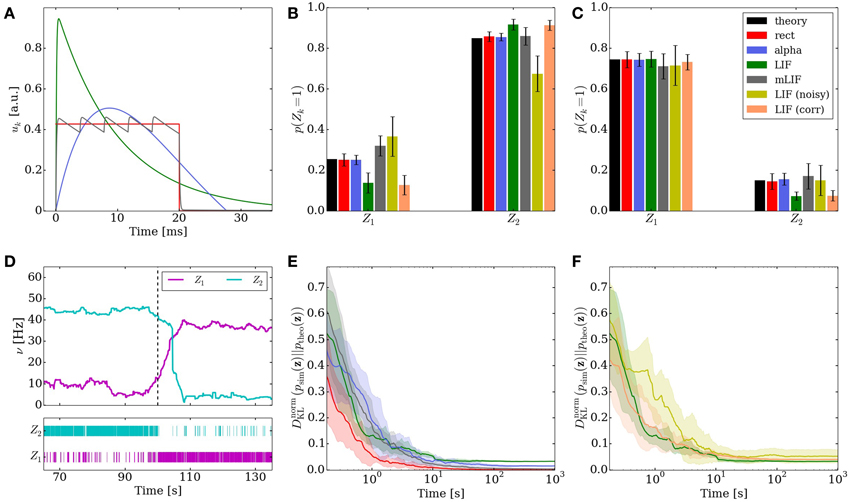
Figure 3. Comparison of the different implementations of the Knill-Kersten graphical model (Figure 1). LIF (green), LIF with noised parameters (yellow), LIF with small cross-correlations between noise channels (orange), mLIF PSPs mediated by a superposition of LIF PSP kernels (gray), abstract model with alpha-shaped PSPs (blue), abstract model with rectangular PSPs (red) and analytically calculated (black). The error bars for the noised LIF networks represent the standard error over 10 trials with different noised parameters. All other error bars represent the standard error over 10 trials with identical parameters. (A) Comparison of the four used PSP shapes. (B,C) Inferred marginals of the hidden variables Z1 and Z2 conditioned on the observed (clamped) states of Z3 and Z4. In (B) (Z3, Z4) = (1, 1). In (C) (Z3, Z4) = (1, 0). The duration of a single simulations is 10 s. (D) Marginal probabilities of the hidden variables reacting to a change in the evidence Z4 = 1 → 0. The change in firing rates (top) appears slower than the one in the raster plot (bottom) due to the smearing effect of the box filter used to translate spike times into firing rates. (E,F) Convergence toward the unconstrained equilibrium distributions compared to the target distribution. In (D) the performance of the four different PSP shapes from (A) is shown. The abstract model with rectangular PSPs converges to DnormKL = 0, since it is guaranteed to sample from the correct distribution in the limit t → ∞. In (E) the performance of the three different LIF implementations is shown.

Table 1. Standard neuron and network parameters used in this paper.
Here, t1 and t2 are the points in time where the alpha kernel is e · t · exp(−t) = 0.5. The value q1 = 2.3 is a scaling factor and τα = 17 ms · is the time constant of the kernel (Pecevski et al., 2011).
In the abstract neural model, by definition, the rectangular PSPs can not superpose, since their width is identical to the refractory period of the neurons. In LIF neurons, PSPs do not end abruptly, possibly leading to (additive) superpositions, and thereby to deviations from the target distribution. To counteract this effect, we have used the Tsodyks-Markram model of short-term synaptic plasticity (Tsodyks and Markram, 1997). Setting the facilitation constant τfacil = 0 leads to un + 1 = U0. With the initial utilization parameter U0 = 1 and the recovery time constant τrec = τsyn, the parameter R, which describes the recovery of the synaptic strength after the arrival of an action potential, yields
where Δt is the time interval between the nth and the (n + 1)th afferent spike. The condition in Equation (22) is equivalent to a renewing synaptic conductance, which, due to the fast membrane in the HCS, is in turn equivalent to renewing PSPs.
2.6. Performance Improvement via a Superposition of LIF PSP Kernels
The difference in PSP shapes between the LIF domain and the theoretically optimal abstract model is the main reason why the direct translation to LIF networks causes slight deviations from the target probability distribution. The sometimes strong interaction involved in the expansion of Bayesian networks into Boltzmann machines (see Equation 5) leads to a large overshoot of the membrane potential at the arrival of a PSP and a nonzero PSP tail beyond t = tspike + τref (see Figure 3A).
In order to reduce this discrepancy, we replaced the single-PSP-interaction between pairs of neurons by a superposition of LIF PSP kernels. For this, we replaced the single neuron that coded for an RV by a chain of neurons (see Figure 4). In this setup, the first neuron in a chain is considered the “main” neuron, and only the spikes it emits are considered to encode the state zk = 1. However, all neurons from a chain project onto the main neuron of the chain representing a related RV. This neuron then registers a superposition of PSPs, which can be adjusted (e.g., with the parameter values from Table 2) to closely approximate the ideal rectangular shape by appropriately setting synaptic weights and delays within as well as between the chains. In particular, the long tail of the last PSP is cut off by setting the effect of the last neuron in the chain to oppose the effect of all the others (e.g., if the interaction between the RVs is to be positive, all neurons in the chain project with excitatory synapses onto their target, while the last one has an inhibitory outgoing connection). While this implementation only scales the number of network components (neurons and synapses) linearly with the chosen length of the chains, it improves the sampling results significantly (Figures 3B,C,E gray bars/traces).
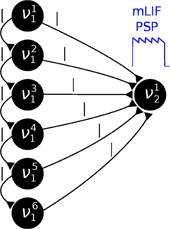
Figure 4. In order to establish a coupling which is closer to the ideal one (rectangular PSP), the following network structure was set up: Instead of using one principal neuron ν per RV, each RV is represented by a neural chain. In addition to the network connections imposed by the translation of the modeled Bayesian graph, feedforward connections between the neurons in this chain are also generated. Furthermore, each of the chain neurons projects onto the first neuron of the postsynaptic interneuron chain (here: all connections from νi1 to ν12). By choosing appropriate synaptic efficacies and delays, the chain generates a superposition of single PSP kernels that results in a sawtooth-like shape which is closer to the desired rectangular shape than a single PSP.

Table 2. Parameters of the interneuron chain of 6 neurons, which are used to generate the mLIF PSP.
3. Results
In the Materials and Methods Section, we have provided a comprehensive description of the translation of arbitrary Bayesian graphs to networks of LIF neurons. Now, we apply these networks to several well-studied cognitive inference problems and study their robustness to various types of substrate imperfections.
3.1. Bayesian Model of the Knill-Kersten Illusion
Figure 1 illustrates the translation of the Bayesian graph describing the well-studied Knill-Kersten illusion (Knill and Kersten, 1991) to the LIF domain. Panel A shows the visual stimuli consisting of two geometrical objects, both of which are composed of two identical 3D shapes (two cylinders and two cubes, respectively). Both stimuli feature the same shading profile in the horizontal direction, but differ in their contours. The perception of the reflectance of each stimulus is influenced by the perceived 3D shape: In the case of a flat surface (cubes), the right object appears brighter than the left one. This perceived change in reflectance does not happen in the case of the cylinders. A cylindrical shape is therefore said to explain away the shading profile, while a cuboid shape does not, therefore leading the observer to the assumption of a jump in reflectance.
We have chosen this experiment since it has been thoroughly studied in literature and it has a rather intuitive Bayesian representation. More importantly, it features some essential properties of Bayesian inference, such as higher-order dependencies within groups of RVs and the “explaining away” effect. The underlying Bayesian model consists of four RVs: Z1 (reflectance step vs. uniform reflectance), Z2 (cylindrical vs. cuboid 3D shape), Z3 (sawtooth-shaped vs. some other shading profile) and Z4 (round vs. flat contour). The network structure defines the decomposition of the underlying probability distribution:
The inference problem consists in estimating the relative reflectance of the objects given the (observed) contour and shading. Analytically, this would require calculating p(Z1 | Z3 = 1, Z4 = 0) for the cuboid shapes and p(Z1 | Z3 = 1, Z4 = 1) for the cylindrical ones.
Figure 3 shows the behavior of the LIF network that represents this inference problem. When no variables are clamped, the network samples freely from the unconstrained joint distribution over the four RVs. The performance of the network, i.e., its ability to sample from the target distribution, is quantified by the Kullback-Leibler (KL) divergence between the target and the sampled distribution normalized by the entropy of the target distribution:
with the KL divergence between the sampled distribution q and the target distribution p
and the entropy of the target distribution p
When presented with the above inference problem the LIF network performs well at sampling from the conditional distributions p(Z1 | Z3, Z4) (Figures 3B,C). When the stimulus is changed during the simulation, the optical illusion, i.e., the change in the inferred (perceived) 3D shape and reflectance profile, is clearly represented by a change in firing rates of the corresponding principal neurons (Figure 3D). For each point in time, the rate is determined by convolution of the spike train with a rectangular kernel
At t = 100 s (red line), the evidence is switched: Z4 = 1 → 0. The network reacts appropriately on the time scale of several seconds, as can be seen in the spike raster plot.
When not constrained by prior evidence, i.e., when sampling from the joint distribution over all RVs, the LIF network settles on an equilibrium distribution that lies close to the target distribution (Figures 3E,F, green traces). For this particular network, the convergence time is of the order of several tens of seconds.
3.2. Robustness to Parameter Distortions
We further investigated the robustness of our proposed implementation of Bayesian inference with LIF neurons to low levels of parameter noise (see Table 1, noisy). Here, we focus on fixed-pattern noise, which is inherent to the production process of semiconductor integrated circuits and is particularly relevant for analog neuromorphic hardware (Mitra et al., 2009; Petrovici et al., 2014). However, such robustness would naturally also benefit in-vivo computation.
Some of the noise (the one affecting the neuron parameters that are not changed when setting weights and biases) can be completely absorbed into the translation rules from Section 2.3. Once the neurons are configured, their activation curves can simply be measured, allowing a correct transformation from the abstract to the LIF domain. However, while the neurons remain the same between different simulation runs, the weights and biases may change depending on the implemented inference problem and are still subject to noise. Nevertheless, even with a noise level of 10% on the weights and biases, the LIF network still produces useful predictions (Figures 3B,C,F yellow bars/traces).
3.3. Robustness to Noise Correlations
The investigated implementation of Bayesian networks ideally requires each neuron to receive independent noise as a Poisson spike train. When aiming for a hardware implementation of large Bayesian networks, this requirement may become prohibitive due to the bandwidth limitations of any physical back-end. We therefore examined the the robustness of our LIF networks to small cross-correlations between the Poissonian noise channels of individual neurons.
For both the excitatory and the inhibitory background pools, we induced pairwise noise correlations by allowing neurons within the network to share 10% of their background Poisson sources. The controlled cross-correlation of 10% between noise channels is achieved in the following way: each neuron receives Poisson background from three shared and seven private Poisson spike trains. The excitatory and inhibitory noise of each individual neuron remained uncorrelated in order to leave its activation function (Equation 13) unaltered. Each of shared sources projects onto exactly two neurons in order to prevent higher-order correlations. The single Poissonian spike trains have a firing rate of ν/10, such that their superposition is also Poisson, with the target firing rate of ν. With this setup, we were able to verify that small pairwise correlations in the background noise do not significantly reduce the ability of the LIF network to produce useful predictions (Figures 3B,C,F orange bars/traces).
3.4. General Bayesian Networks
In order to study the general applicability of the proposed approach, we quantified the convergence behavior of LIF networks generated from random Bayesian graphs. Here, we used a method proposed in Ide and Cozman (2002) to generate random Bayesian networks with K binary RVs and random conditional probabilities. The algorithm starts with a chain graph Z1 → Z2 → … → ZK and runs for N iterations. In each iteration step, random RV pairs (Zi, Zj) with i > j are created. If the connection Zi → Zj does not exist, it is added to the graph, otherwise it removed, with two constraints: any pair of nodes may not have more than 7 connections to other nodes and the procedure may not disconnect the graph. For every possible assignment of pai, the conditional probabilities ppaii: = p(Zi = 1|pai) are drawn from a second-order Dirichlet distribution
with the multinomial Beta function
where Γ(·) denotes the gamma function. We chose the parameters η1 = η2 =: η in order to obtain a symmetrical distribution. Figure 5A shows three examples of a symmetrical two-dimensional Dirichlet distribution. A larger η favors conditional probabilities which are closer to 0.5 than to the boundaries 0 and 1.
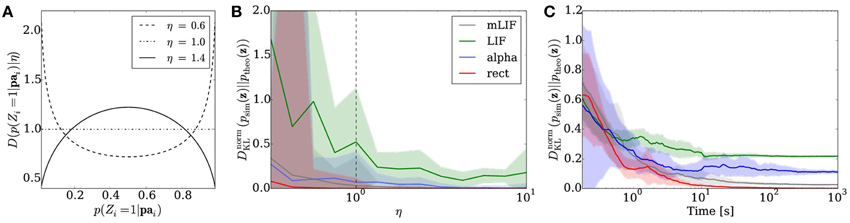
Figure 5. Sampling from random distributions over 5 RVs with different networks: LIF (green), mLIF (gray), abstract model with alpha-shaped PSPs (blue) and abstract model with rectangular PSPs (red). (A) Distributions for different values of η from which conditionals are drawn. (B) DnormKL between the equilibrium and target distributions as a function of η. The error bars denote the standard error over 30 different random graphs drawn from the same distribution. (C) Evolution of the DnormKL over time for a sample network drawn from the distribution with η = 1. Error bars denote the standard error over 10 trials.
We implemented Bayesian networks with K = 5 RVs running for N = 50000 iterations. The random graphs were then translated to sampling neural networks, both with abstract model neurons and LIF neurons. The performance was tested for sampling from the unconstrained joint distributions over the 5 RVs. In the simulations, we varied η between 0.3 and 10 and created 30 random Bayesian graphs for each η. Each network was then run for a total duration of 100 s.
Figure 5B illustrates the average sampling results for the different PSP shapes as a function of the “extremeness” of the randomized conditional probabilities, which is reflected by the parameter η. For larger η, conditionals cluster around 0.5 and the RVs become more independent, making the sampling task easier and therefore improving the sampling performance. The curves show the median of the DnormKL between sampled and target distributions of the 30 random Bayesian graphs. The shaded regions denote the standard error. Overall, the LIF networks perform well, capturing the main modes of the target distributions.
Figure 5C shows the temporal evolution of the DnormKL between sampled and target distributions for a sample Bayesian network drawn from the distribution with η = 1 that lied close to the DnormKL median in Figure 5B. The curves illustrate the average results of 10 simulations, while the shaded regions denote the standard error.
As with the Bayesian model of the Knill-Kersten illusion, the main cause of the remaining discrepancy is the difference in PSP shapes between the LIF domain and the theoretically optimal abstract model. A modification of the RV coupling by means of the neuron chains described in Section 2.6 leads to a significant improvement of the sampling results for arbitrary Bayesian networks (Figures 5B,C gray traces).
4. Discussion
In this article, we have presented a complete theoretical framework that allows the translation of arbitrary probability distributions over binary RVs to networks of LIF neurons. We build upon the theory from Buesing et al. (2011) and Pecevski et al. (2011) and extend their work to a mechanistic neuron model widely used in computational neuroscience based on the approach in Petrovici et al. (2013). In particular, we make use of the conductance-based nature of membrane dynamics to enable fast reponses of neurons to afferent stimuli.
We have demonstrated how networks of conductance-based LIF neurons can represent probability distributions in arbitrary spaces over binary RVs and can perform stochastic inference therein. By comparing our proposed implementation to the theoretically optimal, abstract model we have shown that the LIF networks produce useful results for the considered inference problems. Our framework allows a comparatively sparse implementation in neural networks, both in terms of the absolute number of neurons as well as considering energy expenditure for communication, since state switches are encoded by single spikes. This compares favorably with other implementations of inference with LIF neurons, based on e.g., firing rates or reservoir computing (Steimer et al., 2009).
The main cause for the deviations of the LIF equilibrium distributions from the target distributions lie in the shape of synaptic PSPs. We shave shown how a more complex coupling mechanism based on interneuron chains can improve inference by allowing a more accurate translation of target distributions to networks of LIF neurons. This kind of interaction provides a connection to other well-studied models of chain-based signal propagation in cortex (Diesmann et al., 1999; Kremkow et al., 2010; Petrovici et al., 2014). A similar interaction kernel shape can be achieved by multiple synapses between two neurons (multapses) lying at different points along a dendrite, causing their PSPs to arrive at the soma with different delays. From a computational point of view, the increased sampling performance due to this coupling mechanism only comes at the cost of linearly increasing network resources.
An explicit goal of our theoretical framework was to establish a rigorous translation of abstract models of Bayesian inference to neural networks based on mechanistic neuron models that are commonplace in computational neuroscience. Our particular formulation uses LIF neurons, but a translation to similar integrate-and-fire spiking models such as AdEx (Brette and Gerstner, 2005) is straightforward. An equivalent formulation for more biological models such as Hodgkin-Huxley (Hodgkin and Huxley, 1952) is feasible in principle, but non-trivial, mostly due to the fact that the Hodgkin-Huxley model inherently incorporates a form of relative refractoriness. A study of neural sampling with relative refractoriness does exist (Buesing et al., 2011), but how the abstract model is mappable to Hodgkin-Huxley dynamics remains an open question.
Another important issue concerns how the structure of these networks can be learned from data samples through synaptic plasticity mechanisms such as STDP. The auxiliary subnetworks required by our model are conceptually equivalent to the well-studied winner-take-all (WTA) motif. The emergence of such structures for discriminative tasks based on both supervised and unsupervised STDP protocols has been the subject of recent investigations (Nessler et al., 2013; Kappel et al., 2014). The application of these protocols to networks of integrate-and-fire neurons in general and to our implementation of Bayesian networks in particular is the subject of ongoing research.
Concerning the practical application of our model, we have studied its robustness to small levels of parameter noise as well as weak correlations between the noise channels of individual neurons. We were able to show that imperfections of the physical substrate of the neuronal implementation, be it biological or artificial, can be well tolerated by our networks. Further improvement of the robustness toward parameter noise, as well as a higher degree of biological plausibility, can be achieved by implementing individual RVs as populations of neurons, as has been recently proposed by Legenstein and Maass (2014). We therefore regard our model as a promising candidate for implementation on neuromorphic devices, which can augment these already efficient networks by providing a fast, low-power emulation substrate. Implemented on such substrates, our networks can serve as a basis for machine learning algorithms, thereby facilitating the development of, e.g., autonomous robotic learning agents.
Funding
This research was supported by EU grants #269921 (BrainScaleS), #604102 (Human Brain Project), the Austrian Science Fund FWF #I753-N23 (PNEUMA) and the Manfred Stärk Foundation.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgment
We thank W. Maass for his essential support. We acknowledge financial support of the Deutsche Forschungsgemeinschaft and Ruprecht-Karls-Universität Heidelberg within the funding program Open Access Publishing.
References
Berkes, P., Orbán, G., Lengyel, M., and Fiser, J. (2011). Spontaneous cortical activity reveals hallmarks of an optimal internal model of the environment. Science 331, 83–87. doi: 10.1126/science.1195870
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Brette, R., and Gerstner, W. (2005). Adaptive exponential integrate-and-fire model as an effective description of neuronal activity. J. Neurophysiol. 94, 3637–3642. doi: 10.1152/jn.00686.2005
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Buesing, L., Bill, J., Nessler, B., and Maass, W. (2011). Neural dynamics as sampling: a model for stochastic computation in recurrent networks of spiking neurons. PLoS Comput. Biol. 7:e1002211. doi: 10.1371/journal.pcbi.1002211
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Davison, A. P., Brüderle, D., Eppler, J., Kremkow, J., Muller, E., Pecevski, D., et al. (2008). PyNN: a common interface for neuronal network simulators. Front. Neuroinform. 2:11. doi: 10.3389/neuro.11.011.2008
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Deneve, S. (2008). Bayesian spiking neurons i: inference. Neural Comput. 20, 91–117. doi: 10.1162/neco.2008.20.1.91
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Destexhe, A., Rudolph, M., and Pare, D. (2003). The high-conductance state of neocortical neurons in vivo. Nat. Rev. Neurosci. 4, 739–751. doi: 10.1038/nrn1198
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Diesmann, M., and Gewaltig, M.-O. (2001). NEST: an environment for neural systems simulations. Forschung und Wisschenschaftliches Rechnen Beiträge zum Heinz-Billing-Preis 58, 43–70.
Diesmann, M., Gewaltig, M.-O., and Aertsen, A. (1999). Stable propagation of synchronous spiking in cortical neural networks. Nature 402, 529–533. doi: 10.1038/990101
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Furber, S. B., Lester, D. R., Plana, L. A., Garside, J. D., Painkras, E., Temple, S., et al. (2013). Overview of the spinnaker system architecture. IEEE Trans. Comput. 62, 2454–2467. doi: 10.1109/TC.2012.142
Hines, M., and Carnevale, N. (2003). “Neuron simulation environment,” in The Handbook of Brain Theory and Neural Networks, ed M. A. Arbib (Cambridge, MA; London: The MIT Press), 769–773.
Hodgkin, A. L., and Huxley, A. F. (1952). A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 117, 500–544. doi: 10.1113/jphysiol.1952.sp004764
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Ide, J. S., and Cozman, F. G. (2002). “Random generation of bayesian networks,” in In Brazilian Symposium On Artificial Intelligence (Porto de Galinhas/Recife: Springer-Verlag), 366–375.
Indiveri, G., Chicca, E., and Douglas, R. (2006). A VLSI array of low-power spiking neurons and bistable synapses with spike-timing dependent plasticity. IEEE Trans. Neural Netw. 17, 211–221. doi: 10.1109/TNN.2005.860850
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kappel, D., Nessler, B., and Maass, W. (2014). Stdp installs in winner-take-all circuits an online approximation to hidden markov model learning. PLoS Comput. Biol. 10:e1003511. doi: 10.1371/journal.pcbi.1003511
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Knill, D. C., and Kersten, D. (1991). Apparent surface curvature affects lightness perception. Nature 351, 228–230. doi: 10.1038/351228a0
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kremkow, J., Perrinet, L. U., Masson, G. S., and Aertsen, A. (2010). Functional consequences of correlated excitatory and inhibitory conductances in cortical networks. J. Comput. Neurosci. 28, 579–594.
Legenstein, R., and Maass, W. (2014). Ensembles of spiking neurons with noise support optimal probabilistic inference in a dynamically changing environment. PLoS Comput. Biol. 10:e1003859. doi: 10.1371/journal.pcbi.1003859
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Mainen, Z. F., and Sejnowski, T. J. (1995). Reliability of spike timing in neocortical neurons. Science 268, 1503–1506. doi: 10.1126/science.7770778
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Mitra, S., Fusi, S., and Indiveri, G. (2009). Real-time classification of complex patterns using spike-based learning in neuromorphic VLSI. IEEE Trans. Biomed. Circuits Syst. 3, 32–42. doi: 10.1109/TBCAS.2008.2005781
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Nessler, B., Pfeiffer, M., Buesing, L., and Maass, W. (2013). Bayesian computation emerges in generic cortical microcircuits through spike-timing dependent plasticity. PLoS Comput. Biol. 9:e1003037. doi: 10.1371/journal.pcbi.1003037
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Pecevski, D., Buesing, L., and Maass, W. (2011). Probabilistic inference in general graphical models through sampling in stochastic networks of spiking neurons. PLoS Comput. Biol. 7:e1002294. doi: 10.1371/journal.pcbi.1002294
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Petrovici, M. A., Bill, J., Bytschok, I., Schemmel, J., and Meier, K. (2013). Stochastic inference with deterministic spiking neurons. CoRR arXiv:1311.3211v1.
Petrovici, M. A., Vogginger, B., Müller, P., Breitwieser, O., Lundqvist, M., Muller, L., et al. (2014). Characterization and compensation of network-level anomalies in mixed-signal neuromorphic modeling platforms. PLoS ONE. 9:e108590. doi: 10.1371/journal.pone.0108590
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Rao, R. P. (2004). Hierarchical bayesian inference in networks of spiking neurons. Adv. Neural Inf. Process. Syst. 17, 1113–1120.
Schemmel, J., Brüderle, D., Grübl, A., Hock, M., Meier, K., and Millner, S. (2010). “A wafer-scale neuromorphic hardware system for large-scale neural modeling,” in Proceedings of the 2010 IEEE International Symposium on Circuits and Systems (ISCAS) (Paris), 1947–1950.
Steimer, A., Maass, W., and Douglas, R. J. (2009). Belief propagation in networks of spiking neurons. Neural Comput. 21, 2502–2523. doi: 10.1162/neco.2009.08-08-837
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tsodyks, M., and Markram, H. (1997). The neural code between neocortical pyramidal neurons depends on neurotransmitter release probability. Proc. Natl. Acad. Sci. U.S.A. 94, 719–723. doi: 10.1073/pnas.94.2.719
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Yang, T., and Shadlen, M. N. (2007). Probabilistic reasoning by neurons. Nature 447, 1075–1080. doi: 10.1038/nature05852
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Keywords: theoretical neuroscience, neural coding, computational neural models, probabilistic models and methods, Bayesian theory, graphical models, MCMC, neuromorphic hardware
Citation: Probst D, Petrovici MA, Bytschok I, Bill J, Pecevski D, Schemmel J and Meier K (2015) Probabilistic inference in discrete spaces can be implemented into networks of LIF neurons. Front. Comput. Neurosci. 9:13. doi: 10.3389/fncom.2015.00013
Received: 20 October 2014; Accepted: 27 January 2015;
Published online: 12 February 2015.
Edited by:
Martin Giese, University Clinic Tübingen, GermanyReviewed by:
Hiroshi Okamoto, RIKEN Brain Science Institute, JapanMasami Tatsuno, University of Lethbridge, Canada
Copyright © 2015 Probst, Petrovici, Bytschok, Bill, Pecevski, Schemmel and Meier. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mihai A. Petrovici, Kirchhoff Institute for Physics, University of Heidelberg, Im Neuenheimer Feld 227, 69120 Heidelberg, Germany e-mail:bXBlZHJvQGtpcC51bmktaGVpZGVsYmVyZy5kZQ==
†These authors have contributed equally to this work.