 Wilten Nicola
Wilten Nicola Bryan Tripp
Bryan Tripp Matthew Scott
Matthew Scott- 1Department of Applied Mathematics, University of Waterloo, Waterloo, ON, Canada
- 2Department of Systems Design Engineering, University of Waterloo, Waterloo, ON, Canada
- 3Center for Theoretical Neuroscience, University of Waterloo, Waterloo, ON, Canada
A fundamental question in computational neuroscience is how to connect a network of spiking neurons to produce desired macroscopic or mean field dynamics. One possible approach is through the Neural Engineering Framework (NEF). The NEF approach requires quantities called decoders which are solved through an optimization problem requiring large matrix inversion. Here, we show how a decoder can be obtained analytically for type I and certain type II firing rates as a function of the heterogeneity of its associated neuron. These decoders generate approximants for functions that converge to the desired function in mean-squared error like 1/N, where N is the number of neurons in the network. We refer to these decoders as scale-invariant decoders due to their structure. These decoders generate weights for a network of neurons through the NEF formula for weights. These weights force the spiking network to have arbitrary and prescribed mean field dynamics. The weights generated with scale-invariant decoders all lie on low dimensional hypersurfaces asymptotically. We demonstrate the applicability of these scale-invariant decoders and weight surfaces by constructing networks of spiking theta neurons that replicate the dynamics of various well known dynamical systems such as the neural integrator, Van der Pol system and the Lorenz system. As these decoders are analytically determined and non-unique, the weights are also analytically determined and non-unique. We discuss the implications for measured weights of neuronal networks.
1. Introduction
There are many spiking models that exist in the literature that can be fit to reproduce the membrane potential and the firing rates of real neurons. Examples include the leaky integrate and fire neuron, the Izhikevich model (Izhikevich, 2003, 2007), the theta model (Ermentrout and Kopell, 1986), the quartic integrate and fire model (Touboul, 2008) and the adaptive exponential integrate and fire model (Brette and Gerstner, 2005; Naud et al., 2008). When these models are coupled together to form networks, one can predict the the macroscopic or mean field behavior of a network of these neurons via a suitably derived mean field system (Nicola and Campbell, 2013a,b; Nesse et al., 2008). This can even be done when one considers the effects of heterogeneity in the neurons (Nicola and Campbell, 2013b).
While the mean field system for networks of neurons with prescribed sources of heterogeneity is important for predicting the behavior of the network of equal importance is the inverse problem: given a particular macroscopic behavior or mean field system, what distributions of heterogeneity, either in the neuronal parameters themselves, or the synaptic weights are required to produce said behavior?
One possible numerical solution to the inverse problem is through the Neural Engineering Framework (NEF) (Eliasmith and Anderson, 2004). In the NEF approach, one can specify the macroscopic dynamics or mean field for a spiking neuronal network. Given a network of neurons with a source of heterogeneity, one can find a set of optimal linear weights, referred to as linear decoders, for their firing rates in such a way that the weighted linear sum of the firing rates optimally approximates any function of choice. This allows for specifying the network connectivity in such a way as to obtain arbitrary dynamics from the network(s) of neurons (Eliasmith, 2005). For example, the NEF has been used to develop a wide variety of models, including the most behaviorally sophisticated spiking neural model to date (Eliasmith et al., 2012) as well as more specialized models of path integration (Conklin and Eliasmith, 2005), working memory (Singh and Eliasmith, 2006), visual attention (Bobier et al., 2014), motor control (DeWolf and Eliasmith, 2011), various cognitive functions (Bekolay et al., 2014; Rasmussen and Eliasmith, 2014), and many others.
However, the optimality requirement in the linear decoders introduces complications in the NEF approach. The optimal decoders are computed via least-squares optimization which is a computationally-intensive process; and yet very little information about the network can be determined once the optimal decoders have been obtained. Additionally, one cannot determine how the distribution of heterogeneity in the tuning curves of the neurons is related to the other distributions across the network, such as the distribution of connection weights.
Here, we will show that if one loosens the optimality requirement in the linear decoders, it is possible to obtain linear decoders that converge to any function of choice in the large network limit. Due to their form, we will refer to these decoders as scale-invariant linear decoders. These scale-invariant decoders have several advantages over optimal decoders, at the primary cost of a slower convergence rate in network size. However, using any gradient descent algorithm that does not directly compute the Hessian, one can decrease the error of the scale-invariant decoders very rapidly with very few iterations for any finite network size.
In Section 2.1, we will quickly introduce the NEF. A more thorough introduction can be found in (Eliasmith and Anderson, 2004). This will be followed by Section 2.2 where we will demonstrate that as the networks become arbitrarily large, the optimal decoders tend to an asymptotic limit. This will be our motivation in defining a scale-invariant decoder. In Section 2 we will determine what this asymptotic limit is for the scalar case and for multivariable functions in Section 2.4. In Section 3 we will demonstrate how the decoders can yield the weights to couple neurons together and simulate spiking networks with the specified dynamics by using these weights.
2. Methods: Determining the Decoder Surface
2.1. The Neural Engineering Framework
Suppose we knew the firing rate of a class of neurons, f(I) as a function of the input current I. Then we can take any input variable x and linearly transform it into a current via I = αx + β. If we allow α and β to be drawn from a random distribution, then we can generate a network of neurons with firing rates f(αix + βi) where αi, βi are drawn from some specified probability distribution ρα, β(α, β). As a function of x the curve f(αix + βi) is typically referred to as the tuning curve of neuron i. The output of these neurons is the sum of their weighted firing rates:
Thus, the network takes any input x belonging to the appropriate space, and transforms it into some function ĝN(x). If for example we wanted to compute the function g(x), we would need to pick ϕi such that ĝN(x) ≈ g(x). The ϕi are referred to as the linear decoders in the NEF approach (Eliasmith and Anderson, 2004). They can be determined by minimizing the the following functional with respect to ϕ over some region X in x (Salinas and Abbott, 1995; Eliasmith and Anderson, 2004):
where the first term in 2 corresponds to the error in the approximation and the second term penalizes large ϕi. Minimizing C(ϕ) for ϕ yields the following linear system of equations:
Equations (3–5) correspond to standard function approximation (Bishop, 1995), although the basis functions f are randomly drawn. We will refer to the optimal decoders as Φ and any other decoder as ϕ. There are various functions f that have appeared in the literature. These are derived from complicated neural models using topological normal form theory (Ermentrout and Kopell, 1986; Izhikevich, 2007), are fits to experimental data from real neurons (Shriki et al., 2006), or are analytically derived from integrate and fire neurons. The general form the integrate-and-fire models we will consider is given by
Specific examples include:
(Leaky Integrate-and-Fire Model (Lapicque, 1907 Abbott, 1999; Brunel and Van Rossum, 2007)
(Brette and Gerstner, 2005; Naud et al., 2008).
Other FI curves are fits to the measured FI curves of more sophisticated conductance based models or experimental measurements. For example, the function
can be fit to type-II firing rates when c > 0, and can be shown to be the steady state firing rate for neurons that display spike frequency adaptation when c = 0 (Ermentrout, 2006). Equation (13) has also been fit to conductance based models (Shriki et al., 2006) (with x = 0) and adequately describes the FI curves for many real cortical neurons (Stafstrom et al., 1984; Azouz et al., 1997; Ahmed et al., 1998).
As x is often thought of as a real world input variable in the NEF approach, the αi, βi distribution can only be known once one specifies a distribution of maximal firing rates, ri and x-intercepts, ai for the tuning curves. For the time being, we will restrict the variable x to the interval [−1, 1]. It can be rescaled to an arbitrary interval, so this is no loss of generality. We will show later how x can also be extended to a vector as in the original NEF framework (Eliasmith and Anderson, 2004; Eliasmith, 2005). Once one specifies the distribution of (ri, ai), one can obtain a transformation of random variables. First, let us consider a population of neurons such that the maximal firing rate is achieved at x = 1:
We will refer to these neurons as ON neurons as the neurons can either increase in firing rate with respect to x (ON neurons) or decrease (OFF neurons). The maximal firing rate for the ON population is reached at x = 1 (Eliasmith and Anderson, 2004) while the maximal firing rate for the OFF population is reached at x = −1. To generate a population of OFF neurons, we can reflect the tuning curves in the x = 0 axis by multiplying αi by −1, which yields the following pair of transformations:
where the ± indicates ON/OFF, respectively and by f−1(x). Note that one can generate a population of ON and OFF neurons in different ways, for example by reflecting about the x = ai axis for each neuron. We will treat ai and ri as our primary sources of heterogeneity in the case of approximating a function of a single variable and we will assume that the marginal densities are given by ρa(a) and ρr(r). Furthermore, we will write and to distinguish between the heterogeneous parameters for the ON(+) and OFF(−) populations. In this case, we can rewrite the sum (1) as
where the first half represents the population of ON neurons and the second half of the sum represents the population of OFF neurons. Note that when we refer to the heterogeneous parameters and ai for the ON and OFF populations, we do not imply that they have the same value for both populations for i = 1, 2, …N and they should have a superscript ± to denote which population the parameter belongs to. We do not include this superscript and note the abuse of notation for readers.
Suppose, for example, we wanted to approximate the function g(x) = x using a population of 50 quadratic integrate and fire tuning curves with 25 ON and 25 OFF neurons. This is shown in Figure 1 where the decoders are given by Equation (5). Note that reasonable accuracy is achieved despite the small population of neurons.
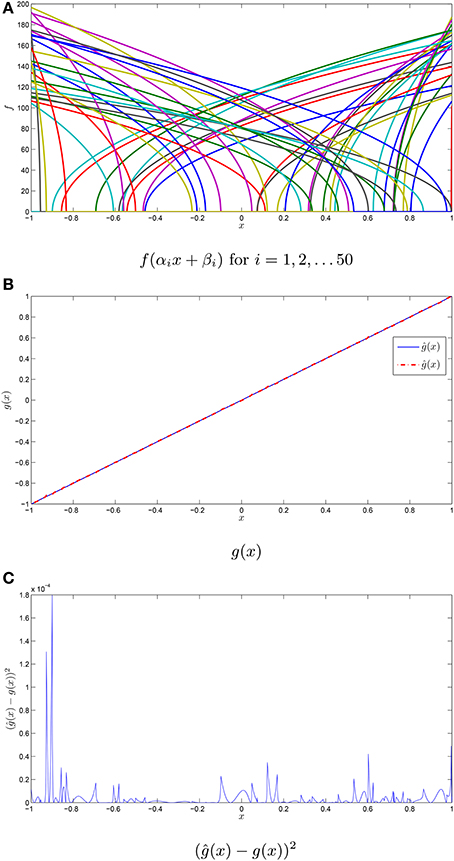
Figure 1. Function approximation with neuronal tuning curves. (A) The tuning curves for a population of 50 quadratic integrate and fire neurons with their intercepts and maximum firing rates drawn from independent uniform random variables on [−1, 1] and [100, 200]. The maximum firing rate is in Hz. (B) The function g(x) = x, in addition to the approximation ĝ(x) using the tuning curves from (A). (C) The squared error in the approximation ĝ(x).
So far this has been fairly standard function approximation with a non-orthogonal basis (Bishop, 1995). The difference in the NEF approach is that one uses these linear decoders obtained from the firing rate curves to design a network of spiking neurons and the function is represented in the output of the network simulation. For example, the differential equation for the quadratic integrate and fire model is given by
where if v(t−) = ∞, v(t+) = −∞. This can be written as the equivalent θ model with the transformation v = tan(θ/2) yielding:
which produces a spike when θ(t−) = π and is reset to θ(t+) = −π.
Each of these differential equations generates a sequence of action potentials at specific spike times, tjk where tjk is the time of the kth spike fired by the jth neuron. These spike times are then fed into a post-synaptic filter s(t);
The linear decoders, ϕj are used to weight the spikes for their respective neuron. This post-synaptic filter equation can be explicitly integrated to yield:
where E(t) = exp(−t/τs). The integrated spike train for the jth neuron is approximately equal to its tuning curve, f(αjx + βj):
provided that x varies on a suitably slow time scale (Dayan and Abbott, 2001; Eliasmith and Anderson, 2004). In this case, the dynamics in Equation (19) are approximately given by
This allows one to approximate an arbitrary dynamical system (Eliasmith, 2005). For example, if we consider a recurrent network (x = s), then to approximate the dynamics s′ = F(s) we merely require
and where the ϕi are given by Equation (3). Returning to the neural equations, if we take x = s and consider a recurrently coupled network of neurons then we have the following:
where ωij = αiϕj is the NEF equation for the weight coupling neuron j to neuron i (Eliasmith and Anderson, 2004; Eliasmith, 2005) and the quantity
is the post-synaptic current going to the ith neuron.
For example, if we wanted the macroscopic dynamics to be exponential decay, F(x) = ks, then we require ĝ(s) = s(1 + τsk). We would obtain the ϕi by using Equations (3–5) which yields the optimal decoders Φi for ĝ(x) = x(1 + τsk) and simulate our spiking network using the weights ωij = αiΦj. This yields a recurrently coupled spiking neural network with macroscopic dynamics s′ = ks.
In addition to recurrent networks, one can also construct feedforward networks with the NEF approach. For example, we can also treat x as an input variable. This allows a network to represent an input variable x in terms of its spiking. If τs is not large, then one can represent the input variable x as a postsynaptic current s:
assuming that x varies on a suitably slow time scale (slower than τs). This is shown for example with networks of various sizes in Figure 2, with a synaptic time constant of τs = 5 ms approximating the function g(x) = x. The network of differential equations for the neurons is simulated using Equation (17). These neurons then generate a spike train which is weighted by the decoders. The weighted spike train is fed into the post-synaptic current variable s(t), which acts as the approximation for g(x) = x. A time varying x(t) is used that varies on a suitably slow time scale.
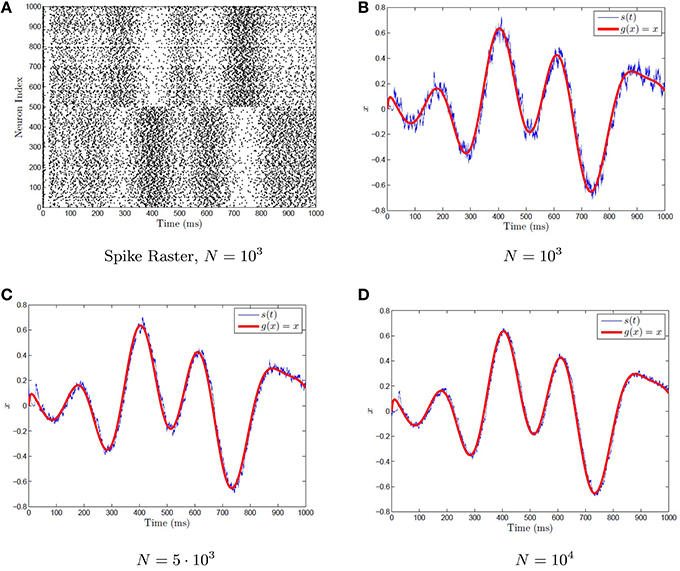
Figure 2. Representation with a spiking neuronal network. (A) A sample raster plot of a neural network with 1000 neurons performing representation. (B–D) The representation problem is approximated by networks of various sizes by imposing the condition (50). The neurons are quadratic integrate-and-fire neurons given by Equation (32). The spike train for (B) is plotted in (A). A time varying randomly generated signal (red) is fed into the network, and is computed via the synaptic current variable s(t) using Equation 36 (blue). As the network size increases, the approximation becomes better.
It is clear that given the fact that arbitrary functions or dynamics (via recurrent networks) can be computed, then one can generate multiple networks that perform different functions, and feed into one another. In this way, one could create large networks composed of interconnected subnetworks that perform functions such as controlling limbs, detecting objects, and performing tasks by using the mathematical approaches that already exist for accomplishing these feats and translating them into an equivalent neural network representation. This is the core idea in the NEF (Eliasmith and Anderson, 2004; Eliasmith et al., 2012).
Although a network of N = 100 neural tuning curves f(αix + βi) is sufficient for a good approximation of many functions, depending on the dynamics being computed, significantly more neurons are needed in spiking simulations, as shown in Figure 2. Hundreds, if not thousands, of neurons are necessary for adequate approximation when spikes are used. The network size becomes even larger when we want to perform complicated functions involving more then one variable x or functions with higher frequency oscillations present. As the decoders are determined by large matrix inversion (Equation 3), this can take quite a while when dealing with more then 5000 neurons on a conventional computer. Furthermore, the smaller the synaptic time constant τs, the more neurons are required. This is due to the fact that Equation (21) is effectively a kernel density estimator of the firing rate and when the bandwidth is too small, the resulting estimate is under-smoothed, thus requiring more neurons for a comparable degree of accuracy as that of a network with larger τs. Furthermore, as the NEF weights are numerically determined (via the NEF decoders), the possible analysis is very limited. Thus, an analytical solution to the NEF decoders (and thus weights) would allow a greater insight into large networks and may also facilitate faster numerics.
2.2. Decoder Asymptotics as N → ∞
In order to proceed analytically, we will first look at the behavior of the optimal decoders Φ for large networks (N → ∞). To facilitate plotting, let us consider the case where for an arbitrary neural model, , that is the maximim firing rate is given by , which reduces the random variables associated with the heterogeneity to the intercept variable, . Additionally, note that for Type-I neurons:
which immediately implies that we can absorb the quantitiy into the decoder and rescale any solution we obtain by this quantity at the end. With Equation (27), the sum in Equation (16) becomes:
where the Φi are determined by Equation (5). One should note that there is an abuse of notation here, as the optimal decoders differ for the ON/OFF subpopulations for i = 1, 2, …N however we have used the same symbol to denote the optimal decoders, Φi for both populations. Additionally, the value is the threshold to firing for the ith ON neuron while the quantity is the threshold to firing for the ith off neuron. If one were to plot the decoders for large N, then one can easily see that in the limit of large network size (N → ∞), the individual decoders vanish (Φi → 0, not shown here). However, for increasing N, it seems that the quantity γi = NΦi/2 converges to some non-zero value γ(ai) and thus it appears that γi converges to some function of the x-intercept, ai, the source of heterogeneity for the neurons. This is shown in Figure 3 for increasingly large networks. The quantity NΦi/2 is plotted vs. ai. The predicted surface for convergence, γ(a), is also plotted which is determined by optimizing over a uniform mesh in the parameter space. We will refer to any γi that satisfies γi = ϕiN/2 for some decoder ϕi as scale invariant decoders and γ±(a) as the decoder surface. We will not necessarily use the same decoders for the ON and OFF neurons hence the superscipt on γ(a). We will show in the subsequent sections how to determine the decoder surfaces for the type-I and type-II (approximate) firing rates for single variable and multivariable functions.
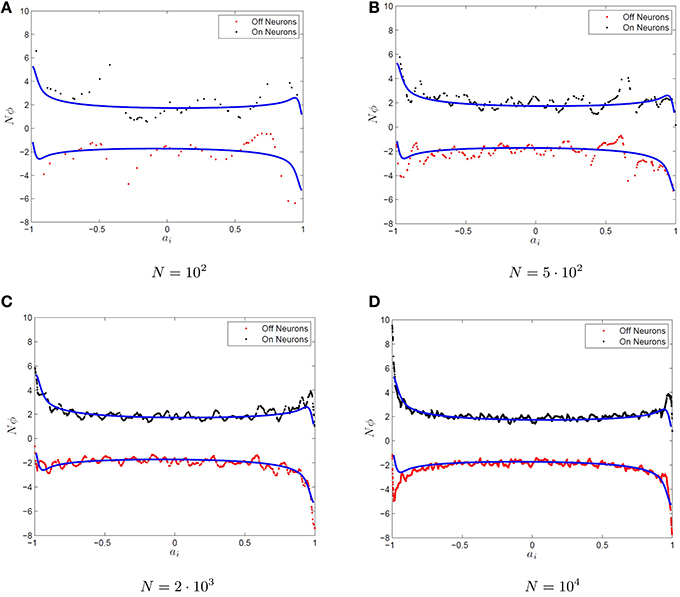
Figure 3. Convergence of the optimal decoders to an invariant surface. (A–D) The function g(x) = x is approximated by networks of various sizes using Equation (17) with firing rate curves. Plotted are the optimal decoders Φi scaled up by the network size N for ON (black dots) and OFF (red dots) neurons as a function of the intercept, f(0) for QIF firing rate functions. The quantity NΦi appears to converge as N → ∞ to the blue curve. The blue curve is determined by using a uniform grid of neurons over the heterogeneous parameter ai and optimizing for the resulting decoders.
In order to determine the decoder surface analytically, we need to understand the behavior of the network as N → ∞. Using the scale invariant decoders from Equation (28):
where the overline denotes the finite average over the inhomogeneity in the intercepts. We should expect that as N → ∞, the finite network averaging turns into an expectation:
where ρa(a) is the probability density describing the heterogeneity variable ai for the neurons. For the Equations (32, 33) to be valid for the optimal decodoers, we would need to formally show that Φi → 2γ(ai)/N, where Φi are the optimal decoders for some particular scale-invariant decoder γ(ai). However, this is unnecessary as we can regard ϕi = 2γ(ai)/N as a suboptimal decoder and independent of the optimal decoders which are generated by minimizing the integral Equation (2). In which case, the limit exists by the law of large numbers. Furthermore, as we shall show later, Φi will not necessarily converge to γ(ai) as γ(ai) is non-unique, where as Φi is the optimal decoder which is unique due to the quadratic error surface in C(ϕ).
Note that γ(a)ρa(a) appears as a product in the integral. These terms can be collapsed into a single function . We will refer to these quantities as the weighted decoders of the ON/OFF neurons and use the weighted decoders to define the linear operators;
which we will refer to as the tuning curve transforms (TCT). The TCTs map functions from the space of the variable(s) assigned to the heterogeneous parameters to the space of functions we are trying to approximate. Note that these operators are actually applied to different weighted decoders as the decoder surfaces are different for ON and OFF neurons. Furthermore, the density ρa(a) need not be identical for both ON and OFF neurons. However, in all numerical implementations, ρa(a) will be identical for the sake of simplicity.
Suppose we could determine analytically. In this case, as , whenever ρa(a) ≠ 0, we can compute and leave γ(a) undefined otherwise (as there is no neuron that has parameter(s) in this region). Now, given the fact that we obtain a linear operator as N → ∞ case, the real problem becomes in finding the such that maps to g(x), the function we want to approximate. That is, we have to invert the operator M for these . If we know these , then as we presumably know the distribution of tuning curve intercepts, we can determine the decoders ϕi with:
and thus the analytically determined scale-invariant decoders γ(ai) are effectively weights for a Monte Carlo estimate of the integral operator TCTs.
Here, we will explicitly invert the tuning curve transforms for single variable functions in Section 2.3. The resulting equation for the weighted decoders is a convolution integral. In Section 2.4 we will show that with a basis to basis mapping, one can also invert the tuning curve transforms for multi-variable functions.
2.3. Single Variable Functions
If we work with the operators L+ and L− separately, the problem becomes entirely tractable. One of the surprising things about the operators L+ and L− is that provided that the functions we are considering are constrained to a subset where g+(x) vanishes to first order at x = −1 and g−(x) vanishes to first order at x = 1, and are both smooth, then the operators are invertible analytically on this constrained subspace of functions using Laplace transforms (see Appendix). Additionally, by using both and , one can compute any smooth function irrespective of the conditions at x = ±1. Furthermore, piecewise smooth continuous functions can also be computed (see Supplementary Materials). Closed form solutions do not exist for all neuronal firing rates as the Laplace transform cannot always be inverted explicitly. However, the type-I and type-II firing rate models do have analytically determined decoders. For the type-I/theta neuron firing rate, we have (see Appendix for derivation):
The weighted decoder solutions for the type-II firing rate are also contained in the Appendix. For example, we have approximated the function g(x) = sin(2πx) using 10,000 type I tuning curves, as shown in Figure 4. An important thing to notice is the linearity in Equations (38,39) and (36) in the target function g and thus linearity for the scale-invariant decoders γ(a). Furthermore, due to the fact we have considered to be separate for the ON and OFF populations, our operator for determining g(x) is . However, while our range in L+ and L− was constrained, it was not constrained enough to provide a unique solution to M(P+, P−) = g(x). In particular, if we consider any function ϵ(x) that lies in both admissable spaces (vanishes to first orders at x = 1 and x = −1), then ϵ(x) can be represented by both populations with , respectively and thus
are also valid solutions to M(P+, P−) = g(x). One can interpret this as a degree of freedom in terms of the decoders (and thus the synaptic weights). For example, we can use e(x) to minimize the expected squared error or other criterion. Thus, in the following we will strictly assume that e(x) = 0.
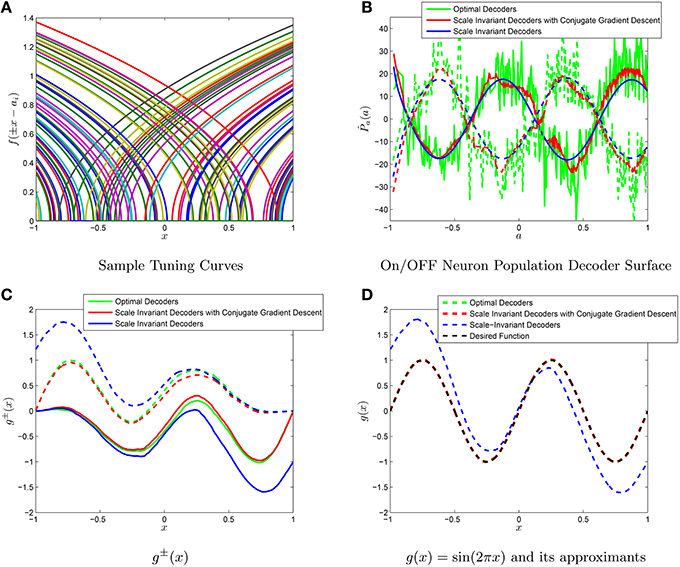
Figure 4. Comparison of the scale-invariant decoders and the NEF decoders. (A) A sample subset of tuning curves from a population of 1000 neurons. The function g(x) = sin(2πx) is approximated using populations of N = 103 ON and OFF neurons. (B) The scale invariant decoders (blue), the scale invariant decoders with conjugate gradient descent fine-tuning (red) and the optimal decoders multiplied by N (green) for both the ON (solid) and OFF (dashed) groups of neurons. (C) The different decoders correspond to different g±(x). (D) Summing the g±(x) yields approximations to g(x). The conjugate gradient descent improves the approximation (from 6*10−1 to 7*10−5) of magnitude while still maintaining a tight correlation with the scale-invariant decoders (p = 0.9811). The optimal decoders have a mean-squared error of 9*10−7 for comparison purposes.
We should note that it is possible to numerically invert the Laplace transforms resulting from the derivation process for the other firing rate curves. However, for now we will primarily work with the type I and type II curves. Our numerics will also primarily consist of networks of theta neurons (type-I).
2.3.1. Convergence Rate for Single-Variable Functions
With our decoder surfaces in hand, we can now proceed to determine the various convergence properties in the limit as N → ∞. In particular, we have the following:
which immediately implies that our approximant ĝN(x) converges in mean-square to g(x) pointwise in x provided that:
A derivation of Equation (42) can be found in the Supplementary Materials. Letting γN = (γ(ai)/N, …γ(aN)/N), then we can also consider how the distribution of the quadratic cost function C(γN) scales as N → ∞ ; from Equation (2):
where ei is the symbolic variable ± denoting the identify of a neuron as OFF/ON. One can show that provided that Equation (43) holds, and γ±(a) is bounded on [−1, 1], then we have the following
which implies that as N → ∞, then C(γN) → 0 in a mean-square sense. This is proven in the Supplementary Materials. As the cost function is strictly positive, then we can interpret this as γN minimizing the cost asymptotically.
For other neuronal models, one can merely use the maximum firing rates and intercepts to approximate their tuning curves with the type I standard form or the linear firing rate tuning curves. This will yield scale-invariant decoders that can be used on the tuning curves for the actual neuronal model with some degree of error. Additionally, gradient descent algorithms can be used to refine the scale-invariant decoders and that take into account the systematic error in using the type-I/type-II tuning curve approximation.
2.4. Multivariable Functions
It is clear that in the preceding section, one could approximate any arbitrary single variable function using scale invariant decoders. The same can be said about multi-variable functions. We will first introduce linear encoding for multi-variable inputs. In the NEF, it is assumed that the current input into each neuron takes the form:
where e is the encoding vector that lies on the n-dimensional unit sphere and x lies in the interior; 〈e, x〉 is the standard dot-product. The maximum firing rate occurs when x = e, and thus 〈e, x〉 = 1 is the maximum. The vector e is also referred to as the preferred direction vector. In this case, there are no ON and OFF neurons as they are effectively taken care of by the angle in between x and e. If x and e are colinear, then the maximum firing rate occurs when e = x, and the firing rate is zero when 〈e, x〉 = a, the equation for the hyperplane with normal vector e. Note that because the unit sphere in one-dimension is merely ±1, we have a direct correspondence with the ei from the single variable analysis in the previous section.
Once again, we can non-dimensionalize:
To simplify the situation, we will again assume that , to remove this term. As before, for type-I firing rates this occurs without any loss of generality.
While it may seem like this setup complicated matters somewhat, in the limit that N → ∞, the end result is simpler then the single variable case as we can make use of the orthogonality of the trigonometric functions to derive an appropriate basis to basis mapping. Consider suboptimal decoders of the form . For a separable decoder we have:
which in the large network limit becomes:
From our previous work, we know that the weighted decoder can be chosen such that:
by treating z = 〈e, x〉 and using Equation (38) to determine . The specific form of that performs this transformation varies from neural model to neural model. For the type I/type II firing rate, it is given by a recurrence relationship in terms of the binomial exponent n and is included in the Supplementary Materials. With determined, the decoders are characterized by the integral equation:
To proceed further, we will exploit the orthogonoality of the Fourier series in a hyper-spherical coordinate system. For example, in two-dimensions we have:
The second term in the integrand is a polynomial in cos(θ) and sin(θ). By DeMoivres formula, this can be expressed as a Fourier series with coefficients that depend on x and y where the series contains no cos(mθ) or sin(mθ) for m > n. Thus, we can extract out polynomial basis functions in the x and y using for m, k < n. For example, the first few and the corresponding ĝN(x) are shown in Table 1.
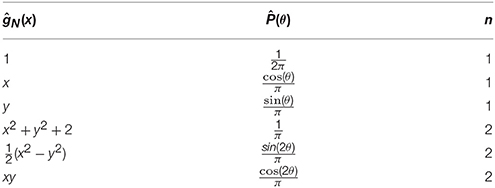
Table 1. The basis-to-basis mapping for a polar coordinate system for the first few n.
As we can obtain a polynomial basis where the maximum polynomial power is arbitrary, we can approximate any arbitrary integrable function. In general, one uses a sequence of trigonometric basis in the heterogeneous space to yield a polynomial basis in the function approximation space. One may wonder if the non-uniqueness in the scalar case was due to the peculiarities of the unit sphere in 1-dimension (an isolated pair of points). This turns out not be the case (see Supplementary Materials).
2.4.1. Convergence Rate for Multivariable Functions
One can again determine the order of convergence for the scale-invariant decoders for a multi-variable funciton. An application of the law of large numbers yields:
and thus the expected square error converges like 1/N implying that ĝN(x) converges to g(x) in mean-squared. The expectation is taken over the random variables ei and ai. As the convergence rate is somewhat slow, it is natural to ask whether or not it is possible to improve the the expected squared error.
While there are many analytical paths one may take, we leave these approaches for future work. We will primarily use gradient descent variants that do not require computing the Hessian. If we knew the Hessian, then for a finite network we could immediately solve the system of Equations (3–5) as the problem is entirely quadratic and can be resolved numerically with the Hessian matrix. However, solving the quadratic problem with the Hessian requires large matrix inversion, and this is simply not feasible for large networks. Thus, we can use Hessian-free gradient descent methods. For example, one can use various conjugate gradient type algorithms to improve the expected squared error significantly with only a few iterations, and no large matrix inversion. Additionally, one can use the methods of stochastic gradient descent, such as weight perturbation, and node perturbation (Werfel et al., 2005). We will primarily use conjugate-gradient descent implemented with the PCG function in MATLAB (MATLAB, 2014). The crucial thing about these approaches is that we can obtain substantial improvements to the expected squared error with only slight perturbations to the scale-invariant decoders, as we shall see when we look at specific examples.
3. Results
To simulate networks with arbitrary dynamics, we can use the decoders derived in the previous sections along with neurons that correspond to the appropriate firing rates (Eliasmith and Anderson, 2004). Suppose the variable s(t) represents a vector of decoded firing rates given by the following equation:
Where ϕj is the decoder for the jth neuron. Equation (54) is referred to as the rate equation while Equation (52) is the equation for si under neuronal spiking with a simulated spiking neuronal network. The time constant used will be 50 ms unless otherwise stated.
Using the same procedure as before, by integrating the spiking equation for s(t) explicitly, one can derive the NEF equation for the synaptic weights:
where ωij is the synaptic weight for the post-synaptic neuron i and the presynaptic neuron j in a recurrent neuronal network and ϕj is the scale invariant decoder for the function
For a scale invariant decoder, this yields the following synaptic weight:
Note that ωij = F(ai, aj, ri, rj, ei, ej), is a function of random variables for the presynaptic and post-synaptic neurons. Thus, instead of thinking the weights as a matrix of numerical values, or as a direct graph, one may think of the weights as defining a hypersurface in a higher dimensional space. For example, the formula (Equation 56) describes a hypersurface with 2m + 4 dimesions where m is the dimension of the dynamics the network simulates.
In the following examples, we will generate networks with these analytically determined weights using scale-invariant decoders that display the prescribed dynamics. Additionally, we will assume that
The variable M controls the maximum firing rate of the neurons, with the range of maximum firing rates being between . We take M to be 60 Hz for all subsequent numerics, unless otherwise specified. Note that we need αi to compute the weights. The αi differs depending on whether or not we are simulating a scalar system or a multi-variable system. For a scalar system, where ei = 1 for ON neurons and −1 for OFF neurons. For a vector, . For multi-variable dynamics we will assume uniform distributions in the hyperspherical coordinate systems. With the former assumption, the tuning curves for the neurons simply become where the M can be absorbed into the decoder. We will generate networks of spiking theta neurons that simulate a neural integrator, a Van der Pol Oscillator, and the Lorenz system.
3.1. Example 1: Neural Integrator
A neural integrator is a recursively coupled neural network that integrates an incoming signal, u(t). The coupling variable s(t), will have dynamics given by
where ei = 1 if neuron i is an ON neuron and −1 for OFF neurons. Note that we have scaled u(t) by τs as this allows us to write:
We then require the scale invariant decoders such that . A set of g±(x) and the corresponding scale-invariant decoders is given by:
which yields ĝ(z) = z. From formula (14) for αi and (58) for the density of ai, and we have and the neuronal weight
All the synaptic weights here are given by for ON/ON and OFF/OFF connections and for ON/OFF and OFF/ON connections. Now, we will exploit symmetry and non-uniqueness to generate two more neuronal integrators with the same initial distributions of heterogeneity ρa(a). In particular, consider the function ϵ(x) = (1 − x2)2, this function lies in both function spaces for g±(x) as it vanishes to second order at both boundaries. Additionally, it can be computed using the following scale-invariant decoders:
which implies the following decoders for the ON/OFF population still give us g(x) = x
which yields the weight matrix
Additionally, we can exploit symmetry to derive yet another weight matrix with precisely the same network of neurons:
and thus, we have the following three separate weight matrices
for i, j = 1, 2, …N that yield identical macroscopic dynamics from the same network of neurons as N → ∞. Furthermore, while all the weights converge to 0 as N → ∞, the scaled weights Nωij do not converge toward one another in the same limit. One important point is that none of the weights necessarily satisfy the constraint that the action of neuron j on all its downstream targets is the same, either excitatory or inhibitory. Or more precisely that
for all i, i′, j = 1, 2, …N. Fortunately however, this issue has already been dealt with in the existing literature (Parisien et al., 2008). To summarize, one is able to take the weights generated by the NEF solution, and linearly transform them to yield a new network consisting of excitatory and inhibitory neurons (instead of ON/OFF) with weights that respect this constraint, which is related to Dale's principle.
We have simualted four neural networks with 5000 neurons each all generated with the same random sample drawn from the distribution (Equation 58) using the weights given by Equations (73–75), in addition to the weights generated by determining the optimal decoders. The scale-invariant decoders that correspond to Equations (73–75) were put through conjugate gradient fine-tuning with the final decoders being correlated to the initial decoders with a correlation coefficient greather than 0.98 in all cases. This lowered the root-mean-squared-error by 2–3 orders of magnitude with only slight perturbations off the scale-invariant decoding surface in each case. A sample set of tuning curves is shown in Figure 5A with the ĝ±(x) that correspond to the four different weight structures in Figure 5B. The neural integrators are shown in Figures 5C–F. The synaptic weights that correspond to the integrators are shown in Figure 6. The neurons have been sorted into ON/OFF populations and increasing a within a sub-population prior to plotting the weight matrix in the left column of Figure 6. A sub-sample of 20 neurons is also selected (which is identical across the four integrator networks) and their weights are plotted in the right column of Figure 6. For the optimal decoders, g±(x) ≈ ±(1 ± x)/2, which results in a weight structure similar to Equation (73). The weights differ substantially however in comparison to Equations (74) and (75) as the ĝ± differ substantially from ±(1 ± x)/2
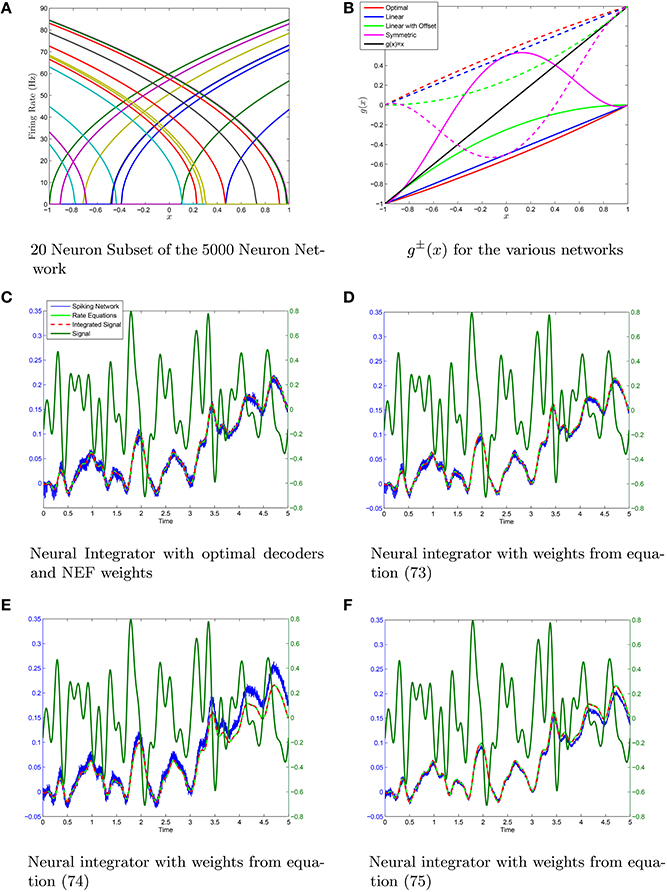
Figure 5. Neural integrators generated using the same initial heterogeneous network of N = 5·103 Theta neurons. (A) A subset of 20 tuning curves from the network. (B) The different neural integrators are generated by using different g±(x) to form g(x). (C–F) The integrators generated using optimal decoders and decoders from Equations (63),(66), and (71) which results in weight matrcies Equations (73),(74), and (75). The scale-invariant decoders are fine-tuned with conjugate gradient descent. In all cases the fine-tuned decoders are very highly correlated (p > 0.98) with the scale-invariant decoders indicating only small perturbations off the scale-invariant decoder surface with substantial improvements in the root mean-squared error (RMSE) in computing ĝ(z) = z. The RMSE was O(10−5) with conjugate-gradient descent vs O(10−2) without. The variable λ = 0.01 was taken in the conjugate gradient descent fine-tuning.
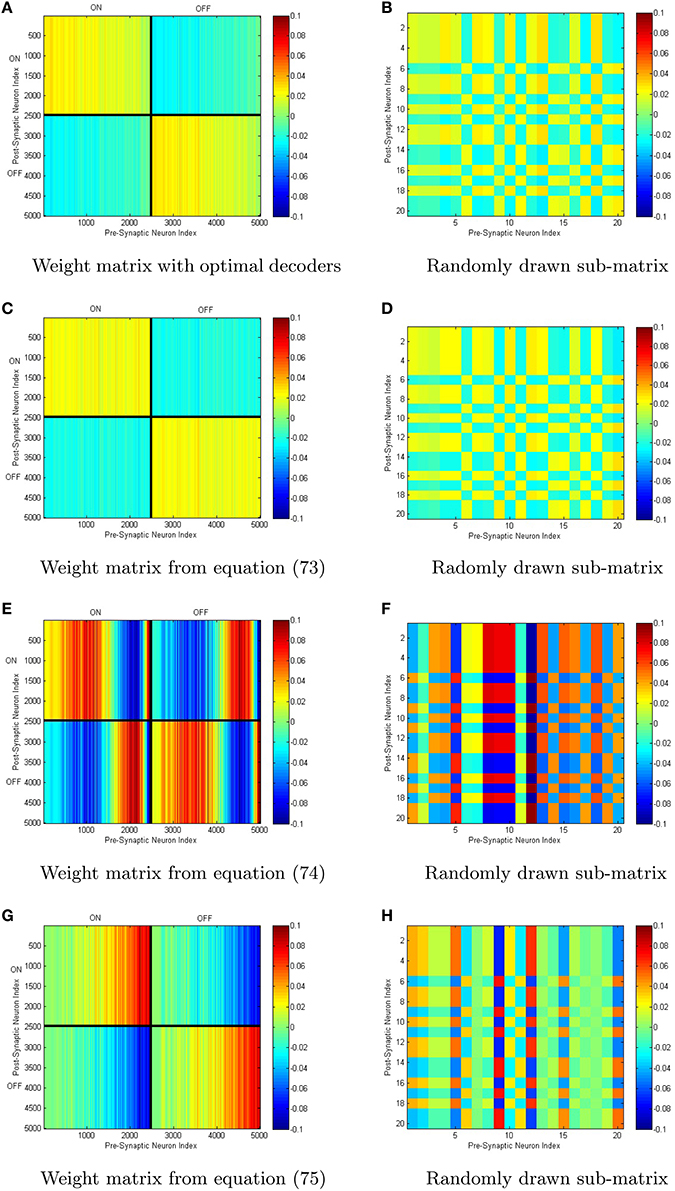
Figure 6. (A–H) Different connectivity weights can generate identical macroscopic dynamics from identical neuronal populations. Shown above are the weight matrices generated for the neural integrators in Figure 5. On the right are smaller sub-matrices of weights between 20 randomly selected neurons (the same 20 in each case).
This example illustrates that identical networks of neurons can have identical macroscopic dynamics with vastly different weight matrices. While this is not particularly surprising as going from a microscopic description (the individual weights) to a macroscopic description (the dynamics) of a dynamical system is seldom a unique process, the surprising thing is one can explore this issue analytically. An important point to note is that even though the weight matrices are non-unique, they all have the form
and the weight matrices are nothing more than sample points drawn from different surfaces.
3.2. Exampe 2: Van der Pol Oscillator
The Van der Pol oscillator (Van der Pol, 1926) is given by the dynamical system:
Here, we will simulate the oscillator with large networks of neurons using the scale-invariant decoders with conjugate gradient descent fine tuning. As the decoding is linear, then from the above equations we only require the decoders for the functions f(x, y) = x, f(x, y) = y and f(x, y) = x3. We use a two-dimensional spherical coordinate system for the encoding ei = (cos(θi), sin(θi)) and assume uniform distributions in the ai and the θi. Note that:
which, immediately allows us to use the following scale-invariant decoders for the sub-functions x, y, and x3:
which yields the decoders for F(x, y) and G(x, y):
Thus, the weights are given by
Both the rate equations and the spiking neural network are simulated using the scale invariant decoders to weight the firing rates/spikes. To more explicitly show the effects of the conjugate-gradient descent fine tuning, we have plotted the scale-invariant decoder surfaces NϕF and NϕG in Figure 7, in addition to the decoders after conjugate gradient descent fine tuning. The scale-invariant decoders and the conjugate gradient descent fine-tuned decoders are again very tightly correlated with r > 0.95. We have simulated the Van der Pol Oscillator, as shown in Figure 8 in both the relaxation (μ = 5) and harmonic (μ = 0.7) oscillator regimes. In both cases, we have excellent correspondence with the network and the actual oscillator. The synaptic weight matrices are also shown in Figure 8 for a subset of neurons. Like the neural integrator, the weights again lie on a surface, only the surface is 3-dimensional.
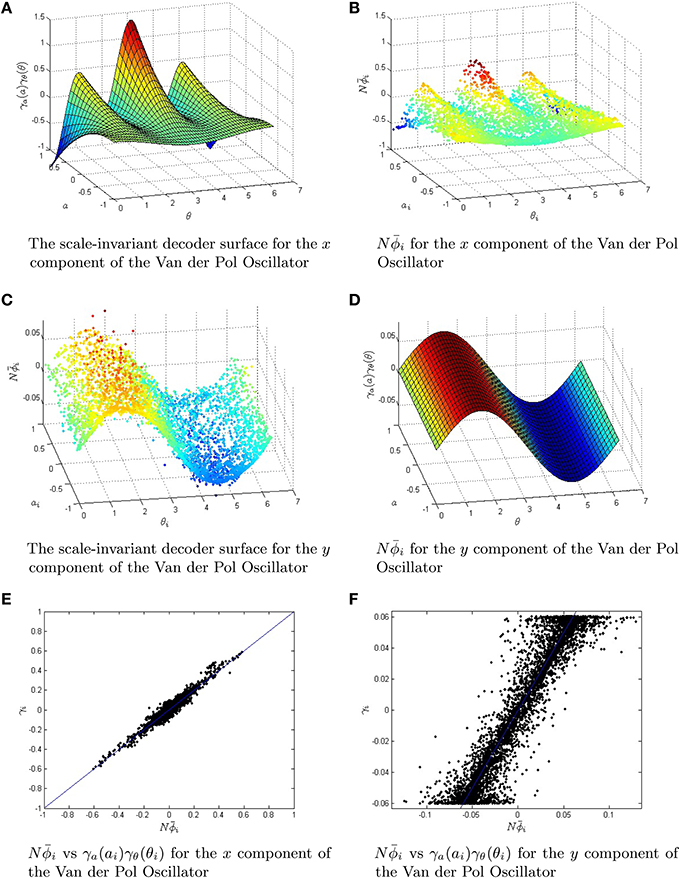
Figure 7. The Van der Pol Oscillator is approximated by using a scale-invariant decoder surface. The two functions F(x, y) and G(x, y) that are responsible for the dynamics of the Van der Pol Oscillator have scale-invariant decoder surfaces given by Equations (82,83). (A,B) The equations for the scale-invariant decoder surfaces are plotted in 3D. These surfaces are used to initialize conjugate gradient descent fine-tuning for a network of 5000 neurons. (C,D) The fine-tuned decoders . They are slightly perturbed off of the surfaces in (A,B). (E,F) The strong linear relationship in the scale-invariant surface and the conjugate gradient descent optimized decoders . The correlation coefficient r≥0.95 in both cases, while the root mean squared error was reduced from O(10−2) to O(10−5). The parameter μ for the Van der Pol Oscillator was taken to be 0.7.
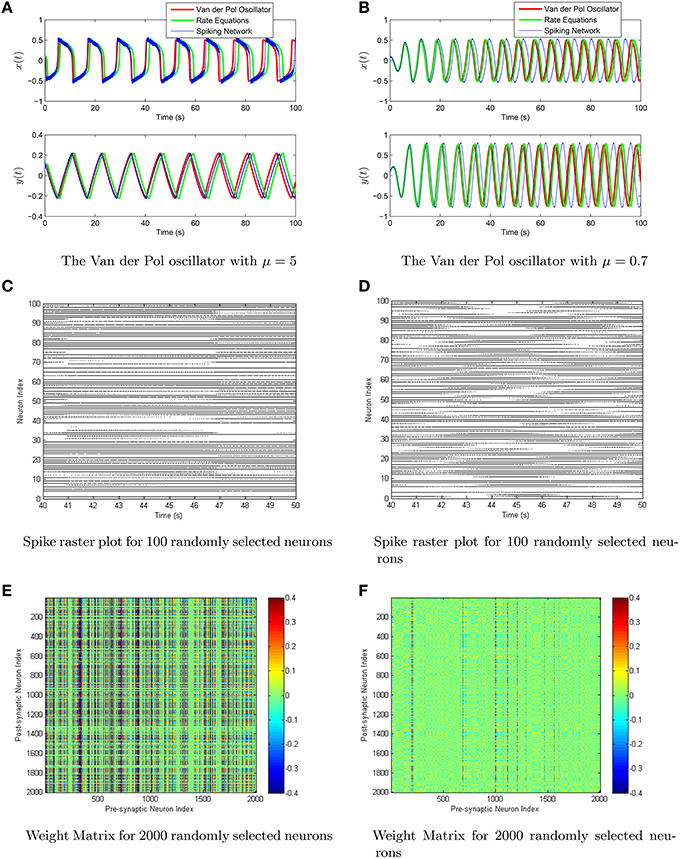
Figure 8. (A,B) The Van der Pol oscillator is simulated using a network of 105 theta neurons with scale-invariant decoders after conjugate-gradient descent fine tuning in the relaxation oscillator regime (μ = 5, left column) and in the harmonic oscillator regime (μ = 0.7, right column). Shown in the top row is the comparison between the oscillator (red), the rate equations (green), and the spiking network (blue). (C,D) Shown in the middle is the spike raster plot for a 10 s interval of both networks. (E,F) The last row consists of a computed weight matrix for 2000 randomly selected neurons in the network.
3.3. Example 3: Lorenz Attractor
The Lorenz system is given by the equations
and is known to exhibit chaotic behavior for specific values of σ, ρ and β (Lorenz, 1963). In order to approximate the Lorenz system, we require the decoders for the functions x, y, z, xz and xy. With a 3-dimensional spherical coordinate system, the encoding vectors e are given by e = (sin(θ)cos(ψ), sin(θ)sin(ψ), cos(θ)) where θ ∈ [0, π] ψ ∈ [0, 2π]. The decoders as a function of (ψ, θ, a) are given by:
which yields the decoders for F, G, H as:
The strange attractor generated by the Lorenz system and the neural rate equations using the decoders from Equations (88–90) are shown in Figure 9. The chaotic behavior and the strange attractor is also preserved when one uses a spiking neuronal network with the decoder weights on the spikes. Note that a great many neurons are required to adequately visualize the strange attractor, however the chaotic behavior is present even for smaller networks. We have also plotted the location of neural spiking with regards to the strange attractor. The neurons tend to spike more in specific regions of the strange attractor in accordance with their preferred orientation vectors and their ai parameters. The weights are again given by the NEF formula:
which defines a five dimensional surface.
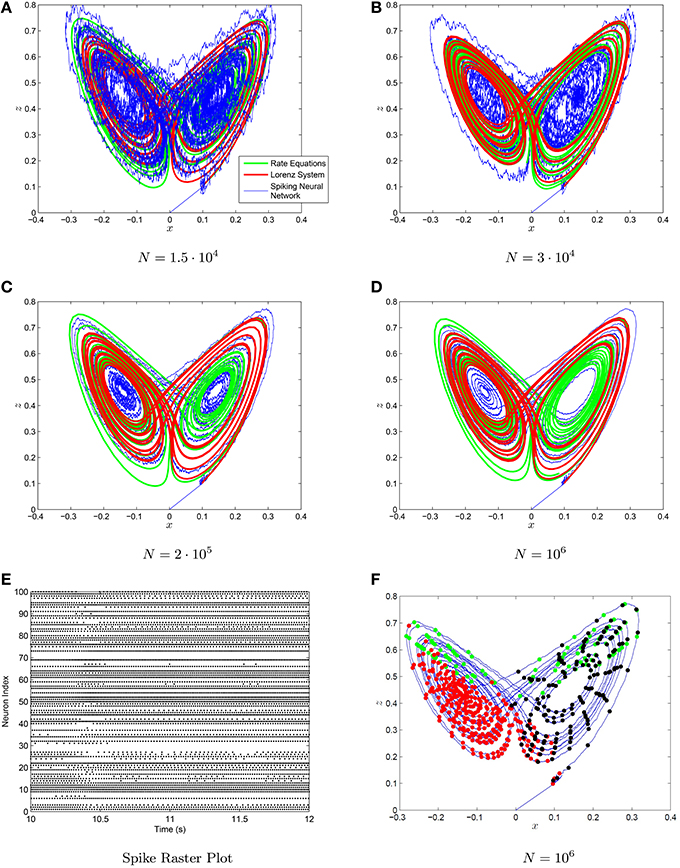
Figure 9. (A–D) The Lorenz attractor generated with a spiking neuronal network (blue) the neural rate equations (green) and integrating the Lorenz system (red) with neural networks of increasing size in figures. The decoders used are scale-invariant with conjugate gradient descent fine-tuning. The synaptic time constant was τs = 50 ms. (E) The spike raster plot for 100 neurons chosen at random from the N = 106 neuron simulation. (F) The location of the spikes with regards to the strange attractor for three randomly selected neurons are shown in (F).
4. Discussion
The NEF has been used to develop a wide variety of neural circuit models. The spiking networks generated from the NEF approach are spiking neural networks that are capable of functionally reproducing very sophisticated behaviors (Eliasmith, 2005). In the NEF approach, a synaptic weight between two neurons is a dot product of the post-synaptic neuron's preferred direction vector and the presynaptic neuron's linear decoding vector or “decoder.” The decoders weight the tuning curves for the neurons and are determined by an optimization criterion that minimizes the L2 error in the linear combination of tuning curves and the target dynamics of the network in addition to a factor that punishes the size of the decoders. The optimal decoders are unique, as they are determined by a convex optimization problem.
The first main point of this study is that in the large network limit, one can define a scale-invariant decoder that scales in inverse proportion to the network size N such that the scale-invariant decoders zero the cost function used to define the optimal decoders asymptotically in the mean-squared error. In the asymptotic limit, the scale-invariant decoders multiplied by the probability density governing the source(s) of heterogeneity converge to a constant function. The resulting linear combination of weighted firing rates converges to the tuning curve transforms asymptotically. We have determined this to also be the case with optimal decoders given by large matrix inversion, where the product of the optimal decoders and the heterogeneous density also converges to the weighted decoder. Furthermore, we have shown how one can invert tuning curve transform operators for type-I (theta model) and type-II firing rates. It turns out that the inversion is non-unique, which results in an infinite-dimensional family of scale-invariant decoder surfaces and thus synaptic weights.
The second contribution of this paper is a method of finding the scale-invariant decoders analytically from the decoded function and the probability density of the neuronal parameters. Additionally, we have demonstrated that as the weighted decoder is non-unique for any particular dynamics, the NEF solution to the weights with scale-invariant decoders also becomes non-unique.
Finally, we have demonstrated how the weights that couple neurons together can actually be thought of as surfaces defined entirely by the source(s) of heterogeneity in the network. In particular, a weight ωij is defined as the inner product of a scale-invariant decoder γ(ej, aj)/N of the post-synaptic neuron j with the encoding vector ei of the presynaptic neuron i. Thus, one can consider this inner product as a function over a higher dimensional space and the weights are merely sample points on this hypersurface. Furthermore, the weights generated via this approach have the advantage that the coupling between the jth presynaptic neuron and the ith postsynaptic neuron depends only upon the local properties of neuron i and neuron j for any specified dynamics. This is different from Hebbian plasticity, in that the coupling does not depend on presynaptic and postsynaptic activity, but rather on an intrinsic property of the presynaptic neuron times an intrinsic property of the postsynaptic neuron. While this perspective has been used before in the literature, for example to model hypercolumns in the primary visual cortex in (Shriki et al., 2006), here we show how it can be extended to arbitrary (smooth) dynamics.
4.1. Relationships between the Analytical and Optimal Decoders
The optimal decoders appear to have an asymptotic weighted decoder, the product of the density function multiplied by the scaled optimal decoder, NΦi, when one computes this quantity numerically after large-matrix inversion (see Figure 2). For the optimal decoders, the weighted decoder has high frequency oscillations that are related to the idiosyncracies of the particular sample of random neurons generated. These seem to attenuate with increasing network size, and regularization parameter λ. These high frequency oscillations are for example eliminated when the neurons are drawn from a grid. Indeed, when the neurons are drawn from a grid, the optimal decoders for a much larger network can be approximated by simply interpolating between the decoder values for the smaller grid network, and rescaling the interpolated decoders in accordance with the network size.
Thus, one may ask is the weighted decoder generated by the optimal decoders (1) convergent as N → ∞, and (2) does it converge to any particular weighted decoder in the set defined by the requirement that ĝ(x) = M(P+, P−) = L+(P+) + L−(P−) = g(x)? It seems that numerically the quantity Nρa(ai)Φi does converge to some surface P± that varies depending on the identity of neuron i as an ON/OFF neuron. The likely candidate for the specific in the set defined by M(P+, P−) is the surface that minimizes Equation (42). However, the relationship between the optimal decoders, and any particular scale-invariant decoder as N → ∞ is outside of the scope of this paper and is best left for future work. Relatedly, there seem to be some systematic differences between scale-invariant and optimal decoders due to finite neurons. For example, a scale-invariant decoder surface can have discontinuities, while corresponding regularized optimal decoder surfaces do not, even with very large numbers of neurons
4.2. Relationship to Other Approaches
We have demonstrated that if one defines a scale-invariant decoder that is a function of the source(s) of heterogeneity of the neurons, one can obtain arbitrary macroscopic dynamics with the NEF weight solution, which is the dot product of the decoder for the presynaptic neuron, and the preferred orientation vector or encoding vector for the post-synaptic neuron. Thus, both the weights and the decoders for the neurons can be thought of as surfaces as they are merely functions of the sources of heterogeneity of the network. While this perspective is novel in the sense that we have shown one can obtain arbitrary dynamics with this approach, similar decoders and weights have been suggested in previous work. In particular, the scale-invariant decoders here can be thought of as an extension of the neuronal population vectors of Georgopolous (Georgopoulos et al., 1986, 1994). It has been previously noted (for example in Eliasmith and Anderson, 2004) that the population vector from (Georgopoulos et al., 1986, 1994) is similar to the case where one uses the encoding vectors ei as the decoding vectors ϕi. Here, we have derived a more general approach where ϕi is a function of ei and the other sources of heterogeneity in the tuning curves. Additionally, weights that are a function of the presynaptic and post-synaptic preferred orientations have been also used in the literature (Ben-Yishai et al., 1995; Shriki et al., 2006).
There are also methods in the literature that construct networks of neurons with prescribed dynamics. For example, spiking networks of leaky integrate-and-fire models have been constructed that can display arbitrary linear dynamics with weights that are seemingly unrelated to the NEF solution for the synaptic weights (Boerlin et al., 2013). The solution obtained in (Boerlin et al., 2013) is derived through minimizing the time integral of the L2 norm of the decoded estimate of the dynamics, and the intended dynamics in addition to other terms intended to minimize the spiking, and distribute the spikes equitably across the network. The end result is a network of leaky integrate and fire neurons and weights that when coupled together display the desired dynamics. While the solution is very elegant, it is unknown if it can be extended to non-linear dynamics.
4.3. Numerical Applications
We considered whether this work has practical applications for neural simulations. As an example, we considered whether (having found the weighted decoders for a given network) it would be useful to adjust ρ in order to make the weights uniform, thus avoiding large fluctuations associated with the spiking of heavily weighted neurons. This sometimes led to modest reductions in spike noise in simulations.
As discussed above, scale-invariant decoders can serve as a starting point for iterative optimization, quickly leading to highly optimized weights for large networks. However, it should be pointed out that since the optimization problem is convex, any starting point can be used, and in our experience scale-invariant decoders are only moderately better than other reasonable choices.
It is possible that our approach could be applied to groups of neurons that are so large as to be impractical even for efficient iterative methods. The cortex consists of a fairly continuous sheet of neurons with few distinct boundaries, suggesting that it may be somehow useful to simultaneously consider the activity of billions of neurons. On the other hand, if the goal is simply to optimize synaptic weights, the degree of convergence onto single neurons (< 200, 000) is within a practical range for iterative methods. Furthermore, our solution for multivariable functions requires encoder distributions that are separable in hyper-spherical coordinates, which may be a limitation for modeling extensive sheets of neurons with overlapping tuning.
In light of these experiences, we consider this work to be valuable mainly as a source of new insights into network function and dynamics, rather than as a basis for new numerical tools.
4.4. Analyzing Measured Synaptic Weights
Using experimental methods, it is possible to measure both the synaptic weights (defined as the peak post-synaptic current) in addition to fitting integrate-and-fire type neurons with heterogeneity using the dynamic current-voltage curve approach (Badel et al., 2008; Harrison, 2014; Harrison et al., 2015). While there are typically many parameters for more complicated integrate-and-fire models (such as the AdEx), one can always reduce the number of heterogeneous parameters to a much smaller set governing the properties of the tuning curves. We refer to these generically as bi, a vector with the parameter values for the ith neuron. Given these assumptions, and the work done in this paper, one kind of analysis that can be conducted without much effort is the construction of a non-linear regression model of the weights:
where F(bi, bj) is either a non-linear or linear model with a number of free coefficients and ωij are the experimentally determined synaptic weights of a recurrently coupled neural network. The coefficients can be estimated using optimization techniques to minimize ϵij. For this weight analysis to be valid, we require the following
where . The core result of this paper is that any dynamics are possible with synaptic weights of the form (Equation 92), and their is no unique weight matrix that confers specfic dynamics. Thus, a regression analysis of the synaptic weights (Equation 92) is a reasonable analysis to conduct if one knows the sources of heterogeneity for the neurons in the network and provided that the residuals are sufficiently small.
4.5. Future Work
While the networks constructed here display the desired macroscopic dynamics, this is not always the case. In particular, if the time constants are too small, then the collective macroscopic state can destabilize. For the weight solution we have determined to be valid, one needs to prove that the macroscopic dynamics form a stable attractor in the large network limit. Unfortunately, resolution of this problem is well outside the scope of this paper. While a great deal of work has been done in determing the stability of asynchronous states in large network limits (for example in Abbott and van Vreeswijk, 1993; van Vreeswijk, 1996), to our knowledge no work has been when the weights have structure present here. The majority of work done on large network stability analysis is devoted to weights that are constant throughout the network, ωij = ω however there is some work on non-constant, randomly distributed weights (Hermann and Touboul, 2012). The authors of (Hermann and Touboul, 2012) note that oscillations arise when considering randomly distributed weights. Here, we demonstrate that with a little bit more structure to the weights/network (the weights are functions of the properties of the f(I) curves of the neurons), arbitrary prescribed macroscopic dynamics can be generated by the network.
Networks of heterogeneous theta oscillators have been extensively analyzed in (Barreto et al., 2008; Luke et al., 2013; So et al., 2014) by using the Ott-Antonsen Anzats initially applied to networks of Kuramoto Oscillators (Martens et al., 2009; Ott and Antonsen, 2009). Additionally, one of the weight solutions for a network with one-dimensional dynamics that arises from the scale-invariant decoders sets all the weights to ±ω by setting the density to where the constant of proportionality normalizes . Given that, it may be possible to apply some of the existing literature on the stability analysis of networks of heterogeneous theta neurons to this network.
In addition to stability analysis of the large network, the weight solutions were derived here under a pair of simplifying assumptions. In particular the two strongest assumptions were that the FI curves were constant in time, and that the neurons were coupled using current-based synapses instead of conductance based synapses. We intend to extend the approach we have taken here with scale-invariant decoders to neurons with conductance based synapses, and f(I) curves that vary due to forces like spike frequency adaptation (Ermentrout, 2006). Fortunately, some of the initial work on generating macroscopic rate-equations (a necessary initial step) for conductance based neurons has been done in (Ermentrout, 1994; Shriki et al., 2006), in addition to work on rate equations for adapting neurons (Nicola and Campbell, 2013b)
Author Contributions
WN and MS performed much of the analysis. The numerical experiments were performed by WN with assistance from BT with regards to the Neural Engineering Framework. WN, BT, and MS contributed to the writing of the manuscript.
Funding
This research was funded by an NSERC Postgraduate Scholarships-Doctoral Program (WN) and NSERC discovery grants (BT, MS).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fncom.2016.00015
References
Abbott, L. F., and van Vreeswijk, C. (1993). Asynchronous states in networks of pulse-coupled oscillators. Learn. Mem. 48, 1483–1490.
Abbott, L. F. (1999). Lapicques introduction of the integrate-and-fire model neuron (1907). Brain Res. Bull. 50, 303–304.
Ahmed, B., Anderson, J. C., Douglas, R. J., Martin, K. A., and Whitteridge, D. (1998). Estimates of the net excitatory currents evoked by visual stimulation of identified neurons in cat visual cortex. Cereb. Cortex 8, 462–476.
Azouz, R., Gray, C. M., Nowak, L. G., and McCormick, D. A. (1997). Physiological properties of inhibitory interneurons in cat striate cortex. Cereb. Cortex 7, 534–545.
Badel, L., Lefort, S., Brette, R., Petersen, C. C. H., Gerstner, W., and Richardson, M. J. E. (2008). Dynamic iv curves are reliable predictors of naturalistic pyramidal-neuron voltage traces. J. Neurophysiol. 99, 656–666. doi: 10.1152/jn.01107.2007
Barreto, E., Hunt, B., Ott, E., and So, P. (2008). Synchronization in networks of networks: the onset of coherent collective behavior in systems of interacting populations of heterogeneous oscillators. Phys. Rev. E 77:036107. doi: 10.1103/PhysRevE.77.036107
Bekolay, T., Laubach, M., and Eliasmith, C. (2014). A spiking neural integrator model of the adaptive control of action by the medial prefrontal cortex. J. Neurosci. 34, 1892–1902. doi: 10.1523/JNEUROSCI.2421-13.2014
Ben-Yishai, R., Bar-Or, R. L., and Sompolinsky, H. (1995). Theory of orientation tuning in visual cortex. Proc. Natl. Acad. Sci. U.S.A. 92, 3844–3848.
Bobier, B., Stewart, T. C., and Eliasmith, C. (2014). A unifying mechanistic model of selective attention in spiking neurons. PLoS Comput. Biol. 10:e1003577. doi: 10.1371/journal.pcbi.1003577
Boerlin, M., Machens, C. K., and Denève, S. (2013). Predictive coding of dynamical variables in balanced spiking networks. PLoS Comput. Biol. 9:e1003258. doi: 10.1371/journal.pcbi.1003258
Brette, R., and Gerstner, W. (2005). Adaptive exponential integrate-and-fire model as an effective description of neuronal activity. J. Neurophysiol. 94, 3637–3642. doi: 10.1152/jn.00686.2005
Brunel, N., and Van Rossum, M. C. W. (2007). Lapicques 1907 paper: from frogs to integrate-and-fire. Biol. Cybern. 97, 337–339. doi: 10.1007/s00422-007-0190-0
Conklin, J., and Eliasmith, C. (2005). A controlled attractor network model of path integration in the rat. J. Comput. Neurosci. 18, 183–203. doi: 10.1007/s10827-005-6558-z
DeWolf, T., and Eliasmith, C. (2011). The neural optimal control hierarchy for motor control. J. Neural Eng. 8:065009. doi: 10.1088/1741-2560/8/6/065009
Eliasmith, C., and Anderson, C. H. (2004). Neural Engineering: Computation, Representation, and Dynamics in Neurobiological Systems. MIT press.
Eliasmith, C., Stewart, T. C., Choo, X., Bekolay, T., DeWolf, T., Tang, C., and Rasmussen, D. (2012). A large-scale model of the functioning brain. Science 338, 1202–1205. doi: 10.1126/science.1225266
Eliasmith, C. (2005). A unified approach to building and controlling spiking attractor networks. Neural Comput. 17, 1276–1314. doi: 10.1162/0899766053630332
Ermentrout, G. B., and Kopell, N. (1986). Parabolic bursting in an excitable system coupled with a slow oscillation. SIAM J. Appl. Math. 46, 233–253.
Ermentrout, G. B. (1994). Reduction of conductance-based models with slow synapses to neural nets. Neural Comput. 6, 679–695.
Ermentrout, B. (2006). Linearization of f-i curves by adaptation. Neural Comput. 10, 1721–1729. doi: 10.1162/089976698300017106
Georgopoulos, A. P., Schwartz, A. B., and Kettner, R. E. (1986). Neuronal population coding of movement direction. Science 233, 1416–1419.
Georgopoulos, A. P., Lurito, J. T., Petrides, M., Schwartz, A. B., and Massey, J. T. (1994). Mental rotation of the neuronal population vector. Biol. Comput. Physicist. Choice 3, 183.
Harrison, P. M., Badel, L., Wall, M. J., and Richardson, M. J. E. (2015). Experimentally verified parameter sets for modelling heterogeneous neocortical pyramidal-cell populations. PLoS Comput. Biol. 11:e1004165. doi: 10.1371/journal.pcbi.1004165
Harrison, P. M. (2014). Experimentally Verified Reduced Models of Neocortical Pyramidal Cells. Ph.D. thesis, University of Warwick.
Hermann, G., and Touboul, J. (2012). Heterogeneous connections induce oscillations in large-scale networks. Phys. Rev. Lett. 109:018702. doi: 10.1103/PhysRevLett.109.018702
Izhikevich, E. M. (2003). Simple model of spiking neurons. Neural Netw. IEEE Trans. 14, 1569–1572. doi: 10.1109/TNN.2003.820440
Lapicque, L. (1907). Recherches quantitatives sur lexcitation électrique des nerfs traitée comme une polarisation. J. Physiol. Pathol. Gen. 9, 620–635.
Luke, T. B., Barreto, E., and So, P. (2013). Complete classification of the macroscopic behavior of a heterogeneous network of theta neurons. Neural Comput. 25, 3207–3234. doi: 10.1162/NECO_a_00525
Martens, E. A., Barreto, E., Strogatz, S. H., Ott, E., So, P., and Antonsen, T. M. (2009). Exact results for the kuramoto model with a bimodal frequency distribution. Phys. Rev. E 79:026204. doi: 10.1103/PhysRevE.79.026204
Naud, R., Marcille, N., Clopath, C., and Gerstner, W. (2008). Firing patterns in the adaptive exponential integrate-and-fire model. Biol. Cybern. 99, 335–347. doi: 10.1007/s00422-008-0264-7
Nesse, W., Borisyuk, A., and Bressloff, P. (2008). Fluctuation-driven rhythmogenesis in an excitatory neuronal network with slow adaptation J. Comput. Neurosci. 25, 317–333. doi: 10.1126/science.1225266
Nicola, W., and Campbell, S. A. (2013a). Bifurcations of large networks of two-dimensional integrate and fire neurons. J. Comput. Neurosci. 35, 87–108. doi: 10.1007/s10827-013-0442-z
Nicola, W., and Campbell, S. A. (2013b). Mean-field models for heterogeneous networks of two-dimensional integrate and fire neurons. Front. Comput. Neurosci. 7:184. doi: 10.3389/fncom.2013.00184
Ott, E., and Antonsen, T. M. (2009). Long time evolution of phase oscillator systems. Chaos 19:023117. doi: 10.1063/1.3136851
Parisien, C., Anderson, C. H., and Eliasmith, C. (2008). Solving the problem of negative synaptic weights in cortical models. Neural Comput. 20, 1473–1494. doi: 10.1162/neco.2008.07-06-295
Rasmussen, D., and Eliasmith, C. (2014). A spiking neural model applied to the study of human performance and cognitive decline on raven's advanced progressive matrices. Intelligence 42, 53–82. doi: 10.1016/j.intell.2013.10.003
Salinas, E., and Abbott, L. F. (1995). Vector reconstruction from firing rates. J. Comput. Neurosci. 1, 89–107.
Shriki, O., Hansel, D., and Sompolinsky, H. (2006). Rate models for conductance-based cortical neuronal networks. Neural Comput. 15, 1809–1841. doi: 10.1162/08997660360675053
Singh, R., and Eliasmith, C. (2006). Higher-dimensional neurons explain the tuning and dynamics of working memory cells. J. Neurosci. 26, 3667–3678. doi: 10.1523/JNEUROSCI.4864-05.2006
So, P., Luke, T. B., and Barreto, E. (2014). Networks of theta neurons with time-varying excitability: Macroscopic chaos, multistability, and final-state uncertainty. Phys. D Nonlinear Phenomena 267, 16–26. doi: 10.1016/j.physd.2013.04.009
Stafstrom, C. E., Schwindt, P. C., and Crill, W. E. (1984). Repetitive firing in layer v neurons from cat neocortex in vitro. J. Neurophysiol. 52, 264–277.
Touboul, J. (2008). Bifurcation analysis of a general class of nonlinear integrate-and-fire neurons. SIAM J. Appl. Math. 68, 1045–1079. doi: 10.1137/070687268
Van der Pol, B. (1926). Lxxxviii. on relaxation-oscillations. Lond. Edinburgh Dublin Philos. Mag. J. Sci. 2, 978–992.
van Vreeswijk, C. V. (1996). Partial synchronization in populations of pulse-coupled oscillators. Phys. Rev. E 54, 5522.
Werfel, J., Xie, X., and Seung, H. S. (2005). Learning curves for stochastic gradient descent in linear feedforward networks. Neural Comput. 17, 2699–2718. doi: 10.1162/089976605774320539
Appendix
Determining the Decoder Surface
Here, we will make use of the Laplace transform to analytically determine the functions one can represent and numerically invert for the decoder surfaces in the NEF approach. In particular, consider the operator which is given by
Using a series of substitutions we can write the following:
where and , and m(y) = ĝ(y−1) = ĝ(x). In this case, the expectation is a convolution when written in the appropriate variables:
where ⋆ denotes the convolution operator. Taking a Laplace transform yields:
for some function C(z). Unfortunately is not invertible as we have:
from the general properties of the Laplace transform. This implies that if , f″(t) = t−3/2 and the Laplace transform is undefined as f′(0) → ∞. Suppose instead that we assume that m(z) is twice differentiable and that m(0) = 0 and m′(0) = 0. Then we can write the following:
This is how to find Q(z) as a convolution with m″(z), the second derivative of the function you want to approximate and . Based on these assumptions, we require that m(z) = bz2 + O(z3). Writing the convolution in terms of the original variables, we have the following:
This implies that we can approximate any function that vanishes to two orders at x = −1 using the following decoder for the ON neurons:
Additionally, if one repeats this process for a population of OFF neurons, then we can immediately write down the decoder for a function g that vanishes to two orders at x = 1:
Given the constraints on the derivatives of ĝ, it is clear that using a population of ON and OFF neurons, the resulting approximant has the form:
by using the ON and OFF populations, where g(x) is the function we want to approximate. The remainder is a linear term, A + Bx. Thus, if we can approximate an arbitrary linear function with a population of type-1 neurons with heterogeneity, then we can accomodate the remainder term. Note the following:
Thus, with the functions and , for the ON and OFF neurons respectively, we can approximate
with C = (A + B)/2 and D = (A − B)/2. Thus, to approximate the function g(x), we can use the following :
To remove the linear error, we used a linear combination of 1 + x and 1 − x. This choice is not unique. For example, we could have used
to eliminate constant term and a separate linear combination of
to eliminate the x term. The reason Equations (A18, A19) are not used for type-I neurons is due to complexity in the associated weighted decoders. However, these forms are simpler for Type-II firing rates and hence they are used there.
The same process can be carried out with the type-II firing rate form, which yields the operators:
with the resulting values for being
for c = 0. For c > 0, the inversion for functions that vanish to second order at x = ±1 yields
One can use the convolution (A22) to compute the weighted decoders for
the solution is lengthy and thus we do not include it here.
Keywords: mean field analysis, neural engineering framework, neuronal heterogeneity, integrate-and-fire neurons, recurrently coupled networks, synaptic weights
Citation: Nicola W, Tripp B and Scott M (2016) Obtaining Arbitrary Prescribed Mean Field Dynamics for Recurrently Coupled Networks of Type-I Spiking Neurons with Analytically Determined Weights. Front. Comput. Neurosci. 10:15. doi: 10.3389/fncom.2016.00015
Received: 17 November 2015; Accepted: 05 February 2016;
Published: 29 February 2016.
Edited by:
Boris Gutkin, École Normale Supérieure, FranceReviewed by:
Alex Roxin, Centre de Recerca Matemàtica, SpainBrian J. Fischer, Seattle University, USA
Copyright © 2016 Nicola, Tripp and Scott. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wilten Nicola, d25pY29sYUB1d2F0ZXJsb28uY2E=