 Jannis Weimar
Jannis Weimar Markus Köhli
Markus Köhli Christian Budach
Christian Budach Ulrich Schmidt
Ulrich Schmidt- 1Physikalisches Institut, Heidelberg University, Heidelberg, Germany
- 2Physikalisches Institut, University of Bonn, Bonn, Germany
- 3Institute of Environmental Science and Geography, University of Potsdam, Potsdam, Germany
Cosmic-Ray neutron sensors are widely used to determine soil moisture on the hectare scale. Precise measurements, especially in the case of mobile application, demand for neutron detectors with high counting rates and high signal-to-noise ratios. For a long time Cosmic Ray Neutron Sensing (CRNS) instruments have relied on 3He as an efficient neutron converter. Its ongoing scarcity demands for technological solutions using alternative converters, which are 6Li and 10B. Recent developments lead to a modular neutron detector consisting of several 10B-lined proportional counter tubes, which feature high counting rates via its large surface area. The modularity allows for individual shieldings of different segments within the detector featuring the capability of gaining spectral information about the detected neutrons. This opens the possibility for active signal correction, especially useful when applied to mobile measurements, where the influence of constantly changing near-field to the overall signal should be corrected. Furthermore, the signal-to-noise ratio could be increased by combining pulse height and pulse length spectra to discriminate between neutrons and other environmental radiation. This novel detector therefore combines high-selective counting electronics with large-scale instrumentation technology.
1. Introduction
The hydrological cycle and energy transfer at the land-atmosphere interface strongly depend on soil moisture. It is therefore a key variable in the effort to understand the Earth's climate system. However, soil moisture detection methods are either locally restricted to point measurements or large-area sensitive, satellite-based techniques with shallow depth resolution (Mohanty et al., 2017). In recent years Cosmic-Ray Neutron Sensing (CRNS) has become a prominent method for non-invasive soil moisture determination, although the basic principles are known for decades (Kodama et al., 1985; Zreda et al., 2008). It measures the environmental hydrogen content within a footprint of several hectares and penetration depths of up to 80 cm (Köhli et al., 2015), which enables CRNS to close the gap between large area and local measurements (Robinson et al., 2008). Further methods with larger support for soil moisture sensing include GNSS-R (Rodriguez-Alvarez et al., 2011) and gamma-ray spectroscopy (Strati et al., 2018). CRNS relies on the inverse relationship between the above-ground epithermal-to-fast cosmic-ray neutron intensity N and the surrounding hydrogen, e.g., the volumetric water content θ (cm3/cm3). The originally proposed equation by Desilets et al. (2010)
included the fitted parameters ai and was extended by the dry soil bulk density ρbd (Bogena et al., 2013). N has to be corrected for pressure, air humidity and incoming radiation variation with regard to one calibration value N0, the intensity over dry soil at this reference point (Zreda et al., 2012). Advances in the CRNS technique within the last years have been achieved from theory as well as due to the broadening applications. Such efforts quantified different signal contributions like vegetation (Baatz et al., 2015), snow (Schattan et al., 2017), atmospheric water vapor (Rosolem et al., 2013), and local heterogeneities (Schrön et al., 2018). Extensive neutron transport simulation studies improved the understanding in the transport of ambient neutrons (Köhli et al., 2015; Andreasen et al., 2016). Mobile campaigns have also extended the spatial scale up to several km2 and therefore could contribute to closing the measurement scale gap, especially relevant for small catchments (Schrön et al., 2018). Furthermore, CRNS has shown to be a prominent candidate for agricultural applications (Franz et al., 2016; Li et al., 2019), for validation of satellite based measurements (Montzka et al., 2017) and to improve hydrological modeling (Shuttleworth et al., 2013). The success of this technique (Andreasen et al., 2017) lead to a worldwide deployment of meanwhile more than 100 sensors.
The design of the neutron detector is essential for the performance of the method. Consequently, several studies examined the most common cosmic-ray neutron probe (CRNP) model. The probe comprises gaseous proportional counters with so-called converters, either 3He or 10BF3. Typically one counter is housed in a plastic moderator in order to focus its sensitivity to the epithermal-to-fast energy regime. In some models it is accompanied by another counter, which is left bare making it most sensitive to thermal neutrons. Furthermore, shielding material around the moderator blocks thermal neutrons and allows for better separation between the thermal and epithermal-to-fast signal (Desilets et al., 2010). Andreasen et al. (2016) elaborated first steps to compare the modeled and measured neutron flux using the Monte Carlo Code MCNPX (Waters et al., 2007). Köhli et al. (2018) extended the understanding of the detector response by calculating the exact energy sensitivity of common CRNPs with the URANOS package (Köhli et al., 2015). Their study revealed the similarity of the CRNPs to Bonner Spheres (Bramblett et al., 1960; Hertel and Davidson, 1985; Mares et al., 1991; Mares and Schraube, 1994) in terms of energy sensitivity. Beyond the standard probes recent developments also aim to introduce scintillation-based instruments (Stevanato et al., 2019). Besides the achievable count rate, the main difference between the two concepts lies in the detector energy response function and the background suppression. In contrast to the previous studies about the standard CRNP detector that were mostly descriptive, this work aims at unfolding the key challenges on a neutron detector dedicated to CRNS. It also introduces a new detection system especially designed for the needs of CRNS.
1.1. Motivation for a New CRNS Detection System
Neutron detectors applied in CRNS have to be improved in order to support a holistic progress of the method. In view of existing systems and the demands of CRNS on the neutron detector, four major challenges are identified:
1. Count rate enhancement: The neutron detector count rate directly relates to the time resolution by its statistical uncertainty. For typical systems and environmental conditions, neutron count rates have to be integrated over 4–12 h in order to achieve a statistical precision of a few percent. While this is sufficient for many hydrological processes, it renders the method incapable of capturing interception or irrigation. But most certainly, large integration times impede mobile measurements where the area to be covered in a certain time is primarily restricted by the detector's count rate.
2. Higher signal-to-noise ratio (SNR): The SNR describes the ratio between the detected neutrons that relate to the environmental hydrogen content (signal) to such which do not (noise). It determines the change in detected neutron count rate per hydrogen content change. With increasingly moist conditions, the sensitivity to hydrogen content changes decreases steadily until it eventually saturates due to the hyperbolic relationship to θ (see Equation 1). In close-to saturated conditions, i.e., humid forests (Bogena et al., 2013) and snow covered areas (Schattan et al., 2017), a high signal-to-noise ratio is critical for the assessment of water resources.
3. Refinement of the energy sensitivity: Some of the CRNPs come with two detectors, which feature peak sensitivities in the thermal and the epithermal energy regime, respectively. Recent studies tried to make use of spectral information (Baatz et al., 2015; Tian et al., 2016) by comparing the two signals. However, the moderated detector suffers from a thermal neutron contamination that constitutes up to 20% of its signal (Köhli et al., 2018). Moreover, preventing thermal neutron leakage is equivalently important for standard soil moisture sensing applications, since thermal neutrons exhibit a different and much smaller dependence on the environmental hydrogen content than epithermal-to-fast neutrons. Andreasen et al. (2016) and Desilets et al. (2010), therefore, already suggested to disentangle the signals to provide a higher contrast. The latter study also determined an appropriate moderator thickness of 25 mm through empirical studies. However, it might not be the ideal setup for any environmental condition and has not been further investigated by means of neutron modeling. Lastly, the spectral resolution can be extended by a modular multiple-counter detector system. Spectral information of higher energy neutrons can be used to actively correct for local effects (Schrön et al., 2018).
4. Replacement of 3He as an efficient neutron converter: Until the 2000s neutron detection almost exclusively relied on the element 3He as an efficient neutron converter. However, the only substantial source of 3He is the radioactive decay of tritium, which is extracted during the maintenance of thermonuclear weapons. As a consequence of the 9/11 attacks in 2001, most U.S. reserves of 3He were spent for homeland security and the stockpile depleted (Shea and Morgan, 2010). Ever since a number of commercially available replacement technologies have been developed, but none of them focused their design on CRNS. Beyond 3He, mostly 10BF3 has been used as a neutron converter for CRNPs. However, it is less efficient and highly toxic which puts concerns on its use for CRNS.
2. Methodology and Theory
2.1. Monte Carlo Packages for Neutron Transport Simulation
A specific CRNS-tailored neutron detector design needs to take into account a large variety of environmental conditions typically found in the context of CRNS. This is achieved most efficiently by neutron transport simulations using Monte Carlo packages. The tools used in this study are MCNP 6.2 (Werner et al., 2018) and URANOS (Köhli et al., 2015).
MCNP 6: MCNP (Monte Carlo N-Particle) is a general purpose software to simulate the propagation and interaction of a multitude of particles. Although originally developed in 1957 to investigate processes involving nuclear reactions, since the release of MCNPX (Waters et al., 2007) it has been also extended to simulate the propagation of particles in the Earth's atmosphere. Especially MCNPX was used in several studies to understand the CRNS signal (Desilets, 2012; Rosolem et al., 2013; Andreasen et al., 2016). With version 6 (Werner et al., 2018) the MCNPX branch was merged into the main development line featuring an optional cosmic-ray source (McKinney, 2013).
URANOS: The Monte Carlo code URANOS (Ultra Rapid Neutron-Only Simulation) was developed at the Physikalisches Institut, Heidelberg University, in collaboration with the UFZ Leipzig. This code has been specifically tailored to the needs of the CRNS method. It is based on a voxel engine and excludes any particles other than neutrons replacing them by effective models. Thereby, URANOS is a computationally efficient code that allows to simulate the large environmental setups typically found in the context of CRNS on standard desktop computers. It uses the validated near-ground cosmic-ray neutron spectrum by Sato (2016). The code was employed for CRNS footprint revision by Köhli et al. (2015) and Schrön et al. (2017), in roving (Schrön et al., 2018) and irrigation studies (Li et al., 2019) as well as understanding the signal for snow height measurements (Schattan et al., 2019). It also features special input options for conducting detector-related neutron transport studies (Köhli et al., 2018).
2.2. Neutrons in the Epithermal-to-Fast Energy Regime, a Proxy for Environmental Hydrogen Content
Cosmic-ray neutrons are generated via three different channels by high-energy primary cosmic-rays, typically protons, while they impinge on Earth. In one channel the interaction of primary cosmic-rays with nuclei in the outer Earth's atmosphere generate neutrons via a spallation process (Letaw and Normand, 1991). In a second channel even more neutrons are produced within the atmosphere as stable products of particle showers while at the same time the primary particles are slowed down or absorbed when propagating toward the Earth's surface (Pfotzer, 1936; Nesterenok, 2013). The soil likewise acts as a third channel. As high-energy neutrons and protons penetrate into the soil, they excite atomic nuclei triggering the emission of evaporation neutrons with energies of ≈ 1 MeV. The neutrons may cross the air-ground interface multiple times, while losing kinetic energy until being absorbed. These processes lead to the buildup of the typical energy spectrum above the ground as depicted in Figure 1 by the light red and light blue curve. The magnitude of the spectrum, i.e., total neutron flux density, mainly depends on the altitude (Kowatari et al., 2005) whereas its shape is mostly dominated by the environmental hydrogen content (Zreda et al., 2012). The use of cosmic-ray neutrons as a proxy for changes in the hydrogen content, e.g., soil moisture, snow and vegetation, requires a precise knowledge about which neutrons are affected most by hydrogen and which are insensitive to it. Understanding the underlying processes which lead to the desired signal is therefore the fundamental prerequisite for any CRNS focused neutron detector design.
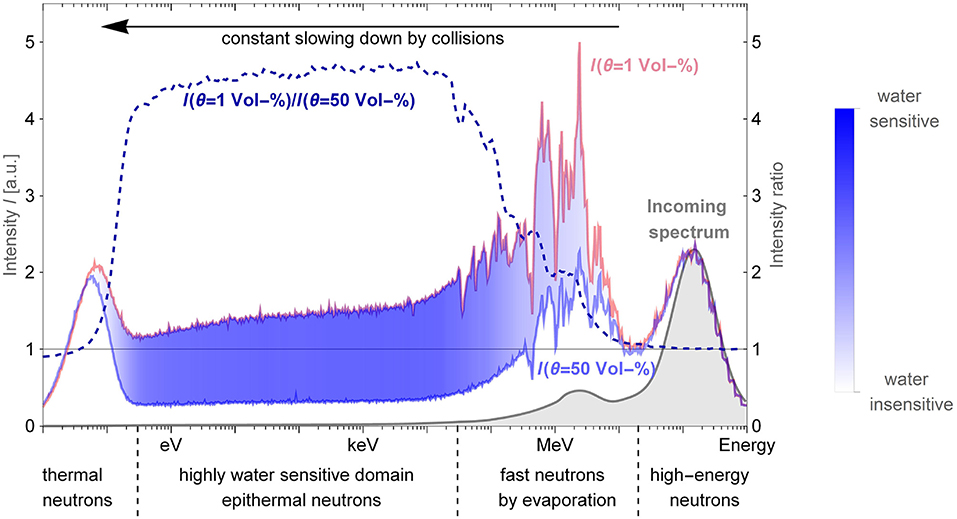
Figure 1. Simulated cosmic-ray neutron spectrum with focus on the hydrogen-sensitive energy domain. The input spectrum, according to Sato (2015) (gray curve), is released in 450 m height and propagated toward the soil. Above-ground neutron intensities are shown for dry (light red) and moist conditions (light blue), both at an air humidity of 1 g/m3. The intensity ratio between dry and moist (dashed blue curve and color-coded filling between the two spectra) reveals the hydrogen-sensitive domain. Neutrons with energies between 0.3 eV and 30 keV are most suitable as a proxy for the environmental hydrogen content. The simulations were carried out using the Monte Carlo Code MCNP 6.2 (Goorley et al., 2012) and cross section definitions from the ENDF/B-VIII.0 (Brown et al., 2018) data base.
The hydrogen-sensitive region of the cosmic-ray neutron spectrum lies in the epithermal-to-fast range, see Figure 1 dashed blue curve. Neutrons of such energies mainly interact with matter via elastic collisions in which the neutron changes its direction and loses kinetic energy, leading to constant deceleration. Hydrogen is the element that most efficiently moderates, i.e., slows down, neutrons down to thermal energies. That is because of the similar mass of neutrons and hydrogen accompanied with a large energy transfer per collision and a high collision probability. Furthermore, the abundance of hydrogen changes significantly in absolute numbers between dry and wet conditions. Hence, any change in environmental hydrogen content directly and predominantly affects the amount of epithermal-to-fast neutrons making them a suitable proxy for soil moisture, snow and other hydrogen bodies. No other element typically found in soil, vegetation, and in the air combines these criteria. Figure 1 reveals that the maximum signal change is limited to a factor of ≈ 4.5. The hydrogen-sensitive domain ends when neutrons are in thermal equilibrium with the environment, i.e., on average no energy loss occurs at collision. Thermal neutrons show a different or more complex response to soil moisture. For wet conditions the soil efficiently slows down neutrons, it acts as a source for thermal neutrons, however, the overall neutron density is lower. For dry conditions the much higher epithermal intensity competes with the poor moderation capability of the soil in absence of hydrogen. For both cases, the thermal neutron flux is nearly identical. Below 10% soil moisture a maximum builds up for sufficiently high ambient flux and average moderation power. Monte Carlo simulations show that the thermal intensity change due to hydrogen for standard soils is more than a magnitude lower than that of epithermal neutrons, see Figure 1 in this work and Figure 11 in Sato and Niita (2006). Moreover, some elements present in soil exhibit a high absorption probability for thermal neutrons. Hence, detailed knowledge of the chemical composition of the soil is required when thermal intensity changes have to be interpreted correctly (Quinta-Ferreira et al., 2016). The evaporation peak represents the upper limit of the hydrogen-sensitive domain. Evaporation neutrons are equally sensitive to hydrogen content as epithermal neutrons, because elastic scattering processes dominate these energies as well. However, there is a significant production of evaporation neutrons in the atmosphere leading to a prominent peak in the incoming flux. As opposed to the epithermal energy regime, a large part of evaporation neutrons has not been in contact with the ground, i.e., was not influenced by soil moisture. Additionally, a few percent of the evaporation neutrons created in the soil do not interact with the latter before entering the air volume. This effect leads to a slow decline of hydrogen sensitivity from energies of 30 keV to 10 MeV. For energies above 10 MeV the intensity is purely made up of incoming neutrons and the sensitivity vanishes completely. Consequentially, a neutron detector design tailored for CRNS should aim at being most sensitive to neutrons with energies between 0.3 eV to 30 keV with lower sensitivity between 30 keV and 1 MeV, while being insensitive to neutrons with other energies.
3. Cosmic-Ray Neutron Probe Design Considerations
3.1. Uncertainties of Neutron Measurements
Precise measurements of environmental hydrogen content via cosmic-ray neutrons require low statistical uncertainty and a high signal-to-noise (SNR) ratio of deployed neutron detectors. From a physical point of view signal may be defined as the detected epithermal-to-fast neutrons that penetrated the soil and underwent at least one scattering event. Following that, noise includes epithermal-to-fast neutrons which did not enter the soil volume, neutrons with different energy and detections that were erroneously assigned to a neutron event. Additionally, it comprises those evaporation neutrons that were created in the soil but leave it without any interaction. From a principle point of view, however, neutrons which were in contact with soil and those which did not are not distinguishable. Even with directional-sensitive detectors, it is not possible to trace back the location of the soil contact. That is because neutrons scatter multiple times in the air changing their direction with each scatter event. The following discussion, nonetheless, focuses on the former definition of SNR as the above mentioned limitation does not hold for Monte Carlo studies where neutrons can be tracked. Additionally to the systematic uncertainty introduced by noise σns, another uncertainty is introduced by counting statistics σstat. The total uncertainty on the neutron count therefore becomes:
The detection of neutrons obeys Poisson statistics, where the variance equals the expected value N, which is the number of detected neutron events. Assuming a constant neutron flux under constant environmental conditions, the relative statistical uncertainty can be determined as:
Hence, the statistical uncertainty can be reduced by prolonging the integration time of a single neutron measurement. Here, the propagation of the neutron measurement uncertainty onto the soil moisture retrieval is discussed briefly, before an appropriate strategy to build CRNS neutron detectors with low measurement uncertainty is discussed in more detail in the following sections. For simplicity, all hydrogen content is considered to be bound in soil moisture. The calculation still holds true if using the total water equivalent approaches like Franz et al. (2013) or Schattan et al. (2019). However, here the uncertainty analysis of specific further parameters such as air humidity or snow is neglected. Equation (1) can be used to estimate the uncertainty σθ:
The derivation can be found in the Appendix. It is important to note that σθ increases linearly with σN and quadratically with the hydrogen content. The ability to detect small hydrogen content variations in saturated environments is therefore strongly coupled to the measurement uncertainty of the neutron detector. Bogena et al. (2013) already discussed σθ with respect to the statistical uncertainty σstat. In the following sections the setup of gaseous neutron counters is described and each factor that may contribute to the noise is analyzed in view of detector design.
In the following the bare neutron detection device is referred to as neutron counter and the whole detection system including moderator, thermal shielding and electronics as neutron detector.
3.2. The Detection of Neutrons With Gaseous Proportional Counters
A proportional counter is a hermetically sealed cylinder with a thin wire in its center, see schematic setup in Figure 2. It is filled with a noble gas, which is ionized when charged particles propagate through the counter volume. Electrons and ions along this ionization track are separated when applying an electric field between the wire (cathode) and the cylinder barrel. The positive ions, therefore, drift to the cylinder wall and the electrons to the central wire. The electrons experience an increase in electric field strength reciprocal to the radius as they drift toward the wire due to the cylindrical shape of the counter. In the very vicinity of the wire, the electric field is strong enough to accelerate electrons beyond the ionization energy between two successive gas collisions and therefore start ionizing the gas. Secondary electrons created in that process ionize the gas further, which leads to a charge avalanche formation. The high voltage applied to the wire is chosen in such a way that this avalanche increases the number of electrons by a constant gain factor. Hence the amount of electrons is proportional to the amount of primarily generated electrons by the track of the incident particle. The electrons collected at the wire form a charge pulse that can be read out by appropriate electronics. Neutrons are non-ionizing particles and, therefore, cannot be detected directly by means of gaseous detectors. Most proportional counters instead use specific elements to convert neutrons into detectable particles. Such converters absorb the neutron and immediately decay into fragments that carry the kinetic energy Q released in these reactions. The three most common converter elements (Chadwick et al., 2011) are
The filling gas itself can act as a converter as 3He and 10BF3 or converters are applied as solid surfaces to the inside of the counter like 6Li metal and boron carbide 10B4C. The absorption probability for thermal neutrons of 10B and 3He are larger than that of 6Li by about a factor of 4 and 5.5, respectively. Conversion is only efficient at low energies as the absorption probability decreases inverse proportional to the square root of the energy of the neutron. The charged reaction products are emitted isotropically in opposite directions. In the case of gaseous converters, the reaction products may deposit their complete kinetic energy Q inside the gas (see Figure 2, 1a). If any of the fragments hit the tube wall its remaining kinetic energy is missing in the ionization process. In the case of solid converters, some of the kinetic energy of the fragment is lost in the conversion layer itself (see Figure 2, 1b), and only one fragment can enter the gas volume. That restricts the thickness of the solid converters and thereby their absorption i.e., detection efficiency. With increasing layer thickness more neutrons are absorbed but less conversion products reach and ionize the gas volume. For solid boron and lithium metal layers, the maximum efficiency is approximately 7 and 24%, respectively (Nelson et al., 2012; Köhli et al., 2016). The 6Li conversion products have higher energies and are lighter than those of 10B, thus allowing thicker conversion layers. Furthermore, 6Li is currently only applied in combination with a Multi-Wire Proportional Chamber (MWPC) readout (Forsyth et al., 2017), which is a detector concept similar to proportional counters with a planar geometry (Nelson et al., 2012). The conversion layer thickness in a MWPC may be larger than for standard proportional counters as the conversion products from a metal sheet can be detected from both layer surfaces. No such limitations exist for gaseous converters and the efficiency is determined by the amount of converter gas or more precisely, the counter dimensions and the converter gas pressure. Proportional counters using solid converters are usually filled with P10 gas (90% argon and 10% CO2). The range of the conversion products in the corresponding gas differs significantly ranging from few millimeters for 10B to few centimeters for 6Li and 3He (Nelson et al., 2012; Langford et al., 2013; Köhli et al., 2016). That means their ionization traces are short and dense. Gas ionization by other particles, indicated in Figure 2, 1c, and their influence on the detector signal is discussed in the following section.
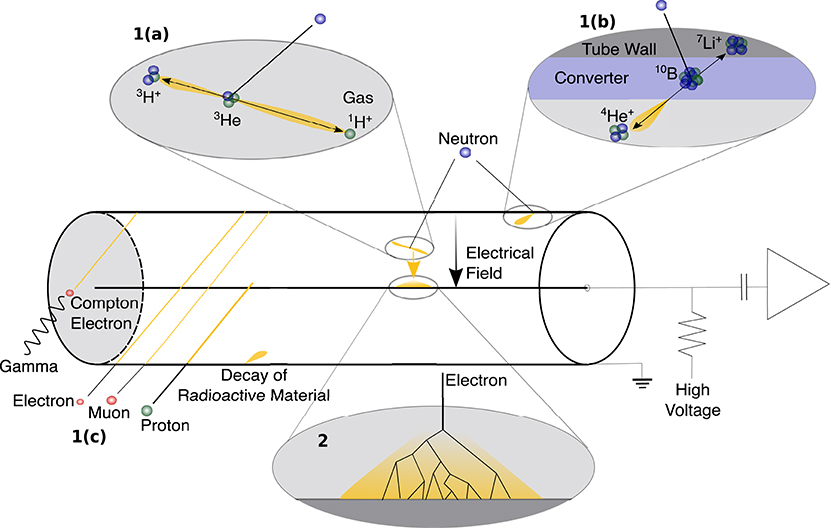
Figure 2. Detection principle of a proportional counter. Neutron conversion into ionizing radiation takes place in either the gas phase (1a) or in solid material (1b). (1a) indicates the 3He and (1b) the 10B conversion processes. The fragments of the conversion process are emitted in opposite directions. The ionization trace is indicated in yellow. An electric field between the tube wall and the axial wire accelerates the generated electrons toward the wire. In the vicinity of the wire, the electron's kinetic energy reaches the gas ionization energy and charge multiplication takes place (2). The resulting pulse is then read out by charge sensitive amplifiers. 1(c) Indicates other types of radiation that may induce a signal. The thickness of the tracks indicate the ionization energy deposition (see section 3.2.1).
3.2.1. False Positive Detections—Neutron Counter Efficiency to Other Types of Radiation
One important source of detector noise are particles that generate a similar signature like neutrons inside the neutron counter and therefore may be mistaken for such (see Figure 2, 1c). Sources of ionizing particles include other cosmic rays, terrestrial radiation and weakly radioactive materials inside the detector itself. In particular, a similar signal compared to neutron conversion is triggered when particles are of the same kind as the conversion products. Such are mainly heavy and highly ionizing particles with short ranges of less than a few millimeters in solid materials (see section 3.2). If possible they should be shielded against by the housing of the counter. Only if for example generated in the innermost layer of the tube wall, they can enter and ionize the gas and contribute to the noise. Hence, only material with lowest intrinsic radioactivity should be used for the production of neutron counters. Even a comparably low abundance of radioisotopes may decrease the signal-to-noise ratio significantly due to the small flux of cosmic-ray neutrons. A key property of particles that penetrate the counter is the energy loss due to ionization per distance traveled, dE/dx. As seen above, the conversion products feature a high dE/dx, are therefore short-ranged and deposit large amounts of energy by ionization. Cosmic-ray muons, although abundant, are weakly ionizing, i.e., have a small dE/dx, and because of the limited track length inside the counter, they trigger small signals in gaseous counters (Groom et al., 2001). Electrons, i.e., beta radiation, though less ionizing than the conversion products, can still deposit a significant amount of energy in the active counter volume. The significance of such contributions depends on the geometry of the system, which allows or prevents long track length for electrons. Gamma rays may also induce electron emissions via Compton scattering (Compton, 1923) and can, therefore, trigger similar ionization traces like beta radiation. Ionization by incident cosmic-ray protons may also lead to false positive detections. However, their overall flux is almost one magnitude lower as the cosmic-ray neutron flux (Sato, 2015) and mostly of too high energies to effectively ionize the gas. In summary, careful material selection can minimize intrinsic radioactive background that may induce false positive signals. The energy E and the energy loss per distance traveled dE/dx can be used to discriminated between the conversion products and other ionizing particles.
3.2.2. Moderator Design Considerations
Neutron absorption, including the conversion process, is most efficient for low energy neutrons. Therefore, the energy dependent detection efficiency of a bare neutron counter lies in the thermal energy regime, see the black curve in Figure 3. In order to shift the neutron counter sensitivity to the hydrogen-sensitive energy domain, a hydrogen-rich casing, called moderator, is mounted around the counter. It slows down epithermal neutrons in the same fashion as hydrogen contained in soil moisture. This necessary statistical deceleration comes with the drawback, that some neutrons are absorbed within the moderator material itself and some are reflected. Additionally, the environmental thermal neutron flux can partly leak into the moderator and increase the detector noise. This can be prevented by mounting a strongly absorbing material at the outside of the moderator case like cadmium, boron or gadolinium oxide (Gd2O3), further referred to as thermal shield. Due to the probabilistic nature of the deceleration sequence, the result is a rather broad energy sensitivity, called response function (see Figure 3, colored curves). The response function R(E, ϕ) describes the detection efficiency for an incoming neutron with energy E and incident angle ϕ. In general the response functions of neutron detectors typically used in CRNS resemble those of Bonner Spheres. For a more comprehensive study focused on standard CRNS detectors (see Köhli et al., 2018). Figure 3A shows the response functions of neutron counters with various moderator and thermal shield configurations. The standard CRNP configuration is shown in green. Multiplication with the cosmic-ray spectrum yields the spectral count rate (see Figure 3B), which, if integrated over all energies, leads to the total count rate. The relative thermal contribution of the signal of the standard CRNP is in particular large for moist soil. The reason for this observation is that the ratio between thermal and epithermal-to-fast neutrons increases with soil moisture, as the thermal intensity is not as sensitive to environmental hydrogen. However, as mentioned above the numbers shown here are subject to a high systematic uncertainty since the intensity of the thermal peak additionally depends on the soil chemistry. Following the signal definition in section 3.1 this thermal contamination of standard probes leads to a lower SNR as compared to shielded detectors (see Figure 4A). A high SNR is especially achieved for thin moderator configurations as the contamination of evaporation neutrons that did not penetrate the ground is relatively low, indicated in Figure 3B. However, excluding the evaporation regime is accompanied by a loss of signal as still a large part of such neutrons probed the soil. The signal normalized to the configuration of 27.5 mm moderator thickness and thermal shield is shown in Figure 4B. Figures 4C,D are also normalized with respect to the same configuration. Figures 4A,B reveal the competition between gain in signal quality by a higher SNR and by higher count rates, i.e., lower statistical uncertainty. Higher SNR leads to higher signal dynamics, i.e., relative count rate change per Vol-% soil moisture change, , as depicted in Figure 4C. However, the statistical uncertainty needs to be sufficiently low in order to resolve these dynamics. Therefore, maximizing
is suggested as an optimization variable, where S is the signal. This product of statistical and dynamic range precision is shown in Figure 4D. It features maximum values for 20 and 22.5 mm moderator thicknesses in dry and moist conditions, respectively. As for dry conditions the signal dynamic is larger, it is concluded that a 22.5 mm moderator accompanied with a thermal shield shows the best overall performance. Yet, the difference to the 25 mm moderator and thermal shield combination as it was presented by Desilets et al. (2010) is marginal. In some use cases the thickness might be reduced further as for example in high altitude for close-to-saturation environments like alpine snow measurements. High altitudes come with the benefit of a high neutron flux and therefore low statistical uncertainty in shorter time frames. It might, thus, be beneficial to opt for a higher SNR with thinner moderators in order to maximize the overall precision. Figure 4 shows the important role of thermal shielding as it significantly improves the dynamic range while keeping the signal count rate constant. If thermal neutrons are not efficiently shielded (5) shifts to thicker moderators and finally yields an optimum of 27.5–30 mm if no thermal shield is applied. The shape of the response functions is dominated by the moderator thickness but is also slightly influenced by the detector geometry and aspect ratio (Köhli et al., 2018). Hence, any detailed moderator optimization procedure should be adapted to the individual detector dimensions and might differ slightly from the above analysis.
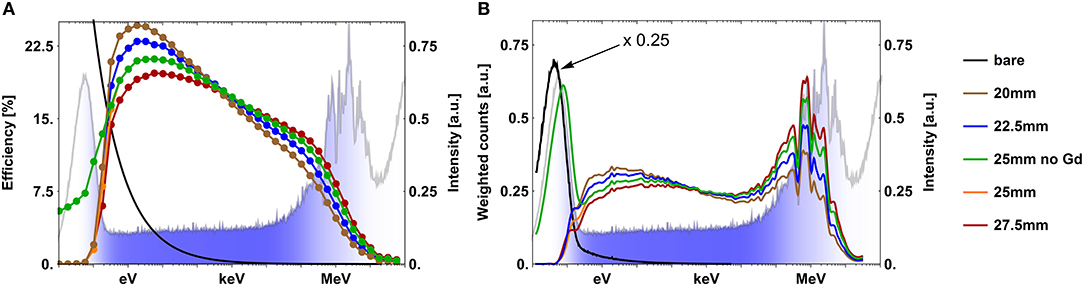
Figure 3. (A) Response functions of a bare neutron counter and detectors with moderator thicknesses of 20–27.5 mm in steps of 2.5 mm. All models except for one of the 25 mm versions are equipped with a thermal shield. The thermal shield consists of a Gd2O3 layer with a thickness of 90 μm in order to provide a sufficiently high absorption cross section for the thermal peak. The chosen thickness reduces the spectral count rate for energies below 100 meV to approximately 1%. For this study the reference density for the high density polyethylene moderator was chosen to be 0.95 g/cm3. The detector model is based on the 3He Rover, introduced in Desilets et al. (2010) and analyzed by Köhli et al. (2018). In order to compare energy ranges a cosmic-ray neutron spectrum above the soil at 20% soil moisture and 15 g/m3 air humidity simulated by MCNP (Goorley et al., 2012) is drawn. The dry soil consists to 75% of SiO2 and to 25% of Al2O3 with a porosity of 50%. The sensitivity to hydrogen according to Figure 1 is shown by the shaded blue filling. (B) Weighting of this neutron spectrum with the response functions reveals the total count rate contribution of the different energy domains. The weighted count rate of the bare counter are decreased by a factor of 4.
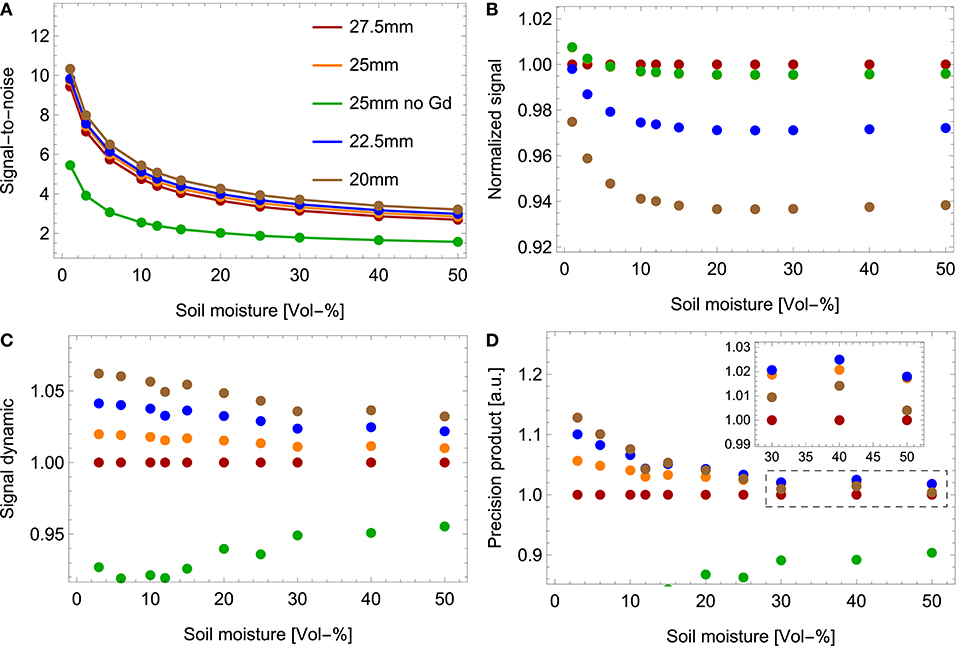
Figure 4. Detector response to soil moisture dependent on the moderator thickness. All detector configurations feature a thermal shield except for “25 mm no Gd.” (A) SNR according to the definition of section 3.1. (B) Signal count rates normalized to the detector setup with 27.5 mm moderator thickness and a thermal shield. (C) Dynamical range or signal contrast, normalized like (B). (D) Suggested optimization procedure, maximizing the product of statistical, and contrast precision according to Equation (5).
3.2.3. Dimensional Considerations
The cosmic-ray neutron flux In at sea level integrated over all energies below 15 MeV is around 50–200 neutrons per second and m2, depending on the magnetic cut-off rigidity and hydrogen pools (Goldhagen et al., 2004; Nesterenok, 2013; Sato, 2015). For most CRNS systems that ensues integration times on the order of hours in order to reduce the relative statistical uncertainty on the neutron count rate to a few per cents (Bogena et al., 2013; Schrön et al., 2018). Two parameters control the detector count rate. Firstly, the flux impinging on the neutron detector is proportional to its surface area A. Secondly, the detector magnitude of the response function R(E, ϕ), as discussed above, is a measure for the efficiency of the system. In total one yields
Surface area and energy response function anticorrelate in the count rate optimization process at a fixed amount of converter material (see Figure 5). An optimal compromise between the two in particular depends on the efficiency and dimensions of the neutron counter. Monte Carlo simulations reveal that a thermalized neutron entering the inside of the moderator casing transits the latter on average 3 times due to backscattering at the inner surface. It may, therefore, traverse the neutron counter inside the moderator several times. The smaller the counter compared to the volume enclosed by the moderator the lower the probability to hit the tube. However, for highly efficient counters multiple traverses or large path lengths through the counter contribute less and less to the detection efficiency due to the exponential absorption law. For neutron counters with high efficiencies, it is advantageous to have a slightly bigger moderator casing, hence a larger surface area in exchange for a lower traverse probability (see Figure 5). The optimum moderator size for a specific counter can be calculated individually using Monte Carlo simulations. As the neutron converter usually makes up for most of the production costs, it is instructive to optimize the detector design for a certain amount of converter. In the ideal case, the converter is evenly spread throughout the inside of the moderator as opposed to a highly efficient but infinitely small counter with the same amount of converter. In the context of CRNS, a cost-efficient detector design, therefore, is large in size while less efficient to maximize the use of its converter.
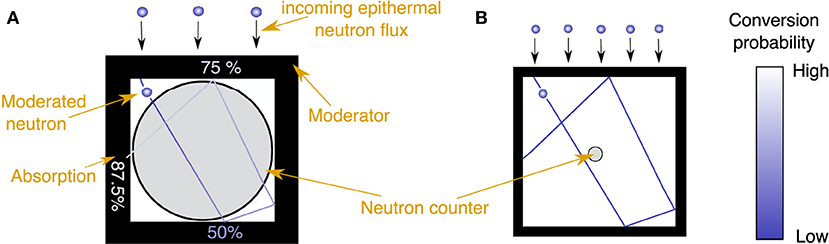
Figure 5. Schematic drawing of the interplay between surface area and response function. The cross sections through two combinations of a rectangular moderator and cylindrical neutron counter at thermal efficiency of 50% are shown. Both figures are not to scale. A typical neutron track after thermalization through the inside of the moderator is shown in blue with the color saturation indicating the absorption probability by the converter material. (A) Maximizes the response function but features the smallest surface area possible, while (B) has a large surface area compared to the neutron counter dimension. Configuration (B) therefore has a large neutron flux impinging the moderator but a low response function because of the lower probability for a counter transect.
4. Large-Area Boron-Lined Neutron Detectors for CRNS
The CRNP design considerations introduced above have led to a CRNS-tailored neutron detector development. This study introduces the first dedicated approach, a large-area boron-lined neutron detector. It makes use of a multitude of boron-lined proportional counters. The B4C converter layer (96% enrichment of 10B) has a thickness of up to 1.5 μm that is sputter-deposited on high purity copper foils. It is filled with a gas mixture of 90% argon and 10% CO2. The efficiency of a single counter for thermal neutrons amounts to roughly 10% (Piscitelli, 2013; Modzel et al., 2014). Another 3% are absorbed but not detected as the conversion products do not reach the gas or their ionization signature is below the detection limit. The foil is embedded at the inner wall of a hermetically sealed aluminum tube with an inner diameter of 54 mm and a length of 1,250 mm. Aluminum is chosen for its low absorption probability for neutrons compared to other materials as for example stainless steel. The gold plated tungsten wire in the center has a diameter of 25 μm and requires a high voltage of 1,200 V. Stationary detectors are equipped with up to five counter tubes and a mobile detection system is composed of four rows with eight counters each as indicated in Table 1. Each row is subdivided into two base units with four neutron counters each. The detector tubes are surrounded by a modular moderator of 25–35 mm thickness and a removable thermal neutron shield made of Gd2O3. Further moderator sheet inlays between the base units allow for modular shielding and a specific energy response function adjustment. The counters of a base unit and those of a stationary detector are connected to one pulse analyzing and digitizing readout electronics module. The readout electronics assigns individual timestamps to each detected event with a temporal resolution of one millisecond. Such information may be used to study the “ship effect” and allows for corrections of occasional spikes in the count rate (Kouzes et al., 2008; Aguayo et al., 2013). A data logger collects the pulse information of the frontend electronics and records temperature, relative humidity and air pressure. The data is stored locally on a SD card and can be transmitted remotely via GSM or LTE. GNSS connectivity enables location tracking for mobile measurements but also updates the real time clock of the data logger ensuring stable timing over long periods. Table 1 shows that the boron-lined detection systems feature a large surface area compared to other systems resulting in a high neutron flux throughput. The neutron counters inside the large moderator housing take up a substantial part of the inner moderator volume. Therefore, moderated neutrons are likely to traverse multiple boron-lined conversion layers, resulting in a moderate response function, which is two times lower than that of a 3He-based CRS-1000 detector. However, due to the larger surface a pseudo efficiency that is approximately five times higher than that of the CRS-1000 detector is achieved (Köhli et al., 2018). An optional thermal shield reduces the count-rate by 10–20%, depending on the environmental conditions, but significantly improves the signal-to-noise ratio (see also section 3.2.2).

Table 1. Key properties of the mobile and stationary detection system presented in this study and the commonly used CRS-1000.
4.1. Modularity: Scientific Use Cases for Adapted Energy Response Functions
The mobile detection system setup (see Figure 6 and Table 1), allows for moderator sheet inlays between rows of counter tubes. Information about the neutron spectrum can be retrieved by comparing the count rates of the differently moderated rows, similarly to the use of Bonner Spheres. The inset of Figure 7 shows a simple configuration of 25 mm moderator sheet inlays between three counter rows, with a 25 mm moderator at each side and 10 mm at the top and bottom as well as a thermal shield (yellow outline). The upper and middle row feature highest sensitivity in the lower and upper energy part of the hydrogen-sensitive domain. The lower row's sensitivity peaks at energies between 10 keV and 1 MeV. Comparing the count rates yields information about the intensity changes of evaporation neutrons. These are mainly affected by the near field and, thus, may help to investigate the “road effect” (Schrön et al., 2018). Moreover, a configuration with rows that are especially sensitive in the thermal energy regime along with rows that show a standard response function may help in biomass focused studies (Baatz et al., 2015). The fourth counter row of the mobile unit may be added to any of the other three rows in order to increase the count rate for this specific energy domain. In principle, all four rows can be moderated differently.

Figure 6. Setup of the large-area boron-lined detector for mobile measurements. Six base units are shown, assembled in two rows with two units each and two units on top of the back row. Each base unit is equipped with moderator sheets on three sides.
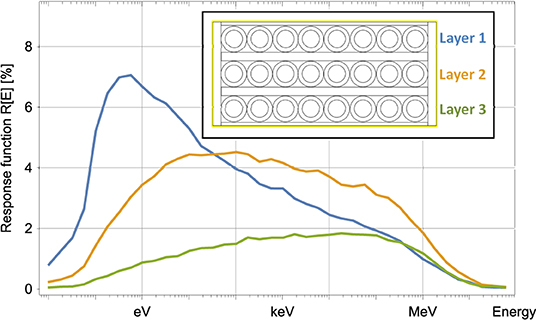
Figure 7. Example for response function adaptation of the mobile unit that may be used for active signal correction of the near-field. Further layers increase the number of energy bands and allows to move toward characteristics of Bonner Sphere spectrometers. However, this calculation is valid for single side irradiation only.
4.2. Noise Reduction and Particle Discrimination by Pulse Shape Analysis
The key feature of any proportional counter is to precisely measure the charge generated in the ionization process by the incoming particle (see section 3.2). A well-adapted analog amplifier stage generates pulses with heights proportional to the energy deposition in the counter. It can therefore discriminate between the dense tracks from the neutron conversion process and weak ionization processes. Energy discrimination can effectively suppress muons as such deposit only low amounts of energy in the counter. However, some electrons and gamma rays that induce electrons can deposit significant amounts of energy in the gas if their track length is large enough. Long ionization traces lead to large differences in the arrival of the primary electrons close to the counter wall and those close to the wire. In general, the projected axial ionization path directly relates to the rise time of the charge pulse. As opposed to electrons, the rise time generated by the 10B conversion is very short due to the short-ranged and dense ionization processes (see section 3.2). Pulse rise time is therefore another tool for particle discrimination as was shown by Izumi and Murata (1971) and Langford et al. (2013). As an upgrade to the commonly used pulse height discrimination, we use two-dimensional information about pulse height and length, which is shown in Figures 8, 9. With the pulse length representing the rise time convoluted by the exponential decay of the amplifier electronics, displayed in Figure 8b. When exposing a boron-lined counter with 1 bar counting gas pressure to a radioactive gamma, beta and neutron source its efficiency to the various particle species can be determined. As suspected, neutrons and electrons populate different but also overlapping regions in the pulse length and height plot (Figure 8c), due to their different ionization characteristics, E and dE/dx. An event cluster that exclusively contains neutrons depicted in blue can be separated by the orange cluster populated by a mix of particle species. In both, the pulse height and pulse length spectrum, these clusters overlap and may not be distinguished completely. Only a combination of the two quantities provides a clear separation. However, a substantial amount of neutron events are contained in the orange cluster that makes up one third of all events. Therefore, a loss in count rate cannot be entirely avoided.
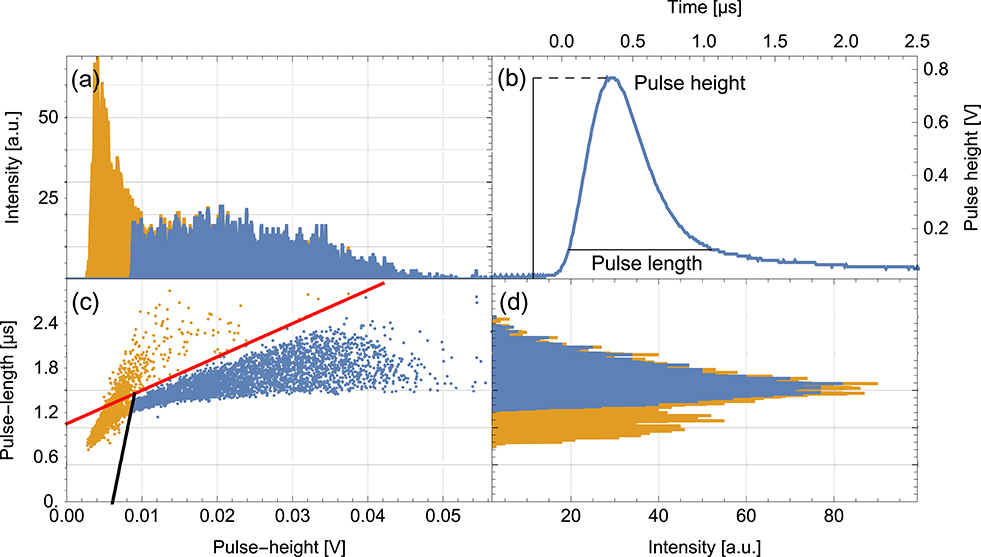
Figure 8. Pulse shape analysis for a boron-lined detector at a counting gas pressure of 1 bar. (a) Shows the pulse height spectrum of 6,200 detected events. (b) Displays a pulse generated by the readout electronics corresponding to a neutron event and indicates how pulse height and length are determined. Pulse length corresponds to the time interval during which the pulse exceeds a certain threshold voltage level. The scatter plot (c) depicts the two-dimensional pulse data of the detected events. (d) Shows the event pulse length data as a histogram. (a,d) Are the projections of (c) to the pulse height and length axis, respectively. The blue events could be identified as neutrons whereas the orange cluster contains both electrons and neutrons. These regions can be separated by appropriate thresholds depicted by the red and black line in (c).
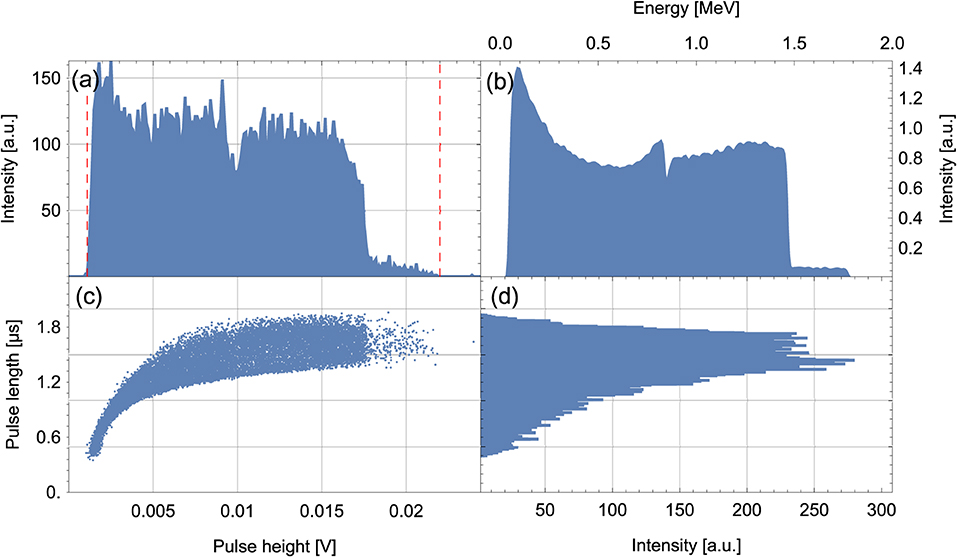
Figure 9. Pulse shape analysis for a boron-lined detector at a counting gas pressure of 250 mbar. A total of ≈ 18,000 events are recorded. (a) Shows the pulse height spectrum and (b) a reference pulse height spectrum simulated by the URANOS Monte Carlo tool for a 1.44 μm thick boron layer. The first red line in (a) shows the hardware threshold discrimination to lower energies. The second red line symbolizes the upper threshold as it is set for detecting cosmic-ray neutrons for soil moisture measurements. In this setup, higher energy particles were also recorded in order to estimate the total background noise. (c) Shows the two-dimensional pulse shape data and the event pulse lengths are plotted as a histogram in (d).
The most efficient scheme to reduce the contamination of weakly ionizing particles, however, is to reduce the gas pressure inside the counter tube. Thereby, the ionization per track length dE/dx and so the total energy deposition is reduced. By reducing the gas pressure to 250 mbar, the efficiency for electrons emitted by a radioactive strontium source was measured to be as low as 10−9. The gamma sensitivity is on the same order of magnitude as the gamma rays ionize the gas indirectly by kick-off electrons. The heavy and highly ionizing conversion products of 10B still deposit the same amount of energy inside the gas, because their track length is still smaller than the radius of the counter tube. The resulting pulse height spectrum (Figure 9a) resembles the theoretical spectrum (Figure 9b) simulated by URANOS and convoluted with a Gaussian distribution function of 2% full width at half maximum (FWHM). The convolution is used to simulate the effects of the detector energy resolution. The events in Figure 9b with energies E, 1.47 MeV < E <1.78 MeV correspond to the 10B decay channel with a probability of 6% (see section 3.2). Particles with higher energies amount to two percent of all events under typical conditions. These alpha particles can easily be discriminated against via their pulse height. This event rate is also extrapolated to the boron conversion energy range, shown in Figures 9a,b to estimate the background noise by radioisotopes to be 0.74 ± 0.06 mHz, i.e., 64 ± 5 events per day. The main reason for this low intrinsic radioactivity is the 50 μm thick, high purity SE-Cu foil inside the boron-lined neutron counter as it has an intrinsic activity that was measured to be as low as (1.05 ± 0.1) events/(s m2) in the energy region between 2.6 and 5 MeV. The copper foil also acts as a barrier between the aluminum housing of the counter and the gas filling. It effectively shields alpha and heavier particles from entering and ionizing the gas. Further contamination can arise from the decay of radon-222 gas, which accumulates on every surface. However, with typical decay energies above 5 MeV it can be easily discriminated against. The hardware discrimination threshold to lower energies is set to be ≈ 100 keV. This lower threshold cuts ≈ 6% of the total 10B pulse height spectrum. The low electron efficiency mentioned above could also be confirmed with the Penelope Monte Carlo package (Salvat, 2015) simulating the electron transport and ionization trace inside the counter. The largest energy deposition for 250 mbar amounted to ≈ 50 keV, even for maximum track lengths through the counter volume and thus lies with a large margin below the hardware threshold.
The same readout electronics is used to record neutrons with a 2 × 12 inch proportional counter filled with 1.5 bar 3He (GE Energy, 2005). This neutron counter is deployed in the widely used CRS-1000 standard CRNP by Hydroinnova LLC (Desilets, 2013). Figure 10A displays the pulse length and height scatter plot of the 3He counter. The pulse height spectrum shown in Figure 10B resembles that given by the manufacturer (GE Energy, 2005). The background noise of the 3He counter was extrapolated using the high energy alpha background similar to above and was estimated to be as low as 0.12 ± 0.04 mHz. This measured background noise has the same order of magnitude as the values reported by other studies (Hashemi-Nezhad and Peak, 1998; Debicki et al., 2011). The data series shown in this section were recorded at the Physikalisches Institut, Heidelberg, Germany with the recently developed new frontend readout electronics.
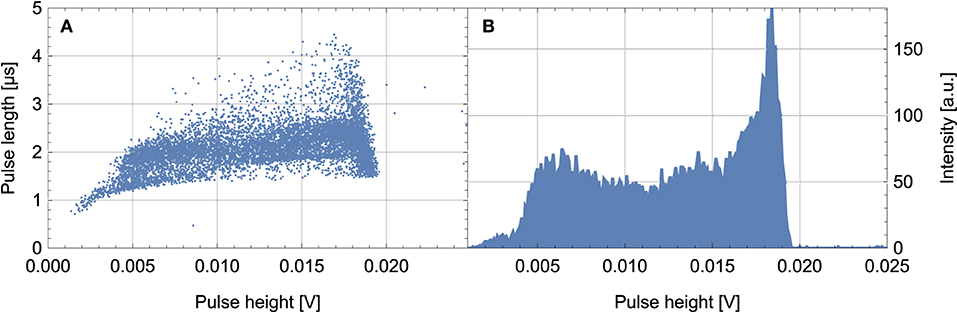
Figure 10. Pulse shape analysis for a 3He proportional counter. (A) Shows the pulse length and height plot and (B) the projected pulse height spectrum.
4.3. Field Data
Four stationary detectors are deployed at the ATB Marquardt test site along with eight other cosmic-ray neutron sensors, operated by the University of Potsdam (see Figure 11). The test site is located close to Potsdam, Germany and has a cut-off rigidity rc of 2.93 GV (Desorgher, 2004). The soil is composed of loamy sand and the biomass distribution is very heterogeneous. Total annual precipitation amounts to approximately 500 mm. The sensors are located in a small area such that their footprints overlap. Figure 12 shows the neutron count rates of one boron-lined stationary detector with five neutron counter tubes with 1 bar counting gas pressure and a CRS-1000 and CRS-2000/B neutron detector in its vicinity. For comparison, all three detectors shown are equipped with a moderator of 25 mm thickness but without thermal neutron shields. The boron-lined stationary detector shows a similar response to precipitation events and pressure variations.
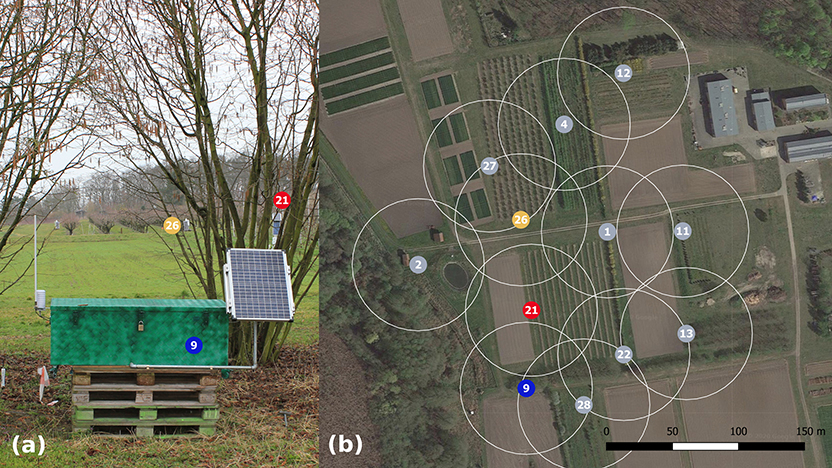
Figure 11. Installation at the Marquardt test site of the Leibniz Institute for Agricultural Engineering and Bioeconomy with CRNPs compared in Figure 12. (a) Preliminary setup of sensor 9 in its camouflage box with external solar panel and GSM antenna. (b) Bird's eye view of the site. The neutron detectors are located with overlapping footprints (50 m radius, white circles). Background image, map data: Google imagery.
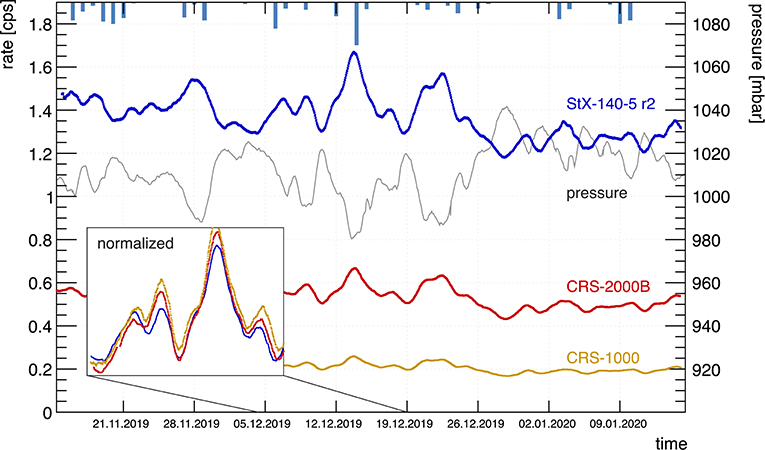
Figure 12. Comparison of different CR probes installed at the Marquardt site (ATB Potsdam). The time series show raw data from the probes, which are tagged using the same color code as in Figure 11. The integration time of the probes was set to 20 min, however, a moving average of ±6 h has been applied to the neutron count time series. As a result the count rate errors are in the order of the plotted line width, yet, the averaging leads to an error of the given time scale. Rainfall with a maximum of 8 mm is indicated at the top, however the uncorrected rate changes are mainly due to atmospheric pressure changes plotted in gray. The inset shows 2 weeks of data with all probes scaled to each other.
5. Conclusion
This study examined critical properties of neutron detectors designed for Cosmic Ray Neutron Sensing and introduced a large-scale detector setup tested in situ at an experimental field site. Extensive Monte Carlo studies using both URANOS and MCNP 6.2 were conducted and detector design implementations suggested. The ideal moderator thickness was found to be a compromise between count rate enhancement and avoiding contamination of neutrons that do not carry information about the environmental hydrogen content. The typical value of 25 mm accompanied with a thermal neutron shield firstly introduced by Desilets et al. (2010) was confirmed to be appropriate for a universal detector approach. However, slightly better results were obtained for 22.5 mm. For some settings a thinner moderator and thermal shield combination were identified to increase the neutron measurement precision. In general, the importance of a thermal shield was demonstrated, as it significantly increases the detector's signal-to-noise ratio. If no thermal shield is applied the optimum moderator thickness is slightly larger, lying between 27.5 and 30 mm. The measurement precision may be further increased by adapting the spatial dimensions of the moderator housing and thereby increasing the count rate. Changing the dimensions alters both the response functions magnitude and the total neutron flux impinging the detector surface with opposed effects on the count rate. Here, the ideal configuration strongly depends on the neutron counter's thermal sensitivity. Overall, high count rates are found to be achieved for large detector systems with large neutron counters. At last, the signal induced by non-neutron radiation and its influence on the overall signal quality was discussed. A novel detection system based on these design considerations was presented. It combines a moderate detection efficiency with a large surface area and achieves count rates that are higher by multiple times than usual systems. An appropriate selection of materials minimizes the relevant intrinsic background of radioisotopes to < 70 events per day per neutron counter. The readout electronics combines pulse height and length analysis to suppress the detection of non-neutron particles. It was shown that a reduction of the counter gas pressure to 250 mbar leads to a reduced efficiency to beta and gamma radiation of about 10−9. Neutron events are recorded with a time resolution of milliseconds that allows for studying the “ship effect.” The large-area detector is composed of several neutron counters. This modularity allows for adaptable response functions of the different counter tubes. Spectral information can then be retrieved and used for signal correction or biomass investigations.
The benefits for the standard soil moisture retrieval are two-fold. Firstly, a high signal-to-noise ratio increases the relative change in neutron detection rate per hydrogen content change. Secondly, high count rates lower the relative statistical uncertainty and the neutron detection rate can be resolved more precisely. Hence, the high signal-to-noise ratio and high count rates of the large-scale boron-lined detector lead to precise soil moisture measurements in short time frames.
Data Availability Statement
The datasets presented in this article are not readily available because, the data presented is partly owned by other research institutes. Requests to access the datasets should be directed to d2VpbWFyQHBoeXNpLnVuaS1oZWlkZWxiZXJnLmRl.
Author Contributions
JW, MK, and US elaborated the introduced detector design with their research group at the Physics Institute Heidelberg, Heidelberg University. JW and MK contributed with neutron transport simulations and all three authors mentioned above contributed equally to the neutron counter and readout electronics design. CB deployed and maintained the sensors in the field and advised on how to transfer theoretical considerations onto a field applicable neutron detector system. All authors contributed to the article and approved the submitted version.
Funding
The project large-scale and high-resolution mapping of soil moisture on field and catchment scales—boosted by cosmic-ray neutrons was funded within the DFG research group Cosmic Sense FOR 2694. During the writing of this article JW was on a scientific exchange with alpS GmbH in Innsbruck, Austria funded by the DAAD program One-Year Grants for Doctoral Candidates.
Conflict of Interest
JW and MK hold CEO positions at StyX Neutronica GmbH.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
JW acknowledges Martin Schrön, UFZ Leipzig, Till Francke, and Sascha Oswald, both University of Potsdam, for their support during field campaigns and valuable comments on the applicability of some design considerations. The author also appreciates the fruitful discussions with Paul Schattan on this article's structure. MK acknowledges Heinrich Wilsenach, IKTP Dresden, for supporting background measurements. This work was supported by the ATB Marquardt where the stationary detectors were deployed. We acknowledge financial support by the Baden-Württemberg Ministry of Science, Research and the Arts and by Ruprecht-Karls-Universität Heidelberg.
References
Aguayo, E., Kouzes, R., and Siciliano, E. (2013). Ship Effect Neutron Measurements and Impacts on Low-Background Experiments. Technical Report PNNL-22953, Pacific Northwest National Laboratory, Richland, WA.
Andreasen, M., Jensen, H. K., Zreda, M., Desilets, D., Bogena, H., and Looms, C. (2016). Modeling cosmic ray neutron field measurements. Water Resour. Res. 52, 6451–6471. doi: 10.1002/2015WR018236
Andreasen, M., Jensen, K., Desilets, D., Franz, T., Zreda, M., Bogena, H., et al. (2017). Status and perspectives on the cosmic-ray neutron method for soil moisture estimation and other environmental science applications. Vadose Zone J. 16, 1–11. doi: 10.2136/vzj2017.04.0086
Baatz, R., Bogena, H., Hendricks-Franssen, H.-J., Huisman, J., Montzka, C., and Vereecken, H. (2015). An empirical vegetation correction for soil water content quantification using cosmic ray probes. Water Resour. Res. 51, 2030–2046. doi: 10.1002/2014WR016443
Bogena, H., Huisman, J., Baatz, R., Hendricks-Franssen, H.-J., and Vereecken, H. (2013). Accuracy of the cosmic-ray soil water content probe in humid forest ecosystems: the worst case scenario. Water Resour. Res. 49, 5778–5791. doi: 10.1002/wrcr.20463
Bramblett, R., Ewing, R., and Bonner, T. (1960). A new type of neutron spectrometer. Nucl. Instrum. Methods 9, 1–12. doi: 10.1016/0029-554X(60)90043-4
Brown, D., Chadwick, M., Capote, R., Kahler, A., Trkov, A., Herman, M., et al. (2018). ENDF/B-VIII.0: the 8th major release of the nuclear reaction data library with CIELO-project cross sections, new standards and thermal scattering data. Nucl. Data Sheets 148, 1–142. doi: 10.1016/j.nds.2018.02.001
Chadwick, M., Herman, M., Obložinský, P., Dunn, M., Danon, Y., Kahler, A., et al. (2011). ENDF/B-VII.1 nuclear data for science and technology: cross sections, covariances, fission product yields and decay data. Nucl. Data Sheets 112, 2887–2996. doi: 10.1016/j.nds.2011.11.002
Compton, A. (1923). A quantum theory of the scattering of x-rays by light elements. Phys. Rev. 21:483. doi: 10.1103/PhysRev.21.483
Debicki, Z., Jedrzejczak, K., Karczmarczyk, J., Kasztelan, M., Lewandowski, R., Orzechowski, J., et al. (2011). Helium counters for low neutron flux measurements. Astrophys. Space Sci. Trans. 7, 511–514. doi: 10.5194/astra-7-511-2011
Desilets, D., Zreda, M., and Ferré, T. (2010). Nature's neutron probe: land surface hydrology at an elusive scale with cosmic rays. Water Resour. Res. 46:W11505. doi: 10.1029/2009WR008726
Desorgher, L. (2004). The Magnetocosmics Code. Technical report. Available online at: http://cosray.unibe.ch/laurent/magnetoscosmics
Forsyth, A., Teal, T., and Inglis, A. (2017). “Silverside neutron detector performance,” in 2017 IEEE International Symposium on Technologies for Homeland Security (HST) (Waltham, MA), 1–7. doi: 10.1109/THS.2017.7943461
Franz, T., Wahbi, A., Vreugdenhil, M., Weltin, G., Heng, L., Oismueller, M., et al. (2016). Using cosmic-ray neutron probes to monitor landscape scale soil water content in mixed land use agricultural systems. Appl. Environ. Soil Sci. 2016:4323742. doi: 10.1155/2016/4323742
Franz, T., Zreda, M., Rosolem, R., Hornbuckle, B., Irvin, S., Adams, H., et al. (2013). Ecosystem-scale measurements of biomass water using cosmic ray neutrons. Geophys. Res. Lett. 40, 3929–3933. doi: 10.1002/grl.50791
GE Energy (2005). Reuter Stokes 3-He Neutron Detectors for Homeland Security Radiation Portal Monitors. Twinsburg, OH: GE Energy.
Goldhagen, P., Clem, J., and Wilson, J. (2004). The energy spectrum of cosmic-ray induced neutrons measured on an airplane over a wide range of altitude and latitude. Radiat. Protect. Dosimet. 110, 387–392. doi: 10.1093/rpd/nch216
Goorley, T., James, M., Booth, T., Brown, F., Bull, J., Cox, L., et al. (2012). Initial MCNP6 release overview. Nucl. Technol. 180, 298–315. doi: 10.13182/NT11-135
Groom, D., Mokhov, N., and Striganov, S. (2001). Muon stopping power and range tables 10 MeV-100 TeV. Atom. Data Nucl. Data Tables 78, 183–356. doi: 10.1006/adnd.2001.0861
Hashemi-Nezhad, S., and Peak, L. (1998). Limitation on the response of 3He counters due to intrinsic alpha emission. Nucl. Instrum. Methods Phys. Res. Sect. A 416, 100–108. doi: 10.1016/S0168-9002(98)00565-8
Hertel, N., and Davidson, J. (1985). The response of Bonner Spheres to neutrons from thermal energies to 17.3 MeV. Nucl. Instrum. Methods Phys. Res. A 238, 509–516. doi: 10.1016/0168-9002(85)90494-2
Izumi, S., and Murata, Y. (1971). Pulse risetime analysis of a 3He proportional counter. Nucl. Instrum. Methods 94, 141–145. doi: 10.1016/0029-554X(71)90351-X
Kodama, M., Kudo, S., and Kosuge, T. (1985). Application of atmospheric neutrons to soil moisture measurement. Soil Sci. 140, 237–242. doi: 10.1097/00010694-198510000-00001
Köhli, M., Allmendinger, F., Häußler, W., Schröder, T., Klein, M., Meven, M., et al. (2016). Efficiency and spatial resolution of the CASCADE thermal neutron detector. Nucl. Instrum. Methods Phys. Res. Sect. A 828, 242–249. doi: 10.1016/j.nima.2016.05.014
Köhli, M., Schrön, M., and Schmidt, U. (2018). Response functions for detectors in cosmic ray neutron sensing. Nucl. Instrum. Methods Phys. Res. Sect. A 902, 184–189. doi: 10.1016/j.nima.2018.06.052
Köhli, M., Schrön, M., Zreda, M., Schmidt, U., Dietrich, P., and Zacharias, S. (2015). Footprint characteristics revised for field-scale soil moisture monitoring with cosmic-ray neutrons. Water Resour. Res. 51, 5772–5790. doi: 10.1002/2015WR017169
Kouzes, R., Ely, J., Seifert, A., Siciliano, E., Weier, D., Windsor, L., et al. (2008). Cosmic-ray-induced ship-effect neutron measurements and implications for cargo scanning at borders. Nucl. Instrum. Methods Phys. Res. Sect. A 587, 89–100. doi: 10.1016/j.nima.2007.12.031
Kowatari, M., Nagaoka, K., Satoh, S., Ohta, Y., Abukawa, J., Tachimori, S., et al. (2005). Evaluation of the altitude variation of the cosmic-ray induced environmental neutrons in the Mt. Fuji Area. J. Nucl. Sci. Technol. 42, 495–502. doi: 10.1080/18811248.2004.9726416
Langford, T., Bass, C., Beise, E., Breuer, H., Erwin, D., Heimbach, C., et al. (2013). Event identification in 3He proportional counters using risetime discrimination. Nucl. Instrum. Methods Phys. Res. Sect. A 717, 51–57. doi: 10.1016/j.nima.2013.03.062
Letaw, J., and Normand, E. (1991). Guidelines for predicting single-event upsets in neutron environments (RAM devices). IEEE Trans. Nucl. Sci. 38, 1500–1506. doi: 10.1109/23.124138
Li, D., Schrön, M., Köhli, M., Bogena, H., Weimar, J., Jiménez Bello, M., et al. (2019). Can drip irrigation be scheduled with cosmic-ray neutron sensing? Vadose Zone J. 18:190053. doi: 10.2136/vzj2019.05.0053
Mares, V., Schraube, G., and Schraube, H. (1991). Calculated neutron response of a Bonner Sphere Spectrometer with 3He counter. Nucl. Instrum. Methods Phys. Res. Sect. A 307, 398–412. doi: 10.1016/0168-9002(91)90210-H
Mares, V., and Schraube, H. (1994). Evaluation of the response matrix of a Bonner Sphere Spectrometer with liI detector from thermal energy to 100 MeV. Nucl. Instrum. Methods Phys. Res. Sect. A 337, 461–473. doi: 10.1016/0168-9002(94)91116-9
McKinney, G. (2013). MCNP6 cosmic and terrestrial background particle fluxes. LA-UR-13-24293. Release 3.
Modzel, G., Henske, M., Houben, A., Klein, M., Köhli, M., Lennert, P., et al. (2014). Absolute efficiency measurements with the 10B based Jalousie detector. Nucl Instrum Meth in Physics Research Section A. 743, 90–95. doi: 10.1016/j.nima.2014.01.007
Mohanty, B., Cosh, M., Lakshmi, V., and Montzka, C. (2017). Soil moisture remote sensing: state-of-the-science. Vadose Zone J. 16, 1-9. doi: 10.2136/vzj2016.10.0105
Montzka, C., Bogena, H., Zreda, M., Monerris, A., Morrison, R., Muddu, S., et al. (2017). Validation of spaceborne and modelled surface soil moisture products with cosmic-ray neutron probes. Remote Sens. 9:103. doi: 10.3390/rs9020103
Nelson, K., Bellinger, S., Montag, B., Neihart, J., Riedel, T., Schmidt, A, J., et al. (2012). Investigation of a lithium foil multi-wire proportional counter for potential 3He replacement. Nucl. Instrum. Methods Phys. Res. Sect. A 669, 79–84. doi: 10.1016/j.nima.2011.12.003
Nesterenok, A. (2013). Numerical calculations of cosmic ray cascade in the Earth's atmosphere - Results for nucleon spectra. Nucl. Instrum. Methods Phys. Res. B 295, 99–106. doi: 10.1016/j.nimb.2012.11.005
Pfotzer, G. (1936). Dreifachkoinzidenzen der ultrastrahlung aus vertikaler richtung in der stratosphäre. Zeitsch. Phys. 102, 41–58. doi: 10.1007/BF01336830
Piscitelli, F. (2013). Boron-10 layers, Neutron Reflectometry and Thermal Neutron Gaseous Detectors. Ph.D. thesis, Universitá degli Studi di Perugia, Perugia, Italy.
Quinta-Ferreira, M., Dias, J., and Alija, S. (2016). False low water content in road field compaction control using nuclear gauges: a case study. Environ. Earth Sci. 75:1114. doi: 10.1007/s12665-016-5901-1
Robinson, D., Campbell, C., Hopmans, J., Hornbuckle, B., Jones, S., Knight, R., et al. (2008). Soil moisture measurement for ecological and hydrological watershed-scale observatories: a review. Vadose Zone J. 7, 358–389. doi: 10.2136/vzj2007.0143
Rodriguez-Alvarez, N., Bosch-Lluis, X., Camps, A., Aguasca, A., Vall-Llossera, M., Valencia, E., et al. (2011). Review of crop growth and soil moisture monitoring from a ground-based instrument implementing the interference pattern GNSS-R technique. Radio Sci. 46, 1–11. doi: 10.1029/2011RS004680
Rosolem, R., Shuttleworth, W., Zreda, M., Franz, T., Zeng, X., and Kurc, S. (2013). The effect of atmospheric water vapor on neutron count in the cosmic-ray soil moisture observing system. J. Hydrometeorol. 14, 1659–1671. doi: 10.1175/JHM-D-12-0120.1
Salvat, F. (2015). “The PENELOPE code system,” in Specific Features and Recent Improvements, Vol. 82, ed EDP, Science (Barcelona: Elsevier), 98–109. doi: 10.1016/j.anucene.2014.08.007
Sato, T. (2015). Analytical model for estimating terrestrial cosmic ray fluxes nearly anytime and anywhere in the world: extension of PARMA/EXPACS. PLoS ONE 10:e144679. doi: 10.1371/journal.pone.0144679
Sato, T. (2016). Analytical model for estimating the zenith angle dependence of terrestrial cosmic ray fluxes. PLoS ONE 11:e160390. doi: 10.1371/journal.pone.0160390
Sato, T., and Niita, K. (2006). Analytical functions to predict cosmic-ray neutron spectra in the atmosphere. Radiat. Res. 166, 544–555. doi: 10.1667/RR0610.1
Schattan, P., Baroni, G., Oswald, S., Schöber, J., Fey, C., Kormann, C., et al. (2017). Continuous monitoring of snowpack dynamics in alpine terrain by aboveground neutron sensing. Water Resour. Res. 53, 3615–3634. doi: 10.1002/2016WR020234
Schattan, P., Köhli, M., Schrön, M., Baroni, G., and Oswald, S. (2019). Sensing area-average snow water equivalent with cosmic-ray neutrons: the influence of fractional snow cover. Water Resour. Res. 55, 10796–10812. doi: 10.1029/2019WR025647
Schrön, M., Köhli, M., Scheiffele, L., Iwema, J., Bogena, H., Lv, L., et al. (2017). Improving calibration and validation of cosmic-ray neutron sensors in the light of spatial sensitivity. Hydrol. Earth Syst. Sci. 21, 5009–5030. doi: 10.5194/hess-21-5009-2017
Schrön, M., Rosolem, R., Köhli, M., Piussi, L., Schröter, I., Iwema, J., et al. (2018). Cosmic-ray neutron rover surveys of field soil moisture and the influence of roads. Water Resour. Res. 54, 6441–6459. doi: 10.1029/2017WR021719
Shea, D., and Morgan, D. (2010). The Helium-3 Shortage: Supply, Demand, and Options for Congress. CRS Report for Congress. R41419. Congressional Research Service.
Shuttleworth, J., Rosolem, R., Zreda, M., and Franz, T. (2013). The COsmic-ray Soil Moisture Interaction Code (COSMIC) for use in data assimilation. Hydrol. Earth Syst. Sci. 17, 3205–3217. doi: 10.5194/hess-17-3205-2013
Stevanato, L., Baroni, G., Cohen, Y., Cristiano Lino, F., Gatto, S., Lunardon, M., et al. (2019). A novel cosmic-ray neutron sensor for soil moisture estimation over large areas. Agriculture 9:202. doi: 10.3390/agriculture9090202
Strati, V., Albéri, M., Anconelli, S., Baldoncini, M., Bittelli, M., Bottardi, C., et al. (2018). Modelling soil water content in a tomato field: proximal gamma ray spectroscopy and soil-crop system models. Agriculture 8:60. doi: 10.3390/agriculture8040060
Tian, Z., Li, Z., Liu, G., Li, B., and Ren, T. (2016). Soil water content determination with cosmic-ray neutron sensor: correcting aboveground hydrogen effects with thermal/fast neutron ratio. J. Hydrol. 540, 923–933. doi: 10.1016/j.jhydrol.2016.07.004
Waters, L., McKinney, G., Durkee, J., Fensin, M., Hendricks, J., James, M., et al. (2007). The MCNPX Monte Carlo radiation transport code. AIP Conf. Proc. 896, 81–90. doi: 10.1063/1.2720459
Werner, C. J., Bull, J. S., Solomon, C. J., Brown, F. B., McKinney, G. W., Rising, M. E., et al. (2018). MCNP Version 6.2 Release Notes. Technical report, Los Alamos National Lab (LANL), Los Alamos, NM, United States.
Zreda, M., Desilets, D., Ferré, T., and Scott, R. (2008). Measuring soil moisture content non-invasively at intermediate spatial scale using cosmic-ray neutrons. Geophys. Res. Lett. 35:L21402. doi: 10.1029/2008GL035655
Zreda, M., Shuttleworth, W., Zeng, X., Zweck, C., Desilets, D., Franz, T., et al. (2012). COSMOS: The COsmic-ray Soil Moisture Observing System. Hydrol. Earth Syst. Sci. 16, 4079–4099. doi: 10.5194/hess-16-4079-2012
Appendix
Detailed Calculus of Soil Moisture Uncertainty
This article aims at analyzing the most relevant neutron count uncertainty sources for gaseous neutron detectors tailored for CRNS. In section 3.1 it is indicated how this uncertainty propagates onto the uncertainty of soil moisture as this is the desired variable. Here the corresponding calculus is shown in more length. For the calculation we use Equation (1) and its inverse:
We use simple uncertainty propagation and neglect the influence of other uncertainty sources on the soil moisture content:
For simplicity we omitted the determination of the absolute value in the second step. Replacing N with Equation (7) to obtain σθ dependent on θ results in:
This result is presented in section 3.1.
Account of Detector Costs
Besides the benefits mentioned above boron-lined neutron detectors are likewise a cost-effective alternative to 3He-based CRNPs. Boron-lined systems require enriched 10B as the absorption cross section of the naturally more abundant 11B is lower by three orders of magnitude. Contrary to helium-3 which is extracted from refurbished thermonuclear warheads, boron is widely used as a semiconductor dopant. For radiation hard applications it needs to be depleted in 10B in order to make it more resilient against neutron-induced damages. 10B enriched boron is therefore a by-product of the semiconductor industry. The price is subject to fluctuations that can be as high as 50% and by the time this article was written amounted to 1,500$ per 100 g. Enriched boron is sputter deposited as 10B4C with a thickness of 1.5 μm on a copper substrate. The current price of such a 96% enriched 10B4C coating amounts to approximately 2,500 $ per m2 with the sputter deposition being the most substantial item in the cost budget. Absorption cross section comparison shows that 1 m2× 1.5 μm has the absorption, and thus neutron conversion, capability of approximately 5 barliters of 3He. However, approximately 43% of the reaction products do not leave the boron layer and thus can not be detected, as indicated in section 3.2. Moreover some of the reaction products may not be distinguished from other radiation when depositing small amounts of energy in the counter's gas. This leads to a factor of 2.5 in neutron detection efficiency between 1 m2 of 10B to 1 barliter of 3He, which for example can approximately be found in CRS-1000 counter tubes. In order to compare neutron count rates the total surface of the CRNP has to be taken into account (see section 3.2.2). The stationary detector introduced in section 4.3 incorporates a total of approximately 1 m2 of 1.5 μm boron-lined copper substrate.
Keywords: CRNS, neutron, detector, soil moisture, readout electronics, boron-10, helium-3 alternative
Citation: Weimar J, Köhli M, Budach C and Schmidt U (2020) Large-Scale Boron-Lined Neutron Detection Systems as a 3He Alternative for Cosmic Ray Neutron Sensing. Front. Water 2:16. doi: 10.3389/frwa.2020.00016
Received: 22 March 2020; Accepted: 15 June 2020;
Published: 17 September 2020.
Edited by:
Virginia Strati, University of Ferrara, ItalyReviewed by:
Trenton Franz, University of Nebraska-Lincoln, United StatesLuca Stevanato, University of Padova, Italy
Copyright © 2020 Weimar, Köhli, Budach and Schmidt. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jannis Weimar, d2VpbWFyQHBoeXNpLnVuaS1oZWlkZWxiZXJnLmRl